mirror of
https://github.com/crewAIInc/crewAI.git
synced 2026-08-01 03:59:22 +00:00
Compare commits
28 Commits
lg-python-
...
fix/consol
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
554ea8fcee | ||
|
|
970a63c13c | ||
|
|
06c991d8c3 | ||
|
|
739eb72fd0 | ||
|
|
b0d2e9fe31 | ||
|
|
5c51349a85 | ||
|
|
5b740467cb | ||
|
|
e9d9dd2a79 | ||
|
|
3e74cb4832 | ||
|
|
db3c8a49bd | ||
|
|
8a37b535ed | ||
|
|
e6ac1311e7 | ||
|
|
b0d89698fd | ||
|
|
21d063a46c | ||
|
|
02912a653e | ||
|
|
f1cfba7527 | ||
|
|
3e075cd48d | ||
|
|
e03ec4d60f | ||
|
|
ba740c6157 | ||
|
|
34c813ed79 | ||
|
|
545cc2ffe4 | ||
|
|
47b97d9b7f | ||
|
|
bf8fbb0a44 | ||
|
|
552921cf83 | ||
|
|
372874fb3a | ||
|
|
2bd6b72aae | ||
|
|
f02e0060fa | ||
|
|
66b7628972 |
5
.github/workflows/linter.yml
vendored
5
.github/workflows/linter.yml
vendored
@@ -30,4 +30,7 @@ jobs:
|
||||
- name: Run Ruff on Changed Files
|
||||
if: ${{ steps.changed-files.outputs.files != '' }}
|
||||
run: |
|
||||
echo "${{ steps.changed-files.outputs.files }}" | tr " " "\n" | xargs -I{} ruff check "{}"
|
||||
echo "${{ steps.changed-files.outputs.files }}" \
|
||||
| tr ' ' '\n' \
|
||||
| grep -v 'src/crewai/cli/templates/' \
|
||||
| xargs -I{} ruff check "{}"
|
||||
|
||||
2
.github/workflows/tests.yml
vendored
2
.github/workflows/tests.yml
vendored
@@ -14,7 +14,7 @@ jobs:
|
||||
timeout-minutes: 15
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ['3.10', '3.11', '3.12']
|
||||
python-version: ['3.10', '3.11', '3.12', '3.13']
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
@@ -161,7 +161,7 @@ To get started with CrewAI, follow these simple steps:
|
||||
|
||||
### 1. Installation
|
||||
|
||||
Ensure you have Python >=3.10 <3.13 installed on your system. CrewAI uses [UV](https://docs.astral.sh/uv/) for dependency management and package handling, offering a seamless setup and execution experience.
|
||||
Ensure you have Python >=3.10 <3.14 installed on your system. CrewAI uses [UV](https://docs.astral.sh/uv/) for dependency management and package handling, offering a seamless setup and execution experience.
|
||||
|
||||
First, install CrewAI:
|
||||
|
||||
|
||||
@@ -43,7 +43,6 @@ The Visual Agent Builder enables:
|
||||
| **Max Iterations** _(optional)_ | `max_iter` | `int` | Maximum iterations before the agent must provide its best answer. Default is 20. |
|
||||
| **Max RPM** _(optional)_ | `max_rpm` | `Optional[int]` | Maximum requests per minute to avoid rate limits. |
|
||||
| **Max Execution Time** _(optional)_ | `max_execution_time` | `Optional[int]` | Maximum time (in seconds) for task execution. |
|
||||
| **Memory** _(optional)_ | `memory` | `bool` | Whether the agent should maintain memory of interactions. Default is True. |
|
||||
| **Verbose** _(optional)_ | `verbose` | `bool` | Enable detailed execution logs for debugging. Default is False. |
|
||||
| **Allow Delegation** _(optional)_ | `allow_delegation` | `bool` | Allow the agent to delegate tasks to other agents. Default is False. |
|
||||
| **Step Callback** _(optional)_ | `step_callback` | `Optional[Any]` | Function called after each agent step, overrides crew callback. |
|
||||
@@ -156,7 +155,6 @@ agent = Agent(
|
||||
"you excel at finding patterns in complex datasets.",
|
||||
llm="gpt-4", # Default: OPENAI_MODEL_NAME or "gpt-4"
|
||||
function_calling_llm=None, # Optional: Separate LLM for tool calling
|
||||
memory=True, # Default: True
|
||||
verbose=False, # Default: False
|
||||
allow_delegation=False, # Default: False
|
||||
max_iter=20, # Default: 20 iterations
|
||||
@@ -537,7 +535,6 @@ The context window management feature works automatically in the background. You
|
||||
- Adjust `max_iter` and `max_retry_limit` based on task complexity
|
||||
|
||||
### Memory and Context Management
|
||||
- Use `memory: true` for tasks requiring historical context
|
||||
- Leverage `knowledge_sources` for domain-specific information
|
||||
- Configure `embedder` when using custom embedding models
|
||||
- Use custom templates (`system_template`, `prompt_template`, `response_template`) for fine-grained control over agent behavior
|
||||
@@ -585,7 +582,6 @@ The context window management feature works automatically in the background. You
|
||||
- Review code sandbox settings
|
||||
|
||||
4. **Memory Issues**: If agent responses seem inconsistent:
|
||||
- Verify memory is enabled
|
||||
- Check knowledge source configuration
|
||||
- Review conversation history management
|
||||
|
||||
|
||||
@@ -200,6 +200,37 @@ Deploy the crew or flow to [CrewAI Enterprise](https://app.crewai.com).
|
||||
```
|
||||
- Reads your local project configuration.
|
||||
- Prompts you to confirm the environment variables (like `OPENAI_API_KEY`, `SERPER_API_KEY`) found locally. These will be securely stored with the deployment on the Enterprise platform. Ensure your sensitive keys are correctly configured locally (e.g., in a `.env` file) before running this.
|
||||
|
||||
### 11. Organization Management
|
||||
|
||||
Manage your CrewAI Enterprise organizations.
|
||||
|
||||
```shell Terminal
|
||||
crewai org [COMMAND] [OPTIONS]
|
||||
```
|
||||
|
||||
#### Commands:
|
||||
|
||||
- `list`: List all organizations you belong to
|
||||
```shell Terminal
|
||||
crewai org list
|
||||
```
|
||||
|
||||
- `current`: Display your currently active organization
|
||||
```shell Terminal
|
||||
crewai org current
|
||||
```
|
||||
|
||||
- `switch`: Switch to a specific organization
|
||||
```shell Terminal
|
||||
crewai org switch <organization_id>
|
||||
```
|
||||
|
||||
<Note>
|
||||
You must be authenticated to CrewAI Enterprise to use these organization management commands.
|
||||
</Note>
|
||||
|
||||
- **Create a deployment** (continued):
|
||||
- Links the deployment to the corresponding remote GitHub repository (it usually detects this automatically).
|
||||
|
||||
- **Deploy the Crew**: Once you are authenticated, you can deploy your crew or flow to CrewAI Enterprise.
|
||||
|
||||
@@ -325,12 +325,12 @@ for result in results:
|
||||
|
||||
# Example of using kickoff_async
|
||||
inputs = {'topic': 'AI in healthcare'}
|
||||
async_result = my_crew.kickoff_async(inputs=inputs)
|
||||
async_result = await my_crew.kickoff_async(inputs=inputs)
|
||||
print(async_result)
|
||||
|
||||
# Example of using kickoff_for_each_async
|
||||
inputs_array = [{'topic': 'AI in healthcare'}, {'topic': 'AI in finance'}]
|
||||
async_results = my_crew.kickoff_for_each_async(inputs=inputs_array)
|
||||
async_results = await my_crew.kickoff_for_each_async(inputs=inputs_array)
|
||||
for async_result in async_results:
|
||||
print(async_result)
|
||||
```
|
||||
|
||||
@@ -602,6 +602,30 @@ agent = Agent(
|
||||
)
|
||||
```
|
||||
|
||||
#### Configuring Azure OpenAI Embeddings
|
||||
|
||||
When using Azure OpenAI embeddings:
|
||||
1. Make sure you deploy the embedding model in Azure platform first
|
||||
2. Then you need to use the following configuration:
|
||||
|
||||
```python
|
||||
agent = Agent(
|
||||
role="Researcher",
|
||||
goal="Research topics",
|
||||
backstory="Expert researcher",
|
||||
knowledge_sources=[knowledge_source],
|
||||
embedder={
|
||||
"provider": "azure",
|
||||
"config": {
|
||||
"api_key": "your-azure-api-key",
|
||||
"model": "text-embedding-ada-002", # change to the model you are using and is deployed in Azure
|
||||
"api_base": "https://your-azure-endpoint.openai.azure.com/",
|
||||
"api_version": "2024-02-01"
|
||||
}
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
## Advanced Features
|
||||
|
||||
### Query Rewriting
|
||||
|
||||
@@ -29,6 +29,10 @@ my_crew = Crew(
|
||||
|
||||
From this point on, your crew will have planning enabled, and the tasks will be planned before each iteration.
|
||||
|
||||
<Warning>
|
||||
When planning is enabled, crewAI will use `gpt-4o-mini` as the default LLM for planning, which requires a valid OpenAI API key. Since your agents might be using different LLMs, this could cause confusion if you don't have an OpenAI API key configured or if you're experiencing unexpected behavior related to LLM API calls.
|
||||
</Warning>
|
||||
|
||||
#### Planning LLM
|
||||
|
||||
Now you can define the LLM that will be used to plan the tasks.
|
||||
|
||||
@@ -32,6 +32,7 @@ The Enterprise Tools Repository includes:
|
||||
- **Customizability**: Provides the flexibility to develop custom tools or utilize existing ones, catering to the specific needs of agents.
|
||||
- **Error Handling**: Incorporates robust error handling mechanisms to ensure smooth operation.
|
||||
- **Caching Mechanism**: Features intelligent caching to optimize performance and reduce redundant operations.
|
||||
- **Asynchronous Support**: Handles both synchronous and asynchronous tools, enabling non-blocking operations.
|
||||
|
||||
## Using CrewAI Tools
|
||||
|
||||
@@ -177,6 +178,62 @@ class MyCustomTool(BaseTool):
|
||||
return "Tool's result"
|
||||
```
|
||||
|
||||
## Asynchronous Tool Support
|
||||
|
||||
CrewAI supports asynchronous tools, allowing you to implement tools that perform non-blocking operations like network requests, file I/O, or other async operations without blocking the main execution thread.
|
||||
|
||||
### Creating Async Tools
|
||||
|
||||
You can create async tools in two ways:
|
||||
|
||||
#### 1. Using the `tool` Decorator with Async Functions
|
||||
|
||||
```python Code
|
||||
from crewai.tools import tool
|
||||
|
||||
@tool("fetch_data_async")
|
||||
async def fetch_data_async(query: str) -> str:
|
||||
"""Asynchronously fetch data based on the query."""
|
||||
# Simulate async operation
|
||||
await asyncio.sleep(1)
|
||||
return f"Data retrieved for {query}"
|
||||
```
|
||||
|
||||
#### 2. Implementing Async Methods in Custom Tool Classes
|
||||
|
||||
```python Code
|
||||
from crewai.tools import BaseTool
|
||||
|
||||
class AsyncCustomTool(BaseTool):
|
||||
name: str = "async_custom_tool"
|
||||
description: str = "An asynchronous custom tool"
|
||||
|
||||
async def _run(self, query: str = "") -> str:
|
||||
"""Asynchronously run the tool"""
|
||||
# Your async implementation here
|
||||
await asyncio.sleep(1)
|
||||
return f"Processed {query} asynchronously"
|
||||
```
|
||||
|
||||
### Using Async Tools
|
||||
|
||||
Async tools work seamlessly in both standard Crew workflows and Flow-based workflows:
|
||||
|
||||
```python Code
|
||||
# In standard Crew
|
||||
agent = Agent(role="researcher", tools=[async_custom_tool])
|
||||
|
||||
# In Flow
|
||||
class MyFlow(Flow):
|
||||
@start()
|
||||
async def begin(self):
|
||||
crew = Crew(agents=[agent])
|
||||
result = await crew.kickoff_async()
|
||||
return result
|
||||
```
|
||||
|
||||
The CrewAI framework automatically handles the execution of both synchronous and asynchronous tools, so you don't need to worry about how to call them differently.
|
||||
|
||||
### Utilizing the `tool` Decorator
|
||||
|
||||
```python Code
|
||||
|
||||
@@ -9,7 +9,12 @@
|
||||
},
|
||||
"favicon": "images/favicon.svg",
|
||||
"contextual": {
|
||||
"options": ["copy", "view", "chatgpt", "claude"]
|
||||
"options": [
|
||||
"copy",
|
||||
"view",
|
||||
"chatgpt",
|
||||
"claude"
|
||||
]
|
||||
},
|
||||
"navigation": {
|
||||
"tabs": [
|
||||
@@ -201,6 +206,7 @@
|
||||
"observability/arize-phoenix",
|
||||
"observability/langfuse",
|
||||
"observability/langtrace",
|
||||
"observability/maxim",
|
||||
"observability/mlflow",
|
||||
"observability/openlit",
|
||||
"observability/opik",
|
||||
@@ -213,6 +219,7 @@
|
||||
"group": "Learn",
|
||||
"pages": [
|
||||
"learn/overview",
|
||||
"learn/llm-selection-guide",
|
||||
"learn/conditional-tasks",
|
||||
"learn/coding-agents",
|
||||
"learn/create-custom-tools",
|
||||
@@ -255,7 +262,8 @@
|
||||
"enterprise/features/tool-repository",
|
||||
"enterprise/features/webhook-streaming",
|
||||
"enterprise/features/traces",
|
||||
"enterprise/features/hallucination-guardrail"
|
||||
"enterprise/features/hallucination-guardrail",
|
||||
"enterprise/features/integrations"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -25,8 +25,13 @@ AI hallucinations occur when language models generate content that appears plaus
|
||||
from crewai.tasks.hallucination_guardrail import HallucinationGuardrail
|
||||
from crewai import LLM
|
||||
|
||||
# Initialize the guardrail with reference context
|
||||
# Basic usage - will use task's expected_output as context
|
||||
guardrail = HallucinationGuardrail(
|
||||
llm=LLM(model="gpt-4o-mini")
|
||||
)
|
||||
|
||||
# With explicit reference context
|
||||
context_guardrail = HallucinationGuardrail(
|
||||
context="AI helps with various tasks including analysis and generation.",
|
||||
llm=LLM(model="gpt-4o-mini")
|
||||
)
|
||||
|
||||
185
docs/enterprise/features/integrations.mdx
Normal file
185
docs/enterprise/features/integrations.mdx
Normal file
@@ -0,0 +1,185 @@
|
||||
---
|
||||
title: Integrations
|
||||
description: "Connected applications for your agents to take actions."
|
||||
icon: "plug"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to authenticate with any OAuth enabled provider and take actions. From Salesforce and HubSpot to Google and GitHub, we've got you covered with 16+ integrated services.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
## Supported Integrations
|
||||
|
||||
### **Communication & Collaboration**
|
||||
- **Gmail** - Manage emails and drafts
|
||||
- **Slack** - Workspace notifications and alerts
|
||||
- **Microsoft** - Office 365 and Teams integration
|
||||
|
||||
### **Project Management**
|
||||
- **Jira** - Issue tracking and project management
|
||||
- **ClickUp** - Task and productivity management
|
||||
- **Asana** - Team task and project coordination
|
||||
- **Notion** - Page and database management
|
||||
- **Linear** - Software project and bug tracking
|
||||
- **GitHub** - Repository and issue management
|
||||
|
||||
### **Customer Relationship Management**
|
||||
- **Salesforce** - CRM account and opportunity management
|
||||
- **HubSpot** - Sales pipeline and contact management
|
||||
- **Zendesk** - Customer support ticket management
|
||||
|
||||
### **Business & Finance**
|
||||
- **Stripe** - Payment processing and customer management
|
||||
- **Shopify** - E-commerce store and product management
|
||||
|
||||
### **Productivity & Storage**
|
||||
- **Google Sheets** - Spreadsheet data synchronization
|
||||
- **Google Calendar** - Event and schedule management
|
||||
- **Box** - File storage and document management
|
||||
|
||||
and more to come!
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using Authentication Integrations, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account. You can get started with a free trial.
|
||||
|
||||
|
||||
## Setting Up Integrations
|
||||
|
||||
### 1. Connect Your Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise](https://app.crewai.com)
|
||||
2. Go to **Integrations** tab - https://app.crewai.com/crewai_plus/connectors
|
||||
3. Click **Connect** on your desired service from the Authentication Integrations section
|
||||
4. Complete the OAuth authentication flow
|
||||
5. Grant necessary permissions for your use case
|
||||
6. Get your Enterprise Token from your [CrewAI Enterprise](https://app.crewai.com) account page - https://app.crewai.com/crewai_plus/settings/account
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### 2. Install Integration Tools
|
||||
|
||||
All you need is the latest version of `crewai-tools` package.
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Usage
|
||||
<Tip>
|
||||
All the services you are authenticated into will be available as tools. So all you need to do is add the `CrewaiEnterpriseTools` to your agent and you are good to go.
|
||||
</Tip>
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Gmail tool will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
# print the tools
|
||||
print(enterprise_tools)
|
||||
|
||||
# Create an agent with Gmail capabilities
|
||||
email_agent = Agent(
|
||||
role="Email Manager",
|
||||
goal="Manage and organize email communications",
|
||||
backstory="An AI assistant specialized in email management and communication.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to send an email
|
||||
email_task = Task(
|
||||
description="Draft and send a follow-up email to john@example.com about the project update",
|
||||
agent=email_agent,
|
||||
expected_output="Confirmation that email was sent successfully"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[email_agent],
|
||||
tasks=[email_task]
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
actions_list=["gmail_find_email"] # only gmail_find_email tool will be available
|
||||
)
|
||||
gmail_tool = enterprise_tools[0]
|
||||
|
||||
gmail_agent = Agent(
|
||||
role="Gmail Manager",
|
||||
goal="Manage gmail communications and notifications",
|
||||
backstory="An AI assistant that helps coordinate gmail communications.",
|
||||
tools=[gmail_tool]
|
||||
)
|
||||
|
||||
notification_task = Task(
|
||||
description="Find the email from john@example.com",
|
||||
agent=gmail_agent,
|
||||
expected_output="Email found from john@example.com"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[slack_agent],
|
||||
tasks=[notification_task]
|
||||
)
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
### Security
|
||||
- **Principle of Least Privilege**: Only grant the minimum permissions required for your agents' tasks
|
||||
- **Regular Audits**: Periodically review connected integrations and their permissions
|
||||
- **Secure Credentials**: Never hardcode credentials; use CrewAI's secure authentication flow
|
||||
|
||||
|
||||
### Filtering Tools
|
||||
On a deployed crew, you can specify which actions are avialbel for each integration from the settings page of the service you connected to.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
|
||||
### Scoped Deployments for multi user organizations
|
||||
You can deploy your crew and scope each integration to a specific user. For example, a crew that connects to google can use a specific user's gmail account.
|
||||
|
||||
<Tip>
|
||||
This is useful for multi user organizations where you want to scope the integration to a specific user.
|
||||
</Tip>
|
||||
|
||||
|
||||
Use the `user_bearer_token` to scope the integration to a specific user so that when the crew is kicked off, it will use the user's bearer token to authenticate with the integration. If user is not logged in, then the crew will not use any connected integrations. Use the default bearer token to authenticate with the integrations thats deployed with the crew.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -21,6 +21,7 @@ Before using the Tool Repository, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account
|
||||
- [CrewAI CLI](https://docs.crewai.com/concepts/cli#cli) installed
|
||||
- uv>=0.5.0 installed. Check out [how to upgrade](https://docs.astral.sh/uv/getting-started/installation/#upgrading-uv)
|
||||
- [Git](https://git-scm.com) installed and configured
|
||||
- Access permissions to publish or install tools in your CrewAI Enterprise organization
|
||||
|
||||
|
||||
@@ -277,22 +277,23 @@ This pattern allows you to combine direct data passing with state updates for ma
|
||||
|
||||
One of CrewAI's most powerful features is the ability to persist flow state across executions. This enables workflows that can be paused, resumed, and even recovered after failures.
|
||||
|
||||
### The @persist Decorator
|
||||
### The @persist() Decorator
|
||||
|
||||
The `@persist` decorator automates state persistence, saving your flow's state at key points in execution.
|
||||
The `@persist()` decorator automates state persistence, saving your flow's state at key points in execution.
|
||||
|
||||
#### Class-Level Persistence
|
||||
|
||||
When applied at the class level, `@persist` saves state after every method execution:
|
||||
When applied at the class level, `@persist()` saves state after every method execution:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, persist, start
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
from crewai.flow.persistence import persist
|
||||
from pydantic import BaseModel
|
||||
|
||||
class CounterState(BaseModel):
|
||||
value: int = 0
|
||||
|
||||
@persist # Apply to the entire flow class
|
||||
@persist() # Apply to the entire flow class
|
||||
class PersistentCounterFlow(Flow[CounterState]):
|
||||
@start()
|
||||
def increment(self):
|
||||
@@ -319,10 +320,11 @@ print(f"Second run result: {result2}") # Will be higher due to persisted state
|
||||
|
||||
#### Method-Level Persistence
|
||||
|
||||
For more granular control, you can apply `@persist` to specific methods:
|
||||
For more granular control, you can apply `@persist()` to specific methods:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, persist, start
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
from crewai.flow.persistence import persist
|
||||
|
||||
class SelectivePersistFlow(Flow):
|
||||
@start()
|
||||
@@ -330,7 +332,7 @@ class SelectivePersistFlow(Flow):
|
||||
self.state["count"] = 1
|
||||
return "First step"
|
||||
|
||||
@persist # Only persist after this method
|
||||
@persist() # Only persist after this method
|
||||
@listen(first_step)
|
||||
def important_step(self, prev_result):
|
||||
self.state["count"] += 1
|
||||
|
||||
BIN
docs/images/enterprise/crew_connectors.png
Normal file
BIN
docs/images/enterprise/crew_connectors.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 1.2 MiB |
BIN
docs/images/enterprise/enterprise-testing.png
Normal file
BIN
docs/images/enterprise/enterprise-testing.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 288 KiB |
BIN
docs/images/enterprise/enterprise_action_auth_token.png
Normal file
BIN
docs/images/enterprise/enterprise_action_auth_token.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 54 KiB |
BIN
docs/images/enterprise/filtering_enterprise_action_tools.png
Normal file
BIN
docs/images/enterprise/filtering_enterprise_action_tools.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 362 KiB |
BIN
docs/images/enterprise/user_bearer_token.png
Normal file
BIN
docs/images/enterprise/user_bearer_token.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 49 KiB |
@@ -22,7 +22,7 @@ Watch this video tutorial for a step-by-step demonstration of the installation p
|
||||
<Note>
|
||||
**Python Version Requirements**
|
||||
|
||||
CrewAI requires `Python >=3.10 and <3.13`. Here's how to check your version:
|
||||
CrewAI requires `Python >=3.10 and <3.14`. Here's how to check your version:
|
||||
```bash
|
||||
python3 --version
|
||||
```
|
||||
|
||||
@@ -108,6 +108,7 @@ crew_2 = Crew(agents=[coding_agent], tasks=[task_2])
|
||||
|
||||
# Async function to kickoff multiple crews asynchronously and wait for all to finish
|
||||
async def async_multiple_crews():
|
||||
# Create coroutines for concurrent execution
|
||||
result_1 = crew_1.kickoff_async(inputs={"ages": [25, 30, 35, 40, 45]})
|
||||
result_2 = crew_2.kickoff_async(inputs={"ages": [20, 22, 24, 28, 30]})
|
||||
|
||||
|
||||
729
docs/learn/llm-selection-guide.mdx
Normal file
729
docs/learn/llm-selection-guide.mdx
Normal file
@@ -0,0 +1,729 @@
|
||||
---
|
||||
title: 'Strategic LLM Selection Guide'
|
||||
description: 'Strategic framework for choosing the right LLM for your CrewAI AI agents and writing effective task and agent definitions'
|
||||
icon: 'brain-circuit'
|
||||
---
|
||||
|
||||
## The CrewAI Approach to LLM Selection
|
||||
|
||||
Rather than prescriptive model recommendations, we advocate for a **thinking framework** that helps you make informed decisions based on your specific use case, constraints, and requirements. The LLM landscape evolves rapidly, with new models emerging regularly and existing ones being updated frequently. What matters most is developing a systematic approach to evaluation that remains relevant regardless of which specific models are available.
|
||||
|
||||
<Note>
|
||||
This guide focuses on strategic thinking rather than specific model recommendations, as the LLM landscape evolves rapidly.
|
||||
</Note>
|
||||
|
||||
## Quick Decision Framework
|
||||
|
||||
<Steps>
|
||||
<Step title="Analyze Your Tasks">
|
||||
Begin by deeply understanding what your tasks actually require. Consider the cognitive complexity involved, the depth of reasoning needed, the format of expected outputs, and the amount of context the model will need to process. This foundational analysis will guide every subsequent decision.
|
||||
</Step>
|
||||
<Step title="Map Model Capabilities">
|
||||
Once you understand your requirements, map them to model strengths. Different model families excel at different types of work; some are optimized for reasoning and analysis, others for creativity and content generation, and others for speed and efficiency.
|
||||
</Step>
|
||||
<Step title="Consider Constraints">
|
||||
Factor in your real-world operational constraints including budget limitations, latency requirements, data privacy needs, and infrastructure capabilities. The theoretically best model may not be the practically best choice for your situation.
|
||||
</Step>
|
||||
<Step title="Test and Iterate">
|
||||
Start with reliable, well-understood models and optimize based on actual performance in your specific use case. Real-world results often differ from theoretical benchmarks, so empirical testing is crucial.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Core Selection Framework
|
||||
|
||||
### a. Task-First Thinking
|
||||
|
||||
The most critical step in LLM selection is understanding what your task actually demands. Too often, teams select models based on general reputation or benchmark scores without carefully analyzing their specific requirements. This approach leads to either over-engineering simple tasks with expensive, complex models, or under-powering sophisticated work with models that lack the necessary capabilities.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Reasoning Complexity">
|
||||
- **Simple Tasks** represent the majority of everyday AI work and include basic instruction following, straightforward data processing, and simple formatting operations. These tasks typically have clear inputs and outputs with minimal ambiguity. The cognitive load is low, and the model primarily needs to follow explicit instructions rather than engage in complex reasoning.
|
||||
|
||||
- **Complex Tasks** require multi-step reasoning, strategic thinking, and the ability to handle ambiguous or incomplete information. These might involve analyzing multiple data sources, developing comprehensive strategies, or solving problems that require breaking down into smaller components. The model needs to maintain context across multiple reasoning steps and often must make inferences that aren't explicitly stated.
|
||||
|
||||
- **Creative Tasks** demand a different type of cognitive capability focused on generating novel, engaging, and contextually appropriate content. This includes storytelling, marketing copy creation, and creative problem-solving. The model needs to understand nuance, tone, and audience while producing content that feels authentic and engaging rather than formulaic.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Output Requirements">
|
||||
- **Structured Data** tasks require precision and consistency in format adherence. When working with JSON, XML, or database formats, the model must reliably produce syntactically correct output that can be programmatically processed. These tasks often have strict validation requirements and little tolerance for format errors, making reliability more important than creativity.
|
||||
|
||||
- **Creative Content** outputs demand a balance of technical competence and creative flair. The model needs to understand audience, tone, and brand voice while producing content that engages readers and achieves specific communication goals. Quality here is often subjective and requires models that can adapt their writing style to different contexts and purposes.
|
||||
|
||||
- **Technical Content** sits between structured data and creative content, requiring both precision and clarity. Documentation, code generation, and technical analysis need to be accurate and comprehensive while remaining accessible to the intended audience. The model must understand complex technical concepts and communicate them effectively.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Context Needs">
|
||||
- **Short Context** scenarios involve focused, immediate tasks where the model needs to process limited information quickly. These are often transactional interactions where speed and efficiency matter more than deep understanding. The model doesn't need to maintain extensive conversation history or process large documents.
|
||||
|
||||
- **Long Context** requirements emerge when working with substantial documents, extended conversations, or complex multi-part tasks. The model needs to maintain coherence across thousands of tokens while referencing earlier information accurately. This capability becomes crucial for document analysis, comprehensive research, and sophisticated dialogue systems.
|
||||
|
||||
- **Very Long Context** scenarios push the boundaries of what's currently possible, involving massive document processing, extensive research synthesis, or complex multi-session interactions. These use cases require models specifically designed for extended context handling and often involve trade-offs between context length and processing speed.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### b. Model Capability Mapping
|
||||
|
||||
Understanding model capabilities requires looking beyond marketing claims and benchmark scores to understand the fundamental strengths and limitations of different model architectures and training approaches.
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Reasoning Models" icon="brain">
|
||||
Reasoning models represent a specialized category designed specifically for complex, multi-step thinking tasks. These models excel when problems require careful analysis, strategic planning, or systematic problem decomposition. They typically employ techniques like chain-of-thought reasoning or tree-of-thought processing to work through complex problems step by step.
|
||||
|
||||
The strength of reasoning models lies in their ability to maintain logical consistency across extended reasoning chains and to break down complex problems into manageable components. They're particularly valuable for strategic planning, complex analysis, and situations where the quality of reasoning matters more than speed of response.
|
||||
|
||||
However, reasoning models often come with trade-offs in terms of speed and cost. They may also be less suitable for creative tasks or simple operations where their sophisticated reasoning capabilities aren't needed. Consider these models when your tasks involve genuine complexity that benefits from systematic, step-by-step analysis.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="General Purpose Models" icon="microchip">
|
||||
General purpose models offer the most balanced approach to LLM selection, providing solid performance across a wide range of tasks without extreme specialization in any particular area. These models are trained on diverse datasets and optimized for versatility rather than peak performance in specific domains.
|
||||
|
||||
The primary advantage of general purpose models is their reliability and predictability across different types of work. They handle most standard business tasks competently, from research and analysis to content creation and data processing. This makes them excellent choices for teams that need consistent performance across varied workflows.
|
||||
|
||||
While general purpose models may not achieve the peak performance of specialized alternatives in specific domains, they offer operational simplicity and reduced complexity in model management. They're often the best starting point for new projects, allowing teams to understand their specific needs before potentially optimizing with more specialized models.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Fast & Efficient Models" icon="bolt">
|
||||
Fast and efficient models prioritize speed, cost-effectiveness, and resource efficiency over sophisticated reasoning capabilities. These models are optimized for high-throughput scenarios where quick responses and low operational costs are more important than nuanced understanding or complex reasoning.
|
||||
|
||||
These models excel in scenarios involving routine operations, simple data processing, function calling, and high-volume tasks where the cognitive requirements are relatively straightforward. They're particularly valuable for applications that need to process many requests quickly or operate within tight budget constraints.
|
||||
|
||||
The key consideration with efficient models is ensuring that their capabilities align with your task requirements. While they can handle many routine operations effectively, they may struggle with tasks requiring nuanced understanding, complex reasoning, or sophisticated content generation. They're best used for well-defined, routine operations where speed and cost matter more than sophistication.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Creative Models" icon="pen">
|
||||
Creative models are specifically optimized for content generation, writing quality, and creative thinking tasks. These models typically excel at understanding nuance, tone, and style while producing engaging, contextually appropriate content that feels natural and authentic.
|
||||
|
||||
The strength of creative models lies in their ability to adapt writing style to different audiences, maintain consistent voice and tone, and generate content that engages readers effectively. They often perform better on tasks involving storytelling, marketing copy, brand communications, and other content where creativity and engagement are primary goals.
|
||||
|
||||
When selecting creative models, consider not just their ability to generate text, but their understanding of audience, context, and purpose. The best creative models can adapt their output to match specific brand voices, target different audience segments, and maintain consistency across extended content pieces.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Open Source Models" icon="code">
|
||||
Open source models offer unique advantages in terms of cost control, customization potential, data privacy, and deployment flexibility. These models can be run locally or on private infrastructure, providing complete control over data handling and model behavior.
|
||||
|
||||
The primary benefits of open source models include elimination of per-token costs, ability to fine-tune for specific use cases, complete data privacy, and independence from external API providers. They're particularly valuable for organizations with strict data privacy requirements, budget constraints, or specific customization needs.
|
||||
|
||||
However, open source models require more technical expertise to deploy and maintain effectively. Teams need to consider infrastructure costs, model management complexity, and the ongoing effort required to keep models updated and optimized. The total cost of ownership may be higher than cloud-based alternatives when factoring in technical overhead.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Strategic Configuration Patterns
|
||||
|
||||
### a. Multi-Model Approach
|
||||
|
||||
<Tip>
|
||||
Use different models for different purposes within the same crew to optimize both performance and cost.
|
||||
</Tip>
|
||||
|
||||
The most sophisticated CrewAI implementations often employ multiple models strategically, assigning different models to different agents based on their specific roles and requirements. This approach allows teams to optimize for both performance and cost by using the most appropriate model for each type of work.
|
||||
|
||||
Planning agents benefit from reasoning models that can handle complex strategic thinking and multi-step analysis. These agents often serve as the "brain" of the operation, developing strategies and coordinating other agents' work. Content agents, on the other hand, perform best with creative models that excel at writing quality and audience engagement. Processing agents handling routine operations can use efficient models that prioritize speed and cost-effectiveness.
|
||||
|
||||
**Example: Research and Analysis Crew**
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM
|
||||
|
||||
# High-capability reasoning model for strategic planning
|
||||
manager_llm = LLM(model="gemini-2.5-flash-preview-05-20", temperature=0.1)
|
||||
|
||||
# Creative model for content generation
|
||||
content_llm = LLM(model="claude-3-5-sonnet-20241022", temperature=0.7)
|
||||
|
||||
# Efficient model for data processing
|
||||
processing_llm = LLM(model="gpt-4o-mini", temperature=0)
|
||||
|
||||
research_manager = Agent(
|
||||
role="Research Strategy Manager",
|
||||
goal="Develop comprehensive research strategies and coordinate team efforts",
|
||||
backstory="Expert research strategist with deep analytical capabilities",
|
||||
llm=manager_llm, # High-capability model for complex reasoning
|
||||
verbose=True
|
||||
)
|
||||
|
||||
content_writer = Agent(
|
||||
role="Research Content Writer",
|
||||
goal="Transform research findings into compelling, well-structured reports",
|
||||
backstory="Skilled writer who excels at making complex topics accessible",
|
||||
llm=content_llm, # Creative model for engaging content
|
||||
verbose=True
|
||||
)
|
||||
|
||||
data_processor = Agent(
|
||||
role="Data Analysis Specialist",
|
||||
goal="Extract and organize key data points from research sources",
|
||||
backstory="Detail-oriented analyst focused on accuracy and efficiency",
|
||||
llm=processing_llm, # Fast, cost-effective model for routine tasks
|
||||
verbose=True
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[research_manager, content_writer, data_processor],
|
||||
tasks=[...], # Your specific tasks
|
||||
manager_llm=manager_llm, # Manager uses the reasoning model
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
The key to successful multi-model implementation is understanding how different agents interact and ensuring that model capabilities align with agent responsibilities. This requires careful planning but can result in significant improvements in both output quality and operational efficiency.
|
||||
|
||||
### b. Component-Specific Selection
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Manager LLM">
|
||||
The manager LLM plays a crucial role in hierarchical CrewAI processes, serving as the coordination point for multiple agents and tasks. This model needs to excel at delegation, task prioritization, and maintaining context across multiple concurrent operations.
|
||||
|
||||
Effective manager LLMs require strong reasoning capabilities to make good delegation decisions, consistent performance to ensure predictable coordination, and excellent context management to track the state of multiple agents simultaneously. The model needs to understand the capabilities and limitations of different agents while optimizing task allocation for efficiency and quality.
|
||||
|
||||
Cost considerations are particularly important for manager LLMs since they're involved in every operation. The model needs to provide sufficient capability for effective coordination while remaining cost-effective for frequent use. This often means finding models that offer good reasoning capabilities without the premium pricing of the most sophisticated options.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Function Calling LLM">
|
||||
Function calling LLMs handle tool usage across all agents, making them critical for crews that rely heavily on external tools and APIs. These models need to excel at understanding tool capabilities, extracting parameters accurately, and handling tool responses effectively.
|
||||
|
||||
The most important characteristics for function calling LLMs are precision and reliability rather than creativity or sophisticated reasoning. The model needs to consistently extract the correct parameters from natural language requests and handle tool responses appropriately. Speed is also important since tool usage often involves multiple round trips that can impact overall performance.
|
||||
|
||||
Many teams find that specialized function calling models or general purpose models with strong tool support work better than creative or reasoning-focused models for this role. The key is ensuring that the model can reliably bridge the gap between natural language instructions and structured tool calls.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Agent-Specific Overrides">
|
||||
Individual agents can override crew-level LLM settings when their specific needs differ significantly from the general crew requirements. This capability allows for fine-tuned optimization while maintaining operational simplicity for most agents.
|
||||
|
||||
Consider agent-specific overrides when an agent's role requires capabilities that differ substantially from other crew members. For example, a creative writing agent might benefit from a model optimized for content generation, while a data analysis agent might perform better with a reasoning-focused model.
|
||||
|
||||
The challenge with agent-specific overrides is balancing optimization with operational complexity. Each additional model adds complexity to deployment, monitoring, and cost management. Teams should focus overrides on agents where the performance improvement justifies the additional complexity.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Task Definition Framework
|
||||
|
||||
### a. Focus on Clarity Over Complexity
|
||||
|
||||
Effective task definition is often more important than model selection in determining the quality of CrewAI outputs. Well-defined tasks provide clear direction and context that enable even modest models to perform well, while poorly defined tasks can cause even sophisticated models to produce unsatisfactory results.
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Effective Task Descriptions" icon="list-check">
|
||||
The best task descriptions strike a balance between providing sufficient detail and maintaining clarity. They should define the specific objective clearly enough that there's no ambiguity about what success looks like, while explaining the approach or methodology in enough detail that the agent understands how to proceed.
|
||||
|
||||
Effective task descriptions include relevant context and constraints that help the agent understand the broader purpose and any limitations they need to work within. They break complex work into focused steps that can be executed systematically, rather than presenting overwhelming, multi-faceted objectives that are difficult to approach systematically.
|
||||
|
||||
Common mistakes include being too vague about objectives, failing to provide necessary context, setting unclear success criteria, or combining multiple unrelated tasks into a single description. The goal is to provide enough information for the agent to succeed while maintaining focus on a single, clear objective.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Expected Output Guidelines" icon="bullseye">
|
||||
Expected output guidelines serve as a contract between the task definition and the agent, clearly specifying what the deliverable should look like and how it will be evaluated. These guidelines should describe both the format and structure needed, as well as the key elements that must be included for the output to be considered complete.
|
||||
|
||||
The best output guidelines provide concrete examples of quality indicators and define completion criteria clearly enough that both the agent and human reviewers can assess whether the task has been completed successfully. This reduces ambiguity and helps ensure consistent results across multiple task executions.
|
||||
|
||||
Avoid generic output descriptions that could apply to any task, missing format specifications that leave agents guessing about structure, unclear quality standards that make evaluation difficult, or failing to provide examples or templates that help agents understand expectations.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### b. Task Sequencing Strategy
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Sequential Dependencies">
|
||||
Sequential task dependencies are essential when tasks build upon previous outputs, information flows from one task to another, or quality depends on the completion of prerequisite work. This approach ensures that each task has access to the information and context it needs to succeed.
|
||||
|
||||
Implementing sequential dependencies effectively requires using the context parameter to chain related tasks, building complexity gradually through task progression, and ensuring that each task produces outputs that serve as meaningful inputs for subsequent tasks. The goal is to maintain logical flow between dependent tasks while avoiding unnecessary bottlenecks.
|
||||
|
||||
Sequential dependencies work best when there's a clear logical progression from one task to another and when the output of one task genuinely improves the quality or feasibility of subsequent tasks. However, they can create bottlenecks if not managed carefully, so it's important to identify which dependencies are truly necessary versus those that are merely convenient.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Parallel Execution">
|
||||
Parallel execution becomes valuable when tasks are independent of each other, time efficiency is important, or different expertise areas are involved that don't require coordination. This approach can significantly reduce overall execution time while allowing specialized agents to work on their areas of strength simultaneously.
|
||||
|
||||
Successful parallel execution requires identifying tasks that can truly run independently, grouping related but separate work streams effectively, and planning for result integration when parallel tasks need to be combined into a final deliverable. The key is ensuring that parallel tasks don't create conflicts or redundancies that reduce overall quality.
|
||||
|
||||
Consider parallel execution when you have multiple independent research streams, different types of analysis that don't depend on each other, or content creation tasks that can be developed simultaneously. However, be mindful of resource allocation and ensure that parallel execution doesn't overwhelm your available model capacity or budget.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Optimizing Agent Configuration for LLM Performance
|
||||
|
||||
### a. Role-Driven LLM Selection
|
||||
|
||||
<Warning>
|
||||
Generic agent roles make it impossible to select the right LLM. Specific roles enable targeted model optimization.
|
||||
</Warning>
|
||||
|
||||
The specificity of your agent roles directly determines which LLM capabilities matter most for optimal performance. This creates a strategic opportunity to match precise model strengths with agent responsibilities.
|
||||
|
||||
**Generic vs. Specific Role Impact on LLM Choice:**
|
||||
|
||||
When defining roles, think about the specific domain knowledge, working style, and decision-making frameworks that would be most valuable for the tasks the agent will handle. The more specific and contextual the role definition, the better the model can embody that role effectively.
|
||||
```python
|
||||
# ✅ Specific role - clear LLM requirements
|
||||
specific_agent = Agent(
|
||||
role="SaaS Revenue Operations Analyst", # Clear domain expertise needed
|
||||
goal="Analyze recurring revenue metrics and identify growth opportunities",
|
||||
backstory="Specialist in SaaS business models with deep understanding of ARR, churn, and expansion revenue",
|
||||
llm=LLM(model="gpt-4o") # Reasoning model justified for complex analysis
|
||||
)
|
||||
```
|
||||
|
||||
**Role-to-Model Mapping Strategy:**
|
||||
|
||||
- **"Research Analyst"** → Reasoning model (GPT-4o, Claude Sonnet) for complex analysis
|
||||
- **"Content Editor"** → Creative model (Claude, GPT-4o) for writing quality
|
||||
- **"Data Processor"** → Efficient model (GPT-4o-mini, Gemini Flash) for structured tasks
|
||||
- **"API Coordinator"** → Function-calling optimized model (GPT-4o, Claude) for tool usage
|
||||
|
||||
### b. Backstory as Model Context Amplifier
|
||||
|
||||
<Info>
|
||||
Strategic backstories multiply your chosen LLM's effectiveness by providing domain-specific context that generic prompting cannot achieve.
|
||||
</Info>
|
||||
|
||||
A well-crafted backstory transforms your LLM choice from generic capability to specialized expertise. This is especially crucial for cost optimization - a well-contextualized efficient model can outperform a premium model without proper context.
|
||||
|
||||
**Context-Driven Performance Example:**
|
||||
|
||||
```python
|
||||
# Context amplifies model effectiveness
|
||||
domain_expert = Agent(
|
||||
role="B2B SaaS Marketing Strategist",
|
||||
goal="Develop comprehensive go-to-market strategies for enterprise software",
|
||||
backstory="""
|
||||
You have 10+ years of experience scaling B2B SaaS companies from Series A to IPO.
|
||||
You understand the nuances of enterprise sales cycles, the importance of product-market
|
||||
fit in different verticals, and how to balance growth metrics with unit economics.
|
||||
You've worked with companies like Salesforce, HubSpot, and emerging unicorns, giving
|
||||
you perspective on both established and disruptive go-to-market strategies.
|
||||
""",
|
||||
llm=LLM(model="claude-3-5-sonnet", temperature=0.3) # Balanced creativity with domain knowledge
|
||||
)
|
||||
|
||||
# This context enables Claude to perform like a domain expert
|
||||
# Without it, even it would produce generic marketing advice
|
||||
```
|
||||
|
||||
**Backstory Elements That Enhance LLM Performance:**
|
||||
- **Domain Experience**: "10+ years in enterprise SaaS sales"
|
||||
- **Specific Expertise**: "Specializes in technical due diligence for Series B+ rounds"
|
||||
- **Working Style**: "Prefers data-driven decisions with clear documentation"
|
||||
- **Quality Standards**: "Insists on citing sources and showing analytical work"
|
||||
|
||||
### c. Holistic Agent-LLM Optimization
|
||||
|
||||
The most effective agent configurations create synergy between role specificity, backstory depth, and LLM selection. Each element reinforces the others to maximize model performance.
|
||||
|
||||
**Optimization Framework:**
|
||||
|
||||
```python
|
||||
# Example: Technical Documentation Agent
|
||||
tech_writer = Agent(
|
||||
role="API Documentation Specialist", # Specific role for clear LLM requirements
|
||||
goal="Create comprehensive, developer-friendly API documentation",
|
||||
backstory="""
|
||||
You're a technical writer with 8+ years documenting REST APIs, GraphQL endpoints,
|
||||
and SDK integration guides. You've worked with developer tools companies and
|
||||
understand what developers need: clear examples, comprehensive error handling,
|
||||
and practical use cases. You prioritize accuracy and usability over marketing fluff.
|
||||
""",
|
||||
llm=LLM(
|
||||
model="claude-3-5-sonnet", # Excellent for technical writing
|
||||
temperature=0.1 # Low temperature for accuracy
|
||||
),
|
||||
tools=[code_analyzer_tool, api_scanner_tool],
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
**Alignment Checklist:**
|
||||
- ✅ **Role Specificity**: Clear domain and responsibilities
|
||||
- ✅ **LLM Match**: Model strengths align with role requirements
|
||||
- ✅ **Backstory Depth**: Provides domain context the LLM can leverage
|
||||
- ✅ **Tool Integration**: Tools support the agent's specialized function
|
||||
- ✅ **Parameter Tuning**: Temperature and settings optimize for role needs
|
||||
|
||||
The key is creating agents where every configuration choice reinforces your LLM selection strategy, maximizing performance while optimizing costs.
|
||||
|
||||
## Practical Implementation Checklist
|
||||
|
||||
Rather than repeating the strategic framework, here's a tactical checklist for implementing your LLM selection decisions in CrewAI:
|
||||
|
||||
<Steps>
|
||||
<Step title="Audit Your Current Setup" icon="clipboard-check">
|
||||
**What to Review:**
|
||||
- Are all agents using the same LLM by default?
|
||||
- Which agents handle the most complex reasoning tasks?
|
||||
- Which agents primarily do data processing or formatting?
|
||||
- Are any agents heavily tool-dependent?
|
||||
|
||||
**Action**: Document current agent roles and identify optimization opportunities.
|
||||
</Step>
|
||||
|
||||
<Step title="Implement Crew-Level Strategy" icon="users-gear">
|
||||
**Set Your Baseline:**
|
||||
```python
|
||||
# Start with a reliable default for the crew
|
||||
default_crew_llm = LLM(model="gpt-4o-mini") # Cost-effective baseline
|
||||
|
||||
crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
memory=True
|
||||
)
|
||||
```
|
||||
|
||||
**Action**: Establish your crew's default LLM before optimizing individual agents.
|
||||
</Step>
|
||||
|
||||
<Step title="Optimize High-Impact Agents" icon="star">
|
||||
**Identify and Upgrade Key Agents:**
|
||||
```python
|
||||
# Manager or coordination agents
|
||||
manager_agent = Agent(
|
||||
role="Project Manager",
|
||||
llm=LLM(model="gemini-2.5-flash-preview-05-20"), # Premium for coordination
|
||||
# ... rest of config
|
||||
)
|
||||
|
||||
# Creative or customer-facing agents
|
||||
content_agent = Agent(
|
||||
role="Content Creator",
|
||||
llm=LLM(model="claude-3-5-sonnet"), # Best for writing
|
||||
# ... rest of config
|
||||
)
|
||||
```
|
||||
|
||||
**Action**: Upgrade 20% of your agents that handle 80% of the complexity.
|
||||
</Step>
|
||||
|
||||
<Step title="Validate with Enterprise Testing" icon="test-tube">
|
||||
**Once you deploy your agents to production:**
|
||||
- Use [CrewAI Enterprise platform](https://app.crewai.com) to A/B test your model selections
|
||||
- Run multiple iterations with real inputs to measure consistency and performance
|
||||
- Compare cost vs. performance across your optimized setup
|
||||
- Share results with your team for collaborative decision-making
|
||||
|
||||
**Action**: Replace guesswork with data-driven validation using the testing platform.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### When to Use Different Model Types
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Reasoning Models">
|
||||
Reasoning models become essential when tasks require genuine multi-step logical thinking, strategic planning, or high-level decision making that benefits from systematic analysis. These models excel when problems need to be broken down into components and analyzed systematically rather than handled through pattern matching or simple instruction following.
|
||||
|
||||
Consider reasoning models for business strategy development, complex data analysis that requires drawing insights from multiple sources, multi-step problem solving where each step depends on previous analysis, and strategic planning tasks that require considering multiple variables and their interactions.
|
||||
|
||||
However, reasoning models often come with higher costs and slower response times, so they're best reserved for tasks where their sophisticated capabilities provide genuine value rather than being used for simple operations that don't require complex reasoning.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Creative Models">
|
||||
Creative models become valuable when content generation is the primary output and the quality, style, and engagement level of that content directly impact success. These models excel when writing quality and style matter significantly, creative ideation or brainstorming is needed, or brand voice and tone are important considerations.
|
||||
|
||||
Use creative models for blog post writing and article creation, marketing copy that needs to engage and persuade, creative storytelling and narrative development, and brand communications where voice and tone are crucial. These models often understand nuance and context better than general purpose alternatives.
|
||||
|
||||
Creative models may be less suitable for technical or analytical tasks where precision and factual accuracy are more important than engagement and style. They're best used when the creative and communicative aspects of the output are primary success factors.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Efficient Models">
|
||||
Efficient models are ideal for high-frequency, routine operations where speed and cost optimization are priorities. These models work best when tasks have clear, well-defined parameters and don't require sophisticated reasoning or creative capabilities.
|
||||
|
||||
Consider efficient models for data processing and transformation tasks, simple formatting and organization operations, function calling and tool usage where precision matters more than sophistication, and high-volume operations where cost per operation is a significant factor.
|
||||
|
||||
The key with efficient models is ensuring that their capabilities align with task requirements. They can handle many routine operations effectively but may struggle with tasks requiring nuanced understanding, complex reasoning, or sophisticated content generation.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Open Source Models">
|
||||
Open source models become attractive when budget constraints are significant, data privacy requirements exist, customization needs are important, or local deployment is required for operational or compliance reasons.
|
||||
|
||||
Consider open source models for internal company tools where data privacy is paramount, privacy-sensitive applications that can't use external APIs, cost-optimized deployments where per-token pricing is prohibitive, and situations requiring custom model modifications or fine-tuning.
|
||||
|
||||
However, open source models require more technical expertise to deploy and maintain effectively. Consider the total cost of ownership including infrastructure, technical overhead, and ongoing maintenance when evaluating open source options.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Common CrewAI Model Selection Pitfalls
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="The 'One Model Fits All' Trap" icon="triangle-exclamation">
|
||||
**The Problem**: Using the same LLM for all agents in a crew, regardless of their specific roles and responsibilities. This is often the default approach but rarely optimal.
|
||||
|
||||
**Real Example**: Using GPT-4o for both a strategic planning manager and a data extraction agent. The manager needs reasoning capabilities worth the premium cost, but the data extractor could perform just as well with GPT-4o-mini at a fraction of the price.
|
||||
|
||||
**CrewAI Solution**: Leverage agent-specific LLM configuration to match model capabilities with agent roles:
|
||||
```python
|
||||
# Strategic agent gets premium model
|
||||
manager = Agent(role="Strategy Manager", llm=LLM(model="gpt-4o"))
|
||||
|
||||
# Processing agent gets efficient model
|
||||
processor = Agent(role="Data Processor", llm=LLM(model="gpt-4o-mini"))
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Ignoring Crew-Level vs Agent-Level LLM Hierarchy" icon="shuffle">
|
||||
**The Problem**: Not understanding how CrewAI's LLM hierarchy works - crew LLM, manager LLM, and agent LLM settings can conflict or be poorly coordinated.
|
||||
|
||||
**Real Example**: Setting a crew to use Claude, but having agents configured with GPT models, creating inconsistent behavior and unnecessary model switching overhead.
|
||||
|
||||
**CrewAI Solution**: Plan your LLM hierarchy strategically:
|
||||
```python
|
||||
crew = Crew(
|
||||
agents=[agent1, agent2],
|
||||
tasks=[task1, task2],
|
||||
manager_llm=LLM(model="gpt-4o"), # For crew coordination
|
||||
process=Process.hierarchical # When using manager_llm
|
||||
)
|
||||
|
||||
# Agents inherit crew LLM unless specifically overridden
|
||||
agent1 = Agent(llm=LLM(model="claude-3-5-sonnet")) # Override for specific needs
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Function Calling Model Mismatch" icon="screwdriver-wrench">
|
||||
**The Problem**: Choosing models based on general capabilities while ignoring function calling performance for tool-heavy CrewAI workflows.
|
||||
|
||||
**Real Example**: Selecting a creative-focused model for an agent that primarily needs to call APIs, search tools, or process structured data. The agent struggles with tool parameter extraction and reliable function calls.
|
||||
|
||||
**CrewAI Solution**: Prioritize function calling capabilities for tool-heavy agents:
|
||||
```python
|
||||
# For agents that use many tools
|
||||
tool_agent = Agent(
|
||||
role="API Integration Specialist",
|
||||
tools=[search_tool, api_tool, data_tool],
|
||||
llm=LLM(model="gpt-4o"), # Excellent function calling
|
||||
# OR
|
||||
llm=LLM(model="claude-3-5-sonnet") # Also strong with tools
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Premature Optimization Without Testing" icon="gear">
|
||||
**The Problem**: Making complex model selection decisions based on theoretical performance without validating with actual CrewAI workflows and tasks.
|
||||
|
||||
**Real Example**: Implementing elaborate model switching logic based on task types without testing if the performance gains justify the operational complexity.
|
||||
|
||||
**CrewAI Solution**: Start simple, then optimize based on real performance data:
|
||||
```python
|
||||
# Start with this
|
||||
crew = Crew(agents=[...], tasks=[...], llm=LLM(model="gpt-4o-mini"))
|
||||
|
||||
# Test performance, then optimize specific agents as needed
|
||||
# Use Enterprise platform testing to validate improvements
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Overlooking Context and Memory Limitations" icon="brain">
|
||||
**The Problem**: Not considering how model context windows interact with CrewAI's memory and context sharing between agents.
|
||||
|
||||
**Real Example**: Using a short-context model for agents that need to maintain conversation history across multiple task iterations, or in crews with extensive agent-to-agent communication.
|
||||
|
||||
**CrewAI Solution**: Match context capabilities to crew communication patterns.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Testing and Iteration Strategy
|
||||
|
||||
<Steps>
|
||||
<Step title="Start Simple" icon="play">
|
||||
Begin with reliable, general-purpose models that are well-understood and widely supported. This provides a stable foundation for understanding your specific requirements and performance expectations before optimizing for specialized needs.
|
||||
</Step>
|
||||
<Step title="Measure What Matters" icon="chart-line">
|
||||
Develop metrics that align with your specific use case and business requirements rather than relying solely on general benchmarks. Focus on measuring outcomes that directly impact your success rather than theoretical performance indicators.
|
||||
</Step>
|
||||
<Step title="Iterate Based on Results" icon="arrows-rotate">
|
||||
Make model changes based on observed performance in your specific context rather than theoretical considerations or general recommendations. Real-world performance often differs significantly from benchmark results or general reputation.
|
||||
</Step>
|
||||
<Step title="Consider Total Cost" icon="calculator">
|
||||
Evaluate the complete cost of ownership including model costs, development time, maintenance overhead, and operational complexity. The cheapest model per token may not be the most cost-effective choice when considering all factors.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<Tip>
|
||||
Focus on understanding your requirements first, then select models that best match those needs. The best LLM choice is the one that consistently delivers the results you need within your operational constraints.
|
||||
</Tip>
|
||||
|
||||
### Enterprise-Grade Model Validation
|
||||
|
||||
For teams serious about optimizing their LLM selection, the **CrewAI Enterprise platform** provides sophisticated testing capabilities that go far beyond basic CLI testing. The platform enables comprehensive model evaluation that helps you make data-driven decisions about your LLM strategy.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
**Advanced Testing Features:**
|
||||
|
||||
- **Multi-Model Comparison**: Test multiple LLMs simultaneously across the same tasks and inputs. Compare performance between GPT-4o, Claude, Llama, Groq, Cerebras, and other leading models in parallel to identify the best fit for your specific use case.
|
||||
|
||||
- **Statistical Rigor**: Configure multiple iterations with consistent inputs to measure reliability and performance variance. This helps identify models that not only perform well but do so consistently across runs.
|
||||
|
||||
- **Real-World Validation**: Use your actual crew inputs and scenarios rather than synthetic benchmarks. The platform allows you to test with your specific industry context, company information, and real use cases for more accurate evaluation.
|
||||
|
||||
- **Comprehensive Analytics**: Access detailed performance metrics, execution times, and cost analysis across all tested models. This enables data-driven decision making rather than relying on general model reputation or theoretical capabilities.
|
||||
|
||||
- **Team Collaboration**: Share testing results and model performance data across your team, enabling collaborative decision-making and consistent model selection strategies across projects.
|
||||
|
||||
Go to [app.crewai.com](https://app.crewai.com) to get started!
|
||||
|
||||
<Info>
|
||||
The Enterprise platform transforms model selection from guesswork into a data-driven process, enabling you to validate the principles in this guide with your actual use cases and requirements.
|
||||
</Info>
|
||||
|
||||
## Key Principles Summary
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Task-Driven Selection" icon="bullseye">
|
||||
Choose models based on what the task actually requires, not theoretical capabilities or general reputation.
|
||||
</Card>
|
||||
|
||||
<Card title="Capability Matching" icon="puzzle-piece">
|
||||
Align model strengths with agent roles and responsibilities for optimal performance.
|
||||
</Card>
|
||||
|
||||
<Card title="Strategic Consistency" icon="link">
|
||||
Maintain coherent model selection strategy across related components and workflows.
|
||||
</Card>
|
||||
|
||||
<Card title="Practical Testing" icon="flask">
|
||||
Validate choices through real-world usage rather than benchmarks alone.
|
||||
</Card>
|
||||
|
||||
<Card title="Iterative Improvement" icon="arrow-up">
|
||||
Start simple and optimize based on actual performance and needs.
|
||||
</Card>
|
||||
|
||||
<Card title="Operational Balance" icon="scale-balanced">
|
||||
Balance performance requirements with cost and complexity constraints.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
<Check>
|
||||
Remember: The best LLM choice is the one that consistently delivers the results you need within your operational constraints. Focus on understanding your requirements first, then select models that best match those needs.
|
||||
</Check>
|
||||
|
||||
## Current Model Landscape (June 2025)
|
||||
|
||||
<Warning>
|
||||
**Snapshot in Time**: The following model rankings represent current leaderboard standings as of June 2025, compiled from [LMSys Arena](https://arena.lmsys.org/), [Artificial Analysis](https://artificialanalysis.ai/), and other leading benchmarks. LLM performance, availability, and pricing change rapidly. Always conduct your own evaluations with your specific use cases and data.
|
||||
</Warning>
|
||||
|
||||
### Leading Models by Category
|
||||
|
||||
The tables below show a representative sample of current top-performing models across different categories, with guidance on their suitability for CrewAI agents:
|
||||
|
||||
<Note>
|
||||
These tables/metrics showcase selected leading models in each category and are not exhaustive. Many excellent models exist beyond those listed here. The goal is to illustrate the types of capabilities to look for rather than provide a complete catalog.
|
||||
</Note>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Reasoning & Planning">
|
||||
**Best for Manager LLMs and Complex Analysis**
|
||||
|
||||
| Model | Intelligence Score | Cost ($/M tokens) | Speed | Best Use in CrewAI |
|
||||
|:------|:------------------|:------------------|:------|:------------------|
|
||||
| **o3** | 70 | $17.50 | Fast | Manager LLM for complex multi-agent coordination |
|
||||
| **Gemini 2.5 Pro** | 69 | $3.44 | Fast | Strategic planning agents, research coordination |
|
||||
| **DeepSeek R1** | 68 | $0.96 | Moderate | Cost-effective reasoning for budget-conscious crews |
|
||||
| **Claude 4 Sonnet** | 53 | $6.00 | Fast | Analysis agents requiring nuanced understanding |
|
||||
| **Qwen3 235B (Reasoning)** | 62 | $2.63 | Moderate | Open-source alternative for reasoning tasks |
|
||||
|
||||
These models excel at multi-step reasoning and are ideal for agents that need to develop strategies, coordinate other agents, or analyze complex information.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Coding & Technical">
|
||||
**Best for Development and Tool-Heavy Workflows**
|
||||
|
||||
| Model | Coding Performance | Tool Use Score | Cost ($/M tokens) | Best Use in CrewAI |
|
||||
|:------|:------------------|:---------------|:------------------|:------------------|
|
||||
| **Claude 4 Sonnet** | Excellent | 72.7% | $6.00 | Primary coding agent, technical documentation |
|
||||
| **Claude 4 Opus** | Excellent | 72.5% | $30.00 | Complex software architecture, code review |
|
||||
| **DeepSeek V3** | Very Good | High | $0.48 | Cost-effective coding for routine development |
|
||||
| **Qwen2.5 Coder 32B** | Very Good | Medium | $0.15 | Budget-friendly coding agent |
|
||||
| **Llama 3.1 405B** | Good | 81.1% | $3.50 | Function calling LLM for tool-heavy workflows |
|
||||
|
||||
These models are optimized for code generation, debugging, and technical problem-solving, making them ideal for development-focused crews.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Speed & Efficiency">
|
||||
**Best for High-Throughput and Real-Time Applications**
|
||||
|
||||
| Model | Speed (tokens/s) | Latency (TTFT) | Cost ($/M tokens) | Best Use in CrewAI |
|
||||
|:------|:-----------------|:---------------|:------------------|:------------------|
|
||||
| **Llama 4 Scout** | 2,600 | 0.33s | $0.27 | High-volume processing agents |
|
||||
| **Gemini 2.5 Flash** | 376 | 0.30s | $0.26 | Real-time response agents |
|
||||
| **DeepSeek R1 Distill** | 383 | Variable | $0.04 | Cost-optimized high-speed processing |
|
||||
| **Llama 3.3 70B** | 2,500 | 0.52s | $0.60 | Balanced speed and capability |
|
||||
| **Nova Micro** | High | 0.30s | $0.04 | Simple, fast task execution |
|
||||
|
||||
These models prioritize speed and efficiency, perfect for agents handling routine operations or requiring quick responses. **Pro tip**: Pairing these models with fast inference providers like Groq can achieve even better performance, especially for open-source models like Llama.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Balanced Performance">
|
||||
**Best All-Around Models for General Crews**
|
||||
|
||||
| Model | Overall Score | Versatility | Cost ($/M tokens) | Best Use in CrewAI |
|
||||
|:------|:--------------|:------------|:------------------|:------------------|
|
||||
| **GPT-4.1** | 53 | Excellent | $3.50 | General-purpose crew LLM |
|
||||
| **Claude 3.7 Sonnet** | 48 | Very Good | $6.00 | Balanced reasoning and creativity |
|
||||
| **Gemini 2.0 Flash** | 48 | Good | $0.17 | Cost-effective general use |
|
||||
| **Llama 4 Maverick** | 51 | Good | $0.37 | Open-source general purpose |
|
||||
| **Qwen3 32B** | 44 | Good | $1.23 | Budget-friendly versatility |
|
||||
|
||||
These models offer good performance across multiple dimensions, suitable for crews with diverse task requirements.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### Selection Framework for Current Models
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="High-Performance Crews" icon="rocket">
|
||||
**When performance is the priority**: Use top-tier models like **o3**, **Gemini 2.5 Pro**, or **Claude 4 Sonnet** for manager LLMs and critical agents. These models excel at complex reasoning and coordination but come with higher costs.
|
||||
|
||||
**Strategy**: Implement a multi-model approach where premium models handle strategic thinking while efficient models handle routine operations.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Cost-Conscious Crews" icon="dollar-sign">
|
||||
**When budget is a primary constraint**: Focus on models like **DeepSeek R1**, **Llama 4 Scout**, or **Gemini 2.0 Flash**. These provide strong performance at significantly lower costs.
|
||||
|
||||
**Strategy**: Use cost-effective models for most agents, reserving premium models only for the most critical decision-making roles.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Specialized Workflows" icon="screwdriver-wrench">
|
||||
**For specific domain expertise**: Choose models optimized for your primary use case. **Claude 4** series for coding, **Gemini 2.5 Pro** for research, **Llama 405B** for function calling.
|
||||
|
||||
**Strategy**: Select models based on your crew's primary function, ensuring the core capability aligns with model strengths.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Enterprise & Privacy" icon="shield">
|
||||
**For data-sensitive operations**: Consider open-source models like **Llama 4** series, **DeepSeek V3**, or **Qwen3** that can be deployed locally while maintaining competitive performance.
|
||||
|
||||
**Strategy**: Deploy open-source models on private infrastructure, accepting potential performance trade-offs for data control.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### Key Considerations for Model Selection
|
||||
|
||||
- **Performance Trends**: The current landscape shows strong competition between reasoning-focused models (o3, Gemini 2.5 Pro) and balanced models (Claude 4, GPT-4.1). Specialized models like DeepSeek R1 offer excellent cost-performance ratios.
|
||||
|
||||
- **Speed vs. Intelligence Trade-offs**: Models like Llama 4 Scout prioritize speed (2,600 tokens/s) while maintaining reasonable intelligence, whereas models like o3 maximize reasoning capability at the cost of speed and price.
|
||||
|
||||
- **Open Source Viability**: The gap between open-source and proprietary models continues to narrow, with models like Llama 4 Maverick and DeepSeek V3 offering competitive performance at attractive price points. Fast inference providers particularly shine with open-source models, often delivering better speed-to-cost ratios than proprietary alternatives.
|
||||
|
||||
<Info>
|
||||
**Testing is Essential**: Leaderboard rankings provide general guidance, but your specific use case, prompting style, and evaluation criteria may produce different results. Always test candidate models with your actual tasks and data before making final decisions.
|
||||
</Info>
|
||||
|
||||
### Practical Implementation Strategy
|
||||
|
||||
<Steps>
|
||||
<Step title="Start with Proven Models">
|
||||
Begin with well-established models like **GPT-4.1**, **Claude 3.7 Sonnet**, or **Gemini 2.0 Flash** that offer good performance across multiple dimensions and have extensive real-world validation.
|
||||
</Step>
|
||||
|
||||
<Step title="Identify Specialized Needs">
|
||||
Determine if your crew has specific requirements (coding, reasoning, speed) that would benefit from specialized models like **Claude 4 Sonnet** for development or **o3** for complex analysis. For speed-critical applications, consider fast inference providers like **Groq** alongside model selection.
|
||||
</Step>
|
||||
|
||||
<Step title="Implement Multi-Model Strategy">
|
||||
Use different models for different agents based on their roles. High-capability models for managers and complex tasks, efficient models for routine operations.
|
||||
</Step>
|
||||
|
||||
<Step title="Monitor and Optimize">
|
||||
Track performance metrics relevant to your use case and be prepared to adjust model selections as new models are released or pricing changes.
|
||||
</Step>
|
||||
</Steps>
|
||||
152
docs/observability/maxim.mdx
Normal file
152
docs/observability/maxim.mdx
Normal file
@@ -0,0 +1,152 @@
|
||||
---
|
||||
title: Maxim Integration
|
||||
description: Start Agent monitoring, evaluation, and observability
|
||||
icon: bars-staggered
|
||||
---
|
||||
|
||||
# Maxim Integration
|
||||
|
||||
Maxim AI provides comprehensive agent monitoring, evaluation, and observability for your CrewAI applications. With Maxim's one-line integration, you can easily trace and analyse agent interactions, performance metrics, and more.
|
||||
|
||||
|
||||
## Features: One Line Integration
|
||||
|
||||
- **End-to-End Agent Tracing**: Monitor the complete lifecycle of your agents
|
||||
- **Performance Analytics**: Track latency, tokens consumed, and costs
|
||||
- **Hyperparameter Monitoring**: View the configuration details of your agent runs
|
||||
- **Tool Call Tracking**: Observe when and how agents use their tools
|
||||
- **Advanced Visualisation**: Understand agent trajectories through intuitive dashboards
|
||||
|
||||
## Getting Started
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- Python version >=3.10
|
||||
- A Maxim account ([sign up here](https://getmaxim.ai/))
|
||||
- A CrewAI project
|
||||
|
||||
### Installation
|
||||
|
||||
Install the Maxim SDK via pip:
|
||||
|
||||
```python
|
||||
pip install maxim-py>=3.6.2
|
||||
```
|
||||
|
||||
Or add it to your `requirements.txt`:
|
||||
|
||||
```
|
||||
maxim-py>=3.6.2
|
||||
```
|
||||
|
||||
|
||||
### Basic Setup
|
||||
|
||||
### 1. Set up environment variables
|
||||
|
||||
```python
|
||||
### Environment Variables Setup
|
||||
|
||||
# Create a `.env` file in your project root:
|
||||
|
||||
# Maxim API Configuration
|
||||
MAXIM_API_KEY=your_api_key_here
|
||||
MAXIM_LOG_REPO_ID=your_repo_id_here
|
||||
```
|
||||
|
||||
### 2. Import the required packages
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
from maxim import Maxim
|
||||
from maxim.logger.crewai import instrument_crewai
|
||||
```
|
||||
|
||||
### 3. Initialise Maxim with your API key
|
||||
|
||||
```python
|
||||
# Initialize Maxim logger
|
||||
logger = Maxim().logger()
|
||||
|
||||
# Instrument CrewAI with just one line
|
||||
instrument_crewai(logger)
|
||||
```
|
||||
|
||||
### 4. Create and run your CrewAI application as usual
|
||||
|
||||
```python
|
||||
|
||||
# Create your agent
|
||||
researcher = Agent(
|
||||
role='Senior Research Analyst',
|
||||
goal='Uncover cutting-edge developments in AI',
|
||||
backstory="You are an expert researcher at a tech think tank...",
|
||||
verbose=True,
|
||||
llm=llm
|
||||
)
|
||||
|
||||
# Define the task
|
||||
research_task = Task(
|
||||
description="Research the latest AI advancements...",
|
||||
expected_output="",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
# Configure and run the crew
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[research_task],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
try:
|
||||
result = crew.kickoff()
|
||||
finally:
|
||||
maxim.cleanup() # Ensure cleanup happens even if errors occur
|
||||
```
|
||||
|
||||
That's it! All your CrewAI agent interactions will now be logged and available in your Maxim dashboard.
|
||||
|
||||
Check this Google Colab Notebook for a quick reference - [Notebook](https://colab.research.google.com/drive/1ZKIZWsmgQQ46n8TH9zLsT1negKkJA6K8?usp=sharing)
|
||||
|
||||
## Viewing Your Traces
|
||||
|
||||
After running your CrewAI application:
|
||||
|
||||
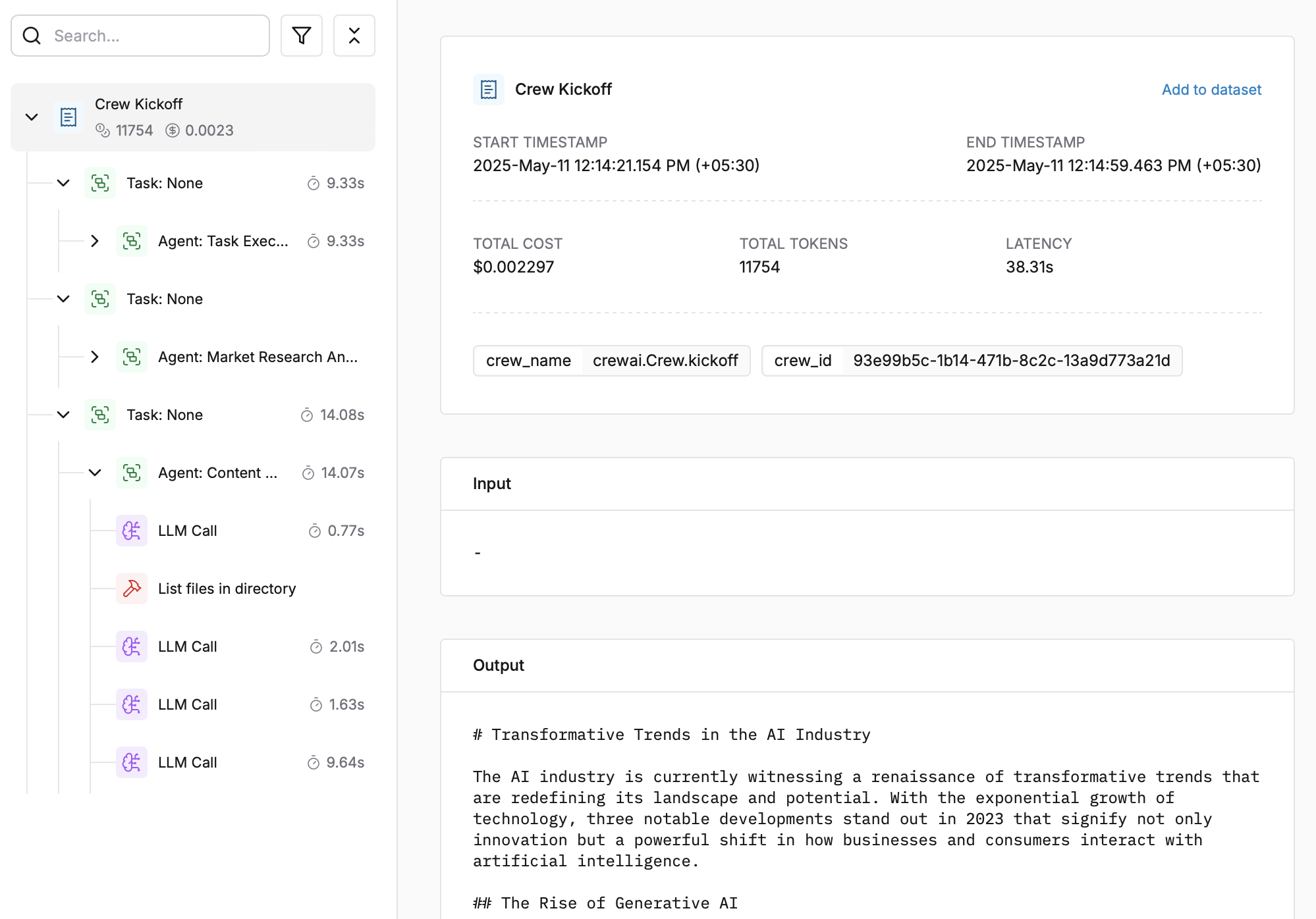
|
||||
|
||||
1. Log in to your [Maxim Dashboard](https://getmaxim.ai/dashboard)
|
||||
2. Navigate to your repository
|
||||
3. View detailed agent traces, including:
|
||||
- Agent conversations
|
||||
- Tool usage patterns
|
||||
- Performance metrics
|
||||
- Cost analytics
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
- **No traces appearing**: Ensure your API key and repository ID are correc
|
||||
- Ensure you've **called `instrument_crewai()`** ***before*** running your crew. This initializes logging hooks correctly.
|
||||
- Set `debug=True` in your `instrument_crewai()` call to surface any internal errors:
|
||||
|
||||
```python
|
||||
instrument_crewai(logger, debug=True)
|
||||
```
|
||||
|
||||
- Configure your agents with `verbose=True` to capture detailed logs:
|
||||
|
||||
```python
|
||||
|
||||
agent = CrewAgent(..., verbose=True)
|
||||
```
|
||||
|
||||
- Double-check that `instrument_crewai()` is called **before** creating or executing agents. This might be obvious, but it's a common oversight.
|
||||
|
||||
### Support
|
||||
|
||||
If you encounter any issues:
|
||||
|
||||
- Check the [Maxim Documentation](https://getmaxim.ai/docs)
|
||||
- Maxim Github [Link](https://github.com/maximhq)
|
||||
@@ -7,196 +7,818 @@ icon: key
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-CrewAI.png" alt="Portkey CrewAI Header Image" width="70%" />
|
||||
|
||||
|
||||
[Portkey](https://portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) is a 2-line upgrade to make your CrewAI agents reliable, cost-efficient, and fast.
|
||||
|
||||
Portkey adds 4 core production capabilities to any CrewAI agent:
|
||||
1. Routing to **200+ LLMs**
|
||||
2. Making each LLM call more robust
|
||||
3. Full-stack tracing & cost, performance analytics
|
||||
4. Real-time guardrails to enforce behavior
|
||||
## Introduction
|
||||
|
||||
## Getting Started
|
||||
Portkey enhances CrewAI with production-readiness features, turning your experimental agent crews into robust systems by providing:
|
||||
|
||||
- **Complete observability** of every agent step, tool use, and interaction
|
||||
- **Built-in reliability** with fallbacks, retries, and load balancing
|
||||
- **Cost tracking and optimization** to manage your AI spend
|
||||
- **Access to 200+ LLMs** through a single integration
|
||||
- **Guardrails** to keep agent behavior safe and compliant
|
||||
- **Version-controlled prompts** for consistent agent performance
|
||||
|
||||
|
||||
### Installation & Setup
|
||||
|
||||
<Steps>
|
||||
<Step title="Install CrewAI and Portkey">
|
||||
```bash
|
||||
pip install -qU crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure the LLM Client">
|
||||
To build CrewAI Agents with Portkey, you'll need two keys:
|
||||
- **Portkey API Key**: Sign up on the [Portkey app](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) and copy your API key
|
||||
- **Virtual Key**: Virtual Keys securely manage your LLM API keys in one place. Store your LLM provider API keys securely in Portkey's vault
|
||||
<Step title="Install the required packages">
|
||||
```bash
|
||||
pip install -U crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
<Step title="Generate API Key" icon="lock">
|
||||
Create a Portkey API key with optional budget/rate limits from the [Portkey dashboard](https://app.portkey.ai/). You can also attach configurations for reliability, caching, and more to this key. More on this later.
|
||||
</Step>
|
||||
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy", # We are using Virtual key
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_VIRTUAL_KEY", # Enter your Virtual key from Portkey
|
||||
)
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Create and Run Your First Agent">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
# Define your agents with roles and goals
|
||||
coder = Agent(
|
||||
role='Software developer',
|
||||
goal='Write clear, concise code on demand',
|
||||
backstory='An expert coder with a keen eye for software trends.',
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description="Define the HTML for making a simple website with heading- Hello World! Portkey is working!",
|
||||
expected_output="A clear and concise HTML code",
|
||||
agent=coder
|
||||
)
|
||||
|
||||
# Instantiate your crew
|
||||
crew = Crew(
|
||||
agents=[coder],
|
||||
tasks=[task1],
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Key Features
|
||||
|
||||
| Feature | Description |
|
||||
|:--------|:------------|
|
||||
| 🌐 Multi-LLM Support | Access OpenAI, Anthropic, Gemini, Azure, and 250+ providers through a unified interface |
|
||||
| 🛡️ Production Reliability | Implement retries, timeouts, load balancing, and fallbacks |
|
||||
| 📊 Advanced Observability | Track 40+ metrics including costs, tokens, latency, and custom metadata |
|
||||
| 🔍 Comprehensive Logging | Debug with detailed execution traces and function call logs |
|
||||
| 🚧 Security Controls | Set budget limits and implement role-based access control |
|
||||
| 🔄 Performance Analytics | Capture and analyze feedback for continuous improvement |
|
||||
| 💾 Intelligent Caching | Reduce costs and latency with semantic or simple caching |
|
||||
|
||||
|
||||
## Production Features with Portkey Configs
|
||||
|
||||
All features mentioned below are through Portkey's Config system. Portkey's Config system allows you to define routing strategies using simple JSON objects in your LLM API calls. You can create and manage Configs directly in your code or through the Portkey Dashboard. Each Config has a unique ID for easy reference.
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/Portkey-AI/docs-core/refs/heads/main/images/libraries/libraries-3.avif"/>
|
||||
</Frame>
|
||||
|
||||
|
||||
### 1. Use 250+ LLMs
|
||||
Access various LLMs like Anthropic, Gemini, Mistral, Azure OpenAI, and more with minimal code changes. Switch between providers or use them together seamlessly. [Learn more about Universal API](https://portkey.ai/docs/product/ai-gateway/universal-api)
|
||||
|
||||
|
||||
Easily switch between different LLM providers:
|
||||
<Step title="Configure CrewAI with Portkey">
|
||||
The integration is simple - you just need to update the LLM configuration in your CrewAI setup:
|
||||
|
||||
```python
|
||||
# Anthropic Configuration
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create an LLM instance with Portkey integration
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
api_key="dummy", # We are using a Virtual key, so this is a placeholder
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY", #You don't need provider when using Virtual keys
|
||||
trace_id="anthropic_agent"
|
||||
virtual_key="YOUR_LLM_VIRTUAL_KEY",
|
||||
trace_id="unique-trace-id", # Optional, for request tracing
|
||||
)
|
||||
)
|
||||
|
||||
# Azure OpenAI Configuration
|
||||
azure_llm = LLM(
|
||||
model="gpt-4",
|
||||
#Use them in your Crew Agents like this:
|
||||
|
||||
@agent
|
||||
def lead_market_analyst(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['lead_market_analyst'],
|
||||
verbose=True,
|
||||
memory=False,
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
<Info>
|
||||
**What are Virtual Keys?** Virtual keys in Portkey securely store your LLM provider API keys (OpenAI, Anthropic, etc.) in an encrypted vault. They allow for easier key rotation and budget management. [Learn more about virtual keys here](https://portkey.ai/docs/product/ai-gateway/virtual-keys).
|
||||
</Info>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Production Features
|
||||
|
||||
### 1. Enhanced Observability
|
||||
|
||||
Portkey provides comprehensive observability for your CrewAI agents, helping you understand exactly what's happening during each execution.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Traces">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Product%2011.1.webp"/>
|
||||
</Frame>
|
||||
|
||||
Traces provide a hierarchical view of your crew's execution, showing the sequence of LLM calls, tool invocations, and state transitions.
|
||||
|
||||
```python
|
||||
# Add trace_id to enable hierarchical tracing in Portkey
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_AZURE_VIRTUAL_KEY", #You don't need provider when using Virtual keys
|
||||
trace_id="azure_agent"
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
trace_id="unique-session-id" # Add unique trace ID
|
||||
)
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Logs">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Metadata.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey logs every interaction with LLMs, including:
|
||||
|
||||
- Complete request and response payloads
|
||||
- Latency and token usage metrics
|
||||
- Cost calculations
|
||||
- Tool calls and function executions
|
||||
|
||||
All logs can be filtered by metadata, trace IDs, models, and more, making it easy to debug specific crew runs.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Metrics & Dashboards">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Dashboard.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey provides built-in dashboards that help you:
|
||||
|
||||
- Track cost and token usage across all crew runs
|
||||
- Analyze performance metrics like latency and success rates
|
||||
- Identify bottlenecks in your agent workflows
|
||||
- Compare different crew configurations and LLMs
|
||||
|
||||
You can filter and segment all metrics by custom metadata to analyze specific crew types, user groups, or use cases.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Metadata Filtering">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png" alt="Analytics with metadata filters" />
|
||||
</Frame>
|
||||
|
||||
Add custom metadata to your CrewAI LLM configuration to enable powerful filtering and segmentation:
|
||||
|
||||
```python
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"crew_type": "research_crew",
|
||||
"environment": "production",
|
||||
"_user": "user_123", # Special _user field for user analytics
|
||||
"request_source": "mobile_app"
|
||||
}
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
This metadata can be used to filter logs, traces, and metrics on the Portkey dashboard, allowing you to analyze specific crew runs, users, or environments.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 2. Caching
|
||||
Improve response times and reduce costs with two powerful caching modes:
|
||||
- **Simple Cache**: Perfect for exact matches
|
||||
- **Semantic Cache**: Matches responses for requests that are semantically similar
|
||||
[Learn more about Caching](https://portkey.ai/docs/product/ai-gateway/cache-simple-and-semantic)
|
||||
### 2. Reliability - Keep Your Crews Running Smoothly
|
||||
|
||||
```py
|
||||
config = {
|
||||
"cache": {
|
||||
"mode": "semantic", # or "simple" for exact matching
|
||||
When running crews in production, things can go wrong - API rate limits, network issues, or provider outages. Portkey's reliability features ensure your agents keep running smoothly even when problems occur.
|
||||
|
||||
It's simple to enable fallback in your CrewAI setup by using a Portkey Config:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create LLM with fallback configuration
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
config={
|
||||
"strategy": {
|
||||
"mode": "fallback"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"provider": "openai",
|
||||
"api_key": "YOUR_OPENAI_API_KEY",
|
||||
"override_params": {"model": "gpt-4o"}
|
||||
},
|
||||
{
|
||||
"provider": "anthropic",
|
||||
"api_key": "YOUR_ANTHROPIC_API_KEY",
|
||||
"override_params": {"model": "claude-3-opus-20240229"}
|
||||
}
|
||||
]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Use this LLM configuration with your agents
|
||||
```
|
||||
|
||||
This configuration will automatically try Claude if the GPT-4o request fails, ensuring your crew can continue operating.
|
||||
|
||||
<CardGroup cols="2">
|
||||
<Card title="Automatic Retries" icon="rotate" href="https://portkey.ai/docs/product/ai-gateway/automatic-retries">
|
||||
Handles temporary failures automatically. If an LLM call fails, Portkey will retry the same request for the specified number of times - perfect for rate limits or network blips.
|
||||
</Card>
|
||||
<Card title="Request Timeouts" icon="clock" href="https://portkey.ai/docs/product/ai-gateway/request-timeouts">
|
||||
Prevent your agents from hanging. Set timeouts to ensure you get responses (or can fail gracefully) within your required timeframes.
|
||||
</Card>
|
||||
<Card title="Conditional Routing" icon="route" href="https://portkey.ai/docs/product/ai-gateway/conditional-routing">
|
||||
Send different requests to different providers. Route complex reasoning to GPT-4, creative tasks to Claude, and quick responses to Gemini based on your needs.
|
||||
</Card>
|
||||
<Card title="Fallbacks" icon="shield" href="https://portkey.ai/docs/product/ai-gateway/fallbacks">
|
||||
Keep running even if your primary provider fails. Automatically switch to backup providers to maintain availability.
|
||||
</Card>
|
||||
<Card title="Load Balancing" icon="scale-balanced" href="https://portkey.ai/docs/product/ai-gateway/load-balancing">
|
||||
Spread requests across multiple API keys or providers. Great for high-volume crew operations and staying within rate limits.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### 3. Prompting in CrewAI
|
||||
|
||||
Portkey's Prompt Engineering Studio helps you create, manage, and optimize the prompts used in your CrewAI agents. Instead of hardcoding prompts or instructions, use Portkey's prompt rendering API to dynamically fetch and apply your versioned prompts.
|
||||
|
||||
<Frame caption="Manage prompts in Portkey's Prompt Library">
|
||||
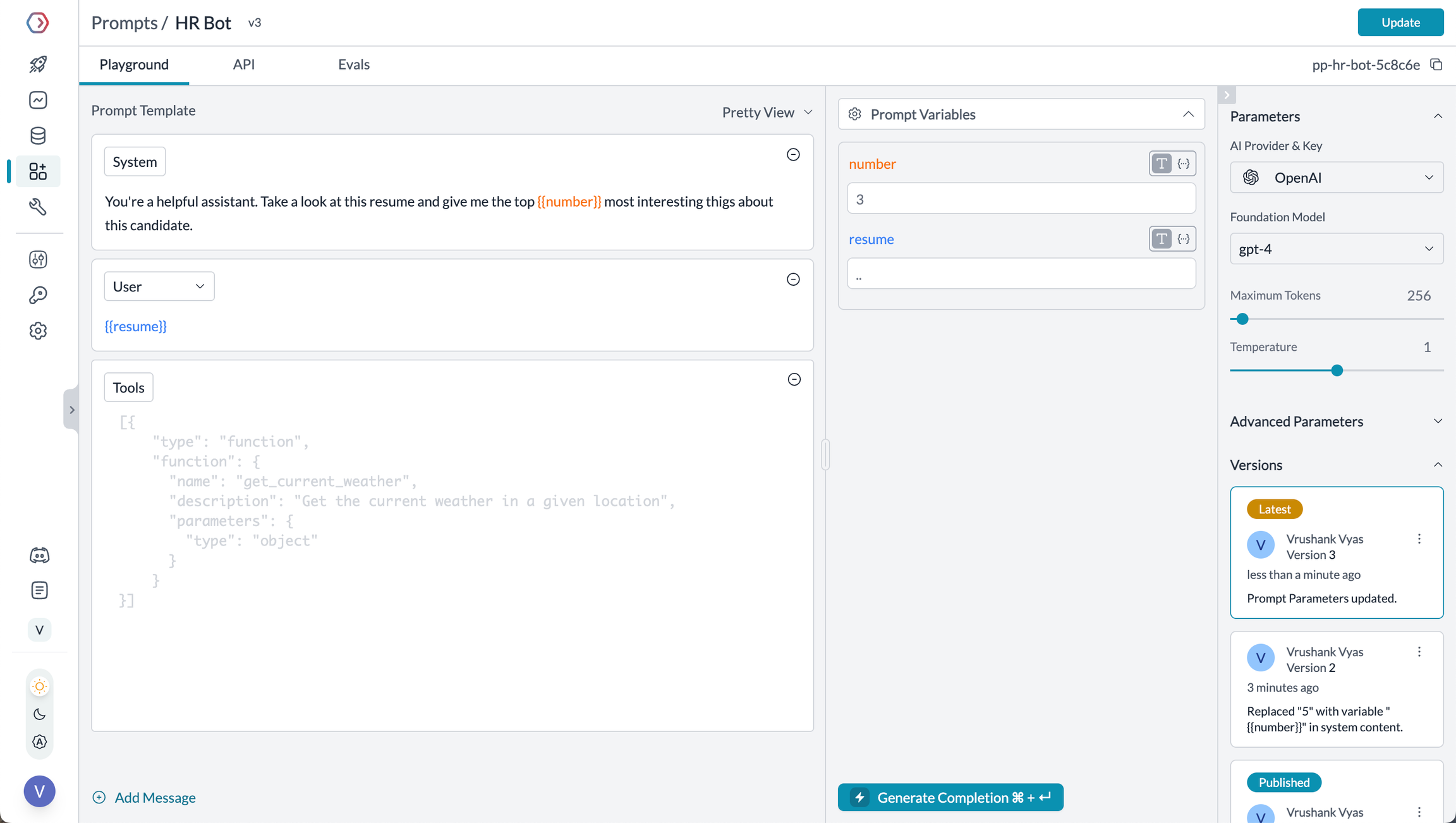
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Prompt Playground">
|
||||
Prompt Playground is a place to compare, test and deploy perfect prompts for your AI application. It's where you experiment with different models, test variables, compare outputs, and refine your prompt engineering strategy before deploying to production. It allows you to:
|
||||
|
||||
1. Iteratively develop prompts before using them in your agents
|
||||
2. Test prompts with different variables and models
|
||||
3. Compare outputs between different prompt versions
|
||||
4. Collaborate with team members on prompt development
|
||||
|
||||
This visual environment makes it easier to craft effective prompts for each step in your CrewAI agents' workflow.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Using Prompt Templates">
|
||||
The Prompt Render API retrieves your prompt templates with all parameters configured:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL, Portkey
|
||||
|
||||
# Initialize Portkey admin client
|
||||
portkey_admin = Portkey(api_key="YOUR_PORTKEY_API_KEY")
|
||||
|
||||
# Retrieve prompt using the render API
|
||||
prompt_data = portkey_client.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
}
|
||||
)
|
||||
|
||||
backstory_agent_prompt=prompt_data.data.messages[0]["content"]
|
||||
|
||||
|
||||
# Set up LLM with Portkey integration
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent using the rendered prompt
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory=backstory_agent, # Use the rendered prompt
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Prompt Versioning">
|
||||
You can:
|
||||
- Create multiple versions of the same prompt
|
||||
- Compare performance between versions
|
||||
- Roll back to previous versions if needed
|
||||
- Specify which version to use in your code:
|
||||
|
||||
```python
|
||||
# Use a specific prompt version
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID@version_number",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"agent_goal": "Discover groundbreaking insights"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Mustache Templating for variables">
|
||||
Portkey prompts use Mustache-style templating for easy variable substitution:
|
||||
|
||||
```
|
||||
You are a {{agent_role}} with expertise in {{domain}}.
|
||||
|
||||
Your mission is to {{agent_goal}} by leveraging your knowledge
|
||||
and experience in the field.
|
||||
|
||||
Always maintain a {{tone}} tone and focus on providing {{focus_area}}.
|
||||
```
|
||||
|
||||
When rendering, simply pass the variables:
|
||||
|
||||
```python
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"domain": "artificial intelligence",
|
||||
"agent_goal": "discover groundbreaking insights",
|
||||
"tone": "professional",
|
||||
"focus_area": "practical applications"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Card title="Prompt Engineering Studio" icon="wand-magic-sparkles" href="https://portkey.ai/docs/product/prompt-library">
|
||||
Learn more about Portkey's prompt management features
|
||||
</Card>
|
||||
|
||||
### 4. Guardrails for Safe Crews
|
||||
|
||||
Guardrails ensure your CrewAI agents operate safely and respond appropriately in all situations.
|
||||
|
||||
**Why Use Guardrails?**
|
||||
|
||||
CrewAI agents can experience various failure modes:
|
||||
- Generating harmful or inappropriate content
|
||||
- Leaking sensitive information like PII
|
||||
- Hallucinating incorrect information
|
||||
- Generating outputs in incorrect formats
|
||||
|
||||
Portkey's guardrails add protections for both inputs and outputs.
|
||||
|
||||
**Implementing Guardrails**
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create LLM with guardrails
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"input_guardrails": ["guardrails-id-xxx", "guardrails-id-yyy"],
|
||||
"output_guardrails": ["guardrails-id-zzz"]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with guardrailed LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Portkey's guardrails can:
|
||||
- Detect and redact PII in both inputs and outputs
|
||||
- Filter harmful or inappropriate content
|
||||
- Validate response formats against schemas
|
||||
- Check for hallucinations against ground truth
|
||||
- Apply custom business logic and rules
|
||||
|
||||
<Card title="Learn More About Guardrails" icon="shield-check" href="https://portkey.ai/docs/product/guardrails">
|
||||
Explore Portkey's guardrail features to enhance agent safety
|
||||
</Card>
|
||||
|
||||
### 5. User Tracking with Metadata
|
||||
|
||||
Track individual users through your CrewAI agents using Portkey's metadata system.
|
||||
|
||||
**What is Metadata in Portkey?**
|
||||
|
||||
Metadata allows you to associate custom data with each request, enabling filtering, segmentation, and analytics. The special `_user` field is specifically designed for user tracking.
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with user tracking
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"_user": "user_123", # Special _user field for user analytics
|
||||
"user_tier": "premium",
|
||||
"user_company": "Acme Corp",
|
||||
"session_id": "abc-123"
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with tracked LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
**Filter Analytics by User**
|
||||
|
||||
With metadata in place, you can filter analytics by user and analyze performance metrics on a per-user basis:
|
||||
|
||||
<Frame caption="Filter analytics by user">
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png"/>
|
||||
</Frame>
|
||||
|
||||
This enables:
|
||||
- Per-user cost tracking and budgeting
|
||||
- Personalized user analytics
|
||||
- Team or organization-level metrics
|
||||
- Environment-specific monitoring (staging vs. production)
|
||||
|
||||
<Card title="Learn More About Metadata" icon="tags" href="https://portkey.ai/docs/product/observability/metadata">
|
||||
Explore how to use custom metadata to enhance your analytics
|
||||
</Card>
|
||||
|
||||
### 6. Caching for Efficient Crews
|
||||
|
||||
Implement caching to make your CrewAI agents more efficient and cost-effective:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Simple Caching">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with simple caching
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "simple"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with cached LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Simple caching performs exact matches on input prompts, caching identical requests to avoid redundant model executions.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Semantic Caching">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with semantic caching
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "semantic"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with semantically cached LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Semantic caching considers the contextual similarity between input requests, caching responses for semantically similar inputs.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 7. Model Interoperability
|
||||
|
||||
CrewAI supports multiple LLM providers, and Portkey extends this capability by providing access to over 200 LLMs through a unified interface. You can easily switch between different models without changing your core agent logic:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Set up LLMs with different providers
|
||||
openai_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Choose which LLM to use for each agent based on your needs
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=openai_llm # Use anthropic_llm for Anthropic
|
||||
)
|
||||
```
|
||||
|
||||
Portkey provides access to LLMs from providers including:
|
||||
|
||||
- OpenAI (GPT-4o, GPT-4 Turbo, etc.)
|
||||
- Anthropic (Claude 3.5 Sonnet, Claude 3 Opus, etc.)
|
||||
- Mistral AI (Mistral Large, Mistral Medium, etc.)
|
||||
- Google Vertex AI (Gemini 1.5 Pro, etc.)
|
||||
- Cohere (Command, Command-R, etc.)
|
||||
- AWS Bedrock (Claude, Titan, etc.)
|
||||
- Local/Private Models
|
||||
|
||||
<Card title="Supported Providers" icon="server" href="https://portkey.ai/docs/integrations/llms">
|
||||
See the full list of LLM providers supported by Portkey
|
||||
</Card>
|
||||
|
||||
## Set Up Enterprise Governance for CrewAI
|
||||
|
||||
**Why Enterprise Governance?**
|
||||
If you are using CrewAI inside your organization, you need to consider several governance aspects:
|
||||
- **Cost Management**: Controlling and tracking AI spending across teams
|
||||
- **Access Control**: Managing which teams can use specific models
|
||||
- **Usage Analytics**: Understanding how AI is being used across the organization
|
||||
- **Security & Compliance**: Maintaining enterprise security standards
|
||||
- **Reliability**: Ensuring consistent service across all users
|
||||
|
||||
Portkey adds a comprehensive governance layer to address these enterprise needs. Let's implement these controls step by step.
|
||||
|
||||
<Steps>
|
||||
<Step title="Create Virtual Key">
|
||||
Virtual Keys are Portkey's secure way to manage your LLM provider API keys. They provide essential controls like:
|
||||
- Budget limits for API usage
|
||||
- Rate limiting capabilities
|
||||
- Secure API key storage
|
||||
|
||||
To create a virtual key:
|
||||
Go to [Virtual Keys](https://app.portkey.ai/virtual-keys) in the Portkey App. Save and copy the virtual key ID
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
|
||||
<Note>
|
||||
Save your virtual key ID - you'll need it for the next step.
|
||||
</Note>
|
||||
</Step>
|
||||
|
||||
<Step title="Create Default Config">
|
||||
Configs in Portkey define how your requests are routed, with features like advanced routing, fallbacks, and retries.
|
||||
|
||||
To create your config:
|
||||
1. Go to [Configs](https://app.portkey.ai/configs) in Portkey dashboard
|
||||
2. Create new config with:
|
||||
```json
|
||||
{
|
||||
"virtual_key": "YOUR_VIRTUAL_KEY_FROM_STEP1",
|
||||
"override_params": {
|
||||
"model": "gpt-4o" // Your preferred model name
|
||||
}
|
||||
}
|
||||
```
|
||||
3. Save and note the Config name for the next step
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Config.png" width="500"/>
|
||||
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Configure Portkey API Key">
|
||||
Now create a Portkey API key and attach the config you created in Step 2:
|
||||
|
||||
1. Go to [API Keys](https://app.portkey.ai/api-keys) in Portkey and Create new API key
|
||||
2. Select your config from `Step 2`
|
||||
3. Generate and save your API key
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20API%20Key.png" width="500"/>
|
||||
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Connect to CrewAI">
|
||||
After setting up your Portkey API key with the attached config, connect it to your CrewAI agents:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with your API key
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="YOUR_PORTKEY_API_KEY"
|
||||
)
|
||||
|
||||
# Create agent with Portkey-enabled LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Step 1: Implement Budget Controls & Rate Limits">
|
||||
### Step 1: Implement Budget Controls & Rate Limits
|
||||
|
||||
Virtual Keys enable granular control over LLM access at the team/department level. This helps you:
|
||||
- Set up [budget limits](https://portkey.ai/docs/product/ai-gateway/virtual-keys/budget-limits)
|
||||
- Prevent unexpected usage spikes using Rate limits
|
||||
- Track departmental spending
|
||||
|
||||
#### Setting Up Department-Specific Controls:
|
||||
1. Navigate to [Virtual Keys](https://app.portkey.ai/virtual-keys) in Portkey dashboard
|
||||
2. Create new Virtual Key for each department with budget limits and rate limits
|
||||
3. Configure department-specific limits
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Step 2: Define Model Access Rules">
|
||||
### Step 2: Define Model Access Rules
|
||||
|
||||
As your AI usage scales, controlling which teams can access specific models becomes crucial. Portkey Configs provide this control layer with features like:
|
||||
|
||||
#### Access Control Features:
|
||||
- **Model Restrictions**: Limit access to specific models
|
||||
- **Data Protection**: Implement guardrails for sensitive data
|
||||
- **Reliability Controls**: Add fallbacks and retry logic
|
||||
|
||||
#### Example Configuration:
|
||||
Here's a basic configuration to route requests to OpenAI, specifically using GPT-4o:
|
||||
|
||||
```json
|
||||
{
|
||||
"strategy": {
|
||||
"mode": "single"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"virtual_key": "YOUR_OPENAI_VIRTUAL_KEY",
|
||||
"override_params": {
|
||||
"model": "gpt-4o"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### 3. Production Reliability
|
||||
Portkey provides comprehensive reliability features:
|
||||
- **Automatic Retries**: Handle temporary failures gracefully
|
||||
- **Request Timeouts**: Prevent hanging operations
|
||||
- **Conditional Routing**: Route requests based on specific conditions
|
||||
- **Fallbacks**: Set up automatic provider failovers
|
||||
- **Load Balancing**: Distribute requests efficiently
|
||||
Create your config on the [Configs page](https://app.portkey.ai/configs) in your Portkey dashboard.
|
||||
|
||||
[Learn more about Reliability Features](https://portkey.ai/docs/product/ai-gateway/)
|
||||
<Note>
|
||||
Configs can be updated anytime to adjust controls without affecting running applications.
|
||||
</Note>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Step 3: Implement Access Controls">
|
||||
### Step 3: Implement Access Controls
|
||||
|
||||
Create User-specific API keys that automatically:
|
||||
- Track usage per user/team with the help of virtual keys
|
||||
- Apply appropriate configs to route requests
|
||||
- Collect relevant metadata to filter logs
|
||||
- Enforce access permissions
|
||||
|
||||
### 4. Metrics
|
||||
Create API keys through:
|
||||
- [Portkey App](https://app.portkey.ai/)
|
||||
- [API Key Management API](/api-reference/admin-api/control-plane/api-keys/create-api-key)
|
||||
|
||||
Agent runs are complex. Portkey automatically logs **40+ comprehensive metrics** for your AI agents, including cost, tokens used, latency, etc. Whether you need a broad overview or granular insights into your agent runs, Portkey's customizable filters provide the metrics you need.
|
||||
Example using Python SDK:
|
||||
```python
|
||||
from portkey_ai import Portkey
|
||||
|
||||
portkey = Portkey(api_key="YOUR_ADMIN_API_KEY")
|
||||
|
||||
- Cost per agent interaction
|
||||
- Response times and latency
|
||||
- Token usage and efficiency
|
||||
- Success/failure rates
|
||||
- Cache hit rates
|
||||
api_key = portkey.api_keys.create(
|
||||
name="engineering-team",
|
||||
type="organisation",
|
||||
workspace_id="YOUR_WORKSPACE_ID",
|
||||
defaults={
|
||||
"config_id": "your-config-id",
|
||||
"metadata": {
|
||||
"environment": "production",
|
||||
"department": "engineering"
|
||||
}
|
||||
},
|
||||
scopes=["logs.view", "configs.read"]
|
||||
)
|
||||
```
|
||||
|
||||
<img src="https://github.com/siddharthsambharia-portkey/Portkey-Product-Images/blob/main/Portkey-Dashboard.png?raw=true" width="70%" alt="Portkey Dashboard" />
|
||||
For detailed key management instructions, see our [API Keys documentation](/api-reference/admin-api/control-plane/api-keys/create-api-key).
|
||||
</Accordion>
|
||||
|
||||
### 5. Detailed Logging
|
||||
Logs are essential for understanding agent behavior, diagnosing issues, and improving performance. They provide a detailed record of agent activities and tool use, which is crucial for debugging and optimizing processes.
|
||||
<Accordion title="Step 4: Deploy & Monitor">
|
||||
### Step 4: Deploy & Monitor
|
||||
After distributing API keys to your team members, your enterprise-ready CrewAI setup is ready to go. Each team member can now use their designated API keys with appropriate access levels and budget controls.
|
||||
|
||||
Monitor usage in Portkey dashboard:
|
||||
- Cost tracking by department
|
||||
- Model usage patterns
|
||||
- Request volumes
|
||||
- Error rates
|
||||
</Accordion>
|
||||
|
||||
Access a dedicated section to view records of agent executions, including parameters, outcomes, function calls, and errors. Filter logs based on multiple parameters such as trace ID, model, tokens used, and metadata.
|
||||
</AccordionGroup>
|
||||
|
||||
<details>
|
||||
<summary><b>Traces</b></summary>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-Traces.png" alt="Portkey Traces" width="70%" />
|
||||
</details>
|
||||
<Note>
|
||||
### Enterprise Features Now Available
|
||||
**Your CrewAI integration now has:**
|
||||
- Departmental budget controls
|
||||
- Model access governance
|
||||
- Usage tracking & attribution
|
||||
- Security guardrails
|
||||
- Reliability features
|
||||
</Note>
|
||||
|
||||
<details>
|
||||
<summary><b>Logs</b></summary>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-Logs.png" alt="Portkey Logs" width="70%" />
|
||||
</details>
|
||||
## Frequently Asked Questions
|
||||
|
||||
### 6. Enterprise Security Features
|
||||
- Set budget limit and rate limts per Virtual Key (disposable API keys)
|
||||
- Implement role-based access control
|
||||
- Track system changes with audit logs
|
||||
- Configure data retention policies
|
||||
<AccordionGroup>
|
||||
<Accordion title="How does Portkey enhance CrewAI?">
|
||||
Portkey adds production-readiness to CrewAI through comprehensive observability (traces, logs, metrics), reliability features (fallbacks, retries, caching), and access to 200+ LLMs through a unified interface. This makes it easier to debug, optimize, and scale your agent applications.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Can I use Portkey with existing CrewAI applications?">
|
||||
Yes! Portkey integrates seamlessly with existing CrewAI applications. You just need to update your LLM configuration code with the Portkey-enabled version. The rest of your agent and crew code remains unchanged.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Does Portkey work with all CrewAI features?">
|
||||
Portkey supports all CrewAI features, including agents, tools, human-in-the-loop workflows, and all task process types (sequential, hierarchical, etc.). It adds observability and reliability without limiting any of the framework's functionality.
|
||||
</Accordion>
|
||||
|
||||
For detailed information on creating and managing Configs, visit the [Portkey documentation](https://docs.portkey.ai/product/ai-gateway/configs).
|
||||
<Accordion title="Can I track usage across multiple agents in a crew?">
|
||||
Yes, Portkey allows you to use a consistent `trace_id` across multiple agents in a crew to track the entire workflow. This is especially useful for complex crews where you want to understand the full execution path across multiple agents.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="How do I filter logs and traces for specific crew runs?">
|
||||
Portkey allows you to add custom metadata to your LLM configuration, which you can then use for filtering. Add fields like `crew_name`, `crew_type`, or `session_id` to easily find and analyze specific crew executions.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Can I use my own API keys with Portkey?">
|
||||
Yes! Portkey uses your own API keys for the various LLM providers. It securely stores them as virtual keys, allowing you to easily manage and rotate keys without changing your code.
|
||||
</Accordion>
|
||||
|
||||
</AccordionGroup>
|
||||
|
||||
## Resources
|
||||
|
||||
- [📘 Portkey Documentation](https://docs.portkey.ai)
|
||||
- [📊 Portkey Dashboard](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai)
|
||||
- [🐦 Twitter](https://twitter.com/portkeyai)
|
||||
- [💬 Discord Community](https://discord.gg/DD7vgKK299)
|
||||
<CardGroup cols="3">
|
||||
<Card title="CrewAI Docs" icon="book" href="https://docs.crewai.com/">
|
||||
<p>Official CrewAI documentation</p>
|
||||
</Card>
|
||||
<Card title="Book a Demo" icon="calendar" href="https://calendly.com/portkey-ai">
|
||||
<p>Get personalized guidance on implementing this integration</p>
|
||||
</Card>
|
||||
</CardGroup>
|
||||
@@ -1,9 +1,9 @@
|
||||
[project]
|
||||
name = "crewai"
|
||||
version = "0.121.1"
|
||||
version = "0.126.0"
|
||||
description = "Cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks."
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.10,<3.13"
|
||||
requires-python = ">=3.10,<3.14"
|
||||
authors = [
|
||||
{ name = "Joao Moura", email = "joao@crewai.com" }
|
||||
]
|
||||
@@ -11,7 +11,7 @@ dependencies = [
|
||||
# Core Dependencies
|
||||
"pydantic>=2.4.2",
|
||||
"openai>=1.13.3",
|
||||
"litellm==1.68.0",
|
||||
"litellm==1.72.0",
|
||||
"instructor>=1.3.3",
|
||||
# Text Processing
|
||||
"pdfplumber>=0.11.4",
|
||||
@@ -22,6 +22,8 @@ dependencies = [
|
||||
"opentelemetry-exporter-otlp-proto-http>=1.30.0",
|
||||
# Data Handling
|
||||
"chromadb>=0.5.23",
|
||||
"tokenizers>=0.20.3",
|
||||
"onnxruntime==1.22.0",
|
||||
"openpyxl>=3.1.5",
|
||||
"pyvis>=0.3.2",
|
||||
# Authentication and Security
|
||||
@@ -45,12 +47,11 @@ Documentation = "https://docs.crewai.com"
|
||||
Repository = "https://github.com/crewAIInc/crewAI"
|
||||
|
||||
[project.optional-dependencies]
|
||||
tools = ["crewai-tools~=0.45.0"]
|
||||
tools = ["crewai-tools~=0.46.0"]
|
||||
embeddings = [
|
||||
"tiktoken~=0.7.0"
|
||||
"tiktoken~=0.8.0"
|
||||
]
|
||||
agentops = ["agentops>=0.3.0"]
|
||||
fastembed = ["fastembed>=0.4.1"]
|
||||
pdfplumber = [
|
||||
"pdfplumber>=0.11.4",
|
||||
]
|
||||
@@ -100,6 +101,27 @@ exclude = ["cli/templates"]
|
||||
[tool.bandit]
|
||||
exclude_dirs = ["src/crewai/cli/templates"]
|
||||
|
||||
# PyTorch index configuration, since torch 2.5.0 is not compatible with python 3.13
|
||||
[[tool.uv.index]]
|
||||
name = "pytorch-nightly"
|
||||
url = "https://download.pytorch.org/whl/nightly/cpu"
|
||||
explicit = true
|
||||
|
||||
[[tool.uv.index]]
|
||||
name = "pytorch"
|
||||
url = "https://download.pytorch.org/whl/cpu"
|
||||
explicit = true
|
||||
|
||||
[tool.uv.sources]
|
||||
torch = [
|
||||
{ index = "pytorch-nightly", marker = "python_version >= '3.13'" },
|
||||
{ index = "pytorch", marker = "python_version < '3.13'" },
|
||||
]
|
||||
torchvision = [
|
||||
{ index = "pytorch-nightly", marker = "python_version >= '3.13'" },
|
||||
{ index = "pytorch", marker = "python_version < '3.13'" },
|
||||
]
|
||||
|
||||
[build-system]
|
||||
requires = ["hatchling"]
|
||||
build-backend = "hatchling.build"
|
||||
|
||||
@@ -18,7 +18,7 @@ warnings.filterwarnings(
|
||||
category=UserWarning,
|
||||
module="pydantic.main",
|
||||
)
|
||||
__version__ = "0.121.1"
|
||||
__version__ = "0.126.0"
|
||||
__all__ = [
|
||||
"Agent",
|
||||
"Crew",
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import shutil
|
||||
import subprocess
|
||||
from typing import Any, Dict, List, Literal, Optional, Sequence, Type, Union
|
||||
from typing import Any, Callable, Dict, List, Literal, Optional, Sequence, Tuple, Type, Union
|
||||
|
||||
from pydantic import Field, InstanceOf, PrivateAttr, model_validator
|
||||
|
||||
@@ -155,6 +155,13 @@ class Agent(BaseAgent):
|
||||
default=None,
|
||||
description="The Agent's role to be used from your repository.",
|
||||
)
|
||||
guardrail: Optional[Union[Callable[[Any], Tuple[bool, Any]], str]] = Field(
|
||||
default=None,
|
||||
description="Function or string description of a guardrail to validate agent output"
|
||||
)
|
||||
guardrail_max_retries: int = Field(
|
||||
default=3, description="Maximum number of retries when guardrail fails"
|
||||
)
|
||||
|
||||
@model_validator(mode="before")
|
||||
def validate_from_repository(cls, v):
|
||||
@@ -200,6 +207,7 @@ class Agent(BaseAgent):
|
||||
collection_name=self.role,
|
||||
storage=self.knowledge_storage or None,
|
||||
)
|
||||
self.knowledge.add_sources()
|
||||
except (TypeError, ValueError) as e:
|
||||
raise ValueError(f"Invalid Knowledge Configuration: {str(e)}")
|
||||
|
||||
@@ -243,21 +251,28 @@ class Agent(BaseAgent):
|
||||
"""
|
||||
if self.reasoning:
|
||||
try:
|
||||
from crewai.utilities.reasoning_handler import AgentReasoning, AgentReasoningOutput
|
||||
|
||||
from crewai.utilities.reasoning_handler import (
|
||||
AgentReasoning,
|
||||
AgentReasoningOutput,
|
||||
)
|
||||
|
||||
reasoning_handler = AgentReasoning(task=task, agent=self)
|
||||
reasoning_output: AgentReasoningOutput = reasoning_handler.handle_agent_reasoning()
|
||||
|
||||
reasoning_output: AgentReasoningOutput = (
|
||||
reasoning_handler.handle_agent_reasoning()
|
||||
)
|
||||
|
||||
# Add the reasoning plan to the task description
|
||||
task.description += f"\n\nReasoning Plan:\n{reasoning_output.plan.plan}"
|
||||
except Exception as e:
|
||||
if hasattr(self, '_logger'):
|
||||
self._logger.log("error", f"Error during reasoning process: {str(e)}")
|
||||
if hasattr(self, "_logger"):
|
||||
self._logger.log(
|
||||
"error", f"Error during reasoning process: {str(e)}"
|
||||
)
|
||||
else:
|
||||
print(f"Error during reasoning process: {str(e)}")
|
||||
|
||||
|
||||
self._inject_date_to_task(task)
|
||||
|
||||
|
||||
if self.tools_handler:
|
||||
self.tools_handler.last_used_tool = {} # type: ignore # Incompatible types in assignment (expression has type "dict[Never, Never]", variable has type "ToolCalling")
|
||||
|
||||
@@ -622,22 +637,33 @@ class Agent(BaseAgent):
|
||||
"""Inject the current date into the task description if inject_date is enabled."""
|
||||
if self.inject_date:
|
||||
from datetime import datetime
|
||||
|
||||
try:
|
||||
valid_format_codes = ['%Y', '%m', '%d', '%H', '%M', '%S', '%B', '%b', '%A', '%a']
|
||||
valid_format_codes = [
|
||||
"%Y",
|
||||
"%m",
|
||||
"%d",
|
||||
"%H",
|
||||
"%M",
|
||||
"%S",
|
||||
"%B",
|
||||
"%b",
|
||||
"%A",
|
||||
"%a",
|
||||
]
|
||||
is_valid = any(code in self.date_format for code in valid_format_codes)
|
||||
|
||||
|
||||
if not is_valid:
|
||||
raise ValueError(f"Invalid date format: {self.date_format}")
|
||||
|
||||
|
||||
current_date: str = datetime.now().strftime(self.date_format)
|
||||
task.description += f"\n\nCurrent Date: {current_date}"
|
||||
except Exception as e:
|
||||
if hasattr(self, '_logger'):
|
||||
if hasattr(self, "_logger"):
|
||||
self._logger.log("warning", f"Failed to inject date: {str(e)}")
|
||||
else:
|
||||
print(f"Warning: Failed to inject date: {str(e)}")
|
||||
|
||||
|
||||
def _validate_docker_installation(self) -> None:
|
||||
"""Check if Docker is installed and running."""
|
||||
if not shutil.which("docker"):
|
||||
@@ -761,6 +787,8 @@ class Agent(BaseAgent):
|
||||
response_format=response_format,
|
||||
i18n=self.i18n,
|
||||
original_agent=self,
|
||||
guardrail=self.guardrail,
|
||||
guardrail_max_retries=self.guardrail_max_retries,
|
||||
)
|
||||
|
||||
return lite_agent.kickoff(messages)
|
||||
|
||||
@@ -7,6 +7,7 @@ from crewai.utilities import I18N
|
||||
from crewai.utilities.converter import ConverterError
|
||||
from crewai.utilities.evaluators.task_evaluator import TaskEvaluator
|
||||
from crewai.utilities.printer import Printer
|
||||
from crewai.utilities.events.event_listener import event_listener
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from crewai.agents.agent_builder.base_agent import BaseAgent
|
||||
@@ -125,33 +126,38 @@ class CrewAgentExecutorMixin:
|
||||
|
||||
def _ask_human_input(self, final_answer: str) -> str:
|
||||
"""Prompt human input with mode-appropriate messaging."""
|
||||
self._printer.print(
|
||||
content=f"\033[1m\033[95m ## Final Result:\033[00m \033[92m{final_answer}\033[00m"
|
||||
)
|
||||
|
||||
# Training mode prompt (single iteration)
|
||||
if self.crew and getattr(self.crew, "_train", False):
|
||||
prompt = (
|
||||
"\n\n=====\n"
|
||||
"## TRAINING MODE: Provide feedback to improve the agent's performance.\n"
|
||||
"This will be used to train better versions of the agent.\n"
|
||||
"Please provide detailed feedback about the result quality and reasoning process.\n"
|
||||
"=====\n"
|
||||
)
|
||||
# Regular human-in-the-loop prompt (multiple iterations)
|
||||
else:
|
||||
prompt = (
|
||||
"\n\n=====\n"
|
||||
"## HUMAN FEEDBACK: Provide feedback on the Final Result and Agent's actions.\n"
|
||||
"Please follow these guidelines:\n"
|
||||
" - If you are happy with the result, simply hit Enter without typing anything.\n"
|
||||
" - Otherwise, provide specific improvement requests.\n"
|
||||
" - You can provide multiple rounds of feedback until satisfied.\n"
|
||||
"=====\n"
|
||||
event_listener.formatter.pause_live_updates()
|
||||
|
||||
try:
|
||||
self._printer.print(
|
||||
content=f"\033[1m\033[95m ## Final Result:\033[00m \033[92m{final_answer}\033[00m"
|
||||
)
|
||||
|
||||
self._printer.print(content=prompt, color="bold_yellow")
|
||||
response = input()
|
||||
if response.strip() != "":
|
||||
self._printer.print(content="\nProcessing your feedback...", color="cyan")
|
||||
return response
|
||||
# Training mode prompt (single iteration)
|
||||
if self.crew and getattr(self.crew, "_train", False):
|
||||
prompt = (
|
||||
"\n\n=====\n"
|
||||
"## TRAINING MODE: Provide feedback to improve the agent's performance.\n"
|
||||
"This will be used to train better versions of the agent.\n"
|
||||
"Please provide detailed feedback about the result quality and reasoning process.\n"
|
||||
"=====\n"
|
||||
)
|
||||
# Regular human-in-the-loop prompt (multiple iterations)
|
||||
else:
|
||||
prompt = (
|
||||
"\n\n=====\n"
|
||||
"## HUMAN FEEDBACK: Provide feedback on the Final Result and Agent's actions.\n"
|
||||
"Please follow these guidelines:\n"
|
||||
" - If you are happy with the result, simply hit Enter without typing anything.\n"
|
||||
" - Otherwise, provide specific improvement requests.\n"
|
||||
" - You can provide multiple rounds of feedback until satisfied.\n"
|
||||
"=====\n"
|
||||
)
|
||||
|
||||
self._printer.print(content=prompt, color="bold_yellow")
|
||||
response = input()
|
||||
if response.strip() != "":
|
||||
self._printer.print(content="\nProcessing your feedback...", color="cyan")
|
||||
return response
|
||||
finally:
|
||||
event_listener.formatter.resume_live_updates()
|
||||
|
||||
@@ -16,6 +16,7 @@ from .deploy.main import DeployCommand
|
||||
from .evaluate_crew import evaluate_crew
|
||||
from .install_crew import install_crew
|
||||
from .kickoff_flow import kickoff_flow
|
||||
from .organization.main import OrganizationCommand
|
||||
from .plot_flow import plot_flow
|
||||
from .replay_from_task import replay_task_command
|
||||
from .reset_memories_command import reset_memories_command
|
||||
@@ -353,5 +354,33 @@ def chat():
|
||||
run_chat()
|
||||
|
||||
|
||||
@crewai.group(invoke_without_command=True)
|
||||
def org():
|
||||
"""Organization management commands."""
|
||||
pass
|
||||
|
||||
|
||||
@org.command()
|
||||
def list():
|
||||
"""List available organizations."""
|
||||
org_command = OrganizationCommand()
|
||||
org_command.list()
|
||||
|
||||
|
||||
@org.command()
|
||||
@click.argument("id")
|
||||
def switch(id):
|
||||
"""Switch to a specific organization."""
|
||||
org_command = OrganizationCommand()
|
||||
org_command.switch(id)
|
||||
|
||||
|
||||
@org.command()
|
||||
def current():
|
||||
"""Show current organization when 'crewai org' is called without subcommands."""
|
||||
org_command = OrganizationCommand()
|
||||
org_command.current()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
crewai()
|
||||
|
||||
@@ -14,6 +14,12 @@ class Settings(BaseModel):
|
||||
tool_repository_password: Optional[str] = Field(
|
||||
None, description="Password for interacting with the Tool Repository"
|
||||
)
|
||||
org_name: Optional[str] = Field(
|
||||
None, description="Name of the currently active organization"
|
||||
)
|
||||
org_uuid: Optional[str] = Field(
|
||||
None, description="UUID of the currently active organization"
|
||||
)
|
||||
config_path: Path = Field(default=DEFAULT_CONFIG_PATH, exclude=True)
|
||||
|
||||
def __init__(self, config_path: Path = DEFAULT_CONFIG_PATH, **data):
|
||||
|
||||
1
src/crewai/cli/organization/__init__.py
Normal file
1
src/crewai/cli/organization/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
|
||||
76
src/crewai/cli/organization/main.py
Normal file
76
src/crewai/cli/organization/main.py
Normal file
@@ -0,0 +1,76 @@
|
||||
from rich.console import Console
|
||||
from rich.table import Table
|
||||
|
||||
from requests import HTTPError
|
||||
from crewai.cli.command import BaseCommand, PlusAPIMixin
|
||||
from crewai.cli.config import Settings
|
||||
|
||||
console = Console()
|
||||
|
||||
class OrganizationCommand(BaseCommand, PlusAPIMixin):
|
||||
def __init__(self):
|
||||
BaseCommand.__init__(self)
|
||||
PlusAPIMixin.__init__(self, telemetry=self._telemetry)
|
||||
|
||||
def list(self):
|
||||
try:
|
||||
response = self.plus_api_client.get_organizations()
|
||||
response.raise_for_status()
|
||||
orgs = response.json()
|
||||
|
||||
if not orgs:
|
||||
console.print("You don't belong to any organizations yet.", style="yellow")
|
||||
return
|
||||
|
||||
table = Table(title="Your Organizations")
|
||||
table.add_column("Name", style="cyan")
|
||||
table.add_column("ID", style="green")
|
||||
for org in orgs:
|
||||
table.add_row(org["name"], org["uuid"])
|
||||
|
||||
console.print(table)
|
||||
except HTTPError as e:
|
||||
if e.response.status_code == 401:
|
||||
console.print("You are not logged in to any organization. Use 'crewai login' to login.", style="bold red")
|
||||
return
|
||||
console.print(f"Failed to retrieve organization list: {str(e)}", style="bold red")
|
||||
raise SystemExit(1)
|
||||
except Exception as e:
|
||||
console.print(f"Failed to retrieve organization list: {str(e)}", style="bold red")
|
||||
raise SystemExit(1)
|
||||
|
||||
def switch(self, org_id):
|
||||
try:
|
||||
response = self.plus_api_client.get_organizations()
|
||||
response.raise_for_status()
|
||||
orgs = response.json()
|
||||
|
||||
org = next((o for o in orgs if o["uuid"] == org_id), None)
|
||||
if not org:
|
||||
console.print(f"Organization with id '{org_id}' not found.", style="bold red")
|
||||
return
|
||||
|
||||
settings = Settings()
|
||||
settings.org_name = org["name"]
|
||||
settings.org_uuid = org["uuid"]
|
||||
settings.dump()
|
||||
|
||||
console.print(f"Successfully switched to {org['name']} ({org['uuid']})", style="bold green")
|
||||
except HTTPError as e:
|
||||
if e.response.status_code == 401:
|
||||
console.print("You are not logged in to any organization. Use 'crewai login' to login.", style="bold red")
|
||||
return
|
||||
console.print(f"Failed to retrieve organization list: {str(e)}", style="bold red")
|
||||
raise SystemExit(1)
|
||||
except Exception as e:
|
||||
console.print(f"Failed to switch organization: {str(e)}", style="bold red")
|
||||
raise SystemExit(1)
|
||||
|
||||
def current(self):
|
||||
settings = Settings()
|
||||
if settings.org_uuid:
|
||||
console.print(f"Currently logged in to organization {settings.org_name} ({settings.org_uuid})", style="bold green")
|
||||
else:
|
||||
console.print("You're not currently logged in to any organization.", style="yellow")
|
||||
console.print("Use 'crewai org list' to see available organizations.", style="yellow")
|
||||
console.print("Use 'crewai org switch <id>' to switch to an organization.", style="yellow")
|
||||
@@ -1,9 +1,10 @@
|
||||
from os import getenv
|
||||
from typing import Optional
|
||||
from typing import List, Optional
|
||||
from urllib.parse import urljoin
|
||||
|
||||
import requests
|
||||
|
||||
from crewai.cli.config import Settings
|
||||
from crewai.cli.version import get_crewai_version
|
||||
|
||||
|
||||
@@ -13,6 +14,7 @@ class PlusAPI:
|
||||
"""
|
||||
|
||||
TOOLS_RESOURCE = "/crewai_plus/api/v1/tools"
|
||||
ORGANIZATIONS_RESOURCE = "/crewai_plus/api/v1/me/organizations"
|
||||
CREWS_RESOURCE = "/crewai_plus/api/v1/crews"
|
||||
AGENTS_RESOURCE = "/crewai_plus/api/v1/agents"
|
||||
|
||||
@@ -24,6 +26,9 @@ class PlusAPI:
|
||||
"User-Agent": f"CrewAI-CLI/{get_crewai_version()}",
|
||||
"X-Crewai-Version": get_crewai_version(),
|
||||
}
|
||||
settings = Settings()
|
||||
if settings.org_uuid:
|
||||
self.headers["X-Crewai-Organization-Id"] = settings.org_uuid
|
||||
self.base_url = getenv("CREWAI_BASE_URL", "https://app.crewai.com")
|
||||
|
||||
def _make_request(self, method: str, endpoint: str, **kwargs) -> requests.Response:
|
||||
@@ -48,6 +53,7 @@ class PlusAPI:
|
||||
version: str,
|
||||
description: Optional[str],
|
||||
encoded_file: str,
|
||||
available_exports: Optional[List[str]] = None,
|
||||
):
|
||||
params = {
|
||||
"handle": handle,
|
||||
@@ -55,6 +61,7 @@ class PlusAPI:
|
||||
"version": version,
|
||||
"file": encoded_file,
|
||||
"description": description,
|
||||
"available_exports": available_exports,
|
||||
}
|
||||
return self._make_request("POST", f"{self.TOOLS_RESOURCE}", json=params)
|
||||
|
||||
@@ -101,3 +108,7 @@ class PlusAPI:
|
||||
|
||||
def create_crew(self, payload) -> requests.Response:
|
||||
return self._make_request("POST", self.CREWS_RESOURCE, json=payload)
|
||||
|
||||
def get_organizations(self) -> requests.Response:
|
||||
return self._make_request("GET", self.ORGANIZATIONS_RESOURCE)
|
||||
|
||||
@@ -4,7 +4,7 @@ Welcome to the {{crew_name}} Crew project, powered by [crewAI](https://crewai.co
|
||||
|
||||
## Installation
|
||||
|
||||
Ensure you have Python >=3.10 <3.13 installed on your system. This project uses [UV](https://docs.astral.sh/uv/) for dependency management and package handling, offering a seamless setup and execution experience.
|
||||
Ensure you have Python >=3.10 <3.14 installed on your system. This project uses [UV](https://docs.astral.sh/uv/) for dependency management and package handling, offering a seamless setup and execution experience.
|
||||
|
||||
First, if you haven't already, install uv:
|
||||
|
||||
|
||||
@@ -3,9 +3,9 @@ name = "{{folder_name}}"
|
||||
version = "0.1.0"
|
||||
description = "{{name}} using crewAI"
|
||||
authors = [{ name = "Your Name", email = "you@example.com" }]
|
||||
requires-python = ">=3.10,<3.13"
|
||||
requires-python = ">=3.10,<3.14"
|
||||
dependencies = [
|
||||
"crewai[tools]>=0.121.1,<1.0.0"
|
||||
"crewai[tools]>=0.126.0,<1.0.0"
|
||||
]
|
||||
|
||||
[project.scripts]
|
||||
|
||||
@@ -4,7 +4,7 @@ Welcome to the {{crew_name}} Crew project, powered by [crewAI](https://crewai.co
|
||||
|
||||
## Installation
|
||||
|
||||
Ensure you have Python >=3.10 <3.13 installed on your system. This project uses [UV](https://docs.astral.sh/uv/) for dependency management and package handling, offering a seamless setup and execution experience.
|
||||
Ensure you have Python >=3.10 <3.14 installed on your system. This project uses [UV](https://docs.astral.sh/uv/) for dependency management and package handling, offering a seamless setup and execution experience.
|
||||
|
||||
First, if you haven't already, install uv:
|
||||
|
||||
|
||||
@@ -3,9 +3,9 @@ name = "{{folder_name}}"
|
||||
version = "0.1.0"
|
||||
description = "{{name}} using crewAI"
|
||||
authors = [{ name = "Your Name", email = "you@example.com" }]
|
||||
requires-python = ">=3.10,<3.13"
|
||||
requires-python = ">=3.10,<3.14"
|
||||
dependencies = [
|
||||
"crewai[tools]>=0.121.1,<1.0.0",
|
||||
"crewai[tools]>=0.126.0,<1.0.0",
|
||||
]
|
||||
|
||||
[project.scripts]
|
||||
|
||||
@@ -5,7 +5,7 @@ custom tools to power up your crews.
|
||||
|
||||
## Installing
|
||||
|
||||
Ensure you have Python >=3.10 <3.13 installed on your system. This project
|
||||
Ensure you have Python >=3.10 <3.14 installed on your system. This project
|
||||
uses [UV](https://docs.astral.sh/uv/) for dependency management and package
|
||||
handling, offering a seamless setup and execution experience.
|
||||
|
||||
|
||||
@@ -3,9 +3,9 @@ name = "{{folder_name}}"
|
||||
version = "0.1.0"
|
||||
description = "Power up your crews with {{folder_name}}"
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.10,<3.13"
|
||||
requires-python = ">=3.10,<3.14"
|
||||
dependencies = [
|
||||
"crewai[tools]>=0.121.1"
|
||||
"crewai[tools]>=0.126.0"
|
||||
]
|
||||
|
||||
[tool.crewai]
|
||||
|
||||
@@ -0,0 +1,3 @@
|
||||
from .tool import {{class_name}}
|
||||
|
||||
__all__ = ["{{class_name}}"]
|
||||
|
||||
@@ -3,6 +3,7 @@ import os
|
||||
import subprocess
|
||||
import tempfile
|
||||
from pathlib import Path
|
||||
from typing import Any
|
||||
|
||||
import click
|
||||
from rich.console import Console
|
||||
@@ -11,6 +12,7 @@ from crewai.cli import git
|
||||
from crewai.cli.command import BaseCommand, PlusAPIMixin
|
||||
from crewai.cli.config import Settings
|
||||
from crewai.cli.utils import (
|
||||
extract_available_exports,
|
||||
get_project_description,
|
||||
get_project_name,
|
||||
get_project_version,
|
||||
@@ -82,6 +84,15 @@ class ToolCommand(BaseCommand, PlusAPIMixin):
|
||||
project_description = get_project_description(require=False)
|
||||
encoded_tarball = None
|
||||
|
||||
console.print("[bold blue]Discovering tools from your project...[/bold blue]")
|
||||
available_exports = extract_available_exports()
|
||||
|
||||
if available_exports:
|
||||
console.print(
|
||||
f"[green]Found these tools to publish: {', '.join([e['name'] for e in available_exports])}[/green]"
|
||||
)
|
||||
self._print_current_organization()
|
||||
|
||||
with tempfile.TemporaryDirectory() as temp_build_dir:
|
||||
subprocess.run(
|
||||
["uv", "build", "--sdist", "--out-dir", temp_build_dir],
|
||||
@@ -105,12 +116,14 @@ class ToolCommand(BaseCommand, PlusAPIMixin):
|
||||
|
||||
encoded_tarball = base64.b64encode(tarball_contents).decode("utf-8")
|
||||
|
||||
console.print("[bold blue]Publishing tool to repository...[/bold blue]")
|
||||
publish_response = self.plus_api_client.publish_tool(
|
||||
handle=project_name,
|
||||
is_public=is_public,
|
||||
version=project_version,
|
||||
description=project_description,
|
||||
encoded_file=f"data:application/x-gzip;base64,{encoded_tarball}",
|
||||
available_exports=available_exports,
|
||||
)
|
||||
|
||||
self._validate_response(publish_response)
|
||||
@@ -124,6 +137,7 @@ class ToolCommand(BaseCommand, PlusAPIMixin):
|
||||
)
|
||||
|
||||
def install(self, handle: str):
|
||||
self._print_current_organization()
|
||||
get_response = self.plus_api_client.get_tool(handle)
|
||||
|
||||
if get_response.status_code == 404:
|
||||
@@ -161,13 +175,20 @@ class ToolCommand(BaseCommand, PlusAPIMixin):
|
||||
settings.tool_repository_password = login_response_json["credential"][
|
||||
"password"
|
||||
]
|
||||
settings.org_uuid = login_response_json["current_organization"][
|
||||
"uuid"
|
||||
]
|
||||
settings.org_name = login_response_json["current_organization"][
|
||||
"name"
|
||||
]
|
||||
settings.dump()
|
||||
|
||||
console.print(
|
||||
"Successfully authenticated to the tool repository.", style="bold green"
|
||||
f"Successfully authenticated to the tool repository as {settings.org_name} ({settings.org_uuid}).", style="bold green"
|
||||
)
|
||||
|
||||
def _add_package(self, tool_details):
|
||||
def _add_package(self, tool_details: dict[str, Any]):
|
||||
is_from_pypi = tool_details.get("source", None) == "pypi"
|
||||
tool_handle = tool_details["handle"]
|
||||
repository_handle = tool_details["repository"]["handle"]
|
||||
repository_url = tool_details["repository"]["url"]
|
||||
@@ -176,10 +197,13 @@ class ToolCommand(BaseCommand, PlusAPIMixin):
|
||||
add_package_command = [
|
||||
"uv",
|
||||
"add",
|
||||
"--index",
|
||||
index,
|
||||
tool_handle,
|
||||
]
|
||||
|
||||
if is_from_pypi:
|
||||
add_package_command.append(tool_handle)
|
||||
else:
|
||||
add_package_command.extend(["--index", index, tool_handle])
|
||||
|
||||
add_package_result = subprocess.run(
|
||||
add_package_command,
|
||||
capture_output=False,
|
||||
@@ -218,3 +242,10 @@ class ToolCommand(BaseCommand, PlusAPIMixin):
|
||||
)
|
||||
|
||||
return env
|
||||
|
||||
def _print_current_organization(self):
|
||||
settings = Settings()
|
||||
if settings.org_uuid:
|
||||
console.print(f"Current organization: {settings.org_name} ({settings.org_uuid})", style="bold blue")
|
||||
else:
|
||||
console.print("No organization currently set. We recommend setting one before using: `crewai org switch <org_id>` command.", style="yellow")
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
import importlib.util
|
||||
import os
|
||||
import shutil
|
||||
import sys
|
||||
from functools import reduce
|
||||
from inspect import isfunction, ismethod
|
||||
from inspect import getmro, isclass, isfunction, ismethod
|
||||
from pathlib import Path
|
||||
from typing import Any, Dict, List, get_type_hints
|
||||
|
||||
import click
|
||||
@@ -339,3 +341,112 @@ def fetch_crews(module_attr) -> list[Crew]:
|
||||
if crew_instance := get_crew_instance(attr):
|
||||
crew_instances.append(crew_instance)
|
||||
return crew_instances
|
||||
|
||||
|
||||
def is_valid_tool(obj):
|
||||
from crewai.tools.base_tool import Tool
|
||||
|
||||
if isclass(obj):
|
||||
try:
|
||||
return any(base.__name__ == "BaseTool" for base in getmro(obj))
|
||||
except (TypeError, AttributeError):
|
||||
return False
|
||||
|
||||
return isinstance(obj, Tool)
|
||||
|
||||
|
||||
def extract_available_exports(dir_path: str = "src"):
|
||||
"""
|
||||
Extract available tool classes from the project's __init__.py files.
|
||||
Only includes classes that inherit from BaseTool or functions decorated with @tool.
|
||||
|
||||
Returns:
|
||||
list: A list of valid tool class names or ["BaseTool"] if none found
|
||||
"""
|
||||
try:
|
||||
init_files = Path(dir_path).glob("**/__init__.py")
|
||||
available_exports = []
|
||||
|
||||
for init_file in init_files:
|
||||
tools = _load_tools_from_init(init_file)
|
||||
available_exports.extend(tools)
|
||||
|
||||
if not available_exports:
|
||||
_print_no_tools_warning()
|
||||
raise SystemExit(1)
|
||||
|
||||
return available_exports
|
||||
|
||||
except Exception as e:
|
||||
console.print(f"[red]Error: Could not extract tool classes: {str(e)}[/red]")
|
||||
console.print(
|
||||
"Please ensure your project contains valid tools (classes inheriting from BaseTool or functions with @tool decorator)."
|
||||
)
|
||||
raise SystemExit(1)
|
||||
|
||||
|
||||
def _load_tools_from_init(init_file: Path) -> list[dict[str, Any]]:
|
||||
"""
|
||||
Load and validate tools from a given __init__.py file.
|
||||
"""
|
||||
spec = importlib.util.spec_from_file_location("temp_module", init_file)
|
||||
|
||||
if not spec or not spec.loader:
|
||||
return []
|
||||
|
||||
module = importlib.util.module_from_spec(spec)
|
||||
sys.modules["temp_module"] = module
|
||||
|
||||
try:
|
||||
spec.loader.exec_module(module)
|
||||
|
||||
if not hasattr(module, "__all__"):
|
||||
console.print(
|
||||
f"[bold yellow]Warning: No __all__ defined in {init_file}[/bold yellow]"
|
||||
)
|
||||
raise SystemExit(1)
|
||||
|
||||
return [
|
||||
{
|
||||
"name": name,
|
||||
}
|
||||
for name in module.__all__
|
||||
if hasattr(module, name) and is_valid_tool(getattr(module, name))
|
||||
]
|
||||
|
||||
except Exception as e:
|
||||
console.print(f"[red]Warning: Could not load {init_file}: {str(e)}[/red]")
|
||||
raise SystemExit(1)
|
||||
|
||||
finally:
|
||||
sys.modules.pop("temp_module", None)
|
||||
|
||||
|
||||
def _print_no_tools_warning():
|
||||
"""
|
||||
Display warning and usage instructions if no tools were found.
|
||||
"""
|
||||
console.print(
|
||||
"\n[bold yellow]Warning: No valid tools were exposed in your __init__.py file![/bold yellow]"
|
||||
)
|
||||
console.print(
|
||||
"Your __init__.py file must contain all classes that inherit from [bold]BaseTool[/bold] "
|
||||
"or functions decorated with [bold]@tool[/bold]."
|
||||
)
|
||||
console.print(
|
||||
"\nExample:\n[dim]# In your __init__.py file[/dim]\n"
|
||||
"[green]__all__ = ['YourTool', 'your_tool_function'][/green]\n\n"
|
||||
"[dim]# In your tool.py file[/dim]\n"
|
||||
"[green]from crewai.tools import BaseTool, tool\n\n"
|
||||
"# Tool class example\n"
|
||||
"class YourTool(BaseTool):\n"
|
||||
' name = "your_tool"\n'
|
||||
' description = "Your tool description"\n'
|
||||
" # ... rest of implementation\n\n"
|
||||
"# Decorated function example\n"
|
||||
"@tool\n"
|
||||
"def your_tool_function(text: str) -> str:\n"
|
||||
' """Your tool description"""\n'
|
||||
" # ... implementation\n"
|
||||
" return result\n"
|
||||
)
|
||||
|
||||
@@ -655,8 +655,6 @@ class Crew(FlowTrackable, BaseModel):
|
||||
if self.planning:
|
||||
self._handle_crew_planning()
|
||||
|
||||
metrics: List[UsageMetrics] = []
|
||||
|
||||
if self.process == Process.sequential:
|
||||
result = self._run_sequential_process()
|
||||
elif self.process == Process.hierarchical:
|
||||
@@ -669,11 +667,8 @@ class Crew(FlowTrackable, BaseModel):
|
||||
for after_callback in self.after_kickoff_callbacks:
|
||||
result = after_callback(result)
|
||||
|
||||
metrics += [agent._token_process.get_summary() for agent in self.agents]
|
||||
self.usage_metrics = self.calculate_usage_metrics()
|
||||
|
||||
self.usage_metrics = UsageMetrics()
|
||||
for metric in metrics:
|
||||
self.usage_metrics.add_usage_metrics(metric)
|
||||
return result
|
||||
except Exception as e:
|
||||
crewai_event_bus.emit(
|
||||
|
||||
@@ -17,7 +17,7 @@ Example
|
||||
|
||||
import ast
|
||||
import inspect
|
||||
from typing import Any, Dict, List, Optional, Tuple, Union
|
||||
from typing import Any, Dict, List, Tuple, Union
|
||||
|
||||
from .utils import (
|
||||
build_ancestor_dict,
|
||||
@@ -140,7 +140,7 @@ def compute_positions(
|
||||
flow: Any,
|
||||
node_levels: Dict[str, int],
|
||||
y_spacing: float = 150,
|
||||
x_spacing: float = 150
|
||||
x_spacing: float = 300
|
||||
) -> Dict[str, Tuple[float, float]]:
|
||||
"""
|
||||
Compute the (x, y) positions for each node in the flow graph.
|
||||
@@ -154,7 +154,7 @@ def compute_positions(
|
||||
y_spacing : float, optional
|
||||
Vertical spacing between levels, by default 150.
|
||||
x_spacing : float, optional
|
||||
Horizontal spacing between nodes, by default 150.
|
||||
Horizontal spacing between nodes, by default 300.
|
||||
|
||||
Returns
|
||||
-------
|
||||
|
||||
@@ -1,93 +0,0 @@
|
||||
from pathlib import Path
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
|
||||
from .base_embedder import BaseEmbedder
|
||||
|
||||
try:
|
||||
from fastembed_gpu import TextEmbedding # type: ignore
|
||||
|
||||
FASTEMBED_AVAILABLE = True
|
||||
except ImportError:
|
||||
try:
|
||||
from fastembed import TextEmbedding
|
||||
|
||||
FASTEMBED_AVAILABLE = True
|
||||
except ImportError:
|
||||
FASTEMBED_AVAILABLE = False
|
||||
|
||||
|
||||
class FastEmbed(BaseEmbedder):
|
||||
"""
|
||||
A wrapper class for text embedding models using FastEmbed
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model_name: str = "BAAI/bge-small-en-v1.5",
|
||||
cache_dir: Optional[Union[str, Path]] = None,
|
||||
):
|
||||
"""
|
||||
Initialize the embedding model
|
||||
|
||||
Args:
|
||||
model_name: Name of the model to use
|
||||
cache_dir: Directory to cache the model
|
||||
gpu: Whether to use GPU acceleration
|
||||
"""
|
||||
if not FASTEMBED_AVAILABLE:
|
||||
raise ImportError(
|
||||
"FastEmbed is not installed. Please install it with: "
|
||||
"uv pip install fastembed or uv pip install fastembed-gpu for GPU support"
|
||||
)
|
||||
|
||||
self.model = TextEmbedding(
|
||||
model_name=model_name,
|
||||
cache_dir=str(cache_dir) if cache_dir else None,
|
||||
)
|
||||
|
||||
def embed_chunks(self, chunks: List[str]) -> List[np.ndarray]:
|
||||
"""
|
||||
Generate embeddings for a list of text chunks
|
||||
|
||||
Args:
|
||||
chunks: List of text chunks to embed
|
||||
|
||||
Returns:
|
||||
List of embeddings
|
||||
"""
|
||||
embeddings = list(self.model.embed(chunks))
|
||||
return embeddings
|
||||
|
||||
def embed_texts(self, texts: List[str]) -> List[np.ndarray]:
|
||||
"""
|
||||
Generate embeddings for a list of texts
|
||||
|
||||
Args:
|
||||
texts: List of texts to embed
|
||||
|
||||
Returns:
|
||||
List of embeddings
|
||||
"""
|
||||
embeddings = list(self.model.embed(texts))
|
||||
return embeddings
|
||||
|
||||
def embed_text(self, text: str) -> np.ndarray:
|
||||
"""
|
||||
Generate embedding for a single text
|
||||
|
||||
Args:
|
||||
text: Text to embed
|
||||
|
||||
Returns:
|
||||
Embedding array
|
||||
"""
|
||||
return self.embed_texts([text])[0]
|
||||
|
||||
@property
|
||||
def dimension(self) -> int:
|
||||
"""Get the dimension of the embeddings"""
|
||||
# Generate a test embedding to get dimensions
|
||||
test_embed = self.embed_text("test")
|
||||
return len(test_embed)
|
||||
@@ -1,9 +1,14 @@
|
||||
import asyncio
|
||||
import inspect
|
||||
import uuid
|
||||
from datetime import datetime
|
||||
from typing import Any, Callable, Dict, List, Optional, Type, Union, cast
|
||||
from typing import Any, Callable, Dict, List, Optional, Tuple, Type, Union, cast, get_args, get_origin
|
||||
|
||||
from pydantic import BaseModel, Field, InstanceOf, PrivateAttr, model_validator
|
||||
try:
|
||||
from typing import Self
|
||||
except ImportError:
|
||||
from typing_extensions import Self
|
||||
|
||||
from pydantic import BaseModel, Field, InstanceOf, PrivateAttr, model_validator, field_validator
|
||||
|
||||
from crewai.agents.agent_builder.base_agent import BaseAgent
|
||||
from crewai.agents.agent_builder.utilities.base_token_process import TokenProcess
|
||||
@@ -18,6 +23,7 @@ from crewai.llm import LLM
|
||||
from crewai.tools.base_tool import BaseTool
|
||||
from crewai.tools.structured_tool import CrewStructuredTool
|
||||
from crewai.utilities import I18N
|
||||
from crewai.utilities.guardrail import process_guardrail
|
||||
from crewai.utilities.agent_utils import (
|
||||
enforce_rpm_limit,
|
||||
format_message_for_llm,
|
||||
@@ -35,7 +41,7 @@ from crewai.utilities.agent_utils import (
|
||||
render_text_description_and_args,
|
||||
show_agent_logs,
|
||||
)
|
||||
from crewai.utilities.converter import convert_to_model, generate_model_description
|
||||
from crewai.utilities.converter import generate_model_description
|
||||
from crewai.utilities.events.agent_events import (
|
||||
LiteAgentExecutionCompletedEvent,
|
||||
LiteAgentExecutionErrorEvent,
|
||||
@@ -146,6 +152,15 @@ class LiteAgent(FlowTrackable, BaseModel):
|
||||
default=[], description="Callbacks to be used for the agent"
|
||||
)
|
||||
|
||||
# Guardrail Properties
|
||||
guardrail: Optional[Union[Callable[[LiteAgentOutput], Tuple[bool, Any]], str]] = Field(
|
||||
default=None,
|
||||
description="Function or string description of a guardrail to validate agent output"
|
||||
)
|
||||
guardrail_max_retries: int = Field(
|
||||
default=3, description="Maximum number of retries when guardrail fails"
|
||||
)
|
||||
|
||||
# State and Results
|
||||
tools_results: List[Dict[str, Any]] = Field(
|
||||
default=[], description="Results of the tools used by the agent."
|
||||
@@ -163,6 +178,9 @@ class LiteAgent(FlowTrackable, BaseModel):
|
||||
_messages: List[Dict[str, str]] = PrivateAttr(default_factory=list)
|
||||
_iterations: int = PrivateAttr(default=0)
|
||||
_printer: Printer = PrivateAttr(default_factory=Printer)
|
||||
_guardrail: Optional[Callable] = PrivateAttr(default=None)
|
||||
_guardrail_retry_count: int = PrivateAttr(default=0)
|
||||
|
||||
|
||||
@model_validator(mode="after")
|
||||
def setup_llm(self):
|
||||
@@ -184,6 +202,60 @@ class LiteAgent(FlowTrackable, BaseModel):
|
||||
|
||||
return self
|
||||
|
||||
@model_validator(mode="after")
|
||||
def ensure_guardrail_is_callable(self) -> Self:
|
||||
if callable(self.guardrail):
|
||||
self._guardrail = self.guardrail
|
||||
elif isinstance(self.guardrail, str):
|
||||
from crewai.tasks.llm_guardrail import LLMGuardrail
|
||||
assert isinstance(self.llm, LLM)
|
||||
|
||||
self._guardrail = LLMGuardrail(
|
||||
description=self.guardrail, llm=self.llm
|
||||
)
|
||||
|
||||
return self
|
||||
|
||||
@field_validator("guardrail", mode="before")
|
||||
@classmethod
|
||||
def validate_guardrail_function(cls, v: Optional[Union[Callable, str]]) -> Optional[Union[Callable, str]]:
|
||||
"""Validate that the guardrail function has the correct signature.
|
||||
|
||||
If v is a callable, validate that it has the correct signature.
|
||||
If v is a string, return it as is.
|
||||
|
||||
Args:
|
||||
v: The guardrail function to validate or a string describing the guardrail task
|
||||
|
||||
Returns:
|
||||
The validated guardrail function or a string describing the guardrail task
|
||||
"""
|
||||
if v is None or isinstance(v, str):
|
||||
return v
|
||||
|
||||
# Check function signature
|
||||
sig = inspect.signature(v)
|
||||
if len(sig.parameters) != 1:
|
||||
raise ValueError(
|
||||
f"Guardrail function must accept exactly 1 parameter (LiteAgentOutput), "
|
||||
f"but it accepts {len(sig.parameters)}"
|
||||
)
|
||||
|
||||
# Check return annotation if present
|
||||
if sig.return_annotation is not sig.empty:
|
||||
if sig.return_annotation == Tuple[bool, Any]:
|
||||
return v
|
||||
|
||||
origin = get_origin(sig.return_annotation)
|
||||
args = get_args(sig.return_annotation)
|
||||
|
||||
if origin is not tuple or len(args) != 2 or args[0] is not bool:
|
||||
raise ValueError(
|
||||
"If return type is annotated, it must be Tuple[bool, Any]"
|
||||
)
|
||||
|
||||
return v
|
||||
|
||||
@property
|
||||
def key(self) -> str:
|
||||
"""Get the unique key for this agent instance."""
|
||||
@@ -223,54 +295,7 @@ class LiteAgent(FlowTrackable, BaseModel):
|
||||
# Format messages for the LLM
|
||||
self._messages = self._format_messages(messages)
|
||||
|
||||
# Emit event for agent execution start
|
||||
crewai_event_bus.emit(
|
||||
self,
|
||||
event=LiteAgentExecutionStartedEvent(
|
||||
agent_info=agent_info,
|
||||
tools=self._parsed_tools,
|
||||
messages=messages,
|
||||
),
|
||||
)
|
||||
|
||||
# Execute the agent using invoke loop
|
||||
agent_finish = self._invoke_loop()
|
||||
formatted_result: Optional[BaseModel] = None
|
||||
if self.response_format:
|
||||
try:
|
||||
# Cast to BaseModel to ensure type safety
|
||||
result = self.response_format.model_validate_json(
|
||||
agent_finish.output
|
||||
)
|
||||
if isinstance(result, BaseModel):
|
||||
formatted_result = result
|
||||
except Exception as e:
|
||||
self._printer.print(
|
||||
content=f"Failed to parse output into response format: {str(e)}",
|
||||
color="yellow",
|
||||
)
|
||||
|
||||
# Calculate token usage metrics
|
||||
usage_metrics = self._token_process.get_summary()
|
||||
|
||||
# Create output
|
||||
output = LiteAgentOutput(
|
||||
raw=agent_finish.output,
|
||||
pydantic=formatted_result,
|
||||
agent_role=self.role,
|
||||
usage_metrics=usage_metrics.model_dump() if usage_metrics else None,
|
||||
)
|
||||
|
||||
# Emit completion event
|
||||
crewai_event_bus.emit(
|
||||
self,
|
||||
event=LiteAgentExecutionCompletedEvent(
|
||||
agent_info=agent_info,
|
||||
output=agent_finish.output,
|
||||
),
|
||||
)
|
||||
|
||||
return output
|
||||
return self._execute_core(agent_info=agent_info)
|
||||
|
||||
except Exception as e:
|
||||
self._printer.print(
|
||||
@@ -288,6 +313,94 @@ class LiteAgent(FlowTrackable, BaseModel):
|
||||
)
|
||||
raise e
|
||||
|
||||
def _execute_core(self, agent_info: Dict[str, Any]) -> LiteAgentOutput:
|
||||
# Emit event for agent execution start
|
||||
crewai_event_bus.emit(
|
||||
self,
|
||||
event=LiteAgentExecutionStartedEvent(
|
||||
agent_info=agent_info,
|
||||
tools=self._parsed_tools,
|
||||
messages=self._messages,
|
||||
),
|
||||
)
|
||||
|
||||
# Execute the agent using invoke loop
|
||||
agent_finish = self._invoke_loop()
|
||||
formatted_result: Optional[BaseModel] = None
|
||||
if self.response_format:
|
||||
try:
|
||||
# Cast to BaseModel to ensure type safety
|
||||
result = self.response_format.model_validate_json(
|
||||
agent_finish.output
|
||||
)
|
||||
if isinstance(result, BaseModel):
|
||||
formatted_result = result
|
||||
except Exception as e:
|
||||
self._printer.print(
|
||||
content=f"Failed to parse output into response format: {str(e)}",
|
||||
color="yellow",
|
||||
)
|
||||
|
||||
# Calculate token usage metrics
|
||||
usage_metrics = self._token_process.get_summary()
|
||||
|
||||
# Create output
|
||||
output = LiteAgentOutput(
|
||||
raw=agent_finish.output,
|
||||
pydantic=formatted_result,
|
||||
agent_role=self.role,
|
||||
usage_metrics=usage_metrics.model_dump() if usage_metrics else None,
|
||||
)
|
||||
|
||||
# Process guardrail if set
|
||||
if self._guardrail is not None:
|
||||
guardrail_result = process_guardrail(
|
||||
output=output,
|
||||
guardrail=self._guardrail,
|
||||
retry_count=self._guardrail_retry_count
|
||||
)
|
||||
|
||||
if not guardrail_result.success:
|
||||
if self._guardrail_retry_count >= self.guardrail_max_retries:
|
||||
raise Exception(
|
||||
f"Agent's guardrail failed validation after {self.guardrail_max_retries} retries. "
|
||||
f"Last error: {guardrail_result.error}"
|
||||
)
|
||||
self._guardrail_retry_count += 1
|
||||
if self.verbose:
|
||||
self._printer.print(
|
||||
f"Guardrail failed. Retrying ({self._guardrail_retry_count}/{self.guardrail_max_retries})..."
|
||||
f"\n{guardrail_result.error}"
|
||||
)
|
||||
|
||||
self._messages.append({
|
||||
"role": "user",
|
||||
"content": guardrail_result.error or "Guardrail validation failed"
|
||||
})
|
||||
|
||||
return self._execute_core(agent_info=agent_info)
|
||||
|
||||
# Apply guardrail result if available
|
||||
if guardrail_result.result is not None:
|
||||
if isinstance(guardrail_result.result, str):
|
||||
output.raw = guardrail_result.result
|
||||
elif isinstance(guardrail_result.result, BaseModel):
|
||||
output.pydantic = guardrail_result.result
|
||||
|
||||
usage_metrics = self._token_process.get_summary()
|
||||
output.usage_metrics = usage_metrics.model_dump() if usage_metrics else None
|
||||
|
||||
# Emit completion event
|
||||
crewai_event_bus.emit(
|
||||
self,
|
||||
event=LiteAgentExecutionCompletedEvent(
|
||||
agent_info=agent_info,
|
||||
output=agent_finish.output,
|
||||
),
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
async def kickoff_async(
|
||||
self, messages: Union[str, List[Dict[str, str]]]
|
||||
) -> LiteAgentOutput:
|
||||
|
||||
@@ -35,12 +35,12 @@ from pydantic_core import PydanticCustomError
|
||||
|
||||
from crewai.agents.agent_builder.base_agent import BaseAgent
|
||||
from crewai.security import Fingerprint, SecurityConfig
|
||||
from crewai.tasks.guardrail_result import GuardrailResult
|
||||
from crewai.tasks.output_format import OutputFormat
|
||||
from crewai.tasks.task_output import TaskOutput
|
||||
from crewai.tools.base_tool import BaseTool
|
||||
from crewai.utilities.config import process_config
|
||||
from crewai.utilities.constants import NOT_SPECIFIED
|
||||
from crewai.utilities.guardrail import process_guardrail, GuardrailResult
|
||||
from crewai.utilities.converter import Converter, convert_to_model
|
||||
from crewai.utilities.events import (
|
||||
TaskCompletedEvent,
|
||||
@@ -431,7 +431,11 @@ class Task(BaseModel):
|
||||
)
|
||||
|
||||
if self._guardrail:
|
||||
guardrail_result = self._process_guardrail(task_output)
|
||||
guardrail_result = process_guardrail(
|
||||
output=task_output,
|
||||
guardrail=self._guardrail,
|
||||
retry_count=self.retry_count
|
||||
)
|
||||
if not guardrail_result.success:
|
||||
if self.retry_count >= self.max_retries:
|
||||
raise Exception(
|
||||
@@ -527,10 +531,10 @@ class Task(BaseModel):
|
||||
|
||||
def prompt(self) -> str:
|
||||
"""Generates the task prompt with optional markdown formatting.
|
||||
|
||||
|
||||
When the markdown attribute is True, instructions for formatting the
|
||||
response in Markdown syntax will be added to the prompt.
|
||||
|
||||
|
||||
Returns:
|
||||
str: The formatted prompt string containing the task description,
|
||||
expected output, and optional markdown formatting instructions.
|
||||
@@ -541,7 +545,7 @@ class Task(BaseModel):
|
||||
expected_output=self.expected_output
|
||||
)
|
||||
tasks_slices = [self.description, output]
|
||||
|
||||
|
||||
if self.markdown:
|
||||
markdown_instruction = """Your final answer MUST be formatted in Markdown syntax.
|
||||
Follow these guidelines:
|
||||
|
||||
@@ -8,7 +8,7 @@ import platform
|
||||
import warnings
|
||||
from contextlib import contextmanager
|
||||
from importlib.metadata import version
|
||||
from typing import TYPE_CHECKING, Any, Optional
|
||||
from typing import TYPE_CHECKING, Any, Callable, Optional
|
||||
import threading
|
||||
|
||||
from opentelemetry import trace
|
||||
@@ -73,11 +73,16 @@ class Telemetry:
|
||||
with cls._lock:
|
||||
if cls._instance is None:
|
||||
cls._instance = super(Telemetry, cls).__new__(cls)
|
||||
cls._instance._initialized = False
|
||||
return cls._instance
|
||||
|
||||
def __init__(self) -> None:
|
||||
if hasattr(self, '_initialized') and self._initialized:
|
||||
return
|
||||
|
||||
self.ready: bool = False
|
||||
self.trace_set: bool = False
|
||||
self._initialized: bool = True
|
||||
|
||||
if self._is_telemetry_disabled():
|
||||
return
|
||||
@@ -113,6 +118,10 @@ class Telemetry:
|
||||
or os.getenv("CREWAI_DISABLE_TELEMETRY", "false").lower() == "true"
|
||||
)
|
||||
|
||||
def _should_execute_telemetry(self) -> bool:
|
||||
"""Check if telemetry operations should be executed."""
|
||||
return self.ready and not self._is_telemetry_disabled()
|
||||
|
||||
def set_tracer(self):
|
||||
if self.ready and not self.trace_set:
|
||||
try:
|
||||
@@ -123,8 +132,9 @@ class Telemetry:
|
||||
self.ready = False
|
||||
self.trace_set = False
|
||||
|
||||
def _safe_telemetry_operation(self, operation):
|
||||
if not self.ready:
|
||||
def _safe_telemetry_operation(self, operation: Callable[[], None]) -> None:
|
||||
"""Execute telemetry operation safely, checking both readiness and environment variables."""
|
||||
if not self._should_execute_telemetry():
|
||||
return
|
||||
try:
|
||||
operation()
|
||||
@@ -423,7 +433,8 @@ class Telemetry:
|
||||
|
||||
return span
|
||||
|
||||
return self._safe_telemetry_operation(operation)
|
||||
self._safe_telemetry_operation(operation)
|
||||
return None
|
||||
|
||||
def task_ended(self, span: Span, task: Task, crew: Crew):
|
||||
"""Records the completion of a task execution in a crew.
|
||||
@@ -773,7 +784,8 @@ class Telemetry:
|
||||
return span
|
||||
|
||||
if crew.share_crew:
|
||||
return self._safe_telemetry_operation(operation)
|
||||
self._safe_telemetry_operation(operation)
|
||||
return operation()
|
||||
return None
|
||||
|
||||
def end_crew(self, crew, final_string_output):
|
||||
|
||||
@@ -1 +1,7 @@
|
||||
from .base_tool import BaseTool, tool
|
||||
from .base_tool import BaseTool, tool, EnvVar
|
||||
|
||||
__all__ = [
|
||||
"BaseTool",
|
||||
"tool",
|
||||
"EnvVar",
|
||||
]
|
||||
@@ -1,7 +1,7 @@
|
||||
import asyncio
|
||||
from abc import ABC, abstractmethod
|
||||
from inspect import signature
|
||||
from typing import Any, Callable, Type, get_args, get_origin
|
||||
from typing import Any, Callable, Type, get_args, get_origin, Optional, List
|
||||
|
||||
from pydantic import (
|
||||
BaseModel,
|
||||
@@ -14,6 +14,11 @@ from pydantic import BaseModel as PydanticBaseModel
|
||||
|
||||
from crewai.tools.structured_tool import CrewStructuredTool
|
||||
|
||||
class EnvVar(BaseModel):
|
||||
name: str
|
||||
description: str
|
||||
required: bool = True
|
||||
default: Optional[str] = None
|
||||
|
||||
class BaseTool(BaseModel, ABC):
|
||||
class _ArgsSchemaPlaceholder(PydanticBaseModel):
|
||||
@@ -25,6 +30,8 @@ class BaseTool(BaseModel, ABC):
|
||||
"""The unique name of the tool that clearly communicates its purpose."""
|
||||
description: str
|
||||
"""Used to tell the model how/when/why to use the tool."""
|
||||
env_vars: List[EnvVar] = []
|
||||
"""List of environment variables used by the tool."""
|
||||
args_schema: Type[PydanticBaseModel] = Field(
|
||||
default_factory=_ArgsSchemaPlaceholder, validate_default=True
|
||||
)
|
||||
@@ -57,7 +64,7 @@ class BaseTool(BaseModel, ABC):
|
||||
},
|
||||
},
|
||||
)
|
||||
|
||||
|
||||
@field_validator("max_usage_count", mode="before")
|
||||
@classmethod
|
||||
def validate_max_usage_count(cls, v: int | None) -> int | None:
|
||||
@@ -81,11 +88,11 @@ class BaseTool(BaseModel, ABC):
|
||||
# If _run is async, we safely run it
|
||||
if asyncio.iscoroutine(result):
|
||||
result = asyncio.run(result)
|
||||
|
||||
|
||||
self.current_usage_count += 1
|
||||
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def reset_usage_count(self) -> None:
|
||||
"""Reset the current usage count to zero."""
|
||||
self.current_usage_count = 0
|
||||
@@ -272,7 +279,7 @@ def to_langchain(
|
||||
def tool(*args, result_as_answer: bool = False, max_usage_count: int | None = None) -> Callable:
|
||||
"""
|
||||
Decorator to create a tool from a function.
|
||||
|
||||
|
||||
Args:
|
||||
*args: Positional arguments, either the function to decorate or the tool name.
|
||||
result_as_answer: Flag to indicate if the tool result should be used as the final agent answer.
|
||||
|
||||
@@ -1,5 +1,7 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import asyncio
|
||||
|
||||
import inspect
|
||||
import textwrap
|
||||
from typing import Any, Callable, Optional, Union, get_type_hints
|
||||
@@ -239,7 +241,17 @@ class CrewStructuredTool:
|
||||
) -> Any:
|
||||
"""Main method for tool execution."""
|
||||
parsed_args = self._parse_args(input)
|
||||
return self.func(**parsed_args, **kwargs)
|
||||
|
||||
if inspect.iscoroutinefunction(self.func):
|
||||
result = asyncio.run(self.func(**parsed_args, **kwargs))
|
||||
return result
|
||||
|
||||
result = self.func(**parsed_args, **kwargs)
|
||||
|
||||
if asyncio.iscoroutine(result):
|
||||
return asyncio.run(result)
|
||||
|
||||
return result
|
||||
|
||||
@property
|
||||
def args(self) -> dict:
|
||||
|
||||
@@ -20,7 +20,10 @@ from crewai.utilities.errors import AgentRepositoryError
|
||||
from crewai.utilities.exceptions.context_window_exceeding_exception import (
|
||||
LLMContextLengthExceededException,
|
||||
)
|
||||
from rich.console import Console
|
||||
from crewai.cli.config import Settings
|
||||
|
||||
console = Console()
|
||||
|
||||
def parse_tools(tools: List[BaseTool]) -> List[CrewStructuredTool]:
|
||||
"""Parse tools to be used for the task."""
|
||||
@@ -215,9 +218,6 @@ def handle_agent_action_core(
|
||||
if show_logs:
|
||||
show_logs(formatted_answer)
|
||||
|
||||
if messages is not None:
|
||||
messages.append({"role": "assistant", "content": tool_result.result})
|
||||
|
||||
return formatted_answer
|
||||
|
||||
|
||||
@@ -438,6 +438,13 @@ def show_agent_logs(
|
||||
)
|
||||
|
||||
|
||||
def _print_current_organization():
|
||||
settings = Settings()
|
||||
if settings.org_uuid:
|
||||
console.print(f"Fetching agent from organization: {settings.org_name} ({settings.org_uuid})", style="bold blue")
|
||||
else:
|
||||
console.print("No organization currently set. We recommend setting one before using: `crewai org switch <org_id>` command.", style="yellow")
|
||||
|
||||
def load_agent_from_repository(from_repository: str) -> Dict[str, Any]:
|
||||
attributes: Dict[str, Any] = {}
|
||||
if from_repository:
|
||||
@@ -447,15 +454,18 @@ def load_agent_from_repository(from_repository: str) -> Dict[str, Any]:
|
||||
from crewai.cli.plus_api import PlusAPI
|
||||
|
||||
client = PlusAPI(api_key=get_auth_token())
|
||||
_print_current_organization()
|
||||
response = client.get_agent(from_repository)
|
||||
if response.status_code == 404:
|
||||
raise AgentRepositoryError(
|
||||
f"Agent {from_repository} does not exist, make sure the name is correct or the agent is available on your organization"
|
||||
f"Agent {from_repository} does not exist, make sure the name is correct or the agent is available on your organization."
|
||||
f"\nIf you are using the wrong organization, switch to the correct one using `crewai org switch <org_id>` command.",
|
||||
)
|
||||
|
||||
if response.status_code != 200:
|
||||
raise AgentRepositoryError(
|
||||
f"Agent {from_repository} could not be loaded: {response.text}"
|
||||
f"\nIf you are using the wrong organization, switch to the correct one using `crewai org switch <org_id>` command.",
|
||||
)
|
||||
|
||||
agent = response.json()
|
||||
@@ -464,7 +474,7 @@ def load_agent_from_repository(from_repository: str) -> Dict[str, Any]:
|
||||
attributes[key] = []
|
||||
for tool in value:
|
||||
try:
|
||||
module = importlib.import_module("crewai_tools")
|
||||
module = importlib.import_module(tool["module"])
|
||||
tool_class = getattr(module, tool["name"])
|
||||
attributes[key].append(tool_class())
|
||||
except Exception as e:
|
||||
|
||||
@@ -326,10 +326,14 @@ class EventListener(BaseEventListener):
|
||||
|
||||
@crewai_event_bus.on(LLMCallStartedEvent)
|
||||
def on_llm_call_started(source, event: LLMCallStartedEvent):
|
||||
self.formatter.handle_llm_call_started(
|
||||
# Capture the returned tool branch and update the current_tool_branch reference
|
||||
thinking_branch = self.formatter.handle_llm_call_started(
|
||||
self.formatter.current_agent_branch,
|
||||
self.formatter.current_crew_tree,
|
||||
)
|
||||
# Update the formatter's current_tool_branch to ensure proper cleanup
|
||||
if thinking_branch is not None:
|
||||
self.formatter.current_tool_branch = thinking_branch
|
||||
|
||||
@crewai_event_bus.on(LLMCallCompletedEvent)
|
||||
def on_llm_call_completed(source, event: LLMCallCompletedEvent):
|
||||
|
||||
@@ -17,6 +17,7 @@ class ConsoleFormatter:
|
||||
current_lite_agent_branch: Optional[Tree] = None
|
||||
tool_usage_counts: Dict[str, int] = {}
|
||||
current_reasoning_branch: Optional[Tree] = None # Track reasoning status
|
||||
_live_paused: bool = False
|
||||
current_llm_tool_tree: Optional[Tree] = None
|
||||
|
||||
def __init__(self, verbose: bool = False):
|
||||
@@ -119,6 +120,19 @@ class ConsoleFormatter:
|
||||
# Finally, pass through to the regular Console.print implementation
|
||||
self.console.print(*args, **kwargs)
|
||||
|
||||
def pause_live_updates(self) -> None:
|
||||
"""Pause Live session updates to allow for human input without interference."""
|
||||
if not self._live_paused:
|
||||
if self._live:
|
||||
self._live.stop()
|
||||
self._live = None
|
||||
self._live_paused = True
|
||||
|
||||
def resume_live_updates(self) -> None:
|
||||
"""Resume Live session updates after human input is complete."""
|
||||
if self._live_paused:
|
||||
self._live_paused = False
|
||||
|
||||
def print_panel(
|
||||
self, content: Text, title: str, style: str = "blue", is_flow: bool = False
|
||||
) -> None:
|
||||
@@ -611,14 +625,22 @@ class ConsoleFormatter:
|
||||
return None
|
||||
|
||||
# Only add thinking status if we don't have a current tool branch
|
||||
if self.current_tool_branch is None:
|
||||
# or if the current tool branch is not a thinking node
|
||||
should_add_thinking = (
|
||||
self.current_tool_branch is None or
|
||||
"Thinking" not in str(self.current_tool_branch.label)
|
||||
)
|
||||
|
||||
if should_add_thinking:
|
||||
tool_branch = branch_to_use.add("")
|
||||
self.update_tree_label(tool_branch, "🧠", "Thinking...", "blue")
|
||||
self.current_tool_branch = tool_branch
|
||||
self.print(tree_to_use)
|
||||
self.print()
|
||||
return tool_branch
|
||||
return None
|
||||
|
||||
# Return the existing tool branch if it's already a thinking node
|
||||
return self.current_tool_branch
|
||||
|
||||
def handle_llm_call_completed(
|
||||
self,
|
||||
@@ -627,7 +649,7 @@ class ConsoleFormatter:
|
||||
crew_tree: Optional[Tree],
|
||||
) -> None:
|
||||
"""Handle LLM call completed event."""
|
||||
if not self.verbose or tool_branch is None:
|
||||
if not self.verbose:
|
||||
return
|
||||
|
||||
# Decide which tree to render: prefer full crew tree, else parent branch
|
||||
@@ -635,23 +657,47 @@ class ConsoleFormatter:
|
||||
if tree_to_use is None:
|
||||
return
|
||||
|
||||
# Remove the thinking status node when complete
|
||||
if "Thinking" in str(tool_branch.label):
|
||||
# Try to remove the thinking status node - first try the provided tool_branch
|
||||
thinking_branch_to_remove = None
|
||||
removed = False
|
||||
|
||||
# Method 1: Use the provided tool_branch if it's a thinking node
|
||||
if tool_branch is not None and "Thinking" in str(tool_branch.label):
|
||||
thinking_branch_to_remove = tool_branch
|
||||
|
||||
# Method 2: Fallback - search for any thinking node if tool_branch is None or not thinking
|
||||
if thinking_branch_to_remove is None:
|
||||
parents = [
|
||||
self.current_lite_agent_branch,
|
||||
self.current_agent_branch,
|
||||
self.current_task_branch,
|
||||
tree_to_use,
|
||||
]
|
||||
removed = False
|
||||
for parent in parents:
|
||||
if isinstance(parent, Tree) and tool_branch in parent.children:
|
||||
parent.children.remove(tool_branch)
|
||||
if isinstance(parent, Tree):
|
||||
for child in parent.children:
|
||||
if "Thinking" in str(child.label):
|
||||
thinking_branch_to_remove = child
|
||||
break
|
||||
if thinking_branch_to_remove:
|
||||
break
|
||||
|
||||
# Remove the thinking node if found
|
||||
if thinking_branch_to_remove:
|
||||
parents = [
|
||||
self.current_lite_agent_branch,
|
||||
self.current_agent_branch,
|
||||
self.current_task_branch,
|
||||
tree_to_use,
|
||||
]
|
||||
for parent in parents:
|
||||
if isinstance(parent, Tree) and thinking_branch_to_remove in parent.children:
|
||||
parent.children.remove(thinking_branch_to_remove)
|
||||
removed = True
|
||||
break
|
||||
|
||||
# Clear pointer if we just removed the current_tool_branch
|
||||
if self.current_tool_branch is tool_branch:
|
||||
if self.current_tool_branch is thinking_branch_to_remove:
|
||||
self.current_tool_branch = None
|
||||
|
||||
if removed:
|
||||
@@ -668,9 +714,36 @@ class ConsoleFormatter:
|
||||
# Decide which tree to render: prefer full crew tree, else parent branch
|
||||
tree_to_use = self.current_crew_tree or crew_tree or self.current_task_branch
|
||||
|
||||
# Update tool branch if it exists
|
||||
if tool_branch:
|
||||
tool_branch.label = Text("❌ LLM Failed", style="red bold")
|
||||
# Find the thinking branch to update (similar to completion logic)
|
||||
thinking_branch_to_update = None
|
||||
|
||||
# Method 1: Use the provided tool_branch if it's a thinking node
|
||||
if tool_branch is not None and "Thinking" in str(tool_branch.label):
|
||||
thinking_branch_to_update = tool_branch
|
||||
|
||||
# Method 2: Fallback - search for any thinking node if tool_branch is None or not thinking
|
||||
if thinking_branch_to_update is None:
|
||||
parents = [
|
||||
self.current_lite_agent_branch,
|
||||
self.current_agent_branch,
|
||||
self.current_task_branch,
|
||||
tree_to_use,
|
||||
]
|
||||
for parent in parents:
|
||||
if isinstance(parent, Tree):
|
||||
for child in parent.children:
|
||||
if "Thinking" in str(child.label):
|
||||
thinking_branch_to_update = child
|
||||
break
|
||||
if thinking_branch_to_update:
|
||||
break
|
||||
|
||||
# Update the thinking branch to show failure
|
||||
if thinking_branch_to_update:
|
||||
thinking_branch_to_update.label = Text("❌ LLM Failed", style="red bold")
|
||||
# Clear the current_tool_branch reference
|
||||
if self.current_tool_branch is thinking_branch_to_update:
|
||||
self.current_tool_branch = None
|
||||
if tree_to_use:
|
||||
self.print(tree_to_use)
|
||||
self.print()
|
||||
|
||||
@@ -1,15 +1,7 @@
|
||||
"""
|
||||
Module for handling task guardrail validation results.
|
||||
|
||||
This module provides the GuardrailResult class which standardizes
|
||||
the way task guardrails return their validation results.
|
||||
"""
|
||||
|
||||
from typing import Any, Optional, Tuple, Union
|
||||
from typing import Any, Callable, Optional, Tuple, Union
|
||||
|
||||
from pydantic import BaseModel, field_validator
|
||||
|
||||
|
||||
class GuardrailResult(BaseModel):
|
||||
"""Result from a task guardrail execution.
|
||||
|
||||
@@ -54,3 +46,48 @@ class GuardrailResult(BaseModel):
|
||||
result=data if success else None,
|
||||
error=data if not success else None
|
||||
)
|
||||
|
||||
|
||||
def process_guardrail(output: Any, guardrail: Callable, retry_count: int) -> GuardrailResult:
|
||||
"""Process the guardrail for the agent output.
|
||||
|
||||
Args:
|
||||
output: The output to validate with the guardrail
|
||||
|
||||
Returns:
|
||||
GuardrailResult: The result of the guardrail validation
|
||||
"""
|
||||
from crewai.task import TaskOutput
|
||||
from crewai.lite_agent import LiteAgentOutput
|
||||
|
||||
assert isinstance(output, TaskOutput) or isinstance(output, LiteAgentOutput), "Output must be a TaskOutput or LiteAgentOutput"
|
||||
|
||||
assert guardrail is not None
|
||||
|
||||
from crewai.utilities.events import (
|
||||
LLMGuardrailCompletedEvent,
|
||||
LLMGuardrailStartedEvent,
|
||||
)
|
||||
from crewai.utilities.events.crewai_event_bus import crewai_event_bus
|
||||
|
||||
crewai_event_bus.emit(
|
||||
None,
|
||||
LLMGuardrailStartedEvent(
|
||||
guardrail=guardrail, retry_count=retry_count
|
||||
),
|
||||
)
|
||||
|
||||
result = guardrail(output)
|
||||
guardrail_result = GuardrailResult.from_tuple(result)
|
||||
|
||||
crewai_event_bus.emit(
|
||||
None,
|
||||
LLMGuardrailCompletedEvent(
|
||||
success=guardrail_result.success,
|
||||
result=guardrail_result.result,
|
||||
error=guardrail_result.error,
|
||||
retry_count=retry_count,
|
||||
),
|
||||
)
|
||||
|
||||
return guardrail_result
|
||||
@@ -309,7 +309,9 @@ def test_cache_hitting():
|
||||
def handle_tool_end(source, event):
|
||||
received_events.append(event)
|
||||
|
||||
with (patch.object(CacheHandler, "read") as read,):
|
||||
with (
|
||||
patch.object(CacheHandler, "read") as read,
|
||||
):
|
||||
read.return_value = "0"
|
||||
task = Task(
|
||||
description="What is 2 times 6? Ignore correctness and just return the result of the multiplication tool, you must use the tool.",
|
||||
@@ -1628,13 +1630,13 @@ def test_agent_execute_task_with_ollama():
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_agent_with_knowledge_sources():
|
||||
# Create a knowledge source with some content
|
||||
content = "Brandon's favorite color is red and he likes Mexican food."
|
||||
string_source = StringKnowledgeSource(content=content)
|
||||
with patch("crewai.knowledge") as MockKnowledge:
|
||||
mock_knowledge_instance = MockKnowledge.return_value
|
||||
mock_knowledge_instance.sources = [string_source]
|
||||
mock_knowledge_instance.search.return_value = [{"content": content}]
|
||||
MockKnowledge.add_sources.return_value = [string_source]
|
||||
|
||||
agent = Agent(
|
||||
role="Information Agent",
|
||||
@@ -1644,7 +1646,6 @@ def test_agent_with_knowledge_sources():
|
||||
knowledge_sources=[string_source],
|
||||
)
|
||||
|
||||
# Create a task that requires the agent to use the knowledge
|
||||
task = Task(
|
||||
description="What is Brandon's favorite color?",
|
||||
expected_output="Brandon's favorite color.",
|
||||
@@ -1652,10 +1653,11 @@ def test_agent_with_knowledge_sources():
|
||||
)
|
||||
|
||||
crew = Crew(agents=[agent], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
|
||||
# Assert that the agent provides the correct information
|
||||
assert "red" in result.raw.lower()
|
||||
with patch.object(Knowledge, "add_sources") as mock_add_sources:
|
||||
result = crew.kickoff()
|
||||
assert mock_add_sources.called, "add_sources() should have been called"
|
||||
mock_add_sources.assert_called_once()
|
||||
assert "red" in result.raw.lower()
|
||||
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
@@ -2036,7 +2038,7 @@ def mock_get_auth_token():
|
||||
|
||||
@patch("crewai.cli.plus_api.PlusAPI.get_agent")
|
||||
def test_agent_from_repository(mock_get_agent, mock_get_auth_token):
|
||||
from crewai_tools import SerperDevTool
|
||||
from crewai_tools import SerperDevTool, XMLSearchTool
|
||||
|
||||
mock_get_response = MagicMock()
|
||||
mock_get_response.status_code = 200
|
||||
@@ -2044,7 +2046,10 @@ def test_agent_from_repository(mock_get_agent, mock_get_auth_token):
|
||||
"role": "test role",
|
||||
"goal": "test goal",
|
||||
"backstory": "test backstory",
|
||||
"tools": [{"name": "SerperDevTool"}],
|
||||
"tools": [
|
||||
{"module": "crewai_tools", "name": "SerperDevTool"},
|
||||
{"module": "crewai_tools", "name": "XMLSearchTool"},
|
||||
],
|
||||
}
|
||||
mock_get_agent.return_value = mock_get_response
|
||||
agent = Agent(from_repository="test_agent")
|
||||
@@ -2052,8 +2057,9 @@ def test_agent_from_repository(mock_get_agent, mock_get_auth_token):
|
||||
assert agent.role == "test role"
|
||||
assert agent.goal == "test goal"
|
||||
assert agent.backstory == "test backstory"
|
||||
assert len(agent.tools) == 1
|
||||
assert len(agent.tools) == 2
|
||||
assert isinstance(agent.tools[0], SerperDevTool)
|
||||
assert isinstance(agent.tools[1], XMLSearchTool)
|
||||
|
||||
|
||||
@patch("crewai.cli.plus_api.PlusAPI.get_agent")
|
||||
@@ -2066,7 +2072,7 @@ def test_agent_from_repository_override_attributes(mock_get_agent, mock_get_auth
|
||||
"role": "test role",
|
||||
"goal": "test goal",
|
||||
"backstory": "test backstory",
|
||||
"tools": [{"name": "SerperDevTool"}],
|
||||
"tools": [{"name": "SerperDevTool", "module": "crewai_tools"}],
|
||||
}
|
||||
mock_get_agent.return_value = mock_get_response
|
||||
agent = Agent(from_repository="test_agent", role="Custom Role")
|
||||
@@ -2086,7 +2092,7 @@ def test_agent_from_repository_with_invalid_tools(mock_get_agent, mock_get_auth_
|
||||
"role": "test role",
|
||||
"goal": "test goal",
|
||||
"backstory": "test backstory",
|
||||
"tools": [{"name": "DoesNotExist"}],
|
||||
"tools": [{"name": "DoesNotExist", "module": "crewai_tools",}],
|
||||
}
|
||||
mock_get_agent.return_value = mock_get_response
|
||||
with pytest.raises(
|
||||
@@ -2120,3 +2126,60 @@ def test_agent_from_repository_agent_not_found(mock_get_agent, mock_get_auth_tok
|
||||
match="Agent test_agent does not exist, make sure the name is correct or the agent is available on your organization",
|
||||
):
|
||||
Agent(from_repository="test_agent")
|
||||
|
||||
|
||||
@patch("crewai.cli.plus_api.PlusAPI.get_agent")
|
||||
@patch("crewai.utilities.agent_utils.Settings")
|
||||
@patch("crewai.utilities.agent_utils.console")
|
||||
def test_agent_from_repository_displays_org_info(mock_console, mock_settings, mock_get_agent, mock_get_auth_token):
|
||||
mock_settings_instance = MagicMock()
|
||||
mock_settings_instance.org_uuid = "test-org-uuid"
|
||||
mock_settings_instance.org_name = "Test Organization"
|
||||
mock_settings.return_value = mock_settings_instance
|
||||
|
||||
mock_get_response = MagicMock()
|
||||
mock_get_response.status_code = 200
|
||||
mock_get_response.json.return_value = {
|
||||
"role": "test role",
|
||||
"goal": "test goal",
|
||||
"backstory": "test backstory",
|
||||
"tools": []
|
||||
}
|
||||
mock_get_agent.return_value = mock_get_response
|
||||
|
||||
agent = Agent(from_repository="test_agent")
|
||||
|
||||
mock_console.print.assert_any_call(
|
||||
"Fetching agent from organization: Test Organization (test-org-uuid)",
|
||||
style="bold blue"
|
||||
)
|
||||
|
||||
assert agent.role == "test role"
|
||||
assert agent.goal == "test goal"
|
||||
assert agent.backstory == "test backstory"
|
||||
|
||||
|
||||
@patch("crewai.cli.plus_api.PlusAPI.get_agent")
|
||||
@patch("crewai.utilities.agent_utils.Settings")
|
||||
@patch("crewai.utilities.agent_utils.console")
|
||||
def test_agent_from_repository_without_org_set(mock_console, mock_settings, mock_get_agent, mock_get_auth_token):
|
||||
mock_settings_instance = MagicMock()
|
||||
mock_settings_instance.org_uuid = None
|
||||
mock_settings_instance.org_name = None
|
||||
mock_settings.return_value = mock_settings_instance
|
||||
|
||||
mock_get_response = MagicMock()
|
||||
mock_get_response.status_code = 401
|
||||
mock_get_response.text = "Unauthorized access"
|
||||
mock_get_agent.return_value = mock_get_response
|
||||
|
||||
with pytest.raises(
|
||||
AgentRepositoryError,
|
||||
match="Agent test_agent could not be loaded: Unauthorized access"
|
||||
):
|
||||
Agent(from_repository="test_agent")
|
||||
|
||||
mock_console.print.assert_any_call(
|
||||
"No organization currently set. We recommend setting one before using: `crewai org switch <org_id>` command.",
|
||||
style="yellow"
|
||||
)
|
||||
|
||||
@@ -0,0 +1,137 @@
|
||||
interactions:
|
||||
- request:
|
||||
body: '{"messages": [{"role": "system", "content": "You are Sports Analyst. You
|
||||
are an expert at gathering and organizing information. You carefully collect
|
||||
details and present them in a structured way.\nYour personal goal is: Gather
|
||||
information about the best soccer players\n\nTo give my best complete final
|
||||
answer to the task respond using the exact following format:\n\nThought: I now
|
||||
can give a great answer\nFinal Answer: Your final answer must be the great and
|
||||
the most complete as possible, it must be outcome described.\n\nI MUST use these
|
||||
formats, my job depends on it!"}, {"role": "user", "content": "Top 10 best players
|
||||
in the world?"}], "model": "gpt-4o-mini", "stop": ["\nObservation:"]}'
|
||||
headers:
|
||||
accept:
|
||||
- application/json
|
||||
accept-encoding:
|
||||
- gzip, deflate, zstd
|
||||
connection:
|
||||
- keep-alive
|
||||
content-length:
|
||||
- '694'
|
||||
content-type:
|
||||
- application/json
|
||||
host:
|
||||
- api.openai.com
|
||||
user-agent:
|
||||
- OpenAI/Python 1.78.0
|
||||
x-stainless-arch:
|
||||
- arm64
|
||||
x-stainless-async:
|
||||
- 'false'
|
||||
x-stainless-lang:
|
||||
- python
|
||||
x-stainless-os:
|
||||
- MacOS
|
||||
x-stainless-package-version:
|
||||
- 1.78.0
|
||||
x-stainless-raw-response:
|
||||
- 'true'
|
||||
x-stainless-read-timeout:
|
||||
- '600.0'
|
||||
x-stainless-retry-count:
|
||||
- '0'
|
||||
x-stainless-runtime:
|
||||
- CPython
|
||||
x-stainless-runtime-version:
|
||||
- 3.12.9
|
||||
method: POST
|
||||
uri: https://api.openai.com/v1/chat/completions
|
||||
response:
|
||||
body:
|
||||
string: !!binary |
|
||||
H4sIAAAAAAAAAwAAAP//nFfNchtHDr7rKVBz0a6KVJGUZMm6SVrJcSw6Ktmb7NY6pQJ7wBlEPd1T
|
||||
6B5S3JTP+yw55AVy9T7YFnr4Jy7pRLmwioP+wfcB+Br4eQ8g4zw7h8yUGE1V2+5l0dh/xOvXo5MT
|
||||
ufDvJk//lNvJm+9HvR9+errPOrrDj34iExe7Do2vakuRvWvNRggj6an90+PXJ69OX50dJUPlc7K6
|
||||
rahj99h3K3bcHfQGx93eabd/Nt9dejYUsnP41x4AwM/pV/10OT1l59DrLL5UFAIWlJ0vFwFk4q1+
|
||||
yTAEDhFdzDoro/Eukkuufyx9U5TxHN6C81Mw6KDgCQFCof4DujAlAfjkbtihhYv0/xw+lgRjb62f
|
||||
siuAAyCEKI2JjVAOfkIyYZqCH0MsCUwjQi5C9DX0exC8MSRQW5yRBGCXFk292BxGGPSA9IkFapKx
|
||||
lwqdodABNCXThCpyUf+59ia0Friq0cT5PiiwIsCg139noh+RwKA3ODr/5D65/iEcHNyyd2RhSCHw
|
||||
wQH85a2LJDBkrPivnxwAdOHg4M4H1ngeHJzDjZcpSr60XfnGRZmp6UIKcpEdLo0Xa27qilO4RGu9
|
||||
g3z/OwHUg0IHqsZGri3B369vLuCqxKpm7wLcEhYNQeRoFbMlzJXj5TUQvaLpw5WvES6qL78IG0xs
|
||||
DHqDAdy8vbmAHxKZV00NEzbRy+xQsQ8U+7uZZXQwHGFdf/lF0d+hcIAPyC5235BUyO7FLNyIxmgn
|
||||
BRtOTdk5Eo38oNc/64BrKhLfBLhlxd5fon90fupg7AVKDhBqorwDufBoZNkVbQ4UHm03GC9KUy1+
|
||||
SiEkuEcK91p0JXyDaNHlCneIzpQUNOJXHGcvhvpeTbPdUDFECnGe3hotITTlCqP6m7J+a+A7aaO6
|
||||
jGCkMYwWtJp1w4bn+wGi0MhSV/nULYEweNfyOhioqhwlJo5T4GnCDv5GcCnNzNEfpmLI+ZjJ5iTb
|
||||
2LgkW3BT7aTjHc0SogofSVIkNy5dq4Q7oYpJNktAg/w8EejJUK3+oYUJB/YuLapV7pS5EVuObc6f
|
||||
KPQr4RAZnYd73ZN7BX9hu+8xBHlxAtx5iU2Bdifmk60Fj9Z2I1e0LGlNBNDEbUtBlWtHSszrxY9X
|
||||
XNl1jnT7tSs0wzvwoUZ2LWtvI9qWhldKw3uaVSjwrRzO8X/DFu2L8V8K/pt3o3/3LFRjiyzJmfDI
|
||||
1nagJCgxwNS7jWpvQ6hVkwPChONa5rdX7gdwOA97JKwgNMZQCB1gZ2yTSF2UgrI5V0hSgUwsnCoL
|
||||
9/ogRLilKbrcT8NjegIuUQxZ7/BPpIPyvpOOe1I+KE+MPNOqeZp2Ehfqb1LJSxWPIbn9AHethKQE
|
||||
mhd1byH0/Q7oOy48aqIeVhJO2M5Uby51l4Nh49iU+2HBEgUY0dgLQeUniSJdOked6DlLb2PziDD0
|
||||
ufB//6PE3BNaGGIunP8ZfbgSj5F3P476ADwrlzbXNaTaUeg6tAp+zY/9sOW9FG6qumyzaFFh88sV
|
||||
qfI71h4mLLqSdPPyTUoEvFYChr7EinL4gBZLZeCWJyS19y+vlOtiVsfflca5Li6v0Rqx9TyJKyUk
|
||||
+buhjorz662DrljqxRtvc3Jw6X2cKxJsPTfx0O8pEd+z+/Kr4SbAt19+c+xlazp8lY+vSMf2YuEk
|
||||
4CGibEg+FqlY1pVkqRU1T/y6WvxOqsxbogV+LaZuap3a5zMx8LGkQMsWtcQJablpM00u2hnkZDVc
|
||||
lAM9RUEvOTuU2bOGddGOpupIjpfe5hC4cDxmgy4Cu7FtyBmCKcfyWSfsx/NGeaPQ21xmSQoY9teq
|
||||
OzVDKI6SurDLecJ5gxbQGG8xp3C4PgYIjZuAOoq4xto1AzrnY9LZNID8OLd8Xo4c1he1+FHY2JqN
|
||||
2XEoHyTRqONFiL7OkvXzHsCPabRpnk0rWS2+quND9I+UrusPBu152WqiWllPjxbWqBFfGc5Ojjtb
|
||||
DnzIKSLbsDYdZQZNSflq62qUwiZnv2bYW4P9/+5sO7uFzq74I8evDEbbGcofaqGczXPIq2VCOnHu
|
||||
WrakOTmcBR3BDD1EJtFQ5DTGxrZzYBZmIVL1MGZXkNTC7TA4rh9eDXBwhGd9Gmd7n/f+BwAA//8D
|
||||
AMMI9CsaDwAA
|
||||
headers:
|
||||
CF-RAY:
|
||||
- 94d9be627c40f260-GRU
|
||||
Connection:
|
||||
- keep-alive
|
||||
Content-Encoding:
|
||||
- gzip
|
||||
Content-Type:
|
||||
- application/json
|
||||
Date:
|
||||
- Tue, 10 Jun 2025 15:02:05 GMT
|
||||
Server:
|
||||
- cloudflare
|
||||
Set-Cookie:
|
||||
- __cf_bm=qYkxv9nLxeWAtPBvECxNw8fLnoBHLorJdRI8.xVEVEA-1749567725-1.0.1.1-75sp4gwHGJocK1MFkSgRcB4xJUiCwz31VRD4LAmQGEmfYB0BMQZ5sgWS8e_UMbjCaEhaPNO88q5XdbLOCWA85_rO0vYTb4hp6tmIiaerhsM;
|
||||
path=/; expires=Tue, 10-Jun-25 15:32:05 GMT; domain=.api.openai.com; HttpOnly;
|
||||
Secure; SameSite=None
|
||||
- _cfuvid=HRKCwkyTqSXpCj9_i_T5lDtlr_INA290o0b3k.26oi8-1749567725794-0.0.1.1-604800000;
|
||||
path=/; domain=.api.openai.com; HttpOnly; Secure; SameSite=None
|
||||
Transfer-Encoding:
|
||||
- chunked
|
||||
X-Content-Type-Options:
|
||||
- nosniff
|
||||
access-control-expose-headers:
|
||||
- X-Request-ID
|
||||
alt-svc:
|
||||
- h3=":443"; ma=86400
|
||||
cf-cache-status:
|
||||
- DYNAMIC
|
||||
openai-organization:
|
||||
- crewai-iuxna1
|
||||
openai-processing-ms:
|
||||
- '42674'
|
||||
openai-version:
|
||||
- '2020-10-01'
|
||||
strict-transport-security:
|
||||
- max-age=31536000; includeSubDomains; preload
|
||||
x-envoy-upstream-service-time:
|
||||
- '42684'
|
||||
x-ratelimit-limit-requests:
|
||||
- '30000'
|
||||
x-ratelimit-limit-tokens:
|
||||
- '150000000'
|
||||
x-ratelimit-remaining-requests:
|
||||
- '29999'
|
||||
x-ratelimit-remaining-tokens:
|
||||
- '149999859'
|
||||
x-ratelimit-reset-requests:
|
||||
- 2ms
|
||||
x-ratelimit-reset-tokens:
|
||||
- 0s
|
||||
x-request-id:
|
||||
- req_d92e6f33fa5e0fbe43349afee8f55921
|
||||
status:
|
||||
code: 200
|
||||
message: OK
|
||||
version: 1
|
||||
299
tests/cassettes/test_async_tool_using_decorator_within_flow.yaml
Normal file
299
tests/cassettes/test_async_tool_using_decorator_within_flow.yaml
Normal file
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
235
tests/cassettes/test_async_tool_using_within_isolated_crew.yaml
Normal file
235
tests/cassettes/test_async_tool_using_within_isolated_crew.yaml
Normal file
File diff suppressed because one or more lines are too long
299
tests/cassettes/test_async_tool_within_flow.yaml
Normal file
299
tests/cassettes/test_async_tool_within_flow.yaml
Normal file
File diff suppressed because one or more lines are too long
130
tests/cassettes/test_guardrail_is_called_using_callable.yaml
Normal file
130
tests/cassettes/test_guardrail_is_called_using_callable.yaml
Normal file
@@ -0,0 +1,130 @@
|
||||
interactions:
|
||||
- request:
|
||||
body: '{"messages": [{"role": "system", "content": "You are Sports Analyst. You
|
||||
are an expert at gathering and organizing information. You carefully collect
|
||||
details and present them in a structured way.\nYour personal goal is: Gather
|
||||
information about the best soccer players\n\nTo give my best complete final
|
||||
answer to the task respond using the exact following format:\n\nThought: I now
|
||||
can give a great answer\nFinal Answer: Your final answer must be the great and
|
||||
the most complete as possible, it must be outcome described.\n\nI MUST use these
|
||||
formats, my job depends on it!"}, {"role": "user", "content": "Top 1 best players
|
||||
in the world?"}], "model": "gpt-4o-mini", "stop": ["\nObservation:"]}'
|
||||
headers:
|
||||
accept:
|
||||
- application/json
|
||||
accept-encoding:
|
||||
- gzip, deflate, zstd
|
||||
connection:
|
||||
- keep-alive
|
||||
content-length:
|
||||
- '693'
|
||||
content-type:
|
||||
- application/json
|
||||
host:
|
||||
- api.openai.com
|
||||
user-agent:
|
||||
- OpenAI/Python 1.78.0
|
||||
x-stainless-arch:
|
||||
- arm64
|
||||
x-stainless-async:
|
||||
- 'false'
|
||||
x-stainless-lang:
|
||||
- python
|
||||
x-stainless-os:
|
||||
- MacOS
|
||||
x-stainless-package-version:
|
||||
- 1.78.0
|
||||
x-stainless-raw-response:
|
||||
- 'true'
|
||||
x-stainless-read-timeout:
|
||||
- '600.0'
|
||||
x-stainless-retry-count:
|
||||
- '0'
|
||||
x-stainless-runtime:
|
||||
- CPython
|
||||
x-stainless-runtime-version:
|
||||
- 3.12.9
|
||||
method: POST
|
||||
uri: https://api.openai.com/v1/chat/completions
|
||||
response:
|
||||
body:
|
||||
string: !!binary |
|
||||
H4sIAAAAAAAAAwAAAP//TFPRbttGEHzPVwz04taQBFt1nFZvsgsnRlvYqI0aafOyPK7IjY97xO1R
|
||||
CpMv6nf0x4qlZLcvBHh3Mzs7s/vtDTCTerbGLLRUQtfHxVUzPF6udsaXHx/Cn7//8fG8e9rf/XxF
|
||||
X+vqaTZ3RKo+cygvqGVIXR+5SNLDdchMhZ31/N3FT28vL99enE0XXao5Oqzpy+IiLTpRWazOVheL
|
||||
s3eL8x+P6DZJYJut8dcbAPg2fV2n1vxltsbENZ10bEYNz9avj4BZTtFPZmQmVkjLbP7fZUhaWCfp
|
||||
j20amrascQtNewRSNLJjEBrXD1LbcwY+6Y0oRWym/zUeW0ZJPfpII2eIorSMfcqxnoMMaYu7UFLF
|
||||
Gauz1Q9ziOFXScoRv7GZLPEkNccRmRvKNdcTSNmBzjRVZyuwFALnY52Jl2JEkY7nBya0ZGipBikk
|
||||
xsFKljQYAmXmjNBSplA4y1euUY3gLyVTyrUo5RH2LDHaHDsxSToHaY2Q1E1jDePSO/+kv/CITWiF
|
||||
d9yxFlv78QKnp9dxqOz0dH2UYj1rmfR39DllKaMLbuVVDRXcXOOKcuCYlObYt5wZLaPiQB1P2BCH
|
||||
6sS8z4X3ichUizawkDLnJT5MzxQlk9qWc+YaJeGeshgeSLQs3nPuSBTf3T+8/97TWZ2tzpcHzbda
|
||||
OCv5pFJ07R+8RI1NbliLKDnZTkJJeXwJ1uG4Tj1h0/3zd5ZAk1PHqxVubm82ePL0cT30cxiHIbtm
|
||||
7z1yQ2H0gAkvddFyTsuji5s95fp/Nnqi+6Tohlikj4wrijEp6pO7DJoez9FK00Zp2vJSxgqVwbxM
|
||||
mfy08jKdTUwVxTgiKYx3nCkihUAeuS094PtIo/M8lDHylO5BiRieNe0V25SnIqIhcy1VZNRZqio6
|
||||
iiqJUsY5+sxBjNH72mlzGKc+pyhbCWgSxYWHKNos8cGd8ZVjz8PnpMm085HxZveGVjpPoiPlYccZ
|
||||
pc2+qyjeNGreshobjKmLbBbHOTp6PrjRgaYx9s13oK9yOkS5FY71chrrW93GgTUcOr7iMWk92ShW
|
||||
JNhxwU4M0vUUXhka8uU7uHEk8CuyXqbMj7t66H5Kpk+5WEdqrfRo6V8AAAD//4xVy24CIRTdz1cQ
|
||||
1m1Tx+nCr+gXGHKFO85NGSDAaF347w2ggtUmXR84931O0hcdLJP5mlC14yNzPfmJQlrB0qkkWWQW
|
||||
VMyhH62fIUVNApUXgWk8oGZH1JqRiTYzzqRe1+8hDRFYEhOY83kWVKEimbcx55mFoLTlM2+IvuoL
|
||||
fuPs0gQxsOMEkVFkM4IJiWmHD9vWaiGLVsHprRVfj+MSIBmAWbRuADDGxpxQlv3tBTnfhF7bvfN2
|
||||
F3595SMZCpPwCMGaJOohWsczeu4Y22ZDWe48gjtvZxdFtF+Yw636vvDx6mMV7TebCxptBF2BoV+9
|
||||
PCEUCiOQDo0ncQlyQlW/VgODRZFtgK4p+zGdZ9yldDL7/9BXQEp0EZVw6aTlfcn1mcfk8389u7U5
|
||||
J8wD+gNJFJHQp1EoHGHRxX15OIWIsxjJ7NE7T8WCRyfWA3wMgJu15N25+wEAAP//AwDdzCHTkAgA
|
||||
AA==
|
||||
headers:
|
||||
CF-RAY:
|
||||
- 94d9a27f5dc000f9-GRU
|
||||
Connection:
|
||||
- keep-alive
|
||||
Content-Encoding:
|
||||
- gzip
|
||||
Content-Type:
|
||||
- application/json
|
||||
Date:
|
||||
- Tue, 10 Jun 2025 14:42:51 GMT
|
||||
Server:
|
||||
- cloudflare
|
||||
Set-Cookie:
|
||||
- __cf_bm=7hq1JYlSmmLvjUR7npK1vcLJYOvCPn947S.EYBtvTcQ-1749566571-1.0.1.1-11XCSwdUqYCYC3zE9DZk20c_BHXTPqEi6YMhVtX9dekgrj0J3a4EHGdHvcnhBNkIxYzhM4zzQsetx2sxisMk62ywkO8Tzo3rlYdo__Kov7w;
|
||||
path=/; expires=Tue, 10-Jun-25 15:12:51 GMT; domain=.api.openai.com; HttpOnly;
|
||||
Secure; SameSite=None
|
||||
- _cfuvid=bhxj6kzt6diFCyNbiiw60v4lKiUKaoHjQ3Yc4KWW4OI-1749566571331-0.0.1.1-604800000;
|
||||
path=/; domain=.api.openai.com; HttpOnly; Secure; SameSite=None
|
||||
Transfer-Encoding:
|
||||
- chunked
|
||||
X-Content-Type-Options:
|
||||
- nosniff
|
||||
access-control-expose-headers:
|
||||
- X-Request-ID
|
||||
alt-svc:
|
||||
- h3=":443"; ma=86400
|
||||
cf-cache-status:
|
||||
- DYNAMIC
|
||||
openai-organization:
|
||||
- crewai-iuxna1
|
||||
openai-processing-ms:
|
||||
- '30419'
|
||||
openai-version:
|
||||
- '2020-10-01'
|
||||
strict-transport-security:
|
||||
- max-age=31536000; includeSubDomains; preload
|
||||
x-envoy-upstream-service-time:
|
||||
- '30424'
|
||||
x-ratelimit-limit-requests:
|
||||
- '30000'
|
||||
x-ratelimit-limit-tokens:
|
||||
- '150000000'
|
||||
x-ratelimit-remaining-requests:
|
||||
- '29999'
|
||||
x-ratelimit-remaining-tokens:
|
||||
- '149999859'
|
||||
x-ratelimit-reset-requests:
|
||||
- 2ms
|
||||
x-ratelimit-reset-tokens:
|
||||
- 0s
|
||||
x-request-id:
|
||||
- req_b5983a9572e28ded39da7b12e678e2b7
|
||||
status:
|
||||
code: 200
|
||||
message: OK
|
||||
version: 1
|
||||
643
tests/cassettes/test_guardrail_is_called_using_string.yaml
Normal file
643
tests/cassettes/test_guardrail_is_called_using_string.yaml
Normal file
@@ -0,0 +1,643 @@
|
||||
interactions:
|
||||
- request:
|
||||
body: '{"messages": [{"role": "system", "content": "You are Sports Analyst. You
|
||||
are an expert at gathering and organizing information. You carefully collect
|
||||
details and present them in a structured way.\nYour personal goal is: Gather
|
||||
information about the best soccer players\n\nTo give my best complete final
|
||||
answer to the task respond using the exact following format:\n\nThought: I now
|
||||
can give a great answer\nFinal Answer: Your final answer must be the great and
|
||||
the most complete as possible, it must be outcome described.\n\nI MUST use these
|
||||
formats, my job depends on it!"}, {"role": "user", "content": "Top 10 best players
|
||||
in the world?"}], "model": "gpt-4o-mini", "stop": ["\nObservation:"]}'
|
||||
headers:
|
||||
accept:
|
||||
- application/json
|
||||
accept-encoding:
|
||||
- gzip, deflate, zstd
|
||||
connection:
|
||||
- keep-alive
|
||||
content-length:
|
||||
- '694'
|
||||
content-type:
|
||||
- application/json
|
||||
host:
|
||||
- api.openai.com
|
||||
user-agent:
|
||||
- OpenAI/Python 1.78.0
|
||||
x-stainless-arch:
|
||||
- arm64
|
||||
x-stainless-async:
|
||||
- 'false'
|
||||
x-stainless-lang:
|
||||
- python
|
||||
x-stainless-os:
|
||||
- MacOS
|
||||
x-stainless-package-version:
|
||||
- 1.78.0
|
||||
x-stainless-raw-response:
|
||||
- 'true'
|
||||
x-stainless-read-timeout:
|
||||
- '600.0'
|
||||
x-stainless-retry-count:
|
||||
- '0'
|
||||
x-stainless-runtime:
|
||||
- CPython
|
||||
x-stainless-runtime-version:
|
||||
- 3.12.9
|
||||
method: POST
|
||||
uri: https://api.openai.com/v1/chat/completions
|
||||
response:
|
||||
body:
|
||||
string: !!binary |
|
||||
H4sIAAAAAAAAA6RXXW4cNxJ+1ykK8+JdoyVII/lH8yZprUi25BVsB0GwDoQadk13ZdgkU2TPaBIY
|
||||
2Lc9wx5hz7F7kj1JUOye38iBgrwImiZZrPr41VdVv+wBDLgcjGBgakymCXb/vGrfyvX4+zCZ/fTd
|
||||
3dWPD69v+N3V7bfjDw/N20GhJ/z4RzJpeerA+CZYSuxdt2yEMJFaPXp1cvri5YvTl6/yQuNLsnqs
|
||||
Cmn/xO837Hh/eDg82T98tX/0uj9dezYUByP4xx4AwC/5r/rpSnoYjOCwWH5pKEasaDBabQIYiLf6
|
||||
ZYAxckzo0qBYLxrvErns+qfat1WdRnANzs/BoIOKZwQIlfoP6OKcBOCzu2SHFs7y7xFckRCgEKSa
|
||||
IPkAR4cwppggemNIIFhckERgl3fMvdgSMIKfwN9N8mMSGB4OjwsYY6QSfN7GAoFk4qVBZ6gAbgKa
|
||||
VAC6EvyMBK0F9V143CrQEZLP5itsaPTZfXZHB/D8+Q17RxZuKUZ+/hz+cu0SCdwyNvzXzw4A9uHO
|
||||
R1YLI7j0Mkcp++8XvnVJFiM4k4pcYof9whVXteWqTnHUGc6OsGspOxFrPzcYCWqOQA+GglpHC6Xw
|
||||
eGzZVQXMOLJ3XTQKT4NTdhXgmC2nRQGWsNQPq6vV8IxN8rJY4jg8HA7h8vryDL7LiF60IduLXDme
|
||||
sEGX7GIDI1epEXXK2Hb8LEJsjaEYKR4oXEOF693CMjq4HWMI//2PAnaHwhE+Iru0/w1Jg+yeDNyl
|
||||
6Ns9gto75+cOJl6yO2PLMZGogzEQlTkKY9mxQQsTdhzrjFrvFnAEhCktemZlQ2Ofarj7+E0+rPBc
|
||||
CjlTg8Me/UTYFDDdunmDYZmeN1y1BEfZBitT1qd9Kw4bcqlD61jReiP6mnCFaNGVitYtOlOTRgMX
|
||||
nBZPRuq9fl48glRv+1mEyqPdj8ZnnIL4OcXYvXcSclWqocYZQYOlMq8B70gzTKFofEwwIRTKu3na
|
||||
Z+ObVnygAmqyQa3ueA+RTCsEkXK+QeJkM07GtpmdavvbN5dncFFjE3IS3hBWLWWITjKhaMYO/kZw
|
||||
Lu3C0ZMwuuVywmRLkl2YzslW3DaP4LS64f///Pd21gWVPWVPzgRvu6TrEhAanP4GrSxdfVLuylYB
|
||||
7GKSVomAVpd2osnXl75hp6TSDaVvKCY2+doOcXSgFYJSDrgj1AtF60I4Jkbn4YP6XnrF68zCe4xR
|
||||
nkymOy+prdA+ClMMnJQRs14PNLSP2JYMd+L75yuW1z9TKJOgl5IdygISWnIph7LFx164YEoUMp49
|
||||
aMa7GUnMWQTY+J40CnGhfNWzNZaAYKkiV+odBoVIAI34GKFpbeJgSSWxanuteqlgvadFgwJv5aBH
|
||||
6Yot2iejdC74Mz+GUWf3WQSsejXO5Ztn+f+ccVO2tku3KYWUA0bVJC1+vaaQKAZdBSxyPe3rQg6Z
|
||||
Yw/lil67bwDzmq2mM7uE7DLImrwK4ZamQRCK5EyXdK8UmQ9aUxPc0Bxd6edxmkvfOYoh6x3+ASKp
|
||||
9jwC0aeaVIKslpmlouwUQeMlP7+2HJQrkeorqsTirgxvSHzofco/FGskYbTryrhbz1ZR5czbLmmv
|
||||
swKhcAPn5H6mBnumXKfENZZ/vpApEP1rfyC0cIulsIosCgjp4y1p0T13ASVH1Rb1Xos8Say5q9uJ
|
||||
TN2VvMyv2LGmR3XJmj45vkKaHPVp7nvaKcKtL4X/9y8NesO7PyK4F+Ix8WONzxk0mFXPT6Dpzy8l
|
||||
tmtrlrrbe7HGwwG7iW21scn1vdIig2kTwWI3W+ghkLDSPBufeJ/G2gJqlbaWq1UCHB1q+Le+xoZK
|
||||
+IgWa43/hmckwfteH7766JvBv6kWIS2/bsaerWZtDNZHbZED9o79vipmkTDkkqwD1yRYebd82Duh
|
||||
hkmWWvDV0lFsCYQCFROmNub2el3SyKroT7o4u9z4VFOkVWuetaykxmt101Flq4RmPhbrbDa9DnY9
|
||||
ee8zK+NjIJMUEFWmrj3pdbuA6C2XPFn0nYM2+P0TxJ3SsFVyDzanFaFJG1EnJtdau7GAzvmUZTHP
|
||||
ST/0K19Wk5H1VRA/jjtHB5323Ath9E6noJh8GOTVL3sAP+QJrN0aqgZBfBPSffJTytcdDYedvcF6
|
||||
8Fuvvjw96leTT2jXC6+PjotHDN6XlJBt3BjiBgZNTeX66HriUwXwGwt7G2H/1p3HbHehs6ueYn69
|
||||
YJQfVN4HoZLNdsjrbUI6GH9t2wrm7PAgkszY0H1iEn2KkibY2m5cHcRFTNTcT9hVJEG4m1kn4f74
|
||||
BF+cIJ0em8Hel71fAQAA//8DAICIe4nBDwAA
|
||||
headers:
|
||||
CF-RAY:
|
||||
- 94d9947e9abcf1fe-GRU
|
||||
Connection:
|
||||
- keep-alive
|
||||
Content-Encoding:
|
||||
- gzip
|
||||
Content-Type:
|
||||
- application/json
|
||||
Date:
|
||||
- Tue, 10 Jun 2025 14:33:27 GMT
|
||||
Server:
|
||||
- cloudflare
|
||||
Set-Cookie:
|
||||
- __cf_bm=UscrLNUFPQp17ivpT2nYqbIb8GsK9e0GpWC7sIKWwnU-1749566007-1.0.1.1-fCm5jdN02Agxc9.Ep4aAnKukyBp9S3iOLK9NY51NLG1zib3MnfjyCm5HhsWtUvr2lIjQpD_EWosVk4JuLbGxrKYZBa4WTendGsY9lCU9naU;
|
||||
path=/; expires=Tue, 10-Jun-25 15:03:27 GMT; domain=.api.openai.com; HttpOnly;
|
||||
Secure; SameSite=None
|
||||
- _cfuvid=CGbpwQsAGlm5OcWs4NP0JuyqJh.mIqHyUZjIdKm8_.I-1749566007688-0.0.1.1-604800000;
|
||||
path=/; domain=.api.openai.com; HttpOnly; Secure; SameSite=None
|
||||
Transfer-Encoding:
|
||||
- chunked
|
||||
X-Content-Type-Options:
|
||||
- nosniff
|
||||
access-control-expose-headers:
|
||||
- X-Request-ID
|
||||
alt-svc:
|
||||
- h3=":443"; ma=86400
|
||||
cf-cache-status:
|
||||
- DYNAMIC
|
||||
openai-organization:
|
||||
- crewai-iuxna1
|
||||
openai-processing-ms:
|
||||
- '40370'
|
||||
openai-version:
|
||||
- '2020-10-01'
|
||||
strict-transport-security:
|
||||
- max-age=31536000; includeSubDomains; preload
|
||||
x-envoy-upstream-service-time:
|
||||
- '40375'
|
||||
x-ratelimit-limit-requests:
|
||||
- '30000'
|
||||
x-ratelimit-limit-tokens:
|
||||
- '150000000'
|
||||
x-ratelimit-remaining-requests:
|
||||
- '29999'
|
||||
x-ratelimit-remaining-tokens:
|
||||
- '149999859'
|
||||
x-ratelimit-reset-requests:
|
||||
- 2ms
|
||||
x-ratelimit-reset-tokens:
|
||||
- 0s
|
||||
x-request-id:
|
||||
- req_94fb13dc93d3bc9714811ff4ede4c08f
|
||||
status:
|
||||
code: 200
|
||||
message: OK
|
||||
- request:
|
||||
body: '{"messages": [{"role": "system", "content": "You are Guardrail Agent. You
|
||||
are a expert at validating the output of a task. By providing effective feedback
|
||||
if the output is not valid.\nYour personal goal is: Validate the output of the
|
||||
task\n\nTo give my best complete final answer to the task respond using the
|
||||
exact following format:\n\nThought: I now can give a great answer\nFinal Answer:
|
||||
Your final answer must be the great and the most complete as possible, it must
|
||||
be outcome described.\n\nI MUST use these formats, my job depends on it!\nIMPORTANT:
|
||||
Your final answer MUST contain all the information requested in the following
|
||||
format: {\n \"valid\": bool,\n \"feedback\": str | None\n}\n\nIMPORTANT: Ensure
|
||||
the final output does not include any code block markers like ```json or ```python."},
|
||||
{"role": "user", "content": "\n Ensure the following task result complies
|
||||
with the given guardrail.\n\n Task result:\n Here are the top
|
||||
10 best soccer players in the world as of October 2023, based on their performance,
|
||||
impact, and overall contributions to the game:\n\n1. **Lionel Messi** (Inter
|
||||
Miami)\n - Position: Forward\n - Country: Argentina\n - Highlights: Messi
|
||||
continues to showcase his exceptional dribbling, vision, and playmaking ability,
|
||||
leading Argentina to victory in the 2022 FIFA World Cup and significantly contributing
|
||||
to his club''s successes.\n\n2. **Kylian Mbapp\u00e9** (Paris Saint-Germain)\n -
|
||||
Position: Forward\n - Country: France\n - Highlights: Known for his blistering
|
||||
speed and clinical finishing, Mbapp\u00e9 is a key player for both PSG and the
|
||||
French national team, known for his performances in Ligue 1 and international
|
||||
tournaments.\n\n3. **Erling Haaland** (Manchester City)\n - Position: Forward\n -
|
||||
Country: Norway\n - Highlights: Haaland''s goal-scoring prowess and strength
|
||||
have made him one of the most feared strikers in Europe, helping Manchester
|
||||
City secure several titles including the UEFA Champions League.\n\n4. **Kevin
|
||||
De Bruyne** (Manchester City)\n - Position: Midfielder\n - Country: Belgium\n -
|
||||
Highlights: De Bruyne\u2019s exceptional passing, control, and vision make him
|
||||
one of the best playmakers in the world, instrumental in Manchester City\u2019s
|
||||
dominance in domestic and European competitions.\n\n5. **Cristiano Ronaldo**
|
||||
(Al Nassr)\n - Position: Forward\n - Country: Portugal\n - Highlights:
|
||||
Despite moving to the Saudi Pro League, Ronaldo''s extraordinary talent and
|
||||
goal-scoring ability keep him in the conversation among the best, having had
|
||||
a legendary career across multiple leagues.\n\n6. **Neymar Jr.** (Al Hilal)\n -
|
||||
Position: Forward\n - Country: Brazil\n - Highlights: Neymar''s agility,
|
||||
creativity, and skill have kept him as a top performer in soccer, now showcasing
|
||||
his talents in the Saudi Pro League while maintaining a strong national team
|
||||
presence.\n\n7. **Robert Lewandowski** (Barcelona)\n - Position: Forward\n -
|
||||
Country: Poland\n - Highlights: The prolific striker continues to score consistently
|
||||
in La Liga, known for his finishing, positioning, and aerial ability, contributing
|
||||
to Barcelona\u2019s successes.\n\n8. **Karim Benzema** (Al Ittihad)\n - Position:
|
||||
Forward\n - Country: France\n - Highlights: The former Real Madrid star
|
||||
remains a top talent, displaying leadership and technical skills, now continuing
|
||||
his career in the Saudi Pro League.\n\n9. **Luka Modri\u0107** (Real Madrid)\n -
|
||||
Position: Midfielder\n - Country: Croatia\n - Highlights: A master of midfield
|
||||
control and passing, Modri\u0107 remains an influential figure at Real Madrid,
|
||||
showcasing his experience and football intelligence.\n\n10. **Mohamed Salah**
|
||||
(Liverpool)\n - Position: Forward\n - Country: Egypt\n - Highlights:
|
||||
Salah''s explosive pace and goal-scoring ability keep him as a central figure
|
||||
for Liverpool in the Premier League and European competitions, maintaining his
|
||||
status as one of the elite forwards.\n\nThese players have demonstrated exceptional
|
||||
skill, consistency, and impact in their respective teams and leagues, solidifying
|
||||
their positions among the best in the world.\n\n Guardrail:\n Only
|
||||
include Brazilian players, both women and men\n \n Your task:\n -
|
||||
Confirm if the Task result complies with the guardrail.\n - If not, provide
|
||||
clear feedback explaining what is wrong (e.g., by how much it violates the rule,
|
||||
or what specific part fails).\n - Focus only on identifying issues \u2014
|
||||
do not propose corrections.\n - If the Task result complies with the
|
||||
guardrail, saying that is valid\n "}], "model": "gpt-4o-mini", "stop":
|
||||
["\nObservation:"]}'
|
||||
headers:
|
||||
accept:
|
||||
- application/json
|
||||
accept-encoding:
|
||||
- gzip, deflate, zstd
|
||||
connection:
|
||||
- keep-alive
|
||||
content-length:
|
||||
- '4676'
|
||||
content-type:
|
||||
- application/json
|
||||
cookie:
|
||||
- __cf_bm=UscrLNUFPQp17ivpT2nYqbIb8GsK9e0GpWC7sIKWwnU-1749566007-1.0.1.1-fCm5jdN02Agxc9.Ep4aAnKukyBp9S3iOLK9NY51NLG1zib3MnfjyCm5HhsWtUvr2lIjQpD_EWosVk4JuLbGxrKYZBa4WTendGsY9lCU9naU;
|
||||
_cfuvid=CGbpwQsAGlm5OcWs4NP0JuyqJh.mIqHyUZjIdKm8_.I-1749566007688-0.0.1.1-604800000
|
||||
host:
|
||||
- api.openai.com
|
||||
user-agent:
|
||||
- OpenAI/Python 1.78.0
|
||||
x-stainless-arch:
|
||||
- arm64
|
||||
x-stainless-async:
|
||||
- 'false'
|
||||
x-stainless-lang:
|
||||
- python
|
||||
x-stainless-os:
|
||||
- MacOS
|
||||
x-stainless-package-version:
|
||||
- 1.78.0
|
||||
x-stainless-raw-response:
|
||||
- 'true'
|
||||
x-stainless-read-timeout:
|
||||
- '600.0'
|
||||
x-stainless-retry-count:
|
||||
- '0'
|
||||
x-stainless-runtime:
|
||||
- CPython
|
||||
x-stainless-runtime-version:
|
||||
- 3.12.9
|
||||
method: POST
|
||||
uri: https://api.openai.com/v1/chat/completions
|
||||
response:
|
||||
body:
|
||||
string: !!binary |
|
||||
H4sIAAAAAAAAA4xUwWobMRC9+ysGnVqwjZ3YjuNbQim0hULBtIc6mLE0uzuxVtpqtHbckH8v2o29
|
||||
TpNCLwuapzfzZvRmH3sAio1agNIFRl1WdnCb119+LIvZh+/+h9zM55Op3Wzv5dt4rKei+onhN/ek
|
||||
45E11L6sLEX2roV1IIyUso6vJtfT2Ww0mjdA6Q3ZRMurOJj4QcmOBxeji8lgdDUYz5/ZhWdNohbw
|
||||
swcA8Nh8k05n6EEtYNQ/RkoSwZzU4nQJQAVvU0ShCEtEF1W/A7V3kVwjfVn4Oi/iAj6B83vQ6CDn
|
||||
HQFCnvQDOtlTAFi5j+zQwk1zXsDjygGs1A4tm5VaQIZWqN8GMyKzQb1N8ZVaFgQRZQuBpLYRjCcB
|
||||
5yM0AzvAnmMBsSDIawwmIFtAAY7ATtvakEBl8UBBIAu+hB0G9rWA9rWLgUkAnQHv7AFKcmn8AnHv
|
||||
4Tbgb7aM7kR/95UOJQb4HIYNpz2+h33BloAeUjV2+Rlz70vq+Cl7IHsYwvKFWqlIc8YarT1AoF81
|
||||
SRSI/thAK+6Vnj5sfCyeayQ9Jbl+EqML4HZCWW0ztpbMcKVW7un8CQNltWCykautPQPQOR+xmUMy
|
||||
z90z8nSyi/V5FfxG/qKqjB1LsQ6E4l2yhkRfqQZ96gHcNbasXzhNVcGXVVxHv6Wm3PV01uZT3TZ0
|
||||
6PwIRh/RdvHxaHLRfyPh2lBEtnLmbKVRF2Q6brcGWBv2Z0DvrO3Xct7K3bbOLv+f9B2gNVWRzLoK
|
||||
ZFi/bLm7Fij9Lf517TTmRrASCjvWtI5MIT2FoQxr2+6wkoNEKtcZu5xCFbhd5KxaX05wOkG6vtSq
|
||||
99T7AwAA//8DABZK9w/WBAAA
|
||||
headers:
|
||||
CF-RAY:
|
||||
- 94d9957c4b46f1fe-GRU
|
||||
Connection:
|
||||
- keep-alive
|
||||
Content-Encoding:
|
||||
- gzip
|
||||
Content-Type:
|
||||
- application/json
|
||||
Date:
|
||||
- Tue, 10 Jun 2025 14:33:46 GMT
|
||||
Server:
|
||||
- cloudflare
|
||||
Transfer-Encoding:
|
||||
- chunked
|
||||
X-Content-Type-Options:
|
||||
- nosniff
|
||||
access-control-expose-headers:
|
||||
- X-Request-ID
|
||||
alt-svc:
|
||||
- h3=":443"; ma=86400
|
||||
cf-cache-status:
|
||||
- DYNAMIC
|
||||
openai-organization:
|
||||
- crewai-iuxna1
|
||||
openai-processing-ms:
|
||||
- '18280'
|
||||
openai-version:
|
||||
- '2020-10-01'
|
||||
strict-transport-security:
|
||||
- max-age=31536000; includeSubDomains; preload
|
||||
x-envoy-upstream-service-time:
|
||||
- '18287'
|
||||
x-ratelimit-limit-requests:
|
||||
- '30000'
|
||||
x-ratelimit-limit-tokens:
|
||||
- '150000000'
|
||||
x-ratelimit-remaining-requests:
|
||||
- '29999'
|
||||
x-ratelimit-remaining-tokens:
|
||||
- '149998889'
|
||||
x-ratelimit-reset-requests:
|
||||
- 2ms
|
||||
x-ratelimit-reset-tokens:
|
||||
- 0s
|
||||
x-request-id:
|
||||
- req_853da6b9ca8f386ff1427c837346290d
|
||||
status:
|
||||
code: 200
|
||||
message: OK
|
||||
- request:
|
||||
body: '{"messages": [{"role": "system", "content": "You are Sports Analyst. You
|
||||
are an expert at gathering and organizing information. You carefully collect
|
||||
details and present them in a structured way.\nYour personal goal is: Gather
|
||||
information about the best soccer players\n\nTo give my best complete final
|
||||
answer to the task respond using the exact following format:\n\nThought: I now
|
||||
can give a great answer\nFinal Answer: Your final answer must be the great and
|
||||
the most complete as possible, it must be outcome described.\n\nI MUST use these
|
||||
formats, my job depends on it!"}, {"role": "user", "content": "Top 10 best players
|
||||
in the world?"}, {"role": "assistant", "content": "Thought: I now can give a
|
||||
great answer \nFinal Answer: Here are the top 10 best soccer players in the
|
||||
world as of October 2023, based on their performance, impact, and overall contributions
|
||||
to the game:\n\n1. **Lionel Messi** (Inter Miami)\n - Position: Forward\n -
|
||||
Country: Argentina\n - Highlights: Messi continues to showcase his exceptional
|
||||
dribbling, vision, and playmaking ability, leading Argentina to victory in the
|
||||
2022 FIFA World Cup and significantly contributing to his club''s successes.\n\n2.
|
||||
**Kylian Mbapp\u00e9** (Paris Saint-Germain)\n - Position: Forward\n - Country:
|
||||
France\n - Highlights: Known for his blistering speed and clinical finishing,
|
||||
Mbapp\u00e9 is a key player for both PSG and the French national team, known
|
||||
for his performances in Ligue 1 and international tournaments.\n\n3. **Erling
|
||||
Haaland** (Manchester City)\n - Position: Forward\n - Country: Norway\n -
|
||||
Highlights: Haaland''s goal-scoring prowess and strength have made him one of
|
||||
the most feared strikers in Europe, helping Manchester City secure several titles
|
||||
including the UEFA Champions League.\n\n4. **Kevin De Bruyne** (Manchester City)\n -
|
||||
Position: Midfielder\n - Country: Belgium\n - Highlights: De Bruyne\u2019s
|
||||
exceptional passing, control, and vision make him one of the best playmakers
|
||||
in the world, instrumental in Manchester City\u2019s dominance in domestic and
|
||||
European competitions.\n\n5. **Cristiano Ronaldo** (Al Nassr)\n - Position:
|
||||
Forward\n - Country: Portugal\n - Highlights: Despite moving to the Saudi
|
||||
Pro League, Ronaldo''s extraordinary talent and goal-scoring ability keep him
|
||||
in the conversation among the best, having had a legendary career across multiple
|
||||
leagues.\n\n6. **Neymar Jr.** (Al Hilal)\n - Position: Forward\n - Country:
|
||||
Brazil\n - Highlights: Neymar''s agility, creativity, and skill have kept
|
||||
him as a top performer in soccer, now showcasing his talents in the Saudi Pro
|
||||
League while maintaining a strong national team presence.\n\n7. **Robert Lewandowski**
|
||||
(Barcelona)\n - Position: Forward\n - Country: Poland\n - Highlights:
|
||||
The prolific striker continues to score consistently in La Liga, known for his
|
||||
finishing, positioning, and aerial ability, contributing to Barcelona\u2019s
|
||||
successes.\n\n8. **Karim Benzema** (Al Ittihad)\n - Position: Forward\n -
|
||||
Country: France\n - Highlights: The former Real Madrid star remains a top
|
||||
talent, displaying leadership and technical skills, now continuing his career
|
||||
in the Saudi Pro League.\n\n9. **Luka Modri\u0107** (Real Madrid)\n - Position:
|
||||
Midfielder\n - Country: Croatia\n - Highlights: A master of midfield control
|
||||
and passing, Modri\u0107 remains an influential figure at Real Madrid, showcasing
|
||||
his experience and football intelligence.\n\n10. **Mohamed Salah** (Liverpool)\n -
|
||||
Position: Forward\n - Country: Egypt\n - Highlights: Salah''s explosive
|
||||
pace and goal-scoring ability keep him as a central figure for Liverpool in
|
||||
the Premier League and European competitions, maintaining his status as one
|
||||
of the elite forwards.\n\nThese players have demonstrated exceptional skill,
|
||||
consistency, and impact in their respective teams and leagues, solidifying their
|
||||
positions among the best in the world."}, {"role": "user", "content": "The task
|
||||
result does not comply with the guardrail as it includes players from various
|
||||
countries and only mentions two Brazilian players (Neymar Jr. and Neymar) while
|
||||
excluding Brazilian women players entirely. The guardrail specifically requests
|
||||
to include only Brazilian players, both women and men, which is not fulfilled."}],
|
||||
"model": "gpt-4o-mini", "stop": ["\nObservation:"]}'
|
||||
headers:
|
||||
accept:
|
||||
- application/json
|
||||
accept-encoding:
|
||||
- gzip, deflate, zstd
|
||||
connection:
|
||||
- keep-alive
|
||||
content-length:
|
||||
- '4338'
|
||||
content-type:
|
||||
- application/json
|
||||
cookie:
|
||||
- __cf_bm=UscrLNUFPQp17ivpT2nYqbIb8GsK9e0GpWC7sIKWwnU-1749566007-1.0.1.1-fCm5jdN02Agxc9.Ep4aAnKukyBp9S3iOLK9NY51NLG1zib3MnfjyCm5HhsWtUvr2lIjQpD_EWosVk4JuLbGxrKYZBa4WTendGsY9lCU9naU;
|
||||
_cfuvid=CGbpwQsAGlm5OcWs4NP0JuyqJh.mIqHyUZjIdKm8_.I-1749566007688-0.0.1.1-604800000
|
||||
host:
|
||||
- api.openai.com
|
||||
user-agent:
|
||||
- OpenAI/Python 1.78.0
|
||||
x-stainless-arch:
|
||||
- arm64
|
||||
x-stainless-async:
|
||||
- 'false'
|
||||
x-stainless-lang:
|
||||
- python
|
||||
x-stainless-os:
|
||||
- MacOS
|
||||
x-stainless-package-version:
|
||||
- 1.78.0
|
||||
x-stainless-raw-response:
|
||||
- 'true'
|
||||
x-stainless-read-timeout:
|
||||
- '600.0'
|
||||
x-stainless-retry-count:
|
||||
- '0'
|
||||
x-stainless-runtime:
|
||||
- CPython
|
||||
x-stainless-runtime-version:
|
||||
- 3.12.9
|
||||
method: POST
|
||||
uri: https://api.openai.com/v1/chat/completions
|
||||
response:
|
||||
body:
|
||||
string: !!binary |
|
||||
H4sIAAAAAAAAAwAAAP//lFfNbhxHDr7rKYi5BDBagiTLsj032QvHceC1ExubIOtAYFdzuhlVs3pZ
|
||||
1TMeBwb2Nfa857xArnqTfZIFq2e6R9J417oImmYVfz5+JIu/HwDMuJrNYeYaTK7t/OGzuv8+vPuu
|
||||
O/2H+9k//vnF8flP4Zcf6uclPj35dlbYjVD+Ri5tbx250HaeEgcZxE4JE5nWk8dnTx+dnx+fnmdB
|
||||
Gyrydq3u0uFZOGxZ+PD0+PTs8Pjx4cmTze0msKM4m8PfDwAAfs9/zU+p6ONsDsfF9ktLMWJNs/l4
|
||||
CGCmwduXGcbIMaGkWTEJXZBEkl1/34S+btIcvgMJK3AoUPOSAKE2/wElrkgBPsgLFvRwkX/P4SUp
|
||||
ASpBaghS6ODkGEqKCWJwjhQ6j2vSCCz5xCqorwpYBNdHlhroo/N95CX5NQSBZ4qf2DPK9l4BZUgN
|
||||
rEJLAigVtCQFlBipsvOpIVboSBdBWxRH+Qy3Hbq0NVljS4ARwgLeuBRKUjg9Pn04/yAf5OQIHjz4
|
||||
K61bVHilRw8eWIAAcAhvQ2TL4RxeBF2hVqPkue/LOVx4eMke/fj5JdeN57pJcQ5vhMycWW+DYXHF
|
||||
3lMFi0FVhNqHEr1fF7Axbplg6SlCClDhp0+eYMWpgYYjVMpl6VnqIsPS4lX+30KtA/rD6IIamFiy
|
||||
57QuoMFl/g2Ra+EFO5S0RSXIAKkpdr4vsxrzdMJe0CJHD4mwPTKcTg2nv7Fc/+G4j/Dq+k/hoPeA
|
||||
60dCD6+xUq72IjbpbjACtaQ1VZY1hCtab9hg+O1qKkBCGmDN4cSOqCogkWuEHfoB9zgg5bR3jD4j
|
||||
lunIbRfUKgJaTK6hWEBswsphJqbpS+hJJsRGtFgS6QiSpyX5mGF6aDD9yK5B9RyD3AOg9yElkgZb
|
||||
eBlS7HrdC9P3ElYyxrskjZhyzrNfSGoRjjTY8STDWpILVguw5IQeWmqtGDZEvZH0rM6umMRht1Fp
|
||||
5HQNSk1TZY0s7XBTfrfomJE5M2Reoya8ByZv1KNUAd4qV7QXjwtI2hN4qkkqiyQ3im/ipvsUkE3m
|
||||
SFwQ64Akya+3iaYKGtKBJgV4woo0Ntztqa1Ow4piLIBQxT5I35KGPgIOJZ0T4FzwWFkVN2r9NPQp
|
||||
WxgcRF2DQyXSjMkjw+RCKrW+DRd+SXEvOK+5WjD5ivR2UYUWvwBLx8tgOd4UDssdZEbDBk7FMZ8c
|
||||
8KCPjroNG4YSGpoEupTLyiImoRiHumAZSsM05IPGz//XUc5z8B4F4R1KCvtD/wstSO4G/ozEmtr+
|
||||
2LNOjqDkQi38adsgSKEydTZttukcsrZD7iBJueyTzbIcA6aE7qoAiglLz7HJzYE0kl/s7U9DcyW9
|
||||
2VzvAvDYAPgWS2Xy8IpiH+8zfTSSfGH4/GQFibDwyINHYz1arPkZkMfHDdsGGApQjCTJmkiHmva2
|
||||
hgKubjShVdArUEw0tkbvuSabxcOAhkzeHPMTi/k9Xv8R4ULx+s/fwv0I/+763wHeYu/DF2ivnJt3
|
||||
TJg5PxHwNvsHJ4z6NbJQtWWLOTDSJSYNVvrT8yIPjnbj3o15kdOei2UzbQgTL7ft72kOvGGsA7xj
|
||||
v8T7sP15Qz7SF9guQB87UjbAq2xayTOWnsCRzanDMvM3W/3PP/8Vd9pcPj7VxFAHTIbLkqDFiqDh
|
||||
FhBcUCGNKQhlcLYefc3T4eTYYn/GCL+gkGJKU9L/B9PH6N+ib4kV4yS4NQHylJ5eVwWYsZ15t8NX
|
||||
0ptdfRxtFrVFM72vxsfD2BPyx+lB5XPH+Npyf2+14jkmaEbv81EWp1SxJWzz3sj8GY0GyU/XOy9j
|
||||
Y+KWzTs8HF7E267tNGy79MB/072tBRvfsYDU9NYsO6Vc+1JvbH0TQdk124e8pxrd+mh3fVBa9BFt
|
||||
hZHe+x0BioSUIciLy68byedxVfGh7jSU8dbV2YKFY3OphDGIrSUxhW6WpZ8PAH7NK1F/Y8uZdRra
|
||||
Ll2mcEXZ3JMnJ4O+2bSJTdLz883CNEs2ICfByaOz7b0bGi8rSsg+7qxVM4euoWq6O+1g2FccdgQH
|
||||
O3Hf9Wef7iF2lvpr1E8CZyObqsvOyORuxjwdU7JV9UvHRpyzw7NIumRHl4lJLRcVLbD3wwI5i+uY
|
||||
qL1csNSknfKwRS66y4dn+OgM6elDNzv4fPBfAAAA//8DAGsE37hTDwAA
|
||||
headers:
|
||||
CF-RAY:
|
||||
- 94d995f0ca0cf1fe-GRU
|
||||
Connection:
|
||||
- keep-alive
|
||||
Content-Encoding:
|
||||
- gzip
|
||||
Content-Type:
|
||||
- application/json
|
||||
Date:
|
||||
- Tue, 10 Jun 2025 14:34:22 GMT
|
||||
Server:
|
||||
- cloudflare
|
||||
Transfer-Encoding:
|
||||
- chunked
|
||||
X-Content-Type-Options:
|
||||
- nosniff
|
||||
access-control-expose-headers:
|
||||
- X-Request-ID
|
||||
alt-svc:
|
||||
- h3=":443"; ma=86400
|
||||
cf-cache-status:
|
||||
- DYNAMIC
|
||||
openai-organization:
|
||||
- crewai-iuxna1
|
||||
openai-processing-ms:
|
||||
- '35941'
|
||||
openai-version:
|
||||
- '2020-10-01'
|
||||
strict-transport-security:
|
||||
- max-age=31536000; includeSubDomains; preload
|
||||
x-envoy-upstream-service-time:
|
||||
- '35946'
|
||||
x-ratelimit-limit-requests:
|
||||
- '30000'
|
||||
x-ratelimit-limit-tokens:
|
||||
- '150000000'
|
||||
x-ratelimit-remaining-requests:
|
||||
- '29999'
|
||||
x-ratelimit-remaining-tokens:
|
||||
- '149998983'
|
||||
x-ratelimit-reset-requests:
|
||||
- 2ms
|
||||
x-ratelimit-reset-tokens:
|
||||
- 0s
|
||||
x-request-id:
|
||||
- req_c874fed664f962f5ee90decb8ebad875
|
||||
status:
|
||||
code: 200
|
||||
message: OK
|
||||
- request:
|
||||
body: '{"messages": [{"role": "system", "content": "You are Guardrail Agent. You
|
||||
are a expert at validating the output of a task. By providing effective feedback
|
||||
if the output is not valid.\nYour personal goal is: Validate the output of the
|
||||
task\n\nTo give my best complete final answer to the task respond using the
|
||||
exact following format:\n\nThought: I now can give a great answer\nFinal Answer:
|
||||
Your final answer must be the great and the most complete as possible, it must
|
||||
be outcome described.\n\nI MUST use these formats, my job depends on it!\nIMPORTANT:
|
||||
Your final answer MUST contain all the information requested in the following
|
||||
format: {\n \"valid\": bool,\n \"feedback\": str | None\n}\n\nIMPORTANT: Ensure
|
||||
the final output does not include any code block markers like ```json or ```python."},
|
||||
{"role": "user", "content": "\n Ensure the following task result complies
|
||||
with the given guardrail.\n\n Task result:\n Here are the top
|
||||
10 best soccer players in the world, focusing exclusively on Brazilian players,
|
||||
both women and men, based on their performance and impact in the game as of
|
||||
October 2023:\n\n1. **Neymar Jr.** \n - Position: Forward \n - Club: Al
|
||||
Hilal \n - Highlights: One of the most skilled forwards globally, Neymar
|
||||
continues to dazzle with his dribbling, playmaking, and goal-scoring ability,
|
||||
having a significant impact on both his club and the Brazilian national team.\n\n2.
|
||||
**Vin\u00edcius J\u00fanior** \n - Position: Forward \n - Club: Real Madrid \n -
|
||||
Highlights: Vin\u00edcius has emerged as a key player for Real Madrid, noted
|
||||
for his speed, technical skills, and crucial goals in important matches, showcasing
|
||||
his talent on both club and international levels.\n\n3. **Richarlison** \n -
|
||||
Position: Forward \n - Club: Tottenham Hotspur \n - Highlights: Known
|
||||
for his versatility and aerial ability, Richarlison has become a vital member
|
||||
of the national team and has the capability to change the game with his pace
|
||||
and scoring ability.\n\n4. **Marta** \n - Position: Forward \n - Club:
|
||||
Orlando Pride \n - Highlights: A true legend of women''s soccer, Marta has
|
||||
consistently showcased her skill, leadership, and goal-scoring prowess, earning
|
||||
numerous awards and accolades throughout her legendary career.\n\n5. **Andressa
|
||||
Alves** \n - Position: Midfielder \n - Club: Roma \n - Highlights:
|
||||
A pivotal player in women''s soccer, Andressa has displayed her exceptional
|
||||
skills and tactical awareness both in club play and for the Brazilian national
|
||||
team.\n\n6. **Alana Santos** \n - Position: Defender \n - Club: Benfica \n -
|
||||
Highlights: Alana is recognized for her defensive prowess and ability to contribute
|
||||
to the attack, establishing herself as a key player for both her club and the
|
||||
national team.\n\n7. **Gabriel Jesus** \n - Position: Forward \n - Club:
|
||||
Arsenal \n - Highlights: With a flair for scoring and assisting, Gabriel
|
||||
Jesus is an essential part of the national team, known for his work rate and
|
||||
intelligence on the field.\n\n8. **Ta\u00eds Ara\u00fajo** \n - Position:
|
||||
Midfielder \n - Club: S\u00e3o Paulo \n - Highlights: A rising star in
|
||||
Brazilian women''s soccer, Ta\u00eds has gained recognition for her strong performances
|
||||
in midfield, showcasing both skill and creativity.\n\n9. **Thiago Silva** \n -
|
||||
Position: Defender \n - Club: Chelsea \n - Highlights: An experienced
|
||||
and reliable center-back, Silva\u2019s leadership and defensive abilities have
|
||||
made him a cornerstone for Chelsea and the Brazilian national team.\n\n10. **Bia
|
||||
Zaneratto** \n - Position: Forward \n - Club: Palmeiras \n - Highlights:
|
||||
A talented forward, Bia has become known for her goal-scoring capabilities and
|
||||
playmaking skills, contributing significantly to both her club and the national
|
||||
team.\n\nThis list highlights the incredible talent and contributions of Brazilian
|
||||
players in soccer, showcasing their skills across both men''s and women''s games,
|
||||
thus representing Brazil''s rich soccer legacy.\n\n Guardrail:\n Only
|
||||
include Brazilian players, both women and men\n \n Your task:\n -
|
||||
Confirm if the Task result complies with the guardrail.\n - If not, provide
|
||||
clear feedback explaining what is wrong (e.g., by how much it violates the rule,
|
||||
or what specific part fails).\n - Focus only on identifying issues \u2014
|
||||
do not propose corrections.\n - If the Task result complies with the
|
||||
guardrail, saying that is valid\n "}], "model": "gpt-4o-mini", "stop":
|
||||
["\nObservation:"]}'
|
||||
headers:
|
||||
accept:
|
||||
- application/json
|
||||
accept-encoding:
|
||||
- gzip, deflate, zstd
|
||||
connection:
|
||||
- keep-alive
|
||||
content-length:
|
||||
- '4571'
|
||||
content-type:
|
||||
- application/json
|
||||
cookie:
|
||||
- __cf_bm=UscrLNUFPQp17ivpT2nYqbIb8GsK9e0GpWC7sIKWwnU-1749566007-1.0.1.1-fCm5jdN02Agxc9.Ep4aAnKukyBp9S3iOLK9NY51NLG1zib3MnfjyCm5HhsWtUvr2lIjQpD_EWosVk4JuLbGxrKYZBa4WTendGsY9lCU9naU;
|
||||
_cfuvid=CGbpwQsAGlm5OcWs4NP0JuyqJh.mIqHyUZjIdKm8_.I-1749566007688-0.0.1.1-604800000
|
||||
host:
|
||||
- api.openai.com
|
||||
user-agent:
|
||||
- OpenAI/Python 1.78.0
|
||||
x-stainless-arch:
|
||||
- arm64
|
||||
x-stainless-async:
|
||||
- 'false'
|
||||
x-stainless-lang:
|
||||
- python
|
||||
x-stainless-os:
|
||||
- MacOS
|
||||
x-stainless-package-version:
|
||||
- 1.78.0
|
||||
x-stainless-raw-response:
|
||||
- 'true'
|
||||
x-stainless-read-timeout:
|
||||
- '600.0'
|
||||
x-stainless-retry-count:
|
||||
- '0'
|
||||
x-stainless-runtime:
|
||||
- CPython
|
||||
x-stainless-runtime-version:
|
||||
- 3.12.9
|
||||
method: POST
|
||||
uri: https://api.openai.com/v1/chat/completions
|
||||
response:
|
||||
body:
|
||||
string: !!binary |
|
||||
H4sIAAAAAAAAA4ySTW/bMAyG7/4VhM72kLj5WHxrDwEKtNilGDYshcFItK1WlgRJTjYE+e+D7DR2
|
||||
tw7YxYD58KX4kjwlAEwKVgDjDQbeWpXd1d3Dl+5Yfb3dPD6K7bri26cw899f5vruG0ujwuxfiIc3
|
||||
1SduWqsoSKMHzB1hoFh1vl5slqvVbJX3oDWCVJTVNmQLk7VSyyyf5Ytsts7mny/qxkhOnhXwIwEA
|
||||
OPXf2KcW9JMVMEvfIi15jzWx4poEwJxRMcLQe+kD6sDSEXKjA+m+9afGdHUTCrgHbY7AUUMtDwQI
|
||||
dewfUPsjOYCd3kqNCm77/wJOOw2wYwdUUuxYAcF1lA6xikjskb/GsO6U2unz9HFHVedRXeAEoNYm
|
||||
YBxgb/v5Qs5Xo8rU1pm9/0PKKqmlb0pH6I2OpnwwlvX0nAA89wPt3s2IWWdaG8pgXql/bpMvh3ps
|
||||
3ONI8/UFBhNQTVTLPP2gXikooFR+shLGkTckRum4P+yENBOQTFz/3c1HtQfnUtf/U34EnJMNJErr
|
||||
SEj+3vGY5iie+b/SrlPuG2ae3EFyKoMkFzchqMJODcfH/C8fqC0rqWty1snhAitb3ixwuUDa3HCW
|
||||
nJPfAAAA//8DAOHOvQuPAwAA
|
||||
headers:
|
||||
CF-RAY:
|
||||
- 94d996d2b877f1fe-GRU
|
||||
Connection:
|
||||
- keep-alive
|
||||
Content-Encoding:
|
||||
- gzip
|
||||
Content-Type:
|
||||
- application/json
|
||||
Date:
|
||||
- Tue, 10 Jun 2025 14:34:38 GMT
|
||||
Server:
|
||||
- cloudflare
|
||||
Transfer-Encoding:
|
||||
- chunked
|
||||
X-Content-Type-Options:
|
||||
- nosniff
|
||||
access-control-expose-headers:
|
||||
- X-Request-ID
|
||||
alt-svc:
|
||||
- h3=":443"; ma=86400
|
||||
cf-cache-status:
|
||||
- DYNAMIC
|
||||
openai-organization:
|
||||
- crewai-iuxna1
|
||||
openai-processing-ms:
|
||||
- '15341'
|
||||
openai-version:
|
||||
- '2020-10-01'
|
||||
strict-transport-security:
|
||||
- max-age=31536000; includeSubDomains; preload
|
||||
x-envoy-upstream-service-time:
|
||||
- '15343'
|
||||
x-ratelimit-limit-requests:
|
||||
- '30000'
|
||||
x-ratelimit-limit-tokens:
|
||||
- '150000000'
|
||||
x-ratelimit-remaining-requests:
|
||||
- '29999'
|
||||
x-ratelimit-remaining-tokens:
|
||||
- '149998917'
|
||||
x-ratelimit-reset-requests:
|
||||
- 2ms
|
||||
x-ratelimit-reset-tokens:
|
||||
- 0s
|
||||
x-request-id:
|
||||
- req_22419b91d42cf1e03278a29f3093ed3d
|
||||
status:
|
||||
code: 200
|
||||
message: OK
|
||||
version: 1
|
||||
726
tests/cassettes/test_guardrail_reached_attempt_limit.yaml
Normal file
726
tests/cassettes/test_guardrail_reached_attempt_limit.yaml
Normal file
@@ -0,0 +1,726 @@
|
||||
interactions:
|
||||
- request:
|
||||
body: '{"messages": [{"role": "system", "content": "You are Sports Analyst. You
|
||||
are an expert at gathering and organizing information. You carefully collect
|
||||
details and present them in a structured way.\nYour personal goal is: Gather
|
||||
information about the best soccer players\n\nTo give my best complete final
|
||||
answer to the task respond using the exact following format:\n\nThought: I now
|
||||
can give a great answer\nFinal Answer: Your final answer must be the great and
|
||||
the most complete as possible, it must be outcome described.\n\nI MUST use these
|
||||
formats, my job depends on it!"}, {"role": "user", "content": "Top 10 best players
|
||||
in the world?"}], "model": "gpt-4o-mini", "stop": ["\nObservation:"]}'
|
||||
headers:
|
||||
accept:
|
||||
- application/json
|
||||
accept-encoding:
|
||||
- gzip, deflate, zstd
|
||||
connection:
|
||||
- keep-alive
|
||||
content-length:
|
||||
- '694'
|
||||
content-type:
|
||||
- application/json
|
||||
host:
|
||||
- api.openai.com
|
||||
user-agent:
|
||||
- OpenAI/Python 1.78.0
|
||||
x-stainless-arch:
|
||||
- arm64
|
||||
x-stainless-async:
|
||||
- 'false'
|
||||
x-stainless-lang:
|
||||
- python
|
||||
x-stainless-os:
|
||||
- MacOS
|
||||
x-stainless-package-version:
|
||||
- 1.78.0
|
||||
x-stainless-raw-response:
|
||||
- 'true'
|
||||
x-stainless-read-timeout:
|
||||
- '600.0'
|
||||
x-stainless-retry-count:
|
||||
- '0'
|
||||
x-stainless-runtime:
|
||||
- CPython
|
||||
x-stainless-runtime-version:
|
||||
- 3.12.9
|
||||
method: POST
|
||||
uri: https://api.openai.com/v1/chat/completions
|
||||
response:
|
||||
body:
|
||||
string: !!binary |
|
||||
H4sIAAAAAAAAA5yXzVIbORDH7zxF11xiqLHLNp/xDUhMssEJm49N1S4pqq1pz/SikYaWxo6Tynmf
|
||||
ZQ/7AnvNPtiWZIMNGAK5UHhaLfVPrW799XUNIOEs6UGiCvSqrHTzIK9HH/yzi6Mv44uT3z93X5fn
|
||||
Fxefs49bR3vya5IGDzv8k5S/9GopW1aaPFszMysh9BRm7exuPd3e2d1s70VDaTPSwS2vfHPLNks2
|
||||
3Oy2u1vN9m6zszf3LiwrckkP/lgDAPga/4Y4TUafkx6008svJTmHOSW9q0EAiVgdviToHDuPxifp
|
||||
wqis8WRi6O8LW+eF78FLMHYCCg3kPCZAyEP8gMZNSABOTZ8NatiPv3vwviDwtoJOG4bkPDirFAlU
|
||||
GqckDtiALwgmVnSWAjqwI3ijvB2SQLfd3UzjSkMCzsh4HjFlMERHGdjoyQJCioyHimRkpUSjyKXg
|
||||
zllrlwKXFSofBudYBgOaDOyYBLWGgCc8rEMuHHg7n9ATlq4FL0gI2MX4nJda+VooA83O907Nqem0
|
||||
YGPjmK0hDQNyjqHx0ngSGDCWDIf99Y2NUwMATTixjsMiPehbmaBk8++vaAr7fhYDuR48Ex4ONZs8
|
||||
hTE7tiaF3KJuOmWFTQ44ZM1+2pq776uCaUwlGe96MKi150oTHKDW1kD25I3AhI0hSeHQVgj7JQkr
|
||||
BFVgWcXZP4Z9h8O6uvoGjW67211vBcJuIHw11YwGBkOsqu9/Q+MEhR28Qza+eURSIpvHg76riLIU
|
||||
PKnC8EVNKYzYsCvY5Kvh+i/7+3dE29lbT+GY85qgA569DmkuLzcjsyU5zwpUXblItRmonkvYZniB
|
||||
qMOJaAzQqIJcSN8h++njiU7sJOyzm4Fdyxob59kov5rsoDYZOc05xjoJTmGiD8/7+3A4x3RwTBgA
|
||||
Z+mMOdpcT+FEqGSSS+sMPkJuxdTRmA08IziQemroQZQDzkZMOiO5CzR0iuUTGvsXj398LldGm0Lg
|
||||
rCv3IOTIth3ZULiEAzJfqERo7OvmS++5wOzxqTtaSlYaO1OJ5/F/j8qzQg1sPGnNORlFqylD1ays
|
||||
vKuTeJPMwYR9AW8JNQwwE84i3U6ge03TEgV+kVZAgxesUT8erK+RJYVs0VUenKurstHXk3UrPVIH
|
||||
zGZdxeB3Q/BvQ/f2cEwTNJmduHOGRv8QDlAUaWvwJ0Aum0MK1dwl/kASRn1/W4yd4yBcPQMyTxyc
|
||||
xJtnKS/LBTinPMbQUPB6U5yfvr2AOLAFlpTBO9RYQOOYxySVtfqnO+FoQXiVrtU8N6po0ctndXR/
|
||||
GUWCp4HgNzbf/1FcO/jl+7+GrUBj6ST+NMcjztoPy727fn8mOu14A9fnCAObCf/310qG+9rbQ/rb
|
||||
PU3g7vq5xXV5tG63iPkdFpHeF+yiwgjCIwhF1rcFj6pFguIJcieFCt1N8RNutDu0jZCrSPmg3KLM
|
||||
CQJsaH2xKPjgHEjFYPBFHeMgHzfQteb1A4Im9EgX9dkYZbqIsiJx0dFWbELOwpRhWR6Fe1jYh7KF
|
||||
OgwfWQEao67jYikMax8idXSlEAscU6AJ8pSM11MYEhkQylEyyoJmdLakIByDUosic1lVrhCVrWWN
|
||||
KzSqHQadbWqtlwxojPUxrKiuP80t3670tLZ5JXbobrgms1o+E0JnTdDOztsqidZvawCfom6vr0nx
|
||||
pBJbVv7M23OKy3W63dl8yeK5sLDubG3Ord561AvD7s52umLCs4w8snZL0j9RqArKFq6LdwLWGdsl
|
||||
w9oS9u1wVs09Q2eTP2T6hUEpqjxlZ5VQxuo68mKYUHhO3TXsaptjwIkjGbOiM88kIRUZjbDWs0dO
|
||||
4qbOU3k2YpOTVMKzl86oOtvcwu0tpKebKln7tvY/AAAA//8DAJ67Vp33DQAA
|
||||
headers:
|
||||
CF-RAY:
|
||||
- 94d9b5400dcd624b-GRU
|
||||
Connection:
|
||||
- keep-alive
|
||||
Content-Encoding:
|
||||
- gzip
|
||||
Content-Type:
|
||||
- application/json
|
||||
Date:
|
||||
- Tue, 10 Jun 2025 14:55:42 GMT
|
||||
Server:
|
||||
- cloudflare
|
||||
Set-Cookie:
|
||||
- __cf_bm=8Yv8F0ZCFAo2lf.qoqxao70yxyjVvIV90zQqVF6bVzQ-1749567342-1.0.1.1-fZgnv3RDfunvCO1koxwwFJrHnxSx_rwS_FHvQ6xxDPpKHwYr7dTqIQLZrNgSX5twGyK4F22rUmkuiS6KMVogcinChk8lmHtJBTUVTFjr2KU;
|
||||
path=/; expires=Tue, 10-Jun-25 15:25:42 GMT; domain=.api.openai.com; HttpOnly;
|
||||
Secure; SameSite=None
|
||||
- _cfuvid=wzh8YnmXvLq1G0RcIVijtzboQtCZyIe2uZiochkBLqE-1749567342267-0.0.1.1-604800000;
|
||||
path=/; domain=.api.openai.com; HttpOnly; Secure; SameSite=None
|
||||
Transfer-Encoding:
|
||||
- chunked
|
||||
X-Content-Type-Options:
|
||||
- nosniff
|
||||
access-control-expose-headers:
|
||||
- X-Request-ID
|
||||
alt-svc:
|
||||
- h3=":443"; ma=86400
|
||||
cf-cache-status:
|
||||
- DYNAMIC
|
||||
openai-organization:
|
||||
- crewai-iuxna1
|
||||
openai-processing-ms:
|
||||
- '33288'
|
||||
openai-version:
|
||||
- '2020-10-01'
|
||||
strict-transport-security:
|
||||
- max-age=31536000; includeSubDomains; preload
|
||||
x-envoy-upstream-service-time:
|
||||
- '33292'
|
||||
x-ratelimit-limit-requests:
|
||||
- '30000'
|
||||
x-ratelimit-limit-tokens:
|
||||
- '150000000'
|
||||
x-ratelimit-remaining-requests:
|
||||
- '29999'
|
||||
x-ratelimit-remaining-tokens:
|
||||
- '149999859'
|
||||
x-ratelimit-reset-requests:
|
||||
- 2ms
|
||||
x-ratelimit-reset-tokens:
|
||||
- 0s
|
||||
x-request-id:
|
||||
- req_6a587ea22edef774ecdada790a320cab
|
||||
status:
|
||||
code: 200
|
||||
message: OK
|
||||
- request:
|
||||
body: '{"messages": [{"role": "system", "content": "You are Sports Analyst. You
|
||||
are an expert at gathering and organizing information. You carefully collect
|
||||
details and present them in a structured way.\nYour personal goal is: Gather
|
||||
information about the best soccer players\n\nTo give my best complete final
|
||||
answer to the task respond using the exact following format:\n\nThought: I now
|
||||
can give a great answer\nFinal Answer: Your final answer must be the great and
|
||||
the most complete as possible, it must be outcome described.\n\nI MUST use these
|
||||
formats, my job depends on it!"}, {"role": "user", "content": "Top 10 best players
|
||||
in the world?"}, {"role": "assistant", "content": "Thought: I now can give a
|
||||
great answer \nFinal Answer: The top 10 best soccer players in the world, as
|
||||
of October 2023, can be identified based on their recent performances, skills,
|
||||
impact on games, and overall contributions to their teams. Here is the structured
|
||||
list:\n\n1. **Lionel Messi (Inter Miami CF)**\n - Position: Forward\n -
|
||||
Key Attributes: Dribbling, vision, goal-scoring ability.\n - Achievements:
|
||||
Multiple Ballon d''Or winner, Copa America champion, World Cup champion (2022).\n\n2.
|
||||
**Kylian Mbapp\u00e9 (Paris Saint-Germain)**\n - Position: Forward\n - Key
|
||||
Attributes: Speed, technique, finishing.\n - Achievements: FIFA World Cup
|
||||
champion (2018), Ligue 1 titles, multiple domestic cups.\n\n3. **Erling Haaland
|
||||
(Manchester City)**\n - Position: Forward\n - Key Attributes: Power, speed,
|
||||
goal-scoring instinct.\n - Achievements: Bundesliga top scorer, UEFA Champions
|
||||
League winner (2023), Premier League titles.\n\n4. **Kevin De Bruyne (Manchester
|
||||
City)**\n - Position: Midfielder\n - Key Attributes: Passing, vision, creativity.\n -
|
||||
Achievements: Multiple Premier League titles, FA Cups, UEFA Champions League
|
||||
winner (2023).\n\n5. **Karim Benzema (Al-Ittihad)**\n - Position: Forward\n -
|
||||
Key Attributes: Goal-scoring, playmaking, tactical intelligence.\n - Achievements:
|
||||
2022 Ballon d''Or winner, multiple Champions Leagues with Real Madrid.\n\n6.
|
||||
**Neymar Jr. (Al Hilal)**\n - Position: Forward\n - Key Attributes: Flair,
|
||||
dribbling, creativity.\n - Achievements: Multiple domestic league titles,
|
||||
Champions League runner-up.\n\n7. **Robert Lewandowski (FC Barcelona)**\n -
|
||||
Position: Forward\n - Key Attributes: Finishing, positioning, aerial ability.\n -
|
||||
Achievements: FIFA Best Men''s Player, multiple Bundesliga titles, La Liga champion
|
||||
(2023).\n\n8. **Mohamed Salah (Liverpool)**\n - Position: Forward\n - Key
|
||||
Attributes: Speed, finishing, dribbling.\n - Achievements: Premier League
|
||||
champion, FA Cup, UEFA Champions League winner.\n\n9. **Vin\u00edcius J\u00fanior
|
||||
(Real Madrid)**\n - Position: Forward\n - Key Attributes: Speed, dribbling,
|
||||
creativity.\n - Achievements: UEFA Champions League winner (2022), La Liga
|
||||
champion (2023).\n\n10. **Luka Modri\u0107 (Real Madrid)**\n - Position:
|
||||
Midfielder\n - Key Attributes: Passing, vision, tactical intelligence.\n -
|
||||
Achievements: Multiple Champions League titles, Ballon d''Or winner (2018).\n\nThis
|
||||
list is compiled based on their current form, past performances, and contributions
|
||||
to their respective teams in both domestic and international competitions. Player
|
||||
rankings can vary based on personal opinion and specific criteria used for evaluation,
|
||||
but these players have consistently been regarded as some of the best in the
|
||||
world as of October 2023."}, {"role": "user", "content": "You are not allowed
|
||||
to include Brazilian players"}], "model": "gpt-4o-mini", "stop": ["\nObservation:"]}'
|
||||
headers:
|
||||
accept:
|
||||
- application/json
|
||||
accept-encoding:
|
||||
- gzip, deflate, zstd
|
||||
connection:
|
||||
- keep-alive
|
||||
content-length:
|
||||
- '3594'
|
||||
content-type:
|
||||
- application/json
|
||||
cookie:
|
||||
- __cf_bm=8Yv8F0ZCFAo2lf.qoqxao70yxyjVvIV90zQqVF6bVzQ-1749567342-1.0.1.1-fZgnv3RDfunvCO1koxwwFJrHnxSx_rwS_FHvQ6xxDPpKHwYr7dTqIQLZrNgSX5twGyK4F22rUmkuiS6KMVogcinChk8lmHtJBTUVTFjr2KU;
|
||||
_cfuvid=wzh8YnmXvLq1G0RcIVijtzboQtCZyIe2uZiochkBLqE-1749567342267-0.0.1.1-604800000
|
||||
host:
|
||||
- api.openai.com
|
||||
user-agent:
|
||||
- OpenAI/Python 1.78.0
|
||||
x-stainless-arch:
|
||||
- arm64
|
||||
x-stainless-async:
|
||||
- 'false'
|
||||
x-stainless-lang:
|
||||
- python
|
||||
x-stainless-os:
|
||||
- MacOS
|
||||
x-stainless-package-version:
|
||||
- 1.78.0
|
||||
x-stainless-raw-response:
|
||||
- 'true'
|
||||
x-stainless-read-timeout:
|
||||
- '600.0'
|
||||
x-stainless-retry-count:
|
||||
- '0'
|
||||
x-stainless-runtime:
|
||||
- CPython
|
||||
x-stainless-runtime-version:
|
||||
- 3.12.9
|
||||
method: POST
|
||||
uri: https://api.openai.com/v1/chat/completions
|
||||
response:
|
||||
body:
|
||||
string: !!binary |
|
||||
H4sIAAAAAAAAAwAAAP//nJfNctpIEMfvfoouXYJdwgXYjm1u4JjEsam4kuzuYZ1yNaNG6njUo50Z
|
||||
QUgq5zzLHvYF9pp9sK0ZwOAEx3EuFKjVTf+mP/TXpy2AhLOkC4kq0Kuy0s1+Xucvb06e+X7ndDzp
|
||||
DflscN6yRBfng75O0uBhRu9J+aXXrjJlpcmzkblZWUJPIWr7cP/44Onh3sFxNJQmIx3c8so3902z
|
||||
ZOFmp9XZb7YOm+2jhXdhWJFLuvDnFgDAp/gZ8pSMPiRdaKXLKyU5hzkl3dubABJrdLiSoHPsPIpP
|
||||
0pVRGfEkMfW3hanzwnfhDMRMQaFAzhMChDzkDyhuShbgSgYsqKEXf3fhBVkCdoACdZUFUNDsPJgx
|
||||
+ILAmwraLRiR8+CMUmSh0jgj64Al3jE1VmeALni8Ut6MyEKn1dlLgT4oXWcsOfQtfmTNKEvn7pVc
|
||||
SXsXdnYu2AhpGJJzDI0z8WRhyFgynAy2d3auBACacGkch4p0YWDsFG22uH5OM+h5b3lUe3JdeGZ5
|
||||
NNIseQoTdmwkhdygbjplbEgER6zZz3YX7j1VME2oJPGuC8Nae640QR+1NgLZk1cWpixCNoUTUyH0
|
||||
SrKsEFSBZRWj/xHpT+rq9ho0Oq1OZ3s3EHYC4fkskg9HWFVf/4bGJVp28AZZfPM52RJZHg/6piLK
|
||||
UvCkCuG/akphzMKuYMk3ww3OBr17sm0fbadwwXlN0AbPXpNLoVweRmZKcp4VqLpykWovUJ3acMzw
|
||||
AlGjZNAYoqiCXCjfCfvZ44kuzTScs5uD3akai/Msym8m69eSkdOcY+zW4BQC/XY66MHJAtPBBWEA
|
||||
nJcz1mhvO4VLSyWTXVrn8BFyP5aOJizwjKBv65nQT1EOORsz6YzsfaBhlNc7NC4YnjzclxuzTSFw
|
||||
1pX7KeTIdhDZ0HIJfZKPVCI0erp55j0XmD2+dM/XipXGES/xJn73qDwr1MDiSWvOSRRtpgxTs3Hy
|
||||
bjvxWzIHU/YFvCbUMMTMchbpnga612EPebigKUpmpu6GoTE4gT5aRdoIPh5ysJyvFKqFS/yBZBn1
|
||||
jzdLHL5+2KFDkicOLuMWXENb7+FFVS8wzCTe3SuLAh4GxKEpsKQM3qDGAhoXPCFbGaN/eZmMV4TZ
|
||||
co9u5vmmEVfrcN6KP+7ESHAUCH5n+fqP4trBy6//ChsLjbVi/jJHtnoIPDRaD05MZ/vHlTiOz7D6
|
||||
BmFoMsv/fXkQ4fH74RFDNLxvVm7b6vsJWzwCIk67FXheoLUzOMew8fqhUwWGtbAqljz31uTB5bD2
|
||||
wFrtid2l712Y50ZnJNA3xt8ug3tWYKzjaW1NRSgr+IIrsHXwbNZVBHxbsJsLnAIdjIgEMHtfu6B7
|
||||
vFlIFvpesEB4yI2Nqh05MEH5GEcwLQwUOCEoMSNwnAuPWaF44LJC5ZciiS0oXY/mUcxcN4ViWsFw
|
||||
hqjBecxpg4rahVNUxSKLoNMsKZMLf6SQjl0Epw+KqmWkG9bapVCRHRtboqhwQOGPce10d9dlpKVx
|
||||
7TBIWam1XjOgiPExxShg3y0sn28lqzZ5Zc3IfeOazFfJtSV0RoI8dd5USbR+3gJ4F6VxfUftJpU1
|
||||
ZeWvvbmh+HeHR+15vGSlyFfWp+2FcE688ahXhvbe8dLvTsTrjDyydmvyOlGoCspWvistjnXGZs2w
|
||||
tcb9fT6bYs/ZWfKfCb8yqFBJyq4rSxmru8yr2yyFV5b7brs955hw4shOWNG1Z7KhFhmNsdbzF4nE
|
||||
zZyn8nrMkpOtLM/fJsbV9d4+HuwjHe+pZOvz1v8AAAD//wMAVoKTVVsNAAA=
|
||||
headers:
|
||||
CF-RAY:
|
||||
- 94d9b6782db84d3b-GRU
|
||||
Connection:
|
||||
- keep-alive
|
||||
Content-Encoding:
|
||||
- gzip
|
||||
Content-Type:
|
||||
- application/json
|
||||
Date:
|
||||
- Tue, 10 Jun 2025 14:56:30 GMT
|
||||
Server:
|
||||
- cloudflare
|
||||
Transfer-Encoding:
|
||||
- chunked
|
||||
X-Content-Type-Options:
|
||||
- nosniff
|
||||
access-control-expose-headers:
|
||||
- X-Request-ID
|
||||
alt-svc:
|
||||
- h3=":443"; ma=86400
|
||||
cf-cache-status:
|
||||
- DYNAMIC
|
||||
openai-organization:
|
||||
- crewai-iuxna1
|
||||
openai-processing-ms:
|
||||
- '31484'
|
||||
openai-version:
|
||||
- '2020-10-01'
|
||||
strict-transport-security:
|
||||
- max-age=31536000; includeSubDomains; preload
|
||||
x-envoy-upstream-service-time:
|
||||
- '31490'
|
||||
x-ratelimit-limit-requests:
|
||||
- '30000'
|
||||
x-ratelimit-limit-tokens:
|
||||
- '150000000'
|
||||
x-ratelimit-remaining-requests:
|
||||
- '29999'
|
||||
x-ratelimit-remaining-tokens:
|
||||
- '149999166'
|
||||
x-ratelimit-reset-requests:
|
||||
- 2ms
|
||||
x-ratelimit-reset-tokens:
|
||||
- 0s
|
||||
x-request-id:
|
||||
- req_aa737cf40bb76af9f458bfd35f7a77a1
|
||||
status:
|
||||
code: 200
|
||||
message: OK
|
||||
- request:
|
||||
body: '{"messages": [{"role": "system", "content": "You are Sports Analyst. You
|
||||
are an expert at gathering and organizing information. You carefully collect
|
||||
details and present them in a structured way.\nYour personal goal is: Gather
|
||||
information about the best soccer players\n\nTo give my best complete final
|
||||
answer to the task respond using the exact following format:\n\nThought: I now
|
||||
can give a great answer\nFinal Answer: Your final answer must be the great and
|
||||
the most complete as possible, it must be outcome described.\n\nI MUST use these
|
||||
formats, my job depends on it!"}, {"role": "user", "content": "Top 10 best players
|
||||
in the world?"}, {"role": "assistant", "content": "Thought: I now can give a
|
||||
great answer \nFinal Answer: The top 10 best soccer players in the world, as
|
||||
of October 2023, can be identified based on their recent performances, skills,
|
||||
impact on games, and overall contributions to their teams. Here is the structured
|
||||
list:\n\n1. **Lionel Messi (Inter Miami CF)**\n - Position: Forward\n -
|
||||
Key Attributes: Dribbling, vision, goal-scoring ability.\n - Achievements:
|
||||
Multiple Ballon d''Or winner, Copa America champion, World Cup champion (2022).\n\n2.
|
||||
**Kylian Mbapp\u00e9 (Paris Saint-Germain)**\n - Position: Forward\n - Key
|
||||
Attributes: Speed, technique, finishing.\n - Achievements: FIFA World Cup
|
||||
champion (2018), Ligue 1 titles, multiple domestic cups.\n\n3. **Erling Haaland
|
||||
(Manchester City)**\n - Position: Forward\n - Key Attributes: Power, speed,
|
||||
goal-scoring instinct.\n - Achievements: Bundesliga top scorer, UEFA Champions
|
||||
League winner (2023), Premier League titles.\n\n4. **Kevin De Bruyne (Manchester
|
||||
City)**\n - Position: Midfielder\n - Key Attributes: Passing, vision, creativity.\n -
|
||||
Achievements: Multiple Premier League titles, FA Cups, UEFA Champions League
|
||||
winner (2023).\n\n5. **Karim Benzema (Al-Ittihad)**\n - Position: Forward\n -
|
||||
Key Attributes: Goal-scoring, playmaking, tactical intelligence.\n - Achievements:
|
||||
2022 Ballon d''Or winner, multiple Champions Leagues with Real Madrid.\n\n6.
|
||||
**Neymar Jr. (Al Hilal)**\n - Position: Forward\n - Key Attributes: Flair,
|
||||
dribbling, creativity.\n - Achievements: Multiple domestic league titles,
|
||||
Champions League runner-up.\n\n7. **Robert Lewandowski (FC Barcelona)**\n -
|
||||
Position: Forward\n - Key Attributes: Finishing, positioning, aerial ability.\n -
|
||||
Achievements: FIFA Best Men''s Player, multiple Bundesliga titles, La Liga champion
|
||||
(2023).\n\n8. **Mohamed Salah (Liverpool)**\n - Position: Forward\n - Key
|
||||
Attributes: Speed, finishing, dribbling.\n - Achievements: Premier League
|
||||
champion, FA Cup, UEFA Champions League winner.\n\n9. **Vin\u00edcius J\u00fanior
|
||||
(Real Madrid)**\n - Position: Forward\n - Key Attributes: Speed, dribbling,
|
||||
creativity.\n - Achievements: UEFA Champions League winner (2022), La Liga
|
||||
champion (2023).\n\n10. **Luka Modri\u0107 (Real Madrid)**\n - Position:
|
||||
Midfielder\n - Key Attributes: Passing, vision, tactical intelligence.\n -
|
||||
Achievements: Multiple Champions League titles, Ballon d''Or winner (2018).\n\nThis
|
||||
list is compiled based on their current form, past performances, and contributions
|
||||
to their respective teams in both domestic and international competitions. Player
|
||||
rankings can vary based on personal opinion and specific criteria used for evaluation,
|
||||
but these players have consistently been regarded as some of the best in the
|
||||
world as of October 2023."}, {"role": "user", "content": "You are not allowed
|
||||
to include Brazilian players"}, {"role": "assistant", "content": "Thought: I
|
||||
now can give a great answer \nFinal Answer: Here is an updated list of the
|
||||
top 10 best soccer players in the world as of October 2023, excluding Brazilian
|
||||
players:\n\n1. **Lionel Messi (Inter Miami CF)**\n - Position: Forward\n -
|
||||
Key Attributes: Dribbling, vision, goal-scoring ability.\n - Achievements:
|
||||
Multiple Ballon d''Or winner, Copa America champion, World Cup champion (2022).\n\n2.
|
||||
**Kylian Mbapp\u00e9 (Paris Saint-Germain)**\n - Position: Forward\n - Key
|
||||
Attributes: Speed, technique, finishing.\n - Achievements: FIFA World Cup
|
||||
champion (2018), Ligue 1 titles, multiple domestic cups.\n\n3. **Erling Haaland
|
||||
(Manchester City)**\n - Position: Forward\n - Key Attributes: Power, speed,
|
||||
goal-scoring instinct.\n - Achievements: Bundesliga top scorer, UEFA Champions
|
||||
League winner (2023), Premier League titles.\n\n4. **Kevin De Bruyne (Manchester
|
||||
City)**\n - Position: Midfielder\n - Key Attributes: Passing, vision, creativity.\n -
|
||||
Achievements: Multiple Premier League titles, FA Cups, UEFA Champions League
|
||||
winner (2023).\n\n5. **Karim Benzema (Al-Ittihad)**\n - Position: Forward\n -
|
||||
Key Attributes: Goal-scoring, playmaking, tactical intelligence.\n - Achievements:
|
||||
2022 Ballon d''Or winner, multiple Champions Leagues with Real Madrid.\n\n6.
|
||||
**Robert Lewandowski (FC Barcelona)**\n - Position: Forward\n - Key Attributes:
|
||||
Finishing, positioning, aerial ability.\n - Achievements: FIFA Best Men''s
|
||||
Player, multiple Bundesliga titles, La Liga champion (2023).\n\n7. **Mohamed
|
||||
Salah (Liverpool)**\n - Position: Forward\n - Key Attributes: Speed, finishing,
|
||||
dribbling.\n - Achievements: Premier League champion, FA Cup, UEFA Champions
|
||||
League winner.\n\n8. **Vin\u00edcius J\u00fanior (Real Madrid)**\n - Position:
|
||||
Forward\n - Key Attributes: Speed, dribbling, creativity.\n - Achievements:
|
||||
UEFA Champions League winner (2022), La Liga champion (2023).\n\n9. **Luka Modri\u0107
|
||||
(Real Madrid)**\n - Position: Midfielder\n - Key Attributes: Passing, vision,
|
||||
tactical intelligence.\n - Achievements: Multiple Champions League titles,
|
||||
Ballon d''Or winner (2018).\n\n10. **Harry Kane (Bayern Munich)**\n - Position:
|
||||
Forward\n - Key Attributes: Goal-scoring, technique, playmaking.\n - Achievements:
|
||||
Golden Boot winner, Premier League titles, UEFA European Championship runner-up.\n\nThis
|
||||
list has been adjusted to exclude Brazilian players and focuses on those who
|
||||
have made significant impacts in their clubs and on the international stage
|
||||
as of October 2023. Each player is recognized for their exceptional skills,
|
||||
performances, and achievements."}, {"role": "user", "content": "You are not
|
||||
allowed to include Brazilian players"}], "model": "gpt-4o-mini", "stop": ["\nObservation:"]}'
|
||||
headers:
|
||||
accept:
|
||||
- application/json
|
||||
accept-encoding:
|
||||
- gzip, deflate, zstd
|
||||
connection:
|
||||
- keep-alive
|
||||
content-length:
|
||||
- '6337'
|
||||
content-type:
|
||||
- application/json
|
||||
cookie:
|
||||
- __cf_bm=8Yv8F0ZCFAo2lf.qoqxao70yxyjVvIV90zQqVF6bVzQ-1749567342-1.0.1.1-fZgnv3RDfunvCO1koxwwFJrHnxSx_rwS_FHvQ6xxDPpKHwYr7dTqIQLZrNgSX5twGyK4F22rUmkuiS6KMVogcinChk8lmHtJBTUVTFjr2KU;
|
||||
_cfuvid=wzh8YnmXvLq1G0RcIVijtzboQtCZyIe2uZiochkBLqE-1749567342267-0.0.1.1-604800000
|
||||
host:
|
||||
- api.openai.com
|
||||
user-agent:
|
||||
- OpenAI/Python 1.78.0
|
||||
x-stainless-arch:
|
||||
- arm64
|
||||
x-stainless-async:
|
||||
- 'false'
|
||||
x-stainless-lang:
|
||||
- python
|
||||
x-stainless-os:
|
||||
- MacOS
|
||||
x-stainless-package-version:
|
||||
- 1.78.0
|
||||
x-stainless-raw-response:
|
||||
- 'true'
|
||||
x-stainless-read-timeout:
|
||||
- '600.0'
|
||||
x-stainless-retry-count:
|
||||
- '0'
|
||||
x-stainless-runtime:
|
||||
- CPython
|
||||
x-stainless-runtime-version:
|
||||
- 3.12.9
|
||||
method: POST
|
||||
uri: https://api.openai.com/v1/chat/completions
|
||||
response:
|
||||
body:
|
||||
string: !!binary |
|
||||
H4sIAAAAAAAAAwAAAP//rJfNbhs3EMfvforBXiIHK0OSv3WTHCsxYiFunKJo6sAYkaPdqbkkS3Il
|
||||
K0HOfZY+R/tgBSnJkhPZtdteDC+HQ82P87H//bIFkLHMupCJEoOorGr2i7rwvWp2tt+qfzi4tCf2
|
||||
6Pjjx5/36FX74nOWRw8z+pVEWHrtCFNZRYGNnpuFIwwUT20f7h3vHxzuHu8lQ2UkqehW2NDcM82K
|
||||
NTc7rc5es3XYbB8tvEvDgnzWhV+2AAC+pL8xTi3pNutCK1+uVOQ9FpR17zYBZM6ouJKh9+wD6pDl
|
||||
K6MwOpBOoX8oTV2UoQtnoM0UBGooeEKAUMT4AbWfkgO40gPWqKCXnrvwhhwBewglgaMJe5Kg2Acw
|
||||
47QWjIV2C0bkA3gjBDmwCmfkPLBOO6bGKQnoo8c7EcyIHHRand0c6NYqFhzUDOhWqFqyLqDv8DMr
|
||||
Rr08p3ulr3R7B16+PGejScGQvGdonOlADoaMFcPJYPvlyysNAE24MJ5jdrowMG6KTi7W39IMeiE4
|
||||
HtWBfBdeOR6NFOsihwl7NjqHwqBqemFcDARHrDjMdhbuPVEyTagiHXwXhrUKbBVBH5UyGuSLdw6m
|
||||
rDW5HE6MRehV5FggiBIrm07/KV3ESW3v1qDRaXU62zuRsBMJ384S+XCE1v75BzQu0LGHS2Qdmq/J
|
||||
Vcj6+aCXlkjmEEiUmn+rKYcxa/Yl62Iz3OBs0Hsg2vbRdg7VEv6ci5qgDYGDIp8DagkTdGxqD9JU
|
||||
5AMLELX1iXA3Ep66eOXwBlHF3Y0halGSj6k84TB7Pt2FmcY793PIexlk7QNrETZT9mstySsuMBVx
|
||||
dIoH/Xg66MHJAtnDOWFknKc25Wt3O4cLRxWTW1rn/AlyL6WRJqzhFUHf1TNNT6IcshwzKUnuIdDY
|
||||
4uvVmgYPT/65RjdGm0PkrK1/EnJi209s6LiCPunPVCE0eqp5FgKXKJ+futdrycpTu1d4k/4PKAIL
|
||||
VMA6kFJckBa0mTJ20MYuvKvSb8k8TDmU8J5QwRClY5noDiLd+zieApzTFLU0U3/D0BicQB+dIGU0
|
||||
Ph9ysOy1HOzCJT0gOUb1+JRJjdiPo3VI+oWHizQR19DWa3iR1XOMbYn3Z8wigYcRcWhKrEjCJSos
|
||||
oXHOE3LWGPWvB8t4RSiXM3UzzzeFuBqN81J8vBITwVF6D9Q3CEMjHf/1OzTW8vj/9NUzim/4UI3d
|
||||
peP7ylyM0YRzHHHeoHMzeItxUPRjgjUMa82i/K8dtTbxV821GeS1UZI09I0Jdw30wNhIOTqtnbGE
|
||||
egVesgVXR89mbRNcuzXvKOn4wQn4WKo2vbNpTNpH3eJvWCmfg11mb9lcsaem6EiT9zvLcx4tw3tg
|
||||
TxiDH0r2cw3EHkTtovqDacmKAGVJ6dUTzEIx+eBYxLii/HlE5ezAKYpy8QSs40aSUKIHSZXRPsx/
|
||||
h24F2QXn/A7SW9dRhe4GR4rAkhsbV6EWEcobxZLHsxRUSezABwy1j4LMm4qWOi4JuH9QbDvr2tLR
|
||||
uPYY9a2ulVozoNYmYAwxqdpPC8vXOx2rTGGdGflvXLP5HLl2hN7oqFl9MDZL1q9bAJ+SXq7vSeDM
|
||||
OlPZcB3MDaWfa++1DucHZiudvjIftPYX1mACqpWh02p38g1HXksKyMqvie5MoChJrnxXCh1ryWbN
|
||||
sLUG/n08m86ew7MunnL8yiBiUZC8to7kvNw2bXMUP2Qe2nZ30SngzJObsKDrwORiMiSNsVbzz4vM
|
||||
z3yg6nrMuiBnHc+/Mcb2+qCDnV08atM42/q69TcAAAD//wMAvqcBwHENAAA=
|
||||
headers:
|
||||
CF-RAY:
|
||||
- 94d9b7561f204d3b-GRU
|
||||
Connection:
|
||||
- keep-alive
|
||||
Content-Encoding:
|
||||
- gzip
|
||||
Content-Type:
|
||||
- application/json
|
||||
Date:
|
||||
- Tue, 10 Jun 2025 14:56:46 GMT
|
||||
Server:
|
||||
- cloudflare
|
||||
Transfer-Encoding:
|
||||
- chunked
|
||||
X-Content-Type-Options:
|
||||
- nosniff
|
||||
access-control-expose-headers:
|
||||
- X-Request-ID
|
||||
alt-svc:
|
||||
- h3=":443"; ma=86400
|
||||
cf-cache-status:
|
||||
- DYNAMIC
|
||||
openai-organization:
|
||||
- crewai-iuxna1
|
||||
openai-processing-ms:
|
||||
- '12189'
|
||||
openai-version:
|
||||
- '2020-10-01'
|
||||
strict-transport-security:
|
||||
- max-age=31536000; includeSubDomains; preload
|
||||
x-envoy-upstream-service-time:
|
||||
- '12193'
|
||||
x-ratelimit-limit-requests:
|
||||
- '30000'
|
||||
x-ratelimit-limit-tokens:
|
||||
- '150000000'
|
||||
x-ratelimit-remaining-requests:
|
||||
- '29999'
|
||||
x-ratelimit-remaining-tokens:
|
||||
- '149998513'
|
||||
x-ratelimit-reset-requests:
|
||||
- 2ms
|
||||
x-ratelimit-reset-tokens:
|
||||
- 0s
|
||||
x-request-id:
|
||||
- req_1098f5a5384f4a26aecf0c9e4e4d1fc0
|
||||
status:
|
||||
code: 200
|
||||
message: OK
|
||||
- request:
|
||||
body: '{"messages": [{"role": "system", "content": "You are Sports Analyst. You
|
||||
are an expert at gathering and organizing information. You carefully collect
|
||||
details and present them in a structured way.\nYour personal goal is: Gather
|
||||
information about the best soccer players\n\nTo give my best complete final
|
||||
answer to the task respond using the exact following format:\n\nThought: I now
|
||||
can give a great answer\nFinal Answer: Your final answer must be the great and
|
||||
the most complete as possible, it must be outcome described.\n\nI MUST use these
|
||||
formats, my job depends on it!"}, {"role": "user", "content": "Top 10 best players
|
||||
in the world?"}, {"role": "assistant", "content": "Thought: I now can give a
|
||||
great answer \nFinal Answer: The top 10 best soccer players in the world, as
|
||||
of October 2023, can be identified based on their recent performances, skills,
|
||||
impact on games, and overall contributions to their teams. Here is the structured
|
||||
list:\n\n1. **Lionel Messi (Inter Miami CF)**\n - Position: Forward\n -
|
||||
Key Attributes: Dribbling, vision, goal-scoring ability.\n - Achievements:
|
||||
Multiple Ballon d''Or winner, Copa America champion, World Cup champion (2022).\n\n2.
|
||||
**Kylian Mbapp\u00e9 (Paris Saint-Germain)**\n - Position: Forward\n - Key
|
||||
Attributes: Speed, technique, finishing.\n - Achievements: FIFA World Cup
|
||||
champion (2018), Ligue 1 titles, multiple domestic cups.\n\n3. **Erling Haaland
|
||||
(Manchester City)**\n - Position: Forward\n - Key Attributes: Power, speed,
|
||||
goal-scoring instinct.\n - Achievements: Bundesliga top scorer, UEFA Champions
|
||||
League winner (2023), Premier League titles.\n\n4. **Kevin De Bruyne (Manchester
|
||||
City)**\n - Position: Midfielder\n - Key Attributes: Passing, vision, creativity.\n -
|
||||
Achievements: Multiple Premier League titles, FA Cups, UEFA Champions League
|
||||
winner (2023).\n\n5. **Karim Benzema (Al-Ittihad)**\n - Position: Forward\n -
|
||||
Key Attributes: Goal-scoring, playmaking, tactical intelligence.\n - Achievements:
|
||||
2022 Ballon d''Or winner, multiple Champions Leagues with Real Madrid.\n\n6.
|
||||
**Neymar Jr. (Al Hilal)**\n - Position: Forward\n - Key Attributes: Flair,
|
||||
dribbling, creativity.\n - Achievements: Multiple domestic league titles,
|
||||
Champions League runner-up.\n\n7. **Robert Lewandowski (FC Barcelona)**\n -
|
||||
Position: Forward\n - Key Attributes: Finishing, positioning, aerial ability.\n -
|
||||
Achievements: FIFA Best Men''s Player, multiple Bundesliga titles, La Liga champion
|
||||
(2023).\n\n8. **Mohamed Salah (Liverpool)**\n - Position: Forward\n - Key
|
||||
Attributes: Speed, finishing, dribbling.\n - Achievements: Premier League
|
||||
champion, FA Cup, UEFA Champions League winner.\n\n9. **Vin\u00edcius J\u00fanior
|
||||
(Real Madrid)**\n - Position: Forward\n - Key Attributes: Speed, dribbling,
|
||||
creativity.\n - Achievements: UEFA Champions League winner (2022), La Liga
|
||||
champion (2023).\n\n10. **Luka Modri\u0107 (Real Madrid)**\n - Position:
|
||||
Midfielder\n - Key Attributes: Passing, vision, tactical intelligence.\n -
|
||||
Achievements: Multiple Champions League titles, Ballon d''Or winner (2018).\n\nThis
|
||||
list is compiled based on their current form, past performances, and contributions
|
||||
to their respective teams in both domestic and international competitions. Player
|
||||
rankings can vary based on personal opinion and specific criteria used for evaluation,
|
||||
but these players have consistently been regarded as some of the best in the
|
||||
world as of October 2023."}, {"role": "user", "content": "You are not allowed
|
||||
to include Brazilian players"}, {"role": "assistant", "content": "Thought: I
|
||||
now can give a great answer \nFinal Answer: Here is an updated list of the
|
||||
top 10 best soccer players in the world as of October 2023, excluding Brazilian
|
||||
players:\n\n1. **Lionel Messi (Inter Miami CF)**\n - Position: Forward\n -
|
||||
Key Attributes: Dribbling, vision, goal-scoring ability.\n - Achievements:
|
||||
Multiple Ballon d''Or winner, Copa America champion, World Cup champion (2022).\n\n2.
|
||||
**Kylian Mbapp\u00e9 (Paris Saint-Germain)**\n - Position: Forward\n - Key
|
||||
Attributes: Speed, technique, finishing.\n - Achievements: FIFA World Cup
|
||||
champion (2018), Ligue 1 titles, multiple domestic cups.\n\n3. **Erling Haaland
|
||||
(Manchester City)**\n - Position: Forward\n - Key Attributes: Power, speed,
|
||||
goal-scoring instinct.\n - Achievements: Bundesliga top scorer, UEFA Champions
|
||||
League winner (2023), Premier League titles.\n\n4. **Kevin De Bruyne (Manchester
|
||||
City)**\n - Position: Midfielder\n - Key Attributes: Passing, vision, creativity.\n -
|
||||
Achievements: Multiple Premier League titles, FA Cups, UEFA Champions League
|
||||
winner (2023).\n\n5. **Karim Benzema (Al-Ittihad)**\n - Position: Forward\n -
|
||||
Key Attributes: Goal-scoring, playmaking, tactical intelligence.\n - Achievements:
|
||||
2022 Ballon d''Or winner, multiple Champions Leagues with Real Madrid.\n\n6.
|
||||
**Robert Lewandowski (FC Barcelona)**\n - Position: Forward\n - Key Attributes:
|
||||
Finishing, positioning, aerial ability.\n - Achievements: FIFA Best Men''s
|
||||
Player, multiple Bundesliga titles, La Liga champion (2023).\n\n7. **Mohamed
|
||||
Salah (Liverpool)**\n - Position: Forward\n - Key Attributes: Speed, finishing,
|
||||
dribbling.\n - Achievements: Premier League champion, FA Cup, UEFA Champions
|
||||
League winner.\n\n8. **Vin\u00edcius J\u00fanior (Real Madrid)**\n - Position:
|
||||
Forward\n - Key Attributes: Speed, dribbling, creativity.\n - Achievements:
|
||||
UEFA Champions League winner (2022), La Liga champion (2023).\n\n9. **Luka Modri\u0107
|
||||
(Real Madrid)**\n - Position: Midfielder\n - Key Attributes: Passing, vision,
|
||||
tactical intelligence.\n - Achievements: Multiple Champions League titles,
|
||||
Ballon d''Or winner (2018).\n\n10. **Harry Kane (Bayern Munich)**\n - Position:
|
||||
Forward\n - Key Attributes: Goal-scoring, technique, playmaking.\n - Achievements:
|
||||
Golden Boot winner, Premier League titles, UEFA European Championship runner-up.\n\nThis
|
||||
list has been adjusted to exclude Brazilian players and focuses on those who
|
||||
have made significant impacts in their clubs and on the international stage
|
||||
as of October 2023. Each player is recognized for their exceptional skills,
|
||||
performances, and achievements."}, {"role": "user", "content": "You are not
|
||||
allowed to include Brazilian players"}, {"role": "assistant", "content": "Thought:
|
||||
I now can give a great answer \nFinal Answer: Here is the revised list of the
|
||||
top 10 best soccer players in the world as of October 2023, explicitly excluding
|
||||
Brazilian players:\n\n1. **Lionel Messi (Inter Miami CF)**\n - Position: Forward\n -
|
||||
Key Attributes: Dribbling, vision, goal-scoring ability.\n - Achievements:
|
||||
Multiple Ballon d''Or winner, Copa America champion, World Cup champion (2022).\n\n2.
|
||||
**Kylian Mbapp\u00e9 (Paris Saint-Germain)**\n - Position: Forward\n - Key
|
||||
Attributes: Speed, technique, finishing.\n - Achievements: FIFA World Cup
|
||||
champion (2018), multiple Ligue 1 titles, and various domestic cups.\n\n3. **Erling
|
||||
Haaland (Manchester City)**\n - Position: Forward\n - Key Attributes: Power,
|
||||
speed, goal-scoring instinct.\n - Achievements: Bundesliga top scorer, UEFA
|
||||
Champions League winner (2023), Premier League titles.\n\n4. **Kevin De Bruyne
|
||||
(Manchester City)**\n - Position: Midfielder\n - Key Attributes: Passing,
|
||||
vision, creativity.\n - Achievements: Multiple Premier League titles, FA Cups,
|
||||
UEFA Champions League winner (2023).\n\n5. **Karim Benzema (Al-Ittihad)**\n -
|
||||
Position: Forward\n - Key Attributes: Goal-scoring, playmaking, tactical intelligence.\n -
|
||||
Achievements: 2022 Ballon d''Or winner, multiple Champions Leagues with Real
|
||||
Madrid.\n\n6. **Robert Lewandowski (FC Barcelona)**\n - Position: Forward\n -
|
||||
Key Attributes: Finishing, positioning, aerial ability.\n - Achievements:
|
||||
FIFA Best Men''s Player, multiple Bundesliga titles, La Liga champion (2023).\n\n7.
|
||||
**Mohamed Salah (Liverpool)**\n - Position: Forward\n - Key Attributes:
|
||||
Speed, finishing, dribbling.\n - Achievements: Premier League champion, FA
|
||||
Cup, UEFA Champions League winner.\n\n8. **Luka Modri\u0107 (Real Madrid)**\n -
|
||||
Position: Midfielder\n - Key Attributes: Passing, vision, tactical intelligence.\n -
|
||||
Achievements: Multiple Champions League titles, Ballon d''Or winner (2018).\n\n9.
|
||||
**Harry Kane (Bayern Munich)**\n - Position: Forward\n - Key Attributes:
|
||||
Goal-scoring, technique, playmaking.\n - Achievements: Golden Boot winner,
|
||||
Premier League titles, UEFA European Championship runner-up.\n\n10. **Rodri
|
||||
(Manchester City)**\n - Position: Midfielder\n - Key Attributes: Defensive
|
||||
skills, passing, positional awareness.\n - Achievements: Premier League titles,
|
||||
UEFA Champions League winner (2023).\n\nThis list is curated while adhering
|
||||
to the restriction of excluding Brazilian players. Each player included has
|
||||
demonstrated exceptional skills and remarkable performances, solidifying their
|
||||
status as some of the best in the world as of October 2023."}, {"role": "user",
|
||||
"content": "You are not allowed to include Brazilian players"}], "model": "gpt-4o-mini",
|
||||
"stop": ["\nObservation:"]}'
|
||||
headers:
|
||||
accept:
|
||||
- application/json
|
||||
accept-encoding:
|
||||
- gzip, deflate, zstd
|
||||
connection:
|
||||
- keep-alive
|
||||
content-length:
|
||||
- '9093'
|
||||
content-type:
|
||||
- application/json
|
||||
cookie:
|
||||
- __cf_bm=8Yv8F0ZCFAo2lf.qoqxao70yxyjVvIV90zQqVF6bVzQ-1749567342-1.0.1.1-fZgnv3RDfunvCO1koxwwFJrHnxSx_rwS_FHvQ6xxDPpKHwYr7dTqIQLZrNgSX5twGyK4F22rUmkuiS6KMVogcinChk8lmHtJBTUVTFjr2KU;
|
||||
_cfuvid=wzh8YnmXvLq1G0RcIVijtzboQtCZyIe2uZiochkBLqE-1749567342267-0.0.1.1-604800000
|
||||
host:
|
||||
- api.openai.com
|
||||
user-agent:
|
||||
- OpenAI/Python 1.78.0
|
||||
x-stainless-arch:
|
||||
- arm64
|
||||
x-stainless-async:
|
||||
- 'false'
|
||||
x-stainless-lang:
|
||||
- python
|
||||
x-stainless-os:
|
||||
- MacOS
|
||||
x-stainless-package-version:
|
||||
- 1.78.0
|
||||
x-stainless-raw-response:
|
||||
- 'true'
|
||||
x-stainless-read-timeout:
|
||||
- '600.0'
|
||||
x-stainless-retry-count:
|
||||
- '0'
|
||||
x-stainless-runtime:
|
||||
- CPython
|
||||
x-stainless-runtime-version:
|
||||
- 3.12.9
|
||||
method: POST
|
||||
uri: https://api.openai.com/v1/chat/completions
|
||||
response:
|
||||
body:
|
||||
string: !!binary |
|
||||
H4sIAAAAAAAAAwAAAP//rJfNThtJEMfvPEVpLjFojGxjEuIbJhCi4ASFRKvVJkLl7vJMLT3Vk+4e
|
||||
O06U8z7LPsfug626bbAhJgm7e0F4aqqmfl0f858vWwAZ62wAmSoxqKo27WHRlEc0edUdv+q9pl/f
|
||||
2P2jsnz38dXw7J3GLI8edvw7qXDttatsVRsKbGVhVo4wUIzafdJ/uv/4Sb/bT4bKajLRrahDu2/b
|
||||
FQu3e51ev9150u4eLL1Ly4p8NoDftgAAvqS/MU/R9CkbQCe/vlKR91hQNri5CSBz1sQrGXrPPqCE
|
||||
LF8ZlZVAklJ/W9qmKMMAXoDYGSgUKHhKgFDE/AHFz8gBvJcTFjRwmH4P4JQcAXtAcDRhIQ2GfQA7
|
||||
gVASBFtDtwNj8gG8VYoc1Abn5DywpDtm1hkN6KPHaxXsmBz0Or29HEh841gKCCUGEAtDh5/ZMMpN
|
||||
DIzPFmUaTXrwXt5Ldxd2ds7YChkYkfcMrRcSyMGIsWI4Otne2XkvANCGc+s5FmkAJ9bN0Onl9Zc0
|
||||
h8MQHI+bQH4AzxyPx4alyGHKnq3kUFg0ba9syg7HbDjMd5fuh6pkmlJFEvwARo0JXBuCIRpjBfSj
|
||||
1w5mLEIuhyNbIxxW5FghqBKrOkX/JZ3IUVPfXINWr9Prbe9Gwl4kfDlPxzAaY13/9Se0ztGxhwtk
|
||||
Ce3n5CpkeTjoRU2kcwikSuGPDeUwYWFfshSb4U5enBzek233YDuH6hr+jIuGoAuBgyGfwxQd28aD
|
||||
thX5wApUU/tEtxfpjl08bjhFNCgaWiMUVZKPZTziMH842bmdxfP2C8Bb1WPxgUWFzYTDRjR5wwWm
|
||||
To5OMdC745NDOFriejgjjHyLsqZa7W3ncO6oYnLX1gV7guynEtKUBZ4RDF0zF/opyhHrCZPR5O4D
|
||||
jVO+3qlp9/D0x/25MdscImdT+59CTmz7iQ0dVzAk+UwVQuvQtF+EwCXqh5fu+Vqx8jT3FV6l/wOq
|
||||
wAoNsAQyhgsSRZsp4/RsnMCbDr1L5mHGoYQ3hAZGqB3rRPc40r2JOyrAGc1QtJ35K4bWyREM0Sky
|
||||
VvDhkCfXc5ZDvXRJP5Aco/n+hklDOIz7dUTyyMN5Wo1raOs9vKzqGcaRxNv7ZVnAJxFxZEusSMMF
|
||||
GiyhdcZTcrW15l8vlcmKUF/v0808dxpxtRYXrfj9TkwEB+kd0FwhjKx2/Pcf0Fqr4/8zVw9ovtF9
|
||||
PXZTjm87c7lCE87TiHOKzs3hJcZFMYwFFhg1wqr8rxO1tu1Xw7UZ5Lk1mgSG1oZvB+ie/ZGKddw4
|
||||
WxPK6gRKrsE1MUS7qRNltxMxL6zAKTVSRC0Erbc2BJISKzi1wdeNu6a9F/enOvAu6I968Lvg6++w
|
||||
9SX/tmS/kEIlehgTCSh0NGmMmYOjKXvSECzQpyRfAI3ZIHBmJRuCkovScFGG+MbytqJreVVZHyCg
|
||||
IQmkgUXzlHWDJqmrpd76VlrtwjGqcvmMlJ4v7UxhzMhRhe4Kx4aAJhNSgack5D3EN7G/YmNyiKox
|
||||
HW9KhwvhCSuUYOYRKJTEDgJh5cEKjG0oV4cUo8SRcYKxeGjAByzI766r0nhKHqMylsaYNQOK2JAc
|
||||
kx7+sLR8vVHAxha1s2N/xzVbFP/SEXorUe36YOssWb9uAXxISru5JZ6z2tmqDpfBXlF6XK/TO1gE
|
||||
zFYKf2V+vBD1AFmwAc2a3+N+L98Q8lJTQDZ+Ta5nClVJeuXb7R2s5D02mu3K1tlaY/82pU3hF/ws
|
||||
xVqUe8OvDEpRHUhf1o40q9vYq9scxa+g+267OeuUcObJTVnRZWBysR6aJtiYxbdJ5uc+UHU5YSnI
|
||||
1Y4XHyiT+nKvj/t9pKd7Ktv6uvUPAAAA//8DAMc1SFGuDQAA
|
||||
headers:
|
||||
CF-RAY:
|
||||
- 94d9b7d24d991d2c-GRU
|
||||
Connection:
|
||||
- keep-alive
|
||||
Content-Encoding:
|
||||
- gzip
|
||||
Content-Type:
|
||||
- application/json
|
||||
Date:
|
||||
- Tue, 10 Jun 2025 14:57:29 GMT
|
||||
Server:
|
||||
- cloudflare
|
||||
Transfer-Encoding:
|
||||
- chunked
|
||||
X-Content-Type-Options:
|
||||
- nosniff
|
||||
access-control-expose-headers:
|
||||
- X-Request-ID
|
||||
alt-svc:
|
||||
- h3=":443"; ma=86400
|
||||
cf-cache-status:
|
||||
- DYNAMIC
|
||||
openai-organization:
|
||||
- crewai-iuxna1
|
||||
openai-processing-ms:
|
||||
- '35291'
|
||||
openai-version:
|
||||
- '2020-10-01'
|
||||
strict-transport-security:
|
||||
- max-age=31536000; includeSubDomains; preload
|
||||
x-envoy-upstream-service-time:
|
||||
- '35294'
|
||||
x-ratelimit-limit-requests:
|
||||
- '30000'
|
||||
x-ratelimit-limit-tokens:
|
||||
- '150000000'
|
||||
x-ratelimit-remaining-requests:
|
||||
- '29999'
|
||||
x-ratelimit-remaining-tokens:
|
||||
- '149997855'
|
||||
x-ratelimit-reset-requests:
|
||||
- 2ms
|
||||
x-ratelimit-reset-tokens:
|
||||
- 0s
|
||||
x-request-id:
|
||||
- req_4676152d4227ac1825d1240ddef231d6
|
||||
status:
|
||||
code: 200
|
||||
message: OK
|
||||
version: 1
|
||||
@@ -231,7 +231,7 @@ class TestDeployCommand(unittest.TestCase):
|
||||
[project]
|
||||
name = "test_project"
|
||||
version = "0.1.0"
|
||||
requires-python = ">=3.10,<3.13"
|
||||
requires-python = ">=3.10,<3.14"
|
||||
dependencies = ["crewai"]
|
||||
""",
|
||||
)
|
||||
@@ -250,7 +250,7 @@ class TestDeployCommand(unittest.TestCase):
|
||||
[project]
|
||||
name = "test_project"
|
||||
version = "0.1.0"
|
||||
requires-python = ">=3.10,<3.13"
|
||||
requires-python = ">=3.10,<3.14"
|
||||
dependencies = ["crewai"]
|
||||
""",
|
||||
)
|
||||
|
||||
1
tests/cli/organization/__init__.py
Normal file
1
tests/cli/organization/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
|
||||
244
tests/cli/organization/test_main.py
Normal file
244
tests/cli/organization/test_main.py
Normal file
@@ -0,0 +1,244 @@
|
||||
import unittest
|
||||
from unittest.mock import MagicMock, patch, call
|
||||
|
||||
import pytest
|
||||
from click.testing import CliRunner
|
||||
import requests
|
||||
|
||||
from crewai.cli.organization.main import OrganizationCommand
|
||||
from crewai.cli.cli import list, switch, current
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def runner():
|
||||
return CliRunner()
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def org_command():
|
||||
with patch.object(OrganizationCommand, '__init__', return_value=None):
|
||||
command = OrganizationCommand()
|
||||
yield command
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def mock_settings():
|
||||
with patch('crewai.cli.organization.main.Settings') as mock_settings_class:
|
||||
mock_settings_instance = MagicMock()
|
||||
mock_settings_class.return_value = mock_settings_instance
|
||||
yield mock_settings_instance
|
||||
|
||||
|
||||
@patch('crewai.cli.cli.OrganizationCommand')
|
||||
def test_org_list_command(mock_org_command_class, runner):
|
||||
mock_org_instance = MagicMock()
|
||||
mock_org_command_class.return_value = mock_org_instance
|
||||
|
||||
result = runner.invoke(list)
|
||||
|
||||
assert result.exit_code == 0
|
||||
mock_org_command_class.assert_called_once()
|
||||
mock_org_instance.list.assert_called_once()
|
||||
|
||||
|
||||
@patch('crewai.cli.cli.OrganizationCommand')
|
||||
def test_org_switch_command(mock_org_command_class, runner):
|
||||
mock_org_instance = MagicMock()
|
||||
mock_org_command_class.return_value = mock_org_instance
|
||||
|
||||
result = runner.invoke(switch, ['test-id'])
|
||||
|
||||
assert result.exit_code == 0
|
||||
mock_org_command_class.assert_called_once()
|
||||
mock_org_instance.switch.assert_called_once_with('test-id')
|
||||
|
||||
|
||||
@patch('crewai.cli.cli.OrganizationCommand')
|
||||
def test_org_current_command(mock_org_command_class, runner):
|
||||
mock_org_instance = MagicMock()
|
||||
mock_org_command_class.return_value = mock_org_instance
|
||||
|
||||
result = runner.invoke(current)
|
||||
|
||||
assert result.exit_code == 0
|
||||
mock_org_command_class.assert_called_once()
|
||||
mock_org_instance.current.assert_called_once()
|
||||
|
||||
|
||||
class TestOrganizationCommand(unittest.TestCase):
|
||||
def setUp(self):
|
||||
with patch.object(OrganizationCommand, '__init__', return_value=None):
|
||||
self.org_command = OrganizationCommand()
|
||||
self.org_command.plus_api_client = MagicMock()
|
||||
|
||||
@patch('crewai.cli.organization.main.console')
|
||||
@patch('crewai.cli.organization.main.Table')
|
||||
def test_list_organizations_success(self, mock_table, mock_console):
|
||||
mock_response = MagicMock()
|
||||
mock_response.raise_for_status = MagicMock()
|
||||
mock_response.json.return_value = [
|
||||
{"name": "Org 1", "uuid": "org-123"},
|
||||
{"name": "Org 2", "uuid": "org-456"}
|
||||
]
|
||||
self.org_command.plus_api_client = MagicMock()
|
||||
self.org_command.plus_api_client.get_organizations.return_value = mock_response
|
||||
|
||||
mock_console.print = MagicMock()
|
||||
|
||||
self.org_command.list()
|
||||
|
||||
self.org_command.plus_api_client.get_organizations.assert_called_once()
|
||||
mock_table.assert_called_once_with(title="Your Organizations")
|
||||
mock_table.return_value.add_column.assert_has_calls([
|
||||
call("Name", style="cyan"),
|
||||
call("ID", style="green")
|
||||
])
|
||||
mock_table.return_value.add_row.assert_has_calls([
|
||||
call("Org 1", "org-123"),
|
||||
call("Org 2", "org-456")
|
||||
])
|
||||
|
||||
@patch('crewai.cli.organization.main.console')
|
||||
def test_list_organizations_empty(self, mock_console):
|
||||
mock_response = MagicMock()
|
||||
mock_response.raise_for_status = MagicMock()
|
||||
mock_response.json.return_value = []
|
||||
self.org_command.plus_api_client = MagicMock()
|
||||
self.org_command.plus_api_client.get_organizations.return_value = mock_response
|
||||
|
||||
self.org_command.list()
|
||||
|
||||
self.org_command.plus_api_client.get_organizations.assert_called_once()
|
||||
mock_console.print.assert_called_once_with(
|
||||
"You don't belong to any organizations yet.",
|
||||
style="yellow"
|
||||
)
|
||||
|
||||
@patch('crewai.cli.organization.main.console')
|
||||
def test_list_organizations_api_error(self, mock_console):
|
||||
self.org_command.plus_api_client = MagicMock()
|
||||
self.org_command.plus_api_client.get_organizations.side_effect = requests.exceptions.RequestException("API Error")
|
||||
|
||||
with pytest.raises(SystemExit):
|
||||
self.org_command.list()
|
||||
|
||||
|
||||
self.org_command.plus_api_client.get_organizations.assert_called_once()
|
||||
mock_console.print.assert_called_once_with(
|
||||
"Failed to retrieve organization list: API Error",
|
||||
style="bold red"
|
||||
)
|
||||
|
||||
@patch('crewai.cli.organization.main.console')
|
||||
@patch('crewai.cli.organization.main.Settings')
|
||||
def test_switch_organization_success(self, mock_settings_class, mock_console):
|
||||
mock_response = MagicMock()
|
||||
mock_response.raise_for_status = MagicMock()
|
||||
mock_response.json.return_value = [
|
||||
{"name": "Org 1", "uuid": "org-123"},
|
||||
{"name": "Test Org", "uuid": "test-id"}
|
||||
]
|
||||
self.org_command.plus_api_client = MagicMock()
|
||||
self.org_command.plus_api_client.get_organizations.return_value = mock_response
|
||||
|
||||
mock_settings_instance = MagicMock()
|
||||
mock_settings_class.return_value = mock_settings_instance
|
||||
|
||||
self.org_command.switch("test-id")
|
||||
|
||||
self.org_command.plus_api_client.get_organizations.assert_called_once()
|
||||
mock_settings_instance.dump.assert_called_once()
|
||||
assert mock_settings_instance.org_name == "Test Org"
|
||||
assert mock_settings_instance.org_uuid == "test-id"
|
||||
mock_console.print.assert_called_once_with(
|
||||
"Successfully switched to Test Org (test-id)",
|
||||
style="bold green"
|
||||
)
|
||||
|
||||
@patch('crewai.cli.organization.main.console')
|
||||
def test_switch_organization_not_found(self, mock_console):
|
||||
mock_response = MagicMock()
|
||||
mock_response.raise_for_status = MagicMock()
|
||||
mock_response.json.return_value = [
|
||||
{"name": "Org 1", "uuid": "org-123"},
|
||||
{"name": "Org 2", "uuid": "org-456"}
|
||||
]
|
||||
self.org_command.plus_api_client = MagicMock()
|
||||
self.org_command.plus_api_client.get_organizations.return_value = mock_response
|
||||
|
||||
self.org_command.switch("non-existent-id")
|
||||
|
||||
self.org_command.plus_api_client.get_organizations.assert_called_once()
|
||||
mock_console.print.assert_called_once_with(
|
||||
"Organization with id 'non-existent-id' not found.",
|
||||
style="bold red"
|
||||
)
|
||||
|
||||
@patch('crewai.cli.organization.main.console')
|
||||
@patch('crewai.cli.organization.main.Settings')
|
||||
def test_current_organization_with_org(self, mock_settings_class, mock_console):
|
||||
mock_settings_instance = MagicMock()
|
||||
mock_settings_instance.org_name = "Test Org"
|
||||
mock_settings_instance.org_uuid = "test-id"
|
||||
mock_settings_class.return_value = mock_settings_instance
|
||||
|
||||
self.org_command.current()
|
||||
|
||||
self.org_command.plus_api_client.get_organizations.assert_not_called()
|
||||
mock_console.print.assert_called_once_with(
|
||||
"Currently logged in to organization Test Org (test-id)",
|
||||
style="bold green"
|
||||
)
|
||||
|
||||
@patch('crewai.cli.organization.main.console')
|
||||
@patch('crewai.cli.organization.main.Settings')
|
||||
def test_current_organization_without_org(self, mock_settings_class, mock_console):
|
||||
mock_settings_instance = MagicMock()
|
||||
mock_settings_instance.org_uuid = None
|
||||
mock_settings_class.return_value = mock_settings_instance
|
||||
|
||||
self.org_command.current()
|
||||
|
||||
assert mock_console.print.call_count == 3
|
||||
mock_console.print.assert_any_call(
|
||||
"You're not currently logged in to any organization.",
|
||||
style="yellow"
|
||||
)
|
||||
|
||||
@patch('crewai.cli.organization.main.console')
|
||||
def test_list_organizations_unauthorized(self, mock_console):
|
||||
mock_response = MagicMock()
|
||||
mock_http_error = requests.exceptions.HTTPError(
|
||||
"401 Client Error: Unauthorized",
|
||||
response=MagicMock(status_code=401)
|
||||
)
|
||||
|
||||
mock_response.raise_for_status.side_effect = mock_http_error
|
||||
self.org_command.plus_api_client.get_organizations.return_value = mock_response
|
||||
|
||||
self.org_command.list()
|
||||
|
||||
self.org_command.plus_api_client.get_organizations.assert_called_once()
|
||||
mock_console.print.assert_called_once_with(
|
||||
"You are not logged in to any organization. Use 'crewai login' to login.",
|
||||
style="bold red"
|
||||
)
|
||||
|
||||
@patch('crewai.cli.organization.main.console')
|
||||
def test_switch_organization_unauthorized(self, mock_console):
|
||||
mock_response = MagicMock()
|
||||
mock_http_error = requests.exceptions.HTTPError(
|
||||
"401 Client Error: Unauthorized",
|
||||
response=MagicMock(status_code=401)
|
||||
)
|
||||
|
||||
mock_response.raise_for_status.side_effect = mock_http_error
|
||||
self.org_command.plus_api_client.get_organizations.return_value = mock_response
|
||||
|
||||
self.org_command.switch("test-id")
|
||||
|
||||
self.org_command.plus_api_client.get_organizations.assert_called_once()
|
||||
mock_console.print.assert_called_once_with(
|
||||
"You are not logged in to any organization. Use 'crewai login' to login.",
|
||||
style="bold red"
|
||||
)
|
||||
@@ -1,6 +1,6 @@
|
||||
import os
|
||||
import unittest
|
||||
from unittest.mock import MagicMock, patch
|
||||
from unittest.mock import MagicMock, patch, ANY
|
||||
|
||||
from crewai.cli.plus_api import PlusAPI
|
||||
|
||||
@@ -9,6 +9,7 @@ class TestPlusAPI(unittest.TestCase):
|
||||
def setUp(self):
|
||||
self.api_key = "test_api_key"
|
||||
self.api = PlusAPI(self.api_key)
|
||||
self.org_uuid = "test-org-uuid"
|
||||
|
||||
def test_init(self):
|
||||
self.assertEqual(self.api.api_key, self.api_key)
|
||||
@@ -29,17 +30,96 @@ class TestPlusAPI(unittest.TestCase):
|
||||
)
|
||||
self.assertEqual(response, mock_response)
|
||||
|
||||
def assert_request_with_org_id(self, mock_make_request, method: str, endpoint: str, **kwargs):
|
||||
mock_make_request.assert_called_once_with(
|
||||
method, f"https://app.crewai.com{endpoint}", headers={'Authorization': ANY, 'Content-Type': ANY, 'User-Agent': ANY, 'X-Crewai-Version': ANY, 'X-Crewai-Organization-Id': self.org_uuid}, **kwargs
|
||||
)
|
||||
|
||||
@patch("crewai.cli.plus_api.Settings")
|
||||
@patch("requests.Session.request")
|
||||
def test_login_to_tool_repository_with_org_uuid(self, mock_make_request, mock_settings_class):
|
||||
mock_settings = MagicMock()
|
||||
mock_settings.org_uuid = self.org_uuid
|
||||
mock_settings_class.return_value = mock_settings
|
||||
# re-initialize Client
|
||||
self.api = PlusAPI(self.api_key)
|
||||
|
||||
mock_response = MagicMock()
|
||||
mock_make_request.return_value = mock_response
|
||||
|
||||
response = self.api.login_to_tool_repository()
|
||||
|
||||
self.assert_request_with_org_id(
|
||||
mock_make_request,
|
||||
'POST',
|
||||
'/crewai_plus/api/v1/tools/login'
|
||||
)
|
||||
self.assertEqual(response, mock_response)
|
||||
|
||||
@patch("crewai.cli.plus_api.PlusAPI._make_request")
|
||||
def test_get_agent(self, mock_make_request):
|
||||
mock_response = MagicMock()
|
||||
mock_make_request.return_value = mock_response
|
||||
|
||||
response = self.api.get_agent("test_agent_handle")
|
||||
mock_make_request.assert_called_once_with(
|
||||
"GET", "/crewai_plus/api/v1/agents/test_agent_handle"
|
||||
)
|
||||
self.assertEqual(response, mock_response)
|
||||
|
||||
@patch("crewai.cli.plus_api.Settings")
|
||||
@patch("requests.Session.request")
|
||||
def test_get_agent_with_org_uuid(self, mock_make_request, mock_settings_class):
|
||||
mock_settings = MagicMock()
|
||||
mock_settings.org_uuid = self.org_uuid
|
||||
mock_settings_class.return_value = mock_settings
|
||||
# re-initialize Client
|
||||
self.api = PlusAPI(self.api_key)
|
||||
|
||||
mock_response = MagicMock()
|
||||
mock_make_request.return_value = mock_response
|
||||
|
||||
response = self.api.get_agent("test_agent_handle")
|
||||
|
||||
self.assert_request_with_org_id(
|
||||
mock_make_request,
|
||||
"GET",
|
||||
"/crewai_plus/api/v1/agents/test_agent_handle"
|
||||
)
|
||||
self.assertEqual(response, mock_response)
|
||||
|
||||
@patch("crewai.cli.plus_api.PlusAPI._make_request")
|
||||
def test_get_tool(self, mock_make_request):
|
||||
mock_response = MagicMock()
|
||||
mock_make_request.return_value = mock_response
|
||||
|
||||
response = self.api.get_tool("test_tool_handle")
|
||||
|
||||
mock_make_request.assert_called_once_with(
|
||||
"GET", "/crewai_plus/api/v1/tools/test_tool_handle"
|
||||
)
|
||||
self.assertEqual(response, mock_response)
|
||||
|
||||
@patch("crewai.cli.plus_api.Settings")
|
||||
@patch("requests.Session.request")
|
||||
def test_get_tool_with_org_uuid(self, mock_make_request, mock_settings_class):
|
||||
mock_settings = MagicMock()
|
||||
mock_settings.org_uuid = self.org_uuid
|
||||
mock_settings_class.return_value = mock_settings
|
||||
# re-initialize Client
|
||||
self.api = PlusAPI(self.api_key)
|
||||
|
||||
# Set up mock response
|
||||
mock_response = MagicMock()
|
||||
mock_make_request.return_value = mock_response
|
||||
|
||||
response = self.api.get_tool("test_tool_handle")
|
||||
|
||||
self.assert_request_with_org_id(
|
||||
mock_make_request,
|
||||
"GET",
|
||||
"/crewai_plus/api/v1/tools/test_tool_handle"
|
||||
)
|
||||
self.assertEqual(response, mock_response)
|
||||
|
||||
@patch("crewai.cli.plus_api.PlusAPI._make_request")
|
||||
def test_publish_tool(self, mock_make_request):
|
||||
@@ -61,11 +141,53 @@ class TestPlusAPI(unittest.TestCase):
|
||||
"version": version,
|
||||
"file": encoded_file,
|
||||
"description": description,
|
||||
"available_exports": None,
|
||||
}
|
||||
mock_make_request.assert_called_once_with(
|
||||
"POST", "/crewai_plus/api/v1/tools", json=params
|
||||
)
|
||||
self.assertEqual(response, mock_response)
|
||||
|
||||
@patch("crewai.cli.plus_api.Settings")
|
||||
@patch("requests.Session.request")
|
||||
def test_publish_tool_with_org_uuid(self, mock_make_request, mock_settings_class):
|
||||
mock_settings = MagicMock()
|
||||
mock_settings.org_uuid = self.org_uuid
|
||||
mock_settings_class.return_value = mock_settings
|
||||
# re-initialize Client
|
||||
self.api = PlusAPI(self.api_key)
|
||||
|
||||
# Set up mock response
|
||||
mock_response = MagicMock()
|
||||
mock_make_request.return_value = mock_response
|
||||
|
||||
handle = "test_tool_handle"
|
||||
public = True
|
||||
version = "1.0.0"
|
||||
description = "Test tool description"
|
||||
encoded_file = "encoded_test_file"
|
||||
|
||||
response = self.api.publish_tool(
|
||||
handle, public, version, description, encoded_file
|
||||
)
|
||||
|
||||
# Expected params including organization_uuid
|
||||
expected_params = {
|
||||
"handle": handle,
|
||||
"public": public,
|
||||
"version": version,
|
||||
"file": encoded_file,
|
||||
"description": description,
|
||||
"available_exports": None,
|
||||
}
|
||||
|
||||
self.assert_request_with_org_id(
|
||||
mock_make_request,
|
||||
"POST",
|
||||
"/crewai_plus/api/v1/tools",
|
||||
json=expected_params
|
||||
)
|
||||
self.assertEqual(response, mock_response)
|
||||
|
||||
@patch("crewai.cli.plus_api.PlusAPI._make_request")
|
||||
def test_publish_tool_without_description(self, mock_make_request):
|
||||
@@ -87,6 +209,7 @@ class TestPlusAPI(unittest.TestCase):
|
||||
"version": version,
|
||||
"file": encoded_file,
|
||||
"description": description,
|
||||
"available_exports": None,
|
||||
}
|
||||
mock_make_request.assert_called_once_with(
|
||||
"POST", "/crewai_plus/api/v1/tools", json=params
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
import os
|
||||
import shutil
|
||||
import tempfile
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
|
||||
@@ -100,3 +101,163 @@ def test_tree_copy_to_existing_directory(temp_tree):
|
||||
assert os.path.isfile(os.path.join(dest_dir, "file1.txt"))
|
||||
finally:
|
||||
shutil.rmtree(dest_dir)
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def temp_project_dir():
|
||||
"""Create a temporary directory for testing tool extraction."""
|
||||
with tempfile.TemporaryDirectory() as temp_dir:
|
||||
yield Path(temp_dir)
|
||||
|
||||
|
||||
def create_init_file(directory, content):
|
||||
return create_file(directory / "__init__.py", content)
|
||||
|
||||
|
||||
def test_extract_available_exports_empty_project(temp_project_dir, capsys):
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "No valid tools were exposed in your __init__.py file" in captured.out
|
||||
|
||||
|
||||
def test_extract_available_exports_no_init_file(temp_project_dir, capsys):
|
||||
(temp_project_dir / "some_file.py").write_text("print('hello')")
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "No valid tools were exposed in your __init__.py file" in captured.out
|
||||
|
||||
|
||||
def test_extract_available_exports_empty_init_file(temp_project_dir, capsys):
|
||||
create_init_file(temp_project_dir, "")
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "Warning: No __all__ defined in" in captured.out
|
||||
|
||||
|
||||
def test_extract_available_exports_no_all_variable(temp_project_dir, capsys):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"from crewai.tools import BaseTool\n\nclass MyTool(BaseTool):\n pass",
|
||||
)
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "Warning: No __all__ defined in" in captured.out
|
||||
|
||||
|
||||
def test_extract_available_exports_valid_base_tool_class(temp_project_dir):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from crewai.tools import BaseTool
|
||||
|
||||
class MyTool(BaseTool):
|
||||
name: str = "my_tool"
|
||||
description: str = "A test tool"
|
||||
|
||||
__all__ = ['MyTool']
|
||||
""",
|
||||
)
|
||||
tools = utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
assert [{"name": "MyTool"}] == tools
|
||||
|
||||
|
||||
def test_extract_available_exports_valid_tool_decorator(temp_project_dir):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from crewai.tools import tool
|
||||
|
||||
@tool
|
||||
def my_tool_function(text: str) -> str:
|
||||
\"\"\"A test tool function\"\"\"
|
||||
return text
|
||||
|
||||
__all__ = ['my_tool_function']
|
||||
""",
|
||||
)
|
||||
tools = utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
assert [{"name": "my_tool_function"}] == tools
|
||||
|
||||
|
||||
def test_extract_available_exports_multiple_valid_tools(temp_project_dir):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from crewai.tools import BaseTool, tool
|
||||
|
||||
class MyTool(BaseTool):
|
||||
name: str = "my_tool"
|
||||
description: str = "A test tool"
|
||||
|
||||
@tool
|
||||
def my_tool_function(text: str) -> str:
|
||||
\"\"\"A test tool function\"\"\"
|
||||
return text
|
||||
|
||||
__all__ = ['MyTool', 'my_tool_function']
|
||||
""",
|
||||
)
|
||||
tools = utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
assert [{"name": "MyTool"}, {"name": "my_tool_function"}] == tools
|
||||
|
||||
|
||||
def test_extract_available_exports_with_invalid_tool_decorator(temp_project_dir):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from crewai.tools import BaseTool
|
||||
|
||||
class MyTool(BaseTool):
|
||||
name: str = "my_tool"
|
||||
description: str = "A test tool"
|
||||
|
||||
def not_a_tool():
|
||||
pass
|
||||
|
||||
__all__ = ['MyTool', 'not_a_tool']
|
||||
""",
|
||||
)
|
||||
tools = utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
assert [{"name": "MyTool"}] == tools
|
||||
|
||||
|
||||
def test_extract_available_exports_import_error(temp_project_dir, capsys):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from nonexistent_module import something
|
||||
|
||||
class MyTool(BaseTool):
|
||||
pass
|
||||
|
||||
__all__ = ['MyTool']
|
||||
""",
|
||||
)
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "nonexistent_module" in captured.out
|
||||
|
||||
|
||||
def test_extract_available_exports_syntax_error(temp_project_dir, capsys):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from crewai.tools import BaseTool
|
||||
|
||||
class MyTool(BaseTool):
|
||||
# Missing closing parenthesis
|
||||
def __init__(self, name:
|
||||
pass
|
||||
|
||||
__all__ = ['MyTool']
|
||||
""",
|
||||
)
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "was never closed" in captured.out
|
||||
|
||||
@@ -56,7 +56,8 @@ def test_create_success(mock_subprocess, capsys, tool_command):
|
||||
|
||||
@patch("crewai.cli.tools.main.subprocess.run")
|
||||
@patch("crewai.cli.plus_api.PlusAPI.get_tool")
|
||||
def test_install_success(mock_get, mock_subprocess_run, capsys, tool_command):
|
||||
@patch("crewai.cli.tools.main.ToolCommand._print_current_organization")
|
||||
def test_install_success(mock_print_org, mock_get, mock_subprocess_run, capsys, tool_command):
|
||||
mock_get_response = MagicMock()
|
||||
mock_get_response.status_code = 200
|
||||
mock_get_response.json.return_value = {
|
||||
@@ -85,6 +86,39 @@ def test_install_success(mock_get, mock_subprocess_run, capsys, tool_command):
|
||||
env=unittest.mock.ANY,
|
||||
)
|
||||
|
||||
# Verify _print_current_organization was called
|
||||
mock_print_org.assert_called_once()
|
||||
|
||||
@patch("crewai.cli.tools.main.subprocess.run")
|
||||
@patch("crewai.cli.plus_api.PlusAPI.get_tool")
|
||||
def test_install_success_from_pypi(mock_get, mock_subprocess_run, capsys, tool_command):
|
||||
mock_get_response = MagicMock()
|
||||
mock_get_response.status_code = 200
|
||||
mock_get_response.json.return_value = {
|
||||
"handle": "sample-tool",
|
||||
"repository": {"handle": "sample-repo", "url": "https://example.com/repo"},
|
||||
"source": "pypi",
|
||||
}
|
||||
mock_get.return_value = mock_get_response
|
||||
mock_subprocess_run.return_value = MagicMock(stderr=None)
|
||||
|
||||
tool_command.install("sample-tool")
|
||||
output = capsys.readouterr().out
|
||||
assert "Successfully installed sample-tool" in output
|
||||
|
||||
mock_get.assert_has_calls([mock.call("sample-tool"), mock.call().json()])
|
||||
mock_subprocess_run.assert_any_call(
|
||||
[
|
||||
"uv",
|
||||
"add",
|
||||
"sample-tool",
|
||||
],
|
||||
capture_output=False,
|
||||
text=True,
|
||||
check=True,
|
||||
env=unittest.mock.ANY,
|
||||
)
|
||||
|
||||
|
||||
@patch("crewai.cli.plus_api.PlusAPI.get_tool")
|
||||
def test_install_tool_not_found(mock_get, capsys, tool_command):
|
||||
@@ -135,7 +169,11 @@ def test_publish_when_not_in_sync(mock_is_synced, capsys, tool_command):
|
||||
)
|
||||
@patch("crewai.cli.plus_api.PlusAPI.publish_tool")
|
||||
@patch("crewai.cli.tools.main.git.Repository.is_synced", return_value=False)
|
||||
@patch("crewai.cli.tools.main.extract_available_exports", return_value=[{"name": "SampleTool"}])
|
||||
@patch("crewai.cli.tools.main.ToolCommand._print_current_organization")
|
||||
def test_publish_when_not_in_sync_and_force(
|
||||
mock_print_org,
|
||||
mock_available_exports,
|
||||
mock_is_synced,
|
||||
mock_publish,
|
||||
mock_open,
|
||||
@@ -168,7 +206,9 @@ def test_publish_when_not_in_sync_and_force(
|
||||
version="1.0.0",
|
||||
description="A sample tool",
|
||||
encoded_file=unittest.mock.ANY,
|
||||
available_exports=[{"name": "SampleTool"}],
|
||||
)
|
||||
mock_print_org.assert_called_once()
|
||||
|
||||
|
||||
@patch("crewai.cli.tools.main.get_project_name", return_value="sample-tool")
|
||||
@@ -183,7 +223,9 @@ def test_publish_when_not_in_sync_and_force(
|
||||
)
|
||||
@patch("crewai.cli.plus_api.PlusAPI.publish_tool")
|
||||
@patch("crewai.cli.tools.main.git.Repository.is_synced", return_value=True)
|
||||
@patch("crewai.cli.tools.main.extract_available_exports", return_value=[{"name": "SampleTool"}])
|
||||
def test_publish_success(
|
||||
mock_available_exports,
|
||||
mock_is_synced,
|
||||
mock_publish,
|
||||
mock_open,
|
||||
@@ -216,6 +258,7 @@ def test_publish_success(
|
||||
version="1.0.0",
|
||||
description="A sample tool",
|
||||
encoded_file=unittest.mock.ANY,
|
||||
available_exports=[{"name": "SampleTool"}],
|
||||
)
|
||||
|
||||
|
||||
@@ -230,7 +273,9 @@ def test_publish_success(
|
||||
read_data=b"sample tarball content",
|
||||
)
|
||||
@patch("crewai.cli.plus_api.PlusAPI.publish_tool")
|
||||
@patch("crewai.cli.tools.main.extract_available_exports", return_value=[{"name": "SampleTool"}])
|
||||
def test_publish_failure(
|
||||
mock_available_exports,
|
||||
mock_publish,
|
||||
mock_open,
|
||||
mock_listdir,
|
||||
@@ -266,7 +311,9 @@ def test_publish_failure(
|
||||
read_data=b"sample tarball content",
|
||||
)
|
||||
@patch("crewai.cli.plus_api.PlusAPI.publish_tool")
|
||||
@patch("crewai.cli.tools.main.extract_available_exports", return_value=[{"name": "SampleTool"}])
|
||||
def test_publish_api_error(
|
||||
mock_available_exports,
|
||||
mock_publish,
|
||||
mock_open,
|
||||
mock_listdir,
|
||||
@@ -289,3 +336,27 @@ def test_publish_api_error(
|
||||
assert "Request to Enterprise API failed" in output
|
||||
|
||||
mock_publish.assert_called_once()
|
||||
|
||||
|
||||
|
||||
@patch("crewai.cli.tools.main.Settings")
|
||||
def test_print_current_organization_with_org(mock_settings, capsys, tool_command):
|
||||
mock_settings_instance = MagicMock()
|
||||
mock_settings_instance.org_uuid = "test-org-uuid"
|
||||
mock_settings_instance.org_name = "Test Organization"
|
||||
mock_settings.return_value = mock_settings_instance
|
||||
tool_command._print_current_organization()
|
||||
output = capsys.readouterr().out
|
||||
assert "Current organization: Test Organization (test-org-uuid)" in output
|
||||
|
||||
|
||||
@patch("crewai.cli.tools.main.Settings")
|
||||
def test_print_current_organization_without_org(mock_settings, capsys, tool_command):
|
||||
mock_settings_instance = MagicMock()
|
||||
mock_settings_instance.org_uuid = None
|
||||
mock_settings_instance.org_name = None
|
||||
mock_settings.return_value = mock_settings_instance
|
||||
tool_command._print_current_organization()
|
||||
output = capsys.readouterr().out
|
||||
assert "No organization currently set" in output
|
||||
assert "org switch <org_id>" in output
|
||||
|
||||
@@ -1765,6 +1765,50 @@ def test_agent_usage_metrics_are_captured_for_hierarchical_process():
|
||||
)
|
||||
|
||||
|
||||
def test_hierarchical_kickoff_usage_metrics_include_manager(researcher):
|
||||
"""Ensure Crew.kickoff() sums UsageMetrics from both regular and manager agents."""
|
||||
|
||||
# ── 1. Build the manager and a simple task ──────────────────────────────────
|
||||
manager = Agent(
|
||||
role="Manager",
|
||||
goal="Coordinate everything.",
|
||||
backstory="Keeps the project on track.",
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Say hello",
|
||||
expected_output="Hello",
|
||||
agent=researcher, # *regular* agent
|
||||
)
|
||||
|
||||
# ── 2. Stub out each agent’s _token_process.get_summary() ───────────────────
|
||||
researcher_metrics = UsageMetrics(total_tokens=120, prompt_tokens=80, completion_tokens=40, successful_requests=2)
|
||||
manager_metrics = UsageMetrics(total_tokens=30, prompt_tokens=20, completion_tokens=10, successful_requests=1)
|
||||
|
||||
# Replace the internal _token_process objects with simple mocks
|
||||
researcher._token_process = MagicMock(get_summary=MagicMock(return_value=researcher_metrics))
|
||||
manager._token_process = MagicMock(get_summary=MagicMock(return_value=manager_metrics))
|
||||
|
||||
# ── 3. Create the crew (hierarchical!) and kick it off ──────────────────────
|
||||
crew = Crew(
|
||||
agents=[researcher], # regular agents
|
||||
manager_agent=manager, # manager to be included
|
||||
tasks=[task],
|
||||
process=Process.hierarchical,
|
||||
)
|
||||
|
||||
# We don’t care about LLM output here; patch execute_sync to avoid network
|
||||
with patch.object(Task, "execute_sync", return_value=TaskOutput(description="dummy", raw="Hello", agent=researcher.role)):
|
||||
crew.kickoff()
|
||||
|
||||
# ── 4. Assert the aggregated numbers are the *sum* of both agents ───────────
|
||||
assert crew.usage_metrics.total_tokens == researcher_metrics.total_tokens + manager_metrics.total_tokens
|
||||
assert crew.usage_metrics.prompt_tokens == researcher_metrics.prompt_tokens + manager_metrics.prompt_tokens
|
||||
assert crew.usage_metrics.completion_tokens == researcher_metrics.completion_tokens + manager_metrics.completion_tokens
|
||||
assert crew.usage_metrics.successful_requests == researcher_metrics.successful_requests + manager_metrics.successful_requests
|
||||
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_hierarchical_crew_creation_tasks_with_agents(researcher, writer):
|
||||
"""
|
||||
@@ -4564,5 +4608,3 @@ def test_reset_agent_knowledge_with_only_agent_knowledge(researcher,writer):
|
||||
|
||||
crew.reset_memories(command_type='agent_knowledge')
|
||||
mock_reset_agent_knowledge.assert_called_once_with([mock_ks_research,mock_ks_writer])
|
||||
|
||||
|
||||
|
||||
@@ -9,6 +9,14 @@ from crewai.telemetry import Telemetry
|
||||
from opentelemetry import trace
|
||||
|
||||
|
||||
@pytest.fixture(autouse=True)
|
||||
def cleanup_telemetry():
|
||||
"""Automatically clean up Telemetry singleton between tests."""
|
||||
Telemetry._instance = None
|
||||
yield
|
||||
Telemetry._instance = None
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"env_var,value,expected_ready",
|
||||
[
|
||||
|
||||
@@ -1,11 +1,19 @@
|
||||
import os
|
||||
from unittest.mock import patch
|
||||
from unittest.mock import patch, MagicMock
|
||||
|
||||
import pytest
|
||||
|
||||
from crewai.telemetry import Telemetry
|
||||
|
||||
|
||||
@pytest.fixture(autouse=True)
|
||||
def cleanup_telemetry():
|
||||
"""Automatically clean up Telemetry singleton between tests."""
|
||||
Telemetry._instance = None
|
||||
yield
|
||||
Telemetry._instance = None
|
||||
|
||||
|
||||
@pytest.mark.parametrize("env_var,value,expected_ready", [
|
||||
("OTEL_SDK_DISABLED", "true", False),
|
||||
("OTEL_SDK_DISABLED", "TRUE", False),
|
||||
@@ -28,3 +36,59 @@ def test_telemetry_enabled_by_default():
|
||||
with patch("crewai.telemetry.telemetry.TracerProvider"):
|
||||
telemetry = Telemetry()
|
||||
assert telemetry.ready is True
|
||||
|
||||
|
||||
def test_telemetry_disable_after_singleton_creation():
|
||||
"""Test that telemetry operations are disabled when env var is set after singleton creation."""
|
||||
with patch.dict(os.environ, {}, clear=True):
|
||||
with patch("crewai.telemetry.telemetry.TracerProvider"):
|
||||
telemetry = Telemetry()
|
||||
assert telemetry.ready is True
|
||||
|
||||
mock_operation = MagicMock()
|
||||
telemetry._safe_telemetry_operation(mock_operation)
|
||||
mock_operation.assert_called_once()
|
||||
|
||||
mock_operation.reset_mock()
|
||||
|
||||
os.environ['CREWAI_DISABLE_TELEMETRY'] = 'true'
|
||||
|
||||
telemetry._safe_telemetry_operation(mock_operation)
|
||||
mock_operation.assert_not_called()
|
||||
|
||||
|
||||
def test_telemetry_disable_with_multiple_instances():
|
||||
"""Test that multiple telemetry instances respect dynamically changed env vars."""
|
||||
with patch.dict(os.environ, {}, clear=True):
|
||||
with patch("crewai.telemetry.telemetry.TracerProvider"):
|
||||
telemetry1 = Telemetry()
|
||||
assert telemetry1.ready is True
|
||||
|
||||
os.environ['CREWAI_DISABLE_TELEMETRY'] = 'true'
|
||||
|
||||
telemetry2 = Telemetry()
|
||||
assert telemetry2 is telemetry1
|
||||
assert telemetry2.ready is True
|
||||
|
||||
mock_operation = MagicMock()
|
||||
telemetry2._safe_telemetry_operation(mock_operation)
|
||||
mock_operation.assert_not_called()
|
||||
|
||||
|
||||
def test_telemetry_otel_sdk_disabled_after_creation():
|
||||
"""Test that OTEL_SDK_DISABLED also works when set after singleton creation."""
|
||||
with patch.dict(os.environ, {}, clear=True):
|
||||
with patch("crewai.telemetry.telemetry.TracerProvider"):
|
||||
telemetry = Telemetry()
|
||||
assert telemetry.ready is True
|
||||
|
||||
mock_operation = MagicMock()
|
||||
telemetry._safe_telemetry_operation(mock_operation)
|
||||
mock_operation.assert_called_once()
|
||||
|
||||
mock_operation.reset_mock()
|
||||
|
||||
os.environ['OTEL_SDK_DISABLED'] = 'true'
|
||||
|
||||
telemetry._safe_telemetry_operation(mock_operation)
|
||||
mock_operation.assert_not_called()
|
||||
|
||||
167
tests/test_flow_human_input_integration.py
Normal file
167
tests/test_flow_human_input_integration.py
Normal file
@@ -0,0 +1,167 @@
|
||||
import pytest
|
||||
from unittest.mock import patch, MagicMock
|
||||
from crewai.utilities.events.event_listener import event_listener
|
||||
|
||||
|
||||
class TestFlowHumanInputIntegration:
|
||||
"""Test integration between Flow execution and human input functionality."""
|
||||
|
||||
def test_console_formatter_pause_resume_methods(self):
|
||||
"""Test that ConsoleFormatter pause/resume methods work correctly."""
|
||||
formatter = event_listener.formatter
|
||||
|
||||
original_paused_state = formatter._live_paused
|
||||
|
||||
try:
|
||||
formatter._live_paused = False
|
||||
|
||||
formatter.pause_live_updates()
|
||||
assert formatter._live_paused
|
||||
|
||||
formatter.resume_live_updates()
|
||||
assert not formatter._live_paused
|
||||
finally:
|
||||
formatter._live_paused = original_paused_state
|
||||
|
||||
@patch('builtins.input', return_value='')
|
||||
def test_human_input_pauses_flow_updates(self, mock_input):
|
||||
"""Test that human input pauses Flow status updates."""
|
||||
from crewai.agents.agent_builder.base_agent_executor_mixin import CrewAgentExecutorMixin
|
||||
|
||||
executor = CrewAgentExecutorMixin()
|
||||
executor.crew = MagicMock()
|
||||
executor.crew._train = False
|
||||
executor._printer = MagicMock()
|
||||
|
||||
formatter = event_listener.formatter
|
||||
|
||||
original_paused_state = formatter._live_paused
|
||||
|
||||
try:
|
||||
formatter._live_paused = False
|
||||
|
||||
with patch.object(formatter, 'pause_live_updates') as mock_pause, \
|
||||
patch.object(formatter, 'resume_live_updates') as mock_resume:
|
||||
|
||||
result = executor._ask_human_input("Test result")
|
||||
|
||||
mock_pause.assert_called_once()
|
||||
mock_resume.assert_called_once()
|
||||
mock_input.assert_called_once()
|
||||
assert result == ''
|
||||
finally:
|
||||
formatter._live_paused = original_paused_state
|
||||
|
||||
@patch('builtins.input', side_effect=['feedback', ''])
|
||||
def test_multiple_human_input_rounds(self, mock_input):
|
||||
"""Test multiple rounds of human input with Flow status management."""
|
||||
from crewai.agents.agent_builder.base_agent_executor_mixin import CrewAgentExecutorMixin
|
||||
|
||||
executor = CrewAgentExecutorMixin()
|
||||
executor.crew = MagicMock()
|
||||
executor.crew._train = False
|
||||
executor._printer = MagicMock()
|
||||
|
||||
formatter = event_listener.formatter
|
||||
|
||||
original_paused_state = formatter._live_paused
|
||||
|
||||
try:
|
||||
pause_calls = []
|
||||
resume_calls = []
|
||||
|
||||
def track_pause():
|
||||
pause_calls.append(True)
|
||||
|
||||
def track_resume():
|
||||
resume_calls.append(True)
|
||||
|
||||
with patch.object(formatter, 'pause_live_updates', side_effect=track_pause), \
|
||||
patch.object(formatter, 'resume_live_updates', side_effect=track_resume):
|
||||
|
||||
result1 = executor._ask_human_input("Test result 1")
|
||||
assert result1 == 'feedback'
|
||||
|
||||
result2 = executor._ask_human_input("Test result 2")
|
||||
assert result2 == ''
|
||||
|
||||
assert len(pause_calls) == 2
|
||||
assert len(resume_calls) == 2
|
||||
finally:
|
||||
formatter._live_paused = original_paused_state
|
||||
|
||||
def test_pause_resume_with_no_live_session(self):
|
||||
"""Test pause/resume methods handle case when no Live session exists."""
|
||||
formatter = event_listener.formatter
|
||||
|
||||
original_live = formatter._live
|
||||
original_paused_state = formatter._live_paused
|
||||
|
||||
try:
|
||||
formatter._live = None
|
||||
formatter._live_paused = False
|
||||
|
||||
formatter.pause_live_updates()
|
||||
formatter.resume_live_updates()
|
||||
|
||||
assert not formatter._live_paused
|
||||
finally:
|
||||
formatter._live = original_live
|
||||
formatter._live_paused = original_paused_state
|
||||
|
||||
def test_pause_resume_exception_handling(self):
|
||||
"""Test that resume is called even if exception occurs during human input."""
|
||||
from crewai.agents.agent_builder.base_agent_executor_mixin import CrewAgentExecutorMixin
|
||||
|
||||
executor = CrewAgentExecutorMixin()
|
||||
executor.crew = MagicMock()
|
||||
executor.crew._train = False
|
||||
executor._printer = MagicMock()
|
||||
|
||||
formatter = event_listener.formatter
|
||||
|
||||
original_paused_state = formatter._live_paused
|
||||
|
||||
try:
|
||||
with patch.object(formatter, 'pause_live_updates') as mock_pause, \
|
||||
patch.object(formatter, 'resume_live_updates') as mock_resume, \
|
||||
patch('builtins.input', side_effect=KeyboardInterrupt("Test exception")):
|
||||
|
||||
with pytest.raises(KeyboardInterrupt):
|
||||
executor._ask_human_input("Test result")
|
||||
|
||||
mock_pause.assert_called_once()
|
||||
mock_resume.assert_called_once()
|
||||
finally:
|
||||
formatter._live_paused = original_paused_state
|
||||
|
||||
def test_training_mode_human_input(self):
|
||||
"""Test human input in training mode."""
|
||||
from crewai.agents.agent_builder.base_agent_executor_mixin import CrewAgentExecutorMixin
|
||||
|
||||
executor = CrewAgentExecutorMixin()
|
||||
executor.crew = MagicMock()
|
||||
executor.crew._train = True
|
||||
executor._printer = MagicMock()
|
||||
|
||||
formatter = event_listener.formatter
|
||||
|
||||
original_paused_state = formatter._live_paused
|
||||
|
||||
try:
|
||||
with patch.object(formatter, 'pause_live_updates') as mock_pause, \
|
||||
patch.object(formatter, 'resume_live_updates') as mock_resume, \
|
||||
patch('builtins.input', return_value='training feedback'):
|
||||
|
||||
result = executor._ask_human_input("Test result")
|
||||
|
||||
mock_pause.assert_called_once()
|
||||
mock_resume.assert_called_once()
|
||||
assert result == 'training feedback'
|
||||
|
||||
executor._printer.print.assert_called()
|
||||
call_args = [call[1]['content'] for call in executor._printer.print.call_args_list]
|
||||
training_prompt_found = any('TRAINING MODE' in content for content in call_args)
|
||||
assert training_prompt_found
|
||||
finally:
|
||||
formatter._live_paused = original_paused_state
|
||||
@@ -1,4 +1,4 @@
|
||||
import asyncio
|
||||
from collections import defaultdict
|
||||
from typing import cast
|
||||
from unittest.mock import Mock
|
||||
|
||||
@@ -313,5 +313,108 @@ def test_sets_parent_flow_when_inside_flow():
|
||||
nonlocal captured_agent
|
||||
captured_agent = source
|
||||
|
||||
result = flow.kickoff()
|
||||
flow.kickoff()
|
||||
assert captured_agent.parent_flow is flow
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_guardrail_is_called_using_string():
|
||||
guardrail_events = defaultdict(list)
|
||||
from crewai.utilities.events import LLMGuardrailCompletedEvent, LLMGuardrailStartedEvent
|
||||
with crewai_event_bus.scoped_handlers():
|
||||
@crewai_event_bus.on(LLMGuardrailStartedEvent)
|
||||
def capture_guardrail_started(source, event):
|
||||
guardrail_events["started"].append(event)
|
||||
|
||||
@crewai_event_bus.on(LLMGuardrailCompletedEvent)
|
||||
def capture_guardrail_completed(source, event):
|
||||
guardrail_events["completed"].append(event)
|
||||
|
||||
agent = Agent(
|
||||
role="Sports Analyst",
|
||||
goal="Gather information about the best soccer players",
|
||||
backstory="""You are an expert at gathering and organizing information. You carefully collect details and present them in a structured way.""",
|
||||
guardrail="""Only include Brazilian players, both women and men""",
|
||||
)
|
||||
|
||||
result = agent.kickoff(messages="Top 10 best players in the world?")
|
||||
|
||||
assert len(guardrail_events['started']) == 2
|
||||
assert len(guardrail_events['completed']) == 2
|
||||
assert not guardrail_events['completed'][0].success
|
||||
assert guardrail_events['completed'][1].success
|
||||
assert "Here are the top 10 best soccer players in the world, focusing exclusively on Brazilian players" in result.raw
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_guardrail_is_called_using_callable():
|
||||
guardrail_events = defaultdict(list)
|
||||
from crewai.utilities.events import LLMGuardrailCompletedEvent, LLMGuardrailStartedEvent
|
||||
with crewai_event_bus.scoped_handlers():
|
||||
@crewai_event_bus.on(LLMGuardrailStartedEvent)
|
||||
def capture_guardrail_started(source, event):
|
||||
guardrail_events["started"].append(event)
|
||||
|
||||
@crewai_event_bus.on(LLMGuardrailCompletedEvent)
|
||||
def capture_guardrail_completed(source, event):
|
||||
guardrail_events["completed"].append(event)
|
||||
|
||||
agent = Agent(
|
||||
role="Sports Analyst",
|
||||
goal="Gather information about the best soccer players",
|
||||
backstory="""You are an expert at gathering and organizing information. You carefully collect details and present them in a structured way.""",
|
||||
guardrail=lambda output: (True, "Pelé - Santos, 1958"),
|
||||
)
|
||||
|
||||
result = agent.kickoff(messages="Top 1 best players in the world?")
|
||||
|
||||
assert len(guardrail_events['started']) == 1
|
||||
assert len(guardrail_events['completed']) == 1
|
||||
assert guardrail_events['completed'][0].success
|
||||
assert "Pelé - Santos, 1958" in result.raw
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_guardrail_reached_attempt_limit():
|
||||
guardrail_events = defaultdict(list)
|
||||
from crewai.utilities.events import LLMGuardrailCompletedEvent, LLMGuardrailStartedEvent
|
||||
with crewai_event_bus.scoped_handlers():
|
||||
@crewai_event_bus.on(LLMGuardrailStartedEvent)
|
||||
def capture_guardrail_started(source, event):
|
||||
guardrail_events["started"].append(event)
|
||||
|
||||
@crewai_event_bus.on(LLMGuardrailCompletedEvent)
|
||||
def capture_guardrail_completed(source, event):
|
||||
guardrail_events["completed"].append(event)
|
||||
|
||||
agent = Agent(
|
||||
role="Sports Analyst",
|
||||
goal="Gather information about the best soccer players",
|
||||
backstory="""You are an expert at gathering and organizing information. You carefully collect details and present them in a structured way.""",
|
||||
guardrail=lambda output: (False, "You are not allowed to include Brazilian players"),
|
||||
guardrail_max_retries=2,
|
||||
)
|
||||
|
||||
with pytest.raises(Exception, match="Agent's guardrail failed validation after 2 retries"):
|
||||
agent.kickoff(messages="Top 10 best players in the world?")
|
||||
|
||||
assert len(guardrail_events['started']) == 3 # 2 retries + 1 initial call
|
||||
assert len(guardrail_events['completed']) == 3 # 2 retries + 1 initial call
|
||||
assert not guardrail_events['completed'][0].success
|
||||
assert not guardrail_events['completed'][1].success
|
||||
assert not guardrail_events['completed'][2].success
|
||||
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_agent_output_when_guardrail_returns_base_model():
|
||||
class Player(BaseModel):
|
||||
name: str
|
||||
country: str
|
||||
|
||||
agent = Agent(
|
||||
role="Sports Analyst",
|
||||
goal="Gather information about the best soccer players",
|
||||
backstory="""You are an expert at gathering and organizing information. You carefully collect details and present them in a structured way.""",
|
||||
guardrail=lambda output: (True, Player(name="Lionel Messi", country="Argentina")),
|
||||
)
|
||||
|
||||
result = agent.kickoff(messages="Top 10 best players in the world?")
|
||||
|
||||
assert result.pydantic == Player(name="Lionel Messi", country="Argentina")
|
||||
|
||||
@@ -25,122 +25,206 @@ def schema_class():
|
||||
return TestSchema
|
||||
|
||||
|
||||
class InternalCrewStructuredTool:
|
||||
def test_initialization(self, basic_function, schema_class):
|
||||
"""Test basic initialization of CrewStructuredTool"""
|
||||
tool = CrewStructuredTool(
|
||||
name="test_tool",
|
||||
description="Test tool description",
|
||||
func=basic_function,
|
||||
args_schema=schema_class,
|
||||
)
|
||||
def test_initialization(basic_function, schema_class):
|
||||
"""Test basic initialization of CrewStructuredTool"""
|
||||
tool = CrewStructuredTool(
|
||||
name="test_tool",
|
||||
description="Test tool description",
|
||||
func=basic_function,
|
||||
args_schema=schema_class,
|
||||
)
|
||||
|
||||
assert tool.name == "test_tool"
|
||||
assert tool.description == "Test tool description"
|
||||
assert tool.func == basic_function
|
||||
assert tool.args_schema == schema_class
|
||||
assert tool.name == "test_tool"
|
||||
assert tool.description == "Test tool description"
|
||||
assert tool.func == basic_function
|
||||
assert tool.args_schema == schema_class
|
||||
|
||||
def test_from_function(self, basic_function):
|
||||
"""Test creating tool from function"""
|
||||
tool = CrewStructuredTool.from_function(
|
||||
func=basic_function, name="test_tool", description="Test description"
|
||||
)
|
||||
def test_from_function(basic_function):
|
||||
"""Test creating tool from function"""
|
||||
tool = CrewStructuredTool.from_function(
|
||||
func=basic_function, name="test_tool", description="Test description"
|
||||
)
|
||||
|
||||
assert tool.name == "test_tool"
|
||||
assert tool.description == "Test description"
|
||||
assert tool.func == basic_function
|
||||
assert isinstance(tool.args_schema, type(BaseModel))
|
||||
assert tool.name == "test_tool"
|
||||
assert tool.description == "Test description"
|
||||
assert tool.func == basic_function
|
||||
assert isinstance(tool.args_schema, type(BaseModel))
|
||||
|
||||
def test_validate_function_signature(self, basic_function, schema_class):
|
||||
"""Test function signature validation"""
|
||||
tool = CrewStructuredTool(
|
||||
name="test_tool",
|
||||
description="Test tool",
|
||||
func=basic_function,
|
||||
args_schema=schema_class,
|
||||
)
|
||||
def test_validate_function_signature(basic_function, schema_class):
|
||||
"""Test function signature validation"""
|
||||
tool = CrewStructuredTool(
|
||||
name="test_tool",
|
||||
description="Test tool",
|
||||
func=basic_function,
|
||||
args_schema=schema_class,
|
||||
)
|
||||
|
||||
# Should not raise any exceptions
|
||||
tool._validate_function_signature()
|
||||
# Should not raise any exceptions
|
||||
tool._validate_function_signature()
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_ainvoke(self, basic_function):
|
||||
"""Test asynchronous invocation"""
|
||||
tool = CrewStructuredTool.from_function(func=basic_function, name="test_tool")
|
||||
@pytest.mark.asyncio
|
||||
async def test_ainvoke(basic_function):
|
||||
"""Test asynchronous invocation"""
|
||||
tool = CrewStructuredTool.from_function(func=basic_function, name="test_tool")
|
||||
|
||||
result = await tool.ainvoke(input={"param1": "test"})
|
||||
assert result == "test 0"
|
||||
result = await tool.ainvoke(input={"param1": "test"})
|
||||
assert result == "test 0"
|
||||
|
||||
def test_parse_args_dict(self, basic_function):
|
||||
"""Test parsing dictionary arguments"""
|
||||
tool = CrewStructuredTool.from_function(func=basic_function, name="test_tool")
|
||||
def test_parse_args_dict(basic_function):
|
||||
"""Test parsing dictionary arguments"""
|
||||
tool = CrewStructuredTool.from_function(func=basic_function, name="test_tool")
|
||||
|
||||
parsed = tool._parse_args({"param1": "test", "param2": 42})
|
||||
assert parsed["param1"] == "test"
|
||||
assert parsed["param2"] == 42
|
||||
parsed = tool._parse_args({"param1": "test", "param2": 42})
|
||||
assert parsed["param1"] == "test"
|
||||
assert parsed["param2"] == 42
|
||||
|
||||
def test_parse_args_string(self, basic_function):
|
||||
"""Test parsing string arguments"""
|
||||
tool = CrewStructuredTool.from_function(func=basic_function, name="test_tool")
|
||||
def test_parse_args_string(basic_function):
|
||||
"""Test parsing string arguments"""
|
||||
tool = CrewStructuredTool.from_function(func=basic_function, name="test_tool")
|
||||
|
||||
parsed = tool._parse_args('{"param1": "test", "param2": 42}')
|
||||
assert parsed["param1"] == "test"
|
||||
assert parsed["param2"] == 42
|
||||
parsed = tool._parse_args('{"param1": "test", "param2": 42}')
|
||||
assert parsed["param1"] == "test"
|
||||
assert parsed["param2"] == 42
|
||||
|
||||
def test_complex_types(self):
|
||||
"""Test handling of complex parameter types"""
|
||||
def test_complex_types():
|
||||
"""Test handling of complex parameter types"""
|
||||
|
||||
def complex_func(nested: dict, items: list) -> str:
|
||||
"""Process complex types."""
|
||||
return f"Processed {len(items)} items with {len(nested)} nested keys"
|
||||
def complex_func(nested: dict, items: list) -> str:
|
||||
"""Process complex types."""
|
||||
return f"Processed {len(items)} items with {len(nested)} nested keys"
|
||||
|
||||
tool = CrewStructuredTool.from_function(
|
||||
func=complex_func, name="test_tool", description="Test complex types"
|
||||
)
|
||||
result = tool.invoke({"nested": {"key": "value"}, "items": [1, 2, 3]})
|
||||
assert result == "Processed 3 items with 1 nested keys"
|
||||
tool = CrewStructuredTool.from_function(
|
||||
func=complex_func, name="test_tool", description="Test complex types"
|
||||
)
|
||||
result = tool.invoke({"nested": {"key": "value"}, "items": [1, 2, 3]})
|
||||
assert result == "Processed 3 items with 1 nested keys"
|
||||
|
||||
def test_schema_inheritance(self):
|
||||
"""Test tool creation with inherited schema"""
|
||||
def test_schema_inheritance():
|
||||
"""Test tool creation with inherited schema"""
|
||||
|
||||
def extended_func(base_param: str, extra_param: int) -> str:
|
||||
"""Test function with inherited schema."""
|
||||
return f"{base_param} {extra_param}"
|
||||
def extended_func(base_param: str, extra_param: int) -> str:
|
||||
"""Test function with inherited schema."""
|
||||
return f"{base_param} {extra_param}"
|
||||
|
||||
class BaseSchema(BaseModel):
|
||||
base_param: str
|
||||
class BaseSchema(BaseModel):
|
||||
base_param: str
|
||||
|
||||
class ExtendedSchema(BaseSchema):
|
||||
extra_param: int
|
||||
class ExtendedSchema(BaseSchema):
|
||||
extra_param: int
|
||||
|
||||
tool = CrewStructuredTool.from_function(
|
||||
func=extended_func, name="test_tool", args_schema=ExtendedSchema
|
||||
)
|
||||
tool = CrewStructuredTool.from_function(
|
||||
func=extended_func, name="test_tool", args_schema=ExtendedSchema
|
||||
)
|
||||
|
||||
result = tool.invoke({"base_param": "test", "extra_param": 42})
|
||||
assert result == "test 42"
|
||||
result = tool.invoke({"base_param": "test", "extra_param": 42})
|
||||
assert result == "test 42"
|
||||
|
||||
def test_default_values_in_schema(self):
|
||||
"""Test handling of default values in schema"""
|
||||
def test_default_values_in_schema():
|
||||
"""Test handling of default values in schema"""
|
||||
|
||||
def default_func(
|
||||
required_param: str,
|
||||
optional_param: str = "default",
|
||||
nullable_param: Optional[int] = None,
|
||||
) -> str:
|
||||
"""Test function with default values."""
|
||||
return f"{required_param} {optional_param} {nullable_param}"
|
||||
def default_func(
|
||||
required_param: str,
|
||||
optional_param: str = "default",
|
||||
nullable_param: Optional[int] = None,
|
||||
) -> str:
|
||||
"""Test function with default values."""
|
||||
return f"{required_param} {optional_param} {nullable_param}"
|
||||
|
||||
tool = CrewStructuredTool.from_function(
|
||||
func=default_func, name="test_tool", description="Test defaults"
|
||||
)
|
||||
tool = CrewStructuredTool.from_function(
|
||||
func=default_func, name="test_tool", description="Test defaults"
|
||||
)
|
||||
|
||||
# Test with minimal parameters
|
||||
result = tool.invoke({"required_param": "test"})
|
||||
assert result == "test default None"
|
||||
# Test with minimal parameters
|
||||
result = tool.invoke({"required_param": "test"})
|
||||
assert result == "test default None"
|
||||
|
||||
# Test with all parameters
|
||||
result = tool.invoke(
|
||||
{"required_param": "test", "optional_param": "custom", "nullable_param": 42}
|
||||
)
|
||||
assert result == "test custom 42"
|
||||
# Test with all parameters
|
||||
result = tool.invoke(
|
||||
{"required_param": "test", "optional_param": "custom", "nullable_param": 42}
|
||||
)
|
||||
assert result == "test custom 42"
|
||||
|
||||
@pytest.fixture
|
||||
def custom_tool_decorator():
|
||||
from crewai.tools import tool
|
||||
|
||||
@tool("custom_tool", result_as_answer=True)
|
||||
async def custom_tool():
|
||||
"""This is a tool that does something"""
|
||||
return "Hello World from Custom Tool"
|
||||
|
||||
return custom_tool
|
||||
|
||||
@pytest.fixture
|
||||
def custom_tool():
|
||||
from crewai.tools import BaseTool
|
||||
|
||||
class CustomTool(BaseTool):
|
||||
name: str = "my_tool"
|
||||
description: str = "This is a tool that does something"
|
||||
result_as_answer: bool = True
|
||||
|
||||
async def _run(self):
|
||||
return "Hello World from Custom Tool"
|
||||
|
||||
return CustomTool()
|
||||
|
||||
def build_simple_crew(tool):
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
agent1 = Agent(role="Simple role", goal="Simple goal", backstory="Simple backstory", tools=[tool])
|
||||
|
||||
say_hi_task = Task(
|
||||
description="Use the custom tool result as answer.", agent=agent1, expected_output="Use the tool result"
|
||||
)
|
||||
|
||||
crew = Crew(agents=[agent1], tasks=[say_hi_task])
|
||||
return crew
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_async_tool_using_within_isolated_crew(custom_tool):
|
||||
crew = build_simple_crew(custom_tool)
|
||||
result = crew.kickoff()
|
||||
|
||||
assert result.raw == "Hello World from Custom Tool"
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_async_tool_using_decorator_within_isolated_crew(custom_tool_decorator):
|
||||
crew = build_simple_crew(custom_tool_decorator)
|
||||
result = crew.kickoff()
|
||||
|
||||
assert result.raw == "Hello World from Custom Tool"
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_async_tool_within_flow(custom_tool):
|
||||
from crewai.flow.flow import Flow
|
||||
|
||||
class StructuredExampleFlow(Flow):
|
||||
from crewai.flow.flow import start
|
||||
|
||||
@start()
|
||||
async def start(self):
|
||||
crew = build_simple_crew(custom_tool)
|
||||
result = await crew.kickoff_async()
|
||||
return result
|
||||
|
||||
flow = StructuredExampleFlow()
|
||||
result = flow.kickoff()
|
||||
assert result.raw == "Hello World from Custom Tool"
|
||||
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_async_tool_using_decorator_within_flow(custom_tool_decorator):
|
||||
from crewai.flow.flow import Flow
|
||||
|
||||
class StructuredExampleFlow(Flow):
|
||||
from crewai.flow.flow import start
|
||||
@start()
|
||||
async def start(self):
|
||||
crew = build_simple_crew(custom_tool_decorator)
|
||||
result = await crew.kickoff_async()
|
||||
return result
|
||||
|
||||
flow = StructuredExampleFlow()
|
||||
result = flow.kickoff()
|
||||
assert result.raw == "Hello World from Custom Tool"
|
||||
116
tests/utilities/test_console_formatter_pause_resume.py
Normal file
116
tests/utilities/test_console_formatter_pause_resume.py
Normal file
@@ -0,0 +1,116 @@
|
||||
from unittest.mock import MagicMock, patch
|
||||
from rich.tree import Tree
|
||||
from rich.live import Live
|
||||
from crewai.utilities.events.utils.console_formatter import ConsoleFormatter
|
||||
|
||||
|
||||
class TestConsoleFormatterPauseResume:
|
||||
"""Test ConsoleFormatter pause/resume functionality."""
|
||||
|
||||
def test_pause_live_updates_with_active_session(self):
|
||||
"""Test pausing when Live session is active."""
|
||||
formatter = ConsoleFormatter()
|
||||
|
||||
mock_live = MagicMock(spec=Live)
|
||||
formatter._live = mock_live
|
||||
formatter._live_paused = False
|
||||
|
||||
formatter.pause_live_updates()
|
||||
|
||||
mock_live.stop.assert_called_once()
|
||||
assert formatter._live_paused
|
||||
|
||||
def test_pause_live_updates_when_already_paused(self):
|
||||
"""Test pausing when already paused does nothing."""
|
||||
formatter = ConsoleFormatter()
|
||||
|
||||
mock_live = MagicMock(spec=Live)
|
||||
formatter._live = mock_live
|
||||
formatter._live_paused = True
|
||||
|
||||
formatter.pause_live_updates()
|
||||
|
||||
mock_live.stop.assert_not_called()
|
||||
assert formatter._live_paused
|
||||
|
||||
def test_pause_live_updates_with_no_session(self):
|
||||
"""Test pausing when no Live session exists."""
|
||||
formatter = ConsoleFormatter()
|
||||
|
||||
formatter._live = None
|
||||
formatter._live_paused = False
|
||||
|
||||
formatter.pause_live_updates()
|
||||
|
||||
assert formatter._live_paused
|
||||
|
||||
def test_resume_live_updates_when_paused(self):
|
||||
"""Test resuming when paused."""
|
||||
formatter = ConsoleFormatter()
|
||||
|
||||
formatter._live_paused = True
|
||||
|
||||
formatter.resume_live_updates()
|
||||
|
||||
assert not formatter._live_paused
|
||||
|
||||
def test_resume_live_updates_when_not_paused(self):
|
||||
"""Test resuming when not paused does nothing."""
|
||||
formatter = ConsoleFormatter()
|
||||
|
||||
formatter._live_paused = False
|
||||
|
||||
formatter.resume_live_updates()
|
||||
|
||||
assert not formatter._live_paused
|
||||
|
||||
def test_print_after_resume_restarts_live_session(self):
|
||||
"""Test that printing a Tree after resume creates new Live session."""
|
||||
formatter = ConsoleFormatter()
|
||||
|
||||
formatter._live_paused = True
|
||||
formatter._live = None
|
||||
|
||||
formatter.resume_live_updates()
|
||||
assert not formatter._live_paused
|
||||
|
||||
tree = Tree("Test")
|
||||
|
||||
with patch('crewai.utilities.events.utils.console_formatter.Live') as mock_live_class:
|
||||
mock_live_instance = MagicMock()
|
||||
mock_live_class.return_value = mock_live_instance
|
||||
|
||||
formatter.print(tree)
|
||||
|
||||
mock_live_class.assert_called_once()
|
||||
mock_live_instance.start.assert_called_once()
|
||||
assert formatter._live == mock_live_instance
|
||||
|
||||
def test_multiple_pause_resume_cycles(self):
|
||||
"""Test multiple pause/resume cycles work correctly."""
|
||||
formatter = ConsoleFormatter()
|
||||
|
||||
mock_live = MagicMock(spec=Live)
|
||||
formatter._live = mock_live
|
||||
formatter._live_paused = False
|
||||
|
||||
formatter.pause_live_updates()
|
||||
assert formatter._live_paused
|
||||
mock_live.stop.assert_called_once()
|
||||
assert formatter._live is None # Live session should be cleared
|
||||
|
||||
formatter.resume_live_updates()
|
||||
assert not formatter._live_paused
|
||||
|
||||
formatter.pause_live_updates()
|
||||
assert formatter._live_paused
|
||||
|
||||
formatter.resume_live_updates()
|
||||
assert not formatter._live_paused
|
||||
|
||||
def test_pause_resume_state_initialization(self):
|
||||
"""Test that _live_paused is properly initialized."""
|
||||
formatter = ConsoleFormatter()
|
||||
|
||||
assert hasattr(formatter, '_live_paused')
|
||||
assert not formatter._live_paused
|
||||
Reference in New Issue
Block a user