mirror of
https://github.com/crewAIInc/crewAI.git
synced 2026-05-04 16:52:37 +00:00
Compare commits
6 Commits
devin/1748
...
lorenze/re
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
f403557274 | ||
|
|
fb16adabde | ||
|
|
2bd6b72aae | ||
|
|
f02e0060fa | ||
|
|
66b7628972 | ||
|
|
c045399d6b |
5
.github/workflows/linter.yml
vendored
5
.github/workflows/linter.yml
vendored
@@ -30,4 +30,7 @@ jobs:
|
||||
- name: Run Ruff on Changed Files
|
||||
if: ${{ steps.changed-files.outputs.files != '' }}
|
||||
run: |
|
||||
echo "${{ steps.changed-files.outputs.files }}" | tr " " "\n" | xargs -I{} ruff check "{}"
|
||||
echo "${{ steps.changed-files.outputs.files }}" \
|
||||
| tr ' ' '\n' \
|
||||
| grep -v 'src/crewai/cli/templates/' \
|
||||
| xargs -I{} ruff check "{}"
|
||||
|
||||
2
.github/workflows/tests.yml
vendored
2
.github/workflows/tests.yml
vendored
@@ -14,7 +14,7 @@ jobs:
|
||||
timeout-minutes: 15
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ['3.10', '3.11', '3.12']
|
||||
python-version: ['3.10', '3.11', '3.12', '3.13']
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
@@ -403,7 +403,7 @@ In addition to the sequential process, you can use the hierarchical process, whi
|
||||
|
||||
## Key Features
|
||||
|
||||
CrewAI stands apart as a lean, standalone, high-performance framework delivering simplicity, flexibility, and precise control—free from the complexity and limitations found in other agent frameworks.
|
||||
CrewAI stands apart as a lean, standalone, high-performance multi-AI Agent framework delivering simplicity, flexibility, and precise control—free from the complexity and limitations found in other agent frameworks.
|
||||
|
||||
- **Standalone & Lean**: Completely independent from other frameworks like LangChain, offering faster execution and lighter resource demands.
|
||||
- **Flexible & Precise**: Easily orchestrate autonomous agents through intuitive [Crews](https://docs.crewai.com/concepts/crews) or precise [Flows](https://docs.crewai.com/concepts/flows), achieving perfect balance for your needs.
|
||||
|
||||
@@ -22,7 +22,7 @@ Watch this video tutorial for a step-by-step demonstration of the installation p
|
||||
<Note>
|
||||
**Python Version Requirements**
|
||||
|
||||
CrewAI requires `Python >=3.10 and <3.13`. Here's how to check your version:
|
||||
CrewAI requires `Python >=3.10 and <=3.13`. Here's how to check your version:
|
||||
```bash
|
||||
python3 --version
|
||||
```
|
||||
|
||||
@@ -7,196 +7,818 @@ icon: key
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-CrewAI.png" alt="Portkey CrewAI Header Image" width="70%" />
|
||||
|
||||
|
||||
[Portkey](https://portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) is a 2-line upgrade to make your CrewAI agents reliable, cost-efficient, and fast.
|
||||
|
||||
Portkey adds 4 core production capabilities to any CrewAI agent:
|
||||
1. Routing to **200+ LLMs**
|
||||
2. Making each LLM call more robust
|
||||
3. Full-stack tracing & cost, performance analytics
|
||||
4. Real-time guardrails to enforce behavior
|
||||
## Introduction
|
||||
|
||||
## Getting Started
|
||||
Portkey enhances CrewAI with production-readiness features, turning your experimental agent crews into robust systems by providing:
|
||||
|
||||
- **Complete observability** of every agent step, tool use, and interaction
|
||||
- **Built-in reliability** with fallbacks, retries, and load balancing
|
||||
- **Cost tracking and optimization** to manage your AI spend
|
||||
- **Access to 200+ LLMs** through a single integration
|
||||
- **Guardrails** to keep agent behavior safe and compliant
|
||||
- **Version-controlled prompts** for consistent agent performance
|
||||
|
||||
|
||||
### Installation & Setup
|
||||
|
||||
<Steps>
|
||||
<Step title="Install CrewAI and Portkey">
|
||||
```bash
|
||||
pip install -qU crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure the LLM Client">
|
||||
To build CrewAI Agents with Portkey, you'll need two keys:
|
||||
- **Portkey API Key**: Sign up on the [Portkey app](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) and copy your API key
|
||||
- **Virtual Key**: Virtual Keys securely manage your LLM API keys in one place. Store your LLM provider API keys securely in Portkey's vault
|
||||
<Step title="Install the required packages">
|
||||
```bash
|
||||
pip install -U crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
<Step title="Generate API Key" icon="lock">
|
||||
Create a Portkey API key with optional budget/rate limits from the [Portkey dashboard](https://app.portkey.ai/). You can also attach configurations for reliability, caching, and more to this key. More on this later.
|
||||
</Step>
|
||||
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy", # We are using Virtual key
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_VIRTUAL_KEY", # Enter your Virtual key from Portkey
|
||||
)
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Create and Run Your First Agent">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
# Define your agents with roles and goals
|
||||
coder = Agent(
|
||||
role='Software developer',
|
||||
goal='Write clear, concise code on demand',
|
||||
backstory='An expert coder with a keen eye for software trends.',
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description="Define the HTML for making a simple website with heading- Hello World! Portkey is working!",
|
||||
expected_output="A clear and concise HTML code",
|
||||
agent=coder
|
||||
)
|
||||
|
||||
# Instantiate your crew
|
||||
crew = Crew(
|
||||
agents=[coder],
|
||||
tasks=[task1],
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Key Features
|
||||
|
||||
| Feature | Description |
|
||||
|:--------|:------------|
|
||||
| 🌐 Multi-LLM Support | Access OpenAI, Anthropic, Gemini, Azure, and 250+ providers through a unified interface |
|
||||
| 🛡️ Production Reliability | Implement retries, timeouts, load balancing, and fallbacks |
|
||||
| 📊 Advanced Observability | Track 40+ metrics including costs, tokens, latency, and custom metadata |
|
||||
| 🔍 Comprehensive Logging | Debug with detailed execution traces and function call logs |
|
||||
| 🚧 Security Controls | Set budget limits and implement role-based access control |
|
||||
| 🔄 Performance Analytics | Capture and analyze feedback for continuous improvement |
|
||||
| 💾 Intelligent Caching | Reduce costs and latency with semantic or simple caching |
|
||||
|
||||
|
||||
## Production Features with Portkey Configs
|
||||
|
||||
All features mentioned below are through Portkey's Config system. Portkey's Config system allows you to define routing strategies using simple JSON objects in your LLM API calls. You can create and manage Configs directly in your code or through the Portkey Dashboard. Each Config has a unique ID for easy reference.
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/Portkey-AI/docs-core/refs/heads/main/images/libraries/libraries-3.avif"/>
|
||||
</Frame>
|
||||
|
||||
|
||||
### 1. Use 250+ LLMs
|
||||
Access various LLMs like Anthropic, Gemini, Mistral, Azure OpenAI, and more with minimal code changes. Switch between providers or use them together seamlessly. [Learn more about Universal API](https://portkey.ai/docs/product/ai-gateway/universal-api)
|
||||
|
||||
|
||||
Easily switch between different LLM providers:
|
||||
<Step title="Configure CrewAI with Portkey">
|
||||
The integration is simple - you just need to update the LLM configuration in your CrewAI setup:
|
||||
|
||||
```python
|
||||
# Anthropic Configuration
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create an LLM instance with Portkey integration
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
api_key="dummy", # We are using a Virtual key, so this is a placeholder
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY", #You don't need provider when using Virtual keys
|
||||
trace_id="anthropic_agent"
|
||||
virtual_key="YOUR_LLM_VIRTUAL_KEY",
|
||||
trace_id="unique-trace-id", # Optional, for request tracing
|
||||
)
|
||||
)
|
||||
|
||||
# Azure OpenAI Configuration
|
||||
azure_llm = LLM(
|
||||
model="gpt-4",
|
||||
#Use them in your Crew Agents like this:
|
||||
|
||||
@agent
|
||||
def lead_market_analyst(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['lead_market_analyst'],
|
||||
verbose=True,
|
||||
memory=False,
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
<Info>
|
||||
**What are Virtual Keys?** Virtual keys in Portkey securely store your LLM provider API keys (OpenAI, Anthropic, etc.) in an encrypted vault. They allow for easier key rotation and budget management. [Learn more about virtual keys here](https://portkey.ai/docs/product/ai-gateway/virtual-keys).
|
||||
</Info>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Production Features
|
||||
|
||||
### 1. Enhanced Observability
|
||||
|
||||
Portkey provides comprehensive observability for your CrewAI agents, helping you understand exactly what's happening during each execution.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Traces">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Product%2011.1.webp"/>
|
||||
</Frame>
|
||||
|
||||
Traces provide a hierarchical view of your crew's execution, showing the sequence of LLM calls, tool invocations, and state transitions.
|
||||
|
||||
```python
|
||||
# Add trace_id to enable hierarchical tracing in Portkey
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_AZURE_VIRTUAL_KEY", #You don't need provider when using Virtual keys
|
||||
trace_id="azure_agent"
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
trace_id="unique-session-id" # Add unique trace ID
|
||||
)
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Logs">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Metadata.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey logs every interaction with LLMs, including:
|
||||
|
||||
- Complete request and response payloads
|
||||
- Latency and token usage metrics
|
||||
- Cost calculations
|
||||
- Tool calls and function executions
|
||||
|
||||
All logs can be filtered by metadata, trace IDs, models, and more, making it easy to debug specific crew runs.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Metrics & Dashboards">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Dashboard.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey provides built-in dashboards that help you:
|
||||
|
||||
- Track cost and token usage across all crew runs
|
||||
- Analyze performance metrics like latency and success rates
|
||||
- Identify bottlenecks in your agent workflows
|
||||
- Compare different crew configurations and LLMs
|
||||
|
||||
You can filter and segment all metrics by custom metadata to analyze specific crew types, user groups, or use cases.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Metadata Filtering">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png" alt="Analytics with metadata filters" />
|
||||
</Frame>
|
||||
|
||||
Add custom metadata to your CrewAI LLM configuration to enable powerful filtering and segmentation:
|
||||
|
||||
```python
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"crew_type": "research_crew",
|
||||
"environment": "production",
|
||||
"_user": "user_123", # Special _user field for user analytics
|
||||
"request_source": "mobile_app"
|
||||
}
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
This metadata can be used to filter logs, traces, and metrics on the Portkey dashboard, allowing you to analyze specific crew runs, users, or environments.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 2. Caching
|
||||
Improve response times and reduce costs with two powerful caching modes:
|
||||
- **Simple Cache**: Perfect for exact matches
|
||||
- **Semantic Cache**: Matches responses for requests that are semantically similar
|
||||
[Learn more about Caching](https://portkey.ai/docs/product/ai-gateway/cache-simple-and-semantic)
|
||||
### 2. Reliability - Keep Your Crews Running Smoothly
|
||||
|
||||
```py
|
||||
config = {
|
||||
"cache": {
|
||||
"mode": "semantic", # or "simple" for exact matching
|
||||
When running crews in production, things can go wrong - API rate limits, network issues, or provider outages. Portkey's reliability features ensure your agents keep running smoothly even when problems occur.
|
||||
|
||||
It's simple to enable fallback in your CrewAI setup by using a Portkey Config:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create LLM with fallback configuration
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
config={
|
||||
"strategy": {
|
||||
"mode": "fallback"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"provider": "openai",
|
||||
"api_key": "YOUR_OPENAI_API_KEY",
|
||||
"override_params": {"model": "gpt-4o"}
|
||||
},
|
||||
{
|
||||
"provider": "anthropic",
|
||||
"api_key": "YOUR_ANTHROPIC_API_KEY",
|
||||
"override_params": {"model": "claude-3-opus-20240229"}
|
||||
}
|
||||
]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Use this LLM configuration with your agents
|
||||
```
|
||||
|
||||
This configuration will automatically try Claude if the GPT-4o request fails, ensuring your crew can continue operating.
|
||||
|
||||
<CardGroup cols="2">
|
||||
<Card title="Automatic Retries" icon="rotate" href="https://portkey.ai/docs/product/ai-gateway/automatic-retries">
|
||||
Handles temporary failures automatically. If an LLM call fails, Portkey will retry the same request for the specified number of times - perfect for rate limits or network blips.
|
||||
</Card>
|
||||
<Card title="Request Timeouts" icon="clock" href="https://portkey.ai/docs/product/ai-gateway/request-timeouts">
|
||||
Prevent your agents from hanging. Set timeouts to ensure you get responses (or can fail gracefully) within your required timeframes.
|
||||
</Card>
|
||||
<Card title="Conditional Routing" icon="route" href="https://portkey.ai/docs/product/ai-gateway/conditional-routing">
|
||||
Send different requests to different providers. Route complex reasoning to GPT-4, creative tasks to Claude, and quick responses to Gemini based on your needs.
|
||||
</Card>
|
||||
<Card title="Fallbacks" icon="shield" href="https://portkey.ai/docs/product/ai-gateway/fallbacks">
|
||||
Keep running even if your primary provider fails. Automatically switch to backup providers to maintain availability.
|
||||
</Card>
|
||||
<Card title="Load Balancing" icon="scale-balanced" href="https://portkey.ai/docs/product/ai-gateway/load-balancing">
|
||||
Spread requests across multiple API keys or providers. Great for high-volume crew operations and staying within rate limits.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### 3. Prompting in CrewAI
|
||||
|
||||
Portkey's Prompt Engineering Studio helps you create, manage, and optimize the prompts used in your CrewAI agents. Instead of hardcoding prompts or instructions, use Portkey's prompt rendering API to dynamically fetch and apply your versioned prompts.
|
||||
|
||||
<Frame caption="Manage prompts in Portkey's Prompt Library">
|
||||
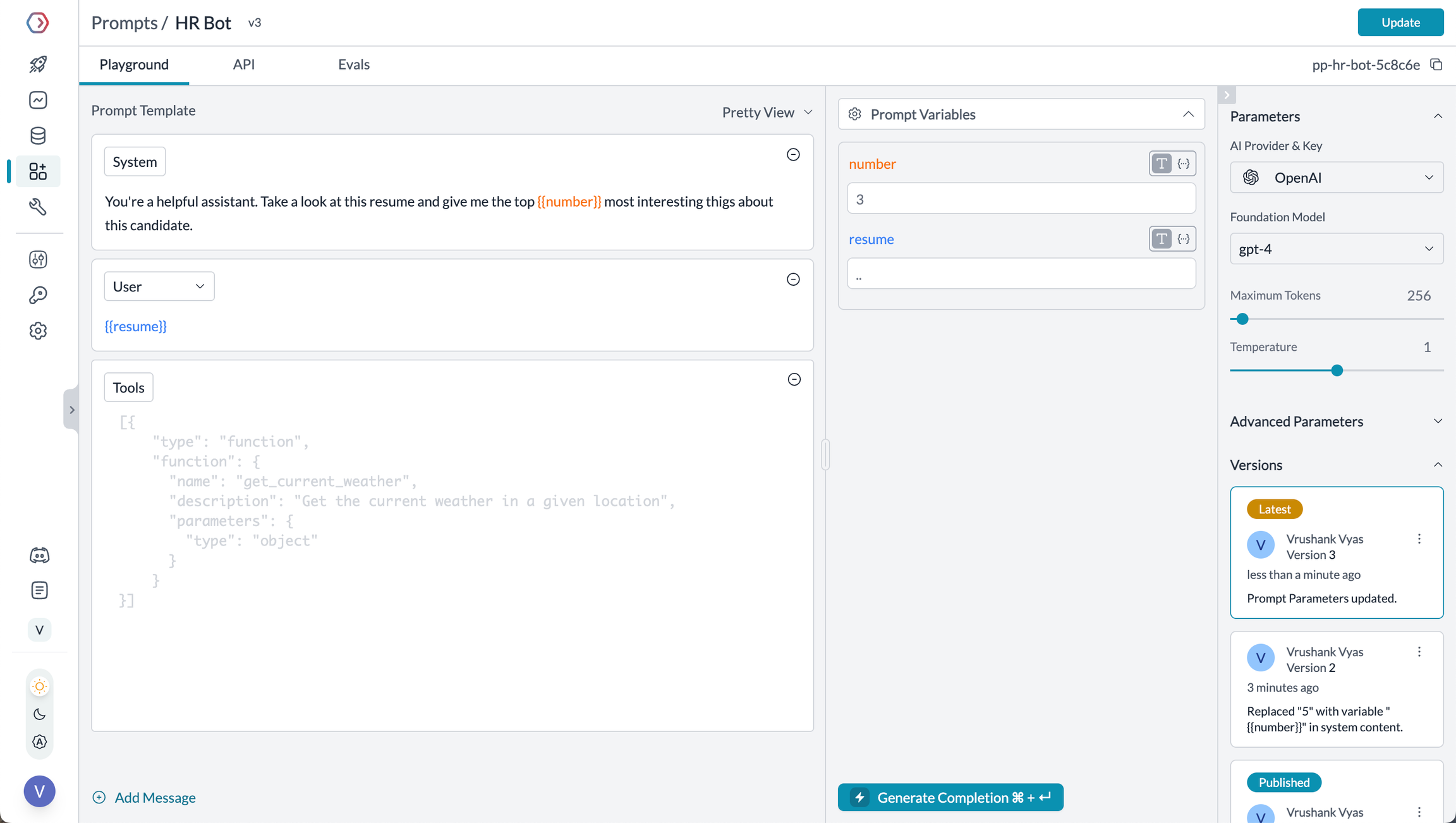
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Prompt Playground">
|
||||
Prompt Playground is a place to compare, test and deploy perfect prompts for your AI application. It's where you experiment with different models, test variables, compare outputs, and refine your prompt engineering strategy before deploying to production. It allows you to:
|
||||
|
||||
1. Iteratively develop prompts before using them in your agents
|
||||
2. Test prompts with different variables and models
|
||||
3. Compare outputs between different prompt versions
|
||||
4. Collaborate with team members on prompt development
|
||||
|
||||
This visual environment makes it easier to craft effective prompts for each step in your CrewAI agents' workflow.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Using Prompt Templates">
|
||||
The Prompt Render API retrieves your prompt templates with all parameters configured:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL, Portkey
|
||||
|
||||
# Initialize Portkey admin client
|
||||
portkey_admin = Portkey(api_key="YOUR_PORTKEY_API_KEY")
|
||||
|
||||
# Retrieve prompt using the render API
|
||||
prompt_data = portkey_client.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
}
|
||||
)
|
||||
|
||||
backstory_agent_prompt=prompt_data.data.messages[0]["content"]
|
||||
|
||||
|
||||
# Set up LLM with Portkey integration
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent using the rendered prompt
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory=backstory_agent, # Use the rendered prompt
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Prompt Versioning">
|
||||
You can:
|
||||
- Create multiple versions of the same prompt
|
||||
- Compare performance between versions
|
||||
- Roll back to previous versions if needed
|
||||
- Specify which version to use in your code:
|
||||
|
||||
```python
|
||||
# Use a specific prompt version
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID@version_number",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"agent_goal": "Discover groundbreaking insights"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Mustache Templating for variables">
|
||||
Portkey prompts use Mustache-style templating for easy variable substitution:
|
||||
|
||||
```
|
||||
You are a {{agent_role}} with expertise in {{domain}}.
|
||||
|
||||
Your mission is to {{agent_goal}} by leveraging your knowledge
|
||||
and experience in the field.
|
||||
|
||||
Always maintain a {{tone}} tone and focus on providing {{focus_area}}.
|
||||
```
|
||||
|
||||
When rendering, simply pass the variables:
|
||||
|
||||
```python
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"domain": "artificial intelligence",
|
||||
"agent_goal": "discover groundbreaking insights",
|
||||
"tone": "professional",
|
||||
"focus_area": "practical applications"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Card title="Prompt Engineering Studio" icon="wand-magic-sparkles" href="https://portkey.ai/docs/product/prompt-library">
|
||||
Learn more about Portkey's prompt management features
|
||||
</Card>
|
||||
|
||||
### 4. Guardrails for Safe Crews
|
||||
|
||||
Guardrails ensure your CrewAI agents operate safely and respond appropriately in all situations.
|
||||
|
||||
**Why Use Guardrails?**
|
||||
|
||||
CrewAI agents can experience various failure modes:
|
||||
- Generating harmful or inappropriate content
|
||||
- Leaking sensitive information like PII
|
||||
- Hallucinating incorrect information
|
||||
- Generating outputs in incorrect formats
|
||||
|
||||
Portkey's guardrails add protections for both inputs and outputs.
|
||||
|
||||
**Implementing Guardrails**
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create LLM with guardrails
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"input_guardrails": ["guardrails-id-xxx", "guardrails-id-yyy"],
|
||||
"output_guardrails": ["guardrails-id-zzz"]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with guardrailed LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Portkey's guardrails can:
|
||||
- Detect and redact PII in both inputs and outputs
|
||||
- Filter harmful or inappropriate content
|
||||
- Validate response formats against schemas
|
||||
- Check for hallucinations against ground truth
|
||||
- Apply custom business logic and rules
|
||||
|
||||
<Card title="Learn More About Guardrails" icon="shield-check" href="https://portkey.ai/docs/product/guardrails">
|
||||
Explore Portkey's guardrail features to enhance agent safety
|
||||
</Card>
|
||||
|
||||
### 5. User Tracking with Metadata
|
||||
|
||||
Track individual users through your CrewAI agents using Portkey's metadata system.
|
||||
|
||||
**What is Metadata in Portkey?**
|
||||
|
||||
Metadata allows you to associate custom data with each request, enabling filtering, segmentation, and analytics. The special `_user` field is specifically designed for user tracking.
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with user tracking
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"_user": "user_123", # Special _user field for user analytics
|
||||
"user_tier": "premium",
|
||||
"user_company": "Acme Corp",
|
||||
"session_id": "abc-123"
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with tracked LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
**Filter Analytics by User**
|
||||
|
||||
With metadata in place, you can filter analytics by user and analyze performance metrics on a per-user basis:
|
||||
|
||||
<Frame caption="Filter analytics by user">
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png"/>
|
||||
</Frame>
|
||||
|
||||
This enables:
|
||||
- Per-user cost tracking and budgeting
|
||||
- Personalized user analytics
|
||||
- Team or organization-level metrics
|
||||
- Environment-specific monitoring (staging vs. production)
|
||||
|
||||
<Card title="Learn More About Metadata" icon="tags" href="https://portkey.ai/docs/product/observability/metadata">
|
||||
Explore how to use custom metadata to enhance your analytics
|
||||
</Card>
|
||||
|
||||
### 6. Caching for Efficient Crews
|
||||
|
||||
Implement caching to make your CrewAI agents more efficient and cost-effective:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Simple Caching">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with simple caching
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "simple"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with cached LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Simple caching performs exact matches on input prompts, caching identical requests to avoid redundant model executions.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Semantic Caching">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with semantic caching
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "semantic"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with semantically cached LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Semantic caching considers the contextual similarity between input requests, caching responses for semantically similar inputs.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 7. Model Interoperability
|
||||
|
||||
CrewAI supports multiple LLM providers, and Portkey extends this capability by providing access to over 200 LLMs through a unified interface. You can easily switch between different models without changing your core agent logic:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Set up LLMs with different providers
|
||||
openai_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Choose which LLM to use for each agent based on your needs
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=openai_llm # Use anthropic_llm for Anthropic
|
||||
)
|
||||
```
|
||||
|
||||
Portkey provides access to LLMs from providers including:
|
||||
|
||||
- OpenAI (GPT-4o, GPT-4 Turbo, etc.)
|
||||
- Anthropic (Claude 3.5 Sonnet, Claude 3 Opus, etc.)
|
||||
- Mistral AI (Mistral Large, Mistral Medium, etc.)
|
||||
- Google Vertex AI (Gemini 1.5 Pro, etc.)
|
||||
- Cohere (Command, Command-R, etc.)
|
||||
- AWS Bedrock (Claude, Titan, etc.)
|
||||
- Local/Private Models
|
||||
|
||||
<Card title="Supported Providers" icon="server" href="https://portkey.ai/docs/integrations/llms">
|
||||
See the full list of LLM providers supported by Portkey
|
||||
</Card>
|
||||
|
||||
## Set Up Enterprise Governance for CrewAI
|
||||
|
||||
**Why Enterprise Governance?**
|
||||
If you are using CrewAI inside your organization, you need to consider several governance aspects:
|
||||
- **Cost Management**: Controlling and tracking AI spending across teams
|
||||
- **Access Control**: Managing which teams can use specific models
|
||||
- **Usage Analytics**: Understanding how AI is being used across the organization
|
||||
- **Security & Compliance**: Maintaining enterprise security standards
|
||||
- **Reliability**: Ensuring consistent service across all users
|
||||
|
||||
Portkey adds a comprehensive governance layer to address these enterprise needs. Let's implement these controls step by step.
|
||||
|
||||
<Steps>
|
||||
<Step title="Create Virtual Key">
|
||||
Virtual Keys are Portkey's secure way to manage your LLM provider API keys. They provide essential controls like:
|
||||
- Budget limits for API usage
|
||||
- Rate limiting capabilities
|
||||
- Secure API key storage
|
||||
|
||||
To create a virtual key:
|
||||
Go to [Virtual Keys](https://app.portkey.ai/virtual-keys) in the Portkey App. Save and copy the virtual key ID
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
|
||||
<Note>
|
||||
Save your virtual key ID - you'll need it for the next step.
|
||||
</Note>
|
||||
</Step>
|
||||
|
||||
<Step title="Create Default Config">
|
||||
Configs in Portkey define how your requests are routed, with features like advanced routing, fallbacks, and retries.
|
||||
|
||||
To create your config:
|
||||
1. Go to [Configs](https://app.portkey.ai/configs) in Portkey dashboard
|
||||
2. Create new config with:
|
||||
```json
|
||||
{
|
||||
"virtual_key": "YOUR_VIRTUAL_KEY_FROM_STEP1",
|
||||
"override_params": {
|
||||
"model": "gpt-4o" // Your preferred model name
|
||||
}
|
||||
}
|
||||
```
|
||||
3. Save and note the Config name for the next step
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Config.png" width="500"/>
|
||||
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Configure Portkey API Key">
|
||||
Now create a Portkey API key and attach the config you created in Step 2:
|
||||
|
||||
1. Go to [API Keys](https://app.portkey.ai/api-keys) in Portkey and Create new API key
|
||||
2. Select your config from `Step 2`
|
||||
3. Generate and save your API key
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20API%20Key.png" width="500"/>
|
||||
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Connect to CrewAI">
|
||||
After setting up your Portkey API key with the attached config, connect it to your CrewAI agents:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with your API key
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="YOUR_PORTKEY_API_KEY"
|
||||
)
|
||||
|
||||
# Create agent with Portkey-enabled LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Step 1: Implement Budget Controls & Rate Limits">
|
||||
### Step 1: Implement Budget Controls & Rate Limits
|
||||
|
||||
Virtual Keys enable granular control over LLM access at the team/department level. This helps you:
|
||||
- Set up [budget limits](https://portkey.ai/docs/product/ai-gateway/virtual-keys/budget-limits)
|
||||
- Prevent unexpected usage spikes using Rate limits
|
||||
- Track departmental spending
|
||||
|
||||
#### Setting Up Department-Specific Controls:
|
||||
1. Navigate to [Virtual Keys](https://app.portkey.ai/virtual-keys) in Portkey dashboard
|
||||
2. Create new Virtual Key for each department with budget limits and rate limits
|
||||
3. Configure department-specific limits
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Step 2: Define Model Access Rules">
|
||||
### Step 2: Define Model Access Rules
|
||||
|
||||
As your AI usage scales, controlling which teams can access specific models becomes crucial. Portkey Configs provide this control layer with features like:
|
||||
|
||||
#### Access Control Features:
|
||||
- **Model Restrictions**: Limit access to specific models
|
||||
- **Data Protection**: Implement guardrails for sensitive data
|
||||
- **Reliability Controls**: Add fallbacks and retry logic
|
||||
|
||||
#### Example Configuration:
|
||||
Here's a basic configuration to route requests to OpenAI, specifically using GPT-4o:
|
||||
|
||||
```json
|
||||
{
|
||||
"strategy": {
|
||||
"mode": "single"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"virtual_key": "YOUR_OPENAI_VIRTUAL_KEY",
|
||||
"override_params": {
|
||||
"model": "gpt-4o"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### 3. Production Reliability
|
||||
Portkey provides comprehensive reliability features:
|
||||
- **Automatic Retries**: Handle temporary failures gracefully
|
||||
- **Request Timeouts**: Prevent hanging operations
|
||||
- **Conditional Routing**: Route requests based on specific conditions
|
||||
- **Fallbacks**: Set up automatic provider failovers
|
||||
- **Load Balancing**: Distribute requests efficiently
|
||||
Create your config on the [Configs page](https://app.portkey.ai/configs) in your Portkey dashboard.
|
||||
|
||||
[Learn more about Reliability Features](https://portkey.ai/docs/product/ai-gateway/)
|
||||
<Note>
|
||||
Configs can be updated anytime to adjust controls without affecting running applications.
|
||||
</Note>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Step 3: Implement Access Controls">
|
||||
### Step 3: Implement Access Controls
|
||||
|
||||
Create User-specific API keys that automatically:
|
||||
- Track usage per user/team with the help of virtual keys
|
||||
- Apply appropriate configs to route requests
|
||||
- Collect relevant metadata to filter logs
|
||||
- Enforce access permissions
|
||||
|
||||
### 4. Metrics
|
||||
Create API keys through:
|
||||
- [Portkey App](https://app.portkey.ai/)
|
||||
- [API Key Management API](/api-reference/admin-api/control-plane/api-keys/create-api-key)
|
||||
|
||||
Agent runs are complex. Portkey automatically logs **40+ comprehensive metrics** for your AI agents, including cost, tokens used, latency, etc. Whether you need a broad overview or granular insights into your agent runs, Portkey's customizable filters provide the metrics you need.
|
||||
Example using Python SDK:
|
||||
```python
|
||||
from portkey_ai import Portkey
|
||||
|
||||
portkey = Portkey(api_key="YOUR_ADMIN_API_KEY")
|
||||
|
||||
- Cost per agent interaction
|
||||
- Response times and latency
|
||||
- Token usage and efficiency
|
||||
- Success/failure rates
|
||||
- Cache hit rates
|
||||
api_key = portkey.api_keys.create(
|
||||
name="engineering-team",
|
||||
type="organisation",
|
||||
workspace_id="YOUR_WORKSPACE_ID",
|
||||
defaults={
|
||||
"config_id": "your-config-id",
|
||||
"metadata": {
|
||||
"environment": "production",
|
||||
"department": "engineering"
|
||||
}
|
||||
},
|
||||
scopes=["logs.view", "configs.read"]
|
||||
)
|
||||
```
|
||||
|
||||
<img src="https://github.com/siddharthsambharia-portkey/Portkey-Product-Images/blob/main/Portkey-Dashboard.png?raw=true" width="70%" alt="Portkey Dashboard" />
|
||||
For detailed key management instructions, see our [API Keys documentation](/api-reference/admin-api/control-plane/api-keys/create-api-key).
|
||||
</Accordion>
|
||||
|
||||
### 5. Detailed Logging
|
||||
Logs are essential for understanding agent behavior, diagnosing issues, and improving performance. They provide a detailed record of agent activities and tool use, which is crucial for debugging and optimizing processes.
|
||||
<Accordion title="Step 4: Deploy & Monitor">
|
||||
### Step 4: Deploy & Monitor
|
||||
After distributing API keys to your team members, your enterprise-ready CrewAI setup is ready to go. Each team member can now use their designated API keys with appropriate access levels and budget controls.
|
||||
|
||||
Monitor usage in Portkey dashboard:
|
||||
- Cost tracking by department
|
||||
- Model usage patterns
|
||||
- Request volumes
|
||||
- Error rates
|
||||
</Accordion>
|
||||
|
||||
Access a dedicated section to view records of agent executions, including parameters, outcomes, function calls, and errors. Filter logs based on multiple parameters such as trace ID, model, tokens used, and metadata.
|
||||
</AccordionGroup>
|
||||
|
||||
<details>
|
||||
<summary><b>Traces</b></summary>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-Traces.png" alt="Portkey Traces" width="70%" />
|
||||
</details>
|
||||
<Note>
|
||||
### Enterprise Features Now Available
|
||||
**Your CrewAI integration now has:**
|
||||
- Departmental budget controls
|
||||
- Model access governance
|
||||
- Usage tracking & attribution
|
||||
- Security guardrails
|
||||
- Reliability features
|
||||
</Note>
|
||||
|
||||
<details>
|
||||
<summary><b>Logs</b></summary>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-Logs.png" alt="Portkey Logs" width="70%" />
|
||||
</details>
|
||||
## Frequently Asked Questions
|
||||
|
||||
### 6. Enterprise Security Features
|
||||
- Set budget limit and rate limts per Virtual Key (disposable API keys)
|
||||
- Implement role-based access control
|
||||
- Track system changes with audit logs
|
||||
- Configure data retention policies
|
||||
<AccordionGroup>
|
||||
<Accordion title="How does Portkey enhance CrewAI?">
|
||||
Portkey adds production-readiness to CrewAI through comprehensive observability (traces, logs, metrics), reliability features (fallbacks, retries, caching), and access to 200+ LLMs through a unified interface. This makes it easier to debug, optimize, and scale your agent applications.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Can I use Portkey with existing CrewAI applications?">
|
||||
Yes! Portkey integrates seamlessly with existing CrewAI applications. You just need to update your LLM configuration code with the Portkey-enabled version. The rest of your agent and crew code remains unchanged.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Does Portkey work with all CrewAI features?">
|
||||
Portkey supports all CrewAI features, including agents, tools, human-in-the-loop workflows, and all task process types (sequential, hierarchical, etc.). It adds observability and reliability without limiting any of the framework's functionality.
|
||||
</Accordion>
|
||||
|
||||
For detailed information on creating and managing Configs, visit the [Portkey documentation](https://docs.portkey.ai/product/ai-gateway/configs).
|
||||
<Accordion title="Can I track usage across multiple agents in a crew?">
|
||||
Yes, Portkey allows you to use a consistent `trace_id` across multiple agents in a crew to track the entire workflow. This is especially useful for complex crews where you want to understand the full execution path across multiple agents.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="How do I filter logs and traces for specific crew runs?">
|
||||
Portkey allows you to add custom metadata to your LLM configuration, which you can then use for filtering. Add fields like `crew_name`, `crew_type`, or `session_id` to easily find and analyze specific crew executions.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Can I use my own API keys with Portkey?">
|
||||
Yes! Portkey uses your own API keys for the various LLM providers. It securely stores them as virtual keys, allowing you to easily manage and rotate keys without changing your code.
|
||||
</Accordion>
|
||||
|
||||
</AccordionGroup>
|
||||
|
||||
## Resources
|
||||
|
||||
- [📘 Portkey Documentation](https://docs.portkey.ai)
|
||||
- [📊 Portkey Dashboard](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai)
|
||||
- [🐦 Twitter](https://twitter.com/portkeyai)
|
||||
- [💬 Discord Community](https://discord.gg/DD7vgKK299)
|
||||
<CardGroup cols="3">
|
||||
<Card title="CrewAI Docs" icon="book" href="https://docs.crewai.com/">
|
||||
<p>Official CrewAI documentation</p>
|
||||
</Card>
|
||||
<Card title="Book a Demo" icon="calendar" href="https://calendly.com/portkey-ai">
|
||||
<p>Get personalized guidance on implementing this integration</p>
|
||||
</Card>
|
||||
</CardGroup>
|
||||
@@ -3,7 +3,7 @@ name = "crewai"
|
||||
version = "0.121.1"
|
||||
description = "Cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks."
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.10,<3.13"
|
||||
requires-python = ">=3.10,<3.14"
|
||||
authors = [
|
||||
{ name = "Joao Moura", email = "joao@crewai.com" }
|
||||
]
|
||||
@@ -22,6 +22,8 @@ dependencies = [
|
||||
"opentelemetry-exporter-otlp-proto-http>=1.30.0",
|
||||
# Data Handling
|
||||
"chromadb>=0.5.23",
|
||||
"tokenizers>=0.20.3",
|
||||
"onnxruntime==1.22.0",
|
||||
"openpyxl>=3.1.5",
|
||||
"pyvis>=0.3.2",
|
||||
# Authentication and Security
|
||||
@@ -47,10 +49,9 @@ Repository = "https://github.com/crewAIInc/crewAI"
|
||||
[project.optional-dependencies]
|
||||
tools = ["crewai-tools~=0.45.0"]
|
||||
embeddings = [
|
||||
"tiktoken~=0.7.0"
|
||||
"tiktoken~=0.8.0"
|
||||
]
|
||||
agentops = ["agentops>=0.3.0"]
|
||||
fastembed = ["fastembed>=0.4.1"]
|
||||
pdfplumber = [
|
||||
"pdfplumber>=0.11.4",
|
||||
]
|
||||
@@ -100,6 +101,27 @@ exclude = ["cli/templates"]
|
||||
[tool.bandit]
|
||||
exclude_dirs = ["src/crewai/cli/templates"]
|
||||
|
||||
# PyTorch index configuration, since torch 2.5.0 is not compatible with python 3.13
|
||||
[[tool.uv.index]]
|
||||
name = "pytorch-nightly"
|
||||
url = "https://download.pytorch.org/whl/nightly/cpu"
|
||||
explicit = true
|
||||
|
||||
[[tool.uv.index]]
|
||||
name = "pytorch"
|
||||
url = "https://download.pytorch.org/whl/cpu"
|
||||
explicit = true
|
||||
|
||||
[tool.uv.sources]
|
||||
torch = [
|
||||
{ index = "pytorch-nightly", marker = "python_version >= '3.13'" },
|
||||
{ index = "pytorch", marker = "python_version < '3.13'" },
|
||||
]
|
||||
torchvision = [
|
||||
{ index = "pytorch-nightly", marker = "python_version >= '3.13'" },
|
||||
{ index = "pytorch", marker = "python_version < '3.13'" },
|
||||
]
|
||||
|
||||
[build-system]
|
||||
requires = ["hatchling"]
|
||||
build-backend = "hatchling.build"
|
||||
|
||||
@@ -200,6 +200,7 @@ class Agent(BaseAgent):
|
||||
collection_name=self.role,
|
||||
storage=self.knowledge_storage or None,
|
||||
)
|
||||
self.knowledge.add_sources()
|
||||
except (TypeError, ValueError) as e:
|
||||
raise ValueError(f"Invalid Knowledge Configuration: {str(e)}")
|
||||
|
||||
@@ -243,21 +244,28 @@ class Agent(BaseAgent):
|
||||
"""
|
||||
if self.reasoning:
|
||||
try:
|
||||
from crewai.utilities.reasoning_handler import AgentReasoning, AgentReasoningOutput
|
||||
|
||||
from crewai.utilities.reasoning_handler import (
|
||||
AgentReasoning,
|
||||
AgentReasoningOutput,
|
||||
)
|
||||
|
||||
reasoning_handler = AgentReasoning(task=task, agent=self)
|
||||
reasoning_output: AgentReasoningOutput = reasoning_handler.handle_agent_reasoning()
|
||||
|
||||
reasoning_output: AgentReasoningOutput = (
|
||||
reasoning_handler.handle_agent_reasoning()
|
||||
)
|
||||
|
||||
# Add the reasoning plan to the task description
|
||||
task.description += f"\n\nReasoning Plan:\n{reasoning_output.plan.plan}"
|
||||
except Exception as e:
|
||||
if hasattr(self, '_logger'):
|
||||
self._logger.log("error", f"Error during reasoning process: {str(e)}")
|
||||
if hasattr(self, "_logger"):
|
||||
self._logger.log(
|
||||
"error", f"Error during reasoning process: {str(e)}"
|
||||
)
|
||||
else:
|
||||
print(f"Error during reasoning process: {str(e)}")
|
||||
|
||||
|
||||
self._inject_date_to_task(task)
|
||||
|
||||
|
||||
if self.tools_handler:
|
||||
self.tools_handler.last_used_tool = {} # type: ignore # Incompatible types in assignment (expression has type "dict[Never, Never]", variable has type "ToolCalling")
|
||||
|
||||
@@ -622,22 +630,33 @@ class Agent(BaseAgent):
|
||||
"""Inject the current date into the task description if inject_date is enabled."""
|
||||
if self.inject_date:
|
||||
from datetime import datetime
|
||||
|
||||
try:
|
||||
valid_format_codes = ['%Y', '%m', '%d', '%H', '%M', '%S', '%B', '%b', '%A', '%a']
|
||||
valid_format_codes = [
|
||||
"%Y",
|
||||
"%m",
|
||||
"%d",
|
||||
"%H",
|
||||
"%M",
|
||||
"%S",
|
||||
"%B",
|
||||
"%b",
|
||||
"%A",
|
||||
"%a",
|
||||
]
|
||||
is_valid = any(code in self.date_format for code in valid_format_codes)
|
||||
|
||||
|
||||
if not is_valid:
|
||||
raise ValueError(f"Invalid date format: {self.date_format}")
|
||||
|
||||
|
||||
current_date: str = datetime.now().strftime(self.date_format)
|
||||
task.description += f"\n\nCurrent Date: {current_date}"
|
||||
except Exception as e:
|
||||
if hasattr(self, '_logger'):
|
||||
if hasattr(self, "_logger"):
|
||||
self._logger.log("warning", f"Failed to inject date: {str(e)}")
|
||||
else:
|
||||
print(f"Warning: Failed to inject date: {str(e)}")
|
||||
|
||||
|
||||
def _validate_docker_installation(self) -> None:
|
||||
"""Check if Docker is installed and running."""
|
||||
if not shutil.which("docker"):
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
from os import getenv
|
||||
from typing import Optional
|
||||
from typing import List, Optional
|
||||
from urllib.parse import urljoin
|
||||
|
||||
import requests
|
||||
@@ -48,6 +48,7 @@ class PlusAPI:
|
||||
version: str,
|
||||
description: Optional[str],
|
||||
encoded_file: str,
|
||||
available_exports: Optional[List[str]] = None,
|
||||
):
|
||||
params = {
|
||||
"handle": handle,
|
||||
@@ -55,6 +56,7 @@ class PlusAPI:
|
||||
"version": version,
|
||||
"file": encoded_file,
|
||||
"description": description,
|
||||
"available_exports": available_exports,
|
||||
}
|
||||
return self._make_request("POST", f"{self.TOOLS_RESOURCE}", json=params)
|
||||
|
||||
|
||||
@@ -0,0 +1,3 @@
|
||||
from .tool import {{class_name}}
|
||||
|
||||
__all__ = ["{{class_name}}"]
|
||||
|
||||
@@ -3,6 +3,7 @@ import os
|
||||
import subprocess
|
||||
import tempfile
|
||||
from pathlib import Path
|
||||
from typing import Any
|
||||
|
||||
import click
|
||||
from rich.console import Console
|
||||
@@ -11,6 +12,7 @@ from crewai.cli import git
|
||||
from crewai.cli.command import BaseCommand, PlusAPIMixin
|
||||
from crewai.cli.config import Settings
|
||||
from crewai.cli.utils import (
|
||||
extract_available_exports,
|
||||
get_project_description,
|
||||
get_project_name,
|
||||
get_project_version,
|
||||
@@ -82,6 +84,14 @@ class ToolCommand(BaseCommand, PlusAPIMixin):
|
||||
project_description = get_project_description(require=False)
|
||||
encoded_tarball = None
|
||||
|
||||
console.print("[bold blue]Discovering tools from your project...[/bold blue]")
|
||||
available_exports = extract_available_exports()
|
||||
|
||||
if available_exports:
|
||||
console.print(
|
||||
f"[green]Found these tools to publish: {', '.join(available_exports)}[/green]"
|
||||
)
|
||||
|
||||
with tempfile.TemporaryDirectory() as temp_build_dir:
|
||||
subprocess.run(
|
||||
["uv", "build", "--sdist", "--out-dir", temp_build_dir],
|
||||
@@ -105,12 +115,14 @@ class ToolCommand(BaseCommand, PlusAPIMixin):
|
||||
|
||||
encoded_tarball = base64.b64encode(tarball_contents).decode("utf-8")
|
||||
|
||||
console.print("[bold blue]Publishing tool to repository...[/bold blue]")
|
||||
publish_response = self.plus_api_client.publish_tool(
|
||||
handle=project_name,
|
||||
is_public=is_public,
|
||||
version=project_version,
|
||||
description=project_description,
|
||||
encoded_file=f"data:application/x-gzip;base64,{encoded_tarball}",
|
||||
available_exports=available_exports,
|
||||
)
|
||||
|
||||
self._validate_response(publish_response)
|
||||
@@ -167,7 +179,8 @@ class ToolCommand(BaseCommand, PlusAPIMixin):
|
||||
"Successfully authenticated to the tool repository.", style="bold green"
|
||||
)
|
||||
|
||||
def _add_package(self, tool_details):
|
||||
def _add_package(self, tool_details: dict[str, Any]):
|
||||
is_from_pypi = tool_details.get("source", None) == "pypi"
|
||||
tool_handle = tool_details["handle"]
|
||||
repository_handle = tool_details["repository"]["handle"]
|
||||
repository_url = tool_details["repository"]["url"]
|
||||
@@ -176,10 +189,13 @@ class ToolCommand(BaseCommand, PlusAPIMixin):
|
||||
add_package_command = [
|
||||
"uv",
|
||||
"add",
|
||||
"--index",
|
||||
index,
|
||||
tool_handle,
|
||||
]
|
||||
|
||||
if is_from_pypi:
|
||||
add_package_command.append(tool_handle)
|
||||
else:
|
||||
add_package_command.extend(["--index", index, tool_handle])
|
||||
|
||||
add_package_result = subprocess.run(
|
||||
add_package_command,
|
||||
capture_output=False,
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
import importlib.util
|
||||
import os
|
||||
import shutil
|
||||
import sys
|
||||
from functools import reduce
|
||||
from inspect import isfunction, ismethod
|
||||
from inspect import getmro, isclass, isfunction, ismethod
|
||||
from pathlib import Path
|
||||
from typing import Any, Dict, List, get_type_hints
|
||||
|
||||
import click
|
||||
@@ -339,3 +341,112 @@ def fetch_crews(module_attr) -> list[Crew]:
|
||||
if crew_instance := get_crew_instance(attr):
|
||||
crew_instances.append(crew_instance)
|
||||
return crew_instances
|
||||
|
||||
|
||||
def is_valid_tool(obj):
|
||||
from crewai.tools.base_tool import Tool
|
||||
|
||||
if isclass(obj):
|
||||
try:
|
||||
return any(base.__name__ == "BaseTool" for base in getmro(obj))
|
||||
except (TypeError, AttributeError):
|
||||
return False
|
||||
|
||||
return isinstance(obj, Tool)
|
||||
|
||||
|
||||
def extract_available_exports(dir_path: str = "src"):
|
||||
"""
|
||||
Extract available tool classes from the project's __init__.py files.
|
||||
Only includes classes that inherit from BaseTool or functions decorated with @tool.
|
||||
|
||||
Returns:
|
||||
list: A list of valid tool class names or ["BaseTool"] if none found
|
||||
"""
|
||||
try:
|
||||
init_files = Path(dir_path).glob("**/__init__.py")
|
||||
available_exports = []
|
||||
|
||||
for init_file in init_files:
|
||||
tools = _load_tools_from_init(init_file)
|
||||
available_exports.extend(tools)
|
||||
|
||||
if not available_exports:
|
||||
_print_no_tools_warning()
|
||||
raise SystemExit(1)
|
||||
|
||||
return available_exports
|
||||
|
||||
except Exception as e:
|
||||
console.print(f"[red]Error: Could not extract tool classes: {str(e)}[/red]")
|
||||
console.print(
|
||||
"Please ensure your project contains valid tools (classes inheriting from BaseTool or functions with @tool decorator)."
|
||||
)
|
||||
raise SystemExit(1)
|
||||
|
||||
|
||||
def _load_tools_from_init(init_file: Path) -> list[dict[str, Any]]:
|
||||
"""
|
||||
Load and validate tools from a given __init__.py file.
|
||||
"""
|
||||
spec = importlib.util.spec_from_file_location("temp_module", init_file)
|
||||
|
||||
if not spec or not spec.loader:
|
||||
return []
|
||||
|
||||
module = importlib.util.module_from_spec(spec)
|
||||
sys.modules["temp_module"] = module
|
||||
|
||||
try:
|
||||
spec.loader.exec_module(module)
|
||||
|
||||
if not hasattr(module, "__all__"):
|
||||
console.print(
|
||||
f"[bold yellow]Warning: No __all__ defined in {init_file}[/bold yellow]"
|
||||
)
|
||||
raise SystemExit(1)
|
||||
|
||||
return [
|
||||
{
|
||||
"name": name,
|
||||
}
|
||||
for name in module.__all__
|
||||
if hasattr(module, name) and is_valid_tool(getattr(module, name))
|
||||
]
|
||||
|
||||
except Exception as e:
|
||||
console.print(f"[red]Warning: Could not load {init_file}: {str(e)}[/red]")
|
||||
raise SystemExit(1)
|
||||
|
||||
finally:
|
||||
sys.modules.pop("temp_module", None)
|
||||
|
||||
|
||||
def _print_no_tools_warning():
|
||||
"""
|
||||
Display warning and usage instructions if no tools were found.
|
||||
"""
|
||||
console.print(
|
||||
"\n[bold yellow]Warning: No valid tools were exposed in your __init__.py file![/bold yellow]"
|
||||
)
|
||||
console.print(
|
||||
"Your __init__.py file must contain all classes that inherit from [bold]BaseTool[/bold] "
|
||||
"or functions decorated with [bold]@tool[/bold]."
|
||||
)
|
||||
console.print(
|
||||
"\nExample:\n[dim]# In your __init__.py file[/dim]\n"
|
||||
"[green]__all__ = ['YourTool', 'your_tool_function'][/green]\n\n"
|
||||
"[dim]# In your tool.py file[/dim]\n"
|
||||
"[green]from crewai.tools import BaseTool, tool\n\n"
|
||||
"# Tool class example\n"
|
||||
"class YourTool(BaseTool):\n"
|
||||
' name = "your_tool"\n'
|
||||
' description = "Your tool description"\n'
|
||||
" # ... rest of implementation\n\n"
|
||||
"# Decorated function example\n"
|
||||
"@tool\n"
|
||||
"def your_tool_function(text: str) -> str:\n"
|
||||
' """Your tool description"""\n'
|
||||
" # ... implementation\n"
|
||||
" return result\n"
|
||||
)
|
||||
|
||||
@@ -1,93 +0,0 @@
|
||||
from pathlib import Path
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
|
||||
from .base_embedder import BaseEmbedder
|
||||
|
||||
try:
|
||||
from fastembed_gpu import TextEmbedding # type: ignore
|
||||
|
||||
FASTEMBED_AVAILABLE = True
|
||||
except ImportError:
|
||||
try:
|
||||
from fastembed import TextEmbedding
|
||||
|
||||
FASTEMBED_AVAILABLE = True
|
||||
except ImportError:
|
||||
FASTEMBED_AVAILABLE = False
|
||||
|
||||
|
||||
class FastEmbed(BaseEmbedder):
|
||||
"""
|
||||
A wrapper class for text embedding models using FastEmbed
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model_name: str = "BAAI/bge-small-en-v1.5",
|
||||
cache_dir: Optional[Union[str, Path]] = None,
|
||||
):
|
||||
"""
|
||||
Initialize the embedding model
|
||||
|
||||
Args:
|
||||
model_name: Name of the model to use
|
||||
cache_dir: Directory to cache the model
|
||||
gpu: Whether to use GPU acceleration
|
||||
"""
|
||||
if not FASTEMBED_AVAILABLE:
|
||||
raise ImportError(
|
||||
"FastEmbed is not installed. Please install it with: "
|
||||
"uv pip install fastembed or uv pip install fastembed-gpu for GPU support"
|
||||
)
|
||||
|
||||
self.model = TextEmbedding(
|
||||
model_name=model_name,
|
||||
cache_dir=str(cache_dir) if cache_dir else None,
|
||||
)
|
||||
|
||||
def embed_chunks(self, chunks: List[str]) -> List[np.ndarray]:
|
||||
"""
|
||||
Generate embeddings for a list of text chunks
|
||||
|
||||
Args:
|
||||
chunks: List of text chunks to embed
|
||||
|
||||
Returns:
|
||||
List of embeddings
|
||||
"""
|
||||
embeddings = list(self.model.embed(chunks))
|
||||
return embeddings
|
||||
|
||||
def embed_texts(self, texts: List[str]) -> List[np.ndarray]:
|
||||
"""
|
||||
Generate embeddings for a list of texts
|
||||
|
||||
Args:
|
||||
texts: List of texts to embed
|
||||
|
||||
Returns:
|
||||
List of embeddings
|
||||
"""
|
||||
embeddings = list(self.model.embed(texts))
|
||||
return embeddings
|
||||
|
||||
def embed_text(self, text: str) -> np.ndarray:
|
||||
"""
|
||||
Generate embedding for a single text
|
||||
|
||||
Args:
|
||||
text: Text to embed
|
||||
|
||||
Returns:
|
||||
Embedding array
|
||||
"""
|
||||
return self.embed_texts([text])[0]
|
||||
|
||||
@property
|
||||
def dimension(self) -> int:
|
||||
"""Get the dimension of the embeddings"""
|
||||
# Generate a test embedding to get dimensions
|
||||
test_embed = self.embed_text("test")
|
||||
return len(test_embed)
|
||||
@@ -1 +1,7 @@
|
||||
from .base_tool import BaseTool, tool
|
||||
from .base_tool import BaseTool, tool, EnvVar
|
||||
|
||||
__all__ = [
|
||||
"BaseTool",
|
||||
"tool",
|
||||
"EnvVar",
|
||||
]
|
||||
@@ -1,7 +1,7 @@
|
||||
import asyncio
|
||||
from abc import ABC, abstractmethod
|
||||
from inspect import signature
|
||||
from typing import Any, Callable, Type, get_args, get_origin
|
||||
from typing import Any, Callable, Type, get_args, get_origin, Optional, List
|
||||
|
||||
from pydantic import (
|
||||
BaseModel,
|
||||
@@ -14,6 +14,11 @@ from pydantic import BaseModel as PydanticBaseModel
|
||||
|
||||
from crewai.tools.structured_tool import CrewStructuredTool
|
||||
|
||||
class EnvVar(BaseModel):
|
||||
name: str
|
||||
description: str
|
||||
required: bool = True
|
||||
default: Optional[str] = None
|
||||
|
||||
class BaseTool(BaseModel, ABC):
|
||||
class _ArgsSchemaPlaceholder(PydanticBaseModel):
|
||||
@@ -25,6 +30,8 @@ class BaseTool(BaseModel, ABC):
|
||||
"""The unique name of the tool that clearly communicates its purpose."""
|
||||
description: str
|
||||
"""Used to tell the model how/when/why to use the tool."""
|
||||
env_vars: List[EnvVar] = []
|
||||
"""List of environment variables used by the tool."""
|
||||
args_schema: Type[PydanticBaseModel] = Field(
|
||||
default_factory=_ArgsSchemaPlaceholder, validate_default=True
|
||||
)
|
||||
|
||||
@@ -309,7 +309,9 @@ def test_cache_hitting():
|
||||
def handle_tool_end(source, event):
|
||||
received_events.append(event)
|
||||
|
||||
with (patch.object(CacheHandler, "read") as read,):
|
||||
with (
|
||||
patch.object(CacheHandler, "read") as read,
|
||||
):
|
||||
read.return_value = "0"
|
||||
task = Task(
|
||||
description="What is 2 times 6? Ignore correctness and just return the result of the multiplication tool, you must use the tool.",
|
||||
@@ -1628,13 +1630,13 @@ def test_agent_execute_task_with_ollama():
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
def test_agent_with_knowledge_sources():
|
||||
# Create a knowledge source with some content
|
||||
content = "Brandon's favorite color is red and he likes Mexican food."
|
||||
string_source = StringKnowledgeSource(content=content)
|
||||
with patch("crewai.knowledge") as MockKnowledge:
|
||||
mock_knowledge_instance = MockKnowledge.return_value
|
||||
mock_knowledge_instance.sources = [string_source]
|
||||
mock_knowledge_instance.search.return_value = [{"content": content}]
|
||||
MockKnowledge.add_sources.return_value = [string_source]
|
||||
|
||||
agent = Agent(
|
||||
role="Information Agent",
|
||||
@@ -1644,7 +1646,6 @@ def test_agent_with_knowledge_sources():
|
||||
knowledge_sources=[string_source],
|
||||
)
|
||||
|
||||
# Create a task that requires the agent to use the knowledge
|
||||
task = Task(
|
||||
description="What is Brandon's favorite color?",
|
||||
expected_output="Brandon's favorite color.",
|
||||
@@ -1652,10 +1653,11 @@ def test_agent_with_knowledge_sources():
|
||||
)
|
||||
|
||||
crew = Crew(agents=[agent], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
|
||||
# Assert that the agent provides the correct information
|
||||
assert "red" in result.raw.lower()
|
||||
with patch.object(Knowledge, "add_sources") as mock_add_sources:
|
||||
result = crew.kickoff()
|
||||
assert mock_add_sources.called, "add_sources() should have been called"
|
||||
mock_add_sources.assert_called_once()
|
||||
assert "red" in result.raw.lower()
|
||||
|
||||
|
||||
@pytest.mark.vcr(filter_headers=["authorization"])
|
||||
|
||||
@@ -61,6 +61,7 @@ class TestPlusAPI(unittest.TestCase):
|
||||
"version": version,
|
||||
"file": encoded_file,
|
||||
"description": description,
|
||||
"available_exports": None,
|
||||
}
|
||||
mock_make_request.assert_called_once_with(
|
||||
"POST", "/crewai_plus/api/v1/tools", json=params
|
||||
@@ -87,6 +88,7 @@ class TestPlusAPI(unittest.TestCase):
|
||||
"version": version,
|
||||
"file": encoded_file,
|
||||
"description": description,
|
||||
"available_exports": None,
|
||||
}
|
||||
mock_make_request.assert_called_once_with(
|
||||
"POST", "/crewai_plus/api/v1/tools", json=params
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
import os
|
||||
import shutil
|
||||
import tempfile
|
||||
from pathlib import Path
|
||||
|
||||
import pytest
|
||||
|
||||
@@ -100,3 +101,163 @@ def test_tree_copy_to_existing_directory(temp_tree):
|
||||
assert os.path.isfile(os.path.join(dest_dir, "file1.txt"))
|
||||
finally:
|
||||
shutil.rmtree(dest_dir)
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def temp_project_dir():
|
||||
"""Create a temporary directory for testing tool extraction."""
|
||||
with tempfile.TemporaryDirectory() as temp_dir:
|
||||
yield Path(temp_dir)
|
||||
|
||||
|
||||
def create_init_file(directory, content):
|
||||
return create_file(directory / "__init__.py", content)
|
||||
|
||||
|
||||
def test_extract_available_exports_empty_project(temp_project_dir, capsys):
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "No valid tools were exposed in your __init__.py file" in captured.out
|
||||
|
||||
|
||||
def test_extract_available_exports_no_init_file(temp_project_dir, capsys):
|
||||
(temp_project_dir / "some_file.py").write_text("print('hello')")
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "No valid tools were exposed in your __init__.py file" in captured.out
|
||||
|
||||
|
||||
def test_extract_available_exports_empty_init_file(temp_project_dir, capsys):
|
||||
create_init_file(temp_project_dir, "")
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "Warning: No __all__ defined in" in captured.out
|
||||
|
||||
|
||||
def test_extract_available_exports_no_all_variable(temp_project_dir, capsys):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"from crewai.tools import BaseTool\n\nclass MyTool(BaseTool):\n pass",
|
||||
)
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "Warning: No __all__ defined in" in captured.out
|
||||
|
||||
|
||||
def test_extract_available_exports_valid_base_tool_class(temp_project_dir):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from crewai.tools import BaseTool
|
||||
|
||||
class MyTool(BaseTool):
|
||||
name: str = "my_tool"
|
||||
description: str = "A test tool"
|
||||
|
||||
__all__ = ['MyTool']
|
||||
""",
|
||||
)
|
||||
tools = utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
assert [{"name": "MyTool"}] == tools
|
||||
|
||||
|
||||
def test_extract_available_exports_valid_tool_decorator(temp_project_dir):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from crewai.tools import tool
|
||||
|
||||
@tool
|
||||
def my_tool_function(text: str) -> str:
|
||||
\"\"\"A test tool function\"\"\"
|
||||
return text
|
||||
|
||||
__all__ = ['my_tool_function']
|
||||
""",
|
||||
)
|
||||
tools = utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
assert [{"name": "my_tool_function"}] == tools
|
||||
|
||||
|
||||
def test_extract_available_exports_multiple_valid_tools(temp_project_dir):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from crewai.tools import BaseTool, tool
|
||||
|
||||
class MyTool(BaseTool):
|
||||
name: str = "my_tool"
|
||||
description: str = "A test tool"
|
||||
|
||||
@tool
|
||||
def my_tool_function(text: str) -> str:
|
||||
\"\"\"A test tool function\"\"\"
|
||||
return text
|
||||
|
||||
__all__ = ['MyTool', 'my_tool_function']
|
||||
""",
|
||||
)
|
||||
tools = utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
assert [{"name": "MyTool"}, {"name": "my_tool_function"}] == tools
|
||||
|
||||
|
||||
def test_extract_available_exports_with_invalid_tool_decorator(temp_project_dir):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from crewai.tools import BaseTool
|
||||
|
||||
class MyTool(BaseTool):
|
||||
name: str = "my_tool"
|
||||
description: str = "A test tool"
|
||||
|
||||
def not_a_tool():
|
||||
pass
|
||||
|
||||
__all__ = ['MyTool', 'not_a_tool']
|
||||
""",
|
||||
)
|
||||
tools = utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
assert [{"name": "MyTool"}] == tools
|
||||
|
||||
|
||||
def test_extract_available_exports_import_error(temp_project_dir, capsys):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from nonexistent_module import something
|
||||
|
||||
class MyTool(BaseTool):
|
||||
pass
|
||||
|
||||
__all__ = ['MyTool']
|
||||
""",
|
||||
)
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "nonexistent_module" in captured.out
|
||||
|
||||
|
||||
def test_extract_available_exports_syntax_error(temp_project_dir, capsys):
|
||||
create_init_file(
|
||||
temp_project_dir,
|
||||
"""from crewai.tools import BaseTool
|
||||
|
||||
class MyTool(BaseTool):
|
||||
# Missing closing parenthesis
|
||||
def __init__(self, name:
|
||||
pass
|
||||
|
||||
__all__ = ['MyTool']
|
||||
""",
|
||||
)
|
||||
with pytest.raises(SystemExit):
|
||||
utils.extract_available_exports(dir_path=temp_project_dir)
|
||||
captured = capsys.readouterr()
|
||||
|
||||
assert "was never closed" in captured.out
|
||||
|
||||
@@ -85,6 +85,36 @@ def test_install_success(mock_get, mock_subprocess_run, capsys, tool_command):
|
||||
env=unittest.mock.ANY,
|
||||
)
|
||||
|
||||
@patch("crewai.cli.tools.main.subprocess.run")
|
||||
@patch("crewai.cli.plus_api.PlusAPI.get_tool")
|
||||
def test_install_success_from_pypi(mock_get, mock_subprocess_run, capsys, tool_command):
|
||||
mock_get_response = MagicMock()
|
||||
mock_get_response.status_code = 200
|
||||
mock_get_response.json.return_value = {
|
||||
"handle": "sample-tool",
|
||||
"repository": {"handle": "sample-repo", "url": "https://example.com/repo"},
|
||||
"source": "pypi",
|
||||
}
|
||||
mock_get.return_value = mock_get_response
|
||||
mock_subprocess_run.return_value = MagicMock(stderr=None)
|
||||
|
||||
tool_command.install("sample-tool")
|
||||
output = capsys.readouterr().out
|
||||
assert "Successfully installed sample-tool" in output
|
||||
|
||||
mock_get.assert_has_calls([mock.call("sample-tool"), mock.call().json()])
|
||||
mock_subprocess_run.assert_any_call(
|
||||
[
|
||||
"uv",
|
||||
"add",
|
||||
"sample-tool",
|
||||
],
|
||||
capture_output=False,
|
||||
text=True,
|
||||
check=True,
|
||||
env=unittest.mock.ANY,
|
||||
)
|
||||
|
||||
|
||||
@patch("crewai.cli.plus_api.PlusAPI.get_tool")
|
||||
def test_install_tool_not_found(mock_get, capsys, tool_command):
|
||||
@@ -135,7 +165,9 @@ def test_publish_when_not_in_sync(mock_is_synced, capsys, tool_command):
|
||||
)
|
||||
@patch("crewai.cli.plus_api.PlusAPI.publish_tool")
|
||||
@patch("crewai.cli.tools.main.git.Repository.is_synced", return_value=False)
|
||||
@patch("crewai.cli.tools.main.extract_available_exports", return_value=["SampleTool"])
|
||||
def test_publish_when_not_in_sync_and_force(
|
||||
mock_available_exports,
|
||||
mock_is_synced,
|
||||
mock_publish,
|
||||
mock_open,
|
||||
@@ -168,6 +200,7 @@ def test_publish_when_not_in_sync_and_force(
|
||||
version="1.0.0",
|
||||
description="A sample tool",
|
||||
encoded_file=unittest.mock.ANY,
|
||||
available_exports=["SampleTool"],
|
||||
)
|
||||
|
||||
|
||||
@@ -183,7 +216,9 @@ def test_publish_when_not_in_sync_and_force(
|
||||
)
|
||||
@patch("crewai.cli.plus_api.PlusAPI.publish_tool")
|
||||
@patch("crewai.cli.tools.main.git.Repository.is_synced", return_value=True)
|
||||
@patch("crewai.cli.tools.main.extract_available_exports", return_value=["SampleTool"])
|
||||
def test_publish_success(
|
||||
mock_available_exports,
|
||||
mock_is_synced,
|
||||
mock_publish,
|
||||
mock_open,
|
||||
@@ -216,6 +251,7 @@ def test_publish_success(
|
||||
version="1.0.0",
|
||||
description="A sample tool",
|
||||
encoded_file=unittest.mock.ANY,
|
||||
available_exports=["SampleTool"],
|
||||
)
|
||||
|
||||
|
||||
@@ -230,7 +266,9 @@ def test_publish_success(
|
||||
read_data=b"sample tarball content",
|
||||
)
|
||||
@patch("crewai.cli.plus_api.PlusAPI.publish_tool")
|
||||
@patch("crewai.cli.tools.main.extract_available_exports", return_value=["SampleTool"])
|
||||
def test_publish_failure(
|
||||
mock_available_exports,
|
||||
mock_publish,
|
||||
mock_open,
|
||||
mock_listdir,
|
||||
@@ -266,7 +304,9 @@ def test_publish_failure(
|
||||
read_data=b"sample tarball content",
|
||||
)
|
||||
@patch("crewai.cli.plus_api.PlusAPI.publish_tool")
|
||||
@patch("crewai.cli.tools.main.extract_available_exports", return_value=["SampleTool"])
|
||||
def test_publish_api_error(
|
||||
mock_available_exports,
|
||||
mock_publish,
|
||||
mock_open,
|
||||
mock_listdir,
|
||||
|
||||
Reference in New Issue
Block a user