mirror of
https://github.com/crewAIInc/crewAI.git
synced 2025-12-17 12:58:31 +00:00
Compare commits
5 Commits
docs/train
...
devin/1748
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6463715567 | ||
|
|
940bf2aa5d | ||
|
|
1bf2e760ab | ||
|
|
80b48208d5 | ||
|
|
acd5aadfd1 |
1429
.cursorrules
1429
.cursorrules
File diff suppressed because it is too large
Load Diff
5
.github/workflows/linter.yml
vendored
5
.github/workflows/linter.yml
vendored
@@ -30,7 +30,4 @@ jobs:
|
||||
- name: Run Ruff on Changed Files
|
||||
if: ${{ steps.changed-files.outputs.files != '' }}
|
||||
run: |
|
||||
echo "${{ steps.changed-files.outputs.files }}" \
|
||||
| tr ' ' '\n' \
|
||||
| grep -v 'src/crewai/cli/templates/' \
|
||||
| xargs -I{} ruff check "{}"
|
||||
echo "${{ steps.changed-files.outputs.files }}" | tr " " "\n" | xargs -I{} ruff check "{}"
|
||||
|
||||
45
.github/workflows/mkdocs.yml
vendored
Normal file
45
.github/workflows/mkdocs.yml
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
name: Deploy MkDocs
|
||||
|
||||
on:
|
||||
release:
|
||||
types: [published]
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
|
||||
jobs:
|
||||
deploy:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.10'
|
||||
|
||||
- name: Calculate requirements hash
|
||||
id: req-hash
|
||||
run: echo "::set-output name=hash::$(sha256sum requirements-doc.txt | awk '{print $1}')"
|
||||
|
||||
- name: Setup cache
|
||||
uses: actions/cache@v4
|
||||
with:
|
||||
key: mkdocs-material-${{ steps.req-hash.outputs.hash }}
|
||||
path: .cache
|
||||
restore-keys: |
|
||||
mkdocs-material-
|
||||
|
||||
- name: Install Requirements
|
||||
run: |
|
||||
sudo apt-get update &&
|
||||
sudo apt-get install pngquant &&
|
||||
pip install mkdocs-material mkdocs-material-extensions pillow cairosvg
|
||||
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.GH_TOKEN }}
|
||||
|
||||
- name: Build and deploy MkDocs
|
||||
run: mkdocs gh-deploy --force
|
||||
22
.github/workflows/tests.yml
vendored
22
.github/workflows/tests.yml
vendored
@@ -7,18 +7,14 @@ permissions:
|
||||
|
||||
env:
|
||||
OPENAI_API_KEY: fake-api-key
|
||||
PYTHONUNBUFFERED: 1
|
||||
|
||||
jobs:
|
||||
tests:
|
||||
name: tests (${{ matrix.python-version }})
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 15
|
||||
strategy:
|
||||
fail-fast: true
|
||||
matrix:
|
||||
python-version: ['3.10', '3.11', '3.12', '3.13']
|
||||
group: [1, 2, 3, 4, 5, 6, 7, 8]
|
||||
python-version: ['3.10', '3.11', '3.12']
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
@@ -27,9 +23,6 @@ jobs:
|
||||
uses: astral-sh/setup-uv@v3
|
||||
with:
|
||||
enable-cache: true
|
||||
cache-dependency-glob: |
|
||||
**/pyproject.toml
|
||||
**/uv.lock
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
run: uv python install ${{ matrix.python-version }}
|
||||
@@ -37,14 +30,5 @@ jobs:
|
||||
- name: Install the project
|
||||
run: uv sync --dev --all-extras
|
||||
|
||||
- name: Run tests (group ${{ matrix.group }} of 8)
|
||||
run: |
|
||||
uv run pytest \
|
||||
--block-network \
|
||||
--timeout=30 \
|
||||
-vv \
|
||||
--splits 8 \
|
||||
--group ${{ matrix.group }} \
|
||||
--durations=10 \
|
||||
-n auto \
|
||||
--maxfail=3
|
||||
- name: Run tests
|
||||
run: uv run pytest --block-network --timeout=60 -vv
|
||||
|
||||
2
.gitignore
vendored
2
.gitignore
vendored
@@ -21,9 +21,9 @@ crew_tasks_output.json
|
||||
.mypy_cache
|
||||
.ruff_cache
|
||||
.venv
|
||||
agentops.log
|
||||
test_flow.html
|
||||
crewairules.mdc
|
||||
plan.md
|
||||
conceptual_plan.md
|
||||
build_image
|
||||
chromadb-*.lock
|
||||
|
||||
@@ -161,7 +161,7 @@ To get started with CrewAI, follow these simple steps:
|
||||
|
||||
### 1. Installation
|
||||
|
||||
Ensure you have Python >=3.10 <3.14 installed on your system. CrewAI uses [UV](https://docs.astral.sh/uv/) for dependency management and package handling, offering a seamless setup and execution experience.
|
||||
Ensure you have Python >=3.10 <3.13 installed on your system. CrewAI uses [UV](https://docs.astral.sh/uv/) for dependency management and package handling, offering a seamless setup and execution experience.
|
||||
|
||||
First, install CrewAI:
|
||||
|
||||
@@ -403,7 +403,7 @@ In addition to the sequential process, you can use the hierarchical process, whi
|
||||
|
||||
## Key Features
|
||||
|
||||
CrewAI stands apart as a lean, standalone, high-performance multi-AI Agent framework delivering simplicity, flexibility, and precise control—free from the complexity and limitations found in other agent frameworks.
|
||||
CrewAI stands apart as a lean, standalone, high-performance framework delivering simplicity, flexibility, and precise control—free from the complexity and limitations found in other agent frameworks.
|
||||
|
||||
- **Standalone & Lean**: Completely independent from other frameworks like LangChain, offering faster execution and lighter resource demands.
|
||||
- **Flexible & Precise**: Easily orchestrate autonomous agents through intuitive [Crews](https://docs.crewai.com/concepts/crews) or precise [Flows](https://docs.crewai.com/concepts/flows), achieving perfect balance for your needs.
|
||||
|
||||
473
docs/changelog.mdx
Normal file
473
docs/changelog.mdx
Normal file
@@ -0,0 +1,473 @@
|
||||
---
|
||||
title: Changelog
|
||||
description: View the latest updates and changes to CrewAI
|
||||
icon: timeline
|
||||
---
|
||||
|
||||
<Update label="2024-05-22" description="v0.121.0" tags={["Latest"]}>
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01210.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.121.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Fixed encoding error when creating tools
|
||||
- Fixed failing llama test
|
||||
- Updated logging configuration for consistency
|
||||
- Enhanced telemetry initialization and event handling
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Added **markdown attribute** to the Task class
|
||||
- Added **reasoning attribute** to the Agent class
|
||||
- Added **inject_date flag** to Agent for automatic date injection
|
||||
- Implemented **HallucinationGuardrail** (no-op with test coverage)
|
||||
|
||||
**Documentation & Guides**
|
||||
- Added documentation for **StagehandTool** and improved MDX structure
|
||||
- Added documentation for **MCP integration** and updated enterprise docs
|
||||
- Documented knowledge events and updated reasoning docs
|
||||
- Added stop parameter documentation
|
||||
- Fixed import references in doc examples (before_kickoff, after_kickoff)
|
||||
- General docs updates and restructuring for clarity
|
||||
</Update>
|
||||
|
||||
<Update label="2024-05-15" description="v0.120.1">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01201.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.120.1">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Fixed **interpolation with hyphens**
|
||||
</Update>
|
||||
|
||||
<Update label="2024-05-14" description="v0.120.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01200.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.120.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Enabled **full Ruff rule set** by default for stricter linting
|
||||
- Addressed race condition in FilteredStream using context managers
|
||||
- Fixed agent knowledge reset issue
|
||||
- Refactored agent fetching logic into utility module
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Added support for **loading an Agent directly from a repository**
|
||||
- Enabled setting an empty context for Task
|
||||
- Enhanced Agent repository feedback and fixed Tool auto-import behavior
|
||||
- Introduced direct initialization of knowledge (bypassing knowledge_sources)
|
||||
|
||||
**Documentation & Guides**
|
||||
- Updated security.md for current security practices
|
||||
- Cleaned up Google setup section for clarity
|
||||
- Added link to AI Studio when entering Gemini key
|
||||
- Updated Arize Phoenix observability guide
|
||||
- Refreshed flow documentation
|
||||
</Update>
|
||||
|
||||
<Update label="2024-05-08" description="v0.119.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01190.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.119.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Improved test reliability by enhancing pytest handling for flaky tests
|
||||
- Fixed memory reset crash when embedding dimensions mismatch
|
||||
- Enabled parent flow identification for Crew and LiteAgent
|
||||
- Prevented telemetry-related crashes when unavailable
|
||||
- Upgraded **LiteLLM version** for better compatibility
|
||||
- Fixed llama converter tests by removing skip_external_api
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Introduced **knowledge retrieval prompt re-writing** in Agent for improved tracking and debugging
|
||||
- Made LLM setup and quickstart guides model-agnostic
|
||||
|
||||
**Documentation & Guides**
|
||||
- Added advanced configuration docs for the RAG tool
|
||||
- Updated Windows troubleshooting guide
|
||||
- Refined documentation examples for better clarity
|
||||
- Fixed typos across docs and config files
|
||||
</Update>
|
||||
|
||||
<Update label="2024-04-28" description="v0.118.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01180.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.118.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Fixed issues with missing prompt or system templates
|
||||
- Removed global logging configuration to avoid unintended overrides
|
||||
- Renamed **TaskGuardrail to LLMGuardrail** for improved clarity
|
||||
- Downgraded litellm to version 1.167.1 for compatibility
|
||||
- Added missing init.py files to ensure proper module initialization
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Added support for **no-code Guardrail creation** to simplify AI behavior controls
|
||||
|
||||
**Documentation & Guides**
|
||||
- Removed CrewStructuredTool from public documentation to reflect internal usage
|
||||
- Updated enterprise documentation and YouTube embed for improved onboarding experience
|
||||
</Update>
|
||||
|
||||
<Update label="2024-04-20" description="v0.117.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01170.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.117.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Added `result_as_answer` parameter support in `@tool` decorator.
|
||||
- Introduced support for new language models: GPT-4.1, Gemini-2.0, and Gemini-2.5 Pro.
|
||||
- Enhanced knowledge management capabilities.
|
||||
- Added Huggingface provider option in CLI.
|
||||
- Improved compatibility and CI support for Python 3.10+.
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Fixed issues with incorrect template parameters and missing inputs.
|
||||
- Improved asynchronous flow handling with coroutine condition checks.
|
||||
- Enhanced memory management with isolated configuration and correct memory object copying.
|
||||
- Fixed initialization of lite agents with correct references.
|
||||
- Addressed Python type hint issues and removed redundant imports.
|
||||
- Updated event placement for improved tool usage tracking.
|
||||
- Raised explicit exceptions when flows fail.
|
||||
- Removed unused code and redundant comments from various modules.
|
||||
- Updated GitHub App token action to v2.
|
||||
|
||||
**Documentation & Guides**
|
||||
- Enhanced documentation structure, including enterprise deployment instructions.
|
||||
- Automatically create output folders for documentation generation.
|
||||
- Fixed broken link in WeaviateVectorSearchTool documentation.
|
||||
- Fixed guardrail documentation usage and import paths for JSON search tools.
|
||||
- Updated documentation for CodeInterpreterTool.
|
||||
- Improved SEO, contextual navigation, and error handling for documentation pages.
|
||||
</Update>
|
||||
|
||||
<Update label="2024-04-25" description="v0.117.1">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01171.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.117.1">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Upgraded **crewai-tools** to latest version
|
||||
- Upgraded **liteLLM** to latest version
|
||||
- Fixed **Mem0 OSS**
|
||||
</Update>
|
||||
|
||||
<Update label="2024-04-07" description="v0.114.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01140.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.114.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Agents as an atomic unit. (`Agent(...).kickoff()`)
|
||||
- Support for [Custom LLM implementations](https://docs.crewai.com/guides/advanced/custom-llm).
|
||||
- Integrated External Memory and [Opik observability](https://docs.crewai.com/how-to/opik-observability).
|
||||
- Enhanced YAML extraction.
|
||||
- Multimodal agent validation.
|
||||
- Added Secure fingerprints for agents and crews.
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Improved serialization, agent copying, and Python compatibility.
|
||||
- Added wildcard support to `emit()`
|
||||
- Added support for additional router calls and context window adjustments.
|
||||
- Fixed typing issues, validation, and import statements.
|
||||
- Improved method performance.
|
||||
- Enhanced agent task handling, event emissions, and memory management.
|
||||
- Fixed CLI issues, conditional tasks, cloning behavior, and tool outputs.
|
||||
|
||||
**Documentation & Guides**
|
||||
- Improved documentation structure, theme, and organization.
|
||||
- Added guides for Local NVIDIA NIM with WSL2, W&B Weave, and Arize Phoenix.
|
||||
- Updated tool configuration examples, prompts, and observability docs.
|
||||
- Guide on using singular agents within Flows.
|
||||
</Update>
|
||||
|
||||
<Update label="2024-03-17" description="v0.108.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01080.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.108.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Converted tabs to spaces in `crew.py` template
|
||||
- Enhanced LLM Streaming Response Handling and Event System
|
||||
- Included `model_name`
|
||||
- Enhanced Event Listener with rich visualization and improved logging
|
||||
- Added fingerprints
|
||||
|
||||
**Bug Fixes**
|
||||
- Fixed Mistral issues
|
||||
- Fixed a bug in documentation
|
||||
- Fixed type check error in fingerprint property
|
||||
|
||||
**Documentation Updates**
|
||||
- Improved tool documentation
|
||||
- Updated installation guide for the `uv` tool package
|
||||
- Added instructions for upgrading crewAI with the `uv` tool
|
||||
- Added documentation for `ApifyActorsTool`
|
||||
</Update>
|
||||
|
||||
<Update label="2024-03-10" description="v0.105.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01050.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.105.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Fixed issues with missing template variables and user memory configuration
|
||||
- Improved async flow support and addressed agent response formatting
|
||||
- Enhanced memory reset functionality and fixed CLI memory commands
|
||||
- Fixed type issues, tool calling properties, and telemetry decoupling
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Added Flow state export and improved state utilities
|
||||
- Enhanced agent knowledge setup with optional crew embedder
|
||||
- Introduced event emitter for better observability and LLM call tracking
|
||||
- Added support for Python 3.10 and ChatOllama from langchain_ollama
|
||||
- Integrated context window size support for the o3-mini model
|
||||
- Added support for multiple router calls
|
||||
|
||||
**Documentation & Guides**
|
||||
- Improved documentation layout and hierarchical structure
|
||||
- Added QdrantVectorSearchTool guide and clarified event listener usage
|
||||
- Fixed typos in prompts and updated Amazon Bedrock model listings
|
||||
</Update>
|
||||
|
||||
<Update label="2024-02-12" description="v0.102.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01020.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.102.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**Core Improvements & Fixes**
|
||||
- Enhanced LLM Support: Improved structured LLM output, parameter handling, and formatting for Anthropic models
|
||||
- Crew & Agent Stability: Fixed issues with cloning agents/crews using knowledge sources, multiple task outputs in conditional tasks, and ignored Crew task callbacks
|
||||
- Memory & Storage Fixes: Fixed short-term memory handling with Bedrock, ensured correct embedder initialization, and added a reset memories function in the crew class
|
||||
- Training & Execution Reliability: Fixed broken training and interpolation issues with dict and list input types
|
||||
|
||||
**New Features & Enhancements**
|
||||
- Advanced Knowledge Management: Improved naming conventions and enhanced embedding configuration with custom embedder support
|
||||
- Expanded Logging & Observability: Added JSON format support for logging and integrated MLflow tracing documentation
|
||||
- Data Handling Improvements: Updated excel_knowledge_source.py to process multi-tab files
|
||||
- General Performance & Codebase Clean-Up: Streamlined enterprise code alignment and resolved linting issues
|
||||
- Adding new tool: `QdrantVectorSearchTool`
|
||||
|
||||
**Documentation & Guides**
|
||||
- Updated AI & Memory Docs: Improved Bedrock, Google AI, and long-term memory documentation
|
||||
- Task & Workflow Clarity: Added "Human Input" row to Task Attributes, Langfuse guide, and FileWriterTool documentation
|
||||
- Fixed Various Typos & Formatting Issues
|
||||
</Update>
|
||||
|
||||
<Update label="2024-01-28" description="v0.100.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v01000.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.100.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**Features**
|
||||
- Add Composio docs
|
||||
- Add SageMaker as a LLM provider
|
||||
|
||||
**Fixes**
|
||||
- Overall LLM connection issues
|
||||
- Using safe accessors on training
|
||||
- Add version check to crew_chat.py
|
||||
|
||||
**Documentation**
|
||||
- New docs for crewai chat
|
||||
- Improve formatting and clarity in CLI and Composio Tool docs
|
||||
</Update>
|
||||
|
||||
<Update label="2024-01-20" description="v0.98.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v0980.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.98.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**Features**
|
||||
- Conversation crew v1
|
||||
- Add unique ID to flow states
|
||||
- Add @persist decorator with FlowPersistence interface
|
||||
|
||||
**Integrations**
|
||||
- Add SambaNova integration
|
||||
- Add NVIDIA NIM provider in cli
|
||||
- Introducing VoyageAI
|
||||
|
||||
**Fixes**
|
||||
- Fix API Key Behavior and Entity Handling in Mem0 Integration
|
||||
- Fixed core invoke loop logic and relevant tests
|
||||
- Make tool inputs actual objects and not strings
|
||||
- Add important missing parts to creating tools
|
||||
- Drop litellm version to prevent windows issue
|
||||
- Before kickoff if inputs are none
|
||||
- Fixed typos, nested pydantic model issue, and docling issues
|
||||
</Update>
|
||||
|
||||
<Update label="2024-01-04" description="v0.95.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v0950.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.95.0">View on GitHub</a>
|
||||
</div>
|
||||
|
||||
**New Features**
|
||||
- Adding Multimodal Abilities to Crew
|
||||
- Programatic Guardrails
|
||||
- HITL multiple rounds
|
||||
- Gemini 2.0 Support
|
||||
- CrewAI Flows Improvements
|
||||
- Add Workflow Permissions
|
||||
- Add support for langfuse with litellm
|
||||
- Portkey Integration with CrewAI
|
||||
- Add interpolate_only method and improve error handling
|
||||
- Docling Support
|
||||
- Weviate Support
|
||||
|
||||
**Fixes**
|
||||
- output_file not respecting system path
|
||||
- disk I/O error when resetting short-term memory
|
||||
- CrewJSONEncoder now accepts enums
|
||||
- Python max version
|
||||
- Interpolation for output_file in Task
|
||||
- Handle coworker role name case/whitespace properly
|
||||
- Add tiktoken as explicit dependency and document Rust requirement
|
||||
- Include agent knowledge in planning process
|
||||
- Change storage initialization to None for KnowledgeStorage
|
||||
- Fix optional storage checks
|
||||
- include event emitter in flows
|
||||
- Docstring, Error Handling, and Type Hints Improvements
|
||||
- Suppressed userWarnings from litellm pydantic issues
|
||||
</Update>
|
||||
|
||||
<Update label="2024-12-05" description="v0.86.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v0860.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.86.0">View on GitHub</a>
|
||||
</div>
|
||||
**Changes**
|
||||
- Remove all references to pipeline and pipeline router
|
||||
- Add Nvidia NIM as provider in Custom LLM
|
||||
- Add knowledge demo + improve knowledge docs
|
||||
- Add HITL multiple rounds of followup
|
||||
- New docs about yaml crew with decorators
|
||||
- Simplify template crew
|
||||
</Update>
|
||||
|
||||
<Update label="2024-12-04" description="v0.85.0">
|
||||
## Release Highlights
|
||||
<Frame>
|
||||
<img src="/images/releases/v0850.png" />
|
||||
</Frame>
|
||||
|
||||
<div style={{ textAlign: 'center', marginBottom: '1rem' }}>
|
||||
<a href="https://github.com/crewAIInc/crewAI/releases/tag/0.85.0">View on GitHub</a>
|
||||
</div>
|
||||
**Features**
|
||||
- Added knowledge to agent level
|
||||
- Feat/remove langchain
|
||||
- Improve typed task outputs
|
||||
- Log in to Tool Repository on crewai login
|
||||
|
||||
**Fixes**
|
||||
- Fixes issues with result as answer not properly exiting LLM loop
|
||||
- Fix missing key name when running with ollama provider
|
||||
- Fix spelling issue found
|
||||
|
||||
**Documentation**
|
||||
- Update readme for running mypy
|
||||
- Add knowledge to mint.json
|
||||
- Update Github actions
|
||||
- Update Agents docs to include two approaches for creating an agent
|
||||
- Improvements to LLM Configuration and Usage
|
||||
</Update>
|
||||
|
||||
<Update label="2024-11-25" description="v0.83.0">
|
||||
**New Features**
|
||||
- New before_kickoff and after_kickoff crew callbacks
|
||||
- Support to pre-seed agents with Knowledge
|
||||
- Add support for retrieving user preferences and memories using Mem0
|
||||
|
||||
**Fixes**
|
||||
- Fix Async Execution
|
||||
- Upgrade chroma and adjust embedder function generator
|
||||
- Update CLI Watson supported models + docs
|
||||
- Reduce level for Bandit
|
||||
- Fixing all tests
|
||||
|
||||
**Documentation**
|
||||
- Update Docs
|
||||
</Update>
|
||||
|
||||
<Update label="2024-11-13" description="v0.80.0">
|
||||
**Fixes**
|
||||
- Fixing Tokens callback replacement bug
|
||||
- Fixing Step callback issue
|
||||
- Add cached prompt tokens info on usage metrics
|
||||
- Fix crew_train_success test
|
||||
</Update>
|
||||
@@ -43,6 +43,7 @@ The Visual Agent Builder enables:
|
||||
| **Max Iterations** _(optional)_ | `max_iter` | `int` | Maximum iterations before the agent must provide its best answer. Default is 20. |
|
||||
| **Max RPM** _(optional)_ | `max_rpm` | `Optional[int]` | Maximum requests per minute to avoid rate limits. |
|
||||
| **Max Execution Time** _(optional)_ | `max_execution_time` | `Optional[int]` | Maximum time (in seconds) for task execution. |
|
||||
| **Memory** _(optional)_ | `memory` | `bool` | Whether the agent should maintain memory of interactions. Default is True. |
|
||||
| **Verbose** _(optional)_ | `verbose` | `bool` | Enable detailed execution logs for debugging. Default is False. |
|
||||
| **Allow Delegation** _(optional)_ | `allow_delegation` | `bool` | Allow the agent to delegate tasks to other agents. Default is False. |
|
||||
| **Step Callback** _(optional)_ | `step_callback` | `Optional[Any]` | Function called after each agent step, overrides crew callback. |
|
||||
@@ -71,7 +72,7 @@ There are two ways to create agents in CrewAI: using **YAML configuration (recom
|
||||
|
||||
Using YAML configuration provides a cleaner, more maintainable way to define agents. We strongly recommend using this approach in your CrewAI projects.
|
||||
|
||||
After creating your CrewAI project as outlined in the [Installation](/en/installation) section, navigate to the `src/latest_ai_development/config/agents.yaml` file and modify the template to match your requirements.
|
||||
After creating your CrewAI project as outlined in the [Installation](/installation) section, navigate to the `src/latest_ai_development/config/agents.yaml` file and modify the template to match your requirements.
|
||||
|
||||
<Note>
|
||||
Variables in your YAML files (like `{topic}`) will be replaced with values from your inputs when running the crew:
|
||||
@@ -155,6 +156,7 @@ agent = Agent(
|
||||
"you excel at finding patterns in complex datasets.",
|
||||
llm="gpt-4", # Default: OPENAI_MODEL_NAME or "gpt-4"
|
||||
function_calling_llm=None, # Optional: Separate LLM for tool calling
|
||||
memory=True, # Default: True
|
||||
verbose=False, # Default: False
|
||||
allow_delegation=False, # Default: False
|
||||
max_iter=20, # Default: 20 iterations
|
||||
@@ -295,11 +297,6 @@ multimodal_agent = Agent(
|
||||
- `"safe"`: Uses Docker (recommended for production)
|
||||
- `"unsafe"`: Direct execution (use only in trusted environments)
|
||||
|
||||
<Note>
|
||||
This runs a default Docker image. If you want to configure the docker image, the checkout the Code Interpreter Tool in the tools section.
|
||||
Add the code interpreter tool as a tool in the agent as a tool parameter.
|
||||
</Note>
|
||||
|
||||
#### Advanced Features
|
||||
- `multimodal`: Enable multimodal capabilities for processing text and visual content
|
||||
- `reasoning`: Enable agent to reflect and create plans before executing tasks
|
||||
@@ -526,103 +523,6 @@ agent = Agent(
|
||||
The context window management feature works automatically in the background. You don't need to call any special functions - just set `respect_context_window` to your preferred behavior and CrewAI handles the rest!
|
||||
</Note>
|
||||
|
||||
## Direct Agent Interaction with `kickoff()`
|
||||
|
||||
Agents can be used directly without going through a task or crew workflow using the `kickoff()` method. This provides a simpler way to interact with an agent when you don't need the full crew orchestration capabilities.
|
||||
|
||||
### How `kickoff()` Works
|
||||
|
||||
The `kickoff()` method allows you to send messages directly to an agent and get a response, similar to how you would interact with an LLM but with all the agent's capabilities (tools, reasoning, etc.).
|
||||
|
||||
```python Code
|
||||
from crewai import Agent
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
# Create an agent
|
||||
researcher = Agent(
|
||||
role="AI Technology Researcher",
|
||||
goal="Research the latest AI developments",
|
||||
tools=[SerperDevTool()],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Use kickoff() to interact directly with the agent
|
||||
result = researcher.kickoff("What are the latest developments in language models?")
|
||||
|
||||
# Access the raw response
|
||||
print(result.raw)
|
||||
```
|
||||
|
||||
### Parameters and Return Values
|
||||
|
||||
| Parameter | Type | Description |
|
||||
| :---------------- | :---------------------------------- | :------------------------------------------------------------------------ |
|
||||
| `messages` | `Union[str, List[Dict[str, str]]]` | Either a string query or a list of message dictionaries with role/content |
|
||||
| `response_format` | `Optional[Type[Any]]` | Optional Pydantic model for structured output |
|
||||
|
||||
The method returns a `LiteAgentOutput` object with the following properties:
|
||||
|
||||
- `raw`: String containing the raw output text
|
||||
- `pydantic`: Parsed Pydantic model (if a `response_format` was provided)
|
||||
- `agent_role`: Role of the agent that produced the output
|
||||
- `usage_metrics`: Token usage metrics for the execution
|
||||
|
||||
### Structured Output
|
||||
|
||||
You can get structured output by providing a Pydantic model as the `response_format`:
|
||||
|
||||
```python Code
|
||||
from pydantic import BaseModel
|
||||
from typing import List
|
||||
|
||||
class ResearchFindings(BaseModel):
|
||||
main_points: List[str]
|
||||
key_technologies: List[str]
|
||||
future_predictions: str
|
||||
|
||||
# Get structured output
|
||||
result = researcher.kickoff(
|
||||
"Summarize the latest developments in AI for 2025",
|
||||
response_format=ResearchFindings
|
||||
)
|
||||
|
||||
# Access structured data
|
||||
print(result.pydantic.main_points)
|
||||
print(result.pydantic.future_predictions)
|
||||
```
|
||||
|
||||
### Multiple Messages
|
||||
|
||||
You can also provide a conversation history as a list of message dictionaries:
|
||||
|
||||
```python Code
|
||||
messages = [
|
||||
{"role": "user", "content": "I need information about large language models"},
|
||||
{"role": "assistant", "content": "I'd be happy to help with that! What specifically would you like to know?"},
|
||||
{"role": "user", "content": "What are the latest developments in 2025?"}
|
||||
]
|
||||
|
||||
result = researcher.kickoff(messages)
|
||||
```
|
||||
|
||||
### Async Support
|
||||
|
||||
An asynchronous version is available via `kickoff_async()` with the same parameters:
|
||||
|
||||
```python Code
|
||||
import asyncio
|
||||
|
||||
async def main():
|
||||
result = await researcher.kickoff_async("What are the latest developments in AI?")
|
||||
print(result.raw)
|
||||
|
||||
asyncio.run(main())
|
||||
```
|
||||
|
||||
<Note>
|
||||
The `kickoff()` method uses a `LiteAgent` internally, which provides a simpler execution flow while preserving all of the agent's configuration (role, goal, backstory, tools, etc.).
|
||||
</Note>
|
||||
|
||||
## Important Considerations and Best Practices
|
||||
|
||||
### Security and Code Execution
|
||||
@@ -637,6 +537,7 @@ The `kickoff()` method uses a `LiteAgent` internally, which provides a simpler e
|
||||
- Adjust `max_iter` and `max_retry_limit` based on task complexity
|
||||
|
||||
### Memory and Context Management
|
||||
- Use `memory: true` for tasks requiring historical context
|
||||
- Leverage `knowledge_sources` for domain-specific information
|
||||
- Configure `embedder` when using custom embedding models
|
||||
- Use custom templates (`system_template`, `prompt_template`, `response_template`) for fine-grained control over agent behavior
|
||||
@@ -684,6 +585,7 @@ The `kickoff()` method uses a `LiteAgent` internally, which provides a simpler e
|
||||
- Review code sandbox settings
|
||||
|
||||
4. **Memory Issues**: If agent responses seem inconsistent:
|
||||
- Verify memory is enabled
|
||||
- Check knowledge source configuration
|
||||
- Review conversation history management
|
||||
|
||||
@@ -4,8 +4,6 @@ description: Learn how to use the CrewAI CLI to interact with CrewAI.
|
||||
icon: terminal
|
||||
---
|
||||
|
||||
<Warning>Since release 0.140.0, CrewAI Enterprise started a process of migrating their login provider. As such, the authentication flow via CLI was updated. Users that use Google to login, or that created their account after July 3rd, 2025 will be unable to log in with older versions of the `crewai` library.</Warning>
|
||||
|
||||
## Overview
|
||||
|
||||
The CrewAI CLI provides a set of commands to interact with CrewAI, allowing you to create, train, run, and manage crews & flows.
|
||||
@@ -188,7 +186,10 @@ def crew(self) -> Crew:
|
||||
Deploy the crew or flow to [CrewAI Enterprise](https://app.crewai.com).
|
||||
|
||||
- **Authentication**: You need to be authenticated to deploy to CrewAI Enterprise.
|
||||
You can login or create an account with:
|
||||
```shell Terminal
|
||||
crewai signup
|
||||
```
|
||||
If you already have an account, you can login with:
|
||||
```shell Terminal
|
||||
crewai login
|
||||
```
|
||||
@@ -199,37 +200,6 @@ Deploy the crew or flow to [CrewAI Enterprise](https://app.crewai.com).
|
||||
```
|
||||
- Reads your local project configuration.
|
||||
- Prompts you to confirm the environment variables (like `OPENAI_API_KEY`, `SERPER_API_KEY`) found locally. These will be securely stored with the deployment on the Enterprise platform. Ensure your sensitive keys are correctly configured locally (e.g., in a `.env` file) before running this.
|
||||
|
||||
### 11. Organization Management
|
||||
|
||||
Manage your CrewAI Enterprise organizations.
|
||||
|
||||
```shell Terminal
|
||||
crewai org [COMMAND] [OPTIONS]
|
||||
```
|
||||
|
||||
#### Commands:
|
||||
|
||||
- `list`: List all organizations you belong to
|
||||
```shell Terminal
|
||||
crewai org list
|
||||
```
|
||||
|
||||
- `current`: Display your currently active organization
|
||||
```shell Terminal
|
||||
crewai org current
|
||||
```
|
||||
|
||||
- `switch`: Switch to a specific organization
|
||||
```shell Terminal
|
||||
crewai org switch <organization_id>
|
||||
```
|
||||
|
||||
<Note>
|
||||
You must be authenticated to CrewAI Enterprise to use these organization management commands.
|
||||
</Note>
|
||||
|
||||
- **Create a deployment** (continued):
|
||||
- Links the deployment to the corresponding remote GitHub repository (it usually detects this automatically).
|
||||
|
||||
- **Deploy the Crew**: Once you are authenticated, you can deploy your crew or flow to CrewAI Enterprise.
|
||||
@@ -284,13 +254,13 @@ Watch this video tutorial for a step-by-step demonstration of deploying your cre
|
||||
|
||||
### 11. API Keys
|
||||
|
||||
When running ```crewai create crew``` command, the CLI will show you a list of available LLM providers to choose from, followed by model selection for your chosen provider.
|
||||
When running ```crewai create crew``` command, the CLI will first show you the top 5 most common LLM providers and ask you to select one.
|
||||
|
||||
Once you've selected an LLM provider and model, you will be prompted for API keys.
|
||||
Once you've selected an LLM provider, you will be prompted for API keys.
|
||||
|
||||
#### Available LLM Providers
|
||||
#### Initial API key providers
|
||||
|
||||
Here's a list of the most popular LLM providers suggested by the CLI:
|
||||
The CLI will initially prompt for API keys for the following services:
|
||||
|
||||
* OpenAI
|
||||
* Groq
|
||||
@@ -298,11 +268,11 @@ Here's a list of the most popular LLM providers suggested by the CLI:
|
||||
* Google Gemini
|
||||
* SambaNova
|
||||
|
||||
When you select a provider, the CLI will then show you available models for that provider and prompt you to enter your API key.
|
||||
When you select a provider, the CLI will prompt you to enter your API key.
|
||||
|
||||
#### Other Options
|
||||
|
||||
If you select "other", you will be able to select from a list of LiteLLM supported providers.
|
||||
If you select option 6, you will be able to select from a list of LiteLLM supported providers.
|
||||
|
||||
When you select a provider, the CLI will prompt you to enter the Key name and the API key.
|
||||
|
||||
@@ -310,81 +280,5 @@ See the following link for each provider's key name:
|
||||
|
||||
* [LiteLLM Providers](https://docs.litellm.ai/docs/providers)
|
||||
|
||||
### 12. Configuration Management
|
||||
|
||||
Manage CLI configuration settings for CrewAI.
|
||||
|
||||
```shell Terminal
|
||||
crewai config [COMMAND] [OPTIONS]
|
||||
```
|
||||
|
||||
#### Commands:
|
||||
|
||||
- `list`: Display all CLI configuration parameters
|
||||
```shell Terminal
|
||||
crewai config list
|
||||
```
|
||||
|
||||
- `set`: Set a CLI configuration parameter
|
||||
```shell Terminal
|
||||
crewai config set <key> <value>
|
||||
```
|
||||
|
||||
- `reset`: Reset all CLI configuration parameters to default values
|
||||
```shell Terminal
|
||||
crewai config reset
|
||||
```
|
||||
|
||||
#### Available Configuration Parameters
|
||||
|
||||
- `enterprise_base_url`: Base URL of the CrewAI Enterprise instance
|
||||
- `oauth2_provider`: OAuth2 provider used for authentication (e.g., workos, okta, auth0)
|
||||
- `oauth2_audience`: OAuth2 audience value, typically used to identify the target API or resource
|
||||
- `oauth2_client_id`: OAuth2 client ID issued by the provider, used during authentication requests
|
||||
- `oauth2_domain`: OAuth2 provider's domain (e.g., your-org.auth0.com) used for issuing tokens
|
||||
|
||||
#### Examples
|
||||
|
||||
Display current configuration:
|
||||
```shell Terminal
|
||||
crewai config list
|
||||
```
|
||||
|
||||
Example output:
|
||||
```
|
||||
CrewAI CLI Configuration
|
||||
┏━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
|
||||
┃ Setting ┃ Value ┃ Description ┃
|
||||
┡━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
|
||||
│ enterprise_base_url│ https://app.crewai.com │ Base URL of the CrewAI Enterprise instance │
|
||||
│ org_name │ Not set │ Name of the currently active organization │
|
||||
│ org_uuid │ Not set │ UUID of the currently active organization │
|
||||
│ oauth2_provider │ workos │ OAuth2 provider used for authentication (e.g., workos, okta, auth0). │
|
||||
│ oauth2_audience │ client_01YYY │ OAuth2 audience value, typically used to identify the target API or resource. │
|
||||
│ oauth2_client_id │ client_01XXX │ OAuth2 client ID issued by the provider, used during authentication requests. │
|
||||
│ oauth2_domain │ login.crewai.com │ OAuth2 provider's domain (e.g., your-org.auth0.com) used for issuing tokens. │
|
||||
```
|
||||
|
||||
Set the enterprise base URL:
|
||||
```shell Terminal
|
||||
crewai config set enterprise_base_url https://my-enterprise.crewai.com
|
||||
```
|
||||
|
||||
Set OAuth2 provider:
|
||||
```shell Terminal
|
||||
crewai config set oauth2_provider auth0
|
||||
```
|
||||
|
||||
Set OAuth2 domain:
|
||||
```shell Terminal
|
||||
crewai config set oauth2_domain my-company.auth0.com
|
||||
```
|
||||
|
||||
Reset all configuration to defaults:
|
||||
```shell Terminal
|
||||
crewai config reset
|
||||
```
|
||||
|
||||
<Note>
|
||||
Configuration settings are stored in `~/.config/crewai/settings.json`. Some settings like organization name and UUID are read-only and managed through authentication and organization commands. Tool repository related settings are hidden and cannot be set directly by users.
|
||||
</Note>
|
||||
@@ -20,7 +20,8 @@ A crew in crewAI represents a collaborative group of agents working together to
|
||||
| **Function Calling LLM** _(optional)_ | `function_calling_llm` | If passed, the crew will use this LLM to do function calling for tools for all agents in the crew. Each agent can have its own LLM, which overrides the crew's LLM for function calling. |
|
||||
| **Config** _(optional)_ | `config` | Optional configuration settings for the crew, in `Json` or `Dict[str, Any]` format. |
|
||||
| **Max RPM** _(optional)_ | `max_rpm` | Maximum requests per minute the crew adheres to during execution. Defaults to `None`. |
|
||||
| **Memory** _(optional)_ | `memory` | Utilized for storing execution memories (short-term, long-term, entity memory). | |
|
||||
| **Memory** _(optional)_ | `memory` | Utilized for storing execution memories (short-term, long-term, entity memory). |
|
||||
| **Memory Config** _(optional)_ | `memory_config` | Configuration for the memory provider to be used by the crew. |
|
||||
| **Cache** _(optional)_ | `cache` | Specifies whether to use a cache for storing the results of tools' execution. Defaults to `True`. |
|
||||
| **Embedder** _(optional)_ | `embedder` | Configuration for the embedder to be used by the crew. Mostly used by memory for now. Default is `{"provider": "openai"}`. |
|
||||
| **Step Callback** _(optional)_ | `step_callback` | A function that is called after each step of every agent. This can be used to log the agent's actions or to perform other operations; it won't override the agent-specific `step_callback`. |
|
||||
@@ -31,7 +32,6 @@ A crew in crewAI represents a collaborative group of agents working together to
|
||||
| **Prompt File** _(optional)_ | `prompt_file` | Path to the prompt JSON file to be used for the crew. |
|
||||
| **Planning** *(optional)* | `planning` | Adds planning ability to the Crew. When activated before each Crew iteration, all Crew data is sent to an AgentPlanner that will plan the tasks and this plan will be added to each task description. |
|
||||
| **Planning LLM** *(optional)* | `planning_llm` | The language model used by the AgentPlanner in a planning process. |
|
||||
| **Knowledge Sources** _(optional)_ | `knowledge_sources` | Knowledge sources available at the crew level, accessible to all the agents. |
|
||||
|
||||
<Tip>
|
||||
**Crew Max RPM**: The `max_rpm` attribute sets the maximum number of requests per minute the crew can perform to avoid rate limits and will override individual agents' `max_rpm` settings if you set it.
|
||||
@@ -45,7 +45,7 @@ There are two ways to create crews in CrewAI: using **YAML configuration (recomm
|
||||
|
||||
Using YAML configuration provides a cleaner, more maintainable way to define crews and is consistent with how agents and tasks are defined in CrewAI projects.
|
||||
|
||||
After creating your CrewAI project as outlined in the [Installation](/en/installation) section, you can define your crew in a class that inherits from `CrewBase` and uses decorators to define agents, tasks, and the crew itself.
|
||||
After creating your CrewAI project as outlined in the [Installation](/installation) section, you can define your crew in a class that inherits from `CrewBase` and uses decorators to define agents, tasks, and the crew itself.
|
||||
|
||||
#### Example Crew Class with Decorators
|
||||
|
||||
@@ -325,12 +325,12 @@ for result in results:
|
||||
|
||||
# Example of using kickoff_async
|
||||
inputs = {'topic': 'AI in healthcare'}
|
||||
async_result = await my_crew.kickoff_async(inputs=inputs)
|
||||
async_result = my_crew.kickoff_async(inputs=inputs)
|
||||
print(async_result)
|
||||
|
||||
# Example of using kickoff_for_each_async
|
||||
inputs_array = [{'topic': 'AI in healthcare'}, {'topic': 'AI in finance'}]
|
||||
async_results = await my_crew.kickoff_for_each_async(inputs=inputs_array)
|
||||
async_results = my_crew.kickoff_for_each_async(inputs=inputs_array)
|
||||
for async_result in async_results:
|
||||
print(async_result)
|
||||
```
|
||||
@@ -177,7 +177,14 @@ class MyCustomCrew:
|
||||
# Your crew implementation...
|
||||
```
|
||||
|
||||
This is how third-party event listeners are registered in the CrewAI codebase.
|
||||
This is exactly how CrewAI's built-in `agentops_listener` is registered. In the CrewAI codebase, you'll find:
|
||||
|
||||
```python
|
||||
# src/crewai/utilities/events/third_party/__init__.py
|
||||
from .agentops_listener import agentops_listener
|
||||
```
|
||||
|
||||
This ensures the `agentops_listener` is loaded when the `crewai.utilities.events` package is imported.
|
||||
|
||||
## Available Event Types
|
||||
|
||||
@@ -226,11 +233,6 @@ CrewAI provides a wide range of events that you can listen for:
|
||||
- **KnowledgeQueryFailedEvent**: Emitted when a knowledge query fails
|
||||
- **KnowledgeSearchQueryFailedEvent**: Emitted when a knowledge search query fails
|
||||
|
||||
### LLM Guardrail Events
|
||||
|
||||
- **LLMGuardrailStartedEvent**: Emitted when a guardrail validation starts. Contains details about the guardrail being applied and retry count.
|
||||
- **LLMGuardrailCompletedEvent**: Emitted when a guardrail validation completes. Contains details about validation success/failure, results, and error messages if any.
|
||||
|
||||
### Flow Events
|
||||
|
||||
- **FlowCreatedEvent**: Emitted when a Flow is created
|
||||
@@ -248,17 +250,6 @@ CrewAI provides a wide range of events that you can listen for:
|
||||
- **LLMCallFailedEvent**: Emitted when an LLM call fails
|
||||
- **LLMStreamChunkEvent**: Emitted for each chunk received during streaming LLM responses
|
||||
|
||||
### Memory Events
|
||||
|
||||
- **MemoryQueryStartedEvent**: Emitted when a memory query is started. Contains the query, limit, and optional score threshold.
|
||||
- **MemoryQueryCompletedEvent**: Emitted when a memory query is completed successfully. Contains the query, results, limit, score threshold, and query execution time.
|
||||
- **MemoryQueryFailedEvent**: Emitted when a memory query fails. Contains the query, limit, score threshold, and error message.
|
||||
- **MemorySaveStartedEvent**: Emitted when a memory save operation is started. Contains the value to be saved, metadata, and optional agent role.
|
||||
- **MemorySaveCompletedEvent**: Emitted when a memory save operation is completed successfully. Contains the saved value, metadata, agent role, and save execution time.
|
||||
- **MemorySaveFailedEvent**: Emitted when a memory save operation fails. Contains the value, metadata, agent role, and error message.
|
||||
- **MemoryRetrievalStartedEvent**: Emitted when memory retrieval for a task prompt starts. Contains the optional task ID.
|
||||
- **MemoryRetrievalCompletedEvent**: Emitted when memory retrieval for a task prompt completes successfully. Contains the task ID, memory content, and retrieval execution time.
|
||||
|
||||
## Event Handler Structure
|
||||
|
||||
Each event handler receives two parameters:
|
||||
@@ -273,6 +264,77 @@ The structure of the event object depends on the event type, but all events inhe
|
||||
|
||||
Additional fields vary by event type. For example, `CrewKickoffCompletedEvent` includes `crew_name` and `output` fields.
|
||||
|
||||
## Real-World Example: Integration with AgentOps
|
||||
|
||||
CrewAI includes an example of a third-party integration with [AgentOps](https://github.com/AgentOps-AI/agentops), a monitoring and observability platform for AI agents. Here's how it's implemented:
|
||||
|
||||
```python
|
||||
from typing import Optional
|
||||
|
||||
from crewai.utilities.events import (
|
||||
CrewKickoffCompletedEvent,
|
||||
ToolUsageErrorEvent,
|
||||
ToolUsageStartedEvent,
|
||||
)
|
||||
from crewai.utilities.events.base_event_listener import BaseEventListener
|
||||
from crewai.utilities.events.crew_events import CrewKickoffStartedEvent
|
||||
from crewai.utilities.events.task_events import TaskEvaluationEvent
|
||||
|
||||
try:
|
||||
import agentops
|
||||
AGENTOPS_INSTALLED = True
|
||||
except ImportError:
|
||||
AGENTOPS_INSTALLED = False
|
||||
|
||||
class AgentOpsListener(BaseEventListener):
|
||||
tool_event: Optional["agentops.ToolEvent"] = None
|
||||
session: Optional["agentops.Session"] = None
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def setup_listeners(self, crewai_event_bus):
|
||||
if not AGENTOPS_INSTALLED:
|
||||
return
|
||||
|
||||
@crewai_event_bus.on(CrewKickoffStartedEvent)
|
||||
def on_crew_kickoff_started(source, event: CrewKickoffStartedEvent):
|
||||
self.session = agentops.init()
|
||||
for agent in source.agents:
|
||||
if self.session:
|
||||
self.session.create_agent(
|
||||
name=agent.role,
|
||||
agent_id=str(agent.id),
|
||||
)
|
||||
|
||||
@crewai_event_bus.on(CrewKickoffCompletedEvent)
|
||||
def on_crew_kickoff_completed(source, event: CrewKickoffCompletedEvent):
|
||||
if self.session:
|
||||
self.session.end_session(
|
||||
end_state="Success",
|
||||
end_state_reason="Finished Execution",
|
||||
)
|
||||
|
||||
@crewai_event_bus.on(ToolUsageStartedEvent)
|
||||
def on_tool_usage_started(source, event: ToolUsageStartedEvent):
|
||||
self.tool_event = agentops.ToolEvent(name=event.tool_name)
|
||||
if self.session:
|
||||
self.session.record(self.tool_event)
|
||||
|
||||
@crewai_event_bus.on(ToolUsageErrorEvent)
|
||||
def on_tool_usage_error(source, event: ToolUsageErrorEvent):
|
||||
agentops.ErrorEvent(exception=event.error, trigger_event=self.tool_event)
|
||||
```
|
||||
|
||||
This listener initializes an AgentOps session when a Crew starts, registers agents with AgentOps, tracks tool usage, and ends the session when the Crew completes.
|
||||
|
||||
The AgentOps listener is registered in CrewAI's event system through the import in `src/crewai/utilities/events/third_party/__init__.py`:
|
||||
|
||||
```python
|
||||
from .agentops_listener import agentops_listener
|
||||
```
|
||||
|
||||
This ensures the `agentops_listener` is loaded when the `crewai.utilities.events` package is imported.
|
||||
|
||||
## Advanced Usage: Scoped Handlers
|
||||
|
||||
@@ -602,30 +602,6 @@ agent = Agent(
|
||||
)
|
||||
```
|
||||
|
||||
#### Configuring Azure OpenAI Embeddings
|
||||
|
||||
When using Azure OpenAI embeddings:
|
||||
1. Make sure you deploy the embedding model in Azure platform first
|
||||
2. Then you need to use the following configuration:
|
||||
|
||||
```python
|
||||
agent = Agent(
|
||||
role="Researcher",
|
||||
goal="Research topics",
|
||||
backstory="Expert researcher",
|
||||
knowledge_sources=[knowledge_source],
|
||||
embedder={
|
||||
"provider": "azure",
|
||||
"config": {
|
||||
"api_key": "your-azure-api-key",
|
||||
"model": "text-embedding-ada-002", # change to the model you are using and is deployed in Azure
|
||||
"api_base": "https://your-azure-endpoint.openai.azure.com/",
|
||||
"api_version": "2024-02-01"
|
||||
}
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
## Advanced Features
|
||||
|
||||
### Query Rewriting
|
||||
@@ -270,7 +270,7 @@ In this section, you'll find detailed examples that help you select, configure,
|
||||
from crewai import LLM
|
||||
|
||||
llm = LLM(
|
||||
model="gemini-1.5-pro-latest", # or vertex_ai/gemini-1.5-pro-latest
|
||||
model="gemini/gemini-1.5-pro-latest",
|
||||
temperature=0.7,
|
||||
vertex_credentials=vertex_credentials_json
|
||||
)
|
||||
@@ -684,28 +684,6 @@ In this section, you'll find detailed examples that help you select, configure,
|
||||
- openrouter/deepseek/deepseek-chat
|
||||
</Info>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Nebius AI Studio">
|
||||
Set the following environment variables in your `.env` file:
|
||||
```toml Code
|
||||
NEBIUS_API_KEY=<your-api-key>
|
||||
```
|
||||
|
||||
Example usage in your CrewAI project:
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="nebius/Qwen/Qwen3-30B-A3B"
|
||||
)
|
||||
```
|
||||
|
||||
<Info>
|
||||
Nebius AI Studio features:
|
||||
- Large collection of open source models
|
||||
- Higher rate limits
|
||||
- Competitive pricing
|
||||
- Good balance of speed and quality
|
||||
</Info>
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Streaming Responses
|
||||
@@ -752,55 +730,6 @@ CrewAI supports streaming responses from LLMs, allowing your application to rece
|
||||
[Click here](https://docs.crewai.com/concepts/event-listener#event-listeners) for more details
|
||||
</Tip>
|
||||
</Tab>
|
||||
|
||||
<Tab title="Agent & Task Tracking">
|
||||
All LLM events in CrewAI include agent and task information, allowing you to track and filter LLM interactions by specific agents or tasks:
|
||||
|
||||
```python
|
||||
from crewai import LLM, Agent, Task, Crew
|
||||
from crewai.utilities.events import LLMStreamChunkEvent
|
||||
from crewai.utilities.events.base_event_listener import BaseEventListener
|
||||
|
||||
class MyCustomListener(BaseEventListener):
|
||||
def setup_listeners(self, crewai_event_bus):
|
||||
@crewai_event_bus.on(LLMStreamChunkEvent)
|
||||
def on_llm_stream_chunk(source, event):
|
||||
if researcher.id == event.agent_id:
|
||||
print("\n==============\n Got event:", event, "\n==============\n")
|
||||
|
||||
|
||||
my_listener = MyCustomListener()
|
||||
|
||||
llm = LLM(model="gpt-4o-mini", temperature=0, stream=True)
|
||||
|
||||
researcher = Agent(
|
||||
role="About User",
|
||||
goal="You know everything about the user.",
|
||||
backstory="""You are a master at understanding people and their preferences.""",
|
||||
llm=llm,
|
||||
)
|
||||
|
||||
search = Task(
|
||||
description="Answer the following questions about the user: {question}",
|
||||
expected_output="An answer to the question.",
|
||||
agent=researcher,
|
||||
)
|
||||
|
||||
crew = Crew(agents=[researcher], tasks=[search])
|
||||
|
||||
result = crew.kickoff(
|
||||
inputs={"question": "..."}
|
||||
)
|
||||
```
|
||||
|
||||
<Info>
|
||||
This feature is particularly useful for:
|
||||
- Debugging specific agent behaviors
|
||||
- Logging LLM usage by task type
|
||||
- Auditing which agents are making what types of LLM calls
|
||||
- Performance monitoring of specific tasks
|
||||
</Info>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Structured LLM Calls
|
||||
@@ -9,7 +9,8 @@ icon: database
|
||||
The CrewAI framework provides a sophisticated memory system designed to significantly enhance AI agent capabilities. CrewAI offers **three distinct memory approaches** that serve different use cases:
|
||||
|
||||
1. **Basic Memory System** - Built-in short-term, long-term, and entity memory
|
||||
2. **External Memory** - Standalone external memory providers
|
||||
2. **User Memory** - User-specific memory with Mem0 integration (legacy approach)
|
||||
3. **External Memory** - Standalone external memory providers (new approach)
|
||||
|
||||
## Memory System Components
|
||||
|
||||
@@ -18,7 +19,7 @@ The CrewAI framework provides a sophisticated memory system designed to signific
|
||||
| **Short-Term Memory**| Temporarily stores recent interactions and outcomes using `RAG`, enabling agents to recall and utilize information relevant to their current context during the current executions.|
|
||||
| **Long-Term Memory** | Preserves valuable insights and learnings from past executions, allowing agents to build and refine their knowledge over time. |
|
||||
| **Entity Memory** | Captures and organizes information about entities (people, places, concepts) encountered during tasks, facilitating deeper understanding and relationship mapping. Uses `RAG` for storing entity information. |
|
||||
| **Contextual Memory**| Maintains the context of interactions by combining `ShortTermMemory`, `LongTermMemory`, `ExternalMemory` and `EntityMemory`, aiding in the coherence and relevance of agent responses over a sequence of tasks or a conversation. |
|
||||
| **Contextual Memory**| Maintains the context of interactions by combining `ShortTermMemory`, `LongTermMemory`, and `EntityMemory`, aiding in the coherence and relevance of agent responses over a sequence of tasks or a conversation. |
|
||||
|
||||
## 1. Basic Memory System (Recommended)
|
||||
|
||||
@@ -539,71 +540,16 @@ crew = Crew(
|
||||
)
|
||||
```
|
||||
|
||||
### Mem0 Provider
|
||||
|
||||
Short-Term Memory and Entity Memory both supports a tight integration with both Mem0 OSS and Mem0 Client as a provider. Here is how you can use Mem0 as a provider.
|
||||
|
||||
```python
|
||||
from crewai.memory.short_term.short_term_memory import ShortTermMemory
|
||||
from crewai.memory.entity_entity_memory import EntityMemory
|
||||
|
||||
mem0_oss_embedder_config = {
|
||||
"provider": "mem0",
|
||||
"config": {
|
||||
"user_id": "john",
|
||||
"local_mem0_config": {
|
||||
"vector_store": {"provider": "qdrant","config": {"host": "localhost", "port": 6333}},
|
||||
"llm": {"provider": "openai","config": {"api_key": "your-api-key", "model": "gpt-4"}},
|
||||
"embedder": {"provider": "openai","config": {"api_key": "your-api-key", "model": "text-embedding-3-small"}}
|
||||
},
|
||||
"infer": True # Optional defaults to True
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
mem0_client_embedder_config = {
|
||||
"provider": "mem0",
|
||||
"config": {
|
||||
"user_id": "john",
|
||||
"org_id": "my_org_id", # Optional
|
||||
"project_id": "my_project_id", # Optional
|
||||
"api_key": "custom-api-key" # Optional - overrides env var
|
||||
"run_id": "my_run_id", # Optional - for short-term memory
|
||||
"includes": "include1", # Optional
|
||||
"excludes": "exclude1", # Optional
|
||||
"infer": True # Optional defaults to True
|
||||
"custom_categories": new_categories # Optional - custom categories for user memory
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
short_term_memory_mem0_oss = ShortTermMemory(embedder_config=mem0_oss_embedder_config) # Short Term Memory with Mem0 OSS
|
||||
short_term_memory_mem0_client = ShortTermMemory(embedder_config=mem0_client_embedder_config) # Short Term Memory with Mem0 Client
|
||||
entity_memory_mem0_oss = EntityMemory(embedder_config=mem0_oss_embedder_config) # Entity Memory with Mem0 OSS
|
||||
entity_memory_mem0_client = EntityMemory(embedder_config=mem0_client_embedder_config) # Short Term Memory with Mem0 Client
|
||||
|
||||
crew = Crew(
|
||||
memory=True,
|
||||
short_term_memory=short_term_memory_mem0_oss, # or short_term_memory_mem0_client
|
||||
entity_memory=entity_memory_mem0_oss # or entity_memory_mem0_client
|
||||
)
|
||||
```
|
||||
|
||||
### Choosing the Right Embedding Provider
|
||||
|
||||
When selecting an embedding provider, consider factors like performance, privacy, cost, and integration needs.
|
||||
Below is a comparison to help you decide:
|
||||
|
||||
| Provider | Best For | Pros | Cons |
|
||||
| -------------- | ------------------------------ | --------------------------------- | ------------------------- |
|
||||
| **OpenAI** | General use, high reliability | High quality, widely tested | Paid service, API key required |
|
||||
| **Ollama** | Privacy-focused, cost savings | Free, runs locally, fully private | Requires local installation/setup |
|
||||
| **Google AI** | Integration in Google ecosystem| Strong performance, good support | Google account required |
|
||||
| **Azure OpenAI** | Enterprise & compliance needs| Enterprise-grade features, security | More complex setup process |
|
||||
| **Cohere** | Multilingual content handling | Excellent language support | More niche use cases |
|
||||
| **VoyageAI** | Information retrieval & search | Optimized for retrieval tasks | Relatively new provider |
|
||||
| **Mem0** | Per-user personalization | Search-optimized embeddings | Paid service, API key required |
|
||||
|
||||
|:---------|:----------|:------|:------|
|
||||
| **OpenAI** | General use, reliability | High quality, well-tested | Cost, requires API key |
|
||||
| **Ollama** | Privacy, cost savings | Free, local, private | Requires local setup |
|
||||
| **Google AI** | Google ecosystem | Good performance | Requires Google account |
|
||||
| **Azure OpenAI** | Enterprise, compliance | Enterprise features | Complex setup |
|
||||
| **Cohere** | Multilingual content | Great language support | Specialized use case |
|
||||
| **VoyageAI** | Retrieval tasks | Optimized for search | Newer provider |
|
||||
|
||||
### Environment Variable Configuration
|
||||
|
||||
@@ -677,7 +623,7 @@ for provider in providers_to_test:
|
||||
**Model not found errors:**
|
||||
```python
|
||||
# Verify model availability
|
||||
from crewai.rag.embeddings.configurator import EmbeddingConfigurator
|
||||
from crewai.utilities.embedding_configurator import EmbeddingConfigurator
|
||||
|
||||
configurator = EmbeddingConfigurator()
|
||||
try:
|
||||
@@ -738,18 +684,67 @@ print(f"OpenAI: {openai_time:.2f}s")
|
||||
print(f"Ollama: {ollama_time:.2f}s")
|
||||
```
|
||||
|
||||
## 2. External Memory
|
||||
External Memory provides a standalone memory system that operates independently from the crew's built-in memory. This is ideal for specialized memory providers or cross-application memory sharing.
|
||||
## 2. User Memory with Mem0 (Legacy)
|
||||
|
||||
### Basic External Memory with Mem0
|
||||
<Warning>
|
||||
**Legacy Approach**: While fully functional, this approach is considered legacy. For new projects requiring user-specific memory, consider using External Memory instead.
|
||||
</Warning>
|
||||
|
||||
User Memory integrates with [Mem0](https://mem0.ai/) to provide user-specific memory that persists across sessions and integrates with the crew's contextual memory system.
|
||||
|
||||
### Prerequisites
|
||||
```bash
|
||||
pip install mem0ai
|
||||
```
|
||||
|
||||
### Mem0 Cloud Configuration
|
||||
```python
|
||||
import os
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai.memory.external.external_memory import ExternalMemory
|
||||
from crewai import Crew, Process
|
||||
|
||||
# Create external memory instance with local Mem0 Configuration
|
||||
external_memory = ExternalMemory(
|
||||
embedder_config={
|
||||
# Set your Mem0 API key
|
||||
os.environ["MEM0_API_KEY"] = "m0-your-api-key"
|
||||
|
||||
crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
memory=True, # Required for contextual memory integration
|
||||
memory_config={
|
||||
"provider": "mem0",
|
||||
"config": {"user_id": "john"},
|
||||
"user_memory": {} # Required - triggers user memory initialization
|
||||
},
|
||||
process=Process.sequential,
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
### Advanced Mem0 Configuration
|
||||
```python
|
||||
crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
memory=True,
|
||||
memory_config={
|
||||
"provider": "mem0",
|
||||
"config": {
|
||||
"user_id": "john",
|
||||
"org_id": "my_org_id", # Optional
|
||||
"project_id": "my_project_id", # Optional
|
||||
"api_key": "custom-api-key" # Optional - overrides env var
|
||||
},
|
||||
"user_memory": {}
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
### Local Mem0 Configuration
|
||||
```python
|
||||
crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
memory=True,
|
||||
memory_config={
|
||||
"provider": "mem0",
|
||||
"config": {
|
||||
"user_id": "john",
|
||||
@@ -766,53 +761,30 @@ external_memory = ExternalMemory(
|
||||
"provider": "openai",
|
||||
"config": {"api_key": "your-api-key", "model": "text-embedding-3-small"}
|
||||
}
|
||||
},
|
||||
"infer": True # Optional defaults to True
|
||||
},
|
||||
}
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
external_memory=external_memory, # Separate from basic memory
|
||||
process=Process.sequential,
|
||||
verbose=True
|
||||
},
|
||||
"user_memory": {}
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
### Advanced External Memory with Mem0 Client
|
||||
When using Mem0 Client, you can customize the memory configuration further, by using parameters like 'includes', 'excludes', 'custom_categories', 'infer' and 'run_id' (this is only for short-term memory).
|
||||
You can find more details in the [Mem0 documentation](https://docs.mem0.ai/).
|
||||
## 3. External Memory (New Approach)
|
||||
|
||||
External Memory provides a standalone memory system that operates independently from the crew's built-in memory. This is ideal for specialized memory providers or cross-application memory sharing.
|
||||
|
||||
### Basic External Memory with Mem0
|
||||
```python
|
||||
import os
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai.memory.external.external_memory import ExternalMemory
|
||||
|
||||
new_categories = [
|
||||
{"lifestyle_management_concerns": "Tracks daily routines, habits, hobbies and interests including cooking, time management and work-life balance"},
|
||||
{"seeking_structure": "Documents goals around creating routines, schedules, and organized systems in various life areas"},
|
||||
{"personal_information": "Basic information about the user including name, preferences, and personality traits"}
|
||||
]
|
||||
|
||||
os.environ["MEM0_API_KEY"] = "your-api-key"
|
||||
|
||||
# Create external memory instance with Mem0 Client
|
||||
# Create external memory instance
|
||||
external_memory = ExternalMemory(
|
||||
embedder_config={
|
||||
"provider": "mem0",
|
||||
"config": {
|
||||
"user_id": "john",
|
||||
"org_id": "my_org_id", # Optional
|
||||
"project_id": "my_project_id", # Optional
|
||||
"api_key": "custom-api-key" # Optional - overrides env var
|
||||
"run_id": "my_run_id", # Optional - for short-term memory
|
||||
"includes": "include1", # Optional
|
||||
"excludes": "exclude1", # Optional
|
||||
"infer": True # Optional defaults to True
|
||||
"custom_categories": new_categories # Optional - custom categories for user memory
|
||||
},
|
||||
"config": {"user_id": "U-123"}
|
||||
}
|
||||
)
|
||||
|
||||
@@ -858,18 +830,17 @@ crew = Crew(
|
||||
)
|
||||
```
|
||||
|
||||
## 🧠 Memory System Comparison
|
||||
|
||||
| **Category** | **Feature** | **Basic Memory** | **External Memory** |
|
||||
|---------------------|------------------------|-----------------------------|------------------------------|
|
||||
| **Ease of Use** | Setup Complexity | Simple | Moderate |
|
||||
| | Integration | Built-in (contextual) | Standalone |
|
||||
| **Persistence** | Storage | Local files | Custom / Mem0 |
|
||||
| | Cross-session Support | ✅ | ✅ |
|
||||
| **Personalization** | User-specific Memory | ❌ | ✅ |
|
||||
| | Custom Providers | Limited | Any provider |
|
||||
| **Use Case Fit** | Recommended For | Most general use cases | Specialized / custom needs |
|
||||
## Memory System Comparison
|
||||
|
||||
| Feature | Basic Memory | User Memory (Legacy) | External Memory |
|
||||
|---------|-------------|---------------------|----------------|
|
||||
| **Setup Complexity** | Simple | Medium | Medium |
|
||||
| **Integration** | Built-in contextual | Contextual + User-specific | Standalone |
|
||||
| **Storage** | Local files | Mem0 Cloud/Local | Custom/Mem0 |
|
||||
| **Cross-session** | ✅ | ✅ | ✅ |
|
||||
| **User-specific** | ❌ | ✅ | ✅ |
|
||||
| **Custom providers** | Limited | Mem0 only | Any provider |
|
||||
| **Recommended for** | Most use cases | Legacy projects | Specialized needs |
|
||||
|
||||
## Supported Embedding Providers
|
||||
|
||||
@@ -1015,200 +986,6 @@ crew = Crew(
|
||||
- 🫡 **Enhanced Personalization:** Memory enables agents to remember user preferences and historical interactions, leading to personalized experiences.
|
||||
- 🧠 **Improved Problem Solving:** Access to a rich memory store aids agents in making more informed decisions, drawing on past learnings and contextual insights.
|
||||
|
||||
## Memory Events
|
||||
|
||||
CrewAI's event system provides powerful insights into memory operations. By leveraging memory events, you can monitor, debug, and optimize your memory system's performance and behavior.
|
||||
|
||||
### Available Memory Events
|
||||
|
||||
CrewAI emits the following memory-related events:
|
||||
|
||||
| Event | Description | Key Properties |
|
||||
| :---- | :---------- | :------------- |
|
||||
| **MemoryQueryStartedEvent** | Emitted when a memory query begins | `query`, `limit`, `score_threshold` |
|
||||
| **MemoryQueryCompletedEvent** | Emitted when a memory query completes successfully | `query`, `results`, `limit`, `score_threshold`, `query_time_ms` |
|
||||
| **MemoryQueryFailedEvent** | Emitted when a memory query fails | `query`, `limit`, `score_threshold`, `error` |
|
||||
| **MemorySaveStartedEvent** | Emitted when a memory save operation begins | `value`, `metadata`, `agent_role` |
|
||||
| **MemorySaveCompletedEvent** | Emitted when a memory save operation completes successfully | `value`, `metadata`, `agent_role`, `save_time_ms` |
|
||||
| **MemorySaveFailedEvent** | Emitted when a memory save operation fails | `value`, `metadata`, `agent_role`, `error` |
|
||||
| **MemoryRetrievalStartedEvent** | Emitted when memory retrieval for a task prompt starts | `task_id` |
|
||||
| **MemoryRetrievalCompletedEvent** | Emitted when memory retrieval completes successfully | `task_id`, `memory_content`, `retrieval_time_ms` |
|
||||
|
||||
### Practical Applications
|
||||
|
||||
#### 1. Memory Performance Monitoring
|
||||
|
||||
Track memory operation timing to optimize your application:
|
||||
|
||||
```python
|
||||
from crewai.utilities.events.base_event_listener import BaseEventListener
|
||||
from crewai.utilities.events import (
|
||||
MemoryQueryCompletedEvent,
|
||||
MemorySaveCompletedEvent
|
||||
)
|
||||
import time
|
||||
|
||||
class MemoryPerformanceMonitor(BaseEventListener):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.query_times = []
|
||||
self.save_times = []
|
||||
|
||||
def setup_listeners(self, crewai_event_bus):
|
||||
@crewai_event_bus.on(MemoryQueryCompletedEvent)
|
||||
def on_memory_query_completed(source, event: MemoryQueryCompletedEvent):
|
||||
self.query_times.append(event.query_time_ms)
|
||||
print(f"Memory query completed in {event.query_time_ms:.2f}ms. Query: '{event.query}'")
|
||||
print(f"Average query time: {sum(self.query_times)/len(self.query_times):.2f}ms")
|
||||
|
||||
@crewai_event_bus.on(MemorySaveCompletedEvent)
|
||||
def on_memory_save_completed(source, event: MemorySaveCompletedEvent):
|
||||
self.save_times.append(event.save_time_ms)
|
||||
print(f"Memory save completed in {event.save_time_ms:.2f}ms")
|
||||
print(f"Average save time: {sum(self.save_times)/len(self.save_times):.2f}ms")
|
||||
|
||||
# Create an instance of your listener
|
||||
memory_monitor = MemoryPerformanceMonitor()
|
||||
```
|
||||
|
||||
#### 2. Memory Content Logging
|
||||
|
||||
Log memory operations for debugging and insights:
|
||||
|
||||
```python
|
||||
from crewai.utilities.events.base_event_listener import BaseEventListener
|
||||
from crewai.utilities.events import (
|
||||
MemorySaveStartedEvent,
|
||||
MemoryQueryStartedEvent,
|
||||
MemoryRetrievalCompletedEvent
|
||||
)
|
||||
import logging
|
||||
|
||||
# Configure logging
|
||||
logger = logging.getLogger('memory_events')
|
||||
|
||||
class MemoryLogger(BaseEventListener):
|
||||
def setup_listeners(self, crewai_event_bus):
|
||||
@crewai_event_bus.on(MemorySaveStartedEvent)
|
||||
def on_memory_save_started(source, event: MemorySaveStartedEvent):
|
||||
if event.agent_role:
|
||||
logger.info(f"Agent '{event.agent_role}' saving memory: {event.value[:50]}...")
|
||||
else:
|
||||
logger.info(f"Saving memory: {event.value[:50]}...")
|
||||
|
||||
@crewai_event_bus.on(MemoryQueryStartedEvent)
|
||||
def on_memory_query_started(source, event: MemoryQueryStartedEvent):
|
||||
logger.info(f"Memory query started: '{event.query}' (limit: {event.limit})")
|
||||
|
||||
@crewai_event_bus.on(MemoryRetrievalCompletedEvent)
|
||||
def on_memory_retrieval_completed(source, event: MemoryRetrievalCompletedEvent):
|
||||
if event.task_id:
|
||||
logger.info(f"Memory retrieved for task {event.task_id} in {event.retrieval_time_ms:.2f}ms")
|
||||
else:
|
||||
logger.info(f"Memory retrieved in {event.retrieval_time_ms:.2f}ms")
|
||||
logger.debug(f"Memory content: {event.memory_content}")
|
||||
|
||||
# Create an instance of your listener
|
||||
memory_logger = MemoryLogger()
|
||||
```
|
||||
|
||||
#### 3. Error Tracking and Notifications
|
||||
|
||||
Capture and respond to memory errors:
|
||||
|
||||
```python
|
||||
from crewai.utilities.events.base_event_listener import BaseEventListener
|
||||
from crewai.utilities.events import (
|
||||
MemorySaveFailedEvent,
|
||||
MemoryQueryFailedEvent
|
||||
)
|
||||
import logging
|
||||
from typing import Optional
|
||||
|
||||
# Configure logging
|
||||
logger = logging.getLogger('memory_errors')
|
||||
|
||||
class MemoryErrorTracker(BaseEventListener):
|
||||
def __init__(self, notify_email: Optional[str] = None):
|
||||
super().__init__()
|
||||
self.notify_email = notify_email
|
||||
self.error_count = 0
|
||||
|
||||
def setup_listeners(self, crewai_event_bus):
|
||||
@crewai_event_bus.on(MemorySaveFailedEvent)
|
||||
def on_memory_save_failed(source, event: MemorySaveFailedEvent):
|
||||
self.error_count += 1
|
||||
agent_info = f"Agent '{event.agent_role}'" if event.agent_role else "Unknown agent"
|
||||
error_message = f"Memory save failed: {event.error}. {agent_info}"
|
||||
logger.error(error_message)
|
||||
|
||||
if self.notify_email and self.error_count % 5 == 0:
|
||||
self._send_notification(error_message)
|
||||
|
||||
@crewai_event_bus.on(MemoryQueryFailedEvent)
|
||||
def on_memory_query_failed(source, event: MemoryQueryFailedEvent):
|
||||
self.error_count += 1
|
||||
error_message = f"Memory query failed: {event.error}. Query: '{event.query}'"
|
||||
logger.error(error_message)
|
||||
|
||||
if self.notify_email and self.error_count % 5 == 0:
|
||||
self._send_notification(error_message)
|
||||
|
||||
def _send_notification(self, message):
|
||||
# Implement your notification system (email, Slack, etc.)
|
||||
print(f"[NOTIFICATION] Would send to {self.notify_email}: {message}")
|
||||
|
||||
# Create an instance of your listener
|
||||
error_tracker = MemoryErrorTracker(notify_email="admin@example.com")
|
||||
```
|
||||
|
||||
### Integrating with Analytics Platforms
|
||||
|
||||
Memory events can be forwarded to analytics and monitoring platforms to track performance metrics, detect anomalies, and visualize memory usage patterns:
|
||||
|
||||
```python
|
||||
from crewai.utilities.events.base_event_listener import BaseEventListener
|
||||
from crewai.utilities.events import (
|
||||
MemoryQueryCompletedEvent,
|
||||
MemorySaveCompletedEvent
|
||||
)
|
||||
|
||||
class MemoryAnalyticsForwarder(BaseEventListener):
|
||||
def __init__(self, analytics_client):
|
||||
super().__init__()
|
||||
self.client = analytics_client
|
||||
|
||||
def setup_listeners(self, crewai_event_bus):
|
||||
@crewai_event_bus.on(MemoryQueryCompletedEvent)
|
||||
def on_memory_query_completed(source, event: MemoryQueryCompletedEvent):
|
||||
# Forward query metrics to analytics platform
|
||||
self.client.track_metric({
|
||||
"event_type": "memory_query",
|
||||
"query": event.query,
|
||||
"duration_ms": event.query_time_ms,
|
||||
"result_count": len(event.results) if hasattr(event.results, "__len__") else 0,
|
||||
"timestamp": event.timestamp
|
||||
})
|
||||
|
||||
@crewai_event_bus.on(MemorySaveCompletedEvent)
|
||||
def on_memory_save_completed(source, event: MemorySaveCompletedEvent):
|
||||
# Forward save metrics to analytics platform
|
||||
self.client.track_metric({
|
||||
"event_type": "memory_save",
|
||||
"agent_role": event.agent_role,
|
||||
"duration_ms": event.save_time_ms,
|
||||
"timestamp": event.timestamp
|
||||
})
|
||||
```
|
||||
|
||||
### Best Practices for Memory Event Listeners
|
||||
|
||||
1. **Keep handlers lightweight**: Avoid complex processing in event handlers to prevent performance impacts
|
||||
2. **Use appropriate logging levels**: Use INFO for normal operations, DEBUG for details, ERROR for issues
|
||||
3. **Batch metrics when possible**: Accumulate metrics before sending to external systems
|
||||
4. **Handle exceptions gracefully**: Ensure your event handlers don't crash due to unexpected data
|
||||
5. **Consider memory consumption**: Be mindful of storing large amounts of event data
|
||||
|
||||
## Conclusion
|
||||
|
||||
Integrating CrewAI's memory system into your projects is straightforward. By leveraging the provided memory components and configurations,
|
||||
@@ -29,10 +29,6 @@ my_crew = Crew(
|
||||
|
||||
From this point on, your crew will have planning enabled, and the tasks will be planned before each iteration.
|
||||
|
||||
<Warning>
|
||||
When planning is enabled, crewAI will use `gpt-4o-mini` as the default LLM for planning, which requires a valid OpenAI API key. Since your agents might be using different LLMs, this could cause confusion if you don't have an OpenAI API key configured or if you're experiencing unexpected behavior related to LLM API calls.
|
||||
</Warning>
|
||||
|
||||
#### Planning LLM
|
||||
|
||||
Now you can define the LLM that will be used to plan the tasks.
|
||||
@@ -54,11 +54,9 @@ crew = Crew(
|
||||
| **Markdown** _(optional)_ | `markdown` | `Optional[bool]` | Whether the task should instruct the agent to return the final answer formatted in Markdown. Defaults to False. |
|
||||
| **Config** _(optional)_ | `config` | `Optional[Dict[str, Any]]` | Task-specific configuration parameters. |
|
||||
| **Output File** _(optional)_ | `output_file` | `Optional[str]` | File path for storing the task output. |
|
||||
| **Create Directory** _(optional)_ | `create_directory` | `Optional[bool]` | Whether to create the directory for output_file if it doesn't exist. Defaults to True. |
|
||||
| **Output JSON** _(optional)_ | `output_json` | `Optional[Type[BaseModel]]` | A Pydantic model to structure the JSON output. |
|
||||
| **Output Pydantic** _(optional)_ | `output_pydantic` | `Optional[Type[BaseModel]]` | A Pydantic model for task output. |
|
||||
| **Callback** _(optional)_ | `callback` | `Optional[Any]` | Function/object to be executed after task completion. |
|
||||
| **Guardrail** _(optional)_ | `guardrail` | `Optional[Callable]` | Function to validate task output before proceeding to next task. |
|
||||
|
||||
## Creating Tasks
|
||||
|
||||
@@ -68,7 +66,7 @@ There are two ways to create tasks in CrewAI: using **YAML configuration (recomm
|
||||
|
||||
Using YAML configuration provides a cleaner, more maintainable way to define tasks. We strongly recommend using this approach to define tasks in your CrewAI projects.
|
||||
|
||||
After creating your CrewAI project as outlined in the [Installation](/en/installation) section, navigate to the `src/latest_ai_development/config/tasks.yaml` file and modify the template to match your specific task requirements.
|
||||
After creating your CrewAI project as outlined in the [Installation](/installation) section, navigate to the `src/latest_ai_development/config/tasks.yaml` file and modify the template to match your specific task requirements.
|
||||
|
||||
<Note>
|
||||
Variables in your YAML files (like `{topic}`) will be replaced with values from your inputs when running the crew:
|
||||
@@ -334,11 +332,9 @@ Task guardrails provide a way to validate and transform task outputs before they
|
||||
are passed to the next task. This feature helps ensure data quality and provides
|
||||
feedback to agents when their output doesn't meet specific criteria.
|
||||
|
||||
Guardrails are implemented as Python functions that contain custom validation logic, giving you complete control over the validation process and ensuring reliable, deterministic results.
|
||||
### Using Task Guardrails
|
||||
|
||||
### Function-Based Guardrails
|
||||
|
||||
To add a function-based guardrail to a task, provide a validation function through the `guardrail` parameter:
|
||||
To add a guardrail to a task, provide a validation function through the `guardrail` parameter:
|
||||
|
||||
```python Code
|
||||
from typing import Tuple, Union, Dict, Any
|
||||
@@ -376,7 +372,9 @@ blog_task = Task(
|
||||
- On success: it returns a tuple of `(bool, Any)`. For example: `(True, validated_result)`
|
||||
- On Failure: it returns a tuple of `(bool, str)`. For example: `(False, "Error message explain the failure")`
|
||||
|
||||
### LLMGuardrail
|
||||
|
||||
The `LLMGuardrail` class offers a robust mechanism for validating task outputs.
|
||||
|
||||
### Error Handling Best Practices
|
||||
|
||||
@@ -800,91 +798,184 @@ While creating and executing tasks, certain validation mechanisms are in place t
|
||||
|
||||
These validations help in maintaining the consistency and reliability of task executions within the crewAI framework.
|
||||
|
||||
## Task Guardrails
|
||||
|
||||
Task guardrails provide a powerful way to validate, transform, or filter task outputs before they are passed to the next task. Guardrails are optional functions that execute before the next task starts, allowing you to ensure that task outputs meet specific requirements or formats.
|
||||
|
||||
### Basic Usage
|
||||
|
||||
#### Define your own logic to validate
|
||||
|
||||
```python Code
|
||||
from typing import Tuple, Union
|
||||
from crewai import Task
|
||||
|
||||
def validate_json_output(result: str) -> Tuple[bool, Union[dict, str]]:
|
||||
"""Validate that the output is valid JSON."""
|
||||
try:
|
||||
json_data = json.loads(result)
|
||||
return (True, json_data)
|
||||
except json.JSONDecodeError:
|
||||
return (False, "Output must be valid JSON")
|
||||
|
||||
task = Task(
|
||||
description="Generate JSON data",
|
||||
expected_output="Valid JSON object",
|
||||
guardrail=validate_json_output
|
||||
)
|
||||
```
|
||||
|
||||
#### Leverage a no-code approach for validation
|
||||
|
||||
```python Code
|
||||
from crewai import Task
|
||||
|
||||
task = Task(
|
||||
description="Generate JSON data",
|
||||
expected_output="Valid JSON object",
|
||||
guardrail="Ensure the response is a valid JSON object"
|
||||
)
|
||||
```
|
||||
|
||||
#### Using YAML
|
||||
|
||||
```yaml
|
||||
research_task:
|
||||
...
|
||||
guardrail: make sure each bullet contains a minimum of 100 words
|
||||
...
|
||||
```
|
||||
|
||||
```python Code
|
||||
@CrewBase
|
||||
class InternalCrew:
|
||||
agents_config = "config/agents.yaml"
|
||||
tasks_config = "config/tasks.yaml"
|
||||
|
||||
...
|
||||
@task
|
||||
def research_task(self):
|
||||
return Task(config=self.tasks_config["research_task"]) # type: ignore[index]
|
||||
...
|
||||
```
|
||||
|
||||
|
||||
#### Use custom models for code generation
|
||||
|
||||
```python Code
|
||||
from crewai import Task
|
||||
from crewai.llm import LLM
|
||||
|
||||
task = Task(
|
||||
description="Generate JSON data",
|
||||
expected_output="Valid JSON object",
|
||||
guardrail=LLMGuardrail(
|
||||
description="Ensure the response is a valid JSON object",
|
||||
llm=LLM(model="gpt-4o-mini"),
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
### How Guardrails Work
|
||||
|
||||
1. **Optional Attribute**: Guardrails are an optional attribute at the task level, allowing you to add validation only where needed.
|
||||
2. **Execution Timing**: The guardrail function is executed before the next task starts, ensuring valid data flow between tasks.
|
||||
3. **Return Format**: Guardrails must return a tuple of `(success, data)`:
|
||||
- If `success` is `True`, `data` is the validated/transformed result
|
||||
- If `success` is `False`, `data` is the error message
|
||||
4. **Result Routing**:
|
||||
- On success (`True`), the result is automatically passed to the next task
|
||||
- On failure (`False`), the error is sent back to the agent to generate a new answer
|
||||
|
||||
### Common Use Cases
|
||||
|
||||
#### Data Format Validation
|
||||
```python Code
|
||||
def validate_email_format(result: str) -> Tuple[bool, Union[str, str]]:
|
||||
"""Ensure the output contains a valid email address."""
|
||||
import re
|
||||
email_pattern = r'^[\w\.-]+@[\w\.-]+\.\w+$'
|
||||
if re.match(email_pattern, result.strip()):
|
||||
return (True, result.strip())
|
||||
return (False, "Output must be a valid email address")
|
||||
```
|
||||
|
||||
#### Content Filtering
|
||||
```python Code
|
||||
def filter_sensitive_info(result: str) -> Tuple[bool, Union[str, str]]:
|
||||
"""Remove or validate sensitive information."""
|
||||
sensitive_patterns = ['SSN:', 'password:', 'secret:']
|
||||
for pattern in sensitive_patterns:
|
||||
if pattern.lower() in result.lower():
|
||||
return (False, f"Output contains sensitive information ({pattern})")
|
||||
return (True, result)
|
||||
```
|
||||
|
||||
#### Data Transformation
|
||||
```python Code
|
||||
def normalize_phone_number(result: str) -> Tuple[bool, Union[str, str]]:
|
||||
"""Ensure phone numbers are in a consistent format."""
|
||||
import re
|
||||
digits = re.sub(r'\D', '', result)
|
||||
if len(digits) == 10:
|
||||
formatted = f"({digits[:3]}) {digits[3:6]}-{digits[6:]}"
|
||||
return (True, formatted)
|
||||
return (False, "Output must be a 10-digit phone number")
|
||||
```
|
||||
|
||||
### Advanced Features
|
||||
|
||||
#### Chaining Multiple Validations
|
||||
```python Code
|
||||
def chain_validations(*validators):
|
||||
"""Chain multiple validators together."""
|
||||
def combined_validator(result):
|
||||
for validator in validators:
|
||||
success, data = validator(result)
|
||||
if not success:
|
||||
return (False, data)
|
||||
result = data
|
||||
return (True, result)
|
||||
return combined_validator
|
||||
|
||||
# Usage
|
||||
task = Task(
|
||||
description="Get user contact info",
|
||||
expected_output="Email and phone",
|
||||
guardrail=chain_validations(
|
||||
validate_email_format,
|
||||
filter_sensitive_info
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
#### Custom Retry Logic
|
||||
```python Code
|
||||
task = Task(
|
||||
description="Generate data",
|
||||
expected_output="Valid data",
|
||||
guardrail=validate_data,
|
||||
max_retries=5 # Override default retry limit
|
||||
)
|
||||
```
|
||||
|
||||
## Creating Directories when Saving Files
|
||||
|
||||
The `create_directory` parameter controls whether CrewAI should automatically create directories when saving task outputs to files. This feature is particularly useful for organizing outputs and ensuring that file paths are correctly structured, especially when working with complex project hierarchies.
|
||||
|
||||
### Default Behavior
|
||||
|
||||
By default, `create_directory=True`, which means CrewAI will automatically create any missing directories in the output file path:
|
||||
You can now specify if a task should create directories when saving its output to a file. This is particularly useful for organizing outputs and ensuring that file paths are correctly structured.
|
||||
|
||||
```python Code
|
||||
# Default behavior - directories are created automatically
|
||||
report_task = Task(
|
||||
description='Generate a comprehensive market analysis report',
|
||||
expected_output='A detailed market analysis with charts and insights',
|
||||
agent=analyst_agent,
|
||||
output_file='reports/2025/market_analysis.md', # Creates 'reports/2025/' if it doesn't exist
|
||||
markdown=True
|
||||
# ...
|
||||
|
||||
save_output_task = Task(
|
||||
description='Save the summarized AI news to a file',
|
||||
expected_output='File saved successfully',
|
||||
agent=research_agent,
|
||||
tools=[file_save_tool],
|
||||
output_file='outputs/ai_news_summary.txt',
|
||||
create_directory=True
|
||||
)
|
||||
```
|
||||
|
||||
### Disabling Directory Creation
|
||||
|
||||
If you want to prevent automatic directory creation and ensure that the directory already exists, set `create_directory=False`:
|
||||
|
||||
```python Code
|
||||
# Strict mode - directory must already exist
|
||||
strict_output_task = Task(
|
||||
description='Save critical data that requires existing infrastructure',
|
||||
expected_output='Data saved to pre-configured location',
|
||||
agent=data_agent,
|
||||
output_file='secure/vault/critical_data.json',
|
||||
create_directory=False # Will raise RuntimeError if 'secure/vault/' doesn't exist
|
||||
)
|
||||
```
|
||||
|
||||
### YAML Configuration
|
||||
|
||||
You can also configure this behavior in your YAML task definitions:
|
||||
|
||||
```yaml tasks.yaml
|
||||
analysis_task:
|
||||
description: >
|
||||
Generate quarterly financial analysis
|
||||
expected_output: >
|
||||
A comprehensive financial report with quarterly insights
|
||||
agent: financial_analyst
|
||||
output_file: reports/quarterly/q4_2024_analysis.pdf
|
||||
create_directory: true # Automatically create 'reports/quarterly/' directory
|
||||
|
||||
audit_task:
|
||||
description: >
|
||||
Perform compliance audit and save to existing audit directory
|
||||
expected_output: >
|
||||
A compliance audit report
|
||||
agent: auditor
|
||||
output_file: audit/compliance_report.md
|
||||
create_directory: false # Directory must already exist
|
||||
```
|
||||
|
||||
### Use Cases
|
||||
|
||||
**Automatic Directory Creation (`create_directory=True`):**
|
||||
- Development and prototyping environments
|
||||
- Dynamic report generation with date-based folders
|
||||
- Automated workflows where directory structure may vary
|
||||
- Multi-tenant applications with user-specific folders
|
||||
|
||||
**Manual Directory Management (`create_directory=False`):**
|
||||
- Production environments with strict file system controls
|
||||
- Security-sensitive applications where directories must be pre-configured
|
||||
- Systems with specific permission requirements
|
||||
- Compliance environments where directory creation is audited
|
||||
|
||||
### Error Handling
|
||||
|
||||
When `create_directory=False` and the directory doesn't exist, CrewAI will raise a `RuntimeError`:
|
||||
|
||||
```python Code
|
||||
try:
|
||||
result = crew.kickoff()
|
||||
except RuntimeError as e:
|
||||
# Handle missing directory error
|
||||
print(f"Directory creation failed: {e}")
|
||||
# Create directory manually or use fallback location
|
||||
#...
|
||||
```
|
||||
|
||||
Check out the video below to see how to use structured outputs in CrewAI:
|
||||
@@ -32,7 +32,6 @@ The Enterprise Tools Repository includes:
|
||||
- **Customizability**: Provides the flexibility to develop custom tools or utilize existing ones, catering to the specific needs of agents.
|
||||
- **Error Handling**: Incorporates robust error handling mechanisms to ensure smooth operation.
|
||||
- **Caching Mechanism**: Features intelligent caching to optimize performance and reduce redundant operations.
|
||||
- **Asynchronous Support**: Handles both synchronous and asynchronous tools, enabling non-blocking operations.
|
||||
|
||||
## Using CrewAI Tools
|
||||
|
||||
@@ -178,62 +177,6 @@ class MyCustomTool(BaseTool):
|
||||
return "Tool's result"
|
||||
```
|
||||
|
||||
## Asynchronous Tool Support
|
||||
|
||||
CrewAI supports asynchronous tools, allowing you to implement tools that perform non-blocking operations like network requests, file I/O, or other async operations without blocking the main execution thread.
|
||||
|
||||
### Creating Async Tools
|
||||
|
||||
You can create async tools in two ways:
|
||||
|
||||
#### 1. Using the `tool` Decorator with Async Functions
|
||||
|
||||
```python Code
|
||||
from crewai.tools import tool
|
||||
|
||||
@tool("fetch_data_async")
|
||||
async def fetch_data_async(query: str) -> str:
|
||||
"""Asynchronously fetch data based on the query."""
|
||||
# Simulate async operation
|
||||
await asyncio.sleep(1)
|
||||
return f"Data retrieved for {query}"
|
||||
```
|
||||
|
||||
#### 2. Implementing Async Methods in Custom Tool Classes
|
||||
|
||||
```python Code
|
||||
from crewai.tools import BaseTool
|
||||
|
||||
class AsyncCustomTool(BaseTool):
|
||||
name: str = "async_custom_tool"
|
||||
description: str = "An asynchronous custom tool"
|
||||
|
||||
async def _run(self, query: str = "") -> str:
|
||||
"""Asynchronously run the tool"""
|
||||
# Your async implementation here
|
||||
await asyncio.sleep(1)
|
||||
return f"Processed {query} asynchronously"
|
||||
```
|
||||
|
||||
### Using Async Tools
|
||||
|
||||
Async tools work seamlessly in both standard Crew workflows and Flow-based workflows:
|
||||
|
||||
```python Code
|
||||
# In standard Crew
|
||||
agent = Agent(role="researcher", tools=[async_custom_tool])
|
||||
|
||||
# In Flow
|
||||
class MyFlow(Flow):
|
||||
@start()
|
||||
async def begin(self):
|
||||
crew = Crew(agents=[agent])
|
||||
result = await crew.kickoff_async()
|
||||
return result
|
||||
```
|
||||
|
||||
The CrewAI framework automatically handles the execution of both synchronous and asynchronous tools, so you don't need to worry about how to call them differently.
|
||||
|
||||
### Utilizing the `tool` Decorator
|
||||
|
||||
```python Code
|
||||
67
docs/concepts/training.mdx
Normal file
67
docs/concepts/training.mdx
Normal file
@@ -0,0 +1,67 @@
|
||||
---
|
||||
title: Training
|
||||
description: Learn how to train your CrewAI agents by giving them feedback early on and get consistent results.
|
||||
icon: dumbbell
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The training feature in CrewAI allows you to train your AI agents using the command-line interface (CLI).
|
||||
By running the command `crewai train -n <n_iterations>`, you can specify the number of iterations for the training process.
|
||||
|
||||
During training, CrewAI utilizes techniques to optimize the performance of your agents along with human feedback.
|
||||
This helps the agents improve their understanding, decision-making, and problem-solving abilities.
|
||||
|
||||
### Training Your Crew Using the CLI
|
||||
|
||||
To use the training feature, follow these steps:
|
||||
|
||||
1. Open your terminal or command prompt.
|
||||
2. Navigate to the directory where your CrewAI project is located.
|
||||
3. Run the following command:
|
||||
|
||||
```shell
|
||||
crewai train -n <n_iterations> <filename> (optional)
|
||||
```
|
||||
<Tip>
|
||||
Replace `<n_iterations>` with the desired number of training iterations and `<filename>` with the appropriate filename ending with `.pkl`.
|
||||
</Tip>
|
||||
|
||||
### Training Your Crew Programmatically
|
||||
|
||||
To train your crew programmatically, use the following steps:
|
||||
|
||||
1. Define the number of iterations for training.
|
||||
2. Specify the input parameters for the training process.
|
||||
3. Execute the training command within a try-except block to handle potential errors.
|
||||
|
||||
```python Code
|
||||
n_iterations = 2
|
||||
inputs = {"topic": "CrewAI Training"}
|
||||
filename = "your_model.pkl"
|
||||
|
||||
try:
|
||||
YourCrewName_Crew().crew().train(
|
||||
n_iterations=n_iterations,
|
||||
inputs=inputs,
|
||||
filename=filename
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
raise Exception(f"An error occurred while training the crew: {e}")
|
||||
```
|
||||
|
||||
### Key Points to Note
|
||||
|
||||
- **Positive Integer Requirement:** Ensure that the number of iterations (`n_iterations`) is a positive integer. The code will raise a `ValueError` if this condition is not met.
|
||||
- **Filename Requirement:** Ensure that the filename ends with `.pkl`. The code will raise a `ValueError` if this condition is not met.
|
||||
- **Error Handling:** The code handles subprocess errors and unexpected exceptions, providing error messages to the user.
|
||||
|
||||
It is important to note that the training process may take some time, depending on the complexity of your agents and will also require your feedback on each iteration.
|
||||
|
||||
Once the training is complete, your agents will be equipped with enhanced capabilities and knowledge, ready to tackle complex tasks and provide more consistent and valuable insights.
|
||||
|
||||
Remember to regularly update and retrain your agents to ensure they stay up-to-date with the latest information and advancements in the field.
|
||||
|
||||
Happy training with CrewAI! 🚀
|
||||
|
||||
1411
docs/docs.json
1411
docs/docs.json
File diff suppressed because it is too large
Load Diff
@@ -1,7 +0,0 @@
|
||||
---
|
||||
title: "GET /inputs"
|
||||
description: "Get required inputs for your crew"
|
||||
openapi: "/enterprise-api.en.yaml GET /inputs"
|
||||
---
|
||||
|
||||
|
||||
@@ -1,7 +0,0 @@
|
||||
---
|
||||
title: "POST /kickoff"
|
||||
description: "Start a crew execution"
|
||||
openapi: "/enterprise-api.en.yaml POST /kickoff"
|
||||
---
|
||||
|
||||
|
||||
@@ -1,7 +0,0 @@
|
||||
---
|
||||
title: "GET /status/{kickoff_id}"
|
||||
description: "Get execution status"
|
||||
openapi: "/enterprise-api.en.yaml GET /status/{kickoff_id}"
|
||||
---
|
||||
|
||||
|
||||
@@ -1,196 +0,0 @@
|
||||
---
|
||||
title: Training
|
||||
description: Learn how to train your CrewAI agents by giving them feedback early on and get consistent results.
|
||||
icon: dumbbell
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The training feature in CrewAI allows you to train your AI agents using the command-line interface (CLI).
|
||||
By running the command `crewai train -n <n_iterations>`, you can specify the number of iterations for the training process.
|
||||
|
||||
During training, CrewAI utilizes techniques to optimize the performance of your agents along with human feedback.
|
||||
This helps the agents improve their understanding, decision-making, and problem-solving abilities.
|
||||
|
||||
### Training Your Crew Using the CLI
|
||||
|
||||
To use the training feature, follow these steps:
|
||||
|
||||
1. Open your terminal or command prompt.
|
||||
2. Navigate to the directory where your CrewAI project is located.
|
||||
3. Run the following command:
|
||||
|
||||
```shell
|
||||
crewai train -n <n_iterations> -f <filename.pkl>
|
||||
```
|
||||
<Tip>
|
||||
Replace `<n_iterations>` with the desired number of training iterations and `<filename>` with the appropriate filename ending with `.pkl`.
|
||||
</Tip>
|
||||
|
||||
<Note>
|
||||
If you omit `-f`, the output defaults to `trained_agents_data.pkl` in the current working directory. You can pass an absolute path to control where the file is written.
|
||||
</Note>
|
||||
|
||||
### Training your Crew programmatically
|
||||
|
||||
To train your crew programmatically, use the following steps:
|
||||
|
||||
1. Define the number of iterations for training.
|
||||
2. Specify the input parameters for the training process.
|
||||
3. Execute the training command within a try-except block to handle potential errors.
|
||||
|
||||
```python Code
|
||||
n_iterations = 2
|
||||
inputs = {"topic": "CrewAI Training"}
|
||||
filename = "your_model.pkl"
|
||||
|
||||
try:
|
||||
YourCrewName_Crew().crew().train(
|
||||
n_iterations=n_iterations,
|
||||
inputs=inputs,
|
||||
filename=filename
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
raise Exception(f"An error occurred while training the crew: {e}")
|
||||
```
|
||||
|
||||
## How trained data is used by agents
|
||||
|
||||
CrewAI uses the training artifacts in two ways: during training to incorporate your human feedback, and after training to guide agents with consolidated suggestions.
|
||||
|
||||
### Training data flow
|
||||
|
||||
```mermaid
|
||||
flowchart TD
|
||||
A["Start training<br/>CLI: crewai train -n -f<br/>or Python: crew.train(...)"] --> B["Setup training mode<br/>- task.human_input = true<br/>- disable delegation<br/>- init training_data.pkl + trained file"]
|
||||
|
||||
subgraph "Iterations"
|
||||
direction LR
|
||||
C["Iteration i<br/>initial_output"] --> D["User human_feedback"]
|
||||
D --> E["improved_output"]
|
||||
E --> F["Append to training_data.pkl<br/>by agent_id and iteration"]
|
||||
end
|
||||
|
||||
B --> C
|
||||
F --> G{"More iterations?"}
|
||||
G -- "Yes" --> C
|
||||
G -- "No" --> H["Evaluate per agent<br/>aggregate iterations"]
|
||||
|
||||
H --> I["Consolidate<br/>suggestions[] + quality + final_summary"]
|
||||
I --> J["Save by agent role to trained file<br/>(default: trained_agents_data.pkl)"]
|
||||
|
||||
J --> K["Normal (non-training) runs"]
|
||||
K --> L["Auto-load suggestions<br/>from trained_agents_data.pkl"]
|
||||
L --> M["Append to prompt<br/>for consistent improvements"]
|
||||
```
|
||||
|
||||
### During training runs
|
||||
|
||||
- On each iteration, the system records for every agent:
|
||||
- `initial_output`: the agent’s first answer
|
||||
- `human_feedback`: your inline feedback when prompted
|
||||
- `improved_output`: the agent’s follow-up answer after feedback
|
||||
- This data is stored in a working file named `training_data.pkl` keyed by the agent’s internal ID and iteration.
|
||||
- While training is active, the agent automatically appends your prior human feedback to its prompt to enforce those instructions on subsequent attempts within the training session.
|
||||
Training is interactive: tasks set `human_input = true`, so running in a non-interactive environment will block on user input.
|
||||
|
||||
### After training completes
|
||||
|
||||
- When `train(...)` finishes, CrewAI evaluates the collected training data per agent and produces a consolidated result containing:
|
||||
- `suggestions`: clear, actionable instructions distilled from your feedback and the difference between initial/improved outputs
|
||||
- `quality`: a 0–10 score capturing improvement
|
||||
- `final_summary`: a step-by-step set of action items for future tasks
|
||||
- These consolidated results are saved to the filename you pass to `train(...)` (default via CLI is `trained_agents_data.pkl`). Entries are keyed by the agent’s `role` so they can be applied across sessions.
|
||||
- During normal (non-training) execution, each agent automatically loads its consolidated `suggestions` and appends them to the task prompt as mandatory instructions. This gives you consistent improvements without changing your agent definitions.
|
||||
|
||||
### File summary
|
||||
|
||||
- `training_data.pkl` (ephemeral, per-session):
|
||||
- Structure: `agent_id -> { iteration_number: { initial_output, human_feedback, improved_output } }`
|
||||
- Purpose: capture raw data and human feedback during training
|
||||
- Location: saved in the current working directory (CWD)
|
||||
- `trained_agents_data.pkl` (or your custom filename):
|
||||
- Structure: `agent_role -> { suggestions: string[], quality: number, final_summary: string }`
|
||||
- Purpose: persist consolidated guidance for future runs
|
||||
- Location: written to the CWD by default; use `-f` to set a custom (including absolute) path
|
||||
|
||||
## Small Language Model Considerations
|
||||
|
||||
<Warning>
|
||||
When using smaller language models (≤7B parameters) for training data evaluation, be aware that they may face challenges with generating structured outputs and following complex instructions.
|
||||
</Warning>
|
||||
|
||||
### Limitations of Small Models in Training Evaluation
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="JSON Output Accuracy" icon="triangle-exclamation">
|
||||
Smaller models often struggle with producing valid JSON responses needed for structured training evaluations, leading to parsing errors and incomplete data.
|
||||
</Card>
|
||||
<Card title="Evaluation Quality" icon="chart-line">
|
||||
Models under 7B parameters may provide less nuanced evaluations with limited reasoning depth compared to larger models.
|
||||
</Card>
|
||||
<Card title="Instruction Following" icon="list-check">
|
||||
Complex training evaluation criteria may not be fully followed or considered by smaller models.
|
||||
</Card>
|
||||
<Card title="Consistency" icon="rotate">
|
||||
Evaluations across multiple training iterations may lack consistency with smaller models.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### Recommendations for Training
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Best Practice">
|
||||
For optimal training quality and reliable evaluations, we strongly recommend using models with at least 7B parameters or larger:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task, LLM
|
||||
|
||||
# Recommended minimum for training evaluation
|
||||
llm = LLM(model="mistral/open-mistral-7b")
|
||||
|
||||
# Better options for reliable training evaluation
|
||||
llm = LLM(model="anthropic/claude-3-sonnet-20240229-v1:0")
|
||||
llm = LLM(model="gpt-4o")
|
||||
|
||||
# Use this LLM with your agents
|
||||
agent = Agent(
|
||||
role="Training Evaluator",
|
||||
goal="Provide accurate training feedback",
|
||||
llm=llm
|
||||
)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
More powerful models provide higher quality feedback with better reasoning, leading to more effective training iterations.
|
||||
</Tip>
|
||||
</Tab>
|
||||
<Tab title="Small Model Usage">
|
||||
If you must use smaller models for training evaluation, be aware of these constraints:
|
||||
|
||||
```python
|
||||
# Using a smaller model (expect some limitations)
|
||||
llm = LLM(model="huggingface/microsoft/Phi-3-mini-4k-instruct")
|
||||
```
|
||||
|
||||
<Warning>
|
||||
While CrewAI includes optimizations for small models, expect less reliable and less nuanced evaluation results that may require more human intervention during training.
|
||||
</Warning>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### Key Points to Note
|
||||
|
||||
- **Positive Integer Requirement:** Ensure that the number of iterations (`n_iterations`) is a positive integer. The code will raise a `ValueError` if this condition is not met.
|
||||
- **Filename Requirement:** Ensure that the filename ends with `.pkl`. The code will raise a `ValueError` if this condition is not met.
|
||||
- **Error Handling:** The code handles subprocess errors and unexpected exceptions, providing error messages to the user.
|
||||
- Trained guidance is applied at prompt time; it does not modify your Python/YAML agent configuration.
|
||||
- Agents automatically load trained suggestions from a file named `trained_agents_data.pkl` located in the current working directory. If you trained to a different filename, either rename it to `trained_agents_data.pkl` before running, or adjust the loader in code.
|
||||
- You can change the output filename when calling `crewai train` with `-f/--filename`. Absolute paths are supported if you want to save outside the CWD.
|
||||
|
||||
It is important to note that the training process may take some time, depending on the complexity of your agents and will also require your feedback on each iteration.
|
||||
|
||||
Once the training is complete, your agents will be equipped with enhanced capabilities and knowledge, ready to tackle complex tasks and provide more consistent and valuable insights.
|
||||
|
||||
Remember to regularly update and retrain your agents to ensure they stay up-to-date with the latest information and advancements in the field.
|
||||
@@ -1,155 +0,0 @@
|
||||
---
|
||||
title: 'Agent Repositories'
|
||||
description: 'Learn how to use Agent Repositories to share and reuse your agents across teams and projects'
|
||||
icon: 'database'
|
||||
---
|
||||
|
||||
Agent Repositories allow enterprise users to store, share, and reuse agent definitions across teams and projects. This feature enables organizations to maintain a centralized library of standardized agents, promoting consistency and reducing duplication of effort.
|
||||
|
||||
## Benefits of Agent Repositories
|
||||
|
||||
- **Standardization**: Maintain consistent agent definitions across your organization
|
||||
- **Reusability**: Create an agent once and use it in multiple crews and projects
|
||||
- **Governance**: Implement organization-wide policies for agent configurations
|
||||
- **Collaboration**: Enable teams to share and build upon each other's work
|
||||
|
||||
## Using Agent Repositories
|
||||
|
||||
### Prerequisites
|
||||
|
||||
1. You must have an account at CrewAI, try the [free plan](https://app.crewai.com).
|
||||
2. You need to be authenticated using the CrewAI CLI.
|
||||
3. If you have more than one organization, make sure you are switched to the correct organization using the CLI command:
|
||||
|
||||
```bash
|
||||
crewai org switch <org_id>
|
||||
```
|
||||
|
||||
### Creating and Managing Agents in Repositories
|
||||
|
||||
To create and manage agents in repositories,Enterprise Dashboard.
|
||||
|
||||
### Loading Agents from Repositories
|
||||
|
||||
You can load agents from repositories in your code using the `from_repository` parameter:
|
||||
|
||||
```python
|
||||
from crewai import Agent
|
||||
|
||||
# Create an agent by loading it from a repository
|
||||
# The agent is loaded with all its predefined configurations
|
||||
researcher = Agent(
|
||||
from_repository="market-research-agent"
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
### Overriding Repository Settings
|
||||
|
||||
You can override specific settings from the repository by providing them in the configuration:
|
||||
|
||||
```python
|
||||
researcher = Agent(
|
||||
from_repository="market-research-agent",
|
||||
goal="Research the latest trends in AI development", # Override the repository goal
|
||||
verbose=True # Add a setting not in the repository
|
||||
)
|
||||
```
|
||||
|
||||
### Example: Creating a Crew with Repository Agents
|
||||
|
||||
```python
|
||||
from crewai import Crew, Agent, Task
|
||||
|
||||
# Load agents from repositories
|
||||
researcher = Agent(
|
||||
from_repository="market-research-agent"
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
from_repository="content-writer-agent"
|
||||
)
|
||||
|
||||
# Create tasks
|
||||
research_task = Task(
|
||||
description="Research the latest trends in AI",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description="Write a comprehensive report based on the research",
|
||||
agent=writer
|
||||
)
|
||||
|
||||
# Create the crew
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Example: Using `kickoff()` with Repository Agents
|
||||
|
||||
You can also use repository agents directly with the `kickoff()` method for simpler interactions:
|
||||
|
||||
```python
|
||||
from crewai import Agent
|
||||
from pydantic import BaseModel
|
||||
from typing import List
|
||||
|
||||
# Define a structured output format
|
||||
class MarketAnalysis(BaseModel):
|
||||
key_trends: List[str]
|
||||
opportunities: List[str]
|
||||
recommendation: str
|
||||
|
||||
# Load an agent from repository
|
||||
analyst = Agent(
|
||||
from_repository="market-analyst-agent",
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Get a free-form response
|
||||
result = analyst.kickoff("Analyze the AI market in 2025")
|
||||
print(result.raw) # Access the raw response
|
||||
|
||||
# Get structured output
|
||||
structured_result = analyst.kickoff(
|
||||
"Provide a structured analysis of the AI market in 2025",
|
||||
response_format=MarketAnalysis
|
||||
)
|
||||
|
||||
# Access structured data
|
||||
print(f"Key Trends: {structured_result.pydantic.key_trends}")
|
||||
print(f"Recommendation: {structured_result.pydantic.recommendation}")
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
1. **Naming Convention**: Use clear, descriptive names for your repository agents
|
||||
2. **Documentation**: Include comprehensive descriptions for each agent
|
||||
3. **Tool Management**: Ensure that tools referenced by repository agents are available in your environment
|
||||
4. **Access Control**: Manage permissions to ensure only authorized team members can modify repository agents
|
||||
|
||||
## Organization Management
|
||||
|
||||
To switch between organizations or see your current organization, use the CrewAI CLI:
|
||||
|
||||
```bash
|
||||
# View current organization
|
||||
crewai org current
|
||||
|
||||
# Switch to a different organization
|
||||
crewai org switch <org_id>
|
||||
|
||||
# List all available organizations
|
||||
crewai org list
|
||||
```
|
||||
|
||||
<Note>
|
||||
When loading agents from repositories, you must be authenticated and switched to the correct organization. If you receive errors, check your authentication status and organization settings using the CLI commands above.
|
||||
</Note>
|
||||
@@ -1,185 +0,0 @@
|
||||
---
|
||||
title: Integrations
|
||||
description: "Connected applications for your agents to take actions."
|
||||
icon: "plug"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to authenticate with any OAuth enabled provider and take actions. From Salesforce and HubSpot to Google and GitHub, we've got you covered with 16+ integrated services.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
## Supported Integrations
|
||||
|
||||
### **Communication & Collaboration**
|
||||
- **Gmail** - Manage emails and drafts
|
||||
- **Slack** - Workspace notifications and alerts
|
||||
- **Microsoft** - Office 365 and Teams integration
|
||||
|
||||
### **Project Management**
|
||||
- **Jira** - Issue tracking and project management
|
||||
- **ClickUp** - Task and productivity management
|
||||
- **Asana** - Team task and project coordination
|
||||
- **Notion** - Page and database management
|
||||
- **Linear** - Software project and bug tracking
|
||||
- **GitHub** - Repository and issue management
|
||||
|
||||
### **Customer Relationship Management**
|
||||
- **Salesforce** - CRM account and opportunity management
|
||||
- **HubSpot** - Sales pipeline and contact management
|
||||
- **Zendesk** - Customer support ticket management
|
||||
|
||||
### **Business & Finance**
|
||||
- **Stripe** - Payment processing and customer management
|
||||
- **Shopify** - E-commerce store and product management
|
||||
|
||||
### **Productivity & Storage**
|
||||
- **Google Sheets** - Spreadsheet data synchronization
|
||||
- **Google Calendar** - Event and schedule management
|
||||
- **Box** - File storage and document management
|
||||
|
||||
and more to come!
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using Authentication Integrations, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account. You can get started with a free trial.
|
||||
|
||||
|
||||
## Setting Up Integrations
|
||||
|
||||
### 1. Connect Your Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise](https://app.crewai.com)
|
||||
2. Go to **Integrations** tab - https://app.crewai.com/crewai_plus/connectors
|
||||
3. Click **Connect** on your desired service from the Authentication Integrations section
|
||||
4. Complete the OAuth authentication flow
|
||||
5. Grant necessary permissions for your use case
|
||||
6. Get your Enterprise Token from your [CrewAI Enterprise](https://app.crewai.com) account page - https://app.crewai.com/crewai_plus/settings/account
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
### 2. Install Integration Tools
|
||||
|
||||
All you need is the latest version of `crewai-tools` package.
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Usage
|
||||
<Tip>
|
||||
All the services you are authenticated into will be available as tools. So all you need to do is add the `CrewaiEnterpriseTools` to your agent and you are good to go.
|
||||
</Tip>
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Gmail tool will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
# print the tools
|
||||
print(enterprise_tools)
|
||||
|
||||
# Create an agent with Gmail capabilities
|
||||
email_agent = Agent(
|
||||
role="Email Manager",
|
||||
goal="Manage and organize email communications",
|
||||
backstory="An AI assistant specialized in email management and communication.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to send an email
|
||||
email_task = Task(
|
||||
description="Draft and send a follow-up email to john@example.com about the project update",
|
||||
agent=email_agent,
|
||||
expected_output="Confirmation that email was sent successfully"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[email_agent],
|
||||
tasks=[email_task]
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
actions_list=["gmail_find_email"] # only gmail_find_email tool will be available
|
||||
)
|
||||
gmail_tool = enterprise_tools["gmail_find_email"]
|
||||
|
||||
gmail_agent = Agent(
|
||||
role="Gmail Manager",
|
||||
goal="Manage gmail communications and notifications",
|
||||
backstory="An AI assistant that helps coordinate gmail communications.",
|
||||
tools=[gmail_tool]
|
||||
)
|
||||
|
||||
notification_task = Task(
|
||||
description="Find the email from john@example.com",
|
||||
agent=gmail_agent,
|
||||
expected_output="Email found from john@example.com"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[slack_agent],
|
||||
tasks=[notification_task]
|
||||
)
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
### Security
|
||||
- **Principle of Least Privilege**: Only grant the minimum permissions required for your agents' tasks
|
||||
- **Regular Audits**: Periodically review connected integrations and their permissions
|
||||
- **Secure Credentials**: Never hardcode credentials; use CrewAI's secure authentication flow
|
||||
|
||||
|
||||
### Filtering Tools
|
||||
On a deployed crew, you can specify which actions are avialbel for each integration from the settings page of the service you connected to.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
|
||||
### Scoped Deployments for multi user organizations
|
||||
You can deploy your crew and scope each integration to a specific user. For example, a crew that connects to google can use a specific user's gmail account.
|
||||
|
||||
<Tip>
|
||||
This is useful for multi user organizations where you want to scope the integration to a specific user.
|
||||
</Tip>
|
||||
|
||||
|
||||
Use the `user_bearer_token` to scope the integration to a specific user so that when the crew is kicked off, it will use the user's bearer token to authenticate with the integration. If user is not logged in, then the crew will not use any connected integrations. Use the default bearer token to authenticate with the integrations thats deployed with the crew.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,103 +0,0 @@
|
||||
---
|
||||
title: "Role-Based Access Control (RBAC)"
|
||||
description: "Control access to crews, tools, and data with roles, scopes, and granular permissions."
|
||||
icon: "shield"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
RBAC in CrewAI Enterprise enables secure, scalable access management through a combination of organization‑level roles and automation‑level visibility controls.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/enterprise/users_and_roles.png" alt="RBAC overview in CrewAI Enterprise" />
|
||||
|
||||
</Frame>
|
||||
|
||||
## Users and Roles
|
||||
|
||||
Each member in your CrewAI workspace is assigned a role, which determines their access across various features.
|
||||
|
||||
You can:
|
||||
|
||||
- Use predefined roles (Owner, Member)
|
||||
- Create custom roles tailored to specific permissions
|
||||
- Assign roles at any time through the settings panel
|
||||
|
||||
You can configure users and roles in Settings → Roles.
|
||||
|
||||
<Steps>
|
||||
<Step title="Open Roles settings">
|
||||
Go to <b>Settings → Roles</b> in CrewAI Enterprise.
|
||||
</Step>
|
||||
<Step title="Choose a role type">
|
||||
Use a predefined role (<b>Owner</b>, <b>Member</b>) or click <b>Create role</b> to define a custom one.
|
||||
</Step>
|
||||
<Step title="Assign to members">
|
||||
Select users and assign the role. You can change this anytime.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Configuration summary
|
||||
|
||||
| Area | Where to configure | Options |
|
||||
|:---|:---|:---|
|
||||
| Users & Roles | Settings → Roles | Predefined: Owner, Member; Custom roles |
|
||||
| Automation visibility | Automation → Settings → Visibility | Private; Whitelist users/roles |
|
||||
|
||||
## Automation‑level Access Control
|
||||
|
||||
In addition to organization‑wide roles, CrewAI Automations support fine‑grained visibility settings that let you restrict access to specific automations by user or role.
|
||||
|
||||
This is useful for:
|
||||
|
||||
- Keeping sensitive or experimental automations private
|
||||
- Managing visibility across large teams or external collaborators
|
||||
- Testing automations in isolated contexts
|
||||
|
||||
Deployments can be configured as private, meaning only whitelisted users and roles will be able to:
|
||||
|
||||
- View the deployment
|
||||
- Run it or interact with its API
|
||||
- Access its logs, metrics, and settings
|
||||
|
||||
The organization owner always has access, regardless of visibility settings.
|
||||
|
||||
You can configure automation‑level access control in Automation → Settings → Visibility tab.
|
||||
|
||||
<Steps>
|
||||
<Step title="Open Visibility tab">
|
||||
Navigate to <b>Automation → Settings → Visibility</b>.
|
||||
</Step>
|
||||
<Step title="Set visibility">
|
||||
Choose <b>Private</b> to restrict access. The organization owner always retains access.
|
||||
</Step>
|
||||
<Step title="Whitelist access">
|
||||
Add specific users and roles allowed to view, run, and access logs/metrics/settings.
|
||||
</Step>
|
||||
<Step title="Save and verify">
|
||||
Save changes, then confirm that non‑whitelisted users cannot view or run the automation.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Private visibility: access outcomes
|
||||
|
||||
| Action | Owner | Whitelisted user/role | Not whitelisted |
|
||||
|:---|:---|:---|:---|
|
||||
| View automation | ✓ | ✓ | ✗ |
|
||||
| Run automation/API | ✓ | ✓ | ✗ |
|
||||
| Access logs/metrics/settings | ✓ | ✓ | ✗ |
|
||||
|
||||
<Tip>
|
||||
The organization owner always has access. In private mode, only whitelisted users and roles can view, run, and access logs/metrics/settings.
|
||||
</Tip>
|
||||
|
||||
<Frame>
|
||||
<img src="/images/enterprise/visibility.png" alt="Automation Visibility settings in CrewAI Enterprise" />
|
||||
|
||||
</Frame>
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with RBAC questions.
|
||||
</Card>
|
||||
|
||||
|
||||
@@ -1,253 +0,0 @@
|
||||
---
|
||||
title: Asana Integration
|
||||
description: "Team task and project coordination with Asana integration for CrewAI."
|
||||
icon: "circle"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage tasks, projects, and team coordination through Asana. Create tasks, update project status, manage assignments, and streamline your team's workflow with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Asana integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- An Asana account with appropriate permissions
|
||||
- Connected your Asana account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors)
|
||||
|
||||
## Setting Up Asana Integration
|
||||
|
||||
### 1. Connect Your Asana Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors)
|
||||
2. Find **Asana** in the Authentication Integrations section
|
||||
3. Click **Connect** and complete the OAuth flow
|
||||
4. Grant the necessary permissions for task and project management
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account)
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="ASANA_CREATE_COMMENT">
|
||||
**Description:** Create a comment in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `task` (string, required): Task ID - The ID of the Task the comment will be added to. The comment will be authored by the currently authenticated user.
|
||||
- `text` (string, required): Text (example: "This is a comment.").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_CREATE_PROJECT">
|
||||
**Description:** Create a project in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `name` (string, required): Name (example: "Stuff to buy").
|
||||
- `workspace` (string, required): Workspace - Use Connect Portal Workflow Settings to allow users to select which Workspace to create Projects in. Defaults to the user's first Workspace if left blank.
|
||||
- `team` (string, optional): Team - Use Connect Portal Workflow Settings to allow users to select which Team to share this Project with. Defaults to the user's first Team if left blank.
|
||||
- `notes` (string, optional): Notes (example: "These are things we need to purchase.").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_GET_PROJECTS">
|
||||
**Description:** Get a list of projects in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `archived` (string, optional): Archived - Choose "true" to show archived projects, "false" to display only active projects, or "default" to show both archived and active projects.
|
||||
- Options: `default`, `true`, `false`
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_GET_PROJECT_BY_ID">
|
||||
**Description:** Get a project by ID in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `projectFilterId` (string, required): Project ID.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_CREATE_TASK">
|
||||
**Description:** Create a task in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `name` (string, required): Name (example: "Task Name").
|
||||
- `workspace` (string, optional): Workspace - Use Connect Portal Workflow Settings to allow users to select which Workspace to create Tasks in. Defaults to the user's first Workspace if left blank..
|
||||
- `project` (string, optional): Project - Use Connect Portal Workflow Settings to allow users to select which Project to create this Task in.
|
||||
- `notes` (string, optional): Notes.
|
||||
- `dueOnDate` (string, optional): Due On - The date on which this task is due. Cannot be used together with Due At. (example: "YYYY-MM-DD").
|
||||
- `dueAtDate` (string, optional): Due At - The date and time (ISO timestamp) at which this task is due. Cannot be used together with Due On. (example: "2019-09-15T02:06:58.147Z").
|
||||
- `assignee` (string, optional): Assignee - The ID of the Asana user this task will be assigned to. Use Connect Portal Workflow Settings to allow users to select an Assignee.
|
||||
- `gid` (string, optional): External ID - An ID from your application to associate this task with. You can use this ID to sync updates to this task later.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_UPDATE_TASK">
|
||||
**Description:** Update a task in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `taskId` (string, required): Task ID - The ID of the Task that will be updated.
|
||||
- `completeStatus` (string, optional): Completed Status.
|
||||
- Options: `true`, `false`
|
||||
- `name` (string, optional): Name (example: "Task Name").
|
||||
- `notes` (string, optional): Notes.
|
||||
- `dueOnDate` (string, optional): Due On - The date on which this task is due. Cannot be used together with Due At. (example: "YYYY-MM-DD").
|
||||
- `dueAtDate` (string, optional): Due At - The date and time (ISO timestamp) at which this task is due. Cannot be used together with Due On. (example: "2019-09-15T02:06:58.147Z").
|
||||
- `assignee` (string, optional): Assignee - The ID of the Asana user this task will be assigned to. Use Connect Portal Workflow Settings to allow users to select an Assignee.
|
||||
- `gid` (string, optional): External ID - An ID from your application to associate this task with. You can use this ID to sync updates to this task later.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_GET_TASKS">
|
||||
**Description:** Get a list of tasks in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `workspace` (string, optional): Workspace - The ID of the Workspace to filter tasks on. Use Connect Portal Workflow Settings to allow users to select a Workspace.
|
||||
- `project` (string, optional): Project - The ID of the Project to filter tasks on. Use Connect Portal Workflow Settings to allow users to select a Project.
|
||||
- `assignee` (string, optional): Assignee - The ID of the assignee to filter tasks on. Use Connect Portal Workflow Settings to allow users to select an Assignee.
|
||||
- `completedSince` (string, optional): Completed since - Only return tasks that are either incomplete or that have been completed since this time (ISO or Unix timestamp). (example: "2014-04-25T16:15:47-04:00").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_GET_TASKS_BY_ID">
|
||||
**Description:** Get a list of tasks by ID in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `taskId` (string, required): Task ID.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_GET_TASK_BY_EXTERNAL_ID">
|
||||
**Description:** Get a task by external ID in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `gid` (string, required): External ID - The ID that this task is associated or synced with, from your application.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_ADD_TASK_TO_SECTION">
|
||||
**Description:** Add a task to a section in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `sectionId` (string, required): Section ID - The ID of the section to add this task to.
|
||||
- `taskId` (string, required): Task ID - The ID of the task. (example: "1204619611402340").
|
||||
- `beforeTaskId` (string, optional): Before Task ID - The ID of a task in this section that this task will be inserted before. Cannot be used with After Task ID. (example: "1204619611402340").
|
||||
- `afterTaskId` (string, optional): After Task ID - The ID of a task in this section that this task will be inserted after. Cannot be used with Before Task ID. (example: "1204619611402340").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_GET_TEAMS">
|
||||
**Description:** Get a list of teams in Asana.
|
||||
|
||||
**Parameters:**
|
||||
- `workspace` (string, required): Workspace - Returns the teams in this workspace visible to the authorized user.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ASANA_GET_WORKSPACES">
|
||||
**Description:** Get a list of workspaces in Asana.
|
||||
|
||||
**Parameters:** None required.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Asana Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Asana tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Asana capabilities
|
||||
asana_agent = Agent(
|
||||
role="Project Manager",
|
||||
goal="Manage tasks and projects in Asana efficiently",
|
||||
backstory="An AI assistant specialized in project management and task coordination.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a new project
|
||||
create_project_task = Task(
|
||||
description="Create a new project called 'Q1 Marketing Campaign' in the Marketing workspace",
|
||||
agent=asana_agent,
|
||||
expected_output="Confirmation that the project was created successfully with project ID"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[asana_agent],
|
||||
tasks=[create_project_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Asana Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Asana tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["asana_create_task", "asana_update_task", "asana_get_tasks"]
|
||||
)
|
||||
|
||||
task_manager_agent = Agent(
|
||||
role="Task Manager",
|
||||
goal="Create and manage tasks efficiently",
|
||||
backstory="An AI assistant that focuses on task creation and management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to create and assign a task
|
||||
task_management = Task(
|
||||
description="Create a task called 'Review quarterly reports' and assign it to the appropriate team member",
|
||||
agent=task_manager_agent,
|
||||
expected_output="Task created and assigned successfully"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[task_manager_agent],
|
||||
tasks=[task_management]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Advanced Project Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
project_coordinator = Agent(
|
||||
role="Project Coordinator",
|
||||
goal="Coordinate project activities and track progress",
|
||||
backstory="An experienced project coordinator who ensures projects run smoothly.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex task involving multiple Asana operations
|
||||
coordination_task = Task(
|
||||
description="""
|
||||
1. Get all active projects in the workspace
|
||||
2. For each project, get the list of incomplete tasks
|
||||
3. Create a summary report task in the 'Management Reports' project
|
||||
4. Add comments to overdue tasks to request status updates
|
||||
""",
|
||||
agent=project_coordinator,
|
||||
expected_output="Summary report created and status update requests sent for overdue tasks"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[project_coordinator],
|
||||
tasks=[coordination_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
@@ -1,268 +0,0 @@
|
||||
---
|
||||
title: Box Integration
|
||||
description: "File storage and document management with Box integration for CrewAI."
|
||||
icon: "box"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage files, folders, and documents through Box. Upload files, organize folder structures, search content, and streamline your team's document management with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Box integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Box account with appropriate permissions
|
||||
- Connected your Box account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors)
|
||||
|
||||
## Setting Up Box Integration
|
||||
|
||||
### 1. Connect Your Box Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors)
|
||||
2. Find **Box** in the Authentication Integrations section
|
||||
3. Click **Connect** and complete the OAuth flow
|
||||
4. Grant the necessary permissions for file and folder management
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account)
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="BOX_SAVE_FILE">
|
||||
**Description:** Save a file from URL in Box.
|
||||
|
||||
**Parameters:**
|
||||
- `fileAttributes` (object, required): Attributes - File metadata including name, parent folder, and timestamps.
|
||||
```json
|
||||
{
|
||||
"content_created_at": "2012-12-12T10:53:43-08:00",
|
||||
"content_modified_at": "2012-12-12T10:53:43-08:00",
|
||||
"name": "qwerty.png",
|
||||
"parent": { "id": "1234567" }
|
||||
}
|
||||
```
|
||||
- `file` (string, required): File URL - Files must be smaller than 50MB in size. (example: "https://picsum.photos/200/300").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="BOX_SAVE_FILE_FROM_OBJECT">
|
||||
**Description:** Save a file in Box.
|
||||
|
||||
**Parameters:**
|
||||
- `file` (string, required): File - Accepts a File Object containing file data. Files must be smaller than 50MB in size.
|
||||
- `fileName` (string, required): File Name (example: "qwerty.png").
|
||||
- `folder` (string, optional): Folder - Use Connect Portal Workflow Settings to allow users to select the File's Folder destination. Defaults to the user's root folder if left blank.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="BOX_GET_FILE_BY_ID">
|
||||
**Description:** Get a file by ID in Box.
|
||||
|
||||
**Parameters:**
|
||||
- `fileId` (string, required): File ID - The unique identifier that represents a file. (example: "12345").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="BOX_LIST_FILES">
|
||||
**Description:** List files in Box.
|
||||
|
||||
**Parameters:**
|
||||
- `folderId` (string, required): Folder ID - The unique identifier that represents a folder. (example: "0").
|
||||
- `filterFormula` (object, optional): A filter in disjunctive normal form - OR of AND groups of single conditions.
|
||||
```json
|
||||
{
|
||||
"operator": "OR",
|
||||
"conditions": [
|
||||
{
|
||||
"operator": "AND",
|
||||
"conditions": [
|
||||
{
|
||||
"field": "direction",
|
||||
"operator": "$stringExactlyMatches",
|
||||
"value": "ASC"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="BOX_CREATE_FOLDER">
|
||||
**Description:** Create a folder in Box.
|
||||
|
||||
**Parameters:**
|
||||
- `folderName` (string, required): Name - The name for the new folder. (example: "New Folder").
|
||||
- `folderParent` (object, required): Parent Folder - The parent folder where the new folder will be created.
|
||||
```json
|
||||
{
|
||||
"id": "123456"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="BOX_MOVE_FOLDER">
|
||||
**Description:** Move a folder in Box.
|
||||
|
||||
**Parameters:**
|
||||
- `folderId` (string, required): Folder ID - The unique identifier that represents a folder. (example: "0").
|
||||
- `folderName` (string, required): Name - The name for the folder. (example: "New Folder").
|
||||
- `folderParent` (object, required): Parent Folder - The new parent folder destination.
|
||||
```json
|
||||
{
|
||||
"id": "123456"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="BOX_GET_FOLDER_BY_ID">
|
||||
**Description:** Get a folder by ID in Box.
|
||||
|
||||
**Parameters:**
|
||||
- `folderId` (string, required): Folder ID - The unique identifier that represents a folder. (example: "0").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="BOX_SEARCH_FOLDERS">
|
||||
**Description:** Search folders in Box.
|
||||
|
||||
**Parameters:**
|
||||
- `folderId` (string, required): Folder ID - The folder to search within.
|
||||
- `filterFormula` (object, optional): A filter in disjunctive normal form - OR of AND groups of single conditions.
|
||||
```json
|
||||
{
|
||||
"operator": "OR",
|
||||
"conditions": [
|
||||
{
|
||||
"operator": "AND",
|
||||
"conditions": [
|
||||
{
|
||||
"field": "sort",
|
||||
"operator": "$stringExactlyMatches",
|
||||
"value": "name"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="BOX_DELETE_FOLDER">
|
||||
**Description:** Delete a folder in Box.
|
||||
|
||||
**Parameters:**
|
||||
- `folderId` (string, required): Folder ID - The unique identifier that represents a folder. (example: "0").
|
||||
- `recursive` (boolean, optional): Recursive - Delete a folder that is not empty by recursively deleting the folder and all of its content.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Box Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Box tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Box capabilities
|
||||
box_agent = Agent(
|
||||
role="Document Manager",
|
||||
goal="Manage files and folders in Box efficiently",
|
||||
backstory="An AI assistant specialized in document management and file organization.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a folder structure
|
||||
create_structure_task = Task(
|
||||
description="Create a folder called 'Project Files' in the root directory and upload a document from URL",
|
||||
agent=box_agent,
|
||||
expected_output="Folder created and file uploaded successfully"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[box_agent],
|
||||
tasks=[create_structure_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Box Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Box tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["box_create_folder", "box_save_file", "box_list_files"]
|
||||
)
|
||||
|
||||
file_organizer_agent = Agent(
|
||||
role="File Organizer",
|
||||
goal="Organize and manage file storage efficiently",
|
||||
backstory="An AI assistant that focuses on file organization and storage management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to organize files
|
||||
organization_task = Task(
|
||||
description="Create a folder structure for the marketing team and organize existing files",
|
||||
agent=file_organizer_agent,
|
||||
expected_output="Folder structure created and files organized"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[file_organizer_agent],
|
||||
tasks=[organization_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Advanced File Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
file_manager = Agent(
|
||||
role="File Manager",
|
||||
goal="Maintain organized file structure and manage document lifecycle",
|
||||
backstory="An experienced file manager who ensures documents are properly organized and accessible.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex task involving multiple Box operations
|
||||
management_task = Task(
|
||||
description="""
|
||||
1. List all files in the root folder
|
||||
2. Create monthly archive folders for the current year
|
||||
3. Move old files to appropriate archive folders
|
||||
4. Generate a summary report of the file organization
|
||||
""",
|
||||
agent=file_manager,
|
||||
expected_output="Files organized into archive structure with summary report"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[file_manager],
|
||||
tasks=[management_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
@@ -1,293 +0,0 @@
|
||||
---
|
||||
title: ClickUp Integration
|
||||
description: "Task and productivity management with ClickUp integration for CrewAI."
|
||||
icon: "list-check"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage tasks, projects, and productivity workflows through ClickUp. Create and update tasks, organize projects, manage team assignments, and streamline your productivity management with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the ClickUp integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A ClickUp account with appropriate permissions
|
||||
- Connected your ClickUp account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors)
|
||||
|
||||
## Setting Up ClickUp Integration
|
||||
|
||||
### 1. Connect Your ClickUp Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors)
|
||||
2. Find **ClickUp** in the Authentication Integrations section
|
||||
3. Click **Connect** and complete the OAuth flow
|
||||
4. Grant the necessary permissions for task and project management
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account)
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="CLICKUP_SEARCH_TASKS">
|
||||
**Description:** Search for tasks in ClickUp using advanced filters.
|
||||
|
||||
**Parameters:**
|
||||
- `taskFilterFormula` (object, optional): A filter in disjunctive normal form - OR of AND groups of single conditions.
|
||||
```json
|
||||
{
|
||||
"operator": "OR",
|
||||
"conditions": [
|
||||
{
|
||||
"operator": "AND",
|
||||
"conditions": [
|
||||
{
|
||||
"field": "statuses%5B%5D",
|
||||
"operator": "$stringExactlyMatches",
|
||||
"value": "open"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
Available fields: `space_ids%5B%5D`, `project_ids%5B%5D`, `list_ids%5B%5D`, `statuses%5B%5D`, `include_closed`, `assignees%5B%5D`, `tags%5B%5D`, `due_date_gt`, `due_date_lt`, `date_created_gt`, `date_created_lt`, `date_updated_gt`, `date_updated_lt`
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="CLICKUP_GET_TASK_IN_LIST">
|
||||
**Description:** Get tasks in a specific list in ClickUp.
|
||||
|
||||
**Parameters:**
|
||||
- `listId` (string, required): List - Select a List to get tasks from. Use Connect Portal User Settings to allow users to select a ClickUp List.
|
||||
- `taskFilterFormula` (string, optional): Search for tasks that match specified filters. For example: name=task1.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="CLICKUP_CREATE_TASK">
|
||||
**Description:** Create a task in ClickUp.
|
||||
|
||||
**Parameters:**
|
||||
- `listId` (string, required): List - Select a List to create this task in. Use Connect Portal User Settings to allow users to select a ClickUp List.
|
||||
- `name` (string, required): Name - The task name.
|
||||
- `description` (string, optional): Description - Task description.
|
||||
- `status` (string, optional): Status - Select a Status for this task. Use Connect Portal User Settings to allow users to select a ClickUp Status.
|
||||
- `assignees` (string, optional): Assignees - Select a Member (or an array of member IDs) to be assigned to this task. Use Connect Portal User Settings to allow users to select a ClickUp Member.
|
||||
- `dueDate` (string, optional): Due Date - Specify a date for this task to be due on.
|
||||
- `additionalFields` (string, optional): Additional Fields - Specify additional fields to include on this task as JSON.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="CLICKUP_UPDATE_TASK">
|
||||
**Description:** Update a task in ClickUp.
|
||||
|
||||
**Parameters:**
|
||||
- `taskId` (string, required): Task ID - The ID of the task to update.
|
||||
- `listId` (string, required): List - Select a List to create this task in. Use Connect Portal User Settings to allow users to select a ClickUp List.
|
||||
- `name` (string, optional): Name - The task name.
|
||||
- `description` (string, optional): Description - Task description.
|
||||
- `status` (string, optional): Status - Select a Status for this task. Use Connect Portal User Settings to allow users to select a ClickUp Status.
|
||||
- `assignees` (string, optional): Assignees - Select a Member (or an array of member IDs) to be assigned to this task. Use Connect Portal User Settings to allow users to select a ClickUp Member.
|
||||
- `dueDate` (string, optional): Due Date - Specify a date for this task to be due on.
|
||||
- `additionalFields` (string, optional): Additional Fields - Specify additional fields to include on this task as JSON.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="CLICKUP_DELETE_TASK">
|
||||
**Description:** Delete a task in ClickUp.
|
||||
|
||||
**Parameters:**
|
||||
- `taskId` (string, required): Task ID - The ID of the task to delete.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="CLICKUP_GET_LIST">
|
||||
**Description:** Get List information in ClickUp.
|
||||
|
||||
**Parameters:**
|
||||
- `spaceId` (string, required): Space ID - The ID of the space containing the lists.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="CLICKUP_GET_CUSTOM_FIELDS_IN_LIST">
|
||||
**Description:** Get Custom Fields in a List in ClickUp.
|
||||
|
||||
**Parameters:**
|
||||
- `listId` (string, required): List ID - The ID of the list to get custom fields from.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="CLICKUP_GET_ALL_FIELDS_IN_LIST">
|
||||
**Description:** Get All Fields in a List in ClickUp.
|
||||
|
||||
**Parameters:**
|
||||
- `listId` (string, required): List ID - The ID of the list to get all fields from.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="CLICKUP_GET_SPACE">
|
||||
**Description:** Get Space information in ClickUp.
|
||||
|
||||
**Parameters:**
|
||||
- `spaceId` (string, optional): Space ID - The ID of the space to retrieve.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="CLICKUP_GET_FOLDERS">
|
||||
**Description:** Get Folders in ClickUp.
|
||||
|
||||
**Parameters:**
|
||||
- `spaceId` (string, required): Space ID - The ID of the space containing the folders.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="CLICKUP_GET_MEMBER">
|
||||
**Description:** Get Member information in ClickUp.
|
||||
|
||||
**Parameters:** None required.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic ClickUp Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (ClickUp tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with ClickUp capabilities
|
||||
clickup_agent = Agent(
|
||||
role="Task Manager",
|
||||
goal="Manage tasks and projects in ClickUp efficiently",
|
||||
backstory="An AI assistant specialized in task management and productivity coordination.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a new task
|
||||
create_task = Task(
|
||||
description="Create a task called 'Review Q1 Reports' in the Marketing list with high priority",
|
||||
agent=clickup_agent,
|
||||
expected_output="Task created successfully with task ID"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[clickup_agent],
|
||||
tasks=[create_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific ClickUp Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific ClickUp tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["clickup_create_task", "clickup_update_task", "clickup_search_tasks"]
|
||||
)
|
||||
|
||||
task_coordinator = Agent(
|
||||
role="Task Coordinator",
|
||||
goal="Create and manage tasks efficiently",
|
||||
backstory="An AI assistant that focuses on task creation and status management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to manage task workflow
|
||||
task_workflow = Task(
|
||||
description="Create a task for project planning and assign it to the development team",
|
||||
agent=task_coordinator,
|
||||
expected_output="Task created and assigned successfully"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[task_coordinator],
|
||||
tasks=[task_workflow]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Advanced Project Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
project_manager = Agent(
|
||||
role="Project Manager",
|
||||
goal="Coordinate project activities and track team productivity",
|
||||
backstory="An experienced project manager who ensures projects are delivered on time.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex task involving multiple ClickUp operations
|
||||
project_coordination = Task(
|
||||
description="""
|
||||
1. Get all open tasks in the current space
|
||||
2. Identify overdue tasks and update their status
|
||||
3. Create a weekly report task summarizing project progress
|
||||
4. Assign the report task to the team lead
|
||||
""",
|
||||
agent=project_manager,
|
||||
expected_output="Project status updated and weekly report task created and assigned"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[project_manager],
|
||||
tasks=[project_coordination]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Task Search and Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
task_analyst = Agent(
|
||||
role="Task Analyst",
|
||||
goal="Analyze task patterns and optimize team productivity",
|
||||
backstory="An AI assistant that analyzes task data to improve team efficiency.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to analyze and optimize task distribution
|
||||
task_analysis = Task(
|
||||
description="""
|
||||
Search for all tasks assigned to team members in the last 30 days,
|
||||
analyze completion patterns, and create optimization recommendations
|
||||
""",
|
||||
agent=task_analyst,
|
||||
expected_output="Task analysis report with optimization recommendations"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[task_analyst],
|
||||
tasks=[task_analysis]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with ClickUp integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,323 +0,0 @@
|
||||
---
|
||||
title: GitHub Integration
|
||||
description: "Repository and issue management with GitHub integration for CrewAI."
|
||||
icon: "github"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage repositories, issues, and releases through GitHub. Create and update issues, manage releases, track project development, and streamline your software development workflow with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the GitHub integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A GitHub account with appropriate repository permissions
|
||||
- Connected your GitHub account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors)
|
||||
|
||||
## Setting Up GitHub Integration
|
||||
|
||||
### 1. Connect Your GitHub Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors)
|
||||
2. Find **GitHub** in the Authentication Integrations section
|
||||
3. Click **Connect** and complete the OAuth flow
|
||||
4. Grant the necessary permissions for repository and issue management
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account)
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="GITHUB_CREATE_ISSUE">
|
||||
**Description:** Create an issue in GitHub.
|
||||
|
||||
**Parameters:**
|
||||
- `owner` (string, required): Owner - Specify the name of the account owner of the associated repository for this Issue. (example: "abc").
|
||||
- `repo` (string, required): Repository - Specify the name of the associated repository for this Issue.
|
||||
- `title` (string, required): Issue Title - Specify the title of the issue to create.
|
||||
- `body` (string, optional): Issue Body - Specify the body contents of the issue to create.
|
||||
- `assignees` (string, optional): Assignees - Specify the assignee(s)' GitHub login as an array of strings for this issue. (example: `["octocat"]`).
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GITHUB_UPDATE_ISSUE">
|
||||
**Description:** Update an issue in GitHub.
|
||||
|
||||
**Parameters:**
|
||||
- `owner` (string, required): Owner - Specify the name of the account owner of the associated repository for this Issue. (example: "abc").
|
||||
- `repo` (string, required): Repository - Specify the name of the associated repository for this Issue.
|
||||
- `issue_number` (string, required): Issue Number - Specify the number of the issue to update.
|
||||
- `title` (string, required): Issue Title - Specify the title of the issue to update.
|
||||
- `body` (string, optional): Issue Body - Specify the body contents of the issue to update.
|
||||
- `assignees` (string, optional): Assignees - Specify the assignee(s)' GitHub login as an array of strings for this issue. (example: `["octocat"]`).
|
||||
- `state` (string, optional): State - Specify the updated state of the issue.
|
||||
- Options: `open`, `closed`
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GITHUB_GET_ISSUE_BY_NUMBER">
|
||||
**Description:** Get an issue by number in GitHub.
|
||||
|
||||
**Parameters:**
|
||||
- `owner` (string, required): Owner - Specify the name of the account owner of the associated repository for this Issue. (example: "abc").
|
||||
- `repo` (string, required): Repository - Specify the name of the associated repository for this Issue.
|
||||
- `issue_number` (string, required): Issue Number - Specify the number of the issue to fetch.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GITHUB_LOCK_ISSUE">
|
||||
**Description:** Lock an issue in GitHub.
|
||||
|
||||
**Parameters:**
|
||||
- `owner` (string, required): Owner - Specify the name of the account owner of the associated repository for this Issue. (example: "abc").
|
||||
- `repo` (string, required): Repository - Specify the name of the associated repository for this Issue.
|
||||
- `issue_number` (string, required): Issue Number - Specify the number of the issue to lock.
|
||||
- `lock_reason` (string, required): Lock Reason - Specify a reason for locking the issue or pull request conversation.
|
||||
- Options: `off-topic`, `too heated`, `resolved`, `spam`
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GITHUB_SEARCH_ISSUE">
|
||||
**Description:** Search for issues in GitHub.
|
||||
|
||||
**Parameters:**
|
||||
- `owner` (string, required): Owner - Specify the name of the account owner of the associated repository for this Issue. (example: "abc").
|
||||
- `repo` (string, required): Repository - Specify the name of the associated repository for this Issue.
|
||||
- `filter` (object, required): A filter in disjunctive normal form - OR of AND groups of single conditions.
|
||||
```json
|
||||
{
|
||||
"operator": "OR",
|
||||
"conditions": [
|
||||
{
|
||||
"operator": "AND",
|
||||
"conditions": [
|
||||
{
|
||||
"field": "assignee",
|
||||
"operator": "$stringExactlyMatches",
|
||||
"value": "octocat"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
Available fields: `assignee`, `creator`, `mentioned`, `labels`
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GITHUB_CREATE_RELEASE">
|
||||
**Description:** Create a release in GitHub.
|
||||
|
||||
**Parameters:**
|
||||
- `owner` (string, required): Owner - Specify the name of the account owner of the associated repository for this Release. (example: "abc").
|
||||
- `repo` (string, required): Repository - Specify the name of the associated repository for this Release.
|
||||
- `tag_name` (string, required): Name - Specify the name of the release tag to be created. (example: "v1.0.0").
|
||||
- `target_commitish` (string, optional): Target - Specify the target of the release. This can either be a branch name or a commit SHA. Defaults to the main branch. (example: "master").
|
||||
- `body` (string, optional): Body - Specify a description for this release.
|
||||
- `draft` (string, optional): Draft - Specify whether the created release should be a draft (unpublished) release.
|
||||
- Options: `true`, `false`
|
||||
- `prerelease` (string, optional): Prerelease - Specify whether the created release should be a prerelease.
|
||||
- Options: `true`, `false`
|
||||
- `discussion_category_name` (string, optional): Discussion Category Name - If specified, a discussion of the specified category is created and linked to the release. The value must be a category that already exists in the repository.
|
||||
- `generate_release_notes` (string, optional): Release Notes - Specify whether the created release should automatically create release notes using the provided name and body specified.
|
||||
- Options: `true`, `false`
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GITHUB_UPDATE_RELEASE">
|
||||
**Description:** Update a release in GitHub.
|
||||
|
||||
**Parameters:**
|
||||
- `owner` (string, required): Owner - Specify the name of the account owner of the associated repository for this Release. (example: "abc").
|
||||
- `repo` (string, required): Repository - Specify the name of the associated repository for this Release.
|
||||
- `id` (string, required): Release ID - Specify the ID of the release to update.
|
||||
- `tag_name` (string, optional): Name - Specify the name of the release tag to be updated. (example: "v1.0.0").
|
||||
- `target_commitish` (string, optional): Target - Specify the target of the release. This can either be a branch name or a commit SHA. Defaults to the main branch. (example: "master").
|
||||
- `body` (string, optional): Body - Specify a description for this release.
|
||||
- `draft` (string, optional): Draft - Specify whether the created release should be a draft (unpublished) release.
|
||||
- Options: `true`, `false`
|
||||
- `prerelease` (string, optional): Prerelease - Specify whether the created release should be a prerelease.
|
||||
- Options: `true`, `false`
|
||||
- `discussion_category_name` (string, optional): Discussion Category Name - If specified, a discussion of the specified category is created and linked to the release. The value must be a category that already exists in the repository.
|
||||
- `generate_release_notes` (string, optional): Release Notes - Specify whether the created release should automatically create release notes using the provided name and body specified.
|
||||
- Options: `true`, `false`
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GITHUB_GET_RELEASE_BY_ID">
|
||||
**Description:** Get a release by ID in GitHub.
|
||||
|
||||
**Parameters:**
|
||||
- `owner` (string, required): Owner - Specify the name of the account owner of the associated repository for this Release. (example: "abc").
|
||||
- `repo` (string, required): Repository - Specify the name of the associated repository for this Release.
|
||||
- `id` (string, required): Release ID - Specify the release ID of the release to fetch.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GITHUB_GET_RELEASE_BY_TAG_NAME">
|
||||
**Description:** Get a release by tag name in GitHub.
|
||||
|
||||
**Parameters:**
|
||||
- `owner` (string, required): Owner - Specify the name of the account owner of the associated repository for this Release. (example: "abc").
|
||||
- `repo` (string, required): Repository - Specify the name of the associated repository for this Release.
|
||||
- `tag_name` (string, required): Name - Specify the tag of the release to fetch. (example: "v1.0.0").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GITHUB_DELETE_RELEASE">
|
||||
**Description:** Delete a release in GitHub.
|
||||
|
||||
**Parameters:**
|
||||
- `owner` (string, required): Owner - Specify the name of the account owner of the associated repository for this Release. (example: "abc").
|
||||
- `repo` (string, required): Repository - Specify the name of the associated repository for this Release.
|
||||
- `id` (string, required): Release ID - Specify the ID of the release to delete.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic GitHub Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (GitHub tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with GitHub capabilities
|
||||
github_agent = Agent(
|
||||
role="Repository Manager",
|
||||
goal="Manage GitHub repositories, issues, and releases efficiently",
|
||||
backstory="An AI assistant specialized in repository management and issue tracking.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a new issue
|
||||
create_issue_task = Task(
|
||||
description="Create a bug report issue for the login functionality in the main repository",
|
||||
agent=github_agent,
|
||||
expected_output="Issue created successfully with issue number"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[github_agent],
|
||||
tasks=[create_issue_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific GitHub Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific GitHub tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["github_create_issue", "github_update_issue", "github_search_issue"]
|
||||
)
|
||||
|
||||
issue_manager = Agent(
|
||||
role="Issue Manager",
|
||||
goal="Create and manage GitHub issues efficiently",
|
||||
backstory="An AI assistant that focuses on issue tracking and management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to manage issue workflow
|
||||
issue_workflow = Task(
|
||||
description="Create a feature request issue and assign it to the development team",
|
||||
agent=issue_manager,
|
||||
expected_output="Feature request issue created and assigned successfully"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[issue_manager],
|
||||
tasks=[issue_workflow]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Release Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
release_manager = Agent(
|
||||
role="Release Manager",
|
||||
goal="Manage software releases and versioning",
|
||||
backstory="An experienced release manager who handles version control and release processes.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a new release
|
||||
release_task = Task(
|
||||
description="""
|
||||
Create a new release v2.1.0 for the project with:
|
||||
- Auto-generated release notes
|
||||
- Target the main branch
|
||||
- Include a description of new features and bug fixes
|
||||
""",
|
||||
agent=release_manager,
|
||||
expected_output="Release v2.1.0 created successfully with release notes"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[release_manager],
|
||||
tasks=[release_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Issue Tracking and Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
project_coordinator = Agent(
|
||||
role="Project Coordinator",
|
||||
goal="Track and coordinate project issues and development progress",
|
||||
backstory="An AI assistant that helps coordinate development work and track project progress.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex task involving multiple GitHub operations
|
||||
coordination_task = Task(
|
||||
description="""
|
||||
1. Search for all open issues assigned to the current milestone
|
||||
2. Identify overdue issues and update their priority labels
|
||||
3. Create a weekly progress report issue
|
||||
4. Lock resolved issues that have been inactive for 30 days
|
||||
""",
|
||||
agent=project_coordinator,
|
||||
expected_output="Project coordination completed with progress report and issue management"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[project_coordinator],
|
||||
tasks=[coordination_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with GitHub integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,356 +0,0 @@
|
||||
---
|
||||
title: Gmail Integration
|
||||
description: "Email and contact management with Gmail integration for CrewAI."
|
||||
icon: "envelope"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage emails, contacts, and drafts through Gmail. Send emails, search messages, manage contacts, create drafts, and streamline your email communications with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Gmail integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Gmail account with appropriate permissions
|
||||
- Connected your Gmail account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors)
|
||||
|
||||
## Setting Up Gmail Integration
|
||||
|
||||
### 1. Connect Your Gmail Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors)
|
||||
2. Find **Gmail** in the Authentication Integrations section
|
||||
3. Click **Connect** and complete the OAuth flow
|
||||
4. Grant the necessary permissions for email and contact management
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account)
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="GMAIL_SEND_EMAIL">
|
||||
**Description:** Send an email in Gmail.
|
||||
|
||||
**Parameters:**
|
||||
- `toRecipients` (array, required): To - Specify the recipients as either a single string or a JSON array.
|
||||
```json
|
||||
[
|
||||
"recipient1@domain.com",
|
||||
"recipient2@domain.com"
|
||||
]
|
||||
```
|
||||
- `from` (string, required): From - Specify the email of the sender.
|
||||
- `subject` (string, required): Subject - Specify the subject of the message.
|
||||
- `messageContent` (string, required): Message Content - Specify the content of the email message as plain text or HTML.
|
||||
- `attachments` (string, optional): Attachments - Accepts either a single file object or a JSON array of file objects.
|
||||
- `additionalHeaders` (object, optional): Additional Headers - Specify any additional header fields here.
|
||||
```json
|
||||
{
|
||||
"reply-to": "Sender Name <sender@domain.com>"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GMAIL_GET_EMAIL_BY_ID">
|
||||
**Description:** Get an email by ID in Gmail.
|
||||
|
||||
**Parameters:**
|
||||
- `userId` (string, required): User ID - Specify the user's email address. (example: "user@domain.com").
|
||||
- `messageId` (string, required): Message ID - Specify the ID of the message to retrieve.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GMAIL_SEARCH_FOR_EMAIL">
|
||||
**Description:** Search for emails in Gmail using advanced filters.
|
||||
|
||||
**Parameters:**
|
||||
- `emailFilterFormula` (object, optional): A filter in disjunctive normal form - OR of AND groups of single conditions.
|
||||
```json
|
||||
{
|
||||
"operator": "OR",
|
||||
"conditions": [
|
||||
{
|
||||
"operator": "AND",
|
||||
"conditions": [
|
||||
{
|
||||
"field": "from",
|
||||
"operator": "$stringContains",
|
||||
"value": "example@domain.com"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
Available fields: `from`, `to`, `date`, `label`, `subject`, `cc`, `bcc`, `category`, `deliveredto:`, `size`, `filename`, `older_than`, `newer_than`, `list`, `is:important`, `is:unread`, `is:snoozed`, `is:starred`, `is:read`, `has:drive`, `has:document`, `has:spreadsheet`, `has:presentation`, `has:attachment`, `has:youtube`, `has:userlabels`
|
||||
- `paginationParameters` (object, optional): Pagination Parameters.
|
||||
```json
|
||||
{
|
||||
"pageCursor": "page_cursor_string"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GMAIL_DELETE_EMAIL">
|
||||
**Description:** Delete an email in Gmail.
|
||||
|
||||
**Parameters:**
|
||||
- `userId` (string, required): User ID - Specify the user's email address. (example: "user@domain.com").
|
||||
- `messageId` (string, required): Message ID - Specify the ID of the message to trash.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GMAIL_CREATE_A_CONTACT">
|
||||
**Description:** Create a contact in Gmail.
|
||||
|
||||
**Parameters:**
|
||||
- `givenName` (string, required): Given Name - Specify the Given Name of the Contact to create. (example: "John").
|
||||
- `familyName` (string, required): Family Name - Specify the Family Name of the Contact to create. (example: "Doe").
|
||||
- `email` (string, required): Email - Specify the Email Address of the Contact to create.
|
||||
- `additionalFields` (object, optional): Additional Fields - Additional contact information.
|
||||
```json
|
||||
{
|
||||
"addresses": [
|
||||
{
|
||||
"streetAddress": "1000 North St.",
|
||||
"city": "Los Angeles"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GMAIL_GET_CONTACT_BY_RESOURCE_NAME">
|
||||
**Description:** Get a contact by resource name in Gmail.
|
||||
|
||||
**Parameters:**
|
||||
- `resourceName` (string, required): Resource Name - Specify the resource name of the contact to fetch.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GMAIL_SEARCH_FOR_CONTACT">
|
||||
**Description:** Search for a contact in Gmail.
|
||||
|
||||
**Parameters:**
|
||||
- `searchTerm` (string, required): Term - Specify a search term to search for near or exact matches on the names, nickNames, emailAddresses, phoneNumbers, or organizations Contact properties.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GMAIL_DELETE_CONTACT">
|
||||
**Description:** Delete a contact in Gmail.
|
||||
|
||||
**Parameters:**
|
||||
- `resourceName` (string, required): Resource Name - Specify the resource name of the contact to delete.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GMAIL_CREATE_DRAFT">
|
||||
**Description:** Create a draft in Gmail.
|
||||
|
||||
**Parameters:**
|
||||
- `toRecipients` (array, optional): To - Specify the recipients as either a single string or a JSON array.
|
||||
```json
|
||||
[
|
||||
"recipient1@domain.com",
|
||||
"recipient2@domain.com"
|
||||
]
|
||||
```
|
||||
- `from` (string, optional): From - Specify the email of the sender.
|
||||
- `subject` (string, optional): Subject - Specify the subject of the message.
|
||||
- `messageContent` (string, optional): Message Content - Specify the content of the email message as plain text or HTML.
|
||||
- `attachments` (string, optional): Attachments - Accepts either a single file object or a JSON array of file objects.
|
||||
- `additionalHeaders` (object, optional): Additional Headers - Specify any additional header fields here.
|
||||
```json
|
||||
{
|
||||
"reply-to": "Sender Name <sender@domain.com>"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Gmail Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Gmail tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Gmail capabilities
|
||||
gmail_agent = Agent(
|
||||
role="Email Manager",
|
||||
goal="Manage email communications and contacts efficiently",
|
||||
backstory="An AI assistant specialized in email management and communication.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to send a follow-up email
|
||||
send_email_task = Task(
|
||||
description="Send a follow-up email to john@example.com about the project update meeting",
|
||||
agent=gmail_agent,
|
||||
expected_output="Email sent successfully with confirmation"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[gmail_agent],
|
||||
tasks=[send_email_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Gmail Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Gmail tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["gmail_send_email", "gmail_search_for_email", "gmail_create_draft"]
|
||||
)
|
||||
|
||||
email_coordinator = Agent(
|
||||
role="Email Coordinator",
|
||||
goal="Coordinate email communications and manage drafts",
|
||||
backstory="An AI assistant that focuses on email coordination and draft management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to prepare and send emails
|
||||
email_coordination = Task(
|
||||
description="Search for emails from the marketing team, create a summary draft, and send it to stakeholders",
|
||||
agent=email_coordinator,
|
||||
expected_output="Summary email sent to stakeholders"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[email_coordinator],
|
||||
tasks=[email_coordination]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Contact Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
contact_manager = Agent(
|
||||
role="Contact Manager",
|
||||
goal="Manage and organize email contacts efficiently",
|
||||
backstory="An experienced contact manager who maintains organized contact databases.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to manage contacts
|
||||
contact_task = Task(
|
||||
description="""
|
||||
1. Search for contacts from the 'example.com' domain
|
||||
2. Create new contacts for recent email senders not in the contact list
|
||||
3. Update contact information with recent interaction data
|
||||
""",
|
||||
agent=contact_manager,
|
||||
expected_output="Contact database updated with new contacts and recent interactions"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[contact_manager],
|
||||
tasks=[contact_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Email Search and Analysis
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
email_analyst = Agent(
|
||||
role="Email Analyst",
|
||||
goal="Analyze email patterns and provide insights",
|
||||
backstory="An AI assistant that analyzes email data to provide actionable insights.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to analyze email patterns
|
||||
analysis_task = Task(
|
||||
description="""
|
||||
Search for all unread emails from the last 7 days,
|
||||
categorize them by sender domain,
|
||||
and create a summary report of communication patterns
|
||||
""",
|
||||
agent=email_analyst,
|
||||
expected_output="Email analysis report with communication patterns and recommendations"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[email_analyst],
|
||||
tasks=[analysis_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Automated Email Workflows
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
workflow_manager = Agent(
|
||||
role="Email Workflow Manager",
|
||||
goal="Automate email workflows and responses",
|
||||
backstory="An AI assistant that manages automated email workflows and responses.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex task involving multiple Gmail operations
|
||||
workflow_task = Task(
|
||||
description="""
|
||||
1. Search for emails with 'urgent' in the subject from the last 24 hours
|
||||
2. Create draft responses for each urgent email
|
||||
3. Send automated acknowledgment emails to senders
|
||||
4. Create a summary report of urgent items requiring attention
|
||||
""",
|
||||
agent=workflow_manager,
|
||||
expected_output="Urgent emails processed with automated responses and summary report"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[workflow_manager],
|
||||
tasks=[workflow_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with Gmail integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,391 +0,0 @@
|
||||
---
|
||||
title: Google Calendar Integration
|
||||
description: "Event and schedule management with Google Calendar integration for CrewAI."
|
||||
icon: "calendar"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage calendar events, schedules, and availability through Google Calendar. Create and update events, manage attendees, check availability, and streamline your scheduling workflows with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Google Calendar integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Google account with Google Calendar access
|
||||
- Connected your Google account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors)
|
||||
|
||||
## Setting Up Google Calendar Integration
|
||||
|
||||
### 1. Connect Your Google Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors)
|
||||
2. Find **Google Calendar** in the Authentication Integrations section
|
||||
3. Click **Connect** and complete the OAuth flow
|
||||
4. Grant the necessary permissions for calendar and contact access
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account)
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="GOOGLE_CALENDAR_CREATE_EVENT">
|
||||
**Description:** Create an event in Google Calendar.
|
||||
|
||||
**Parameters:**
|
||||
- `eventName` (string, required): Event name.
|
||||
- `startTime` (string, required): Start time - Accepts Unix timestamp or ISO8601 date formats.
|
||||
- `endTime` (string, optional): End time - Defaults to one hour after the start time if left blank.
|
||||
- `calendar` (string, optional): Calendar - Use Connect Portal Workflow Settings to allow users to select which calendar the event will be added to. Defaults to the user's primary calendar if left blank.
|
||||
- `attendees` (string, optional): Attendees - Accepts an array of email addresses or email addresses separated by commas.
|
||||
- `eventLocation` (string, optional): Event location.
|
||||
- `eventDescription` (string, optional): Event description.
|
||||
- `eventId` (string, optional): Event ID - An ID from your application to associate this event with. You can use this ID to sync updates to this event later.
|
||||
- `includeMeetLink` (boolean, optional): Include Google Meet link? - Automatically creates Google Meet conference link for this event.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_UPDATE_EVENT">
|
||||
**Description:** Update an existing event in Google Calendar.
|
||||
|
||||
**Parameters:**
|
||||
- `eventId` (string, required): Event ID - The ID of the event to update.
|
||||
- `eventName` (string, optional): Event name.
|
||||
- `startTime` (string, optional): Start time - Accepts Unix timestamp or ISO8601 date formats.
|
||||
- `endTime` (string, optional): End time - Defaults to one hour after the start time if left blank.
|
||||
- `calendar` (string, optional): Calendar - Use Connect Portal Workflow Settings to allow users to select which calendar the event will be added to. Defaults to the user's primary calendar if left blank.
|
||||
- `attendees` (string, optional): Attendees - Accepts an array of email addresses or email addresses separated by commas.
|
||||
- `eventLocation` (string, optional): Event location.
|
||||
- `eventDescription` (string, optional): Event description.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_LIST_EVENTS">
|
||||
**Description:** List events from Google Calendar.
|
||||
|
||||
**Parameters:**
|
||||
- `calendar` (string, optional): Calendar - Use Connect Portal Workflow Settings to allow users to select which calendar the event will be added to. Defaults to the user's primary calendar if left blank.
|
||||
- `after` (string, optional): After - Filters events that start after the provided date (Unix in milliseconds or ISO timestamp). (example: "2025-04-12T10:00:00Z or 1712908800000").
|
||||
- `before` (string, optional): Before - Filters events that end before the provided date (Unix in milliseconds or ISO timestamp). (example: "2025-04-12T10:00:00Z or 1712908800000").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_GET_EVENT_BY_ID">
|
||||
**Description:** Get a specific event by ID from Google Calendar.
|
||||
|
||||
**Parameters:**
|
||||
- `eventId` (string, required): Event ID.
|
||||
- `calendar` (string, optional): Calendar - Use Connect Portal Workflow Settings to allow users to select which calendar the event will be added to. Defaults to the user's primary calendar if left blank.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_DELETE_EVENT">
|
||||
**Description:** Delete an event from Google Calendar.
|
||||
|
||||
**Parameters:**
|
||||
- `eventId` (string, required): Event ID - The ID of the calendar event to be deleted.
|
||||
- `calendar` (string, optional): Calendar - Use Connect Portal Workflow Settings to allow users to select which calendar the event will be added to. Defaults to the user's primary calendar if left blank.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_GET_CONTACTS">
|
||||
**Description:** Get contacts from Google Calendar.
|
||||
|
||||
**Parameters:**
|
||||
- `paginationParameters` (object, optional): Pagination Parameters.
|
||||
```json
|
||||
{
|
||||
"pageCursor": "page_cursor_string"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_SEARCH_CONTACTS">
|
||||
**Description:** Search for contacts in Google Calendar.
|
||||
|
||||
**Parameters:**
|
||||
- `query` (string, optional): Search query to search contacts.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_LIST_DIRECTORY_PEOPLE">
|
||||
**Description:** List directory people.
|
||||
|
||||
**Parameters:**
|
||||
- `paginationParameters` (object, optional): Pagination Parameters.
|
||||
```json
|
||||
{
|
||||
"pageCursor": "page_cursor_string"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_SEARCH_DIRECTORY_PEOPLE">
|
||||
**Description:** Search directory people.
|
||||
|
||||
**Parameters:**
|
||||
- `query` (string, required): Search query to search contacts.
|
||||
- `paginationParameters` (object, optional): Pagination Parameters.
|
||||
```json
|
||||
{
|
||||
"pageCursor": "page_cursor_string"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_LIST_OTHER_CONTACTS">
|
||||
**Description:** List other contacts.
|
||||
|
||||
**Parameters:**
|
||||
- `paginationParameters` (object, optional): Pagination Parameters.
|
||||
```json
|
||||
{
|
||||
"pageCursor": "page_cursor_string"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_SEARCH_OTHER_CONTACTS">
|
||||
**Description:** Search other contacts.
|
||||
|
||||
**Parameters:**
|
||||
- `query` (string, optional): Search query to search contacts.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_CALENDAR_GET_AVAILABILITY">
|
||||
**Description:** Get availability information for calendars.
|
||||
|
||||
**Parameters:**
|
||||
- `timeMin` (string, required): The start of the interval. In ISO format.
|
||||
- `timeMax` (string, required): The end of the interval. In ISO format.
|
||||
- `timeZone` (string, optional): Time zone used in the response. Optional. The default is UTC.
|
||||
- `items` (array, optional): List of calendars and/or groups to query. Defaults to the user default calendar.
|
||||
```json
|
||||
[
|
||||
{
|
||||
"id": "calendar_id_1"
|
||||
},
|
||||
{
|
||||
"id": "calendar_id_2"
|
||||
}
|
||||
]
|
||||
```
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Calendar Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Google Calendar tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Google Calendar capabilities
|
||||
calendar_agent = Agent(
|
||||
role="Schedule Manager",
|
||||
goal="Manage calendar events and scheduling efficiently",
|
||||
backstory="An AI assistant specialized in calendar management and scheduling coordination.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a meeting
|
||||
create_meeting_task = Task(
|
||||
description="Create a team standup meeting for tomorrow at 9 AM with the development team",
|
||||
agent=calendar_agent,
|
||||
expected_output="Meeting created successfully with Google Meet link"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[calendar_agent],
|
||||
tasks=[create_meeting_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Calendar Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Google Calendar tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["google_calendar_create_event", "google_calendar_list_events", "google_calendar_get_availability"]
|
||||
)
|
||||
|
||||
meeting_coordinator = Agent(
|
||||
role="Meeting Coordinator",
|
||||
goal="Coordinate meetings and check availability",
|
||||
backstory="An AI assistant that focuses on meeting scheduling and availability management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to schedule a meeting with availability check
|
||||
schedule_meeting = Task(
|
||||
description="Check availability for next week and schedule a project review meeting with stakeholders",
|
||||
agent=meeting_coordinator,
|
||||
expected_output="Meeting scheduled after checking availability of all participants"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[meeting_coordinator],
|
||||
tasks=[schedule_meeting]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Event Management and Updates
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
event_manager = Agent(
|
||||
role="Event Manager",
|
||||
goal="Manage and update calendar events efficiently",
|
||||
backstory="An experienced event manager who handles event logistics and updates.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to manage event updates
|
||||
event_management = Task(
|
||||
description="""
|
||||
1. List all events for this week
|
||||
2. Update any events that need location changes to include video conference links
|
||||
3. Send calendar invitations to new team members for recurring meetings
|
||||
""",
|
||||
agent=event_manager,
|
||||
expected_output="Weekly events updated with proper locations and new attendees added"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[event_manager],
|
||||
tasks=[event_management]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Contact and Availability Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
availability_coordinator = Agent(
|
||||
role="Availability Coordinator",
|
||||
goal="Coordinate availability and manage contacts for scheduling",
|
||||
backstory="An AI assistant that specializes in availability management and contact coordination.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to coordinate availability
|
||||
availability_task = Task(
|
||||
description="""
|
||||
1. Search for contacts in the engineering department
|
||||
2. Check availability for all engineers next Friday afternoon
|
||||
3. Create a team meeting for the first available 2-hour slot
|
||||
4. Include Google Meet link and send invitations
|
||||
""",
|
||||
agent=availability_coordinator,
|
||||
expected_output="Team meeting scheduled based on availability with all engineers invited"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[availability_coordinator],
|
||||
tasks=[availability_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Automated Scheduling Workflows
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
scheduling_automator = Agent(
|
||||
role="Scheduling Automator",
|
||||
goal="Automate scheduling workflows and calendar management",
|
||||
backstory="An AI assistant that automates complex scheduling scenarios and calendar workflows.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex scheduling automation task
|
||||
automation_task = Task(
|
||||
description="""
|
||||
1. List all upcoming events for the next two weeks
|
||||
2. Identify any scheduling conflicts or back-to-back meetings
|
||||
3. Suggest optimal meeting times by checking availability
|
||||
4. Create buffer time between meetings where needed
|
||||
5. Update event descriptions with agenda items and meeting links
|
||||
""",
|
||||
agent=scheduling_automator,
|
||||
expected_output="Calendar optimized with resolved conflicts, buffer times, and updated meeting details"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[scheduling_automator],
|
||||
tasks=[automation_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
**Authentication Errors**
|
||||
- Ensure your Google account has the necessary permissions for calendar access
|
||||
- Verify that the OAuth connection includes all required scopes for Google Calendar API
|
||||
- Check if calendar sharing settings allow the required access level
|
||||
|
||||
**Event Creation Issues**
|
||||
- Verify that time formats are correct (ISO8601 or Unix timestamps)
|
||||
- Ensure attendee email addresses are properly formatted
|
||||
- Check that the target calendar exists and is accessible
|
||||
- Verify time zones are correctly specified
|
||||
|
||||
**Availability and Time Conflicts**
|
||||
- Use proper ISO format for time ranges when checking availability
|
||||
- Ensure time zones are consistent across all operations
|
||||
- Verify that calendar IDs are correct when checking multiple calendars
|
||||
|
||||
**Contact and People Search**
|
||||
- Ensure search queries are properly formatted
|
||||
- Check that directory access permissions are granted
|
||||
- Verify that contact information is up to date and accessible
|
||||
|
||||
**Event Updates and Deletions**
|
||||
- Verify that event IDs are correct and events exist
|
||||
- Ensure you have edit permissions for the events
|
||||
- Check that calendar ownership allows modifications
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with Google Calendar integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,321 +0,0 @@
|
||||
---
|
||||
title: Google Sheets Integration
|
||||
description: "Spreadsheet data synchronization with Google Sheets integration for CrewAI."
|
||||
icon: "google"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage spreadsheet data through Google Sheets. Read rows, create new entries, update existing data, and streamline your data management workflows with AI-powered automation. Perfect for data tracking, reporting, and collaborative data management.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Google Sheets integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Google account with Google Sheets access
|
||||
- Connected your Google account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors)
|
||||
- Spreadsheets with proper column headers for data operations
|
||||
|
||||
## Setting Up Google Sheets Integration
|
||||
|
||||
### 1. Connect Your Google Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors)
|
||||
2. Find **Google Sheets** in the Authentication Integrations section
|
||||
3. Click **Connect** and complete the OAuth flow
|
||||
4. Grant the necessary permissions for spreadsheet access
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account)
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="GOOGLE_SHEETS_GET_ROW">
|
||||
**Description:** Get rows from a Google Sheets spreadsheet.
|
||||
|
||||
**Parameters:**
|
||||
- `spreadsheetId` (string, required): Spreadsheet - Use Connect Portal Workflow Settings to allow users to select a spreadsheet. Defaults to using the first worksheet in the selected spreadsheet.
|
||||
- `limit` (string, optional): Limit rows - Limit the maximum number of rows to return.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_SHEETS_CREATE_ROW">
|
||||
**Description:** Create a new row in a Google Sheets spreadsheet.
|
||||
|
||||
**Parameters:**
|
||||
- `spreadsheetId` (string, required): Spreadsheet - Use Connect Portal Workflow Settings to allow users to select a spreadsheet. Defaults to using the first worksheet in the selected spreadsheet..
|
||||
- `worksheet` (string, required): Worksheet - Your worksheet must have column headers.
|
||||
- `additionalFields` (object, required): Fields - Include fields to create this row with, as an object with keys of Column Names. Use Connect Portal Workflow Settings to allow users to select a Column Mapping.
|
||||
```json
|
||||
{
|
||||
"columnName1": "columnValue1",
|
||||
"columnName2": "columnValue2",
|
||||
"columnName3": "columnValue3",
|
||||
"columnName4": "columnValue4"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="GOOGLE_SHEETS_UPDATE_ROW">
|
||||
**Description:** Update existing rows in a Google Sheets spreadsheet.
|
||||
|
||||
**Parameters:**
|
||||
- `spreadsheetId` (string, required): Spreadsheet - Use Connect Portal Workflow Settings to allow users to select a spreadsheet. Defaults to using the first worksheet in the selected spreadsheet.
|
||||
- `worksheet` (string, required): Worksheet - Your worksheet must have column headers.
|
||||
- `filterFormula` (object, optional): A filter in disjunctive normal form - OR of AND groups of single conditions to identify which rows to update.
|
||||
```json
|
||||
{
|
||||
"operator": "OR",
|
||||
"conditions": [
|
||||
{
|
||||
"operator": "AND",
|
||||
"conditions": [
|
||||
{
|
||||
"field": "status",
|
||||
"operator": "$stringExactlyMatches",
|
||||
"value": "pending"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
Available operators: `$stringContains`, `$stringDoesNotContain`, `$stringExactlyMatches`, `$stringDoesNotExactlyMatch`, `$stringStartsWith`, `$stringDoesNotStartWith`, `$stringEndsWith`, `$stringDoesNotEndWith`, `$numberGreaterThan`, `$numberLessThan`, `$numberEquals`, `$numberDoesNotEqual`, `$dateTimeAfter`, `$dateTimeBefore`, `$dateTimeEquals`, `$booleanTrue`, `$booleanFalse`, `$exists`, `$doesNotExist`
|
||||
- `additionalFields` (object, required): Fields - Include fields to update, as an object with keys of Column Names. Use Connect Portal Workflow Settings to allow users to select a Column Mapping.
|
||||
```json
|
||||
{
|
||||
"columnName1": "newValue1",
|
||||
"columnName2": "newValue2",
|
||||
"columnName3": "newValue3",
|
||||
"columnName4": "newValue4"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Google Sheets Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Google Sheets tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Google Sheets capabilities
|
||||
sheets_agent = Agent(
|
||||
role="Data Manager",
|
||||
goal="Manage spreadsheet data and track information efficiently",
|
||||
backstory="An AI assistant specialized in data management and spreadsheet operations.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to add new data to a spreadsheet
|
||||
data_entry_task = Task(
|
||||
description="Add a new customer record to the customer database spreadsheet with name, email, and signup date",
|
||||
agent=sheets_agent,
|
||||
expected_output="New customer record added successfully to the spreadsheet"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[sheets_agent],
|
||||
tasks=[data_entry_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Google Sheets Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Google Sheets tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["google_sheets_get_row", "google_sheets_create_row"]
|
||||
)
|
||||
|
||||
data_collector = Agent(
|
||||
role="Data Collector",
|
||||
goal="Collect and organize data in spreadsheets",
|
||||
backstory="An AI assistant that focuses on data collection and organization.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to collect and organize data
|
||||
data_collection = Task(
|
||||
description="Retrieve current inventory data and add new product entries to the inventory spreadsheet",
|
||||
agent=data_collector,
|
||||
expected_output="Inventory data retrieved and new products added successfully"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[data_collector],
|
||||
tasks=[data_collection]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Data Analysis and Reporting
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
data_analyst = Agent(
|
||||
role="Data Analyst",
|
||||
goal="Analyze spreadsheet data and generate insights",
|
||||
backstory="An experienced data analyst who extracts insights from spreadsheet data.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to analyze data and create reports
|
||||
analysis_task = Task(
|
||||
description="""
|
||||
1. Retrieve all sales data from the current month's spreadsheet
|
||||
2. Analyze the data for trends and patterns
|
||||
3. Create a summary report in a new row with key metrics
|
||||
""",
|
||||
agent=data_analyst,
|
||||
expected_output="Sales data analyzed and summary report created with key insights"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[data_analyst],
|
||||
tasks=[analysis_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Automated Data Updates
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
data_updater = Agent(
|
||||
role="Data Updater",
|
||||
goal="Automatically update and maintain spreadsheet data",
|
||||
backstory="An AI assistant that maintains data accuracy and updates records automatically.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to update data based on conditions
|
||||
update_task = Task(
|
||||
description="""
|
||||
1. Find all pending orders in the orders spreadsheet
|
||||
2. Update their status to 'processing'
|
||||
3. Add a timestamp for when the status was updated
|
||||
4. Log the changes in a separate tracking sheet
|
||||
""",
|
||||
agent=data_updater,
|
||||
expected_output="All pending orders updated to processing status with timestamps logged"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[data_updater],
|
||||
tasks=[update_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Complex Data Management Workflow
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
workflow_manager = Agent(
|
||||
role="Data Workflow Manager",
|
||||
goal="Manage complex data workflows across multiple spreadsheets",
|
||||
backstory="An AI assistant that orchestrates complex data operations across multiple spreadsheets.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex workflow task
|
||||
workflow_task = Task(
|
||||
description="""
|
||||
1. Get all customer data from the main customer spreadsheet
|
||||
2. Create monthly summary entries for active customers
|
||||
3. Update customer status based on activity in the last 30 days
|
||||
4. Generate a monthly report with customer metrics
|
||||
5. Archive inactive customer records to a separate sheet
|
||||
""",
|
||||
agent=workflow_manager,
|
||||
expected_output="Monthly customer workflow completed with updated statuses and generated reports"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[workflow_manager],
|
||||
tasks=[workflow_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
**Permission Errors**
|
||||
- Ensure your Google account has edit access to the target spreadsheets
|
||||
- Verify that the OAuth connection includes required scopes for Google Sheets API
|
||||
- Check that spreadsheets are shared with the authenticated account
|
||||
|
||||
**Spreadsheet Structure Issues**
|
||||
- Ensure worksheets have proper column headers before creating or updating rows
|
||||
- Verify that column names in `additionalFields` match the actual column headers
|
||||
- Check that the specified worksheet exists in the spreadsheet
|
||||
|
||||
**Data Type and Format Issues**
|
||||
- Ensure data values match the expected format for each column
|
||||
- Use proper date formats for date columns (ISO format recommended)
|
||||
- Verify that numeric values are properly formatted for number columns
|
||||
|
||||
**Filter Formula Issues**
|
||||
- Ensure filter formulas follow the correct JSON structure for disjunctive normal form
|
||||
- Use valid field names that match actual column headers
|
||||
- Test simple filters before building complex multi-condition queries
|
||||
- Verify that operator types match the data types in the columns
|
||||
|
||||
**Row Limits and Performance**
|
||||
- Be mindful of row limits when using `GOOGLE_SHEETS_GET_ROW`
|
||||
- Consider pagination for large datasets
|
||||
- Use specific filters to reduce the amount of data processed
|
||||
|
||||
**Update Operations**
|
||||
- Ensure filter conditions properly identify the intended rows for updates
|
||||
- Test filter conditions with small datasets before large updates
|
||||
- Verify that all required fields are included in update operations
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with Google Sheets integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,579 +0,0 @@
|
||||
---
|
||||
title: "HubSpot Integration"
|
||||
description: "Manage companies and contacts in HubSpot with CrewAI."
|
||||
icon: "briefcase"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage companies and contacts within HubSpot. Create new records and streamline your CRM processes with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the HubSpot integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription.
|
||||
- A HubSpot account with appropriate permissions.
|
||||
- Connected your HubSpot account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors).
|
||||
|
||||
## Setting Up HubSpot Integration
|
||||
|
||||
### 1. Connect Your HubSpot Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors).
|
||||
2. Find **HubSpot** in the Authentication Integrations section.
|
||||
3. Click **Connect** and complete the OAuth flow.
|
||||
4. Grant the necessary permissions for company and contact management.
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account).
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="HUBSPOT_CREATE_RECORD_COMPANIES">
|
||||
**Description:** Create a new company record in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `name` (string, required): Name of the company.
|
||||
- `domain` (string, optional): Company Domain Name.
|
||||
- `industry` (string, optional): Industry. Must be one of the predefined values from HubSpot.
|
||||
- `phone` (string, optional): Phone Number.
|
||||
- `hubspot_owner_id` (string, optional): Company owner ID.
|
||||
- `type` (string, optional): Type of the company. Available values: `PROSPECT`, `PARTNER`, `RESELLER`, `VENDOR`, `OTHER`.
|
||||
- `city` (string, optional): City.
|
||||
- `state` (string, optional): State/Region.
|
||||
- `zip` (string, optional): Postal Code.
|
||||
- `numberofemployees` (number, optional): Number of Employees.
|
||||
- `annualrevenue` (number, optional): Annual Revenue.
|
||||
- `timezone` (string, optional): Time Zone.
|
||||
- `description` (string, optional): Description.
|
||||
- `linkedin_company_page` (string, optional): LinkedIn Company Page URL.
|
||||
- `company_email` (string, optional): Company Email.
|
||||
- `first_name` (string, optional): First Name of a contact at the company.
|
||||
- `last_name` (string, optional): Last Name of a contact at the company.
|
||||
- `about_us` (string, optional): About Us.
|
||||
- `hs_csm_sentiment` (string, optional): CSM Sentiment. Available values: `at_risk`, `neutral`, `healthy`.
|
||||
- `closedate` (string, optional): Close Date.
|
||||
- `hs_keywords` (string, optional): Company Keywords. Must be one of the predefined values.
|
||||
- `country` (string, optional): Country/Region.
|
||||
- `hs_country_code` (string, optional): Country/Region Code.
|
||||
- `hs_employee_range` (string, optional): Employee range.
|
||||
- `facebook_company_page` (string, optional): Facebook Company Page URL.
|
||||
- `facebookfans` (number, optional): Number of Facebook Fans.
|
||||
- `hs_gps_coordinates` (string, optional): GPS Coordinates.
|
||||
- `hs_gps_error` (string, optional): GPS Error.
|
||||
- `googleplus_page` (string, optional): Google Plus Page URL.
|
||||
- `owneremail` (string, optional): HubSpot Owner Email.
|
||||
- `ownername` (string, optional): HubSpot Owner Name.
|
||||
- `hs_ideal_customer_profile` (string, optional): Ideal Customer Profile Tier. Available values: `tier_1`, `tier_2`, `tier_3`.
|
||||
- `hs_industry_group` (string, optional): Industry group.
|
||||
- `is_public` (boolean, optional): Is Public.
|
||||
- `hs_last_metered_enrichment_timestamp` (string, optional): Last Metered Enrichment Timestamp.
|
||||
- `hs_lead_status` (string, optional): Lead Status. Available values: `NEW`, `OPEN`, `IN_PROGRESS`, `OPEN_DEAL`, `UNQUALIFIED`, `ATTEMPTED_TO_CONTACT`, `CONNECTED`, `BAD_TIMING`.
|
||||
- `lifecyclestage` (string, optional): Lifecycle Stage. Available values: `subscriber`, `lead`, `marketingqualifiedlead`, `salesqualifiedlead`, `opportunity`, `customer`, `evangelist`, `other`.
|
||||
- `linkedinbio` (string, optional): LinkedIn Bio.
|
||||
- `hs_linkedin_handle` (string, optional): LinkedIn handle.
|
||||
- `hs_live_enrichment_deadline` (string, optional): Live enrichment deadline.
|
||||
- `hs_logo_url` (string, optional): Logo URL.
|
||||
- `hs_analytics_source` (string, optional): Original Traffic Source.
|
||||
- `hs_pinned_engagement_id` (number, optional): Pinned Engagement ID.
|
||||
- `hs_quick_context` (string, optional): Quick context.
|
||||
- `hs_revenue_range` (string, optional): Revenue range.
|
||||
- `hs_state_code` (string, optional): State/Region Code.
|
||||
- `address` (string, optional): Street Address.
|
||||
- `address2` (string, optional): Street Address 2.
|
||||
- `hs_is_target_account` (boolean, optional): Target Account.
|
||||
- `hs_target_account` (string, optional): Target Account Tier. Available values: `tier_1`, `tier_2`, `tier_3`.
|
||||
- `hs_target_account_recommendation_snooze_time` (string, optional): Target Account Recommendation Snooze Time.
|
||||
- `hs_target_account_recommendation_state` (string, optional): Target Account Recommendation State. Available values: `DISMISSED`, `NONE`, `SNOOZED`.
|
||||
- `total_money_raised` (string, optional): Total Money Raised.
|
||||
- `twitterbio` (string, optional): Twitter Bio.
|
||||
- `twitterfollowers` (number, optional): Twitter Followers.
|
||||
- `twitterhandle` (string, optional): Twitter Handle.
|
||||
- `web_technologies` (string, optional): Web Technologies used. Must be one of the predefined values.
|
||||
- `website` (string, optional): Website URL.
|
||||
- `founded_year` (string, optional): Year Founded.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_CREATE_RECORD_CONTACTS">
|
||||
**Description:** Create a new contact record in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `email` (string, required): Email address of the contact.
|
||||
- `firstname` (string, optional): First Name.
|
||||
- `lastname` (string, optional): Last Name.
|
||||
- `phone` (string, optional): Phone Number.
|
||||
- `hubspot_owner_id` (string, optional): Contact owner.
|
||||
- `lifecyclestage` (string, optional): Lifecycle Stage. Available values: `subscriber`, `lead`, `marketingqualifiedlead`, `salesqualifiedlead`, `opportunity`, `customer`, `evangelist`, `other`.
|
||||
- `hs_lead_status` (string, optional): Lead Status. Available values: `NEW`, `OPEN`, `IN_PROGRESS`, `OPEN_DEAL`, `UNQUALIFIED`, `ATTEMPTED_TO_CONTACT`, `CONNECTED`, `BAD_TIMING`.
|
||||
- `annualrevenue` (string, optional): Annual Revenue.
|
||||
- `hs_buying_role` (string, optional): Buying Role.
|
||||
- `cc_emails` (string, optional): CC Emails.
|
||||
- `ch_customer_id` (string, optional): Chargify Customer ID.
|
||||
- `ch_customer_reference` (string, optional): Chargify Customer Reference.
|
||||
- `chargify_sites` (string, optional): Chargify Site(s).
|
||||
- `city` (string, optional): City.
|
||||
- `hs_facebook_ad_clicked` (boolean, optional): Clicked Facebook ad.
|
||||
- `hs_linkedin_ad_clicked` (string, optional): Clicked LinkedIn Ad.
|
||||
- `hs_clicked_linkedin_ad` (string, optional): Clicked on a LinkedIn Ad.
|
||||
- `closedate` (string, optional): Close Date.
|
||||
- `company` (string, optional): Company Name.
|
||||
- `company_size` (string, optional): Company size.
|
||||
- `country` (string, optional): Country/Region.
|
||||
- `hs_country_region_code` (string, optional): Country/Region Code.
|
||||
- `date_of_birth` (string, optional): Date of birth.
|
||||
- `degree` (string, optional): Degree.
|
||||
- `hs_email_customer_quarantined_reason` (string, optional): Email address quarantine reason.
|
||||
- `hs_role` (string, optional): Employment Role. Must be one of the predefined values.
|
||||
- `hs_seniority` (string, optional): Employment Seniority. Must be one of the predefined values.
|
||||
- `hs_sub_role` (string, optional): Employment Sub Role. Must be one of the predefined values.
|
||||
- `hs_employment_change_detected_date` (string, optional): Employment change detected date.
|
||||
- `hs_enriched_email_bounce_detected` (boolean, optional): Enriched Email Bounce Detected.
|
||||
- `hs_facebookid` (string, optional): Facebook ID.
|
||||
- `hs_facebook_click_id` (string, optional): Facebook click id.
|
||||
- `fax` (string, optional): Fax Number.
|
||||
- `field_of_study` (string, optional): Field of study.
|
||||
- `followercount` (number, optional): Follower Count.
|
||||
- `gender` (string, optional): Gender.
|
||||
- `hs_google_click_id` (string, optional): Google ad click id.
|
||||
- `graduation_date` (string, optional): Graduation date.
|
||||
- `owneremail` (string, optional): HubSpot Owner Email (legacy).
|
||||
- `ownername` (string, optional): HubSpot Owner Name (legacy).
|
||||
- `industry` (string, optional): Industry.
|
||||
- `hs_inferred_language_codes` (string, optional): Inferred Language Codes. Must be one of the predefined values.
|
||||
- `jobtitle` (string, optional): Job Title.
|
||||
- `hs_job_change_detected_date` (string, optional): Job change detected date.
|
||||
- `job_function` (string, optional): Job function.
|
||||
- `hs_journey_stage` (string, optional): Journey Stage. Must be one of the predefined values.
|
||||
- `kloutscoregeneral` (number, optional): Klout Score.
|
||||
- `hs_last_metered_enrichment_timestamp` (string, optional): Last Metered Enrichment Timestamp.
|
||||
- `hs_latest_source` (string, optional): Latest Traffic Source.
|
||||
- `hs_latest_source_timestamp` (string, optional): Latest Traffic Source Date.
|
||||
- `hs_legal_basis` (string, optional): Legal basis for processing contact's data.
|
||||
- `linkedinbio` (string, optional): LinkedIn Bio.
|
||||
- `linkedinconnections` (number, optional): LinkedIn Connections.
|
||||
- `hs_linkedin_url` (string, optional): LinkedIn URL.
|
||||
- `hs_linkedinid` (string, optional): Linkedin ID.
|
||||
- `hs_live_enrichment_deadline` (string, optional): Live enrichment deadline.
|
||||
- `marital_status` (string, optional): Marital Status.
|
||||
- `hs_content_membership_email` (string, optional): Member email.
|
||||
- `hs_content_membership_notes` (string, optional): Membership Notes.
|
||||
- `message` (string, optional): Message.
|
||||
- `military_status` (string, optional): Military status.
|
||||
- `mobilephone` (string, optional): Mobile Phone Number.
|
||||
- `numemployees` (string, optional): Number of Employees.
|
||||
- `hs_analytics_source` (string, optional): Original Traffic Source.
|
||||
- `photo` (string, optional): Photo.
|
||||
- `hs_pinned_engagement_id` (number, optional): Pinned engagement ID.
|
||||
- `zip` (string, optional): Postal Code.
|
||||
- `hs_language` (string, optional): Preferred language. Must be one of the predefined values.
|
||||
- `associatedcompanyid` (number, optional): Primary Associated Company ID.
|
||||
- `hs_email_optout_survey_reason` (string, optional): Reason for opting out of email.
|
||||
- `relationship_status` (string, optional): Relationship Status.
|
||||
- `hs_returning_to_office_detected_date` (string, optional): Returning to office detected date.
|
||||
- `salutation` (string, optional): Salutation.
|
||||
- `school` (string, optional): School.
|
||||
- `seniority` (string, optional): Seniority.
|
||||
- `hs_feedback_show_nps_web_survey` (boolean, optional): Should be shown an NPS web survey.
|
||||
- `start_date` (string, optional): Start date.
|
||||
- `state` (string, optional): State/Region.
|
||||
- `hs_state_code` (string, optional): State/Region Code.
|
||||
- `hs_content_membership_status` (string, optional): Status.
|
||||
- `address` (string, optional): Street Address.
|
||||
- `tax_exempt` (string, optional): Tax Exempt.
|
||||
- `hs_timezone` (string, optional): Time Zone. Must be one of the predefined values.
|
||||
- `twitterbio` (string, optional): Twitter Bio.
|
||||
- `hs_twitterid` (string, optional): Twitter ID.
|
||||
- `twitterprofilephoto` (string, optional): Twitter Profile Photo.
|
||||
- `twitterhandle` (string, optional): Twitter Username.
|
||||
- `vat_number` (string, optional): VAT Number.
|
||||
- `ch_verified` (string, optional): Verified for ACH/eCheck Payments.
|
||||
- `website` (string, optional): Website URL.
|
||||
- `hs_whatsapp_phone_number` (string, optional): WhatsApp Phone Number.
|
||||
- `work_email` (string, optional): Work email.
|
||||
- `hs_googleplusid` (string, optional): googleplus ID.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_CREATE_RECORD_DEALS">
|
||||
**Description:** Create a new deal record in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `dealname` (string, required): Name of the deal.
|
||||
- `amount` (number, optional): The value of the deal.
|
||||
- `dealstage` (string, optional): The pipeline stage of the deal.
|
||||
- `pipeline` (string, optional): The pipeline the deal belongs to.
|
||||
- `closedate` (string, optional): The date the deal is expected to close.
|
||||
- `hubspot_owner_id` (string, optional): The owner of the deal.
|
||||
- `dealtype` (string, optional): The type of deal. Available values: `newbusiness`, `existingbusiness`.
|
||||
- `description` (string, optional): A description of the deal.
|
||||
- `hs_priority` (string, optional): The priority of the deal. Available values: `low`, `medium`, `high`.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_CREATE_RECORD_ENGAGEMENTS">
|
||||
**Description:** Create a new engagement (e.g., note, email, call, meeting, task) in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `engagementType` (string, required): The type of engagement. Available values: `NOTE`, `EMAIL`, `CALL`, `MEETING`, `TASK`.
|
||||
- `hubspot_owner_id` (string, optional): The user the activity is assigned to.
|
||||
- `hs_timestamp` (string, optional): The date and time of the activity.
|
||||
- `hs_note_body` (string, optional): The body of the note. (Used for `NOTE`)
|
||||
- `hs_task_subject` (string, optional): The title of the task. (Used for `TASK`)
|
||||
- `hs_task_body` (string, optional): The notes for the task. (Used for `TASK`)
|
||||
- `hs_task_status` (string, optional): The status of the task. (Used for `TASK`)
|
||||
- `hs_meeting_title` (string, optional): The title of the meeting. (Used for `MEETING`)
|
||||
- `hs_meeting_body` (string, optional): The description for the meeting. (Used for `MEETING`)
|
||||
- `hs_meeting_start_time` (string, optional): The start time of the meeting. (Used for `MEETING`)
|
||||
- `hs_meeting_end_time` (string, optional): The end time of the meeting. (Used for `MEETING`)
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_UPDATE_RECORD_COMPANIES">
|
||||
**Description:** Update an existing company record in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the company to update.
|
||||
- `name` (string, optional): Name of the company.
|
||||
- `domain` (string, optional): Company Domain Name.
|
||||
- `industry` (string, optional): Industry.
|
||||
- `phone` (string, optional): Phone Number.
|
||||
- `city` (string, optional): City.
|
||||
- `state` (string, optional): State/Region.
|
||||
- `zip` (string, optional): Postal Code.
|
||||
- `numberofemployees` (number, optional): Number of Employees.
|
||||
- `annualrevenue` (number, optional): Annual Revenue.
|
||||
- `description` (string, optional): Description.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_CREATE_RECORD_ANY">
|
||||
**Description:** Create a record for a specified object type in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `recordType` (string, required): The object type ID of the custom object.
|
||||
- Additional parameters depend on the custom object's schema.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_UPDATE_RECORD_CONTACTS">
|
||||
**Description:** Update an existing contact record in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the contact to update.
|
||||
- `firstname` (string, optional): First Name.
|
||||
- `lastname` (string, optional): Last Name.
|
||||
- `email` (string, optional): Email address.
|
||||
- `phone` (string, optional): Phone Number.
|
||||
- `company` (string, optional): Company Name.
|
||||
- `jobtitle` (string, optional): Job Title.
|
||||
- `lifecyclestage` (string, optional): Lifecycle Stage.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_UPDATE_RECORD_DEALS">
|
||||
**Description:** Update an existing deal record in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the deal to update.
|
||||
- `dealname` (string, optional): Name of the deal.
|
||||
- `amount` (number, optional): The value of the deal.
|
||||
- `dealstage` (string, optional): The pipeline stage of the deal.
|
||||
- `pipeline` (string, optional): The pipeline the deal belongs to.
|
||||
- `closedate` (string, optional): The date the deal is expected to close.
|
||||
- `dealtype` (string, optional): The type of deal.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_UPDATE_RECORD_ENGAGEMENTS">
|
||||
**Description:** Update an existing engagement in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the engagement to update.
|
||||
- `hs_note_body` (string, optional): The body of the note.
|
||||
- `hs_task_subject` (string, optional): The title of the task.
|
||||
- `hs_task_body` (string, optional): The notes for the task.
|
||||
- `hs_task_status` (string, optional): The status of the task.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_UPDATE_RECORD_ANY">
|
||||
**Description:** Update a record for a specified object type in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the record to update.
|
||||
- `recordType` (string, required): The object type ID of the custom object.
|
||||
- Additional parameters depend on the custom object's schema.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_RECORDS_COMPANIES">
|
||||
**Description:** Get a list of company records from HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` to fetch subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_RECORDS_CONTACTS">
|
||||
**Description:** Get a list of contact records from HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` to fetch subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_RECORDS_DEALS">
|
||||
**Description:** Get a list of deal records from HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` to fetch subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_RECORDS_ENGAGEMENTS">
|
||||
**Description:** Get a list of engagement records from HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `objectName` (string, required): The type of engagement to fetch (e.g., "notes").
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` to fetch subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_RECORDS_ANY">
|
||||
**Description:** Get a list of records for any specified object type in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `recordType` (string, required): The object type ID of the custom object.
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` to fetch subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_RECORD_BY_ID_COMPANIES">
|
||||
**Description:** Get a single company record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the company to retrieve.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_RECORD_BY_ID_CONTACTS">
|
||||
**Description:** Get a single contact record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the contact to retrieve.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_RECORD_BY_ID_DEALS">
|
||||
**Description:** Get a single deal record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the deal to retrieve.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_RECORD_BY_ID_ENGAGEMENTS">
|
||||
**Description:** Get a single engagement record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the engagement to retrieve.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_RECORD_BY_ID_ANY">
|
||||
**Description:** Get a single record of any specified object type by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordType` (string, required): The object type ID of the custom object.
|
||||
- `recordId` (string, required): The ID of the record to retrieve.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_SEARCH_RECORDS_COMPANIES">
|
||||
**Description:** Search for company records in HubSpot using a filter formula.
|
||||
|
||||
**Parameters:**
|
||||
- `filterFormula` (object, optional): A filter in disjunctive normal form (OR of ANDs).
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` to fetch subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_SEARCH_RECORDS_CONTACTS">
|
||||
**Description:** Search for contact records in HubSpot using a filter formula.
|
||||
|
||||
**Parameters:**
|
||||
- `filterFormula` (object, optional): A filter in disjunctive normal form (OR of ANDs).
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` to fetch subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_SEARCH_RECORDS_DEALS">
|
||||
**Description:** Search for deal records in HubSpot using a filter formula.
|
||||
|
||||
**Parameters:**
|
||||
- `filterFormula` (object, optional): A filter in disjunctive normal form (OR of ANDs).
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` to fetch subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_SEARCH_RECORDS_ENGAGEMENTS">
|
||||
**Description:** Search for engagement records in HubSpot using a filter formula.
|
||||
|
||||
**Parameters:**
|
||||
- `engagementFilterFormula` (object, optional): A filter for engagements.
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` to fetch subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_SEARCH_RECORDS_ANY">
|
||||
**Description:** Search for records of any specified object type in HubSpot.
|
||||
|
||||
**Parameters:**
|
||||
- `recordType` (string, required): The object type ID to search.
|
||||
- `filterFormula` (string, optional): The filter formula to apply.
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` to fetch subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_DELETE_RECORD_COMPANIES">
|
||||
**Description:** Delete a company record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the company to delete.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_DELETE_RECORD_CONTACTS">
|
||||
**Description:** Delete a contact record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the contact to delete.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_DELETE_RECORD_DEALS">
|
||||
**Description:** Delete a deal record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the deal to delete.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_DELETE_RECORD_ENGAGEMENTS">
|
||||
**Description:** Delete an engagement record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the engagement to delete.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_DELETE_RECORD_ANY">
|
||||
**Description:** Delete a record of any specified object type by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordType` (string, required): The object type ID of the custom object.
|
||||
- `recordId` (string, required): The ID of the record to delete.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_GET_CONTACTS_BY_LIST_ID">
|
||||
**Description:** Get contacts from a specific list by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `listId` (string, required): The ID of the list to get contacts from.
|
||||
- `paginationParameters` (object, optional): Use `pageCursor` for subsequent pages.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="HUBSPOT_DESCRIBE_ACTION_SCHEMA">
|
||||
**Description:** Get the expected schema for a given object type and operation.
|
||||
|
||||
**Parameters:**
|
||||
- `recordType` (string, required): The object type ID (e.g., 'companies').
|
||||
- `operation` (string, required): The operation type (e.g., 'CREATE_RECORD').
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic HubSpot Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (HubSpot tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with HubSpot capabilities
|
||||
hubspot_agent = Agent(
|
||||
role="CRM Manager",
|
||||
goal="Manage company and contact records in HubSpot",
|
||||
backstory="An AI assistant specialized in CRM management.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a new company
|
||||
create_company_task = Task(
|
||||
description="Create a new company in HubSpot with name 'Innovate Corp' and domain 'innovatecorp.com'.",
|
||||
agent=hubspot_agent,
|
||||
expected_output="Company created successfully with confirmation"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[hubspot_agent],
|
||||
tasks=[create_company_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific HubSpot Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only the tool to create contacts
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["hubspot_create_record_contacts"]
|
||||
)
|
||||
|
||||
contact_creator = Agent(
|
||||
role="Contact Creator",
|
||||
goal="Create new contacts in HubSpot",
|
||||
backstory="An AI assistant that focuses on creating new contact entries in the CRM.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a contact
|
||||
create_contact = Task(
|
||||
description="Create a new contact for 'John Doe' with email 'john.doe@example.com'.",
|
||||
agent=contact_creator,
|
||||
expected_output="Contact created successfully in HubSpot."
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[contact_creator],
|
||||
tasks=[create_contact]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Contact Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
crm_manager = Agent(
|
||||
role="CRM Manager",
|
||||
goal="Manage and organize HubSpot contacts efficiently.",
|
||||
backstory="An experienced CRM manager who maintains an organized contact database.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to manage contacts
|
||||
contact_task = Task(
|
||||
description="Create a new contact for 'Jane Smith' at 'Global Tech Inc.' with email 'jane.smith@globaltech.com'.",
|
||||
agent=crm_manager,
|
||||
expected_output="Contact database updated with the new contact."
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[crm_manager],
|
||||
tasks=[contact_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with HubSpot integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,394 +0,0 @@
|
||||
---
|
||||
title: Jira Integration
|
||||
description: "Issue tracking and project management with Jira integration for CrewAI."
|
||||
icon: "bug"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage issues, projects, and workflows through Jira. Create and update issues, track project progress, manage assignments, and streamline your project management with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Jira integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Jira account with appropriate project permissions
|
||||
- Connected your Jira account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors)
|
||||
|
||||
## Setting Up Jira Integration
|
||||
|
||||
### 1. Connect Your Jira Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors)
|
||||
2. Find **Jira** in the Authentication Integrations section
|
||||
3. Click **Connect** and complete the OAuth flow
|
||||
4. Grant the necessary permissions for issue and project management
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account)
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="JIRA_CREATE_ISSUE">
|
||||
**Description:** Create an issue in Jira.
|
||||
|
||||
**Parameters:**
|
||||
- `summary` (string, required): Summary - A brief one-line summary of the issue. (example: "The printer stopped working").
|
||||
- `project` (string, optional): Project - The project which the issue belongs to. Defaults to the user's first project if not provided. Use Connect Portal Workflow Settings to allow users to select a Project.
|
||||
- `issueType` (string, optional): Issue type - Defaults to Task if not provided.
|
||||
- `jiraIssueStatus` (string, optional): Status - Defaults to the project's first status if not provided.
|
||||
- `assignee` (string, optional): Assignee - Defaults to the authenticated user if not provided.
|
||||
- `descriptionType` (string, optional): Description Type - Select the Description Type.
|
||||
- Options: `description`, `descriptionJSON`
|
||||
- `description` (string, optional): Description - A detailed description of the issue. This field appears only when 'descriptionType' = 'description'.
|
||||
- `additionalFields` (string, optional): Additional Fields - Specify any other fields that should be included in JSON format. Use Connect Portal Workflow Settings to allow users to select which Issue Fields to update.
|
||||
```json
|
||||
{
|
||||
"customfield_10001": "value"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_UPDATE_ISSUE">
|
||||
**Description:** Update an issue in Jira.
|
||||
|
||||
**Parameters:**
|
||||
- `issueKey` (string, required): Issue Key (example: "TEST-1234").
|
||||
- `summary` (string, optional): Summary - A brief one-line summary of the issue. (example: "The printer stopped working").
|
||||
- `issueType` (string, optional): Issue type - Use Connect Portal Workflow Settings to allow users to select an Issue Type.
|
||||
- `jiraIssueStatus` (string, optional): Status - Use Connect Portal Workflow Settings to allow users to select a Status.
|
||||
- `assignee` (string, optional): Assignee - Use Connect Portal Workflow Settings to allow users to select an Assignee.
|
||||
- `descriptionType` (string, optional): Description Type - Select the Description Type.
|
||||
- Options: `description`, `descriptionJSON`
|
||||
- `description` (string, optional): Description - A detailed description of the issue. This field appears only when 'descriptionType' = 'description'.
|
||||
- `additionalFields` (string, optional): Additional Fields - Specify any other fields that should be included in JSON format.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_GET_ISSUE_BY_KEY">
|
||||
**Description:** Get an issue by key in Jira.
|
||||
|
||||
**Parameters:**
|
||||
- `issueKey` (string, required): Issue Key (example: "TEST-1234").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_FILTER_ISSUES">
|
||||
**Description:** Search issues in Jira using filters.
|
||||
|
||||
**Parameters:**
|
||||
- `jqlQuery` (object, optional): A filter in disjunctive normal form - OR of AND groups of single conditions.
|
||||
```json
|
||||
{
|
||||
"operator": "OR",
|
||||
"conditions": [
|
||||
{
|
||||
"operator": "AND",
|
||||
"conditions": [
|
||||
{
|
||||
"field": "status",
|
||||
"operator": "$stringExactlyMatches",
|
||||
"value": "Open"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
Available operators: `$stringExactlyMatches`, `$stringDoesNotExactlyMatch`, `$stringIsIn`, `$stringIsNotIn`, `$stringContains`, `$stringDoesNotContain`, `$stringGreaterThan`, `$stringLessThan`
|
||||
- `limit` (string, optional): Limit results - Limit the maximum number of issues to return. Defaults to 10 if left blank.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_SEARCH_BY_JQL">
|
||||
**Description:** Search issues by JQL in Jira.
|
||||
|
||||
**Parameters:**
|
||||
- `jqlQuery` (string, required): JQL Query (example: "project = PROJECT").
|
||||
- `paginationParameters` (object, optional): Pagination parameters for paginated results.
|
||||
```json
|
||||
{
|
||||
"pageCursor": "cursor_string"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_UPDATE_ISSUE_ANY">
|
||||
**Description:** Update any issue in Jira. Use DESCRIBE_ACTION_SCHEMA to get properties schema for this function.
|
||||
|
||||
**Parameters:** No specific parameters - use JIRA_DESCRIBE_ACTION_SCHEMA first to get the expected schema.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_DESCRIBE_ACTION_SCHEMA">
|
||||
**Description:** Get the expected schema for an issue type. Use this function first if no other function matches the issue type you want to operate on.
|
||||
|
||||
**Parameters:**
|
||||
- `issueTypeId` (string, required): Issue Type ID.
|
||||
- `projectKey` (string, required): Project key.
|
||||
- `operation` (string, required): Operation Type value, for example CREATE_ISSUE or UPDATE_ISSUE.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_GET_PROJECTS">
|
||||
**Description:** Get Projects in Jira.
|
||||
|
||||
**Parameters:**
|
||||
- `paginationParameters` (object, optional): Pagination Parameters.
|
||||
```json
|
||||
{
|
||||
"pageCursor": "cursor_string"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_GET_ISSUE_TYPES_BY_PROJECT">
|
||||
**Description:** Get Issue Types by project in Jira.
|
||||
|
||||
**Parameters:**
|
||||
- `project` (string, required): Project key.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_GET_ISSUE_TYPES">
|
||||
**Description:** Get all Issue Types in Jira.
|
||||
|
||||
**Parameters:** None required.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_GET_ISSUE_STATUS_BY_PROJECT">
|
||||
**Description:** Get issue statuses for a given project.
|
||||
|
||||
**Parameters:**
|
||||
- `project` (string, required): Project key.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="JIRA_GET_ALL_ASSIGNEES_BY_PROJECT">
|
||||
**Description:** Get assignees for a given project.
|
||||
|
||||
**Parameters:**
|
||||
- `project` (string, required): Project key.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Jira Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Jira tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Jira capabilities
|
||||
jira_agent = Agent(
|
||||
role="Issue Manager",
|
||||
goal="Manage Jira issues and track project progress efficiently",
|
||||
backstory="An AI assistant specialized in issue tracking and project management.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a bug report
|
||||
create_bug_task = Task(
|
||||
description="Create a bug report for the login functionality with high priority and assign it to the development team",
|
||||
agent=jira_agent,
|
||||
expected_output="Bug report created successfully with issue key"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[jira_agent],
|
||||
tasks=[create_bug_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Jira Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Jira tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["jira_create_issue", "jira_update_issue", "jira_search_by_jql"]
|
||||
)
|
||||
|
||||
issue_coordinator = Agent(
|
||||
role="Issue Coordinator",
|
||||
goal="Create and manage Jira issues efficiently",
|
||||
backstory="An AI assistant that focuses on issue creation and management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to manage issue workflow
|
||||
issue_workflow = Task(
|
||||
description="Create a feature request issue and update the status of related issues",
|
||||
agent=issue_coordinator,
|
||||
expected_output="Feature request created and related issues updated"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[issue_coordinator],
|
||||
tasks=[issue_workflow]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Project Analysis and Reporting
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
project_analyst = Agent(
|
||||
role="Project Analyst",
|
||||
goal="Analyze project data and generate insights from Jira",
|
||||
backstory="An experienced project analyst who extracts insights from project management data.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to analyze project status
|
||||
analysis_task = Task(
|
||||
description="""
|
||||
1. Get all projects and their issue types
|
||||
2. Search for all open issues across projects
|
||||
3. Analyze issue distribution by status and assignee
|
||||
4. Create a summary report issue with findings
|
||||
""",
|
||||
agent=project_analyst,
|
||||
expected_output="Project analysis completed with summary report created"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[project_analyst],
|
||||
tasks=[analysis_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Automated Issue Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
automation_manager = Agent(
|
||||
role="Automation Manager",
|
||||
goal="Automate issue management and workflow processes",
|
||||
backstory="An AI assistant that automates repetitive issue management tasks.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to automate issue management
|
||||
automation_task = Task(
|
||||
description="""
|
||||
1. Search for all unassigned issues using JQL
|
||||
2. Get available assignees for each project
|
||||
3. Automatically assign issues based on workload and expertise
|
||||
4. Update issue priorities based on age and type
|
||||
5. Create weekly sprint planning issues
|
||||
""",
|
||||
agent=automation_manager,
|
||||
expected_output="Issues automatically assigned and sprint planning issues created"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[automation_manager],
|
||||
tasks=[automation_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Advanced Schema-Based Operations
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
schema_specialist = Agent(
|
||||
role="Schema Specialist",
|
||||
goal="Handle complex Jira operations using dynamic schemas",
|
||||
backstory="An AI assistant that can work with dynamic Jira schemas and custom issue types.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task using schema-based operations
|
||||
schema_task = Task(
|
||||
description="""
|
||||
1. Get all projects and their custom issue types
|
||||
2. For each custom issue type, describe the action schema
|
||||
3. Create issues using the dynamic schema for complex custom fields
|
||||
4. Update issues with custom field values based on business rules
|
||||
""",
|
||||
agent=schema_specialist,
|
||||
expected_output="Custom issues created and updated using dynamic schemas"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[schema_specialist],
|
||||
tasks=[schema_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
**Permission Errors**
|
||||
- Ensure your Jira account has necessary permissions for the target projects
|
||||
- Verify that the OAuth connection includes required scopes for Jira API
|
||||
- Check if you have create/edit permissions for issues in the specified projects
|
||||
|
||||
**Invalid Project or Issue Keys**
|
||||
- Double-check project keys and issue keys for correct format (e.g., "PROJ-123")
|
||||
- Ensure projects exist and are accessible to your account
|
||||
- Verify that issue keys reference existing issues
|
||||
|
||||
**Issue Type and Status Issues**
|
||||
- Use JIRA_GET_ISSUE_TYPES_BY_PROJECT to get valid issue types for a project
|
||||
- Use JIRA_GET_ISSUE_STATUS_BY_PROJECT to get valid statuses
|
||||
- Ensure issue types and statuses are available in the target project
|
||||
|
||||
**JQL Query Problems**
|
||||
- Test JQL queries in Jira's issue search before using in API calls
|
||||
- Ensure field names in JQL are spelled correctly and exist in your Jira instance
|
||||
- Use proper JQL syntax for complex queries
|
||||
|
||||
**Custom Fields and Schema Issues**
|
||||
- Use JIRA_DESCRIBE_ACTION_SCHEMA to get the correct schema for complex issue types
|
||||
- Ensure custom field IDs are correct (e.g., "customfield_10001")
|
||||
- Verify that custom fields are available in the target project and issue type
|
||||
|
||||
**Filter Formula Issues**
|
||||
- Ensure filter formulas follow the correct JSON structure for disjunctive normal form
|
||||
- Use valid field names that exist in your Jira configuration
|
||||
- Test simple filters before building complex multi-condition queries
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with Jira integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,453 +0,0 @@
|
||||
---
|
||||
title: Linear Integration
|
||||
description: "Software project and bug tracking with Linear integration for CrewAI."
|
||||
icon: "list-check"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage issues, projects, and development workflows through Linear. Create and update issues, manage project timelines, organize teams, and streamline your software development process with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Linear integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Linear account with appropriate workspace permissions
|
||||
- Connected your Linear account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors)
|
||||
|
||||
## Setting Up Linear Integration
|
||||
|
||||
### 1. Connect Your Linear Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors)
|
||||
2. Find **Linear** in the Authentication Integrations section
|
||||
3. Click **Connect** and complete the OAuth flow
|
||||
4. Grant the necessary permissions for issue and project management
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account)
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="LINEAR_CREATE_ISSUE">
|
||||
**Description:** Create a new issue in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `teamId` (string, required): Team ID - Specify the Team ID of the parent for this new issue. Use Connect Portal Workflow Settings to allow users to select a Team ID. (example: "a70bdf0f-530a-4887-857d-46151b52b47c").
|
||||
- `title` (string, required): Title - Specify a title for this issue.
|
||||
- `description` (string, optional): Description - Specify a description for this issue.
|
||||
- `statusId` (string, optional): Status - Specify the state or status of this issue.
|
||||
- `priority` (string, optional): Priority - Specify the priority of this issue as an integer.
|
||||
- `dueDate` (string, optional): Due Date - Specify the due date of this issue in ISO 8601 format.
|
||||
- `cycleId` (string, optional): Cycle ID - Specify the cycle associated with this issue.
|
||||
- `additionalFields` (object, optional): Additional Fields.
|
||||
```json
|
||||
{
|
||||
"assigneeId": "a70bdf0f-530a-4887-857d-46151b52b47c",
|
||||
"labelIds": ["a70bdf0f-530a-4887-857d-46151b52b47c"]
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_UPDATE_ISSUE">
|
||||
**Description:** Update an issue in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `issueId` (string, required): Issue ID - Specify the Issue ID of the issue to update. (example: "90fbc706-18cd-42c9-ae66-6bd344cc8977").
|
||||
- `title` (string, optional): Title - Specify a title for this issue.
|
||||
- `description` (string, optional): Description - Specify a description for this issue.
|
||||
- `statusId` (string, optional): Status - Specify the state or status of this issue.
|
||||
- `priority` (string, optional): Priority - Specify the priority of this issue as an integer.
|
||||
- `dueDate` (string, optional): Due Date - Specify the due date of this issue in ISO 8601 format.
|
||||
- `cycleId` (string, optional): Cycle ID - Specify the cycle associated with this issue.
|
||||
- `additionalFields` (object, optional): Additional Fields.
|
||||
```json
|
||||
{
|
||||
"assigneeId": "a70bdf0f-530a-4887-857d-46151b52b47c",
|
||||
"labelIds": ["a70bdf0f-530a-4887-857d-46151b52b47c"]
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_GET_ISSUE_BY_ID">
|
||||
**Description:** Get an issue by ID in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `issueId` (string, required): Issue ID - Specify the record ID of the issue to fetch. (example: "90fbc706-18cd-42c9-ae66-6bd344cc8977").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_GET_ISSUE_BY_ISSUE_IDENTIFIER">
|
||||
**Description:** Get an issue by issue identifier in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `externalId` (string, required): External ID - Specify the human-readable Issue identifier of the issue to fetch. (example: "ABC-1").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_SEARCH_ISSUE">
|
||||
**Description:** Search issues in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `queryTerm` (string, required): Query Term - The search term to look for.
|
||||
- `issueFilterFormula` (object, optional): A filter in disjunctive normal form - OR of AND groups of single conditions.
|
||||
```json
|
||||
{
|
||||
"operator": "OR",
|
||||
"conditions": [
|
||||
{
|
||||
"operator": "AND",
|
||||
"conditions": [
|
||||
{
|
||||
"field": "title",
|
||||
"operator": "$stringContains",
|
||||
"value": "bug"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
Available fields: `title`, `number`, `project`, `createdAt`
|
||||
Available operators: `$stringExactlyMatches`, `$stringDoesNotExactlyMatch`, `$stringIsIn`, `$stringIsNotIn`, `$stringStartsWith`, `$stringDoesNotStartWith`, `$stringEndsWith`, `$stringDoesNotEndWith`, `$stringContains`, `$stringDoesNotContain`, `$stringGreaterThan`, `$stringLessThan`, `$numberGreaterThanOrEqualTo`, `$numberLessThanOrEqualTo`, `$numberGreaterThan`, `$numberLessThan`, `$dateTimeAfter`, `$dateTimeBefore`
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_DELETE_ISSUE">
|
||||
**Description:** Delete an issue in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `issueId` (string, required): Issue ID - Specify the record ID of the issue to delete. (example: "90fbc706-18cd-42c9-ae66-6bd344cc8977").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_ARCHIVE_ISSUE">
|
||||
**Description:** Archive an issue in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `issueId` (string, required): Issue ID - Specify the record ID of the issue to archive. (example: "90fbc706-18cd-42c9-ae66-6bd344cc8977").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_CREATE_SUB_ISSUE">
|
||||
**Description:** Create a sub-issue in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `parentId` (string, required): Parent ID - Specify the Issue ID for the parent of this new issue.
|
||||
- `teamId` (string, required): Team ID - Specify the Team ID of the parent for this new sub-issue. Use Connect Portal Workflow Settings to allow users to select a Team ID. (example: "a70bdf0f-530a-4887-857d-46151b52b47c").
|
||||
- `title` (string, required): Title - Specify a title for this issue.
|
||||
- `description` (string, optional): Description - Specify a description for this issue.
|
||||
- `additionalFields` (object, optional): Additional Fields.
|
||||
```json
|
||||
{
|
||||
"lead": "linear_user_id"
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_CREATE_PROJECT">
|
||||
**Description:** Create a new project in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `teamIds` (object, required): Team ID - Specify the team ID(s) this project is associated with as a string or a JSON array. Use Connect Portal User Settings to allow your user to select a Team ID.
|
||||
```json
|
||||
[
|
||||
"a70bdf0f-530a-4887-857d-46151b52b47c",
|
||||
"4ac7..."
|
||||
]
|
||||
```
|
||||
- `projectName` (string, required): Project Name - Specify the name of the project. (example: "My Linear Project").
|
||||
- `description` (string, optional): Project Description - Specify a description for this project.
|
||||
- `additionalFields` (object, optional): Additional Fields.
|
||||
```json
|
||||
{
|
||||
"state": "planned",
|
||||
"description": ""
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_UPDATE_PROJECT">
|
||||
**Description:** Update a project in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `projectId` (string, required): Project ID - Specify the ID of the project to update. (example: "a6634484-6061-4ac7-9739-7dc5e52c796b").
|
||||
- `projectName` (string, optional): Project Name - Specify the name of the project to update. (example: "My Linear Project").
|
||||
- `description` (string, optional): Project Description - Specify a description for this project.
|
||||
- `additionalFields` (object, optional): Additional Fields.
|
||||
```json
|
||||
{
|
||||
"state": "planned",
|
||||
"description": ""
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_GET_PROJECT_BY_ID">
|
||||
**Description:** Get a project by ID in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `projectId` (string, required): Project ID - Specify the Project ID of the project to fetch. (example: "a6634484-6061-4ac7-9739-7dc5e52c796b").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_DELETE_PROJECT">
|
||||
**Description:** Delete a project in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `projectId` (string, required): Project ID - Specify the Project ID of the project to delete. (example: "a6634484-6061-4ac7-9739-7dc5e52c796b").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="LINEAR_SEARCH_TEAMS">
|
||||
**Description:** Search teams in Linear.
|
||||
|
||||
**Parameters:**
|
||||
- `teamFilterFormula` (object, optional): A filter in disjunctive normal form - OR of AND groups of single conditions.
|
||||
```json
|
||||
{
|
||||
"operator": "OR",
|
||||
"conditions": [
|
||||
{
|
||||
"operator": "AND",
|
||||
"conditions": [
|
||||
{
|
||||
"field": "name",
|
||||
"operator": "$stringContains",
|
||||
"value": "Engineering"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
Available fields: `id`, `name`
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Linear Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Linear tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Linear capabilities
|
||||
linear_agent = Agent(
|
||||
role="Development Manager",
|
||||
goal="Manage Linear issues and track development progress efficiently",
|
||||
backstory="An AI assistant specialized in software development project management.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a bug report
|
||||
create_bug_task = Task(
|
||||
description="Create a high-priority bug report for the authentication system and assign it to the backend team",
|
||||
agent=linear_agent,
|
||||
expected_output="Bug report created successfully with issue ID"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[linear_agent],
|
||||
tasks=[create_bug_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Linear Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Linear tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["linear_create_issue", "linear_update_issue", "linear_search_issue"]
|
||||
)
|
||||
|
||||
issue_manager = Agent(
|
||||
role="Issue Manager",
|
||||
goal="Create and manage Linear issues efficiently",
|
||||
backstory="An AI assistant that focuses on issue creation and lifecycle management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to manage issue workflow
|
||||
issue_workflow = Task(
|
||||
description="Create a feature request issue and update the status of related issues to reflect current progress",
|
||||
agent=issue_manager,
|
||||
expected_output="Feature request created and related issues updated"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[issue_manager],
|
||||
tasks=[issue_workflow]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Project and Team Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
project_coordinator = Agent(
|
||||
role="Project Coordinator",
|
||||
goal="Coordinate projects and teams in Linear efficiently",
|
||||
backstory="An experienced project coordinator who manages development cycles and team workflows.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to coordinate project setup
|
||||
project_coordination = Task(
|
||||
description="""
|
||||
1. Search for engineering teams in Linear
|
||||
2. Create a new project for Q2 feature development
|
||||
3. Associate the project with relevant teams
|
||||
4. Create initial project milestones as issues
|
||||
""",
|
||||
agent=project_coordinator,
|
||||
expected_output="Q2 project created with teams assigned and initial milestones established"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[project_coordinator],
|
||||
tasks=[project_coordination]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Issue Hierarchy and Sub-task Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
task_organizer = Agent(
|
||||
role="Task Organizer",
|
||||
goal="Organize complex issues into manageable sub-tasks",
|
||||
backstory="An AI assistant that breaks down complex development work into organized sub-tasks.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create issue hierarchy
|
||||
hierarchy_task = Task(
|
||||
description="""
|
||||
1. Search for large feature issues that need to be broken down
|
||||
2. For each complex issue, create sub-issues for different components
|
||||
3. Update the parent issues with proper descriptions and links to sub-issues
|
||||
4. Assign sub-issues to appropriate team members based on expertise
|
||||
""",
|
||||
agent=task_organizer,
|
||||
expected_output="Complex issues broken down into manageable sub-tasks with proper assignments"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[task_organizer],
|
||||
tasks=[hierarchy_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Automated Development Workflow
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
workflow_automator = Agent(
|
||||
role="Workflow Automator",
|
||||
goal="Automate development workflow processes in Linear",
|
||||
backstory="An AI assistant that automates repetitive development workflow tasks.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex workflow automation task
|
||||
automation_task = Task(
|
||||
description="""
|
||||
1. Search for issues that have been in progress for more than 7 days
|
||||
2. Update their priorities based on due dates and project importance
|
||||
3. Create weekly sprint planning issues for each team
|
||||
4. Archive completed issues from the previous cycle
|
||||
5. Generate project status reports as new issues
|
||||
""",
|
||||
agent=workflow_automator,
|
||||
expected_output="Development workflow automated with updated priorities, sprint planning, and status reports"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[workflow_automator],
|
||||
tasks=[automation_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
**Permission Errors**
|
||||
- Ensure your Linear account has necessary permissions for the target workspace
|
||||
- Verify that the OAuth connection includes required scopes for Linear API
|
||||
- Check if you have create/edit permissions for issues and projects in the workspace
|
||||
|
||||
**Invalid IDs and References**
|
||||
- Double-check team IDs, issue IDs, and project IDs for correct UUID format
|
||||
- Ensure referenced entities (teams, projects, cycles) exist and are accessible
|
||||
- Verify that issue identifiers follow the correct format (e.g., "ABC-1")
|
||||
|
||||
**Team and Project Association Issues**
|
||||
- Use LINEAR_SEARCH_TEAMS to get valid team IDs before creating issues or projects
|
||||
- Ensure teams exist and are active in your workspace
|
||||
- Verify that team IDs are properly formatted as UUIDs
|
||||
|
||||
**Issue Status and Priority Problems**
|
||||
- Check that status IDs reference valid workflow states for the team
|
||||
- Ensure priority values are within the valid range for your Linear configuration
|
||||
- Verify that custom fields and labels exist before referencing them
|
||||
|
||||
**Date and Time Format Issues**
|
||||
- Use ISO 8601 format for due dates and timestamps
|
||||
- Ensure time zones are handled correctly for due date calculations
|
||||
- Verify that date values are valid and in the future for due dates
|
||||
|
||||
**Search and Filter Issues**
|
||||
- Ensure search queries are properly formatted and not empty
|
||||
- Use valid field names in filter formulas: `title`, `number`, `project`, `createdAt`
|
||||
- Test simple filters before building complex multi-condition queries
|
||||
- Verify that operator types match the data types of the fields being filtered
|
||||
|
||||
**Sub-issue Creation Problems**
|
||||
- Ensure parent issue IDs are valid and accessible
|
||||
- Verify that the team ID for sub-issues matches or is compatible with the parent issue's team
|
||||
- Check that parent issues are not already archived or deleted
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with Linear integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,509 +0,0 @@
|
||||
---
|
||||
title: Notion Integration
|
||||
description: "Page and database management with Notion integration for CrewAI."
|
||||
icon: "book"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage pages, databases, and content through Notion. Create and update pages, manage content blocks, organize knowledge bases, and streamline your documentation workflows with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Notion integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Notion account with appropriate workspace permissions
|
||||
- Connected your Notion account through the [Integrations page](https://app.crewai.com/crewai_plus/connectors)
|
||||
|
||||
## Setting Up Notion Integration
|
||||
|
||||
### 1. Connect Your Notion Account
|
||||
|
||||
1. Navigate to [CrewAI Enterprise Integrations](https://app.crewai.com/crewai_plus/connectors)
|
||||
2. Find **Notion** in the Authentication Integrations section
|
||||
3. Click **Connect** and complete the OAuth flow
|
||||
4. Grant the necessary permissions for page and database management
|
||||
5. Copy your Enterprise Token from [Account Settings](https://app.crewai.com/crewai_plus/settings/account)
|
||||
|
||||
### 2. Install Required Package
|
||||
|
||||
```bash
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
## Available Actions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="NOTION_CREATE_PAGE">
|
||||
**Description:** Create a page in Notion.
|
||||
|
||||
**Parameters:**
|
||||
- `parent` (object, required): Parent - The parent page or database where the new page is inserted, represented as a JSON object with a page_id or database_id key.
|
||||
```json
|
||||
{
|
||||
"database_id": "DATABASE_ID"
|
||||
}
|
||||
```
|
||||
- `properties` (object, required): Properties - The values of the page's properties. If the parent is a database, then the schema must match the parent database's properties.
|
||||
```json
|
||||
{
|
||||
"title": [
|
||||
{
|
||||
"text": {
|
||||
"content": "My Page"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
- `icon` (object, required): Icon - The page icon.
|
||||
```json
|
||||
{
|
||||
"emoji": "🥬"
|
||||
}
|
||||
```
|
||||
- `children` (object, optional): Children - Content blocks to add to the page.
|
||||
```json
|
||||
[
|
||||
{
|
||||
"object": "block",
|
||||
"type": "heading_2",
|
||||
"heading_2": {
|
||||
"rich_text": [
|
||||
{
|
||||
"type": "text",
|
||||
"text": {
|
||||
"content": "Lacinato kale"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
]
|
||||
```
|
||||
- `cover` (object, optional): Cover - The page cover image.
|
||||
```json
|
||||
{
|
||||
"external": {
|
||||
"url": "https://upload.wikimedia.org/wikipedia/commons/6/62/Tuscankale.jpg"
|
||||
}
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="NOTION_UPDATE_PAGE">
|
||||
**Description:** Update a page in Notion.
|
||||
|
||||
**Parameters:**
|
||||
- `pageId` (string, required): Page ID - Specify the ID of the Page to Update. (example: "59833787-2cf9-4fdf-8782-e53db20768a5").
|
||||
- `icon` (object, required): Icon - The page icon.
|
||||
```json
|
||||
{
|
||||
"emoji": "🥬"
|
||||
}
|
||||
```
|
||||
- `archived` (boolean, optional): Archived - Whether the page is archived (deleted). Set to true to archive a page. Set to false to un-archive (restore) a page.
|
||||
- `properties` (object, optional): Properties - The property values to update for the page.
|
||||
```json
|
||||
{
|
||||
"title": [
|
||||
{
|
||||
"text": {
|
||||
"content": "My Updated Page"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
- `cover` (object, optional): Cover - The page cover image.
|
||||
```json
|
||||
{
|
||||
"external": {
|
||||
"url": "https://upload.wikimedia.org/wikipedia/commons/6/62/Tuscankale.jpg"
|
||||
}
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="NOTION_GET_PAGE_BY_ID">
|
||||
**Description:** Get a page by ID in Notion.
|
||||
|
||||
**Parameters:**
|
||||
- `pageId` (string, required): Page ID - Specify the ID of the Page to Get. (example: "59833787-2cf9-4fdf-8782-e53db20768a5").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="NOTION_ARCHIVE_PAGE">
|
||||
**Description:** Archive a page in Notion.
|
||||
|
||||
**Parameters:**
|
||||
- `pageId` (string, required): Page ID - Specify the ID of the Page to Archive. (example: "59833787-2cf9-4fdf-8782-e53db20768a5").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="NOTION_SEARCH_PAGES">
|
||||
**Description:** Search pages in Notion using filters.
|
||||
|
||||
**Parameters:**
|
||||
- `searchByTitleFilterSearch` (object, optional): A filter in disjunctive normal form - OR of AND groups of single conditions.
|
||||
```json
|
||||
{
|
||||
"operator": "OR",
|
||||
"conditions": [
|
||||
{
|
||||
"operator": "AND",
|
||||
"conditions": [
|
||||
{
|
||||
"field": "query",
|
||||
"operator": "$stringExactlyMatches",
|
||||
"value": "meeting notes"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
Available fields: `query`, `filter.value`, `direction`, `page_size`
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="NOTION_GET_PAGE_CONTENT">
|
||||
**Description:** Get page content (blocks) in Notion.
|
||||
|
||||
**Parameters:**
|
||||
- `blockId` (string, required): Page ID - Specify a Block or Page ID to receive all of its block's children in order. (example: "59833787-2cf9-4fdf-8782-e53db20768a5").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="NOTION_UPDATE_BLOCK">
|
||||
**Description:** Update a block in Notion.
|
||||
|
||||
**Parameters:**
|
||||
- `blockId` (string, required): Block ID - Specify the ID of the Block to Update. (example: "9bc30ad4-9373-46a5-84ab-0a7845ee52e6").
|
||||
- `archived` (boolean, optional): Archived - Set to true to archive (delete) a block. Set to false to un-archive (restore) a block.
|
||||
- `paragraph` (object, optional): Paragraph content.
|
||||
```json
|
||||
{
|
||||
"rich_text": [
|
||||
{
|
||||
"type": "text",
|
||||
"text": {
|
||||
"content": "Lacinato kale",
|
||||
"link": null
|
||||
}
|
||||
}
|
||||
],
|
||||
"color": "default"
|
||||
}
|
||||
```
|
||||
- `image` (object, optional): Image block.
|
||||
```json
|
||||
{
|
||||
"type": "external",
|
||||
"external": {
|
||||
"url": "https://website.domain/images/image.png"
|
||||
}
|
||||
}
|
||||
```
|
||||
- `bookmark` (object, optional): Bookmark block.
|
||||
```json
|
||||
{
|
||||
"caption": [],
|
||||
"url": "https://companywebsite.com"
|
||||
}
|
||||
```
|
||||
- `code` (object, optional): Code block.
|
||||
```json
|
||||
{
|
||||
"rich_text": [
|
||||
{
|
||||
"type": "text",
|
||||
"text": {
|
||||
"content": "const a = 3"
|
||||
}
|
||||
}
|
||||
],
|
||||
"language": "javascript"
|
||||
}
|
||||
```
|
||||
- `pdf` (object, optional): PDF block.
|
||||
```json
|
||||
{
|
||||
"type": "external",
|
||||
"external": {
|
||||
"url": "https://website.domain/files/doc.pdf"
|
||||
}
|
||||
}
|
||||
```
|
||||
- `table` (object, optional): Table block.
|
||||
```json
|
||||
{
|
||||
"table_width": 2,
|
||||
"has_column_header": false,
|
||||
"has_row_header": false
|
||||
}
|
||||
```
|
||||
- `tableOfContent` (object, optional): Table of Contents block.
|
||||
```json
|
||||
{
|
||||
"color": "default"
|
||||
}
|
||||
```
|
||||
- `additionalFields` (object, optional): Additional block types.
|
||||
```json
|
||||
{
|
||||
"child_page": {
|
||||
"title": "Lacinato kale"
|
||||
},
|
||||
"child_database": {
|
||||
"title": "My database"
|
||||
}
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="NOTION_GET_BLOCK_BY_ID">
|
||||
**Description:** Get a block by ID in Notion.
|
||||
|
||||
**Parameters:**
|
||||
- `blockId` (string, required): Block ID - Specify the ID of the Block to Get. (example: "9bc30ad4-9373-46a5-84ab-0a7845ee52e6").
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="NOTION_DELETE_BLOCK">
|
||||
**Description:** Delete a block in Notion.
|
||||
|
||||
**Parameters:**
|
||||
- `blockId` (string, required): Block ID - Specify the ID of the Block to Delete. (example: "9bc30ad4-9373-46a5-84ab-0a7845ee52e6").
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Notion Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Notion tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Notion capabilities
|
||||
notion_agent = Agent(
|
||||
role="Documentation Manager",
|
||||
goal="Manage documentation and knowledge base in Notion efficiently",
|
||||
backstory="An AI assistant specialized in content management and documentation.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a meeting notes page
|
||||
create_notes_task = Task(
|
||||
description="Create a new meeting notes page in the team database with today's date and agenda items",
|
||||
agent=notion_agent,
|
||||
expected_output="Meeting notes page created successfully with structured content"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[notion_agent],
|
||||
tasks=[create_notes_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Notion Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Notion tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["notion_create_page", "notion_update_block", "notion_search_pages"]
|
||||
)
|
||||
|
||||
content_manager = Agent(
|
||||
role="Content Manager",
|
||||
goal="Create and manage content pages efficiently",
|
||||
backstory="An AI assistant that focuses on content creation and management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to manage content workflow
|
||||
content_workflow = Task(
|
||||
description="Create a new project documentation page and add structured content blocks for requirements and specifications",
|
||||
agent=content_manager,
|
||||
expected_output="Project documentation created with organized content sections"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[content_manager],
|
||||
tasks=[content_workflow]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Knowledge Base Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
knowledge_curator = Agent(
|
||||
role="Knowledge Curator",
|
||||
goal="Curate and organize knowledge base content in Notion",
|
||||
backstory="An experienced knowledge manager who organizes and maintains comprehensive documentation.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to curate knowledge base
|
||||
curation_task = Task(
|
||||
description="""
|
||||
1. Search for existing documentation pages related to our new product feature
|
||||
2. Create a comprehensive feature documentation page with proper structure
|
||||
3. Add code examples, images, and links to related resources
|
||||
4. Update existing pages with cross-references to the new documentation
|
||||
""",
|
||||
agent=knowledge_curator,
|
||||
expected_output="Feature documentation created and integrated with existing knowledge base"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[knowledge_curator],
|
||||
tasks=[curation_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Content Structure and Organization
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
content_organizer = Agent(
|
||||
role="Content Organizer",
|
||||
goal="Organize and structure content blocks for optimal readability",
|
||||
backstory="An AI assistant that specializes in content structure and user experience.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to organize content structure
|
||||
organization_task = Task(
|
||||
description="""
|
||||
1. Get content from existing project pages
|
||||
2. Analyze the structure and identify improvement opportunities
|
||||
3. Update content blocks to use proper headings, tables, and formatting
|
||||
4. Add table of contents and improve navigation between related pages
|
||||
5. Create templates for future documentation consistency
|
||||
""",
|
||||
agent=content_organizer,
|
||||
expected_output="Content reorganized with improved structure and navigation"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[content_organizer],
|
||||
tasks=[organization_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Automated Documentation Workflows
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
doc_automator = Agent(
|
||||
role="Documentation Automator",
|
||||
goal="Automate documentation workflows and maintenance",
|
||||
backstory="An AI assistant that automates repetitive documentation tasks.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex documentation automation task
|
||||
automation_task = Task(
|
||||
description="""
|
||||
1. Search for pages that haven't been updated in the last 30 days
|
||||
2. Review and update outdated content blocks
|
||||
3. Create weekly team update pages with consistent formatting
|
||||
4. Add status indicators and progress tracking to project pages
|
||||
5. Generate monthly documentation health reports
|
||||
6. Archive completed project pages and organize them in archive sections
|
||||
""",
|
||||
agent=doc_automator,
|
||||
expected_output="Documentation automated with updated content, weekly reports, and organized archives"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[doc_automator],
|
||||
tasks=[automation_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
**Permission Errors**
|
||||
- Ensure your Notion account has edit access to the target workspace
|
||||
- Verify that the OAuth connection includes required scopes for Notion API
|
||||
- Check that pages and databases are shared with the authenticated integration
|
||||
|
||||
**Invalid Page and Block IDs**
|
||||
- Double-check page IDs and block IDs for correct UUID format
|
||||
- Ensure referenced pages and blocks exist and are accessible
|
||||
- Verify that parent page or database IDs are valid when creating new pages
|
||||
|
||||
**Property Schema Issues**
|
||||
- Ensure page properties match the database schema when creating pages in databases
|
||||
- Verify that property names and types are correct for the target database
|
||||
- Check that required properties are included when creating or updating pages
|
||||
|
||||
**Content Block Structure**
|
||||
- Ensure block content follows Notion's rich text format specifications
|
||||
- Verify that nested block structures are properly formatted
|
||||
- Check that media URLs are accessible and properly formatted
|
||||
|
||||
**Search and Filter Issues**
|
||||
- Ensure search queries are properly formatted and not empty
|
||||
- Use valid field names in filter formulas: `query`, `filter.value`, `direction`, `page_size`
|
||||
- Test simple searches before building complex filter conditions
|
||||
|
||||
**Parent-Child Relationships**
|
||||
- Verify that parent page or database exists before creating child pages
|
||||
- Ensure proper permissions exist for the parent container
|
||||
- Check that database schemas allow the properties you're trying to set
|
||||
|
||||
**Rich Text and Media Content**
|
||||
- Ensure URLs for external images, PDFs, and bookmarks are accessible
|
||||
- Verify that rich text formatting follows Notion's API specifications
|
||||
- Check that code block language types are supported by Notion
|
||||
|
||||
**Archive and Deletion Operations**
|
||||
- Understand the difference between archiving (reversible) and deleting (permanent)
|
||||
- Verify that you have permissions to archive or delete the target content
|
||||
- Be cautious with bulk operations that might affect multiple pages or blocks
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with Notion integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,632 +0,0 @@
|
||||
---
|
||||
title: Salesforce Integration
|
||||
description: "CRM and sales automation with Salesforce integration for CrewAI."
|
||||
icon: "salesforce"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage customer relationships, sales processes, and data through Salesforce. Create and update records, manage leads and opportunities, execute SOQL queries, and streamline your CRM workflows with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Salesforce integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Salesforce account with appropriate permissions
|
||||
- Connected your Salesforce account through the [Integrations page](https://app.crewai.com/integrations)
|
||||
|
||||
## Available Tools
|
||||
|
||||
### **Record Management**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SALESFORCE_CREATE_RECORD_CONTACT">
|
||||
**Description:** Create a new Contact record in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `FirstName` (string, optional): First Name
|
||||
- `LastName` (string, required): Last Name - This field is required
|
||||
- `accountId` (string, optional): Account ID - The Account that the Contact belongs to
|
||||
- `Email` (string, optional): Email address
|
||||
- `Title` (string, optional): Title of the contact, such as CEO or Vice President
|
||||
- `Description` (string, optional): A description of the Contact
|
||||
- `additionalFields` (object, optional): Additional fields in JSON format for custom Contact fields
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_RECORD_LEAD">
|
||||
**Description:** Create a new Lead record in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `FirstName` (string, optional): First Name
|
||||
- `LastName` (string, required): Last Name - This field is required
|
||||
- `Company` (string, required): Company - This field is required
|
||||
- `Email` (string, optional): Email address
|
||||
- `Phone` (string, optional): Phone number
|
||||
- `Website` (string, optional): Website URL
|
||||
- `Title` (string, optional): Title of the contact, such as CEO or Vice President
|
||||
- `Status` (string, optional): Lead Status - Use Connect Portal Workflow Settings to select Lead Status
|
||||
- `Description` (string, optional): A description of the Lead
|
||||
- `additionalFields` (object, optional): Additional fields in JSON format for custom Lead fields
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_RECORD_OPPORTUNITY">
|
||||
**Description:** Create a new Opportunity record in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `Name` (string, required): The Opportunity name - This field is required
|
||||
- `StageName` (string, optional): Opportunity Stage - Use Connect Portal Workflow Settings to select stage
|
||||
- `CloseDate` (string, optional): Close Date in YYYY-MM-DD format - Defaults to 30 days from current date
|
||||
- `AccountId` (string, optional): The Account that the Opportunity belongs to
|
||||
- `Amount` (string, optional): Estimated total sale amount
|
||||
- `Description` (string, optional): A description of the Opportunity
|
||||
- `OwnerId` (string, optional): The Salesforce user assigned to work on this Opportunity
|
||||
- `NextStep` (string, optional): Description of next task in closing Opportunity
|
||||
- `additionalFields` (object, optional): Additional fields in JSON format for custom Opportunity fields
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_RECORD_TASK">
|
||||
**Description:** Create a new Task record in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `whatId` (string, optional): Related to ID - The ID of the Account or Opportunity this Task is related to
|
||||
- `whoId` (string, optional): Name ID - The ID of the Contact or Lead this Task is related to
|
||||
- `subject` (string, required): Subject of the task
|
||||
- `activityDate` (string, optional): Activity Date in YYYY-MM-DD format
|
||||
- `description` (string, optional): A description of the Task
|
||||
- `taskSubtype` (string, required): Task Subtype - Options: task, email, listEmail, call
|
||||
- `Status` (string, optional): Status - Options: Not Started, In Progress, Completed
|
||||
- `ownerId` (string, optional): Assigned To ID - The Salesforce user assigned to this Task
|
||||
- `callDurationInSeconds` (string, optional): Call Duration in seconds
|
||||
- `isReminderSet` (boolean, optional): Whether reminder is set
|
||||
- `reminderDateTime` (string, optional): Reminder Date/Time in ISO format
|
||||
- `additionalFields` (object, optional): Additional fields in JSON format for custom Task fields
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_RECORD_ACCOUNT">
|
||||
**Description:** Create a new Account record in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `Name` (string, required): The Account name - This field is required
|
||||
- `OwnerId` (string, optional): The Salesforce user assigned to this Account
|
||||
- `Website` (string, optional): Website URL
|
||||
- `Phone` (string, optional): Phone number
|
||||
- `Description` (string, optional): Account description
|
||||
- `additionalFields` (object, optional): Additional fields in JSON format for custom Account fields
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_RECORD_ANY">
|
||||
**Description:** Create a record of any object type in Salesforce.
|
||||
|
||||
**Note:** This is a flexible tool for creating records of custom or unknown object types.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Record Updates**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SALESFORCE_UPDATE_RECORD_CONTACT">
|
||||
**Description:** Update an existing Contact record in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the record to update
|
||||
- `FirstName` (string, optional): First Name
|
||||
- `LastName` (string, optional): Last Name
|
||||
- `accountId` (string, optional): Account ID - The Account that the Contact belongs to
|
||||
- `Email` (string, optional): Email address
|
||||
- `Title` (string, optional): Title of the contact
|
||||
- `Description` (string, optional): A description of the Contact
|
||||
- `additionalFields` (object, optional): Additional fields in JSON format for custom Contact fields
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_UPDATE_RECORD_LEAD">
|
||||
**Description:** Update an existing Lead record in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the record to update
|
||||
- `FirstName` (string, optional): First Name
|
||||
- `LastName` (string, optional): Last Name
|
||||
- `Company` (string, optional): Company name
|
||||
- `Email` (string, optional): Email address
|
||||
- `Phone` (string, optional): Phone number
|
||||
- `Website` (string, optional): Website URL
|
||||
- `Title` (string, optional): Title of the contact
|
||||
- `Status` (string, optional): Lead Status
|
||||
- `Description` (string, optional): A description of the Lead
|
||||
- `additionalFields` (object, optional): Additional fields in JSON format for custom Lead fields
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_UPDATE_RECORD_OPPORTUNITY">
|
||||
**Description:** Update an existing Opportunity record in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the record to update
|
||||
- `Name` (string, optional): The Opportunity name
|
||||
- `StageName` (string, optional): Opportunity Stage
|
||||
- `CloseDate` (string, optional): Close Date in YYYY-MM-DD format
|
||||
- `AccountId` (string, optional): The Account that the Opportunity belongs to
|
||||
- `Amount` (string, optional): Estimated total sale amount
|
||||
- `Description` (string, optional): A description of the Opportunity
|
||||
- `OwnerId` (string, optional): The Salesforce user assigned to work on this Opportunity
|
||||
- `NextStep` (string, optional): Description of next task in closing Opportunity
|
||||
- `additionalFields` (object, optional): Additional fields in JSON format for custom Opportunity fields
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_UPDATE_RECORD_TASK">
|
||||
**Description:** Update an existing Task record in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the record to update
|
||||
- `whatId` (string, optional): Related to ID - The ID of the Account or Opportunity this Task is related to
|
||||
- `whoId` (string, optional): Name ID - The ID of the Contact or Lead this Task is related to
|
||||
- `subject` (string, optional): Subject of the task
|
||||
- `activityDate` (string, optional): Activity Date in YYYY-MM-DD format
|
||||
- `description` (string, optional): A description of the Task
|
||||
- `Status` (string, optional): Status - Options: Not Started, In Progress, Completed
|
||||
- `ownerId` (string, optional): Assigned To ID - The Salesforce user assigned to this Task
|
||||
- `callDurationInSeconds` (string, optional): Call Duration in seconds
|
||||
- `isReminderSet` (boolean, optional): Whether reminder is set
|
||||
- `reminderDateTime` (string, optional): Reminder Date/Time in ISO format
|
||||
- `additionalFields` (object, optional): Additional fields in JSON format for custom Task fields
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_UPDATE_RECORD_ACCOUNT">
|
||||
**Description:** Update an existing Account record in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): The ID of the record to update
|
||||
- `Name` (string, optional): The Account name
|
||||
- `OwnerId` (string, optional): The Salesforce user assigned to this Account
|
||||
- `Website` (string, optional): Website URL
|
||||
- `Phone` (string, optional): Phone number
|
||||
- `Description` (string, optional): Account description
|
||||
- `additionalFields` (object, optional): Additional fields in JSON format for custom Account fields
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_UPDATE_RECORD_ANY">
|
||||
**Description:** Update a record of any object type in Salesforce.
|
||||
|
||||
**Note:** This is a flexible tool for updating records of custom or unknown object types.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Record Retrieval**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_ID_CONTACT">
|
||||
**Description:** Get a Contact record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): Record ID of the Contact
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_ID_LEAD">
|
||||
**Description:** Get a Lead record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): Record ID of the Lead
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_ID_OPPORTUNITY">
|
||||
**Description:** Get an Opportunity record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): Record ID of the Opportunity
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_ID_TASK">
|
||||
**Description:** Get a Task record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): Record ID of the Task
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_ID_ACCOUNT">
|
||||
**Description:** Get an Account record by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordId` (string, required): Record ID of the Account
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_ID_ANY">
|
||||
**Description:** Get a record of any object type by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `recordType` (string, required): Record Type (e.g., "CustomObject__c")
|
||||
- `recordId` (string, required): Record ID
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Record Search**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SALESFORCE_SEARCH_RECORDS_CONTACT">
|
||||
**Description:** Search for Contact records with advanced filtering.
|
||||
|
||||
**Parameters:**
|
||||
- `filterFormula` (object, optional): Advanced filter in disjunctive normal form with field-specific operators
|
||||
- `sortBy` (string, optional): Sort field (e.g., "CreatedDate")
|
||||
- `sortDirection` (string, optional): Sort direction - Options: ASC, DESC
|
||||
- `includeAllFields` (boolean, optional): Include all fields in results
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_SEARCH_RECORDS_LEAD">
|
||||
**Description:** Search for Lead records with advanced filtering.
|
||||
|
||||
**Parameters:**
|
||||
- `filterFormula` (object, optional): Advanced filter in disjunctive normal form with field-specific operators
|
||||
- `sortBy` (string, optional): Sort field (e.g., "CreatedDate")
|
||||
- `sortDirection` (string, optional): Sort direction - Options: ASC, DESC
|
||||
- `includeAllFields` (boolean, optional): Include all fields in results
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_SEARCH_RECORDS_OPPORTUNITY">
|
||||
**Description:** Search for Opportunity records with advanced filtering.
|
||||
|
||||
**Parameters:**
|
||||
- `filterFormula` (object, optional): Advanced filter in disjunctive normal form with field-specific operators
|
||||
- `sortBy` (string, optional): Sort field (e.g., "CreatedDate")
|
||||
- `sortDirection` (string, optional): Sort direction - Options: ASC, DESC
|
||||
- `includeAllFields` (boolean, optional): Include all fields in results
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_SEARCH_RECORDS_TASK">
|
||||
**Description:** Search for Task records with advanced filtering.
|
||||
|
||||
**Parameters:**
|
||||
- `filterFormula` (object, optional): Advanced filter in disjunctive normal form with field-specific operators
|
||||
- `sortBy` (string, optional): Sort field (e.g., "CreatedDate")
|
||||
- `sortDirection` (string, optional): Sort direction - Options: ASC, DESC
|
||||
- `includeAllFields` (boolean, optional): Include all fields in results
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_SEARCH_RECORDS_ACCOUNT">
|
||||
**Description:** Search for Account records with advanced filtering.
|
||||
|
||||
**Parameters:**
|
||||
- `filterFormula` (object, optional): Advanced filter in disjunctive normal form with field-specific operators
|
||||
- `sortBy` (string, optional): Sort field (e.g., "CreatedDate")
|
||||
- `sortDirection` (string, optional): Sort direction - Options: ASC, DESC
|
||||
- `includeAllFields` (boolean, optional): Include all fields in results
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_SEARCH_RECORDS_ANY">
|
||||
**Description:** Search for records of any object type.
|
||||
|
||||
**Parameters:**
|
||||
- `recordType` (string, required): Record Type to search
|
||||
- `filterFormula` (string, optional): Filter search criteria
|
||||
- `includeAllFields` (boolean, optional): Include all fields in results
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **List View Retrieval**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_VIEW_ID_CONTACT">
|
||||
**Description:** Get Contact records from a specific List View.
|
||||
|
||||
**Parameters:**
|
||||
- `listViewId` (string, required): List View ID
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_VIEW_ID_LEAD">
|
||||
**Description:** Get Lead records from a specific List View.
|
||||
|
||||
**Parameters:**
|
||||
- `listViewId` (string, required): List View ID
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_VIEW_ID_OPPORTUNITY">
|
||||
**Description:** Get Opportunity records from a specific List View.
|
||||
|
||||
**Parameters:**
|
||||
- `listViewId` (string, required): List View ID
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_VIEW_ID_TASK">
|
||||
**Description:** Get Task records from a specific List View.
|
||||
|
||||
**Parameters:**
|
||||
- `listViewId` (string, required): List View ID
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_VIEW_ID_ACCOUNT">
|
||||
**Description:** Get Account records from a specific List View.
|
||||
|
||||
**Parameters:**
|
||||
- `listViewId` (string, required): List View ID
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_GET_RECORD_BY_VIEW_ID_ANY">
|
||||
**Description:** Get records of any object type from a specific List View.
|
||||
|
||||
**Parameters:**
|
||||
- `recordType` (string, required): Record Type
|
||||
- `listViewId` (string, required): List View ID
|
||||
- `paginationParameters` (object, optional): Pagination settings with pageCursor
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Custom Fields**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SALESFORCE_CREATE_CUSTOM_FIELD_CONTACT">
|
||||
**Description:** Deploy custom fields for Contact objects.
|
||||
|
||||
**Parameters:**
|
||||
- `label` (string, required): Field Label for displays and internal reference
|
||||
- `type` (string, required): Field Type - Options: Checkbox, Currency, Date, Email, Number, Percent, Phone, Picklist, MultiselectPicklist, Text, TextArea, LongTextArea, Html, Time, Url
|
||||
- `defaultCheckboxValue` (boolean, optional): Default value for checkbox fields
|
||||
- `length` (string, required): Length for numeric/text fields
|
||||
- `decimalPlace` (string, required): Decimal places for numeric fields
|
||||
- `pickListValues` (string, required): Values for picklist fields (separated by new lines)
|
||||
- `visibleLines` (string, required): Visible lines for multiselect/text area fields
|
||||
- `description` (string, optional): Field description
|
||||
- `helperText` (string, optional): Helper text shown on hover
|
||||
- `defaultFieldValue` (string, optional): Default field value
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_CUSTOM_FIELD_LEAD">
|
||||
**Description:** Deploy custom fields for Lead objects.
|
||||
|
||||
**Parameters:**
|
||||
- `label` (string, required): Field Label for displays and internal reference
|
||||
- `type` (string, required): Field Type - Options: Checkbox, Currency, Date, Email, Number, Percent, Phone, Picklist, MultiselectPicklist, Text, TextArea, LongTextArea, Html, Time, Url
|
||||
- `defaultCheckboxValue` (boolean, optional): Default value for checkbox fields
|
||||
- `length` (string, required): Length for numeric/text fields
|
||||
- `decimalPlace` (string, required): Decimal places for numeric fields
|
||||
- `pickListValues` (string, required): Values for picklist fields (separated by new lines)
|
||||
- `visibleLines` (string, required): Visible lines for multiselect/text area fields
|
||||
- `description` (string, optional): Field description
|
||||
- `helperText` (string, optional): Helper text shown on hover
|
||||
- `defaultFieldValue` (string, optional): Default field value
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_CUSTOM_FIELD_OPPORTUNITY">
|
||||
**Description:** Deploy custom fields for Opportunity objects.
|
||||
|
||||
**Parameters:**
|
||||
- `label` (string, required): Field Label for displays and internal reference
|
||||
- `type` (string, required): Field Type - Options: Checkbox, Currency, Date, Email, Number, Percent, Phone, Picklist, MultiselectPicklist, Text, TextArea, LongTextArea, Html, Time, Url
|
||||
- `defaultCheckboxValue` (boolean, optional): Default value for checkbox fields
|
||||
- `length` (string, required): Length for numeric/text fields
|
||||
- `decimalPlace` (string, required): Decimal places for numeric fields
|
||||
- `pickListValues` (string, required): Values for picklist fields (separated by new lines)
|
||||
- `visibleLines` (string, required): Visible lines for multiselect/text area fields
|
||||
- `description` (string, optional): Field description
|
||||
- `helperText` (string, optional): Helper text shown on hover
|
||||
- `defaultFieldValue` (string, optional): Default field value
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_CUSTOM_FIELD_TASK">
|
||||
**Description:** Deploy custom fields for Task objects.
|
||||
|
||||
**Parameters:**
|
||||
- `label` (string, required): Field Label for displays and internal reference
|
||||
- `type` (string, required): Field Type - Options: Checkbox, Currency, Date, Email, Number, Percent, Phone, Picklist, MultiselectPicklist, Text, TextArea, Time, Url
|
||||
- `defaultCheckboxValue` (boolean, optional): Default value for checkbox fields
|
||||
- `length` (string, required): Length for numeric/text fields
|
||||
- `decimalPlace` (string, required): Decimal places for numeric fields
|
||||
- `pickListValues` (string, required): Values for picklist fields (separated by new lines)
|
||||
- `visibleLines` (string, required): Visible lines for multiselect fields
|
||||
- `description` (string, optional): Field description
|
||||
- `helperText` (string, optional): Helper text shown on hover
|
||||
- `defaultFieldValue` (string, optional): Default field value
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_CUSTOM_FIELD_ACCOUNT">
|
||||
**Description:** Deploy custom fields for Account objects.
|
||||
|
||||
**Parameters:**
|
||||
- `label` (string, required): Field Label for displays and internal reference
|
||||
- `type` (string, required): Field Type - Options: Checkbox, Currency, Date, Email, Number, Percent, Phone, Picklist, MultiselectPicklist, Text, TextArea, LongTextArea, Html, Time, Url
|
||||
- `defaultCheckboxValue` (boolean, optional): Default value for checkbox fields
|
||||
- `length` (string, required): Length for numeric/text fields
|
||||
- `decimalPlace` (string, required): Decimal places for numeric fields
|
||||
- `pickListValues` (string, required): Values for picklist fields (separated by new lines)
|
||||
- `visibleLines` (string, required): Visible lines for multiselect/text area fields
|
||||
- `description` (string, optional): Field description
|
||||
- `helperText` (string, optional): Helper text shown on hover
|
||||
- `defaultFieldValue` (string, optional): Default field value
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_CUSTOM_FIELD_ANY">
|
||||
**Description:** Deploy custom fields for any object type.
|
||||
|
||||
**Note:** This is a flexible tool for creating custom fields on custom or unknown object types.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Advanced Operations**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SALESFORCE_WRITE_SOQL_QUERY">
|
||||
**Description:** Execute custom SOQL queries against your Salesforce data.
|
||||
|
||||
**Parameters:**
|
||||
- `query` (string, required): SOQL Query (e.g., "SELECT Id, Name FROM Account WHERE Name = 'Example'")
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_CREATE_CUSTOM_OBJECT">
|
||||
**Description:** Deploy a new custom object in Salesforce.
|
||||
|
||||
**Parameters:**
|
||||
- `label` (string, required): Object Label for tabs, page layouts, and reports
|
||||
- `pluralLabel` (string, required): Plural Label (e.g., "Accounts")
|
||||
- `description` (string, optional): A description of the Custom Object
|
||||
- `recordName` (string, required): Record Name that appears in layouts and searches (e.g., "Account Name")
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SALESFORCE_DESCRIBE_ACTION_SCHEMA">
|
||||
**Description:** Get the expected schema for operations on specific object types.
|
||||
|
||||
**Parameters:**
|
||||
- `recordType` (string, required): Record Type to describe
|
||||
- `operation` (string, required): Operation Type (e.g., "CREATE_RECORD" or "UPDATE_RECORD")
|
||||
|
||||
**Note:** Use this function first when working with custom objects to understand their schema before performing operations.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Salesforce Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Salesforce tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Salesforce capabilities
|
||||
salesforce_agent = Agent(
|
||||
role="CRM Manager",
|
||||
goal="Manage customer relationships and sales processes efficiently",
|
||||
backstory="An AI assistant specialized in CRM operations and sales automation.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a new lead
|
||||
create_lead_task = Task(
|
||||
description="Create a new lead for John Doe from Example Corp with email john.doe@example.com",
|
||||
agent=salesforce_agent,
|
||||
expected_output="Lead created successfully with lead ID"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[salesforce_agent],
|
||||
tasks=[create_lead_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Salesforce Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Salesforce tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["salesforce_create_record_lead", "salesforce_update_record_opportunity", "salesforce_search_records_contact"]
|
||||
)
|
||||
|
||||
sales_manager = Agent(
|
||||
role="Sales Manager",
|
||||
goal="Manage leads and opportunities in the sales pipeline",
|
||||
backstory="An experienced sales manager who handles lead qualification and opportunity management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to manage sales pipeline
|
||||
pipeline_task = Task(
|
||||
description="Create a qualified lead and convert it to an opportunity with $50,000 value",
|
||||
agent=sales_manager,
|
||||
expected_output="Lead created and opportunity established successfully"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[sales_manager],
|
||||
tasks=[pipeline_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Contact and Account Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
account_manager = Agent(
|
||||
role="Account Manager",
|
||||
goal="Manage customer accounts and maintain strong relationships",
|
||||
backstory="An AI assistant that specializes in account management and customer relationship building.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to manage customer accounts
|
||||
account_task = Task(
|
||||
description="""
|
||||
1. Create a new account for TechCorp Inc.
|
||||
2. Add John Doe as the primary contact for this account
|
||||
3. Create a follow-up task for next week to check on their project status
|
||||
""",
|
||||
agent=account_manager,
|
||||
expected_output="Account, contact, and follow-up task created successfully"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[account_manager],
|
||||
tasks=[account_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Advanced SOQL Queries and Reporting
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
data_analyst = Agent(
|
||||
role="Sales Data Analyst",
|
||||
goal="Generate insights from Salesforce data using SOQL queries",
|
||||
backstory="An analytical AI that excels at extracting meaningful insights from CRM data.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex task involving SOQL queries and data analysis
|
||||
analysis_task = Task(
|
||||
description="""
|
||||
1. Execute a SOQL query to find all opportunities closing this quarter
|
||||
2. Search for contacts at companies with opportunities over $100K
|
||||
3. Create a summary report of the sales pipeline status
|
||||
4. Update high-value opportunities with next steps
|
||||
""",
|
||||
agent=data_analyst,
|
||||
expected_output="Comprehensive sales pipeline analysis with actionable insights"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[data_analyst],
|
||||
tasks=[analysis_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
This comprehensive documentation covers all the Salesforce tools organized by functionality, making it easy for users to find the specific operations they need for their CRM automation tasks.
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with Salesforce integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,382 +0,0 @@
|
||||
---
|
||||
title: Shopify Integration
|
||||
description: "E-commerce and online store management with Shopify integration for CrewAI."
|
||||
icon: "shopify"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage e-commerce operations through Shopify. Handle customers, orders, products, inventory, and store analytics to streamline your online business with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Shopify integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Shopify store with appropriate admin permissions
|
||||
- Connected your Shopify store through the [Integrations page](https://app.crewai.com/integrations)
|
||||
|
||||
## Available Tools
|
||||
|
||||
### **Customer Management**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SHOPIFY_GET_CUSTOMERS">
|
||||
**Description:** Retrieve a list of customers from your Shopify store.
|
||||
|
||||
**Parameters:**
|
||||
- `customerIds` (string, optional): Comma-separated list of customer IDs to filter by (example: "207119551, 207119552")
|
||||
- `createdAtMin` (string, optional): Only return customers created after this date (ISO or Unix timestamp)
|
||||
- `createdAtMax` (string, optional): Only return customers created before this date (ISO or Unix timestamp)
|
||||
- `updatedAtMin` (string, optional): Only return customers updated after this date (ISO or Unix timestamp)
|
||||
- `updatedAtMax` (string, optional): Only return customers updated before this date (ISO or Unix timestamp)
|
||||
- `limit` (string, optional): Maximum number of customers to return (defaults to 250)
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SHOPIFY_SEARCH_CUSTOMERS">
|
||||
**Description:** Search for customers using advanced filtering criteria.
|
||||
|
||||
**Parameters:**
|
||||
- `filterFormula` (object, optional): Advanced filter in disjunctive normal form with field-specific operators
|
||||
- `limit` (string, optional): Maximum number of customers to return (defaults to 250)
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SHOPIFY_CREATE_CUSTOMER">
|
||||
**Description:** Create a new customer in your Shopify store.
|
||||
|
||||
**Parameters:**
|
||||
- `firstName` (string, required): Customer's first name
|
||||
- `lastName` (string, required): Customer's last name
|
||||
- `email` (string, required): Customer's email address
|
||||
- `company` (string, optional): Company name
|
||||
- `streetAddressLine1` (string, optional): Street address
|
||||
- `streetAddressLine2` (string, optional): Street address line 2
|
||||
- `city` (string, optional): City
|
||||
- `state` (string, optional): State or province code
|
||||
- `country` (string, optional): Country
|
||||
- `zipCode` (string, optional): Zip code
|
||||
- `phone` (string, optional): Phone number
|
||||
- `tags` (string, optional): Tags as array or comma-separated list
|
||||
- `note` (string, optional): Customer note
|
||||
- `sendEmailInvite` (boolean, optional): Whether to send email invitation
|
||||
- `metafields` (object, optional): Additional metafields in JSON format
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SHOPIFY_UPDATE_CUSTOMER">
|
||||
**Description:** Update an existing customer in your Shopify store.
|
||||
|
||||
**Parameters:**
|
||||
- `customerId` (string, required): The ID of the customer to update
|
||||
- `firstName` (string, optional): Customer's first name
|
||||
- `lastName` (string, optional): Customer's last name
|
||||
- `email` (string, optional): Customer's email address
|
||||
- `company` (string, optional): Company name
|
||||
- `streetAddressLine1` (string, optional): Street address
|
||||
- `streetAddressLine2` (string, optional): Street address line 2
|
||||
- `city` (string, optional): City
|
||||
- `state` (string, optional): State or province code
|
||||
- `country` (string, optional): Country
|
||||
- `zipCode` (string, optional): Zip code
|
||||
- `phone` (string, optional): Phone number
|
||||
- `tags` (string, optional): Tags as array or comma-separated list
|
||||
- `note` (string, optional): Customer note
|
||||
- `sendEmailInvite` (boolean, optional): Whether to send email invitation
|
||||
- `metafields` (object, optional): Additional metafields in JSON format
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Order Management**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SHOPIFY_GET_ORDERS">
|
||||
**Description:** Retrieve a list of orders from your Shopify store.
|
||||
|
||||
**Parameters:**
|
||||
- `orderIds` (string, optional): Comma-separated list of order IDs to filter by (example: "450789469, 450789470")
|
||||
- `createdAtMin` (string, optional): Only return orders created after this date (ISO or Unix timestamp)
|
||||
- `createdAtMax` (string, optional): Only return orders created before this date (ISO or Unix timestamp)
|
||||
- `updatedAtMin` (string, optional): Only return orders updated after this date (ISO or Unix timestamp)
|
||||
- `updatedAtMax` (string, optional): Only return orders updated before this date (ISO or Unix timestamp)
|
||||
- `limit` (string, optional): Maximum number of orders to return (defaults to 250)
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SHOPIFY_CREATE_ORDER">
|
||||
**Description:** Create a new order in your Shopify store.
|
||||
|
||||
**Parameters:**
|
||||
- `email` (string, required): Customer email address
|
||||
- `lineItems` (object, required): Order line items in JSON format with title, price, quantity, and variant_id
|
||||
- `sendReceipt` (boolean, optional): Whether to send order receipt
|
||||
- `fulfillmentStatus` (string, optional): Fulfillment status - Options: fulfilled, null, partial, restocked
|
||||
- `financialStatus` (string, optional): Financial status - Options: pending, authorized, partially_paid, paid, partially_refunded, refunded, voided
|
||||
- `inventoryBehaviour` (string, optional): Inventory behavior - Options: bypass, decrement_ignoring_policy, decrement_obeying_policy
|
||||
- `note` (string, optional): Order note
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SHOPIFY_UPDATE_ORDER">
|
||||
**Description:** Update an existing order in your Shopify store.
|
||||
|
||||
**Parameters:**
|
||||
- `orderId` (string, required): The ID of the order to update
|
||||
- `email` (string, optional): Customer email address
|
||||
- `lineItems` (object, optional): Updated order line items in JSON format
|
||||
- `sendReceipt` (boolean, optional): Whether to send order receipt
|
||||
- `fulfillmentStatus` (string, optional): Fulfillment status - Options: fulfilled, null, partial, restocked
|
||||
- `financialStatus` (string, optional): Financial status - Options: pending, authorized, partially_paid, paid, partially_refunded, refunded, voided
|
||||
- `inventoryBehaviour` (string, optional): Inventory behavior - Options: bypass, decrement_ignoring_policy, decrement_obeying_policy
|
||||
- `note` (string, optional): Order note
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SHOPIFY_GET_ABANDONED_CARTS">
|
||||
**Description:** Retrieve abandoned carts from your Shopify store.
|
||||
|
||||
**Parameters:**
|
||||
- `createdWithInLast` (string, optional): Restrict results to checkouts created within specified time
|
||||
- `createdAfterId` (string, optional): Restrict results to after the specified ID
|
||||
- `status` (string, optional): Show checkouts with given status - Options: open, closed (defaults to open)
|
||||
- `createdAtMin` (string, optional): Only return carts created after this date (ISO or Unix timestamp)
|
||||
- `createdAtMax` (string, optional): Only return carts created before this date (ISO or Unix timestamp)
|
||||
- `limit` (string, optional): Maximum number of carts to return (defaults to 250)
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Product Management (REST API)**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SHOPIFY_GET_PRODUCTS">
|
||||
**Description:** Retrieve a list of products from your Shopify store using REST API.
|
||||
|
||||
**Parameters:**
|
||||
- `productIds` (string, optional): Comma-separated list of product IDs to filter by (example: "632910392, 632910393")
|
||||
- `title` (string, optional): Filter by product title
|
||||
- `productType` (string, optional): Filter by product type
|
||||
- `vendor` (string, optional): Filter by vendor
|
||||
- `status` (string, optional): Filter by status - Options: active, archived, draft
|
||||
- `createdAtMin` (string, optional): Only return products created after this date (ISO or Unix timestamp)
|
||||
- `createdAtMax` (string, optional): Only return products created before this date (ISO or Unix timestamp)
|
||||
- `updatedAtMin` (string, optional): Only return products updated after this date (ISO or Unix timestamp)
|
||||
- `updatedAtMax` (string, optional): Only return products updated before this date (ISO or Unix timestamp)
|
||||
- `limit` (string, optional): Maximum number of products to return (defaults to 250)
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SHOPIFY_CREATE_PRODUCT">
|
||||
**Description:** Create a new product in your Shopify store using REST API.
|
||||
|
||||
**Parameters:**
|
||||
- `title` (string, required): Product title
|
||||
- `productType` (string, required): Product type/category
|
||||
- `vendor` (string, required): Product vendor
|
||||
- `productDescription` (string, optional): Product description (accepts plain text or HTML)
|
||||
- `tags` (string, optional): Product tags as array or comma-separated list
|
||||
- `price` (string, optional): Product price
|
||||
- `inventoryPolicy` (string, optional): Inventory policy - Options: deny, continue
|
||||
- `imageUrl` (string, optional): Product image URL
|
||||
- `isPublished` (boolean, optional): Whether product is published
|
||||
- `publishToPointToSale` (boolean, optional): Whether to publish to point of sale
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SHOPIFY_UPDATE_PRODUCT">
|
||||
**Description:** Update an existing product in your Shopify store using REST API.
|
||||
|
||||
**Parameters:**
|
||||
- `productId` (string, required): The ID of the product to update
|
||||
- `title` (string, optional): Product title
|
||||
- `productType` (string, optional): Product type/category
|
||||
- `vendor` (string, optional): Product vendor
|
||||
- `productDescription` (string, optional): Product description (accepts plain text or HTML)
|
||||
- `tags` (string, optional): Product tags as array or comma-separated list
|
||||
- `price` (string, optional): Product price
|
||||
- `inventoryPolicy` (string, optional): Inventory policy - Options: deny, continue
|
||||
- `imageUrl` (string, optional): Product image URL
|
||||
- `isPublished` (boolean, optional): Whether product is published
|
||||
- `publishToPointToSale` (boolean, optional): Whether to publish to point of sale
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Product Management (GraphQL)**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SHOPIFY_GET_PRODUCTS_GRAPHQL">
|
||||
**Description:** Retrieve products using advanced GraphQL filtering capabilities.
|
||||
|
||||
**Parameters:**
|
||||
- `productFilterFormula` (object, optional): Advanced filter in disjunctive normal form with support for fields like id, title, vendor, status, handle, tag, created_at, updated_at, published_at
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SHOPIFY_CREATE_PRODUCT_GRAPHQL">
|
||||
**Description:** Create a new product using GraphQL API with enhanced media support.
|
||||
|
||||
**Parameters:**
|
||||
- `title` (string, required): Product title
|
||||
- `productType` (string, required): Product type/category
|
||||
- `vendor` (string, required): Product vendor
|
||||
- `productDescription` (string, optional): Product description (accepts plain text or HTML)
|
||||
- `tags` (string, optional): Product tags as array or comma-separated list
|
||||
- `media` (object, optional): Media objects with alt text, content type, and source URL
|
||||
- `additionalFields` (object, optional): Additional product fields like status, requiresSellingPlan, giftCard
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SHOPIFY_UPDATE_PRODUCT_GRAPHQL">
|
||||
**Description:** Update an existing product using GraphQL API with enhanced media support.
|
||||
|
||||
**Parameters:**
|
||||
- `productId` (string, required): The GraphQL ID of the product to update (e.g., "gid://shopify/Product/913144112")
|
||||
- `title` (string, optional): Product title
|
||||
- `productType` (string, optional): Product type/category
|
||||
- `vendor` (string, optional): Product vendor
|
||||
- `productDescription` (string, optional): Product description (accepts plain text or HTML)
|
||||
- `tags` (string, optional): Product tags as array or comma-separated list
|
||||
- `media` (object, optional): Updated media objects with alt text, content type, and source URL
|
||||
- `additionalFields` (object, optional): Additional product fields like status, requiresSellingPlan, giftCard
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Shopify Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Shopify tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Shopify capabilities
|
||||
shopify_agent = Agent(
|
||||
role="E-commerce Manager",
|
||||
goal="Manage online store operations and customer relationships efficiently",
|
||||
backstory="An AI assistant specialized in e-commerce operations and online store management.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a new customer
|
||||
create_customer_task = Task(
|
||||
description="Create a new VIP customer Jane Smith with email jane.smith@example.com and phone +1-555-0123",
|
||||
agent=shopify_agent,
|
||||
expected_output="Customer created successfully with customer ID"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[shopify_agent],
|
||||
tasks=[create_customer_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Shopify Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Shopify tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["shopify_create_customer", "shopify_create_order", "shopify_get_products"]
|
||||
)
|
||||
|
||||
store_manager = Agent(
|
||||
role="Store Manager",
|
||||
goal="Manage customer orders and product catalog",
|
||||
backstory="An experienced store manager who handles customer relationships and inventory management.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to manage store operations
|
||||
store_task = Task(
|
||||
description="Create a new customer and process their order for 2 Premium Coffee Mugs",
|
||||
agent=store_manager,
|
||||
expected_output="Customer created and order processed successfully"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[store_manager],
|
||||
tasks=[store_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Product Management with GraphQL
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
product_manager = Agent(
|
||||
role="Product Manager",
|
||||
goal="Manage product catalog and inventory with advanced GraphQL capabilities",
|
||||
backstory="An AI assistant that specializes in product management and catalog optimization.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to manage product catalog
|
||||
catalog_task = Task(
|
||||
description="""
|
||||
1. Create a new product "Premium Coffee Mug" from Coffee Co vendor
|
||||
2. Add high-quality product images and descriptions
|
||||
3. Search for similar products from the same vendor
|
||||
4. Update product tags and pricing strategy
|
||||
""",
|
||||
agent=product_manager,
|
||||
expected_output="Product created and catalog optimized successfully"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[product_manager],
|
||||
tasks=[catalog_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Order and Customer Analytics
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
analytics_agent = Agent(
|
||||
role="E-commerce Analyst",
|
||||
goal="Analyze customer behavior and order patterns to optimize store performance",
|
||||
backstory="An analytical AI that excels at extracting insights from e-commerce data.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex task involving multiple operations
|
||||
analytics_task = Task(
|
||||
description="""
|
||||
1. Retrieve recent customer data and order history
|
||||
2. Identify abandoned carts from the last 7 days
|
||||
3. Analyze product performance and inventory levels
|
||||
4. Generate recommendations for customer retention
|
||||
""",
|
||||
agent=analytics_agent,
|
||||
expected_output="Comprehensive e-commerce analytics report with actionable insights"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[analytics_agent],
|
||||
tasks=[analytics_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Getting Help
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with Shopify integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,293 +0,0 @@
|
||||
---
|
||||
title: Slack Integration
|
||||
description: "Team communication and collaboration with Slack integration for CrewAI."
|
||||
icon: "slack"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage team communication through Slack. Send messages, search conversations, manage channels, and coordinate team activities to streamline your collaboration workflows with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Slack integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Slack workspace with appropriate permissions
|
||||
- Connected your Slack workspace through the [Integrations page](https://app.crewai.com/integrations)
|
||||
|
||||
## Available Tools
|
||||
|
||||
### **User Management**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SLACK_LIST_MEMBERS">
|
||||
**Description:** List all members in a Slack channel.
|
||||
|
||||
**Parameters:**
|
||||
- No parameters required - retrieves all channel members
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SLACK_GET_USER_BY_EMAIL">
|
||||
**Description:** Find a user in your Slack workspace by their email address.
|
||||
|
||||
**Parameters:**
|
||||
- `email` (string, required): The email address of a user in the workspace
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SLACK_GET_USERS_BY_NAME">
|
||||
**Description:** Search for users by their name or display name.
|
||||
|
||||
**Parameters:**
|
||||
- `name` (string, required): User's real name to search for
|
||||
- `displayName` (string, required): User's display name to search for
|
||||
- `paginationParameters` (object, optional): Pagination settings
|
||||
- `pageCursor` (string, optional): Page cursor for pagination
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Channel Management**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SLACK_LIST_CHANNELS">
|
||||
**Description:** List all channels in your Slack workspace.
|
||||
|
||||
**Parameters:**
|
||||
- No parameters required - retrieves all accessible channels
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Messaging**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SLACK_SEND_MESSAGE">
|
||||
**Description:** Send a message to a Slack channel.
|
||||
|
||||
**Parameters:**
|
||||
- `channel` (string, required): Channel name or ID - Use Connect Portal Workflow Settings to allow users to select a channel, or enter a channel name to create a new channel
|
||||
- `message` (string, required): The message text to send
|
||||
- `botName` (string, required): The name of the bot that sends this message
|
||||
- `botIcon` (string, required): Bot icon - Can be either an image URL or an emoji (e.g., ":dog:")
|
||||
- `blocks` (object, optional): Slack Block Kit JSON for rich message formatting with attachments and interactive elements
|
||||
- `authenticatedUser` (boolean, optional): If true, message appears to come from your authenticated Slack user instead of the application (defaults to false)
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="SLACK_SEND_DIRECT_MESSAGE">
|
||||
**Description:** Send a direct message to a specific user in Slack.
|
||||
|
||||
**Parameters:**
|
||||
- `memberId` (string, required): Recipient user ID - Use Connect Portal Workflow Settings to allow users to select a workspace member
|
||||
- `message` (string, required): The message text to send
|
||||
- `botName` (string, required): The name of the bot that sends this message
|
||||
- `botIcon` (string, required): Bot icon - Can be either an image URL or an emoji (e.g., ":dog:")
|
||||
- `blocks` (object, optional): Slack Block Kit JSON for rich message formatting with attachments and interactive elements
|
||||
- `authenticatedUser` (boolean, optional): If true, message appears to come from your authenticated Slack user instead of the application (defaults to false)
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Search & Discovery**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="SLACK_SEARCH_MESSAGES">
|
||||
**Description:** Search for messages across your Slack workspace.
|
||||
|
||||
**Parameters:**
|
||||
- `query` (string, required): Search query using Slack search syntax to find messages that match specified criteria
|
||||
|
||||
**Search Query Examples:**
|
||||
- `"project update"` - Search for messages containing "project update"
|
||||
- `from:@john in:#general` - Search for messages from John in the #general channel
|
||||
- `has:link after:2023-01-01` - Search for messages with links after January 1, 2023
|
||||
- `in:@channel before:yesterday` - Search for messages in a specific channel before yesterday
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Block Kit Integration
|
||||
|
||||
Slack's Block Kit allows you to create rich, interactive messages. Here are some examples of how to use the `blocks` parameter:
|
||||
|
||||
### Simple Text with Attachment
|
||||
```json
|
||||
[
|
||||
{
|
||||
"text": "I am a test message",
|
||||
"attachments": [
|
||||
{
|
||||
"text": "And here's an attachment!"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
### Rich Formatting with Sections
|
||||
```json
|
||||
[
|
||||
{
|
||||
"type": "section",
|
||||
"text": {
|
||||
"type": "mrkdwn",
|
||||
"text": "*Project Update*\nStatus: ✅ Complete"
|
||||
}
|
||||
},
|
||||
{
|
||||
"type": "divider"
|
||||
},
|
||||
{
|
||||
"type": "section",
|
||||
"text": {
|
||||
"type": "plain_text",
|
||||
"text": "All tasks have been completed successfully."
|
||||
}
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Slack Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Slack tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Slack capabilities
|
||||
slack_agent = Agent(
|
||||
role="Team Communication Manager",
|
||||
goal="Facilitate team communication and coordinate collaboration efficiently",
|
||||
backstory="An AI assistant specialized in team communication and workspace coordination.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to send project updates
|
||||
update_task = Task(
|
||||
description="Send a project status update to the #general channel with current progress",
|
||||
agent=slack_agent,
|
||||
expected_output="Project update message sent successfully to team channel"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[slack_agent],
|
||||
tasks=[update_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Slack Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Slack tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["slack_send_message", "slack_send_direct_message", "slack_search_messages"]
|
||||
)
|
||||
|
||||
communication_manager = Agent(
|
||||
role="Communication Coordinator",
|
||||
goal="Manage team communications and ensure important messages reach the right people",
|
||||
backstory="An experienced communication coordinator who handles team messaging and notifications.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to coordinate team communication
|
||||
coordination_task = Task(
|
||||
description="Send task completion notifications to team members and update project channels",
|
||||
agent=communication_manager,
|
||||
expected_output="Team notifications sent and project channels updated successfully"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[communication_manager],
|
||||
tasks=[coordination_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Advanced Messaging with Block Kit
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
notification_agent = Agent(
|
||||
role="Notification Manager",
|
||||
goal="Create rich, interactive notifications and manage workspace communication",
|
||||
backstory="An AI assistant that specializes in creating engaging team notifications and updates.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to send rich notifications
|
||||
notification_task = Task(
|
||||
description="""
|
||||
1. Send a formatted project completion message to #general with progress charts
|
||||
2. Send direct messages to team leads with task summaries
|
||||
3. Create interactive notification with action buttons for team feedback
|
||||
""",
|
||||
agent=notification_agent,
|
||||
expected_output="Rich notifications sent with interactive elements and formatted content"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[notification_agent],
|
||||
tasks=[notification_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Message Search and Analytics
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
analytics_agent = Agent(
|
||||
role="Communication Analyst",
|
||||
goal="Analyze team communication patterns and extract insights from conversations",
|
||||
backstory="An analytical AI that excels at understanding team dynamics through communication data.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex task involving search and analysis
|
||||
analysis_task = Task(
|
||||
description="""
|
||||
1. Search for recent project-related messages across all channels
|
||||
2. Find users by email to identify team members
|
||||
3. Analyze communication patterns and response times
|
||||
4. Generate weekly team communication summary
|
||||
""",
|
||||
agent=analytics_agent,
|
||||
expected_output="Comprehensive communication analysis with team insights and recommendations"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[analytics_agent],
|
||||
tasks=[analysis_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
## Contact Support
|
||||
|
||||
<Card title="Need Help?" icon="headset" href="mailto:support@crewai.com">
|
||||
Contact our support team for assistance with Slack integration setup or troubleshooting.
|
||||
</Card>
|
||||
@@ -1,305 +0,0 @@
|
||||
---
|
||||
title: Stripe Integration
|
||||
description: "Payment processing and subscription management with Stripe integration for CrewAI."
|
||||
icon: "stripe"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage payments, subscriptions, and customer billing through Stripe. Handle customer data, process subscriptions, manage products, and track financial transactions to streamline your payment workflows with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Stripe integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Stripe account with appropriate API permissions
|
||||
- Connected your Stripe account through the [Integrations page](https://app.crewai.com/integrations)
|
||||
|
||||
## Available Tools
|
||||
|
||||
### **Customer Management**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="STRIPE_CREATE_CUSTOMER">
|
||||
**Description:** Create a new customer in your Stripe account.
|
||||
|
||||
**Parameters:**
|
||||
- `emailCreateCustomer` (string, required): Customer's email address
|
||||
- `name` (string, optional): Customer's full name
|
||||
- `description` (string, optional): Customer description for internal reference
|
||||
- `metadataCreateCustomer` (object, optional): Additional metadata as key-value pairs (e.g., `{"field1": 1, "field2": 2}`)
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="STRIPE_GET_CUSTOMER_BY_ID">
|
||||
**Description:** Retrieve a specific customer by their Stripe customer ID.
|
||||
|
||||
**Parameters:**
|
||||
- `idGetCustomer` (string, required): The Stripe customer ID to retrieve
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="STRIPE_GET_CUSTOMERS">
|
||||
**Description:** Retrieve a list of customers with optional filtering.
|
||||
|
||||
**Parameters:**
|
||||
- `emailGetCustomers` (string, optional): Filter customers by email address
|
||||
- `createdAfter` (string, optional): Filter customers created after this date (Unix timestamp)
|
||||
- `createdBefore` (string, optional): Filter customers created before this date (Unix timestamp)
|
||||
- `limitGetCustomers` (string, optional): Maximum number of customers to return (defaults to 10)
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="STRIPE_UPDATE_CUSTOMER">
|
||||
**Description:** Update an existing customer's information.
|
||||
|
||||
**Parameters:**
|
||||
- `customerId` (string, required): The ID of the customer to update
|
||||
- `emailUpdateCustomer` (string, optional): Updated email address
|
||||
- `name` (string, optional): Updated customer name
|
||||
- `description` (string, optional): Updated customer description
|
||||
- `metadataUpdateCustomer` (object, optional): Updated metadata as key-value pairs
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Subscription Management**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="STRIPE_CREATE_SUBSCRIPTION">
|
||||
**Description:** Create a new subscription for a customer.
|
||||
|
||||
**Parameters:**
|
||||
- `customerIdCreateSubscription` (string, required): The customer ID for whom the subscription will be created
|
||||
- `plan` (string, required): The plan ID for the subscription - Use Connect Portal Workflow Settings to allow users to select a plan
|
||||
- `metadataCreateSubscription` (object, optional): Additional metadata for the subscription
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="STRIPE_GET_SUBSCRIPTIONS">
|
||||
**Description:** Retrieve subscriptions with optional filtering.
|
||||
|
||||
**Parameters:**
|
||||
- `customerIdGetSubscriptions` (string, optional): Filter subscriptions by customer ID
|
||||
- `subscriptionStatus` (string, optional): Filter by subscription status - Options: incomplete, incomplete_expired, trialing, active, past_due, canceled, unpaid
|
||||
- `limitGetSubscriptions` (string, optional): Maximum number of subscriptions to return (defaults to 10)
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Product Management**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="STRIPE_CREATE_PRODUCT">
|
||||
**Description:** Create a new product in your Stripe catalog.
|
||||
|
||||
**Parameters:**
|
||||
- `productName` (string, required): The product name
|
||||
- `description` (string, optional): Product description
|
||||
- `metadataProduct` (object, optional): Additional product metadata as key-value pairs
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="STRIPE_GET_PRODUCT_BY_ID">
|
||||
**Description:** Retrieve a specific product by its Stripe product ID.
|
||||
|
||||
**Parameters:**
|
||||
- `productId` (string, required): The Stripe product ID to retrieve
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="STRIPE_GET_PRODUCTS">
|
||||
**Description:** Retrieve a list of products with optional filtering.
|
||||
|
||||
**Parameters:**
|
||||
- `createdAfter` (string, optional): Filter products created after this date (Unix timestamp)
|
||||
- `createdBefore` (string, optional): Filter products created before this date (Unix timestamp)
|
||||
- `limitGetProducts` (string, optional): Maximum number of products to return (defaults to 10)
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Financial Operations**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="STRIPE_GET_BALANCE_TRANSACTIONS">
|
||||
**Description:** Retrieve balance transactions from your Stripe account.
|
||||
|
||||
**Parameters:**
|
||||
- `balanceTransactionType` (string, optional): Filter by transaction type - Options: charge, refund, payment, payment_refund
|
||||
- `paginationParameters` (object, optional): Pagination settings
|
||||
- `pageCursor` (string, optional): Page cursor for pagination
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="STRIPE_GET_PLANS">
|
||||
**Description:** Retrieve subscription plans from your Stripe account.
|
||||
|
||||
**Parameters:**
|
||||
- `isPlanActive` (boolean, optional): Filter by plan status - true for active plans, false for inactive plans
|
||||
- `paginationParameters` (object, optional): Pagination settings
|
||||
- `pageCursor` (string, optional): Page cursor for pagination
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Stripe Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Stripe tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Stripe capabilities
|
||||
stripe_agent = Agent(
|
||||
role="Payment Manager",
|
||||
goal="Manage customer payments, subscriptions, and billing operations efficiently",
|
||||
backstory="An AI assistant specialized in payment processing and subscription management.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a new customer
|
||||
create_customer_task = Task(
|
||||
description="Create a new premium customer John Doe with email john.doe@example.com",
|
||||
agent=stripe_agent,
|
||||
expected_output="Customer created successfully with customer ID"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[stripe_agent],
|
||||
tasks=[create_customer_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Stripe Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Stripe tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["stripe_create_customer", "stripe_create_subscription", "stripe_get_balance_transactions"]
|
||||
)
|
||||
|
||||
billing_manager = Agent(
|
||||
role="Billing Manager",
|
||||
goal="Handle customer billing, subscriptions, and payment processing",
|
||||
backstory="An experienced billing manager who handles subscription lifecycle and payment operations.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to manage billing operations
|
||||
billing_task = Task(
|
||||
description="Create a new customer and set up their premium subscription plan",
|
||||
agent=billing_manager,
|
||||
expected_output="Customer created and subscription activated successfully"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[billing_manager],
|
||||
tasks=[billing_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Subscription Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
subscription_manager = Agent(
|
||||
role="Subscription Manager",
|
||||
goal="Manage customer subscriptions and optimize recurring revenue",
|
||||
backstory="An AI assistant that specializes in subscription lifecycle management and customer retention.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to manage subscription operations
|
||||
subscription_task = Task(
|
||||
description="""
|
||||
1. Create a new product "Premium Service Plan" with advanced features
|
||||
2. Set up subscription plans with different tiers
|
||||
3. Create customers and assign them to appropriate plans
|
||||
4. Monitor subscription status and handle billing issues
|
||||
""",
|
||||
agent=subscription_manager,
|
||||
expected_output="Subscription management system configured with customers and active plans"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[subscription_manager],
|
||||
tasks=[subscription_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Financial Analytics and Reporting
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
financial_analyst = Agent(
|
||||
role="Financial Analyst",
|
||||
goal="Analyze payment data and generate financial insights",
|
||||
backstory="An analytical AI that excels at extracting insights from payment and subscription data.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex task involving financial analysis
|
||||
analytics_task = Task(
|
||||
description="""
|
||||
1. Retrieve balance transactions for the current month
|
||||
2. Analyze customer payment patterns and subscription trends
|
||||
3. Identify high-value customers and subscription performance
|
||||
4. Generate monthly financial performance report
|
||||
""",
|
||||
agent=financial_analyst,
|
||||
expected_output="Comprehensive financial analysis with payment insights and recommendations"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[financial_analyst],
|
||||
tasks=[analytics_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
## Subscription Status Reference
|
||||
|
||||
Understanding subscription statuses:
|
||||
|
||||
- **incomplete** - Subscription requires payment method or payment confirmation
|
||||
- **incomplete_expired** - Subscription expired before payment was confirmed
|
||||
- **trialing** - Subscription is in trial period
|
||||
- **active** - Subscription is active and current
|
||||
- **past_due** - Payment failed but subscription is still active
|
||||
- **canceled** - Subscription has been canceled
|
||||
- **unpaid** - Payment failed and subscription is no longer active
|
||||
|
||||
## Metadata Usage
|
||||
|
||||
Metadata allows you to store additional information about customers, subscriptions, and products:
|
||||
|
||||
```json
|
||||
{
|
||||
"customer_segment": "enterprise",
|
||||
"acquisition_source": "google_ads",
|
||||
"lifetime_value": "high",
|
||||
"custom_field_1": "value1"
|
||||
}
|
||||
```
|
||||
|
||||
This integration enables comprehensive payment and subscription management automation, allowing your AI agents to handle billing operations seamlessly within your Stripe ecosystem.
|
||||
@@ -1,343 +0,0 @@
|
||||
---
|
||||
title: Zendesk Integration
|
||||
description: "Customer support and helpdesk management with Zendesk integration for CrewAI."
|
||||
icon: "headset"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Enable your agents to manage customer support operations through Zendesk. Create and update tickets, manage users, track support metrics, and streamline your customer service workflows with AI-powered automation.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using the Zendesk integration, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account with an active subscription
|
||||
- A Zendesk account with appropriate API permissions
|
||||
- Connected your Zendesk account through the [Integrations page](https://app.crewai.com/integrations)
|
||||
|
||||
## Available Tools
|
||||
|
||||
### **Ticket Management**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="ZENDESK_CREATE_TICKET">
|
||||
**Description:** Create a new support ticket in Zendesk.
|
||||
|
||||
**Parameters:**
|
||||
- `ticketSubject` (string, required): Ticket subject line (e.g., "Help, my printer is on fire!")
|
||||
- `ticketDescription` (string, required): First comment that appears on the ticket (e.g., "The smoke is very colorful.")
|
||||
- `requesterName` (string, required): Name of the user requesting support (e.g., "Jane Customer")
|
||||
- `requesterEmail` (string, required): Email of the user requesting support (e.g., "jane@example.com")
|
||||
- `assigneeId` (string, optional): Zendesk Agent ID assigned to this ticket - Use Connect Portal Workflow Settings to allow users to select an assignee
|
||||
- `ticketType` (string, optional): Ticket type - Options: problem, incident, question, task
|
||||
- `ticketPriority` (string, optional): Priority level - Options: urgent, high, normal, low
|
||||
- `ticketStatus` (string, optional): Ticket status - Options: new, open, pending, hold, solved, closed
|
||||
- `ticketDueAt` (string, optional): Due date for task-type tickets (ISO 8601 timestamp)
|
||||
- `ticketTags` (string, optional): Array of tags to apply (e.g., `["enterprise", "other_tag"]`)
|
||||
- `ticketExternalId` (string, optional): External ID to link tickets to local records
|
||||
- `ticketCustomFields` (object, optional): Custom field values in JSON format
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ZENDESK_UPDATE_TICKET">
|
||||
**Description:** Update an existing support ticket in Zendesk.
|
||||
|
||||
**Parameters:**
|
||||
- `ticketId` (string, required): ID of the ticket to update (e.g., "35436")
|
||||
- `ticketSubject` (string, optional): Updated ticket subject
|
||||
- `requesterName` (string, required): Name of the user who requested this ticket
|
||||
- `requesterEmail` (string, required): Email of the user who requested this ticket
|
||||
- `assigneeId` (string, optional): Updated assignee ID - Use Connect Portal Workflow Settings
|
||||
- `ticketType` (string, optional): Updated ticket type - Options: problem, incident, question, task
|
||||
- `ticketPriority` (string, optional): Updated priority - Options: urgent, high, normal, low
|
||||
- `ticketStatus` (string, optional): Updated status - Options: new, open, pending, hold, solved, closed
|
||||
- `ticketDueAt` (string, optional): Updated due date (ISO 8601 timestamp)
|
||||
- `ticketTags` (string, optional): Updated tags array
|
||||
- `ticketExternalId` (string, optional): Updated external ID
|
||||
- `ticketCustomFields` (object, optional): Updated custom field values
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ZENDESK_GET_TICKET_BY_ID">
|
||||
**Description:** Retrieve a specific ticket by its ID.
|
||||
|
||||
**Parameters:**
|
||||
- `ticketId` (string, required): The ticket ID to retrieve (e.g., "35436")
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ZENDESK_ADD_COMMENT_TO_TICKET">
|
||||
**Description:** Add a comment or internal note to an existing ticket.
|
||||
|
||||
**Parameters:**
|
||||
- `ticketId` (string, required): ID of the ticket to add comment to (e.g., "35436")
|
||||
- `commentBody` (string, required): Comment message (accepts plain text or HTML, e.g., "Thanks for your help!")
|
||||
- `isInternalNote` (boolean, optional): Set to true for internal notes instead of public replies (defaults to false)
|
||||
- `isPublic` (boolean, optional): True for public comments, false for internal notes
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ZENDESK_SEARCH_TICKETS">
|
||||
**Description:** Search for tickets using various filters and criteria.
|
||||
|
||||
**Parameters:**
|
||||
- `ticketSubject` (string, optional): Filter by text in ticket subject
|
||||
- `ticketDescription` (string, optional): Filter by text in ticket description and comments
|
||||
- `ticketStatus` (string, optional): Filter by status - Options: new, open, pending, hold, solved, closed
|
||||
- `ticketType` (string, optional): Filter by type - Options: problem, incident, question, task, no_type
|
||||
- `ticketPriority` (string, optional): Filter by priority - Options: urgent, high, normal, low, no_priority
|
||||
- `requesterId` (string, optional): Filter by requester user ID
|
||||
- `assigneeId` (string, optional): Filter by assigned agent ID
|
||||
- `recipientEmail` (string, optional): Filter by original recipient email address
|
||||
- `ticketTags` (string, optional): Filter by ticket tags
|
||||
- `ticketExternalId` (string, optional): Filter by external ID
|
||||
- `createdDate` (object, optional): Filter by creation date with operator (EQUALS, LESS_THAN_EQUALS, GREATER_THAN_EQUALS) and value
|
||||
- `updatedDate` (object, optional): Filter by update date with operator and value
|
||||
- `dueDate` (object, optional): Filter by due date with operator and value
|
||||
- `sort_by` (string, optional): Sort field - Options: created_at, updated_at, priority, status, ticket_type
|
||||
- `sort_order` (string, optional): Sort direction - Options: asc, desc
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **User Management**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="ZENDESK_CREATE_USER">
|
||||
**Description:** Create a new user in Zendesk.
|
||||
|
||||
**Parameters:**
|
||||
- `name` (string, required): User's full name
|
||||
- `email` (string, optional): User's email address (e.g., "jane@example.com")
|
||||
- `phone` (string, optional): User's phone number
|
||||
- `role` (string, optional): User role - Options: admin, agent, end-user
|
||||
- `externalId` (string, optional): Unique identifier from another system
|
||||
- `details` (string, optional): Additional user details
|
||||
- `notes` (string, optional): Internal notes about the user
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ZENDESK_UPDATE_USER">
|
||||
**Description:** Update an existing user's information.
|
||||
|
||||
**Parameters:**
|
||||
- `userId` (string, required): ID of the user to update
|
||||
- `name` (string, optional): Updated user name
|
||||
- `email` (string, optional): Updated email (adds as secondary email on update)
|
||||
- `phone` (string, optional): Updated phone number
|
||||
- `role` (string, optional): Updated role - Options: admin, agent, end-user
|
||||
- `externalId` (string, optional): Updated external ID
|
||||
- `details` (string, optional): Updated user details
|
||||
- `notes` (string, optional): Updated internal notes
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ZENDESK_GET_USER_BY_ID">
|
||||
**Description:** Retrieve a specific user by their ID.
|
||||
|
||||
**Parameters:**
|
||||
- `userId` (string, required): The user ID to retrieve
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ZENDESK_SEARCH_USERS">
|
||||
**Description:** Search for users using various criteria.
|
||||
|
||||
**Parameters:**
|
||||
- `name` (string, optional): Filter by user name
|
||||
- `email` (string, optional): Filter by user email (e.g., "jane@example.com")
|
||||
- `role` (string, optional): Filter by role - Options: admin, agent, end-user
|
||||
- `externalId` (string, optional): Filter by external ID
|
||||
- `sort_by` (string, optional): Sort field - Options: created_at, updated_at
|
||||
- `sort_order` (string, optional): Sort direction - Options: asc, desc
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### **Administrative Tools**
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="ZENDESK_GET_TICKET_FIELDS">
|
||||
**Description:** Retrieve all standard and custom fields available for tickets.
|
||||
|
||||
**Parameters:**
|
||||
- `paginationParameters` (object, optional): Pagination settings
|
||||
- `pageCursor` (string, optional): Page cursor for pagination
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="ZENDESK_GET_TICKET_AUDITS">
|
||||
**Description:** Get audit records (read-only history) for tickets.
|
||||
|
||||
**Parameters:**
|
||||
- `ticketId` (string, optional): Get audits for specific ticket (if empty, retrieves audits for all non-archived tickets, e.g., "1234")
|
||||
- `paginationParameters` (object, optional): Pagination settings
|
||||
- `pageCursor` (string, optional): Page cursor for pagination
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Custom Fields
|
||||
|
||||
Custom fields allow you to store additional information specific to your organization:
|
||||
|
||||
```json
|
||||
[
|
||||
{ "id": 27642, "value": "745" },
|
||||
{ "id": 27648, "value": "yes" }
|
||||
]
|
||||
```
|
||||
|
||||
## Ticket Priority Levels
|
||||
|
||||
Understanding priority levels:
|
||||
|
||||
- **urgent** - Critical issues requiring immediate attention
|
||||
- **high** - Important issues that should be addressed quickly
|
||||
- **normal** - Standard priority for most tickets
|
||||
- **low** - Minor issues that can be addressed when convenient
|
||||
|
||||
## Ticket Status Workflow
|
||||
|
||||
Standard ticket status progression:
|
||||
|
||||
- **new** - Recently created, not yet assigned
|
||||
- **open** - Actively being worked on
|
||||
- **pending** - Waiting for customer response or external action
|
||||
- **hold** - Temporarily paused
|
||||
- **solved** - Issue resolved, awaiting customer confirmation
|
||||
- **closed** - Ticket completed and closed
|
||||
|
||||
## Usage Examples
|
||||
|
||||
### Basic Zendesk Agent Setup
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get enterprise tools (Zendesk tools will be included)
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
# Create an agent with Zendesk capabilities
|
||||
zendesk_agent = Agent(
|
||||
role="Support Manager",
|
||||
goal="Manage customer support tickets and provide excellent customer service",
|
||||
backstory="An AI assistant specialized in customer support operations and ticket management.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to create a new support ticket
|
||||
create_ticket_task = Task(
|
||||
description="Create a high-priority support ticket for John Smith who is unable to access his account after password reset",
|
||||
agent=zendesk_agent,
|
||||
expected_output="Support ticket created successfully with ticket ID"
|
||||
)
|
||||
|
||||
# Run the task
|
||||
crew = Crew(
|
||||
agents=[zendesk_agent],
|
||||
tasks=[create_ticket_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Filtering Specific Zendesk Tools
|
||||
|
||||
```python
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
# Get only specific Zendesk tools
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token",
|
||||
actions_list=["zendesk_create_ticket", "zendesk_update_ticket", "zendesk_add_comment_to_ticket"]
|
||||
)
|
||||
|
||||
support_agent = Agent(
|
||||
role="Customer Support Agent",
|
||||
goal="Handle customer inquiries and resolve support issues efficiently",
|
||||
backstory="An experienced support agent who specializes in ticket resolution and customer communication.",
|
||||
tools=enterprise_tools
|
||||
)
|
||||
|
||||
# Task to manage support workflow
|
||||
support_task = Task(
|
||||
description="Create a ticket for login issues, add troubleshooting comments, and update status to resolved",
|
||||
agent=support_agent,
|
||||
expected_output="Support ticket managed through complete resolution workflow"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[support_agent],
|
||||
tasks=[support_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Advanced Ticket Management
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
ticket_manager = Agent(
|
||||
role="Ticket Manager",
|
||||
goal="Manage support ticket workflows and ensure timely resolution",
|
||||
backstory="An AI assistant that specializes in support ticket triage and workflow optimization.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Task to manage ticket lifecycle
|
||||
ticket_workflow = Task(
|
||||
description="""
|
||||
1. Create a new support ticket for account access issues
|
||||
2. Add internal notes with troubleshooting steps
|
||||
3. Update ticket priority based on customer tier
|
||||
4. Add resolution comments and close the ticket
|
||||
""",
|
||||
agent=ticket_manager,
|
||||
expected_output="Complete ticket lifecycle managed from creation to resolution"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[ticket_manager],
|
||||
tasks=[ticket_workflow]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
|
||||
### Support Analytics and Reporting
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import CrewaiEnterpriseTools
|
||||
|
||||
enterprise_tools = CrewaiEnterpriseTools(
|
||||
enterprise_token="your_enterprise_token"
|
||||
)
|
||||
|
||||
support_analyst = Agent(
|
||||
role="Support Analyst",
|
||||
goal="Analyze support metrics and generate insights for team performance",
|
||||
backstory="An analytical AI that excels at extracting insights from support data and ticket patterns.",
|
||||
tools=[enterprise_tools]
|
||||
)
|
||||
|
||||
# Complex task involving analytics and reporting
|
||||
analytics_task = Task(
|
||||
description="""
|
||||
1. Search for all open tickets from the last 30 days
|
||||
2. Analyze ticket resolution times and customer satisfaction
|
||||
3. Identify common issues and support patterns
|
||||
4. Generate weekly support performance report
|
||||
""",
|
||||
agent=support_analyst,
|
||||
expected_output="Comprehensive support analytics report with performance insights and recommendations"
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[support_analyst],
|
||||
tasks=[analytics_task]
|
||||
)
|
||||
|
||||
crew.kickoff()
|
||||
```
|
||||
@@ -1,22 +0,0 @@
|
||||
---
|
||||
title: CrewAI Cookbooks
|
||||
description: Feature-focused quickstarts and notebooks for learning patterns fast.
|
||||
icon: book
|
||||
---
|
||||
|
||||
## Quickstarts & Demos
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Task Guardrails" icon="shield-check" href="https://github.com/crewAIInc/crewAI-quickstarts/tree/main/Task%20Guardrails">
|
||||
Interactive notebooks for hands-on exploration.
|
||||
</Card>
|
||||
<Card title="Browse Quickstarts" icon="bolt" href="https://github.com/crewAIInc/crewAI-quickstarts">
|
||||
Feature demos and small projects showcasing specific CrewAI capabilities.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
<Tip>
|
||||
Use Cookbooks to learn a pattern quickly, then jump to Full Examples for production‑grade implementations.
|
||||
</Tip>
|
||||
|
||||
|
||||
@@ -1,85 +0,0 @@
|
||||
---
|
||||
title: CrewAI Examples
|
||||
description: Explore curated examples organized by Crews, Flows, Integrations, and Notebooks.
|
||||
icon: rocket-launch
|
||||
---
|
||||
|
||||
## Crews
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="Marketing Strategy" icon="bullhorn" href="https://github.com/crewAIInc/crewAI-examples/tree/main/crews/marketing_strategy">
|
||||
Multi‑agent marketing campaign planning.
|
||||
</Card>
|
||||
<Card title="Surprise Trip" icon="plane" href="https://github.com/crewAIInc/crewAI-examples/tree/main/crews/surprise_trip">
|
||||
Personalized surprise travel planning.
|
||||
</Card>
|
||||
<Card title="Match Profile to Positions" icon="id-card" href="https://github.com/crewAIInc/crewAI-examples/tree/main/crews/match_profile_to_positions">
|
||||
CV‑to‑job matching with vector search.
|
||||
</Card>
|
||||
<Card title="Job Posting" icon="newspaper" href="https://github.com/crewAIInc/crewAI-examples/tree/main/crews/job-posting">
|
||||
Automated job description creation.
|
||||
</Card>
|
||||
<Card title="Game Builder Crew" icon="gamepad" href="https://github.com/crewAIInc/crewAI-examples/tree/main/crews/game-builder-crew">
|
||||
Multi‑agent team that designs and builds Python games.
|
||||
</Card>
|
||||
<Card title="Recruitment" icon="user-group" href="https://github.com/crewAIInc/crewAI-examples/tree/main/crews/recruitment">
|
||||
Candidate sourcing and evaluation.
|
||||
</Card>
|
||||
<Card title="Browse all Crews" icon="users" href="https://github.com/crewAIInc/crewAI-examples/tree/main/crews">
|
||||
See the full list of crew examples.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Flows
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="Content Creator Flow" icon="pen" href="https://github.com/crewAIInc/crewAI-examples/tree/main/flows/content_creator_flow">
|
||||
Multi‑crew content generation with routing.
|
||||
</Card>
|
||||
<Card title="Email Auto Responder" icon="envelope" href="https://github.com/crewAIInc/crewAI-examples/tree/main/flows/email_auto_responder_flow">
|
||||
Automated email monitoring and replies.
|
||||
</Card>
|
||||
<Card title="Lead Score Flow" icon="chart-line" href="https://github.com/crewAIInc/crewAI-examples/tree/main/flows/lead_score_flow">
|
||||
Lead qualification with human‑in‑the‑loop.
|
||||
</Card>
|
||||
<Card title="Meeting Assistant Flow" icon="calendar" href="https://github.com/crewAIInc/crewAI-examples/tree/main/flows/meeting_assistant_flow">
|
||||
Notes processing with integrations.
|
||||
</Card>
|
||||
<Card title="Self Evaluation Loop" icon="rotate" href="https://github.com/crewAIInc/crewAI-examples/tree/main/flows/self_evaluation_loop_flow">
|
||||
Iterative self‑improvement workflows.
|
||||
</Card>
|
||||
<Card title="Write a Book (Flows)" icon="book" href="https://github.com/crewAIInc/crewAI-examples/tree/main/flows/write_a_book_with_flows">
|
||||
Parallel chapter generation.
|
||||
</Card>
|
||||
<Card title="Browse all Flows" icon="diagram-project" href="https://github.com/crewAIInc/crewAI-examples/tree/main/flows">
|
||||
See the full list of flow examples.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Integrations
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="CrewAI ↔ LangGraph" icon="link" href="https://github.com/crewAIInc/crewAI-examples/tree/main/integrations/crewai-langgraph">
|
||||
Integration with LangGraph framework.
|
||||
</Card>
|
||||
<Card title="Azure OpenAI" icon="cloud" href="https://github.com/crewAIInc/crewAI-examples/tree/main/integrations/azure_model">
|
||||
Using CrewAI with Azure OpenAI.
|
||||
</Card>
|
||||
<Card title="NVIDIA Models" icon="microchip" href="https://github.com/crewAIInc/crewAI-examples/tree/main/integrations/nvidia_models">
|
||||
NVIDIA ecosystem integrations.
|
||||
</Card>
|
||||
<Card title="Browse Integrations" icon="puzzle-piece" href="https://github.com/crewAIInc/crewAI-examples/tree/main/integrations">
|
||||
See all integration examples.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Notebooks
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Simple QA Crew + Flow" icon="book" href="https://github.com/crewAIInc/crewAI-examples/tree/main/Notebooks/Simple%20QA%20Crew%20%2B%20Flow">
|
||||
Simple QA Crew + Flow.
|
||||
</Card>
|
||||
<Card title="All Notebooks" icon="book" href="https://github.com/crewAIInc/crewAI-examples/tree/main/Notebooks">
|
||||
Interactive examples for learning and experimentation.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
@@ -1,729 +0,0 @@
|
||||
---
|
||||
title: 'Strategic LLM Selection Guide'
|
||||
description: 'Strategic framework for choosing the right LLM for your CrewAI AI agents and writing effective task and agent definitions'
|
||||
icon: 'brain-circuit'
|
||||
---
|
||||
|
||||
## The CrewAI Approach to LLM Selection
|
||||
|
||||
Rather than prescriptive model recommendations, we advocate for a **thinking framework** that helps you make informed decisions based on your specific use case, constraints, and requirements. The LLM landscape evolves rapidly, with new models emerging regularly and existing ones being updated frequently. What matters most is developing a systematic approach to evaluation that remains relevant regardless of which specific models are available.
|
||||
|
||||
<Note>
|
||||
This guide focuses on strategic thinking rather than specific model recommendations, as the LLM landscape evolves rapidly.
|
||||
</Note>
|
||||
|
||||
## Quick Decision Framework
|
||||
|
||||
<Steps>
|
||||
<Step title="Analyze Your Tasks">
|
||||
Begin by deeply understanding what your tasks actually require. Consider the cognitive complexity involved, the depth of reasoning needed, the format of expected outputs, and the amount of context the model will need to process. This foundational analysis will guide every subsequent decision.
|
||||
</Step>
|
||||
<Step title="Map Model Capabilities">
|
||||
Once you understand your requirements, map them to model strengths. Different model families excel at different types of work; some are optimized for reasoning and analysis, others for creativity and content generation, and others for speed and efficiency.
|
||||
</Step>
|
||||
<Step title="Consider Constraints">
|
||||
Factor in your real-world operational constraints including budget limitations, latency requirements, data privacy needs, and infrastructure capabilities. The theoretically best model may not be the practically best choice for your situation.
|
||||
</Step>
|
||||
<Step title="Test and Iterate">
|
||||
Start with reliable, well-understood models and optimize based on actual performance in your specific use case. Real-world results often differ from theoretical benchmarks, so empirical testing is crucial.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Core Selection Framework
|
||||
|
||||
### a. Task-First Thinking
|
||||
|
||||
The most critical step in LLM selection is understanding what your task actually demands. Too often, teams select models based on general reputation or benchmark scores without carefully analyzing their specific requirements. This approach leads to either over-engineering simple tasks with expensive, complex models, or under-powering sophisticated work with models that lack the necessary capabilities.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Reasoning Complexity">
|
||||
- **Simple Tasks** represent the majority of everyday AI work and include basic instruction following, straightforward data processing, and simple formatting operations. These tasks typically have clear inputs and outputs with minimal ambiguity. The cognitive load is low, and the model primarily needs to follow explicit instructions rather than engage in complex reasoning.
|
||||
|
||||
- **Complex Tasks** require multi-step reasoning, strategic thinking, and the ability to handle ambiguous or incomplete information. These might involve analyzing multiple data sources, developing comprehensive strategies, or solving problems that require breaking down into smaller components. The model needs to maintain context across multiple reasoning steps and often must make inferences that aren't explicitly stated.
|
||||
|
||||
- **Creative Tasks** demand a different type of cognitive capability focused on generating novel, engaging, and contextually appropriate content. This includes storytelling, marketing copy creation, and creative problem-solving. The model needs to understand nuance, tone, and audience while producing content that feels authentic and engaging rather than formulaic.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Output Requirements">
|
||||
- **Structured Data** tasks require precision and consistency in format adherence. When working with JSON, XML, or database formats, the model must reliably produce syntactically correct output that can be programmatically processed. These tasks often have strict validation requirements and little tolerance for format errors, making reliability more important than creativity.
|
||||
|
||||
- **Creative Content** outputs demand a balance of technical competence and creative flair. The model needs to understand audience, tone, and brand voice while producing content that engages readers and achieves specific communication goals. Quality here is often subjective and requires models that can adapt their writing style to different contexts and purposes.
|
||||
|
||||
- **Technical Content** sits between structured data and creative content, requiring both precision and clarity. Documentation, code generation, and technical analysis need to be accurate and comprehensive while remaining accessible to the intended audience. The model must understand complex technical concepts and communicate them effectively.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Context Needs">
|
||||
- **Short Context** scenarios involve focused, immediate tasks where the model needs to process limited information quickly. These are often transactional interactions where speed and efficiency matter more than deep understanding. The model doesn't need to maintain extensive conversation history or process large documents.
|
||||
|
||||
- **Long Context** requirements emerge when working with substantial documents, extended conversations, or complex multi-part tasks. The model needs to maintain coherence across thousands of tokens while referencing earlier information accurately. This capability becomes crucial for document analysis, comprehensive research, and sophisticated dialogue systems.
|
||||
|
||||
- **Very Long Context** scenarios push the boundaries of what's currently possible, involving massive document processing, extensive research synthesis, or complex multi-session interactions. These use cases require models specifically designed for extended context handling and often involve trade-offs between context length and processing speed.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### b. Model Capability Mapping
|
||||
|
||||
Understanding model capabilities requires looking beyond marketing claims and benchmark scores to understand the fundamental strengths and limitations of different model architectures and training approaches.
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Reasoning Models" icon="brain">
|
||||
Reasoning models represent a specialized category designed specifically for complex, multi-step thinking tasks. These models excel when problems require careful analysis, strategic planning, or systematic problem decomposition. They typically employ techniques like chain-of-thought reasoning or tree-of-thought processing to work through complex problems step by step.
|
||||
|
||||
The strength of reasoning models lies in their ability to maintain logical consistency across extended reasoning chains and to break down complex problems into manageable components. They're particularly valuable for strategic planning, complex analysis, and situations where the quality of reasoning matters more than speed of response.
|
||||
|
||||
However, reasoning models often come with trade-offs in terms of speed and cost. They may also be less suitable for creative tasks or simple operations where their sophisticated reasoning capabilities aren't needed. Consider these models when your tasks involve genuine complexity that benefits from systematic, step-by-step analysis.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="General Purpose Models" icon="microchip">
|
||||
General purpose models offer the most balanced approach to LLM selection, providing solid performance across a wide range of tasks without extreme specialization in any particular area. These models are trained on diverse datasets and optimized for versatility rather than peak performance in specific domains.
|
||||
|
||||
The primary advantage of general purpose models is their reliability and predictability across different types of work. They handle most standard business tasks competently, from research and analysis to content creation and data processing. This makes them excellent choices for teams that need consistent performance across varied workflows.
|
||||
|
||||
While general purpose models may not achieve the peak performance of specialized alternatives in specific domains, they offer operational simplicity and reduced complexity in model management. They're often the best starting point for new projects, allowing teams to understand their specific needs before potentially optimizing with more specialized models.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Fast & Efficient Models" icon="bolt">
|
||||
Fast and efficient models prioritize speed, cost-effectiveness, and resource efficiency over sophisticated reasoning capabilities. These models are optimized for high-throughput scenarios where quick responses and low operational costs are more important than nuanced understanding or complex reasoning.
|
||||
|
||||
These models excel in scenarios involving routine operations, simple data processing, function calling, and high-volume tasks where the cognitive requirements are relatively straightforward. They're particularly valuable for applications that need to process many requests quickly or operate within tight budget constraints.
|
||||
|
||||
The key consideration with efficient models is ensuring that their capabilities align with your task requirements. While they can handle many routine operations effectively, they may struggle with tasks requiring nuanced understanding, complex reasoning, or sophisticated content generation. They're best used for well-defined, routine operations where speed and cost matter more than sophistication.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Creative Models" icon="pen">
|
||||
Creative models are specifically optimized for content generation, writing quality, and creative thinking tasks. These models typically excel at understanding nuance, tone, and style while producing engaging, contextually appropriate content that feels natural and authentic.
|
||||
|
||||
The strength of creative models lies in their ability to adapt writing style to different audiences, maintain consistent voice and tone, and generate content that engages readers effectively. They often perform better on tasks involving storytelling, marketing copy, brand communications, and other content where creativity and engagement are primary goals.
|
||||
|
||||
When selecting creative models, consider not just their ability to generate text, but their understanding of audience, context, and purpose. The best creative models can adapt their output to match specific brand voices, target different audience segments, and maintain consistency across extended content pieces.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Open Source Models" icon="code">
|
||||
Open source models offer unique advantages in terms of cost control, customization potential, data privacy, and deployment flexibility. These models can be run locally or on private infrastructure, providing complete control over data handling and model behavior.
|
||||
|
||||
The primary benefits of open source models include elimination of per-token costs, ability to fine-tune for specific use cases, complete data privacy, and independence from external API providers. They're particularly valuable for organizations with strict data privacy requirements, budget constraints, or specific customization needs.
|
||||
|
||||
However, open source models require more technical expertise to deploy and maintain effectively. Teams need to consider infrastructure costs, model management complexity, and the ongoing effort required to keep models updated and optimized. The total cost of ownership may be higher than cloud-based alternatives when factoring in technical overhead.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Strategic Configuration Patterns
|
||||
|
||||
### a. Multi-Model Approach
|
||||
|
||||
<Tip>
|
||||
Use different models for different purposes within the same crew to optimize both performance and cost.
|
||||
</Tip>
|
||||
|
||||
The most sophisticated CrewAI implementations often employ multiple models strategically, assigning different models to different agents based on their specific roles and requirements. This approach allows teams to optimize for both performance and cost by using the most appropriate model for each type of work.
|
||||
|
||||
Planning agents benefit from reasoning models that can handle complex strategic thinking and multi-step analysis. These agents often serve as the "brain" of the operation, developing strategies and coordinating other agents' work. Content agents, on the other hand, perform best with creative models that excel at writing quality and audience engagement. Processing agents handling routine operations can use efficient models that prioritize speed and cost-effectiveness.
|
||||
|
||||
**Example: Research and Analysis Crew**
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM
|
||||
|
||||
# High-capability reasoning model for strategic planning
|
||||
manager_llm = LLM(model="gemini-2.5-flash-preview-05-20", temperature=0.1)
|
||||
|
||||
# Creative model for content generation
|
||||
content_llm = LLM(model="claude-3-5-sonnet-20241022", temperature=0.7)
|
||||
|
||||
# Efficient model for data processing
|
||||
processing_llm = LLM(model="gpt-4o-mini", temperature=0)
|
||||
|
||||
research_manager = Agent(
|
||||
role="Research Strategy Manager",
|
||||
goal="Develop comprehensive research strategies and coordinate team efforts",
|
||||
backstory="Expert research strategist with deep analytical capabilities",
|
||||
llm=manager_llm, # High-capability model for complex reasoning
|
||||
verbose=True
|
||||
)
|
||||
|
||||
content_writer = Agent(
|
||||
role="Research Content Writer",
|
||||
goal="Transform research findings into compelling, well-structured reports",
|
||||
backstory="Skilled writer who excels at making complex topics accessible",
|
||||
llm=content_llm, # Creative model for engaging content
|
||||
verbose=True
|
||||
)
|
||||
|
||||
data_processor = Agent(
|
||||
role="Data Analysis Specialist",
|
||||
goal="Extract and organize key data points from research sources",
|
||||
backstory="Detail-oriented analyst focused on accuracy and efficiency",
|
||||
llm=processing_llm, # Fast, cost-effective model for routine tasks
|
||||
verbose=True
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[research_manager, content_writer, data_processor],
|
||||
tasks=[...], # Your specific tasks
|
||||
manager_llm=manager_llm, # Manager uses the reasoning model
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
The key to successful multi-model implementation is understanding how different agents interact and ensuring that model capabilities align with agent responsibilities. This requires careful planning but can result in significant improvements in both output quality and operational efficiency.
|
||||
|
||||
### b. Component-Specific Selection
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Manager LLM">
|
||||
The manager LLM plays a crucial role in hierarchical CrewAI processes, serving as the coordination point for multiple agents and tasks. This model needs to excel at delegation, task prioritization, and maintaining context across multiple concurrent operations.
|
||||
|
||||
Effective manager LLMs require strong reasoning capabilities to make good delegation decisions, consistent performance to ensure predictable coordination, and excellent context management to track the state of multiple agents simultaneously. The model needs to understand the capabilities and limitations of different agents while optimizing task allocation for efficiency and quality.
|
||||
|
||||
Cost considerations are particularly important for manager LLMs since they're involved in every operation. The model needs to provide sufficient capability for effective coordination while remaining cost-effective for frequent use. This often means finding models that offer good reasoning capabilities without the premium pricing of the most sophisticated options.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Function Calling LLM">
|
||||
Function calling LLMs handle tool usage across all agents, making them critical for crews that rely heavily on external tools and APIs. These models need to excel at understanding tool capabilities, extracting parameters accurately, and handling tool responses effectively.
|
||||
|
||||
The most important characteristics for function calling LLMs are precision and reliability rather than creativity or sophisticated reasoning. The model needs to consistently extract the correct parameters from natural language requests and handle tool responses appropriately. Speed is also important since tool usage often involves multiple round trips that can impact overall performance.
|
||||
|
||||
Many teams find that specialized function calling models or general purpose models with strong tool support work better than creative or reasoning-focused models for this role. The key is ensuring that the model can reliably bridge the gap between natural language instructions and structured tool calls.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Agent-Specific Overrides">
|
||||
Individual agents can override crew-level LLM settings when their specific needs differ significantly from the general crew requirements. This capability allows for fine-tuned optimization while maintaining operational simplicity for most agents.
|
||||
|
||||
Consider agent-specific overrides when an agent's role requires capabilities that differ substantially from other crew members. For example, a creative writing agent might benefit from a model optimized for content generation, while a data analysis agent might perform better with a reasoning-focused model.
|
||||
|
||||
The challenge with agent-specific overrides is balancing optimization with operational complexity. Each additional model adds complexity to deployment, monitoring, and cost management. Teams should focus overrides on agents where the performance improvement justifies the additional complexity.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Task Definition Framework
|
||||
|
||||
### a. Focus on Clarity Over Complexity
|
||||
|
||||
Effective task definition is often more important than model selection in determining the quality of CrewAI outputs. Well-defined tasks provide clear direction and context that enable even modest models to perform well, while poorly defined tasks can cause even sophisticated models to produce unsatisfactory results.
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Effective Task Descriptions" icon="list-check">
|
||||
The best task descriptions strike a balance between providing sufficient detail and maintaining clarity. They should define the specific objective clearly enough that there's no ambiguity about what success looks like, while explaining the approach or methodology in enough detail that the agent understands how to proceed.
|
||||
|
||||
Effective task descriptions include relevant context and constraints that help the agent understand the broader purpose and any limitations they need to work within. They break complex work into focused steps that can be executed systematically, rather than presenting overwhelming, multi-faceted objectives that are difficult to approach systematically.
|
||||
|
||||
Common mistakes include being too vague about objectives, failing to provide necessary context, setting unclear success criteria, or combining multiple unrelated tasks into a single description. The goal is to provide enough information for the agent to succeed while maintaining focus on a single, clear objective.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Expected Output Guidelines" icon="bullseye">
|
||||
Expected output guidelines serve as a contract between the task definition and the agent, clearly specifying what the deliverable should look like and how it will be evaluated. These guidelines should describe both the format and structure needed, as well as the key elements that must be included for the output to be considered complete.
|
||||
|
||||
The best output guidelines provide concrete examples of quality indicators and define completion criteria clearly enough that both the agent and human reviewers can assess whether the task has been completed successfully. This reduces ambiguity and helps ensure consistent results across multiple task executions.
|
||||
|
||||
Avoid generic output descriptions that could apply to any task, missing format specifications that leave agents guessing about structure, unclear quality standards that make evaluation difficult, or failing to provide examples or templates that help agents understand expectations.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### b. Task Sequencing Strategy
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Sequential Dependencies">
|
||||
Sequential task dependencies are essential when tasks build upon previous outputs, information flows from one task to another, or quality depends on the completion of prerequisite work. This approach ensures that each task has access to the information and context it needs to succeed.
|
||||
|
||||
Implementing sequential dependencies effectively requires using the context parameter to chain related tasks, building complexity gradually through task progression, and ensuring that each task produces outputs that serve as meaningful inputs for subsequent tasks. The goal is to maintain logical flow between dependent tasks while avoiding unnecessary bottlenecks.
|
||||
|
||||
Sequential dependencies work best when there's a clear logical progression from one task to another and when the output of one task genuinely improves the quality or feasibility of subsequent tasks. However, they can create bottlenecks if not managed carefully, so it's important to identify which dependencies are truly necessary versus those that are merely convenient.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Parallel Execution">
|
||||
Parallel execution becomes valuable when tasks are independent of each other, time efficiency is important, or different expertise areas are involved that don't require coordination. This approach can significantly reduce overall execution time while allowing specialized agents to work on their areas of strength simultaneously.
|
||||
|
||||
Successful parallel execution requires identifying tasks that can truly run independently, grouping related but separate work streams effectively, and planning for result integration when parallel tasks need to be combined into a final deliverable. The key is ensuring that parallel tasks don't create conflicts or redundancies that reduce overall quality.
|
||||
|
||||
Consider parallel execution when you have multiple independent research streams, different types of analysis that don't depend on each other, or content creation tasks that can be developed simultaneously. However, be mindful of resource allocation and ensure that parallel execution doesn't overwhelm your available model capacity or budget.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Optimizing Agent Configuration for LLM Performance
|
||||
|
||||
### a. Role-Driven LLM Selection
|
||||
|
||||
<Warning>
|
||||
Generic agent roles make it impossible to select the right LLM. Specific roles enable targeted model optimization.
|
||||
</Warning>
|
||||
|
||||
The specificity of your agent roles directly determines which LLM capabilities matter most for optimal performance. This creates a strategic opportunity to match precise model strengths with agent responsibilities.
|
||||
|
||||
**Generic vs. Specific Role Impact on LLM Choice:**
|
||||
|
||||
When defining roles, think about the specific domain knowledge, working style, and decision-making frameworks that would be most valuable for the tasks the agent will handle. The more specific and contextual the role definition, the better the model can embody that role effectively.
|
||||
```python
|
||||
# ✅ Specific role - clear LLM requirements
|
||||
specific_agent = Agent(
|
||||
role="SaaS Revenue Operations Analyst", # Clear domain expertise needed
|
||||
goal="Analyze recurring revenue metrics and identify growth opportunities",
|
||||
backstory="Specialist in SaaS business models with deep understanding of ARR, churn, and expansion revenue",
|
||||
llm=LLM(model="gpt-4o") # Reasoning model justified for complex analysis
|
||||
)
|
||||
```
|
||||
|
||||
**Role-to-Model Mapping Strategy:**
|
||||
|
||||
- **"Research Analyst"** → Reasoning model (GPT-4o, Claude Sonnet) for complex analysis
|
||||
- **"Content Editor"** → Creative model (Claude, GPT-4o) for writing quality
|
||||
- **"Data Processor"** → Efficient model (GPT-4o-mini, Gemini Flash) for structured tasks
|
||||
- **"API Coordinator"** → Function-calling optimized model (GPT-4o, Claude) for tool usage
|
||||
|
||||
### b. Backstory as Model Context Amplifier
|
||||
|
||||
<Info>
|
||||
Strategic backstories multiply your chosen LLM's effectiveness by providing domain-specific context that generic prompting cannot achieve.
|
||||
</Info>
|
||||
|
||||
A well-crafted backstory transforms your LLM choice from generic capability to specialized expertise. This is especially crucial for cost optimization - a well-contextualized efficient model can outperform a premium model without proper context.
|
||||
|
||||
**Context-Driven Performance Example:**
|
||||
|
||||
```python
|
||||
# Context amplifies model effectiveness
|
||||
domain_expert = Agent(
|
||||
role="B2B SaaS Marketing Strategist",
|
||||
goal="Develop comprehensive go-to-market strategies for enterprise software",
|
||||
backstory="""
|
||||
You have 10+ years of experience scaling B2B SaaS companies from Series A to IPO.
|
||||
You understand the nuances of enterprise sales cycles, the importance of product-market
|
||||
fit in different verticals, and how to balance growth metrics with unit economics.
|
||||
You've worked with companies like Salesforce, HubSpot, and emerging unicorns, giving
|
||||
you perspective on both established and disruptive go-to-market strategies.
|
||||
""",
|
||||
llm=LLM(model="claude-3-5-sonnet", temperature=0.3) # Balanced creativity with domain knowledge
|
||||
)
|
||||
|
||||
# This context enables Claude to perform like a domain expert
|
||||
# Without it, even it would produce generic marketing advice
|
||||
```
|
||||
|
||||
**Backstory Elements That Enhance LLM Performance:**
|
||||
- **Domain Experience**: "10+ years in enterprise SaaS sales"
|
||||
- **Specific Expertise**: "Specializes in technical due diligence for Series B+ rounds"
|
||||
- **Working Style**: "Prefers data-driven decisions with clear documentation"
|
||||
- **Quality Standards**: "Insists on citing sources and showing analytical work"
|
||||
|
||||
### c. Holistic Agent-LLM Optimization
|
||||
|
||||
The most effective agent configurations create synergy between role specificity, backstory depth, and LLM selection. Each element reinforces the others to maximize model performance.
|
||||
|
||||
**Optimization Framework:**
|
||||
|
||||
```python
|
||||
# Example: Technical Documentation Agent
|
||||
tech_writer = Agent(
|
||||
role="API Documentation Specialist", # Specific role for clear LLM requirements
|
||||
goal="Create comprehensive, developer-friendly API documentation",
|
||||
backstory="""
|
||||
You're a technical writer with 8+ years documenting REST APIs, GraphQL endpoints,
|
||||
and SDK integration guides. You've worked with developer tools companies and
|
||||
understand what developers need: clear examples, comprehensive error handling,
|
||||
and practical use cases. You prioritize accuracy and usability over marketing fluff.
|
||||
""",
|
||||
llm=LLM(
|
||||
model="claude-3-5-sonnet", # Excellent for technical writing
|
||||
temperature=0.1 # Low temperature for accuracy
|
||||
),
|
||||
tools=[code_analyzer_tool, api_scanner_tool],
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
**Alignment Checklist:**
|
||||
- ✅ **Role Specificity**: Clear domain and responsibilities
|
||||
- ✅ **LLM Match**: Model strengths align with role requirements
|
||||
- ✅ **Backstory Depth**: Provides domain context the LLM can leverage
|
||||
- ✅ **Tool Integration**: Tools support the agent's specialized function
|
||||
- ✅ **Parameter Tuning**: Temperature and settings optimize for role needs
|
||||
|
||||
The key is creating agents where every configuration choice reinforces your LLM selection strategy, maximizing performance while optimizing costs.
|
||||
|
||||
## Practical Implementation Checklist
|
||||
|
||||
Rather than repeating the strategic framework, here's a tactical checklist for implementing your LLM selection decisions in CrewAI:
|
||||
|
||||
<Steps>
|
||||
<Step title="Audit Your Current Setup" icon="clipboard-check">
|
||||
**What to Review:**
|
||||
- Are all agents using the same LLM by default?
|
||||
- Which agents handle the most complex reasoning tasks?
|
||||
- Which agents primarily do data processing or formatting?
|
||||
- Are any agents heavily tool-dependent?
|
||||
|
||||
**Action**: Document current agent roles and identify optimization opportunities.
|
||||
</Step>
|
||||
|
||||
<Step title="Implement Crew-Level Strategy" icon="users-gear">
|
||||
**Set Your Baseline:**
|
||||
```python
|
||||
# Start with a reliable default for the crew
|
||||
default_crew_llm = LLM(model="gpt-4o-mini") # Cost-effective baseline
|
||||
|
||||
crew = Crew(
|
||||
agents=[...],
|
||||
tasks=[...],
|
||||
memory=True
|
||||
)
|
||||
```
|
||||
|
||||
**Action**: Establish your crew's default LLM before optimizing individual agents.
|
||||
</Step>
|
||||
|
||||
<Step title="Optimize High-Impact Agents" icon="star">
|
||||
**Identify and Upgrade Key Agents:**
|
||||
```python
|
||||
# Manager or coordination agents
|
||||
manager_agent = Agent(
|
||||
role="Project Manager",
|
||||
llm=LLM(model="gemini-2.5-flash-preview-05-20"), # Premium for coordination
|
||||
# ... rest of config
|
||||
)
|
||||
|
||||
# Creative or customer-facing agents
|
||||
content_agent = Agent(
|
||||
role="Content Creator",
|
||||
llm=LLM(model="claude-3-5-sonnet"), # Best for writing
|
||||
# ... rest of config
|
||||
)
|
||||
```
|
||||
|
||||
**Action**: Upgrade 20% of your agents that handle 80% of the complexity.
|
||||
</Step>
|
||||
|
||||
<Step title="Validate with Enterprise Testing" icon="test-tube">
|
||||
**Once you deploy your agents to production:**
|
||||
- Use [CrewAI Enterprise platform](https://app.crewai.com) to A/B test your model selections
|
||||
- Run multiple iterations with real inputs to measure consistency and performance
|
||||
- Compare cost vs. performance across your optimized setup
|
||||
- Share results with your team for collaborative decision-making
|
||||
|
||||
**Action**: Replace guesswork with data-driven validation using the testing platform.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### When to Use Different Model Types
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Reasoning Models">
|
||||
Reasoning models become essential when tasks require genuine multi-step logical thinking, strategic planning, or high-level decision making that benefits from systematic analysis. These models excel when problems need to be broken down into components and analyzed systematically rather than handled through pattern matching or simple instruction following.
|
||||
|
||||
Consider reasoning models for business strategy development, complex data analysis that requires drawing insights from multiple sources, multi-step problem solving where each step depends on previous analysis, and strategic planning tasks that require considering multiple variables and their interactions.
|
||||
|
||||
However, reasoning models often come with higher costs and slower response times, so they're best reserved for tasks where their sophisticated capabilities provide genuine value rather than being used for simple operations that don't require complex reasoning.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Creative Models">
|
||||
Creative models become valuable when content generation is the primary output and the quality, style, and engagement level of that content directly impact success. These models excel when writing quality and style matter significantly, creative ideation or brainstorming is needed, or brand voice and tone are important considerations.
|
||||
|
||||
Use creative models for blog post writing and article creation, marketing copy that needs to engage and persuade, creative storytelling and narrative development, and brand communications where voice and tone are crucial. These models often understand nuance and context better than general purpose alternatives.
|
||||
|
||||
Creative models may be less suitable for technical or analytical tasks where precision and factual accuracy are more important than engagement and style. They're best used when the creative and communicative aspects of the output are primary success factors.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Efficient Models">
|
||||
Efficient models are ideal for high-frequency, routine operations where speed and cost optimization are priorities. These models work best when tasks have clear, well-defined parameters and don't require sophisticated reasoning or creative capabilities.
|
||||
|
||||
Consider efficient models for data processing and transformation tasks, simple formatting and organization operations, function calling and tool usage where precision matters more than sophistication, and high-volume operations where cost per operation is a significant factor.
|
||||
|
||||
The key with efficient models is ensuring that their capabilities align with task requirements. They can handle many routine operations effectively but may struggle with tasks requiring nuanced understanding, complex reasoning, or sophisticated content generation.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Open Source Models">
|
||||
Open source models become attractive when budget constraints are significant, data privacy requirements exist, customization needs are important, or local deployment is required for operational or compliance reasons.
|
||||
|
||||
Consider open source models for internal company tools where data privacy is paramount, privacy-sensitive applications that can't use external APIs, cost-optimized deployments where per-token pricing is prohibitive, and situations requiring custom model modifications or fine-tuning.
|
||||
|
||||
However, open source models require more technical expertise to deploy and maintain effectively. Consider the total cost of ownership including infrastructure, technical overhead, and ongoing maintenance when evaluating open source options.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Common CrewAI Model Selection Pitfalls
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="The 'One Model Fits All' Trap" icon="triangle-exclamation">
|
||||
**The Problem**: Using the same LLM for all agents in a crew, regardless of their specific roles and responsibilities. This is often the default approach but rarely optimal.
|
||||
|
||||
**Real Example**: Using GPT-4o for both a strategic planning manager and a data extraction agent. The manager needs reasoning capabilities worth the premium cost, but the data extractor could perform just as well with GPT-4o-mini at a fraction of the price.
|
||||
|
||||
**CrewAI Solution**: Leverage agent-specific LLM configuration to match model capabilities with agent roles:
|
||||
```python
|
||||
# Strategic agent gets premium model
|
||||
manager = Agent(role="Strategy Manager", llm=LLM(model="gpt-4o"))
|
||||
|
||||
# Processing agent gets efficient model
|
||||
processor = Agent(role="Data Processor", llm=LLM(model="gpt-4o-mini"))
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Ignoring Crew-Level vs Agent-Level LLM Hierarchy" icon="shuffle">
|
||||
**The Problem**: Not understanding how CrewAI's LLM hierarchy works - crew LLM, manager LLM, and agent LLM settings can conflict or be poorly coordinated.
|
||||
|
||||
**Real Example**: Setting a crew to use Claude, but having agents configured with GPT models, creating inconsistent behavior and unnecessary model switching overhead.
|
||||
|
||||
**CrewAI Solution**: Plan your LLM hierarchy strategically:
|
||||
```python
|
||||
crew = Crew(
|
||||
agents=[agent1, agent2],
|
||||
tasks=[task1, task2],
|
||||
manager_llm=LLM(model="gpt-4o"), # For crew coordination
|
||||
process=Process.hierarchical # When using manager_llm
|
||||
)
|
||||
|
||||
# Agents inherit crew LLM unless specifically overridden
|
||||
agent1 = Agent(llm=LLM(model="claude-3-5-sonnet")) # Override for specific needs
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Function Calling Model Mismatch" icon="screwdriver-wrench">
|
||||
**The Problem**: Choosing models based on general capabilities while ignoring function calling performance for tool-heavy CrewAI workflows.
|
||||
|
||||
**Real Example**: Selecting a creative-focused model for an agent that primarily needs to call APIs, search tools, or process structured data. The agent struggles with tool parameter extraction and reliable function calls.
|
||||
|
||||
**CrewAI Solution**: Prioritize function calling capabilities for tool-heavy agents:
|
||||
```python
|
||||
# For agents that use many tools
|
||||
tool_agent = Agent(
|
||||
role="API Integration Specialist",
|
||||
tools=[search_tool, api_tool, data_tool],
|
||||
llm=LLM(model="gpt-4o"), # Excellent function calling
|
||||
# OR
|
||||
llm=LLM(model="claude-3-5-sonnet") # Also strong with tools
|
||||
)
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Premature Optimization Without Testing" icon="gear">
|
||||
**The Problem**: Making complex model selection decisions based on theoretical performance without validating with actual CrewAI workflows and tasks.
|
||||
|
||||
**Real Example**: Implementing elaborate model switching logic based on task types without testing if the performance gains justify the operational complexity.
|
||||
|
||||
**CrewAI Solution**: Start simple, then optimize based on real performance data:
|
||||
```python
|
||||
# Start with this
|
||||
crew = Crew(agents=[...], tasks=[...], llm=LLM(model="gpt-4o-mini"))
|
||||
|
||||
# Test performance, then optimize specific agents as needed
|
||||
# Use Enterprise platform testing to validate improvements
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Overlooking Context and Memory Limitations" icon="brain">
|
||||
**The Problem**: Not considering how model context windows interact with CrewAI's memory and context sharing between agents.
|
||||
|
||||
**Real Example**: Using a short-context model for agents that need to maintain conversation history across multiple task iterations, or in crews with extensive agent-to-agent communication.
|
||||
|
||||
**CrewAI Solution**: Match context capabilities to crew communication patterns.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## Testing and Iteration Strategy
|
||||
|
||||
<Steps>
|
||||
<Step title="Start Simple" icon="play">
|
||||
Begin with reliable, general-purpose models that are well-understood and widely supported. This provides a stable foundation for understanding your specific requirements and performance expectations before optimizing for specialized needs.
|
||||
</Step>
|
||||
<Step title="Measure What Matters" icon="chart-line">
|
||||
Develop metrics that align with your specific use case and business requirements rather than relying solely on general benchmarks. Focus on measuring outcomes that directly impact your success rather than theoretical performance indicators.
|
||||
</Step>
|
||||
<Step title="Iterate Based on Results" icon="arrows-rotate">
|
||||
Make model changes based on observed performance in your specific context rather than theoretical considerations or general recommendations. Real-world performance often differs significantly from benchmark results or general reputation.
|
||||
</Step>
|
||||
<Step title="Consider Total Cost" icon="calculator">
|
||||
Evaluate the complete cost of ownership including model costs, development time, maintenance overhead, and operational complexity. The cheapest model per token may not be the most cost-effective choice when considering all factors.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<Tip>
|
||||
Focus on understanding your requirements first, then select models that best match those needs. The best LLM choice is the one that consistently delivers the results you need within your operational constraints.
|
||||
</Tip>
|
||||
|
||||
### Enterprise-Grade Model Validation
|
||||
|
||||
For teams serious about optimizing their LLM selection, the **CrewAI Enterprise platform** provides sophisticated testing capabilities that go far beyond basic CLI testing. The platform enables comprehensive model evaluation that helps you make data-driven decisions about your LLM strategy.
|
||||
|
||||
<Frame>
|
||||

|
||||
</Frame>
|
||||
|
||||
**Advanced Testing Features:**
|
||||
|
||||
- **Multi-Model Comparison**: Test multiple LLMs simultaneously across the same tasks and inputs. Compare performance between GPT-4o, Claude, Llama, Groq, Cerebras, and other leading models in parallel to identify the best fit for your specific use case.
|
||||
|
||||
- **Statistical Rigor**: Configure multiple iterations with consistent inputs to measure reliability and performance variance. This helps identify models that not only perform well but do so consistently across runs.
|
||||
|
||||
- **Real-World Validation**: Use your actual crew inputs and scenarios rather than synthetic benchmarks. The platform allows you to test with your specific industry context, company information, and real use cases for more accurate evaluation.
|
||||
|
||||
- **Comprehensive Analytics**: Access detailed performance metrics, execution times, and cost analysis across all tested models. This enables data-driven decision making rather than relying on general model reputation or theoretical capabilities.
|
||||
|
||||
- **Team Collaboration**: Share testing results and model performance data across your team, enabling collaborative decision-making and consistent model selection strategies across projects.
|
||||
|
||||
Go to [app.crewai.com](https://app.crewai.com) to get started!
|
||||
|
||||
<Info>
|
||||
The Enterprise platform transforms model selection from guesswork into a data-driven process, enabling you to validate the principles in this guide with your actual use cases and requirements.
|
||||
</Info>
|
||||
|
||||
## Key Principles Summary
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Task-Driven Selection" icon="bullseye">
|
||||
Choose models based on what the task actually requires, not theoretical capabilities or general reputation.
|
||||
</Card>
|
||||
|
||||
<Card title="Capability Matching" icon="puzzle-piece">
|
||||
Align model strengths with agent roles and responsibilities for optimal performance.
|
||||
</Card>
|
||||
|
||||
<Card title="Strategic Consistency" icon="link">
|
||||
Maintain coherent model selection strategy across related components and workflows.
|
||||
</Card>
|
||||
|
||||
<Card title="Practical Testing" icon="flask">
|
||||
Validate choices through real-world usage rather than benchmarks alone.
|
||||
</Card>
|
||||
|
||||
<Card title="Iterative Improvement" icon="arrow-up">
|
||||
Start simple and optimize based on actual performance and needs.
|
||||
</Card>
|
||||
|
||||
<Card title="Operational Balance" icon="scale-balanced">
|
||||
Balance performance requirements with cost and complexity constraints.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
<Check>
|
||||
Remember: The best LLM choice is the one that consistently delivers the results you need within your operational constraints. Focus on understanding your requirements first, then select models that best match those needs.
|
||||
</Check>
|
||||
|
||||
## Current Model Landscape (June 2025)
|
||||
|
||||
<Warning>
|
||||
**Snapshot in Time**: The following model rankings represent current leaderboard standings as of June 2025, compiled from [LMSys Arena](https://arena.lmsys.org/), [Artificial Analysis](https://artificialanalysis.ai/), and other leading benchmarks. LLM performance, availability, and pricing change rapidly. Always conduct your own evaluations with your specific use cases and data.
|
||||
</Warning>
|
||||
|
||||
### Leading Models by Category
|
||||
|
||||
The tables below show a representative sample of current top-performing models across different categories, with guidance on their suitability for CrewAI agents:
|
||||
|
||||
<Note>
|
||||
These tables/metrics showcase selected leading models in each category and are not exhaustive. Many excellent models exist beyond those listed here. The goal is to illustrate the types of capabilities to look for rather than provide a complete catalog.
|
||||
</Note>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Reasoning & Planning">
|
||||
**Best for Manager LLMs and Complex Analysis**
|
||||
|
||||
| Model | Intelligence Score | Cost ($/M tokens) | Speed | Best Use in CrewAI |
|
||||
|:------|:------------------|:------------------|:------|:------------------|
|
||||
| **o3** | 70 | $17.50 | Fast | Manager LLM for complex multi-agent coordination |
|
||||
| **Gemini 2.5 Pro** | 69 | $3.44 | Fast | Strategic planning agents, research coordination |
|
||||
| **DeepSeek R1** | 68 | $0.96 | Moderate | Cost-effective reasoning for budget-conscious crews |
|
||||
| **Claude 4 Sonnet** | 53 | $6.00 | Fast | Analysis agents requiring nuanced understanding |
|
||||
| **Qwen3 235B (Reasoning)** | 62 | $2.63 | Moderate | Open-source alternative for reasoning tasks |
|
||||
|
||||
These models excel at multi-step reasoning and are ideal for agents that need to develop strategies, coordinate other agents, or analyze complex information.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Coding & Technical">
|
||||
**Best for Development and Tool-Heavy Workflows**
|
||||
|
||||
| Model | Coding Performance | Tool Use Score | Cost ($/M tokens) | Best Use in CrewAI |
|
||||
|:------|:------------------|:---------------|:------------------|:------------------|
|
||||
| **Claude 4 Sonnet** | Excellent | 72.7% | $6.00 | Primary coding agent, technical documentation |
|
||||
| **Claude 4 Opus** | Excellent | 72.5% | $30.00 | Complex software architecture, code review |
|
||||
| **DeepSeek V3** | Very Good | High | $0.48 | Cost-effective coding for routine development |
|
||||
| **Qwen2.5 Coder 32B** | Very Good | Medium | $0.15 | Budget-friendly coding agent |
|
||||
| **Llama 3.1 405B** | Good | 81.1% | $3.50 | Function calling LLM for tool-heavy workflows |
|
||||
|
||||
These models are optimized for code generation, debugging, and technical problem-solving, making them ideal for development-focused crews.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Speed & Efficiency">
|
||||
**Best for High-Throughput and Real-Time Applications**
|
||||
|
||||
| Model | Speed (tokens/s) | Latency (TTFT) | Cost ($/M tokens) | Best Use in CrewAI |
|
||||
|:------|:-----------------|:---------------|:------------------|:------------------|
|
||||
| **Llama 4 Scout** | 2,600 | 0.33s | $0.27 | High-volume processing agents |
|
||||
| **Gemini 2.5 Flash** | 376 | 0.30s | $0.26 | Real-time response agents |
|
||||
| **DeepSeek R1 Distill** | 383 | Variable | $0.04 | Cost-optimized high-speed processing |
|
||||
| **Llama 3.3 70B** | 2,500 | 0.52s | $0.60 | Balanced speed and capability |
|
||||
| **Nova Micro** | High | 0.30s | $0.04 | Simple, fast task execution |
|
||||
|
||||
These models prioritize speed and efficiency, perfect for agents handling routine operations or requiring quick responses. **Pro tip**: Pairing these models with fast inference providers like Groq can achieve even better performance, especially for open-source models like Llama.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Balanced Performance">
|
||||
**Best All-Around Models for General Crews**
|
||||
|
||||
| Model | Overall Score | Versatility | Cost ($/M tokens) | Best Use in CrewAI |
|
||||
|:------|:--------------|:------------|:------------------|:------------------|
|
||||
| **GPT-4.1** | 53 | Excellent | $3.50 | General-purpose crew LLM |
|
||||
| **Claude 3.7 Sonnet** | 48 | Very Good | $6.00 | Balanced reasoning and creativity |
|
||||
| **Gemini 2.0 Flash** | 48 | Good | $0.17 | Cost-effective general use |
|
||||
| **Llama 4 Maverick** | 51 | Good | $0.37 | Open-source general purpose |
|
||||
| **Qwen3 32B** | 44 | Good | $1.23 | Budget-friendly versatility |
|
||||
|
||||
These models offer good performance across multiple dimensions, suitable for crews with diverse task requirements.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### Selection Framework for Current Models
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="High-Performance Crews" icon="rocket">
|
||||
**When performance is the priority**: Use top-tier models like **o3**, **Gemini 2.5 Pro**, or **Claude 4 Sonnet** for manager LLMs and critical agents. These models excel at complex reasoning and coordination but come with higher costs.
|
||||
|
||||
**Strategy**: Implement a multi-model approach where premium models handle strategic thinking while efficient models handle routine operations.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Cost-Conscious Crews" icon="dollar-sign">
|
||||
**When budget is a primary constraint**: Focus on models like **DeepSeek R1**, **Llama 4 Scout**, or **Gemini 2.0 Flash**. These provide strong performance at significantly lower costs.
|
||||
|
||||
**Strategy**: Use cost-effective models for most agents, reserving premium models only for the most critical decision-making roles.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Specialized Workflows" icon="screwdriver-wrench">
|
||||
**For specific domain expertise**: Choose models optimized for your primary use case. **Claude 4** series for coding, **Gemini 2.5 Pro** for research, **Llama 405B** for function calling.
|
||||
|
||||
**Strategy**: Select models based on your crew's primary function, ensuring the core capability aligns with model strengths.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Enterprise & Privacy" icon="shield">
|
||||
**For data-sensitive operations**: Consider open-source models like **Llama 4** series, **DeepSeek V3**, or **Qwen3** that can be deployed locally while maintaining competitive performance.
|
||||
|
||||
**Strategy**: Deploy open-source models on private infrastructure, accepting potential performance trade-offs for data control.
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
### Key Considerations for Model Selection
|
||||
|
||||
- **Performance Trends**: The current landscape shows strong competition between reasoning-focused models (o3, Gemini 2.5 Pro) and balanced models (Claude 4, GPT-4.1). Specialized models like DeepSeek R1 offer excellent cost-performance ratios.
|
||||
|
||||
- **Speed vs. Intelligence Trade-offs**: Models like Llama 4 Scout prioritize speed (2,600 tokens/s) while maintaining reasonable intelligence, whereas models like o3 maximize reasoning capability at the cost of speed and price.
|
||||
|
||||
- **Open Source Viability**: The gap between open-source and proprietary models continues to narrow, with models like Llama 4 Maverick and DeepSeek V3 offering competitive performance at attractive price points. Fast inference providers particularly shine with open-source models, often delivering better speed-to-cost ratios than proprietary alternatives.
|
||||
|
||||
<Info>
|
||||
**Testing is Essential**: Leaderboard rankings provide general guidance, but your specific use case, prompting style, and evaluation criteria may produce different results. Always test candidate models with your actual tasks and data before making final decisions.
|
||||
</Info>
|
||||
|
||||
### Practical Implementation Strategy
|
||||
|
||||
<Steps>
|
||||
<Step title="Start with Proven Models">
|
||||
Begin with well-established models like **GPT-4.1**, **Claude 3.7 Sonnet**, or **Gemini 2.0 Flash** that offer good performance across multiple dimensions and have extensive real-world validation.
|
||||
</Step>
|
||||
|
||||
<Step title="Identify Specialized Needs">
|
||||
Determine if your crew has specific requirements (coding, reasoning, speed) that would benefit from specialized models like **Claude 4 Sonnet** for development or **o3** for complex analysis. For speed-critical applications, consider fast inference providers like **Groq** alongside model selection.
|
||||
</Step>
|
||||
|
||||
<Step title="Implement Multi-Model Strategy">
|
||||
Use different models for different agents based on their roles. High-capability models for managers and complex tasks, efficient models for routine operations.
|
||||
</Step>
|
||||
|
||||
<Step title="Monitor and Optimize">
|
||||
Track performance metrics relevant to your use case and be prepared to adjust model selections as new models are released or pricing changes.
|
||||
</Step>
|
||||
</Steps>
|
||||
@@ -1,286 +0,0 @@
|
||||
---
|
||||
title: LangDB Integration
|
||||
description: Govern, secure, and optimize your CrewAI workflows with LangDB AI Gateway—access 350+ models, automatic routing, cost optimization, and full observability.
|
||||
icon: database
|
||||
---
|
||||
|
||||
# Introduction
|
||||
|
||||
[LangDB AI Gateway](https://langdb.ai) provides OpenAI-compatible APIs to connect with multiple Large Language Models and serves as an observability platform that makes it effortless to trace CrewAI workflows end-to-end while providing access to 350+ language models. With a single `init()` call, all agent interactions, task executions, and LLM calls are captured, providing comprehensive observability and production-ready AI infrastructure for your applications.
|
||||
|
||||
<Frame caption="LangDB CrewAI Trace Example">
|
||||
<img src="/images/langdb-1.png" alt="LangDB CrewAI trace example" />
|
||||
</Frame>
|
||||
|
||||
**Checkout:** [View the live trace example](https://app.langdb.ai/sharing/threads/3becbfed-a1be-ae84-ea3c-4942867a3e22)
|
||||
|
||||
## Features
|
||||
|
||||
### AI Gateway Capabilities
|
||||
- **Access to 350+ LLMs**: Connect to all major language models through a single integration
|
||||
- **Virtual Models**: Create custom model configurations with specific parameters and routing rules
|
||||
- **Virtual MCP**: Enable compatibility and integration with MCP (Model Context Protocol) systems for enhanced agent communication
|
||||
- **Guardrails**: Implement safety measures and compliance controls for agent behavior
|
||||
|
||||
### Observability & Tracing
|
||||
- **Automatic Tracing**: Single `init()` call captures all CrewAI interactions
|
||||
- **End-to-End Visibility**: Monitor agent workflows from start to finish
|
||||
- **Tool Usage Tracking**: Track which tools agents use and their outcomes
|
||||
- **Model Call Monitoring**: Detailed insights into LLM interactions
|
||||
- **Performance Analytics**: Monitor latency, token usage, and costs
|
||||
- **Debugging Support**: Step-through execution for troubleshooting
|
||||
- **Real-time Monitoring**: Live traces and metrics dashboard
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Install LangDB">
|
||||
Install the LangDB client with CrewAI feature flag:
|
||||
```bash
|
||||
pip install 'pylangdb[crewai]'
|
||||
```
|
||||
</Step>
|
||||
<Step title="Set Environment Variables">
|
||||
Configure your LangDB credentials:
|
||||
```bash
|
||||
export LANGDB_API_KEY="<your_langdb_api_key>"
|
||||
export LANGDB_PROJECT_ID="<your_langdb_project_id>"
|
||||
export LANGDB_API_BASE_URL='https://api.us-east-1.langdb.ai'
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize Tracing">
|
||||
Import and initialize LangDB before configuring your CrewAI code:
|
||||
```python
|
||||
from pylangdb.crewai import init
|
||||
# Initialize LangDB
|
||||
init()
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure CrewAI with LangDB">
|
||||
Set up your LLM with LangDB headers:
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM
|
||||
import os
|
||||
|
||||
# Configure LLM with LangDB headers
|
||||
llm = LLM(
|
||||
model="openai/gpt-4o", # Replace with the model you want to use
|
||||
api_key=os.getenv("LANGDB_API_KEY"),
|
||||
base_url=os.getenv("LANGDB_API_BASE_URL"),
|
||||
extra_headers={"x-project-id": os.getenv("LANGDB_PROJECT_ID")}
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Quick Start Example
|
||||
|
||||
Here's a simple example to get you started with LangDB and CrewAI:
|
||||
|
||||
```python
|
||||
import os
|
||||
from pylangdb.crewai import init
|
||||
from crewai import Agent, Task, Crew, LLM
|
||||
|
||||
# Initialize LangDB before any CrewAI imports
|
||||
init()
|
||||
|
||||
def create_llm(model):
|
||||
return LLM(
|
||||
model=model,
|
||||
api_key=os.environ.get("LANGDB_API_KEY"),
|
||||
base_url=os.environ.get("LANGDB_API_BASE_URL"),
|
||||
extra_headers={"x-project-id": os.environ.get("LANGDB_PROJECT_ID")}
|
||||
)
|
||||
|
||||
# Define your agent
|
||||
researcher = Agent(
|
||||
role="Research Specialist",
|
||||
goal="Research topics thoroughly",
|
||||
backstory="Expert researcher with skills in finding information",
|
||||
llm=create_llm("openai/gpt-4o"), # Replace with the model you want to use
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Create a task
|
||||
task = Task(
|
||||
description="Research the given topic and provide a comprehensive summary",
|
||||
agent=researcher,
|
||||
expected_output="Detailed research summary with key findings"
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[researcher], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
|
||||
## Complete Example: Research and Planning Agent
|
||||
|
||||
This comprehensive example demonstrates a multi-agent workflow with research and planning capabilities.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
```bash
|
||||
pip install crewai 'pylangdb[crewai]' crewai_tools setuptools python-dotenv
|
||||
```
|
||||
|
||||
### Environment Setup
|
||||
|
||||
```bash
|
||||
# LangDB credentials
|
||||
export LANGDB_API_KEY="<your_langdb_api_key>"
|
||||
export LANGDB_PROJECT_ID="<your_langdb_project_id>"
|
||||
export LANGDB_API_BASE_URL='https://api.us-east-1.langdb.ai'
|
||||
|
||||
# Additional API keys (optional)
|
||||
export SERPER_API_KEY="<your_serper_api_key>" # For web search capabilities
|
||||
```
|
||||
|
||||
### Complete Implementation
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import os
|
||||
import sys
|
||||
from pylangdb.crewai import init
|
||||
init() # Initialize LangDB before any CrewAI imports
|
||||
from dotenv import load_dotenv
|
||||
from crewai import Agent, Task, Crew, Process, LLM
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
load_dotenv()
|
||||
|
||||
def create_llm(model):
|
||||
return LLM(
|
||||
model=model,
|
||||
api_key=os.environ.get("LANGDB_API_KEY"),
|
||||
base_url=os.environ.get("LANGDB_API_BASE_URL"),
|
||||
extra_headers={"x-project-id": os.environ.get("LANGDB_PROJECT_ID")}
|
||||
)
|
||||
|
||||
class ResearchPlanningCrew:
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
role="Research Specialist",
|
||||
goal="Research topics thoroughly and compile comprehensive information",
|
||||
backstory="Expert researcher with skills in finding and analyzing information from various sources",
|
||||
tools=[SerperDevTool()],
|
||||
llm=create_llm("openai/gpt-4o"),
|
||||
verbose=True
|
||||
)
|
||||
|
||||
def planner(self) -> Agent:
|
||||
return Agent(
|
||||
role="Strategic Planner",
|
||||
goal="Create actionable plans based on research findings",
|
||||
backstory="Strategic planner who breaks down complex challenges into executable plans",
|
||||
reasoning=True,
|
||||
max_reasoning_attempts=3,
|
||||
llm=create_llm("openai/anthropic/claude-3.7-sonnet"),
|
||||
verbose=True
|
||||
)
|
||||
|
||||
def research_task(self) -> Task:
|
||||
return Task(
|
||||
description="Research the topic thoroughly and compile comprehensive information",
|
||||
agent=self.researcher(),
|
||||
expected_output="Comprehensive research report with key findings and insights"
|
||||
)
|
||||
|
||||
def planning_task(self) -> Task:
|
||||
return Task(
|
||||
description="Create a strategic plan based on the research findings",
|
||||
agent=self.planner(),
|
||||
expected_output="Strategic execution plan with phases, goals, and actionable steps",
|
||||
context=[self.research_task()]
|
||||
)
|
||||
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[self.researcher(), self.planner()],
|
||||
tasks=[self.research_task(), self.planning_task()],
|
||||
verbose=True,
|
||||
process=Process.sequential
|
||||
)
|
||||
|
||||
def main():
|
||||
topic = sys.argv[1] if len(sys.argv) > 1 else "Artificial Intelligence in Healthcare"
|
||||
|
||||
crew_instance = ResearchPlanningCrew()
|
||||
|
||||
# Update task descriptions with the specific topic
|
||||
crew_instance.research_task().description = f"Research {topic} thoroughly and compile comprehensive information"
|
||||
crew_instance.planning_task().description = f"Create a strategic plan for {topic} based on the research findings"
|
||||
|
||||
result = crew_instance.crew().kickoff()
|
||||
print(result)
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
### Running the Example
|
||||
|
||||
```bash
|
||||
python main.py "Sustainable Energy Solutions"
|
||||
```
|
||||
|
||||
## Viewing Traces in LangDB
|
||||
|
||||
After running your CrewAI application, you can view detailed traces in the LangDB dashboard:
|
||||
|
||||
<Frame caption="LangDB Trace Dashboard">
|
||||
<img src="/images/langdb-2.png" alt="LangDB trace dashboard showing CrewAI workflow" />
|
||||
</Frame>
|
||||
|
||||
### What You'll See
|
||||
|
||||
- **Agent Interactions**: Complete flow of agent conversations and task handoffs
|
||||
- **Tool Usage**: Which tools were called, their inputs, and outputs
|
||||
- **Model Calls**: Detailed LLM interactions with prompts image.pngand responses
|
||||
- **Performance Metrics**: Latency, token usage, and cost tracking
|
||||
- **Execution Timeline**: Step-by-step view of the entire workflow
|
||||
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
- **No traces appearing**: Ensure `init()` is called before any CrewAI imports
|
||||
- **Authentication errors**: Verify your LangDB API key and project ID
|
||||
|
||||
|
||||
## Resources
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="LangDB Documentation" icon="book" href="https://docs.langdb.ai">
|
||||
Official LangDB documentation and guides
|
||||
</Card>
|
||||
<Card title="LangDB Guides" icon="graduation-cap" href="https://docs.langdb.ai/guides">
|
||||
Step-by-step tutorials for building AI agents
|
||||
</Card>
|
||||
<Card title="GitHub Examples" icon="github" href="https://github.com/langdb/langdb-samples/tree/main/examples/crewai" >
|
||||
Complete CrewAI integration examples
|
||||
</Card>
|
||||
<Card title="LangDB Dashboard" icon="chart-line" href="https://app.langdb.ai">
|
||||
Access your traces and analytics
|
||||
</Card>
|
||||
<Card title="Model Catalog" icon="list" href="https://app.langdb.ai/models">
|
||||
Browse 350+ available language models
|
||||
</Card>
|
||||
<Card title="Enterprise Features" icon="building" href="https://docs.langdb.ai/enterprise">
|
||||
Self-hosted options and enterprise capabilities
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Next Steps
|
||||
|
||||
This guide covered the basics of integrating LangDB AI Gateway with CrewAI. To further enhance your AI workflows, explore:
|
||||
|
||||
- **Virtual Models**: Create custom model configurations with routing strategies
|
||||
- **Guardrails & Safety**: Implement content filtering and compliance controls
|
||||
- **Production Deployment**: Configure fallbacks, retries, and load balancing
|
||||
|
||||
For more advanced features and use cases, visit the [LangDB Documentation](https://docs.langdb.ai) or explore the [Model Catalog](https://app.langdb.ai/models) to discover all available models.
|
||||
@@ -1,231 +0,0 @@
|
||||
---
|
||||
title: "Maxim Integration"
|
||||
description: "Start Agent monitoring, evaluation, and observability"
|
||||
icon: "infinity"
|
||||
---
|
||||
|
||||
# Maxim Overview
|
||||
|
||||
Maxim AI provides comprehensive agent monitoring, evaluation, and observability for your CrewAI applications. With Maxim's one-line integration, you can easily trace and analyse agent interactions, performance metrics, and more.
|
||||
|
||||
## Features
|
||||
|
||||
### Prompt Management
|
||||
|
||||
Maxim's Prompt Management capabilities enable you to create, organize, and optimize prompts for your CrewAI agents. Rather than hardcoding instructions, leverage Maxim’s SDK to dynamically retrieve and apply version-controlled prompts.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Prompt Playground">
|
||||
Create, refine, experiment and deploy your prompts via the playground. Organize of your prompts using folders and versions, experimenting with the real world cases by linking tools and context, and deploying based on custom logic.
|
||||
|
||||
Easily experiment across models by [**configuring models**](https://www.getmaxim.ai/docs/introduction/quickstart/setting-up-workspace#add-model-api-keys) and selecting the relevant model from the dropdown at the top of the prompt playground.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_playground.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="Prompt Versions">
|
||||
As teams build their AI applications, a big part of experimentation is iterating on the prompt structure. In order to collaborate effectively and organize your changes clearly, Maxim allows prompt versioning and comparison runs across versions.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_versions.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="Prompt Comparisons">
|
||||
Iterating on Prompts as you evolve your AI application would need experiments across models, prompt structures, etc. In order to compare versions and make informed decisions about changes, the comparison playground allows a side by side view of results.
|
||||
|
||||
## **Why use Prompt comparison?**
|
||||
|
||||
Prompt comparison combines multiple single Prompts into one view, enabling a streamlined approach for various workflows:
|
||||
|
||||
1. **Model comparison**: Evaluate the performance of different models on the same Prompt.
|
||||
2. **Prompt optimization**: Compare different versions of a Prompt to identify the most effective formulation.
|
||||
3. **Cross-Model consistency**: Ensure consistent outputs across various models for the same Prompt.
|
||||
4. **Performance benchmarking**: Analyze metrics like latency, cost, and token count across different models and Prompts.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### Observability & Evals
|
||||
|
||||
Maxim AI provides comprehensive observability & evaluation for your CrewAI agents, helping you understand exactly what's happening during each execution.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Agent Tracing">
|
||||
Track your agent’s complete lifecycle, including tool calls, agent trajectories, and decision flows effortlessly.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_agent_tracking.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="Analytics + Evals">
|
||||
Run detailed evaluations on full traces or individual nodes with support for:
|
||||
|
||||
- Multi-step interactions and granular trace analysis
|
||||
- Session Level Evaluations
|
||||
- Simulations for real-world testing
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_trace_eval.png'> </img>
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="Auto Evals on Logs" icon="e" href="https://www.getmaxim.ai/docs/observe/how-to/evaluate-logs/auto-evaluation">
|
||||
<p>
|
||||
Evaluate captured logs automatically from the UI based on filters and sampling
|
||||
|
||||
</p>
|
||||
</Card>
|
||||
<Card title="Human Evals on Logs" icon="hand" href="https://www.getmaxim.ai/docs/observe/how-to/evaluate-logs/human-evaluation">
|
||||
<p>
|
||||
Use human evaluation or rating to assess the quality of your logs and evaluate them.
|
||||
|
||||
</p>
|
||||
</Card>
|
||||
<Card title="Node Level Evals" icon="road" href="https://www.getmaxim.ai/docs/observe/how-to/evaluate-logs/node-level-evaluation">
|
||||
<p>
|
||||
Evaluate any component of your trace or log to gain insights into your agent’s behavior.
|
||||
|
||||
</p>
|
||||
</Card>
|
||||
</CardGroup>
|
||||
---
|
||||
</Tab>
|
||||
<Tab title="Alerting">
|
||||
Set thresholds on **error**, **cost, token usage, user feedback, latency** and get real-time alerts via Slack or PagerDuty.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_alerts_1.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="Dashboards">
|
||||
Visualize Traces over time, usage metrics, latency & error rates with ease.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_dashboard_1.png'> </img>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Getting Started
|
||||
|
||||
### Prerequisites
|
||||
|
||||
|
||||
- Python version \>=3.10
|
||||
- A Maxim account ([sign up here](https://getmaxim.ai/))
|
||||
- Generate Maxim API Key
|
||||
- A CrewAI project
|
||||
|
||||
### Installation
|
||||
|
||||
Install the Maxim SDK via pip:
|
||||
|
||||
```python
|
||||
pip install maxim-py
|
||||
```
|
||||
|
||||
Or add it to your `requirements.txt`:
|
||||
|
||||
```
|
||||
maxim-py
|
||||
```
|
||||
### Basic Setup
|
||||
|
||||
### 1. Set up environment variables
|
||||
|
||||
```python
|
||||
### Environment Variables Setup
|
||||
|
||||
# Create a `.env` file in your project root:
|
||||
|
||||
# Maxim API Configuration
|
||||
MAXIM_API_KEY=your_api_key_here
|
||||
MAXIM_LOG_REPO_ID=your_repo_id_here
|
||||
```
|
||||
|
||||
### 2. Import the required packages
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
from maxim import Maxim
|
||||
from maxim.logger.crewai import instrument_crewai
|
||||
```
|
||||
|
||||
### 3. Initialise Maxim with your API key
|
||||
|
||||
|
||||
```python {8}
|
||||
# Instrument CrewAI with just one line
|
||||
instrument_crewai(Maxim().logger())
|
||||
```
|
||||
|
||||
### 4. Create and run your CrewAI application as usual
|
||||
|
||||
```python
|
||||
# Create your agent
|
||||
researcher = Agent(
|
||||
role='Senior Research Analyst',
|
||||
goal='Uncover cutting-edge developments in AI',
|
||||
backstory="You are an expert researcher at a tech think tank...",
|
||||
verbose=True,
|
||||
llm=llm
|
||||
)
|
||||
|
||||
# Define the task
|
||||
research_task = Task(
|
||||
description="Research the latest AI advancements...",
|
||||
expected_output="",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
# Configure and run the crew
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[research_task],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
try:
|
||||
result = crew.kickoff()
|
||||
finally:
|
||||
maxim.cleanup() # Ensure cleanup happens even if errors occur
|
||||
```
|
||||
|
||||
|
||||
That's it\! All your CrewAI agent interactions will now be logged and available in your Maxim dashboard.
|
||||
|
||||
Check this Google Colab Notebook for a quick reference - [Notebook](https://colab.research.google.com/drive/1ZKIZWsmgQQ46n8TH9zLsT1negKkJA6K8?usp=sharing)
|
||||
|
||||
## Viewing Your Traces
|
||||
|
||||
After running your CrewAI application:
|
||||
|
||||
1. Log in to your [Maxim Dashboard](https://app.getmaxim.ai/login)
|
||||
2. Navigate to your repository
|
||||
3. View detailed agent traces, including:
|
||||
- Agent conversations
|
||||
- Tool usage patterns
|
||||
- Performance metrics
|
||||
- Cost analytics
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/crewai_traces.gif'> </img>
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
- **No traces appearing**: Ensure your API key and repository ID are correct
|
||||
- Ensure you've **`called instrument_crewai()`** **_before_** running your crew. This initializes logging hooks correctly.
|
||||
- Set `debug=True` in your `instrument_crewai()` call to surface any internal errors:
|
||||
|
||||
```python
|
||||
instrument_crewai(logger, debug=True)
|
||||
```
|
||||
- Configure your agents with `verbose=True` to capture detailed logs:
|
||||
|
||||
```python
|
||||
agent = CrewAgent(..., verbose=True)
|
||||
```
|
||||
- Double-check that `instrument_crewai()` is called **before** creating or executing agents. This might be obvious, but it's a common oversight.
|
||||
|
||||
## Resources
|
||||
|
||||
<CardGroup cols="3">
|
||||
<Card title="CrewAI Docs" icon="book" href="https://docs.crewai.com/">
|
||||
Official CrewAI documentation
|
||||
</Card>
|
||||
<Card title="Maxim Docs" icon="book" href="https://getmaxim.ai/docs">
|
||||
Official Maxim documentation
|
||||
</Card>
|
||||
<Card title="Maxim Github" icon="github" href="https://github.com/maximhq">
|
||||
Maxim Github
|
||||
</Card>
|
||||
</CardGroup>
|
||||
@@ -1,134 +0,0 @@
|
||||
---
|
||||
title: Neatlogs Integration
|
||||
description: Understand, debug, and share your CrewAI agent runs
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# Introduction
|
||||
|
||||
Neatlogs helps you **see what your agent did**, **why**, and **share it**.
|
||||
|
||||
It captures every step: thoughts, tool calls, responses, evaluations. No raw logs. Just clear, structured traces. Great for debugging and collaboration.
|
||||
|
||||
## Why use Neatlogs?
|
||||
|
||||
CrewAI agents use multiple tools and reasoning steps. When something goes wrong, you need context — not just errors.
|
||||
|
||||
Neatlogs lets you:
|
||||
|
||||
- Follow the full decision path
|
||||
- Add feedback directly on steps
|
||||
- Chat with the trace using AI assistant
|
||||
- Share runs publicly for feedback
|
||||
- Turn insights into tasks
|
||||
|
||||
All in one place.
|
||||
|
||||
Manage your traces effortlessly
|
||||
|
||||

|
||||

|
||||
|
||||
The best UX to view a CrewAI trace. Post comments anywhere you want. Use AI to debug.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
## Core Features
|
||||
|
||||
- **Trace Viewer**: Track thoughts, tools, and decisions in sequence
|
||||
- **Inline Comments**: Tag teammates on any trace step
|
||||
- **Feedback & Evaluation**: Mark outputs as correct or incorrect
|
||||
- **Error Highlighting**: Automatic flagging of API/tool failures
|
||||
- **Task Conversion**: Convert comments into assigned tasks
|
||||
- **Ask the Trace (AI)**: Chat with your trace using Neatlogs AI bot
|
||||
- **Public Sharing**: Publish trace links to your community
|
||||
|
||||
## Quick Setup with CrewAI
|
||||
|
||||
<Steps>
|
||||
<Step title="Sign Up & Get API Key">
|
||||
Visit [neatlogs.com](https://neatlogs.com/?utm_source=crewAI-docs), create a project, copy the API key.
|
||||
</Step>
|
||||
<Step title="Install SDK">
|
||||
```bash
|
||||
pip install neatlogs
|
||||
```
|
||||
(Latest version 0.8.0, Python 3.8+; MIT license)
|
||||
</Step>
|
||||
<Step title="Initialize Neatlogs">
|
||||
Before starting Crew agents, add:
|
||||
|
||||
```python
|
||||
import neatlogs
|
||||
neatlogs.init("YOUR_PROJECT_API_KEY")
|
||||
```
|
||||
|
||||
Agents run as usual. Neatlogs captures everything automatically.
|
||||
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
|
||||
|
||||
## Under the Hood
|
||||
|
||||
According to GitHub, Neatlogs:
|
||||
|
||||
- Captures thoughts, tool calls, responses, errors, and token stats
|
||||
- Supports AI-powered task generation and robust evaluation workflows
|
||||
|
||||
All with just two lines of code.
|
||||
|
||||
|
||||
|
||||
## Watch It Work
|
||||
|
||||
### 🔍 Full Demo (4 min)
|
||||
|
||||
<iframe
|
||||
width="100%"
|
||||
height="315"
|
||||
src="https://www.youtube.com/embed/8KDme9T2I7Q?si=b8oHteaBwFNs_Duk"
|
||||
title="YouTube video player"
|
||||
frameBorder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowFullScreen
|
||||
></iframe>
|
||||
|
||||
### ⚙️ CrewAI Integration (30 s)
|
||||
|
||||
<iframe
|
||||
className="w-full aspect-video rounded-xl"
|
||||
src="https://www.loom.com/embed/9c78b552af43452bb3e4783cb8d91230?sid=e9d7d370-a91a-49b0-809e-2f375d9e801d"
|
||||
title="Loom video player"
|
||||
frameBorder="0"
|
||||
allowFullScreen
|
||||
></iframe>
|
||||
|
||||
|
||||
|
||||
## Links & Support
|
||||
|
||||
- 📘 [Neatlogs Docs](https://docs.neatlogs.com/)
|
||||
- 🔐 [Dashboard & API Key](https://app.neatlogs.com/)
|
||||
- 🐦 [Follow on Twitter](https://twitter.com/neatlogs)
|
||||
- 📧 Contact: hello@neatlogs.com
|
||||
- 🛠 [GitHub SDK](https://github.com/NeatLogs/neatlogs)
|
||||
|
||||
|
||||
|
||||
## TL;DR
|
||||
|
||||
With just:
|
||||
|
||||
```bash
|
||||
pip install neatlogs
|
||||
|
||||
import neatlogs
|
||||
neatlogs.init("YOUR_API_KEY")
|
||||
|
||||
You can now capture, understand, share, and act on your CrewAI agent runs in seconds.
|
||||
No setup overhead. Full trace transparency. Full team collaboration.
|
||||
```
|
||||
@@ -1,824 +0,0 @@
|
||||
---
|
||||
title: Portkey Integration
|
||||
description: How to use Portkey with CrewAI
|
||||
icon: key
|
||||
---
|
||||
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-CrewAI.png" alt="Portkey CrewAI Header Image" width="70%" />
|
||||
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
Portkey enhances CrewAI with production-readiness features, turning your experimental agent crews into robust systems by providing:
|
||||
|
||||
- **Complete observability** of every agent step, tool use, and interaction
|
||||
- **Built-in reliability** with fallbacks, retries, and load balancing
|
||||
- **Cost tracking and optimization** to manage your AI spend
|
||||
- **Access to 200+ LLMs** through a single integration
|
||||
- **Guardrails** to keep agent behavior safe and compliant
|
||||
- **Version-controlled prompts** for consistent agent performance
|
||||
|
||||
|
||||
### Installation & Setup
|
||||
|
||||
<Steps>
|
||||
<Step title="Install the required packages">
|
||||
```bash
|
||||
pip install -U crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="Generate API Key" icon="lock">
|
||||
Create a Portkey API key with optional budget/rate limits from the [Portkey dashboard](https://app.portkey.ai/). You can also attach configurations for reliability, caching, and more to this key. More on this later.
|
||||
</Step>
|
||||
|
||||
<Step title="Configure CrewAI with Portkey">
|
||||
The integration is simple - you just need to update the LLM configuration in your CrewAI setup:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create an LLM instance with Portkey integration
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy", # We are using a Virtual key, so this is a placeholder
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_LLM_VIRTUAL_KEY",
|
||||
trace_id="unique-trace-id", # Optional, for request tracing
|
||||
)
|
||||
)
|
||||
|
||||
#Use them in your Crew Agents like this:
|
||||
|
||||
@agent
|
||||
def lead_market_analyst(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['lead_market_analyst'],
|
||||
verbose=True,
|
||||
memory=False,
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
<Info>
|
||||
**What are Virtual Keys?** Virtual keys in Portkey securely store your LLM provider API keys (OpenAI, Anthropic, etc.) in an encrypted vault. They allow for easier key rotation and budget management. [Learn more about virtual keys here](https://portkey.ai/docs/product/ai-gateway/virtual-keys).
|
||||
</Info>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Production Features
|
||||
|
||||
### 1. Enhanced Observability
|
||||
|
||||
Portkey provides comprehensive observability for your CrewAI agents, helping you understand exactly what's happening during each execution.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Traces">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Product%2011.1.webp"/>
|
||||
</Frame>
|
||||
|
||||
Traces provide a hierarchical view of your crew's execution, showing the sequence of LLM calls, tool invocations, and state transitions.
|
||||
|
||||
```python
|
||||
# Add trace_id to enable hierarchical tracing in Portkey
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
trace_id="unique-session-id" # Add unique trace ID
|
||||
)
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Logs">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Metadata.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey logs every interaction with LLMs, including:
|
||||
|
||||
- Complete request and response payloads
|
||||
- Latency and token usage metrics
|
||||
- Cost calculations
|
||||
- Tool calls and function executions
|
||||
|
||||
All logs can be filtered by metadata, trace IDs, models, and more, making it easy to debug specific crew runs.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Metrics & Dashboards">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Dashboard.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey provides built-in dashboards that help you:
|
||||
|
||||
- Track cost and token usage across all crew runs
|
||||
- Analyze performance metrics like latency and success rates
|
||||
- Identify bottlenecks in your agent workflows
|
||||
- Compare different crew configurations and LLMs
|
||||
|
||||
You can filter and segment all metrics by custom metadata to analyze specific crew types, user groups, or use cases.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Metadata Filtering">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png" alt="Analytics with metadata filters" />
|
||||
</Frame>
|
||||
|
||||
Add custom metadata to your CrewAI LLM configuration to enable powerful filtering and segmentation:
|
||||
|
||||
```python
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"crew_type": "research_crew",
|
||||
"environment": "production",
|
||||
"_user": "user_123", # Special _user field for user analytics
|
||||
"request_source": "mobile_app"
|
||||
}
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
This metadata can be used to filter logs, traces, and metrics on the Portkey dashboard, allowing you to analyze specific crew runs, users, or environments.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 2. Reliability - Keep Your Crews Running Smoothly
|
||||
|
||||
When running crews in production, things can go wrong - API rate limits, network issues, or provider outages. Portkey's reliability features ensure your agents keep running smoothly even when problems occur.
|
||||
|
||||
It's simple to enable fallback in your CrewAI setup by using a Portkey Config:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create LLM with fallback configuration
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
config={
|
||||
"strategy": {
|
||||
"mode": "fallback"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"provider": "openai",
|
||||
"api_key": "YOUR_OPENAI_API_KEY",
|
||||
"override_params": {"model": "gpt-4o"}
|
||||
},
|
||||
{
|
||||
"provider": "anthropic",
|
||||
"api_key": "YOUR_ANTHROPIC_API_KEY",
|
||||
"override_params": {"model": "claude-3-opus-20240229"}
|
||||
}
|
||||
]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Use this LLM configuration with your agents
|
||||
```
|
||||
|
||||
This configuration will automatically try Claude if the GPT-4o request fails, ensuring your crew can continue operating.
|
||||
|
||||
<CardGroup cols="2">
|
||||
<Card title="Automatic Retries" icon="rotate" href="https://portkey.ai/docs/product/ai-gateway/automatic-retries">
|
||||
Handles temporary failures automatically. If an LLM call fails, Portkey will retry the same request for the specified number of times - perfect for rate limits or network blips.
|
||||
</Card>
|
||||
<Card title="Request Timeouts" icon="clock" href="https://portkey.ai/docs/product/ai-gateway/request-timeouts">
|
||||
Prevent your agents from hanging. Set timeouts to ensure you get responses (or can fail gracefully) within your required timeframes.
|
||||
</Card>
|
||||
<Card title="Conditional Routing" icon="route" href="https://portkey.ai/docs/product/ai-gateway/conditional-routing">
|
||||
Send different requests to different providers. Route complex reasoning to GPT-4, creative tasks to Claude, and quick responses to Gemini based on your needs.
|
||||
</Card>
|
||||
<Card title="Fallbacks" icon="shield" href="https://portkey.ai/docs/product/ai-gateway/fallbacks">
|
||||
Keep running even if your primary provider fails. Automatically switch to backup providers to maintain availability.
|
||||
</Card>
|
||||
<Card title="Load Balancing" icon="scale-balanced" href="https://portkey.ai/docs/product/ai-gateway/load-balancing">
|
||||
Spread requests across multiple API keys or providers. Great for high-volume crew operations and staying within rate limits.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### 3. Prompting in CrewAI
|
||||
|
||||
Portkey's Prompt Engineering Studio helps you create, manage, and optimize the prompts used in your CrewAI agents. Instead of hardcoding prompts or instructions, use Portkey's prompt rendering API to dynamically fetch and apply your versioned prompts.
|
||||
|
||||
<Frame caption="Manage prompts in Portkey's Prompt Library">
|
||||
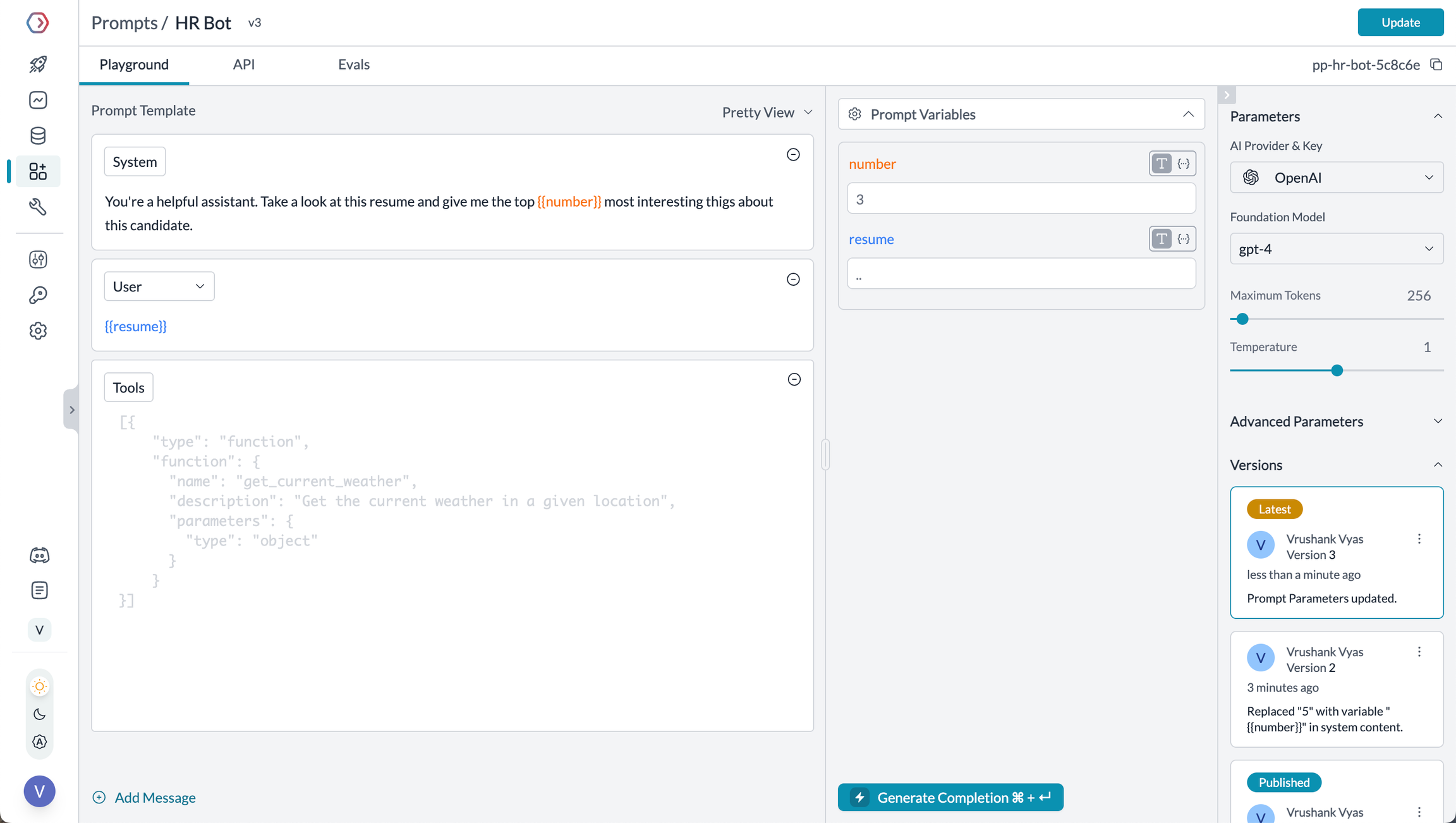
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Prompt Playground">
|
||||
Prompt Playground is a place to compare, test and deploy perfect prompts for your AI application. It's where you experiment with different models, test variables, compare outputs, and refine your prompt engineering strategy before deploying to production. It allows you to:
|
||||
|
||||
1. Iteratively develop prompts before using them in your agents
|
||||
2. Test prompts with different variables and models
|
||||
3. Compare outputs between different prompt versions
|
||||
4. Collaborate with team members on prompt development
|
||||
|
||||
This visual environment makes it easier to craft effective prompts for each step in your CrewAI agents' workflow.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Using Prompt Templates">
|
||||
The Prompt Render API retrieves your prompt templates with all parameters configured:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL, Portkey
|
||||
|
||||
# Initialize Portkey admin client
|
||||
portkey_admin = Portkey(api_key="YOUR_PORTKEY_API_KEY")
|
||||
|
||||
# Retrieve prompt using the render API
|
||||
prompt_data = portkey_client.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
}
|
||||
)
|
||||
|
||||
backstory_agent_prompt=prompt_data.data.messages[0]["content"]
|
||||
|
||||
|
||||
# Set up LLM with Portkey integration
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent using the rendered prompt
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory=backstory_agent, # Use the rendered prompt
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Prompt Versioning">
|
||||
You can:
|
||||
- Create multiple versions of the same prompt
|
||||
- Compare performance between versions
|
||||
- Roll back to previous versions if needed
|
||||
- Specify which version to use in your code:
|
||||
|
||||
```python
|
||||
# Use a specific prompt version
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID@version_number",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"agent_goal": "Discover groundbreaking insights"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Mustache Templating for variables">
|
||||
Portkey prompts use Mustache-style templating for easy variable substitution:
|
||||
|
||||
```
|
||||
You are a {{agent_role}} with expertise in {{domain}}.
|
||||
|
||||
Your mission is to {{agent_goal}} by leveraging your knowledge
|
||||
and experience in the field.
|
||||
|
||||
Always maintain a {{tone}} tone and focus on providing {{focus_area}}.
|
||||
```
|
||||
|
||||
When rendering, simply pass the variables:
|
||||
|
||||
```python
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"domain": "artificial intelligence",
|
||||
"agent_goal": "discover groundbreaking insights",
|
||||
"tone": "professional",
|
||||
"focus_area": "practical applications"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Card title="Prompt Engineering Studio" icon="wand-magic-sparkles" href="https://portkey.ai/docs/product/prompt-library">
|
||||
Learn more about Portkey's prompt management features
|
||||
</Card>
|
||||
|
||||
### 4. Guardrails for Safe Crews
|
||||
|
||||
Guardrails ensure your CrewAI agents operate safely and respond appropriately in all situations.
|
||||
|
||||
**Why Use Guardrails?**
|
||||
|
||||
CrewAI agents can experience various failure modes:
|
||||
- Generating harmful or inappropriate content
|
||||
- Leaking sensitive information like PII
|
||||
- Hallucinating incorrect information
|
||||
- Generating outputs in incorrect formats
|
||||
|
||||
Portkey's guardrails add protections for both inputs and outputs.
|
||||
|
||||
**Implementing Guardrails**
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create LLM with guardrails
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"input_guardrails": ["guardrails-id-xxx", "guardrails-id-yyy"],
|
||||
"output_guardrails": ["guardrails-id-zzz"]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with guardrailed LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Portkey's guardrails can:
|
||||
- Detect and redact PII in both inputs and outputs
|
||||
- Filter harmful or inappropriate content
|
||||
- Validate response formats against schemas
|
||||
- Check for hallucinations against ground truth
|
||||
- Apply custom business logic and rules
|
||||
|
||||
<Card title="Learn More About Guardrails" icon="shield-check" href="https://portkey.ai/docs/product/guardrails">
|
||||
Explore Portkey's guardrail features to enhance agent safety
|
||||
</Card>
|
||||
|
||||
### 5. User Tracking with Metadata
|
||||
|
||||
Track individual users through your CrewAI agents using Portkey's metadata system.
|
||||
|
||||
**What is Metadata in Portkey?**
|
||||
|
||||
Metadata allows you to associate custom data with each request, enabling filtering, segmentation, and analytics. The special `_user` field is specifically designed for user tracking.
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with user tracking
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"_user": "user_123", # Special _user field for user analytics
|
||||
"user_tier": "premium",
|
||||
"user_company": "Acme Corp",
|
||||
"session_id": "abc-123"
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with tracked LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
**Filter Analytics by User**
|
||||
|
||||
With metadata in place, you can filter analytics by user and analyze performance metrics on a per-user basis:
|
||||
|
||||
<Frame caption="Filter analytics by user">
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png"/>
|
||||
</Frame>
|
||||
|
||||
This enables:
|
||||
- Per-user cost tracking and budgeting
|
||||
- Personalized user analytics
|
||||
- Team or organization-level metrics
|
||||
- Environment-specific monitoring (staging vs. production)
|
||||
|
||||
<Card title="Learn More About Metadata" icon="tags" href="https://portkey.ai/docs/product/observability/metadata">
|
||||
Explore how to use custom metadata to enhance your analytics
|
||||
</Card>
|
||||
|
||||
### 6. Caching for Efficient Crews
|
||||
|
||||
Implement caching to make your CrewAI agents more efficient and cost-effective:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Simple Caching">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with simple caching
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "simple"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with cached LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Simple caching performs exact matches on input prompts, caching identical requests to avoid redundant model executions.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Semantic Caching">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with semantic caching
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "semantic"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with semantically cached LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Semantic caching considers the contextual similarity between input requests, caching responses for semantically similar inputs.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 7. Model Interoperability
|
||||
|
||||
CrewAI supports multiple LLM providers, and Portkey extends this capability by providing access to over 200 LLMs through a unified interface. You can easily switch between different models without changing your core agent logic:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Set up LLMs with different providers
|
||||
openai_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Choose which LLM to use for each agent based on your needs
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=openai_llm # Use anthropic_llm for Anthropic
|
||||
)
|
||||
```
|
||||
|
||||
Portkey provides access to LLMs from providers including:
|
||||
|
||||
- OpenAI (GPT-4o, GPT-4 Turbo, etc.)
|
||||
- Anthropic (Claude 3.5 Sonnet, Claude 3 Opus, etc.)
|
||||
- Mistral AI (Mistral Large, Mistral Medium, etc.)
|
||||
- Google Vertex AI (Gemini 1.5 Pro, etc.)
|
||||
- Cohere (Command, Command-R, etc.)
|
||||
- AWS Bedrock (Claude, Titan, etc.)
|
||||
- Local/Private Models
|
||||
|
||||
<Card title="Supported Providers" icon="server" href="https://portkey.ai/docs/integrations/llms">
|
||||
See the full list of LLM providers supported by Portkey
|
||||
</Card>
|
||||
|
||||
## Set Up Enterprise Governance for CrewAI
|
||||
|
||||
**Why Enterprise Governance?**
|
||||
If you are using CrewAI inside your organization, you need to consider several governance aspects:
|
||||
- **Cost Management**: Controlling and tracking AI spending across teams
|
||||
- **Access Control**: Managing which teams can use specific models
|
||||
- **Usage Analytics**: Understanding how AI is being used across the organization
|
||||
- **Security & Compliance**: Maintaining enterprise security standards
|
||||
- **Reliability**: Ensuring consistent service across all users
|
||||
|
||||
Portkey adds a comprehensive governance layer to address these enterprise needs. Let's implement these controls step by step.
|
||||
|
||||
<Steps>
|
||||
<Step title="Create Virtual Key">
|
||||
Virtual Keys are Portkey's secure way to manage your LLM provider API keys. They provide essential controls like:
|
||||
- Budget limits for API usage
|
||||
- Rate limiting capabilities
|
||||
- Secure API key storage
|
||||
|
||||
To create a virtual key:
|
||||
Go to [Virtual Keys](https://app.portkey.ai/virtual-keys) in the Portkey App. Save and copy the virtual key ID
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
|
||||
<Note>
|
||||
Save your virtual key ID - you'll need it for the next step.
|
||||
</Note>
|
||||
</Step>
|
||||
|
||||
<Step title="Create Default Config">
|
||||
Configs in Portkey define how your requests are routed, with features like advanced routing, fallbacks, and retries.
|
||||
|
||||
To create your config:
|
||||
1. Go to [Configs](https://app.portkey.ai/configs) in Portkey dashboard
|
||||
2. Create new config with:
|
||||
```json
|
||||
{
|
||||
"virtual_key": "YOUR_VIRTUAL_KEY_FROM_STEP1",
|
||||
"override_params": {
|
||||
"model": "gpt-4o" // Your preferred model name
|
||||
}
|
||||
}
|
||||
```
|
||||
3. Save and note the Config name for the next step
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Config.png" width="500"/>
|
||||
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Configure Portkey API Key">
|
||||
Now create a Portkey API key and attach the config you created in Step 2:
|
||||
|
||||
1. Go to [API Keys](https://app.portkey.ai/api-keys) in Portkey and Create new API key
|
||||
2. Select your config from `Step 2`
|
||||
3. Generate and save your API key
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20API%20Key.png" width="500"/>
|
||||
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Connect to CrewAI">
|
||||
After setting up your Portkey API key with the attached config, connect it to your CrewAI agents:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with your API key
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="YOUR_PORTKEY_API_KEY"
|
||||
)
|
||||
|
||||
# Create agent with Portkey-enabled LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Step 1: Implement Budget Controls & Rate Limits">
|
||||
### Step 1: Implement Budget Controls & Rate Limits
|
||||
|
||||
Virtual Keys enable granular control over LLM access at the team/department level. This helps you:
|
||||
- Set up [budget limits](https://portkey.ai/docs/product/ai-gateway/virtual-keys/budget-limits)
|
||||
- Prevent unexpected usage spikes using Rate limits
|
||||
- Track departmental spending
|
||||
|
||||
#### Setting Up Department-Specific Controls:
|
||||
1. Navigate to [Virtual Keys](https://app.portkey.ai/virtual-keys) in Portkey dashboard
|
||||
2. Create new Virtual Key for each department with budget limits and rate limits
|
||||
3. Configure department-specific limits
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Step 2: Define Model Access Rules">
|
||||
### Step 2: Define Model Access Rules
|
||||
|
||||
As your AI usage scales, controlling which teams can access specific models becomes crucial. Portkey Configs provide this control layer with features like:
|
||||
|
||||
#### Access Control Features:
|
||||
- **Model Restrictions**: Limit access to specific models
|
||||
- **Data Protection**: Implement guardrails for sensitive data
|
||||
- **Reliability Controls**: Add fallbacks and retry logic
|
||||
|
||||
#### Example Configuration:
|
||||
Here's a basic configuration to route requests to OpenAI, specifically using GPT-4o:
|
||||
|
||||
```json
|
||||
{
|
||||
"strategy": {
|
||||
"mode": "single"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"virtual_key": "YOUR_OPENAI_VIRTUAL_KEY",
|
||||
"override_params": {
|
||||
"model": "gpt-4o"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Create your config on the [Configs page](https://app.portkey.ai/configs) in your Portkey dashboard.
|
||||
|
||||
<Note>
|
||||
Configs can be updated anytime to adjust controls without affecting running applications.
|
||||
</Note>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Step 3: Implement Access Controls">
|
||||
### Step 3: Implement Access Controls
|
||||
|
||||
Create User-specific API keys that automatically:
|
||||
- Track usage per user/team with the help of virtual keys
|
||||
- Apply appropriate configs to route requests
|
||||
- Collect relevant metadata to filter logs
|
||||
- Enforce access permissions
|
||||
|
||||
Create API keys through:
|
||||
- [Portkey App](https://app.portkey.ai/)
|
||||
- [API Key Management API](/en/api-reference/admin-api/control-plane/api-keys/create-api-key)
|
||||
|
||||
Example using Python SDK:
|
||||
```python
|
||||
from portkey_ai import Portkey
|
||||
|
||||
portkey = Portkey(api_key="YOUR_ADMIN_API_KEY")
|
||||
|
||||
api_key = portkey.api_keys.create(
|
||||
name="engineering-team",
|
||||
type="organisation",
|
||||
workspace_id="YOUR_WORKSPACE_ID",
|
||||
defaults={
|
||||
"config_id": "your-config-id",
|
||||
"metadata": {
|
||||
"environment": "production",
|
||||
"department": "engineering"
|
||||
}
|
||||
},
|
||||
scopes=["logs.view", "configs.read"]
|
||||
)
|
||||
```
|
||||
|
||||
For detailed key management instructions, see our [API Keys documentation](/en/api-reference/admin-api/control-plane/api-keys/create-api-key).
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Step 4: Deploy & Monitor">
|
||||
### Step 4: Deploy & Monitor
|
||||
After distributing API keys to your team members, your enterprise-ready CrewAI setup is ready to go. Each team member can now use their designated API keys with appropriate access levels and budget controls.
|
||||
|
||||
Monitor usage in Portkey dashboard:
|
||||
- Cost tracking by department
|
||||
- Model usage patterns
|
||||
- Request volumes
|
||||
- Error rates
|
||||
</Accordion>
|
||||
|
||||
</AccordionGroup>
|
||||
|
||||
<Note>
|
||||
### Enterprise Features Now Available
|
||||
**Your CrewAI integration now has:**
|
||||
- Departmental budget controls
|
||||
- Model access governance
|
||||
- Usage tracking & attribution
|
||||
- Security guardrails
|
||||
- Reliability features
|
||||
</Note>
|
||||
|
||||
## Frequently Asked Questions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="How does Portkey enhance CrewAI?">
|
||||
Portkey adds production-readiness to CrewAI through comprehensive observability (traces, logs, metrics), reliability features (fallbacks, retries, caching), and access to 200+ LLMs through a unified interface. This makes it easier to debug, optimize, and scale your agent applications.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Can I use Portkey with existing CrewAI applications?">
|
||||
Yes! Portkey integrates seamlessly with existing CrewAI applications. You just need to update your LLM configuration code with the Portkey-enabled version. The rest of your agent and crew code remains unchanged.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Does Portkey work with all CrewAI features?">
|
||||
Portkey supports all CrewAI features, including agents, tools, human-in-the-loop workflows, and all task process types (sequential, hierarchical, etc.). It adds observability and reliability without limiting any of the framework's functionality.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Can I track usage across multiple agents in a crew?">
|
||||
Yes, Portkey allows you to use a consistent `trace_id` across multiple agents in a crew to track the entire workflow. This is especially useful for complex crews where you want to understand the full execution path across multiple agents.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="How do I filter logs and traces for specific crew runs?">
|
||||
Portkey allows you to add custom metadata to your LLM configuration, which you can then use for filtering. Add fields like `crew_name`, `crew_type`, or `session_id` to easily find and analyze specific crew executions.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Can I use my own API keys with Portkey?">
|
||||
Yes! Portkey uses your own API keys for the various LLM providers. It securely stores them as virtual keys, allowing you to easily manage and rotate keys without changing your code.
|
||||
</Accordion>
|
||||
|
||||
</AccordionGroup>
|
||||
|
||||
## Resources
|
||||
|
||||
<CardGroup cols="3">
|
||||
<Card title="CrewAI Docs" icon="book" href="https://docs.crewai.com/">
|
||||
<p>Official CrewAI documentation</p>
|
||||
</Card>
|
||||
<Card title="Book a Demo" icon="calendar" href="https://calendly.com/portkey-ai">
|
||||
<p>Get personalized guidance on implementing this integration</p>
|
||||
</Card>
|
||||
</CardGroup>
|
||||
@@ -1,146 +0,0 @@
|
||||
---
|
||||
title: TrueFoundry Integration
|
||||
icon: chart-line
|
||||
---
|
||||
|
||||
TrueFoundry provides an enterprise-ready [AI Gateway](https://www.truefoundry.com/ai-gateway) which can integrate with agentic frameworks like CrewAI and provides governance and observability for your AI Applications. TrueFoundry AI Gateway serves as a unified interface for LLM access, providing:
|
||||
|
||||
- **Unified API Access**: Connect to 250+ LLMs (OpenAI, Claude, Gemini, Groq, Mistral) through one API
|
||||
- **Low Latency**: Sub-3ms internal latency with intelligent routing and load balancing
|
||||
- **Enterprise Security**: SOC 2, HIPAA, GDPR compliance with RBAC and audit logging
|
||||
- **Quota and cost management**: Token-based quotas, rate limiting, and comprehensive usage tracking
|
||||
- **Observability**: Full request/response logging, metrics, and traces with customizable retention
|
||||
|
||||
## How TrueFoundry Integrates with CrewAI
|
||||
|
||||
|
||||
### Installation & Setup
|
||||
|
||||
<Steps>
|
||||
<Step title="Install CrewAI">
|
||||
```bash
|
||||
pip install crewai
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="Get TrueFoundry Access Token">
|
||||
1. Sign up for a [TrueFoundry account](https://www.truefoundry.com/register)
|
||||
2. Follow the steps here in [Quick start](https://docs.truefoundry.com/gateway/quick-start)
|
||||
</Step>
|
||||
|
||||
<Step title="Configure CrewAI with TrueFoundry">
|
||||

|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
|
||||
# Create an LLM instance with TrueFoundry AI Gateway
|
||||
truefoundry_llm = LLM(
|
||||
model="openai-main/gpt-4o", # Similarly, you can call any model from any provider
|
||||
base_url="your_truefoundry_gateway_base_url",
|
||||
api_key="your_truefoundry_api_key"
|
||||
)
|
||||
|
||||
# Use in your CrewAI agents
|
||||
from crewai import Agent
|
||||
|
||||
@agent
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['researcher'],
|
||||
llm=truefoundry_llm,
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Complete CrewAI Example
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM
|
||||
|
||||
# Configure LLM with TrueFoundry
|
||||
llm = LLM(
|
||||
model="openai-main/gpt-4o",
|
||||
base_url="your_truefoundry_gateway_base_url",
|
||||
api_key="your_truefoundry_api_key"
|
||||
)
|
||||
|
||||
# Create agents
|
||||
researcher = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Conduct detailed market research',
|
||||
backstory='Expert market analyst with attention to detail',
|
||||
llm=llm,
|
||||
verbose=True
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role='Content Writer',
|
||||
goal='Create comprehensive reports',
|
||||
backstory='Experienced technical writer',
|
||||
llm=llm,
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Create tasks
|
||||
research_task = Task(
|
||||
description='Research AI market trends for 2024',
|
||||
agent=researcher,
|
||||
expected_output='Comprehensive research summary'
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description='Create a market research report',
|
||||
agent=writer,
|
||||
expected_output='Well-structured report with insights',
|
||||
context=[research_task]
|
||||
)
|
||||
|
||||
# Create and execute crew
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Observability and Governance
|
||||
|
||||
Monitor your CrewAI agents through TrueFoundry's metrics tab:
|
||||

|
||||
|
||||
With Truefoundry's AI gateway, you can monitor and analyze:
|
||||
|
||||
- **Performance Metrics**: Track key latency metrics like Request Latency, Time to First Token (TTFS), and Inter-Token Latency (ITL) with P99, P90, and P50 percentiles
|
||||
- **Cost and Token Usage**: Gain visibility into your application's costs with detailed breakdowns of input/output tokens and the associated expenses for each model
|
||||
- **Usage Patterns**: Understand how your application is being used with detailed analytics on user activity, model distribution, and team-based usage
|
||||
- **Rate limit and Load balancing**: You can set up rate limiting, load balancing and fallback for your models
|
||||
|
||||
## Tracing
|
||||
|
||||
For a more detailed understanding on tracing, please see [getting-started-tracing](https://docs.truefoundry.com/docs/tracing/tracing-getting-started).For tracing, you can add the Traceloop SDK:
|
||||
For tracing, you can add the Traceloop SDK:
|
||||
|
||||
```bash
|
||||
pip install traceloop-sdk
|
||||
```
|
||||
|
||||
```python
|
||||
from traceloop.sdk import Traceloop
|
||||
|
||||
# Initialize enhanced tracing
|
||||
Traceloop.init(
|
||||
api_endpoint="https://your-truefoundry-endpoint/api/tracing",
|
||||
headers={
|
||||
"Authorization": f"Bearer {your_truefoundry_pat_token}",
|
||||
"TFY-Tracing-Project": "your_project_name",
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
This provides additional trace correlation across your entire CrewAI workflow.
|
||||

|
||||
@@ -1,58 +0,0 @@
|
||||
---
|
||||
title: Zapier Actions Tool
|
||||
description: The `ZapierActionsAdapter` exposes Zapier actions as CrewAI tools for automation.
|
||||
icon: bolt
|
||||
---
|
||||
|
||||
# `ZapierActionsAdapter`
|
||||
|
||||
## Description
|
||||
|
||||
Use the Zapier adapter to list and call Zapier actions as CrewAI tools. This enables agents to trigger automations across thousands of apps.
|
||||
|
||||
## Installation
|
||||
|
||||
This adapter is included with `crewai-tools`. No extra install required.
|
||||
|
||||
## Environment Variables
|
||||
|
||||
- `ZAPIER_API_KEY` (required): Zapier API key. Get one from the Zapier Actions dashboard at https://actions.zapier.com/ (create an account, then generate an API key). You can also pass `zapier_api_key` directly when constructing the adapter.
|
||||
|
||||
## Example
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools.adapters.zapier_adapter import ZapierActionsAdapter
|
||||
|
||||
adapter = ZapierActionsAdapter(api_key="your_zapier_api_key")
|
||||
tools = adapter.tools()
|
||||
|
||||
agent = Agent(
|
||||
role="Automator",
|
||||
goal="Execute Zapier actions",
|
||||
backstory="Automation specialist",
|
||||
tools=tools,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Create a new Google Sheet and add a row using Zapier actions",
|
||||
expected_output="Confirmation with created resource IDs",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(agents=[agent], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
## Notes & limits
|
||||
|
||||
- The adapter lists available actions for your key and creates `BaseTool` wrappers dynamically.
|
||||
- Handle action‑specific required fields in your task instructions or tool call.
|
||||
- Rate limits depend on your Zapier plan; see the Zapier Actions docs.
|
||||
|
||||
## Notes
|
||||
|
||||
- The adapter fetches available actions and generates `BaseTool` wrappers dynamically.
|
||||
|
||||
|
||||
@@ -1,168 +0,0 @@
|
||||
---
|
||||
title: MongoDB Vector Search Tool
|
||||
description: The `MongoDBVectorSearchTool` performs vector search on MongoDB Atlas with optional indexing helpers.
|
||||
icon: "leaf"
|
||||
---
|
||||
|
||||
# `MongoDBVectorSearchTool`
|
||||
|
||||
## Description
|
||||
|
||||
Perform vector similarity queries on MongoDB Atlas collections. Supports index creation helpers and bulk insert of embedded texts.
|
||||
|
||||
MongoDB Atlas supports native vector search. Learn more:
|
||||
https://www.mongodb.com/docs/atlas/atlas-vector-search/vector-search-overview/
|
||||
|
||||
## Installation
|
||||
|
||||
Install with the MongoDB extra:
|
||||
|
||||
```shell
|
||||
pip install crewai-tools[mongodb]
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```shell
|
||||
uv add crewai-tools --extra mongodb
|
||||
```
|
||||
|
||||
## Parameters
|
||||
|
||||
### Initialization
|
||||
|
||||
- `connection_string` (str, required)
|
||||
- `database_name` (str, required)
|
||||
- `collection_name` (str, required)
|
||||
- `vector_index_name` (str, default `vector_index`)
|
||||
- `text_key` (str, default `text`)
|
||||
- `embedding_key` (str, default `embedding`)
|
||||
- `dimensions` (int, default `1536`)
|
||||
|
||||
### Run Parameters
|
||||
|
||||
- `query` (str, required): Natural language query to embed and search.
|
||||
|
||||
## Quick start
|
||||
|
||||
```python Code
|
||||
from crewai_tools import MongoDBVectorSearchTool
|
||||
|
||||
tool = MongoDBVectorSearchTool(
|
||||
connection_string="mongodb+srv://...",
|
||||
database_name="mydb",
|
||||
collection_name="docs",
|
||||
)
|
||||
|
||||
print(tool.run(query="how to create vector index"))
|
||||
```
|
||||
|
||||
## Index creation helpers
|
||||
|
||||
Use `create_vector_search_index(...)` to provision an Atlas Vector Search index with the correct dimensions and similarity.
|
||||
|
||||
## Common issues
|
||||
|
||||
- Authentication failures: ensure your Atlas IP Access List allows your runner and the connection string includes credentials.
|
||||
- Index not found: create the vector index first; name must match `vector_index_name`.
|
||||
- Dimensions mismatch: align embedding model dimensions with `dimensions`.
|
||||
|
||||
## More examples
|
||||
|
||||
### Basic initialization
|
||||
|
||||
```python Code
|
||||
from crewai_tools import MongoDBVectorSearchTool
|
||||
|
||||
tool = MongoDBVectorSearchTool(
|
||||
database_name="example_database",
|
||||
collection_name="example_collection",
|
||||
connection_string="<your_mongodb_connection_string>",
|
||||
)
|
||||
```
|
||||
|
||||
### Custom query configuration
|
||||
|
||||
```python Code
|
||||
from crewai_tools import MongoDBVectorSearchConfig, MongoDBVectorSearchTool
|
||||
|
||||
query_config = MongoDBVectorSearchConfig(limit=10, oversampling_factor=2)
|
||||
tool = MongoDBVectorSearchTool(
|
||||
database_name="example_database",
|
||||
collection_name="example_collection",
|
||||
connection_string="<your_mongodb_connection_string>",
|
||||
query_config=query_config,
|
||||
vector_index_name="my_vector_index",
|
||||
)
|
||||
|
||||
rag_agent = Agent(
|
||||
name="rag_agent",
|
||||
role="You are a helpful assistant that can answer questions with the help of the MongoDBVectorSearchTool.",
|
||||
goal="...",
|
||||
backstory="...",
|
||||
tools=[tool],
|
||||
)
|
||||
```
|
||||
|
||||
### Preloading the database and creating the index
|
||||
|
||||
```python Code
|
||||
import os
|
||||
from crewai_tools import MongoDBVectorSearchTool
|
||||
|
||||
tool = MongoDBVectorSearchTool(
|
||||
database_name="example_database",
|
||||
collection_name="example_collection",
|
||||
connection_string="<your_mongodb_connection_string>",
|
||||
)
|
||||
|
||||
# Load text content from a local folder and add to MongoDB
|
||||
texts = []
|
||||
for fname in os.listdir("knowledge"):
|
||||
path = os.path.join("knowledge", fname)
|
||||
if os.path.isfile(path):
|
||||
with open(path, "r", encoding="utf-8") as f:
|
||||
texts.append(f.read())
|
||||
|
||||
tool.add_texts(texts)
|
||||
|
||||
# Create the Atlas Vector Search index (e.g., 3072 dims for text-embedding-3-large)
|
||||
tool.create_vector_search_index(dimensions=3072)
|
||||
```
|
||||
|
||||
## Example
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import MongoDBVectorSearchTool
|
||||
|
||||
tool = MongoDBVectorSearchTool(
|
||||
connection_string="mongodb+srv://...",
|
||||
database_name="mydb",
|
||||
collection_name="docs",
|
||||
)
|
||||
|
||||
agent = Agent(
|
||||
role="RAG Agent",
|
||||
goal="Answer using MongoDB vector search",
|
||||
backstory="Knowledge retrieval specialist",
|
||||
tools=[tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Find relevant content for 'indexing guidance'",
|
||||
expected_output="A concise answer citing the most relevant matches",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
|
||||
@@ -1,61 +0,0 @@
|
||||
---
|
||||
title: SingleStore Search Tool
|
||||
description: The `SingleStoreSearchTool` safely executes SELECT/SHOW queries on SingleStore with pooling.
|
||||
icon: circle
|
||||
---
|
||||
|
||||
# `SingleStoreSearchTool`
|
||||
|
||||
## Description
|
||||
|
||||
Execute read‑only queries (`SELECT`/`SHOW`) against SingleStore with connection pooling and input validation.
|
||||
|
||||
## Installation
|
||||
|
||||
```shell
|
||||
uv add crewai-tools[singlestore]
|
||||
```
|
||||
|
||||
## Environment Variables
|
||||
|
||||
Variables like `SINGLESTOREDB_HOST`, `SINGLESTOREDB_USER`, `SINGLESTOREDB_PASSWORD`, etc., can be used, or `SINGLESTOREDB_URL` as a single DSN.
|
||||
|
||||
Generate the API key from the SingleStore dashboard, [docs here](https://docs.singlestore.com/cloud/reference/management-api/#generate-an-api-key).
|
||||
|
||||
## Example
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import SingleStoreSearchTool
|
||||
|
||||
tool = SingleStoreSearchTool(
|
||||
tables=["products"],
|
||||
host="host",
|
||||
user="user",
|
||||
password="pass",
|
||||
database="db",
|
||||
)
|
||||
|
||||
agent = Agent(
|
||||
role="Analyst",
|
||||
goal="Query SingleStore",
|
||||
tools=[tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="List 5 products",
|
||||
expected_output="5 rows as JSON/text",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
|
||||
@@ -1,89 +0,0 @@
|
||||
---
|
||||
title: OCR Tool
|
||||
description: The `OCRTool` extracts text from local images or image URLs using an LLM with vision.
|
||||
icon: image
|
||||
---
|
||||
|
||||
# `OCRTool`
|
||||
|
||||
## Description
|
||||
|
||||
Extract text from images (local path or URL). Uses a vision‑capable LLM via CrewAI’s LLM interface.
|
||||
|
||||
## Installation
|
||||
|
||||
No extra install beyond `crewai-tools`. Ensure your selected LLM supports vision.
|
||||
|
||||
## Parameters
|
||||
|
||||
### Run Parameters
|
||||
|
||||
- `image_path_url` (str, required): Local image path or HTTP(S) URL.
|
||||
|
||||
## Examples
|
||||
|
||||
### Direct usage
|
||||
|
||||
```python Code
|
||||
from crewai_tools import OCRTool
|
||||
|
||||
print(OCRTool().run(image_path_url="/tmp/receipt.png"))
|
||||
```
|
||||
|
||||
### With an agent
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import OCRTool
|
||||
|
||||
ocr = OCRTool()
|
||||
|
||||
agent = Agent(
|
||||
role="OCR",
|
||||
goal="Extract text",
|
||||
tools=[ocr],
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Extract text from https://example.com/invoice.jpg",
|
||||
expected_output="All detected text in plain text",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(agents=[agent], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
## Notes
|
||||
|
||||
- Ensure the selected LLM supports image inputs.
|
||||
- For large images, consider downscaling to reduce token usage.
|
||||
- You can pass a specific LLM instance to the tool (e.g., `LLM(model="gpt-4o")`) if needed, matching the README guidance.
|
||||
|
||||
## Example
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import OCRTool
|
||||
|
||||
tool = OCRTool()
|
||||
|
||||
agent = Agent(
|
||||
role="OCR Specialist",
|
||||
goal="Extract text from images",
|
||||
backstory="Vision‑enabled analyst",
|
||||
tools=[tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Extract text from https://example.com/receipt.png",
|
||||
expected_output="All detected text in plain text",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(agents=[agent], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
|
||||
@@ -1,76 +0,0 @@
|
||||
---
|
||||
title: PDF Text Writing Tool
|
||||
description: The `PDFTextWritingTool` writes text to specific positions in a PDF, supporting custom fonts.
|
||||
icon: file-pdf
|
||||
---
|
||||
|
||||
# `PDFTextWritingTool`
|
||||
|
||||
## Description
|
||||
|
||||
Write text at precise coordinates on a PDF page, optionally embedding a custom TrueType font.
|
||||
|
||||
## Parameters
|
||||
|
||||
### Run Parameters
|
||||
|
||||
- `pdf_path` (str, required): Path to the input PDF.
|
||||
- `text` (str, required): Text to add.
|
||||
- `position` (tuple[int, int], required): `(x, y)` coordinates.
|
||||
- `font_size` (int, default `12`)
|
||||
- `font_color` (str, default `"0 0 0 rg"`)
|
||||
- `font_name` (str, default `"F1"`)
|
||||
- `font_file` (str, optional): Path to `.ttf` file.
|
||||
- `page_number` (int, default `0`)
|
||||
|
||||
## Example
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PDFTextWritingTool
|
||||
|
||||
tool = PDFTextWritingTool()
|
||||
|
||||
agent = Agent(
|
||||
role="PDF Editor",
|
||||
goal="Annotate PDFs",
|
||||
backstory="Documentation specialist",
|
||||
tools=[tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Write 'CONFIDENTIAL' at (72, 720) on page 1 of ./sample.pdf",
|
||||
expected_output="Confirmation message",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Direct usage
|
||||
|
||||
```python Code
|
||||
from crewai_tools import PDFTextWritingTool
|
||||
|
||||
PDFTextWritingTool().run(
|
||||
pdf_path="./input.pdf",
|
||||
text="CONFIDENTIAL",
|
||||
position=(72, 720),
|
||||
font_size=18,
|
||||
page_number=0,
|
||||
)
|
||||
```
|
||||
|
||||
## Tips
|
||||
|
||||
- Coordinate origin is the bottom‑left corner.
|
||||
- If using a custom font (`font_file`), ensure it is a valid `.ttf`.
|
||||
|
||||
|
||||
@@ -1,112 +0,0 @@
|
||||
---
|
||||
title: Arxiv Paper Tool
|
||||
description: The `ArxivPaperTool` searches arXiv for papers matching a query and optionally downloads PDFs.
|
||||
icon: box-archive
|
||||
---
|
||||
|
||||
# `ArxivPaperTool`
|
||||
|
||||
## Description
|
||||
|
||||
The `ArxivPaperTool` queries the arXiv API for academic papers and returns compact, readable results. It can also optionally download PDFs to disk.
|
||||
|
||||
## Installation
|
||||
|
||||
This tool has no special installation beyond `crewai-tools`.
|
||||
|
||||
```shell
|
||||
uv add crewai-tools
|
||||
```
|
||||
|
||||
No API key is required. This tool uses the public arXiv Atom API.
|
||||
|
||||
## Steps to Get Started
|
||||
|
||||
1. Initialize the tool.
|
||||
2. Provide a `search_query` (e.g., "transformer neural network").
|
||||
3. Optionally set `max_results` (1–100) and enable PDF downloads in the constructor.
|
||||
|
||||
## Example
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import ArxivPaperTool
|
||||
|
||||
tool = ArxivPaperTool(
|
||||
download_pdfs=False,
|
||||
save_dir="./arxiv_pdfs",
|
||||
use_title_as_filename=True,
|
||||
)
|
||||
|
||||
agent = Agent(
|
||||
role="Researcher",
|
||||
goal="Find relevant arXiv papers",
|
||||
backstory="Expert at literature discovery",
|
||||
tools=[tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Search arXiv for 'transformer neural network' and list top 5 results.",
|
||||
expected_output="A concise list of 5 relevant papers with titles, links, and summaries.",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(agents=[agent], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Direct usage (without Agent)
|
||||
|
||||
```python Code
|
||||
from crewai_tools import ArxivPaperTool
|
||||
|
||||
tool = ArxivPaperTool(
|
||||
download_pdfs=True,
|
||||
save_dir="./arxiv_pdfs",
|
||||
)
|
||||
print(tool.run(search_query="mixture of experts", max_results=3))
|
||||
```
|
||||
|
||||
## Parameters
|
||||
|
||||
### Initialization Parameters
|
||||
|
||||
- `download_pdfs` (bool, default `False`): Whether to download PDFs.
|
||||
- `save_dir` (str, default `./arxiv_pdfs`): Directory to save PDFs.
|
||||
- `use_title_as_filename` (bool, default `False`): Use paper titles for filenames.
|
||||
|
||||
### Run Parameters
|
||||
|
||||
- `search_query` (str, required): The arXiv search query.
|
||||
- `max_results` (int, default `5`, range 1–100): Number of results.
|
||||
|
||||
## Output format
|
||||
|
||||
The tool returns a human‑readable list of papers with:
|
||||
- Title
|
||||
- Link (abs page)
|
||||
- Snippet/summary (truncated)
|
||||
|
||||
When `download_pdfs=True`, PDFs are saved to disk and the summary mentions saved files.
|
||||
|
||||
## Usage Notes
|
||||
|
||||
- The tool returns formatted text with key metadata and links.
|
||||
- When `download_pdfs=True`, PDFs will be stored in `save_dir`.
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
- If you receive a network timeout, re‑try or reduce `max_results`.
|
||||
- Invalid XML errors indicate an arXiv response parse issue; try a simpler query.
|
||||
- File system errors (e.g., permission denied) may occur when saving PDFs; ensure `save_dir` is writable.
|
||||
|
||||
## Related links
|
||||
|
||||
- arXiv API docs: https://info.arxiv.org/help/api/index.html
|
||||
|
||||
## Error Handling
|
||||
|
||||
- Network issues, invalid XML, and OS errors are handled with informative messages.
|
||||
|
||||
|
||||
@@ -1,80 +0,0 @@
|
||||
---
|
||||
title: Databricks SQL Query Tool
|
||||
description: The `DatabricksQueryTool` executes SQL queries against Databricks workspace tables.
|
||||
icon: trowel-bricks
|
||||
---
|
||||
|
||||
# `DatabricksQueryTool`
|
||||
|
||||
## Description
|
||||
|
||||
Run SQL against Databricks workspace tables with either CLI profile or direct host/token authentication.
|
||||
|
||||
## Installation
|
||||
|
||||
```shell
|
||||
uv add crewai-tools[databricks-sdk]
|
||||
```
|
||||
|
||||
## Environment Variables
|
||||
|
||||
- `DATABRICKS_CONFIG_PROFILE` or (`DATABRICKS_HOST` + `DATABRICKS_TOKEN`)
|
||||
|
||||
Create a personal access token and find host details in the Databricks workspace under User Settings → Developer.
|
||||
Docs: https://docs.databricks.com/en/dev-tools/auth/pat.html
|
||||
|
||||
## Example
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import DatabricksQueryTool
|
||||
|
||||
tool = DatabricksQueryTool(
|
||||
default_catalog="main",
|
||||
default_schema="default",
|
||||
)
|
||||
|
||||
agent = Agent(
|
||||
role="Data Analyst",
|
||||
goal="Query Databricks",
|
||||
tools=[tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="SELECT * FROM my_table LIMIT 10",
|
||||
expected_output="10 rows",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
verbose=True,
|
||||
)
|
||||
result = crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
|
||||
## Parameters
|
||||
|
||||
- `query` (required): SQL query to execute
|
||||
- `catalog` (optional): Override default catalog
|
||||
- `db_schema` (optional): Override default schema
|
||||
- `warehouse_id` (optional): Override default SQL warehouse
|
||||
- `row_limit` (optional): Maximum rows to return (default: 1000)
|
||||
|
||||
## Defaults on initialization
|
||||
|
||||
- `default_catalog`
|
||||
- `default_schema`
|
||||
- `default_warehouse_id`
|
||||
|
||||
### Error handling & tips
|
||||
|
||||
- Authentication errors: verify `DATABRICKS_HOST` begins with `https://` and token is valid.
|
||||
- Permissions: ensure your SQL warehouse and schema are accessible by your token.
|
||||
- Limits: long‑running queries should be avoided in agent loops; add filters/limits.
|
||||
|
||||
|
||||
@@ -1,93 +0,0 @@
|
||||
---
|
||||
title: "Overview"
|
||||
description: "Perform web searches, find repositories, and research information across the internet"
|
||||
icon: "face-smile"
|
||||
---
|
||||
|
||||
These tools enable your agents to search the web, research topics, and find information across various platforms including search engines, GitHub, and YouTube.
|
||||
|
||||
## **Available Tools**
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Serper Dev Tool" icon="google" href="/en/tools/search-research/serperdevtool">
|
||||
Google search API integration for comprehensive web search capabilities.
|
||||
</Card>
|
||||
|
||||
<Card title="Brave Search Tool" icon="shield" href="/en/tools/search-research/bravesearchtool">
|
||||
Privacy-focused search with Brave's independent search index.
|
||||
</Card>
|
||||
|
||||
<Card title="Exa Search Tool" icon="magnifying-glass" href="/en/tools/search-research/exasearchtool">
|
||||
AI-powered search for finding specific and relevant content.
|
||||
</Card>
|
||||
|
||||
<Card title="LinkUp Search Tool" icon="link" href="/en/tools/search-research/linkupsearchtool">
|
||||
Real-time web search with fresh content indexing.
|
||||
</Card>
|
||||
|
||||
<Card title="GitHub Search Tool" icon="github" href="/en/tools/search-research/githubsearchtool">
|
||||
Search GitHub repositories, code, issues, and documentation.
|
||||
</Card>
|
||||
|
||||
<Card title="Website Search Tool" icon="globe" href="/en/tools/search-research/websitesearchtool">
|
||||
Search within specific websites and domains.
|
||||
</Card>
|
||||
|
||||
<Card title="Code Docs Search Tool" icon="code" href="/en/tools/search-research/codedocssearchtool">
|
||||
Search through code documentation and technical resources.
|
||||
</Card>
|
||||
|
||||
<Card title="YouTube Channel Search" icon="youtube" href="/en/tools/search-research/youtubechannelsearchtool">
|
||||
Search YouTube channels for specific content and creators.
|
||||
</Card>
|
||||
|
||||
<Card title="YouTube Video Search" icon="play" href="/en/tools/search-research/youtubevideosearchtool">
|
||||
Find and analyze YouTube videos by topic, keyword, or criteria.
|
||||
</Card>
|
||||
|
||||
<Card title="Tavily Search Tool" icon="magnifying-glass" href="/en/tools/search-research/tavilysearchtool">
|
||||
Comprehensive web search using Tavily's AI-powered search API.
|
||||
</Card>
|
||||
|
||||
<Card title="Tavily Extractor Tool" icon="file-text" href="/en/tools/search-research/tavilyextractortool">
|
||||
Extract structured content from web pages using the Tavily API.
|
||||
</Card>
|
||||
|
||||
<Card title="Arxiv Paper Tool" icon="box-archive" href="/en/tools/search-research/arxivpapertool">
|
||||
Search arXiv and optionally download PDFs.
|
||||
</Card>
|
||||
|
||||
<Card title="SerpApi Google Search" icon="search" href="/en/tools/search-research/serpapi-googlesearchtool">
|
||||
Google search via SerpApi with structured results.
|
||||
</Card>
|
||||
|
||||
<Card title="SerpApi Google Shopping" icon="cart-shopping" href="/en/tools/search-research/serpapi-googleshoppingtool">
|
||||
Google Shopping queries via SerpApi.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## **Common Use Cases**
|
||||
|
||||
- **Market Research**: Search for industry trends and competitor analysis
|
||||
- **Content Discovery**: Find relevant articles, videos, and resources
|
||||
- **Code Research**: Search repositories and documentation for solutions
|
||||
- **Lead Generation**: Research companies and individuals
|
||||
- **Academic Research**: Find scholarly articles and technical papers
|
||||
|
||||
```python
|
||||
from crewai_tools import SerperDevTool, GitHubSearchTool, YoutubeVideoSearchTool, TavilySearchTool, TavilyExtractorTool
|
||||
|
||||
# Create research tools
|
||||
web_search = SerperDevTool()
|
||||
code_search = GitHubSearchTool()
|
||||
video_research = YoutubeVideoSearchTool()
|
||||
tavily_search = TavilySearchTool()
|
||||
content_extractor = TavilyExtractorTool()
|
||||
|
||||
# Add to your agent
|
||||
agent = Agent(
|
||||
role="Research Analyst",
|
||||
tools=[web_search, code_search, video_research, tavily_search, content_extractor],
|
||||
goal="Gather comprehensive information on any topic"
|
||||
)
|
||||
```
|
||||
@@ -1,65 +0,0 @@
|
||||
---
|
||||
title: SerpApi Google Search Tool
|
||||
description: The `SerpApiGoogleSearchTool` performs Google searches using the SerpApi service.
|
||||
icon: google
|
||||
---
|
||||
|
||||
# `SerpApiGoogleSearchTool`
|
||||
|
||||
## Description
|
||||
|
||||
Use the `SerpApiGoogleSearchTool` to run Google searches with SerpApi and retrieve structured results. Requires a SerpApi API key.
|
||||
|
||||
## Installation
|
||||
|
||||
```shell
|
||||
uv add crewai-tools[serpapi]
|
||||
```
|
||||
|
||||
## Environment Variables
|
||||
|
||||
- `SERPAPI_API_KEY` (required): API key for SerpApi. Create one at https://serpapi.com/ (free tier available).
|
||||
|
||||
## Example
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import SerpApiGoogleSearchTool
|
||||
|
||||
tool = SerpApiGoogleSearchTool()
|
||||
|
||||
agent = Agent(
|
||||
role="Researcher",
|
||||
goal="Answer questions using Google search",
|
||||
backstory="Search specialist",
|
||||
tools=[tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Search for the latest CrewAI releases",
|
||||
expected_output="A concise list of relevant results with titles and links",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(agents=[agent], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
## Notes
|
||||
|
||||
- Set `SERPAPI_API_KEY` in the environment. Create a key at https://serpapi.com/
|
||||
- See also Google Shopping via SerpApi: `/en/tools/search-research/serpapi-googleshoppingtool`
|
||||
|
||||
## Parameters
|
||||
|
||||
### Run Parameters
|
||||
|
||||
- `search_query` (str, required): The Google query.
|
||||
- `location` (str, optional): Geographic location parameter.
|
||||
|
||||
## Notes
|
||||
|
||||
- This tool wraps SerpApi and returns structured search results.
|
||||
|
||||
|
||||
@@ -1,61 +0,0 @@
|
||||
---
|
||||
title: SerpApi Google Shopping Tool
|
||||
description: The `SerpApiGoogleShoppingTool` searches Google Shopping results using SerpApi.
|
||||
icon: cart-shopping
|
||||
---
|
||||
|
||||
# `SerpApiGoogleShoppingTool`
|
||||
|
||||
## Description
|
||||
|
||||
Leverage `SerpApiGoogleShoppingTool` to query Google Shopping via SerpApi and retrieve product-oriented results.
|
||||
|
||||
## Installation
|
||||
|
||||
```shell
|
||||
uv add crewai-tools[serpapi]
|
||||
```
|
||||
|
||||
## Environment Variables
|
||||
|
||||
- `SERPAPI_API_KEY` (required): API key for SerpApi. Create one at https://serpapi.com/ (free tier available).
|
||||
|
||||
## Example
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import SerpApiGoogleShoppingTool
|
||||
|
||||
tool = SerpApiGoogleShoppingTool()
|
||||
|
||||
agent = Agent(
|
||||
role="Shopping Researcher",
|
||||
goal="Find relevant products",
|
||||
backstory="Expert in product search",
|
||||
tools=[tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Search Google Shopping for 'wireless noise-canceling headphones'",
|
||||
expected_output="Top relevant products with titles and links",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(agents=[agent], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
## Notes
|
||||
|
||||
- Set `SERPAPI_API_KEY` in the environment. Create a key at https://serpapi.com/
|
||||
- See also Google Web Search via SerpApi: `/en/tools/search-research/serpapi-googlesearchtool`
|
||||
|
||||
## Parameters
|
||||
|
||||
### Run Parameters
|
||||
|
||||
- `search_query` (str, required): Product search query.
|
||||
- `location` (str, optional): Geographic location parameter.
|
||||
|
||||
|
||||
@@ -1,139 +0,0 @@
|
||||
---
|
||||
title: "Tavily Extractor Tool"
|
||||
description: "Extract structured content from web pages using the Tavily API"
|
||||
icon: square-poll-horizontal
|
||||
---
|
||||
|
||||
The `TavilyExtractorTool` allows CrewAI agents to extract structured content from web pages using the Tavily API. It can process single URLs or lists of URLs and provides options for controlling the extraction depth and including images.
|
||||
|
||||
## Installation
|
||||
|
||||
To use the `TavilyExtractorTool`, you need to install the `tavily-python` library:
|
||||
|
||||
```shell
|
||||
pip install 'crewai[tools]' tavily-python
|
||||
```
|
||||
|
||||
You also need to set your Tavily API key as an environment variable:
|
||||
|
||||
```bash
|
||||
export TAVILY_API_KEY='your-tavily-api-key'
|
||||
```
|
||||
|
||||
## Example Usage
|
||||
|
||||
Here's how to initialize and use the `TavilyExtractorTool` within a CrewAI agent:
|
||||
|
||||
```python
|
||||
import os
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import TavilyExtractorTool
|
||||
|
||||
# Ensure TAVILY_API_KEY is set in your environment
|
||||
# os.environ["TAVILY_API_KEY"] = "YOUR_API_KEY"
|
||||
|
||||
# Initialize the tool
|
||||
tavily_tool = TavilyExtractorTool()
|
||||
|
||||
# Create an agent that uses the tool
|
||||
extractor_agent = Agent(
|
||||
role='Web Content Extractor',
|
||||
goal='Extract key information from specified web pages',
|
||||
backstory='You are an expert at extracting relevant content from websites using the Tavily API.',
|
||||
tools=[tavily_tool],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Define a task for the agent
|
||||
extract_task = Task(
|
||||
description='Extract the main content from the URL https://example.com using basic extraction depth.',
|
||||
expected_output='A JSON string containing the extracted content from the URL.',
|
||||
agent=extractor_agent
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(
|
||||
agents=[extractor_agent],
|
||||
tasks=[extract_task],
|
||||
verbose=2
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
|
||||
## Configuration Options
|
||||
|
||||
The `TavilyExtractorTool` accepts the following arguments:
|
||||
|
||||
- `urls` (Union[List[str], str]): **Required**. A single URL string or a list of URL strings to extract data from.
|
||||
- `include_images` (Optional[bool]): Whether to include images in the extraction results. Defaults to `False`.
|
||||
- `extract_depth` (Literal["basic", "advanced"]): The depth of extraction. Use `"basic"` for faster, surface-level extraction or `"advanced"` for more comprehensive extraction. Defaults to `"basic"`.
|
||||
- `timeout` (int): The maximum time in seconds to wait for the extraction request to complete. Defaults to `60`.
|
||||
|
||||
## Advanced Usage
|
||||
|
||||
### Multiple URLs with Advanced Extraction
|
||||
|
||||
```python
|
||||
# Example with multiple URLs and advanced extraction
|
||||
multi_extract_task = Task(
|
||||
description='Extract content from https://example.com and https://anotherexample.org using advanced extraction.',
|
||||
expected_output='A JSON string containing the extracted content from both URLs.',
|
||||
agent=extractor_agent
|
||||
)
|
||||
|
||||
# Configure the tool with custom parameters
|
||||
custom_extractor = TavilyExtractorTool(
|
||||
extract_depth='advanced',
|
||||
include_images=True,
|
||||
timeout=120
|
||||
)
|
||||
|
||||
agent_with_custom_tool = Agent(
|
||||
role="Advanced Content Extractor",
|
||||
goal="Extract comprehensive content with images",
|
||||
tools=[custom_extractor]
|
||||
)
|
||||
```
|
||||
|
||||
### Tool Parameters
|
||||
|
||||
You can customize the tool's behavior by setting parameters during initialization:
|
||||
|
||||
```python
|
||||
# Initialize with custom configuration
|
||||
extractor_tool = TavilyExtractorTool(
|
||||
extract_depth='advanced', # More comprehensive extraction
|
||||
include_images=True, # Include image results
|
||||
timeout=90 # Custom timeout
|
||||
)
|
||||
```
|
||||
|
||||
## Features
|
||||
|
||||
- **Single or Multiple URLs**: Extract content from one URL or process multiple URLs in a single request
|
||||
- **Configurable Depth**: Choose between basic (fast) and advanced (comprehensive) extraction modes
|
||||
- **Image Support**: Optionally include images in the extraction results
|
||||
- **Structured Output**: Returns well-formatted JSON containing the extracted content
|
||||
- **Error Handling**: Robust handling of network timeouts and extraction errors
|
||||
|
||||
## Response Format
|
||||
|
||||
The tool returns a JSON string representing the structured data extracted from the provided URL(s). The exact structure depends on the content of the pages and the `extract_depth` used.
|
||||
|
||||
Common response elements include:
|
||||
- **Title**: The page title
|
||||
- **Content**: Main text content of the page
|
||||
- **Images**: Image URLs and metadata (when `include_images=True`)
|
||||
- **Metadata**: Additional page information like author, description, etc.
|
||||
|
||||
## Use Cases
|
||||
|
||||
- **Content Analysis**: Extract and analyze content from competitor websites
|
||||
- **Research**: Gather structured data from multiple sources for analysis
|
||||
- **Content Migration**: Extract content from existing websites for migration
|
||||
- **Monitoring**: Regular extraction of content for change detection
|
||||
- **Data Collection**: Systematic extraction of information from web sources
|
||||
|
||||
Refer to the [Tavily API documentation](https://docs.tavily.com/docs/tavily-api/python-sdk#extract) for detailed information about the response structure and available options.
|
||||
@@ -1,124 +0,0 @@
|
||||
---
|
||||
title: "Tavily Search Tool"
|
||||
description: "Perform comprehensive web searches using the Tavily Search API"
|
||||
icon: "magnifying-glass"
|
||||
---
|
||||
|
||||
The `TavilySearchTool` provides an interface to the Tavily Search API, enabling CrewAI agents to perform comprehensive web searches. It allows for specifying search depth, topics, time ranges, included/excluded domains, and whether to include direct answers, raw content, or images in the results.
|
||||
|
||||
## Installation
|
||||
|
||||
To use the `TavilySearchTool`, you need to install the `tavily-python` library:
|
||||
|
||||
```shell
|
||||
pip install 'crewai[tools]' tavily-python
|
||||
```
|
||||
|
||||
## Environment Variables
|
||||
|
||||
Ensure your Tavily API key is set as an environment variable:
|
||||
|
||||
```bash
|
||||
export TAVILY_API_KEY='your_tavily_api_key'
|
||||
```
|
||||
|
||||
Get an API key at https://app.tavily.com/ (sign up, then create a key).
|
||||
|
||||
## Example Usage
|
||||
|
||||
Here's how to initialize and use the `TavilySearchTool` within a CrewAI agent:
|
||||
|
||||
```python
|
||||
import os
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import TavilySearchTool
|
||||
|
||||
# Ensure the TAVILY_API_KEY environment variable is set
|
||||
# os.environ["TAVILY_API_KEY"] = "YOUR_TAVILY_API_KEY"
|
||||
|
||||
# Initialize the tool
|
||||
tavily_tool = TavilySearchTool()
|
||||
|
||||
# Create an agent that uses the tool
|
||||
researcher = Agent(
|
||||
role='Market Researcher',
|
||||
goal='Find information about the latest AI trends',
|
||||
backstory='An expert market researcher specializing in technology.',
|
||||
tools=[tavily_tool],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Create a task for the agent
|
||||
research_task = Task(
|
||||
description='Search for the top 3 AI trends in 2024.',
|
||||
expected_output='A JSON report summarizing the top 3 AI trends found.',
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
# Form the crew and kick it off
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[research_task],
|
||||
verbose=2
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
|
||||
## Configuration Options
|
||||
|
||||
The `TavilySearchTool` accepts the following arguments during initialization or when calling the `run` method:
|
||||
|
||||
- `query` (str): **Required**. The search query string.
|
||||
- `search_depth` (Literal["basic", "advanced"], optional): The depth of the search. Defaults to `"basic"`.
|
||||
- `topic` (Literal["general", "news", "finance"], optional): The topic to focus the search on. Defaults to `"general"`.
|
||||
- `time_range` (Literal["day", "week", "month", "year"], optional): The time range for the search. Defaults to `None`.
|
||||
- `days` (int, optional): The number of days to search back. Relevant if `time_range` is not set. Defaults to `7`.
|
||||
- `max_results` (int, optional): The maximum number of search results to return. Defaults to `5`.
|
||||
- `include_domains` (Sequence[str], optional): A list of domains to prioritize in the search. Defaults to `None`.
|
||||
- `exclude_domains` (Sequence[str], optional): A list of domains to exclude from the search. Defaults to `None`.
|
||||
- `include_answer` (Union[bool, Literal["basic", "advanced"]], optional): Whether to include a direct answer synthesized from the search results. Defaults to `False`.
|
||||
- `include_raw_content` (bool, optional): Whether to include the raw HTML content of the searched pages. Defaults to `False`.
|
||||
- `include_images` (bool, optional): Whether to include image results. Defaults to `False`.
|
||||
- `timeout` (int, optional): The request timeout in seconds. Defaults to `60`.
|
||||
|
||||
## Advanced Usage
|
||||
|
||||
You can configure the tool with custom parameters:
|
||||
|
||||
```python
|
||||
# Example: Initialize with specific parameters
|
||||
custom_tavily_tool = TavilySearchTool(
|
||||
search_depth='advanced',
|
||||
max_results=10,
|
||||
include_answer=True
|
||||
)
|
||||
|
||||
# The agent will use these defaults
|
||||
agent_with_custom_tool = Agent(
|
||||
role="Advanced Researcher",
|
||||
goal="Conduct detailed research with comprehensive results",
|
||||
tools=[custom_tavily_tool]
|
||||
)
|
||||
```
|
||||
|
||||
## Features
|
||||
|
||||
- **Comprehensive Search**: Access to Tavily's powerful search index
|
||||
- **Configurable Depth**: Choose between basic and advanced search modes
|
||||
- **Topic Filtering**: Focus searches on general, news, or finance topics
|
||||
- **Time Range Control**: Limit results to specific time periods
|
||||
- **Domain Control**: Include or exclude specific domains
|
||||
- **Direct Answers**: Get synthesized answers from search results
|
||||
- **Content Filtering**: Prevent context window issues with automatic content truncation
|
||||
|
||||
## Response Format
|
||||
|
||||
The tool returns search results as a JSON string containing:
|
||||
- Search results with titles, URLs, and content snippets
|
||||
- Optional direct answers to queries
|
||||
- Optional image results
|
||||
- Optional raw HTML content (when enabled)
|
||||
|
||||
Content for each result is automatically truncated to prevent context window issues while maintaining the most relevant information.
|
||||
@@ -1,111 +0,0 @@
|
||||
---
|
||||
title: Bright Data Tools
|
||||
description: Bright Data integrations for SERP search, Web Unlocker scraping, and Dataset API.
|
||||
icon: spider
|
||||
---
|
||||
|
||||
# Bright Data Tools
|
||||
|
||||
This set of tools integrates Bright Data services for web extraction.
|
||||
|
||||
## Installation
|
||||
|
||||
```shell
|
||||
uv add crewai-tools requests aiohttp
|
||||
```
|
||||
|
||||
## Environment Variables
|
||||
|
||||
- `BRIGHT_DATA_API_KEY` (required)
|
||||
- `BRIGHT_DATA_ZONE` (for SERP/Web Unlocker)
|
||||
|
||||
Create credentials at https://brightdata.com/ (sign up, then create an API token and zone).
|
||||
See their docs: https://developers.brightdata.com/
|
||||
|
||||
## Included Tools
|
||||
|
||||
- `BrightDataSearchTool`: SERP search (Google/Bing/Yandex) with geo/language/device options.
|
||||
- `BrightDataWebUnlockerTool`: Scrape pages with anti-bot bypass and rendering.
|
||||
- `BrightDataDatasetTool`: Run Dataset API jobs and fetch results.
|
||||
|
||||
## Examples
|
||||
|
||||
### SERP Search
|
||||
|
||||
```python Code
|
||||
from crewai_tools import BrightDataSearchTool
|
||||
|
||||
tool = BrightDataSearchTool(
|
||||
query="CrewAI",
|
||||
country="us",
|
||||
)
|
||||
|
||||
print(tool.run())
|
||||
```
|
||||
|
||||
### Web Unlocker
|
||||
|
||||
```python Code
|
||||
from crewai_tools import BrightDataWebUnlockerTool
|
||||
|
||||
tool = BrightDataWebUnlockerTool(
|
||||
url="https://example.com",
|
||||
format="markdown",
|
||||
)
|
||||
|
||||
print(tool.run(url="https://example.com"))
|
||||
```
|
||||
|
||||
### Dataset API
|
||||
|
||||
```python Code
|
||||
from crewai_tools import BrightDataDatasetTool
|
||||
|
||||
tool = BrightDataDatasetTool(
|
||||
dataset_type="ecommerce",
|
||||
url="https://example.com/product",
|
||||
)
|
||||
|
||||
print(tool.run())
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
- 401/403: verify `BRIGHT_DATA_API_KEY` and `BRIGHT_DATA_ZONE`.
|
||||
- Empty/blocked content: enable rendering or try a different zone.
|
||||
|
||||
## Example
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import BrightDataSearchTool
|
||||
|
||||
tool = BrightDataSearchTool(
|
||||
query="CrewAI",
|
||||
country="us",
|
||||
)
|
||||
|
||||
agent = Agent(
|
||||
role="Web Researcher",
|
||||
goal="Search with Bright Data",
|
||||
backstory="Finds reliable results",
|
||||
tools=[tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description="Search for CrewAI and summarize top results",
|
||||
expected_output="Short summary with links",
|
||||
agent=agent,
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
|
||||
@@ -1,236 +0,0 @@
|
||||
---
|
||||
title: Oxylabs Scrapers
|
||||
description: >
|
||||
Oxylabs Scrapers allow to easily access the information from the respective sources. Please see the list of available sources below:
|
||||
- `Amazon Product`
|
||||
- `Amazon Search`
|
||||
- `Google Seach`
|
||||
- `Universal`
|
||||
icon: globe
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
Get the credentials by creating an Oxylabs Account [here](https://oxylabs.io).
|
||||
```shell
|
||||
pip install 'crewai[tools]' oxylabs
|
||||
```
|
||||
Check [Oxylabs Documentation](https://developers.oxylabs.io/scraping-solutions/web-scraper-api/targets) to get more information about API parameters.
|
||||
|
||||
# `OxylabsAmazonProductScraperTool`
|
||||
|
||||
### Example
|
||||
|
||||
```python
|
||||
from crewai_tools import OxylabsAmazonProductScraperTool
|
||||
|
||||
# make sure OXYLABS_USERNAME and OXYLABS_PASSWORD variables are set
|
||||
tool = OxylabsAmazonProductScraperTool()
|
||||
|
||||
result = tool.run(query="AAAAABBBBCC")
|
||||
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Parameters
|
||||
|
||||
- `query` - 10-symbol ASIN code.
|
||||
- `domain` - domain localization for Amazon.
|
||||
- `geo_location` - the _Deliver to_ location.
|
||||
- `user_agent_type` - device type and browser.
|
||||
- `render` - enables JavaScript rendering when set to `html`.
|
||||
- `callback_url` - URL to your callback endpoint.
|
||||
- `context` - Additional advanced settings and controls for specialized requirements.
|
||||
- `parse` - returns parsed data when set to true.
|
||||
- `parsing_instructions` - define your own parsing and data transformation logic that will be executed on an HTML scraping result.
|
||||
|
||||
### Advanced example
|
||||
|
||||
```python
|
||||
from crewai_tools import OxylabsAmazonProductScraperTool
|
||||
|
||||
# make sure OXYLABS_USERNAME and OXYLABS_PASSWORD variables are set
|
||||
tool = OxylabsAmazonProductScraperTool(
|
||||
config={
|
||||
"domain": "com",
|
||||
"parse": True,
|
||||
"context": [
|
||||
{
|
||||
"key": "autoselect_variant",
|
||||
"value": True
|
||||
}
|
||||
]
|
||||
}
|
||||
)
|
||||
|
||||
result = tool.run(query="AAAAABBBBCC")
|
||||
|
||||
print(result)
|
||||
```
|
||||
|
||||
# `OxylabsAmazonSearchScraperTool`
|
||||
|
||||
### Example
|
||||
|
||||
```python
|
||||
from crewai_tools import OxylabsAmazonSearchScraperTool
|
||||
|
||||
# make sure OXYLABS_USERNAME and OXYLABS_PASSWORD variables are set
|
||||
tool = OxylabsAmazonSearchScraperTool()
|
||||
|
||||
result = tool.run(query="headsets")
|
||||
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Parameters
|
||||
|
||||
- `query` - Amazon search term.
|
||||
- `domain` - Domain localization for Bestbuy.
|
||||
- `start_page` - starting page number.
|
||||
- `pages` - number of pages to retrieve.
|
||||
- `geo_location` - the _Deliver to_ location.
|
||||
- `user_agent_type` - device type and browser.
|
||||
- `render` - enables JavaScript rendering when set to `html`.
|
||||
- `callback_url` - URL to your callback endpoint.
|
||||
- `context` - Additional advanced settings and controls for specialized requirements.
|
||||
- `parse` - returns parsed data when set to true.
|
||||
- `parsing_instructions` - define your own parsing and data transformation logic that will be executed on an HTML scraping result.
|
||||
|
||||
### Advanced example
|
||||
|
||||
```python
|
||||
from crewai_tools import OxylabsAmazonSearchScraperTool
|
||||
|
||||
# make sure OXYLABS_USERNAME and OXYLABS_PASSWORD variables are set
|
||||
tool = OxylabsAmazonSearchScraperTool(
|
||||
config={
|
||||
"domain": 'nl',
|
||||
"start_page": 2,
|
||||
"pages": 2,
|
||||
"parse": True,
|
||||
"context": [
|
||||
{'key': 'category_id', 'value': 16391693031}
|
||||
],
|
||||
}
|
||||
)
|
||||
|
||||
result = tool.run(query='nirvana tshirt')
|
||||
|
||||
print(result)
|
||||
```
|
||||
|
||||
# `OxylabsGoogleSearchScraperTool`
|
||||
|
||||
### Example
|
||||
|
||||
```python
|
||||
from crewai_tools import OxylabsGoogleSearchScraperTool
|
||||
|
||||
# make sure OXYLABS_USERNAME and OXYLABS_PASSWORD variables are set
|
||||
tool = OxylabsGoogleSearchScraperTool()
|
||||
|
||||
result = tool.run(query="iPhone 16")
|
||||
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Parameters
|
||||
|
||||
- `query` - search keyword.
|
||||
- `domain` - domain localization for Google.
|
||||
- `start_page` - starting page number.
|
||||
- `pages` - number of pages to retrieve.
|
||||
- `limit` - number of results to retrieve in each page.
|
||||
- `locale` - `Accept-Language` header value which changes your Google search page web interface language.
|
||||
- `geo_location` - the geographical location that the result should be adapted for. Using this parameter correctly is extremely important to get the right data.
|
||||
- `user_agent_type` - device type and browser.
|
||||
- `render` - enables JavaScript rendering when set to `html`.
|
||||
- `callback_url` - URL to your callback endpoint.
|
||||
- `context` - Additional advanced settings and controls for specialized requirements.
|
||||
- `parse` - returns parsed data when set to true.
|
||||
- `parsing_instructions` - define your own parsing and data transformation logic that will be executed on an HTML scraping result.
|
||||
|
||||
### Advanced example
|
||||
|
||||
```python
|
||||
from crewai_tools import OxylabsGoogleSearchScraperTool
|
||||
|
||||
# make sure OXYLABS_USERNAME and OXYLABS_PASSWORD variables are set
|
||||
tool = OxylabsGoogleSearchScraperTool(
|
||||
config={
|
||||
"parse": True,
|
||||
"geo_location": "Paris, France",
|
||||
"user_agent_type": "tablet",
|
||||
}
|
||||
)
|
||||
|
||||
result = tool.run(query="iPhone 16")
|
||||
|
||||
print(result)
|
||||
```
|
||||
|
||||
# `OxylabsUniversalScraperTool`
|
||||
|
||||
### Example
|
||||
|
||||
```python
|
||||
from crewai_tools import OxylabsUniversalScraperTool
|
||||
|
||||
# make sure OXYLABS_USERNAME and OXYLABS_PASSWORD variables are set
|
||||
tool = OxylabsUniversalScraperTool()
|
||||
|
||||
result = tool.run(url="https://ip.oxylabs.io")
|
||||
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Parameters
|
||||
|
||||
- `url` - website url to scrape.
|
||||
- `user_agent_type` - device type and browser.
|
||||
- `geo_location` - sets the proxy's geolocation to retrieve data.
|
||||
- `render` - enables JavaScript rendering when set to `html`.
|
||||
- `callback_url` - URL to your callback endpoint.
|
||||
- `context` - Additional advanced settings and controls for specialized requirements.
|
||||
- `parse` - returns parsed data when set to `true`, as long as a dedicated parser exists for the submitted URL's page type.
|
||||
- `parsing_instructions` - define your own parsing and data transformation logic that will be executed on an HTML scraping result.
|
||||
|
||||
|
||||
### Advanced example
|
||||
|
||||
```python
|
||||
from crewai_tools import OxylabsUniversalScraperTool
|
||||
|
||||
# make sure OXYLABS_USERNAME and OXYLABS_PASSWORD variables are set
|
||||
tool = OxylabsUniversalScraperTool(
|
||||
config={
|
||||
"render": "html",
|
||||
"user_agent_type": "mobile",
|
||||
"context": [
|
||||
{"key": "force_headers", "value": True},
|
||||
{"key": "force_cookies", "value": True},
|
||||
{
|
||||
"key": "headers",
|
||||
"value": {
|
||||
"Custom-Header-Name": "custom header content",
|
||||
},
|
||||
},
|
||||
{
|
||||
"key": "cookies",
|
||||
"value": [
|
||||
{"key": "NID", "value": "1234567890"},
|
||||
{"key": "1P JAR", "value": "0987654321"},
|
||||
],
|
||||
},
|
||||
{"key": "http_method", "value": "get"},
|
||||
{"key": "follow_redirects", "value": True},
|
||||
{"key": "successful_status_codes", "value": [808, 909]},
|
||||
],
|
||||
}
|
||||
)
|
||||
|
||||
result = tool.run(url="https://ip.oxylabs.io")
|
||||
|
||||
print(result)
|
||||
```
|
||||
@@ -1,100 +0,0 @@
|
||||
---
|
||||
title: Serper Scrape Website
|
||||
description: The `SerperScrapeWebsiteTool` is designed to scrape websites and extract clean, readable content using Serper's scraping API.
|
||||
icon: globe
|
||||
---
|
||||
|
||||
# `SerperScrapeWebsiteTool`
|
||||
|
||||
## Description
|
||||
|
||||
This tool is designed to scrape website content and extract clean, readable text from any website URL. It utilizes the [serper.dev](https://serper.dev) scraping API to fetch and process web pages, optionally including markdown formatting for better structure and readability.
|
||||
|
||||
## Installation
|
||||
|
||||
To effectively use the `SerperScrapeWebsiteTool`, follow these steps:
|
||||
|
||||
1. **Package Installation**: Confirm that the `crewai[tools]` package is installed in your Python environment.
|
||||
2. **API Key Acquisition**: Acquire a `serper.dev` API key by registering for an account at `serper.dev`.
|
||||
3. **Environment Configuration**: Store your obtained API key in an environment variable named `SERPER_API_KEY` to facilitate its use by the tool.
|
||||
|
||||
To incorporate this tool into your project, follow the installation instructions below:
|
||||
|
||||
```shell
|
||||
pip install 'crewai[tools]'
|
||||
```
|
||||
|
||||
## Example
|
||||
|
||||
The following example demonstrates how to initialize the tool and scrape a website:
|
||||
|
||||
```python Code
|
||||
from crewai_tools import SerperScrapeWebsiteTool
|
||||
|
||||
# Initialize the tool for website scraping capabilities
|
||||
tool = SerperScrapeWebsiteTool()
|
||||
|
||||
# Scrape a website with markdown formatting
|
||||
result = tool.run(url="https://example.com", include_markdown=True)
|
||||
```
|
||||
|
||||
## Arguments
|
||||
|
||||
The `SerperScrapeWebsiteTool` accepts the following arguments:
|
||||
|
||||
- **url**: Required. The URL of the website to scrape.
|
||||
- **include_markdown**: Optional. Whether to include markdown formatting in the scraped content. Defaults to `True`.
|
||||
|
||||
## Example with Parameters
|
||||
|
||||
Here is an example demonstrating how to use the tool with different parameters:
|
||||
|
||||
```python Code
|
||||
from crewai_tools import SerperScrapeWebsiteTool
|
||||
|
||||
tool = SerperScrapeWebsiteTool()
|
||||
|
||||
# Scrape with markdown formatting (default)
|
||||
markdown_result = tool.run(
|
||||
url="https://docs.crewai.com",
|
||||
include_markdown=True
|
||||
)
|
||||
|
||||
# Scrape without markdown formatting for plain text
|
||||
plain_result = tool.run(
|
||||
url="https://docs.crewai.com",
|
||||
include_markdown=False
|
||||
)
|
||||
|
||||
print("Markdown formatted content:")
|
||||
print(markdown_result)
|
||||
|
||||
print("\nPlain text content:")
|
||||
print(plain_result)
|
||||
```
|
||||
|
||||
## Use Cases
|
||||
|
||||
The `SerperScrapeWebsiteTool` is particularly useful for:
|
||||
|
||||
- **Content Analysis**: Extract and analyze website content for research purposes
|
||||
- **Data Collection**: Gather structured information from web pages
|
||||
- **Documentation Processing**: Convert web-based documentation into readable formats
|
||||
- **Competitive Analysis**: Scrape competitor websites for market research
|
||||
- **Content Migration**: Extract content from existing websites for migration purposes
|
||||
|
||||
## Error Handling
|
||||
|
||||
The tool includes comprehensive error handling for:
|
||||
|
||||
- **Network Issues**: Handles connection timeouts and network errors gracefully
|
||||
- **API Errors**: Provides detailed error messages for API-related issues
|
||||
- **Invalid URLs**: Validates and reports issues with malformed URLs
|
||||
- **Authentication**: Clear error messages for missing or invalid API keys
|
||||
|
||||
## Security Considerations
|
||||
|
||||
- Always store your `SERPER_API_KEY` in environment variables, never hardcode it in your source code
|
||||
- Be mindful of rate limits imposed by the Serper API
|
||||
- Respect robots.txt and website terms of service when scraping content
|
||||
- Consider implementing delays between requests for large-scale scraping operations
|
||||
@@ -1,435 +0,0 @@
|
||||
openapi: 3.0.3
|
||||
info:
|
||||
title: CrewAI Enterprise API
|
||||
description: |
|
||||
REST API for interacting with your deployed CrewAI crews on CrewAI Enterprise.
|
||||
|
||||
## Getting Started
|
||||
|
||||
1. **Find your crew URL**: Get your unique crew URL from the CrewAI Enterprise dashboard
|
||||
2. **Copy examples**: Use the code examples from each endpoint page as templates
|
||||
3. **Replace placeholders**: Update URLs and tokens with your actual values
|
||||
4. **Test with your tools**: Use cURL, Postman, or your preferred API client
|
||||
|
||||
## Authentication
|
||||
|
||||
All API requests require a bearer token for authentication. There are two types of tokens:
|
||||
|
||||
- **Bearer Token**: Organization-level token for full crew operations
|
||||
- **User Bearer Token**: User-scoped token for individual access with limited permissions
|
||||
|
||||
You can find your bearer tokens in the Status tab of your crew's detail page in the CrewAI Enterprise dashboard.
|
||||
|
||||
## Reference Documentation
|
||||
|
||||
This documentation provides comprehensive examples for each endpoint:
|
||||
|
||||
- **Request formats** with all required and optional parameters
|
||||
- **Response examples** for success and error scenarios
|
||||
- **Code samples** in multiple programming languages
|
||||
- **Authentication patterns** with proper Bearer token usage
|
||||
|
||||
Copy the examples and customize them with your actual crew URL and authentication tokens.
|
||||
|
||||
## Workflow
|
||||
|
||||
1. **Discover inputs** using `GET /inputs`
|
||||
2. **Start execution** using `POST /kickoff`
|
||||
3. **Monitor progress** using `GET /status/{kickoff_id}`
|
||||
version: 1.0.0
|
||||
contact:
|
||||
name: CrewAI Support
|
||||
email: support@crewai.com
|
||||
url: https://crewai.com
|
||||
servers:
|
||||
- url: https://your-actual-crew-name.crewai.com
|
||||
description: Replace with your actual deployed crew URL from the CrewAI Enterprise dashboard
|
||||
- url: https://my-travel-crew.crewai.com
|
||||
description: Example travel planning crew (replace with your URL)
|
||||
- url: https://content-creation-crew.crewai.com
|
||||
description: Example content creation crew (replace with your URL)
|
||||
- url: https://research-assistant-crew.crewai.com
|
||||
description: Example research assistant crew (replace with your URL)
|
||||
security:
|
||||
- BearerAuth: []
|
||||
paths:
|
||||
/inputs:
|
||||
get:
|
||||
summary: Get Required Inputs
|
||||
description: |
|
||||
**📋 Reference Example Only** - *This shows the request format. To test with your actual crew, copy the cURL example and replace the URL + token with your real values.*
|
||||
|
||||
Retrieves the list of all required input parameters that your crew expects for execution.
|
||||
Use this endpoint to discover what inputs you need to provide when starting a crew execution.
|
||||
operationId: getRequiredInputs
|
||||
responses:
|
||||
'200':
|
||||
description: Successfully retrieved required inputs
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
inputs:
|
||||
type: array
|
||||
items:
|
||||
type: string
|
||||
description: Array of required input parameter names
|
||||
example: ["budget", "interests", "duration", "age"]
|
||||
examples:
|
||||
travel_crew:
|
||||
summary: Travel planning crew inputs
|
||||
value:
|
||||
inputs: ["budget", "interests", "duration", "age"]
|
||||
outreach_crew:
|
||||
summary: Outreach crew inputs
|
||||
value:
|
||||
inputs: ["name", "title", "company", "industry", "our_product", "linkedin_url"]
|
||||
'401':
|
||||
$ref: '#/components/responses/UnauthorizedError'
|
||||
'404':
|
||||
$ref: '#/components/responses/NotFoundError'
|
||||
'500':
|
||||
$ref: '#/components/responses/ServerError'
|
||||
|
||||
/kickoff:
|
||||
post:
|
||||
summary: Start Crew Execution
|
||||
description: |
|
||||
**📋 Reference Example Only** - *This shows the request format. To test with your actual crew, copy the cURL example and replace the URL + token with your real values.*
|
||||
|
||||
Initiates a new crew execution with the provided inputs. Returns a kickoff ID that can be used
|
||||
to track the execution progress and retrieve results.
|
||||
|
||||
Crew executions can take anywhere from seconds to minutes depending on their complexity.
|
||||
Consider using webhooks for real-time notifications or implement polling with the status endpoint.
|
||||
operationId: startCrewExecution
|
||||
requestBody:
|
||||
required: true
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
required:
|
||||
- inputs
|
||||
properties:
|
||||
inputs:
|
||||
type: object
|
||||
description: Key-value pairs of all required inputs for your crew
|
||||
additionalProperties:
|
||||
type: string
|
||||
example:
|
||||
budget: "1000 USD"
|
||||
interests: "games, tech, ai, relaxing hikes, amazing food"
|
||||
duration: "7 days"
|
||||
age: "35"
|
||||
meta:
|
||||
type: object
|
||||
description: Additional metadata to pass to the crew
|
||||
additionalProperties: true
|
||||
example:
|
||||
requestId: "user-request-12345"
|
||||
source: "mobile-app"
|
||||
taskWebhookUrl:
|
||||
type: string
|
||||
format: uri
|
||||
description: Callback URL executed after each task completion
|
||||
example: "https://your-server.com/webhooks/task"
|
||||
stepWebhookUrl:
|
||||
type: string
|
||||
format: uri
|
||||
description: Callback URL executed after each agent thought/action
|
||||
example: "https://your-server.com/webhooks/step"
|
||||
crewWebhookUrl:
|
||||
type: string
|
||||
format: uri
|
||||
description: Callback URL executed when the crew execution completes
|
||||
example: "https://your-server.com/webhooks/crew"
|
||||
examples:
|
||||
travel_planning:
|
||||
summary: Travel planning crew
|
||||
value:
|
||||
inputs:
|
||||
budget: "1000 USD"
|
||||
interests: "games, tech, ai, relaxing hikes, amazing food"
|
||||
duration: "7 days"
|
||||
age: "35"
|
||||
meta:
|
||||
requestId: "travel-req-123"
|
||||
source: "web-app"
|
||||
outreach_campaign:
|
||||
summary: Outreach crew with webhooks
|
||||
value:
|
||||
inputs:
|
||||
name: "John Smith"
|
||||
title: "CTO"
|
||||
company: "TechCorp"
|
||||
industry: "Software"
|
||||
our_product: "AI Development Platform"
|
||||
linkedin_url: "https://linkedin.com/in/johnsmith"
|
||||
taskWebhookUrl: "https://api.example.com/webhooks/task"
|
||||
crewWebhookUrl: "https://api.example.com/webhooks/crew"
|
||||
responses:
|
||||
'200':
|
||||
description: Crew execution started successfully
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
kickoff_id:
|
||||
type: string
|
||||
format: uuid
|
||||
description: Unique identifier for tracking this execution
|
||||
example: "abcd1234-5678-90ef-ghij-klmnopqrstuv"
|
||||
'400':
|
||||
description: Invalid request body or missing required inputs
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
'401':
|
||||
$ref: '#/components/responses/UnauthorizedError'
|
||||
'422':
|
||||
description: Validation error - ensure all required inputs are provided
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/ValidationError'
|
||||
'500':
|
||||
$ref: '#/components/responses/ServerError'
|
||||
|
||||
/status/{kickoff_id}:
|
||||
get:
|
||||
summary: Get Execution Status
|
||||
description: |
|
||||
**📋 Reference Example Only** - *This shows the request format. To test with your actual crew, copy the cURL example and replace the URL + token with your real values.*
|
||||
|
||||
Retrieves the current status and results of a crew execution using its kickoff ID.
|
||||
|
||||
The response structure varies depending on the execution state:
|
||||
- **running**: Execution in progress with current task info
|
||||
- **completed**: Execution finished with full results
|
||||
- **error**: Execution failed with error details
|
||||
operationId: getExecutionStatus
|
||||
parameters:
|
||||
- name: kickoff_id
|
||||
in: path
|
||||
required: true
|
||||
description: The kickoff ID returned from the /kickoff endpoint
|
||||
schema:
|
||||
type: string
|
||||
format: uuid
|
||||
example: "abcd1234-5678-90ef-ghij-klmnopqrstuv"
|
||||
responses:
|
||||
'200':
|
||||
description: Successfully retrieved execution status
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
oneOf:
|
||||
- $ref: '#/components/schemas/ExecutionRunning'
|
||||
- $ref: '#/components/schemas/ExecutionCompleted'
|
||||
- $ref: '#/components/schemas/ExecutionError'
|
||||
examples:
|
||||
running:
|
||||
summary: Execution in progress
|
||||
value:
|
||||
status: "running"
|
||||
current_task: "research_task"
|
||||
progress:
|
||||
completed_tasks: 1
|
||||
total_tasks: 3
|
||||
completed:
|
||||
summary: Execution completed successfully
|
||||
value:
|
||||
status: "completed"
|
||||
result:
|
||||
output: "Comprehensive travel itinerary for 7 days in Japan focusing on tech culture..."
|
||||
tasks:
|
||||
- task_id: "research_task"
|
||||
output: "Research findings on tech destinations in Japan..."
|
||||
agent: "Travel Researcher"
|
||||
execution_time: 45.2
|
||||
- task_id: "planning_task"
|
||||
output: "7-day detailed itinerary with activities and recommendations..."
|
||||
agent: "Trip Planner"
|
||||
execution_time: 62.8
|
||||
execution_time: 108.5
|
||||
error:
|
||||
summary: Execution failed
|
||||
value:
|
||||
status: "error"
|
||||
error: "Task execution failed: Invalid API key for external service"
|
||||
execution_time: 23.1
|
||||
'401':
|
||||
$ref: '#/components/responses/UnauthorizedError'
|
||||
'404':
|
||||
description: Kickoff ID not found
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
example:
|
||||
error: "Execution not found"
|
||||
message: "No execution found with ID: abcd1234-5678-90ef-ghij-klmnopqrstuv"
|
||||
'500':
|
||||
$ref: '#/components/responses/ServerError'
|
||||
|
||||
components:
|
||||
securitySchemes:
|
||||
BearerAuth:
|
||||
type: http
|
||||
scheme: bearer
|
||||
description: |
|
||||
**📋 Reference Documentation** - *The tokens shown in examples are placeholders for reference only.*
|
||||
|
||||
Use your actual Bearer Token or User Bearer Token from the CrewAI Enterprise dashboard for real API calls.
|
||||
|
||||
**Bearer Token**: Organization-level access for full crew operations
|
||||
**User Bearer Token**: User-scoped access with limited permissions
|
||||
|
||||
schemas:
|
||||
ExecutionRunning:
|
||||
type: object
|
||||
properties:
|
||||
status:
|
||||
type: string
|
||||
enum: ["running"]
|
||||
example: "running"
|
||||
current_task:
|
||||
type: string
|
||||
description: Name of the currently executing task
|
||||
example: "research_task"
|
||||
progress:
|
||||
type: object
|
||||
properties:
|
||||
completed_tasks:
|
||||
type: integer
|
||||
description: Number of completed tasks
|
||||
example: 1
|
||||
total_tasks:
|
||||
type: integer
|
||||
description: Total number of tasks in the crew
|
||||
example: 3
|
||||
|
||||
ExecutionCompleted:
|
||||
type: object
|
||||
properties:
|
||||
status:
|
||||
type: string
|
||||
enum: ["completed"]
|
||||
example: "completed"
|
||||
result:
|
||||
type: object
|
||||
properties:
|
||||
output:
|
||||
type: string
|
||||
description: Final output from the crew execution
|
||||
example: "Comprehensive travel itinerary..."
|
||||
tasks:
|
||||
type: array
|
||||
items:
|
||||
$ref: '#/components/schemas/TaskResult'
|
||||
execution_time:
|
||||
type: number
|
||||
description: Total execution time in seconds
|
||||
example: 108.5
|
||||
|
||||
ExecutionError:
|
||||
type: object
|
||||
properties:
|
||||
status:
|
||||
type: string
|
||||
enum: ["error"]
|
||||
example: "error"
|
||||
error:
|
||||
type: string
|
||||
description: Error message describing what went wrong
|
||||
example: "Task execution failed: Invalid API key"
|
||||
execution_time:
|
||||
type: number
|
||||
description: Time until error occurred in seconds
|
||||
example: 23.1
|
||||
|
||||
TaskResult:
|
||||
type: object
|
||||
properties:
|
||||
task_id:
|
||||
type: string
|
||||
description: Unique identifier for the task
|
||||
example: "research_task"
|
||||
output:
|
||||
type: string
|
||||
description: Output generated by this task
|
||||
example: "Research findings..."
|
||||
agent:
|
||||
type: string
|
||||
description: Name of the agent that executed this task
|
||||
example: "Travel Researcher"
|
||||
execution_time:
|
||||
type: number
|
||||
description: Time taken to execute this task in seconds
|
||||
example: 45.2
|
||||
|
||||
Error:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
description: Error type or title
|
||||
example: "Authentication Error"
|
||||
message:
|
||||
type: string
|
||||
description: Detailed error message
|
||||
example: "Invalid bearer token provided"
|
||||
|
||||
ValidationError:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
example: "Validation Error"
|
||||
message:
|
||||
type: string
|
||||
example: "Missing required inputs"
|
||||
details:
|
||||
type: object
|
||||
properties:
|
||||
missing_inputs:
|
||||
type: array
|
||||
items:
|
||||
type: string
|
||||
example: ["budget", "interests"]
|
||||
|
||||
responses:
|
||||
UnauthorizedError:
|
||||
description: Authentication failed - check your bearer token
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
example:
|
||||
error: "Unauthorized"
|
||||
message: "Invalid or missing bearer token"
|
||||
|
||||
NotFoundError:
|
||||
description: Resource not found
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
example:
|
||||
error: "Not Found"
|
||||
message: "The requested resource was not found"
|
||||
|
||||
ServerError:
|
||||
description: Internal server error
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
example:
|
||||
error: "Internal Server Error"
|
||||
message: "An unexpected error occurred"
|
||||
|
||||
@@ -1,231 +0,0 @@
|
||||
openapi: 3.0.3
|
||||
info:
|
||||
title: CrewAI 엔터프라이즈 API
|
||||
description: |
|
||||
CrewAI Enterprise에 배포된 crew와 상호작용하기 위한 REST API입니다.
|
||||
|
||||
## 시작하기
|
||||
1. **Crew URL 확인**: 대시보드에서 고유한 crew URL을 확인하세요
|
||||
2. **예제 복사**: 각 엔드포인트의 예제를 템플릿으로 사용하세요
|
||||
3. **플레이스홀더 교체**: 실제 URL과 토큰으로 바꾸세요
|
||||
4. **도구로 테스트**: cURL, Postman 등 선호하는 도구로 테스트하세요
|
||||
version: 1.0.0
|
||||
contact:
|
||||
name: CrewAI 지원
|
||||
email: support@crewai.com
|
||||
url: https://crewai.com
|
||||
servers:
|
||||
- url: https://your-actual-crew-name.crewai.com
|
||||
description: 대시보드의 실제 crew URL로 교체하세요
|
||||
security:
|
||||
- BearerAuth: []
|
||||
paths:
|
||||
/inputs:
|
||||
get:
|
||||
summary: 필요 입력값 조회
|
||||
description: |
|
||||
**📋 참조 예제만 제공** - *요청 형식을 보여줍니다. 실제 호출은 cURL 예제를 복사해 URL과 토큰을 교체하세요.*
|
||||
|
||||
실행에 필요한 입력 파라미터 목록을 반환합니다.
|
||||
operationId: getRequiredInputs
|
||||
responses:
|
||||
'200':
|
||||
description: 입력값을 성공적으로 조회
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
inputs:
|
||||
type: array
|
||||
items:
|
||||
type: string
|
||||
'401':
|
||||
$ref: '#/components/responses/UnauthorizedError'
|
||||
'404':
|
||||
$ref: '#/components/responses/NotFoundError'
|
||||
'500':
|
||||
$ref: '#/components/responses/ServerError'
|
||||
|
||||
/kickoff:
|
||||
post:
|
||||
summary: Crew 실행 시작
|
||||
description: |
|
||||
**📋 참조 예제만 제공** - *요청 형식을 보여줍니다. 실제 호출은 cURL 예제를 복사해 URL과 토큰을 교체하세요.*
|
||||
|
||||
제공된 입력으로 새로운 실행을 시작하고 kickoff ID를 반환합니다.
|
||||
operationId: startCrewExecution
|
||||
requestBody:
|
||||
required: true
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
required:
|
||||
- inputs
|
||||
properties:
|
||||
inputs:
|
||||
type: object
|
||||
additionalProperties:
|
||||
type: string
|
||||
responses:
|
||||
'200':
|
||||
description: 실행이 성공적으로 시작됨
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
kickoff_id:
|
||||
type: string
|
||||
format: uuid
|
||||
'401':
|
||||
$ref: '#/components/responses/UnauthorizedError'
|
||||
'500':
|
||||
$ref: '#/components/responses/ServerError'
|
||||
|
||||
/status/{kickoff_id}:
|
||||
get:
|
||||
summary: 실행 상태 조회
|
||||
description: |
|
||||
**📋 참조 예제만 제공** - *요청 형식을 보여줍니다. 실제 호출은 cURL 예제를 복사해 URL과 토큰을 교체하세요.*
|
||||
|
||||
kickoff ID로 실행 상태와 결과를 조회합니다.
|
||||
operationId: getExecutionStatus
|
||||
parameters:
|
||||
- name: kickoff_id
|
||||
in: path
|
||||
required: true
|
||||
schema:
|
||||
type: string
|
||||
format: uuid
|
||||
responses:
|
||||
'200':
|
||||
description: 상태를 성공적으로 조회
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
oneOf:
|
||||
- $ref: '#/components/schemas/ExecutionRunning'
|
||||
- $ref: '#/components/schemas/ExecutionCompleted'
|
||||
- $ref: '#/components/schemas/ExecutionError'
|
||||
'401':
|
||||
$ref: '#/components/responses/UnauthorizedError'
|
||||
'404':
|
||||
description: Kickoff ID를 찾을 수 없음
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
'500':
|
||||
$ref: '#/components/responses/ServerError'
|
||||
|
||||
components:
|
||||
securitySchemes:
|
||||
BearerAuth:
|
||||
type: http
|
||||
scheme: bearer
|
||||
description: |
|
||||
**📋 참고** - *예시의 토큰은 자리 표시자입니다.* 실제 토큰을 사용하세요.
|
||||
|
||||
schemas:
|
||||
ExecutionRunning:
|
||||
type: object
|
||||
properties:
|
||||
status:
|
||||
type: string
|
||||
enum: ["running"]
|
||||
current_task:
|
||||
type: string
|
||||
progress:
|
||||
type: object
|
||||
properties:
|
||||
completed_tasks:
|
||||
type: integer
|
||||
total_tasks:
|
||||
type: integer
|
||||
|
||||
ExecutionCompleted:
|
||||
type: object
|
||||
properties:
|
||||
status:
|
||||
type: string
|
||||
enum: ["completed"]
|
||||
result:
|
||||
type: object
|
||||
properties:
|
||||
output:
|
||||
type: string
|
||||
tasks:
|
||||
type: array
|
||||
items:
|
||||
$ref: '#/components/schemas/TaskResult'
|
||||
execution_time:
|
||||
type: number
|
||||
|
||||
ExecutionError:
|
||||
type: object
|
||||
properties:
|
||||
status:
|
||||
type: string
|
||||
enum: ["error"]
|
||||
error:
|
||||
type: string
|
||||
execution_time:
|
||||
type: number
|
||||
|
||||
TaskResult:
|
||||
type: object
|
||||
properties:
|
||||
task_id:
|
||||
type: string
|
||||
output:
|
||||
type: string
|
||||
agent:
|
||||
type: string
|
||||
execution_time:
|
||||
type: number
|
||||
|
||||
Error:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
message:
|
||||
type: string
|
||||
|
||||
ValidationError:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
message:
|
||||
type: string
|
||||
details:
|
||||
type: object
|
||||
properties:
|
||||
missing_inputs:
|
||||
type: array
|
||||
items:
|
||||
type: string
|
||||
|
||||
responses:
|
||||
UnauthorizedError:
|
||||
description: 인증 실패
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
NotFoundError:
|
||||
description: 리소스를 찾을 수 없음
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
ServerError:
|
||||
description: 서버 내부 오류
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
|
||||
@@ -1,268 +0,0 @@
|
||||
openapi: 3.0.3
|
||||
info:
|
||||
title: CrewAI Enterprise API
|
||||
description: |
|
||||
REST API para interagir com suas crews implantadas no CrewAI Enterprise.
|
||||
|
||||
## Introdução
|
||||
|
||||
1. **Encontre a URL da sua crew**: Obtenha sua URL única no painel do CrewAI Enterprise
|
||||
2. **Copie os exemplos**: Use os exemplos de cada endpoint como modelo
|
||||
3. **Substitua os placeholders**: Atualize URLs e tokens com seus valores reais
|
||||
4. **Teste com suas ferramentas**: Use cURL, Postman ou seu cliente preferido
|
||||
|
||||
## Autenticação
|
||||
|
||||
Todas as requisições exigem um token bearer. Existem dois tipos:
|
||||
|
||||
- **Bearer Token**: Token em nível de organização para operações completas
|
||||
- **User Bearer Token**: Token com escopo de usuário com permissões limitadas
|
||||
|
||||
Você encontra os tokens na aba Status da sua crew no painel do CrewAI Enterprise.
|
||||
|
||||
## Documentação de Referência
|
||||
|
||||
Este documento fornece exemplos completos para cada endpoint:
|
||||
|
||||
- **Formatos de requisição** com parâmetros obrigatórios e opcionais
|
||||
- **Exemplos de resposta** para sucesso e erro
|
||||
- **Amostras de código** em várias linguagens
|
||||
- **Padrões de autenticação** com uso correto de Bearer token
|
||||
|
||||
Copie os exemplos e personalize com sua URL e tokens reais.
|
||||
|
||||
## Fluxo
|
||||
|
||||
1. **Descubra os inputs** usando `GET /inputs`
|
||||
2. **Inicie a execução** usando `POST /kickoff`
|
||||
3. **Monitore o progresso** usando `GET /status/{kickoff_id}`
|
||||
version: 1.0.0
|
||||
contact:
|
||||
name: CrewAI Suporte
|
||||
email: support@crewai.com
|
||||
url: https://crewai.com
|
||||
servers:
|
||||
- url: https://your-actual-crew-name.crewai.com
|
||||
description: Substitua pela URL real da sua crew no painel do CrewAI Enterprise
|
||||
security:
|
||||
- BearerAuth: []
|
||||
paths:
|
||||
/inputs:
|
||||
get:
|
||||
summary: Obter Inputs Requeridos
|
||||
description: |
|
||||
**📋 Exemplo de Referência** - *Mostra o formato da requisição. Para testar com sua crew real, copie o cURL e substitua URL + token.*
|
||||
|
||||
Retorna a lista de parâmetros de entrada que sua crew espera.
|
||||
operationId: getRequiredInputs
|
||||
responses:
|
||||
'200':
|
||||
description: Inputs requeridos obtidos com sucesso
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
inputs:
|
||||
type: array
|
||||
items:
|
||||
type: string
|
||||
description: Nomes dos parâmetros de entrada
|
||||
example: ["budget", "interests", "duration", "age"]
|
||||
'401':
|
||||
$ref: '#/components/responses/UnauthorizedError'
|
||||
'404':
|
||||
$ref: '#/components/responses/NotFoundError'
|
||||
'500':
|
||||
$ref: '#/components/responses/ServerError'
|
||||
|
||||
/kickoff:
|
||||
post:
|
||||
summary: Iniciar Execução da Crew
|
||||
description: |
|
||||
**📋 Exemplo de Referência** - *Mostra o formato da requisição. Para testar com sua crew real, copie o cURL e substitua URL + token.*
|
||||
|
||||
Inicia uma nova execução da crew com os inputs fornecidos e retorna um kickoff ID.
|
||||
operationId: startCrewExecution
|
||||
requestBody:
|
||||
required: true
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
required:
|
||||
- inputs
|
||||
properties:
|
||||
inputs:
|
||||
type: object
|
||||
additionalProperties:
|
||||
type: string
|
||||
example:
|
||||
budget: "1000 USD"
|
||||
interests: "games, tech, ai, relaxing hikes, amazing food"
|
||||
duration: "7 days"
|
||||
age: "35"
|
||||
|
||||
responses:
|
||||
'200':
|
||||
description: Execução iniciada com sucesso
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
kickoff_id:
|
||||
type: string
|
||||
format: uuid
|
||||
example: "abcd1234-5678-90ef-ghij-klmnopqrstuv"
|
||||
'401':
|
||||
$ref: '#/components/responses/UnauthorizedError'
|
||||
'500':
|
||||
$ref: '#/components/responses/ServerError'
|
||||
|
||||
/status/{kickoff_id}:
|
||||
get:
|
||||
summary: Obter Status da Execução
|
||||
description: |
|
||||
**📋 Exemplo de Referência** - *Mostra o formato da requisição. Para testar com sua crew real, copie o cURL e substitua URL + token.*
|
||||
|
||||
Retorna o status atual e os resultados de uma execução usando o kickoff ID.
|
||||
operationId: getExecutionStatus
|
||||
parameters:
|
||||
- name: kickoff_id
|
||||
in: path
|
||||
required: true
|
||||
schema:
|
||||
type: string
|
||||
format: uuid
|
||||
responses:
|
||||
'200':
|
||||
description: Status recuperado com sucesso
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
oneOf:
|
||||
- $ref: '#/components/schemas/ExecutionRunning'
|
||||
- $ref: '#/components/schemas/ExecutionCompleted'
|
||||
- $ref: '#/components/schemas/ExecutionError'
|
||||
'401':
|
||||
$ref: '#/components/responses/UnauthorizedError'
|
||||
'404':
|
||||
description: Kickoff ID não encontrado
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
'500':
|
||||
$ref: '#/components/responses/ServerError'
|
||||
|
||||
components:
|
||||
securitySchemes:
|
||||
BearerAuth:
|
||||
type: http
|
||||
scheme: bearer
|
||||
description: |
|
||||
**📋 Referência** - *Os tokens mostrados são apenas exemplos.*
|
||||
Use seus tokens reais do painel do CrewAI Enterprise.
|
||||
|
||||
schemas:
|
||||
ExecutionRunning:
|
||||
type: object
|
||||
properties:
|
||||
status:
|
||||
type: string
|
||||
enum: ["running"]
|
||||
current_task:
|
||||
type: string
|
||||
progress:
|
||||
type: object
|
||||
properties:
|
||||
completed_tasks:
|
||||
type: integer
|
||||
total_tasks:
|
||||
type: integer
|
||||
|
||||
ExecutionCompleted:
|
||||
type: object
|
||||
properties:
|
||||
status:
|
||||
type: string
|
||||
enum: ["completed"]
|
||||
result:
|
||||
type: object
|
||||
properties:
|
||||
output:
|
||||
type: string
|
||||
tasks:
|
||||
type: array
|
||||
items:
|
||||
$ref: '#/components/schemas/TaskResult'
|
||||
execution_time:
|
||||
type: number
|
||||
|
||||
ExecutionError:
|
||||
type: object
|
||||
properties:
|
||||
status:
|
||||
type: string
|
||||
enum: ["error"]
|
||||
error:
|
||||
type: string
|
||||
execution_time:
|
||||
type: number
|
||||
|
||||
TaskResult:
|
||||
type: object
|
||||
properties:
|
||||
task_id:
|
||||
type: string
|
||||
output:
|
||||
type: string
|
||||
agent:
|
||||
type: string
|
||||
execution_time:
|
||||
type: number
|
||||
|
||||
Error:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
message:
|
||||
type: string
|
||||
|
||||
ValidationError:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
message:
|
||||
type: string
|
||||
details:
|
||||
type: object
|
||||
properties:
|
||||
missing_inputs:
|
||||
type: array
|
||||
items:
|
||||
type: string
|
||||
|
||||
responses:
|
||||
UnauthorizedError:
|
||||
description: Autenticação falhou
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
NotFoundError:
|
||||
description: Recurso não encontrado
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
ServerError:
|
||||
description: Erro interno do servidor
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/Error'
|
||||
|
||||
@@ -25,13 +25,8 @@ AI hallucinations occur when language models generate content that appears plaus
|
||||
from crewai.tasks.hallucination_guardrail import HallucinationGuardrail
|
||||
from crewai import LLM
|
||||
|
||||
# Basic usage - will use task's expected_output as context
|
||||
# Initialize the guardrail with reference context
|
||||
guardrail = HallucinationGuardrail(
|
||||
llm=LLM(model="gpt-4o-mini")
|
||||
)
|
||||
|
||||
# With explicit reference context
|
||||
context_guardrail = HallucinationGuardrail(
|
||||
context="AI helps with various tasks including analysis and generation.",
|
||||
llm=LLM(model="gpt-4o-mini")
|
||||
)
|
||||
@@ -21,7 +21,6 @@ Before using the Tool Repository, ensure you have:
|
||||
|
||||
- A [CrewAI Enterprise](https://app.crewai.com) account
|
||||
- [CrewAI CLI](https://docs.crewai.com/concepts/cli#cli) installed
|
||||
- uv>=0.5.0 installed. Check out [how to upgrade](https://docs.astral.sh/uv/getting-started/installation/#upgrading-uv)
|
||||
- [Git](https://git-scm.com) installed and configured
|
||||
- Access permissions to publish or install tools in your CrewAI Enterprise organization
|
||||
|
||||
@@ -35,22 +34,6 @@ crewai tool install <tool-name>
|
||||
|
||||
This installs the tool and adds it to `pyproject.toml`.
|
||||
|
||||
You can use the tool by importing it and adding it to your agents:
|
||||
|
||||
```python
|
||||
from your_tool.tool import YourTool
|
||||
|
||||
custom_tool = YourTool()
|
||||
|
||||
researcher = Agent(
|
||||
role='Market Research Analyst',
|
||||
goal='Provide up-to-date market analysis of the AI industry',
|
||||
backstory='An expert analyst with a keen eye for market trends.',
|
||||
tools=[custom_tool],
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
## Creating and Publishing Tools
|
||||
|
||||
To create a new tool project:
|
||||
@@ -23,13 +23,13 @@ icon: "people-arrows"
|
||||
|
||||
### Installation and Setup
|
||||
|
||||
<Card title="Follow Standard Installation" icon="wrench" href="/en/installation">
|
||||
<Card title="Follow Standard Installation" icon="wrench" href="/installation">
|
||||
Follow our standard installation guide to set up CrewAI CLI and create your first project.
|
||||
</Card>
|
||||
|
||||
### Building Your Crew
|
||||
|
||||
<Card title="Quickstart Tutorial" icon="rocket" href="/en/quickstart">
|
||||
<Card title="Quickstart Tutorial" icon="rocket" href="/quickstart">
|
||||
Follow our quickstart guide to create your first agent crew using YAML configuration.
|
||||
</Card>
|
||||
|
||||
@@ -41,8 +41,11 @@ The CLI provides the fastest way to deploy locally developed crews to the Enterp
|
||||
First, you need to authenticate your CLI with the CrewAI Enterprise platform:
|
||||
|
||||
```bash
|
||||
# If you already have a CrewAI Enterprise account, or want to create one:
|
||||
# If you already have a CrewAI Enterprise account
|
||||
crewai login
|
||||
|
||||
# If you're creating a new account
|
||||
crewai signup
|
||||
```
|
||||
|
||||
When you run either command, the CLI will:
|
||||
@@ -129,7 +132,7 @@ You can also deploy your crews directly through the CrewAI Enterprise web interf
|
||||
|
||||
<Step title="Pushing to GitHub">
|
||||
|
||||
You need to push your crew to a GitHub repository. If you haven't created a crew yet, you can [follow this tutorial](/en/quickstart).
|
||||
You need to push your crew to a GitHub repository. If you haven't created a crew yet, you can [follow this tutorial](/quickstart).
|
||||
|
||||
</Step>
|
||||
|
||||
@@ -69,7 +69,7 @@ CrewAI Enterprise extends the power of the open-source framework with features d
|
||||
<Card
|
||||
title="Build Crew"
|
||||
icon="paintbrush"
|
||||
href="/en/enterprise/guides/build-crew"
|
||||
href="/enterprise/guides/build-crew"
|
||||
>
|
||||
Build Crew
|
||||
</Card>
|
||||
@@ -79,7 +79,7 @@ CrewAI Enterprise extends the power of the open-source framework with features d
|
||||
<Card
|
||||
title="Deploy Crew"
|
||||
icon="rocket"
|
||||
href="/en/enterprise/guides/deploy-crew"
|
||||
href="/enterprise/guides/deploy-crew"
|
||||
>
|
||||
Deploy Crew
|
||||
</Card>
|
||||
@@ -89,11 +89,11 @@ CrewAI Enterprise extends the power of the open-source framework with features d
|
||||
<Card
|
||||
title="API Access"
|
||||
icon="code"
|
||||
href="/en/enterprise/guides/kickoff-crew"
|
||||
href="/enterprise/guides/use-crew-api"
|
||||
>
|
||||
Use the Crew API
|
||||
</Card>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
For detailed instructions, check out our [deployment guide](/en/enterprise/guides/deploy-crew) or click the button below to get started.
|
||||
For detailed instructions, check out our [deployment guide](/enterprise/guides/deploy-crew) or click the button below to get started.
|
||||
@@ -48,7 +48,7 @@ icon: "circle-question"
|
||||
|
||||
To integrate human input into agent execution, set the `human_input` flag in the task definition. When enabled, the agent prompts the user for input before delivering its final answer. This input can provide extra context, clarify ambiguities, or validate the agent's output.
|
||||
|
||||
For detailed implementation guidance, see our [Human-in-the-Loop guide](/en/how-to/human-in-the-loop).
|
||||
For detailed implementation guidance, see our [Human-in-the-Loop guide](/how-to/human-in-the-loop).
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="What advanced customization options are available for tailoring and enhancing agent behavior and capabilities in CrewAI?">
|
||||
62
docs/examples/example.mdx
Normal file
62
docs/examples/example.mdx
Normal file
@@ -0,0 +1,62 @@
|
||||
---
|
||||
title: CrewAI Examples
|
||||
description: A collection of examples that show how to use CrewAI framework to automate workflows.
|
||||
icon: rocket-launch
|
||||
---
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card
|
||||
title="Marketing Strategy"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/crewAIInc/crewAI-examples/tree/main/marketing_strategy"
|
||||
icon="bullhorn"
|
||||
iconType="solid"
|
||||
>
|
||||
Automate marketing strategy creation with CrewAI.
|
||||
</Card>
|
||||
<Card
|
||||
title="Surprise Trip"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/crewAIInc/crewAI-examples/tree/main/surprise_trip"
|
||||
icon="plane"
|
||||
iconType="duotone"
|
||||
>
|
||||
Create a surprise trip itinerary with CrewAI.
|
||||
</Card>
|
||||
<Card
|
||||
title="Match Profile to Positions"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/crewAIInc/crewAI-examples/tree/main/match_profile_to_positions"
|
||||
icon="linkedin"
|
||||
iconType="duotone"
|
||||
>
|
||||
Match a profile to jobpositions with CrewAI.
|
||||
</Card>
|
||||
<Card
|
||||
title="Create Job Posting"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/crewAIInc/crewAI-examples/tree/main/job-posting"
|
||||
icon="newspaper"
|
||||
iconType="duotone"
|
||||
>
|
||||
Create a job posting with CrewAI.
|
||||
</Card>
|
||||
<Card
|
||||
title="Game Generator"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/crewAIInc/crewAI-examples/tree/main/game-builder-crew"
|
||||
icon="gamepad"
|
||||
iconType="duotone"
|
||||
>
|
||||
Create a game with CrewAI.
|
||||
</Card>
|
||||
<Card
|
||||
title="Find Job Candidates"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/crewAIInc/crewAI-examples/tree/main/recruitment"
|
||||
icon="user-group"
|
||||
iconType="duotone"
|
||||
>
|
||||
Find job candidates with CrewAI.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
@@ -174,13 +174,13 @@ agent = Agent(
|
||||
|
||||
For production transparency, integrate with observability platforms to monitor all prompts and LLM interactions. This allows you to see exactly what prompts (including default instructions) are being sent to your LLMs.
|
||||
|
||||
See our [Observability documentation](/en/observability/overview) for detailed integration guides with various platforms including Langfuse, MLflow, Weights & Biases, and custom logging solutions.
|
||||
See our [Observability documentation](/how-to/observability) for detailed integration guides with various platforms including Langfuse, MLflow, Weights & Biases, and custom logging solutions.
|
||||
|
||||
### Best Practices for Production
|
||||
|
||||
1. **Always inspect generated prompts** before deploying to production
|
||||
2. **Use custom templates** when you need full control over prompt content
|
||||
3. **Integrate observability tools** for ongoing prompt monitoring (see [Observability docs](/en/observability/overview))
|
||||
3. **Integrate observability tools** for ongoing prompt monitoring (see [Observability docs](/how-to/observability))
|
||||
4. **Test with different LLMs** as default instructions may work differently across models
|
||||
5. **Document your prompt customizations** for team transparency
|
||||
|
||||
@@ -448,5 +448,5 @@ Congratulations! You now understand the principles and practices of effective ag
|
||||
## Next Steps
|
||||
|
||||
- Experiment with different agent configurations for your specific use case
|
||||
- Learn about [building your first crew](/en/guides/crews/first-crew) to see how agents work together
|
||||
- Explore [CrewAI Flows](/en/guides/flows/first-flow) for more advanced orchestration
|
||||
- Learn about [building your first crew](/guides/crews/first-crew) to see how agents work together
|
||||
- Explore [CrewAI Flows](/guides/flows/first-flow) for more advanced orchestration
|
||||
@@ -11,7 +11,7 @@ When building AI applications with CrewAI, one of the most important decisions y
|
||||
At the heart of this decision is understanding the relationship between **complexity** and **precision** in your application:
|
||||
|
||||
<Frame caption="Complexity vs. Precision Matrix for CrewAI Applications">
|
||||
<img src="/images/complexity_precision.png" alt="Complexity vs. Precision Matrix" />
|
||||
<img src="../../images/complexity_precision.png" alt="Complexity vs. Precision Matrix" />
|
||||
</Frame>
|
||||
|
||||
This matrix helps visualize how different approaches align with varying requirements for complexity and precision. Let's explore what each quadrant means and how it guides your architectural choices.
|
||||
@@ -497,7 +497,7 @@ You now have a framework for evaluating CrewAI use cases and choosing the right
|
||||
|
||||
## Next Steps
|
||||
|
||||
- Learn more about [crafting effective agents](/en/guides/agents/crafting-effective-agents)
|
||||
- Explore [building your first crew](/en/guides/crews/first-crew)
|
||||
- Dive into [mastering flow state management](/en/guides/flows/mastering-flow-state)
|
||||
- Check out the [core concepts](/en/concepts/agents) for deeper understanding
|
||||
- Learn more about [crafting effective agents](/guides/agents/crafting-effective-agents)
|
||||
- Explore [building your first crew](/guides/crews/first-crew)
|
||||
- Dive into [mastering flow state management](/guides/flows/mastering-flow-state)
|
||||
- Check out the [core concepts](/concepts/agents) for deeper understanding
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user