Compare commits
501 Commits
0.75.1
...
devin/1745
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
0360988835 | ||
|
|
fa39ce9db2 | ||
|
|
2f66aa0efc | ||
|
|
25c8155609 | ||
|
|
55b07506c2 | ||
|
|
59f34d900a | ||
|
|
4f6054d439 | ||
|
|
a86a1213c7 | ||
|
|
566935fb94 | ||
|
|
3a66746a99 | ||
|
|
337a6d5719 | ||
|
|
51eb5e9998 | ||
|
|
b2969e9441 | ||
|
|
5b9606e8b6 | ||
|
|
685d20f46c | ||
|
|
9ebf3aa043 | ||
|
|
2e4c97661a | ||
|
|
16eb4df556 | ||
|
|
3d9000495c | ||
|
|
6d0039b117 | ||
|
|
311a078ca6 | ||
|
|
371f19f3cd | ||
|
|
870dffbb89 | ||
|
|
ced3c8f0e0 | ||
|
|
8e555149f7 | ||
|
|
a96a27f064 | ||
|
|
a2f3566cd9 | ||
|
|
e655412aca | ||
|
|
1d91ab5d1b | ||
|
|
37359a34f0 | ||
|
|
6eb4045339 | ||
|
|
aebbc75dea | ||
|
|
bc91e94f03 | ||
|
|
d659151dca | ||
|
|
9dffd42e6d | ||
|
|
88455cd52c | ||
|
|
6a1eb10830 | ||
|
|
10edde100e | ||
|
|
40a441f30e | ||
|
|
ea5ae9086a | ||
|
|
0cd524af86 | ||
|
|
4bff5408d8 | ||
|
|
d2caf11191 | ||
|
|
37979a0ca1 | ||
|
|
c9f47e6a37 | ||
|
|
5780c3147a | ||
|
|
98ccbeb4bd | ||
|
|
fbb156b9de | ||
|
|
b73960cebe | ||
|
|
10328f3db4 | ||
|
|
da42ec7eb9 | ||
|
|
97d4439872 | ||
|
|
c3bb221fb3 | ||
|
|
e68cad380e | ||
|
|
96a78a97f0 | ||
|
|
337d2b634b | ||
|
|
475b704f95 | ||
|
|
b992ee9d6b | ||
|
|
d7fa8464c7 | ||
|
|
918c0589eb | ||
|
|
c9d3eb7ccf | ||
|
|
d216edb022 | ||
|
|
afa8783750 | ||
|
|
a661050464 | ||
|
|
c14f990098 | ||
|
|
26ccaf78ec | ||
|
|
12e98e1f3c | ||
|
|
efe27bd570 | ||
|
|
403ea385d7 | ||
|
|
9b51e1174c | ||
|
|
a3b5413f16 | ||
|
|
bce4bb5c4e | ||
|
|
3f92e217f9 | ||
|
|
b0f9637662 | ||
|
|
63ef3918dd | ||
|
|
3c24350306 | ||
|
|
356d4d9729 | ||
|
|
e290064ecc | ||
|
|
77fa1b18c7 | ||
|
|
08a6a82071 | ||
|
|
625748e462 | ||
|
|
6e209d5d77 | ||
|
|
f845fac4da | ||
|
|
b6c32b014c | ||
|
|
06950921e9 | ||
|
|
fc9da22c38 | ||
|
|
02f790ffcb | ||
|
|
af7983be43 | ||
|
|
a83661fd6e | ||
|
|
e1a73e0c44 | ||
|
|
48983773f5 | ||
|
|
73701fda1e | ||
|
|
3deeba4cab | ||
|
|
e3dde17af0 | ||
|
|
49b8cc95ae | ||
|
|
6145331ee4 | ||
|
|
f1839bc6db | ||
|
|
0b58911153 | ||
|
|
ee78446cc5 | ||
|
|
50fe5080e6 | ||
|
|
e1b8394265 | ||
|
|
c23e8fbb02 | ||
|
|
65aeb85e88 | ||
|
|
6c003e0382 | ||
|
|
6b14ffcffb | ||
|
|
df25703cc2 | ||
|
|
12a815e5db | ||
|
|
102836a2c2 | ||
|
|
d38be25d33 | ||
|
|
ac848f9ff4 | ||
|
|
a25a27c3d3 | ||
|
|
22c8e5f433 | ||
|
|
8df8255f18 | ||
|
|
66124d9afb | ||
|
|
7def3a8acc | ||
|
|
5b7fed2cb6 | ||
|
|
838b3bc09d | ||
|
|
ebb585e494 | ||
|
|
7c67c2c6af | ||
|
|
e4f5c7cdf2 | ||
|
|
f09238e512 | ||
|
|
da5f60e7f3 | ||
|
|
807c13e144 | ||
|
|
3dea3d0183 | ||
|
|
35cb7fcf4d | ||
|
|
d2a9a4a4e4 | ||
|
|
e62e9c7401 | ||
|
|
3c5031e711 | ||
|
|
82e84c0f88 | ||
|
|
2c550dc175 | ||
|
|
bdc92deade | ||
|
|
448d31cad9 | ||
|
|
ed1f009c64 | ||
|
|
bb3829a9ed | ||
|
|
0a116202f0 | ||
|
|
4daa88fa59 | ||
|
|
53067f8b92 | ||
|
|
d3a09c3180 | ||
|
|
4d7aacb5f2 | ||
|
|
6b1cf78e41 | ||
|
|
80f1a88b63 | ||
|
|
32da76a2ca | ||
|
|
b3667a8c09 | ||
|
|
3aa48dcd58 | ||
|
|
03f1d57463 | ||
|
|
4725d0de0d | ||
|
|
b766af75f2 | ||
|
|
b2c8779f4c | ||
|
|
df266bda01 | ||
|
|
eed7919d72 | ||
|
|
1e49d1b592 | ||
|
|
ded7197fcb | ||
|
|
2155acb3a3 | ||
|
|
794574957e | ||
|
|
66b19311a7 | ||
|
|
9fc84fc1ac | ||
|
|
f8f9df6d1d | ||
|
|
6e94edb777 | ||
|
|
5f2ac8c33e | ||
|
|
bbe896d48c | ||
|
|
9298054436 | ||
|
|
90b7937796 | ||
|
|
520933b4c5 | ||
|
|
9ea4fb8c82 | ||
|
|
fe0813e831 | ||
|
|
33cebea15b | ||
|
|
e723e5ca3f | ||
|
|
24f1a19310 | ||
|
|
d0959573dc | ||
|
|
939afd5f82 | ||
|
|
d42e58e199 | ||
|
|
000bab4cf5 | ||
|
|
8df1042180 | ||
|
|
313038882c | ||
|
|
41a670166a | ||
|
|
a77496a217 | ||
|
|
430260c985 | ||
|
|
334b0959b0 | ||
|
|
2b31e26ba5 | ||
|
|
7122a29a20 | ||
|
|
f3ddb430a7 | ||
|
|
435bfca186 | ||
|
|
2ef896bdd5 | ||
|
|
59c6c29706 | ||
|
|
a1f35e768f | ||
|
|
00eede0d5d | ||
|
|
cf1864ce0f | ||
|
|
a3d5c86218 | ||
|
|
60d13bf7e8 | ||
|
|
52e0a84829 | ||
|
|
86825e1769 | ||
|
|
7afc531fbb | ||
|
|
ed0490112b | ||
|
|
66c66e3d84 | ||
|
|
b9b625a70d | ||
|
|
b58253cacc | ||
|
|
fbf8732784 | ||
|
|
8fedbe49cb | ||
|
|
1e8ee247ca | ||
|
|
34d2993456 | ||
|
|
e3c5c174ee | ||
|
|
b4e2db0306 | ||
|
|
9cc759ba32 | ||
|
|
ac9f8b9d5a | ||
|
|
3d4a1e4b18 | ||
|
|
123f302744 | ||
|
|
5bae78639e | ||
|
|
5235442a5b | ||
|
|
c62fb615b1 | ||
|
|
78797c64b0 | ||
|
|
8a7584798b | ||
|
|
b50772a38b | ||
|
|
96a7e8038f | ||
|
|
ec050e5d33 | ||
|
|
e2ce65fc5b | ||
|
|
14503bc43b | ||
|
|
00c2f5043e | ||
|
|
bcd90e26b0 | ||
|
|
4eaa8755eb | ||
|
|
ba66910fbd | ||
|
|
90f1bee602 | ||
|
|
1cb5f57864 | ||
|
|
7dc47adb5c | ||
|
|
ac819bcb6e | ||
|
|
b6d668fc66 | ||
|
|
1b488b6da7 | ||
|
|
d3b398ed52 | ||
|
|
d52fd09602 | ||
|
|
d6800d8957 | ||
|
|
2fd7506ed9 | ||
|
|
161084aff2 | ||
|
|
b145cb3247 | ||
|
|
1adbcf697d | ||
|
|
e51355200a | ||
|
|
47818f4f41 | ||
|
|
9b10fd47b0 | ||
|
|
c408368267 | ||
|
|
90b3145e92 | ||
|
|
fbd0e015d5 | ||
|
|
17e25fb842 | ||
|
|
d6d98ee969 | ||
|
|
e0600e3bb9 | ||
|
|
a79d77dfd7 | ||
|
|
56ec9bc224 | ||
|
|
8eef02739a | ||
|
|
6f4ad532e6 | ||
|
|
74a1de8550 | ||
|
|
e529766391 | ||
|
|
a7f5d574dc | ||
|
|
0cc02d9492 | ||
|
|
fa26f6ebae | ||
|
|
f6c2982619 | ||
|
|
5a8649a97f | ||
|
|
e6100debac | ||
|
|
abee94d056 | ||
|
|
92731544ae | ||
|
|
77c7b7dfa1 | ||
|
|
ea64c29fee | ||
|
|
f4bb040ad8 | ||
|
|
515478473a | ||
|
|
9cf3fadd0f | ||
|
|
89c4b3fe88 | ||
|
|
9e5c599f58 | ||
|
|
a950e67c7d | ||
|
|
de6933b2d2 | ||
|
|
748383d74c | ||
|
|
23b9e10323 | ||
|
|
ddb7958da7 | ||
|
|
477cce321f | ||
|
|
7bed63a693 | ||
|
|
2709a9205a | ||
|
|
d19d7b01ec | ||
|
|
a3ad2c1957 | ||
|
|
c3e7a3ec19 | ||
|
|
cba8c9faec | ||
|
|
bcb7fb27d0 | ||
|
|
c310044bec | ||
|
|
5263df24b6 | ||
|
|
dea6ed7ef0 | ||
|
|
d3a0dad323 | ||
|
|
67bf4aea56 | ||
|
|
8c76bad50f | ||
|
|
e27a15023c | ||
|
|
a836f466f4 | ||
|
|
67f0de1f90 | ||
|
|
c642ebf97e | ||
|
|
a21e310d78 | ||
|
|
aba68da542 | ||
|
|
e254f11933 | ||
|
|
ab2274caf0 | ||
|
|
3e4f112f39 | ||
|
|
cc018bf128 | ||
|
|
46d3e4d4d9 | ||
|
|
627bb3f5f6 | ||
|
|
4a44245de9 | ||
|
|
30d027158a | ||
|
|
3fecde49b6 | ||
|
|
cc129a0bce | ||
|
|
b5779dca12 | ||
|
|
42311d9c7a | ||
|
|
294f2cc3a9 | ||
|
|
3dc442801f | ||
|
|
c12343a8b8 | ||
|
|
835557e648 | ||
|
|
4185ea688f | ||
|
|
0532089246 | ||
|
|
24b155015c | ||
|
|
8ceeec7d36 | ||
|
|
75e68f6fc8 | ||
|
|
3de81cedd6 | ||
|
|
5dc8dd0e8a | ||
|
|
b8d07fee83 | ||
|
|
be8e33daf6 | ||
|
|
efc8323c63 | ||
|
|
831951efc4 | ||
|
|
2131b94ddb | ||
|
|
b3504e768c | ||
|
|
350457b9b8 | ||
|
|
355bf3b48b | ||
|
|
0e94236735 | ||
|
|
673a38c5d9 | ||
|
|
8f57753656 | ||
|
|
a2f839fada | ||
|
|
440883e9e8 | ||
|
|
d3da73136c | ||
|
|
7272fd15ac | ||
|
|
518800239c | ||
|
|
30bd79390a | ||
|
|
d1e2430aac | ||
|
|
bfe2c44f55 | ||
|
|
845951a0db | ||
|
|
c1172a685a | ||
|
|
4bcc3b532d | ||
|
|
ba89e43b62 | ||
|
|
4469461b38 | ||
|
|
a548463fae | ||
|
|
45b802a625 | ||
|
|
ba0965ef87 | ||
|
|
d85898cf29 | ||
|
|
73f328860b | ||
|
|
a0c322a535 | ||
|
|
86f58c95de | ||
|
|
99fe91586d | ||
|
|
0c2d23dfe0 | ||
|
|
2433819c4f | ||
|
|
97fc44c930 | ||
|
|
409892d65f | ||
|
|
62f3df7ed5 | ||
|
|
4cf8913d31 | ||
|
|
82647358b2 | ||
|
|
6cc2f510bf | ||
|
|
9a65abf6b8 | ||
|
|
b3185ad90c | ||
|
|
c887ff1f47 | ||
|
|
22e5d39884 | ||
|
|
9ee6824ccd | ||
|
|
da73865f25 | ||
|
|
627b9f1abb | ||
|
|
1b8001bf98 | ||
|
|
e59e07e4f7 | ||
|
|
ee239b1c06 | ||
|
|
bf459bf983 | ||
|
|
94eaa6740e | ||
|
|
6d7c1b0743 | ||
|
|
6b864ee21d | ||
|
|
1ffa8904db | ||
|
|
ad916abd76 | ||
|
|
9702711094 | ||
|
|
8094754239 | ||
|
|
bc5e303d5f | ||
|
|
ec89e003c8 | ||
|
|
0b0f2d30ab | ||
|
|
1df61aba4c | ||
|
|
da9220fa81 | ||
|
|
da4f356fab | ||
|
|
d932b20c6e | ||
|
|
2f9a2afd9e | ||
|
|
c1df7c410e | ||
|
|
54ebd6cf90 | ||
|
|
6b87d22a70 | ||
|
|
c4f7eaf259 | ||
|
|
236e42d0bc | ||
|
|
8c90db04b5 | ||
|
|
1261ce513f | ||
|
|
b07c51532c | ||
|
|
d763eefc2e | ||
|
|
e01c0a0f4c | ||
|
|
5a7a323f3a | ||
|
|
46be5e8097 | ||
|
|
bc2a86d66a | ||
|
|
11a3d4b840 | ||
|
|
6930b68484 | ||
|
|
c7c0647dd2 | ||
|
|
7b276e6797 | ||
|
|
3daba0c79e | ||
|
|
2c85e8e23a | ||
|
|
b0f1d1fcf0 | ||
|
|
611526596a | ||
|
|
fa373f9660 | ||
|
|
48bb8ef775 | ||
|
|
bbea797b0c | ||
|
|
066ad73423 | ||
|
|
0695c26703 | ||
|
|
4fb3331c6a | ||
|
|
b6c6eea6f5 | ||
|
|
1af95f5146 | ||
|
|
ed3487aa22 | ||
|
|
77af733e44 | ||
|
|
aaf80d1d43 | ||
|
|
9e9b945a46 | ||
|
|
308a8dc925 | ||
|
|
7d9d0ff6f7 | ||
|
|
f8a8e7b2a5 | ||
|
|
3285c1b196 | ||
|
|
4bc23affe0 | ||
|
|
bca56eea48 | ||
|
|
588ad3c4a4 | ||
|
|
c6a6c918e0 | ||
|
|
366bbbbea3 | ||
|
|
293305790d | ||
|
|
8bc09eb054 | ||
|
|
db1b678c3a | ||
|
|
6f32bf52cc | ||
|
|
49d173a02d | ||
|
|
4069b621d5 | ||
|
|
a7147c99c6 | ||
|
|
6fe308202e | ||
|
|
63ecb7395d | ||
|
|
8cf1cd5a62 | ||
|
|
93c0467bba | ||
|
|
8f5f67de41 | ||
|
|
f8ca49d8df | ||
|
|
c119230fd6 | ||
|
|
14a36d3f5e | ||
|
|
fde1ee45f9 | ||
|
|
6774bc2c53 | ||
|
|
94c62263ed | ||
|
|
495c3859af | ||
|
|
3e003f5e32 | ||
|
|
1c8b509d7d | ||
|
|
58af5c08f9 | ||
|
|
55e968c9e0 | ||
|
|
0b9092702b | ||
|
|
8376698534 | ||
|
|
3dc02310b6 | ||
|
|
e70bc94ab6 | ||
|
|
9285ebf8a2 | ||
|
|
4ca785eb15 | ||
|
|
c57cbd8591 | ||
|
|
7fb1289205 | ||
|
|
f02681ae01 | ||
|
|
c725105b1f | ||
|
|
36aa4bcb46 | ||
|
|
b98f8f9fe1 | ||
|
|
bcfcf88e78 | ||
|
|
fd0de3a47e | ||
|
|
c7b9ae02fd | ||
|
|
4afb022572 | ||
|
|
8610faef22 | ||
|
|
6d677541c7 | ||
|
|
49220ec163 | ||
|
|
40a676b7ac | ||
|
|
50bf146d1e | ||
|
|
40d378abfb | ||
|
|
1b09b085a7 | ||
|
|
9f2acfe91f | ||
|
|
e856359e23 | ||
|
|
faa231e278 | ||
|
|
3d44795476 | ||
|
|
f50e709985 | ||
|
|
d70c542547 | ||
|
|
57201fb856 | ||
|
|
9b142e580b | ||
|
|
3878daffd6 | ||
|
|
34954e6f74 | ||
|
|
e66a135d5d | ||
|
|
66698503b8 | ||
|
|
ec2967c362 | ||
|
|
4ae07468f3 | ||
|
|
6193eb13fa | ||
|
|
55cd15bfc6 | ||
|
|
5f46ff8836 | ||
|
|
cdfbd5f62b | ||
|
|
b43f3987ec | ||
|
|
240527d06c | ||
|
|
276cb7b7e8 | ||
|
|
048aa6cbcc | ||
|
|
fa9949b9d0 | ||
|
|
500072d855 | ||
|
|
04bcfa6e2d | ||
|
|
26afee9bed | ||
|
|
f29f4abdd7 | ||
|
|
4589d6fe9d | ||
|
|
201e652fa2 | ||
|
|
8bc07e6071 | ||
|
|
6baaad045a | ||
|
|
74c1703310 | ||
|
|
a921828e51 | ||
|
|
e1fd83e6a7 | ||
|
|
7d68e287cc | ||
|
|
f39a975e20 |
3
.github/ISSUE_TEMPLATE/bug_report.yml
vendored
@@ -65,7 +65,6 @@ body:
|
||||
- '3.10'
|
||||
- '3.11'
|
||||
- '3.12'
|
||||
- '3.13'
|
||||
validations:
|
||||
required: true
|
||||
- type: input
|
||||
@@ -113,4 +112,4 @@ body:
|
||||
label: Additional context
|
||||
description: Add any other context about the problem here.
|
||||
validations:
|
||||
required: true
|
||||
required: true
|
||||
|
||||
19
.github/security.md
vendored
Normal file
@@ -0,0 +1,19 @@
|
||||
CrewAI takes the security of our software products and services seriously, which includes all source code repositories managed through our GitHub organization.
|
||||
If you believe you have found a security vulnerability in any CrewAI product or service, please report it to us as described below.
|
||||
|
||||
## Reporting a Vulnerability
|
||||
Please do not report security vulnerabilities through public GitHub issues.
|
||||
To report a vulnerability, please email us at security@crewai.com.
|
||||
Please include the requested information listed below so that we can triage your report more quickly
|
||||
|
||||
- Type of issue (e.g. SQL injection, cross-site scripting, etc.)
|
||||
- Full paths of source file(s) related to the manifestation of the issue
|
||||
- The location of the affected source code (tag/branch/commit or direct URL)
|
||||
- Any special configuration required to reproduce the issue
|
||||
- Step-by-step instructions to reproduce the issue (please include screenshots if needed)
|
||||
- Proof-of-concept or exploit code (if possible)
|
||||
- Impact of the issue, including how an attacker might exploit the issue
|
||||
|
||||
Once we have received your report, we will respond to you at the email address you provide. If the issue is confirmed, we will release a patch as soon as possible depending on the complexity of the issue.
|
||||
|
||||
At this time, we are not offering a bug bounty program. Any rewards will be at our discretion.
|
||||
4
.github/workflows/linter.yml
vendored
@@ -6,11 +6,11 @@ jobs:
|
||||
lint:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Install Requirements
|
||||
run: |
|
||||
pip install ruff
|
||||
|
||||
- name: Run Ruff Linter
|
||||
run: ruff check --exclude "templates","__init__.py"
|
||||
run: ruff check
|
||||
|
||||
8
.github/workflows/mkdocs.yml
vendored
@@ -13,10 +13,10 @@ jobs:
|
||||
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v2
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v4
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.10'
|
||||
|
||||
@@ -25,7 +25,7 @@ jobs:
|
||||
run: echo "::set-output name=hash::$(sha256sum requirements-doc.txt | awk '{print $1}')"
|
||||
|
||||
- name: Setup cache
|
||||
uses: actions/cache@v3
|
||||
uses: actions/cache@v4
|
||||
with:
|
||||
key: mkdocs-material-${{ steps.req-hash.outputs.hash }}
|
||||
path: .cache
|
||||
@@ -42,4 +42,4 @@ jobs:
|
||||
GH_TOKEN: ${{ secrets.GH_TOKEN }}
|
||||
|
||||
- name: Build and deploy MkDocs
|
||||
run: mkdocs gh-deploy --force
|
||||
run: mkdocs gh-deploy --force
|
||||
|
||||
33
.github/workflows/notify-downstream.yml
vendored
Normal file
@@ -0,0 +1,33 @@
|
||||
name: Notify Downstream
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
|
||||
jobs:
|
||||
notify-downstream:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Generate GitHub App token
|
||||
id: app-token
|
||||
uses: tibdex/github-app-token@v2
|
||||
with:
|
||||
app_id: ${{ secrets.OSS_SYNC_APP_ID }}
|
||||
private_key: ${{ secrets.OSS_SYNC_APP_PRIVATE_KEY }}
|
||||
|
||||
- name: Notify Repo B
|
||||
uses: peter-evans/repository-dispatch@v3
|
||||
with:
|
||||
token: ${{ steps.app-token.outputs.token }}
|
||||
repository: ${{ secrets.OSS_SYNC_DOWNSTREAM_REPO }}
|
||||
event-type: upstream-commit
|
||||
client-payload: |
|
||||
{
|
||||
"commit_sha": "${{ github.sha }}"
|
||||
}
|
||||
|
||||
4
.github/workflows/security-checker.yml
vendored
@@ -11,7 +11,7 @@ jobs:
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: "3.11.9"
|
||||
|
||||
@@ -19,5 +19,5 @@ jobs:
|
||||
run: pip install bandit
|
||||
|
||||
- name: Run Bandit
|
||||
run: bandit -c pyproject.toml -r src/ -lll
|
||||
run: bandit -c pyproject.toml -r src/ -ll
|
||||
|
||||
|
||||
8
.github/workflows/stale.yml
vendored
@@ -1,5 +1,10 @@
|
||||
name: Mark stale issues and pull requests
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
issues: write
|
||||
pull-requests: write
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: '10 12 * * *'
|
||||
@@ -8,9 +13,6 @@ on:
|
||||
jobs:
|
||||
stale:
|
||||
runs-on: ubuntu-latest
|
||||
permissions:
|
||||
issues: write
|
||||
pull-requests: write
|
||||
steps:
|
||||
- uses: actions/stale@v9
|
||||
with:
|
||||
|
||||
12
.github/workflows/tests.yml
vendored
@@ -12,6 +12,9 @@ jobs:
|
||||
tests:
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 15
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ['3.10', '3.11', '3.12']
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
@@ -21,12 +24,11 @@ jobs:
|
||||
with:
|
||||
enable-cache: true
|
||||
|
||||
|
||||
- name: Set up Python
|
||||
run: uv python install 3.11.9
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
run: uv python install ${{ matrix.python-version }}
|
||||
|
||||
- name: Install the project
|
||||
run: uv sync --dev
|
||||
run: uv sync --dev --all-extras
|
||||
|
||||
- name: Run tests
|
||||
run: uv run pytest tests
|
||||
run: uv run pytest tests -vv
|
||||
|
||||
2
.github/workflows/type-checker.yml
vendored
@@ -14,7 +14,7 @@ jobs:
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v4
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: "3.11.9"
|
||||
|
||||
|
||||
10
.gitignore
vendored
@@ -17,3 +17,13 @@ rc-tests/*
|
||||
temp/*
|
||||
.vscode/*
|
||||
crew_tasks_output.json
|
||||
.codesight
|
||||
.mypy_cache
|
||||
.ruff_cache
|
||||
.venv
|
||||
agentops.log
|
||||
test_flow.html
|
||||
crewairules.mdc
|
||||
plan.md
|
||||
conceptual_plan.md
|
||||
build_image
|
||||
@@ -1,9 +1,7 @@
|
||||
repos:
|
||||
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
rev: v0.4.4
|
||||
rev: v0.8.2
|
||||
hooks:
|
||||
- id: ruff
|
||||
args: ["--fix"]
|
||||
exclude: "templates"
|
||||
- id: ruff-format
|
||||
exclude: "templates"
|
||||
|
||||
9
.ruff.toml
Normal file
@@ -0,0 +1,9 @@
|
||||
exclude = [
|
||||
"templates",
|
||||
"__init__.py",
|
||||
]
|
||||
|
||||
[lint]
|
||||
select = [
|
||||
"I", # isort rules
|
||||
]
|
||||
2
LICENSE
@@ -1,4 +1,4 @@
|
||||
Copyright (c) 2018 The Python Packaging Authority
|
||||
Copyright (c) 2025 crewAI, Inc.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
|
||||
345
README.md
@@ -1,14 +1,47 @@
|
||||
<div align="center">
|
||||
|
||||

|
||||

|
||||
|
||||
# **CrewAI**
|
||||
|
||||
🤖 **CrewAI**: Cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks.
|
||||
</div>
|
||||
|
||||
### Fast and Flexible Multi-Agent Automation Framework
|
||||
|
||||
CrewAI is a lean, lightning-fast Python framework built entirely from
|
||||
scratch—completely **independent of LangChain or other agent frameworks**.
|
||||
It empowers developers with both high-level simplicity and precise low-level
|
||||
control, ideal for creating autonomous AI agents tailored to any scenario.
|
||||
|
||||
- **CrewAI Crews**: Optimize for autonomy and collaborative intelligence.
|
||||
- **CrewAI Flows**: Enable granular, event-driven control, single LLM calls for precise task orchestration and supports Crews natively
|
||||
|
||||
With over 100,000 developers certified through our community courses at
|
||||
[learn.crewai.com](https://learn.crewai.com), CrewAI is rapidly becoming the
|
||||
standard for enterprise-ready AI automation.
|
||||
|
||||
# CrewAI Enterprise Suite
|
||||
|
||||
CrewAI Enterprise Suite is a comprehensive bundle tailored for organizations
|
||||
that require secure, scalable, and easy-to-manage agent-driven automation.
|
||||
|
||||
You can try one part of the suite the [Crew Control Plane for free](https://app.crewai.com)
|
||||
|
||||
## Crew Control Plane Key Features:
|
||||
- **Tracing & Observability**: Monitor and track your AI agents and workflows in real-time, including metrics, logs, and traces.
|
||||
- **Unified Control Plane**: A centralized platform for managing, monitoring, and scaling your AI agents and workflows.
|
||||
- **Seamless Integrations**: Easily connect with existing enterprise systems, data sources, and cloud infrastructure.
|
||||
- **Advanced Security**: Built-in robust security and compliance measures ensuring safe deployment and management.
|
||||
- **Actionable Insights**: Real-time analytics and reporting to optimize performance and decision-making.
|
||||
- **24/7 Support**: Dedicated enterprise support to ensure uninterrupted operation and quick resolution of issues.
|
||||
- **On-premise and Cloud Deployment Options**: Deploy CrewAI Enterprise on-premise or in the cloud, depending on your security and compliance requirements.
|
||||
|
||||
CrewAI Enterprise is designed for enterprises seeking a powerful,
|
||||
reliable solution to transform complex business processes into efficient,
|
||||
intelligent automations.
|
||||
|
||||
<h3>
|
||||
|
||||
[Homepage](https://www.crewai.com/) | [Documentation](https://docs.crewai.com/) | [Chat with Docs](https://chatg.pt/DWjSBZn) | [Examples](https://github.com/crewAIInc/crewAI-examples) | [Discourse](https://community.crewai.com)
|
||||
[Homepage](https://www.crewai.com/) | [Documentation](https://docs.crewai.com/) | [Chat with Docs](https://chatg.pt/DWjSBZn) | [Discourse](https://community.crewai.com)
|
||||
|
||||
</h3>
|
||||
|
||||
@@ -22,36 +55,80 @@
|
||||
- [Why CrewAI?](#why-crewai)
|
||||
- [Getting Started](#getting-started)
|
||||
- [Key Features](#key-features)
|
||||
- [Understanding Flows and Crews](#understanding-flows-and-crews)
|
||||
- [CrewAI vs LangGraph](#how-crewai-compares)
|
||||
- [Examples](#examples)
|
||||
- [Quick Tutorial](#quick-tutorial)
|
||||
- [Write Job Descriptions](#write-job-descriptions)
|
||||
- [Trip Planner](#trip-planner)
|
||||
- [Stock Analysis](#stock-analysis)
|
||||
- [Using Crews and Flows Together](#using-crews-and-flows-together)
|
||||
- [Connecting Your Crew to a Model](#connecting-your-crew-to-a-model)
|
||||
- [How CrewAI Compares](#how-crewai-compares)
|
||||
- [Frequently Asked Questions (FAQ)](#frequently-asked-questions-faq)
|
||||
- [Contribution](#contribution)
|
||||
- [Telemetry](#telemetry)
|
||||
- [License](#license)
|
||||
|
||||
## Why CrewAI?
|
||||
|
||||
The power of AI collaboration has too much to offer.
|
||||
CrewAI is designed to enable AI agents to assume roles, share goals, and operate in a cohesive unit - much like a well-oiled crew. Whether you're building a smart assistant platform, an automated customer service ensemble, or a multi-agent research team, CrewAI provides the backbone for sophisticated multi-agent interactions.
|
||||
<div align="center" style="margin-bottom: 30px;">
|
||||
<img src="docs/asset.png" alt="CrewAI Logo" width="100%">
|
||||
</div>
|
||||
|
||||
CrewAI unlocks the true potential of multi-agent automation, delivering the best-in-class combination of speed, flexibility, and control with either Crews of AI Agents or Flows of Events:
|
||||
|
||||
- **Standalone Framework**: Built from scratch, independent of LangChain or any other agent framework.
|
||||
- **High Performance**: Optimized for speed and minimal resource usage, enabling faster execution.
|
||||
- **Flexible Low Level Customization**: Complete freedom to customize at both high and low levels - from overall workflows and system architecture to granular agent behaviors, internal prompts, and execution logic.
|
||||
- **Ideal for Every Use Case**: Proven effective for both simple tasks and highly complex, real-world, enterprise-grade scenarios.
|
||||
- **Robust Community**: Backed by a rapidly growing community of over **100,000 certified** developers offering comprehensive support and resources.
|
||||
|
||||
CrewAI empowers developers and enterprises to confidently build intelligent automations, bridging the gap between simplicity, flexibility, and performance.
|
||||
|
||||
## Getting Started
|
||||
|
||||
### Learning Resources
|
||||
|
||||
Learn CrewAI through our comprehensive courses:
|
||||
- [Multi AI Agent Systems with CrewAI](https://www.deeplearning.ai/short-courses/multi-ai-agent-systems-with-crewai/) - Master the fundamentals of multi-agent systems
|
||||
- [Practical Multi AI Agents and Advanced Use Cases](https://www.deeplearning.ai/short-courses/practical-multi-ai-agents-and-advanced-use-cases-with-crewai/) - Deep dive into advanced implementations
|
||||
|
||||
### Understanding Flows and Crews
|
||||
|
||||
CrewAI offers two powerful, complementary approaches that work seamlessly together to build sophisticated AI applications:
|
||||
|
||||
1. **Crews**: Teams of AI agents with true autonomy and agency, working together to accomplish complex tasks through role-based collaboration. Crews enable:
|
||||
- Natural, autonomous decision-making between agents
|
||||
- Dynamic task delegation and collaboration
|
||||
- Specialized roles with defined goals and expertise
|
||||
- Flexible problem-solving approaches
|
||||
|
||||
2. **Flows**: Production-ready, event-driven workflows that deliver precise control over complex automations. Flows provide:
|
||||
- Fine-grained control over execution paths for real-world scenarios
|
||||
- Secure, consistent state management between tasks
|
||||
- Clean integration of AI agents with production Python code
|
||||
- Conditional branching for complex business logic
|
||||
|
||||
The true power of CrewAI emerges when combining Crews and Flows. This synergy allows you to:
|
||||
- Build complex, production-grade applications
|
||||
- Balance autonomy with precise control
|
||||
- Handle sophisticated real-world scenarios
|
||||
- Maintain clean, maintainable code structure
|
||||
|
||||
### Getting Started with Installation
|
||||
|
||||
To get started with CrewAI, follow these simple steps:
|
||||
|
||||
### 1. Installation
|
||||
|
||||
Ensure you have Python >=3.10 <=3.13 installed on your system. CrewAI uses [UV](https://docs.astral.sh/uv/) for dependency management and package handling, offering a seamless setup and execution experience.
|
||||
Ensure you have Python >=3.10 <3.13 installed on your system. CrewAI uses [UV](https://docs.astral.sh/uv/) for dependency management and package handling, offering a seamless setup and execution experience.
|
||||
|
||||
First, install CrewAI:
|
||||
|
||||
```shell
|
||||
pip install crewai
|
||||
```
|
||||
|
||||
If you want to install the 'crewai' package along with its optional features that include additional tools for agents, you can do so by using the following command:
|
||||
|
||||
```shell
|
||||
@@ -59,6 +136,22 @@ pip install 'crewai[tools]'
|
||||
```
|
||||
The command above installs the basic package and also adds extra components which require more dependencies to function.
|
||||
|
||||
### Troubleshooting Dependencies
|
||||
|
||||
If you encounter issues during installation or usage, here are some common solutions:
|
||||
|
||||
#### Common Issues
|
||||
|
||||
1. **ModuleNotFoundError: No module named 'tiktoken'**
|
||||
- Install tiktoken explicitly: `pip install 'crewai[embeddings]'`
|
||||
- If using embedchain or other tools: `pip install 'crewai[tools]'`
|
||||
|
||||
2. **Failed building wheel for tiktoken**
|
||||
- Ensure Rust compiler is installed (see installation steps above)
|
||||
- For Windows: Verify Visual C++ Build Tools are installed
|
||||
- Try upgrading pip: `pip install --upgrade pip`
|
||||
- If issues persist, use a pre-built wheel: `pip install tiktoken --prefer-binary`
|
||||
|
||||
### 2. Setting Up Your Crew with the YAML Configuration
|
||||
|
||||
To create a new CrewAI project, run the following CLI (Command Line Interface) command:
|
||||
@@ -100,7 +193,7 @@ You can now start developing your crew by editing the files in the `src/my_proje
|
||||
|
||||
#### Example of a simple crew with a sequential process:
|
||||
|
||||
Instatiate your crew:
|
||||
Instantiate your crew:
|
||||
|
||||
```shell
|
||||
crewai create crew latest-ai-development
|
||||
@@ -121,7 +214,7 @@ researcher:
|
||||
You're a seasoned researcher with a knack for uncovering the latest
|
||||
developments in {topic}. Known for your ability to find the most relevant
|
||||
information and present it in a clear and concise manner.
|
||||
|
||||
|
||||
reporting_analyst:
|
||||
role: >
|
||||
{topic} Reporting Analyst
|
||||
@@ -141,7 +234,7 @@ research_task:
|
||||
description: >
|
||||
Conduct a thorough research about {topic}
|
||||
Make sure you find any interesting and relevant information given
|
||||
the current year is 2024.
|
||||
the current year is 2025.
|
||||
expected_output: >
|
||||
A list with 10 bullet points of the most relevant information about {topic}
|
||||
agent: researcher
|
||||
@@ -164,10 +257,14 @@ reporting_task:
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai.project import CrewBase, agent, crew, task
|
||||
from crewai_tools import SerperDevTool
|
||||
from crewai.agents.agent_builder.base_agent import BaseAgent
|
||||
from typing import List
|
||||
|
||||
@CrewBase
|
||||
class LatestAiDevelopmentCrew():
|
||||
"""LatestAiDevelopment crew"""
|
||||
agents: List[BaseAgent]
|
||||
tasks: List[Task]
|
||||
|
||||
@agent
|
||||
def researcher(self) -> Agent:
|
||||
@@ -205,7 +302,7 @@ class LatestAiDevelopmentCrew():
|
||||
tasks=self.tasks, # Automatically created by the @task decorator
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
**main.py**
|
||||
@@ -264,15 +361,16 @@ In addition to the sequential process, you can use the hierarchical process, whi
|
||||
|
||||
## Key Features
|
||||
|
||||
- **Role-Based Agent Design**: Customize agents with specific roles, goals, and tools.
|
||||
- **Autonomous Inter-Agent Delegation**: Agents can autonomously delegate tasks and inquire amongst themselves, enhancing problem-solving efficiency.
|
||||
- **Flexible Task Management**: Define tasks with customizable tools and assign them to agents dynamically.
|
||||
- **Processes Driven**: Currently only supports `sequential` task execution and `hierarchical` processes, but more complex processes like consensual and autonomous are being worked on.
|
||||
- **Save output as file**: Save the output of individual tasks as a file, so you can use it later.
|
||||
- **Parse output as Pydantic or Json**: Parse the output of individual tasks as a Pydantic model or as a Json if you want to.
|
||||
- **Works with Open Source Models**: Run your crew using Open AI or open source models refer to the [Connect CrewAI to LLMs](https://docs.crewai.com/how-to/LLM-Connections/) page for details on configuring your agents' connections to models, even ones running locally!
|
||||
CrewAI stands apart as a lean, standalone, high-performance framework delivering simplicity, flexibility, and precise control—free from the complexity and limitations found in other agent frameworks.
|
||||
|
||||

|
||||
- **Standalone & Lean**: Completely independent from other frameworks like LangChain, offering faster execution and lighter resource demands.
|
||||
- **Flexible & Precise**: Easily orchestrate autonomous agents through intuitive [Crews](https://docs.crewai.com/concepts/crews) or precise [Flows](https://docs.crewai.com/concepts/flows), achieving perfect balance for your needs.
|
||||
- **Seamless Integration**: Effortlessly combine Crews (autonomy) and Flows (precision) to create complex, real-world automations.
|
||||
- **Deep Customization**: Tailor every aspect—from high-level workflows down to low-level internal prompts and agent behaviors.
|
||||
- **Reliable Performance**: Consistent results across simple tasks and complex, enterprise-level automations.
|
||||
- **Thriving Community**: Backed by robust documentation and over 100,000 certified developers, providing exceptional support and guidance.
|
||||
|
||||
Choose CrewAI to easily build powerful, adaptable, and production-ready AI automations.
|
||||
|
||||
## Examples
|
||||
|
||||
@@ -305,6 +403,103 @@ You can test different real life examples of AI crews in the [CrewAI-examples re
|
||||
|
||||
[](https://www.youtube.com/watch?v=e0Uj4yWdaAg "Stock Analysis")
|
||||
|
||||
### Using Crews and Flows Together
|
||||
|
||||
CrewAI's power truly shines when combining Crews with Flows to create sophisticated automation pipelines.
|
||||
CrewAI flows support logical operators like `or_` and `and_` to combine multiple conditions. This can be used with `@start`, `@listen`, or `@router` decorators to create complex triggering conditions.
|
||||
- `or_`: Triggers when any of the specified conditions are met.
|
||||
- `and_`Triggers when all of the specified conditions are met.
|
||||
|
||||
Here's how you can orchestrate multiple Crews within a Flow:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, start, router, or_
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
from pydantic import BaseModel
|
||||
|
||||
# Define structured state for precise control
|
||||
class MarketState(BaseModel):
|
||||
sentiment: str = "neutral"
|
||||
confidence: float = 0.0
|
||||
recommendations: list = []
|
||||
|
||||
class AdvancedAnalysisFlow(Flow[MarketState]):
|
||||
@start()
|
||||
def fetch_market_data(self):
|
||||
# Demonstrate low-level control with structured state
|
||||
self.state.sentiment = "analyzing"
|
||||
return {"sector": "tech", "timeframe": "1W"} # These parameters match the task description template
|
||||
|
||||
@listen(fetch_market_data)
|
||||
def analyze_with_crew(self, market_data):
|
||||
# Show crew agency through specialized roles
|
||||
analyst = Agent(
|
||||
role="Senior Market Analyst",
|
||||
goal="Conduct deep market analysis with expert insight",
|
||||
backstory="You're a veteran analyst known for identifying subtle market patterns"
|
||||
)
|
||||
researcher = Agent(
|
||||
role="Data Researcher",
|
||||
goal="Gather and validate supporting market data",
|
||||
backstory="You excel at finding and correlating multiple data sources"
|
||||
)
|
||||
|
||||
analysis_task = Task(
|
||||
description="Analyze {sector} sector data for the past {timeframe}",
|
||||
expected_output="Detailed market analysis with confidence score",
|
||||
agent=analyst
|
||||
)
|
||||
research_task = Task(
|
||||
description="Find supporting data to validate the analysis",
|
||||
expected_output="Corroborating evidence and potential contradictions",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
# Demonstrate crew autonomy
|
||||
analysis_crew = Crew(
|
||||
agents=[analyst, researcher],
|
||||
tasks=[analysis_task, research_task],
|
||||
process=Process.sequential,
|
||||
verbose=True
|
||||
)
|
||||
return analysis_crew.kickoff(inputs=market_data) # Pass market_data as named inputs
|
||||
|
||||
@router(analyze_with_crew)
|
||||
def determine_next_steps(self):
|
||||
# Show flow control with conditional routing
|
||||
if self.state.confidence > 0.8:
|
||||
return "high_confidence"
|
||||
elif self.state.confidence > 0.5:
|
||||
return "medium_confidence"
|
||||
return "low_confidence"
|
||||
|
||||
@listen("high_confidence")
|
||||
def execute_strategy(self):
|
||||
# Demonstrate complex decision making
|
||||
strategy_crew = Crew(
|
||||
agents=[
|
||||
Agent(role="Strategy Expert",
|
||||
goal="Develop optimal market strategy")
|
||||
],
|
||||
tasks=[
|
||||
Task(description="Create detailed strategy based on analysis",
|
||||
expected_output="Step-by-step action plan")
|
||||
]
|
||||
)
|
||||
return strategy_crew.kickoff()
|
||||
|
||||
@listen(or_("medium_confidence", "low_confidence"))
|
||||
def request_additional_analysis(self):
|
||||
self.state.recommendations.append("Gather more data")
|
||||
return "Additional analysis required"
|
||||
```
|
||||
|
||||
This example demonstrates how to:
|
||||
1. Use Python code for basic data operations
|
||||
2. Create and execute Crews as steps in your workflow
|
||||
3. Use Flow decorators to manage the sequence of operations
|
||||
4. Implement conditional branching based on Crew results
|
||||
|
||||
## Connecting Your Crew to a Model
|
||||
|
||||
CrewAI supports using various LLMs through a variety of connection options. By default your agents will use the OpenAI API when querying the model. However, there are several other ways to allow your agents to connect to models. For example, you can configure your agents to use a local model via the Ollama tool.
|
||||
@@ -313,9 +508,13 @@ Please refer to the [Connect CrewAI to LLMs](https://docs.crewai.com/how-to/LLM-
|
||||
|
||||
## How CrewAI Compares
|
||||
|
||||
**CrewAI's Advantage**: CrewAI is built with production in mind. It offers the flexibility of Autogen's conversational agents and the structured process approach of ChatDev, but without the rigidity. CrewAI's processes are designed to be dynamic and adaptable, fitting seamlessly into both development and production workflows.
|
||||
**CrewAI's Advantage**: CrewAI combines autonomous agent intelligence with precise workflow control through its unique Crews and Flows architecture. The framework excels at both high-level orchestration and low-level customization, enabling complex, production-grade systems with granular control.
|
||||
|
||||
- **Autogen**: While Autogen does good in creating conversational agents capable of working together, it lacks an inherent concept of process. In Autogen, orchestrating agents' interactions requires additional programming, which can become complex and cumbersome as the scale of tasks grows.
|
||||
- **LangGraph**: While LangGraph provides a foundation for building agent workflows, its approach requires significant boilerplate code and complex state management patterns. The framework's tight coupling with LangChain can limit flexibility when implementing custom agent behaviors or integrating with external systems.
|
||||
|
||||
*P.S. CrewAI demonstrates significant performance advantages over LangGraph, executing 5.76x faster in certain cases like this QA task example ([see comparison](https://github.com/crewAIInc/crewAI-examples/tree/main/Notebooks/CrewAI%20Flows%20%26%20Langgraph/QA%20Agent)) while achieving higher evaluation scores with faster completion times in certain coding tasks, like in this example ([detailed analysis](https://github.com/crewAIInc/crewAI-examples/blob/main/Notebooks/CrewAI%20Flows%20%26%20Langgraph/Coding%20Assistant/coding_assistant_eval.ipynb)).*
|
||||
|
||||
- **Autogen**: While Autogen excels at creating conversational agents capable of working together, it lacks an inherent concept of process. In Autogen, orchestrating agents' interactions requires additional programming, which can become complex and cumbersome as the scale of tasks grows.
|
||||
|
||||
- **ChatDev**: ChatDev introduced the idea of processes into the realm of AI agents, but its implementation is quite rigid. Customizations in ChatDev are limited and not geared towards production environments, which can hinder scalability and flexibility in real-world applications.
|
||||
|
||||
@@ -351,13 +550,13 @@ pre-commit install
|
||||
### Running Tests
|
||||
|
||||
```bash
|
||||
uvx pytest
|
||||
uv run pytest .
|
||||
```
|
||||
|
||||
### Running static type checks
|
||||
|
||||
```bash
|
||||
uvx mypy
|
||||
uvx mypy src
|
||||
```
|
||||
|
||||
### Packaging
|
||||
@@ -376,7 +575,7 @@ pip install dist/*.tar.gz
|
||||
|
||||
CrewAI uses anonymous telemetry to collect usage data with the main purpose of helping us improve the library by focusing our efforts on the most used features, integrations and tools.
|
||||
|
||||
It's pivotal to understand that **NO data is collected** concerning prompts, task descriptions, agents' backstories or goals, usage of tools, API calls, responses, any data processed by the agents, or secrets and environment variables, with the exception of the conditions mentioned. When the `share_crew` feature is enabled, detailed data including task descriptions, agents' backstories or goals, and other specific attributes are collected to provide deeper insights while respecting user privacy. We don't offer a way to disable it now, but we will in the future.
|
||||
It's pivotal to understand that **NO data is collected** concerning prompts, task descriptions, agents' backstories or goals, usage of tools, API calls, responses, any data processed by the agents, or secrets and environment variables, with the exception of the conditions mentioned. When the `share_crew` feature is enabled, detailed data including task descriptions, agents' backstories or goals, and other specific attributes are collected to provide deeper insights while respecting user privacy. Users can disable telemetry by setting the environment variable OTEL_SDK_DISABLED to true.
|
||||
|
||||
Data collected includes:
|
||||
|
||||
@@ -399,7 +598,7 @@ Data collected includes:
|
||||
- Roles of agents in a crew
|
||||
- Understand high level use cases so we can build better tools, integrations and examples about it
|
||||
- Tools names available
|
||||
- Understand out of the publically available tools, which ones are being used the most so we can improve them
|
||||
- Understand out of the publicly available tools, which ones are being used the most so we can improve them
|
||||
|
||||
Users can opt-in to Further Telemetry, sharing the complete telemetry data by setting the `share_crew` attribute to `True` on their Crews. Enabling `share_crew` results in the collection of detailed crew and task execution data, including `goal`, `backstory`, `context`, and `output` of tasks. This enables a deeper insight into usage patterns while respecting the user's choice to share.
|
||||
|
||||
@@ -407,13 +606,39 @@ Users can opt-in to Further Telemetry, sharing the complete telemetry data by se
|
||||
|
||||
CrewAI is released under the [MIT License](https://github.com/crewAIInc/crewAI/blob/main/LICENSE).
|
||||
|
||||
|
||||
## Frequently Asked Questions (FAQ)
|
||||
|
||||
### Q: What is CrewAI?
|
||||
A: CrewAI is a cutting-edge framework for orchestrating role-playing, autonomous AI agents. It enables agents to work together seamlessly, tackling complex tasks through collaborative intelligence.
|
||||
### General
|
||||
- [What exactly is CrewAI?](#q-what-exactly-is-crewai)
|
||||
- [How do I install CrewAI?](#q-how-do-i-install-crewai)
|
||||
- [Does CrewAI depend on LangChain?](#q-does-crewai-depend-on-langchain)
|
||||
- [Is CrewAI open-source?](#q-is-crewai-open-source)
|
||||
- [Does CrewAI collect data from users?](#q-does-crewai-collect-data-from-users)
|
||||
|
||||
### Features and Capabilities
|
||||
- [Can CrewAI handle complex use cases?](#q-can-crewai-handle-complex-use-cases)
|
||||
- [Can I use CrewAI with local AI models?](#q-can-i-use-crewai-with-local-ai-models)
|
||||
- [What makes Crews different from Flows?](#q-what-makes-crews-different-from-flows)
|
||||
- [How is CrewAI better than LangChain?](#q-how-is-crewai-better-than-langchain)
|
||||
- [Does CrewAI support fine-tuning or training custom models?](#q-does-crewai-support-fine-tuning-or-training-custom-models)
|
||||
|
||||
### Resources and Community
|
||||
- [Where can I find real-world CrewAI examples?](#q-where-can-i-find-real-world-crewai-examples)
|
||||
- [How can I contribute to CrewAI?](#q-how-can-i-contribute-to-crewai)
|
||||
|
||||
### Enterprise Features
|
||||
- [What additional features does CrewAI Enterprise offer?](#q-what-additional-features-does-crewai-enterprise-offer)
|
||||
- [Is CrewAI Enterprise available for cloud and on-premise deployments?](#q-is-crewai-enterprise-available-for-cloud-and-on-premise-deployments)
|
||||
- [Can I try CrewAI Enterprise for free?](#q-can-i-try-crewai-enterprise-for-free)
|
||||
|
||||
|
||||
|
||||
### Q: What exactly is CrewAI?
|
||||
A: CrewAI is a standalone, lean, and fast Python framework built specifically for orchestrating autonomous AI agents. Unlike frameworks like LangChain, CrewAI does not rely on external dependencies, making it leaner, faster, and simpler.
|
||||
|
||||
### Q: How do I install CrewAI?
|
||||
A: You can install CrewAI using pip:
|
||||
A: Install CrewAI using pip:
|
||||
```shell
|
||||
pip install crewai
|
||||
```
|
||||
@@ -421,24 +646,62 @@ For additional tools, use:
|
||||
```shell
|
||||
pip install 'crewai[tools]'
|
||||
```
|
||||
### Q: Does CrewAI depend on LangChain?
|
||||
A: No. CrewAI is built entirely from the ground up, with no dependencies on LangChain or other agent frameworks. This ensures a lean, fast, and flexible experience.
|
||||
|
||||
### Q: Can I use CrewAI with local models?
|
||||
A: Yes, CrewAI supports various LLMs, including local models. You can configure your agents to use local models via tools like Ollama & LM Studio. Check the [LLM Connections documentation](https://docs.crewai.com/how-to/LLM-Connections/) for more details.
|
||||
### Q: Can CrewAI handle complex use cases?
|
||||
A: Yes. CrewAI excels at both simple and highly complex real-world scenarios, offering deep customization options at both high and low levels, from internal prompts to sophisticated workflow orchestration.
|
||||
|
||||
### Q: What are the key features of CrewAI?
|
||||
A: Key features include role-based agent design, autonomous inter-agent delegation, flexible task management, process-driven execution, output saving as files, and compatibility with both open-source and proprietary models.
|
||||
### Q: Can I use CrewAI with local AI models?
|
||||
A: Absolutely! CrewAI supports various language models, including local ones. Tools like Ollama and LM Studio allow seamless integration. Check the [LLM Connections documentation](https://docs.crewai.com/how-to/LLM-Connections/) for more details.
|
||||
|
||||
### Q: How does CrewAI compare to other AI orchestration tools?
|
||||
A: CrewAI is designed with production in mind, offering flexibility similar to Autogen's conversational agents and structured processes like ChatDev, but with more adaptability for real-world applications.
|
||||
### Q: What makes Crews different from Flows?
|
||||
A: Crews provide autonomous agent collaboration, ideal for tasks requiring flexible decision-making and dynamic interaction. Flows offer precise, event-driven control, ideal for managing detailed execution paths and secure state management. You can seamlessly combine both for maximum effectiveness.
|
||||
|
||||
### Q: How is CrewAI better than LangChain?
|
||||
A: CrewAI provides simpler, more intuitive APIs, faster execution speeds, more reliable and consistent results, robust documentation, and an active community—addressing common criticisms and limitations associated with LangChain.
|
||||
|
||||
### Q: Is CrewAI open-source?
|
||||
A: Yes, CrewAI is open-source and welcomes contributions from the community.
|
||||
A: Yes, CrewAI is open-source and actively encourages community contributions and collaboration.
|
||||
|
||||
### Q: Does CrewAI collect any data?
|
||||
A: CrewAI uses anonymous telemetry to collect usage data for improvement purposes. No sensitive data (like prompts, task descriptions, or API calls) is collected. Users can opt-in to share more detailed data by setting `share_crew=True` on their Crews.
|
||||
### Q: Does CrewAI collect data from users?
|
||||
A: CrewAI collects anonymous telemetry data strictly for improvement purposes. Sensitive data such as prompts, tasks, or API responses are never collected unless explicitly enabled by the user.
|
||||
|
||||
### Q: Where can I find examples of CrewAI in action?
|
||||
A: You can find various real-life examples in the [CrewAI-examples repository](https://github.com/crewAIInc/crewAI-examples), including trip planners, stock analysis tools, and more.
|
||||
### Q: Where can I find real-world CrewAI examples?
|
||||
A: Check out practical examples in the [CrewAI-examples repository](https://github.com/crewAIInc/crewAI-examples), covering use cases like trip planners, stock analysis, and job postings.
|
||||
|
||||
### Q: How can I contribute to CrewAI?
|
||||
A: Contributions are welcome! You can fork the repository, create a new branch for your feature, add your improvement, and send a pull request. Check the Contribution section in the README for more details.
|
||||
A: Contributions are warmly welcomed! Fork the repository, create your branch, implement your changes, and submit a pull request. See the Contribution section of the README for detailed guidelines.
|
||||
|
||||
### Q: What additional features does CrewAI Enterprise offer?
|
||||
A: CrewAI Enterprise provides advanced features such as a unified control plane, real-time observability, secure integrations, advanced security, actionable insights, and dedicated 24/7 enterprise support.
|
||||
|
||||
### Q: Is CrewAI Enterprise available for cloud and on-premise deployments?
|
||||
A: Yes, CrewAI Enterprise supports both cloud-based and on-premise deployment options, allowing enterprises to meet their specific security and compliance requirements.
|
||||
|
||||
### Q: Can I try CrewAI Enterprise for free?
|
||||
A: Yes, you can explore part of the CrewAI Enterprise Suite by accessing the [Crew Control Plane](https://app.crewai.com) for free.
|
||||
|
||||
### Q: Does CrewAI support fine-tuning or training custom models?
|
||||
A: Yes, CrewAI can integrate with custom-trained or fine-tuned models, allowing you to enhance your agents with domain-specific knowledge and accuracy.
|
||||
|
||||
### Q: Can CrewAI agents interact with external tools and APIs?
|
||||
A: Absolutely! CrewAI agents can easily integrate with external tools, APIs, and databases, empowering them to leverage real-world data and resources.
|
||||
|
||||
### Q: Is CrewAI suitable for production environments?
|
||||
A: Yes, CrewAI is explicitly designed with production-grade standards, ensuring reliability, stability, and scalability for enterprise deployments.
|
||||
|
||||
### Q: How scalable is CrewAI?
|
||||
A: CrewAI is highly scalable, supporting simple automations and large-scale enterprise workflows involving numerous agents and complex tasks simultaneously.
|
||||
|
||||
### Q: Does CrewAI offer debugging and monitoring tools?
|
||||
A: Yes, CrewAI Enterprise includes advanced debugging, tracing, and real-time observability features, simplifying the management and troubleshooting of your automations.
|
||||
|
||||
### Q: What programming languages does CrewAI support?
|
||||
A: CrewAI is primarily Python-based but easily integrates with services and APIs written in any programming language through its flexible API integration capabilities.
|
||||
|
||||
### Q: Does CrewAI offer educational resources for beginners?
|
||||
A: Yes, CrewAI provides extensive beginner-friendly tutorials, courses, and documentation through learn.crewai.com, supporting developers at all skill levels.
|
||||
|
||||
### Q: Can CrewAI automate human-in-the-loop workflows?
|
||||
A: Yes, CrewAI fully supports human-in-the-loop workflows, allowing seamless collaboration between human experts and AI agents for enhanced decision-making.
|
||||
|
||||
BIN
docs/asset.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 66 KiB |
217
docs/changelog.mdx
Normal file
@@ -0,0 +1,217 @@
|
||||
---
|
||||
title: Changelog
|
||||
description: View the latest updates and changes to CrewAI
|
||||
icon: timeline
|
||||
---
|
||||
|
||||
<Update label="2025-04-07" description="v0.114.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/v01140.png" />
|
||||
</Frame>
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Agents as an atomic unit. (`Agent(...).kickoff()`)
|
||||
- Support for [Custom LLM implementations](https://docs.crewai.com/guides/advanced/custom-llm).
|
||||
- Integrated External Memory and [Opik observability](https://docs.crewai.com/how-to/opik-observability).
|
||||
- Enhanced YAML extraction.
|
||||
- Multimodal agent validation.
|
||||
- Added Secure fingerprints for agents and crews.
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Improved serialization, agent copying, and Python compatibility.
|
||||
- Added wildcard support to `emit()`
|
||||
- Added support for additional router calls and context window adjustments.
|
||||
- Fixed typing issues, validation, and import statements.
|
||||
- Improved method performance.
|
||||
- Enhanced agent task handling, event emissions, and memory management.
|
||||
- Fixed CLI issues, conditional tasks, cloning behavior, and tool outputs.
|
||||
|
||||
**Documentation & Guides**
|
||||
- Improved documentation structure, theme, and organization.
|
||||
- Added guides for Local NVIDIA NIM with WSL2, W&B Weave, and Arize Phoenix.
|
||||
- Updated tool configuration examples, prompts, and observability docs.
|
||||
- Guide on using singular agents within Flows.
|
||||
</Update>
|
||||
|
||||
<Update label="2025-03-17" description="v0.108.0">
|
||||
**Features**
|
||||
- Converted tabs to spaces in `crew.py` template
|
||||
- Enhanced LLM Streaming Response Handling and Event System
|
||||
- Included `model_name`
|
||||
- Enhanced Event Listener with rich visualization and improved logging
|
||||
- Added fingerprints
|
||||
|
||||
**Bug Fixes**
|
||||
- Fixed Mistral issues
|
||||
- Fixed a bug in documentation
|
||||
- Fixed type check error in fingerprint property
|
||||
|
||||
**Documentation Updates**
|
||||
- Improved tool documentation
|
||||
- Updated installation guide for the `uv` tool package
|
||||
- Added instructions for upgrading crewAI with the `uv` tool
|
||||
- Added documentation for `ApifyActorsTool`
|
||||
</Update>
|
||||
|
||||
<Update label="2025-03-10" description="v0.105.0">
|
||||
**Core Improvements & Fixes**
|
||||
- Fixed issues with missing template variables and user memory configuration
|
||||
- Improved async flow support and addressed agent response formatting
|
||||
- Enhanced memory reset functionality and fixed CLI memory commands
|
||||
- Fixed type issues, tool calling properties, and telemetry decoupling
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Added Flow state export and improved state utilities
|
||||
- Enhanced agent knowledge setup with optional crew embedder
|
||||
- Introduced event emitter for better observability and LLM call tracking
|
||||
- Added support for Python 3.10 and ChatOllama from langchain_ollama
|
||||
- Integrated context window size support for the o3-mini model
|
||||
- Added support for multiple router calls
|
||||
|
||||
**Documentation & Guides**
|
||||
- Improved documentation layout and hierarchical structure
|
||||
- Added QdrantVectorSearchTool guide and clarified event listener usage
|
||||
- Fixed typos in prompts and updated Amazon Bedrock model listings
|
||||
</Update>
|
||||
|
||||
<Update label="2025-02-12" description="v0.102.0">
|
||||
**Core Improvements & Fixes**
|
||||
- Enhanced LLM Support: Improved structured LLM output, parameter handling, and formatting for Anthropic models
|
||||
- Crew & Agent Stability: Fixed issues with cloning agents/crews using knowledge sources, multiple task outputs in conditional tasks, and ignored Crew task callbacks
|
||||
- Memory & Storage Fixes: Fixed short-term memory handling with Bedrock, ensured correct embedder initialization, and added a reset memories function in the crew class
|
||||
- Training & Execution Reliability: Fixed broken training and interpolation issues with dict and list input types
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Advanced Knowledge Management: Improved naming conventions and enhanced embedding configuration with custom embedder support
|
||||
- Expanded Logging & Observability: Added JSON format support for logging and integrated MLflow tracing documentation
|
||||
- Data Handling Improvements: Updated excel_knowledge_source.py to process multi-tab files
|
||||
- General Performance & Codebase Clean-Up: Streamlined enterprise code alignment and resolved linting issues
|
||||
- Adding new tool: `QdrantVectorSearchTool`
|
||||
|
||||
**Documentation & Guides**
|
||||
- Updated AI & Memory Docs: Improved Bedrock, Google AI, and long-term memory documentation
|
||||
- Task & Workflow Clarity: Added "Human Input" row to Task Attributes, Langfuse guide, and FileWriterTool documentation
|
||||
- Fixed Various Typos & Formatting Issues
|
||||
</Update>
|
||||
|
||||
<Update label="2025-01-28" description="v0.100.0">
|
||||
**Features**
|
||||
- Add Composio docs
|
||||
- Add SageMaker as a LLM provider
|
||||
|
||||
**Fixes**
|
||||
- Overall LLM connection issues
|
||||
- Using safe accessors on training
|
||||
- Add version check to crew_chat.py
|
||||
|
||||
**Documentation**
|
||||
- New docs for crewai chat
|
||||
- Improve formatting and clarity in CLI and Composio Tool docs
|
||||
</Update>
|
||||
|
||||
<Update label="2025-01-20" description="v0.98.0">
|
||||
**Features**
|
||||
- Conversation crew v1
|
||||
- Add unique ID to flow states
|
||||
- Add @persist decorator with FlowPersistence interface
|
||||
|
||||
**Integrations**
|
||||
- Add SambaNova integration
|
||||
- Add NVIDIA NIM provider in cli
|
||||
- Introducing VoyageAI
|
||||
|
||||
**Fixes**
|
||||
- Fix API Key Behavior and Entity Handling in Mem0 Integration
|
||||
- Fixed core invoke loop logic and relevant tests
|
||||
- Make tool inputs actual objects and not strings
|
||||
- Add important missing parts to creating tools
|
||||
- Drop litellm version to prevent windows issue
|
||||
- Before kickoff if inputs are none
|
||||
- Fixed typos, nested pydantic model issue, and docling issues
|
||||
</Update>
|
||||
|
||||
<Update label="2025-01-04" description="v0.95.0">
|
||||
**New Features**
|
||||
- Adding Multimodal Abilities to Crew
|
||||
- Programatic Guardrails
|
||||
- HITL multiple rounds
|
||||
- Gemini 2.0 Support
|
||||
- CrewAI Flows Improvements
|
||||
- Add Workflow Permissions
|
||||
- Add support for langfuse with litellm
|
||||
- Portkey Integration with CrewAI
|
||||
- Add interpolate_only method and improve error handling
|
||||
- Docling Support
|
||||
- Weviate Support
|
||||
|
||||
**Fixes**
|
||||
- output_file not respecting system path
|
||||
- disk I/O error when resetting short-term memory
|
||||
- CrewJSONEncoder now accepts enums
|
||||
- Python max version
|
||||
- Interpolation for output_file in Task
|
||||
- Handle coworker role name case/whitespace properly
|
||||
- Add tiktoken as explicit dependency and document Rust requirement
|
||||
- Include agent knowledge in planning process
|
||||
- Change storage initialization to None for KnowledgeStorage
|
||||
- Fix optional storage checks
|
||||
- include event emitter in flows
|
||||
- Docstring, Error Handling, and Type Hints Improvements
|
||||
- Suppressed userWarnings from litellm pydantic issues
|
||||
</Update>
|
||||
|
||||
<Update label="2024-12-05" description="v0.86.0">
|
||||
**Changes**
|
||||
- Remove all references to pipeline and pipeline router
|
||||
- Add Nvidia NIM as provider in Custom LLM
|
||||
- Add knowledge demo + improve knowledge docs
|
||||
- Add HITL multiple rounds of followup
|
||||
- New docs about yaml crew with decorators
|
||||
- Simplify template crew
|
||||
</Update>
|
||||
|
||||
<Update label="2024-12-04" description="v0.85.0">
|
||||
**Features**
|
||||
- Added knowledge to agent level
|
||||
- Feat/remove langchain
|
||||
- Improve typed task outputs
|
||||
- Log in to Tool Repository on crewai login
|
||||
|
||||
**Fixes**
|
||||
- Fixes issues with result as answer not properly exiting LLM loop
|
||||
- Fix missing key name when running with ollama provider
|
||||
- Fix spelling issue found
|
||||
|
||||
**Documentation**
|
||||
- Update readme for running mypy
|
||||
- Add knowledge to mint.json
|
||||
- Update Github actions
|
||||
- Update Agents docs to include two approaches for creating an agent
|
||||
- Improvements to LLM Configuration and Usage
|
||||
</Update>
|
||||
|
||||
<Update label="2024-11-25" description="v0.83.0">
|
||||
**New Features**
|
||||
- New before_kickoff and after_kickoff crew callbacks
|
||||
- Support to pre-seed agents with Knowledge
|
||||
- Add support for retrieving user preferences and memories using Mem0
|
||||
|
||||
**Fixes**
|
||||
- Fix Async Execution
|
||||
- Upgrade chroma and adjust embedder function generator
|
||||
- Update CLI Watson supported models + docs
|
||||
- Reduce level for Bandit
|
||||
- Fixing all tests
|
||||
|
||||
**Documentation**
|
||||
- Update Docs
|
||||
</Update>
|
||||
|
||||
<Update label="2024-11-13" description="v0.80.0">
|
||||
**Fixes**
|
||||
- Fixing Tokens callback replacement bug
|
||||
- Fixing Step callback issue
|
||||
- Add cached prompt tokens info on usage metrics
|
||||
- Fix crew_train_success test
|
||||
</Update>
|
||||
BIN
docs/complexity_precision.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
@@ -1,159 +1,361 @@
|
||||
---
|
||||
title: Agents
|
||||
description: What are CrewAI Agents and how to use them.
|
||||
description: Detailed guide on creating and managing agents within the CrewAI framework.
|
||||
icon: robot
|
||||
---
|
||||
|
||||
## What is an agent?
|
||||
## Overview of an Agent
|
||||
|
||||
An agent is an **autonomous unit** programmed to:
|
||||
<ul>
|
||||
<li class='leading-3'>Perform tasks</li>
|
||||
<li class='leading-3'>Make decisions</li>
|
||||
<li class='leading-3'>Communicate with other agents</li>
|
||||
</ul>
|
||||
In the CrewAI framework, an `Agent` is an autonomous unit that can:
|
||||
- Perform specific tasks
|
||||
- Make decisions based on its role and goal
|
||||
- Use tools to accomplish objectives
|
||||
- Communicate and collaborate with other agents
|
||||
- Maintain memory of interactions
|
||||
- Delegate tasks when allowed
|
||||
|
||||
<Tip>
|
||||
Think of an agent as a member of a team, with specific skills and a particular job to do. Agents can have different roles like `Researcher`, `Writer`, or `Customer Support`, each contributing to the overall goal of the crew.
|
||||
Think of an agent as a specialized team member with specific skills, expertise, and responsibilities. For example, a `Researcher` agent might excel at gathering and analyzing information, while a `Writer` agent might be better at creating content.
|
||||
</Tip>
|
||||
|
||||
## Agent attributes
|
||||
<Note type="info" title="Enterprise Enhancement: Visual Agent Builder">
|
||||
CrewAI Enterprise includes a Visual Agent Builder that simplifies agent creation and configuration without writing code. Design your agents visually and test them in real-time.
|
||||
|
||||
| Attribute | Parameter | Description |
|
||||
| :------------------------- | :--------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Role** | `role` | Defines the agent's function within the crew. It determines the kind of tasks the agent is best suited for. |
|
||||
| **Goal** | `goal` | The individual objective that the agent aims to achieve. It guides the agent's decision-making process. |
|
||||
| **Backstory** | `backstory`| Provides context to the agent's role and goal, enriching the interaction and collaboration dynamics. |
|
||||
| **LLM** *(optional)* | `llm` | Represents the language model that will run the agent. It dynamically fetches the model name from the `OPENAI_MODEL_NAME` environment variable, defaulting to "gpt-4" if not specified. |
|
||||
| **Tools** *(optional)* | `tools` | Set of capabilities or functions that the agent can use to perform tasks. Expected to be instances of custom classes compatible with the agent's execution environment. Tools are initialized with a default value of an empty list. |
|
||||
| **Function Calling LLM** *(optional)* | `function_calling_llm` | Specifies the language model that will handle the tool calling for this agent, overriding the crew function calling LLM if passed. Default is `None`. |
|
||||
| **Max Iter** *(optional)* | `max_iter` | Max Iter is the maximum number of iterations the agent can perform before being forced to give its best answer. Default is `25`. |
|
||||
| **Max RPM** *(optional)* | `max_rpm` | Max RPM is the maximum number of requests per minute the agent can perform to avoid rate limits. It's optional and can be left unspecified, with a default value of `None`. |
|
||||
| **Max Execution Time** *(optional)* | `max_execution_time` | Max Execution Time is the maximum execution time for an agent to execute a task. It's optional and can be left unspecified, with a default value of `None`, meaning no max execution time. |
|
||||
| **Verbose** *(optional)* | `verbose` | Setting this to `True` configures the internal logger to provide detailed execution logs, aiding in debugging and monitoring. Default is `False`. |
|
||||
| **Allow Delegation** *(optional)* | `allow_delegation` | Agents can delegate tasks or questions to one another, ensuring that each task is handled by the most suitable agent. Default is `False`.
|
||||
| **Step Callback** *(optional)* | `step_callback` | A function that is called after each step of the agent. This can be used to log the agent's actions or to perform other operations. It will overwrite the crew `step_callback`. |
|
||||
| **Cache** *(optional)* | `cache` | Indicates if the agent should use a cache for tool usage. Default is `True`. |
|
||||
| **System Template** *(optional)* | `system_template` | Specifies the system format for the agent. Default is `None`. |
|
||||
| **Prompt Template** *(optional)* | `prompt_template` | Specifies the prompt format for the agent. Default is `None`. |
|
||||
| **Response Template** *(optional)* | `response_template` | Specifies the response format for the agent. Default is `None`. |
|
||||
| **Allow Code Execution** *(optional)* | `allow_code_execution` | Enable code execution for the agent. Default is `False`. |
|
||||
| **Max Retry Limit** *(optional)* | `max_retry_limit` | Maximum number of retries for an agent to execute a task when an error occurs. Default is `2`.
|
||||
| **Use System Prompt** *(optional)* | `use_system_prompt` | Adds the ability to not use system prompt (to support o1 models). Default is `True`. |
|
||||
| **Respect Context Window** *(optional)* | `respect_context_window` | Summary strategy to avoid overflowing the context window. Default is `True`. |
|
||||

|
||||
|
||||
## Creating an agent
|
||||
|
||||
<Note>
|
||||
**Agent interaction**: Agents can interact with each other using CrewAI's built-in delegation and communication mechanisms. This allows for dynamic task management and problem-solving within the crew.
|
||||
The Visual Agent Builder enables:
|
||||
- Intuitive agent configuration with form-based interfaces
|
||||
- Real-time testing and validation
|
||||
- Template library with pre-configured agent types
|
||||
- Easy customization of agent attributes and behaviors
|
||||
</Note>
|
||||
|
||||
To create an agent, you would typically initialize an instance of the `Agent` class with the desired properties. Here's a conceptual example including all attributes:
|
||||
## Agent Attributes
|
||||
|
||||
```python Code example
|
||||
| Attribute | Parameter | Type | Description |
|
||||
| :-------------------------------------- | :----------------------- | :---------------------------- | :------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Role** | `role` | `str` | Defines the agent's function and expertise within the crew. |
|
||||
| **Goal** | `goal` | `str` | The individual objective that guides the agent's decision-making. |
|
||||
| **Backstory** | `backstory` | `str` | Provides context and personality to the agent, enriching interactions. |
|
||||
| **LLM** _(optional)_ | `llm` | `Union[str, LLM, Any]` | Language model that powers the agent. Defaults to the model specified in `OPENAI_MODEL_NAME` or "gpt-4". |
|
||||
| **Tools** _(optional)_ | `tools` | `List[BaseTool]` | Capabilities or functions available to the agent. Defaults to an empty list. |
|
||||
| **Function Calling LLM** _(optional)_ | `function_calling_llm` | `Optional[Any]` | Language model for tool calling, overrides crew's LLM if specified. |
|
||||
| **Max Iterations** _(optional)_ | `max_iter` | `int` | Maximum iterations before the agent must provide its best answer. Default is 20. |
|
||||
| **Max RPM** _(optional)_ | `max_rpm` | `Optional[int]` | Maximum requests per minute to avoid rate limits. |
|
||||
| **Max Execution Time** _(optional)_ | `max_execution_time` | `Optional[int]` | Maximum time (in seconds) for task execution. |
|
||||
| **Memory** _(optional)_ | `memory` | `bool` | Whether the agent should maintain memory of interactions. Default is True. |
|
||||
| **Verbose** _(optional)_ | `verbose` | `bool` | Enable detailed execution logs for debugging. Default is False. |
|
||||
| **Allow Delegation** _(optional)_ | `allow_delegation` | `bool` | Allow the agent to delegate tasks to other agents. Default is False. |
|
||||
| **Step Callback** _(optional)_ | `step_callback` | `Optional[Any]` | Function called after each agent step, overrides crew callback. |
|
||||
| **Cache** _(optional)_ | `cache` | `bool` | Enable caching for tool usage. Default is True. |
|
||||
| **System Template** _(optional)_ | `system_template` | `Optional[str]` | Custom system prompt template for the agent. |
|
||||
| **Prompt Template** _(optional)_ | `prompt_template` | `Optional[str]` | Custom prompt template for the agent. |
|
||||
| **Response Template** _(optional)_ | `response_template` | `Optional[str]` | Custom response template for the agent. |
|
||||
| **Allow Code Execution** _(optional)_ | `allow_code_execution` | `Optional[bool]` | Enable code execution for the agent. Default is False. |
|
||||
| **Max Retry Limit** _(optional)_ | `max_retry_limit` | `int` | Maximum number of retries when an error occurs. Default is 2. |
|
||||
| **Respect Context Window** _(optional)_ | `respect_context_window` | `bool` | Keep messages under context window size by summarizing. Default is True. |
|
||||
| **Code Execution Mode** _(optional)_ | `code_execution_mode` | `Literal["safe", "unsafe"]` | Mode for code execution: 'safe' (using Docker) or 'unsafe' (direct). Default is 'safe'. |
|
||||
| **Embedder** _(optional)_ | `embedder` | `Optional[Dict[str, Any]]` | Configuration for the embedder used by the agent. |
|
||||
| **Knowledge Sources** _(optional)_ | `knowledge_sources` | `Optional[List[BaseKnowledgeSource]]` | Knowledge sources available to the agent. |
|
||||
| **Use System Prompt** _(optional)_ | `use_system_prompt` | `Optional[bool]` | Whether to use system prompt (for o1 model support). Default is True. |
|
||||
|
||||
## Creating Agents
|
||||
|
||||
There are two ways to create agents in CrewAI: using **YAML configuration (recommended)** or defining them **directly in code**.
|
||||
|
||||
### YAML Configuration (Recommended)
|
||||
|
||||
Using YAML configuration provides a cleaner, more maintainable way to define agents. We strongly recommend using this approach in your CrewAI projects.
|
||||
|
||||
After creating your CrewAI project as outlined in the [Installation](/installation) section, navigate to the `src/latest_ai_development/config/agents.yaml` file and modify the template to match your requirements.
|
||||
|
||||
<Note>
|
||||
Variables in your YAML files (like `{topic}`) will be replaced with values from your inputs when running the crew:
|
||||
```python Code
|
||||
crew.kickoff(inputs={'topic': 'AI Agents'})
|
||||
```
|
||||
</Note>
|
||||
|
||||
Here's an example of how to configure agents using YAML:
|
||||
|
||||
```yaml agents.yaml
|
||||
# src/latest_ai_development/config/agents.yaml
|
||||
researcher:
|
||||
role: >
|
||||
{topic} Senior Data Researcher
|
||||
goal: >
|
||||
Uncover cutting-edge developments in {topic}
|
||||
backstory: >
|
||||
You're a seasoned researcher with a knack for uncovering the latest
|
||||
developments in {topic}. Known for your ability to find the most relevant
|
||||
information and present it in a clear and concise manner.
|
||||
|
||||
reporting_analyst:
|
||||
role: >
|
||||
{topic} Reporting Analyst
|
||||
goal: >
|
||||
Create detailed reports based on {topic} data analysis and research findings
|
||||
backstory: >
|
||||
You're a meticulous analyst with a keen eye for detail. You're known for
|
||||
your ability to turn complex data into clear and concise reports, making
|
||||
it easy for others to understand and act on the information you provide.
|
||||
```
|
||||
|
||||
To use this YAML configuration in your code, create a crew class that inherits from `CrewBase`:
|
||||
|
||||
```python Code
|
||||
# src/latest_ai_development/crew.py
|
||||
from crewai import Agent, Crew, Process
|
||||
from crewai.project import CrewBase, agent, crew
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
@CrewBase
|
||||
class LatestAiDevelopmentCrew():
|
||||
"""LatestAiDevelopment crew"""
|
||||
|
||||
agents_config = "config/agents.yaml"
|
||||
|
||||
@agent
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['researcher'], # type: ignore[index]
|
||||
verbose=True,
|
||||
tools=[SerperDevTool()]
|
||||
)
|
||||
|
||||
@agent
|
||||
def reporting_analyst(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['reporting_analyst'], # type: ignore[index]
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
<Note>
|
||||
The names you use in your YAML files (`agents.yaml`) should match the method names in your Python code.
|
||||
</Note>
|
||||
|
||||
### Direct Code Definition
|
||||
|
||||
You can create agents directly in code by instantiating the `Agent` class. Here's a comprehensive example showing all available parameters:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
# Create an agent with all available parameters
|
||||
agent = Agent(
|
||||
role='Data Analyst',
|
||||
goal='Extract actionable insights',
|
||||
backstory="""You're a data analyst at a large company.
|
||||
You're responsible for analyzing data and providing insights
|
||||
to the business.
|
||||
You're currently working on a project to analyze the
|
||||
performance of our marketing campaigns.""",
|
||||
tools=[my_tool1, my_tool2], # Optional, defaults to an empty list
|
||||
llm=my_llm, # Optional
|
||||
function_calling_llm=my_llm, # Optional
|
||||
max_iter=15, # Optional
|
||||
max_rpm=None, # Optional
|
||||
max_execution_time=None, # Optional
|
||||
verbose=True, # Optional
|
||||
allow_delegation=False, # Optional
|
||||
step_callback=my_intermediate_step_callback, # Optional
|
||||
cache=True, # Optional
|
||||
system_template=my_system_template, # Optional
|
||||
prompt_template=my_prompt_template, # Optional
|
||||
response_template=my_response_template, # Optional
|
||||
config=my_config, # Optional
|
||||
crew=my_crew, # Optional
|
||||
tools_handler=my_tools_handler, # Optional
|
||||
cache_handler=my_cache_handler, # Optional
|
||||
callbacks=[callback1, callback2], # Optional
|
||||
allow_code_execution=True, # Optional
|
||||
max_retry_limit=2, # Optional
|
||||
use_system_prompt=True, # Optional
|
||||
respect_context_window=True, # Optional
|
||||
role="Senior Data Scientist",
|
||||
goal="Analyze and interpret complex datasets to provide actionable insights",
|
||||
backstory="With over 10 years of experience in data science and machine learning, "
|
||||
"you excel at finding patterns in complex datasets.",
|
||||
llm="gpt-4", # Default: OPENAI_MODEL_NAME or "gpt-4"
|
||||
function_calling_llm=None, # Optional: Separate LLM for tool calling
|
||||
memory=True, # Default: True
|
||||
verbose=False, # Default: False
|
||||
allow_delegation=False, # Default: False
|
||||
max_iter=20, # Default: 20 iterations
|
||||
max_rpm=None, # Optional: Rate limit for API calls
|
||||
max_execution_time=None, # Optional: Maximum execution time in seconds
|
||||
max_retry_limit=2, # Default: 2 retries on error
|
||||
allow_code_execution=False, # Default: False
|
||||
code_execution_mode="safe", # Default: "safe" (options: "safe", "unsafe")
|
||||
respect_context_window=True, # Default: True
|
||||
use_system_prompt=True, # Default: True
|
||||
tools=[SerperDevTool()], # Optional: List of tools
|
||||
knowledge_sources=None, # Optional: List of knowledge sources
|
||||
embedder=None, # Optional: Custom embedder configuration
|
||||
system_template=None, # Optional: Custom system prompt template
|
||||
prompt_template=None, # Optional: Custom prompt template
|
||||
response_template=None, # Optional: Custom response template
|
||||
step_callback=None, # Optional: Callback function for monitoring
|
||||
)
|
||||
```
|
||||
|
||||
## Setting prompt templates
|
||||
Let's break down some key parameter combinations for common use cases:
|
||||
|
||||
Prompt templates are used to format the prompt for the agent. You can use to update the system, regular and response templates for the agent. Here's an example of how to set prompt templates:
|
||||
#### Basic Research Agent
|
||||
```python Code
|
||||
research_agent = Agent(
|
||||
role="Research Analyst",
|
||||
goal="Find and summarize information about specific topics",
|
||||
backstory="You are an experienced researcher with attention to detail",
|
||||
tools=[SerperDevTool()],
|
||||
verbose=True # Enable logging for debugging
|
||||
)
|
||||
```
|
||||
|
||||
```python Code example
|
||||
agent = Agent(
|
||||
role="{topic} specialist",
|
||||
goal="Figure {goal} out",
|
||||
backstory="I am the master of {role}",
|
||||
system_template="""<|start_header_id|>system<|end_header_id|>
|
||||
#### Code Development Agent
|
||||
```python Code
|
||||
dev_agent = Agent(
|
||||
role="Senior Python Developer",
|
||||
goal="Write and debug Python code",
|
||||
backstory="Expert Python developer with 10 years of experience",
|
||||
allow_code_execution=True,
|
||||
code_execution_mode="safe", # Uses Docker for safety
|
||||
max_execution_time=300, # 5-minute timeout
|
||||
max_retry_limit=3 # More retries for complex code tasks
|
||||
)
|
||||
```
|
||||
|
||||
#### Long-Running Analysis Agent
|
||||
```python Code
|
||||
analysis_agent = Agent(
|
||||
role="Data Analyst",
|
||||
goal="Perform deep analysis of large datasets",
|
||||
backstory="Specialized in big data analysis and pattern recognition",
|
||||
memory=True,
|
||||
respect_context_window=True,
|
||||
max_rpm=10, # Limit API calls
|
||||
function_calling_llm="gpt-4o-mini" # Cheaper model for tool calls
|
||||
)
|
||||
```
|
||||
|
||||
#### Custom Template Agent
|
||||
```python Code
|
||||
custom_agent = Agent(
|
||||
role="Customer Service Representative",
|
||||
goal="Assist customers with their inquiries",
|
||||
backstory="Experienced in customer support with a focus on satisfaction",
|
||||
system_template="""<|start_header_id|>system<|end_header_id|>
|
||||
{{ .System }}<|eot_id|>""",
|
||||
prompt_template="""<|start_header_id|>user<|end_header_id|>
|
||||
prompt_template="""<|start_header_id|>user<|end_header_id|>
|
||||
{{ .Prompt }}<|eot_id|>""",
|
||||
response_template="""<|start_header_id|>assistant<|end_header_id|>
|
||||
response_template="""<|start_header_id|>assistant<|end_header_id|>
|
||||
{{ .Response }}<|eot_id|>""",
|
||||
)
|
||||
```
|
||||
|
||||
## Bring your third-party agents
|
||||
### Parameter Details
|
||||
|
||||
Extend your third-party agents like LlamaIndex, Langchain, Autogen or fully custom agents using the the CrewAI's `BaseAgent` class.
|
||||
#### Critical Parameters
|
||||
- `role`, `goal`, and `backstory` are required and shape the agent's behavior
|
||||
- `llm` determines the language model used (default: OpenAI's GPT-4)
|
||||
|
||||
<Note>
|
||||
**BaseAgent** includes attributes and methods required to integrate with your crews to run and delegate tasks to other agents within your own crew.
|
||||
#### Memory and Context
|
||||
- `memory`: Enable to maintain conversation history
|
||||
- `respect_context_window`: Prevents token limit issues
|
||||
- `knowledge_sources`: Add domain-specific knowledge bases
|
||||
|
||||
#### Execution Control
|
||||
- `max_iter`: Maximum attempts before giving best answer
|
||||
- `max_execution_time`: Timeout in seconds
|
||||
- `max_rpm`: Rate limiting for API calls
|
||||
- `max_retry_limit`: Retries on error
|
||||
|
||||
#### Code Execution
|
||||
- `allow_code_execution`: Must be True to run code
|
||||
- `code_execution_mode`:
|
||||
- `"safe"`: Uses Docker (recommended for production)
|
||||
- `"unsafe"`: Direct execution (use only in trusted environments)
|
||||
|
||||
#### Templates
|
||||
- `system_template`: Defines agent's core behavior
|
||||
- `prompt_template`: Structures input format
|
||||
- `response_template`: Formats agent responses
|
||||
|
||||
<Note>
|
||||
When using custom templates, ensure that both `system_template` and `prompt_template` are defined. The `response_template` is optional but recommended for consistent output formatting.
|
||||
</Note>
|
||||
|
||||
<Note>
|
||||
When using custom templates, you can use variables like `{role}`, `{goal}`, and `{backstory}` in your templates. These will be automatically populated during execution.
|
||||
</Note>
|
||||
|
||||
CrewAI is a universal multi-agent framework that allows for all agents to work together to automate tasks and solve problems.
|
||||
## Agent Tools
|
||||
|
||||
```python Code example
|
||||
from crewai import Agent, Task, Crew
|
||||
from custom_agent import CustomAgent # You need to build and extend your own agent logic with the CrewAI BaseAgent class then import it here.
|
||||
Agents can be equipped with various tools to enhance their capabilities. CrewAI supports tools from:
|
||||
- [CrewAI Toolkit](https://github.com/joaomdmoura/crewai-tools)
|
||||
- [LangChain Tools](https://python.langchain.com/docs/integrations/tools)
|
||||
|
||||
from langchain.agents import load_tools
|
||||
Here's how to add tools to an agent:
|
||||
|
||||
langchain_tools = load_tools(["google-serper"], llm=llm)
|
||||
```python Code
|
||||
from crewai import Agent
|
||||
from crewai_tools import SerperDevTool, WikipediaTools
|
||||
|
||||
agent1 = CustomAgent(
|
||||
role="agent role",
|
||||
goal="who is {input}?",
|
||||
backstory="agent backstory",
|
||||
verbose=True,
|
||||
# Create tools
|
||||
search_tool = SerperDevTool()
|
||||
wiki_tool = WikipediaTools()
|
||||
|
||||
# Add tools to agent
|
||||
researcher = Agent(
|
||||
role="AI Technology Researcher",
|
||||
goal="Research the latest AI developments",
|
||||
tools=[search_tool, wiki_tool],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
task1 = Task(
|
||||
expected_output="a short biography of {input}",
|
||||
description="a short biography of {input}",
|
||||
agent=agent1,
|
||||
)
|
||||
|
||||
agent2 = Agent(
|
||||
role="agent role",
|
||||
goal="summarize the short bio for {input} and if needed do more research",
|
||||
backstory="agent backstory",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task2 = Task(
|
||||
description="a tldr summary of the short biography",
|
||||
expected_output="5 bullet point summary of the biography",
|
||||
agent=agent2,
|
||||
context=[task1],
|
||||
)
|
||||
|
||||
my_crew = Crew(agents=[agent1, agent2], tasks=[task1, task2])
|
||||
crew = my_crew.kickoff(inputs={"input": "Mark Twain"})
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
## Agent Memory and Context
|
||||
|
||||
Agents are the building blocks of the CrewAI framework. By understanding how to define and interact with agents,
|
||||
you can create sophisticated AI systems that leverage the power of collaborative intelligence.
|
||||
Agents can maintain memory of their interactions and use context from previous tasks. This is particularly useful for complex workflows where information needs to be retained across multiple tasks.
|
||||
|
||||
```python Code
|
||||
from crewai import Agent
|
||||
|
||||
analyst = Agent(
|
||||
role="Data Analyst",
|
||||
goal="Analyze and remember complex data patterns",
|
||||
memory=True, # Enable memory
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
<Note>
|
||||
When `memory` is enabled, the agent will maintain context across multiple interactions, improving its ability to handle complex, multi-step tasks.
|
||||
</Note>
|
||||
|
||||
## Important Considerations and Best Practices
|
||||
|
||||
### Security and Code Execution
|
||||
- When using `allow_code_execution`, be cautious with user input and always validate it
|
||||
- Use `code_execution_mode: "safe"` (Docker) in production environments
|
||||
- Consider setting appropriate `max_execution_time` limits to prevent infinite loops
|
||||
|
||||
### Performance Optimization
|
||||
- Use `respect_context_window: true` to prevent token limit issues
|
||||
- Set appropriate `max_rpm` to avoid rate limiting
|
||||
- Enable `cache: true` to improve performance for repetitive tasks
|
||||
- Adjust `max_iter` and `max_retry_limit` based on task complexity
|
||||
|
||||
### Memory and Context Management
|
||||
- Use `memory: true` for tasks requiring historical context
|
||||
- Leverage `knowledge_sources` for domain-specific information
|
||||
- Configure `embedder_config` when using custom embedding models
|
||||
- Use custom templates (`system_template`, `prompt_template`, `response_template`) for fine-grained control over agent behavior
|
||||
|
||||
### Agent Collaboration
|
||||
- Enable `allow_delegation: true` when agents need to work together
|
||||
- Use `step_callback` to monitor and log agent interactions
|
||||
- Consider using different LLMs for different purposes:
|
||||
- Main `llm` for complex reasoning
|
||||
- `function_calling_llm` for efficient tool usage
|
||||
|
||||
### Model Compatibility
|
||||
- Set `use_system_prompt: false` for older models that don't support system messages
|
||||
- Ensure your chosen `llm` supports the features you need (like function calling)
|
||||
|
||||
## Troubleshooting Common Issues
|
||||
|
||||
1. **Rate Limiting**: If you're hitting API rate limits:
|
||||
- Implement appropriate `max_rpm`
|
||||
- Use caching for repetitive operations
|
||||
- Consider batching requests
|
||||
|
||||
2. **Context Window Errors**: If you're exceeding context limits:
|
||||
- Enable `respect_context_window`
|
||||
- Use more efficient prompts
|
||||
- Clear agent memory periodically
|
||||
|
||||
3. **Code Execution Issues**: If code execution fails:
|
||||
- Verify Docker is installed for safe mode
|
||||
- Check execution permissions
|
||||
- Review code sandbox settings
|
||||
|
||||
4. **Memory Issues**: If agent responses seem inconsistent:
|
||||
- Verify memory is enabled
|
||||
- Check knowledge source configuration
|
||||
- Review conversation history management
|
||||
|
||||
Remember that agents are most effective when configured according to their specific use case. Take time to understand your requirements and adjust these parameters accordingly.
|
||||
|
||||
@@ -6,13 +6,13 @@ icon: terminal
|
||||
|
||||
# CrewAI CLI Documentation
|
||||
|
||||
The CrewAI CLI provides a set of commands to interact with CrewAI, allowing you to create, train, run, and manage crews and pipelines.
|
||||
The CrewAI CLI provides a set of commands to interact with CrewAI, allowing you to create, train, run, and manage crews & flows.
|
||||
|
||||
## Installation
|
||||
|
||||
To use the CrewAI CLI, make sure you have CrewAI installed:
|
||||
|
||||
```shell
|
||||
```shell Terminal
|
||||
pip install crewai
|
||||
```
|
||||
|
||||
@@ -20,7 +20,7 @@ pip install crewai
|
||||
|
||||
The basic structure of a CrewAI CLI command is:
|
||||
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai [COMMAND] [OPTIONS] [ARGUMENTS]
|
||||
```
|
||||
|
||||
@@ -28,34 +28,33 @@ crewai [COMMAND] [OPTIONS] [ARGUMENTS]
|
||||
|
||||
### 1. Create
|
||||
|
||||
Create a new crew or pipeline.
|
||||
Create a new crew or flow.
|
||||
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai create [OPTIONS] TYPE NAME
|
||||
```
|
||||
|
||||
- `TYPE`: Choose between "crew" or "pipeline"
|
||||
- `NAME`: Name of the crew or pipeline
|
||||
- `--router`: (Optional) Create a pipeline with router functionality
|
||||
- `TYPE`: Choose between "crew" or "flow"
|
||||
- `NAME`: Name of the crew or flow
|
||||
|
||||
Example:
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai create crew my_new_crew
|
||||
crewai create pipeline my_new_pipeline --router
|
||||
crewai create flow my_new_flow
|
||||
```
|
||||
|
||||
### 2. Version
|
||||
|
||||
Show the installed version of CrewAI.
|
||||
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai version [OPTIONS]
|
||||
```
|
||||
|
||||
- `--tools`: (Optional) Show the installed version of CrewAI tools
|
||||
|
||||
Example:
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai version
|
||||
crewai version --tools
|
||||
```
|
||||
@@ -64,7 +63,7 @@ crewai version --tools
|
||||
|
||||
Train the crew for a specified number of iterations.
|
||||
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai train [OPTIONS]
|
||||
```
|
||||
|
||||
@@ -72,7 +71,7 @@ crewai train [OPTIONS]
|
||||
- `-f, --filename TEXT`: Path to a custom file for training (default: "trained_agents_data.pkl")
|
||||
|
||||
Example:
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai train -n 10 -f my_training_data.pkl
|
||||
```
|
||||
|
||||
@@ -80,14 +79,14 @@ crewai train -n 10 -f my_training_data.pkl
|
||||
|
||||
Replay the crew execution from a specific task.
|
||||
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai replay [OPTIONS]
|
||||
```
|
||||
|
||||
- `-t, --task_id TEXT`: Replay the crew from this task ID, including all subsequent tasks
|
||||
|
||||
Example:
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai replay -t task_123456
|
||||
```
|
||||
|
||||
@@ -95,7 +94,7 @@ crewai replay -t task_123456
|
||||
|
||||
Retrieve your latest crew.kickoff() task outputs.
|
||||
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai log-tasks-outputs
|
||||
```
|
||||
|
||||
@@ -103,7 +102,7 @@ crewai log-tasks-outputs
|
||||
|
||||
Reset the crew memories (long, short, entity, latest_crew_kickoff_outputs).
|
||||
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai reset-memories [OPTIONS]
|
||||
```
|
||||
|
||||
@@ -114,7 +113,7 @@ crewai reset-memories [OPTIONS]
|
||||
- `-a, --all`: Reset ALL memories
|
||||
|
||||
Example:
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai reset-memories --long --short
|
||||
crewai reset-memories --all
|
||||
```
|
||||
@@ -123,7 +122,7 @@ crewai reset-memories --all
|
||||
|
||||
Test the crew and evaluate the results.
|
||||
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai test [OPTIONS]
|
||||
```
|
||||
|
||||
@@ -131,18 +130,153 @@ crewai test [OPTIONS]
|
||||
- `-m, --model TEXT`: LLM Model to run the tests on the Crew (default: "gpt-4o-mini")
|
||||
|
||||
Example:
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai test -n 5 -m gpt-3.5-turbo
|
||||
```
|
||||
|
||||
### 8. Run
|
||||
|
||||
Run the crew.
|
||||
Run the crew or flow.
|
||||
|
||||
```shell
|
||||
```shell Terminal
|
||||
crewai run
|
||||
```
|
||||
|
||||
<Note>
|
||||
Starting from version 0.103.0, the `crewai run` command can be used to run both standard crews and flows. For flows, it automatically detects the type from pyproject.toml and runs the appropriate command. This is now the recommended way to run both crews and flows.
|
||||
</Note>
|
||||
|
||||
<Note>
|
||||
Make sure to run these commands from the directory where your CrewAI project is set up.
|
||||
Some commands may require additional configuration or setup within your project structure.
|
||||
</Note>
|
||||
|
||||
### 9. Chat
|
||||
|
||||
Starting in version `0.98.0`, when you run the `crewai chat` command, you start an interactive session with your crew. The AI assistant will guide you by asking for necessary inputs to execute the crew. Once all inputs are provided, the crew will execute its tasks.
|
||||
|
||||
After receiving the results, you can continue interacting with the assistant for further instructions or questions.
|
||||
|
||||
```shell Terminal
|
||||
crewai chat
|
||||
```
|
||||
<Note>
|
||||
Ensure you execute these commands from your CrewAI project's root directory.
|
||||
</Note>
|
||||
<Note>
|
||||
IMPORTANT: Set the `chat_llm` property in your `crew.py` file to enable this command.
|
||||
|
||||
```python
|
||||
@crew
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=self.agents,
|
||||
tasks=self.tasks,
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
chat_llm="gpt-4o", # LLM for chat orchestration
|
||||
)
|
||||
```
|
||||
</Note>
|
||||
|
||||
### 10. Deploy
|
||||
|
||||
Deploy the crew or flow to [CrewAI Enterprise](https://app.crewai.com).
|
||||
|
||||
- **Authentication**: You need to be authenticated to deploy to CrewAI Enterprise.
|
||||
```shell Terminal
|
||||
crewai signup
|
||||
```
|
||||
If you already have an account, you can login with:
|
||||
```shell Terminal
|
||||
crewai login
|
||||
```
|
||||
|
||||
- **Create a deployment**: Once you are authenticated, you can create a deployment for your crew or flow from the root of your localproject.
|
||||
```shell Terminal
|
||||
crewai deploy create
|
||||
```
|
||||
- Reads your local project configuration.
|
||||
- Prompts you to confirm the environment variables (like `OPENAI_API_KEY`, `SERPER_API_KEY`) found locally. These will be securely stored with the deployment on the Enterprise platform. Ensure your sensitive keys are correctly configured locally (e.g., in a `.env` file) before running this.
|
||||
- Links the deployment to the corresponding remote GitHub repository (it usually detects this automatically).
|
||||
|
||||
- **Deploy the Crew**: Once you are authenticated, you can deploy your crew or flow to CrewAI Enterprise.
|
||||
```shell Terminal
|
||||
crewai deploy push
|
||||
```
|
||||
- Initiates the deployment process on the CrewAI Enterprise platform.
|
||||
- Upon successful initiation, it will output the Deployment created successfully! message along with the Deployment Name and a unique Deployment ID (UUID).
|
||||
|
||||
- **Deployment Status**: You can check the status of your deployment with:
|
||||
```shell Terminal
|
||||
crewai deploy status
|
||||
```
|
||||
This fetches the latest deployment status of your most recent deployment attempt (e.g., `Building Images for Crew`, `Deploy Enqueued`, `Online`).
|
||||
|
||||
- **Deployment Logs**: You can check the logs of your deployment with:
|
||||
```shell Terminal
|
||||
crewai deploy logs
|
||||
```
|
||||
This streams the deployment logs to your terminal.
|
||||
|
||||
- **List deployments**: You can list all your deployments with:
|
||||
```shell Terminal
|
||||
crewai deploy list
|
||||
```
|
||||
This lists all your deployments.
|
||||
|
||||
- **Delete a deployment**: You can delete a deployment with:
|
||||
```shell Terminal
|
||||
crewai deploy remove
|
||||
```
|
||||
This deletes the deployment from the CrewAI Enterprise platform.
|
||||
|
||||
- **Help Command**: You can get help with the CLI with:
|
||||
```shell Terminal
|
||||
crewai deploy --help
|
||||
```
|
||||
This shows the help message for the CrewAI Deploy CLI.
|
||||
|
||||
Watch this video tutorial for a step-by-step demonstration of deploying your crew to [CrewAI Enterprise](http://app.crewai.com) using the CLI.
|
||||
|
||||
<iframe
|
||||
width="100%"
|
||||
height="400"
|
||||
src="https://www.youtube.com/embed/3EqSV-CYDZA"
|
||||
title="CrewAI Deployment Guide"
|
||||
frameborder="0"
|
||||
style={{ borderRadius: '10px' }}
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
### 11. API Keys
|
||||
|
||||
When running ```crewai create crew``` command, the CLI will first show you the top 5 most common LLM providers and ask you to select one.
|
||||
|
||||
Once you've selected an LLM provider, you will be prompted for API keys.
|
||||
|
||||
#### Initial API key providers
|
||||
|
||||
The CLI will initially prompt for API keys for the following services:
|
||||
|
||||
* OpenAI
|
||||
* Groq
|
||||
* Anthropic
|
||||
* Google Gemini
|
||||
* SambaNova
|
||||
|
||||
When you select a provider, the CLI will prompt you to enter your API key.
|
||||
|
||||
#### Other Options
|
||||
|
||||
If you select option 6, you will be able to select from a list of LiteLLM supported providers.
|
||||
|
||||
When you select a provider, the CLI will prompt you to enter the Key name and the API key.
|
||||
|
||||
See the following link for each provider's key name:
|
||||
|
||||
* [LiteLLM Providers](https://docs.litellm.ai/docs/providers)
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -23,8 +23,7 @@ The `Crew` class has been enriched with several attributes to support advanced f
|
||||
| **Process Flow** (`process`) | Defines execution logic (e.g., sequential, hierarchical) for task distribution. |
|
||||
| **Verbose Logging** (`verbose`) | Provides detailed logging for monitoring and debugging. Accepts integer and boolean values to control verbosity level. |
|
||||
| **Rate Limiting** (`max_rpm`) | Limits requests per minute to optimize resource usage. Setting guidelines depend on task complexity and load. |
|
||||
| **Internationalization / Customization** (`language`, `prompt_file`) | Supports prompt customization for global usability. [Example of file](https://github.com/joaomdmoura/crewAI/blob/main/src/crewai/translations/en.json) |
|
||||
| **Execution and Output Handling** (`full_output`) | Controls output granularity, distinguishing between full and final outputs. |
|
||||
| **Internationalization / Customization** (`prompt_file`) | Supports prompt customization for global usability. [Example of file](https://github.com/joaomdmoura/crewAI/blob/main/src/crewai/translations/en.json) |
|
||||
| **Callback and Telemetry** (`step_callback`, `task_callback`) | Enables step-wise and task-level execution monitoring and telemetry for performance analytics. |
|
||||
| **Crew Sharing** (`share_crew`) | Allows sharing crew data with CrewAI for model improvement. Privacy implications and benefits should be considered. |
|
||||
| **Usage Metrics** (`usage_metrics`) | Logs all LLM usage metrics during task execution for performance insights. |
|
||||
@@ -49,4 +48,4 @@ Consider a crew with a researcher agent tasked with data gathering and a writer
|
||||
|
||||
## Conclusion
|
||||
|
||||
The integration of advanced attributes and functionalities into the CrewAI framework significantly enriches the agent collaboration ecosystem. These enhancements not only simplify interactions but also offer unprecedented flexibility and control, paving the way for sophisticated AI-driven solutions capable of tackling complex tasks through intelligent collaboration and delegation.
|
||||
The integration of advanced attributes and functionalities into the CrewAI framework significantly enriches the agent collaboration ecosystem. These enhancements not only simplify interactions but also offer unprecedented flexibility and control, paving the way for sophisticated AI-driven solutions capable of tackling complex tasks through intelligent collaboration and delegation.
|
||||
|
||||
@@ -20,18 +20,15 @@ A crew in crewAI represents a collaborative group of agents working together to
|
||||
| **Function Calling LLM** _(optional)_ | `function_calling_llm` | If passed, the crew will use this LLM to do function calling for tools for all agents in the crew. Each agent can have its own LLM, which overrides the crew's LLM for function calling. |
|
||||
| **Config** _(optional)_ | `config` | Optional configuration settings for the crew, in `Json` or `Dict[str, Any]` format. |
|
||||
| **Max RPM** _(optional)_ | `max_rpm` | Maximum requests per minute the crew adheres to during execution. Defaults to `None`. |
|
||||
| **Language** _(optional)_ | `language` | Language used for the crew, defaults to English. |
|
||||
| **Language File** _(optional)_ | `language_file` | Path to the language file to be used for the crew. |
|
||||
| **Memory** _(optional)_ | `memory` | Utilized for storing execution memories (short-term, long-term, entity memory). Defaults to `False`. |
|
||||
| **Cache** _(optional)_ | `cache` | Specifies whether to use a cache for storing the results of tools' execution. Defaults to `True`. |
|
||||
| **Embedder** _(optional)_ | `embedder` | Configuration for the embedder to be used by the crew. Mostly used by memory for now. Default is `{"provider": "openai"}`. |
|
||||
| **Full Output** _(optional)_ | `full_output` | Whether the crew should return the full output with all tasks outputs or just the final output. Defaults to `False`. |
|
||||
| **Memory** _(optional)_ | `memory` | Utilized for storing execution memories (short-term, long-term, entity memory). |
|
||||
| **Memory Config** _(optional)_ | `memory_config` | Configuration for the memory provider to be used by the crew. |
|
||||
| **Cache** _(optional)_ | `cache` | Specifies whether to use a cache for storing the results of tools' execution. Defaults to `True`. |
|
||||
| **Embedder** _(optional)_ | `embedder` | Configuration for the embedder to be used by the crew. Mostly used by memory for now. Default is `{"provider": "openai"}`. |
|
||||
| **Step Callback** _(optional)_ | `step_callback` | A function that is called after each step of every agent. This can be used to log the agent's actions or to perform other operations; it won't override the agent-specific `step_callback`. |
|
||||
| **Task Callback** _(optional)_ | `task_callback` | A function that is called after the completion of each task. Useful for monitoring or additional operations post-task execution. |
|
||||
| **Share Crew** _(optional)_ | `share_crew` | Whether you want to share the complete crew information and execution with the crewAI team to make the library better, and allow us to train models. |
|
||||
| **Output Log File** _(optional)_ | `output_log_file` | Whether you want to have a file with the complete crew output and execution. You can set it using True and it will default to the folder you are currently in and it will be called logs.txt or passing a string with the full path and name of the file. |
|
||||
| **Output Log File** _(optional)_ | `output_log_file` | Set to True to save logs as logs.txt in the current directory or provide a file path. Logs will be in JSON format if the filename ends in .json, otherwise .txt. Defautls to `None`. |
|
||||
| **Manager Agent** _(optional)_ | `manager_agent` | `manager` sets a custom agent that will be used as a manager. |
|
||||
| **Manager Callbacks** _(optional)_ | `manager_callbacks` | `manager_callbacks` takes a list of callback handlers to be executed by the manager agent when a hierarchical process is used. |
|
||||
| **Prompt File** _(optional)_ | `prompt_file` | Path to the prompt JSON file to be used for the crew. |
|
||||
| **Planning** *(optional)* | `planning` | Adds planning ability to the Crew. When activated before each Crew iteration, all Crew data is sent to an AgentPlanner that will plan the tasks and this plan will be added to each task description. |
|
||||
| **Planning LLM** *(optional)* | `planning_llm` | The language model used by the AgentPlanner in a planning process. |
|
||||
@@ -40,6 +37,159 @@ A crew in crewAI represents a collaborative group of agents working together to
|
||||
**Crew Max RPM**: The `max_rpm` attribute sets the maximum number of requests per minute the crew can perform to avoid rate limits and will override individual agents' `max_rpm` settings if you set it.
|
||||
</Tip>
|
||||
|
||||
## Creating Crews
|
||||
|
||||
There are two ways to create crews in CrewAI: using **YAML configuration (recommended)** or defining them **directly in code**.
|
||||
|
||||
### YAML Configuration (Recommended)
|
||||
|
||||
Using YAML configuration provides a cleaner, more maintainable way to define crews and is consistent with how agents and tasks are defined in CrewAI projects.
|
||||
|
||||
After creating your CrewAI project as outlined in the [Installation](/installation) section, you can define your crew in a class that inherits from `CrewBase` and uses decorators to define agents, tasks, and the crew itself.
|
||||
|
||||
#### Example Crew Class with Decorators
|
||||
|
||||
```python code
|
||||
from crewai import Agent, Crew, Task, Process
|
||||
from crewai.project import CrewBase, agent, task, crew, before_kickoff, after_kickoff
|
||||
from crewai.agents.agent_builder.base_agent import BaseAgent
|
||||
from typing import List
|
||||
|
||||
@CrewBase
|
||||
class YourCrewName:
|
||||
"""Description of your crew"""
|
||||
|
||||
agents: List[BaseAgent]
|
||||
tasks: List[Task]
|
||||
|
||||
# Paths to your YAML configuration files
|
||||
# To see an example agent and task defined in YAML, checkout the following:
|
||||
# - Task: https://docs.crewai.com/concepts/tasks#yaml-configuration-recommended
|
||||
# - Agents: https://docs.crewai.com/concepts/agents#yaml-configuration-recommended
|
||||
agents_config = 'config/agents.yaml'
|
||||
tasks_config = 'config/tasks.yaml'
|
||||
|
||||
@before_kickoff
|
||||
def prepare_inputs(self, inputs):
|
||||
# Modify inputs before the crew starts
|
||||
inputs['additional_data'] = "Some extra information"
|
||||
return inputs
|
||||
|
||||
@after_kickoff
|
||||
def process_output(self, output):
|
||||
# Modify output after the crew finishes
|
||||
output.raw += "\nProcessed after kickoff."
|
||||
return output
|
||||
|
||||
@agent
|
||||
def agent_one(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['agent_one'], # type: ignore[index]
|
||||
verbose=True
|
||||
)
|
||||
|
||||
@agent
|
||||
def agent_two(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['agent_two'], # type: ignore[index]
|
||||
verbose=True
|
||||
)
|
||||
|
||||
@task
|
||||
def task_one(self) -> Task:
|
||||
return Task(
|
||||
config=self.tasks_config['task_one'] # type: ignore[index]
|
||||
)
|
||||
|
||||
@task
|
||||
def task_two(self) -> Task:
|
||||
return Task(
|
||||
config=self.tasks_config['task_two'] # type: ignore[index]
|
||||
)
|
||||
|
||||
@crew
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=self.agents, # Automatically collected by the @agent decorator
|
||||
tasks=self.tasks, # Automatically collected by the @task decorator.
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
)
|
||||
```
|
||||
|
||||
<Note>
|
||||
Tasks will be executed in the order they are defined.
|
||||
</Note>
|
||||
|
||||
The `CrewBase` class, along with these decorators, automates the collection of agents and tasks, reducing the need for manual management.
|
||||
|
||||
#### Decorators overview from `annotations.py`
|
||||
|
||||
CrewAI provides several decorators in the `annotations.py` file that are used to mark methods within your crew class for special handling:
|
||||
|
||||
- `@CrewBase`: Marks the class as a crew base class.
|
||||
- `@agent`: Denotes a method that returns an `Agent` object.
|
||||
- `@task`: Denotes a method that returns a `Task` object.
|
||||
- `@crew`: Denotes the method that returns the `Crew` object.
|
||||
- `@before_kickoff`: (Optional) Marks a method to be executed before the crew starts.
|
||||
- `@after_kickoff`: (Optional) Marks a method to be executed after the crew finishes.
|
||||
|
||||
These decorators help in organizing your crew's structure and automatically collecting agents and tasks without manually listing them.
|
||||
|
||||
### Direct Code Definition (Alternative)
|
||||
|
||||
Alternatively, you can define the crew directly in code without using YAML configuration files.
|
||||
|
||||
```python code
|
||||
from crewai import Agent, Crew, Task, Process
|
||||
from crewai_tools import YourCustomTool
|
||||
|
||||
class YourCrewName:
|
||||
def agent_one(self) -> Agent:
|
||||
return Agent(
|
||||
role="Data Analyst",
|
||||
goal="Analyze data trends in the market",
|
||||
backstory="An experienced data analyst with a background in economics",
|
||||
verbose=True,
|
||||
tools=[YourCustomTool()]
|
||||
)
|
||||
|
||||
def agent_two(self) -> Agent:
|
||||
return Agent(
|
||||
role="Market Researcher",
|
||||
goal="Gather information on market dynamics",
|
||||
backstory="A diligent researcher with a keen eye for detail",
|
||||
verbose=True
|
||||
)
|
||||
|
||||
def task_one(self) -> Task:
|
||||
return Task(
|
||||
description="Collect recent market data and identify trends.",
|
||||
expected_output="A report summarizing key trends in the market.",
|
||||
agent=self.agent_one()
|
||||
)
|
||||
|
||||
def task_two(self) -> Task:
|
||||
return Task(
|
||||
description="Research factors affecting market dynamics.",
|
||||
expected_output="An analysis of factors influencing the market.",
|
||||
agent=self.agent_two()
|
||||
)
|
||||
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[self.agent_one(), self.agent_two()],
|
||||
tasks=[self.task_one(), self.task_two()],
|
||||
process=Process.sequential,
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
In this example:
|
||||
|
||||
- Agents and tasks are defined directly within the class without decorators.
|
||||
- We manually create and manage the list of agents and tasks.
|
||||
- This approach provides more control but can be less maintainable for larger projects.
|
||||
|
||||
## Crew Output
|
||||
|
||||
@@ -91,6 +241,23 @@ print(f"Tasks Output: {crew_output.tasks_output}")
|
||||
print(f"Token Usage: {crew_output.token_usage}")
|
||||
```
|
||||
|
||||
## Accessing Crew Logs
|
||||
|
||||
You can see real time log of the crew execution, by setting `output_log_file` as a `True(Boolean)` or a `file_name(str)`. Supports logging of events as both `file_name.txt` and `file_name.json`.
|
||||
In case of `True(Boolean)` will save as `logs.txt`.
|
||||
|
||||
In case of `output_log_file` is set as `False(Booelan)` or `None`, the logs will not be populated.
|
||||
|
||||
```python Code
|
||||
# Save crew logs
|
||||
crew = Crew(output_log_file = True) # Logs will be saved as logs.txt
|
||||
crew = Crew(output_log_file = file_name) # Logs will be saved as file_name.txt
|
||||
crew = Crew(output_log_file = file_name.txt) # Logs will be saved as file_name.txt
|
||||
crew = Crew(output_log_file = file_name.json) # Logs will be saved as file_name.json
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Memory Utilization
|
||||
|
||||
Crews can utilize memory (short-term, long-term, and entity memory) to enhance their execution and learning over time. This feature allows crews to store and recall execution memories, aiding in decision-making and task execution strategies.
|
||||
@@ -130,9 +297,9 @@ print(result)
|
||||
Once your crew is assembled, initiate the workflow with the appropriate kickoff method. CrewAI provides several methods for better control over the kickoff process: `kickoff()`, `kickoff_for_each()`, `kickoff_async()`, and `kickoff_for_each_async()`.
|
||||
|
||||
- `kickoff()`: Starts the execution process according to the defined process flow.
|
||||
- `kickoff_for_each()`: Executes tasks for each agent individually.
|
||||
- `kickoff_for_each()`: Executes tasks sequentially for each provided input event or item in the collection.
|
||||
- `kickoff_async()`: Initiates the workflow asynchronously.
|
||||
- `kickoff_for_each_async()`: Executes tasks for each agent individually in an asynchronous manner.
|
||||
- `kickoff_for_each_async()`: Executes tasks concurrently for each provided input event or item, leveraging asynchronous processing.
|
||||
|
||||
```python Code
|
||||
# Start the crew's task execution
|
||||
@@ -187,4 +354,4 @@ Then, to replay from a specific task, use:
|
||||
crewai replay -t <task_id>
|
||||
```
|
||||
|
||||
These commands let you replay from your latest kickoff tasks, still retaining context from previously executed tasks.
|
||||
These commands let you replay from your latest kickoff tasks, still retaining context from previously executed tasks.
|
||||
|
||||
365
docs/concepts/event-listener.mdx
Normal file
@@ -0,0 +1,365 @@
|
||||
---
|
||||
title: 'Event Listeners'
|
||||
description: 'Tap into CrewAI events to build custom integrations and monitoring'
|
||||
icon: spinner
|
||||
---
|
||||
|
||||
# Event Listeners
|
||||
|
||||
CrewAI provides a powerful event system that allows you to listen for and react to various events that occur during the execution of your Crew. This feature enables you to build custom integrations, monitoring solutions, logging systems, or any other functionality that needs to be triggered based on CrewAI's internal events.
|
||||
|
||||
## How It Works
|
||||
|
||||
CrewAI uses an event bus architecture to emit events throughout the execution lifecycle. The event system is built on the following components:
|
||||
|
||||
1. **CrewAIEventsBus**: A singleton event bus that manages event registration and emission
|
||||
2. **BaseEvent**: Base class for all events in the system
|
||||
3. **BaseEventListener**: Abstract base class for creating custom event listeners
|
||||
|
||||
When specific actions occur in CrewAI (like a Crew starting execution, an Agent completing a task, or a tool being used), the system emits corresponding events. You can register handlers for these events to execute custom code when they occur.
|
||||
|
||||
<Note type="info" title="Enterprise Enhancement: Prompt Tracing">
|
||||
CrewAI Enterprise provides a built-in Prompt Tracing feature that leverages the event system to track, store, and visualize all prompts, completions, and associated metadata. This provides powerful debugging capabilities and transparency into your agent operations.
|
||||
|
||||

|
||||
|
||||
With Prompt Tracing you can:
|
||||
- View the complete history of all prompts sent to your LLM
|
||||
- Track token usage and costs
|
||||
- Debug agent reasoning failures
|
||||
- Share prompt sequences with your team
|
||||
- Compare different prompt strategies
|
||||
- Export traces for compliance and auditing
|
||||
</Note>
|
||||
|
||||
## Creating a Custom Event Listener
|
||||
|
||||
To create a custom event listener, you need to:
|
||||
|
||||
1. Create a class that inherits from `BaseEventListener`
|
||||
2. Implement the `setup_listeners` method
|
||||
3. Register handlers for the events you're interested in
|
||||
4. Create an instance of your listener in the appropriate file
|
||||
|
||||
Here's a simple example of a custom event listener class:
|
||||
|
||||
```python
|
||||
from crewai.utilities.events import (
|
||||
CrewKickoffStartedEvent,
|
||||
CrewKickoffCompletedEvent,
|
||||
AgentExecutionCompletedEvent,
|
||||
)
|
||||
from crewai.utilities.events.base_event_listener import BaseEventListener
|
||||
|
||||
class MyCustomListener(BaseEventListener):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def setup_listeners(self, crewai_event_bus):
|
||||
@crewai_event_bus.on(CrewKickoffStartedEvent)
|
||||
def on_crew_started(source, event):
|
||||
print(f"Crew '{event.crew_name}' has started execution!")
|
||||
|
||||
@crewai_event_bus.on(CrewKickoffCompletedEvent)
|
||||
def on_crew_completed(source, event):
|
||||
print(f"Crew '{event.crew_name}' has completed execution!")
|
||||
print(f"Output: {event.output}")
|
||||
|
||||
@crewai_event_bus.on(AgentExecutionCompletedEvent)
|
||||
def on_agent_execution_completed(source, event):
|
||||
print(f"Agent '{event.agent.role}' completed task")
|
||||
print(f"Output: {event.output}")
|
||||
```
|
||||
|
||||
## Properly Registering Your Listener
|
||||
|
||||
Simply defining your listener class isn't enough. You need to create an instance of it and ensure it's imported in your application. This ensures that:
|
||||
|
||||
1. The event handlers are registered with the event bus
|
||||
2. The listener instance remains in memory (not garbage collected)
|
||||
3. The listener is active when events are emitted
|
||||
|
||||
### Option 1: Import and Instantiate in Your Crew or Flow Implementation
|
||||
|
||||
The most important thing is to create an instance of your listener in the file where your Crew or Flow is defined and executed:
|
||||
|
||||
#### For Crew-based Applications
|
||||
|
||||
Create and import your listener at the top of your Crew implementation file:
|
||||
|
||||
```python
|
||||
# In your crew.py file
|
||||
from crewai import Agent, Crew, Task
|
||||
from my_listeners import MyCustomListener
|
||||
|
||||
# Create an instance of your listener
|
||||
my_listener = MyCustomListener()
|
||||
|
||||
class MyCustomCrew:
|
||||
# Your crew implementation...
|
||||
|
||||
def crew(self):
|
||||
return Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
# ...
|
||||
)
|
||||
```
|
||||
|
||||
#### For Flow-based Applications
|
||||
|
||||
Create and import your listener at the top of your Flow implementation file:
|
||||
|
||||
```python
|
||||
# In your main.py or flow.py file
|
||||
from crewai.flow import Flow, listen, start
|
||||
from my_listeners import MyCustomListener
|
||||
|
||||
# Create an instance of your listener
|
||||
my_listener = MyCustomListener()
|
||||
|
||||
class MyCustomFlow(Flow):
|
||||
# Your flow implementation...
|
||||
|
||||
@start()
|
||||
def first_step(self):
|
||||
# ...
|
||||
```
|
||||
|
||||
This ensures that your listener is loaded and active when your Crew or Flow is executed.
|
||||
|
||||
### Option 2: Create a Package for Your Listeners
|
||||
|
||||
For a more structured approach, especially if you have multiple listeners:
|
||||
|
||||
1. Create a package for your listeners:
|
||||
|
||||
```
|
||||
my_project/
|
||||
├── listeners/
|
||||
│ ├── __init__.py
|
||||
│ ├── my_custom_listener.py
|
||||
│ └── another_listener.py
|
||||
```
|
||||
|
||||
2. In `my_custom_listener.py`, define your listener class and create an instance:
|
||||
|
||||
```python
|
||||
# my_custom_listener.py
|
||||
from crewai.utilities.events.base_event_listener import BaseEventListener
|
||||
# ... import events ...
|
||||
|
||||
class MyCustomListener(BaseEventListener):
|
||||
# ... implementation ...
|
||||
|
||||
# Create an instance of your listener
|
||||
my_custom_listener = MyCustomListener()
|
||||
```
|
||||
|
||||
3. In `__init__.py`, import the listener instances to ensure they're loaded:
|
||||
|
||||
```python
|
||||
# __init__.py
|
||||
from .my_custom_listener import my_custom_listener
|
||||
from .another_listener import another_listener
|
||||
|
||||
# Optionally export them if you need to access them elsewhere
|
||||
__all__ = ['my_custom_listener', 'another_listener']
|
||||
```
|
||||
|
||||
4. Import your listeners package in your Crew or Flow file:
|
||||
|
||||
```python
|
||||
# In your crew.py or flow.py file
|
||||
import my_project.listeners # This loads all your listeners
|
||||
|
||||
class MyCustomCrew:
|
||||
# Your crew implementation...
|
||||
```
|
||||
|
||||
This is exactly how CrewAI's built-in `agentops_listener` is registered. In the CrewAI codebase, you'll find:
|
||||
|
||||
```python
|
||||
# src/crewai/utilities/events/third_party/__init__.py
|
||||
from .agentops_listener import agentops_listener
|
||||
```
|
||||
|
||||
This ensures the `agentops_listener` is loaded when the `crewai.utilities.events` package is imported.
|
||||
|
||||
## Available Event Types
|
||||
|
||||
CrewAI provides a wide range of events that you can listen for:
|
||||
|
||||
### Crew Events
|
||||
|
||||
- **CrewKickoffStartedEvent**: Emitted when a Crew starts execution
|
||||
- **CrewKickoffCompletedEvent**: Emitted when a Crew completes execution
|
||||
- **CrewKickoffFailedEvent**: Emitted when a Crew fails to complete execution
|
||||
- **CrewTestStartedEvent**: Emitted when a Crew starts testing
|
||||
- **CrewTestCompletedEvent**: Emitted when a Crew completes testing
|
||||
- **CrewTestFailedEvent**: Emitted when a Crew fails to complete testing
|
||||
- **CrewTrainStartedEvent**: Emitted when a Crew starts training
|
||||
- **CrewTrainCompletedEvent**: Emitted when a Crew completes training
|
||||
- **CrewTrainFailedEvent**: Emitted when a Crew fails to complete training
|
||||
|
||||
### Agent Events
|
||||
|
||||
- **AgentExecutionStartedEvent**: Emitted when an Agent starts executing a task
|
||||
- **AgentExecutionCompletedEvent**: Emitted when an Agent completes executing a task
|
||||
- **AgentExecutionErrorEvent**: Emitted when an Agent encounters an error during execution
|
||||
|
||||
### Task Events
|
||||
|
||||
- **TaskStartedEvent**: Emitted when a Task starts execution
|
||||
- **TaskCompletedEvent**: Emitted when a Task completes execution
|
||||
- **TaskFailedEvent**: Emitted when a Task fails to complete execution
|
||||
- **TaskEvaluationEvent**: Emitted when a Task is evaluated
|
||||
|
||||
### Tool Usage Events
|
||||
|
||||
- **ToolUsageStartedEvent**: Emitted when a tool execution is started
|
||||
- **ToolUsageFinishedEvent**: Emitted when a tool execution is completed
|
||||
- **ToolUsageErrorEvent**: Emitted when a tool execution encounters an error
|
||||
- **ToolValidateInputErrorEvent**: Emitted when a tool input validation encounters an error
|
||||
- **ToolExecutionErrorEvent**: Emitted when a tool execution encounters an error
|
||||
- **ToolSelectionErrorEvent**: Emitted when there's an error selecting a tool
|
||||
|
||||
### Flow Events
|
||||
|
||||
- **FlowCreatedEvent**: Emitted when a Flow is created
|
||||
- **FlowStartedEvent**: Emitted when a Flow starts execution
|
||||
- **FlowFinishedEvent**: Emitted when a Flow completes execution
|
||||
- **FlowPlotEvent**: Emitted when a Flow is plotted
|
||||
- **MethodExecutionStartedEvent**: Emitted when a Flow method starts execution
|
||||
- **MethodExecutionFinishedEvent**: Emitted when a Flow method completes execution
|
||||
- **MethodExecutionFailedEvent**: Emitted when a Flow method fails to complete execution
|
||||
|
||||
### LLM Events
|
||||
|
||||
- **LLMCallStartedEvent**: Emitted when an LLM call starts
|
||||
- **LLMCallCompletedEvent**: Emitted when an LLM call completes
|
||||
- **LLMCallFailedEvent**: Emitted when an LLM call fails
|
||||
- **LLMStreamChunkEvent**: Emitted for each chunk received during streaming LLM responses
|
||||
|
||||
## Event Handler Structure
|
||||
|
||||
Each event handler receives two parameters:
|
||||
|
||||
1. **source**: The object that emitted the event
|
||||
2. **event**: The event instance, containing event-specific data
|
||||
|
||||
The structure of the event object depends on the event type, but all events inherit from `BaseEvent` and include:
|
||||
|
||||
- **timestamp**: The time when the event was emitted
|
||||
- **type**: A string identifier for the event type
|
||||
|
||||
Additional fields vary by event type. For example, `CrewKickoffCompletedEvent` includes `crew_name` and `output` fields.
|
||||
|
||||
## Real-World Example: Integration with AgentOps
|
||||
|
||||
CrewAI includes an example of a third-party integration with [AgentOps](https://github.com/AgentOps-AI/agentops), a monitoring and observability platform for AI agents. Here's how it's implemented:
|
||||
|
||||
```python
|
||||
from typing import Optional
|
||||
|
||||
from crewai.utilities.events import (
|
||||
CrewKickoffCompletedEvent,
|
||||
ToolUsageErrorEvent,
|
||||
ToolUsageStartedEvent,
|
||||
)
|
||||
from crewai.utilities.events.base_event_listener import BaseEventListener
|
||||
from crewai.utilities.events.crew_events import CrewKickoffStartedEvent
|
||||
from crewai.utilities.events.task_events import TaskEvaluationEvent
|
||||
|
||||
try:
|
||||
import agentops
|
||||
AGENTOPS_INSTALLED = True
|
||||
except ImportError:
|
||||
AGENTOPS_INSTALLED = False
|
||||
|
||||
class AgentOpsListener(BaseEventListener):
|
||||
tool_event: Optional["agentops.ToolEvent"] = None
|
||||
session: Optional["agentops.Session"] = None
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def setup_listeners(self, crewai_event_bus):
|
||||
if not AGENTOPS_INSTALLED:
|
||||
return
|
||||
|
||||
@crewai_event_bus.on(CrewKickoffStartedEvent)
|
||||
def on_crew_kickoff_started(source, event: CrewKickoffStartedEvent):
|
||||
self.session = agentops.init()
|
||||
for agent in source.agents:
|
||||
if self.session:
|
||||
self.session.create_agent(
|
||||
name=agent.role,
|
||||
agent_id=str(agent.id),
|
||||
)
|
||||
|
||||
@crewai_event_bus.on(CrewKickoffCompletedEvent)
|
||||
def on_crew_kickoff_completed(source, event: CrewKickoffCompletedEvent):
|
||||
if self.session:
|
||||
self.session.end_session(
|
||||
end_state="Success",
|
||||
end_state_reason="Finished Execution",
|
||||
)
|
||||
|
||||
@crewai_event_bus.on(ToolUsageStartedEvent)
|
||||
def on_tool_usage_started(source, event: ToolUsageStartedEvent):
|
||||
self.tool_event = agentops.ToolEvent(name=event.tool_name)
|
||||
if self.session:
|
||||
self.session.record(self.tool_event)
|
||||
|
||||
@crewai_event_bus.on(ToolUsageErrorEvent)
|
||||
def on_tool_usage_error(source, event: ToolUsageErrorEvent):
|
||||
agentops.ErrorEvent(exception=event.error, trigger_event=self.tool_event)
|
||||
```
|
||||
|
||||
This listener initializes an AgentOps session when a Crew starts, registers agents with AgentOps, tracks tool usage, and ends the session when the Crew completes.
|
||||
|
||||
The AgentOps listener is registered in CrewAI's event system through the import in `src/crewai/utilities/events/third_party/__init__.py`:
|
||||
|
||||
```python
|
||||
from .agentops_listener import agentops_listener
|
||||
```
|
||||
|
||||
This ensures the `agentops_listener` is loaded when the `crewai.utilities.events` package is imported.
|
||||
|
||||
## Advanced Usage: Scoped Handlers
|
||||
|
||||
For temporary event handling (useful for testing or specific operations), you can use the `scoped_handlers` context manager:
|
||||
|
||||
```python
|
||||
from crewai.utilities.events import crewai_event_bus, CrewKickoffStartedEvent
|
||||
|
||||
with crewai_event_bus.scoped_handlers():
|
||||
@crewai_event_bus.on(CrewKickoffStartedEvent)
|
||||
def temp_handler(source, event):
|
||||
print("This handler only exists within this context")
|
||||
|
||||
# Do something that emits events
|
||||
|
||||
# Outside the context, the temporary handler is removed
|
||||
```
|
||||
|
||||
## Use Cases
|
||||
|
||||
Event listeners can be used for a variety of purposes:
|
||||
|
||||
1. **Logging and Monitoring**: Track the execution of your Crew and log important events
|
||||
2. **Analytics**: Collect data about your Crew's performance and behavior
|
||||
3. **Debugging**: Set up temporary listeners to debug specific issues
|
||||
4. **Integration**: Connect CrewAI with external systems like monitoring platforms, databases, or notification services
|
||||
5. **Custom Behavior**: Trigger custom actions based on specific events
|
||||
|
||||
## Best Practices
|
||||
|
||||
1. **Keep Handlers Light**: Event handlers should be lightweight and avoid blocking operations
|
||||
2. **Error Handling**: Include proper error handling in your event handlers to prevent exceptions from affecting the main execution
|
||||
3. **Cleanup**: If your listener allocates resources, ensure they're properly cleaned up
|
||||
4. **Selective Listening**: Only listen for events you actually need to handle
|
||||
5. **Testing**: Test your event listeners in isolation to ensure they behave as expected
|
||||
|
||||
By leveraging CrewAI's event system, you can extend its functionality and integrate it seamlessly with your existing infrastructure.
|
||||
@@ -35,6 +35,8 @@ class ExampleFlow(Flow):
|
||||
@start()
|
||||
def generate_city(self):
|
||||
print("Starting flow")
|
||||
# Each flow state automatically gets a unique ID
|
||||
print(f"Flow State ID: {self.state['id']}")
|
||||
|
||||
response = completion(
|
||||
model=self.model,
|
||||
@@ -47,6 +49,8 @@ class ExampleFlow(Flow):
|
||||
)
|
||||
|
||||
random_city = response["choices"][0]["message"]["content"]
|
||||
# Store the city in our state
|
||||
self.state["city"] = random_city
|
||||
print(f"Random City: {random_city}")
|
||||
|
||||
return random_city
|
||||
@@ -64,6 +68,8 @@ class ExampleFlow(Flow):
|
||||
)
|
||||
|
||||
fun_fact = response["choices"][0]["message"]["content"]
|
||||
# Store the fun fact in our state
|
||||
self.state["fun_fact"] = fun_fact
|
||||
return fun_fact
|
||||
|
||||
|
||||
@@ -76,7 +82,15 @@ print(f"Generated fun fact: {result}")
|
||||
|
||||
In the above example, we have created a simple Flow that generates a random city using OpenAI and then generates a fun fact about that city. The Flow consists of two tasks: `generate_city` and `generate_fun_fact`. The `generate_city` task is the starting point of the Flow, and the `generate_fun_fact` task listens for the output of the `generate_city` task.
|
||||
|
||||
When you run the Flow, it will generate a random city and then generate a fun fact about that city. The output will be printed to the console.
|
||||
Each Flow instance automatically receives a unique identifier (UUID) in its state, which helps track and manage flow executions. The state can also store additional data (like the generated city and fun fact) that persists throughout the flow's execution.
|
||||
|
||||
When you run the Flow, it will:
|
||||
1. Generate a unique ID for the flow state
|
||||
2. Generate a random city and store it in the state
|
||||
3. Generate a fun fact about that city and store it in the state
|
||||
4. Print the results to the console
|
||||
|
||||
The state's unique ID and stored data can be useful for tracking flow executions and maintaining context between tasks.
|
||||
|
||||
**Note:** Ensure you have set up your `.env` file to store your `OPENAI_API_KEY`. This key is necessary for authenticating requests to the OpenAI API.
|
||||
|
||||
@@ -136,12 +150,12 @@ final_output = flow.kickoff()
|
||||
|
||||
print("---- Final Output ----")
|
||||
print(final_output)
|
||||
````
|
||||
```
|
||||
|
||||
``` text Output
|
||||
```text Output
|
||||
---- Final Output ----
|
||||
Second method received: Output from first_method
|
||||
````
|
||||
```
|
||||
|
||||
</CodeGroup>
|
||||
|
||||
@@ -207,34 +221,39 @@ allowing developers to choose the approach that best fits their application's ne
|
||||
|
||||
In unstructured state management, all state is stored in the `state` attribute of the `Flow` class.
|
||||
This approach offers flexibility, enabling developers to add or modify state attributes on the fly without defining a strict schema.
|
||||
Even with unstructured states, CrewAI Flows automatically generates and maintains a unique identifier (UUID) for each state instance.
|
||||
|
||||
```python Code
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
|
||||
class UntructuredExampleFlow(Flow):
|
||||
class UnstructuredExampleFlow(Flow):
|
||||
|
||||
@start()
|
||||
def first_method(self):
|
||||
self.state.message = "Hello from structured flow"
|
||||
self.state.counter = 0
|
||||
# The state automatically includes an 'id' field
|
||||
print(f"State ID: {self.state['id']}")
|
||||
self.state['counter'] = 0
|
||||
self.state['message'] = "Hello from structured flow"
|
||||
|
||||
@listen(first_method)
|
||||
def second_method(self):
|
||||
self.state.counter += 1
|
||||
self.state.message += " - updated"
|
||||
self.state['counter'] += 1
|
||||
self.state['message'] += " - updated"
|
||||
|
||||
@listen(second_method)
|
||||
def third_method(self):
|
||||
self.state.counter += 1
|
||||
self.state.message += " - updated again"
|
||||
self.state['counter'] += 1
|
||||
self.state['message'] += " - updated again"
|
||||
|
||||
print(f"State after third_method: {self.state}")
|
||||
|
||||
|
||||
flow = UntructuredExampleFlow()
|
||||
flow = UnstructuredExampleFlow()
|
||||
flow.kickoff()
|
||||
```
|
||||
|
||||
**Note:** The `id` field is automatically generated and preserved throughout the flow's execution. You don't need to manage or set it manually, and it will be maintained even when updating the state with new data.
|
||||
|
||||
**Key Points:**
|
||||
|
||||
- **Flexibility:** You can dynamically add attributes to `self.state` without predefined constraints.
|
||||
@@ -245,12 +264,15 @@ flow.kickoff()
|
||||
Structured state management leverages predefined schemas to ensure consistency and type safety across the workflow.
|
||||
By using models like Pydantic's `BaseModel`, developers can define the exact shape of the state, enabling better validation and auto-completion in development environments.
|
||||
|
||||
Each state in CrewAI Flows automatically receives a unique identifier (UUID) to help track and manage state instances. This ID is automatically generated and managed by the Flow system.
|
||||
|
||||
```python Code
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
class ExampleState(BaseModel):
|
||||
# Note: 'id' field is automatically added to all states
|
||||
counter: int = 0
|
||||
message: str = ""
|
||||
|
||||
@@ -259,6 +281,8 @@ class StructuredExampleFlow(Flow[ExampleState]):
|
||||
|
||||
@start()
|
||||
def first_method(self):
|
||||
# Access the auto-generated ID if needed
|
||||
print(f"State ID: {self.state.id}")
|
||||
self.state.message = "Hello from structured flow"
|
||||
|
||||
@listen(first_method)
|
||||
@@ -299,6 +323,91 @@ flow.kickoff()
|
||||
|
||||
By providing both unstructured and structured state management options, CrewAI Flows empowers developers to build AI workflows that are both flexible and robust, catering to a wide range of application requirements.
|
||||
|
||||
## Flow Persistence
|
||||
|
||||
The @persist decorator enables automatic state persistence in CrewAI Flows, allowing you to maintain flow state across restarts or different workflow executions. This decorator can be applied at either the class level or method level, providing flexibility in how you manage state persistence.
|
||||
|
||||
### Class-Level Persistence
|
||||
|
||||
When applied at the class level, the @persist decorator automatically persists all flow method states:
|
||||
|
||||
```python
|
||||
@persist # Using SQLiteFlowPersistence by default
|
||||
class MyFlow(Flow[MyState]):
|
||||
@start()
|
||||
def initialize_flow(self):
|
||||
# This method will automatically have its state persisted
|
||||
self.state.counter = 1
|
||||
print("Initialized flow. State ID:", self.state.id)
|
||||
|
||||
@listen(initialize_flow)
|
||||
def next_step(self):
|
||||
# The state (including self.state.id) is automatically reloaded
|
||||
self.state.counter += 1
|
||||
print("Flow state is persisted. Counter:", self.state.counter)
|
||||
```
|
||||
|
||||
### Method-Level Persistence
|
||||
|
||||
For more granular control, you can apply @persist to specific methods:
|
||||
|
||||
```python
|
||||
class AnotherFlow(Flow[dict]):
|
||||
@persist # Persists only this method's state
|
||||
@start()
|
||||
def begin(self):
|
||||
if "runs" not in self.state:
|
||||
self.state["runs"] = 0
|
||||
self.state["runs"] += 1
|
||||
print("Method-level persisted runs:", self.state["runs"])
|
||||
```
|
||||
|
||||
### How It Works
|
||||
|
||||
1. **Unique State Identification**
|
||||
- Each flow state automatically receives a unique UUID
|
||||
- The ID is preserved across state updates and method calls
|
||||
- Supports both structured (Pydantic BaseModel) and unstructured (dictionary) states
|
||||
|
||||
2. **Default SQLite Backend**
|
||||
- SQLiteFlowPersistence is the default storage backend
|
||||
- States are automatically saved to a local SQLite database
|
||||
- Robust error handling ensures clear messages if database operations fail
|
||||
|
||||
3. **Error Handling**
|
||||
- Comprehensive error messages for database operations
|
||||
- Automatic state validation during save and load
|
||||
- Clear feedback when persistence operations encounter issues
|
||||
|
||||
### Important Considerations
|
||||
|
||||
- **State Types**: Both structured (Pydantic BaseModel) and unstructured (dictionary) states are supported
|
||||
- **Automatic ID**: The `id` field is automatically added if not present
|
||||
- **State Recovery**: Failed or restarted flows can automatically reload their previous state
|
||||
- **Custom Implementation**: You can provide your own FlowPersistence implementation for specialized storage needs
|
||||
|
||||
### Technical Advantages
|
||||
|
||||
1. **Precise Control Through Low-Level Access**
|
||||
- Direct access to persistence operations for advanced use cases
|
||||
- Fine-grained control via method-level persistence decorators
|
||||
- Built-in state inspection and debugging capabilities
|
||||
- Full visibility into state changes and persistence operations
|
||||
|
||||
2. **Enhanced Reliability**
|
||||
- Automatic state recovery after system failures or restarts
|
||||
- Transaction-based state updates for data integrity
|
||||
- Comprehensive error handling with clear error messages
|
||||
- Robust validation during state save and load operations
|
||||
|
||||
3. **Extensible Architecture**
|
||||
- Customizable persistence backend through FlowPersistence interface
|
||||
- Support for specialized storage solutions beyond SQLite
|
||||
- Compatible with both structured (Pydantic) and unstructured (dict) states
|
||||
- Seamless integration with existing CrewAI flow patterns
|
||||
|
||||
The persistence system's architecture emphasizes technical precision and customization options, allowing developers to maintain full control over state management while benefiting from built-in reliability features.
|
||||
|
||||
## Flow Control
|
||||
|
||||
### Conditional Logic: `or`
|
||||
@@ -436,6 +545,119 @@ The `third_method` and `fourth_method` listen to the output of the `second_metho
|
||||
|
||||
When you run this Flow, the output will change based on the random boolean value generated by the `start_method`.
|
||||
|
||||
## Adding Agents to Flows
|
||||
|
||||
Agents can be seamlessly integrated into your flows, providing a lightweight alternative to full Crews when you need simpler, focused task execution. Here's an example of how to use an Agent within a flow to perform market research:
|
||||
|
||||
```python
|
||||
import asyncio
|
||||
from typing import Any, Dict, List
|
||||
|
||||
from crewai_tools import SerperDevTool
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from crewai.agent import Agent
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
|
||||
|
||||
# Define a structured output format
|
||||
class MarketAnalysis(BaseModel):
|
||||
key_trends: List[str] = Field(description="List of identified market trends")
|
||||
market_size: str = Field(description="Estimated market size")
|
||||
competitors: List[str] = Field(description="Major competitors in the space")
|
||||
|
||||
|
||||
# Define flow state
|
||||
class MarketResearchState(BaseModel):
|
||||
product: str = ""
|
||||
analysis: MarketAnalysis | None = None
|
||||
|
||||
|
||||
# Create a flow class
|
||||
class MarketResearchFlow(Flow[MarketResearchState]):
|
||||
@start()
|
||||
def initialize_research(self) -> Dict[str, Any]:
|
||||
print(f"Starting market research for {self.state.product}")
|
||||
return {"product": self.state.product}
|
||||
|
||||
@listen(initialize_research)
|
||||
async def analyze_market(self) -> Dict[str, Any]:
|
||||
# Create an Agent for market research
|
||||
analyst = Agent(
|
||||
role="Market Research Analyst",
|
||||
goal=f"Analyze the market for {self.state.product}",
|
||||
backstory="You are an experienced market analyst with expertise in "
|
||||
"identifying market trends and opportunities.",
|
||||
tools=[SerperDevTool()],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Define the research query
|
||||
query = f"""
|
||||
Research the market for {self.state.product}. Include:
|
||||
1. Key market trends
|
||||
2. Market size
|
||||
3. Major competitors
|
||||
|
||||
Format your response according to the specified structure.
|
||||
"""
|
||||
|
||||
# Execute the analysis with structured output format
|
||||
result = await analyst.kickoff_async(query, response_format=MarketAnalysis)
|
||||
if result.pydantic:
|
||||
print("result", result.pydantic)
|
||||
else:
|
||||
print("result", result)
|
||||
|
||||
# Return the analysis to update the state
|
||||
return {"analysis": result.pydantic}
|
||||
|
||||
@listen(analyze_market)
|
||||
def present_results(self, analysis) -> None:
|
||||
print("\nMarket Analysis Results")
|
||||
print("=====================")
|
||||
|
||||
if isinstance(analysis, dict):
|
||||
# If we got a dict with 'analysis' key, extract the actual analysis object
|
||||
market_analysis = analysis.get("analysis")
|
||||
else:
|
||||
market_analysis = analysis
|
||||
|
||||
if market_analysis and isinstance(market_analysis, MarketAnalysis):
|
||||
print("\nKey Market Trends:")
|
||||
for trend in market_analysis.key_trends:
|
||||
print(f"- {trend}")
|
||||
|
||||
print(f"\nMarket Size: {market_analysis.market_size}")
|
||||
|
||||
print("\nMajor Competitors:")
|
||||
for competitor in market_analysis.competitors:
|
||||
print(f"- {competitor}")
|
||||
else:
|
||||
print("No structured analysis data available.")
|
||||
print("Raw analysis:", analysis)
|
||||
|
||||
|
||||
# Usage example
|
||||
async def run_flow():
|
||||
flow = MarketResearchFlow()
|
||||
result = await flow.kickoff_async(inputs={"product": "AI-powered chatbots"})
|
||||
return result
|
||||
|
||||
|
||||
# Run the flow
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(run_flow())
|
||||
```
|
||||
|
||||
This example demonstrates several key features of using Agents in flows:
|
||||
|
||||
1. **Structured Output**: Using Pydantic models to define the expected output format (`MarketAnalysis`) ensures type safety and structured data throughout the flow.
|
||||
|
||||
2. **State Management**: The flow state (`MarketResearchState`) maintains context between steps and stores both inputs and outputs.
|
||||
|
||||
3. **Tool Integration**: Agents can use tools (like `WebsiteSearchTool`) to enhance their capabilities.
|
||||
|
||||
## Adding Crews to Flows
|
||||
|
||||
Creating a flow with multiple crews in CrewAI is straightforward.
|
||||
@@ -629,3 +851,34 @@ Also, check out our YouTube video on how to use flows in CrewAI below!
|
||||
referrerpolicy="strict-origin-when-cross-origin"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
## Running Flows
|
||||
|
||||
There are two ways to run a flow:
|
||||
|
||||
### Using the Flow API
|
||||
|
||||
You can run a flow programmatically by creating an instance of your flow class and calling the `kickoff()` method:
|
||||
|
||||
```python
|
||||
flow = ExampleFlow()
|
||||
result = flow.kickoff()
|
||||
```
|
||||
|
||||
### Using the CLI
|
||||
|
||||
Starting from version 0.103.0, you can run flows using the `crewai run` command:
|
||||
|
||||
```shell
|
||||
crewai run
|
||||
```
|
||||
|
||||
This command automatically detects if your project is a flow (based on the `type = "flow"` setting in your pyproject.toml) and runs it accordingly. This is the recommended way to run flows from the command line.
|
||||
|
||||
For backward compatibility, you can also use:
|
||||
|
||||
```shell
|
||||
crewai flow kickoff
|
||||
```
|
||||
|
||||
However, the `crewai run` command is now the preferred method as it works for both crews and flows.
|
||||
|
||||
656
docs/concepts/knowledge.mdx
Normal file
@@ -0,0 +1,656 @@
|
||||
---
|
||||
title: Knowledge
|
||||
description: What is knowledge in CrewAI and how to use it.
|
||||
icon: book
|
||||
---
|
||||
|
||||
## What is Knowledge?
|
||||
|
||||
Knowledge in CrewAI is a powerful system that allows AI agents to access and utilize external information sources during their tasks.
|
||||
Think of it as giving your agents a reference library they can consult while working.
|
||||
|
||||
<Info>
|
||||
Key benefits of using Knowledge:
|
||||
- Enhance agents with domain-specific information
|
||||
- Support decisions with real-world data
|
||||
- Maintain context across conversations
|
||||
- Ground responses in factual information
|
||||
</Info>
|
||||
|
||||
## Supported Knowledge Sources
|
||||
|
||||
CrewAI supports various types of knowledge sources out of the box:
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Text Sources" icon="text">
|
||||
- Raw strings
|
||||
- Text files (.txt)
|
||||
- PDF documents
|
||||
</Card>
|
||||
<Card title="Structured Data" icon="table">
|
||||
- CSV files
|
||||
- Excel spreadsheets
|
||||
- JSON documents
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Supported Knowledge Parameters
|
||||
|
||||
| Parameter | Type | Required | Description |
|
||||
| :--------------------------- | :---------------------------------- | :------- | :---------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `sources` | **List[BaseKnowledgeSource]** | Yes | List of knowledge sources that provide content to be stored and queried. Can include PDF, CSV, Excel, JSON, text files, or string content. |
|
||||
| `collection_name` | **str** | No | Name of the collection where the knowledge will be stored. Used to identify different sets of knowledge. Defaults to "knowledge" if not provided. |
|
||||
| `storage` | **Optional[KnowledgeStorage]** | No | Custom storage configuration for managing how the knowledge is stored and retrieved. If not provided, a default storage will be created. |
|
||||
|
||||
|
||||
<Tip>
|
||||
Unlike retrieval from a vector database using a tool, agents preloaded with knowledge will not need a retrieval persona or task.
|
||||
Simply add the relevant knowledge sources your agent or crew needs to function.
|
||||
|
||||
Knowledge sources can be added at the agent or crew level.
|
||||
Crew level knowledge sources will be used by **all agents** in the crew.
|
||||
Agent level knowledge sources will be used by the **specific agent** that is preloaded with the knowledge.
|
||||
</Tip>
|
||||
|
||||
## Quickstart Example
|
||||
|
||||
<Tip>
|
||||
For file-Based Knowledge Sources, make sure to place your files in a `knowledge` directory at the root of your project.
|
||||
Also, use relative paths from the `knowledge` directory when creating the source.
|
||||
</Tip>
|
||||
|
||||
Here's an example using string-based knowledge:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew, Process, LLM
|
||||
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
|
||||
|
||||
# Create a knowledge source
|
||||
content = "Users name is John. He is 30 years old and lives in San Francisco."
|
||||
string_source = StringKnowledgeSource(
|
||||
content=content,
|
||||
)
|
||||
|
||||
# Create an LLM with a temperature of 0 to ensure deterministic outputs
|
||||
llm = LLM(model="gpt-4o-mini", temperature=0)
|
||||
|
||||
# Create an agent with the knowledge store
|
||||
agent = Agent(
|
||||
role="About User",
|
||||
goal="You know everything about the user.",
|
||||
backstory="""You are a master at understanding people and their preferences.""",
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
llm=llm,
|
||||
)
|
||||
task = Task(
|
||||
description="Answer the following questions about the user: {question}",
|
||||
expected_output="An answer to the question.",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
knowledge_sources=[string_source], # Enable knowledge by adding the sources here. You can also add more sources to the sources list.
|
||||
)
|
||||
|
||||
result = crew.kickoff(inputs={"question": "What city does John live in and how old is he?"})
|
||||
```
|
||||
|
||||
|
||||
Here's another example with the `CrewDoclingSource`. The CrewDoclingSource is actually quite versatile and can handle multiple file formats including MD, PDF, DOCX, HTML, and more.
|
||||
|
||||
<Note>
|
||||
You need to install `docling` for the following example to work: `uv add docling`
|
||||
</Note>
|
||||
|
||||
|
||||
|
||||
```python Code
|
||||
from crewai import LLM, Agent, Crew, Process, Task
|
||||
from crewai.knowledge.source.crew_docling_source import CrewDoclingSource
|
||||
|
||||
# Create a knowledge source
|
||||
content_source = CrewDoclingSource(
|
||||
file_paths=[
|
||||
"https://lilianweng.github.io/posts/2024-11-28-reward-hacking",
|
||||
"https://lilianweng.github.io/posts/2024-07-07-hallucination",
|
||||
],
|
||||
)
|
||||
|
||||
# Create an LLM with a temperature of 0 to ensure deterministic outputs
|
||||
llm = LLM(model="gpt-4o-mini", temperature=0)
|
||||
|
||||
# Create an agent with the knowledge store
|
||||
agent = Agent(
|
||||
role="About papers",
|
||||
goal="You know everything about the papers.",
|
||||
backstory="""You are a master at understanding papers and their content.""",
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
llm=llm,
|
||||
)
|
||||
task = Task(
|
||||
description="Answer the following questions about the papers: {question}",
|
||||
expected_output="An answer to the question.",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
knowledge_sources=[
|
||||
content_source
|
||||
], # Enable knowledge by adding the sources here. You can also add more sources to the sources list.
|
||||
)
|
||||
|
||||
result = crew.kickoff(
|
||||
inputs={
|
||||
"question": "What is the reward hacking paper about? Be sure to provide sources."
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
## Knowledge Configuration
|
||||
|
||||
You can configure the knowledge configuration for the crew or agent.
|
||||
|
||||
```python Code
|
||||
from crewai.knowledge.knowledge_config import KnowledgeConfig
|
||||
|
||||
knowledge_config = KnowledgeConfig(results_limit=10, score_threshold=0.5)
|
||||
|
||||
agent = Agent(
|
||||
...
|
||||
knowledge_config=knowledge_config
|
||||
)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
`results_limit`: is the number of relevant documents to return. Default is 3.
|
||||
`score_threshold`: is the minimum score for a document to be considered relevant. Default is 0.35.
|
||||
</Tip>
|
||||
|
||||
## More Examples
|
||||
|
||||
Here are examples of how to use different types of knowledge sources:
|
||||
|
||||
Note: Please ensure that you create the ./knowldge folder. All source files (e.g., .txt, .pdf, .xlsx, .json) should be placed in this folder for centralized management.
|
||||
|
||||
### Text File Knowledge Source
|
||||
```python
|
||||
from crewai.knowledge.source.text_file_knowledge_source import TextFileKnowledgeSource
|
||||
|
||||
# Create a text file knowledge source
|
||||
text_source = TextFileKnowledgeSource(
|
||||
file_paths=["document.txt", "another.txt"]
|
||||
)
|
||||
|
||||
# Create crew with text file source on agents or crew level
|
||||
agent = Agent(
|
||||
...
|
||||
knowledge_sources=[text_source]
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
...
|
||||
knowledge_sources=[text_source]
|
||||
)
|
||||
```
|
||||
|
||||
### PDF Knowledge Source
|
||||
```python
|
||||
from crewai.knowledge.source.pdf_knowledge_source import PDFKnowledgeSource
|
||||
|
||||
# Create a PDF knowledge source
|
||||
pdf_source = PDFKnowledgeSource(
|
||||
file_paths=["document.pdf", "another.pdf"]
|
||||
)
|
||||
|
||||
# Create crew with PDF knowledge source on agents or crew level
|
||||
agent = Agent(
|
||||
...
|
||||
knowledge_sources=[pdf_source]
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
...
|
||||
knowledge_sources=[pdf_source]
|
||||
)
|
||||
```
|
||||
|
||||
### CSV Knowledge Source
|
||||
```python
|
||||
from crewai.knowledge.source.csv_knowledge_source import CSVKnowledgeSource
|
||||
|
||||
# Create a CSV knowledge source
|
||||
csv_source = CSVKnowledgeSource(
|
||||
file_paths=["data.csv"]
|
||||
)
|
||||
|
||||
# Create crew with CSV knowledge source or on agent level
|
||||
agent = Agent(
|
||||
...
|
||||
knowledge_sources=[csv_source]
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
...
|
||||
knowledge_sources=[csv_source]
|
||||
)
|
||||
```
|
||||
|
||||
### Excel Knowledge Source
|
||||
```python
|
||||
from crewai.knowledge.source.excel_knowledge_source import ExcelKnowledgeSource
|
||||
|
||||
# Create an Excel knowledge source
|
||||
excel_source = ExcelKnowledgeSource(
|
||||
file_paths=["spreadsheet.xlsx"]
|
||||
)
|
||||
|
||||
# Create crew with Excel knowledge source on agents or crew level
|
||||
agent = Agent(
|
||||
...
|
||||
knowledge_sources=[excel_source]
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
...
|
||||
knowledge_sources=[excel_source]
|
||||
)
|
||||
```
|
||||
|
||||
### JSON Knowledge Source
|
||||
```python
|
||||
from crewai.knowledge.source.json_knowledge_source import JSONKnowledgeSource
|
||||
|
||||
# Create a JSON knowledge source
|
||||
json_source = JSONKnowledgeSource(
|
||||
file_paths=["data.json"]
|
||||
)
|
||||
|
||||
# Create crew with JSON knowledge source on agents or crew level
|
||||
agent = Agent(
|
||||
...
|
||||
knowledge_sources=[json_source]
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
...
|
||||
knowledge_sources=[json_source]
|
||||
)
|
||||
```
|
||||
|
||||
## Knowledge Configuration
|
||||
|
||||
### Chunking Configuration
|
||||
|
||||
Knowledge sources automatically chunk content for better processing.
|
||||
You can configure chunking behavior in your knowledge sources:
|
||||
|
||||
```python
|
||||
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
|
||||
|
||||
source = StringKnowledgeSource(
|
||||
content="Your content here",
|
||||
chunk_size=4000, # Maximum size of each chunk (default: 4000)
|
||||
chunk_overlap=200 # Overlap between chunks (default: 200)
|
||||
)
|
||||
```
|
||||
|
||||
The chunking configuration helps in:
|
||||
- Breaking down large documents into manageable pieces
|
||||
- Maintaining context through chunk overlap
|
||||
- Optimizing retrieval accuracy
|
||||
|
||||
### Embeddings Configuration
|
||||
|
||||
You can also configure the embedder for the knowledge store.
|
||||
This is useful if you want to use a different embedder for the knowledge store than the one used for the agents.
|
||||
The `embedder` parameter supports various embedding model providers that include:
|
||||
- `openai`: OpenAI's embedding models
|
||||
- `google`: Google's text embedding models
|
||||
- `azure`: Azure OpenAI embeddings
|
||||
- `ollama`: Local embeddings with Ollama
|
||||
- `vertexai`: Google Cloud VertexAI embeddings
|
||||
- `cohere`: Cohere's embedding models
|
||||
- `voyageai`: VoyageAI's embedding models
|
||||
- `bedrock`: AWS Bedrock embeddings
|
||||
- `huggingface`: Hugging Face models
|
||||
- `watson`: IBM Watson embeddings
|
||||
|
||||
Here's an example of how to configure the embedder for the knowledge store using Google's `text-embedding-004` model:
|
||||
<CodeGroup>
|
||||
```python Example
|
||||
from crewai import Agent, Task, Crew, Process, LLM
|
||||
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
|
||||
import os
|
||||
|
||||
# Get the GEMINI API key
|
||||
GEMINI_API_KEY = os.environ.get("GEMINI_API_KEY")
|
||||
|
||||
# Create a knowledge source
|
||||
content = "Users name is John. He is 30 years old and lives in San Francisco."
|
||||
string_source = StringKnowledgeSource(
|
||||
content=content,
|
||||
)
|
||||
|
||||
# Create an LLM with a temperature of 0 to ensure deterministic outputs
|
||||
gemini_llm = LLM(
|
||||
model="gemini/gemini-1.5-pro-002",
|
||||
api_key=GEMINI_API_KEY,
|
||||
temperature=0,
|
||||
)
|
||||
|
||||
# Create an agent with the knowledge store
|
||||
agent = Agent(
|
||||
role="About User",
|
||||
goal="You know everything about the user.",
|
||||
backstory="""You are a master at understanding people and their preferences.""",
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
llm=gemini_llm,
|
||||
embedder={
|
||||
"provider": "google",
|
||||
"config": {
|
||||
"model": "models/text-embedding-004",
|
||||
"api_key": GEMINI_API_KEY,
|
||||
}
|
||||
}
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Answer the following questions about the user: {question}",
|
||||
expected_output="An answer to the question.",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
knowledge_sources=[string_source],
|
||||
embedder={
|
||||
"provider": "google",
|
||||
"config": {
|
||||
"model": "models/text-embedding-004",
|
||||
"api_key": GEMINI_API_KEY,
|
||||
}
|
||||
}
|
||||
)
|
||||
|
||||
result = crew.kickoff(inputs={"question": "What city does John live in and how old is he?"})
|
||||
```
|
||||
```text Output
|
||||
# Agent: About User
|
||||
## Task: Answer the following questions about the user: What city does John live in and how old is he?
|
||||
|
||||
# Agent: About User
|
||||
## Final Answer:
|
||||
John is 30 years old and lives in San Francisco.
|
||||
```
|
||||
</CodeGroup>
|
||||
## Clearing Knowledge
|
||||
|
||||
If you need to clear the knowledge stored in CrewAI, you can use the `crewai reset-memories` command with the `--knowledge` option.
|
||||
|
||||
```bash Command
|
||||
crewai reset-memories --knowledge
|
||||
```
|
||||
|
||||
This is useful when you've updated your knowledge sources and want to ensure that the agents are using the most recent information.
|
||||
|
||||
## Agent-Specific Knowledge
|
||||
|
||||
While knowledge can be provided at the crew level using `crew.knowledge_sources`, individual agents can also have their own knowledge sources using the `knowledge_sources` parameter:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
|
||||
|
||||
# Create agent-specific knowledge about a product
|
||||
product_specs = StringKnowledgeSource(
|
||||
content="""The XPS 13 laptop features:
|
||||
- 13.4-inch 4K display
|
||||
- Intel Core i7 processor
|
||||
- 16GB RAM
|
||||
- 512GB SSD storage
|
||||
- 12-hour battery life""",
|
||||
metadata={"category": "product_specs"}
|
||||
)
|
||||
|
||||
# Create a support agent with product knowledge
|
||||
support_agent = Agent(
|
||||
role="Technical Support Specialist",
|
||||
goal="Provide accurate product information and support.",
|
||||
backstory="You are an expert on our laptop products and specifications.",
|
||||
knowledge_sources=[product_specs] # Agent-specific knowledge
|
||||
)
|
||||
|
||||
# Create a task that requires product knowledge
|
||||
support_task = Task(
|
||||
description="Answer this customer question: {question}",
|
||||
agent=support_agent
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(
|
||||
agents=[support_agent],
|
||||
tasks=[support_task]
|
||||
)
|
||||
|
||||
# Get answer about the laptop's specifications
|
||||
result = crew.kickoff(
|
||||
inputs={"question": "What is the storage capacity of the XPS 13?"}
|
||||
)
|
||||
```
|
||||
|
||||
<Info>
|
||||
Benefits of agent-specific knowledge:
|
||||
- Give agents specialized information for their roles
|
||||
- Maintain separation of concerns between agents
|
||||
- Combine with crew-level knowledge for layered information access
|
||||
</Info>
|
||||
|
||||
## Custom Knowledge Sources
|
||||
|
||||
CrewAI allows you to create custom knowledge sources for any type of data by extending the `BaseKnowledgeSource` class. Let's create a practical example that fetches and processes space news articles.
|
||||
|
||||
#### Space News Knowledge Source Example
|
||||
|
||||
<CodeGroup>
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew, Process, LLM
|
||||
from crewai.knowledge.source.base_knowledge_source import BaseKnowledgeSource
|
||||
import requests
|
||||
from datetime import datetime
|
||||
from typing import Dict, Any
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
class SpaceNewsKnowledgeSource(BaseKnowledgeSource):
|
||||
"""Knowledge source that fetches data from Space News API."""
|
||||
|
||||
api_endpoint: str = Field(description="API endpoint URL")
|
||||
limit: int = Field(default=10, description="Number of articles to fetch")
|
||||
|
||||
def load_content(self) -> Dict[Any, str]:
|
||||
"""Fetch and format space news articles."""
|
||||
try:
|
||||
response = requests.get(
|
||||
f"{self.api_endpoint}?limit={self.limit}"
|
||||
)
|
||||
response.raise_for_status()
|
||||
|
||||
data = response.json()
|
||||
articles = data.get('results', [])
|
||||
|
||||
formatted_data = self.validate_content(articles)
|
||||
return {self.api_endpoint: formatted_data}
|
||||
except Exception as e:
|
||||
raise ValueError(f"Failed to fetch space news: {str(e)}")
|
||||
|
||||
def validate_content(self, articles: list) -> str:
|
||||
"""Format articles into readable text."""
|
||||
formatted = "Space News Articles:\n\n"
|
||||
for article in articles:
|
||||
formatted += f"""
|
||||
Title: {article['title']}
|
||||
Published: {article['published_at']}
|
||||
Summary: {article['summary']}
|
||||
News Site: {article['news_site']}
|
||||
URL: {article['url']}
|
||||
-------------------"""
|
||||
return formatted
|
||||
|
||||
def add(self) -> None:
|
||||
"""Process and store the articles."""
|
||||
content = self.load_content()
|
||||
for _, text in content.items():
|
||||
chunks = self._chunk_text(text)
|
||||
self.chunks.extend(chunks)
|
||||
|
||||
self._save_documents()
|
||||
|
||||
# Create knowledge source
|
||||
recent_news = SpaceNewsKnowledgeSource(
|
||||
api_endpoint="https://api.spaceflightnewsapi.net/v4/articles",
|
||||
limit=10,
|
||||
)
|
||||
|
||||
# Create specialized agent
|
||||
space_analyst = Agent(
|
||||
role="Space News Analyst",
|
||||
goal="Answer questions about space news accurately and comprehensively",
|
||||
backstory="""You are a space industry analyst with expertise in space exploration,
|
||||
satellite technology, and space industry trends. You excel at answering questions
|
||||
about space news and providing detailed, accurate information.""",
|
||||
knowledge_sources=[recent_news],
|
||||
llm=LLM(model="gpt-4", temperature=0.0)
|
||||
)
|
||||
|
||||
# Create task that handles user questions
|
||||
analysis_task = Task(
|
||||
description="Answer this question about space news: {user_question}",
|
||||
expected_output="A detailed answer based on the recent space news articles",
|
||||
agent=space_analyst
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(
|
||||
agents=[space_analyst],
|
||||
tasks=[analysis_task],
|
||||
verbose=True,
|
||||
process=Process.sequential
|
||||
)
|
||||
|
||||
# Example usage
|
||||
result = crew.kickoff(
|
||||
inputs={"user_question": "What are the latest developments in space exploration?"}
|
||||
)
|
||||
```
|
||||
|
||||
```output Output
|
||||
# Agent: Space News Analyst
|
||||
## Task: Answer this question about space news: What are the latest developments in space exploration?
|
||||
|
||||
|
||||
# Agent: Space News Analyst
|
||||
## Final Answer:
|
||||
The latest developments in space exploration, based on recent space news articles, include the following:
|
||||
|
||||
1. SpaceX has received the final regulatory approvals to proceed with the second integrated Starship/Super Heavy launch, scheduled for as soon as the morning of Nov. 17, 2023. This is a significant step in SpaceX's ambitious plans for space exploration and colonization. [Source: SpaceNews](https://spacenews.com/starship-cleared-for-nov-17-launch/)
|
||||
|
||||
2. SpaceX has also informed the US Federal Communications Commission (FCC) that it plans to begin launching its first next-generation Starlink Gen2 satellites. This represents a major upgrade to the Starlink satellite internet service, which aims to provide high-speed internet access worldwide. [Source: Teslarati](https://www.teslarati.com/spacex-first-starlink-gen2-satellite-launch-2022/)
|
||||
|
||||
3. AI startup Synthetaic has raised $15 million in Series B funding. The company uses artificial intelligence to analyze data from space and air sensors, which could have significant applications in space exploration and satellite technology. [Source: SpaceNews](https://spacenews.com/ai-startup-synthetaic-raises-15-million-in-series-b-funding/)
|
||||
|
||||
4. The Space Force has formally established a unit within the U.S. Indo-Pacific Command, marking a permanent presence in the Indo-Pacific region. This could have significant implications for space security and geopolitics. [Source: SpaceNews](https://spacenews.com/space-force-establishes-permanent-presence-in-indo-pacific-region/)
|
||||
|
||||
5. Slingshot Aerospace, a space tracking and data analytics company, is expanding its network of ground-based optical telescopes to increase coverage of low Earth orbit. This could improve our ability to track and analyze objects in low Earth orbit, including satellites and space debris. [Source: SpaceNews](https://spacenews.com/slingshots-space-tracking-network-to-extend-coverage-of-low-earth-orbit/)
|
||||
|
||||
6. The National Natural Science Foundation of China has outlined a five-year project for researchers to study the assembly of ultra-large spacecraft. This could lead to significant advancements in spacecraft technology and space exploration capabilities. [Source: SpaceNews](https://spacenews.com/china-researching-challenges-of-kilometer-scale-ultra-large-spacecraft/)
|
||||
|
||||
7. The Center for AEroSpace Autonomy Research (CAESAR) at Stanford University is focusing on spacecraft autonomy. The center held a kickoff event on May 22, 2024, to highlight the industry, academia, and government collaboration it seeks to foster. This could lead to significant advancements in autonomous spacecraft technology. [Source: SpaceNews](https://spacenews.com/stanford-center-focuses-on-spacecraft-autonomy/)
|
||||
```
|
||||
|
||||
</CodeGroup>
|
||||
#### Key Components Explained
|
||||
|
||||
1. **Custom Knowledge Source (`SpaceNewsKnowledgeSource`)**:
|
||||
|
||||
- Extends `BaseKnowledgeSource` for integration with CrewAI
|
||||
- Configurable API endpoint and article limit
|
||||
- Implements three key methods:
|
||||
- `load_content()`: Fetches articles from the API
|
||||
- `_format_articles()`: Structures the articles into readable text
|
||||
- `add()`: Processes and stores the content
|
||||
|
||||
2. **Agent Configuration**:
|
||||
|
||||
- Specialized role as a Space News Analyst
|
||||
- Uses the knowledge source to access space news
|
||||
|
||||
3. **Task Setup**:
|
||||
|
||||
- Takes a user question as input through `{user_question}`
|
||||
- Designed to provide detailed answers based on the knowledge source
|
||||
|
||||
4. **Crew Orchestration**:
|
||||
- Manages the workflow between agent and task
|
||||
- Handles input/output through the kickoff method
|
||||
|
||||
This example demonstrates how to:
|
||||
|
||||
- Create a custom knowledge source that fetches real-time data
|
||||
- Process and format external data for AI consumption
|
||||
- Use the knowledge source to answer specific user questions
|
||||
- Integrate everything seamlessly with CrewAI's agent system
|
||||
|
||||
#### About the Spaceflight News API
|
||||
|
||||
The example uses the [Spaceflight News API](https://api.spaceflightnewsapi.net/v4/docs/), which:
|
||||
|
||||
- Provides free access to space-related news articles
|
||||
- Requires no authentication
|
||||
- Returns structured data about space news
|
||||
- Supports pagination and filtering
|
||||
|
||||
You can customize the API query by modifying the endpoint URL:
|
||||
|
||||
```python
|
||||
# Fetch more articles
|
||||
recent_news = SpaceNewsKnowledgeSource(
|
||||
api_endpoint="https://api.spaceflightnewsapi.net/v4/articles",
|
||||
limit=20, # Increase the number of articles
|
||||
)
|
||||
|
||||
# Add search parameters
|
||||
recent_news = SpaceNewsKnowledgeSource(
|
||||
api_endpoint="https://api.spaceflightnewsapi.net/v4/articles?search=NASA", # Search for NASA news
|
||||
limit=10,
|
||||
)
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Content Organization">
|
||||
- Keep chunk sizes appropriate for your content type
|
||||
- Consider content overlap for context preservation
|
||||
- Organize related information into separate knowledge sources
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Performance Tips">
|
||||
- Adjust chunk sizes based on content complexity
|
||||
- Configure appropriate embedding models
|
||||
- Consider using local embedding providers for faster processing
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
@@ -1,45 +0,0 @@
|
||||
---
|
||||
title: Using LangChain Tools
|
||||
description: Learn how to integrate LangChain tools with CrewAI agents to enhance search-based queries and more.
|
||||
icon: link
|
||||
---
|
||||
|
||||
## Using LangChain Tools
|
||||
|
||||
<Info>
|
||||
CrewAI seamlessly integrates with LangChain’s comprehensive [list of tools](https://python.langchain.com/docs/integrations/tools/), all of which can be used with CrewAI.
|
||||
</Info>
|
||||
|
||||
```python Code
|
||||
import os
|
||||
from crewai import Agent
|
||||
from langchain.agents import Tool
|
||||
from langchain.utilities import GoogleSerperAPIWrapper
|
||||
|
||||
# Setup API keys
|
||||
os.environ["SERPER_API_KEY"] = "Your Key"
|
||||
|
||||
search = GoogleSerperAPIWrapper()
|
||||
|
||||
# Create and assign the search tool to an agent
|
||||
serper_tool = Tool(
|
||||
name="Intermediate Answer",
|
||||
func=search.run,
|
||||
description="Useful for search-based queries",
|
||||
)
|
||||
|
||||
agent = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Provide up-to-date market analysis',
|
||||
backstory='An expert analyst with a keen eye for market trends.',
|
||||
tools=[serper_tool]
|
||||
)
|
||||
|
||||
# rest of the code ...
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
|
||||
Tools are pivotal in extending the capabilities of CrewAI agents, enabling them to undertake a broad spectrum of tasks and collaborate effectively.
|
||||
When building solutions with CrewAI, leverage both custom and existing tools to empower your agents and enhance the AI ecosystem. Consider utilizing error handling, caching mechanisms,
|
||||
and the flexibility of tool arguments to optimize your agents' performance and capabilities.
|
||||
@@ -1,71 +0,0 @@
|
||||
---
|
||||
title: Using LlamaIndex Tools
|
||||
description: Learn how to integrate LlamaIndex tools with CrewAI agents to enhance search-based queries and more.
|
||||
icon: toolbox
|
||||
---
|
||||
|
||||
## Using LlamaIndex Tools
|
||||
|
||||
<Info>
|
||||
CrewAI seamlessly integrates with LlamaIndex’s comprehensive toolkit for RAG (Retrieval-Augmented Generation) and agentic pipelines, enabling advanced search-based queries and more.
|
||||
</Info>
|
||||
|
||||
Here are the available built-in tools offered by LlamaIndex.
|
||||
|
||||
```python Code
|
||||
from crewai import Agent
|
||||
from crewai_tools import LlamaIndexTool
|
||||
|
||||
# Example 1: Initialize from FunctionTool
|
||||
from llama_index.core.tools import FunctionTool
|
||||
|
||||
your_python_function = lambda ...: ...
|
||||
og_tool = FunctionTool.from_defaults(
|
||||
your_python_function,
|
||||
name="<name>",
|
||||
description='<description>'
|
||||
)
|
||||
tool = LlamaIndexTool.from_tool(og_tool)
|
||||
|
||||
# Example 2: Initialize from LlamaHub Tools
|
||||
from llama_index.tools.wolfram_alpha import WolframAlphaToolSpec
|
||||
wolfram_spec = WolframAlphaToolSpec(app_id="<app_id>")
|
||||
wolfram_tools = wolfram_spec.to_tool_list()
|
||||
tools = [LlamaIndexTool.from_tool(t) for t in wolfram_tools]
|
||||
|
||||
# Example 3: Initialize Tool from a LlamaIndex Query Engine
|
||||
query_engine = index.as_query_engine()
|
||||
query_tool = LlamaIndexTool.from_query_engine(
|
||||
query_engine,
|
||||
name="Uber 2019 10K Query Tool",
|
||||
description="Use this tool to lookup the 2019 Uber 10K Annual Report"
|
||||
)
|
||||
|
||||
# Create and assign the tools to an agent
|
||||
agent = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Provide up-to-date market analysis',
|
||||
backstory='An expert analyst with a keen eye for market trends.',
|
||||
tools=[tool, *tools, query_tool]
|
||||
)
|
||||
|
||||
# rest of the code ...
|
||||
```
|
||||
|
||||
## Steps to Get Started
|
||||
|
||||
To effectively use the LlamaIndexTool, follow these steps:
|
||||
|
||||
<Steps>
|
||||
<Step title="Package Installation">
|
||||
Make sure that `crewai[tools]` package is installed in your Python environment:
|
||||
<CodeGroup>
|
||||
```shell Terminal
|
||||
pip install 'crewai[tools]'
|
||||
```
|
||||
</CodeGroup>
|
||||
</Step>
|
||||
<Step title="Install and Use LlamaIndex">
|
||||
Follow the LlamaIndex documentation [LlamaIndex Documentation](https://docs.llamaindex.ai/) to set up a RAG/agent pipeline.
|
||||
</Step>
|
||||
</Steps>
|
||||
@@ -1,180 +1,794 @@
|
||||
---
|
||||
title: LLMs
|
||||
description: Learn how to configure and optimize LLMs for your CrewAI projects.
|
||||
icon: microchip-ai
|
||||
title: 'LLMs'
|
||||
description: 'A comprehensive guide to configuring and using Large Language Models (LLMs) in your CrewAI projects'
|
||||
icon: 'microchip-ai'
|
||||
---
|
||||
|
||||
# Large Language Models (LLMs) in CrewAI
|
||||
<Note>
|
||||
CrewAI integrates with multiple LLM providers through LiteLLM, giving you the flexibility to choose the right model for your specific use case. This guide will help you understand how to configure and use different LLM providers in your CrewAI projects.
|
||||
</Note>
|
||||
|
||||
Large Language Models (LLMs) are the backbone of intelligent agents in the CrewAI framework. This guide will help you understand, configure, and optimize LLM usage for your CrewAI projects.
|
||||
## What are LLMs?
|
||||
|
||||
## Key Concepts
|
||||
Large Language Models (LLMs) are the core intelligence behind CrewAI agents. They enable agents to understand context, make decisions, and generate human-like responses. Here's what you need to know:
|
||||
|
||||
- **LLM**: Large Language Model, the AI powering agent intelligence
|
||||
- **Agent**: A CrewAI entity that uses an LLM to perform tasks
|
||||
- **Provider**: A service that offers LLM capabilities (e.g., OpenAI, Anthropic, Ollama, [more providers](https://docs.litellm.ai/docs/providers))
|
||||
<CardGroup cols={2}>
|
||||
<Card title="LLM Basics" icon="brain">
|
||||
Large Language Models are AI systems trained on vast amounts of text data. They power the intelligence of your CrewAI agents, enabling them to understand and generate human-like text.
|
||||
</Card>
|
||||
<Card title="Context Window" icon="window">
|
||||
The context window determines how much text an LLM can process at once. Larger windows (e.g., 128K tokens) allow for more context but may be more expensive and slower.
|
||||
</Card>
|
||||
<Card title="Temperature" icon="temperature-three-quarters">
|
||||
Temperature (0.0 to 1.0) controls response randomness. Lower values (e.g., 0.2) produce more focused, deterministic outputs, while higher values (e.g., 0.8) increase creativity and variability.
|
||||
</Card>
|
||||
<Card title="Provider Selection" icon="server">
|
||||
Each LLM provider (e.g., OpenAI, Anthropic, Google) offers different models with varying capabilities, pricing, and features. Choose based on your needs for accuracy, speed, and cost.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Configuring LLMs for Agents
|
||||
## Setting Up Your LLM
|
||||
|
||||
CrewAI offers flexible options for setting up LLMs:
|
||||
There are three ways to configure LLMs in CrewAI. Choose the method that best fits your workflow:
|
||||
|
||||
### 1. Default Configuration
|
||||
<Tabs>
|
||||
<Tab title="1. Environment Variables">
|
||||
The simplest way to get started. Set these variables in your environment:
|
||||
|
||||
By default, CrewAI uses the `gpt-4o-mini` model. It uses environment variables if no LLM is specified:
|
||||
- `OPENAI_MODEL_NAME` (defaults to "gpt-4o-mini" if not set)
|
||||
- `OPENAI_API_BASE`
|
||||
- `OPENAI_API_KEY`
|
||||
```bash
|
||||
# Required: Your API key for authentication
|
||||
OPENAI_API_KEY=<your-api-key>
|
||||
|
||||
### 2. String Identifier
|
||||
# Optional: Default model selection
|
||||
OPENAI_MODEL_NAME=gpt-4o-mini # Default if not set
|
||||
|
||||
```python Code
|
||||
agent = Agent(llm="gpt-4o", ...)
|
||||
```
|
||||
# Optional: Organization ID (if applicable)
|
||||
OPENAI_ORGANIZATION_ID=<your-org-id>
|
||||
```
|
||||
|
||||
### 3. LLM Instance
|
||||
<Warning>
|
||||
Never commit API keys to version control. Use environment files (.env) or your system's secret management.
|
||||
</Warning>
|
||||
</Tab>
|
||||
<Tab title="2. YAML Configuration">
|
||||
Create a YAML file to define your agent configurations. This method is great for version control and team collaboration:
|
||||
|
||||
List of [more providers](https://docs.litellm.ai/docs/providers).
|
||||
```yaml
|
||||
researcher:
|
||||
role: Research Specialist
|
||||
goal: Conduct comprehensive research and analysis
|
||||
backstory: A dedicated research professional with years of experience
|
||||
verbose: true
|
||||
llm: openai/gpt-4o-mini # your model here
|
||||
# (see provider configuration examples below for more)
|
||||
```
|
||||
|
||||
<Info>
|
||||
The YAML configuration allows you to:
|
||||
- Version control your agent settings
|
||||
- Easily switch between different models
|
||||
- Share configurations across team members
|
||||
- Document model choices and their purposes
|
||||
</Info>
|
||||
</Tab>
|
||||
<Tab title="3. Direct Code">
|
||||
For maximum flexibility, configure LLMs directly in your Python code:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
|
||||
# Basic configuration
|
||||
llm = LLM(model="gpt-4")
|
||||
|
||||
# Advanced configuration with detailed parameters
|
||||
llm = LLM(
|
||||
model="gpt-4o-mini",
|
||||
temperature=0.7, # Higher for more creative outputs
|
||||
timeout=120, # Seconds to wait for response
|
||||
max_tokens=4000, # Maximum length of response
|
||||
top_p=0.9, # Nucleus sampling parameter
|
||||
frequency_penalty=0.1, # Reduce repetition
|
||||
presence_penalty=0.1, # Encourage topic diversity
|
||||
response_format={"type": "json"}, # For structured outputs
|
||||
seed=42 # For reproducible results
|
||||
)
|
||||
```
|
||||
|
||||
<Info>
|
||||
Parameter explanations:
|
||||
- `temperature`: Controls randomness (0.0-1.0)
|
||||
- `timeout`: Maximum wait time for response
|
||||
- `max_tokens`: Limits response length
|
||||
- `top_p`: Alternative to temperature for sampling
|
||||
- `frequency_penalty`: Reduces word repetition
|
||||
- `presence_penalty`: Encourages new topics
|
||||
- `response_format`: Specifies output structure
|
||||
- `seed`: Ensures consistent outputs
|
||||
</Info>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Provider Configuration Examples
|
||||
|
||||
|
||||
CrewAI supports a multitude of LLM providers, each offering unique features, authentication methods, and model capabilities.
|
||||
In this section, you'll find detailed examples that help you select, configure, and optimize the LLM that best fits your project's needs.
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="OpenAI">
|
||||
Set the following environment variables in your `.env` file:
|
||||
|
||||
```toml Code
|
||||
# Required
|
||||
OPENAI_API_KEY=sk-...
|
||||
|
||||
# Optional
|
||||
OPENAI_API_BASE=<custom-base-url>
|
||||
OPENAI_ORGANIZATION=<your-org-id>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
from crewai import LLM
|
||||
|
||||
llm = LLM(
|
||||
model="openai/gpt-4", # call model by provider/model_name
|
||||
temperature=0.8,
|
||||
max_tokens=150,
|
||||
top_p=0.9,
|
||||
frequency_penalty=0.1,
|
||||
presence_penalty=0.1,
|
||||
stop=["END"],
|
||||
seed=42
|
||||
)
|
||||
```
|
||||
|
||||
OpenAI is one of the leading providers of LLMs with a wide range of models and features.
|
||||
|
||||
| Model | Context Window | Best For |
|
||||
|---------------------|------------------|-----------------------------------------------|
|
||||
| GPT-4 | 8,192 tokens | High-accuracy tasks, complex reasoning |
|
||||
| GPT-4 Turbo | 128,000 tokens | Long-form content, document analysis |
|
||||
| GPT-4o & GPT-4o-mini | 128,000 tokens | Cost-effective large context processing |
|
||||
| o3-mini | 200,000 tokens | Fast reasoning, complex reasoning |
|
||||
| o1-mini | 128,000 tokens | Fast reasoning, complex reasoning |
|
||||
| o1-preview | 128,000 tokens | Fast reasoning, complex reasoning |
|
||||
| o1 | 200,000 tokens | Fast reasoning, complex reasoning |
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Anthropic">
|
||||
```toml Code
|
||||
# Required
|
||||
ANTHROPIC_API_KEY=sk-ant-...
|
||||
|
||||
# Optional
|
||||
ANTHROPIC_API_BASE=<custom-base-url>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="anthropic/claude-3-sonnet-20240229-v1:0",
|
||||
temperature=0.7
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Google">
|
||||
Set the following environment variables in your `.env` file:
|
||||
|
||||
```toml Code
|
||||
# Option 1: Gemini accessed with an API key.
|
||||
# https://ai.google.dev/gemini-api/docs/api-key
|
||||
GEMINI_API_KEY=<your-api-key>
|
||||
|
||||
# Option 2: Vertex AI IAM credentials for Gemini, Anthropic, and Model Garden.
|
||||
# https://cloud.google.com/vertex-ai/generative-ai/docs/overview
|
||||
```
|
||||
|
||||
Get credentials from your Google Cloud Console and save it to a JSON file with the following code:
|
||||
```python Code
|
||||
import json
|
||||
|
||||
file_path = 'path/to/vertex_ai_service_account.json'
|
||||
|
||||
# Load the JSON file
|
||||
with open(file_path, 'r') as file:
|
||||
vertex_credentials = json.load(file)
|
||||
|
||||
# Convert the credentials to a JSON string
|
||||
vertex_credentials_json = json.dumps(vertex_credentials)
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
from crewai import LLM
|
||||
|
||||
llm = LLM(
|
||||
model="gemini/gemini-1.5-pro-latest",
|
||||
temperature=0.7,
|
||||
vertex_credentials=vertex_credentials_json
|
||||
)
|
||||
```
|
||||
Google offers a range of powerful models optimized for different use cases:
|
||||
|
||||
| Model | Context Window | Best For |
|
||||
|-----------------------|----------------|------------------------------------------------------------------|
|
||||
| gemini-2.0-flash-exp | 1M tokens | Higher quality at faster speed, multimodal model, good for most tasks |
|
||||
| gemini-1.5-flash | 1M tokens | Balanced multimodal model, good for most tasks |
|
||||
| gemini-1.5-flash-8B | 1M tokens | Fastest, most cost-efficient, good for high-frequency tasks |
|
||||
| gemini-1.5-pro | 2M tokens | Best performing, wide variety of reasoning tasks including logical reasoning, coding, and creative collaboration |
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Azure">
|
||||
```toml Code
|
||||
# Required
|
||||
AZURE_API_KEY=<your-api-key>
|
||||
AZURE_API_BASE=<your-resource-url>
|
||||
AZURE_API_VERSION=<api-version>
|
||||
|
||||
# Optional
|
||||
AZURE_AD_TOKEN=<your-azure-ad-token>
|
||||
AZURE_API_TYPE=<your-azure-api-type>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="azure/gpt-4",
|
||||
api_version="2023-05-15"
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="AWS Bedrock">
|
||||
```toml Code
|
||||
AWS_ACCESS_KEY_ID=<your-access-key>
|
||||
AWS_SECRET_ACCESS_KEY=<your-secret-key>
|
||||
AWS_DEFAULT_REGION=<your-region>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
|
||||
)
|
||||
```
|
||||
|
||||
Before using Amazon Bedrock, make sure you have boto3 installed in your environment
|
||||
|
||||
[Amazon Bedrock](https://docs.aws.amazon.com/bedrock/latest/userguide/models-regions.html) is a managed service that provides access to multiple foundation models from top AI companies through a unified API, enabling secure and responsible AI application development.
|
||||
|
||||
| Model | Context Window | Best For |
|
||||
|-------------------------|----------------------|-------------------------------------------------------------------|
|
||||
| Amazon Nova Pro | Up to 300k tokens | High-performance, model balancing accuracy, speed, and cost-effectiveness across diverse tasks. |
|
||||
| Amazon Nova Micro | Up to 128k tokens | High-performance, cost-effective text-only model optimized for lowest latency responses. |
|
||||
| Amazon Nova Lite | Up to 300k tokens | High-performance, affordable multimodal processing for images, video, and text with real-time capabilities. |
|
||||
| Claude 3.7 Sonnet | Up to 128k tokens | High-performance, best for complex reasoning, coding & AI agents |
|
||||
| Claude 3.5 Sonnet v2 | Up to 200k tokens | State-of-the-art model specialized in software engineering, agentic capabilities, and computer interaction at optimized cost. |
|
||||
| Claude 3.5 Sonnet | Up to 200k tokens | High-performance model delivering superior intelligence and reasoning across diverse tasks with optimal speed-cost balance. |
|
||||
| Claude 3.5 Haiku | Up to 200k tokens | Fast, compact multimodal model optimized for quick responses and seamless human-like interactions |
|
||||
| Claude 3 Sonnet | Up to 200k tokens | Multimodal model balancing intelligence and speed for high-volume deployments. |
|
||||
| Claude 3 Haiku | Up to 200k tokens | Compact, high-speed multimodal model optimized for quick responses and natural conversational interactions |
|
||||
| Claude 3 Opus | Up to 200k tokens | Most advanced multimodal model exceling at complex tasks with human-like reasoning and superior contextual understanding. |
|
||||
| Claude 2.1 | Up to 200k tokens | Enhanced version with expanded context window, improved reliability, and reduced hallucinations for long-form and RAG applications |
|
||||
| Claude | Up to 100k tokens | Versatile model excelling in sophisticated dialogue, creative content, and precise instruction following. |
|
||||
| Claude Instant | Up to 100k tokens | Fast, cost-effective model for everyday tasks like dialogue, analysis, summarization, and document Q&A |
|
||||
| Llama 3.1 405B Instruct | Up to 128k tokens | Advanced LLM for synthetic data generation, distillation, and inference for chatbots, coding, and domain-specific tasks. |
|
||||
| Llama 3.1 70B Instruct | Up to 128k tokens | Powers complex conversations with superior contextual understanding, reasoning and text generation. |
|
||||
| Llama 3.1 8B Instruct | Up to 128k tokens | Advanced state-of-the-art model with language understanding, superior reasoning, and text generation. |
|
||||
| Llama 3 70B Instruct | Up to 8k tokens | Powers complex conversations with superior contextual understanding, reasoning and text generation. |
|
||||
| Llama 3 8B Instruct | Up to 8k tokens | Advanced state-of-the-art LLM with language understanding, superior reasoning, and text generation. |
|
||||
| Titan Text G1 - Lite | Up to 4k tokens | Lightweight, cost-effective model optimized for English tasks and fine-tuning with focus on summarization and content generation. |
|
||||
| Titan Text G1 - Express | Up to 8k tokens | Versatile model for general language tasks, chat, and RAG applications with support for English and 100+ languages. |
|
||||
| Cohere Command | Up to 4k tokens | Model specialized in following user commands and delivering practical enterprise solutions. |
|
||||
| Jurassic-2 Mid | Up to 8,191 tokens | Cost-effective model balancing quality and affordability for diverse language tasks like Q&A, summarization, and content generation. |
|
||||
| Jurassic-2 Ultra | Up to 8,191 tokens | Model for advanced text generation and comprehension, excelling in complex tasks like analysis and content creation. |
|
||||
| Jamba-Instruct | Up to 256k tokens | Model with extended context window optimized for cost-effective text generation, summarization, and Q&A. |
|
||||
| Mistral 7B Instruct | Up to 32k tokens | This LLM follows instructions, completes requests, and generates creative text. |
|
||||
| Mistral 8x7B Instruct | Up to 32k tokens | An MOE LLM that follows instructions, completes requests, and generates creative text. |
|
||||
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Amazon SageMaker">
|
||||
```toml Code
|
||||
AWS_ACCESS_KEY_ID=<your-access-key>
|
||||
AWS_SECRET_ACCESS_KEY=<your-secret-key>
|
||||
AWS_DEFAULT_REGION=<your-region>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="sagemaker/<my-endpoint>"
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Mistral">
|
||||
Set the following environment variables in your `.env` file:
|
||||
```toml Code
|
||||
MISTRAL_API_KEY=<your-api-key>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="mistral/mistral-large-latest",
|
||||
temperature=0.7
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Nvidia NIM">
|
||||
Set the following environment variables in your `.env` file:
|
||||
```toml Code
|
||||
NVIDIA_API_KEY=<your-api-key>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="nvidia_nim/meta/llama3-70b-instruct",
|
||||
temperature=0.7
|
||||
)
|
||||
```
|
||||
|
||||
Nvidia NIM provides a comprehensive suite of models for various use cases, from general-purpose tasks to specialized applications.
|
||||
|
||||
| Model | Context Window | Best For |
|
||||
|-------------------------------------------------------------------------|----------------|-------------------------------------------------------------------|
|
||||
| nvidia/mistral-nemo-minitron-8b-8k-instruct | 8,192 tokens | State-of-the-art small language model delivering superior accuracy for chatbot, virtual assistants, and content generation. |
|
||||
| nvidia/nemotron-4-mini-hindi-4b-instruct | 4,096 tokens | A bilingual Hindi-English SLM for on-device inference, tailored specifically for Hindi Language. |
|
||||
| nvidia/llama-3.1-nemotron-70b-instruct | 128k tokens | Customized for enhanced helpfulness in responses |
|
||||
| nvidia/llama3-chatqa-1.5-8b | 128k tokens | Advanced LLM to generate high-quality, context-aware responses for chatbots and search engines. |
|
||||
| nvidia/llama3-chatqa-1.5-70b | 128k tokens | Advanced LLM to generate high-quality, context-aware responses for chatbots and search engines. |
|
||||
| nvidia/vila | 128k tokens | Multi-modal vision-language model that understands text/img/video and creates informative responses |
|
||||
| nvidia/neva-22 | 4,096 tokens | Multi-modal vision-language model that understands text/images and generates informative responses |
|
||||
| nvidia/nemotron-mini-4b-instruct | 8,192 tokens | General-purpose tasks |
|
||||
| nvidia/usdcode-llama3-70b-instruct | 128k tokens | State-of-the-art LLM that answers OpenUSD knowledge queries and generates USD-Python code. |
|
||||
| nvidia/nemotron-4-340b-instruct | 4,096 tokens | Creates diverse synthetic data that mimics the characteristics of real-world data. |
|
||||
| meta/codellama-70b | 100k tokens | LLM capable of generating code from natural language and vice versa. |
|
||||
| meta/llama2-70b | 4,096 tokens | Cutting-edge large language AI model capable of generating text and code in response to prompts. |
|
||||
| meta/llama3-8b-instruct | 8,192 tokens | Advanced state-of-the-art LLM with language understanding, superior reasoning, and text generation. |
|
||||
| meta/llama3-70b-instruct | 8,192 tokens | Powers complex conversations with superior contextual understanding, reasoning and text generation. |
|
||||
| meta/llama-3.1-8b-instruct | 128k tokens | Advanced state-of-the-art model with language understanding, superior reasoning, and text generation. |
|
||||
| meta/llama-3.1-70b-instruct | 128k tokens | Powers complex conversations with superior contextual understanding, reasoning and text generation. |
|
||||
| meta/llama-3.1-405b-instruct | 128k tokens | Advanced LLM for synthetic data generation, distillation, and inference for chatbots, coding, and domain-specific tasks. |
|
||||
| meta/llama-3.2-1b-instruct | 128k tokens | Advanced state-of-the-art small language model with language understanding, superior reasoning, and text generation. |
|
||||
| meta/llama-3.2-3b-instruct | 128k tokens | Advanced state-of-the-art small language model with language understanding, superior reasoning, and text generation. |
|
||||
| meta/llama-3.2-11b-vision-instruct | 128k tokens | Advanced state-of-the-art small language model with language understanding, superior reasoning, and text generation. |
|
||||
| meta/llama-3.2-90b-vision-instruct | 128k tokens | Advanced state-of-the-art small language model with language understanding, superior reasoning, and text generation. |
|
||||
| google/gemma-7b | 8,192 tokens | Cutting-edge text generation model text understanding, transformation, and code generation. |
|
||||
| google/gemma-2b | 8,192 tokens | Cutting-edge text generation model text understanding, transformation, and code generation. |
|
||||
| google/codegemma-7b | 8,192 tokens | Cutting-edge model built on Google's Gemma-7B specialized for code generation and code completion. |
|
||||
| google/codegemma-1.1-7b | 8,192 tokens | Advanced programming model for code generation, completion, reasoning, and instruction following. |
|
||||
| google/recurrentgemma-2b | 8,192 tokens | Novel recurrent architecture based language model for faster inference when generating long sequences. |
|
||||
| google/gemma-2-9b-it | 8,192 tokens | Cutting-edge text generation model text understanding, transformation, and code generation. |
|
||||
| google/gemma-2-27b-it | 8,192 tokens | Cutting-edge text generation model text understanding, transformation, and code generation. |
|
||||
| google/gemma-2-2b-it | 8,192 tokens | Cutting-edge text generation model text understanding, transformation, and code generation. |
|
||||
| google/deplot | 512 tokens | One-shot visual language understanding model that translates images of plots into tables. |
|
||||
| google/paligemma | 8,192 tokens | Vision language model adept at comprehending text and visual inputs to produce informative responses. |
|
||||
| mistralai/mistral-7b-instruct-v0.2 | 32k tokens | This LLM follows instructions, completes requests, and generates creative text. |
|
||||
| mistralai/mixtral-8x7b-instruct-v0.1 | 8,192 tokens | An MOE LLM that follows instructions, completes requests, and generates creative text. |
|
||||
| mistralai/mistral-large | 4,096 tokens | Creates diverse synthetic data that mimics the characteristics of real-world data. |
|
||||
| mistralai/mixtral-8x22b-instruct-v0.1 | 8,192 tokens | Creates diverse synthetic data that mimics the characteristics of real-world data. |
|
||||
| mistralai/mistral-7b-instruct-v0.3 | 32k tokens | This LLM follows instructions, completes requests, and generates creative text. |
|
||||
| nv-mistralai/mistral-nemo-12b-instruct | 128k tokens | Most advanced language model for reasoning, code, multilingual tasks; runs on a single GPU. |
|
||||
| mistralai/mamba-codestral-7b-v0.1 | 256k tokens | Model for writing and interacting with code across a wide range of programming languages and tasks. |
|
||||
| microsoft/phi-3-mini-128k-instruct | 128K tokens | Lightweight, state-of-the-art open LLM with strong math and logical reasoning skills. |
|
||||
| microsoft/phi-3-mini-4k-instruct | 4,096 tokens | Lightweight, state-of-the-art open LLM with strong math and logical reasoning skills. |
|
||||
| microsoft/phi-3-small-8k-instruct | 8,192 tokens | Lightweight, state-of-the-art open LLM with strong math and logical reasoning skills. |
|
||||
| microsoft/phi-3-small-128k-instruct | 128K tokens | Lightweight, state-of-the-art open LLM with strong math and logical reasoning skills. |
|
||||
| microsoft/phi-3-medium-4k-instruct | 4,096 tokens | Lightweight, state-of-the-art open LLM with strong math and logical reasoning skills. |
|
||||
| microsoft/phi-3-medium-128k-instruct | 128K tokens | Lightweight, state-of-the-art open LLM with strong math and logical reasoning skills. |
|
||||
| microsoft/phi-3.5-mini-instruct | 128K tokens | Lightweight multilingual LLM powering AI applications in latency bound, memory/compute constrained environments |
|
||||
| microsoft/phi-3.5-moe-instruct | 128K tokens | Advanced LLM based on Mixture of Experts architecure to deliver compute efficient content generation |
|
||||
| microsoft/kosmos-2 | 1,024 tokens | Groundbreaking multimodal model designed to understand and reason about visual elements in images. |
|
||||
| microsoft/phi-3-vision-128k-instruct | 128k tokens | Cutting-edge open multimodal model exceling in high-quality reasoning from images. |
|
||||
| microsoft/phi-3.5-vision-instruct | 128k tokens | Cutting-edge open multimodal model exceling in high-quality reasoning from images. |
|
||||
| databricks/dbrx-instruct | 12k tokens | A general-purpose LLM with state-of-the-art performance in language understanding, coding, and RAG. |
|
||||
| snowflake/arctic | 1,024 tokens | Delivers high efficiency inference for enterprise applications focused on SQL generation and coding. |
|
||||
| aisingapore/sea-lion-7b-instruct | 4,096 tokens | LLM to represent and serve the linguistic and cultural diversity of Southeast Asia |
|
||||
| ibm/granite-8b-code-instruct | 4,096 tokens | Software programming LLM for code generation, completion, explanation, and multi-turn conversion. |
|
||||
| ibm/granite-34b-code-instruct | 8,192 tokens | Software programming LLM for code generation, completion, explanation, and multi-turn conversion. |
|
||||
| ibm/granite-3.0-8b-instruct | 4,096 tokens | Advanced Small Language Model supporting RAG, summarization, classification, code, and agentic AI |
|
||||
| ibm/granite-3.0-3b-a800m-instruct | 4,096 tokens | Highly efficient Mixture of Experts model for RAG, summarization, entity extraction, and classification |
|
||||
| mediatek/breeze-7b-instruct | 4,096 tokens | Creates diverse synthetic data that mimics the characteristics of real-world data. |
|
||||
| upstage/solar-10.7b-instruct | 4,096 tokens | Excels in NLP tasks, particularly in instruction-following, reasoning, and mathematics. |
|
||||
| writer/palmyra-med-70b-32k | 32k tokens | Leading LLM for accurate, contextually relevant responses in the medical domain. |
|
||||
| writer/palmyra-med-70b | 32k tokens | Leading LLM for accurate, contextually relevant responses in the medical domain. |
|
||||
| writer/palmyra-fin-70b-32k | 32k tokens | Specialized LLM for financial analysis, reporting, and data processing |
|
||||
| 01-ai/yi-large | 32k tokens | Powerful model trained on English and Chinese for diverse tasks including chatbot and creative writing. |
|
||||
| deepseek-ai/deepseek-coder-6.7b-instruct | 2k tokens | Powerful coding model offering advanced capabilities in code generation, completion, and infilling |
|
||||
| rakuten/rakutenai-7b-instruct | 1,024 tokens | Advanced state-of-the-art LLM with language understanding, superior reasoning, and text generation. |
|
||||
| rakuten/rakutenai-7b-chat | 1,024 tokens | Advanced state-of-the-art LLM with language understanding, superior reasoning, and text generation. |
|
||||
| baichuan-inc/baichuan2-13b-chat | 4,096 tokens | Support Chinese and English chat, coding, math, instruction following, solving quizzes |
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Local NVIDIA NIM Deployed using WSL2">
|
||||
|
||||
NVIDIA NIM enables you to run powerful LLMs locally on your Windows machine using WSL2 (Windows Subsystem for Linux).
|
||||
This approach allows you to leverage your NVIDIA GPU for private, secure, and cost-effective AI inference without relying on cloud services.
|
||||
Perfect for development, testing, or production scenarios where data privacy or offline capabilities are required.
|
||||
|
||||
Here is a step-by-step guide to setting up a local NVIDIA NIM model:
|
||||
|
||||
1. Follow installation instructions from [NVIDIA Website](https://docs.nvidia.com/nim/wsl2/latest/getting-started.html)
|
||||
|
||||
2. Install the local model. For Llama 3.1-8b follow [instructions](https://build.nvidia.com/meta/llama-3_1-8b-instruct/deploy)
|
||||
|
||||
3. Configure your crewai local models:
|
||||
|
||||
```python Code
|
||||
from crewai.llm import LLM
|
||||
|
||||
local_nvidia_nim_llm = LLM(
|
||||
model="openai/meta/llama-3.1-8b-instruct", # it's an openai-api compatible model
|
||||
base_url="http://localhost:8000/v1",
|
||||
api_key="<your_api_key|any text if you have not configured it>", # api_key is required, but you can use any text
|
||||
)
|
||||
|
||||
# Then you can use it in your crew:
|
||||
|
||||
@CrewBase
|
||||
class MyCrew():
|
||||
# ...
|
||||
|
||||
@agent
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['researcher'], # type: ignore[index]
|
||||
llm=local_nvidia_nim_llm
|
||||
)
|
||||
|
||||
# ...
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Groq">
|
||||
Set the following environment variables in your `.env` file:
|
||||
|
||||
```toml Code
|
||||
GROQ_API_KEY=<your-api-key>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="groq/llama-3.2-90b-text-preview",
|
||||
temperature=0.7
|
||||
)
|
||||
```
|
||||
| Model | Context Window | Best For |
|
||||
|-------------------|------------------|--------------------------------------------|
|
||||
| Llama 3.1 70B/8B | 131,072 tokens | High-performance, large context tasks |
|
||||
| Llama 3.2 Series | 8,192 tokens | General-purpose tasks |
|
||||
| Mixtral 8x7B | 32,768 tokens | Balanced performance and context |
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="IBM watsonx.ai">
|
||||
Set the following environment variables in your `.env` file:
|
||||
```toml Code
|
||||
# Required
|
||||
WATSONX_URL=<your-url>
|
||||
WATSONX_APIKEY=<your-apikey>
|
||||
WATSONX_PROJECT_ID=<your-project-id>
|
||||
|
||||
# Optional
|
||||
WATSONX_TOKEN=<your-token>
|
||||
WATSONX_DEPLOYMENT_SPACE_ID=<your-space-id>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="watsonx/meta-llama/llama-3-1-70b-instruct",
|
||||
base_url="https://api.watsonx.ai/v1"
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Ollama (Local LLMs)">
|
||||
1. Install Ollama: [ollama.ai](https://ollama.ai/)
|
||||
2. Run a model: `ollama run llama3`
|
||||
3. Configure:
|
||||
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="ollama/llama3:70b",
|
||||
base_url="http://localhost:11434"
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Fireworks AI">
|
||||
Set the following environment variables in your `.env` file:
|
||||
```toml Code
|
||||
FIREWORKS_API_KEY=<your-api-key>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="fireworks_ai/accounts/fireworks/models/llama-v3-70b-instruct",
|
||||
temperature=0.7
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Perplexity AI">
|
||||
Set the following environment variables in your `.env` file:
|
||||
```toml Code
|
||||
PERPLEXITY_API_KEY=<your-api-key>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="llama-3.1-sonar-large-128k-online",
|
||||
base_url="https://api.perplexity.ai/"
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Hugging Face">
|
||||
Set the following environment variables in your `.env` file:
|
||||
```toml Code
|
||||
HF_TOKEN=<your-api-key>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="huggingface/meta-llama/Meta-Llama-3.1-8B-Instruct"
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SambaNova">
|
||||
Set the following environment variables in your `.env` file:
|
||||
|
||||
```toml Code
|
||||
SAMBANOVA_API_KEY=<your-api-key>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="sambanova/Meta-Llama-3.1-8B-Instruct",
|
||||
temperature=0.7
|
||||
)
|
||||
```
|
||||
| Model | Context Window | Best For |
|
||||
|--------------------|------------------------|----------------------------------------------|
|
||||
| Llama 3.1 70B/8B | Up to 131,072 tokens | High-performance, large context tasks |
|
||||
| Llama 3.1 405B | 8,192 tokens | High-performance and output quality |
|
||||
| Llama 3.2 Series | 8,192 tokens | General-purpose, multimodal tasks |
|
||||
| Llama 3.3 70B | Up to 131,072 tokens | High-performance and output quality |
|
||||
| Qwen2 familly | 8,192 tokens | High-performance and output quality |
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Cerebras">
|
||||
Set the following environment variables in your `.env` file:
|
||||
```toml Code
|
||||
# Required
|
||||
CEREBRAS_API_KEY=<your-api-key>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="cerebras/llama3.1-70b",
|
||||
temperature=0.7,
|
||||
max_tokens=8192
|
||||
)
|
||||
```
|
||||
|
||||
<Info>
|
||||
Cerebras features:
|
||||
- Fast inference speeds
|
||||
- Competitive pricing
|
||||
- Good balance of speed and quality
|
||||
- Support for long context windows
|
||||
</Info>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Open Router">
|
||||
Set the following environment variables in your `.env` file:
|
||||
```toml Code
|
||||
OPENROUTER_API_KEY=<your-api-key>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="openrouter/deepseek/deepseek-r1",
|
||||
base_url="https://openrouter.ai/api/v1",
|
||||
api_key=OPENROUTER_API_KEY
|
||||
)
|
||||
```
|
||||
|
||||
<Info>
|
||||
Open Router models:
|
||||
- openrouter/deepseek/deepseek-r1
|
||||
- openrouter/deepseek/deepseek-chat
|
||||
</Info>
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Streaming Responses
|
||||
|
||||
CrewAI supports streaming responses from LLMs, allowing your application to receive and process outputs in real-time as they're generated.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Basic Setup">
|
||||
Enable streaming by setting the `stream` parameter to `True` when initializing your LLM:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
|
||||
# Create an LLM with streaming enabled
|
||||
llm = LLM(
|
||||
model="openai/gpt-4o",
|
||||
stream=True # Enable streaming
|
||||
)
|
||||
```
|
||||
|
||||
When streaming is enabled, responses are delivered in chunks as they're generated, creating a more responsive user experience.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Event Handling">
|
||||
CrewAI emits events for each chunk received during streaming:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from crewai.utilities.events import EventHandler, LLMStreamChunkEvent
|
||||
|
||||
class MyEventHandler(EventHandler):
|
||||
def on_llm_stream_chunk(self, event: LLMStreamChunkEvent):
|
||||
# Process each chunk as it arrives
|
||||
print(f"Received chunk: {event.chunk}")
|
||||
|
||||
# Register the event handler
|
||||
from crewai.utilities.events import crewai_event_bus
|
||||
crewai_event_bus.register_handler(MyEventHandler())
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Structured LLM Calls
|
||||
|
||||
CrewAI supports structured responses from LLM calls by allowing you to define a `response_format` using a Pydantic model. This enables the framework to automatically parse and validate the output, making it easier to integrate the response into your application without manual post-processing.
|
||||
|
||||
For example, you can define a Pydantic model to represent the expected response structure and pass it as the `response_format` when instantiating the LLM. The model will then be used to convert the LLM output into a structured Python object.
|
||||
|
||||
```python Code
|
||||
from crewai import LLM
|
||||
|
||||
llm = LLM(model="gpt-4", temperature=0.7)
|
||||
agent = Agent(llm=llm, ...)
|
||||
```
|
||||
class Dog(BaseModel):
|
||||
name: str
|
||||
age: int
|
||||
breed: str
|
||||
|
||||
### 4. Custom LLM Objects
|
||||
|
||||
Pass a custom LLM implementation or object from another library.
|
||||
llm = LLM(model="gpt-4o", response_format=Dog)
|
||||
|
||||
## Connecting to OpenAI-Compatible LLMs
|
||||
|
||||
You can connect to OpenAI-compatible LLMs using either environment variables or by setting specific attributes on the LLM class:
|
||||
|
||||
1. Using environment variables:
|
||||
|
||||
```python Code
|
||||
import os
|
||||
|
||||
os.environ["OPENAI_API_KEY"] = "your-api-key"
|
||||
os.environ["OPENAI_API_BASE"] = "https://api.your-provider.com/v1"
|
||||
```
|
||||
|
||||
2. Using LLM class attributes:
|
||||
|
||||
```python Code
|
||||
from crewai import LLM
|
||||
|
||||
llm = LLM(
|
||||
model="custom-model-name",
|
||||
api_key="your-api-key",
|
||||
base_url="https://api.your-provider.com/v1"
|
||||
response = llm.call(
|
||||
"Analyze the following messages and return the name, age, and breed. "
|
||||
"Meet Kona! She is 3 years old and is a black german shepherd."
|
||||
)
|
||||
agent = Agent(llm=llm, ...)
|
||||
print(response)
|
||||
|
||||
# Output:
|
||||
# Dog(name='Kona', age=3, breed='black german shepherd')
|
||||
```
|
||||
|
||||
## LLM Configuration Options
|
||||
## Advanced Features and Optimization
|
||||
|
||||
When configuring an LLM for your agent, you have access to a wide range of parameters:
|
||||
Learn how to get the most out of your LLM configuration:
|
||||
|
||||
| Parameter | Type | Description |
|
||||
|:------------------|:---------------:|:-------------------------------------------------------------------------------------------------|
|
||||
| **model** | `str` | Name of the model to use (e.g., "gpt-4", "gpt-3.5-turbo", "ollama/llama3.1"). For more options, visit the providers documentation. |
|
||||
| **timeout** | `float, int` | Maximum time (in seconds) to wait for a response. |
|
||||
| **temperature** | `float` | Controls randomness in output (0.0 to 1.0). |
|
||||
| **top_p** | `float` | Controls diversity of output (0.0 to 1.0). |
|
||||
| **n** | `int` | Number of completions to generate. |
|
||||
| **stop** | `str, List[str]` | Sequence(s) where generation should stop. |
|
||||
| **max_tokens** | `int` | Maximum number of tokens to generate. |
|
||||
| **presence_penalty** | `float` | Penalizes new tokens based on their presence in prior text. |
|
||||
| **frequency_penalty**| `float` | Penalizes new tokens based on their frequency in prior text. |
|
||||
| **logit_bias** | `Dict[int, float]`| Modifies likelihood of specified tokens appearing. |
|
||||
| **response_format** | `Dict[str, Any]` | Specifies the format of the response (e.g., JSON object). |
|
||||
| **seed** | `int` | Sets a random seed for deterministic results. |
|
||||
| **logprobs** | `bool` | Returns log probabilities of output tokens if enabled. |
|
||||
| **top_logprobs** | `int` | Number of most likely tokens for which to return log probabilities. |
|
||||
| **base_url** | `str` | The base URL for the API endpoint. |
|
||||
| **api_version** | `str` | Version of the API to use. |
|
||||
| **api_key** | `str` | Your API key for authentication. |
|
||||
<AccordionGroup>
|
||||
<Accordion title="Context Window Management">
|
||||
CrewAI includes smart context management features:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
|
||||
## OpenAI Example Configuration
|
||||
# CrewAI automatically handles:
|
||||
# 1. Token counting and tracking
|
||||
# 2. Content summarization when needed
|
||||
# 3. Task splitting for large contexts
|
||||
|
||||
```python Code
|
||||
from crewai import LLM
|
||||
llm = LLM(
|
||||
model="gpt-4",
|
||||
max_tokens=4000, # Limit response length
|
||||
)
|
||||
```
|
||||
|
||||
llm = LLM(
|
||||
model="gpt-4",
|
||||
temperature=0.8,
|
||||
max_tokens=150,
|
||||
top_p=0.9,
|
||||
frequency_penalty=0.1,
|
||||
presence_penalty=0.1,
|
||||
stop=["END"],
|
||||
seed=42,
|
||||
base_url="https://api.openai.com/v1",
|
||||
api_key="your-api-key-here"
|
||||
)
|
||||
agent = Agent(llm=llm, ...)
|
||||
```
|
||||
<Info>
|
||||
Best practices for context management:
|
||||
1. Choose models with appropriate context windows
|
||||
2. Pre-process long inputs when possible
|
||||
3. Use chunking for large documents
|
||||
4. Monitor token usage to optimize costs
|
||||
</Info>
|
||||
</Accordion>
|
||||
|
||||
## Cerebras Example Configuration
|
||||
<Accordion title="Performance Optimization">
|
||||
<Steps>
|
||||
<Step title="Token Usage Optimization">
|
||||
Choose the right context window for your task:
|
||||
- Small tasks (up to 4K tokens): Standard models
|
||||
- Medium tasks (between 4K-32K): Enhanced models
|
||||
- Large tasks (over 32K): Large context models
|
||||
|
||||
```python Code
|
||||
from crewai import LLM
|
||||
```python
|
||||
# Configure model with appropriate settings
|
||||
llm = LLM(
|
||||
model="openai/gpt-4-turbo-preview",
|
||||
temperature=0.7, # Adjust based on task
|
||||
max_tokens=4096, # Set based on output needs
|
||||
timeout=300 # Longer timeout for complex tasks
|
||||
)
|
||||
```
|
||||
<Tip>
|
||||
- Lower temperature (0.1 to 0.3) for factual responses
|
||||
- Higher temperature (0.7 to 0.9) for creative tasks
|
||||
</Tip>
|
||||
</Step>
|
||||
|
||||
llm = LLM(
|
||||
model="cerebras/llama-3.1-70b",
|
||||
base_url="https://api.cerebras.ai/v1",
|
||||
api_key="your-api-key-here"
|
||||
)
|
||||
agent = Agent(llm=llm, ...)
|
||||
```
|
||||
<Step title="Best Practices">
|
||||
1. Monitor token usage
|
||||
2. Implement rate limiting
|
||||
3. Use caching when possible
|
||||
4. Set appropriate max_tokens limits
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Using Ollama (Local LLMs)
|
||||
<Info>
|
||||
Remember to regularly monitor your token usage and adjust your configuration as needed to optimize costs and performance.
|
||||
</Info>
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
CrewAI supports using Ollama for running open-source models locally:
|
||||
## Common Issues and Solutions
|
||||
|
||||
1. Install Ollama: [ollama.ai](https://ollama.ai/)
|
||||
2. Run a model: `ollama run llama2`
|
||||
3. Configure agent:
|
||||
<Tabs>
|
||||
<Tab title="Authentication">
|
||||
<Warning>
|
||||
Most authentication issues can be resolved by checking API key format and environment variable names.
|
||||
</Warning>
|
||||
|
||||
```python Code
|
||||
from crewai import LLM
|
||||
```bash
|
||||
# OpenAI
|
||||
OPENAI_API_KEY=sk-...
|
||||
|
||||
agent = Agent(
|
||||
llm=LLM(model="ollama/llama3.1", base_url="http://localhost:11434"),
|
||||
...
|
||||
)
|
||||
```
|
||||
# Anthropic
|
||||
ANTHROPIC_API_KEY=sk-ant-...
|
||||
```
|
||||
</Tab>
|
||||
<Tab title="Model Names">
|
||||
<Check>
|
||||
Always include the provider prefix in model names
|
||||
</Check>
|
||||
|
||||
## Changing the Base API URL
|
||||
```python
|
||||
# Correct
|
||||
llm = LLM(model="openai/gpt-4")
|
||||
|
||||
You can change the base API URL for any LLM provider by setting the `base_url` parameter:
|
||||
|
||||
```python Code
|
||||
from crewai import LLM
|
||||
|
||||
llm = LLM(
|
||||
model="custom-model-name",
|
||||
base_url="https://api.your-provider.com/v1",
|
||||
api_key="your-api-key"
|
||||
)
|
||||
agent = Agent(llm=llm, ...)
|
||||
```
|
||||
|
||||
This is particularly useful when working with OpenAI-compatible APIs or when you need to specify a different endpoint for your chosen provider.
|
||||
|
||||
## Best Practices
|
||||
|
||||
1. **Choose the right model**: Balance capability and cost.
|
||||
2. **Optimize prompts**: Clear, concise instructions improve output.
|
||||
3. **Manage tokens**: Monitor and limit token usage for efficiency.
|
||||
4. **Use appropriate temperature**: Lower for factual tasks, higher for creative ones.
|
||||
5. **Implement error handling**: Gracefully manage API errors and rate limits.
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
- **API Errors**: Check your API key, network connection, and rate limits.
|
||||
- **Unexpected Outputs**: Refine your prompts and adjust temperature or top_p.
|
||||
- **Performance Issues**: Consider using a more powerful model or optimizing your queries.
|
||||
- **Timeout Errors**: Increase the `timeout` parameter or optimize your input.
|
||||
# Incorrect
|
||||
llm = LLM(model="gpt-4")
|
||||
```
|
||||
</Tab>
|
||||
<Tab title="Context Length">
|
||||
<Tip>
|
||||
Use larger context models for extensive tasks
|
||||
</Tip>
|
||||
|
||||
```python
|
||||
# Large context model
|
||||
llm = LLM(model="openai/gpt-4o") # 128K tokens
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
@@ -18,6 +18,8 @@ reason, and learn from past interactions.
|
||||
| **Long-Term Memory** | Preserves valuable insights and learnings from past executions, allowing agents to build and refine their knowledge over time. |
|
||||
| **Entity Memory** | Captures and organizes information about entities (people, places, concepts) encountered during tasks, facilitating deeper understanding and relationship mapping. Uses `RAG` for storing entity information. |
|
||||
| **Contextual Memory**| Maintains the context of interactions by combining `ShortTermMemory`, `LongTermMemory`, and `EntityMemory`, aiding in the coherence and relevance of agent responses over a sequence of tasks or a conversation. |
|
||||
| **External Memory** | Enables integration with external memory systems and providers (like Mem0), allowing for specialized memory storage and retrieval across different applications. Supports custom storage implementations for flexible memory management. |
|
||||
| **User Memory** | ⚠️ **DEPRECATED**: This component is deprecated and will be removed in a future version. Please use [External Memory](#using-external-memory) instead. |
|
||||
|
||||
## How Memory Systems Empower Agents
|
||||
|
||||
@@ -57,41 +59,322 @@ my_crew = Crew(
|
||||
### Example: Use Custom Memory Instances e.g FAISS as the VectorDB
|
||||
|
||||
```python Code
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
from crewai import Crew, Process
|
||||
from crewai.memory import LongTermMemory, ShortTermMemory, EntityMemory
|
||||
from crewai.memory.storage.rag_storage import RAGStorage
|
||||
from crewai.memory.storage.ltm_sqlite_storage import LTMSQLiteStorage
|
||||
from typing import List, Optional
|
||||
|
||||
# Assemble your crew with memory capabilities
|
||||
my_crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
process="Process.sequential",
|
||||
memory=True,
|
||||
long_term_memory=EnhanceLongTermMemory(
|
||||
my_crew: Crew = Crew(
|
||||
agents = [...],
|
||||
tasks = [...],
|
||||
process = Process.sequential,
|
||||
memory = True,
|
||||
# Long-term memory for persistent storage across sessions
|
||||
long_term_memory = LongTermMemory(
|
||||
storage=LTMSQLiteStorage(
|
||||
db_path="/my_data_dir/my_crew1/long_term_memory_storage.db"
|
||||
db_path="/my_crew1/long_term_memory_storage.db"
|
||||
)
|
||||
),
|
||||
short_term_memory=EnhanceShortTermMemory(
|
||||
storage=CustomRAGStorage(
|
||||
crew_name="my_crew",
|
||||
storage_type="short_term",
|
||||
data_dir="//my_data_dir",
|
||||
model=embedder["model"],
|
||||
dimension=embedder["dimension"],
|
||||
# Short-term memory for current context using RAG
|
||||
short_term_memory = ShortTermMemory(
|
||||
storage = RAGStorage(
|
||||
embedder_config={
|
||||
"provider": "openai",
|
||||
"config": {
|
||||
"model": 'text-embedding-3-small'
|
||||
}
|
||||
},
|
||||
type="short_term",
|
||||
path="/my_crew1/"
|
||||
)
|
||||
),
|
||||
),
|
||||
entity_memory=EnhanceEntityMemory(
|
||||
storage=CustomRAGStorage(
|
||||
crew_name="my_crew",
|
||||
storage_type="entities",
|
||||
data_dir="//my_data_dir",
|
||||
model=embedder["model"],
|
||||
dimension=embedder["dimension"],
|
||||
),
|
||||
# Entity memory for tracking key information about entities
|
||||
entity_memory = EntityMemory(
|
||||
storage=RAGStorage(
|
||||
embedder_config={
|
||||
"provider": "openai",
|
||||
"config": {
|
||||
"model": 'text-embedding-3-small'
|
||||
}
|
||||
},
|
||||
type="short_term",
|
||||
path="/my_crew1/"
|
||||
)
|
||||
),
|
||||
verbose=True,
|
||||
)
|
||||
```
|
||||
|
||||
## Security Considerations
|
||||
|
||||
When configuring memory storage:
|
||||
- Use environment variables for storage paths (e.g., `CREWAI_STORAGE_DIR`)
|
||||
- Never hardcode sensitive information like database credentials
|
||||
- Consider access permissions for storage directories
|
||||
- Use relative paths when possible to maintain portability
|
||||
|
||||
Example using environment variables:
|
||||
```python
|
||||
import os
|
||||
from crewai import Crew
|
||||
from crewai.memory import LongTermMemory
|
||||
from crewai.memory.storage.ltm_sqlite_storage import LTMSQLiteStorage
|
||||
|
||||
# Configure storage path using environment variable
|
||||
storage_path = os.getenv("CREWAI_STORAGE_DIR", "./storage")
|
||||
crew = Crew(
|
||||
memory=True,
|
||||
long_term_memory=LongTermMemory(
|
||||
storage=LTMSQLiteStorage(
|
||||
db_path="{storage_path}/memory.db".format(storage_path=storage_path)
|
||||
)
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
## Configuration Examples
|
||||
|
||||
### Basic Memory Configuration
|
||||
```python
|
||||
from crewai import Crew
|
||||
from crewai.memory import LongTermMemory
|
||||
|
||||
# Simple memory configuration
|
||||
crew = Crew(memory=True) # Uses default storage locations
|
||||
```
|
||||
Note that External Memory won’t be defined when `memory=True` is set, as we can’t infer which external memory would be suitable for your case
|
||||
|
||||
### Custom Storage Configuration
|
||||
```python
|
||||
from crewai import Crew
|
||||
from crewai.memory import LongTermMemory
|
||||
from crewai.memory.storage.ltm_sqlite_storage import LTMSQLiteStorage
|
||||
|
||||
# Configure custom storage paths
|
||||
crew = Crew(
|
||||
memory=True,
|
||||
long_term_memory=LongTermMemory(
|
||||
storage=LTMSQLiteStorage(db_path="./memory.db")
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
## Integrating Mem0 for Enhanced User Memory
|
||||
|
||||
[Mem0](https://mem0.ai/) is a self-improving memory layer for LLM applications, enabling personalized AI experiences.
|
||||
|
||||
|
||||
### Using Mem0 API platform
|
||||
|
||||
To include user-specific memory you can get your API key [here](https://app.mem0.ai/dashboard/api-keys) and refer the [docs](https://docs.mem0.ai/platform/quickstart#4-1-create-memories) for adding user preferences. In this case `user_memory` is set to `MemoryClient` from mem0.
|
||||
|
||||
|
||||
```python Code
|
||||
import os
|
||||
from crewai import Crew, Process
|
||||
from mem0 import MemoryClient
|
||||
|
||||
# Set environment variables for Mem0
|
||||
os.environ["MEM0_API_KEY"] = "m0-xx"
|
||||
|
||||
# Step 1: Create a Crew with User Memory
|
||||
|
||||
crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
memory=True,
|
||||
memory_config={
|
||||
"provider": "mem0",
|
||||
"config": {"user_id": "john"},
|
||||
"user_memory" : {} #Set user_memory explicitly to a dictionary, we are working on this issue.
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
#### Additional Memory Configuration Options
|
||||
If you want to access a specific organization and project, you can set the `org_id` and `project_id` parameters in the memory configuration.
|
||||
|
||||
```python Code
|
||||
from crewai import Crew
|
||||
|
||||
crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
verbose=True,
|
||||
memory=True,
|
||||
memory_config={
|
||||
"provider": "mem0",
|
||||
"config": {"user_id": "john", "org_id": "my_org_id", "project_id": "my_project_id"},
|
||||
"user_memory" : {} #Set user_memory explicitly to a dictionary, we are working on this issue.
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
### Using Local Mem0 memory
|
||||
If you want to use local mem0 memory, with a custom configuration, you can set a parameter `local_mem0_config` in the config itself.
|
||||
If both os environment key is set and local_mem0_config is given, the API platform takes higher priority over the local configuration.
|
||||
Check [this](https://docs.mem0.ai/open-source/python-quickstart#run-mem0-locally) mem0 local configuration docs for more understanding.
|
||||
In this case `user_memory` is set to `Memory` from mem0.
|
||||
|
||||
|
||||
```python Code
|
||||
from crewai import Crew
|
||||
|
||||
|
||||
#local mem0 config
|
||||
config = {
|
||||
"vector_store": {
|
||||
"provider": "qdrant",
|
||||
"config": {
|
||||
"host": "localhost",
|
||||
"port": 6333
|
||||
}
|
||||
},
|
||||
"llm": {
|
||||
"provider": "openai",
|
||||
"config": {
|
||||
"api_key": "your-api-key",
|
||||
"model": "gpt-4"
|
||||
}
|
||||
},
|
||||
"embedder": {
|
||||
"provider": "openai",
|
||||
"config": {
|
||||
"api_key": "your-api-key",
|
||||
"model": "text-embedding-3-small"
|
||||
}
|
||||
},
|
||||
"graph_store": {
|
||||
"provider": "neo4j",
|
||||
"config": {
|
||||
"url": "neo4j+s://your-instance",
|
||||
"username": "neo4j",
|
||||
"password": "password"
|
||||
}
|
||||
},
|
||||
"history_db_path": "/path/to/history.db",
|
||||
"version": "v1.1",
|
||||
"custom_fact_extraction_prompt": "Optional custom prompt for fact extraction for memory",
|
||||
"custom_update_memory_prompt": "Optional custom prompt for update memory"
|
||||
}
|
||||
|
||||
crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
verbose=True,
|
||||
memory=True,
|
||||
memory_config={
|
||||
"provider": "mem0",
|
||||
"config": {"user_id": "john", 'local_mem0_config': config},
|
||||
"user_memory" : {} #Set user_memory explicitly to a dictionary, we are working on this issue.
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
### Using External Memory
|
||||
|
||||
External Memory is a powerful feature that allows you to integrate external memory systems with your CrewAI applications. This is particularly useful when you want to use specialized memory providers or maintain memory across different applications.
|
||||
Since it’s an external memory, we’re not able to add a default value to it - unlike with Long Term and Short Term memory.
|
||||
|
||||
#### Basic Usage with Mem0
|
||||
|
||||
The most common way to use External Memory is with Mem0 as the provider:
|
||||
|
||||
```python
|
||||
import os
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai.memory.external.external_memory import ExternalMemory
|
||||
|
||||
os.environ["MEM0_API_KEY"] = "YOUR-API-KEY"
|
||||
|
||||
agent = Agent(
|
||||
role="You are a helpful assistant",
|
||||
goal="Plan a vacation for the user",
|
||||
backstory="You are a helpful assistant that can plan a vacation for the user",
|
||||
verbose=True,
|
||||
)
|
||||
task = Task(
|
||||
description="Give things related to the user's vacation",
|
||||
expected_output="A plan for the vacation",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
external_memory=ExternalMemory(
|
||||
embedder_config={"provider": "mem0", "config": {"user_id": "U-123"}} # you can provide an entire Mem0 configuration
|
||||
),
|
||||
)
|
||||
|
||||
crew.kickoff(
|
||||
inputs={"question": "which destination is better for a beach vacation?"}
|
||||
)
|
||||
```
|
||||
|
||||
#### Using External Memory with Custom Storage
|
||||
|
||||
You can also create custom storage implementations for External Memory. Here's an example of how to create a custom storage:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai.memory.external.external_memory import ExternalMemory
|
||||
from crewai.memory.storage.interface import Storage
|
||||
|
||||
|
||||
class CustomStorage(Storage):
|
||||
def __init__(self):
|
||||
self.memories = []
|
||||
|
||||
def save(self, value, metadata=None, agent=None):
|
||||
self.memories.append({"value": value, "metadata": metadata, "agent": agent})
|
||||
|
||||
def search(self, query, limit=10, score_threshold=0.5):
|
||||
# Implement your search logic here
|
||||
return []
|
||||
|
||||
def reset(self):
|
||||
self.memories = []
|
||||
|
||||
|
||||
# Create external memory with custom storage
|
||||
external_memory = ExternalMemory(
|
||||
storage=CustomStorage(),
|
||||
embedder_config={"provider": "mem0", "config": {"user_id": "U-123"}},
|
||||
)
|
||||
|
||||
agent = Agent(
|
||||
role="You are a helpful assistant",
|
||||
goal="Plan a vacation for the user",
|
||||
backstory="You are a helpful assistant that can plan a vacation for the user",
|
||||
verbose=True,
|
||||
)
|
||||
task = Task(
|
||||
description="Give things related to the user's vacation",
|
||||
expected_output="A plan for the vacation",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
external_memory=external_memory,
|
||||
)
|
||||
|
||||
crew.kickoff(
|
||||
inputs={"question": "which destination is better for a beach vacation?"}
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
## Additional Embedding Providers
|
||||
|
||||
@@ -118,7 +401,7 @@ Alternatively, you can directly pass the OpenAIEmbeddingFunction to the embedder
|
||||
Example:
|
||||
```python Code
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
from chromadb.utils.embedding_functions.openai_embedding_function import OpenAIEmbeddingFunction
|
||||
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
|
||||
|
||||
my_crew = Crew(
|
||||
agents=[...],
|
||||
@@ -126,7 +409,12 @@ my_crew = Crew(
|
||||
process=Process.sequential,
|
||||
memory=True,
|
||||
verbose=True,
|
||||
embedder=OpenAIEmbeddingFunction(api_key=os.getenv("OPENAI_API_KEY"), model_name="text-embedding-3-small"),
|
||||
embedder={
|
||||
"provider": "openai",
|
||||
"config": {
|
||||
"model": 'text-embedding-3-small'
|
||||
}
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
@@ -152,6 +440,19 @@ my_crew = Crew(
|
||||
|
||||
### Using Google AI embeddings
|
||||
|
||||
#### Prerequisites
|
||||
Before using Google AI embeddings, ensure you have:
|
||||
- Access to the Gemini API
|
||||
- The necessary API keys and permissions
|
||||
|
||||
You will need to update your *pyproject.toml* dependencies:
|
||||
```YAML
|
||||
dependencies = [
|
||||
"google-generativeai>=0.8.4", #main version in January/2025 - crewai v.0.100.0 and crewai-tools 0.33.0
|
||||
"crewai[tools]>=0.100.0,<1.0.0"
|
||||
]
|
||||
```
|
||||
|
||||
```python Code
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
|
||||
@@ -165,7 +466,7 @@ my_crew = Crew(
|
||||
"provider": "google",
|
||||
"config": {
|
||||
"api_key": "<YOUR_API_KEY>",
|
||||
"model_name": "<model_name>"
|
||||
"model": "<model_name>"
|
||||
}
|
||||
}
|
||||
)
|
||||
@@ -174,6 +475,7 @@ my_crew = Crew(
|
||||
### Using Azure OpenAI embeddings
|
||||
|
||||
```python Code
|
||||
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
|
||||
my_crew = Crew(
|
||||
@@ -182,19 +484,22 @@ my_crew = Crew(
|
||||
process=Process.sequential,
|
||||
memory=True,
|
||||
verbose=True,
|
||||
embedder=embedding_functions.OpenAIEmbeddingFunction(
|
||||
api_key="YOUR_API_KEY",
|
||||
api_base="YOUR_API_BASE_PATH",
|
||||
api_type="azure",
|
||||
api_version="YOUR_API_VERSION",
|
||||
model_name="text-embedding-3-small"
|
||||
)
|
||||
embedder={
|
||||
"provider": "openai",
|
||||
"config": {
|
||||
"api_key": "YOUR_API_KEY",
|
||||
"api_base": "YOUR_API_BASE_PATH",
|
||||
"api_version": "YOUR_API_VERSION",
|
||||
"model_name": 'text-embedding-3-small'
|
||||
}
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
### Using Vertex AI embeddings
|
||||
|
||||
```python Code
|
||||
from chromadb.utils.embedding_functions import GoogleVertexEmbeddingFunction
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
|
||||
my_crew = Crew(
|
||||
@@ -203,12 +508,15 @@ my_crew = Crew(
|
||||
process=Process.sequential,
|
||||
memory=True,
|
||||
verbose=True,
|
||||
embedder=embedding_functions.GoogleVertexEmbeddingFunction(
|
||||
project_id="YOUR_PROJECT_ID",
|
||||
region="YOUR_REGION",
|
||||
api_key="YOUR_API_KEY",
|
||||
model_name="textembedding-gecko"
|
||||
)
|
||||
embedder={
|
||||
"provider": "vertexai",
|
||||
"config": {
|
||||
"project_id"="YOUR_PROJECT_ID",
|
||||
"region"="YOUR_REGION",
|
||||
"api_key"="YOUR_API_KEY",
|
||||
"model_name"="textembedding-gecko"
|
||||
}
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
@@ -227,7 +535,27 @@ my_crew = Crew(
|
||||
"provider": "cohere",
|
||||
"config": {
|
||||
"api_key": "YOUR_API_KEY",
|
||||
"model_name": "<model_name>"
|
||||
"model": "<model_name>"
|
||||
}
|
||||
}
|
||||
)
|
||||
```
|
||||
### Using VoyageAI embeddings
|
||||
|
||||
```python Code
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
|
||||
my_crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
process=Process.sequential,
|
||||
memory=True,
|
||||
verbose=True,
|
||||
embedder={
|
||||
"provider": "voyageai",
|
||||
"config": {
|
||||
"api_key": "YOUR_API_KEY",
|
||||
"model": "<model_name>"
|
||||
}
|
||||
}
|
||||
)
|
||||
@@ -252,7 +580,91 @@ my_crew = Crew(
|
||||
)
|
||||
```
|
||||
|
||||
### Resetting Memory
|
||||
### Using Watson embeddings
|
||||
|
||||
```python Code
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
|
||||
# Note: Ensure you have installed and imported `ibm_watsonx_ai` for Watson embeddings to work.
|
||||
|
||||
my_crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
process=Process.sequential,
|
||||
memory=True,
|
||||
verbose=True,
|
||||
embedder={
|
||||
"provider": "watson",
|
||||
"config": {
|
||||
"model": "<model_name>",
|
||||
"api_url": "<api_url>",
|
||||
"api_key": "<YOUR_API_KEY>",
|
||||
"project_id": "<YOUR_PROJECT_ID>",
|
||||
}
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
### Using Amazon Bedrock embeddings
|
||||
|
||||
```python Code
|
||||
# Note: Ensure you have installed `boto3` for Bedrock embeddings to work.
|
||||
|
||||
import os
|
||||
import boto3
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
|
||||
boto3_session = boto3.Session(
|
||||
region_name=os.environ.get("AWS_REGION_NAME"),
|
||||
aws_access_key_id=os.environ.get("AWS_ACCESS_KEY_ID"),
|
||||
aws_secret_access_key=os.environ.get("AWS_SECRET_ACCESS_KEY")
|
||||
)
|
||||
|
||||
my_crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
process=Process.sequential,
|
||||
memory=True,
|
||||
embedder={
|
||||
"provider": "bedrock",
|
||||
"config":{
|
||||
"session": boto3_session,
|
||||
"model": "amazon.titan-embed-text-v2:0",
|
||||
"vector_dimension": 1024
|
||||
}
|
||||
}
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
### Adding Custom Embedding Function
|
||||
|
||||
```python Code
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
from chromadb import Documents, EmbeddingFunction, Embeddings
|
||||
|
||||
# Create a custom embedding function
|
||||
class CustomEmbedder(EmbeddingFunction):
|
||||
def __call__(self, input: Documents) -> Embeddings:
|
||||
# generate embeddings
|
||||
return [1, 2, 3] # this is a dummy embedding
|
||||
|
||||
my_crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
process=Process.sequential,
|
||||
memory=True,
|
||||
verbose=True,
|
||||
embedder={
|
||||
"provider": "custom",
|
||||
"config": {
|
||||
"embedder": CustomEmbedder()
|
||||
}
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
### Resetting Memory via cli
|
||||
|
||||
```shell
|
||||
crewai reset-memories [OPTIONS]
|
||||
@@ -266,8 +678,46 @@ crewai reset-memories [OPTIONS]
|
||||
| `-s`, `--short` | Reset SHORT TERM memory. | Flag (boolean) | False |
|
||||
| `-e`, `--entities` | Reset ENTITIES memory. | Flag (boolean) | False |
|
||||
| `-k`, `--kickoff-outputs` | Reset LATEST KICKOFF TASK OUTPUTS. | Flag (boolean) | False |
|
||||
| `-kn`, `--knowledge` | Reset KNOWLEDEGE storage | Flag (boolean) | False |
|
||||
| `-a`, `--all` | Reset ALL memories. | Flag (boolean) | False |
|
||||
|
||||
Note: To use the cli command you need to have your crew in a file called crew.py in the same directory.
|
||||
|
||||
|
||||
|
||||
|
||||
### Resetting Memory via crew object
|
||||
|
||||
```python
|
||||
|
||||
my_crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
process=Process.sequential,
|
||||
memory=True,
|
||||
verbose=True,
|
||||
embedder={
|
||||
"provider": "custom",
|
||||
"config": {
|
||||
"embedder": CustomEmbedder()
|
||||
}
|
||||
}
|
||||
)
|
||||
|
||||
my_crew.reset_memories(command_type = 'all') # Resets all the memory
|
||||
```
|
||||
|
||||
#### Resetting Memory Options
|
||||
|
||||
| Command Type | Description |
|
||||
| :----------------- | :------------------------------- |
|
||||
| `long` | Reset LONG TERM memory. |
|
||||
| `short` | Reset SHORT TERM memory. |
|
||||
| `entities` | Reset ENTITIES memory. |
|
||||
| `kickoff_outputs` | Reset LATEST KICKOFF TASK OUTPUTS. |
|
||||
| `knowledge` | Reset KNOWLEDGE memory. |
|
||||
| `all` | Reset ALL memories. |
|
||||
|
||||
|
||||
## Benefits of Using CrewAI's Memory System
|
||||
|
||||
|
||||
@@ -31,7 +31,7 @@ From this point on, your crew will have planning enabled, and the tasks will be
|
||||
|
||||
#### Planning LLM
|
||||
|
||||
Now you can define the LLM that will be used to plan the tasks. You can use any ChatOpenAI LLM model available.
|
||||
Now you can define the LLM that will be used to plan the tasks.
|
||||
|
||||
When running the base case example, you will see something like the output below, which represents the output of the `AgentPlanner`
|
||||
responsible for creating the step-by-step logic to add to the Agents' tasks.
|
||||
@@ -39,7 +39,6 @@ responsible for creating the step-by-step logic to add to the Agents' tasks.
|
||||
<CodeGroup>
|
||||
```python Code
|
||||
from crewai import Crew, Agent, Task, Process
|
||||
from langchain_openai import ChatOpenAI
|
||||
|
||||
# Assemble your crew with planning capabilities and custom LLM
|
||||
my_crew = Crew(
|
||||
@@ -47,7 +46,7 @@ my_crew = Crew(
|
||||
tasks=self.tasks,
|
||||
process=Process.sequential,
|
||||
planning=True,
|
||||
planning_llm=ChatOpenAI(model="gpt-4o")
|
||||
planning_llm="gpt-4o"
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
@@ -82,8 +81,8 @@ my_crew.kickoff()
|
||||
|
||||
3. **Collect Data:**
|
||||
|
||||
- Search for the latest papers, articles, and reports published in 2023 and early 2024.
|
||||
- Use keywords like "Large Language Models 2024", "AI LLM advancements", "AI ethics 2024", etc.
|
||||
- Search for the latest papers, articles, and reports published in 2024 and early 2025.
|
||||
- Use keywords like "Large Language Models 2025", "AI LLM advancements", "AI ethics 2025", etc.
|
||||
|
||||
4. **Analyze Findings:**
|
||||
|
||||
|
||||
@@ -23,9 +23,7 @@ Processes enable individual agents to operate as a cohesive unit, streamlining t
|
||||
To assign a process to a crew, specify the process type upon crew creation to set the execution strategy. For a hierarchical process, ensure to define `manager_llm` or `manager_agent` for the manager agent.
|
||||
|
||||
```python
|
||||
from crewai import Crew
|
||||
from crewai.process import Process
|
||||
from langchain_openai import ChatOpenAI
|
||||
from crewai import Crew, Process
|
||||
|
||||
# Example: Creating a crew with a sequential process
|
||||
crew = Crew(
|
||||
@@ -40,7 +38,7 @@ crew = Crew(
|
||||
agents=my_agents,
|
||||
tasks=my_tasks,
|
||||
process=Process.hierarchical,
|
||||
manager_llm=ChatOpenAI(model="gpt-4")
|
||||
manager_llm="gpt-4o"
|
||||
# or
|
||||
# manager_agent=my_manager_agent
|
||||
)
|
||||
|
||||
@@ -1,48 +1,191 @@
|
||||
---
|
||||
title: Tasks
|
||||
description: Detailed guide on managing and creating tasks within the CrewAI framework, reflecting the latest codebase updates.
|
||||
description: Detailed guide on managing and creating tasks within the CrewAI framework.
|
||||
icon: list-check
|
||||
---
|
||||
|
||||
## Overview of a Task
|
||||
|
||||
In the CrewAI framework, a `Task` is a specific assignment completed by an `Agent`.
|
||||
|
||||
They provide all necessary details for execution, such as a description, the agent responsible, required tools, and more, facilitating a wide range of action complexities.
|
||||
In the CrewAI framework, a `Task` is a specific assignment completed by an `Agent`.
|
||||
|
||||
Tasks provide all necessary details for execution, such as a description, the agent responsible, required tools, and more, facilitating a wide range of action complexities.
|
||||
|
||||
Tasks within CrewAI can be collaborative, requiring multiple agents to work together. This is managed through the task properties and orchestrated by the Crew's process, enhancing teamwork and efficiency.
|
||||
|
||||
<Note type="info" title="Enterprise Enhancement: Visual Task Builder">
|
||||
CrewAI Enterprise includes a Visual Task Builder in Crew Studio that simplifies complex task creation and chaining. Design your task flows visually and test them in real-time without writing code.
|
||||
|
||||

|
||||
|
||||
The Visual Task Builder enables:
|
||||
- Drag-and-drop task creation
|
||||
- Visual task dependencies and flow
|
||||
- Real-time testing and validation
|
||||
- Easy sharing and collaboration
|
||||
</Note>
|
||||
|
||||
### Task Execution Flow
|
||||
|
||||
Tasks can be executed in two ways:
|
||||
- **Sequential**: Tasks are executed in the order they are defined
|
||||
- **Hierarchical**: Tasks are assigned to agents based on their roles and expertise
|
||||
|
||||
The execution flow is defined when creating the crew:
|
||||
```python Code
|
||||
crew = Crew(
|
||||
agents=[agent1, agent2],
|
||||
tasks=[task1, task2],
|
||||
process=Process.sequential # or Process.hierarchical
|
||||
)
|
||||
```
|
||||
|
||||
## Task Attributes
|
||||
|
||||
| Attribute | Parameters | Type | Description |
|
||||
| :------------------------------- | :---------------- | :---------------------------- | :------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Description** | `description` | `str` | A clear, concise statement of what the task entails. |
|
||||
| **Agent** | `agent` | `Optional[BaseAgent]` | The agent responsible for the task, assigned either directly or by the crew's process. |
|
||||
| **Expected Output** | `expected_output` | `str` | A detailed description of what the task's completion looks like. |
|
||||
| **Tools** _(optional)_ | `tools` | `Optional[List[Any]]` | The functions or capabilities the agent can utilize to perform the task. Defaults to an empty list. |
|
||||
| **Async Execution** _(optional)_ | `async_execution` | `Optional[bool]` | If set, the task executes asynchronously, allowing progression without waiting for completion. Defaults to False. |
|
||||
| **Context** _(optional)_ | `context` | `Optional[List["Task"]]` | Specifies tasks whose outputs are used as context for this task. |
|
||||
| **Config** _(optional)_ | `config` | `Optional[Dict[str, Any]]` | Additional configuration details for the agent executing the task, allowing further customization. Defaults to None. |
|
||||
| **Output JSON** _(optional)_ | `output_json` | `Optional[Type[BaseModel]]` | Outputs a JSON object, requiring an OpenAI client. Only one output format can be set. |
|
||||
| **Output Pydantic** _(optional)_ | `output_pydantic` | `Optional[Type[BaseModel]]` | Outputs a Pydantic model object, requiring an OpenAI client. Only one output format can be set. |
|
||||
| **Output File** _(optional)_ | `output_file` | `Optional[str]` | Saves the task output to a file. If used with `Output JSON` or `Output Pydantic`, specifies how the output is saved. |
|
||||
| **Output** _(optional)_ | `output` | `Optional[TaskOutput]` | An instance of `TaskOutput`, containing the raw, JSON, and Pydantic output plus additional details. |
|
||||
| **Callback** _(optional)_ | `callback` | `Optional[Any]` | A callable that is executed with the task's output upon completion. |
|
||||
| **Human Input** _(optional)_ | `human_input` | `Optional[bool]` | Indicates if the task should involve human review at the end, useful for tasks needing human oversight. Defaults to False.|
|
||||
| **Converter Class** _(optional)_ | `converter_cls` | `Optional[Type[Converter]]` | A converter class used to export structured output. Defaults to None. |
|
||||
| **Name** _(optional)_ | `name` | `Optional[str]` | A name identifier for the task. |
|
||||
| **Agent** _(optional)_ | `agent` | `Optional[BaseAgent]` | The agent responsible for executing the task. |
|
||||
| **Tools** _(optional)_ | `tools` | `List[BaseTool]` | The tools/resources the agent is limited to use for this task. |
|
||||
| **Context** _(optional)_ | `context` | `Optional[List["Task"]]` | Other tasks whose outputs will be used as context for this task. |
|
||||
| **Async Execution** _(optional)_ | `async_execution` | `Optional[bool]` | Whether the task should be executed asynchronously. Defaults to False. |
|
||||
| **Human Input** _(optional)_ | `human_input` | `Optional[bool]` | Whether the task should have a human review the final answer of the agent. Defaults to False. |
|
||||
| **Config** _(optional)_ | `config` | `Optional[Dict[str, Any]]` | Task-specific configuration parameters. |
|
||||
| **Output File** _(optional)_ | `output_file` | `Optional[str]` | File path for storing the task output. |
|
||||
| **Output JSON** _(optional)_ | `output_json` | `Optional[Type[BaseModel]]` | A Pydantic model to structure the JSON output. |
|
||||
| **Output Pydantic** _(optional)_ | `output_pydantic` | `Optional[Type[BaseModel]]` | A Pydantic model for task output. |
|
||||
| **Callback** _(optional)_ | `callback` | `Optional[Any]` | Function/object to be executed after task completion. |
|
||||
|
||||
## Creating a Task
|
||||
## Creating Tasks
|
||||
|
||||
Creating a task involves defining its scope, responsible agent, and any additional attributes for flexibility:
|
||||
There are two ways to create tasks in CrewAI: using **YAML configuration (recommended)** or defining them **directly in code**.
|
||||
|
||||
### YAML Configuration (Recommended)
|
||||
|
||||
Using YAML configuration provides a cleaner, more maintainable way to define tasks. We strongly recommend using this approach to define tasks in your CrewAI projects.
|
||||
|
||||
After creating your CrewAI project as outlined in the [Installation](/installation) section, navigate to the `src/latest_ai_development/config/tasks.yaml` file and modify the template to match your specific task requirements.
|
||||
|
||||
<Note>
|
||||
Variables in your YAML files (like `{topic}`) will be replaced with values from your inputs when running the crew:
|
||||
```python Code
|
||||
crew.kickoff(inputs={'topic': 'AI Agents'})
|
||||
```
|
||||
</Note>
|
||||
|
||||
Here's an example of how to configure tasks using YAML:
|
||||
|
||||
```yaml tasks.yaml
|
||||
research_task:
|
||||
description: >
|
||||
Conduct a thorough research about {topic}
|
||||
Make sure you find any interesting and relevant information given
|
||||
the current year is 2025.
|
||||
expected_output: >
|
||||
A list with 10 bullet points of the most relevant information about {topic}
|
||||
agent: researcher
|
||||
|
||||
reporting_task:
|
||||
description: >
|
||||
Review the context you got and expand each topic into a full section for a report.
|
||||
Make sure the report is detailed and contains any and all relevant information.
|
||||
expected_output: >
|
||||
A fully fledge reports with the mains topics, each with a full section of information.
|
||||
Formatted as markdown without '```'
|
||||
agent: reporting_analyst
|
||||
output_file: report.md
|
||||
```
|
||||
|
||||
To use this YAML configuration in your code, create a crew class that inherits from `CrewBase`:
|
||||
|
||||
```python crew.py
|
||||
# src/latest_ai_development/crew.py
|
||||
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai.project import CrewBase, agent, crew, task
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
@CrewBase
|
||||
class LatestAiDevelopmentCrew():
|
||||
"""LatestAiDevelopment crew"""
|
||||
|
||||
@agent
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['researcher'], # type: ignore[index]
|
||||
verbose=True,
|
||||
tools=[SerperDevTool()]
|
||||
)
|
||||
|
||||
@agent
|
||||
def reporting_analyst(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['reporting_analyst'], # type: ignore[index]
|
||||
verbose=True
|
||||
)
|
||||
|
||||
@task
|
||||
def research_task(self) -> Task:
|
||||
return Task(
|
||||
config=self.tasks_config['research_task'] # type: ignore[index]
|
||||
)
|
||||
|
||||
@task
|
||||
def reporting_task(self) -> Task:
|
||||
return Task(
|
||||
config=self.tasks_config['reporting_task'] # type: ignore[index]
|
||||
)
|
||||
|
||||
@crew
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[
|
||||
self.researcher(),
|
||||
self.reporting_analyst()
|
||||
],
|
||||
tasks=[
|
||||
self.research_task(),
|
||||
self.reporting_task()
|
||||
],
|
||||
process=Process.sequential
|
||||
)
|
||||
```
|
||||
|
||||
<Note>
|
||||
The names you use in your YAML files (`agents.yaml` and `tasks.yaml`) should match the method names in your Python code.
|
||||
</Note>
|
||||
|
||||
### Direct Code Definition (Alternative)
|
||||
|
||||
Alternatively, you can define tasks directly in your code without using YAML configuration:
|
||||
|
||||
```python task.py
|
||||
from crewai import Task
|
||||
|
||||
task = Task(
|
||||
description='Find and summarize the latest and most relevant news on AI',
|
||||
agent=sales_agent,
|
||||
expected_output='A bullet list summary of the top 5 most important AI news',
|
||||
research_task = Task(
|
||||
description="""
|
||||
Conduct a thorough research about AI Agents.
|
||||
Make sure you find any interesting and relevant information given
|
||||
the current year is 2025.
|
||||
""",
|
||||
expected_output="""
|
||||
A list with 10 bullet points of the most relevant information about AI Agents
|
||||
""",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
reporting_task = Task(
|
||||
description="""
|
||||
Review the context you got and expand each topic into a full section for a report.
|
||||
Make sure the report is detailed and contains any and all relevant information.
|
||||
""",
|
||||
expected_output="""
|
||||
A fully fledge reports with the mains topics, each with a full section of information.
|
||||
Formatted as markdown without '```'
|
||||
""",
|
||||
agent=reporting_analyst,
|
||||
output_file="report.md"
|
||||
)
|
||||
```
|
||||
|
||||
@@ -52,6 +195,8 @@ task = Task(
|
||||
|
||||
## Task Output
|
||||
|
||||
Understanding task outputs is crucial for building effective AI workflows. CrewAI provides a structured way to handle task results through the `TaskOutput` class, which supports multiple output formats and can be easily passed between tasks.
|
||||
|
||||
The output of a task in CrewAI framework is encapsulated within the `TaskOutput` class. This class provides a structured way to access results of a task, including various formats such as raw output, JSON, and Pydantic models.
|
||||
|
||||
By default, the `TaskOutput` will only include the `raw` output. A `TaskOutput` will only include the `pydantic` or `json_dict` output if the original `Task` object was configured with `output_pydantic` or `output_json`, respectively.
|
||||
@@ -112,6 +257,309 @@ if task_output.pydantic:
|
||||
print(f"Pydantic Output: {task_output.pydantic}")
|
||||
```
|
||||
|
||||
## Task Dependencies and Context
|
||||
|
||||
Tasks can depend on the output of other tasks using the `context` attribute. For example:
|
||||
|
||||
```python Code
|
||||
research_task = Task(
|
||||
description="Research the latest developments in AI",
|
||||
expected_output="A list of recent AI developments",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
analysis_task = Task(
|
||||
description="Analyze the research findings and identify key trends",
|
||||
expected_output="Analysis report of AI trends",
|
||||
agent=analyst,
|
||||
context=[research_task] # This task will wait for research_task to complete
|
||||
)
|
||||
```
|
||||
|
||||
## Task Guardrails
|
||||
|
||||
Task guardrails provide a way to validate and transform task outputs before they
|
||||
are passed to the next task. This feature helps ensure data quality and provides
|
||||
feedback to agents when their output doesn't meet specific criteria.
|
||||
|
||||
### Using Task Guardrails
|
||||
|
||||
To add a guardrail to a task, provide a validation function through the `guardrail` parameter:
|
||||
|
||||
```python Code
|
||||
from typing import Tuple, Union, Dict, Any
|
||||
from crewai import TaskOutput
|
||||
|
||||
def validate_blog_content(result: TaskOutput) -> Tuple[bool, Any]:
|
||||
"""Validate blog content meets requirements."""
|
||||
try:
|
||||
# Check word count
|
||||
word_count = len(result.split())
|
||||
if word_count > 200:
|
||||
return (False, "Blog content exceeds 200 words")
|
||||
|
||||
# Additional validation logic here
|
||||
return (True, result.strip())
|
||||
except Exception as e:
|
||||
return (False, "Unexpected error during validation")
|
||||
|
||||
blog_task = Task(
|
||||
description="Write a blog post about AI",
|
||||
expected_output="A blog post under 200 words",
|
||||
agent=blog_agent,
|
||||
guardrail=validate_blog_content # Add the guardrail function
|
||||
)
|
||||
```
|
||||
|
||||
### Guardrail Function Requirements
|
||||
|
||||
1. **Function Signature**:
|
||||
- Must accept exactly one parameter (the task output)
|
||||
- Should return a tuple of `(bool, Any)`
|
||||
- Type hints are recommended but optional
|
||||
|
||||
2. **Return Values**:
|
||||
- On success: it returns a tuple of `(bool, Any)`. For example: `(True, validated_result)`
|
||||
- On Failure: it returns a tuple of `(bool, str)`. For example: `(False, "Error message explain the failure")`
|
||||
|
||||
### Error Handling Best Practices
|
||||
|
||||
1. **Structured Error Responses**:
|
||||
```python Code
|
||||
from crewai import TaskOutput
|
||||
|
||||
def validate_with_context(result: TaskOutput) -> Tuple[bool, Any]:
|
||||
try:
|
||||
# Main validation logic
|
||||
validated_data = perform_validation(result)
|
||||
return (True, validated_data)
|
||||
except ValidationError as e:
|
||||
return (False, f"VALIDATION_ERROR: {str(e)}")
|
||||
except Exception as e:
|
||||
return (False, str(e))
|
||||
```
|
||||
|
||||
2. **Error Categories**:
|
||||
- Use specific error codes
|
||||
- Include relevant context
|
||||
- Provide actionable feedback
|
||||
|
||||
3. **Validation Chain**:
|
||||
```python Code
|
||||
from typing import Any, Dict, List, Tuple, Union
|
||||
from crewai import TaskOutput
|
||||
|
||||
def complex_validation(result: TaskOutput) -> Tuple[bool, Any]:
|
||||
"""Chain multiple validation steps."""
|
||||
# Step 1: Basic validation
|
||||
if not result:
|
||||
return (False, "Empty result")
|
||||
|
||||
# Step 2: Content validation
|
||||
try:
|
||||
validated = validate_content(result)
|
||||
if not validated:
|
||||
return (False, "Invalid content")
|
||||
|
||||
# Step 3: Format validation
|
||||
formatted = format_output(validated)
|
||||
return (True, formatted)
|
||||
except Exception as e:
|
||||
return (False, str(e))
|
||||
```
|
||||
|
||||
### Handling Guardrail Results
|
||||
|
||||
When a guardrail returns `(False, error)`:
|
||||
1. The error is sent back to the agent
|
||||
2. The agent attempts to fix the issue
|
||||
3. The process repeats until:
|
||||
- The guardrail returns `(True, result)`
|
||||
- Maximum retries are reached
|
||||
|
||||
Example with retry handling:
|
||||
```python Code
|
||||
from typing import Optional, Tuple, Union
|
||||
from crewai import TaskOutput, Task
|
||||
|
||||
def validate_json_output(result: TaskOutput) -> Tuple[bool, Any]:
|
||||
"""Validate and parse JSON output."""
|
||||
try:
|
||||
# Try to parse as JSON
|
||||
data = json.loads(result)
|
||||
return (True, data)
|
||||
except json.JSONDecodeError as e:
|
||||
return (False, "Invalid JSON format")
|
||||
|
||||
task = Task(
|
||||
description="Generate a JSON report",
|
||||
expected_output="A valid JSON object",
|
||||
agent=analyst,
|
||||
guardrail=validate_json_output,
|
||||
max_retries=3 # Limit retry attempts
|
||||
)
|
||||
```
|
||||
|
||||
## Getting Structured Consistent Outputs from Tasks
|
||||
|
||||
<Note>
|
||||
It's also important to note that the output of the final task of a crew becomes the final output of the actual crew itself.
|
||||
</Note>
|
||||
|
||||
### Using `output_pydantic`
|
||||
The `output_pydantic` property allows you to define a Pydantic model that the task output should conform to. This ensures that the output is not only structured but also validated according to the Pydantic model.
|
||||
|
||||
Here's an example demonstrating how to use output_pydantic:
|
||||
|
||||
```python Code
|
||||
import json
|
||||
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
class Blog(BaseModel):
|
||||
title: str
|
||||
content: str
|
||||
|
||||
|
||||
blog_agent = Agent(
|
||||
role="Blog Content Generator Agent",
|
||||
goal="Generate a blog title and content",
|
||||
backstory="""You are an expert content creator, skilled in crafting engaging and informative blog posts.""",
|
||||
verbose=False,
|
||||
allow_delegation=False,
|
||||
llm="gpt-4o",
|
||||
)
|
||||
|
||||
task1 = Task(
|
||||
description="""Create a blog title and content on a given topic. Make sure the content is under 200 words.""",
|
||||
expected_output="A compelling blog title and well-written content.",
|
||||
agent=blog_agent,
|
||||
output_pydantic=Blog,
|
||||
)
|
||||
|
||||
# Instantiate your crew with a sequential process
|
||||
crew = Crew(
|
||||
agents=[blog_agent],
|
||||
tasks=[task1],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
|
||||
# Option 1: Accessing Properties Using Dictionary-Style Indexing
|
||||
print("Accessing Properties - Option 1")
|
||||
title = result["title"]
|
||||
content = result["content"]
|
||||
print("Title:", title)
|
||||
print("Content:", content)
|
||||
|
||||
# Option 2: Accessing Properties Directly from the Pydantic Model
|
||||
print("Accessing Properties - Option 2")
|
||||
title = result.pydantic.title
|
||||
content = result.pydantic.content
|
||||
print("Title:", title)
|
||||
print("Content:", content)
|
||||
|
||||
# Option 3: Accessing Properties Using the to_dict() Method
|
||||
print("Accessing Properties - Option 3")
|
||||
output_dict = result.to_dict()
|
||||
title = output_dict["title"]
|
||||
content = output_dict["content"]
|
||||
print("Title:", title)
|
||||
print("Content:", content)
|
||||
|
||||
# Option 4: Printing the Entire Blog Object
|
||||
print("Accessing Properties - Option 5")
|
||||
print("Blog:", result)
|
||||
|
||||
```
|
||||
In this example:
|
||||
* A Pydantic model Blog is defined with title and content fields.
|
||||
* The task task1 uses the output_pydantic property to specify that its output should conform to the Blog model.
|
||||
* After executing the crew, you can access the structured output in multiple ways as shown.
|
||||
|
||||
#### Explanation of Accessing the Output
|
||||
1. Dictionary-Style Indexing: You can directly access the fields using result["field_name"]. This works because the CrewOutput class implements the __getitem__ method.
|
||||
2. Directly from Pydantic Model: Access the attributes directly from the result.pydantic object.
|
||||
3. Using to_dict() Method: Convert the output to a dictionary and access the fields.
|
||||
4. Printing the Entire Object: Simply print the result object to see the structured output.
|
||||
|
||||
### Using `output_json`
|
||||
The `output_json` property allows you to define the expected output in JSON format. This ensures that the task's output is a valid JSON structure that can be easily parsed and used in your application.
|
||||
|
||||
Here's an example demonstrating how to use `output_json`:
|
||||
|
||||
```python Code
|
||||
import json
|
||||
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
# Define the Pydantic model for the blog
|
||||
class Blog(BaseModel):
|
||||
title: str
|
||||
content: str
|
||||
|
||||
|
||||
# Define the agent
|
||||
blog_agent = Agent(
|
||||
role="Blog Content Generator Agent",
|
||||
goal="Generate a blog title and content",
|
||||
backstory="""You are an expert content creator, skilled in crafting engaging and informative blog posts.""",
|
||||
verbose=False,
|
||||
allow_delegation=False,
|
||||
llm="gpt-4o",
|
||||
)
|
||||
|
||||
# Define the task with output_json set to the Blog model
|
||||
task1 = Task(
|
||||
description="""Create a blog title and content on a given topic. Make sure the content is under 200 words.""",
|
||||
expected_output="A JSON object with 'title' and 'content' fields.",
|
||||
agent=blog_agent,
|
||||
output_json=Blog,
|
||||
)
|
||||
|
||||
# Instantiate the crew with a sequential process
|
||||
crew = Crew(
|
||||
agents=[blog_agent],
|
||||
tasks=[task1],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
)
|
||||
|
||||
# Kickoff the crew to execute the task
|
||||
result = crew.kickoff()
|
||||
|
||||
# Option 1: Accessing Properties Using Dictionary-Style Indexing
|
||||
print("Accessing Properties - Option 1")
|
||||
title = result["title"]
|
||||
content = result["content"]
|
||||
print("Title:", title)
|
||||
print("Content:", content)
|
||||
|
||||
# Option 2: Printing the Entire Blog Object
|
||||
print("Accessing Properties - Option 2")
|
||||
print("Blog:", result)
|
||||
```
|
||||
|
||||
In this example:
|
||||
* A Pydantic model Blog is defined with title and content fields, which is used to specify the structure of the JSON output.
|
||||
* The task task1 uses the output_json property to indicate that it expects a JSON output conforming to the Blog model.
|
||||
* After executing the crew, you can access the structured JSON output in two ways as shown.
|
||||
|
||||
#### Explanation of Accessing the Output
|
||||
|
||||
1. Accessing Properties Using Dictionary-Style Indexing: You can access the fields directly using result["field_name"]. This is possible because the CrewOutput class implements the __getitem__ method, allowing you to treat the output like a dictionary. In this option, we're retrieving the title and content from the result.
|
||||
2. Printing the Entire Blog Object: By printing result, you get the string representation of the CrewOutput object. Since the __str__ method is implemented to return the JSON output, this will display the entire output as a formatted string representing the Blog object.
|
||||
|
||||
---
|
||||
|
||||
By using output_pydantic or output_json, you ensure that your tasks produce outputs in a consistent and structured format, making it easier to process and utilize the data within your application or across multiple tasks.
|
||||
|
||||
## Integrating Tools with Tasks
|
||||
|
||||
Leverage tools from the [CrewAI Toolkit](https://github.com/joaomdmoura/crewai-tools) and [LangChain Tools](https://python.langchain.com/docs/integrations/tools) for enhanced task performance and agent interaction.
|
||||
@@ -167,16 +615,16 @@ This is useful when you have a task that depends on the output of another task t
|
||||
# ...
|
||||
|
||||
research_ai_task = Task(
|
||||
description='Find and summarize the latest AI news',
|
||||
expected_output='A bullet list summary of the top 5 most important AI news',
|
||||
description="Research the latest developments in AI",
|
||||
expected_output="A list of recent AI developments",
|
||||
async_execution=True,
|
||||
agent=research_agent,
|
||||
tools=[search_tool]
|
||||
)
|
||||
|
||||
research_ops_task = Task(
|
||||
description='Find and summarize the latest AI Ops news',
|
||||
expected_output='A bullet list summary of the top 5 most important AI Ops news',
|
||||
description="Research the latest developments in AI Ops",
|
||||
expected_output="A list of recent AI Ops developments",
|
||||
async_execution=True,
|
||||
agent=research_agent,
|
||||
tools=[search_tool]
|
||||
@@ -184,7 +632,7 @@ research_ops_task = Task(
|
||||
|
||||
write_blog_task = Task(
|
||||
description="Write a full blog post about the importance of AI and its latest news",
|
||||
expected_output='Full blog post that is 4 paragraphs long',
|
||||
expected_output="Full blog post that is 4 paragraphs long",
|
||||
agent=writer_agent,
|
||||
context=[research_ai_task, research_ops_task]
|
||||
)
|
||||
@@ -296,6 +744,114 @@ While creating and executing tasks, certain validation mechanisms are in place t
|
||||
|
||||
These validations help in maintaining the consistency and reliability of task executions within the crewAI framework.
|
||||
|
||||
## Task Guardrails
|
||||
|
||||
Task guardrails provide a powerful way to validate, transform, or filter task outputs before they are passed to the next task. Guardrails are optional functions that execute before the next task starts, allowing you to ensure that task outputs meet specific requirements or formats.
|
||||
|
||||
### Basic Usage
|
||||
|
||||
```python Code
|
||||
from typing import Tuple, Union
|
||||
from crewai import Task
|
||||
|
||||
def validate_json_output(result: str) -> Tuple[bool, Union[dict, str]]:
|
||||
"""Validate that the output is valid JSON."""
|
||||
try:
|
||||
json_data = json.loads(result)
|
||||
return (True, json_data)
|
||||
except json.JSONDecodeError:
|
||||
return (False, "Output must be valid JSON")
|
||||
|
||||
task = Task(
|
||||
description="Generate JSON data",
|
||||
expected_output="Valid JSON object",
|
||||
guardrail=validate_json_output
|
||||
)
|
||||
```
|
||||
|
||||
### How Guardrails Work
|
||||
|
||||
1. **Optional Attribute**: Guardrails are an optional attribute at the task level, allowing you to add validation only where needed.
|
||||
2. **Execution Timing**: The guardrail function is executed before the next task starts, ensuring valid data flow between tasks.
|
||||
3. **Return Format**: Guardrails must return a tuple of `(success, data)`:
|
||||
- If `success` is `True`, `data` is the validated/transformed result
|
||||
- If `success` is `False`, `data` is the error message
|
||||
4. **Result Routing**:
|
||||
- On success (`True`), the result is automatically passed to the next task
|
||||
- On failure (`False`), the error is sent back to the agent to generate a new answer
|
||||
|
||||
### Common Use Cases
|
||||
|
||||
#### Data Format Validation
|
||||
```python Code
|
||||
def validate_email_format(result: str) -> Tuple[bool, Union[str, str]]:
|
||||
"""Ensure the output contains a valid email address."""
|
||||
import re
|
||||
email_pattern = r'^[\w\.-]+@[\w\.-]+\.\w+$'
|
||||
if re.match(email_pattern, result.strip()):
|
||||
return (True, result.strip())
|
||||
return (False, "Output must be a valid email address")
|
||||
```
|
||||
|
||||
#### Content Filtering
|
||||
```python Code
|
||||
def filter_sensitive_info(result: str) -> Tuple[bool, Union[str, str]]:
|
||||
"""Remove or validate sensitive information."""
|
||||
sensitive_patterns = ['SSN:', 'password:', 'secret:']
|
||||
for pattern in sensitive_patterns:
|
||||
if pattern.lower() in result.lower():
|
||||
return (False, f"Output contains sensitive information ({pattern})")
|
||||
return (True, result)
|
||||
```
|
||||
|
||||
#### Data Transformation
|
||||
```python Code
|
||||
def normalize_phone_number(result: str) -> Tuple[bool, Union[str, str]]:
|
||||
"""Ensure phone numbers are in a consistent format."""
|
||||
import re
|
||||
digits = re.sub(r'\D', '', result)
|
||||
if len(digits) == 10:
|
||||
formatted = f"({digits[:3]}) {digits[3:6]}-{digits[6:]}"
|
||||
return (True, formatted)
|
||||
return (False, "Output must be a 10-digit phone number")
|
||||
```
|
||||
|
||||
### Advanced Features
|
||||
|
||||
#### Chaining Multiple Validations
|
||||
```python Code
|
||||
def chain_validations(*validators):
|
||||
"""Chain multiple validators together."""
|
||||
def combined_validator(result):
|
||||
for validator in validators:
|
||||
success, data = validator(result)
|
||||
if not success:
|
||||
return (False, data)
|
||||
result = data
|
||||
return (True, result)
|
||||
return combined_validator
|
||||
|
||||
# Usage
|
||||
task = Task(
|
||||
description="Get user contact info",
|
||||
expected_output="Email and phone",
|
||||
guardrail=chain_validations(
|
||||
validate_email_format,
|
||||
filter_sensitive_info
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
#### Custom Retry Logic
|
||||
```python Code
|
||||
task = Task(
|
||||
description="Generate data",
|
||||
expected_output="Valid data",
|
||||
guardrail=validate_data,
|
||||
max_retries=5 # Override default retry limit
|
||||
)
|
||||
```
|
||||
|
||||
## Creating Directories when Saving Files
|
||||
|
||||
You can now specify if a task should create directories when saving its output to a file. This is particularly useful for organizing outputs and ensuring that file paths are correctly structured.
|
||||
@@ -315,9 +871,22 @@ save_output_task = Task(
|
||||
#...
|
||||
```
|
||||
|
||||
Check out the video below to see how to use structured outputs in CrewAI:
|
||||
|
||||
<iframe
|
||||
width="560"
|
||||
height="315"
|
||||
src="https://www.youtube.com/embed/dNpKQk5uxHw"
|
||||
title="YouTube video player"
|
||||
frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
referrerpolicy="strict-origin-when-cross-origin"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
## Conclusion
|
||||
|
||||
Tasks are the driving force behind the actions of agents in CrewAI.
|
||||
By properly defining tasks and their outcomes, you set the stage for your AI agents to work effectively, either independently or as a collaborative unit.
|
||||
Equipping tasks with appropriate tools, understanding the execution process, and following robust validation practices are crucial for maximizing CrewAI's potential,
|
||||
ensuring agents are effectively prepared for their assignments and that tasks are executed as intended.
|
||||
Tasks are the driving force behind the actions of agents in CrewAI.
|
||||
By properly defining tasks and their outcomes, you set the stage for your AI agents to work effectively, either independently or as a collaborative unit.
|
||||
Equipping tasks with appropriate tools, understanding the execution process, and following robust validation practices are crucial for maximizing CrewAI's potential,
|
||||
ensuring agents are effectively prepared for their assignments and that tasks are executed as intended.
|
||||
|
||||
@@ -5,15 +5,28 @@ icon: screwdriver-wrench
|
||||
---
|
||||
|
||||
## Introduction
|
||||
CrewAI tools empower agents with capabilities ranging from web searching and data analysis to collaboration and delegating tasks among coworkers.
|
||||
|
||||
CrewAI tools empower agents with capabilities ranging from web searching and data analysis to collaboration and delegating tasks among coworkers.
|
||||
This documentation outlines how to create, integrate, and leverage these tools within the CrewAI framework, including a new focus on collaboration tools.
|
||||
|
||||
## What is a Tool?
|
||||
|
||||
A tool in CrewAI is a skill or function that agents can utilize to perform various actions.
|
||||
This includes tools from the [CrewAI Toolkit](https://github.com/joaomdmoura/crewai-tools) and [LangChain Tools](https://python.langchain.com/docs/integrations/tools),
|
||||
A tool in CrewAI is a skill or function that agents can utilize to perform various actions.
|
||||
This includes tools from the [CrewAI Toolkit](https://github.com/joaomdmoura/crewai-tools) and [LangChain Tools](https://python.langchain.com/docs/integrations/tools),
|
||||
enabling everything from simple searches to complex interactions and effective teamwork among agents.
|
||||
|
||||
<Note type="info" title="Enterprise Enhancement: Tools Repository">
|
||||
CrewAI Enterprise provides a comprehensive Tools Repository with pre-built integrations for common business systems and APIs. Deploy agents with enterprise tools in minutes instead of days.
|
||||
|
||||

|
||||
|
||||
The Enterprise Tools Repository includes:
|
||||
- Pre-built connectors for popular enterprise systems
|
||||
- Custom tool creation interface
|
||||
- Version control and sharing capabilities
|
||||
- Security and compliance features
|
||||
</Note>
|
||||
|
||||
## Key Characteristics of Tools
|
||||
|
||||
- **Utility**: Crafted for tasks such as web searching, data analysis, content generation, and agent collaboration.
|
||||
@@ -78,7 +91,7 @@ research = Task(
|
||||
)
|
||||
|
||||
write = Task(
|
||||
description='Write an engaging blog post about the AI industry, based on the research analyst’s summary. Draw inspiration from the latest blog posts in the directory.',
|
||||
description='Write an engaging blog post about the AI industry, based on the research analyst's summary. Draw inspiration from the latest blog posts in the directory.',
|
||||
expected_output='A 4-paragraph blog post formatted in markdown with engaging, informative, and accessible content, avoiding complex jargon.',
|
||||
agent=writer,
|
||||
output_file='blog-posts/new_post.md' # The final blog post will be saved here
|
||||
@@ -103,71 +116,73 @@ crew.kickoff()
|
||||
|
||||
Here is a list of the available tools and their descriptions:
|
||||
|
||||
| Tool | Description |
|
||||
| :-------------------------- | :-------------------------------------------------------------------------------------------- |
|
||||
| **BrowserbaseLoadTool** | A tool for interacting with and extracting data from web browsers. |
|
||||
| **CodeDocsSearchTool** | A RAG tool optimized for searching through code documentation and related technical documents. |
|
||||
| **CodeInterpreterTool** | A tool for interpreting python code. |
|
||||
| **ComposioTool** | Enables use of Composio tools. |
|
||||
| **CSVSearchTool** | A RAG tool designed for searching within CSV files, tailored to handle structured data. |
|
||||
| **DALL-E Tool** | A tool for generating images using the DALL-E API. |
|
||||
| **DirectorySearchTool** | A RAG tool for searching within directories, useful for navigating through file systems. |
|
||||
| **DOCXSearchTool** | A RAG tool aimed at searching within DOCX documents, ideal for processing Word files. |
|
||||
| **DirectoryReadTool** | Facilitates reading and processing of directory structures and their contents. |
|
||||
| **EXASearchTool** | A tool designed for performing exhaustive searches across various data sources. |
|
||||
| **FileReadTool** | Enables reading and extracting data from files, supporting various file formats. |
|
||||
| **FirecrawlSearchTool** | A tool to search webpages using Firecrawl and return the results. |
|
||||
| **FirecrawlCrawlWebsiteTool** | A tool for crawling webpages using Firecrawl. |
|
||||
| **FirecrawlScrapeWebsiteTool** | A tool for scraping webpages URL using Firecrawl and returning its contents. |
|
||||
| **GithubSearchTool** | A RAG tool for searching within GitHub repositories, useful for code and documentation search.|
|
||||
| **SerperDevTool** | A specialized tool for development purposes, with specific functionalities under development. |
|
||||
| **TXTSearchTool** | A RAG tool focused on searching within text (.txt) files, suitable for unstructured data. |
|
||||
| **JSONSearchTool** | A RAG tool designed for searching within JSON files, catering to structured data handling. |
|
||||
| **LlamaIndexTool** | Enables the use of LlamaIndex tools. |
|
||||
| **MDXSearchTool** | A RAG tool tailored for searching within Markdown (MDX) files, useful for documentation. |
|
||||
| **PDFSearchTool** | A RAG tool aimed at searching within PDF documents, ideal for processing scanned documents. |
|
||||
| **PGSearchTool** | A RAG tool optimized for searching within PostgreSQL databases, suitable for database queries. |
|
||||
| **Vision Tool** | A tool for generating images using the DALL-E API. |
|
||||
| **RagTool** | A general-purpose RAG tool capable of handling various data sources and types. |
|
||||
| **ScrapeElementFromWebsiteTool** | Enables scraping specific elements from websites, useful for targeted data extraction. |
|
||||
| **ScrapeWebsiteTool** | Facilitates scraping entire websites, ideal for comprehensive data collection. |
|
||||
| **WebsiteSearchTool** | A RAG tool for searching website content, optimized for web data extraction. |
|
||||
| **XMLSearchTool** | A RAG tool designed for searching within XML files, suitable for structured data formats. |
|
||||
| **YoutubeChannelSearchTool**| A RAG tool for searching within YouTube channels, useful for video content analysis. |
|
||||
| **YoutubeVideoSearchTool** | A RAG tool aimed at searching within YouTube videos, ideal for video data extraction. |
|
||||
| Tool | Description |
|
||||
| :------------------------------- | :--------------------------------------------------------------------------------------------- |
|
||||
| **ApifyActorsTool** | A tool that integrates Apify Actors with your workflows for web scraping and automation tasks. |
|
||||
| **BrowserbaseLoadTool** | A tool for interacting with and extracting data from web browsers. |
|
||||
| **CodeDocsSearchTool** | A RAG tool optimized for searching through code documentation and related technical documents. |
|
||||
| **CodeInterpreterTool** | A tool for interpreting python code. |
|
||||
| **ComposioTool** | Enables use of Composio tools. |
|
||||
| **CSVSearchTool** | A RAG tool designed for searching within CSV files, tailored to handle structured data. |
|
||||
| **DALL-E Tool** | A tool for generating images using the DALL-E API. |
|
||||
| **DirectorySearchTool** | A RAG tool for searching within directories, useful for navigating through file systems. |
|
||||
| **DOCXSearchTool** | A RAG tool aimed at searching within DOCX documents, ideal for processing Word files. |
|
||||
| **DirectoryReadTool** | Facilitates reading and processing of directory structures and their contents. |
|
||||
| **EXASearchTool** | A tool designed for performing exhaustive searches across various data sources. |
|
||||
| **FileReadTool** | Enables reading and extracting data from files, supporting various file formats. |
|
||||
| **FirecrawlSearchTool** | A tool to search webpages using Firecrawl and return the results. |
|
||||
| **FirecrawlCrawlWebsiteTool** | A tool for crawling webpages using Firecrawl. |
|
||||
| **FirecrawlScrapeWebsiteTool** | A tool for scraping webpages URL using Firecrawl and returning its contents. |
|
||||
| **GithubSearchTool** | A RAG tool for searching within GitHub repositories, useful for code and documentation search. |
|
||||
| **SerperDevTool** | A specialized tool for development purposes, with specific functionalities under development. |
|
||||
| **TXTSearchTool** | A RAG tool focused on searching within text (.txt) files, suitable for unstructured data. |
|
||||
| **JSONSearchTool** | A RAG tool designed for searching within JSON files, catering to structured data handling. |
|
||||
| **LlamaIndexTool** | Enables the use of LlamaIndex tools. |
|
||||
| **MDXSearchTool** | A RAG tool tailored for searching within Markdown (MDX) files, useful for documentation. |
|
||||
| **PDFSearchTool** | A RAG tool aimed at searching within PDF documents, ideal for processing scanned documents. |
|
||||
| **PGSearchTool** | A RAG tool optimized for searching within PostgreSQL databases, suitable for database queries. |
|
||||
| **Vision Tool** | A tool for generating images using the DALL-E API. |
|
||||
| **RagTool** | A general-purpose RAG tool capable of handling various data sources and types. |
|
||||
| **ScrapeElementFromWebsiteTool** | Enables scraping specific elements from websites, useful for targeted data extraction. |
|
||||
| **ScrapeWebsiteTool** | Facilitates scraping entire websites, ideal for comprehensive data collection. |
|
||||
| **WebsiteSearchTool** | A RAG tool for searching website content, optimized for web data extraction. |
|
||||
| **XMLSearchTool** | A RAG tool designed for searching within XML files, suitable for structured data formats. |
|
||||
| **YoutubeChannelSearchTool** | A RAG tool for searching within YouTube channels, useful for video content analysis. |
|
||||
| **YoutubeVideoSearchTool** | A RAG tool aimed at searching within YouTube videos, ideal for video data extraction. |
|
||||
|
||||
## Creating your own Tools
|
||||
|
||||
<Tip>
|
||||
Developers can craft `custom tools` tailored for their agent’s needs or utilize pre-built options.
|
||||
Developers can craft `custom tools` tailored for their agent's needs or
|
||||
utilize pre-built options.
|
||||
</Tip>
|
||||
|
||||
To create your own CrewAI tools you will need to install our extra tools package:
|
||||
|
||||
```bash
|
||||
pip install 'crewai[tools]'
|
||||
```
|
||||
|
||||
Once you do that there are two main ways for one to create a CrewAI tool:
|
||||
There are two main ways for one to create a CrewAI tool:
|
||||
|
||||
### Subclassing `BaseTool`
|
||||
|
||||
```python Code
|
||||
from crewai_tools import BaseTool
|
||||
from crewai.tools import BaseTool
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
class MyToolInput(BaseModel):
|
||||
"""Input schema for MyCustomTool."""
|
||||
argument: str = Field(..., description="Description of the argument.")
|
||||
|
||||
class MyCustomTool(BaseTool):
|
||||
name: str = "Name of my tool"
|
||||
description: str = "Clear description for what this tool is useful for, your agent will need this information to use it."
|
||||
description: str = "What this tool does. It's vital for effective utilization."
|
||||
args_schema: Type[BaseModel] = MyToolInput
|
||||
|
||||
def _run(self, argument: str) -> str:
|
||||
# Implementation goes here
|
||||
return "Result from custom tool"
|
||||
# Your tool's logic here
|
||||
return "Tool's result"
|
||||
```
|
||||
|
||||
### Utilizing the `tool` Decorator
|
||||
|
||||
```python Code
|
||||
from crewai_tools import tool
|
||||
from crewai.tools import tool
|
||||
@tool("Name of my tool")
|
||||
def my_tool(question: str) -> str:
|
||||
"""Clear description for what this tool is useful for, your agent will need this information to use it."""
|
||||
@@ -175,14 +190,58 @@ def my_tool(question: str) -> str:
|
||||
return "Result from your custom tool"
|
||||
```
|
||||
|
||||
### Structured Tools
|
||||
|
||||
The `StructuredTool` class wraps functions as tools, providing flexibility and validation while reducing boilerplate. It supports custom schemas and dynamic logic for seamless integration of complex functionalities.
|
||||
|
||||
#### Example:
|
||||
Using `StructuredTool.from_function`, you can wrap a function that interacts with an external API or system, providing a structured interface. This enables robust validation and consistent execution, making it easier to integrate complex functionalities into your applications as demonstrated in the following example:
|
||||
|
||||
```python
|
||||
from crewai.tools.structured_tool import CrewStructuredTool
|
||||
from pydantic import BaseModel
|
||||
|
||||
# Define the schema for the tool's input using Pydantic
|
||||
class APICallInput(BaseModel):
|
||||
endpoint: str
|
||||
parameters: dict
|
||||
|
||||
# Wrapper function to execute the API call
|
||||
def tool_wrapper(*args, **kwargs):
|
||||
# Here, you would typically call the API using the parameters
|
||||
# For demonstration, we'll return a placeholder string
|
||||
return f"Call the API at {kwargs['endpoint']} with parameters {kwargs['parameters']}"
|
||||
|
||||
# Create and return the structured tool
|
||||
def create_structured_tool():
|
||||
return CrewStructuredTool.from_function(
|
||||
name='Wrapper API',
|
||||
description="A tool to wrap API calls with structured input.",
|
||||
args_schema=APICallInput,
|
||||
func=tool_wrapper,
|
||||
)
|
||||
|
||||
# Example usage
|
||||
structured_tool = create_structured_tool()
|
||||
|
||||
# Execute the tool with structured input
|
||||
result = structured_tool._run(**{
|
||||
"endpoint": "https://example.com/api",
|
||||
"parameters": {"key1": "value1", "key2": "value2"}
|
||||
})
|
||||
print(result) # Output: Call the API at https://example.com/api with parameters {'key1': 'value1', 'key2': 'value2'}
|
||||
```
|
||||
|
||||
### Custom Caching Mechanism
|
||||
|
||||
<Tip>
|
||||
Tools can optionally implement a `cache_function` to fine-tune caching behavior. This function determines when to cache results based on specific conditions, offering granular control over caching logic.
|
||||
Tools can optionally implement a `cache_function` to fine-tune caching
|
||||
behavior. This function determines when to cache results based on specific
|
||||
conditions, offering granular control over caching logic.
|
||||
</Tip>
|
||||
|
||||
```python Code
|
||||
from crewai_tools import tool
|
||||
from crewai.tools import tool
|
||||
|
||||
@tool
|
||||
def multiplication_tool(first_number: int, second_number: int) -> str:
|
||||
@@ -208,6 +267,6 @@ writer1 = Agent(
|
||||
|
||||
## Conclusion
|
||||
|
||||
Tools are pivotal in extending the capabilities of CrewAI agents, enabling them to undertake a broad spectrum of tasks and collaborate effectively.
|
||||
When building solutions with CrewAI, leverage both custom and existing tools to empower your agents and enhance the AI ecosystem. Consider utilizing error handling,
|
||||
caching mechanisms, and the flexibility of tool arguments to optimize your agents' performance and capabilities.
|
||||
Tools are pivotal in extending the capabilities of CrewAI agents, enabling them to undertake a broad spectrum of tasks and collaborate effectively.
|
||||
When building solutions with CrewAI, leverage both custom and existing tools to empower your agents and enhance the AI ecosystem. Consider utilizing error handling,
|
||||
caching mechanisms, and the flexibility of tool arguments to optimize your agents' performance and capabilities.
|
||||
|
||||
BIN
docs/crews.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
303
docs/docs.json
Normal file
@@ -0,0 +1,303 @@
|
||||
{
|
||||
"$schema": "https://mintlify.com/docs.json",
|
||||
"theme": "mint",
|
||||
"name": "CrewAI",
|
||||
"colors": {
|
||||
"primary": "#EB6658",
|
||||
"light": "#F3A78B",
|
||||
"dark": "#C94C3C"
|
||||
},
|
||||
"favicon": "favicon.svg",
|
||||
"contextual": {
|
||||
"options": ["copy", "view", "chatgpt", "claude"]
|
||||
},
|
||||
"navigation": {
|
||||
"tabs": [
|
||||
{
|
||||
"tab": "Documentation",
|
||||
"groups": [
|
||||
{
|
||||
"group": "Get Started",
|
||||
"pages": [
|
||||
"introduction",
|
||||
"installation",
|
||||
"quickstart"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Guides",
|
||||
"pages": [
|
||||
{
|
||||
"group": "Strategy",
|
||||
"pages": [
|
||||
"guides/concepts/evaluating-use-cases"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Agents",
|
||||
"pages": [
|
||||
"guides/agents/crafting-effective-agents"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Crews",
|
||||
"pages": [
|
||||
"guides/crews/first-crew"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Flows",
|
||||
"pages": [
|
||||
"guides/flows/first-flow",
|
||||
"guides/flows/mastering-flow-state"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Advanced",
|
||||
"pages": [
|
||||
"guides/advanced/customizing-prompts",
|
||||
"guides/advanced/fingerprinting"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Core Concepts",
|
||||
"pages": [
|
||||
"concepts/agents",
|
||||
"concepts/tasks",
|
||||
"concepts/crews",
|
||||
"concepts/flows",
|
||||
"concepts/knowledge",
|
||||
"concepts/llms",
|
||||
"concepts/processes",
|
||||
"concepts/collaboration",
|
||||
"concepts/training",
|
||||
"concepts/memory",
|
||||
"concepts/planning",
|
||||
"concepts/testing",
|
||||
"concepts/cli",
|
||||
"concepts/tools",
|
||||
"concepts/event-listener"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Tools",
|
||||
"pages": [
|
||||
"tools/aimindtool",
|
||||
"tools/apifyactorstool",
|
||||
"tools/bedrockinvokeagenttool",
|
||||
"tools/bedrockkbretriever",
|
||||
"tools/bravesearchtool",
|
||||
"tools/browserbaseloadtool",
|
||||
"tools/codedocssearchtool",
|
||||
"tools/codeinterpretertool",
|
||||
"tools/composiotool",
|
||||
"tools/csvsearchtool",
|
||||
"tools/dalletool",
|
||||
"tools/directorysearchtool",
|
||||
"tools/directoryreadtool",
|
||||
"tools/docxsearchtool",
|
||||
"tools/exasearchtool",
|
||||
"tools/filereadtool",
|
||||
"tools/filewritetool",
|
||||
"tools/firecrawlcrawlwebsitetool",
|
||||
"tools/firecrawlscrapewebsitetool",
|
||||
"tools/firecrawlsearchtool",
|
||||
"tools/githubsearchtool",
|
||||
"tools/hyperbrowserloadtool",
|
||||
"tools/linkupsearchtool",
|
||||
"tools/llamaindextool",
|
||||
"tools/langchaintool",
|
||||
"tools/serperdevtool",
|
||||
"tools/s3readertool",
|
||||
"tools/s3writertool",
|
||||
"tools/scrapegraphscrapetool",
|
||||
"tools/scrapeelementfromwebsitetool",
|
||||
"tools/jsonsearchtool",
|
||||
"tools/mdxsearchtool",
|
||||
"tools/mysqltool",
|
||||
"tools/multiontool",
|
||||
"tools/nl2sqltool",
|
||||
"tools/patronustools",
|
||||
"tools/pdfsearchtool",
|
||||
"tools/pgsearchtool",
|
||||
"tools/qdrantvectorsearchtool",
|
||||
"tools/ragtool",
|
||||
"tools/scrapewebsitetool",
|
||||
"tools/scrapflyscrapetool",
|
||||
"tools/seleniumscrapingtool",
|
||||
"tools/snowflakesearchtool",
|
||||
"tools/spidertool",
|
||||
"tools/txtsearchtool",
|
||||
"tools/visiontool",
|
||||
"tools/weaviatevectorsearchtool",
|
||||
"tools/websitesearchtool",
|
||||
"tools/xmlsearchtool",
|
||||
"tools/youtubechannelsearchtool",
|
||||
"tools/youtubevideosearchtool"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Agent Monitoring & Observability",
|
||||
"pages": [
|
||||
"how-to/agentops-observability",
|
||||
"how-to/arize-phoenix-observability",
|
||||
"how-to/langfuse-observability",
|
||||
"how-to/langtrace-observability",
|
||||
"how-to/mlflow-observability",
|
||||
"how-to/openlit-observability",
|
||||
"how-to/opik-observability",
|
||||
"how-to/portkey-observability",
|
||||
"how-to/weave-integration"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Learn",
|
||||
"pages": [
|
||||
"how-to/conditional-tasks",
|
||||
"how-to/coding-agents",
|
||||
"how-to/create-custom-tools",
|
||||
"how-to/custom-llm",
|
||||
"how-to/custom-manager-agent",
|
||||
"how-to/customizing-agents",
|
||||
"how-to/force-tool-output-as-result",
|
||||
"how-to/hierarchical-process",
|
||||
"how-to/human-input-on-execution",
|
||||
"how-to/kickoff-async",
|
||||
"how-to/kickoff-for-each",
|
||||
"how-to/llm-connections",
|
||||
"how-to/multimodal-agents",
|
||||
"how-to/replay-tasks-from-latest-crew-kickoff",
|
||||
"how-to/sequential-process"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Telemetry",
|
||||
"pages": [
|
||||
"telemetry"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"tab": "Enterprise",
|
||||
"groups": [
|
||||
{
|
||||
"group": "Getting Started",
|
||||
"pages": [
|
||||
"enterprise/introduction"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "How-To Guides",
|
||||
"pages": [
|
||||
"enterprise/guides/build-crew",
|
||||
"enterprise/guides/deploy-crew",
|
||||
"enterprise/guides/kickoff-crew",
|
||||
"enterprise/guides/update-crew",
|
||||
"enterprise/guides/use-crew-api",
|
||||
"enterprise/guides/enable-crew-studio"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Features",
|
||||
"pages": [
|
||||
"enterprise/features/tool-repository",
|
||||
"enterprise/features/webhook-streaming",
|
||||
"enterprise/features/traces"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Resources",
|
||||
"pages": [
|
||||
"enterprise/resources/frequently-asked-questions"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"tab": "Examples",
|
||||
"groups": [
|
||||
{
|
||||
"group": "Examples",
|
||||
"pages": [
|
||||
"examples/example"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"tab": "Releases",
|
||||
"groups": [
|
||||
{
|
||||
"group": "Releases",
|
||||
"pages": [
|
||||
"changelog"
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"global": {
|
||||
"anchors": [
|
||||
{
|
||||
"anchor": "Website",
|
||||
"href": "https://crewai.com",
|
||||
"icon": "globe"
|
||||
},
|
||||
{
|
||||
"anchor": "Forum",
|
||||
"href": "https://community.crewai.com",
|
||||
"icon": "discourse"
|
||||
},
|
||||
{
|
||||
"anchor": "Get Help",
|
||||
"href": "mailto:support@crewai.com",
|
||||
"icon": "headset"
|
||||
}
|
||||
]
|
||||
}
|
||||
},
|
||||
"logo": {
|
||||
"light": "crew_only_logo.png",
|
||||
"dark": "crew_only_logo.png"
|
||||
},
|
||||
"appearance": {
|
||||
"default": "dark",
|
||||
"strict": false
|
||||
},
|
||||
"navbar": {
|
||||
"links": [
|
||||
{
|
||||
"label": "Start Free Trial",
|
||||
"href": "https://app.crewai.com"
|
||||
}
|
||||
],
|
||||
"primary": {
|
||||
"type": "github",
|
||||
"href": "https://github.com/crewAIInc/crewAI"
|
||||
}
|
||||
},
|
||||
"search": {
|
||||
"prompt": "Search CrewAI docs"
|
||||
},
|
||||
"seo": {
|
||||
"indexing": "all"
|
||||
},
|
||||
"errors": {
|
||||
"404": {
|
||||
"redirect": true
|
||||
}
|
||||
},
|
||||
"footer": {
|
||||
"socials": {
|
||||
"website": "https://crewai.com",
|
||||
"x": "https://x.com/crewAIInc",
|
||||
"github": "https://github.com/crewAIInc/crewAI",
|
||||
"linkedin": "https://www.linkedin.com/company/crewai-inc",
|
||||
"youtube": "https://youtube.com/@crewAIInc",
|
||||
"reddit": "https://www.reddit.com/r/crewAIInc/"
|
||||
}
|
||||
}
|
||||
}
|
||||
106
docs/enterprise/features/tool-repository.mdx
Normal file
@@ -0,0 +1,106 @@
|
||||
---
|
||||
title: Tool Repository
|
||||
description: "Using the Tool Repository to manage your tools"
|
||||
icon: "toolbox"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Tool Repository is a package manager for CrewAI tools. It allows users to publish, install, and manage tools that integrate with CrewAI crews and flows.
|
||||
|
||||
Tools can be:
|
||||
|
||||
- **Private**: accessible only within your organization (default)
|
||||
- **Public**: accessible to all CrewAI users if published with the `--public` flag
|
||||
|
||||
The repository is not a version control system. Use Git to track code changes and enable collaboration.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Tool Repository, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account
|
||||
- [CrewAI CLI](https://docs.crewai.com/concepts/cli#cli) installed
|
||||
- [Git](https://git-scm.com) installed and configured
|
||||
- Access permissions to publish or install tools in your CrewAI Enterprise organization
|
||||
|
||||
## Installing Tools
|
||||
|
||||
To install a tool:
|
||||
|
||||
```bash
|
||||
crewai tool install <tool-name>
|
||||
```
|
||||
|
||||
This installs the tool and adds it to `pyproject.toml`.
|
||||
|
||||
## Creating and Publishing Tools
|
||||
|
||||
To create a new tool project:
|
||||
|
||||
```bash
|
||||
crewai tool create <tool-name>
|
||||
```
|
||||
|
||||
This generates a scaffolded tool project locally.
|
||||
|
||||
After making changes, initialize a Git repository and commit the code:
|
||||
|
||||
```bash
|
||||
git init
|
||||
git add .
|
||||
git commit -m "Initial version"
|
||||
```
|
||||
|
||||
To publish the tool:
|
||||
|
||||
```bash
|
||||
crewai tool publish
|
||||
```
|
||||
|
||||
By default, tools are published as private. To make a tool public:
|
||||
|
||||
```bash
|
||||
crewai tool publish --public
|
||||
```
|
||||
|
||||
For more details on how to build tools, see [Creating your own tools](https://docs.crewai.com/concepts/tools#creating-your-own-tools).
|
||||
|
||||
## Updating Tools
|
||||
|
||||
To update a published tool:
|
||||
|
||||
1. Modify the tool locally
|
||||
2. Update the version in `pyproject.toml` (e.g., from `0.1.0` to `0.1.1`)
|
||||
3. Commit the changes and publish
|
||||
|
||||
```bash
|
||||
git commit -m "Update version to 0.1.1"
|
||||
crewai tool publish
|
||||
```
|
||||
|
||||
## Deleting Tools
|
||||
|
||||
To delete a tool:
|
||||
|
||||
1. Go to [CrewAI Enterprise](https://app.crewai.com)
|
||||
2. Navigate to **Tools**
|
||||
3. Select the tool
|
||||
4. Click **Delete**
|
||||
|
||||
<Warning>
|
||||
Deletion is permanent. Deleted tools cannot be restored or re-installed.
|
||||
</Warning>
|
||||
|
||||
## Security Checks
|
||||
|
||||
Every published version undergoes automated security checks, and are only available to install after they pass.
|
||||
|
||||
You can check the security check status of a tool at:
|
||||
|
||||
`CrewAI Enterprise > Tools > Your Tool > Versions`
|
||||
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with API integration or troubleshooting.
|
||||
</Card>
|
||||
146
docs/enterprise/features/traces.mdx
Normal file
@@ -0,0 +1,146 @@
|
||||
---
|
||||
title: Traces
|
||||
description: "Using Traces to monitor your Crews"
|
||||
icon: "timeline"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Traces provide comprehensive visibility into your crew executions, helping you monitor performance, debug issues, and optimize your AI agent workflows.
|
||||
|
||||
## What are Traces?
|
||||
|
||||
Traces in CrewAI Enterprise are detailed execution records that capture every aspect of your crew's operation, from initial inputs to final outputs. They record:
|
||||
|
||||
- Agent thoughts and reasoning
|
||||
- Task execution details
|
||||
- Tool usage and outputs
|
||||
- Token consumption metrics
|
||||
- Execution times
|
||||
- Cost estimates
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
## Accessing Traces
|
||||
|
||||
<Steps>
|
||||
<Step title="Navigate to the Traces Tab">
|
||||
Once in your CrewAI Enterprise dashboard, click on the **Traces** to view all execution records.
|
||||
</Step>
|
||||
|
||||
<Step title="Select an Execution">
|
||||
You'll see a list of all crew executions, sorted by date. Click on any execution to view its detailed trace.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Understanding the Trace Interface
|
||||
|
||||
The trace interface is divided into several sections, each providing different insights into your crew's execution:
|
||||
|
||||
### 1. Execution Summary
|
||||
|
||||
The top section displays high-level metrics about the execution:
|
||||
|
||||
- **Total Tokens**: Number of tokens consumed across all tasks
|
||||
- **Prompt Tokens**: Tokens used in prompts to the LLM
|
||||
- **Completion Tokens**: Tokens generated in LLM responses
|
||||
- **Requests**: Number of API calls made
|
||||
- **Execution Time**: Total duration of the crew run
|
||||
- **Estimated Cost**: Approximate cost based on token usage
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### 2. Tasks & Agents
|
||||
|
||||
This section shows all tasks and agents that were part of the crew execution:
|
||||
|
||||
- Task name and agent assignment
|
||||
- Agents and LLMs used for each task
|
||||
- Status (completed/failed)
|
||||
- Individual execution time of the task
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### 3. Final Output
|
||||
|
||||
Displays the final result produced by the crew after all tasks are completed.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### 4. Execution Timeline
|
||||
|
||||
A visual representation of when each task started and ended, helping you identify bottlenecks or parallel execution patterns.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### 5. Detailed Task View
|
||||
|
||||
When you click on a specific task in the timeline or task list, you'll see:
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
- **Task Key**: Unique identifier for the task
|
||||
- **Task ID**: Technical identifier in the system
|
||||
- **Status**: Current state (completed/running/failed)
|
||||
- **Agent**: Which agent performed the task
|
||||
- **LLM**: Language model used for this task
|
||||
- **Start/End Time**: When the task began and completed
|
||||
- **Execution Time**: Duration of this specific task
|
||||
- **Task Description**: What the agent was instructed to do
|
||||
- **Expected Output**: What output format was requested
|
||||
- **Input**: Any input provided to this task from previous tasks
|
||||
- **Output**: The actual result produced by the agent
|
||||
|
||||
|
||||
## Using Traces for Debugging
|
||||
|
||||
Traces are invaluable for troubleshooting issues with your crews:
|
||||
|
||||
<Steps>
|
||||
<Step title="Identify Failure Points">
|
||||
When a crew execution doesn't produce the expected results, examine the trace to find where things went wrong. Look for:
|
||||
|
||||
- Failed tasks
|
||||
- Unexpected agent decisions
|
||||
- Tool usage errors
|
||||
- Misinterpreted instructions
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Optimize Performance">
|
||||
Use execution metrics to identify performance bottlenecks:
|
||||
|
||||
- Tasks that took longer than expected
|
||||
- Excessive token usage
|
||||
- Redundant tool operations
|
||||
- Unnecessary API calls
|
||||
</Step>
|
||||
|
||||
<Step title="Improve Cost Efficiency">
|
||||
Analyze token usage and cost estimates to optimize your crew's efficiency:
|
||||
|
||||
- Consider using smaller models for simpler tasks
|
||||
- Refine prompts to be more concise
|
||||
- Cache frequently accessed information
|
||||
- Structure tasks to minimize redundant operations
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with trace analysis or any other CrewAI Enterprise features.
|
||||
</Card>
|
||||
82
docs/enterprise/features/webhook-streaming.mdx
Normal file
@@ -0,0 +1,82 @@
|
||||
---
|
||||
title: Webhook Streaming
|
||||
description: "Using Webhook Streaming to stream events to your webhook"
|
||||
icon: "webhook"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enterprise Event Streaming lets you receive real-time webhook updates about your crews and flows deployed to
|
||||
CrewAI Enterprise, such as model calls, tool usage, and flow steps.
|
||||
|
||||
## Usage
|
||||
|
||||
When using the Kickoff API, include a `webhooks` object to your request, for example:
|
||||
|
||||
```json
|
||||
{
|
||||
"inputs": {"foo": "bar"},
|
||||
"webhooks": {
|
||||
"events": ["crew_kickoff_started", "llm_call_started"],
|
||||
"url": "https://your.endpoint/webhook",
|
||||
"realtime": false,
|
||||
"authentication": {
|
||||
"strategy": "bearer",
|
||||
"token": "my-secret-token"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
If `realtime` is set to `true`, each event is delivered individually and immediately, at the cost of crew/flow performance.
|
||||
|
||||
## Webhook Format
|
||||
|
||||
Each webhook sends a list of events:
|
||||
|
||||
```json
|
||||
{
|
||||
"events": [
|
||||
{
|
||||
"id": "event-id",
|
||||
"execution_id": "crew-run-id",
|
||||
"timestamp": "2025-02-16T10:58:44.965Z",
|
||||
"type": "llm_call_started",
|
||||
"data": {
|
||||
"model": "gpt-4",
|
||||
"messages": [
|
||||
{"role": "system", "content": "You are an assistant."},
|
||||
{"role": "user", "content": "Summarize this article."}
|
||||
]
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
The `data` object structure varies by event type. Refer to the [event list](https://github.com/crewAIInc/crewAI/tree/main/src/crewai/utilities/events) on GitHub.
|
||||
|
||||
As requests are sent over HTTP, the order of events can't be guaranteed. If you need ordering, use the `timestamp` field.
|
||||
|
||||
## Supported Events
|
||||
|
||||
CrewAI supports both system events and custom events in Enterprise Event Streaming. These events are sent to your configured webhook endpoint during crew and flow execution.
|
||||
|
||||
- `crew_kickoff_started`
|
||||
- `crew_step_started`
|
||||
- `crew_step_completed`
|
||||
- `crew_execution_completed`
|
||||
- `llm_call_started`
|
||||
- `llm_call_completed`
|
||||
- `tool_usage_started`
|
||||
- `tool_usage_completed`
|
||||
- `crew_test_failed`
|
||||
- *...and others*
|
||||
|
||||
Event names match the internal event bus. See [GitHub source](https://github.com/crewAIInc/crewAI/tree/main/src/crewai/utilities/events) for the full list.
|
||||
|
||||
You can emit your own custom events, and they will be delivered through the webhook stream alongside system events.
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with webhook integration or troubleshooting.
|
||||
</Card>
|
||||
43
docs/enterprise/guides/build-crew.mdx
Normal file
@@ -0,0 +1,43 @@
|
||||
---
|
||||
title: "Build Crew"
|
||||
description: "A Crew is a group of agents that work together to complete a task."
|
||||
icon: "people-arrows"
|
||||
---
|
||||
|
||||
<Tip>
|
||||
[CrewAI Enterprise](https://app.crewai.com) streamlines the process of **creating**, **deploying**, and **managing** your AI agents in production environments.
|
||||
</Tip>
|
||||
|
||||
## Getting Started
|
||||
|
||||
<iframe
|
||||
width="100%"
|
||||
height="400"
|
||||
src="https://www.youtube.com/embed/d1Yp8eeknDk?si=tIxnTRI5UlyCp3z_"
|
||||
title="Building Crews with CrewAI CLI"
|
||||
frameborder="0"
|
||||
style={{ borderRadius: '10px' }}
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
### Installation and Setup
|
||||
|
||||
<Card title="Follow Standard Installation" icon="wrench" href="/installation">
|
||||
Follow our standard installation guide to set up CrewAI CLI and create your first project.
|
||||
</Card>
|
||||
|
||||
### Building Your Crew
|
||||
|
||||
<Card title="Quickstart Tutorial" icon="rocket" href="/quickstart">
|
||||
Follow our quickstart guide to create your first agent crew using YAML configuration.
|
||||
</Card>
|
||||
|
||||
## Support and Resources
|
||||
|
||||
For Enterprise-specific support or questions, contact our dedicated support team at [support@crewai.com](mailto:support@crewai.com).
|
||||
|
||||
|
||||
<Card title="Schedule a Demo" icon="calendar" href="mailto:support@crewai.com">
|
||||
Book time with our team to learn more about Enterprise features and how they can benefit your organization.
|
||||
</Card>
|
||||
216
docs/enterprise/guides/deploy-crew.mdx
Normal file
@@ -0,0 +1,216 @@
|
||||
---
|
||||
title: "Deploy Crew"
|
||||
description: "Deploy your local CrewAI project to the Enterprise platform"
|
||||
icon: "cloud-arrow-up"
|
||||
---
|
||||
|
||||
## Option 1: CLI Deployment
|
||||
|
||||
<Tip>
|
||||
This video tutorial walks you through the process of deploying your locally developed CrewAI project to the CrewAI Enterprise platform,
|
||||
transforming it into a production-ready API endpoint.
|
||||
</Tip>
|
||||
|
||||
<iframe
|
||||
width="100%"
|
||||
height="400"
|
||||
src="https://www.youtube.com/embed/3EqSV-CYDZA"
|
||||
title="Deploying a Crew to CrewAI Enterprise"
|
||||
frameborder="0"
|
||||
style={{ borderRadius: '10px' }}
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before starting the deployment process, make sure you have:
|
||||
|
||||
- A CrewAI project built locally ([follow our quickstart guide](/quickstart) if you haven't created one yet)
|
||||
- Your code pushed to a GitHub repository
|
||||
- The latest version of the CrewAI CLI installed (`uv tool install crewai`)
|
||||
|
||||
<Note>
|
||||
For a quick reference project, you can clone our example repository at [github.com/tonykipkemboi/crewai-latest-ai-development](https://github.com/tonykipkemboi/crewai-latest-ai-development).
|
||||
</Note>
|
||||
|
||||
|
||||
|
||||
### Step 1: Authenticate with the Enterprise Platform
|
||||
|
||||
First, you need to authenticate your CLI with the CrewAI Enterprise platform:
|
||||
|
||||
```bash
|
||||
# If you already have a CrewAI Enterprise account
|
||||
crewai login
|
||||
|
||||
# If you're creating a new account
|
||||
crewai signup
|
||||
```
|
||||
|
||||
When you run either command, the CLI will:
|
||||
1. Display a URL and a unique device code
|
||||
2. Open your browser to the authentication page
|
||||
3. Prompt you to confirm the device
|
||||
4. Complete the authentication process
|
||||
|
||||
Upon successful authentication, you'll see a confirmation message in your terminal!
|
||||
|
||||
### Step 2: Create a Deployment
|
||||
|
||||
From your project directory, run:
|
||||
|
||||
```bash
|
||||
crewai deploy create
|
||||
```
|
||||
|
||||
This command will:
|
||||
1. Detect your GitHub repository information
|
||||
2. Identify environment variables in your local `.env` file
|
||||
3. Securely transfer these variables to the Enterprise platform
|
||||
4. Create a new deployment with a unique identifier
|
||||
|
||||
On successful creation, you'll see a message like:
|
||||
```shell
|
||||
Deployment created successfully!
|
||||
Name: your_project_name
|
||||
Deployment ID: 01234567-89ab-cdef-0123-456789abcdef
|
||||
Current Status: Deploy Enqueued
|
||||
```
|
||||
|
||||
### Step 3: Monitor Deployment Progress
|
||||
|
||||
Track the deployment status with:
|
||||
|
||||
```bash
|
||||
crewai deploy status
|
||||
```
|
||||
|
||||
For detailed logs of the build process:
|
||||
|
||||
```bash
|
||||
crewai deploy logs
|
||||
```
|
||||
|
||||
<Tip>
|
||||
The first deployment typically takes 10-15 minutes as it builds the container images. Subsequent deployments are much faster.
|
||||
</Tip>
|
||||
|
||||
### Additional CLI Commands
|
||||
|
||||
The CrewAI CLI offers several commands to manage your deployments:
|
||||
|
||||
```bash
|
||||
# List all your deployments
|
||||
crewai deploy list
|
||||
|
||||
# Get the status of your deployment
|
||||
crewai deploy status
|
||||
|
||||
# View the logs of your deployment
|
||||
crewai deploy logs
|
||||
|
||||
# Push updates after code changes
|
||||
crewai deploy push
|
||||
|
||||
# Remove a deployment
|
||||
crewai deploy remove <deployment_id>
|
||||
```
|
||||
|
||||
## Option 2: Deploy Directly via Web Interface
|
||||
|
||||
You can also deploy your crews directly through the CrewAI Enterprise web interface by connecting your GitHub account. This approach doesn't require using the CLI on your local machine.
|
||||
|
||||
### Step 1: Pushing to GitHub
|
||||
|
||||
First, you need to push your crew to a GitHub repository. If you haven't created a crew yet, you can [follow this tutorial](/quickstart).
|
||||
|
||||
### Step 2: Connecting GitHub to CrewAI Enterprise
|
||||
|
||||
1. Log in to [CrewAI Enterprise](https://app.crewai.com)
|
||||
2. Click on the button "Connect GitHub"
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### Step 3: Select the Repository
|
||||
|
||||
After connecting your GitHub account, you'll be able to select which repository to deploy:
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### Step 4: Set Environment Variables
|
||||
|
||||
Before deploying, you'll need to set up your environment variables to connect to your LLM provider or other services:
|
||||
|
||||
1. You can add variables individually or in bulk
|
||||
2. Enter your environment variables in `KEY=VALUE` format (one per line)
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### Step 5: Deploy Your Crew
|
||||
|
||||
1. Click the "Deploy" button to start the deployment process
|
||||
2. You can monitor the progress through the progress bar
|
||||
3. The first deployment typically takes around 10-15 minutes; subsequent deployments will be faster
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
Once deployment is complete, you'll see:
|
||||
- Your crew's unique URL
|
||||
- A Bearer token to protect your crew API
|
||||
- A "Delete" button if you need to remove the deployment
|
||||
|
||||
### Interact with Your Deployed Crew
|
||||
|
||||
Once deployment is complete, you can access your crew through:
|
||||
|
||||
1. **REST API**: The platform generates a unique HTTPS endpoint with these key routes:
|
||||
- `/inputs`: Lists the required input parameters
|
||||
- `/kickoff`: Initiates an execution with provided inputs
|
||||
- `/status/{kickoff_id}`: Checks the execution status
|
||||
|
||||
2. **Web Interface**: Visit [app.crewai.com](https://app.crewai.com) to access:
|
||||
- **Status tab**: View deployment information, API endpoint details, and authentication token
|
||||
- **Run tab**: Visual representation of your crew's structure
|
||||
- **Executions tab**: History of all executions
|
||||
- **Metrics tab**: Performance analytics
|
||||
- **Traces tab**: Detailed execution insights
|
||||
|
||||
### Trigger an Execution
|
||||
|
||||
From the Enterprise dashboard, you can:
|
||||
|
||||
1. Click on your crew's name to open its details
|
||||
2. Select "Trigger Crew" from the management interface
|
||||
3. Enter the required inputs in the modal that appears
|
||||
4. Monitor progress as the execution moves through the pipeline
|
||||
|
||||
## Monitoring and Analytics
|
||||
|
||||
The Enterprise platform provides comprehensive observability features:
|
||||
|
||||
- **Execution Management**: Track active and completed runs
|
||||
- **Traces**: Detailed breakdowns of each execution
|
||||
- **Metrics**: Token usage, execution times, and costs
|
||||
- **Timeline View**: Visual representation of task sequences
|
||||
|
||||
## Advanced Features
|
||||
|
||||
The Enterprise platform also offers:
|
||||
|
||||
- **Environment Variables Management**: Securely store and manage API keys
|
||||
- **LLM Connections**: Configure integrations with various LLM providers
|
||||
- **Custom Tools Repository**: Create, share, and install tools
|
||||
- **Crew Studio**: Build crews through a chat interface without writing code
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with deployment issues or questions about the Enterprise platform.
|
||||
</Card>
|
||||
166
docs/enterprise/guides/enable-crew-studio.mdx
Normal file
@@ -0,0 +1,166 @@
|
||||
---
|
||||
title: "Enable Crew Studio"
|
||||
description: "Enabling Crew Studio on CrewAI Enterprise"
|
||||
icon: "comments"
|
||||
---
|
||||
|
||||
<Tip>
|
||||
Crew Studio is a powerful **no-code/low-code** tool that allows you to quickly scaffold or build Crews through a conversational interface.
|
||||
</Tip>
|
||||
|
||||
## What is Crew Studio?
|
||||
|
||||
Crew Studio is an innovative way to create AI agent crews without writing code.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
With Crew Studio, you can:
|
||||
|
||||
- Chat with the Crew Assistant to describe your problem
|
||||
- Automatically generate agents and tasks
|
||||
- Select appropriate tools
|
||||
- Configure necessary inputs
|
||||
- Generate downloadable code for customization
|
||||
- Deploy directly to the CrewAI Enterprise platform
|
||||
|
||||
## Configuration Steps
|
||||
|
||||
Before you can start using Crew Studio, you need to configure your LLM connections:
|
||||
|
||||
<Steps>
|
||||
<Step title="Set Up LLM Connection">
|
||||
Go to the **LLM Connections** tab in your CrewAI Enterprise dashboard and create a new LLM connection.
|
||||
|
||||
<Note>
|
||||
Feel free to use any LLM provider you want that is supported by CrewAI.
|
||||
</Note>
|
||||
|
||||
Configure your LLM connection:
|
||||
|
||||
- Enter a `Connection Name` (e.g., `OpenAI`)
|
||||
- Select your model provider: `openai` or `azure`
|
||||
- Select models you'd like to use in your Studio-generated Crews
|
||||
- We recommend at least `gpt-4o`, `o1-mini`, and `gpt-4o-mini`
|
||||
- Add your API key as an environment variable:
|
||||
- For OpenAI: Add `OPENAI_API_KEY` with your API key
|
||||
- For Azure OpenAI: Refer to [this article](https://blog.crewai.com/configuring-azure-openai-with-crewai-a-comprehensive-guide/) for configuration details
|
||||
- Click `Add Connection` to save your configuration
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Verify Connection Added">
|
||||
Once you complete the setup, you'll see your new connection added to the list of available connections.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Configure LLM Defaults">
|
||||
In the main menu, go to **Settings → Defaults** and configure the LLM Defaults settings:
|
||||
|
||||
- Select default models for agents and other components
|
||||
- Set default configurations for Crew Studio
|
||||
|
||||
Click `Save Settings` to apply your changes.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Using Crew Studio
|
||||
|
||||
Now that you've configured your LLM connection and default settings, you're ready to start using Crew Studio!
|
||||
|
||||
<Steps>
|
||||
<Step title="Access Studio">
|
||||
Navigate to the **Studio** section in your CrewAI Enterprise dashboard.
|
||||
</Step>
|
||||
|
||||
<Step title="Start a Conversation">
|
||||
Start a conversation with the Crew Assistant by describing the problem you want to solve:
|
||||
|
||||
```md
|
||||
I need a crew that can research the latest AI developments and create a summary report.
|
||||
```
|
||||
|
||||
The Crew Assistant will ask clarifying questions to better understand your requirements.
|
||||
</Step>
|
||||
|
||||
<Step title="Review Generated Crew">
|
||||
Review the generated crew configuration, including:
|
||||
|
||||
- Agents and their roles
|
||||
- Tasks to be performed
|
||||
- Required inputs
|
||||
- Tools to be used
|
||||
|
||||
This is your opportunity to refine the configuration before proceeding.
|
||||
</Step>
|
||||
|
||||
<Step title="Deploy or Download">
|
||||
Once you're satisfied with the configuration, you can:
|
||||
|
||||
- Download the generated code for local customization
|
||||
- Deploy the crew directly to the CrewAI Enterprise platform
|
||||
- Modify the configuration and regenerate the crew
|
||||
</Step>
|
||||
|
||||
<Step title="Test Your Crew">
|
||||
After deployment, test your crew with sample inputs to ensure it performs as expected.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<Tip>
|
||||
For best results, provide clear, detailed descriptions of what you want your crew to accomplish. Include specific inputs and expected outputs in your description.
|
||||
</Tip>
|
||||
|
||||
## Example Workflow
|
||||
|
||||
Here's a typical workflow for creating a crew with Crew Studio:
|
||||
|
||||
<Steps>
|
||||
<Step title="Describe Your Problem">
|
||||
Start by describing your problem:
|
||||
|
||||
```md
|
||||
I need a crew that can analyze financial news and provide investment recommendations
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="Answer Questions">
|
||||
Respond to clarifying questions from the Crew Assistant to refine your requirements.
|
||||
</Step>
|
||||
|
||||
<Step title="Review the Plan">
|
||||
Review the generated crew plan, which might include:
|
||||
|
||||
- A Research Agent to gather financial news
|
||||
- An Analysis Agent to interpret the data
|
||||
- A Recommendations Agent to provide investment advice
|
||||
</Step>
|
||||
|
||||
<Step title="Approve or Modify">
|
||||
Approve the plan or request changes if necessary.
|
||||
</Step>
|
||||
|
||||
<Step title="Download or Deploy">
|
||||
Download the code for customization or deploy directly to the platform.
|
||||
</Step>
|
||||
|
||||
<Step title="Test and Refine">
|
||||
Test your crew with sample inputs and refine as needed.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with Crew Studio or any other CrewAI Enterprise features.
|
||||
</Card>
|
||||
|
||||
186
docs/enterprise/guides/kickoff-crew.mdx
Normal file
@@ -0,0 +1,186 @@
|
||||
---
|
||||
title: "Kickoff Crew"
|
||||
description: "Kickoff a Crew on CrewAI Enterprise"
|
||||
icon: "flag-checkered"
|
||||
---
|
||||
|
||||
# Kickoff a Crew on CrewAI Enterprise
|
||||
|
||||
Once you've deployed your crew to the CrewAI Enterprise platform, you can kickoff executions through the web interface or the API. This guide covers both approaches.
|
||||
|
||||
## Method 1: Using the Web Interface
|
||||
|
||||
### Step 1: Navigate to Your Deployed Crew
|
||||
|
||||
1. Log in to [CrewAI Enterprise](https://app.crewai.com)
|
||||
2. Click on the crew name from your projects list
|
||||
3. You'll be taken to the crew's detail page
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### Step 2: Initiate Execution
|
||||
|
||||
From your crew's detail page, you have two options to kickoff an execution:
|
||||
|
||||
#### Option A: Quick Kickoff
|
||||
|
||||
1. Click the `Kickoff` link in the Test Endpoints section
|
||||
2. Enter the required input parameters for your crew in the JSON editor
|
||||
3. Click the `Send Request` button
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
#### Option B: Using the Visual Interface
|
||||
|
||||
1. Click the `Run` tab in the crew detail page
|
||||
2. Enter the required inputs in the form fields
|
||||
3. Click the `Run Crew` button
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### Step 3: Monitor Execution Progress
|
||||
|
||||
After initiating the execution:
|
||||
|
||||
1. You'll receive a response containing a `kickoff_id` - **copy this ID**
|
||||
2. This ID is essential for tracking your execution
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### Step 4: Check Execution Status
|
||||
|
||||
To monitor the progress of your execution:
|
||||
|
||||
1. Click the "Status" endpoint in the Test Endpoints section
|
||||
2. Paste the `kickoff_id` into the designated field
|
||||
3. Click the "Get Status" button
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
The status response will show:
|
||||
- Current execution state (`running`, `completed`, etc.)
|
||||
- Details about which tasks are in progress
|
||||
- Any outputs produced so far
|
||||
|
||||
### Step 5: View Final Results
|
||||
|
||||
Once execution is complete:
|
||||
|
||||
1. The status will change to `completed`
|
||||
2. You can view the full execution results and outputs
|
||||
3. For a more detailed view, check the `Executions` tab in the crew detail page
|
||||
|
||||
## Method 2: Using the API
|
||||
|
||||
You can also kickoff crews programmatically using the CrewAI Enterprise REST API.
|
||||
|
||||
### Authentication
|
||||
|
||||
All API requests require a bearer token for authentication:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer YOUR_CREW_TOKEN" https://your-crew-url.crewai.com
|
||||
```
|
||||
|
||||
Your bearer token is available on the Status tab of your crew's detail page.
|
||||
|
||||
### Checking Crew Health
|
||||
|
||||
Before executing operations, you can verify that your crew is running properly:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer YOUR_CREW_TOKEN" https://your-crew-url.crewai.com
|
||||
```
|
||||
|
||||
A successful response will return a message indicating the crew is operational:
|
||||
|
||||
```
|
||||
Healthy%
|
||||
```
|
||||
|
||||
### Step 1: Retrieve Required Inputs
|
||||
|
||||
First, determine what inputs your crew requires:
|
||||
|
||||
```bash
|
||||
curl -X GET \
|
||||
-H "Authorization: Bearer YOUR_CREW_TOKEN" \
|
||||
https://your-crew-url.crewai.com/inputs
|
||||
```
|
||||
|
||||
The response will be a JSON object containing an array of required input parameters, for example:
|
||||
|
||||
```json
|
||||
{"inputs":["topic","current_year"]}
|
||||
```
|
||||
|
||||
This example shows that this particular crew requires two inputs: `topic` and `current_year`.
|
||||
|
||||
### Step 2: Kickoff Execution
|
||||
|
||||
Initiate execution by providing the required inputs:
|
||||
|
||||
```bash
|
||||
curl -X POST \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_CREW_TOKEN" \
|
||||
-d '{"inputs": {"topic": "AI Agent Frameworks", "current_year": "2025"}}' \
|
||||
https://your-crew-url.crewai.com/kickoff
|
||||
```
|
||||
|
||||
The response will include a `kickoff_id` that you'll need for tracking:
|
||||
|
||||
```json
|
||||
{"kickoff_id":"abcd1234-5678-90ef-ghij-klmnopqrstuv"}
|
||||
```
|
||||
|
||||
### Step 3: Check Execution Status
|
||||
|
||||
Monitor the execution progress using the kickoff_id:
|
||||
|
||||
```bash
|
||||
curl -X GET \
|
||||
-H "Authorization: Bearer YOUR_CREW_TOKEN" \
|
||||
https://your-crew-url.crewai.com/status/abcd1234-5678-90ef-ghij-klmnopqrstuv
|
||||
```
|
||||
|
||||
## Handling Executions
|
||||
|
||||
### Long-Running Executions
|
||||
|
||||
For executions that may take a long time:
|
||||
|
||||
1. Consider implementing a polling mechanism to check status periodically
|
||||
2. Use webhooks (if available) for notification when execution completes
|
||||
3. Implement error handling for potential timeouts
|
||||
|
||||
### Execution Context
|
||||
|
||||
The execution context includes:
|
||||
|
||||
- Inputs provided at kickoff
|
||||
- Environment variables configured during deployment
|
||||
- Any state maintained between tasks
|
||||
|
||||
### Debugging Failed Executions
|
||||
|
||||
If an execution fails:
|
||||
|
||||
1. Check the "Executions" tab for detailed logs
|
||||
2. Review the "Traces" tab for step-by-step execution details
|
||||
3. Look for LLM responses and tool usage in the trace details
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with execution issues or questions about the Enterprise platform.
|
||||
</Card>
|
||||
|
||||
89
docs/enterprise/guides/update-crew.mdx
Normal file
@@ -0,0 +1,89 @@
|
||||
---
|
||||
title: "Update Crew"
|
||||
description: "Updating a Crew on CrewAI Enterprise"
|
||||
icon: "pencil"
|
||||
---
|
||||
|
||||
<Note>
|
||||
After deploying your crew to CrewAI Enterprise, you may need to make updates to the code, security settings, or configuration.
|
||||
This guide explains how to perform these common update operations.
|
||||
</Note>
|
||||
|
||||
## Why Update Your Crew?
|
||||
|
||||
CrewAI won't automatically pick up GitHub updates by default, so you'll need to manually trigger updates, unless you checked the `Auto-update` option when deploying your crew.
|
||||
|
||||
There are several reasons you might want to update your crew deployment:
|
||||
- You want to update the code with a latest commit you pushed to GitHub
|
||||
- You want to reset the bearer token for security reasons
|
||||
- You want to update environment variables
|
||||
|
||||
## 1. Updating Your Crew Code for a Latest Commit
|
||||
|
||||
When you've pushed new commits to your GitHub repository and want to update your deployment:
|
||||
|
||||
1. Navigate to your crew in the CrewAI Enterprise platform
|
||||
2. Click on the `Re-deploy` button on your crew details page
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
This will trigger an update that you can track using the progress bar. The system will pull the latest code from your repository and rebuild your deployment.
|
||||
|
||||
## 2. Resetting Bearer Token
|
||||
|
||||
If you need to generate a new bearer token (for example, if you suspect the current token might have been compromised):
|
||||
|
||||
1. Navigate to your crew in the CrewAI Enterprise platform
|
||||
2. Find the `Bearer Token` section
|
||||
3. Click the `Reset` button next to your current token
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
<Warning>
|
||||
Resetting your bearer token will invalidate the previous token immediately. Make sure to update any applications or scripts that are using the old token.
|
||||
</Warning>
|
||||
|
||||
## 3. Updating Environment Variables
|
||||
|
||||
To update the environment variables for your crew:
|
||||
|
||||
1. First access the deployment page by clicking on your crew's name
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
2. Locate the `Environment Variables` section (you will need to click the `Settings` icon to access it)
|
||||
3. Edit the existing variables or add new ones in the fields provided
|
||||
4. Click the `Update` button next to each variable you modify
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
5. Finally, click the `Update Deployment` button at the bottom of the page to apply the changes
|
||||
|
||||
<Note>
|
||||
Updating environment variables will trigger a new deployment, but this will only update the environment configuration and not the code itself.
|
||||
</Note>
|
||||
|
||||
## After Updating
|
||||
|
||||
After performing any update:
|
||||
|
||||
1. The system will rebuild and redeploy your crew
|
||||
2. You can monitor the deployment progress in real-time
|
||||
3. Once complete, test your crew to ensure the changes are working as expected
|
||||
|
||||
<Tip>
|
||||
If you encounter any issues after updating, you can view deployment logs in the platform or contact support for assistance.
|
||||
</Tip>
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with updating your crew or troubleshooting deployment issues.
|
||||
</Card>
|
||||
|
||||
319
docs/enterprise/guides/use-crew-api.mdx
Normal file
@@ -0,0 +1,319 @@
|
||||
---
|
||||
title: "Trigger Deployed Crew API"
|
||||
description: "Using your deployed crew's API on CrewAI Enterprise"
|
||||
icon: "arrow-up-right-from-square"
|
||||
---
|
||||
|
||||
Once you have deployed your crew to CrewAI Enterprise, it automatically becomes available as a REST API. This guide explains how to interact with your crew programmatically.
|
||||
|
||||
## API Basics
|
||||
|
||||
Your deployed crew exposes several endpoints that allow you to:
|
||||
1. Discover required inputs
|
||||
2. Start crew executions
|
||||
3. Monitor execution status
|
||||
4. Receive results
|
||||
|
||||
### Authentication
|
||||
|
||||
All API requests require a bearer token for authentication, which is generated when you deploy your crew:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer YOUR_CREW_TOKEN" https://your-crew-url.crewai.com/...
|
||||
```
|
||||
|
||||
<Tip>
|
||||
You can find your bearer token in the Status tab of your crew's detail page in the CrewAI Enterprise dashboard.
|
||||
</Tip>
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
## Available Endpoints
|
||||
|
||||
Your crew API provides three main endpoints:
|
||||
|
||||
| Endpoint | Method | Description |
|
||||
|----------|--------|-------------|
|
||||
| `/inputs` | GET | Lists all required inputs for crew execution |
|
||||
| `/kickoff` | POST | Starts a crew execution with provided inputs |
|
||||
| `/status/{kickoff_id}` | GET | Retrieves the status and results of an execution |
|
||||
|
||||
## GET /inputs
|
||||
|
||||
The inputs endpoint allows you to discover what parameters your crew requires:
|
||||
|
||||
```bash
|
||||
curl -X GET \
|
||||
-H "Authorization: Bearer YOUR_CREW_TOKEN" \
|
||||
https://your-crew-url.crewai.com/inputs
|
||||
```
|
||||
|
||||
### Response
|
||||
|
||||
```json
|
||||
{
|
||||
"inputs": ["budget", "interests", "duration", "age"]
|
||||
}
|
||||
```
|
||||
|
||||
This response indicates that your crew expects four input parameters: `budget`, `interests`, `duration`, and `age`.
|
||||
|
||||
## POST /kickoff
|
||||
|
||||
The kickoff endpoint starts a new crew execution:
|
||||
|
||||
```bash
|
||||
curl -X POST \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_CREW_TOKEN" \
|
||||
-d '{
|
||||
"inputs": {
|
||||
"budget": "1000 USD",
|
||||
"interests": "games, tech, ai, relaxing hikes, amazing food",
|
||||
"duration": "7 days",
|
||||
"age": "35"
|
||||
}
|
||||
}' \
|
||||
https://your-crew-url.crewai.com/kickoff
|
||||
```
|
||||
|
||||
### Request Parameters
|
||||
|
||||
| Parameter | Type | Required | Description |
|
||||
|-----------|------|----------|-------------|
|
||||
| `inputs` | Object | Yes | Key-value pairs of all required inputs |
|
||||
| `meta` | Object | No | Additional metadata to pass to the crew |
|
||||
| `taskWebhookUrl` | String | No | Callback URL executed after each task |
|
||||
| `stepWebhookUrl` | String | No | Callback URL executed after each agent thought |
|
||||
| `crewWebhookUrl` | String | No | Callback URL executed when the crew finishes |
|
||||
|
||||
### Example with Webhooks
|
||||
|
||||
```json
|
||||
{
|
||||
"inputs": {
|
||||
"budget": "1000 USD",
|
||||
"interests": "games, tech, ai, relaxing hikes, amazing food",
|
||||
"duration": "7 days",
|
||||
"age": "35"
|
||||
},
|
||||
"meta": {
|
||||
"requestId": "user-request-12345",
|
||||
"source": "mobile-app"
|
||||
},
|
||||
"taskWebhookUrl": "https://your-server.com/webhooks/task",
|
||||
"stepWebhookUrl": "https://your-server.com/webhooks/step",
|
||||
"crewWebhookUrl": "https://your-server.com/webhooks/crew"
|
||||
}
|
||||
```
|
||||
|
||||
### Response
|
||||
|
||||
```json
|
||||
{
|
||||
"kickoff_id": "abcd1234-5678-90ef-ghij-klmnopqrstuv"
|
||||
}
|
||||
```
|
||||
|
||||
The `kickoff_id` is used to track and retrieve the execution results.
|
||||
|
||||
## GET /status/{kickoff_id}
|
||||
|
||||
The status endpoint allows you to check the progress and results of a crew execution:
|
||||
|
||||
```bash
|
||||
curl -X GET \
|
||||
-H "Authorization: Bearer YOUR_CREW_TOKEN" \
|
||||
https://your-crew-url.crewai.com/status/abcd1234-5678-90ef-ghij-klmnopqrstuv
|
||||
```
|
||||
|
||||
### Response Structure
|
||||
|
||||
The response structure will vary depending on the execution state:
|
||||
|
||||
#### In Progress
|
||||
|
||||
```json
|
||||
{
|
||||
"status": "running",
|
||||
"current_task": "research_task",
|
||||
"progress": {
|
||||
"completed_tasks": 0,
|
||||
"total_tasks": 2
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Completed
|
||||
|
||||
```json
|
||||
{
|
||||
"status": "completed",
|
||||
"result": {
|
||||
"output": "Comprehensive travel itinerary...",
|
||||
"tasks": [
|
||||
{
|
||||
"task_id": "research_task",
|
||||
"output": "Research findings...",
|
||||
"agent": "Researcher",
|
||||
"execution_time": 45.2
|
||||
},
|
||||
{
|
||||
"task_id": "planning_task",
|
||||
"output": "7-day itinerary plan...",
|
||||
"agent": "Trip Planner",
|
||||
"execution_time": 62.8
|
||||
}
|
||||
]
|
||||
},
|
||||
"execution_time": 108.5
|
||||
}
|
||||
```
|
||||
|
||||
## Webhook Integration
|
||||
|
||||
When you provide webhook URLs in your kickoff request, the system will make POST requests to those URLs at specific points in the execution:
|
||||
|
||||
### taskWebhookUrl
|
||||
|
||||
Called when each task completes:
|
||||
|
||||
```json
|
||||
{
|
||||
"kickoff_id": "abcd1234-5678-90ef-ghij-klmnopqrstuv",
|
||||
"task_id": "research_task",
|
||||
"status": "completed",
|
||||
"output": "Research findings...",
|
||||
"agent": "Researcher",
|
||||
"execution_time": 45.2
|
||||
}
|
||||
```
|
||||
|
||||
### stepWebhookUrl
|
||||
|
||||
Called after each agent thought or action:
|
||||
|
||||
```json
|
||||
{
|
||||
"kickoff_id": "abcd1234-5678-90ef-ghij-klmnopqrstuv",
|
||||
"task_id": "research_task",
|
||||
"agent": "Researcher",
|
||||
"step_type": "thought",
|
||||
"content": "I should first search for popular destinations that match these interests..."
|
||||
}
|
||||
```
|
||||
|
||||
### crewWebhookUrl
|
||||
|
||||
Called when the entire crew execution completes:
|
||||
|
||||
```json
|
||||
{
|
||||
"kickoff_id": "abcd1234-5678-90ef-ghij-klmnopqrstuv",
|
||||
"status": "completed",
|
||||
"result": {
|
||||
"output": "Comprehensive travel itinerary...",
|
||||
"tasks": [
|
||||
{
|
||||
"task_id": "research_task",
|
||||
"output": "Research findings...",
|
||||
"agent": "Researcher",
|
||||
"execution_time": 45.2
|
||||
},
|
||||
{
|
||||
"task_id": "planning_task",
|
||||
"output": "7-day itinerary plan...",
|
||||
"agent": "Trip Planner",
|
||||
"execution_time": 62.8
|
||||
}
|
||||
]
|
||||
},
|
||||
"execution_time": 108.5,
|
||||
"meta": {
|
||||
"requestId": "user-request-12345",
|
||||
"source": "mobile-app"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
### Handling Long-Running Executions
|
||||
|
||||
Crew executions can take anywhere from seconds to minutes depending on their complexity. Consider these approaches:
|
||||
|
||||
1. **Webhooks (Recommended)**: Set up webhook endpoints to receive notifications when the execution completes
|
||||
2. **Polling**: Implement a polling mechanism with exponential backoff
|
||||
3. **Client-Side Timeout**: Set appropriate timeouts for your API requests
|
||||
|
||||
### Error Handling
|
||||
|
||||
The API may return various error codes:
|
||||
|
||||
| Code | Description | Recommended Action |
|
||||
|------|-------------|-------------------|
|
||||
| 401 | Unauthorized | Check your bearer token |
|
||||
| 404 | Not Found | Verify your crew URL and kickoff_id |
|
||||
| 422 | Validation Error | Ensure all required inputs are provided |
|
||||
| 500 | Server Error | Contact support with the error details |
|
||||
|
||||
### Sample Code
|
||||
|
||||
Here's a complete Python example for interacting with your crew API:
|
||||
|
||||
```python
|
||||
import requests
|
||||
import time
|
||||
|
||||
# Configuration
|
||||
CREW_URL = "https://your-crew-url.crewai.com"
|
||||
BEARER_TOKEN = "your-crew-token"
|
||||
HEADERS = {
|
||||
"Authorization": f"Bearer {BEARER_TOKEN}",
|
||||
"Content-Type": "application/json"
|
||||
}
|
||||
|
||||
# 1. Get required inputs
|
||||
response = requests.get(f"{CREW_URL}/inputs", headers=HEADERS)
|
||||
required_inputs = response.json()["inputs"]
|
||||
print(f"Required inputs: {required_inputs}")
|
||||
|
||||
# 2. Start crew execution
|
||||
payload = {
|
||||
"inputs": {
|
||||
"budget": "1000 USD",
|
||||
"interests": "games, tech, ai, relaxing hikes, amazing food",
|
||||
"duration": "7 days",
|
||||
"age": "35"
|
||||
}
|
||||
}
|
||||
|
||||
response = requests.post(f"{CREW_URL}/kickoff", headers=HEADERS, json=payload)
|
||||
kickoff_id = response.json()["kickoff_id"]
|
||||
print(f"Execution started with ID: {kickoff_id}")
|
||||
|
||||
# 3. Poll for results
|
||||
MAX_RETRIES = 30
|
||||
POLL_INTERVAL = 10 # seconds
|
||||
for i in range(MAX_RETRIES):
|
||||
print(f"Checking status (attempt {i+1}/{MAX_RETRIES})...")
|
||||
response = requests.get(f"{CREW_URL}/status/{kickoff_id}", headers=HEADERS)
|
||||
data = response.json()
|
||||
|
||||
if data["status"] == "completed":
|
||||
print("Execution completed!")
|
||||
print(f"Result: {data['result']['output']}")
|
||||
break
|
||||
elif data["status"] == "error":
|
||||
print(f"Execution failed: {data.get('error', 'Unknown error')}")
|
||||
break
|
||||
else:
|
||||
print(f"Status: {data['status']}, waiting {POLL_INTERVAL} seconds...")
|
||||
time.sleep(POLL_INTERVAL)
|
||||
```
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with API integration or troubleshooting.
|
||||
</Card>
|
||||
67
docs/enterprise/introduction.mdx
Normal file
@@ -0,0 +1,67 @@
|
||||
---
|
||||
title: "CrewAI Enterprise"
|
||||
description: "Deploy, monitor, and scale your AI agent workflows"
|
||||
icon: "globe"
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
CrewAI Enterprise provides a platform for deploying, monitoring, and scaling your crews and agents in a production environment.
|
||||
|
||||
CrewAI Enterprise extends the power of the open-source framework with features designed for production deployments, collaboration, and scalability. Deploy your crews to a managed infrastructure and monitor their execution in real-time.
|
||||
|
||||
## Key Features
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Crew Deployments" icon="rocket">
|
||||
Deploy your crews to a managed infrastructure with a few clicks
|
||||
</Card>
|
||||
<Card title="API Access" icon="code">
|
||||
Access your deployed crews via REST API for integration with existing systems
|
||||
</Card>
|
||||
<Card title="Observability" icon="chart-line">
|
||||
Monitor your crews with detailed execution traces and logs
|
||||
</Card>
|
||||
<Card title="Tool Repository" icon="toolbox">
|
||||
Publish and install tools to enhance your crews' capabilities
|
||||
</Card>
|
||||
<Card title="Webhook Streaming" icon="webhook">
|
||||
Stream real-time events and updates to your systems
|
||||
</Card>
|
||||
<Card title="Crew Studio" icon="paintbrush">
|
||||
Create and customize crews using a no-code/low-code interface
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Deployment Options
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="GitHub Integration" icon="github">
|
||||
Connect directly to your GitHub repositories to deploy code
|
||||
</Card>
|
||||
<Card title="Crew Studio" icon="palette">
|
||||
Deploy crews created through the no-code Crew Studio interface
|
||||
</Card>
|
||||
<Card title="CLI Deployment" icon="terminal">
|
||||
Use the CrewAI CLI for more advanced deployment workflows
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Getting Started
|
||||
|
||||
<Steps>
|
||||
<Step title="Sign up for an account">
|
||||
Create your account at [app.crewai.com](https://app.crewai.com)
|
||||
</Step>
|
||||
<Step title="Create your first crew">
|
||||
Use code or Crew Studio to create your crew
|
||||
</Step>
|
||||
<Step title="Deploy your crew">
|
||||
Deploy your crew to the Enterprise platform
|
||||
</Step>
|
||||
<Step title="Access your crew">
|
||||
Integrate with your crew via the generated API endpoints
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
For detailed instructions, check out our [deployment guide](/enterprise/guides/deploy-crew) or click the button below to get started.
|
||||
181
docs/enterprise/resources/frequently-asked-questions.mdx
Normal file
@@ -0,0 +1,181 @@
|
||||
---
|
||||
title: FAQs
|
||||
description: "Frequently asked questions about CrewAI Enterprise"
|
||||
icon: "code"
|
||||
---
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="How is task execution handled in the hierarchical process?">
|
||||
In the hierarchical process, a manager agent is automatically created and coordinates the workflow, delegating tasks and validating outcomes for
|
||||
streamlined and effective execution. The manager agent utilizes tools to facilitate task delegation and execution by agents under the manager's guidance.
|
||||
The manager LLM is crucial for the hierarchical process and must be set up correctly for proper function.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Where can I get the latest CrewAI documentation?">
|
||||
The most up-to-date documentation for CrewAI is available on our official documentation website; https://docs.crewai.com/
|
||||
<Card href="https://docs.crewai.com/" icon="books">CrewAI Docs</Card>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="What are the key differences between Hierarchical and Sequential Processes in CrewAI?">
|
||||
#### Hierarchical Process:
|
||||
Tasks are delegated and executed based on a structured chain of command.
|
||||
A manager language model (`manager_llm`) must be specified for the manager agent.
|
||||
Manager agent oversees task execution, planning, delegation, and validation.
|
||||
Tasks are not pre-assigned; the manager allocates tasks to agents based on their capabilities.
|
||||
|
||||
#### Sequential Process:
|
||||
Tasks are executed one after another, ensuring tasks are completed in an orderly progression.
|
||||
Output of one task serves as context for the next.
|
||||
Task execution follows the predefined order in the task list.
|
||||
|
||||
#### Which Process is Better Suited for Complex Projects?
|
||||
|
||||
The hierarchical process is better suited for complex projects because it allows for:
|
||||
|
||||
- **Dynamic task allocation and delegation**: Manager agent can assign tasks based on agent capabilities, allowing for efficient resource utilization.
|
||||
- **Structured validation and oversight**: Manager agent reviews task outputs and ensures task completion, increasing reliability and accuracy.
|
||||
- **Complex task management**: Assigning tools at the agent level allows for precise control over tool availability, facilitating the execution of intricate tasks.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="What are the benefits of using memory in the CrewAI framework?">
|
||||
- **Adaptive Learning**: Crews become more efficient over time, adapting to new information and refining their approach to tasks.
|
||||
- **Enhanced Personalization**: Memory enables agents to remember user preferences and historical interactions, leading to personalized experiences.
|
||||
- **Improved Problem Solving**: Access to a rich memory store aids agents in making more informed decisions, drawing on past learnings and contextual insights.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="What is the purpose of setting a maximum RPM limit for an agent?">
|
||||
Setting a maximum RPM limit for an agent prevents the agent from making too many requests to external services, which can help to avoid rate limits and improve performance.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="What role does human input play in the execution of tasks within a CrewAI crew?">
|
||||
It allows agents to request additional information or clarification when necessary.
|
||||
This feature is crucial in complex decision-making processes or when agents require more details to complete a task effectively.
|
||||
|
||||
To integrate human input into agent execution, set the `human_input` flag in the task definition. When enabled, the agent prompts the user for input before delivering its final answer.
|
||||
This input can provide extra context, clarify ambiguities, or validate the agent's output.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="What advanced customization options are available for tailoring and enhancing agent behavior and capabilities in CrewAI?">
|
||||
CrewAI provides a range of advanced customization options to tailor and enhance agent behavior and capabilities:
|
||||
|
||||
- **Language Model Customization**: Agents can be customized with specific language models (`llm`) and function-calling language models (`function_calling_llm`), offering advanced control over their processing and decision-making abilities.
|
||||
|
||||
- **Performance and Debugging Settings**: Adjust an agent's performance and monitor its operations for efficient task execution.
|
||||
|
||||
- **Verbose Mode**: Enables detailed logging of an agent's actions, useful for debugging and optimization.
|
||||
|
||||
- **RPM Limit**: Sets the maximum number of requests per minute (`max_rpm`).
|
||||
|
||||
- **Maximum Iterations for Task Execution**: The `max_iter` attribute allows users to define the maximum number of iterations an agent can perform for a single task, preventing infinite loops or excessively long executions.
|
||||
|
||||
- **Delegation and Autonomy**: Control an agent's ability to delegate or ask questions, tailoring its autonomy and collaborative dynamics within the CrewAI framework. By default, the `allow_delegation` attribute is set to True, enabling agents to seek assistance or delegate tasks as needed. This default behavior promotes collaborative problem-solving and efficiency within the CrewAI ecosystem. If needed, delegation can be disabled to suit specific operational requirements.
|
||||
|
||||
- **Human Input in Agent Execution**: Human input is critical in several agent execution scenarios, allowing agents to request additional information or clarification when necessary. This feature is especially useful in complex decision-making processes or when agents require more details to complete a task effectively.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="In what scenarios is human input particularly useful in agent execution?">
|
||||
Human input is particularly useful in agent execution when:
|
||||
- **Agents require additional information or clarification**: When agents encounter ambiguity or incomplete data, human input can provide the necessary context to complete the task effectively.
|
||||
- **Agents need to make complex or sensitive decisions**: Human input can assist agents in ethical or nuanced decision-making, ensuring responsible and informed outcomes.
|
||||
- **Oversight and validation of agent output**: Human input can help validate the results generated by agents, ensuring accuracy and preventing any misinterpretation or errors.
|
||||
- **Customizing agent behavior**: Human input can provide feedback on agent responses, allowing users to refine the agent's behavior and responses over time.
|
||||
- **Identifying and resolving errors or limitations**: Human input can help identify and address any errors or limitations in the agent's capabilities, enabling continuous improvement and optimization.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="What are the different types of memory that are available in crewAI?">
|
||||
The different types of memory available in CrewAI are:
|
||||
- `short-term memory`
|
||||
- `long-term memory`
|
||||
- `entity memory`
|
||||
- `contextual memory`
|
||||
|
||||
Learn more about the different types of memory here:
|
||||
<Card href="https://docs.crewai.com/concepts/memory" icon="brain">CrewAI Memory</Card>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="How can I create custom tools for my CrewAI agents?">
|
||||
You can create custom tools by subclassing the `BaseTool` class provided by CrewAI or by using the tool decorator. Subclassing involves defining a new class that inherits from `BaseTool`, specifying the name, description, and the `_run` method for operational logic. The tool decorator allows you to create a `Tool` object directly with the required attributes and a functional logic.
|
||||
Click here for more details:
|
||||
<Card href="https://docs.crewai.com/how-to/create-custom-tools" icon="code">CrewAI Tools</Card>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="How do I use Output Pydantic in a Task?">
|
||||
To use Output Pydantic in a task, you need to define the expected output of the task as a Pydantic model. Here's an example:
|
||||
<Steps>
|
||||
<Step title="Define a Pydantic model">
|
||||
First, you need to define a Pydantic model. For instance, let's create a simple model for a user:
|
||||
|
||||
```python
|
||||
from pydantic import BaseModel
|
||||
|
||||
class User(BaseModel):
|
||||
name: str
|
||||
age: int
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="Then, when creating a task, specify the expected output as this Pydantic model:">
|
||||
|
||||
```python
|
||||
from crewai import Task, Crew, Agent
|
||||
|
||||
# Import the User model
|
||||
from my_models import User
|
||||
|
||||
# Create a task with Output Pydantic
|
||||
task = Task(
|
||||
description="Create a user with the provided name and age",
|
||||
expected_output=User, # This is the Pydantic model
|
||||
agent=agent,
|
||||
tools=[tool1, tool2]
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="In your agent, make sure to set the output_pydantic attribute to the Pydantic model you're using:">
|
||||
|
||||
```python
|
||||
from crewai import Agent
|
||||
|
||||
# Import the User model
|
||||
from my_models import User
|
||||
|
||||
# Create an agent with Output Pydantic
|
||||
agent = Agent(
|
||||
role='User Creator',
|
||||
goal='Create users',
|
||||
backstory='I am skilled in creating user accounts',
|
||||
tools=[tool1, tool2],
|
||||
output_pydantic=User
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="When executing the crew, the output of the task will be a User object:">
|
||||
|
||||
```python
|
||||
from crewai import Crew
|
||||
|
||||
# Create a crew with the agent and task
|
||||
crew = Crew(agents=[agent], tasks=[task])
|
||||
|
||||
# Kick off the crew
|
||||
result = crew.kickoff()
|
||||
|
||||
# The output of the task will be a User object
|
||||
print(result.tasks[0].output)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
Here's a tutorial on how to consistently get structured outputs from your agents:
|
||||
<Frame>
|
||||
<iframe
|
||||
height="400"
|
||||
width="100%"
|
||||
src="https://www.youtube.com/embed/dNpKQk5uxHw"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowfullscreen></iframe>
|
||||
</Frame>
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
BIN
docs/flows.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 27 KiB |
157
docs/guides/advanced/customizing-prompts.mdx
Normal file
@@ -0,0 +1,157 @@
|
||||
---
|
||||
title: Customizing Prompts
|
||||
description: Dive deeper into low-level prompt customization for CrewAI, enabling super custom and complex use cases for different models and languages.
|
||||
icon: message-pen
|
||||
---
|
||||
|
||||
# Customizing Prompts at a Low Level
|
||||
|
||||
## Why Customize Prompts?
|
||||
|
||||
Although CrewAI's default prompts work well for many scenarios, low-level customization opens the door to significantly more flexible and powerful agent behavior. Here’s why you might want to take advantage of this deeper control:
|
||||
|
||||
1. **Optimize for specific LLMs** – Different models (such as GPT-4, Claude, or Llama) thrive with prompt formats tailored to their unique architectures.
|
||||
2. **Change the language** – Build agents that operate exclusively in languages beyond English, handling nuances with precision.
|
||||
3. **Specialize for complex domains** – Adapt prompts for highly specialized industries like healthcare, finance, or legal.
|
||||
4. **Adjust tone and style** – Make agents more formal, casual, creative, or analytical.
|
||||
5. **Support super custom use cases** – Utilize advanced prompt structures and formatting to meet intricate, project-specific requirements.
|
||||
|
||||
This guide explores how to tap into CrewAI's prompts at a lower level, giving you fine-grained control over how agents think and interact.
|
||||
|
||||
## Understanding CrewAI's Prompt System
|
||||
|
||||
Under the hood, CrewAI employs a modular prompt system that you can customize extensively:
|
||||
|
||||
- **Agent templates** – Govern each agent’s approach to their assigned role.
|
||||
- **Prompt slices** – Control specialized behaviors such as tasks, tool usage, and output structure.
|
||||
- **Error handling** – Direct how agents respond to failures, exceptions, or timeouts.
|
||||
- **Tool-specific prompts** – Define detailed instructions for how tools are invoked or utilized.
|
||||
|
||||
Check out the [original prompt templates in CrewAI's repository](https://github.com/crewAIInc/crewAI/blob/main/src/crewai/translations/en.json) to see how these elements are organized. From there, you can override or adapt them as needed to unlock advanced behaviors.
|
||||
|
||||
## Best Practices for Managing Prompt Files
|
||||
|
||||
When engaging in low-level prompt customization, follow these guidelines to keep things organized and maintainable:
|
||||
|
||||
1. **Keep files separate** – Store your customized prompts in dedicated JSON files outside your main codebase.
|
||||
2. **Version control** – Track changes within your repository, ensuring clear documentation of prompt adjustments over time.
|
||||
3. **Organize by model or language** – Use naming schemes like `prompts_llama.json` or `prompts_es.json` to quickly identify specialized configurations.
|
||||
4. **Document changes** – Provide comments or maintain a README detailing the purpose and scope of your customizations.
|
||||
5. **Minimize alterations** – Only override the specific slices you genuinely need to adjust, keeping default functionality intact for everything else.
|
||||
|
||||
## The Simplest Way to Customize Prompts
|
||||
|
||||
One straightforward approach is to create a JSON file for the prompts you want to override and then point your Crew at that file:
|
||||
|
||||
1. Craft a JSON file with your updated prompt slices.
|
||||
2. Reference that file via the `prompt_file` parameter in your Crew.
|
||||
|
||||
CrewAI then merges your customizations with the defaults, so you don’t have to redefine every prompt. Here’s how:
|
||||
|
||||
### Example: Basic Prompt Customization
|
||||
|
||||
Create a `custom_prompts.json` file with the prompts you want to modify. Ensure you list all top-level prompts it should contain, not just your changes:
|
||||
|
||||
```json
|
||||
{
|
||||
"slices": {
|
||||
"format": "When responding, follow this structure:\n\nTHOUGHTS: Your step-by-step thinking\nACTION: Any tool you're using\nRESULT: Your final answer or conclusion"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Then integrate it like so:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task, Process
|
||||
|
||||
# Create agents and tasks as normal
|
||||
researcher = Agent(
|
||||
role="Research Specialist",
|
||||
goal="Find information on quantum computing",
|
||||
backstory="You are a quantum physics expert",
|
||||
verbose=True
|
||||
)
|
||||
|
||||
research_task = Task(
|
||||
description="Research quantum computing applications",
|
||||
expected_output="A summary of practical applications",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
# Create a crew with your custom prompt file
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[research_task],
|
||||
prompt_file="path/to/custom_prompts.json",
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
With these few edits, you gain low-level control over how your agents communicate and solve tasks.
|
||||
|
||||
## Optimizing for Specific Models
|
||||
|
||||
Different models thrive on differently structured prompts. Making deeper adjustments can significantly boost performance by aligning your prompts with a model’s nuances.
|
||||
|
||||
### Example: Llama 3.3 Prompting Template
|
||||
|
||||
For instance, when dealing with Meta’s Llama 3.3, deeper-level customization may reflect the recommended structure described at:
|
||||
https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_1/#prompt-template
|
||||
|
||||
Here’s an example to highlight how you might fine-tune an Agent to leverage Llama 3.3 in code:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task, Process
|
||||
from crewai_tools import DirectoryReadTool, FileReadTool
|
||||
|
||||
# Define templates for system, user (prompt), and assistant (response) messages
|
||||
system_template = """<|begin_of_text|><|start_header_id|>system<|end_header_id|>{{ .System }}<|eot_id|>"""
|
||||
prompt_template = """<|start_header_id|>user<|end_header_id|>{{ .Prompt }}<|eot_id|>"""
|
||||
response_template = """<|start_header_id|>assistant<|end_header_id|>{{ .Response }}<|eot_id|>"""
|
||||
|
||||
# Create an Agent using Llama-specific layouts
|
||||
principal_engineer = Agent(
|
||||
role="Principal Engineer",
|
||||
goal="Oversee AI architecture and make high-level decisions",
|
||||
backstory="You are the lead engineer responsible for critical AI systems",
|
||||
verbose=True,
|
||||
llm="groq/llama-3.3-70b-versatile", # Using the Llama 3 model
|
||||
system_template=system_template,
|
||||
prompt_template=prompt_template,
|
||||
response_template=response_template,
|
||||
tools=[DirectoryReadTool(), FileReadTool()]
|
||||
)
|
||||
|
||||
# Define a sample task
|
||||
engineering_task = Task(
|
||||
description="Review AI implementation files for potential improvements",
|
||||
expected_output="A summary of key findings and recommendations",
|
||||
agent=principal_engineer
|
||||
)
|
||||
|
||||
# Create a Crew for the task
|
||||
llama_crew = Crew(
|
||||
agents=[principal_engineer],
|
||||
tasks=[engineering_task],
|
||||
process=Process.sequential,
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Execute the crew
|
||||
result = llama_crew.kickoff()
|
||||
print(result.raw)
|
||||
```
|
||||
|
||||
Through this deeper configuration, you can exercise comprehensive, low-level control over your Llama-based workflows without needing a separate JSON file.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Low-level prompt customization in CrewAI opens the door to super custom, complex use cases. By establishing well-organized prompt files (or direct inline templates), you can accommodate various models, languages, and specialized domains. This level of flexibility ensures you can craft precisely the AI behavior you need, all while knowing CrewAI still provides reliable defaults when you don’t override them.
|
||||
|
||||
<Check>
|
||||
You now have the foundation for advanced prompt customizations in CrewAI. Whether you’re adapting for model-specific structures or domain-specific constraints, this low-level approach lets you shape agent interactions in highly specialized ways.
|
||||
</Check>
|
||||
135
docs/guides/advanced/fingerprinting.mdx
Normal file
@@ -0,0 +1,135 @@
|
||||
---
|
||||
title: Fingerprinting
|
||||
description: Learn how to use CrewAI's fingerprinting system to uniquely identify and track components throughout their lifecycle.
|
||||
icon: fingerprint
|
||||
---
|
||||
|
||||
# Fingerprinting in CrewAI
|
||||
|
||||
## Overview
|
||||
|
||||
Fingerprints in CrewAI provide a way to uniquely identify and track components throughout their lifecycle. Each `Agent`, `Crew`, and `Task` automatically receives a unique fingerprint when created, which cannot be manually overridden.
|
||||
|
||||
These fingerprints can be used for:
|
||||
- Auditing and tracking component usage
|
||||
- Ensuring component identity integrity
|
||||
- Attaching metadata to components
|
||||
- Creating a traceable chain of operations
|
||||
|
||||
## How Fingerprints Work
|
||||
|
||||
A fingerprint is an instance of the `Fingerprint` class from the `crewai.security` module. Each fingerprint contains:
|
||||
|
||||
- A UUID string: A unique identifier for the component that is automatically generated and cannot be manually set
|
||||
- A creation timestamp: When the fingerprint was generated, automatically set and cannot be manually modified
|
||||
- Metadata: A dictionary of additional information that can be customized
|
||||
|
||||
Fingerprints are automatically generated and assigned when a component is created. Each component exposes its fingerprint through a read-only property.
|
||||
|
||||
## Basic Usage
|
||||
|
||||
### Accessing Fingerprints
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task
|
||||
|
||||
# Create components - fingerprints are automatically generated
|
||||
agent = Agent(
|
||||
role="Data Scientist",
|
||||
goal="Analyze data",
|
||||
backstory="Expert in data analysis"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[]
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Analyze customer data",
|
||||
expected_output="Insights from data analysis",
|
||||
agent=agent
|
||||
)
|
||||
|
||||
# Access the fingerprints
|
||||
agent_fingerprint = agent.fingerprint
|
||||
crew_fingerprint = crew.fingerprint
|
||||
task_fingerprint = task.fingerprint
|
||||
|
||||
# Print the UUID strings
|
||||
print(f"Agent fingerprint: {agent_fingerprint.uuid_str}")
|
||||
print(f"Crew fingerprint: {crew_fingerprint.uuid_str}")
|
||||
print(f"Task fingerprint: {task_fingerprint.uuid_str}")
|
||||
```
|
||||
|
||||
### Working with Fingerprint Metadata
|
||||
|
||||
You can add metadata to fingerprints for additional context:
|
||||
|
||||
```python
|
||||
# Add metadata to the agent's fingerprint
|
||||
agent.security_config.fingerprint.metadata = {
|
||||
"version": "1.0",
|
||||
"department": "Data Science",
|
||||
"project": "Customer Analysis"
|
||||
}
|
||||
|
||||
# Access the metadata
|
||||
print(f"Agent metadata: {agent.fingerprint.metadata}")
|
||||
```
|
||||
|
||||
## Fingerprint Persistence
|
||||
|
||||
Fingerprints are designed to persist and remain unchanged throughout a component's lifecycle. If you modify a component, the fingerprint remains the same:
|
||||
|
||||
```python
|
||||
original_fingerprint = agent.fingerprint.uuid_str
|
||||
|
||||
# Modify the agent
|
||||
agent.goal = "New goal for analysis"
|
||||
|
||||
# The fingerprint remains unchanged
|
||||
assert agent.fingerprint.uuid_str == original_fingerprint
|
||||
```
|
||||
|
||||
## Deterministic Fingerprints
|
||||
|
||||
While you cannot directly set the UUID and creation timestamp, you can create deterministic fingerprints using the `generate` method with a seed:
|
||||
|
||||
```python
|
||||
from crewai.security import Fingerprint
|
||||
|
||||
# Create a deterministic fingerprint using a seed string
|
||||
deterministic_fingerprint = Fingerprint.generate(seed="my-agent-id")
|
||||
|
||||
# The same seed always produces the same fingerprint
|
||||
same_fingerprint = Fingerprint.generate(seed="my-agent-id")
|
||||
assert deterministic_fingerprint.uuid_str == same_fingerprint.uuid_str
|
||||
|
||||
# You can also set metadata
|
||||
custom_fingerprint = Fingerprint.generate(
|
||||
seed="my-agent-id",
|
||||
metadata={"version": "1.0"}
|
||||
)
|
||||
```
|
||||
|
||||
## Advanced Usage
|
||||
|
||||
### Fingerprint Structure
|
||||
|
||||
Each fingerprint has the following structure:
|
||||
|
||||
```python
|
||||
from crewai.security import Fingerprint
|
||||
|
||||
fingerprint = agent.fingerprint
|
||||
|
||||
# UUID string - the unique identifier (auto-generated)
|
||||
uuid_str = fingerprint.uuid_str # e.g., "123e4567-e89b-12d3-a456-426614174000"
|
||||
|
||||
# Creation timestamp (auto-generated)
|
||||
created_at = fingerprint.created_at # A datetime object
|
||||
|
||||
# Metadata - for additional information (can be customized)
|
||||
metadata = fingerprint.metadata # A dictionary, defaults to {}
|
||||
```
|
||||
454
docs/guides/agents/crafting-effective-agents.mdx
Normal file
@@ -0,0 +1,454 @@
|
||||
---
|
||||
title: Crafting Effective Agents
|
||||
description: Learn best practices for designing powerful, specialized AI agents that collaborate effectively to solve complex problems.
|
||||
icon: robot
|
||||
---
|
||||
|
||||
# Crafting Effective Agents
|
||||
|
||||
## The Art and Science of Agent Design
|
||||
|
||||
At the heart of CrewAI lies the agent - a specialized AI entity designed to perform specific roles within a collaborative framework. While creating basic agents is simple, crafting truly effective agents that produce exceptional results requires understanding key design principles and best practices.
|
||||
|
||||
This guide will help you master the art of agent design, enabling you to create specialized AI personas that collaborate effectively, think critically, and produce high-quality outputs tailored to your specific needs.
|
||||
|
||||
### Why Agent Design Matters
|
||||
|
||||
The way you define your agents significantly impacts:
|
||||
|
||||
1. **Output quality**: Well-designed agents produce more relevant, high-quality results
|
||||
2. **Collaboration effectiveness**: Agents with complementary skills work together more efficiently
|
||||
3. **Task performance**: Agents with clear roles and goals execute tasks more effectively
|
||||
4. **System scalability**: Thoughtfully designed agents can be reused across multiple crews and contexts
|
||||
|
||||
Let's explore best practices for creating agents that excel in these dimensions.
|
||||
|
||||
## The 80/20 Rule: Focus on Tasks Over Agents
|
||||
|
||||
When building effective AI systems, remember this crucial principle: **80% of your effort should go into designing tasks, and only 20% into defining agents**.
|
||||
|
||||
Why? Because even the most perfectly defined agent will fail with poorly designed tasks, but well-designed tasks can elevate even a simple agent. This means:
|
||||
|
||||
- Spend most of your time writing clear task instructions
|
||||
- Define detailed inputs and expected outputs
|
||||
- Add examples and context to guide execution
|
||||
- Dedicate the remaining time to agent role, goal, and backstory
|
||||
|
||||
This doesn't mean agent design isn't important - it absolutely is. But task design is where most execution failures occur, so prioritize accordingly.
|
||||
|
||||
## Core Principles of Effective Agent Design
|
||||
|
||||
### 1. The Role-Goal-Backstory Framework
|
||||
|
||||
The most powerful agents in CrewAI are built on a strong foundation of three key elements:
|
||||
|
||||
#### Role: The Agent's Specialized Function
|
||||
|
||||
The role defines what the agent does and their area of expertise. When crafting roles:
|
||||
|
||||
- **Be specific and specialized**: Instead of "Writer," use "Technical Documentation Specialist" or "Creative Storyteller"
|
||||
- **Align with real-world professions**: Base roles on recognizable professional archetypes
|
||||
- **Include domain expertise**: Specify the agent's field of knowledge (e.g., "Financial Analyst specializing in market trends")
|
||||
|
||||
**Examples of effective roles:**
|
||||
```yaml
|
||||
role: "Senior UX Researcher specializing in user interview analysis"
|
||||
role: "Full-Stack Software Architect with expertise in distributed systems"
|
||||
role: "Corporate Communications Director specializing in crisis management"
|
||||
```
|
||||
|
||||
#### Goal: The Agent's Purpose and Motivation
|
||||
|
||||
The goal directs the agent's efforts and shapes their decision-making process. Effective goals should:
|
||||
|
||||
- **Be clear and outcome-focused**: Define what the agent is trying to achieve
|
||||
- **Emphasize quality standards**: Include expectations about the quality of work
|
||||
- **Incorporate success criteria**: Help the agent understand what "good" looks like
|
||||
|
||||
**Examples of effective goals:**
|
||||
```yaml
|
||||
goal: "Uncover actionable user insights by analyzing interview data and identifying recurring patterns, unmet needs, and improvement opportunities"
|
||||
goal: "Design robust, scalable system architectures that balance performance, maintainability, and cost-effectiveness"
|
||||
goal: "Craft clear, empathetic crisis communications that address stakeholder concerns while protecting organizational reputation"
|
||||
```
|
||||
|
||||
#### Backstory: The Agent's Experience and Perspective
|
||||
|
||||
The backstory gives depth to the agent, influencing how they approach problems and interact with others. Good backstories:
|
||||
|
||||
- **Establish expertise and experience**: Explain how the agent gained their skills
|
||||
- **Define working style and values**: Describe how the agent approaches their work
|
||||
- **Create a cohesive persona**: Ensure all elements of the backstory align with the role and goal
|
||||
|
||||
**Examples of effective backstories:**
|
||||
```yaml
|
||||
backstory: "You have spent 15 years conducting and analyzing user research for top tech companies. You have a talent for reading between the lines and identifying patterns that others miss. You believe that good UX is invisible and that the best insights come from listening to what users don't say as much as what they do say."
|
||||
|
||||
backstory: "With 20+ years of experience building distributed systems at scale, you've developed a pragmatic approach to software architecture. You've seen both successful and failed systems and have learned valuable lessons from each. You balance theoretical best practices with practical constraints and always consider the maintenance and operational aspects of your designs."
|
||||
|
||||
backstory: "As a seasoned communications professional who has guided multiple organizations through high-profile crises, you understand the importance of transparency, speed, and empathy in crisis response. You have a methodical approach to crafting messages that address concerns while maintaining organizational credibility."
|
||||
```
|
||||
|
||||
### 2. Specialists Over Generalists
|
||||
|
||||
Agents perform significantly better when given specialized roles rather than general ones. A highly focused agent delivers more precise, relevant outputs:
|
||||
|
||||
**Generic (Less Effective):**
|
||||
```yaml
|
||||
role: "Writer"
|
||||
```
|
||||
|
||||
**Specialized (More Effective):**
|
||||
```yaml
|
||||
role: "Technical Blog Writer specializing in explaining complex AI concepts to non-technical audiences"
|
||||
```
|
||||
|
||||
**Specialist Benefits:**
|
||||
- Clearer understanding of expected output
|
||||
- More consistent performance
|
||||
- Better alignment with specific tasks
|
||||
- Improved ability to make domain-specific judgments
|
||||
|
||||
### 3. Balancing Specialization and Versatility
|
||||
|
||||
Effective agents strike the right balance between specialization (doing one thing extremely well) and versatility (being adaptable to various situations):
|
||||
|
||||
- **Specialize in role, versatile in application**: Create agents with specialized skills that can be applied across multiple contexts
|
||||
- **Avoid overly narrow definitions**: Ensure agents can handle variations within their domain of expertise
|
||||
- **Consider the collaborative context**: Design agents whose specializations complement the other agents they'll work with
|
||||
|
||||
### 4. Setting Appropriate Expertise Levels
|
||||
|
||||
The expertise level you assign to your agent shapes how they approach tasks:
|
||||
|
||||
- **Novice agents**: Good for straightforward tasks, brainstorming, or initial drafts
|
||||
- **Intermediate agents**: Suitable for most standard tasks with reliable execution
|
||||
- **Expert agents**: Best for complex, specialized tasks requiring depth and nuance
|
||||
- **World-class agents**: Reserved for critical tasks where exceptional quality is needed
|
||||
|
||||
Choose the appropriate expertise level based on task complexity and quality requirements. For most collaborative crews, a mix of expertise levels often works best, with higher expertise assigned to core specialized functions.
|
||||
|
||||
## Practical Examples: Before and After
|
||||
|
||||
Let's look at some examples of agent definitions before and after applying these best practices:
|
||||
|
||||
### Example 1: Content Creation Agent
|
||||
|
||||
**Before:**
|
||||
```yaml
|
||||
role: "Writer"
|
||||
goal: "Write good content"
|
||||
backstory: "You are a writer who creates content for websites."
|
||||
```
|
||||
|
||||
**After:**
|
||||
```yaml
|
||||
role: "B2B Technology Content Strategist"
|
||||
goal: "Create compelling, technically accurate content that explains complex topics in accessible language while driving reader engagement and supporting business objectives"
|
||||
backstory: "You have spent a decade creating content for leading technology companies, specializing in translating technical concepts for business audiences. You excel at research, interviewing subject matter experts, and structuring information for maximum clarity and impact. You believe that the best B2B content educates first and sells second, building trust through genuine expertise rather than marketing hype."
|
||||
```
|
||||
|
||||
### Example 2: Research Agent
|
||||
|
||||
**Before:**
|
||||
```yaml
|
||||
role: "Researcher"
|
||||
goal: "Find information"
|
||||
backstory: "You are good at finding information online."
|
||||
```
|
||||
|
||||
**After:**
|
||||
```yaml
|
||||
role: "Academic Research Specialist in Emerging Technologies"
|
||||
goal: "Discover and synthesize cutting-edge research, identifying key trends, methodologies, and findings while evaluating the quality and reliability of sources"
|
||||
backstory: "With a background in both computer science and library science, you've mastered the art of digital research. You've worked with research teams at prestigious universities and know how to navigate academic databases, evaluate research quality, and synthesize findings across disciplines. You're methodical in your approach, always cross-referencing information and tracing claims to primary sources before drawing conclusions."
|
||||
```
|
||||
|
||||
## Crafting Effective Tasks for Your Agents
|
||||
|
||||
While agent design is important, task design is critical for successful execution. Here are best practices for designing tasks that set your agents up for success:
|
||||
|
||||
### The Anatomy of an Effective Task
|
||||
|
||||
A well-designed task has two key components that serve different purposes:
|
||||
|
||||
#### Task Description: The Process
|
||||
The description should focus on what to do and how to do it, including:
|
||||
- Detailed instructions for execution
|
||||
- Context and background information
|
||||
- Scope and constraints
|
||||
- Process steps to follow
|
||||
|
||||
#### Expected Output: The Deliverable
|
||||
The expected output should define what the final result should look like:
|
||||
- Format specifications (markdown, JSON, etc.)
|
||||
- Structure requirements
|
||||
- Quality criteria
|
||||
- Examples of good outputs (when possible)
|
||||
|
||||
### Task Design Best Practices
|
||||
|
||||
#### 1. Single Purpose, Single Output
|
||||
Tasks perform best when focused on one clear objective:
|
||||
|
||||
**Bad Example (Too Broad):**
|
||||
```yaml
|
||||
task_description: "Research market trends, analyze the data, and create a visualization."
|
||||
```
|
||||
|
||||
**Good Example (Focused):**
|
||||
```yaml
|
||||
# Task 1
|
||||
research_task:
|
||||
description: "Research the top 5 market trends in the AI industry for 2024."
|
||||
expected_output: "A markdown list of the 5 trends with supporting evidence."
|
||||
|
||||
# Task 2
|
||||
analysis_task:
|
||||
description: "Analyze the identified trends to determine potential business impacts."
|
||||
expected_output: "A structured analysis with impact ratings (High/Medium/Low)."
|
||||
|
||||
# Task 3
|
||||
visualization_task:
|
||||
description: "Create a visual representation of the analyzed trends."
|
||||
expected_output: "A description of a chart showing trends and their impact ratings."
|
||||
```
|
||||
|
||||
#### 2. Be Explicit About Inputs and Outputs
|
||||
Always clearly specify what inputs the task will use and what the output should look like:
|
||||
|
||||
**Example:**
|
||||
```yaml
|
||||
analysis_task:
|
||||
description: >
|
||||
Analyze the customer feedback data from the CSV file.
|
||||
Focus on identifying recurring themes related to product usability.
|
||||
Consider sentiment and frequency when determining importance.
|
||||
expected_output: >
|
||||
A markdown report with the following sections:
|
||||
1. Executive summary (3-5 bullet points)
|
||||
2. Top 3 usability issues with supporting data
|
||||
3. Recommendations for improvement
|
||||
```
|
||||
|
||||
#### 3. Include Purpose and Context
|
||||
Explain why the task matters and how it fits into the larger workflow:
|
||||
|
||||
**Example:**
|
||||
```yaml
|
||||
competitor_analysis_task:
|
||||
description: >
|
||||
Analyze our three main competitors' pricing strategies.
|
||||
This analysis will inform our upcoming pricing model revision.
|
||||
Focus on identifying patterns in how they price premium features
|
||||
and how they structure their tiered offerings.
|
||||
```
|
||||
|
||||
#### 4. Use Structured Output Tools
|
||||
For machine-readable outputs, specify the format clearly:
|
||||
|
||||
**Example:**
|
||||
```yaml
|
||||
data_extraction_task:
|
||||
description: "Extract key metrics from the quarterly report."
|
||||
expected_output: "JSON object with the following keys: revenue, growth_rate, customer_acquisition_cost, and retention_rate."
|
||||
```
|
||||
|
||||
## Common Mistakes to Avoid
|
||||
|
||||
Based on lessons learned from real-world implementations, here are the most common pitfalls in agent and task design:
|
||||
|
||||
### 1. Unclear Task Instructions
|
||||
|
||||
**Problem:** Tasks lack sufficient detail, making it difficult for agents to execute effectively.
|
||||
|
||||
**Example of Poor Design:**
|
||||
```yaml
|
||||
research_task:
|
||||
description: "Research AI trends."
|
||||
expected_output: "A report on AI trends."
|
||||
```
|
||||
|
||||
**Improved Version:**
|
||||
```yaml
|
||||
research_task:
|
||||
description: >
|
||||
Research the top emerging AI trends for 2024 with a focus on:
|
||||
1. Enterprise adoption patterns
|
||||
2. Technical breakthroughs in the past 6 months
|
||||
3. Regulatory developments affecting implementation
|
||||
|
||||
For each trend, identify key companies, technologies, and potential business impacts.
|
||||
expected_output: >
|
||||
A comprehensive markdown report with:
|
||||
- Executive summary (5 bullet points)
|
||||
- 5-7 major trends with supporting evidence
|
||||
- For each trend: definition, examples, and business implications
|
||||
- References to authoritative sources
|
||||
```
|
||||
|
||||
### 2. "God Tasks" That Try to Do Too Much
|
||||
|
||||
**Problem:** Tasks that combine multiple complex operations into one instruction set.
|
||||
|
||||
**Example of Poor Design:**
|
||||
```yaml
|
||||
comprehensive_task:
|
||||
description: "Research market trends, analyze competitor strategies, create a marketing plan, and design a launch timeline."
|
||||
```
|
||||
|
||||
**Improved Version:**
|
||||
Break this into sequential, focused tasks:
|
||||
```yaml
|
||||
# Task 1: Research
|
||||
market_research_task:
|
||||
description: "Research current market trends in the SaaS project management space."
|
||||
expected_output: "A markdown summary of key market trends."
|
||||
|
||||
# Task 2: Competitive Analysis
|
||||
competitor_analysis_task:
|
||||
description: "Analyze strategies of the top 3 competitors based on the market research."
|
||||
expected_output: "A comparison table of competitor strategies."
|
||||
context: [market_research_task]
|
||||
|
||||
# Continue with additional focused tasks...
|
||||
```
|
||||
|
||||
### 3. Misaligned Description and Expected Output
|
||||
|
||||
**Problem:** The task description asks for one thing while the expected output specifies something different.
|
||||
|
||||
**Example of Poor Design:**
|
||||
```yaml
|
||||
analysis_task:
|
||||
description: "Analyze customer feedback to find areas of improvement."
|
||||
expected_output: "A marketing plan for the next quarter."
|
||||
```
|
||||
|
||||
**Improved Version:**
|
||||
```yaml
|
||||
analysis_task:
|
||||
description: "Analyze customer feedback to identify the top 3 areas for product improvement."
|
||||
expected_output: "A report listing the 3 priority improvement areas with supporting customer quotes and data points."
|
||||
```
|
||||
|
||||
### 4. Not Understanding the Process Yourself
|
||||
|
||||
**Problem:** Asking agents to execute tasks that you yourself don't fully understand.
|
||||
|
||||
**Solution:**
|
||||
1. Try to perform the task manually first
|
||||
2. Document your process, decision points, and information sources
|
||||
3. Use this documentation as the basis for your task description
|
||||
|
||||
### 5. Premature Use of Hierarchical Structures
|
||||
|
||||
**Problem:** Creating unnecessarily complex agent hierarchies where sequential processes would work better.
|
||||
|
||||
**Solution:** Start with sequential processes and only move to hierarchical models when the workflow complexity truly requires it.
|
||||
|
||||
### 6. Vague or Generic Agent Definitions
|
||||
|
||||
**Problem:** Generic agent definitions lead to generic outputs.
|
||||
|
||||
**Example of Poor Design:**
|
||||
```yaml
|
||||
agent:
|
||||
role: "Business Analyst"
|
||||
goal: "Analyze business data"
|
||||
backstory: "You are good at business analysis."
|
||||
```
|
||||
|
||||
**Improved Version:**
|
||||
```yaml
|
||||
agent:
|
||||
role: "SaaS Metrics Specialist focusing on growth-stage startups"
|
||||
goal: "Identify actionable insights from business data that can directly impact customer retention and revenue growth"
|
||||
backstory: "With 10+ years analyzing SaaS business models, you've developed a keen eye for the metrics that truly matter for sustainable growth. You've helped numerous companies identify the leverage points that turned around their business trajectory. You believe in connecting data to specific, actionable recommendations rather than general observations."
|
||||
```
|
||||
|
||||
## Advanced Agent Design Strategies
|
||||
|
||||
### Designing for Collaboration
|
||||
|
||||
When creating agents that will work together in a crew, consider:
|
||||
|
||||
- **Complementary skills**: Design agents with distinct but complementary abilities
|
||||
- **Handoff points**: Define clear interfaces for how work passes between agents
|
||||
- **Constructive tension**: Sometimes, creating agents with slightly different perspectives can lead to better outcomes through productive dialogue
|
||||
|
||||
For example, a content creation crew might include:
|
||||
|
||||
```yaml
|
||||
# Research Agent
|
||||
role: "Research Specialist for technical topics"
|
||||
goal: "Gather comprehensive, accurate information from authoritative sources"
|
||||
backstory: "You are a meticulous researcher with a background in library science..."
|
||||
|
||||
# Writer Agent
|
||||
role: "Technical Content Writer"
|
||||
goal: "Transform research into engaging, clear content that educates and informs"
|
||||
backstory: "You are an experienced writer who excels at explaining complex concepts..."
|
||||
|
||||
# Editor Agent
|
||||
role: "Content Quality Editor"
|
||||
goal: "Ensure content is accurate, well-structured, and polished while maintaining consistency"
|
||||
backstory: "With years of experience in publishing, you have a keen eye for detail..."
|
||||
```
|
||||
|
||||
### Creating Specialized Tool Users
|
||||
|
||||
Some agents can be designed specifically to leverage certain tools effectively:
|
||||
|
||||
```yaml
|
||||
role: "Data Analysis Specialist"
|
||||
goal: "Derive meaningful insights from complex datasets through statistical analysis"
|
||||
backstory: "With a background in data science, you excel at working with structured and unstructured data..."
|
||||
tools: [PythonREPLTool, DataVisualizationTool, CSVAnalysisTool]
|
||||
```
|
||||
|
||||
### Tailoring Agents to LLM Capabilities
|
||||
|
||||
Different LLMs have different strengths. Design your agents with these capabilities in mind:
|
||||
|
||||
```yaml
|
||||
# For complex reasoning tasks
|
||||
analyst:
|
||||
role: "Data Insights Analyst"
|
||||
goal: "..."
|
||||
backstory: "..."
|
||||
llm: openai/gpt-4o
|
||||
|
||||
# For creative content
|
||||
writer:
|
||||
role: "Creative Content Writer"
|
||||
goal: "..."
|
||||
backstory: "..."
|
||||
llm: anthropic/claude-3-opus
|
||||
```
|
||||
|
||||
## Testing and Iterating on Agent Design
|
||||
|
||||
Agent design is often an iterative process. Here's a practical approach:
|
||||
|
||||
1. **Start with a prototype**: Create an initial agent definition
|
||||
2. **Test with sample tasks**: Evaluate performance on representative tasks
|
||||
3. **Analyze outputs**: Identify strengths and weaknesses
|
||||
4. **Refine the definition**: Adjust role, goal, and backstory based on observations
|
||||
5. **Test in collaboration**: Evaluate how the agent performs in a crew setting
|
||||
|
||||
## Conclusion
|
||||
|
||||
Crafting effective agents is both an art and a science. By carefully defining roles, goals, and backstories that align with your specific needs, and combining them with well-designed tasks, you can create specialized AI collaborators that produce exceptional results.
|
||||
|
||||
Remember that agent and task design is an iterative process. Start with these best practices, observe your agents in action, and refine your approach based on what you learn. And always keep in mind the 80/20 rule - focus most of your effort on creating clear, focused tasks to get the best results from your agents.
|
||||
|
||||
<Check>
|
||||
Congratulations! You now understand the principles and practices of effective agent design. Apply these techniques to create powerful, specialized agents that work together seamlessly to accomplish complex tasks.
|
||||
</Check>
|
||||
|
||||
## Next Steps
|
||||
|
||||
- Experiment with different agent configurations for your specific use case
|
||||
- Learn about [building your first crew](/guides/crews/first-crew) to see how agents work together
|
||||
- Explore [CrewAI Flows](/guides/flows/first-flow) for more advanced orchestration
|
||||
505
docs/guides/concepts/evaluating-use-cases.mdx
Normal file
@@ -0,0 +1,505 @@
|
||||
---
|
||||
title: Evaluating Use Cases for CrewAI
|
||||
description: Learn how to assess your AI application needs and choose the right approach between Crews and Flows based on complexity and precision requirements.
|
||||
icon: scale-balanced
|
||||
---
|
||||
|
||||
# Evaluating Use Cases for CrewAI
|
||||
|
||||
## Understanding the Decision Framework
|
||||
|
||||
When building AI applications with CrewAI, one of the most important decisions you'll make is choosing the right approach for your specific use case. Should you use a Crew? A Flow? A combination of both? This guide will help you evaluate your requirements and make informed architectural decisions.
|
||||
|
||||
At the heart of this decision is understanding the relationship between **complexity** and **precision** in your application:
|
||||
|
||||
<Frame caption="Complexity vs. Precision Matrix for CrewAI Applications">
|
||||
<img src="../..//complexity_precision.png" alt="Complexity vs. Precision Matrix" />
|
||||
</Frame>
|
||||
|
||||
This matrix helps visualize how different approaches align with varying requirements for complexity and precision. Let's explore what each quadrant means and how it guides your architectural choices.
|
||||
|
||||
## The Complexity-Precision Matrix Explained
|
||||
|
||||
### What is Complexity?
|
||||
|
||||
In the context of CrewAI applications, **complexity** refers to:
|
||||
|
||||
- The number of distinct steps or operations required
|
||||
- The diversity of tasks that need to be performed
|
||||
- The interdependencies between different components
|
||||
- The need for conditional logic and branching
|
||||
- The sophistication of the overall workflow
|
||||
|
||||
### What is Precision?
|
||||
|
||||
**Precision** in this context refers to:
|
||||
|
||||
- The accuracy required in the final output
|
||||
- The need for structured, predictable results
|
||||
- The importance of reproducibility
|
||||
- The level of control needed over each step
|
||||
- The tolerance for variation in outputs
|
||||
|
||||
### The Four Quadrants
|
||||
|
||||
#### 1. Low Complexity, Low Precision
|
||||
|
||||
**Characteristics:**
|
||||
- Simple, straightforward tasks
|
||||
- Tolerance for some variation in outputs
|
||||
- Limited number of steps
|
||||
- Creative or exploratory applications
|
||||
|
||||
**Recommended Approach:** Simple Crews with minimal agents
|
||||
|
||||
**Example Use Cases:**
|
||||
- Basic content generation
|
||||
- Idea brainstorming
|
||||
- Simple summarization tasks
|
||||
- Creative writing assistance
|
||||
|
||||
#### 2. Low Complexity, High Precision
|
||||
|
||||
**Characteristics:**
|
||||
- Simple workflows that require exact, structured outputs
|
||||
- Need for reproducible results
|
||||
- Limited steps but high accuracy requirements
|
||||
- Often involves data processing or transformation
|
||||
|
||||
**Recommended Approach:** Flows with direct LLM calls or simple Crews with structured outputs
|
||||
|
||||
**Example Use Cases:**
|
||||
- Data extraction and transformation
|
||||
- Form filling and validation
|
||||
- Structured content generation (JSON, XML)
|
||||
- Simple classification tasks
|
||||
|
||||
#### 3. High Complexity, Low Precision
|
||||
|
||||
**Characteristics:**
|
||||
- Multi-stage processes with many steps
|
||||
- Creative or exploratory outputs
|
||||
- Complex interactions between components
|
||||
- Tolerance for variation in final results
|
||||
|
||||
**Recommended Approach:** Complex Crews with multiple specialized agents
|
||||
|
||||
**Example Use Cases:**
|
||||
- Research and analysis
|
||||
- Content creation pipelines
|
||||
- Exploratory data analysis
|
||||
- Creative problem-solving
|
||||
|
||||
#### 4. High Complexity, High Precision
|
||||
|
||||
**Characteristics:**
|
||||
- Complex workflows requiring structured outputs
|
||||
- Multiple interdependent steps with strict accuracy requirements
|
||||
- Need for both sophisticated processing and precise results
|
||||
- Often mission-critical applications
|
||||
|
||||
**Recommended Approach:** Flows orchestrating multiple Crews with validation steps
|
||||
|
||||
**Example Use Cases:**
|
||||
- Enterprise decision support systems
|
||||
- Complex data processing pipelines
|
||||
- Multi-stage document processing
|
||||
- Regulated industry applications
|
||||
|
||||
## Choosing Between Crews and Flows
|
||||
|
||||
### When to Choose Crews
|
||||
|
||||
Crews are ideal when:
|
||||
|
||||
1. **You need collaborative intelligence** - Multiple agents with different specializations need to work together
|
||||
2. **The problem requires emergent thinking** - The solution benefits from different perspectives and approaches
|
||||
3. **The task is primarily creative or analytical** - The work involves research, content creation, or analysis
|
||||
4. **You value adaptability over strict structure** - The workflow can benefit from agent autonomy
|
||||
5. **The output format can be somewhat flexible** - Some variation in output structure is acceptable
|
||||
|
||||
```python
|
||||
# Example: Research Crew for market analysis
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
|
||||
# Create specialized agents
|
||||
researcher = Agent(
|
||||
role="Market Research Specialist",
|
||||
goal="Find comprehensive market data on emerging technologies",
|
||||
backstory="You are an expert at discovering market trends and gathering data."
|
||||
)
|
||||
|
||||
analyst = Agent(
|
||||
role="Market Analyst",
|
||||
goal="Analyze market data and identify key opportunities",
|
||||
backstory="You excel at interpreting market data and spotting valuable insights."
|
||||
)
|
||||
|
||||
# Define their tasks
|
||||
research_task = Task(
|
||||
description="Research the current market landscape for AI-powered healthcare solutions",
|
||||
expected_output="Comprehensive market data including key players, market size, and growth trends",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
analysis_task = Task(
|
||||
description="Analyze the market data and identify the top 3 investment opportunities",
|
||||
expected_output="Analysis report with 3 recommended investment opportunities and rationale",
|
||||
agent=analyst,
|
||||
context=[research_task]
|
||||
)
|
||||
|
||||
# Create the crew
|
||||
market_analysis_crew = Crew(
|
||||
agents=[researcher, analyst],
|
||||
tasks=[research_task, analysis_task],
|
||||
process=Process.sequential,
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
result = market_analysis_crew.kickoff()
|
||||
```
|
||||
|
||||
### When to Choose Flows
|
||||
|
||||
Flows are ideal when:
|
||||
|
||||
1. **You need precise control over execution** - The workflow requires exact sequencing and state management
|
||||
2. **The application has complex state requirements** - You need to maintain and transform state across multiple steps
|
||||
3. **You need structured, predictable outputs** - The application requires consistent, formatted results
|
||||
4. **The workflow involves conditional logic** - Different paths need to be taken based on intermediate results
|
||||
5. **You need to combine AI with procedural code** - The solution requires both AI capabilities and traditional programming
|
||||
|
||||
```python
|
||||
# Example: Customer Support Flow with structured processing
|
||||
from crewai.flow.flow import Flow, listen, router, start
|
||||
from pydantic import BaseModel
|
||||
from typing import List, Dict
|
||||
|
||||
# Define structured state
|
||||
class SupportTicketState(BaseModel):
|
||||
ticket_id: str = ""
|
||||
customer_name: str = ""
|
||||
issue_description: str = ""
|
||||
category: str = ""
|
||||
priority: str = "medium"
|
||||
resolution: str = ""
|
||||
satisfaction_score: int = 0
|
||||
|
||||
class CustomerSupportFlow(Flow[SupportTicketState]):
|
||||
@start()
|
||||
def receive_ticket(self):
|
||||
# In a real app, this might come from an API
|
||||
self.state.ticket_id = "TKT-12345"
|
||||
self.state.customer_name = "Alex Johnson"
|
||||
self.state.issue_description = "Unable to access premium features after payment"
|
||||
return "Ticket received"
|
||||
|
||||
@listen(receive_ticket)
|
||||
def categorize_ticket(self, _):
|
||||
# Use a direct LLM call for categorization
|
||||
from crewai import LLM
|
||||
llm = LLM(model="openai/gpt-4o-mini")
|
||||
|
||||
prompt = f"""
|
||||
Categorize the following customer support issue into one of these categories:
|
||||
- Billing
|
||||
- Account Access
|
||||
- Technical Issue
|
||||
- Feature Request
|
||||
- Other
|
||||
|
||||
Issue: {self.state.issue_description}
|
||||
|
||||
Return only the category name.
|
||||
"""
|
||||
|
||||
self.state.category = llm.call(prompt).strip()
|
||||
return self.state.category
|
||||
|
||||
@router(categorize_ticket)
|
||||
def route_by_category(self, category):
|
||||
# Route to different handlers based on category
|
||||
return category.lower().replace(" ", "_")
|
||||
|
||||
@listen("billing")
|
||||
def handle_billing_issue(self):
|
||||
# Handle billing-specific logic
|
||||
self.state.priority = "high"
|
||||
# More billing-specific processing...
|
||||
return "Billing issue handled"
|
||||
|
||||
@listen("account_access")
|
||||
def handle_access_issue(self):
|
||||
# Handle access-specific logic
|
||||
self.state.priority = "high"
|
||||
# More access-specific processing...
|
||||
return "Access issue handled"
|
||||
|
||||
# Additional category handlers...
|
||||
|
||||
@listen("billing", "account_access", "technical_issue", "feature_request", "other")
|
||||
def resolve_ticket(self, resolution_info):
|
||||
# Final resolution step
|
||||
self.state.resolution = f"Issue resolved: {resolution_info}"
|
||||
return self.state.resolution
|
||||
|
||||
# Run the flow
|
||||
support_flow = CustomerSupportFlow()
|
||||
result = support_flow.kickoff()
|
||||
```
|
||||
|
||||
### When to Combine Crews and Flows
|
||||
|
||||
The most sophisticated applications often benefit from combining Crews and Flows:
|
||||
|
||||
1. **Complex multi-stage processes** - Use Flows to orchestrate the overall process and Crews for complex subtasks
|
||||
2. **Applications requiring both creativity and structure** - Use Crews for creative tasks and Flows for structured processing
|
||||
3. **Enterprise-grade AI applications** - Use Flows to manage state and process flow while leveraging Crews for specialized work
|
||||
|
||||
```python
|
||||
# Example: Content Production Pipeline combining Crews and Flows
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from pydantic import BaseModel
|
||||
from typing import List, Dict
|
||||
|
||||
class ContentState(BaseModel):
|
||||
topic: str = ""
|
||||
target_audience: str = ""
|
||||
content_type: str = ""
|
||||
outline: Dict = {}
|
||||
draft_content: str = ""
|
||||
final_content: str = ""
|
||||
seo_score: int = 0
|
||||
|
||||
class ContentProductionFlow(Flow[ContentState]):
|
||||
@start()
|
||||
def initialize_project(self):
|
||||
# Set initial parameters
|
||||
self.state.topic = "Sustainable Investing"
|
||||
self.state.target_audience = "Millennial Investors"
|
||||
self.state.content_type = "Blog Post"
|
||||
return "Project initialized"
|
||||
|
||||
@listen(initialize_project)
|
||||
def create_outline(self, _):
|
||||
# Use a research crew to create an outline
|
||||
researcher = Agent(
|
||||
role="Content Researcher",
|
||||
goal=f"Research {self.state.topic} for {self.state.target_audience}",
|
||||
backstory="You are an expert researcher with deep knowledge of content creation."
|
||||
)
|
||||
|
||||
outliner = Agent(
|
||||
role="Content Strategist",
|
||||
goal=f"Create an engaging outline for a {self.state.content_type}",
|
||||
backstory="You excel at structuring content for maximum engagement."
|
||||
)
|
||||
|
||||
research_task = Task(
|
||||
description=f"Research {self.state.topic} focusing on what would interest {self.state.target_audience}",
|
||||
expected_output="Comprehensive research notes with key points and statistics",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
outline_task = Task(
|
||||
description=f"Create an outline for a {self.state.content_type} about {self.state.topic}",
|
||||
expected_output="Detailed content outline with sections and key points",
|
||||
agent=outliner,
|
||||
context=[research_task]
|
||||
)
|
||||
|
||||
outline_crew = Crew(
|
||||
agents=[researcher, outliner],
|
||||
tasks=[research_task, outline_task],
|
||||
process=Process.sequential,
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Run the crew and store the result
|
||||
result = outline_crew.kickoff()
|
||||
|
||||
# Parse the outline (in a real app, you might use a more robust parsing approach)
|
||||
import json
|
||||
try:
|
||||
self.state.outline = json.loads(result.raw)
|
||||
except:
|
||||
# Fallback if not valid JSON
|
||||
self.state.outline = {"sections": result.raw}
|
||||
|
||||
return "Outline created"
|
||||
|
||||
@listen(create_outline)
|
||||
def write_content(self, _):
|
||||
# Use a writing crew to create the content
|
||||
writer = Agent(
|
||||
role="Content Writer",
|
||||
goal=f"Write engaging content for {self.state.target_audience}",
|
||||
backstory="You are a skilled writer who creates compelling content."
|
||||
)
|
||||
|
||||
editor = Agent(
|
||||
role="Content Editor",
|
||||
goal="Ensure content is polished, accurate, and engaging",
|
||||
backstory="You have a keen eye for detail and a talent for improving content."
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description=f"Write a {self.state.content_type} about {self.state.topic} following this outline: {self.state.outline}",
|
||||
expected_output="Complete draft content in markdown format",
|
||||
agent=writer
|
||||
)
|
||||
|
||||
editing_task = Task(
|
||||
description="Edit and improve the draft content for clarity, engagement, and accuracy",
|
||||
expected_output="Polished final content in markdown format",
|
||||
agent=editor,
|
||||
context=[writing_task]
|
||||
)
|
||||
|
||||
writing_crew = Crew(
|
||||
agents=[writer, editor],
|
||||
tasks=[writing_task, editing_task],
|
||||
process=Process.sequential,
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Run the crew and store the result
|
||||
result = writing_crew.kickoff()
|
||||
self.state.final_content = result.raw
|
||||
|
||||
return "Content created"
|
||||
|
||||
@listen(write_content)
|
||||
def optimize_for_seo(self, _):
|
||||
# Use a direct LLM call for SEO optimization
|
||||
from crewai import LLM
|
||||
llm = LLM(model="openai/gpt-4o-mini")
|
||||
|
||||
prompt = f"""
|
||||
Analyze this content for SEO effectiveness for the keyword "{self.state.topic}".
|
||||
Rate it on a scale of 1-100 and provide 3 specific recommendations for improvement.
|
||||
|
||||
Content: {self.state.final_content[:1000]}... (truncated for brevity)
|
||||
|
||||
Format your response as JSON with the following structure:
|
||||
{{
|
||||
"score": 85,
|
||||
"recommendations": [
|
||||
"Recommendation 1",
|
||||
"Recommendation 2",
|
||||
"Recommendation 3"
|
||||
]
|
||||
}}
|
||||
"""
|
||||
|
||||
seo_analysis = llm.call(prompt)
|
||||
|
||||
# Parse the SEO analysis
|
||||
import json
|
||||
try:
|
||||
analysis = json.loads(seo_analysis)
|
||||
self.state.seo_score = analysis.get("score", 0)
|
||||
return analysis
|
||||
except:
|
||||
self.state.seo_score = 50
|
||||
return {"score": 50, "recommendations": ["Unable to parse SEO analysis"]}
|
||||
|
||||
# Run the flow
|
||||
content_flow = ContentProductionFlow()
|
||||
result = content_flow.kickoff()
|
||||
```
|
||||
|
||||
## Practical Evaluation Framework
|
||||
|
||||
To determine the right approach for your specific use case, follow this step-by-step evaluation framework:
|
||||
|
||||
### Step 1: Assess Complexity
|
||||
|
||||
Rate your application's complexity on a scale of 1-10 by considering:
|
||||
|
||||
1. **Number of steps**: How many distinct operations are required?
|
||||
- 1-3 steps: Low complexity (1-3)
|
||||
- 4-7 steps: Medium complexity (4-7)
|
||||
- 8+ steps: High complexity (8-10)
|
||||
|
||||
2. **Interdependencies**: How interconnected are the different parts?
|
||||
- Few dependencies: Low complexity (1-3)
|
||||
- Some dependencies: Medium complexity (4-7)
|
||||
- Many complex dependencies: High complexity (8-10)
|
||||
|
||||
3. **Conditional logic**: How much branching and decision-making is needed?
|
||||
- Linear process: Low complexity (1-3)
|
||||
- Some branching: Medium complexity (4-7)
|
||||
- Complex decision trees: High complexity (8-10)
|
||||
|
||||
4. **Domain knowledge**: How specialized is the knowledge required?
|
||||
- General knowledge: Low complexity (1-3)
|
||||
- Some specialized knowledge: Medium complexity (4-7)
|
||||
- Deep expertise in multiple domains: High complexity (8-10)
|
||||
|
||||
Calculate your average score to determine overall complexity.
|
||||
|
||||
### Step 2: Assess Precision Requirements
|
||||
|
||||
Rate your precision requirements on a scale of 1-10 by considering:
|
||||
|
||||
1. **Output structure**: How structured must the output be?
|
||||
- Free-form text: Low precision (1-3)
|
||||
- Semi-structured: Medium precision (4-7)
|
||||
- Strictly formatted (JSON, XML): High precision (8-10)
|
||||
|
||||
2. **Accuracy needs**: How important is factual accuracy?
|
||||
- Creative content: Low precision (1-3)
|
||||
- Informational content: Medium precision (4-7)
|
||||
- Critical information: High precision (8-10)
|
||||
|
||||
3. **Reproducibility**: How consistent must results be across runs?
|
||||
- Variation acceptable: Low precision (1-3)
|
||||
- Some consistency needed: Medium precision (4-7)
|
||||
- Exact reproducibility required: High precision (8-10)
|
||||
|
||||
4. **Error tolerance**: What is the impact of errors?
|
||||
- Low impact: Low precision (1-3)
|
||||
- Moderate impact: Medium precision (4-7)
|
||||
- High impact: High precision (8-10)
|
||||
|
||||
Calculate your average score to determine overall precision requirements.
|
||||
|
||||
### Step 3: Map to the Matrix
|
||||
|
||||
Plot your complexity and precision scores on the matrix:
|
||||
|
||||
- **Low Complexity (1-4), Low Precision (1-4)**: Simple Crews
|
||||
- **Low Complexity (1-4), High Precision (5-10)**: Flows with direct LLM calls
|
||||
- **High Complexity (5-10), Low Precision (1-4)**: Complex Crews
|
||||
- **High Complexity (5-10), High Precision (5-10)**: Flows orchestrating Crews
|
||||
|
||||
### Step 4: Consider Additional Factors
|
||||
|
||||
Beyond complexity and precision, consider:
|
||||
|
||||
1. **Development time**: Crews are often faster to prototype
|
||||
2. **Maintenance needs**: Flows provide better long-term maintainability
|
||||
3. **Team expertise**: Consider your team's familiarity with different approaches
|
||||
4. **Scalability requirements**: Flows typically scale better for complex applications
|
||||
5. **Integration needs**: Consider how the solution will integrate with existing systems
|
||||
|
||||
## Conclusion
|
||||
|
||||
Choosing between Crews and Flows—or combining them—is a critical architectural decision that impacts the effectiveness, maintainability, and scalability of your CrewAI application. By evaluating your use case along the dimensions of complexity and precision, you can make informed decisions that align with your specific requirements.
|
||||
|
||||
Remember that the best approach often evolves as your application matures. Start with the simplest solution that meets your needs, and be prepared to refine your architecture as you gain experience and your requirements become clearer.
|
||||
|
||||
<Check>
|
||||
You now have a framework for evaluating CrewAI use cases and choosing the right approach based on complexity and precision requirements. This will help you build more effective, maintainable, and scalable AI applications.
|
||||
</Check>
|
||||
|
||||
## Next Steps
|
||||
|
||||
- Learn more about [crafting effective agents](/guides/agents/crafting-effective-agents)
|
||||
- Explore [building your first crew](/guides/crews/first-crew)
|
||||
- Dive into [mastering flow state management](/guides/flows/mastering-flow-state)
|
||||
- Check out the [core concepts](/concepts/agents) for deeper understanding
|
||||
395
docs/guides/crews/first-crew.mdx
Normal file
@@ -0,0 +1,395 @@
|
||||
---
|
||||
title: Build Your First Crew
|
||||
description: Step-by-step tutorial to create a collaborative AI team that works together to solve complex problems.
|
||||
icon: users-gear
|
||||
---
|
||||
|
||||
# Build Your First Crew
|
||||
|
||||
## Unleashing the Power of Collaborative AI
|
||||
|
||||
Imagine having a team of specialized AI agents working together seamlessly to solve complex problems, each contributing their unique skills to achieve a common goal. This is the power of CrewAI - a framework that enables you to create collaborative AI systems that can accomplish tasks far beyond what a single AI could achieve alone.
|
||||
|
||||
In this guide, we'll walk through creating a research crew that will help us research and analyze a topic, then create a comprehensive report. This practical example demonstrates how AI agents can collaborate to accomplish complex tasks, but it's just the beginning of what's possible with CrewAI.
|
||||
|
||||
### What You'll Build and Learn
|
||||
|
||||
By the end of this guide, you'll have:
|
||||
|
||||
1. **Created a specialized AI research team** with distinct roles and responsibilities
|
||||
2. **Orchestrated collaboration** between multiple AI agents
|
||||
3. **Automated a complex workflow** that involves gathering information, analysis, and report generation
|
||||
4. **Built foundational skills** that you can apply to more ambitious projects
|
||||
|
||||
While we're building a simple research crew in this guide, the same patterns and techniques can be applied to create much more sophisticated teams for tasks like:
|
||||
|
||||
- Multi-stage content creation with specialized writers, editors, and fact-checkers
|
||||
- Complex customer service systems with tiered support agents
|
||||
- Autonomous business analysts that gather data, create visualizations, and generate insights
|
||||
- Product development teams that ideate, design, and plan implementation
|
||||
|
||||
Let's get started building your first crew!
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Before starting, make sure you have:
|
||||
|
||||
1. Installed CrewAI following the [installation guide](/installation)
|
||||
2. Set up your OpenAI API key in your environment variables
|
||||
3. Basic understanding of Python
|
||||
|
||||
## Step 1: Create a New CrewAI Project
|
||||
|
||||
First, let's create a new CrewAI project using the CLI. This command will set up a complete project structure with all the necessary files, allowing you to focus on defining your agents and their tasks rather than setting up boilerplate code.
|
||||
|
||||
```bash
|
||||
crewai create crew research_crew
|
||||
cd research_crew
|
||||
```
|
||||
|
||||
This will generate a project with the basic structure needed for your crew. The CLI automatically creates:
|
||||
|
||||
- A project directory with the necessary files
|
||||
- Configuration files for agents and tasks
|
||||
- A basic crew implementation
|
||||
- A main script to run the crew
|
||||
|
||||
<Frame caption="CrewAI Framework Overview">
|
||||
<img src="../../crews.png" alt="CrewAI Framework Overview" />
|
||||
</Frame>
|
||||
|
||||
|
||||
## Step 2: Explore the Project Structure
|
||||
|
||||
Let's take a moment to understand the project structure created by the CLI. CrewAI follows best practices for Python projects, making it easy to maintain and extend your code as your crews become more complex.
|
||||
|
||||
```
|
||||
research_crew/
|
||||
├── .gitignore
|
||||
├── pyproject.toml
|
||||
├── README.md
|
||||
├── .env
|
||||
└── src/
|
||||
└── research_crew/
|
||||
├── __init__.py
|
||||
├── main.py
|
||||
├── crew.py
|
||||
├── tools/
|
||||
│ ├── custom_tool.py
|
||||
│ └── __init__.py
|
||||
└── config/
|
||||
├── agents.yaml
|
||||
└── tasks.yaml
|
||||
```
|
||||
|
||||
This structure follows best practices for Python projects and makes it easy to organize your code. The separation of configuration files (in YAML) from implementation code (in Python) makes it easy to modify your crew's behavior without changing the underlying code.
|
||||
|
||||
## Step 3: Configure Your Agents
|
||||
|
||||
Now comes the fun part - defining your AI agents! In CrewAI, agents are specialized entities with specific roles, goals, and backstories that shape their behavior. Think of them as characters in a play, each with their own personality and purpose.
|
||||
|
||||
For our research crew, we'll create two agents:
|
||||
1. A **researcher** who excels at finding and organizing information
|
||||
2. An **analyst** who can interpret research findings and create insightful reports
|
||||
|
||||
Let's modify the `agents.yaml` file to define these specialized agents:
|
||||
|
||||
```yaml
|
||||
# src/research_crew/config/agents.yaml
|
||||
researcher:
|
||||
role: >
|
||||
Senior Research Specialist for {topic}
|
||||
goal: >
|
||||
Find comprehensive and accurate information about {topic}
|
||||
with a focus on recent developments and key insights
|
||||
backstory: >
|
||||
You are an experienced research specialist with a talent for
|
||||
finding relevant information from various sources. You excel at
|
||||
organizing information in a clear and structured manner, making
|
||||
complex topics accessible to others.
|
||||
llm: openai/gpt-4o-mini
|
||||
|
||||
analyst:
|
||||
role: >
|
||||
Data Analyst and Report Writer for {topic}
|
||||
goal: >
|
||||
Analyze research findings and create a comprehensive, well-structured
|
||||
report that presents insights in a clear and engaging way
|
||||
backstory: >
|
||||
You are a skilled analyst with a background in data interpretation
|
||||
and technical writing. You have a talent for identifying patterns
|
||||
and extracting meaningful insights from research data, then
|
||||
communicating those insights effectively through well-crafted reports.
|
||||
llm: openai/gpt-4o-mini
|
||||
```
|
||||
|
||||
Notice how each agent has a distinct role, goal, and backstory. These elements aren't just descriptive - they actively shape how the agent approaches its tasks. By crafting these carefully, you can create agents with specialized skills and perspectives that complement each other.
|
||||
|
||||
## Step 4: Define Your Tasks
|
||||
|
||||
With our agents defined, we now need to give them specific tasks to perform. Tasks in CrewAI represent the concrete work that agents will perform, with detailed instructions and expected outputs.
|
||||
|
||||
For our research crew, we'll define two main tasks:
|
||||
1. A **research task** for gathering comprehensive information
|
||||
2. An **analysis task** for creating an insightful report
|
||||
|
||||
Let's modify the `tasks.yaml` file:
|
||||
|
||||
```yaml
|
||||
# src/research_crew/config/tasks.yaml
|
||||
research_task:
|
||||
description: >
|
||||
Conduct thorough research on {topic}. Focus on:
|
||||
1. Key concepts and definitions
|
||||
2. Historical development and recent trends
|
||||
3. Major challenges and opportunities
|
||||
4. Notable applications or case studies
|
||||
5. Future outlook and potential developments
|
||||
|
||||
Make sure to organize your findings in a structured format with clear sections.
|
||||
expected_output: >
|
||||
A comprehensive research document with well-organized sections covering
|
||||
all the requested aspects of {topic}. Include specific facts, figures,
|
||||
and examples where relevant.
|
||||
agent: researcher
|
||||
|
||||
analysis_task:
|
||||
description: >
|
||||
Analyze the research findings and create a comprehensive report on {topic}.
|
||||
Your report should:
|
||||
1. Begin with an executive summary
|
||||
2. Include all key information from the research
|
||||
3. Provide insightful analysis of trends and patterns
|
||||
4. Offer recommendations or future considerations
|
||||
5. Be formatted in a professional, easy-to-read style with clear headings
|
||||
expected_output: >
|
||||
A polished, professional report on {topic} that presents the research
|
||||
findings with added analysis and insights. The report should be well-structured
|
||||
with an executive summary, main sections, and conclusion.
|
||||
agent: analyst
|
||||
context:
|
||||
- research_task
|
||||
output_file: output/report.md
|
||||
```
|
||||
|
||||
Note the `context` field in the analysis task - this is a powerful feature that allows the analyst to access the output of the research task. This creates a workflow where information flows naturally between agents, just as it would in a human team.
|
||||
|
||||
## Step 5: Configure Your Crew
|
||||
|
||||
Now it's time to bring everything together by configuring our crew. The crew is the container that orchestrates how agents work together to complete tasks.
|
||||
|
||||
Let's modify the `crew.py` file:
|
||||
|
||||
```python
|
||||
# src/research_crew/crew.py
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai.project import CrewBase, agent, crew, task
|
||||
from crewai_tools import SerperDevTool
|
||||
from crewai.agents.agent_builder.base_agent import BaseAgent
|
||||
from typing import List
|
||||
|
||||
@CrewBase
|
||||
class ResearchCrew():
|
||||
"""Research crew for comprehensive topic analysis and reporting"""
|
||||
|
||||
agents: List[BaseAgent]
|
||||
tasks: List[Task]
|
||||
|
||||
@agent
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['researcher'], # type: ignore[index]
|
||||
verbose=True,
|
||||
tools=[SerperDevTool()]
|
||||
)
|
||||
|
||||
@agent
|
||||
def analyst(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['analyst'], # type: ignore[index]
|
||||
verbose=True
|
||||
)
|
||||
|
||||
@task
|
||||
def research_task(self) -> Task:
|
||||
return Task(
|
||||
config=self.tasks_config['research_task'] # type: ignore[index]
|
||||
)
|
||||
|
||||
@task
|
||||
def analysis_task(self) -> Task:
|
||||
return Task(
|
||||
config=self.tasks_config['analysis_task'], # type: ignore[index]
|
||||
output_file='output/report.md'
|
||||
)
|
||||
|
||||
@crew
|
||||
def crew(self) -> Crew:
|
||||
"""Creates the research crew"""
|
||||
return Crew(
|
||||
agents=self.agents,
|
||||
tasks=self.tasks,
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
)
|
||||
```
|
||||
|
||||
In this code, we're:
|
||||
1. Creating the researcher agent and equipping it with the SerperDevTool to search the web
|
||||
2. Creating the analyst agent
|
||||
3. Setting up the research and analysis tasks
|
||||
4. Configuring the crew to run tasks sequentially (the analyst will wait for the researcher to finish)
|
||||
|
||||
This is where the magic happens - with just a few lines of code, we've defined a collaborative AI system where specialized agents work together in a coordinated process.
|
||||
|
||||
## Step 6: Set Up Your Main Script
|
||||
|
||||
Now, let's set up the main script that will run our crew. This is where we provide the specific topic we want our crew to research.
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python
|
||||
# src/research_crew/main.py
|
||||
import os
|
||||
from research_crew.crew import ResearchCrew
|
||||
|
||||
# Create output directory if it doesn't exist
|
||||
os.makedirs('output', exist_ok=True)
|
||||
|
||||
def run():
|
||||
"""
|
||||
Run the research crew.
|
||||
"""
|
||||
inputs = {
|
||||
'topic': 'Artificial Intelligence in Healthcare'
|
||||
}
|
||||
|
||||
# Create and run the crew
|
||||
result = ResearchCrew().crew().kickoff(inputs=inputs)
|
||||
|
||||
# Print the result
|
||||
print("\n\n=== FINAL REPORT ===\n\n")
|
||||
print(result.raw)
|
||||
|
||||
print("\n\nReport has been saved to output/report.md")
|
||||
|
||||
if __name__ == "__main__":
|
||||
run()
|
||||
```
|
||||
|
||||
This script prepares the environment, specifies our research topic, and kicks off the crew's work. The power of CrewAI is evident in how simple this code is - all the complexity of managing multiple AI agents is handled by the framework.
|
||||
|
||||
## Step 7: Set Up Your Environment Variables
|
||||
|
||||
Create a `.env` file in your project root with your API keys:
|
||||
|
||||
```
|
||||
OPENAI_API_KEY=your_openai_api_key
|
||||
SERPER_API_KEY=your_serper_api_key
|
||||
```
|
||||
|
||||
You can get a Serper API key from [Serper.dev](https://serper.dev/).
|
||||
|
||||
## Step 8: Install Dependencies
|
||||
|
||||
Install the required dependencies using the CrewAI CLI:
|
||||
|
||||
```bash
|
||||
crewai install
|
||||
```
|
||||
|
||||
This command will:
|
||||
1. Read the dependencies from your project configuration
|
||||
2. Create a virtual environment if needed
|
||||
3. Install all required packages
|
||||
|
||||
## Step 9: Run Your Crew
|
||||
|
||||
Now for the exciting moment - it's time to run your crew and see AI collaboration in action!
|
||||
|
||||
```bash
|
||||
crewai run
|
||||
```
|
||||
|
||||
When you run this command, you'll see your crew spring to life. The researcher will gather information about the specified topic, and the analyst will then create a comprehensive report based on that research. You'll see the agents' thought processes, actions, and outputs in real-time as they work together to complete their tasks.
|
||||
|
||||
## Step 10: Review the Output
|
||||
|
||||
Once the crew completes its work, you'll find the final report in the `output/report.md` file. The report will include:
|
||||
|
||||
1. An executive summary
|
||||
2. Detailed information about the topic
|
||||
3. Analysis and insights
|
||||
4. Recommendations or future considerations
|
||||
|
||||
Take a moment to appreciate what you've accomplished - you've created a system where multiple AI agents collaborated on a complex task, each contributing their specialized skills to produce a result that's greater than what any single agent could achieve alone.
|
||||
|
||||
## Exploring Other CLI Commands
|
||||
|
||||
CrewAI offers several other useful CLI commands for working with crews:
|
||||
|
||||
```bash
|
||||
# View all available commands
|
||||
crewai --help
|
||||
|
||||
# Run the crew
|
||||
crewai run
|
||||
|
||||
# Test the crew
|
||||
crewai test
|
||||
|
||||
# Reset crew memories
|
||||
crewai reset-memories
|
||||
|
||||
# Replay from a specific task
|
||||
crewai replay -t <task_id>
|
||||
```
|
||||
|
||||
## The Art of the Possible: Beyond Your First Crew
|
||||
|
||||
What you've built in this guide is just the beginning. The skills and patterns you've learned can be applied to create increasingly sophisticated AI systems. Here are some ways you could extend this basic research crew:
|
||||
|
||||
### Expanding Your Crew
|
||||
|
||||
You could add more specialized agents to your crew:
|
||||
- A **fact-checker** to verify research findings
|
||||
- A **data visualizer** to create charts and graphs
|
||||
- A **domain expert** with specialized knowledge in a particular area
|
||||
- A **critic** to identify weaknesses in the analysis
|
||||
|
||||
### Adding Tools and Capabilities
|
||||
|
||||
You could enhance your agents with additional tools:
|
||||
- Web browsing tools for real-time research
|
||||
- CSV/database tools for data analysis
|
||||
- Code execution tools for data processing
|
||||
- API connections to external services
|
||||
|
||||
### Creating More Complex Workflows
|
||||
|
||||
You could implement more sophisticated processes:
|
||||
- Hierarchical processes where manager agents delegate to worker agents
|
||||
- Iterative processes with feedback loops for refinement
|
||||
- Parallel processes where multiple agents work simultaneously
|
||||
- Dynamic processes that adapt based on intermediate results
|
||||
|
||||
### Applying to Different Domains
|
||||
|
||||
The same patterns can be applied to create crews for:
|
||||
- **Content creation**: Writers, editors, fact-checkers, and designers working together
|
||||
- **Customer service**: Triage agents, specialists, and quality control working together
|
||||
- **Product development**: Researchers, designers, and planners collaborating
|
||||
- **Data analysis**: Data collectors, analysts, and visualization specialists
|
||||
|
||||
## Next Steps
|
||||
|
||||
Now that you've built your first crew, you can:
|
||||
|
||||
1. Experiment with different agent configurations and personalities
|
||||
2. Try more complex task structures and workflows
|
||||
3. Implement custom tools to give your agents new capabilities
|
||||
4. Apply your crew to different topics or problem domains
|
||||
5. Explore [CrewAI Flows](/guides/flows/first-flow) for more advanced workflows with procedural programming
|
||||
|
||||
<Check>
|
||||
Congratulations! You've successfully built your first CrewAI crew that can research and analyze any topic you provide. This foundational experience has equipped you with the skills to create increasingly sophisticated AI systems that can tackle complex, multi-stage problems through collaborative intelligence.
|
||||
</Check>
|
||||
613
docs/guides/flows/first-flow.mdx
Normal file
@@ -0,0 +1,613 @@
|
||||
---
|
||||
title: Build Your First Flow
|
||||
description: Learn how to create structured, event-driven workflows with precise control over execution.
|
||||
icon: diagram-project
|
||||
---
|
||||
|
||||
# Build Your First Flow
|
||||
|
||||
## Taking Control of AI Workflows with Flows
|
||||
|
||||
CrewAI Flows represent the next level in AI orchestration - combining the collaborative power of AI agent crews with the precision and flexibility of procedural programming. While crews excel at agent collaboration, flows give you fine-grained control over exactly how and when different components of your AI system interact.
|
||||
|
||||
In this guide, we'll walk through creating a powerful CrewAI Flow that generates a comprehensive learning guide on any topic. This tutorial will demonstrate how Flows provide structured, event-driven control over your AI workflows by combining regular code, direct LLM calls, and crew-based processing.
|
||||
|
||||
### What Makes Flows Powerful
|
||||
|
||||
Flows enable you to:
|
||||
|
||||
1. **Combine different AI interaction patterns** - Use crews for complex collaborative tasks, direct LLM calls for simpler operations, and regular code for procedural logic
|
||||
2. **Build event-driven systems** - Define how components respond to specific events and data changes
|
||||
3. **Maintain state across components** - Share and transform data between different parts of your application
|
||||
4. **Integrate with external systems** - Seamlessly connect your AI workflow with databases, APIs, and user interfaces
|
||||
5. **Create complex execution paths** - Design conditional branches, parallel processing, and dynamic workflows
|
||||
|
||||
### What You'll Build and Learn
|
||||
|
||||
By the end of this guide, you'll have:
|
||||
|
||||
1. **Created a sophisticated content generation system** that combines user input, AI planning, and multi-agent content creation
|
||||
2. **Orchestrated the flow of information** between different components of your system
|
||||
3. **Implemented event-driven architecture** where each step responds to the completion of previous steps
|
||||
4. **Built a foundation for more complex AI applications** that you can expand and customize
|
||||
|
||||
This guide creator flow demonstrates fundamental patterns that can be applied to create much more advanced applications, such as:
|
||||
|
||||
- Interactive AI assistants that combine multiple specialized subsystems
|
||||
- Complex data processing pipelines with AI-enhanced transformations
|
||||
- Autonomous agents that integrate with external services and APIs
|
||||
- Multi-stage decision-making systems with human-in-the-loop processes
|
||||
|
||||
Let's dive in and build your first flow!
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before starting, make sure you have:
|
||||
|
||||
1. Installed CrewAI following the [installation guide](/installation)
|
||||
2. Set up your OpenAI API key in your environment variables
|
||||
3. Basic understanding of Python
|
||||
|
||||
## Step 1: Create a New CrewAI Flow Project
|
||||
|
||||
First, let's create a new CrewAI Flow project using the CLI. This command sets up a scaffolded project with all the necessary directories and template files for your flow.
|
||||
|
||||
```bash
|
||||
crewai create flow guide_creator_flow
|
||||
cd guide_creator_flow
|
||||
```
|
||||
|
||||
This will generate a project with the basic structure needed for your flow.
|
||||
|
||||
<Frame caption="CrewAI Framework Overview">
|
||||
<img src="../../flows.png" alt="CrewAI Framework Overview" />
|
||||
</Frame>
|
||||
|
||||
## Step 2: Understanding the Project Structure
|
||||
|
||||
The generated project has the following structure. Take a moment to familiarize yourself with it, as understanding this structure will help you create more complex flows in the future.
|
||||
|
||||
```
|
||||
guide_creator_flow/
|
||||
├── .gitignore
|
||||
├── pyproject.toml
|
||||
├── README.md
|
||||
├── .env
|
||||
├── main.py
|
||||
├── crews/
|
||||
│ └── poem_crew/
|
||||
│ ├── config/
|
||||
│ │ ├── agents.yaml
|
||||
│ │ └── tasks.yaml
|
||||
│ └── poem_crew.py
|
||||
└── tools/
|
||||
└── custom_tool.py
|
||||
```
|
||||
|
||||
This structure provides a clear separation between different components of your flow:
|
||||
- The main flow logic in the `main.py` file
|
||||
- Specialized crews in the `crews` directory
|
||||
- Custom tools in the `tools` directory
|
||||
|
||||
We'll modify this structure to create our guide creator flow, which will orchestrate the process of generating comprehensive learning guides.
|
||||
|
||||
## Step 3: Add a Content Writer Crew
|
||||
|
||||
Our flow will need a specialized crew to handle the content creation process. Let's use the CrewAI CLI to add a content writer crew:
|
||||
|
||||
```bash
|
||||
crewai flow add-crew content-crew
|
||||
```
|
||||
|
||||
This command automatically creates the necessary directories and template files for your crew. The content writer crew will be responsible for writing and reviewing sections of our guide, working within the overall flow orchestrated by our main application.
|
||||
|
||||
## Step 4: Configure the Content Writer Crew
|
||||
|
||||
Now, let's modify the generated files for the content writer crew. We'll set up two specialized agents - a writer and a reviewer - that will collaborate to create high-quality content for our guide.
|
||||
|
||||
1. First, update the agents configuration file to define our content creation team:
|
||||
|
||||
```yaml
|
||||
# src/guide_creator_flow/crews/content_crew/config/agents.yaml
|
||||
content_writer:
|
||||
role: >
|
||||
Educational Content Writer
|
||||
goal: >
|
||||
Create engaging, informative content that thoroughly explains the assigned topic
|
||||
and provides valuable insights to the reader
|
||||
backstory: >
|
||||
You are a talented educational writer with expertise in creating clear, engaging
|
||||
content. You have a gift for explaining complex concepts in accessible language
|
||||
and organizing information in a way that helps readers build their understanding.
|
||||
llm: openai/gpt-4o-mini
|
||||
|
||||
content_reviewer:
|
||||
role: >
|
||||
Educational Content Reviewer and Editor
|
||||
goal: >
|
||||
Ensure content is accurate, comprehensive, well-structured, and maintains
|
||||
consistency with previously written sections
|
||||
backstory: >
|
||||
You are a meticulous editor with years of experience reviewing educational
|
||||
content. You have an eye for detail, clarity, and coherence. You excel at
|
||||
improving content while maintaining the original author's voice and ensuring
|
||||
consistent quality across multiple sections.
|
||||
llm: openai/gpt-4o-mini
|
||||
```
|
||||
|
||||
These agent definitions establish the specialized roles and perspectives that will shape how our AI agents approach content creation. Notice how each agent has a distinct purpose and expertise.
|
||||
|
||||
2. Next, update the tasks configuration file to define the specific writing and reviewing tasks:
|
||||
|
||||
```yaml
|
||||
# src/guide_creator_flow/crews/content_crew/config/tasks.yaml
|
||||
write_section_task:
|
||||
description: >
|
||||
Write a comprehensive section on the topic: "{section_title}"
|
||||
|
||||
Section description: {section_description}
|
||||
Target audience: {audience_level} level learners
|
||||
|
||||
Your content should:
|
||||
1. Begin with a brief introduction to the section topic
|
||||
2. Explain all key concepts clearly with examples
|
||||
3. Include practical applications or exercises where appropriate
|
||||
4. End with a summary of key points
|
||||
5. Be approximately 500-800 words in length
|
||||
|
||||
Format your content in Markdown with appropriate headings, lists, and emphasis.
|
||||
|
||||
Previously written sections:
|
||||
{previous_sections}
|
||||
|
||||
Make sure your content maintains consistency with previously written sections
|
||||
and builds upon concepts that have already been explained.
|
||||
expected_output: >
|
||||
A well-structured, comprehensive section in Markdown format that thoroughly
|
||||
explains the topic and is appropriate for the target audience.
|
||||
agent: content_writer
|
||||
|
||||
review_section_task:
|
||||
description: >
|
||||
Review and improve the following section on "{section_title}":
|
||||
|
||||
{draft_content}
|
||||
|
||||
Target audience: {audience_level} level learners
|
||||
|
||||
Previously written sections:
|
||||
{previous_sections}
|
||||
|
||||
Your review should:
|
||||
1. Fix any grammatical or spelling errors
|
||||
2. Improve clarity and readability
|
||||
3. Ensure content is comprehensive and accurate
|
||||
4. Verify consistency with previously written sections
|
||||
5. Enhance the structure and flow
|
||||
6. Add any missing key information
|
||||
|
||||
Provide the improved version of the section in Markdown format.
|
||||
expected_output: >
|
||||
An improved, polished version of the section that maintains the original
|
||||
structure but enhances clarity, accuracy, and consistency.
|
||||
agent: content_reviewer
|
||||
context:
|
||||
- write_section_task
|
||||
```
|
||||
|
||||
These task definitions provide detailed instructions to our agents, ensuring they produce content that meets our quality standards. Note how the `context` parameter in the review task creates a workflow where the reviewer has access to the writer's output.
|
||||
|
||||
3. Now, update the crew implementation file to define how our agents and tasks work together:
|
||||
|
||||
```python
|
||||
# src/guide_creator_flow/crews/content_crew/content_crew.py
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai.project import CrewBase, agent, crew, task
|
||||
from crewai.agents.agent_builder.base_agent import BaseAgent
|
||||
from typing import List
|
||||
|
||||
@CrewBase
|
||||
class ContentCrew():
|
||||
"""Content writing crew"""
|
||||
|
||||
agents: List[BaseAgent]
|
||||
tasks: List[Task]
|
||||
|
||||
@agent
|
||||
def content_writer(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['content_writer'], # type: ignore[index]
|
||||
verbose=True
|
||||
)
|
||||
|
||||
@agent
|
||||
def content_reviewer(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['content_reviewer'], # type: ignore[index]
|
||||
verbose=True
|
||||
)
|
||||
|
||||
@task
|
||||
def write_section_task(self) -> Task:
|
||||
return Task(
|
||||
config=self.tasks_config['write_section_task'] # type: ignore[index]
|
||||
)
|
||||
|
||||
@task
|
||||
def review_section_task(self) -> Task:
|
||||
return Task(
|
||||
config=self.tasks_config['review_section_task'], # type: ignore[index]
|
||||
context=[self.write_section_task()]
|
||||
)
|
||||
|
||||
@crew
|
||||
def crew(self) -> Crew:
|
||||
"""Creates the content writing crew"""
|
||||
return Crew(
|
||||
agents=self.agents,
|
||||
tasks=self.tasks,
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
)
|
||||
```
|
||||
|
||||
This crew definition establishes the relationship between our agents and tasks, setting up a sequential process where the content writer creates a draft and then the reviewer improves it. While this crew can function independently, in our flow it will be orchestrated as part of a larger system.
|
||||
|
||||
## Step 5: Create the Flow
|
||||
|
||||
Now comes the exciting part - creating the flow that will orchestrate the entire guide creation process. This is where we'll combine regular Python code, direct LLM calls, and our content creation crew into a cohesive system.
|
||||
|
||||
Our flow will:
|
||||
1. Get user input for a topic and audience level
|
||||
2. Make a direct LLM call to create a structured guide outline
|
||||
3. Process each section sequentially using the content writer crew
|
||||
4. Combine everything into a final comprehensive document
|
||||
|
||||
Let's create our flow in the `main.py` file:
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python
|
||||
import json
|
||||
import os
|
||||
from typing import List, Dict
|
||||
from pydantic import BaseModel, Field
|
||||
from crewai import LLM
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
from guide_creator_flow.crews.content_crew.content_crew import ContentCrew
|
||||
|
||||
# Define our models for structured data
|
||||
class Section(BaseModel):
|
||||
title: str = Field(description="Title of the section")
|
||||
description: str = Field(description="Brief description of what the section should cover")
|
||||
|
||||
class GuideOutline(BaseModel):
|
||||
title: str = Field(description="Title of the guide")
|
||||
introduction: str = Field(description="Introduction to the topic")
|
||||
target_audience: str = Field(description="Description of the target audience")
|
||||
sections: List[Section] = Field(description="List of sections in the guide")
|
||||
conclusion: str = Field(description="Conclusion or summary of the guide")
|
||||
|
||||
# Define our flow state
|
||||
class GuideCreatorState(BaseModel):
|
||||
topic: str = ""
|
||||
audience_level: str = ""
|
||||
guide_outline: GuideOutline = None
|
||||
sections_content: Dict[str, str] = {}
|
||||
|
||||
class GuideCreatorFlow(Flow[GuideCreatorState]):
|
||||
"""Flow for creating a comprehensive guide on any topic"""
|
||||
|
||||
@start()
|
||||
def get_user_input(self):
|
||||
"""Get input from the user about the guide topic and audience"""
|
||||
print("\n=== Create Your Comprehensive Guide ===\n")
|
||||
|
||||
# Get user input
|
||||
self.state.topic = input("What topic would you like to create a guide for? ")
|
||||
|
||||
# Get audience level with validation
|
||||
while True:
|
||||
audience = input("Who is your target audience? (beginner/intermediate/advanced) ").lower()
|
||||
if audience in ["beginner", "intermediate", "advanced"]:
|
||||
self.state.audience_level = audience
|
||||
break
|
||||
print("Please enter 'beginner', 'intermediate', or 'advanced'")
|
||||
|
||||
print(f"\nCreating a guide on {self.state.topic} for {self.state.audience_level} audience...\n")
|
||||
return self.state
|
||||
|
||||
@listen(get_user_input)
|
||||
def create_guide_outline(self, state):
|
||||
"""Create a structured outline for the guide using a direct LLM call"""
|
||||
print("Creating guide outline...")
|
||||
|
||||
# Initialize the LLM
|
||||
llm = LLM(model="openai/gpt-4o-mini", response_format=GuideOutline)
|
||||
|
||||
# Create the messages for the outline
|
||||
messages = [
|
||||
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
|
||||
{"role": "user", "content": f"""
|
||||
Create a detailed outline for a comprehensive guide on "{state.topic}" for {state.audience_level} level learners.
|
||||
|
||||
The outline should include:
|
||||
1. A compelling title for the guide
|
||||
2. An introduction to the topic
|
||||
3. 4-6 main sections that cover the most important aspects of the topic
|
||||
4. A conclusion or summary
|
||||
|
||||
For each section, provide a clear title and a brief description of what it should cover.
|
||||
"""}
|
||||
]
|
||||
|
||||
# Make the LLM call with JSON response format
|
||||
response = llm.call(messages=messages)
|
||||
|
||||
# Parse the JSON response
|
||||
outline_dict = json.loads(response)
|
||||
self.state.guide_outline = GuideOutline(**outline_dict)
|
||||
|
||||
# Ensure output directory exists before saving
|
||||
os.makedirs("output", exist_ok=True)
|
||||
|
||||
# Save the outline to a file
|
||||
with open("output/guide_outline.json", "w") as f:
|
||||
json.dump(outline_dict, f, indent=2)
|
||||
|
||||
print(f"Guide outline created with {len(self.state.guide_outline.sections)} sections")
|
||||
return self.state.guide_outline
|
||||
|
||||
@listen(create_guide_outline)
|
||||
def write_and_compile_guide(self, outline):
|
||||
"""Write all sections and compile the guide"""
|
||||
print("Writing guide sections and compiling...")
|
||||
completed_sections = []
|
||||
|
||||
# Process sections one by one to maintain context flow
|
||||
for section in outline.sections:
|
||||
print(f"Processing section: {section.title}")
|
||||
|
||||
# Build context from previous sections
|
||||
previous_sections_text = ""
|
||||
if completed_sections:
|
||||
previous_sections_text = "# Previously Written Sections\n\n"
|
||||
for title in completed_sections:
|
||||
previous_sections_text += f"## {title}\n\n"
|
||||
previous_sections_text += self.state.sections_content.get(title, "") + "\n\n"
|
||||
else:
|
||||
previous_sections_text = "No previous sections written yet."
|
||||
|
||||
# Run the content crew for this section
|
||||
result = ContentCrew().crew().kickoff(inputs={
|
||||
"section_title": section.title,
|
||||
"section_description": section.description,
|
||||
"audience_level": self.state.audience_level,
|
||||
"previous_sections": previous_sections_text,
|
||||
"draft_content": ""
|
||||
})
|
||||
|
||||
# Store the content
|
||||
self.state.sections_content[section.title] = result.raw
|
||||
completed_sections.append(section.title)
|
||||
print(f"Section completed: {section.title}")
|
||||
|
||||
# Compile the final guide
|
||||
guide_content = f"# {outline.title}\n\n"
|
||||
guide_content += f"## Introduction\n\n{outline.introduction}\n\n"
|
||||
|
||||
# Add each section in order
|
||||
for section in outline.sections:
|
||||
section_content = self.state.sections_content.get(section.title, "")
|
||||
guide_content += f"\n\n{section_content}\n\n"
|
||||
|
||||
# Add conclusion
|
||||
guide_content += f"## Conclusion\n\n{outline.conclusion}\n\n"
|
||||
|
||||
# Save the guide
|
||||
with open("output/complete_guide.md", "w") as f:
|
||||
f.write(guide_content)
|
||||
|
||||
print("\nComplete guide compiled and saved to output/complete_guide.md")
|
||||
return "Guide creation completed successfully"
|
||||
|
||||
def kickoff():
|
||||
"""Run the guide creator flow"""
|
||||
GuideCreatorFlow().kickoff()
|
||||
print("\n=== Flow Complete ===")
|
||||
print("Your comprehensive guide is ready in the output directory.")
|
||||
print("Open output/complete_guide.md to view it.")
|
||||
|
||||
def plot():
|
||||
"""Generate a visualization of the flow"""
|
||||
flow = GuideCreatorFlow()
|
||||
flow.plot("guide_creator_flow")
|
||||
print("Flow visualization saved to guide_creator_flow.html")
|
||||
|
||||
if __name__ == "__main__":
|
||||
kickoff()
|
||||
```
|
||||
|
||||
Let's analyze what's happening in this flow:
|
||||
|
||||
1. We define Pydantic models for structured data, ensuring type safety and clear data representation
|
||||
2. We create a state class to maintain data across different steps of the flow
|
||||
3. We implement three main flow steps:
|
||||
- Getting user input with the `@start()` decorator
|
||||
- Creating a guide outline with a direct LLM call
|
||||
- Processing sections with our content crew
|
||||
4. We use the `@listen()` decorator to establish event-driven relationships between steps
|
||||
|
||||
This is the power of flows - combining different types of processing (user interaction, direct LLM calls, crew-based tasks) into a coherent, event-driven system.
|
||||
|
||||
## Step 6: Set Up Your Environment Variables
|
||||
|
||||
Create a `.env` file in your project root with your API keys:
|
||||
|
||||
```
|
||||
OPENAI_API_KEY=your_openai_api_key
|
||||
```
|
||||
|
||||
## Step 7: Install Dependencies
|
||||
|
||||
Install the required dependencies:
|
||||
|
||||
```bash
|
||||
crewai install
|
||||
```
|
||||
|
||||
## Step 8: Run Your Flow
|
||||
|
||||
Now it's time to see your flow in action! Run it using the CrewAI CLI:
|
||||
|
||||
```bash
|
||||
crewai flow kickoff
|
||||
```
|
||||
|
||||
When you run this command, you'll see your flow spring to life:
|
||||
1. It will prompt you for a topic and audience level
|
||||
2. It will create a structured outline for your guide
|
||||
3. It will process each section, with the content writer and reviewer collaborating on each
|
||||
4. Finally, it will compile everything into a comprehensive guide
|
||||
|
||||
This demonstrates the power of flows to orchestrate complex processes involving multiple components, both AI and non-AI.
|
||||
|
||||
## Step 9: Visualize Your Flow
|
||||
|
||||
One of the powerful features of flows is the ability to visualize their structure:
|
||||
|
||||
```bash
|
||||
crewai flow plot
|
||||
```
|
||||
|
||||
This will create an HTML file that shows the structure of your flow, including the relationships between different steps and the data that flows between them. This visualization can be invaluable for understanding and debugging complex flows.
|
||||
|
||||
## Step 10: Review the Output
|
||||
|
||||
Once the flow completes, you'll find two files in the `output` directory:
|
||||
|
||||
1. `guide_outline.json`: Contains the structured outline of the guide
|
||||
2. `complete_guide.md`: The comprehensive guide with all sections
|
||||
|
||||
Take a moment to review these files and appreciate what you've built - a system that combines user input, direct AI interactions, and collaborative agent work to produce a complex, high-quality output.
|
||||
|
||||
## The Art of the Possible: Beyond Your First Flow
|
||||
|
||||
What you've learned in this guide provides a foundation for creating much more sophisticated AI systems. Here are some ways you could extend this basic flow:
|
||||
|
||||
### Enhancing User Interaction
|
||||
|
||||
You could create more interactive flows with:
|
||||
- Web interfaces for input and output
|
||||
- Real-time progress updates
|
||||
- Interactive feedback and refinement loops
|
||||
- Multi-stage user interactions
|
||||
|
||||
### Adding More Processing Steps
|
||||
|
||||
You could expand your flow with additional steps for:
|
||||
- Research before outline creation
|
||||
- Image generation for illustrations
|
||||
- Code snippet generation for technical guides
|
||||
- Final quality assurance and fact-checking
|
||||
|
||||
### Creating More Complex Flows
|
||||
|
||||
You could implement more sophisticated flow patterns:
|
||||
- Conditional branching based on user preferences or content type
|
||||
- Parallel processing of independent sections
|
||||
- Iterative refinement loops with feedback
|
||||
- Integration with external APIs and services
|
||||
|
||||
### Applying to Different Domains
|
||||
|
||||
The same patterns can be applied to create flows for:
|
||||
- **Interactive storytelling**: Create personalized stories based on user input
|
||||
- **Business intelligence**: Process data, generate insights, and create reports
|
||||
- **Product development**: Facilitate ideation, design, and planning
|
||||
- **Educational systems**: Create personalized learning experiences
|
||||
|
||||
## Key Features Demonstrated
|
||||
|
||||
This guide creator flow demonstrates several powerful features of CrewAI:
|
||||
|
||||
1. **User interaction**: The flow collects input directly from the user
|
||||
2. **Direct LLM calls**: Uses the LLM class for efficient, single-purpose AI interactions
|
||||
3. **Structured data with Pydantic**: Uses Pydantic models to ensure type safety
|
||||
4. **Sequential processing with context**: Writes sections in order, providing previous sections for context
|
||||
5. **Multi-agent crews**: Leverages specialized agents (writer and reviewer) for content creation
|
||||
6. **State management**: Maintains state across different steps of the process
|
||||
7. **Event-driven architecture**: Uses the `@listen` decorator to respond to events
|
||||
|
||||
## Understanding the Flow Structure
|
||||
|
||||
Let's break down the key components of flows to help you understand how to build your own:
|
||||
|
||||
### 1. Direct LLM Calls
|
||||
|
||||
Flows allow you to make direct calls to language models when you need simple, structured responses:
|
||||
|
||||
```python
|
||||
llm = LLM(model="openai/gpt-4o-mini", response_format=GuideOutline)
|
||||
response = llm.call(messages=messages)
|
||||
```
|
||||
|
||||
This is more efficient than using a crew when you need a specific, structured output.
|
||||
|
||||
### 2. Event-Driven Architecture
|
||||
|
||||
Flows use decorators to establish relationships between components:
|
||||
|
||||
```python
|
||||
@start()
|
||||
def get_user_input(self):
|
||||
# First step in the flow
|
||||
# ...
|
||||
|
||||
@listen(get_user_input)
|
||||
def create_guide_outline(self, state):
|
||||
# This runs when get_user_input completes
|
||||
# ...
|
||||
```
|
||||
|
||||
This creates a clear, declarative structure for your application.
|
||||
|
||||
### 3. State Management
|
||||
|
||||
Flows maintain state across steps, making it easy to share data:
|
||||
|
||||
```python
|
||||
class GuideCreatorState(BaseModel):
|
||||
topic: str = ""
|
||||
audience_level: str = ""
|
||||
guide_outline: GuideOutline = None
|
||||
sections_content: Dict[str, str] = {}
|
||||
```
|
||||
|
||||
This provides a type-safe way to track and transform data throughout your flow.
|
||||
|
||||
### 4. Crew Integration
|
||||
|
||||
Flows can seamlessly integrate with crews for complex collaborative tasks:
|
||||
|
||||
```python
|
||||
result = ContentCrew().crew().kickoff(inputs={
|
||||
"section_title": section.title,
|
||||
# ...
|
||||
})
|
||||
```
|
||||
|
||||
This allows you to use the right tool for each part of your application - direct LLM calls for simple tasks and crews for complex collaboration.
|
||||
|
||||
## Next Steps
|
||||
|
||||
Now that you've built your first flow, you can:
|
||||
|
||||
1. Experiment with more complex flow structures and patterns
|
||||
2. Try using `@router()` to create conditional branches in your flows
|
||||
3. Explore the `and_` and `or_` functions for more complex parallel execution
|
||||
4. Connect your flow to external APIs, databases, or user interfaces
|
||||
5. Combine multiple specialized crews in a single flow
|
||||
|
||||
<Check>
|
||||
Congratulations! You've successfully built your first CrewAI Flow that combines regular code, direct LLM calls, and crew-based processing to create a comprehensive guide. These foundational skills enable you to create increasingly sophisticated AI applications that can tackle complex, multi-stage problems through a combination of procedural control and collaborative intelligence.
|
||||
</Check>
|
||||
771
docs/guides/flows/mastering-flow-state.mdx
Normal file
@@ -0,0 +1,771 @@
|
||||
---
|
||||
title: Mastering Flow State Management
|
||||
description: A comprehensive guide to managing, persisting, and leveraging state in CrewAI Flows for building robust AI applications.
|
||||
icon: diagram-project
|
||||
---
|
||||
|
||||
# Mastering Flow State Management
|
||||
|
||||
## Understanding the Power of State in Flows
|
||||
|
||||
State management is the backbone of any sophisticated AI workflow. In CrewAI Flows, the state system allows you to maintain context, share data between steps, and build complex application logic. Mastering state management is essential for creating reliable, maintainable, and powerful AI applications.
|
||||
|
||||
This guide will walk you through everything you need to know about managing state in CrewAI Flows, from basic concepts to advanced techniques, with practical code examples along the way.
|
||||
|
||||
### Why State Management Matters
|
||||
|
||||
Effective state management enables you to:
|
||||
|
||||
1. **Maintain context across execution steps** - Pass information seamlessly between different stages of your workflow
|
||||
2. **Build complex conditional logic** - Make decisions based on accumulated data
|
||||
3. **Create persistent applications** - Save and restore workflow progress
|
||||
4. **Handle errors gracefully** - Implement recovery patterns for more robust applications
|
||||
5. **Scale your applications** - Support complex workflows with proper data organization
|
||||
6. **Enable conversational applications** - Store and access conversation history for context-aware AI interactions
|
||||
|
||||
Let's explore how to leverage these capabilities effectively.
|
||||
|
||||
## State Management Fundamentals
|
||||
|
||||
### The Flow State Lifecycle
|
||||
|
||||
In CrewAI Flows, the state follows a predictable lifecycle:
|
||||
|
||||
1. **Initialization** - When a flow is created, its state is initialized (either as an empty dictionary or a Pydantic model instance)
|
||||
2. **Modification** - Flow methods access and modify the state as they execute
|
||||
3. **Transmission** - State is passed automatically between flow methods
|
||||
4. **Persistence** (optional) - State can be saved to storage and later retrieved
|
||||
5. **Completion** - The final state reflects the cumulative changes from all executed methods
|
||||
|
||||
Understanding this lifecycle is crucial for designing effective flows.
|
||||
|
||||
### Two Approaches to State Management
|
||||
|
||||
CrewAI offers two ways to manage state in your flows:
|
||||
|
||||
1. **Unstructured State** - Using dictionary-like objects for flexibility
|
||||
2. **Structured State** - Using Pydantic models for type safety and validation
|
||||
|
||||
Let's examine each approach in detail.
|
||||
|
||||
## Unstructured State Management
|
||||
|
||||
Unstructured state uses a dictionary-like approach, offering flexibility and simplicity for straightforward applications.
|
||||
|
||||
### How It Works
|
||||
|
||||
With unstructured state:
|
||||
- You access state via `self.state` which behaves like a dictionary
|
||||
- You can freely add, modify, or remove keys at any point
|
||||
- All state is automatically available to all flow methods
|
||||
|
||||
### Basic Example
|
||||
|
||||
Here's a simple example of unstructured state management:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
|
||||
class UnstructuredStateFlow(Flow):
|
||||
@start()
|
||||
def initialize_data(self):
|
||||
print("Initializing flow data")
|
||||
# Add key-value pairs to state
|
||||
self.state["user_name"] = "Alex"
|
||||
self.state["preferences"] = {
|
||||
"theme": "dark",
|
||||
"language": "English"
|
||||
}
|
||||
self.state["items"] = []
|
||||
|
||||
# The flow state automatically gets a unique ID
|
||||
print(f"Flow ID: {self.state['id']}")
|
||||
|
||||
return "Initialized"
|
||||
|
||||
@listen(initialize_data)
|
||||
def process_data(self, previous_result):
|
||||
print(f"Previous step returned: {previous_result}")
|
||||
|
||||
# Access and modify state
|
||||
user = self.state["user_name"]
|
||||
print(f"Processing data for {user}")
|
||||
|
||||
# Add items to a list in state
|
||||
self.state["items"].append("item1")
|
||||
self.state["items"].append("item2")
|
||||
|
||||
# Add a new key-value pair
|
||||
self.state["processed"] = True
|
||||
|
||||
return "Processed"
|
||||
|
||||
@listen(process_data)
|
||||
def generate_summary(self, previous_result):
|
||||
# Access multiple state values
|
||||
user = self.state["user_name"]
|
||||
theme = self.state["preferences"]["theme"]
|
||||
items = self.state["items"]
|
||||
processed = self.state.get("processed", False)
|
||||
|
||||
summary = f"User {user} has {len(items)} items with {theme} theme. "
|
||||
summary += "Data is processed." if processed else "Data is not processed."
|
||||
|
||||
return summary
|
||||
|
||||
# Run the flow
|
||||
flow = UnstructuredStateFlow()
|
||||
result = flow.kickoff()
|
||||
print(f"Final result: {result}")
|
||||
print(f"Final state: {flow.state}")
|
||||
```
|
||||
|
||||
### When to Use Unstructured State
|
||||
|
||||
Unstructured state is ideal for:
|
||||
- Quick prototyping and simple flows
|
||||
- Dynamically evolving state needs
|
||||
- Cases where the structure may not be known in advance
|
||||
- Flows with simple state requirements
|
||||
|
||||
While flexible, unstructured state lacks type checking and schema validation, which can lead to errors in complex applications.
|
||||
|
||||
## Structured State Management
|
||||
|
||||
Structured state uses Pydantic models to define a schema for your flow's state, providing type safety, validation, and better developer experience.
|
||||
|
||||
### How It Works
|
||||
|
||||
With structured state:
|
||||
- You define a Pydantic model that represents your state structure
|
||||
- You pass this model type to your Flow class as a type parameter
|
||||
- You access state via `self.state`, which behaves like a Pydantic model instance
|
||||
- All fields are validated according to their defined types
|
||||
- You get IDE autocompletion and type checking support
|
||||
|
||||
### Basic Example
|
||||
|
||||
Here's how to implement structured state management:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
from pydantic import BaseModel, Field
|
||||
from typing import List, Dict, Optional
|
||||
|
||||
# Define your state model
|
||||
class UserPreferences(BaseModel):
|
||||
theme: str = "light"
|
||||
language: str = "English"
|
||||
|
||||
class AppState(BaseModel):
|
||||
user_name: str = ""
|
||||
preferences: UserPreferences = UserPreferences()
|
||||
items: List[str] = []
|
||||
processed: bool = False
|
||||
completion_percentage: float = 0.0
|
||||
|
||||
# Create a flow with typed state
|
||||
class StructuredStateFlow(Flow[AppState]):
|
||||
@start()
|
||||
def initialize_data(self):
|
||||
print("Initializing flow data")
|
||||
# Set state values (type-checked)
|
||||
self.state.user_name = "Taylor"
|
||||
self.state.preferences.theme = "dark"
|
||||
|
||||
# The ID field is automatically available
|
||||
print(f"Flow ID: {self.state.id}")
|
||||
|
||||
return "Initialized"
|
||||
|
||||
@listen(initialize_data)
|
||||
def process_data(self, previous_result):
|
||||
print(f"Processing data for {self.state.user_name}")
|
||||
|
||||
# Modify state (with type checking)
|
||||
self.state.items.append("item1")
|
||||
self.state.items.append("item2")
|
||||
self.state.processed = True
|
||||
self.state.completion_percentage = 50.0
|
||||
|
||||
return "Processed"
|
||||
|
||||
@listen(process_data)
|
||||
def generate_summary(self, previous_result):
|
||||
# Access state (with autocompletion)
|
||||
summary = f"User {self.state.user_name} has {len(self.state.items)} items "
|
||||
summary += f"with {self.state.preferences.theme} theme. "
|
||||
summary += "Data is processed." if self.state.processed else "Data is not processed."
|
||||
summary += f" Completion: {self.state.completion_percentage}%"
|
||||
|
||||
return summary
|
||||
|
||||
# Run the flow
|
||||
flow = StructuredStateFlow()
|
||||
result = flow.kickoff()
|
||||
print(f"Final result: {result}")
|
||||
print(f"Final state: {flow.state}")
|
||||
```
|
||||
|
||||
### Benefits of Structured State
|
||||
|
||||
Using structured state provides several advantages:
|
||||
|
||||
1. **Type Safety** - Catch type errors at development time
|
||||
2. **Self-Documentation** - The state model clearly documents what data is available
|
||||
3. **Validation** - Automatic validation of data types and constraints
|
||||
4. **IDE Support** - Get autocomplete and inline documentation
|
||||
5. **Default Values** - Easily define fallbacks for missing data
|
||||
|
||||
### When to Use Structured State
|
||||
|
||||
Structured state is recommended for:
|
||||
- Complex flows with well-defined data schemas
|
||||
- Team projects where multiple developers work on the same code
|
||||
- Applications where data validation is important
|
||||
- Flows that need to enforce specific data types and constraints
|
||||
|
||||
## The Automatic State ID
|
||||
|
||||
Both unstructured and structured states automatically receive a unique identifier (UUID) to help track and manage state instances.
|
||||
|
||||
### How It Works
|
||||
|
||||
- For unstructured state, the ID is accessible as `self.state["id"]`
|
||||
- For structured state, the ID is accessible as `self.state.id`
|
||||
- This ID is generated automatically when the flow is created
|
||||
- The ID remains the same throughout the flow's lifecycle
|
||||
- The ID can be used for tracking, logging, and retrieving persisted states
|
||||
|
||||
This UUID is particularly valuable when implementing persistence or tracking multiple flow executions.
|
||||
|
||||
## Dynamic State Updates
|
||||
|
||||
Regardless of whether you're using structured or unstructured state, you can update state dynamically throughout your flow's execution.
|
||||
|
||||
### Passing Data Between Steps
|
||||
|
||||
Flow methods can return values that are then passed as arguments to listening methods:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
|
||||
class DataPassingFlow(Flow):
|
||||
@start()
|
||||
def generate_data(self):
|
||||
# This return value will be passed to listening methods
|
||||
return "Generated data"
|
||||
|
||||
@listen(generate_data)
|
||||
def process_data(self, data_from_previous_step):
|
||||
print(f"Received: {data_from_previous_step}")
|
||||
# You can modify the data and pass it along
|
||||
processed_data = f"{data_from_previous_step} - processed"
|
||||
# Also update state
|
||||
self.state["last_processed"] = processed_data
|
||||
return processed_data
|
||||
|
||||
@listen(process_data)
|
||||
def finalize_data(self, processed_data):
|
||||
print(f"Received processed data: {processed_data}")
|
||||
# Access both the passed data and state
|
||||
last_processed = self.state.get("last_processed", "")
|
||||
return f"Final: {processed_data} (from state: {last_processed})"
|
||||
```
|
||||
|
||||
This pattern allows you to combine direct data passing with state updates for maximum flexibility.
|
||||
|
||||
## Persisting Flow State
|
||||
|
||||
One of CrewAI's most powerful features is the ability to persist flow state across executions. This enables workflows that can be paused, resumed, and even recovered after failures.
|
||||
|
||||
### The @persist Decorator
|
||||
|
||||
The `@persist` decorator automates state persistence, saving your flow's state at key points in execution.
|
||||
|
||||
#### Class-Level Persistence
|
||||
|
||||
When applied at the class level, `@persist` saves state after every method execution:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, persist, start
|
||||
from pydantic import BaseModel
|
||||
|
||||
class CounterState(BaseModel):
|
||||
value: int = 0
|
||||
|
||||
@persist # Apply to the entire flow class
|
||||
class PersistentCounterFlow(Flow[CounterState]):
|
||||
@start()
|
||||
def increment(self):
|
||||
self.state.value += 1
|
||||
print(f"Incremented to {self.state.value}")
|
||||
return self.state.value
|
||||
|
||||
@listen(increment)
|
||||
def double(self, value):
|
||||
self.state.value = value * 2
|
||||
print(f"Doubled to {self.state.value}")
|
||||
return self.state.value
|
||||
|
||||
# First run
|
||||
flow1 = PersistentCounterFlow()
|
||||
result1 = flow1.kickoff()
|
||||
print(f"First run result: {result1}")
|
||||
|
||||
# Second run - state is automatically loaded
|
||||
flow2 = PersistentCounterFlow()
|
||||
result2 = flow2.kickoff()
|
||||
print(f"Second run result: {result2}") # Will be higher due to persisted state
|
||||
```
|
||||
|
||||
#### Method-Level Persistence
|
||||
|
||||
For more granular control, you can apply `@persist` to specific methods:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, persist, start
|
||||
|
||||
class SelectivePersistFlow(Flow):
|
||||
@start()
|
||||
def first_step(self):
|
||||
self.state["count"] = 1
|
||||
return "First step"
|
||||
|
||||
@persist # Only persist after this method
|
||||
@listen(first_step)
|
||||
def important_step(self, prev_result):
|
||||
self.state["count"] += 1
|
||||
self.state["important_data"] = "This will be persisted"
|
||||
return "Important step completed"
|
||||
|
||||
@listen(important_step)
|
||||
def final_step(self, prev_result):
|
||||
self.state["count"] += 1
|
||||
return f"Complete with count {self.state['count']}"
|
||||
```
|
||||
|
||||
|
||||
## Advanced State Patterns
|
||||
|
||||
### State-Based Conditional Logic
|
||||
|
||||
You can use state to implement complex conditional logic in your flows:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, router, start
|
||||
from pydantic import BaseModel
|
||||
|
||||
class PaymentState(BaseModel):
|
||||
amount: float = 0.0
|
||||
is_approved: bool = False
|
||||
retry_count: int = 0
|
||||
|
||||
class PaymentFlow(Flow[PaymentState]):
|
||||
@start()
|
||||
def process_payment(self):
|
||||
# Simulate payment processing
|
||||
self.state.amount = 100.0
|
||||
self.state.is_approved = self.state.amount < 1000
|
||||
return "Payment processed"
|
||||
|
||||
@router(process_payment)
|
||||
def check_approval(self, previous_result):
|
||||
if self.state.is_approved:
|
||||
return "approved"
|
||||
elif self.state.retry_count < 3:
|
||||
return "retry"
|
||||
else:
|
||||
return "rejected"
|
||||
|
||||
@listen("approved")
|
||||
def handle_approval(self):
|
||||
return f"Payment of ${self.state.amount} approved!"
|
||||
|
||||
@listen("retry")
|
||||
def handle_retry(self):
|
||||
self.state.retry_count += 1
|
||||
print(f"Retrying payment (attempt {self.state.retry_count})...")
|
||||
# Could implement retry logic here
|
||||
return "Retry initiated"
|
||||
|
||||
@listen("rejected")
|
||||
def handle_rejection(self):
|
||||
return f"Payment of ${self.state.amount} rejected after {self.state.retry_count} retries."
|
||||
```
|
||||
|
||||
### Handling Complex State Transformations
|
||||
|
||||
For complex state transformations, you can create dedicated methods:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
from pydantic import BaseModel
|
||||
from typing import List, Dict
|
||||
|
||||
class UserData(BaseModel):
|
||||
name: str
|
||||
active: bool = True
|
||||
login_count: int = 0
|
||||
|
||||
class ComplexState(BaseModel):
|
||||
users: Dict[str, UserData] = {}
|
||||
active_user_count: int = 0
|
||||
|
||||
class TransformationFlow(Flow[ComplexState]):
|
||||
@start()
|
||||
def initialize(self):
|
||||
# Add some users
|
||||
self.add_user("alice", "Alice")
|
||||
self.add_user("bob", "Bob")
|
||||
self.add_user("charlie", "Charlie")
|
||||
return "Initialized"
|
||||
|
||||
@listen(initialize)
|
||||
def process_users(self, _):
|
||||
# Increment login counts
|
||||
for user_id in self.state.users:
|
||||
self.increment_login(user_id)
|
||||
|
||||
# Deactivate one user
|
||||
self.deactivate_user("bob")
|
||||
|
||||
# Update active count
|
||||
self.update_active_count()
|
||||
|
||||
return f"Processed {len(self.state.users)} users"
|
||||
|
||||
# Helper methods for state transformations
|
||||
def add_user(self, user_id: str, name: str):
|
||||
self.state.users[user_id] = UserData(name=name)
|
||||
self.update_active_count()
|
||||
|
||||
def increment_login(self, user_id: str):
|
||||
if user_id in self.state.users:
|
||||
self.state.users[user_id].login_count += 1
|
||||
|
||||
def deactivate_user(self, user_id: str):
|
||||
if user_id in self.state.users:
|
||||
self.state.users[user_id].active = False
|
||||
self.update_active_count()
|
||||
|
||||
def update_active_count(self):
|
||||
self.state.active_user_count = sum(
|
||||
1 for user in self.state.users.values() if user.active
|
||||
)
|
||||
```
|
||||
|
||||
This pattern of creating helper methods keeps your flow methods clean while enabling complex state manipulations.
|
||||
|
||||
## State Management with Crews
|
||||
|
||||
One of the most powerful patterns in CrewAI is combining flow state management with crew execution.
|
||||
|
||||
### Passing State to Crews
|
||||
|
||||
You can use flow state to parameterize crews:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from pydantic import BaseModel
|
||||
|
||||
class ResearchState(BaseModel):
|
||||
topic: str = ""
|
||||
depth: str = "medium"
|
||||
results: str = ""
|
||||
|
||||
class ResearchFlow(Flow[ResearchState]):
|
||||
@start()
|
||||
def get_parameters(self):
|
||||
# In a real app, this might come from user input
|
||||
self.state.topic = "Artificial Intelligence Ethics"
|
||||
self.state.depth = "deep"
|
||||
return "Parameters set"
|
||||
|
||||
@listen(get_parameters)
|
||||
def execute_research(self, _):
|
||||
# Create agents
|
||||
researcher = Agent(
|
||||
role="Research Specialist",
|
||||
goal=f"Research {self.state.topic} in {self.state.depth} detail",
|
||||
backstory="You are an expert researcher with a talent for finding accurate information."
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role="Content Writer",
|
||||
goal="Transform research into clear, engaging content",
|
||||
backstory="You excel at communicating complex ideas clearly and concisely."
|
||||
)
|
||||
|
||||
# Create tasks
|
||||
research_task = Task(
|
||||
description=f"Research {self.state.topic} with {self.state.depth} analysis",
|
||||
expected_output="Comprehensive research notes in markdown format",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description=f"Create a summary on {self.state.topic} based on the research",
|
||||
expected_output="Well-written article in markdown format",
|
||||
agent=writer,
|
||||
context=[research_task]
|
||||
)
|
||||
|
||||
# Create and run crew
|
||||
research_crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
process=Process.sequential,
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Run crew and store result in state
|
||||
result = research_crew.kickoff()
|
||||
self.state.results = result.raw
|
||||
|
||||
return "Research completed"
|
||||
|
||||
@listen(execute_research)
|
||||
def summarize_results(self, _):
|
||||
# Access the stored results
|
||||
result_length = len(self.state.results)
|
||||
return f"Research on {self.state.topic} completed with {result_length} characters of results."
|
||||
```
|
||||
|
||||
### Handling Crew Outputs in State
|
||||
|
||||
When a crew completes, you can process its output and store it in your flow state:
|
||||
|
||||
```python
|
||||
@listen(execute_crew)
|
||||
def process_crew_results(self, _):
|
||||
# Parse the raw results (assuming JSON output)
|
||||
import json
|
||||
try:
|
||||
results_dict = json.loads(self.state.raw_results)
|
||||
self.state.processed_results = {
|
||||
"title": results_dict.get("title", ""),
|
||||
"main_points": results_dict.get("main_points", []),
|
||||
"conclusion": results_dict.get("conclusion", "")
|
||||
}
|
||||
return "Results processed successfully"
|
||||
except json.JSONDecodeError:
|
||||
self.state.error = "Failed to parse crew results as JSON"
|
||||
return "Error processing results"
|
||||
```
|
||||
|
||||
## Best Practices for State Management
|
||||
|
||||
### 1. Keep State Focused
|
||||
|
||||
Design your state to contain only what's necessary:
|
||||
|
||||
```python
|
||||
# Too broad
|
||||
class BloatedState(BaseModel):
|
||||
user_data: Dict = {}
|
||||
system_settings: Dict = {}
|
||||
temporary_calculations: List = []
|
||||
debug_info: Dict = {}
|
||||
# ...many more fields
|
||||
|
||||
# Better: Focused state
|
||||
class FocusedState(BaseModel):
|
||||
user_id: str
|
||||
preferences: Dict[str, str]
|
||||
completion_status: Dict[str, bool]
|
||||
```
|
||||
|
||||
### 2. Use Structured State for Complex Flows
|
||||
|
||||
As your flows grow in complexity, structured state becomes increasingly valuable:
|
||||
|
||||
```python
|
||||
# Simple flow can use unstructured state
|
||||
class SimpleGreetingFlow(Flow):
|
||||
@start()
|
||||
def greet(self):
|
||||
self.state["name"] = "World"
|
||||
return f"Hello, {self.state['name']}!"
|
||||
|
||||
# Complex flow benefits from structured state
|
||||
class UserRegistrationState(BaseModel):
|
||||
username: str
|
||||
email: str
|
||||
verification_status: bool = False
|
||||
registration_date: datetime = Field(default_factory=datetime.now)
|
||||
last_login: Optional[datetime] = None
|
||||
|
||||
class RegistrationFlow(Flow[UserRegistrationState]):
|
||||
# Methods with strongly-typed state access
|
||||
```
|
||||
|
||||
### 3. Document State Transitions
|
||||
|
||||
For complex flows, document how state changes throughout the execution:
|
||||
|
||||
```python
|
||||
@start()
|
||||
def initialize_order(self):
|
||||
"""
|
||||
Initialize order state with empty values.
|
||||
|
||||
State before: {}
|
||||
State after: {order_id: str, items: [], status: 'new'}
|
||||
"""
|
||||
self.state.order_id = str(uuid.uuid4())
|
||||
self.state.items = []
|
||||
self.state.status = "new"
|
||||
return "Order initialized"
|
||||
```
|
||||
|
||||
### 4. Handle State Errors Gracefully
|
||||
|
||||
Implement error handling for state access:
|
||||
|
||||
```python
|
||||
@listen(previous_step)
|
||||
def process_data(self, _):
|
||||
try:
|
||||
# Try to access a value that might not exist
|
||||
user_preference = self.state.preferences.get("theme", "default")
|
||||
except (AttributeError, KeyError):
|
||||
# Handle the error gracefully
|
||||
self.state.errors = self.state.get("errors", [])
|
||||
self.state.errors.append("Failed to access preferences")
|
||||
user_preference = "default"
|
||||
|
||||
return f"Used preference: {user_preference}"
|
||||
```
|
||||
|
||||
### 5. Use State for Progress Tracking
|
||||
|
||||
Leverage state to track progress in long-running flows:
|
||||
|
||||
```python
|
||||
class ProgressTrackingFlow(Flow):
|
||||
@start()
|
||||
def initialize(self):
|
||||
self.state["total_steps"] = 3
|
||||
self.state["current_step"] = 0
|
||||
self.state["progress"] = 0.0
|
||||
self.update_progress()
|
||||
return "Initialized"
|
||||
|
||||
def update_progress(self):
|
||||
"""Helper method to calculate and update progress"""
|
||||
if self.state.get("total_steps", 0) > 0:
|
||||
self.state["progress"] = (self.state.get("current_step", 0) /
|
||||
self.state["total_steps"]) * 100
|
||||
print(f"Progress: {self.state['progress']:.1f}%")
|
||||
|
||||
@listen(initialize)
|
||||
def step_one(self, _):
|
||||
# Do work...
|
||||
self.state["current_step"] = 1
|
||||
self.update_progress()
|
||||
return "Step 1 complete"
|
||||
|
||||
# Additional steps...
|
||||
```
|
||||
|
||||
### 6. Use Immutable Operations When Possible
|
||||
|
||||
Especially with structured state, prefer immutable operations for clarity:
|
||||
|
||||
```python
|
||||
# Instead of modifying lists in place:
|
||||
self.state.items.append(new_item) # Mutable operation
|
||||
|
||||
# Consider creating new state:
|
||||
from pydantic import BaseModel
|
||||
from typing import List
|
||||
|
||||
class ItemState(BaseModel):
|
||||
items: List[str] = []
|
||||
|
||||
class ImmutableFlow(Flow[ItemState]):
|
||||
@start()
|
||||
def add_item(self):
|
||||
# Create new list with the added item
|
||||
self.state.items = [*self.state.items, "new item"]
|
||||
return "Item added"
|
||||
```
|
||||
|
||||
## Debugging Flow State
|
||||
|
||||
### Logging State Changes
|
||||
|
||||
When developing, add logging to track state changes:
|
||||
|
||||
```python
|
||||
import logging
|
||||
logging.basicConfig(level=logging.INFO)
|
||||
|
||||
class LoggingFlow(Flow):
|
||||
def log_state(self, step_name):
|
||||
logging.info(f"State after {step_name}: {self.state}")
|
||||
|
||||
@start()
|
||||
def initialize(self):
|
||||
self.state["counter"] = 0
|
||||
self.log_state("initialize")
|
||||
return "Initialized"
|
||||
|
||||
@listen(initialize)
|
||||
def increment(self, _):
|
||||
self.state["counter"] += 1
|
||||
self.log_state("increment")
|
||||
return f"Incremented to {self.state['counter']}"
|
||||
```
|
||||
|
||||
### State Visualization
|
||||
|
||||
You can add methods to visualize your state for debugging:
|
||||
|
||||
```python
|
||||
def visualize_state(self):
|
||||
"""Create a simple visualization of the current state"""
|
||||
import json
|
||||
from rich.console import Console
|
||||
from rich.panel import Panel
|
||||
|
||||
console = Console()
|
||||
|
||||
if hasattr(self.state, "model_dump"):
|
||||
# Pydantic v2
|
||||
state_dict = self.state.model_dump()
|
||||
elif hasattr(self.state, "dict"):
|
||||
# Pydantic v1
|
||||
state_dict = self.state.dict()
|
||||
else:
|
||||
# Unstructured state
|
||||
state_dict = dict(self.state)
|
||||
|
||||
# Remove id for cleaner output
|
||||
if "id" in state_dict:
|
||||
state_dict.pop("id")
|
||||
|
||||
state_json = json.dumps(state_dict, indent=2, default=str)
|
||||
console.print(Panel(state_json, title="Current Flow State"))
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
|
||||
Mastering state management in CrewAI Flows gives you the power to build sophisticated, robust AI applications that maintain context, make complex decisions, and deliver consistent results.
|
||||
|
||||
Whether you choose unstructured or structured state, implementing proper state management practices will help you create flows that are maintainable, extensible, and effective at solving real-world problems.
|
||||
|
||||
As you develop more complex flows, remember that good state management is about finding the right balance between flexibility and structure, making your code both powerful and easy to understand.
|
||||
|
||||
<Check>
|
||||
You've now mastered the concepts and practices of state management in CrewAI Flows! With this knowledge, you can create robust AI workflows that effectively maintain context, share data between steps, and build sophisticated application logic.
|
||||
</Check>
|
||||
|
||||
## Next Steps
|
||||
|
||||
- Experiment with both structured and unstructured state in your flows
|
||||
- Try implementing state persistence for long-running workflows
|
||||
- Explore [building your first crew](/guides/crews/first-crew) to see how crews and flows can work together
|
||||
- Check out the [Flow reference documentation](/concepts/flows) for more advanced features
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: Agent Monitoring with AgentOps
|
||||
title: AgentOps Integration
|
||||
description: Understanding and logging your agent performance with AgentOps.
|
||||
icon: paperclip
|
||||
---
|
||||
@@ -57,7 +57,7 @@ This feature is useful for debugging and understanding how agents interact with
|
||||
<Step title="Install AgentOps">
|
||||
Install AgentOps with:
|
||||
```bash
|
||||
pip install crewai[agentops]
|
||||
pip install 'crewai[agentops]'
|
||||
```
|
||||
or
|
||||
```bash
|
||||
|
||||
145
docs/how-to/arize-phoenix-observability.mdx
Normal file
@@ -0,0 +1,145 @@
|
||||
---
|
||||
title: Arize Phoenix
|
||||
description: Arize Phoenix integration for CrewAI with OpenTelemetry and OpenInference
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# Arize Phoenix Integration
|
||||
|
||||
This guide demonstrates how to integrate **Arize Phoenix** with **CrewAI** using OpenTelemetry via the [OpenInference](https://github.com/openinference/openinference) SDK. By the end of this guide, you will be able to trace your CrewAI agents and easily debug your agents.
|
||||
|
||||
> **What is Arize Phoenix?** [Arize Phoenix](https://phoenix.arize.com) is an LLM observability platform that provides tracing and evaluation for AI applications.
|
||||
|
||||
[](https://www.youtube.com/watch?v=Yc5q3l6F7Ww)
|
||||
|
||||
## Get Started
|
||||
|
||||
We'll walk through a simple example of using CrewAI and integrating it with Arize Phoenix via OpenTelemetry using OpenInference.
|
||||
|
||||
You can also access this guide on [Google Colab](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/crewai_tracing_tutorial.ipynb).
|
||||
|
||||
### Step 1: Install Dependencies
|
||||
|
||||
```bash
|
||||
pip install openinference-instrumentation-crewai crewai crewai-tools arize-phoenix-otel
|
||||
```
|
||||
|
||||
### Step 2: Set Up Environment Variables
|
||||
|
||||
Setup Phoenix Cloud API keys and configure OpenTelemetry to send traces to Phoenix. Phoenix Cloud is a hosted version of Arize Phoenix, but it is not required to use this integration.
|
||||
|
||||
You can get your free Serper API key [here](https://serper.dev/).
|
||||
|
||||
```python
|
||||
import os
|
||||
from getpass import getpass
|
||||
|
||||
# Get your Phoenix Cloud credentials
|
||||
PHOENIX_API_KEY = getpass("🔑 Enter your Phoenix Cloud API Key: ")
|
||||
|
||||
# Get API keys for services
|
||||
OPENAI_API_KEY = getpass("🔑 Enter your OpenAI API key: ")
|
||||
SERPER_API_KEY = getpass("🔑 Enter your Serper API key: ")
|
||||
|
||||
# Set environment variables
|
||||
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
|
||||
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com" # Phoenix Cloud, change this to your own endpoint if you are using a self-hosted instance
|
||||
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
|
||||
os.environ["SERPER_API_KEY"] = SERPER_API_KEY
|
||||
```
|
||||
|
||||
### Step 3: Initialize OpenTelemetry with Phoenix
|
||||
|
||||
Initialize the OpenInference OpenTelemetry instrumentation SDK to start capturing traces and send them to Phoenix.
|
||||
|
||||
```python
|
||||
from phoenix.otel import register
|
||||
|
||||
tracer_provider = register(
|
||||
project_name="crewai-tracing-demo",
|
||||
auto_instrument=True,
|
||||
)
|
||||
```
|
||||
|
||||
### Step 4: Create a CrewAI Application
|
||||
|
||||
We'll create a CrewAI application where two agents collaborate to research and write a blog post about AI advancements.
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
search_tool = SerperDevTool()
|
||||
|
||||
# Define your agents with roles and goals
|
||||
researcher = Agent(
|
||||
role="Senior Research Analyst",
|
||||
goal="Uncover cutting-edge developments in AI and data science",
|
||||
backstory="""You work at a leading tech think tank.
|
||||
Your expertise lies in identifying emerging trends.
|
||||
You have a knack for dissecting complex data and presenting actionable insights.""",
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
# You can pass an optional llm attribute specifying what model you wanna use.
|
||||
# llm=ChatOpenAI(model_name="gpt-3.5", temperature=0.7),
|
||||
tools=[search_tool],
|
||||
)
|
||||
writer = Agent(
|
||||
role="Tech Content Strategist",
|
||||
goal="Craft compelling content on tech advancements",
|
||||
backstory="""You are a renowned Content Strategist, known for your insightful and engaging articles.
|
||||
You transform complex concepts into compelling narratives.""",
|
||||
verbose=True,
|
||||
allow_delegation=True,
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description="""Conduct a comprehensive analysis of the latest advancements in AI in 2024.
|
||||
Identify key trends, breakthrough technologies, and potential industry impacts.""",
|
||||
expected_output="Full analysis report in bullet points",
|
||||
agent=researcher,
|
||||
)
|
||||
|
||||
task2 = Task(
|
||||
description="""Using the insights provided, develop an engaging blog
|
||||
post that highlights the most significant AI advancements.
|
||||
Your post should be informative yet accessible, catering to a tech-savvy audience.
|
||||
Make it sound cool, avoid complex words so it doesn't sound like AI.""",
|
||||
expected_output="Full blog post of at least 4 paragraphs",
|
||||
agent=writer,
|
||||
)
|
||||
|
||||
# Instantiate your crew with a sequential process
|
||||
crew = Crew(
|
||||
agents=[researcher, writer], tasks=[task1, task2], verbose=1, process=Process.sequential
|
||||
)
|
||||
|
||||
# Get your crew to work!
|
||||
result = crew.kickoff()
|
||||
|
||||
print("######################")
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Step 5: View Traces in Phoenix
|
||||
|
||||
After running the agent, you can view the traces generated by your CrewAI application in Phoenix. You should see detailed steps of the agent interactions and LLM calls, which can help you debug and optimize your AI agents.
|
||||
|
||||
Log into your Phoenix Cloud account and navigate to the project you specified in the `project_name` parameter. You'll see a timeline view of your trace with all the agent interactions, tool usages, and LLM calls.
|
||||
|
||||
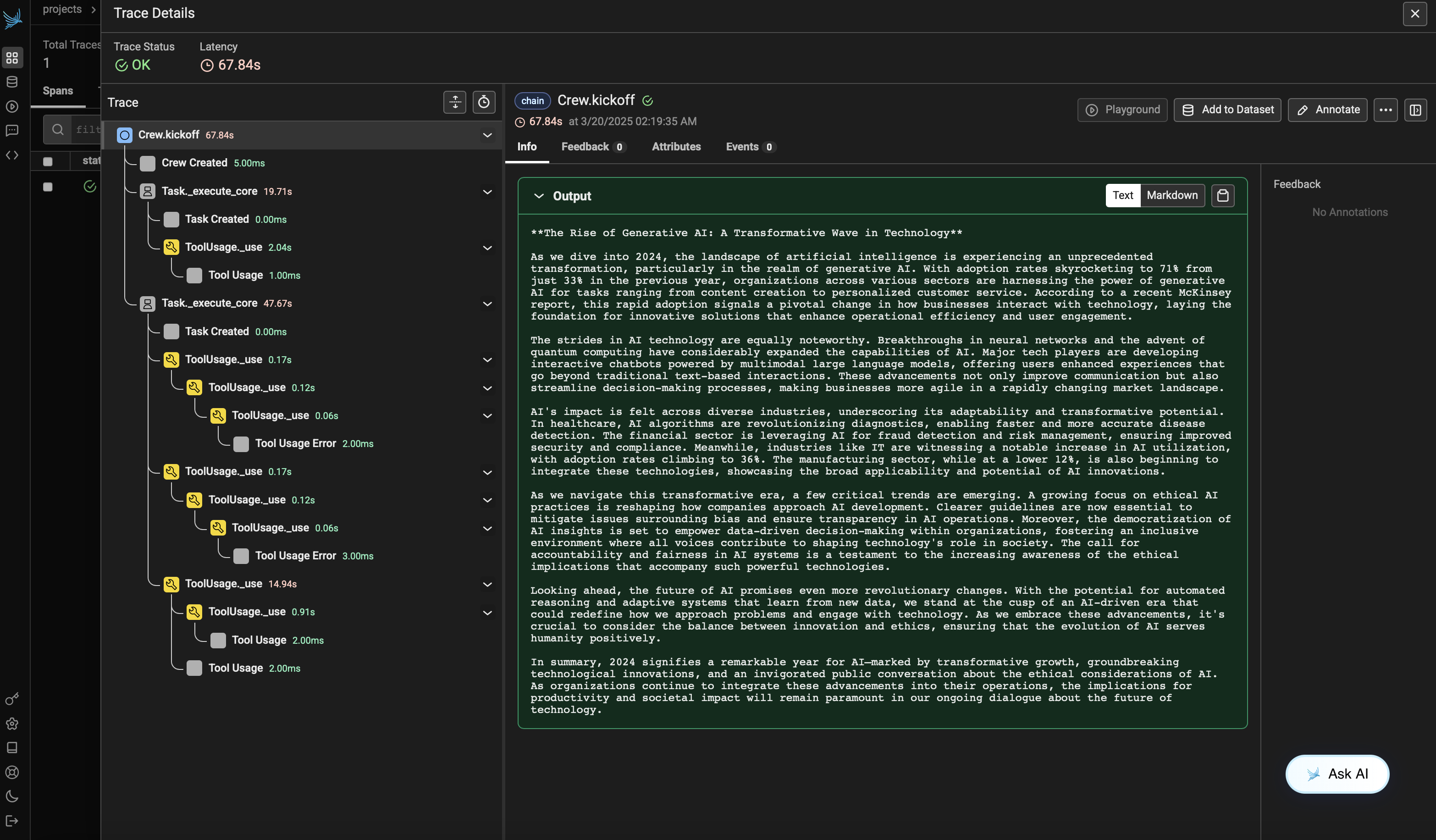
|
||||
|
||||
|
||||
### Version Compatibility Information
|
||||
- Python 3.8+
|
||||
- CrewAI >= 0.86.0
|
||||
- Arize Phoenix >= 7.0.1
|
||||
- OpenTelemetry SDK >= 1.31.0
|
||||
|
||||
|
||||
### References
|
||||
- [Phoenix Documentation](https://docs.arize.com/phoenix/) - Overview of the Phoenix platform.
|
||||
- [CrewAI Documentation](https://docs.crewai.com/) - Overview of the CrewAI framework.
|
||||
- [OpenTelemetry Docs](https://opentelemetry.io/docs/) - OpenTelemetry guide
|
||||
- [OpenInference GitHub](https://github.com/openinference/openinference) - Source code for OpenInference SDK.
|
||||
59
docs/how-to/before-and-after-kickoff-hooks.mdx
Normal file
@@ -0,0 +1,59 @@
|
||||
---
|
||||
title: Before and After Kickoff Hooks
|
||||
description: Learn how to use before and after kickoff hooks in CrewAI
|
||||
---
|
||||
|
||||
CrewAI provides hooks that allow you to execute code before and after a crew's kickoff. These hooks are useful for preprocessing inputs or post-processing results.
|
||||
|
||||
## Before Kickoff Hook
|
||||
|
||||
The before kickoff hook is executed before the crew starts its tasks. It receives the input dictionary and can modify it before passing it to the crew. You can use this hook to set up your environment, load necessary data, or preprocess your inputs. This is useful in scenarios where the input data might need enrichment or validation before being processed by the crew.
|
||||
|
||||
Here's an example of defining a before kickoff function in your `crew.py`:
|
||||
|
||||
```python
|
||||
from crewai import CrewBase, before_kickoff
|
||||
|
||||
@CrewBase
|
||||
class MyCrew:
|
||||
@before_kickoff
|
||||
def prepare_data(self, inputs):
|
||||
# Preprocess or modify inputs
|
||||
inputs['processed'] = True
|
||||
return inputs
|
||||
|
||||
#...
|
||||
```
|
||||
|
||||
In this example, the prepare_data function modifies the inputs by adding a new key-value pair indicating that the inputs have been processed.
|
||||
|
||||
## After Kickoff Hook
|
||||
|
||||
The after kickoff hook is executed after the crew has completed its tasks. It receives the result object, which contains the outputs of the crew's execution. This hook is ideal for post-processing results, such as logging, data transformation, or further analysis.
|
||||
|
||||
Here's how you can define an after kickoff function in your `crew.py`:
|
||||
|
||||
```python
|
||||
from crewai import CrewBase, after_kickoff
|
||||
|
||||
@CrewBase
|
||||
class MyCrew:
|
||||
@after_kickoff
|
||||
def log_results(self, result):
|
||||
# Log or modify the results
|
||||
print("Crew execution completed with result:", result)
|
||||
return result
|
||||
|
||||
# ...
|
||||
```
|
||||
|
||||
|
||||
In the `log_results` function, the results of the crew execution are simply printed out. You can extend this to perform more complex operations such as sending notifications or integrating with other services.
|
||||
|
||||
## Utilizing Both Hooks
|
||||
|
||||
Both hooks can be used together to provide a comprehensive setup and teardown process for your crew's execution. They are particularly useful in maintaining clean code architecture by separating concerns and enhancing the modularity of your CrewAI implementations.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Before and after kickoff hooks in CrewAI offer powerful ways to interact with the lifecycle of a crew's execution. By understanding and utilizing these hooks, you can greatly enhance the robustness and flexibility of your AI agents.
|
||||
443
docs/how-to/bring-your-own-agent.mdx
Normal file
@@ -0,0 +1,443 @@
|
||||
---
|
||||
title: Bring your own agent
|
||||
description: Learn how to bring your own agents that work within a Crew.
|
||||
icon: robots
|
||||
---
|
||||
|
||||
Interoperability is a core concept in CrewAI. This guide will show you how to bring your own agents that work within a Crew.
|
||||
|
||||
|
||||
## Adapter Guide for Bringing your own agents (Langgraph Agents, OpenAI Agents, etc...)
|
||||
We require 3 adapters to turn any agent from different frameworks to work within crew.
|
||||
|
||||
1. BaseAgentAdapter
|
||||
2. BaseToolAdapter
|
||||
3. BaseConverter
|
||||
|
||||
|
||||
## BaseAgentAdapter
|
||||
This abstract class defines the common interface and functionality that all
|
||||
agent adapters must implement. It extends BaseAgent to maintain compatibility
|
||||
with the CrewAI framework while adding adapter-specific requirements.
|
||||
|
||||
Required Methods:
|
||||
|
||||
1. `def configure_tools`
|
||||
2. `def configure_structured_output`
|
||||
|
||||
## Creating your own Adapter
|
||||
To integrate an agent from a different framework (e.g., LangGraph, Autogen, OpenAI Assistants) into CrewAI, you need to create a custom adapter by inheriting from `BaseAgentAdapter`. This adapter acts as a compatibility layer, translating between the CrewAI interfaces and the specific requirements of your external agent.
|
||||
|
||||
Here's how you implement your custom adapter:
|
||||
|
||||
1. **Inherit from `BaseAgentAdapter`**:
|
||||
```python
|
||||
from crewai.agents.agent_adapters.base_agent_adapter import BaseAgentAdapter
|
||||
from crewai.tools import BaseTool
|
||||
from typing import List, Optional, Any, Dict
|
||||
|
||||
class MyCustomAgentAdapter(BaseAgentAdapter):
|
||||
# ... implementation details ...
|
||||
```
|
||||
|
||||
2. **Implement `__init__`**:
|
||||
The constructor should call the parent class constructor `super().__init__(**kwargs)` and perform any initialization specific to your external agent. You can use the optional `agent_config` dictionary passed during CrewAI's `Agent` initialization to configure your adapter and the underlying agent.
|
||||
|
||||
```python
|
||||
def __init__(self, agent_config: Optional[Dict[str, Any]] = None, **kwargs: Any):
|
||||
super().__init__(agent_config=agent_config, **kwargs)
|
||||
# Initialize your external agent here, possibly using agent_config
|
||||
# Example: self.external_agent = initialize_my_agent(agent_config)
|
||||
print(f"Initializing MyCustomAgentAdapter with config: {agent_config}")
|
||||
```
|
||||
|
||||
3. **Implement `configure_tools`**:
|
||||
This abstract method is crucial. It receives a list of CrewAI `BaseTool` instances. Your implementation must convert or adapt these tools into the format expected by your external agent framework. This might involve wrapping them, extracting specific attributes, or registering them with the external agent instance.
|
||||
|
||||
```python
|
||||
def configure_tools(self, tools: Optional[List[BaseTool]] = None) -> None:
|
||||
if tools:
|
||||
adapted_tools = []
|
||||
for tool in tools:
|
||||
# Adapt CrewAI BaseTool to the format your agent expects
|
||||
# Example: adapted_tool = adapt_to_my_framework(tool)
|
||||
# adapted_tools.append(adapted_tool)
|
||||
pass # Replace with your actual adaptation logic
|
||||
|
||||
# Configure the external agent with the adapted tools
|
||||
# Example: self.external_agent.set_tools(adapted_tools)
|
||||
print(f"Configuring tools for MyCustomAgentAdapter: {adapted_tools}") # Placeholder
|
||||
else:
|
||||
# Handle the case where no tools are provided
|
||||
# Example: self.external_agent.set_tools([])
|
||||
print("No tools provided for MyCustomAgentAdapter.")
|
||||
```
|
||||
|
||||
4. **Implement `configure_structured_output`**:
|
||||
This method is called when the CrewAI `Agent` is configured with structured output requirements (e.g., `output_json` or `output_pydantic`). Your adapter needs to ensure the external agent is set up to comply with these requirements. This might involve setting specific parameters on the external agent or ensuring its underlying model supports the requested format. If the external agent doesn't support structured output in a way compatible with CrewAI's expectations, you might need to handle the conversion or raise an appropriate error.
|
||||
|
||||
```python
|
||||
def configure_structured_output(self, structured_output: Any) -> None:
|
||||
# Configure your external agent to produce output in the specified format
|
||||
# Example: self.external_agent.set_output_format(structured_output)
|
||||
self.adapted_structured_output = True # Signal that structured output is handled
|
||||
print(f"Configuring structured output for MyCustomAgentAdapter: {structured_output}")
|
||||
```
|
||||
|
||||
By implementing these methods, your `MyCustomAgentAdapter` will allow your custom agent implementation to function correctly within a CrewAI crew, interacting with tasks and tools seamlessly. Remember to replace the example comments and print statements with your actual adaptation logic specific to the external agent framework you are integrating.
|
||||
|
||||
## BaseToolAdapter implementation
|
||||
The `BaseToolAdapter` class is responsible for converting CrewAI's native `BaseTool` objects into a format that your specific external agent framework can understand and utilize. Different agent frameworks (like LangGraph, OpenAI Assistants, etc.) have their own unique ways of defining and handling tools, and the `BaseToolAdapter` acts as the translator.
|
||||
|
||||
Here's how you implement your custom tool adapter:
|
||||
|
||||
1. **Inherit from `BaseToolAdapter`**:
|
||||
```python
|
||||
from crewai.agents.agent_adapters.base_tool_adapter import BaseToolAdapter
|
||||
from crewai.tools import BaseTool
|
||||
from typing import List, Any
|
||||
|
||||
class MyCustomToolAdapter(BaseToolAdapter):
|
||||
# ... implementation details ...
|
||||
```
|
||||
|
||||
2. **Implement `configure_tools`**:
|
||||
This is the core abstract method you must implement. It receives a list of CrewAI `BaseTool` instances provided to the agent. Your task is to iterate through this list, adapt each `BaseTool` into the format expected by your external framework, and store the converted tools in the `self.converted_tools` list (which is initialized in the base class constructor).
|
||||
|
||||
```python
|
||||
def configure_tools(self, tools: List[BaseTool]) -> None:
|
||||
"""Configure and convert CrewAI tools for the specific implementation."""
|
||||
self.converted_tools = [] # Reset in case it's called multiple times
|
||||
for tool in tools:
|
||||
# Sanitize the tool name if required by the target framework
|
||||
sanitized_name = self.sanitize_tool_name(tool.name)
|
||||
|
||||
# --- Your Conversion Logic Goes Here ---
|
||||
# Example: Convert BaseTool to a dictionary format for LangGraph
|
||||
# converted_tool = {
|
||||
# "name": sanitized_name,
|
||||
# "description": tool.description,
|
||||
# "parameters": tool.args_schema.schema() if tool.args_schema else {},
|
||||
# # Add any other framework-specific fields
|
||||
# }
|
||||
|
||||
# Example: Convert BaseTool to an OpenAI function definition
|
||||
# converted_tool = {
|
||||
# "type": "function",
|
||||
# "function": {
|
||||
# "name": sanitized_name,
|
||||
# "description": tool.description,
|
||||
# "parameters": tool.args_schema.schema() if tool.args_schema else {"type": "object", "properties": {}},
|
||||
# }
|
||||
# }
|
||||
|
||||
# --- Replace above examples with your actual adaptation ---
|
||||
converted_tool = self.adapt_tool_to_my_framework(tool, sanitized_name) # Placeholder
|
||||
|
||||
self.converted_tools.append(converted_tool)
|
||||
print(f"Adapted tool '{tool.name}' to '{sanitized_name}' for MyCustomToolAdapter") # Placeholder
|
||||
|
||||
print(f"MyCustomToolAdapter finished configuring tools: {len(self.converted_tools)} adapted.") # Placeholder
|
||||
|
||||
# --- Helper method for adaptation (Example) ---
|
||||
def adapt_tool_to_my_framework(self, tool: BaseTool, sanitized_name: str) -> Any:
|
||||
# Replace this with the actual logic to convert a CrewAI BaseTool
|
||||
# to the format needed by your specific external agent framework.
|
||||
# This will vary greatly depending on the target framework.
|
||||
adapted_representation = {
|
||||
"framework_specific_name": sanitized_name,
|
||||
"framework_specific_description": tool.description,
|
||||
"inputs": tool.args_schema.schema() if tool.args_schema else None,
|
||||
"implementation_reference": tool.run # Or however the framework needs to call it
|
||||
}
|
||||
# Also ensure the tool works both sync and async
|
||||
async def async_tool_wrapper(*args, **kwargs):
|
||||
output = tool.run(*args, **kwargs)
|
||||
if inspect.isawaitable(output):
|
||||
return await output
|
||||
else:
|
||||
return output
|
||||
|
||||
adapted_tool = MyFrameworkTool(
|
||||
name=sanitized_name,
|
||||
description=tool.description,
|
||||
inputs=tool.args_schema.schema() if tool.args_schema else None,
|
||||
implementation_reference=async_tool_wrapper
|
||||
)
|
||||
|
||||
return adapted_representation
|
||||
|
||||
```
|
||||
|
||||
3. **Using the Adapter**:
|
||||
Typically, you would instantiate your `MyCustomToolAdapter` within your `MyCustomAgentAdapter`'s `configure_tools` method and use it to process the tools before configuring your external agent.
|
||||
|
||||
```python
|
||||
# Inside MyCustomAgentAdapter.configure_tools
|
||||
def configure_tools(self, tools: Optional[List[BaseTool]] = None) -> None:
|
||||
if tools:
|
||||
tool_adapter = MyCustomToolAdapter() # Instantiate your tool adapter
|
||||
tool_adapter.configure_tools(tools) # Convert the tools
|
||||
adapted_tools = tool_adapter.tools() # Get the converted tools
|
||||
|
||||
# Now configure your external agent with the adapted_tools
|
||||
# Example: self.external_agent.set_tools(adapted_tools)
|
||||
print(f"Configuring external agent with adapted tools: {adapted_tools}") # Placeholder
|
||||
else:
|
||||
# Handle no tools case
|
||||
print("No tools provided for MyCustomAgentAdapter.")
|
||||
```
|
||||
|
||||
By creating a `BaseToolAdapter`, you decouple the tool conversion logic from the agent adaptation, making the integration cleaner and more modular. Remember to replace the placeholder examples with the actual conversion logic required by your specific external agent framework.
|
||||
|
||||
## BaseConverter
|
||||
The `BaseConverterAdapter` plays a crucial role when a CrewAI `Task` requires an agent to return its final output in a specific structured format, such as JSON or a Pydantic model. It bridges the gap between CrewAI's structured output requirements and the capabilities of your external agent.
|
||||
|
||||
Its primary responsibilities are:
|
||||
1. **Configuring the Agent for Structured Output:** Based on the `Task`'s requirements (`output_json` or `output_pydantic`), it instructs the associated `BaseAgentAdapter` (and indirectly, the external agent) on what format is expected.
|
||||
2. **Enhancing the System Prompt:** It modifies the agent's system prompt to include clear instructions on *how* to generate the output in the required structure.
|
||||
3. **Post-processing the Result:** It takes the raw output from the agent and attempts to parse, validate, and format it according to the required structure, ultimately returning a string representation (e.g., a JSON string).
|
||||
|
||||
Here's how you implement your custom converter adapter:
|
||||
|
||||
1. **Inherit from `BaseConverterAdapter`**:
|
||||
```python
|
||||
from crewai.agents.agent_adapters.base_converter_adapter import BaseConverterAdapter
|
||||
# Assuming you have your MyCustomAgentAdapter defined
|
||||
# from .my_custom_agent_adapter import MyCustomAgentAdapter
|
||||
from crewai.task import Task
|
||||
from typing import Any
|
||||
|
||||
class MyCustomConverterAdapter(BaseConverterAdapter):
|
||||
# Store the expected output type (e.g., 'json', 'pydantic', 'text')
|
||||
_output_type: str = 'text'
|
||||
_output_schema: Any = None # Store JSON schema or Pydantic model
|
||||
|
||||
# ... implementation details ...
|
||||
```
|
||||
|
||||
2. **Implement `__init__`**:
|
||||
The constructor must accept the corresponding `agent_adapter` instance it will work with.
|
||||
|
||||
```python
|
||||
def __init__(self, agent_adapter: Any): # Use your specific AgentAdapter type hint
|
||||
self.agent_adapter = agent_adapter
|
||||
print(f"Initializing MyCustomConverterAdapter for agent adapter: {type(agent_adapter).__name__}")
|
||||
```
|
||||
|
||||
3. **Implement `configure_structured_output`**:
|
||||
This method receives the CrewAI `Task` object. You need to check the task's `output_json` and `output_pydantic` attributes to determine the required output structure. Store this information (e.g., in `_output_type` and `_output_schema`) and potentially call configuration methods on your `self.agent_adapter` if the external agent needs specific setup for structured output (which might have been partially handled in the agent adapter's `configure_structured_output` already).
|
||||
|
||||
```python
|
||||
def configure_structured_output(self, task: Task) -> None:
|
||||
"""Configure the expected structured output based on the task."""
|
||||
if task.output_pydantic:
|
||||
self._output_type = 'pydantic'
|
||||
self._output_schema = task.output_pydantic
|
||||
print(f"Converter: Configured for Pydantic output: {self._output_schema.__name__}")
|
||||
elif task.output_json:
|
||||
self._output_type = 'json'
|
||||
self._output_schema = task.output_json
|
||||
print(f"Converter: Configured for JSON output with schema: {self._output_schema}")
|
||||
else:
|
||||
self._output_type = 'text'
|
||||
self._output_schema = None
|
||||
print("Converter: Configured for standard text output.")
|
||||
|
||||
# Optionally, inform the agent adapter if needed
|
||||
# self.agent_adapter.set_output_mode(self._output_type, self._output_schema)
|
||||
```
|
||||
|
||||
4. **Implement `enhance_system_prompt`**:
|
||||
This method takes the agent's base system prompt string and should append instructions tailored to the currently configured `_output_type` and `_output_schema`. The goal is to guide the LLM powering the agent to produce output in the correct format.
|
||||
|
||||
```python
|
||||
def enhance_system_prompt(self, base_prompt: str) -> str:
|
||||
"""Enhance the system prompt with structured output instructions."""
|
||||
if self._output_type == 'text':
|
||||
return base_prompt # No enhancement needed for plain text
|
||||
|
||||
instructions = "\n\nYour final answer MUST be formatted as "
|
||||
if self._output_type == 'json':
|
||||
schema_str = json.dumps(self._output_schema, indent=2)
|
||||
instructions += f"a JSON object conforming to the following schema:\n```json\n{schema_str}\n```"
|
||||
elif self._output_type == 'pydantic':
|
||||
schema_str = json.dumps(self._output_schema.model_json_schema(), indent=2)
|
||||
instructions += f"a JSON object conforming to the Pydantic model '{self._output_schema.__name__}' with the following schema:\n```json\n{schema_str}\n```"
|
||||
|
||||
instructions += "\nEnsure your entire response is ONLY the valid JSON object, without any introductory text, explanations, or concluding remarks."
|
||||
|
||||
print(f"Converter: Enhancing prompt for {self._output_type} output.")
|
||||
return base_prompt + instructions
|
||||
```
|
||||
*Note: The exact prompt engineering might need tuning based on the agent/LLM being used.*
|
||||
|
||||
5. **Implement `post_process_result`**:
|
||||
This method receives the raw string output from the agent. If structured output was requested (`json` or `pydantic`), you should attempt to parse the string into the expected format. Handle potential parsing errors (e.g., log them, attempt simple fixes, or raise an exception). Crucially, the method must **always return a string**, even if the intermediate format was a dictionary or Pydantic object (e.g., by serializing it back to a JSON string).
|
||||
|
||||
```python
|
||||
import json
|
||||
from pydantic import ValidationError
|
||||
|
||||
def post_process_result(self, result: str) -> str:
|
||||
"""Post-process the agent's result to ensure it matches the expected format."""
|
||||
print(f"Converter: Post-processing result for {self._output_type} output.")
|
||||
if self._output_type == 'json':
|
||||
try:
|
||||
# Attempt to parse and re-serialize to ensure validity and consistent format
|
||||
parsed_json = json.loads(result)
|
||||
# Optional: Validate against self._output_schema if it's a JSON schema dictionary
|
||||
# from jsonschema import validate
|
||||
# validate(instance=parsed_json, schema=self._output_schema)
|
||||
return json.dumps(parsed_json)
|
||||
except json.JSONDecodeError as e:
|
||||
print(f"Error: Failed to parse JSON output: {e}\nRaw output:\n{result}")
|
||||
# Handle error: return raw, raise exception, or try to fix
|
||||
return result # Example: return raw output on failure
|
||||
# except Exception as e: # Catch validation errors if using jsonschema
|
||||
# print(f"Error: JSON output failed schema validation: {e}\nRaw output:\n{result}")
|
||||
# return result
|
||||
elif self._output_type == 'pydantic':
|
||||
try:
|
||||
# Attempt to parse into the Pydantic model
|
||||
model_instance = self._output_schema.model_validate_json(result)
|
||||
# Return the model serialized back to JSON
|
||||
return model_instance.model_dump_json()
|
||||
except ValidationError as e:
|
||||
print(f"Error: Failed to validate Pydantic output: {e}\nRaw output:\n{result}")
|
||||
# Handle error
|
||||
return result # Example: return raw output on failure
|
||||
except json.JSONDecodeError as e:
|
||||
print(f"Error: Failed to parse JSON for Pydantic model: {e}\nRaw output:\n{result}")
|
||||
return result
|
||||
else: # 'text'
|
||||
return result # No processing needed for plain text
|
||||
```
|
||||
|
||||
By implementing these methods, your `MyCustomConverterAdapter` ensures that structured output requests from CrewAI tasks are correctly handled by your integrated external agent, improving the reliability and usability of your custom agent within the CrewAI framework.
|
||||
|
||||
## Out of the Box Adapters
|
||||
|
||||
We provide out of the box adapters for the following frameworks:
|
||||
1. LangGraph
|
||||
2. OpenAI Agents
|
||||
|
||||
## Kicking off a crew with adapted agents:
|
||||
|
||||
```python
|
||||
import json
|
||||
import os
|
||||
from typing import List
|
||||
|
||||
from crewai_tools import SerperDevTool
|
||||
from src.crewai import Agent, Crew, Task
|
||||
from langchain_openai import ChatOpenAI
|
||||
from pydantic import BaseModel
|
||||
|
||||
from crewai.agents.agent_adapters.langgraph.langgraph_adapter import (
|
||||
LangGraphAgentAdapter,
|
||||
)
|
||||
from crewai.agents.agent_adapters.openai_agents.openai_adapter import OpenAIAgentAdapter
|
||||
|
||||
# CrewAI Agent
|
||||
code_helper_agent = Agent(
|
||||
role="Code Helper",
|
||||
goal="Help users solve coding problems effectively and provide clear explanations.",
|
||||
backstory="You are an experienced programmer with deep knowledge across multiple programming languages and frameworks. You specialize in solving complex coding challenges and explaining solutions clearly.",
|
||||
allow_delegation=False,
|
||||
verbose=True,
|
||||
)
|
||||
# OpenAI Agent Adapter
|
||||
link_finder_agent = OpenAIAgentAdapter(
|
||||
role="Link Finder",
|
||||
goal="Find the most relevant and high-quality resources for coding tasks.",
|
||||
backstory="You are a research specialist with a talent for finding the most helpful resources. You're skilled at using search tools to discover documentation, tutorials, and examples that directly address the user's coding needs.",
|
||||
tools=[SerperDevTool()],
|
||||
allow_delegation=False,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# LangGraph Agent Adapter
|
||||
reporter_agent = LangGraphAgentAdapter(
|
||||
role="Reporter",
|
||||
goal="Report the results of the tasks.",
|
||||
backstory="You are a reporter who reports the results of the other tasks",
|
||||
llm=ChatOpenAI(model="gpt-4o"),
|
||||
allow_delegation=True,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
|
||||
class Code(BaseModel):
|
||||
code: str
|
||||
|
||||
|
||||
task = Task(
|
||||
description="Give an answer to the coding question: {task}",
|
||||
expected_output="A thorough answer to the coding question: {task}",
|
||||
agent=code_helper_agent,
|
||||
output_json=Code,
|
||||
)
|
||||
task2 = Task(
|
||||
description="Find links to resources that can help with coding tasks. Use the serper tool to find resources that can help.",
|
||||
expected_output="A list of links to resources that can help with coding tasks",
|
||||
agent=link_finder_agent,
|
||||
)
|
||||
|
||||
|
||||
class Report(BaseModel):
|
||||
code: str
|
||||
links: List[str]
|
||||
|
||||
|
||||
task3 = Task(
|
||||
description="Report the results of the tasks.",
|
||||
expected_output="A report of the results of the tasks. this is the code produced and then the links to the resources that can help with the coding task.",
|
||||
agent=reporter_agent,
|
||||
output_json=Report,
|
||||
)
|
||||
# Use in CrewAI
|
||||
crew = Crew(
|
||||
agents=[code_helper_agent, link_finder_agent, reporter_agent],
|
||||
tasks=[task, task2, task3],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
result = crew.kickoff(
|
||||
inputs={"task": "How do you implement an abstract class in python?"}
|
||||
)
|
||||
|
||||
# Print raw result first
|
||||
print("Raw result:", result)
|
||||
|
||||
# Handle result based on its type
|
||||
if hasattr(result, "json_dict") and result.json_dict:
|
||||
json_result = result.json_dict
|
||||
print("\nStructured JSON result:")
|
||||
print(f"{json.dumps(json_result, indent=2)}")
|
||||
|
||||
# Access fields safely
|
||||
if isinstance(json_result, dict):
|
||||
if "code" in json_result:
|
||||
print("\nCode:")
|
||||
print(
|
||||
json_result["code"][:200] + "..."
|
||||
if len(json_result["code"]) > 200
|
||||
else json_result["code"]
|
||||
)
|
||||
|
||||
if "links" in json_result:
|
||||
print("\nLinks:")
|
||||
for link in json_result["links"][:5]: # Print first 5 links
|
||||
print(f"- {link}")
|
||||
if len(json_result["links"]) > 5:
|
||||
print(f"...and {len(json_result['links']) - 5} more links")
|
||||
elif hasattr(result, "pydantic") and result.pydantic:
|
||||
print("\nPydantic model result:")
|
||||
print(result.pydantic.model_dump_json(indent=2))
|
||||
else:
|
||||
# Fallback to raw output
|
||||
print("\nNo structured result available, using raw output:")
|
||||
print(result.raw[:500] + "..." if len(result.raw) > 500 else result.raw)
|
||||
|
||||
```
|
||||
@@ -6,28 +6,27 @@ icon: hammer
|
||||
|
||||
## Creating and Utilizing Tools in CrewAI
|
||||
|
||||
This guide provides detailed instructions on creating custom tools for the CrewAI framework and how to efficiently manage and utilize these tools,
|
||||
incorporating the latest functionalities such as tool delegation, error handling, and dynamic tool calling. It also highlights the importance of collaboration tools,
|
||||
This guide provides detailed instructions on creating custom tools for the CrewAI framework and how to efficiently manage and utilize these tools,
|
||||
incorporating the latest functionalities such as tool delegation, error handling, and dynamic tool calling. It also highlights the importance of collaboration tools,
|
||||
enabling agents to perform a wide range of actions.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Before creating your own tools, ensure you have the crewAI extra tools package installed:
|
||||
|
||||
```bash
|
||||
pip install 'crewai[tools]'
|
||||
```
|
||||
|
||||
### Subclassing `BaseTool`
|
||||
|
||||
To create a personalized tool, inherit from `BaseTool` and define the necessary attributes and the `_run` method.
|
||||
To create a personalized tool, inherit from `BaseTool` and define the necessary attributes, including the `args_schema` for input validation, and the `_run` method.
|
||||
|
||||
```python Code
|
||||
from crewai_tools import BaseTool
|
||||
from typing import Type
|
||||
from crewai.tools import BaseTool
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
class MyToolInput(BaseModel):
|
||||
"""Input schema for MyCustomTool."""
|
||||
argument: str = Field(..., description="Description of the argument.")
|
||||
|
||||
class MyCustomTool(BaseTool):
|
||||
name: str = "Name of my tool"
|
||||
description: str = "What this tool does. It's vital for effective utilization."
|
||||
args_schema: Type[BaseModel] = MyToolInput
|
||||
|
||||
def _run(self, argument: str) -> str:
|
||||
# Your tool's logic here
|
||||
@@ -40,7 +39,7 @@ Alternatively, you can use the tool decorator `@tool`. This approach allows you
|
||||
offering a concise and efficient way to create specialized tools tailored to your needs.
|
||||
|
||||
```python Code
|
||||
from crewai_tools import tool
|
||||
from crewai.tools import tool
|
||||
|
||||
@tool("Tool Name")
|
||||
def my_simple_tool(question: str) -> str:
|
||||
@@ -66,5 +65,5 @@ def my_cache_strategy(arguments: dict, result: str) -> bool:
|
||||
cached_tool.cache_function = my_cache_strategy
|
||||
```
|
||||
|
||||
By adhering to these guidelines and incorporating new functionalities and collaboration tools into your tool creation and management processes,
|
||||
By adhering to these guidelines and incorporating new functionalities and collaboration tools into your tool creation and management processes,
|
||||
you can leverage the full capabilities of the CrewAI framework, enhancing both the development experience and the efficiency of your AI agents.
|
||||
|
||||
646
docs/how-to/custom-llm.mdx
Normal file
@@ -0,0 +1,646 @@
|
||||
---
|
||||
title: Custom LLM Implementation
|
||||
description: Learn how to create custom LLM implementations in CrewAI.
|
||||
icon: code
|
||||
---
|
||||
|
||||
## Custom LLM Implementations
|
||||
|
||||
CrewAI now supports custom LLM implementations through the `BaseLLM` abstract base class. This allows you to create your own LLM implementations that don't rely on litellm's authentication mechanism.
|
||||
|
||||
To create a custom LLM implementation, you need to:
|
||||
|
||||
1. Inherit from the `BaseLLM` abstract base class
|
||||
2. Implement the required methods:
|
||||
- `call()`: The main method to call the LLM with messages
|
||||
- `supports_function_calling()`: Whether the LLM supports function calling
|
||||
- `supports_stop_words()`: Whether the LLM supports stop words
|
||||
- `get_context_window_size()`: The context window size of the LLM
|
||||
|
||||
## Example: Basic Custom LLM
|
||||
|
||||
```python
|
||||
from crewai import BaseLLM
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
class CustomLLM(BaseLLM):
|
||||
def __init__(self, api_key: str, endpoint: str):
|
||||
super().__init__() # Initialize the base class to set default attributes
|
||||
if not api_key or not isinstance(api_key, str):
|
||||
raise ValueError("Invalid API key: must be a non-empty string")
|
||||
if not endpoint or not isinstance(endpoint, str):
|
||||
raise ValueError("Invalid endpoint URL: must be a non-empty string")
|
||||
self.api_key = api_key
|
||||
self.endpoint = endpoint
|
||||
self.stop = [] # You can customize stop words if needed
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
"""Call the LLM with the given messages.
|
||||
|
||||
Args:
|
||||
messages: Input messages for the LLM.
|
||||
tools: Optional list of tool schemas for function calling.
|
||||
callbacks: Optional list of callback functions.
|
||||
available_functions: Optional dict mapping function names to callables.
|
||||
|
||||
Returns:
|
||||
Either a text response from the LLM or the result of a tool function call.
|
||||
|
||||
Raises:
|
||||
TimeoutError: If the LLM request times out.
|
||||
RuntimeError: If the LLM request fails for other reasons.
|
||||
ValueError: If the response format is invalid.
|
||||
"""
|
||||
# Implement your own logic to call the LLM
|
||||
# For example, using requests:
|
||||
import requests
|
||||
|
||||
try:
|
||||
headers = {
|
||||
"Authorization": f"Bearer {self.api_key}",
|
||||
"Content-Type": "application/json"
|
||||
}
|
||||
|
||||
# Convert string message to proper format if needed
|
||||
if isinstance(messages, str):
|
||||
messages = [{"role": "user", "content": messages}]
|
||||
|
||||
data = {
|
||||
"messages": messages,
|
||||
"tools": tools
|
||||
}
|
||||
|
||||
response = requests.post(
|
||||
self.endpoint,
|
||||
headers=headers,
|
||||
json=data,
|
||||
timeout=30 # Set a reasonable timeout
|
||||
)
|
||||
response.raise_for_status() # Raise an exception for HTTP errors
|
||||
return response.json()["choices"][0]["message"]["content"]
|
||||
except requests.Timeout:
|
||||
raise TimeoutError("LLM request timed out")
|
||||
except requests.RequestException as e:
|
||||
raise RuntimeError(f"LLM request failed: {str(e)}")
|
||||
except (KeyError, IndexError, ValueError) as e:
|
||||
raise ValueError(f"Invalid response format: {str(e)}")
|
||||
|
||||
def supports_function_calling(self) -> bool:
|
||||
"""Check if the LLM supports function calling.
|
||||
|
||||
Returns:
|
||||
True if the LLM supports function calling, False otherwise.
|
||||
"""
|
||||
# Return True if your LLM supports function calling
|
||||
return True
|
||||
|
||||
def supports_stop_words(self) -> bool:
|
||||
"""Check if the LLM supports stop words.
|
||||
|
||||
Returns:
|
||||
True if the LLM supports stop words, False otherwise.
|
||||
"""
|
||||
# Return True if your LLM supports stop words
|
||||
return True
|
||||
|
||||
def get_context_window_size(self) -> int:
|
||||
"""Get the context window size of the LLM.
|
||||
|
||||
Returns:
|
||||
The context window size as an integer.
|
||||
"""
|
||||
# Return the context window size of your LLM
|
||||
return 8192
|
||||
```
|
||||
|
||||
## Error Handling Best Practices
|
||||
|
||||
When implementing custom LLMs, it's important to handle errors properly to ensure robustness and reliability. Here are some best practices:
|
||||
|
||||
### 1. Implement Try-Except Blocks for API Calls
|
||||
|
||||
Always wrap API calls in try-except blocks to handle different types of errors:
|
||||
|
||||
```python
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
try:
|
||||
# API call implementation
|
||||
response = requests.post(
|
||||
self.endpoint,
|
||||
headers=self.headers,
|
||||
json=self.prepare_payload(messages),
|
||||
timeout=30 # Set a reasonable timeout
|
||||
)
|
||||
response.raise_for_status() # Raise an exception for HTTP errors
|
||||
return response.json()["choices"][0]["message"]["content"]
|
||||
except requests.Timeout:
|
||||
raise TimeoutError("LLM request timed out")
|
||||
except requests.RequestException as e:
|
||||
raise RuntimeError(f"LLM request failed: {str(e)}")
|
||||
except (KeyError, IndexError, ValueError) as e:
|
||||
raise ValueError(f"Invalid response format: {str(e)}")
|
||||
```
|
||||
|
||||
### 2. Implement Retry Logic for Transient Failures
|
||||
|
||||
For transient failures like network issues or rate limiting, implement retry logic with exponential backoff:
|
||||
|
||||
```python
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
import time
|
||||
|
||||
max_retries = 3
|
||||
retry_delay = 1 # seconds
|
||||
|
||||
for attempt in range(max_retries):
|
||||
try:
|
||||
response = requests.post(
|
||||
self.endpoint,
|
||||
headers=self.headers,
|
||||
json=self.prepare_payload(messages),
|
||||
timeout=30
|
||||
)
|
||||
response.raise_for_status()
|
||||
return response.json()["choices"][0]["message"]["content"]
|
||||
except (requests.Timeout, requests.ConnectionError) as e:
|
||||
if attempt < max_retries - 1:
|
||||
time.sleep(retry_delay * (2 ** attempt)) # Exponential backoff
|
||||
continue
|
||||
raise TimeoutError(f"LLM request failed after {max_retries} attempts: {str(e)}")
|
||||
except requests.RequestException as e:
|
||||
raise RuntimeError(f"LLM request failed: {str(e)}")
|
||||
```
|
||||
|
||||
### 3. Validate Input Parameters
|
||||
|
||||
Always validate input parameters to prevent runtime errors:
|
||||
|
||||
```python
|
||||
def __init__(self, api_key: str, endpoint: str):
|
||||
super().__init__()
|
||||
if not api_key or not isinstance(api_key, str):
|
||||
raise ValueError("Invalid API key: must be a non-empty string")
|
||||
if not endpoint or not isinstance(endpoint, str):
|
||||
raise ValueError("Invalid endpoint URL: must be a non-empty string")
|
||||
self.api_key = api_key
|
||||
self.endpoint = endpoint
|
||||
```
|
||||
|
||||
### 4. Handle Authentication Errors Gracefully
|
||||
|
||||
Provide clear error messages for authentication failures:
|
||||
|
||||
```python
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
try:
|
||||
response = requests.post(self.endpoint, headers=self.headers, json=data)
|
||||
if response.status_code == 401:
|
||||
raise ValueError("Authentication failed: Invalid API key or token")
|
||||
elif response.status_code == 403:
|
||||
raise ValueError("Authorization failed: Insufficient permissions")
|
||||
response.raise_for_status()
|
||||
# Process response
|
||||
except Exception as e:
|
||||
# Handle error
|
||||
raise
|
||||
```
|
||||
|
||||
## Example: JWT-based Authentication
|
||||
|
||||
For services that use JWT-based authentication instead of API keys, you can implement a custom LLM like this:
|
||||
|
||||
```python
|
||||
from crewai import BaseLLM, Agent, Task
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
class JWTAuthLLM(BaseLLM):
|
||||
def __init__(self, jwt_token: str, endpoint: str):
|
||||
super().__init__() # Initialize the base class to set default attributes
|
||||
if not jwt_token or not isinstance(jwt_token, str):
|
||||
raise ValueError("Invalid JWT token: must be a non-empty string")
|
||||
if not endpoint or not isinstance(endpoint, str):
|
||||
raise ValueError("Invalid endpoint URL: must be a non-empty string")
|
||||
self.jwt_token = jwt_token
|
||||
self.endpoint = endpoint
|
||||
self.stop = [] # You can customize stop words if needed
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
"""Call the LLM with JWT authentication.
|
||||
|
||||
Args:
|
||||
messages: Input messages for the LLM.
|
||||
tools: Optional list of tool schemas for function calling.
|
||||
callbacks: Optional list of callback functions.
|
||||
available_functions: Optional dict mapping function names to callables.
|
||||
|
||||
Returns:
|
||||
Either a text response from the LLM or the result of a tool function call.
|
||||
|
||||
Raises:
|
||||
TimeoutError: If the LLM request times out.
|
||||
RuntimeError: If the LLM request fails for other reasons.
|
||||
ValueError: If the response format is invalid.
|
||||
"""
|
||||
# Implement your own logic to call the LLM with JWT authentication
|
||||
import requests
|
||||
|
||||
try:
|
||||
headers = {
|
||||
"Authorization": f"Bearer {self.jwt_token}",
|
||||
"Content-Type": "application/json"
|
||||
}
|
||||
|
||||
# Convert string message to proper format if needed
|
||||
if isinstance(messages, str):
|
||||
messages = [{"role": "user", "content": messages}]
|
||||
|
||||
data = {
|
||||
"messages": messages,
|
||||
"tools": tools
|
||||
}
|
||||
|
||||
response = requests.post(
|
||||
self.endpoint,
|
||||
headers=headers,
|
||||
json=data,
|
||||
timeout=30 # Set a reasonable timeout
|
||||
)
|
||||
|
||||
if response.status_code == 401:
|
||||
raise ValueError("Authentication failed: Invalid JWT token")
|
||||
elif response.status_code == 403:
|
||||
raise ValueError("Authorization failed: Insufficient permissions")
|
||||
|
||||
response.raise_for_status() # Raise an exception for HTTP errors
|
||||
return response.json()["choices"][0]["message"]["content"]
|
||||
except requests.Timeout:
|
||||
raise TimeoutError("LLM request timed out")
|
||||
except requests.RequestException as e:
|
||||
raise RuntimeError(f"LLM request failed: {str(e)}")
|
||||
except (KeyError, IndexError, ValueError) as e:
|
||||
raise ValueError(f"Invalid response format: {str(e)}")
|
||||
|
||||
def supports_function_calling(self) -> bool:
|
||||
"""Check if the LLM supports function calling.
|
||||
|
||||
Returns:
|
||||
True if the LLM supports function calling, False otherwise.
|
||||
"""
|
||||
return True
|
||||
|
||||
def supports_stop_words(self) -> bool:
|
||||
"""Check if the LLM supports stop words.
|
||||
|
||||
Returns:
|
||||
True if the LLM supports stop words, False otherwise.
|
||||
"""
|
||||
return True
|
||||
|
||||
def get_context_window_size(self) -> int:
|
||||
"""Get the context window size of the LLM.
|
||||
|
||||
Returns:
|
||||
The context window size as an integer.
|
||||
"""
|
||||
return 8192
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
Here are some common issues you might encounter when implementing custom LLMs and how to resolve them:
|
||||
|
||||
### 1. Authentication Failures
|
||||
|
||||
**Symptoms**: 401 Unauthorized or 403 Forbidden errors
|
||||
|
||||
**Solutions**:
|
||||
- Verify that your API key or JWT token is valid and not expired
|
||||
- Check that you're using the correct authentication header format
|
||||
- Ensure that your token has the necessary permissions
|
||||
|
||||
### 2. Timeout Issues
|
||||
|
||||
**Symptoms**: Requests taking too long or timing out
|
||||
|
||||
**Solutions**:
|
||||
- Implement timeout handling as shown in the examples
|
||||
- Use retry logic with exponential backoff
|
||||
- Consider using a more reliable network connection
|
||||
|
||||
### 3. Response Parsing Errors
|
||||
|
||||
**Symptoms**: KeyError, IndexError, or ValueError when processing responses
|
||||
|
||||
**Solutions**:
|
||||
- Validate the response format before accessing nested fields
|
||||
- Implement proper error handling for malformed responses
|
||||
- Check the API documentation for the expected response format
|
||||
|
||||
### 4. Rate Limiting
|
||||
|
||||
**Symptoms**: 429 Too Many Requests errors
|
||||
|
||||
**Solutions**:
|
||||
- Implement rate limiting in your custom LLM
|
||||
- Add exponential backoff for retries
|
||||
- Consider using a token bucket algorithm for more precise rate control
|
||||
|
||||
## Advanced Features
|
||||
|
||||
### Logging
|
||||
|
||||
Adding logging to your custom LLM can help with debugging and monitoring:
|
||||
|
||||
```python
|
||||
import logging
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
class LoggingLLM(BaseLLM):
|
||||
def __init__(self, api_key: str, endpoint: str):
|
||||
super().__init__()
|
||||
self.api_key = api_key
|
||||
self.endpoint = endpoint
|
||||
self.logger = logging.getLogger("crewai.llm.custom")
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
self.logger.info(f"Calling LLM with {len(messages) if isinstance(messages, list) else 1} messages")
|
||||
try:
|
||||
# API call implementation
|
||||
response = self._make_api_call(messages, tools)
|
||||
self.logger.debug(f"LLM response received: {response[:100]}...")
|
||||
return response
|
||||
except Exception as e:
|
||||
self.logger.error(f"LLM call failed: {str(e)}")
|
||||
raise
|
||||
```
|
||||
|
||||
### Rate Limiting
|
||||
|
||||
Implementing rate limiting can help avoid overwhelming the LLM API:
|
||||
|
||||
```python
|
||||
import time
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
class RateLimitedLLM(BaseLLM):
|
||||
def __init__(
|
||||
self,
|
||||
api_key: str,
|
||||
endpoint: str,
|
||||
requests_per_minute: int = 60
|
||||
):
|
||||
super().__init__()
|
||||
self.api_key = api_key
|
||||
self.endpoint = endpoint
|
||||
self.requests_per_minute = requests_per_minute
|
||||
self.request_times: List[float] = []
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
self._enforce_rate_limit()
|
||||
# Record this request time
|
||||
self.request_times.append(time.time())
|
||||
# Make the actual API call
|
||||
return self._make_api_call(messages, tools)
|
||||
|
||||
def _enforce_rate_limit(self) -> None:
|
||||
"""Enforce the rate limit by waiting if necessary."""
|
||||
now = time.time()
|
||||
# Remove request times older than 1 minute
|
||||
self.request_times = [t for t in self.request_times if now - t < 60]
|
||||
|
||||
if len(self.request_times) >= self.requests_per_minute:
|
||||
# Calculate how long to wait
|
||||
oldest_request = min(self.request_times)
|
||||
wait_time = 60 - (now - oldest_request)
|
||||
if wait_time > 0:
|
||||
time.sleep(wait_time)
|
||||
```
|
||||
|
||||
### Metrics Collection
|
||||
|
||||
Collecting metrics can help you monitor your LLM usage:
|
||||
|
||||
```python
|
||||
import time
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
class MetricsCollectingLLM(BaseLLM):
|
||||
def __init__(self, api_key: str, endpoint: str):
|
||||
super().__init__()
|
||||
self.api_key = api_key
|
||||
self.endpoint = endpoint
|
||||
self.metrics: Dict[str, Any] = {
|
||||
"total_calls": 0,
|
||||
"total_tokens": 0,
|
||||
"errors": 0,
|
||||
"latency": []
|
||||
}
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
start_time = time.time()
|
||||
self.metrics["total_calls"] += 1
|
||||
|
||||
try:
|
||||
response = self._make_api_call(messages, tools)
|
||||
# Estimate tokens (simplified)
|
||||
if isinstance(messages, str):
|
||||
token_estimate = len(messages) // 4
|
||||
else:
|
||||
token_estimate = sum(len(m.get("content", "")) // 4 for m in messages)
|
||||
self.metrics["total_tokens"] += token_estimate
|
||||
return response
|
||||
except Exception as e:
|
||||
self.metrics["errors"] += 1
|
||||
raise
|
||||
finally:
|
||||
latency = time.time() - start_time
|
||||
self.metrics["latency"].append(latency)
|
||||
|
||||
def get_metrics(self) -> Dict[str, Any]:
|
||||
"""Return the collected metrics."""
|
||||
avg_latency = sum(self.metrics["latency"]) / len(self.metrics["latency"]) if self.metrics["latency"] else 0
|
||||
return {
|
||||
**self.metrics,
|
||||
"avg_latency": avg_latency
|
||||
}
|
||||
```
|
||||
|
||||
## Advanced Usage: Function Calling
|
||||
|
||||
If your LLM supports function calling, you can implement the function calling logic in your custom LLM:
|
||||
|
||||
```python
|
||||
import json
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
import requests
|
||||
|
||||
try:
|
||||
headers = {
|
||||
"Authorization": f"Bearer {self.jwt_token}",
|
||||
"Content-Type": "application/json"
|
||||
}
|
||||
|
||||
# Convert string message to proper format if needed
|
||||
if isinstance(messages, str):
|
||||
messages = [{"role": "user", "content": messages}]
|
||||
|
||||
data = {
|
||||
"messages": messages,
|
||||
"tools": tools
|
||||
}
|
||||
|
||||
response = requests.post(
|
||||
self.endpoint,
|
||||
headers=headers,
|
||||
json=data,
|
||||
timeout=30
|
||||
)
|
||||
response.raise_for_status()
|
||||
response_data = response.json()
|
||||
|
||||
# Check if the LLM wants to call a function
|
||||
if response_data["choices"][0]["message"].get("tool_calls"):
|
||||
tool_calls = response_data["choices"][0]["message"]["tool_calls"]
|
||||
|
||||
# Process each tool call
|
||||
for tool_call in tool_calls:
|
||||
function_name = tool_call["function"]["name"]
|
||||
function_args = json.loads(tool_call["function"]["arguments"])
|
||||
|
||||
if available_functions and function_name in available_functions:
|
||||
function_to_call = available_functions[function_name]
|
||||
function_response = function_to_call(**function_args)
|
||||
|
||||
# Add the function response to the messages
|
||||
messages.append({
|
||||
"role": "tool",
|
||||
"tool_call_id": tool_call["id"],
|
||||
"name": function_name,
|
||||
"content": str(function_response)
|
||||
})
|
||||
|
||||
# Call the LLM again with the updated messages
|
||||
return self.call(messages, tools, callbacks, available_functions)
|
||||
|
||||
# Return the text response if no function call
|
||||
return response_data["choices"][0]["message"]["content"]
|
||||
except requests.Timeout:
|
||||
raise TimeoutError("LLM request timed out")
|
||||
except requests.RequestException as e:
|
||||
raise RuntimeError(f"LLM request failed: {str(e)}")
|
||||
except (KeyError, IndexError, ValueError) as e:
|
||||
raise ValueError(f"Invalid response format: {str(e)}")
|
||||
```
|
||||
|
||||
## Using Your Custom LLM with CrewAI
|
||||
|
||||
Once you've implemented your custom LLM, you can use it with CrewAI agents and crews:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from typing import Dict, Any
|
||||
|
||||
# Create your custom LLM instance
|
||||
jwt_llm = JWTAuthLLM(
|
||||
jwt_token="your.jwt.token",
|
||||
endpoint="https://your-llm-endpoint.com/v1/chat/completions"
|
||||
)
|
||||
|
||||
# Use it with an agent
|
||||
agent = Agent(
|
||||
role="Research Assistant",
|
||||
goal="Find information on a topic",
|
||||
backstory="You are a research assistant tasked with finding information.",
|
||||
llm=jwt_llm,
|
||||
)
|
||||
|
||||
# Create a task for the agent
|
||||
task = Task(
|
||||
description="Research the benefits of exercise",
|
||||
agent=agent,
|
||||
expected_output="A summary of the benefits of exercise",
|
||||
)
|
||||
|
||||
# Execute the task
|
||||
result = agent.execute_task(task)
|
||||
print(result)
|
||||
|
||||
# Or use it with a crew
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
manager_llm=jwt_llm, # Use your custom LLM for the manager
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
|
||||
## Implementing Your Own Authentication Mechanism
|
||||
|
||||
The `BaseLLM` class allows you to implement any authentication mechanism you need, not just JWT or API keys. You can use:
|
||||
|
||||
- OAuth tokens
|
||||
- Client certificates
|
||||
- Custom headers
|
||||
- Session-based authentication
|
||||
- Any other authentication method required by your LLM provider
|
||||
|
||||
Simply implement the appropriate authentication logic in your custom LLM class.
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: Create Your Own Manager Agent
|
||||
title: Custom Manager Agent
|
||||
description: Learn how to set a custom agent as the manager in CrewAI, providing more control over task management and coordination.
|
||||
icon: user-shield
|
||||
---
|
||||
@@ -73,9 +73,9 @@ result = crew.kickoff()
|
||||
If you're using the hierarchical process and don't want to set a custom manager agent, you can specify the language model for the manager:
|
||||
|
||||
```python Code
|
||||
from langchain_openai import ChatOpenAI
|
||||
from crewai import LLM
|
||||
|
||||
manager_llm = ChatOpenAI(model_name="gpt-4")
|
||||
manager_llm = LLM(model="gpt-4o")
|
||||
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
|
||||
@@ -48,7 +48,6 @@ Define a crew with a designated manager and establish a clear chain of command.
|
||||
</Tip>
|
||||
|
||||
```python Code
|
||||
from langchain_openai import ChatOpenAI
|
||||
from crewai import Crew, Process, Agent
|
||||
|
||||
# Agents are defined with attributes for backstory, cache, and verbose mode
|
||||
@@ -56,38 +55,51 @@ researcher = Agent(
|
||||
role='Researcher',
|
||||
goal='Conduct in-depth analysis',
|
||||
backstory='Experienced data analyst with a knack for uncovering hidden trends.',
|
||||
cache=True,
|
||||
verbose=False,
|
||||
# tools=[] # This can be optionally specified; defaults to an empty list
|
||||
use_system_prompt=True, # Enable or disable system prompts for this agent
|
||||
max_rpm=30, # Limit on the number of requests per minute
|
||||
max_iter=5 # Maximum number of iterations for a final answer
|
||||
)
|
||||
writer = Agent(
|
||||
role='Writer',
|
||||
goal='Create engaging content',
|
||||
backstory='Creative writer passionate about storytelling in technical domains.',
|
||||
cache=True,
|
||||
verbose=False,
|
||||
# tools=[] # Optionally specify tools; defaults to an empty list
|
||||
use_system_prompt=True, # Enable or disable system prompts for this agent
|
||||
max_rpm=30, # Limit on the number of requests per minute
|
||||
max_iter=5 # Maximum number of iterations for a final answer
|
||||
)
|
||||
|
||||
# Establishing the crew with a hierarchical process and additional configurations
|
||||
project_crew = Crew(
|
||||
tasks=[...], # Tasks to be delegated and executed under the manager's supervision
|
||||
agents=[researcher, writer],
|
||||
manager_llm=ChatOpenAI(temperature=0, model="gpt-4"), # Mandatory if manager_agent is not set
|
||||
process=Process.hierarchical, # Specifies the hierarchical management approach
|
||||
respect_context_window=True, # Enable respect of the context window for tasks
|
||||
memory=True, # Enable memory usage for enhanced task execution
|
||||
manager_agent=None, # Optional: explicitly set a specific agent as manager instead of the manager_llm
|
||||
planning=True, # Enable planning feature for pre-execution strategy
|
||||
manager_llm="gpt-4o", # Specify which LLM the manager should use
|
||||
process=Process.hierarchical,
|
||||
planning=True,
|
||||
)
|
||||
```
|
||||
|
||||
### Using a Custom Manager Agent
|
||||
|
||||
Alternatively, you can create a custom manager agent with specific attributes tailored to your project's management needs. This gives you more control over the manager's behavior and capabilities.
|
||||
|
||||
```python
|
||||
# Define a custom manager agent
|
||||
manager = Agent(
|
||||
role="Project Manager",
|
||||
goal="Efficiently manage the crew and ensure high-quality task completion",
|
||||
backstory="You're an experienced project manager, skilled in overseeing complex projects and guiding teams to success.",
|
||||
allow_delegation=True,
|
||||
)
|
||||
|
||||
# Use the custom manager in your crew
|
||||
project_crew = Crew(
|
||||
tasks=[...],
|
||||
agents=[researcher, writer],
|
||||
manager_agent=manager, # Use your custom manager agent
|
||||
process=Process.hierarchical,
|
||||
planning=True,
|
||||
)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
For more details on creating and customizing a manager agent, check out the [Custom Manager Agent documentation](https://docs.crewai.com/how-to/custom-manager-agent#custom-manager-agent).
|
||||
</Tip>
|
||||
|
||||
|
||||
### Workflow in Action
|
||||
|
||||
1. **Task Assignment**: The manager assigns tasks strategically, considering each agent's capabilities and available tools.
|
||||
@@ -97,4 +109,4 @@ project_crew = Crew(
|
||||
## Conclusion
|
||||
|
||||
Adopting the hierarchical process in CrewAI, with the correct configurations and understanding of the system's capabilities, facilitates an organized and efficient approach to project management.
|
||||
Utilize the advanced features and customizations to tailor the workflow to your specific needs, ensuring optimal task execution and project success.
|
||||
Utilize the advanced features and customizations to tailor the workflow to your specific needs, ensuring optimal task execution and project success.
|
||||
|
||||
@@ -60,12 +60,12 @@ writer = Agent(
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description=(
|
||||
"Conduct a comprehensive analysis of the latest advancements in AI in 2024. "
|
||||
"Conduct a comprehensive analysis of the latest advancements in AI in 2025. "
|
||||
"Identify key trends, breakthrough technologies, and potential industry impacts. "
|
||||
"Compile your findings in a detailed report. "
|
||||
"Make sure to check with a human if the draft is good before finalizing your answer."
|
||||
),
|
||||
expected_output='A comprehensive full report on the latest AI advancements in 2024, leave nothing out',
|
||||
expected_output='A comprehensive full report on the latest AI advancements in 2025, leave nothing out',
|
||||
agent=researcher,
|
||||
human_input=True
|
||||
)
|
||||
@@ -76,7 +76,7 @@ task2 = Task(
|
||||
"Your post should be informative yet accessible, catering to a tech-savvy audience. "
|
||||
"Aim for a narrative that captures the essence of these breakthroughs and their implications for the future."
|
||||
),
|
||||
expected_output='A compelling 3 paragraphs blog post formatted as markdown about the latest AI advancements in 2024',
|
||||
expected_output='A compelling 3 paragraphs blog post formatted as markdown about the latest AI advancements in 2025',
|
||||
agent=writer,
|
||||
human_input=True
|
||||
)
|
||||
|
||||
@@ -54,7 +54,8 @@ coding_agent = Agent(
|
||||
# Create a task that requires code execution
|
||||
data_analysis_task = Task(
|
||||
description="Analyze the given dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent
|
||||
agent=coding_agent,
|
||||
expected_output="The average age of the participants."
|
||||
)
|
||||
|
||||
# Create a crew and add the task
|
||||
@@ -91,12 +92,14 @@ coding_agent = Agent(
|
||||
# Create tasks that require code execution
|
||||
task_1 = Task(
|
||||
description="Analyze the first dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent
|
||||
agent=coding_agent,
|
||||
expected_output="The average age of the participants."
|
||||
)
|
||||
|
||||
task_2 = Task(
|
||||
description="Analyze the second dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent
|
||||
agent=coding_agent,
|
||||
expected_output="The average age of the participants."
|
||||
)
|
||||
|
||||
# Create two crews and add tasks
|
||||
@@ -116,4 +119,4 @@ async def async_multiple_crews():
|
||||
|
||||
# Run the async function
|
||||
asyncio.run(async_multiple_crews())
|
||||
```
|
||||
```
|
||||
|
||||
@@ -39,8 +39,7 @@ analysis_crew = Crew(
|
||||
agents=[coding_agent],
|
||||
tasks=[data_analysis_task],
|
||||
verbose=True,
|
||||
memory=False,
|
||||
respect_context_window=True # enable by default
|
||||
memory=False
|
||||
)
|
||||
|
||||
datasets = [
|
||||
|
||||
100
docs/how-to/langfuse-observability.mdx
Normal file
@@ -0,0 +1,100 @@
|
||||
---
|
||||
title: Langfuse Integration
|
||||
description: Learn how to integrate Langfuse with CrewAI via OpenTelemetry using OpenLit
|
||||
icon: vials
|
||||
---
|
||||
|
||||
# Integrate Langfuse with CrewAI
|
||||
|
||||
This notebook demonstrates how to integrate **Langfuse** with **CrewAI** using OpenTelemetry via the **OpenLit** SDK. By the end of this notebook, you will be able to trace your CrewAI applications with Langfuse for improved observability and debugging.
|
||||
|
||||
> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source LLM engineering platform. It provides tracing and monitoring capabilities for LLM applications, helping developers debug, analyze, and optimize their AI systems. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and APIs/SDKs.
|
||||
|
||||
[](https://langfuse.com/watch-demo)
|
||||
|
||||
## Get Started
|
||||
|
||||
We'll walk through a simple example of using CrewAI and integrating it with Langfuse via OpenTelemetry using OpenLit.
|
||||
|
||||
### Step 1: Install Dependencies
|
||||
|
||||
|
||||
```python
|
||||
%pip install langfuse openlit crewai crewai_tools
|
||||
```
|
||||
|
||||
### Step 2: Set Up Environment Variables
|
||||
|
||||
Set your Langfuse API keys and configure OpenTelemetry export settings to send traces to Langfuse. Please refer to the [Langfuse OpenTelemetry Docs](https://langfuse.com/docs/opentelemetry/get-started) for more information on the Langfuse OpenTelemetry endpoint `/api/public/otel` and authentication.
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
import base64
|
||||
|
||||
LANGFUSE_PUBLIC_KEY="pk-lf-..."
|
||||
LANGFUSE_SECRET_KEY="sk-lf-..."
|
||||
LANGFUSE_AUTH=base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
|
||||
|
||||
os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel" # EU data region
|
||||
# os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://us.cloud.langfuse.com/api/public/otel" # US data region
|
||||
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
|
||||
|
||||
# your openai key
|
||||
os.environ["OPENAI_API_KEY"] = "sk-..."
|
||||
```
|
||||
|
||||
### Step 3: Initialize OpenLit
|
||||
|
||||
Initialize the OpenLit OpenTelemetry instrumentation SDK to start capturing OpenTelemetry traces.
|
||||
|
||||
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
### Step 4: Create a Simple CrewAI Application
|
||||
|
||||
We'll create a simple CrewAI application where multiple agents collaborate to answer a user's question.
|
||||
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
from crewai_tools import (
|
||||
WebsiteSearchTool
|
||||
)
|
||||
|
||||
web_rag_tool = WebsiteSearchTool()
|
||||
|
||||
writer = Agent(
|
||||
role="Writer",
|
||||
goal="You make math engaging and understandable for young children through poetry",
|
||||
backstory="You're an expert in writing haikus but you know nothing of math.",
|
||||
tools=[web_rag_tool],
|
||||
)
|
||||
|
||||
task = Task(description=("What is {multiplication}?"),
|
||||
expected_output=("Compose a haiku that includes the answer."),
|
||||
agent=writer)
|
||||
|
||||
crew = Crew(
|
||||
agents=[writer],
|
||||
tasks=[task],
|
||||
share_crew=False
|
||||
)
|
||||
```
|
||||
|
||||
### Step 5: See Traces in Langfuse
|
||||
|
||||
After running the agent, you can view the traces generated by your CrewAI application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.
|
||||
|
||||
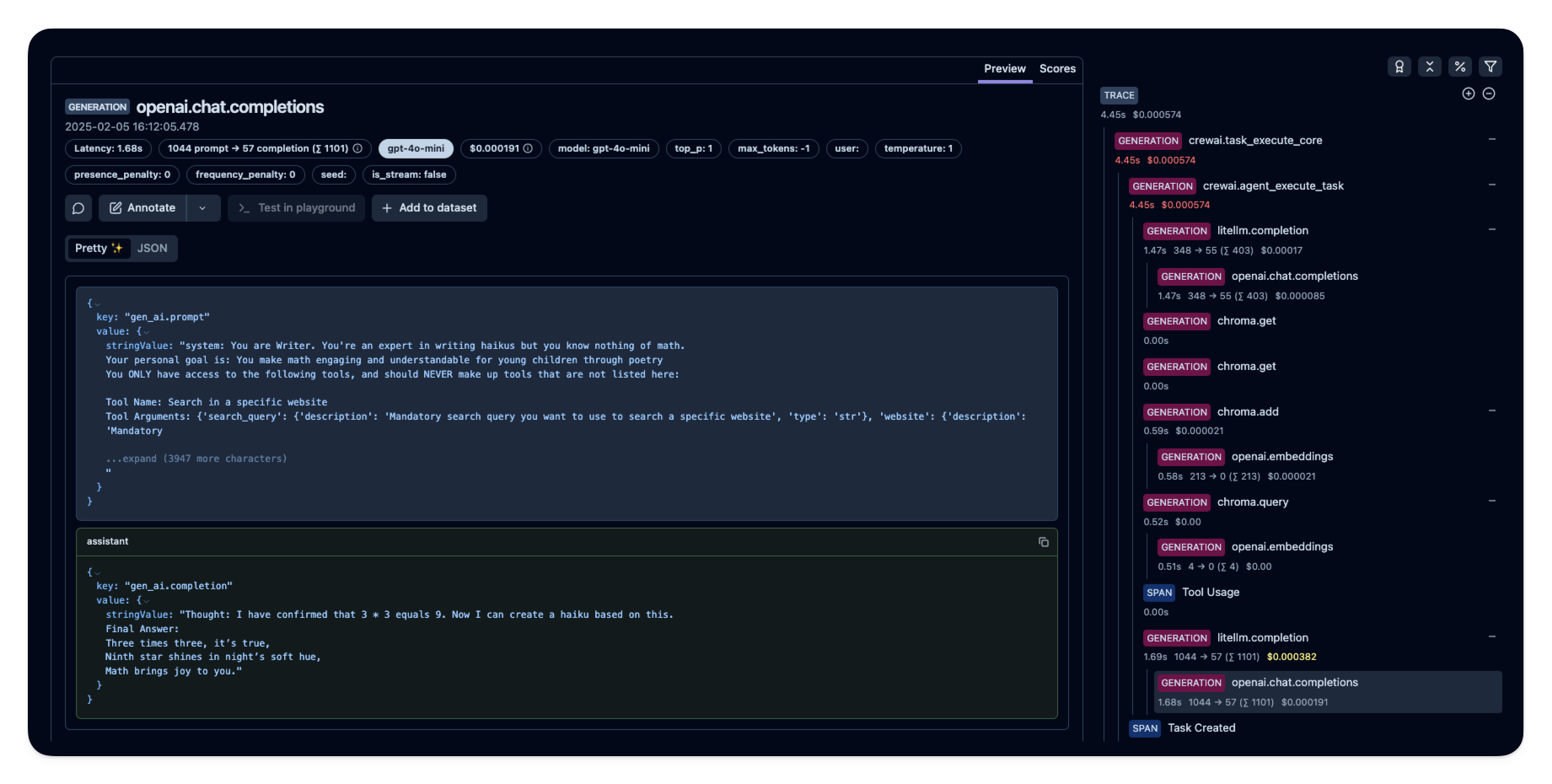
|
||||
|
||||
_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/e2cf380ffc8d47d28da98f136140642b?timestamp=2025-02-05T15%3A12%3A02.717Z&observation=3b32338ee6a5d9af)_
|
||||
|
||||
## References
|
||||
|
||||
- [Langfuse OpenTelemetry Docs](https://langfuse.com/docs/opentelemetry/get-started)
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: Agent Monitoring with Langtrace
|
||||
title: Langtrace Integration
|
||||
description: How to monitor cost, latency, and performance of CrewAI Agents using Langtrace, an external observability tool.
|
||||
icon: chart-line
|
||||
---
|
||||
|
||||
@@ -23,6 +23,7 @@ LiteLLM supports a wide range of providers, including but not limited to:
|
||||
- Azure OpenAI
|
||||
- AWS (Bedrock, SageMaker)
|
||||
- Cohere
|
||||
- VoyageAI
|
||||
- Hugging Face
|
||||
- Ollama
|
||||
- Mistral AI
|
||||
@@ -32,6 +33,8 @@ LiteLLM supports a wide range of providers, including but not limited to:
|
||||
- Cloudflare Workers AI
|
||||
- DeepInfra
|
||||
- Groq
|
||||
- SambaNova
|
||||
- [NVIDIA NIMs](https://docs.api.nvidia.com/nim/reference/models-1)
|
||||
- And many more!
|
||||
|
||||
For a complete and up-to-date list of supported providers, please refer to the [LiteLLM Providers documentation](https://docs.litellm.ai/docs/providers).
|
||||
@@ -125,10 +128,10 @@ You can connect to OpenAI-compatible LLMs using either environment variables or
|
||||
</Tab>
|
||||
<Tab title="Using LLM Class Attributes">
|
||||
<CodeGroup>
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="custom-model-name",
|
||||
api_key="your-api-key",
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="custom-model-name",
|
||||
api_key="your-api-key",
|
||||
base_url="https://api.your-provider.com/v1"
|
||||
)
|
||||
agent = Agent(llm=llm, ...)
|
||||
@@ -179,4 +182,4 @@ This is particularly useful when working with OpenAI-compatible APIs or when you
|
||||
|
||||
## Conclusion
|
||||
|
||||
By leveraging LiteLLM, CrewAI offers seamless integration with a vast array of LLMs. This flexibility allows you to choose the most suitable model for your specific needs, whether you prioritize performance, cost-efficiency, or local deployment. Remember to consult the [LiteLLM documentation](https://docs.litellm.ai/docs/) for the most up-to-date information on supported models and configuration options.
|
||||
By leveraging LiteLLM, CrewAI offers seamless integration with a vast array of LLMs. This flexibility allows you to choose the most suitable model for your specific needs, whether you prioritize performance, cost-efficiency, or local deployment. Remember to consult the [LiteLLM documentation](https://docs.litellm.ai/docs/) for the most up-to-date information on supported models and configuration options.
|
||||
|
||||
206
docs/how-to/mlflow-observability.mdx
Normal file
@@ -0,0 +1,206 @@
|
||||
---
|
||||
title: MLflow Integration
|
||||
description: Quickly start monitoring your Agents with MLflow.
|
||||
icon: bars-staggered
|
||||
---
|
||||
|
||||
# MLflow Overview
|
||||
|
||||
[MLflow](https://mlflow.org/) is an open-source platform to assist machine learning practitioners and teams in handling the complexities of the machine learning process.
|
||||
|
||||
It provides a tracing feature that enhances LLM observability in your Generative AI applications by capturing detailed information about the execution of your application’s services.
|
||||
Tracing provides a way to record the inputs, outputs, and metadata associated with each intermediate step of a request, enabling you to easily pinpoint the source of bugs and unexpected behaviors.
|
||||
|
||||

|
||||
|
||||
### Features
|
||||
|
||||
- **Tracing Dashboard**: Monitor activities of your crewAI agents with detailed dashboards that include inputs, outputs and metadata of spans.
|
||||
- **Automated Tracing**: A fully automated integration with crewAI, which can be enabled by running `mlflow.crewai.autolog()`.
|
||||
- **Manual Trace Instrumentation with minor efforts**: Customize trace instrumentation through MLflow's high-level fluent APIs such as decorators, function wrappers and context managers.
|
||||
- **OpenTelemetry Compatibility**: MLflow Tracing supports exporting traces to an OpenTelemetry Collector, which can then be used to export traces to various backends such as Jaeger, Zipkin, and AWS X-Ray.
|
||||
- **Package and Deploy Agents**: Package and deploy your crewAI agents to an inference server with a variety of deployment targets.
|
||||
- **Securely Host LLMs**: Host multiple LLM from various providers in one unified endpoint through MFflow gateway.
|
||||
- **Evaluation**: Evaluate your crewAI agents with a wide range of metrics using a convenient API `mlflow.evaluate()`.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Install MLflow package">
|
||||
```shell
|
||||
# The crewAI integration is available in mlflow>=2.19.0
|
||||
pip install mlflow
|
||||
```
|
||||
</Step>
|
||||
<Step title="Start MFflow tracking server">
|
||||
```shell
|
||||
# This process is optional, but it is recommended to use MLflow tracking server for better visualization and broader features.
|
||||
mlflow server
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize MLflow in Your Application">
|
||||
Add the following two lines to your application code:
|
||||
|
||||
```python
|
||||
import mlflow
|
||||
|
||||
mlflow.crewai.autolog()
|
||||
|
||||
# Optional: Set a tracking URI and an experiment name if you have a tracking server
|
||||
mlflow.set_tracking_uri("http://localhost:5000")
|
||||
mlflow.set_experiment("CrewAI")
|
||||
```
|
||||
|
||||
Example Usage for tracing CrewAI Agents:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task
|
||||
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
|
||||
from crewai_tools import SerperDevTool, WebsiteSearchTool
|
||||
|
||||
from textwrap import dedent
|
||||
|
||||
content = "Users name is John. He is 30 years old and lives in San Francisco."
|
||||
string_source = StringKnowledgeSource(
|
||||
content=content, metadata={"preference": "personal"}
|
||||
)
|
||||
|
||||
search_tool = WebsiteSearchTool()
|
||||
|
||||
|
||||
class TripAgents:
|
||||
def city_selection_agent(self):
|
||||
return Agent(
|
||||
role="City Selection Expert",
|
||||
goal="Select the best city based on weather, season, and prices",
|
||||
backstory="An expert in analyzing travel data to pick ideal destinations",
|
||||
tools=[
|
||||
search_tool,
|
||||
],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def local_expert(self):
|
||||
return Agent(
|
||||
role="Local Expert at this city",
|
||||
goal="Provide the BEST insights about the selected city",
|
||||
backstory="""A knowledgeable local guide with extensive information
|
||||
about the city, it's attractions and customs""",
|
||||
tools=[search_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
|
||||
class TripTasks:
|
||||
def identify_task(self, agent, origin, cities, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
Analyze and select the best city for the trip based
|
||||
on specific criteria such as weather patterns, seasonal
|
||||
events, and travel costs. This task involves comparing
|
||||
multiple cities, considering factors like current weather
|
||||
conditions, upcoming cultural or seasonal events, and
|
||||
overall travel expenses.
|
||||
Your final answer must be a detailed
|
||||
report on the chosen city, and everything you found out
|
||||
about it, including the actual flight costs, weather
|
||||
forecast and attractions.
|
||||
|
||||
Traveling from: {origin}
|
||||
City Options: {cities}
|
||||
Trip Date: {range}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Detailed report on the chosen city including flight costs, weather forecast, and attractions",
|
||||
)
|
||||
|
||||
def gather_task(self, agent, origin, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
As a local expert on this city you must compile an
|
||||
in-depth guide for someone traveling there and wanting
|
||||
to have THE BEST trip ever!
|
||||
Gather information about key attractions, local customs,
|
||||
special events, and daily activity recommendations.
|
||||
Find the best spots to go to, the kind of place only a
|
||||
local would know.
|
||||
This guide should provide a thorough overview of what
|
||||
the city has to offer, including hidden gems, cultural
|
||||
hotspots, must-visit landmarks, weather forecasts, and
|
||||
high level costs.
|
||||
The final answer must be a comprehensive city guide,
|
||||
rich in cultural insights and practical tips,
|
||||
tailored to enhance the travel experience.
|
||||
|
||||
Trip Date: {range}
|
||||
Traveling from: {origin}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Comprehensive city guide including hidden gems, cultural hotspots, and practical travel tips",
|
||||
)
|
||||
|
||||
|
||||
class TripCrew:
|
||||
def __init__(self, origin, cities, date_range, interests):
|
||||
self.cities = cities
|
||||
self.origin = origin
|
||||
self.interests = interests
|
||||
self.date_range = date_range
|
||||
|
||||
def run(self):
|
||||
agents = TripAgents()
|
||||
tasks = TripTasks()
|
||||
|
||||
city_selector_agent = agents.city_selection_agent()
|
||||
local_expert_agent = agents.local_expert()
|
||||
|
||||
identify_task = tasks.identify_task(
|
||||
city_selector_agent,
|
||||
self.origin,
|
||||
self.cities,
|
||||
self.interests,
|
||||
self.date_range,
|
||||
)
|
||||
gather_task = tasks.gather_task(
|
||||
local_expert_agent, self.origin, self.interests, self.date_range
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[city_selector_agent, local_expert_agent],
|
||||
tasks=[identify_task, gather_task],
|
||||
verbose=True,
|
||||
memory=True,
|
||||
knowledge={
|
||||
"sources": [string_source],
|
||||
"metadata": {"preference": "personal"},
|
||||
},
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
return result
|
||||
|
||||
|
||||
trip_crew = TripCrew("California", "Tokyo", "Dec 12 - Dec 20", "sports")
|
||||
result = trip_crew.run()
|
||||
|
||||
print(result)
|
||||
```
|
||||
Refer to [MLflow Tracing Documentation](https://mlflow.org/docs/latest/llms/tracing/index.html) for more configurations and use cases.
|
||||
</Step>
|
||||
<Step title="Visualize Activities of Agents">
|
||||
Now traces for your crewAI agents are captured by MLflow.
|
||||
Let's visit MLflow tracking server to view the traces and get insights into your Agents.
|
||||
|
||||
Open `127.0.0.1:5000` on your browser to visit MLflow tracking server.
|
||||
<Frame caption="MLflow Tracing Dashboard">
|
||||
<img src="/images/mlflow1.png" alt="MLflow tracing example with crewai" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
140
docs/how-to/multimodal-agents.mdx
Normal file
@@ -0,0 +1,140 @@
|
||||
---
|
||||
title: Using Multimodal Agents
|
||||
description: Learn how to enable and use multimodal capabilities in your agents for processing images and other non-text content within the CrewAI framework.
|
||||
icon: video
|
||||
---
|
||||
|
||||
## Using Multimodal Agents
|
||||
|
||||
CrewAI supports multimodal agents that can process both text and non-text content like images. This guide will show you how to enable and use multimodal capabilities in your agents.
|
||||
|
||||
### Enabling Multimodal Capabilities
|
||||
|
||||
To create a multimodal agent, simply set the `multimodal` parameter to `True` when initializing your agent:
|
||||
|
||||
```python
|
||||
from crewai import Agent
|
||||
|
||||
agent = Agent(
|
||||
role="Image Analyst",
|
||||
goal="Analyze and extract insights from images",
|
||||
backstory="An expert in visual content interpretation with years of experience in image analysis",
|
||||
multimodal=True # This enables multimodal capabilities
|
||||
)
|
||||
```
|
||||
|
||||
When you set `multimodal=True`, the agent is automatically configured with the necessary tools for handling non-text content, including the `AddImageTool`.
|
||||
|
||||
### Working with Images
|
||||
|
||||
The multimodal agent comes pre-configured with the `AddImageTool`, which allows it to process images. You don't need to manually add this tool - it's automatically included when you enable multimodal capabilities.
|
||||
|
||||
Here's a complete example showing how to use a multimodal agent to analyze an image:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
# Create a multimodal agent
|
||||
image_analyst = Agent(
|
||||
role="Product Analyst",
|
||||
goal="Analyze product images and provide detailed descriptions",
|
||||
backstory="Expert in visual product analysis with deep knowledge of design and features",
|
||||
multimodal=True
|
||||
)
|
||||
|
||||
# Create a task for image analysis
|
||||
task = Task(
|
||||
description="Analyze the product image at https://example.com/product.jpg and provide a detailed description",
|
||||
expected_output="A detailed description of the product image",
|
||||
agent=image_analyst
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(
|
||||
agents=[image_analyst],
|
||||
tasks=[task]
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Advanced Usage with Context
|
||||
|
||||
You can provide additional context or specific questions about the image when creating tasks for multimodal agents. The task description can include specific aspects you want the agent to focus on:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
# Create a multimodal agent for detailed analysis
|
||||
expert_analyst = Agent(
|
||||
role="Visual Quality Inspector",
|
||||
goal="Perform detailed quality analysis of product images",
|
||||
backstory="Senior quality control expert with expertise in visual inspection",
|
||||
multimodal=True # AddImageTool is automatically included
|
||||
)
|
||||
|
||||
# Create a task with specific analysis requirements
|
||||
inspection_task = Task(
|
||||
description="""
|
||||
Analyze the product image at https://example.com/product.jpg with focus on:
|
||||
1. Quality of materials
|
||||
2. Manufacturing defects
|
||||
3. Compliance with standards
|
||||
Provide a detailed report highlighting any issues found.
|
||||
""",
|
||||
expected_output="A detailed report highlighting any issues found",
|
||||
agent=expert_analyst
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(
|
||||
agents=[expert_analyst],
|
||||
tasks=[inspection_task]
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Tool Details
|
||||
|
||||
When working with multimodal agents, the `AddImageTool` is automatically configured with the following schema:
|
||||
|
||||
```python
|
||||
class AddImageToolSchema:
|
||||
image_url: str # Required: The URL or path of the image to process
|
||||
action: Optional[str] = None # Optional: Additional context or specific questions about the image
|
||||
```
|
||||
|
||||
The multimodal agent will automatically handle the image processing through its built-in tools, allowing it to:
|
||||
- Access images via URLs or local file paths
|
||||
- Process image content with optional context or specific questions
|
||||
- Provide analysis and insights based on the visual information and task requirements
|
||||
|
||||
### Best Practices
|
||||
|
||||
When working with multimodal agents, keep these best practices in mind:
|
||||
|
||||
1. **Image Access**
|
||||
- Ensure your images are accessible via URLs that the agent can reach
|
||||
- For local images, consider hosting them temporarily or using absolute file paths
|
||||
- Verify that image URLs are valid and accessible before running tasks
|
||||
|
||||
2. **Task Description**
|
||||
- Be specific about what aspects of the image you want the agent to analyze
|
||||
- Include clear questions or requirements in the task description
|
||||
- Consider using the optional `action` parameter for focused analysis
|
||||
|
||||
3. **Resource Management**
|
||||
- Image processing may require more computational resources than text-only tasks
|
||||
- Some language models may require base64 encoding for image data
|
||||
- Consider batch processing for multiple images to optimize performance
|
||||
|
||||
4. **Environment Setup**
|
||||
- Verify that your environment has the necessary dependencies for image processing
|
||||
- Ensure your language model supports multimodal capabilities
|
||||
- Test with small images first to validate your setup
|
||||
|
||||
5. **Error Handling**
|
||||
- Implement proper error handling for image loading failures
|
||||
- Have fallback strategies for when image processing fails
|
||||
- Monitor and log image processing operations for debugging
|
||||
181
docs/how-to/openlit-observability.mdx
Normal file
@@ -0,0 +1,181 @@
|
||||
---
|
||||
title: OpenLIT Integration
|
||||
description: Quickly start monitoring your Agents in just a single line of code with OpenTelemetry.
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# OpenLIT Overview
|
||||
|
||||
[OpenLIT](https://github.com/openlit/openlit?src=crewai-docs) is an open-source tool that makes it simple to monitor the performance of AI agents, LLMs, VectorDBs, and GPUs with just **one** line of code.
|
||||
|
||||
It provides OpenTelemetry-native tracing and metrics to track important parameters like cost, latency, interactions and task sequences.
|
||||
This setup enables you to track hyperparameters and monitor for performance issues, helping you find ways to enhance and fine-tune your agents over time.
|
||||
|
||||
<Frame caption="OpenLIT Dashboard">
|
||||
<img src="/images/openlit1.png" alt="Overview Agent usage including cost and tokens" />
|
||||
<img src="/images/openlit2.png" alt="Overview of agent otel traces and metrics" />
|
||||
<img src="/images/openlit3.png" alt="Overview of agent traces in details" />
|
||||
</Frame>
|
||||
|
||||
### Features
|
||||
|
||||
- **Analytics Dashboard**: Monitor your Agents health and performance with detailed dashboards that track metrics, costs, and user interactions.
|
||||
- **OpenTelemetry-native Observability SDK**: Vendor-neutral SDKs to send traces and metrics to your existing observability tools like Grafana, DataDog and more.
|
||||
- **Cost Tracking for Custom and Fine-Tuned Models**: Tailor cost estimations for specific models using custom pricing files for precise budgeting.
|
||||
- **Exceptions Monitoring Dashboard**: Quickly spot and resolve issues by tracking common exceptions and errors with a monitoring dashboard.
|
||||
- **Compliance and Security**: Detect potential threats such as profanity and PII leaks.
|
||||
- **Prompt Injection Detection**: Identify potential code injection and secret leaks.
|
||||
- **API Keys and Secrets Management**: Securely handle your LLM API keys and secrets centrally, avoiding insecure practices.
|
||||
- **Prompt Management**: Manage and version Agent prompts using PromptHub for consistent and easy access across Agents.
|
||||
- **Model Playground** Test and compare different models for your CrewAI agents before deployment.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Deploy OpenLIT">
|
||||
<Steps>
|
||||
<Step title="Git Clone OpenLIT Repository">
|
||||
```shell
|
||||
git clone git@github.com:openlit/openlit.git
|
||||
```
|
||||
</Step>
|
||||
<Step title="Start Docker Compose">
|
||||
From the root directory of the [OpenLIT Repo](https://github.com/openlit/openlit), Run the below command:
|
||||
```shell
|
||||
docker compose up -d
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
</Step>
|
||||
<Step title="Install OpenLIT SDK">
|
||||
```shell
|
||||
pip install openlit
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize OpenLIT in Your Application">
|
||||
Add the following two lines to your application code:
|
||||
<Tabs>
|
||||
<Tab title="Setup using function arguments">
|
||||
```python
|
||||
import openlit
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
```
|
||||
|
||||
Example Usage for monitoring a CrewAI Agent:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
import openlit
|
||||
|
||||
openlit.init(disable_metrics=True)
|
||||
# Define your agents
|
||||
researcher = Agent(
|
||||
role="Researcher",
|
||||
goal="Conduct thorough research and analysis on AI and AI agents",
|
||||
backstory="You're an expert researcher, specialized in technology, software engineering, AI, and startups. You work as a freelancer and are currently researching for a new client.",
|
||||
allow_delegation=False,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
|
||||
# Define your task
|
||||
task = Task(
|
||||
description="Generate a list of 5 interesting ideas for an article, then write one captivating paragraph for each idea that showcases the potential of a full article on this topic. Return the list of ideas with their paragraphs and your notes.",
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Define the manager agent
|
||||
manager = Agent(
|
||||
role="Project Manager",
|
||||
goal="Efficiently manage the crew and ensure high-quality task completion",
|
||||
backstory="You're an experienced project manager, skilled in overseeing complex projects and guiding teams to success. Your role is to coordinate the efforts of the crew members, ensuring that each task is completed on time and to the highest standard.",
|
||||
allow_delegation=True,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
# Instantiate your crew with a custom manager
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[task],
|
||||
manager_agent=manager,
|
||||
process=Process.hierarchical,
|
||||
)
|
||||
|
||||
# Start the crew's work
|
||||
result = crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
</Tab>
|
||||
<Tab title="Setup using Environment Variables">
|
||||
|
||||
Add the following two lines to your application code:
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
Run the following command to configure the OTEL export endpoint:
|
||||
```shell
|
||||
export OTEL_EXPORTER_OTLP_ENDPOINT = "http://127.0.0.1:4318"
|
||||
```
|
||||
|
||||
Example Usage for monitoring a CrewAI Async Agent:
|
||||
|
||||
```python
|
||||
import asyncio
|
||||
from crewai import Crew, Agent, Task
|
||||
import openlit
|
||||
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
|
||||
# Create an agent with code execution enabled
|
||||
coding_agent = Agent(
|
||||
role="Python Data Analyst",
|
||||
goal="Analyze data and provide insights using Python",
|
||||
backstory="You are an experienced data analyst with strong Python skills.",
|
||||
allow_code_execution=True,
|
||||
llm="command-r"
|
||||
)
|
||||
|
||||
# Create a task that requires code execution
|
||||
data_analysis_task = Task(
|
||||
description="Analyze the given dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent,
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Create a crew and add the task
|
||||
analysis_crew = Crew(
|
||||
agents=[coding_agent],
|
||||
tasks=[data_analysis_task]
|
||||
)
|
||||
|
||||
# Async function to kickoff the crew asynchronously
|
||||
async def async_crew_execution():
|
||||
result = await analysis_crew.kickoff_async(inputs={"ages": [25, 30, 35, 40, 45]})
|
||||
print("Crew Result:", result)
|
||||
|
||||
# Run the async function
|
||||
asyncio.run(async_crew_execution())
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
Refer to OpenLIT [Python SDK repository](https://github.com/openlit/openlit/tree/main/sdk/python) for more advanced configurations and use cases.
|
||||
</Step>
|
||||
<Step title="Visualize and Analyze">
|
||||
With the Agent Observability data now being collected and sent to OpenLIT, the next step is to visualize and analyze this data to get insights into your Agent's performance, behavior, and identify areas of improvement.
|
||||
|
||||
Just head over to OpenLIT at `127.0.0.1:3000` on your browser to start exploring. You can login using the default credentials
|
||||
- **Email**: `user@openlit.io`
|
||||
- **Password**: `openlituser`
|
||||
|
||||
<Frame caption="OpenLIT Dashboard">
|
||||
<img src="/images/openlit1.png" alt="Overview Agent usage including cost and tokens" />
|
||||
<img src="/images/openlit2.png" alt="Overview of agent otel traces and metrics" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
129
docs/how-to/opik-observability.mdx
Normal file
@@ -0,0 +1,129 @@
|
||||
---
|
||||
title: Opik Integration
|
||||
description: Learn how to use Comet Opik to debug, evaluate, and monitor your CrewAI applications with comprehensive tracing, automated evaluations, and production-ready dashboards.
|
||||
icon: meteor
|
||||
---
|
||||
|
||||
# Opik Overview
|
||||
|
||||
With [Comet Opik](https://www.comet.com/docs/opik/), debug, evaluate, and monitor your LLM applications, RAG systems, and agentic workflows with comprehensive tracing, automated evaluations, and production-ready dashboards.
|
||||
|
||||
<Frame caption="Opik Agent Dashboard">
|
||||
<img src="/images/opik-crewai-dashboard.png" alt="Opik agent monitoring example with CrewAI" />
|
||||
</Frame>
|
||||
|
||||
Opik provides comprehensive support for every stage of your CrewAI application development:
|
||||
|
||||
- **Log Traces and Spans**: Automatically track LLM calls and application logic to debug and analyze development and production systems. Manually or programmatically annotate, view, and compare responses across projects.
|
||||
- **Evaluate Your LLM Application's Performance**: Evaluate against a custom test set and run built-in evaluation metrics or define your own metrics in the SDK or UI.
|
||||
- **Test Within Your CI/CD Pipeline**: Establish reliable performance baselines with Opik's LLM unit tests, built on PyTest. Run online evaluations for continuous monitoring in production.
|
||||
- **Monitor & Analyze Production Data**: Understand your models' performance on unseen data in production and generate datasets for new dev iterations.
|
||||
|
||||
## Setup
|
||||
Comet provides a hosted version of the Opik platform, or you can run the platform locally.
|
||||
|
||||
To use the hosted version, simply [create a free Comet account](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) and grab you API Key.
|
||||
|
||||
To run the Opik platform locally, see our [installation guide](https://www.comet.com/docs/opik/self-host/overview/) for more information.
|
||||
|
||||
For this guide we will use CrewAI’s quickstart example.
|
||||
|
||||
<Steps>
|
||||
<Step title="Install required packages">
|
||||
```shell
|
||||
pip install crewai crewai-tools opik --upgrade
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure Opik">
|
||||
```python
|
||||
import opik
|
||||
opik.configure(use_local=False)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Prepare environment">
|
||||
First, we set up our API keys for our LLM-provider as environment variables:
|
||||
|
||||
```python
|
||||
import os
|
||||
import getpass
|
||||
|
||||
if "OPENAI_API_KEY" not in os.environ:
|
||||
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
|
||||
```
|
||||
</Step>
|
||||
<Step title="Using CrewAI">
|
||||
The first step is to create our project. We will use an example from CrewAI’s documentation:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task, Process
|
||||
|
||||
|
||||
class YourCrewName:
|
||||
def agent_one(self) -> Agent:
|
||||
return Agent(
|
||||
role="Data Analyst",
|
||||
goal="Analyze data trends in the market",
|
||||
backstory="An experienced data analyst with a background in economics",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def agent_two(self) -> Agent:
|
||||
return Agent(
|
||||
role="Market Researcher",
|
||||
goal="Gather information on market dynamics",
|
||||
backstory="A diligent researcher with a keen eye for detail",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def task_one(self) -> Task:
|
||||
return Task(
|
||||
name="Collect Data Task",
|
||||
description="Collect recent market data and identify trends.",
|
||||
expected_output="A report summarizing key trends in the market.",
|
||||
agent=self.agent_one(),
|
||||
)
|
||||
|
||||
def task_two(self) -> Task:
|
||||
return Task(
|
||||
name="Market Research Task",
|
||||
description="Research factors affecting market dynamics.",
|
||||
expected_output="An analysis of factors influencing the market.",
|
||||
agent=self.agent_two(),
|
||||
)
|
||||
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[self.agent_one(), self.agent_two()],
|
||||
tasks=[self.task_one(), self.task_two()],
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
Now we can import Opik’s tracker and run our crew:
|
||||
|
||||
```python
|
||||
from opik.integrations.crewai import track_crewai
|
||||
|
||||
track_crewai(project_name="crewai-integration-demo")
|
||||
|
||||
my_crew = YourCrewName().crew()
|
||||
result = my_crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
After running your CrewAI application, visit the Opik app to view:
|
||||
- LLM traces, spans, and their metadata
|
||||
- Agent interactions and task execution flow
|
||||
- Performance metrics like latency and token usage
|
||||
- Evaluation metrics (built-in or custom)
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Resources
|
||||
|
||||
- [🦉 Opik Documentation](https://www.comet.com/docs/opik/)
|
||||
- [👉 Opik + CrewAI Colab](https://colab.research.google.com/github/comet-ml/opik/blob/main/apps/opik-documentation/documentation/docs/cookbook/crewai.ipynb)
|
||||
- [🐦 X](https://x.com/cometml)
|
||||
- [💬 Slack](https://slack.comet.com/)
|
||||
202
docs/how-to/portkey-observability.mdx
Normal file
@@ -0,0 +1,202 @@
|
||||
---
|
||||
title: Portkey Integration
|
||||
description: How to use Portkey with CrewAI
|
||||
icon: key
|
||||
---
|
||||
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-CrewAI.png" alt="Portkey CrewAI Header Image" width="70%" />
|
||||
|
||||
|
||||
[Portkey](https://portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) is a 2-line upgrade to make your CrewAI agents reliable, cost-efficient, and fast.
|
||||
|
||||
Portkey adds 4 core production capabilities to any CrewAI agent:
|
||||
1. Routing to **200+ LLMs**
|
||||
2. Making each LLM call more robust
|
||||
3. Full-stack tracing & cost, performance analytics
|
||||
4. Real-time guardrails to enforce behavior
|
||||
|
||||
## Getting Started
|
||||
|
||||
<Steps>
|
||||
<Step title="Install CrewAI and Portkey">
|
||||
```bash
|
||||
pip install -qU crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure the LLM Client">
|
||||
To build CrewAI Agents with Portkey, you'll need two keys:
|
||||
- **Portkey API Key**: Sign up on the [Portkey app](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) and copy your API key
|
||||
- **Virtual Key**: Virtual Keys securely manage your LLM API keys in one place. Store your LLM provider API keys securely in Portkey's vault
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy", # We are using Virtual key
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_VIRTUAL_KEY", # Enter your Virtual key from Portkey
|
||||
)
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Create and Run Your First Agent">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
# Define your agents with roles and goals
|
||||
coder = Agent(
|
||||
role='Software developer',
|
||||
goal='Write clear, concise code on demand',
|
||||
backstory='An expert coder with a keen eye for software trends.',
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description="Define the HTML for making a simple website with heading- Hello World! Portkey is working!",
|
||||
expected_output="A clear and concise HTML code",
|
||||
agent=coder
|
||||
)
|
||||
|
||||
# Instantiate your crew
|
||||
crew = Crew(
|
||||
agents=[coder],
|
||||
tasks=[task1],
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Key Features
|
||||
|
||||
| Feature | Description |
|
||||
|:--------|:------------|
|
||||
| 🌐 Multi-LLM Support | Access OpenAI, Anthropic, Gemini, Azure, and 250+ providers through a unified interface |
|
||||
| 🛡️ Production Reliability | Implement retries, timeouts, load balancing, and fallbacks |
|
||||
| 📊 Advanced Observability | Track 40+ metrics including costs, tokens, latency, and custom metadata |
|
||||
| 🔍 Comprehensive Logging | Debug with detailed execution traces and function call logs |
|
||||
| 🚧 Security Controls | Set budget limits and implement role-based access control |
|
||||
| 🔄 Performance Analytics | Capture and analyze feedback for continuous improvement |
|
||||
| 💾 Intelligent Caching | Reduce costs and latency with semantic or simple caching |
|
||||
|
||||
|
||||
## Production Features with Portkey Configs
|
||||
|
||||
All features mentioned below are through Portkey's Config system. Portkey's Config system allows you to define routing strategies using simple JSON objects in your LLM API calls. You can create and manage Configs directly in your code or through the Portkey Dashboard. Each Config has a unique ID for easy reference.
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/Portkey-AI/docs-core/refs/heads/main/images/libraries/libraries-3.avif"/>
|
||||
</Frame>
|
||||
|
||||
|
||||
### 1. Use 250+ LLMs
|
||||
Access various LLMs like Anthropic, Gemini, Mistral, Azure OpenAI, and more with minimal code changes. Switch between providers or use them together seamlessly. [Learn more about Universal API](https://portkey.ai/docs/product/ai-gateway/universal-api)
|
||||
|
||||
|
||||
Easily switch between different LLM providers:
|
||||
|
||||
```python
|
||||
# Anthropic Configuration
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY", #You don't need provider when using Virtual keys
|
||||
trace_id="anthropic_agent"
|
||||
)
|
||||
)
|
||||
|
||||
# Azure OpenAI Configuration
|
||||
azure_llm = LLM(
|
||||
model="gpt-4",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_AZURE_VIRTUAL_KEY", #You don't need provider when using Virtual keys
|
||||
trace_id="azure_agent"
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
### 2. Caching
|
||||
Improve response times and reduce costs with two powerful caching modes:
|
||||
- **Simple Cache**: Perfect for exact matches
|
||||
- **Semantic Cache**: Matches responses for requests that are semantically similar
|
||||
[Learn more about Caching](https://portkey.ai/docs/product/ai-gateway/cache-simple-and-semantic)
|
||||
|
||||
```py
|
||||
config = {
|
||||
"cache": {
|
||||
"mode": "semantic", # or "simple" for exact matching
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 3. Production Reliability
|
||||
Portkey provides comprehensive reliability features:
|
||||
- **Automatic Retries**: Handle temporary failures gracefully
|
||||
- **Request Timeouts**: Prevent hanging operations
|
||||
- **Conditional Routing**: Route requests based on specific conditions
|
||||
- **Fallbacks**: Set up automatic provider failovers
|
||||
- **Load Balancing**: Distribute requests efficiently
|
||||
|
||||
[Learn more about Reliability Features](https://portkey.ai/docs/product/ai-gateway/)
|
||||
|
||||
|
||||
|
||||
### 4. Metrics
|
||||
|
||||
Agent runs are complex. Portkey automatically logs **40+ comprehensive metrics** for your AI agents, including cost, tokens used, latency, etc. Whether you need a broad overview or granular insights into your agent runs, Portkey's customizable filters provide the metrics you need.
|
||||
|
||||
|
||||
- Cost per agent interaction
|
||||
- Response times and latency
|
||||
- Token usage and efficiency
|
||||
- Success/failure rates
|
||||
- Cache hit rates
|
||||
|
||||
<img src="https://github.com/siddharthsambharia-portkey/Portkey-Product-Images/blob/main/Portkey-Dashboard.png?raw=true" width="70%" alt="Portkey Dashboard" />
|
||||
|
||||
### 5. Detailed Logging
|
||||
Logs are essential for understanding agent behavior, diagnosing issues, and improving performance. They provide a detailed record of agent activities and tool use, which is crucial for debugging and optimizing processes.
|
||||
|
||||
|
||||
Access a dedicated section to view records of agent executions, including parameters, outcomes, function calls, and errors. Filter logs based on multiple parameters such as trace ID, model, tokens used, and metadata.
|
||||
|
||||
<details>
|
||||
<summary><b>Traces</b></summary>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-Traces.png" alt="Portkey Traces" width="70%" />
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary><b>Logs</b></summary>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-Logs.png" alt="Portkey Logs" width="70%" />
|
||||
</details>
|
||||
|
||||
### 6. Enterprise Security Features
|
||||
- Set budget limit and rate limts per Virtual Key (disposable API keys)
|
||||
- Implement role-based access control
|
||||
- Track system changes with audit logs
|
||||
- Configure data retention policies
|
||||
|
||||
|
||||
|
||||
For detailed information on creating and managing Configs, visit the [Portkey documentation](https://docs.portkey.ai/product/ai-gateway/configs).
|
||||
|
||||
## Resources
|
||||
|
||||
- [📘 Portkey Documentation](https://docs.portkey.ai)
|
||||
- [📊 Portkey Dashboard](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai)
|
||||
- [🐦 Twitter](https://twitter.com/portkeyai)
|
||||
- [💬 Discord Community](https://discord.gg/DD7vgKK299)
|
||||
@@ -20,10 +20,8 @@ Here's an example of how to replay from a task:
|
||||
To use the replay feature, follow these steps:
|
||||
|
||||
<Steps>
|
||||
<Step title="Open your terminal or command prompt.">
|
||||
</Step>
|
||||
<Step title="Navigate to the directory where your CrewAI project is located.">
|
||||
</Step>
|
||||
<Step title="Open your terminal or command prompt."></Step>
|
||||
<Step title="Navigate to the directory where your CrewAI project is located."></Step>
|
||||
<Step title="Run the following commands:">
|
||||
To view the latest kickoff task_ids use:
|
||||
|
||||
|
||||
124
docs/how-to/weave-integration.mdx
Normal file
@@ -0,0 +1,124 @@
|
||||
---
|
||||
title: Weave Integration
|
||||
description: Learn how to use Weights & Biases (W&B) Weave to track, experiment with, evaluate, and improve your CrewAI applications.
|
||||
icon: radar
|
||||
---
|
||||
|
||||
# Weave Overview
|
||||
|
||||
[Weights & Biases (W&B) Weave](https://weave-docs.wandb.ai/) is a framework for tracking, experimenting with, evaluating, deploying, and improving LLM-based applications.
|
||||
|
||||

|
||||
|
||||
Weave provides comprehensive support for every stage of your CrewAI application development:
|
||||
|
||||
- **Tracing & Monitoring**: Automatically track LLM calls and application logic to debug and analyze production systems
|
||||
- **Systematic Iteration**: Refine and iterate on prompts, datasets, and models
|
||||
- **Evaluation**: Use custom or pre-built scorers to systematically assess and enhance agent performance
|
||||
- **Guardrails**: Protect your agents with pre- and post-safeguards for content moderation and prompt safety
|
||||
|
||||
Weave automatically captures traces for your CrewAI applications, enabling you to monitor and analyze your agents' performance, interactions, and execution flow. This helps you build better evaluation datasets and optimize your agent workflows.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Install required packages">
|
||||
```shell
|
||||
pip install crewai weave
|
||||
```
|
||||
</Step>
|
||||
<Step title="Set up W&B Account">
|
||||
Sign up for a [Weights & Biases account](https://wandb.ai) if you haven't already. You'll need this to view your traces and metrics.
|
||||
</Step>
|
||||
<Step title="Initialize Weave in Your Application">
|
||||
Add the following code to your application:
|
||||
|
||||
```python
|
||||
import weave
|
||||
|
||||
# Initialize Weave with your project name
|
||||
weave.init(project_name="crewai_demo")
|
||||
```
|
||||
|
||||
After initialization, Weave will provide a URL where you can view your traces and metrics.
|
||||
</Step>
|
||||
<Step title="Create your Crews/Flows">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM, Process
|
||||
|
||||
# Create an LLM with a temperature of 0 to ensure deterministic outputs
|
||||
llm = LLM(model="gpt-4o", temperature=0)
|
||||
|
||||
# Create agents
|
||||
researcher = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Find and analyze the best investment opportunities',
|
||||
backstory='Expert in financial analysis and market research',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role='Report Writer',
|
||||
goal='Write clear and concise investment reports',
|
||||
backstory='Experienced in creating detailed financial reports',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
# Create tasks
|
||||
research_task = Task(
|
||||
description='Deep research on the {topic}',
|
||||
expected_output='Comprehensive market data including key players, market size, and growth trends.',
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description='Write a detailed report based on the research',
|
||||
expected_output='The report should be easy to read and understand. Use bullet points where applicable.',
|
||||
agent=writer
|
||||
)
|
||||
|
||||
# Create a crew
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
result = crew.kickoff(inputs={"topic": "AI in material science"})
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
<Step title="View Traces in Weave">
|
||||
After running your CrewAI application, visit the Weave URL provided during initialization to view:
|
||||
- LLM calls and their metadata
|
||||
- Agent interactions and task execution flow
|
||||
- Performance metrics like latency and token usage
|
||||
- Any errors or issues that occurred during execution
|
||||
|
||||
<Frame caption="Weave Tracing Dashboard">
|
||||
<img src="/images/weave-tracing.png" alt="Weave tracing example with CrewAI" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Features
|
||||
|
||||
- Weave automatically captures all CrewAI operations: agent interactions and task executions; LLM calls with metadata and token usage; tool usage and results.
|
||||
- The integration supports all CrewAI execution methods: `kickoff()`, `kickoff_for_each()`, `kickoff_async()`, and `kickoff_for_each_async()`.
|
||||
- Automatic tracing of all [crewAI-tools](https://github.com/crewAIInc/crewAI-tools).
|
||||
- Flow feature support with decorator patching (`@start`, `@listen`, `@router`, `@or_`, `@and_`).
|
||||
- Track custom guardrails passed to CrewAI `Task` with `@weave.op()`.
|
||||
|
||||
For detailed information on what's supported, visit the [Weave CrewAI documentation](https://weave-docs.wandb.ai/guides/integrations/crewai/#getting-started-with-flow).
|
||||
|
||||
## Resources
|
||||
|
||||
- [📘 Weave Documentation](https://weave-docs.wandb.ai)
|
||||
- [📊 Example Weave x CrewAI dashboard](https://wandb.ai/ayut/crewai_demo/weave/traces?cols=%7B%22wb_run_id%22%3Afalse%2C%22attributes.weave.client_version%22%3Afalse%2C%22attributes.weave.os_name%22%3Afalse%2C%22attributes.weave.os_release%22%3Afalse%2C%22attributes.weave.os_version%22%3Afalse%2C%22attributes.weave.source%22%3Afalse%2C%22attributes.weave.sys_version%22%3Afalse%7D&peekPath=%2Fayut%2Fcrewai_demo%2Fcalls%2F0195c838-38cb-71a2-8a15-651ecddf9d89)
|
||||
- [🐦 X](https://x.com/weave_wb)
|
||||
BIN
docs/images/enterprise/bearer-token.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 57 KiB |
BIN
docs/images/enterprise/connect-github.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 73 KiB |
BIN
docs/images/enterprise/connection-added.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 101 KiB |
BIN
docs/images/enterprise/copy-task-id.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 143 KiB |
BIN
docs/images/enterprise/crew-dashboard.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 144 KiB |
BIN
docs/images/enterprise/crew-studio-interface.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 705 KiB |
BIN
docs/images/enterprise/deploy-progress.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 258 KiB |
BIN
docs/images/enterprise/env-vars-button.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 61 KiB |
BIN
docs/images/enterprise/failure.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 146 KiB |
BIN
docs/images/enterprise/final-output.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 547 KiB |
BIN
docs/images/enterprise/get-status.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 67 KiB |
BIN
docs/images/enterprise/kickoff-endpoint.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 183 KiB |
BIN
docs/images/enterprise/llm-connection-config.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 332 KiB |
BIN
docs/images/enterprise/llm-defaults.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 249 KiB |
BIN
docs/images/enterprise/redeploy-button.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 63 KiB |
BIN
docs/images/enterprise/reset-token.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 63 KiB |
BIN
docs/images/enterprise/run-crew.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 348 KiB |
BIN
docs/images/enterprise/select-repo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 218 KiB |
BIN
docs/images/enterprise/set-env-variables.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 128 KiB |
BIN
docs/images/enterprise/trace-detailed-task.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 333 KiB |
BIN
docs/images/enterprise/trace-summary.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 150 KiB |
BIN
docs/images/enterprise/trace-tasks.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 145 KiB |
BIN
docs/images/enterprise/trace-timeline.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 182 KiB |
BIN
docs/images/enterprise/traces-overview.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 358 KiB |
BIN
docs/images/enterprise/update-env-vars.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 259 KiB |
BIN
docs/images/mlflow-tracing.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 16 MiB |