mirror of
https://github.com/crewAIInc/crewAI.git
synced 2026-05-12 12:39:03 +00:00
Add pt-BR docs translation (#3039)
* docs: add pt-br translations Powered by a CrewAI Flow https://github.com/danielfsbarreto/docs_translator * Update mcp/overview.mdx brazilian docs Its en-US counterpart was updated after I did a pass, so now it includes the new section about @CrewBase
This commit is contained in:
126
docs/pt-BR/observability/agentops.mdx
Normal file
126
docs/pt-BR/observability/agentops.mdx
Normal file
@@ -0,0 +1,126 @@
|
||||
---
|
||||
title: Integração com AgentOps
|
||||
description: Entendendo e registrando a performance do seu agente com AgentOps.
|
||||
icon: paperclip
|
||||
---
|
||||
|
||||
# Introdução
|
||||
|
||||
Observabilidade é um aspecto fundamental no desenvolvimento e implantação de agentes de IA conversacional. Ela permite que desenvolvedores compreendam como seus agentes estão performando,
|
||||
como eles estão interagindo com os usuários e como utilizam ferramentas externas e APIs.
|
||||
AgentOps é um produto independente do CrewAI que fornece uma solução completa de observabilidade para agentes.
|
||||
|
||||
## AgentOps
|
||||
|
||||
[AgentOps](https://agentops.ai/?=crew) oferece replay de sessões, métricas e monitoramento para agentes.
|
||||
|
||||
Em um alto nível, o AgentOps oferece a capacidade de monitorar custos, uso de tokens, latência, falhas do agente, estatísticas de sessão e muito mais.
|
||||
Para mais informações, confira o [Repositório do AgentOps](https://github.com/AgentOps-AI/agentops).
|
||||
|
||||
### Visão Geral
|
||||
|
||||
AgentOps fornece monitoramento para agentes em desenvolvimento e produção.
|
||||
Disponibiliza um dashboard para acompanhamento de performance dos agentes, replay de sessões e relatórios personalizados.
|
||||
|
||||
Além disso, o AgentOps traz análises detalhadas das sessões para visualizar interações do agente Crew, chamadas LLM e uso de ferramentas em tempo real.
|
||||
Esse recurso é útil para depuração e entendimento de como os agentes interagem com usuários e entre si.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
### Funcionalidades
|
||||
|
||||
- **Gerenciamento e Rastreamento de Custos de LLM**: Acompanhe gastos com provedores de modelos fundamentais.
|
||||
- **Análises de Replay**: Assista gráficos de execução do agente, passo a passo.
|
||||
- **Detecção de Pensamento Recursivo**: Identifique quando agentes entram em loops infinitos.
|
||||
- **Relatórios Personalizados**: Crie análises customizadas sobre a performance dos agentes.
|
||||
- **Dashboard Analítico**: Monitore estatísticas gerais de agentes em desenvolvimento e produção.
|
||||
- **Teste de Modelos Públicos**: Teste seus agentes em benchmarks e rankings.
|
||||
- **Testes Personalizados**: Execute seus agentes em testes específicos de domínio.
|
||||
- **Depuração com Viagem no Tempo**: Reinicie suas sessões a partir de checkpoints.
|
||||
- **Conformidade e Segurança**: Crie registros de auditoria e detecte possíveis ameaças como uso de palavrões e vazamento de dados pessoais.
|
||||
- **Detecção de Prompt Injection**: Identifique possíveis injeções de código e vazamentos de segredos.
|
||||
|
||||
### Utilizando o AgentOps
|
||||
|
||||
<Steps>
|
||||
<Step title="Crie uma Chave de API">
|
||||
Crie uma chave de API de usuário aqui: [Create API Key](https://app.agentops.ai/account)
|
||||
</Step>
|
||||
<Step title="Configure seu Ambiente">
|
||||
Adicione sua chave API nas variáveis de ambiente:
|
||||
```bash
|
||||
AGENTOPS_API_KEY=<YOUR_AGENTOPS_API_KEY>
|
||||
```
|
||||
</Step>
|
||||
<Step title="Instale o AgentOps">
|
||||
Instale o AgentOps com:
|
||||
```bash
|
||||
pip install 'crewai[agentops]'
|
||||
```
|
||||
ou
|
||||
```bash
|
||||
pip install agentops
|
||||
```
|
||||
</Step>
|
||||
<Step title="Inicialize o AgentOps">
|
||||
Antes de utilizar o `Crew` no seu script, inclua estas linhas:
|
||||
|
||||
```python
|
||||
import agentops
|
||||
agentops.init()
|
||||
```
|
||||
|
||||
Isso irá iniciar uma sessão do AgentOps e também rastrear automaticamente os agentes Crew. Para mais detalhes sobre como adaptar sistemas de agentes mais complexos,
|
||||
confira a [documentação do AgentOps](https://docs.agentops.ai) ou participe do [Discord](https://discord.gg/j4f3KbeH).
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Exemplos de Crew + AgentOps
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card
|
||||
title="Vaga de Emprego"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/job-posting"
|
||||
icon="briefcase"
|
||||
iconType="solid"
|
||||
>
|
||||
Exemplo de um agente Crew que gera vagas de emprego.
|
||||
</Card>
|
||||
<Card
|
||||
title="Validador de Markdown"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/markdown_validator"
|
||||
icon="markdown"
|
||||
iconType="solid"
|
||||
>
|
||||
Exemplo de um agente Crew que valida arquivos Markdown.
|
||||
</Card>
|
||||
<Card
|
||||
title="Post no Instagram"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/instagram_post"
|
||||
icon="square-instagram"
|
||||
iconType="brands"
|
||||
>
|
||||
Exemplo de um agente Crew que gera posts para Instagram.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### Mais Informações
|
||||
|
||||
Para começar, crie uma [conta AgentOps](https://agentops.ai/?=crew).
|
||||
|
||||
Para sugestões de funcionalidades ou relatos de bugs, entre em contato com o time do AgentOps pelo [Repositório do AgentOps](https://github.com/AgentOps-AI/agentops).
|
||||
|
||||
#### Links Extras
|
||||
|
||||
<a href="https://twitter.com/agentopsai/">🐦 Twitter</a>
|
||||
<span> • </span>
|
||||
<a href="https://discord.gg/JHPt4C7r">📢 Discord</a>
|
||||
<span> • </span>
|
||||
<a href="https://app.agentops.ai/?=crew">🖇️ Dashboard AgentOps</a>
|
||||
<span> • </span>
|
||||
<a href="https://docs.agentops.ai/introduction">📙 Documentação</a>
|
||||
151
docs/pt-BR/observability/arize-phoenix.mdx
Normal file
151
docs/pt-BR/observability/arize-phoenix.mdx
Normal file
@@ -0,0 +1,151 @@
|
||||
---
|
||||
title: Arize Phoenix
|
||||
description: Integração do Arize Phoenix para CrewAI com OpenTelemetry e OpenInference
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# Integração com Arize Phoenix
|
||||
|
||||
Este guia demonstra como integrar o **Arize Phoenix** ao **CrewAI** usando o OpenTelemetry através do [OpenInference](https://github.com/openinference/openinference) SDK. Ao final deste guia, você será capaz de rastrear seus agentes CrewAI e depurá-los com facilidade.
|
||||
|
||||
> **O que é o Arize Phoenix?** O [Arize Phoenix](https://phoenix.arize.com) é uma plataforma de observabilidade de LLM que oferece rastreamento e avaliação para aplicações de IA.
|
||||
|
||||
[](https://www.youtube.com/watch?v=Yc5q3l6F7Ww)
|
||||
|
||||
## Primeiros Passos
|
||||
|
||||
Vamos percorrer um exemplo simples de uso do CrewAI e integração com o Arize Phoenix via OpenTelemetry utilizando o OpenInference.
|
||||
|
||||
Você também pode acessar este guia no [Google Colab](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/crewai_tracing_tutorial.ipynb).
|
||||
|
||||
### Passo 1: Instale as Dependências
|
||||
|
||||
```bash
|
||||
pip install openinference-instrumentation-crewai crewai crewai-tools arize-phoenix-otel
|
||||
```
|
||||
|
||||
### Passo 2: Configure as Variáveis de Ambiente
|
||||
|
||||
Configure as chaves de API do Phoenix Cloud e ajuste o OpenTelemetry para enviar rastros ao Phoenix. O Phoenix Cloud é uma versão hospedada do Arize Phoenix, mas não é obrigatório para utilizar esta integração.
|
||||
|
||||
Você pode obter uma chave de API gratuita do Serper [aqui](https://serper.dev/).
|
||||
|
||||
```python
|
||||
import os
|
||||
from getpass import getpass
|
||||
|
||||
# Obtenha suas credenciais do Phoenix Cloud
|
||||
PHOENIX_API_KEY = getpass("🔑 Digite sua Phoenix Cloud API Key: ")
|
||||
|
||||
# Obtenha as chaves de API para os serviços
|
||||
OPENAI_API_KEY = getpass("🔑 Digite sua OpenAI API key: ")
|
||||
SERPER_API_KEY = getpass("🔑 Digite sua Serper API key: ")
|
||||
|
||||
# Defina as variáveis de ambiente
|
||||
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
|
||||
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com" # Phoenix Cloud, altere para seu endpoint se estiver utilizando uma instância self-hosted
|
||||
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
|
||||
os.environ["SERPER_API_KEY"] = SERPER_API_KEY
|
||||
```
|
||||
|
||||
### Passo 3: Inicialize o OpenTelemetry com o Phoenix
|
||||
|
||||
Inicialize o SDK de instrumentação OpenTelemetry do OpenInference para começar a capturar rastros e enviá-los ao Phoenix.
|
||||
|
||||
```python
|
||||
from phoenix.otel import register
|
||||
|
||||
tracer_provider = register(
|
||||
project_name="crewai-tracing-demo",
|
||||
auto_instrument=True,
|
||||
)
|
||||
```
|
||||
|
||||
### Passo 4: Crie uma Aplicação CrewAI
|
||||
|
||||
Vamos criar uma aplicação CrewAI em que dois agentes colaboram para pesquisar e escrever um post de blog sobre avanços em IA.
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai_tools import SerperDevTool
|
||||
from openinference.instrumentation.crewai import CrewAIInstrumentor
|
||||
from phoenix.otel import register
|
||||
|
||||
# configure o monitoramento para seu crew
|
||||
tracer_provider = register(
|
||||
endpoint="http://localhost:6006/v1/traces")
|
||||
CrewAIInstrumentor().instrument(skip_dep_check=True, tracer_provider=tracer_provider)
|
||||
search_tool = SerperDevTool()
|
||||
|
||||
# Defina seus agentes com papéis e objetivos
|
||||
researcher = Agent(
|
||||
role="Senior Research Analyst",
|
||||
goal="Uncover cutting-edge developments in AI and data science",
|
||||
backstory="""You work at a leading tech think tank.
|
||||
Your expertise lies in identifying emerging trends.
|
||||
You have a knack for dissecting complex data and presenting actionable insights.""",
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
# You can pass an optional llm attribute specifying what model you wanna use.
|
||||
# llm=ChatOpenAI(model_name="gpt-3.5", temperature=0.7),
|
||||
tools=[search_tool],
|
||||
)
|
||||
writer = Agent(
|
||||
role="Tech Content Strategist",
|
||||
goal="Craft compelling content on tech advancements",
|
||||
backstory="""You are a renowned Content Strategist, known for your insightful and engaging articles.
|
||||
You transform complex concepts into compelling narratives.""",
|
||||
verbose=True,
|
||||
allow_delegation=True,
|
||||
)
|
||||
|
||||
# Crie tarefas para seus agentes
|
||||
task1 = Task(
|
||||
description="""Conduct a comprehensive analysis of the latest advancements in AI in 2024.
|
||||
Identify key trends, breakthrough technologies, and potential industry impacts.""",
|
||||
expected_output="Full analysis report in bullet points",
|
||||
agent=researcher,
|
||||
)
|
||||
|
||||
task2 = Task(
|
||||
description="""Using the insights provided, develop an engaging blog
|
||||
post that highlights the most significant AI advancements.
|
||||
Your post should be informative yet accessible, catering to a tech-savvy audience.
|
||||
Make it sound cool, avoid complex words so it doesn't sound like AI.""",
|
||||
expected_output="Full blog post of at least 4 paragraphs",
|
||||
agent=writer,
|
||||
)
|
||||
|
||||
# Instancie seu crew com um processo sequencial
|
||||
crew = Crew(
|
||||
agents=[researcher, writer], tasks=[task1, task2], verbose=1, process=Process.sequential
|
||||
)
|
||||
|
||||
# Coloque seu crew para trabalhar!
|
||||
result = crew.kickoff()
|
||||
|
||||
print("######################")
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Passo 5: Visualize os Rastros no Phoenix
|
||||
|
||||
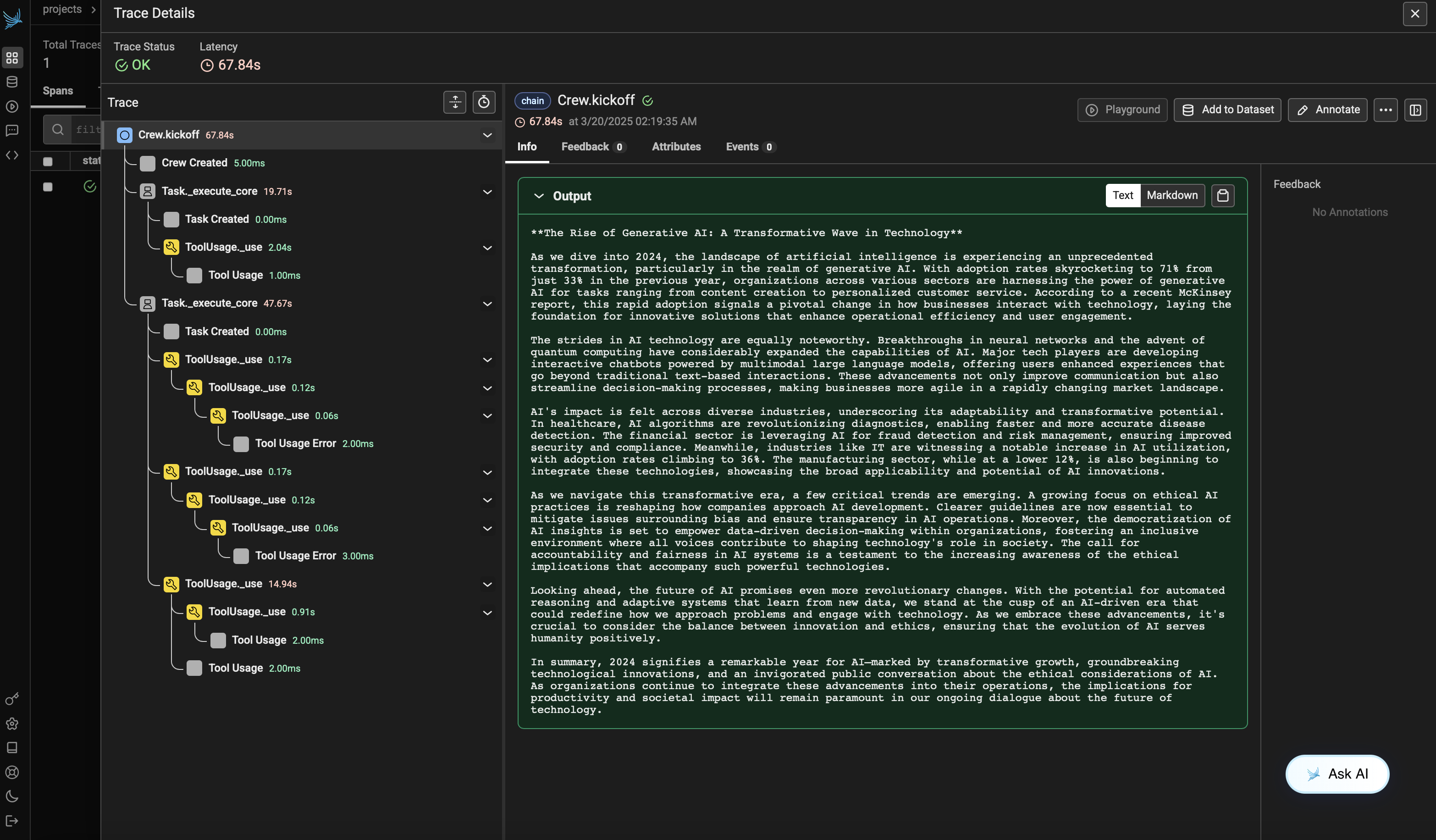
Após executar o agente, você poderá visualizar os rastros gerados pela sua aplicação CrewAI no Phoenix. Você verá etapas detalhadas das interações dos agentes e chamadas de LLM, o que pode ajudar na depuração e otimização dos seus agentes de IA.
|
||||
|
||||
Acesse sua conta Phoenix Cloud e navegue até o projeto que você especificou no parâmetro `project_name`. Você verá uma visualização de linha do tempo do seu rastro, incluindo todas as interações dos agentes, uso de ferramentas e chamadas LLM.
|
||||
|
||||
|
||||
|
||||
|
||||
### Informações de Compatibilidade de Versão
|
||||
- Python 3.8+
|
||||
- CrewAI >= 0.86.0
|
||||
- Arize Phoenix >= 7.0.1
|
||||
- OpenTelemetry SDK >= 1.31.0
|
||||
|
||||
|
||||
### Referências
|
||||
- [Documentação do Phoenix](https://docs.arize.com/phoenix/) - Visão geral da plataforma Phoenix.
|
||||
- [Documentação do CrewAI](https://docs.crewai.com/) - Visão geral do framework CrewAI.
|
||||
- [Documentação do OpenTelemetry](https://opentelemetry.io/docs/) - Guia do OpenTelemetry
|
||||
- [OpenInference GitHub](https://github.com/openinference/openinference) - Código-fonte do SDK OpenInference.
|
||||
107
docs/pt-BR/observability/langfuse.mdx
Normal file
107
docs/pt-BR/observability/langfuse.mdx
Normal file
@@ -0,0 +1,107 @@
|
||||
---
|
||||
title: Integração Langfuse
|
||||
description: Saiba como integrar o Langfuse ao CrewAI via OpenTelemetry usando OpenLit
|
||||
icon: vials
|
||||
---
|
||||
|
||||
# Integre o Langfuse ao CrewAI
|
||||
|
||||
Este notebook demonstra como integrar o **Langfuse** ao **CrewAI** usando OpenTelemetry via o SDK **OpenLit**. Ao final deste notebook, você será capaz de rastrear suas aplicações CrewAI com o Langfuse para melhorar a observabilidade e a depuração.
|
||||
|
||||
> **O que é Langfuse?** [Langfuse](https://langfuse.com) é uma plataforma open-source de engenharia LLM. Ela fornece recursos de rastreamento e monitoramento para aplicações LLM, ajudando desenvolvedores a depurar, analisar e otimizar seus sistemas de IA. O Langfuse se integra com várias ferramentas e frameworks através de integrações nativas, OpenTelemetry e APIs/SDKs.
|
||||
|
||||
[](https://langfuse.com/watch-demo)
|
||||
|
||||
## Primeiros Passos
|
||||
|
||||
Vamos passar por um exemplo simples usando CrewAI e integrando ao Langfuse via OpenTelemetry utilizando o OpenLit.
|
||||
|
||||
### Passo 1: Instale as Dependências
|
||||
|
||||
```python
|
||||
%pip install langfuse openlit crewai crewai_tools
|
||||
```
|
||||
|
||||
### Passo 2: Configure as Variáveis de Ambiente
|
||||
|
||||
Defina suas chaves de API do Langfuse e configure as opções de exportação do OpenTelemetry para enviar os traces ao Langfuse. Consulte a [Documentação Langfuse OpenTelemetry](https://langfuse.com/docs/opentelemetry/get-started) para mais informações sobre o endpoint Langfuse OpenTelemetry `/api/public/otel` e autenticação.
|
||||
|
||||
```python
|
||||
import os
|
||||
|
||||
# Obtenha as chaves do seu projeto na página de configurações do projeto: https://cloud.langfuse.com
|
||||
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
|
||||
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
|
||||
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 Região UE
|
||||
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 Região EUA
|
||||
|
||||
|
||||
# Sua chave OpenAI
|
||||
os.environ["OPENAI_API_KEY"] = "sk-proj-..."
|
||||
```
|
||||
Com as variáveis de ambiente configuradas, agora podemos inicializar o cliente Langfuse. A função get_client() inicializa o cliente Langfuse usando as credenciais fornecidas nas variáveis de ambiente.
|
||||
|
||||
```python
|
||||
from langfuse import get_client
|
||||
|
||||
langfuse = get_client()
|
||||
|
||||
# Verificar conexão
|
||||
if langfuse.auth_check():
|
||||
print("Cliente Langfuse autenticado e pronto!")
|
||||
else:
|
||||
print("Falha na autenticação. Verifique suas credenciais e host.")
|
||||
```
|
||||
|
||||
### Passo 3: Inicialize o OpenLit
|
||||
|
||||
Inicialize o SDK de instrumentação OpenTelemetry do OpenLit para começar a capturar traces do OpenTelemetry.
|
||||
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
### Passo 4: Crie uma Aplicação Simples CrewAI
|
||||
|
||||
Vamos criar uma aplicação simples CrewAI onde múltiplos agentes colaboram para responder à pergunta de um usuário.
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
from crewai_tools import (
|
||||
WebsiteSearchTool
|
||||
)
|
||||
|
||||
web_rag_tool = WebsiteSearchTool()
|
||||
|
||||
writer = Agent(
|
||||
role="Writer",
|
||||
goal="Você torna a matemática envolvente e compreensível para crianças pequenas através de poesias",
|
||||
backstory="Você é especialista em escrever haicais mas não sabe nada de matemática.",
|
||||
tools=[web_rag_tool],
|
||||
)
|
||||
|
||||
task = Task(description=("O que é {multiplicação}?"),
|
||||
expected_output=("Componha um haicai que inclua a resposta."),
|
||||
agent=writer)
|
||||
|
||||
crew = Crew(
|
||||
agents=[writer],
|
||||
tasks=[task],
|
||||
share_crew=False
|
||||
)
|
||||
```
|
||||
|
||||
### Passo 5: Veja os Traces no Langfuse
|
||||
|
||||
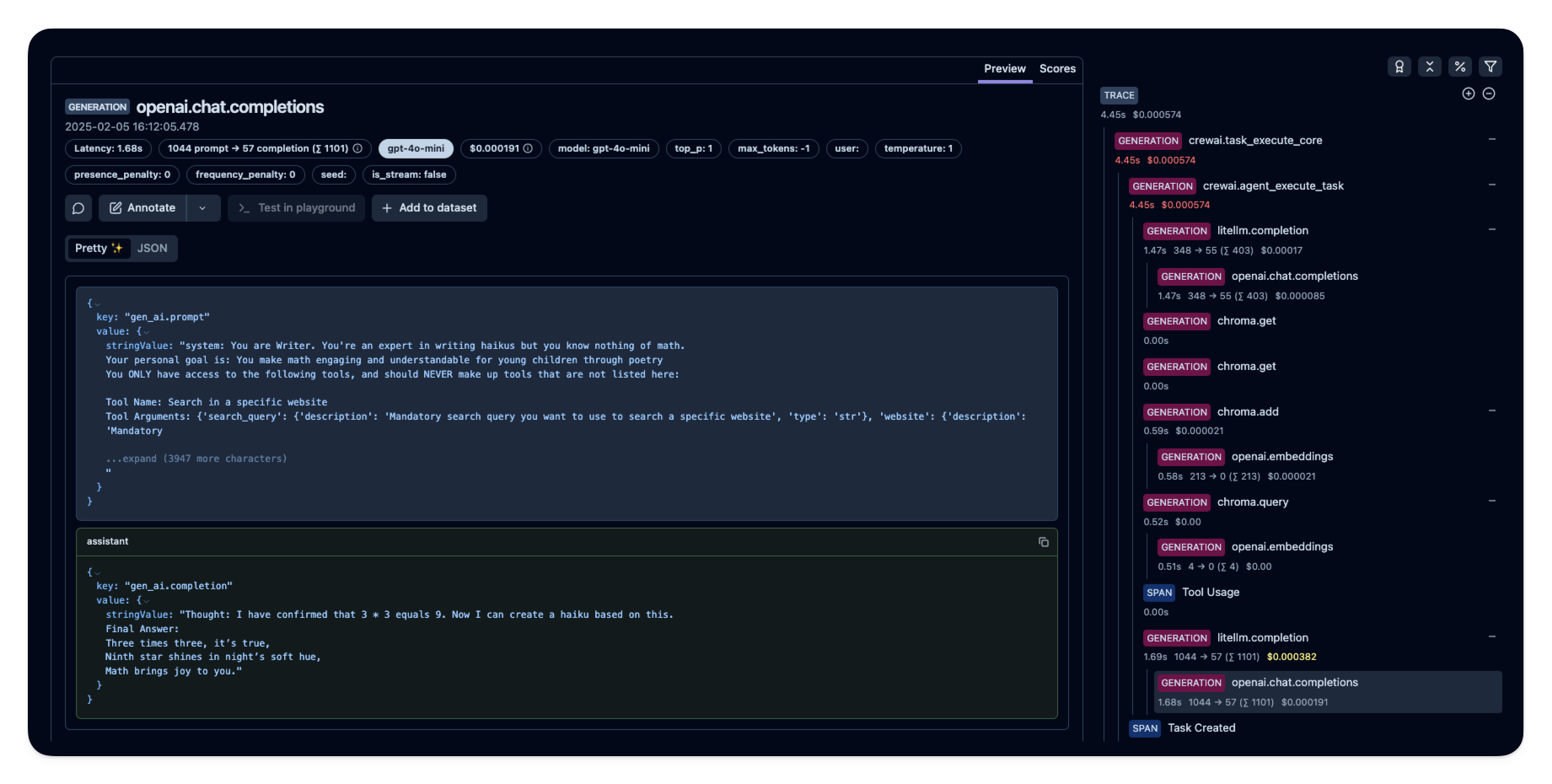
Após rodar o agente, você pode visualizar os traces gerados pela sua aplicação CrewAI no [Langfuse](https://cloud.langfuse.com). Você verá etapas detalhadas das interações do LLM, o que pode ajudar na depuração e otimização do seu agente de IA.
|
||||
|
||||
|
||||
|
||||
_[Exemplo público de trace no Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/e2cf380ffc8d47d28da98f136140642b?timestamp=2025-02-05T15%3A12%3A02.717Z&observation=3b32338ee6a5d9af)_
|
||||
|
||||
## Referências
|
||||
|
||||
- [Documentação Langfuse OpenTelemetry](https://langfuse.com/docs/opentelemetry/get-started)
|
||||
72
docs/pt-BR/observability/langtrace.mdx
Normal file
72
docs/pt-BR/observability/langtrace.mdx
Normal file
@@ -0,0 +1,72 @@
|
||||
---
|
||||
title: Integração com Langtrace
|
||||
description: Como monitorar custo, latência e desempenho dos Agentes CrewAI usando o Langtrace, uma ferramenta externa de observabilidade.
|
||||
icon: chart-line
|
||||
---
|
||||
|
||||
# Visão Geral do Langtrace
|
||||
|
||||
O Langtrace é uma ferramenta externa e open-source que auxilia na configuração de observabilidade e avaliações para Modelos de Linguagem de Grande Porte (LLMs), frameworks de LLM e Bancos de Dados Vetoriais.
|
||||
Apesar de não ser integrado diretamente ao CrewAI, o Langtrace pode ser utilizado em conjunto com o CrewAI para fornecer uma visibilidade aprofundada sobre o custo, latência e desempenho dos seus Agentes CrewAI.
|
||||
Essa integração permite o registro de hiperparâmetros, o monitoramento de regressões de desempenho e o estabelecimento de um processo de melhoria contínua dos seus Agentes.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
## Instruções de Configuração
|
||||
|
||||
<Steps>
|
||||
<Step title="Crie uma conta no Langtrace">
|
||||
Cadastre-se acessando [https://langtrace.ai/signup](https://langtrace.ai/signup).
|
||||
</Step>
|
||||
<Step title="Crie um projeto">
|
||||
Defina o tipo do projeto como `CrewAI` e gere uma chave de API.
|
||||
</Step>
|
||||
<Step title="Instale o Langtrace no seu projeto CrewAI">
|
||||
Use o seguinte comando:
|
||||
|
||||
```bash
|
||||
pip install langtrace-python-sdk
|
||||
```
|
||||
</Step>
|
||||
<Step title="Importe o Langtrace">
|
||||
Importe e inicialize o Langtrace no início do seu script, antes de quaisquer imports do CrewAI:
|
||||
|
||||
```python
|
||||
from langtrace_python_sdk import langtrace
|
||||
langtrace.init(api_key='<LANGTRACE_API_KEY>')
|
||||
|
||||
# Agora importe os módulos do CrewAI
|
||||
from crewai import Agent, Task, Crew
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Funcionalidades e Sua Aplicação no CrewAI
|
||||
|
||||
1. **Rastreamento de Token e Custo do LLM**
|
||||
|
||||
- Monitore o uso de tokens e os custos associados para cada interação dos agentes CrewAI.
|
||||
|
||||
2. **Gráfico de Trace para Etapas de Execução**
|
||||
|
||||
- Visualize o fluxo de execução das suas tarefas CrewAI, incluindo latência e logs.
|
||||
- Útil para identificar gargalos nos fluxos de trabalho dos seus agentes.
|
||||
|
||||
3. **Curadoria de Dataset com Anotação Manual**
|
||||
|
||||
- Crie conjuntos de dados a partir das saídas das suas tarefas CrewAI para futuros treinamentos ou avaliações.
|
||||
|
||||
4. **Versionamento e Gerenciamento de Prompt**
|
||||
|
||||
- Acompanhe as diferentes versões de prompts utilizados em seus agentes CrewAI.
|
||||
- Útil para testes A/B e otimização de desempenho dos agentes.
|
||||
|
||||
5. **Playground de Prompt com Comparações de Modelos**
|
||||
|
||||
- Teste e compare diferentes prompts e modelos para seus agentes CrewAI antes da implantação.
|
||||
|
||||
6. **Testes e Avaliações**
|
||||
|
||||
- Configure testes automatizados para seus agentes e tarefas CrewAI.
|
||||
150
docs/pt-BR/observability/maxim.mdx
Normal file
150
docs/pt-BR/observability/maxim.mdx
Normal file
@@ -0,0 +1,150 @@
|
||||
---
|
||||
title: Integração Maxim
|
||||
description: Inicie o monitoramento, avaliação e observabilidade de agentes
|
||||
icon: bars-staggered
|
||||
---
|
||||
|
||||
# Integração Maxim
|
||||
|
||||
Maxim AI oferece monitoramento completo de agentes, avaliação e observabilidade para suas aplicações CrewAI. Com a integração de uma linha do Maxim, você pode facilmente rastrear e analisar interações dos agentes, métricas de desempenho e muito mais.
|
||||
|
||||
## Funcionalidades: Integração com Uma Linha
|
||||
|
||||
- **Rastreamento de Agentes de Ponta a Ponta**: Monitore todo o ciclo de vida dos seus agentes
|
||||
- **Análise de Desempenho**: Acompanhe latência, tokens consumidos e custos
|
||||
- **Monitoramento de Hiperparâmetros**: Visualize detalhes de configuração das execuções dos agentes
|
||||
- **Rastreamento de Chamadas de Ferramentas**: Observe quando e como os agentes usam suas ferramentas
|
||||
- **Visualização Avançada**: Entenda as trajetórias dos agentes através de dashboards intuitivos
|
||||
|
||||
## Começando
|
||||
|
||||
### Pré-requisitos
|
||||
|
||||
- Python versão >=3.10
|
||||
- Uma conta Maxim ([cadastre-se aqui](https://getmaxim.ai/))
|
||||
- Um projeto CrewAI
|
||||
|
||||
### Instalação
|
||||
|
||||
Instale o SDK do Maxim via pip:
|
||||
|
||||
```python
|
||||
pip install maxim-py>=3.6.2
|
||||
```
|
||||
|
||||
Ou adicione ao seu `requirements.txt`:
|
||||
|
||||
```
|
||||
maxim-py>=3.6.2
|
||||
```
|
||||
|
||||
### Configuração Básica
|
||||
|
||||
### 1. Configure as variáveis de ambiente
|
||||
|
||||
```python
|
||||
### Configuração de Variáveis de Ambiente
|
||||
|
||||
# Crie um arquivo `.env` na raiz do seu projeto:
|
||||
|
||||
# Configuração da API Maxim
|
||||
MAXIM_API_KEY=your_api_key_here
|
||||
MAXIM_LOG_REPO_ID=your_repo_id_here
|
||||
```
|
||||
|
||||
### 2. Importe os pacotes necessários
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
from maxim import Maxim
|
||||
from maxim.logger.crewai import instrument_crewai
|
||||
```
|
||||
|
||||
### 3. Inicialize o Maxim com sua chave de API
|
||||
|
||||
```python
|
||||
# Inicialize o logger do Maxim
|
||||
logger = Maxim().logger()
|
||||
|
||||
# Instrumente o CrewAI com apenas uma linha
|
||||
instrument_crewai(logger)
|
||||
```
|
||||
|
||||
### 4. Crie e execute sua aplicação CrewAI normalmente
|
||||
|
||||
```python
|
||||
|
||||
# Crie seu agente
|
||||
researcher = Agent(
|
||||
role='Senior Research Analyst',
|
||||
goal='Uncover cutting-edge developments in AI',
|
||||
backstory="You are an expert researcher at a tech think tank...",
|
||||
verbose=True,
|
||||
llm=llm
|
||||
)
|
||||
|
||||
# Defina a tarefa
|
||||
research_task = Task(
|
||||
description="Research the latest AI advancements...",
|
||||
expected_output="",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
# Configure e execute a crew
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[research_task],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
try:
|
||||
result = crew.kickoff()
|
||||
finally:
|
||||
maxim.cleanup() # Garanta o cleanup mesmo em caso de erros
|
||||
```
|
||||
|
||||
É isso! Todas as interações dos seus agentes CrewAI agora serão registradas e estarão disponíveis em seu painel Maxim.
|
||||
|
||||
Confira este Google Colab Notebook para referência rápida – [Notebook](https://colab.research.google.com/drive/1ZKIZWsmgQQ46n8TH9zLsT1negKkJA6K8?usp=sharing)
|
||||
|
||||
## Visualizando Seus Rastreamentos
|
||||
|
||||
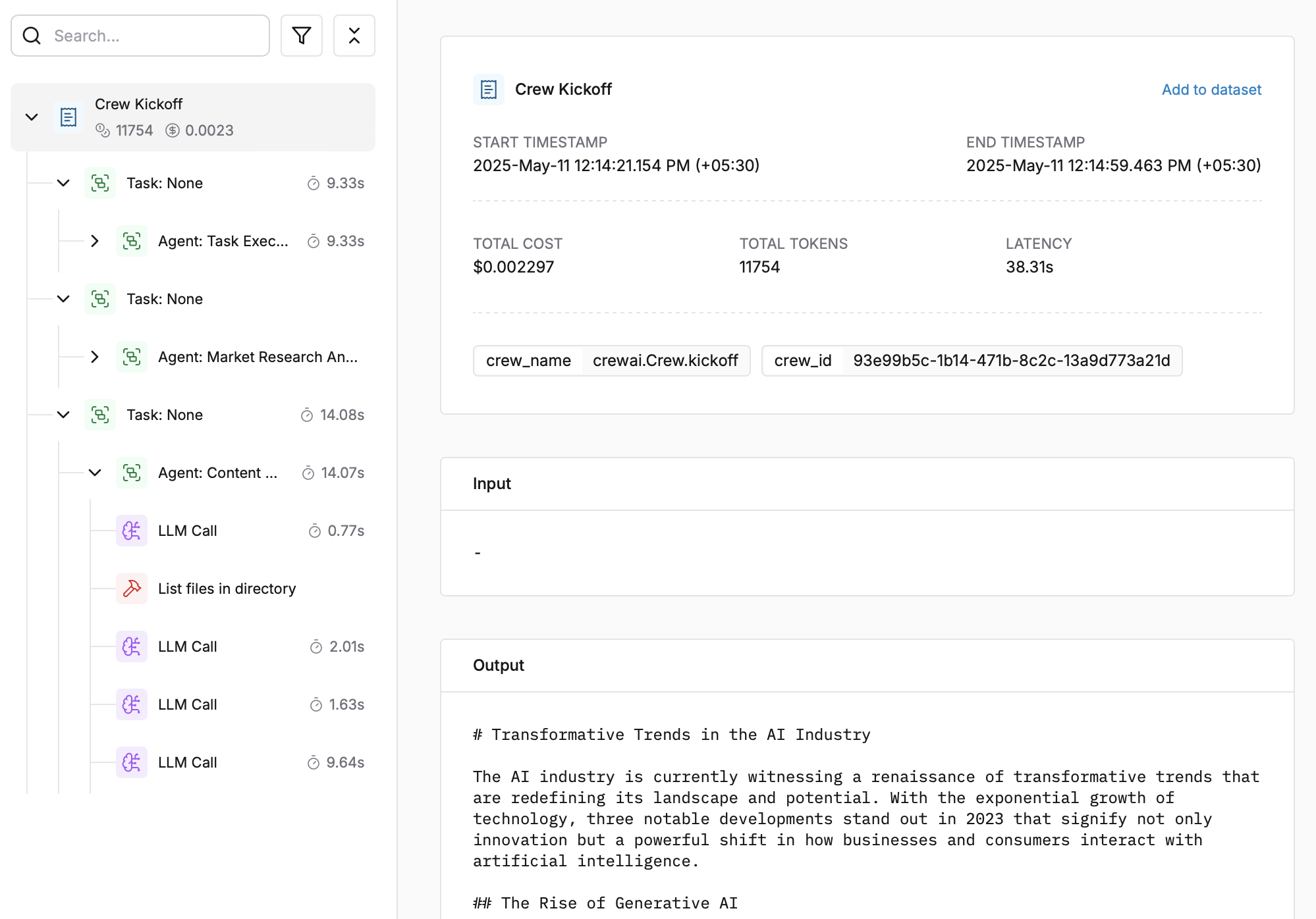
Após executar sua aplicação CrewAI:
|
||||
|
||||
|
||||
|
||||
1. Faça login no seu [Painel Maxim](https://getmaxim.ai/dashboard)
|
||||
2. Navegue até seu repositório
|
||||
3. Visualize rastreamentos detalhados de agentes, incluindo:
|
||||
- Conversas dos agentes
|
||||
- Padrões de uso de ferramentas
|
||||
- Métricas de desempenho
|
||||
- Análises de custos
|
||||
|
||||
## Solução de Problemas
|
||||
|
||||
### Problemas Comuns
|
||||
|
||||
- **Nenhum rastreamento aparecendo**: Certifique-se de que sua chave de API e o ID do repositório estão corretos
|
||||
- Certifique-se de que você **chamou `instrument_crewai()`** ***antes*** de executar sua crew. Isso inicializa corretamente os hooks de logging.
|
||||
- Defina `debug=True` na chamada do `instrument_crewai()` para expor erros internos:
|
||||
|
||||
```python
|
||||
instrument_crewai(logger, debug=True)
|
||||
```
|
||||
|
||||
- Configure seus agentes com `verbose=True` para capturar logs detalhados:
|
||||
|
||||
```python
|
||||
|
||||
agent = CrewAgent(..., verbose=True)
|
||||
```
|
||||
|
||||
- Verifique cuidadosamente se `instrument_crewai()` foi chamado **antes** de criar ou executar agentes. Isso pode parecer óbvio, mas é um erro comum.
|
||||
|
||||
### Suporte
|
||||
|
||||
Se você encontrar algum problema:
|
||||
|
||||
- Consulte a [Documentação do Maxim](https://getmaxim.ai/docs)
|
||||
- Maxim Github [Link](https://github.com/maximhq)
|
||||
205
docs/pt-BR/observability/mlflow.mdx
Normal file
205
docs/pt-BR/observability/mlflow.mdx
Normal file
@@ -0,0 +1,205 @@
|
||||
---
|
||||
title: Integração com MLflow
|
||||
description: Comece rapidamente a monitorar seus Agents com MLflow.
|
||||
icon: bars-staggered
|
||||
---
|
||||
|
||||
# Visão Geral do MLflow
|
||||
|
||||
[MLflow](https://mlflow.org/) é uma plataforma open-source que auxilia profissionais e equipes de machine learning a lidar com as complexidades do processo de aprendizagem de máquina.
|
||||
|
||||
Ela oferece um recurso de tracing que aprimora a observabilidade de LLMs em suas aplicações de IA Generativa, capturando informações detalhadas sobre a execução dos serviços de sua aplicação.
|
||||
O tracing fornece uma forma de registrar os inputs, outputs e metadados associados a cada etapa intermediária de uma requisição, permitindo que você identifique facilmente a origem de bugs e comportamentos inesperados.
|
||||
|
||||

|
||||
|
||||
### Funcionalidades
|
||||
|
||||
- **Painel de Tracing**: Monitore as atividades dos seus agentes crewAI com painéis detalhados que incluem entradas, saídas e metadados dos spans.
|
||||
- **Tracing Automatizado**: Uma integração totalmente automatizada com crewAI, que pode ser habilitada executando `mlflow.crewai.autolog()`.
|
||||
- **Instrumentação Manual de Tracing com pouco esforço**: Personalize a instrumentação dos traces usando as APIs de alto nível do MLflow, como decorators, wrappers de funções e context managers.
|
||||
- **Compatibilidade com OpenTelemetry**: O MLflow Tracing suporta a exportação de traces para um OpenTelemetry Collector, que pode então ser usado para exportar traces para diversos backends como Jaeger, Zipkin e AWS X-Ray.
|
||||
- **Empacote e Faça Deploy dos Agents**: Empacote e faça deploy de seus agents crewAI em um servidor de inferência com diversas opções de destino.
|
||||
- **Hospede LLMs com Segurança**: Hospede múltiplos LLMs de vários provedores em um endpoint unificado através do gateway do MFflow.
|
||||
- **Avaliação**: Avalie seus agents crewAI com uma ampla variedade de métricas utilizando a API conveniente `mlflow.evaluate()`.
|
||||
|
||||
## Instruções de Configuração
|
||||
|
||||
<Steps>
|
||||
<Step title="Instale o pacote MLflow">
|
||||
```shell
|
||||
# A integração crewAI está disponível no mlflow>=2.19.0
|
||||
pip install mlflow
|
||||
```
|
||||
</Step>
|
||||
<Step title="Inicie o servidor de tracking do MFflow">
|
||||
```shell
|
||||
# Este processo é opcional, mas é recomendado utilizar o servidor de tracking do MLflow para melhor visualização e mais funcionalidades.
|
||||
mlflow server
|
||||
```
|
||||
</Step>
|
||||
<Step title="Inicialize o MLflow em sua aplicação">
|
||||
Adicione as duas linhas a seguir ao código da sua aplicação:
|
||||
|
||||
```python
|
||||
import mlflow
|
||||
|
||||
mlflow.crewai.autolog()
|
||||
|
||||
# Opcional: Defina uma tracking URI e um nome de experimento caso utilize um servidor de tracking
|
||||
mlflow.set_tracking_uri("http://localhost:5000")
|
||||
mlflow.set_experiment("CrewAI")
|
||||
```
|
||||
|
||||
Exemplo de uso para tracing de Agents do CrewAI:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task
|
||||
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
|
||||
from crewai_tools import SerperDevTool, WebsiteSearchTool
|
||||
|
||||
from textwrap import dedent
|
||||
|
||||
content = "Users name is John. He is 30 years old and lives in San Francisco."
|
||||
string_source = StringKnowledgeSource(
|
||||
content=content, metadata={"preference": "personal"}
|
||||
)
|
||||
|
||||
search_tool = WebsiteSearchTool()
|
||||
|
||||
|
||||
class TripAgents:
|
||||
def city_selection_agent(self):
|
||||
return Agent(
|
||||
role="City Selection Expert",
|
||||
goal="Select the best city based on weather, season, and prices",
|
||||
backstory="An expert in analyzing travel data to pick ideal destinations",
|
||||
tools=[
|
||||
search_tool,
|
||||
],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def local_expert(self):
|
||||
return Agent(
|
||||
role="Local Expert at this city",
|
||||
goal="Provide the BEST insights about the selected city",
|
||||
backstory="""A knowledgeable local guide with extensive information
|
||||
about the city, it's attractions and customs""",
|
||||
tools=[search_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
|
||||
class TripTasks:
|
||||
def identify_task(self, agent, origin, cities, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
Analyze and select the best city for the trip based
|
||||
on specific criteria such as weather patterns, seasonal
|
||||
events, and travel costs. This task involves comparing
|
||||
multiple cities, considering factors like current weather
|
||||
conditions, upcoming cultural or seasonal events, and
|
||||
overall travel expenses.
|
||||
Your final answer must be a detailed
|
||||
report on the chosen city, and everything you found out
|
||||
about it, including the actual flight costs, weather
|
||||
forecast and attractions.
|
||||
|
||||
Traveling from: {origin}
|
||||
City Options: {cities}
|
||||
Trip Date: {range}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Detailed report on the chosen city including flight costs, weather forecast, and attractions",
|
||||
)
|
||||
|
||||
def gather_task(self, agent, origin, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
As a local expert on this city you must compile an
|
||||
in-depth guide for someone traveling there and wanting
|
||||
to have THE BEST trip ever!
|
||||
Gather information about key attractions, local customs,
|
||||
special events, and daily activity recommendations.
|
||||
Find the best spots to go to, the kind of place only a
|
||||
local would know.
|
||||
This guide should provide a thorough overview of what
|
||||
the city has to offer, including hidden gems, cultural
|
||||
hotspots, must-visit landmarks, weather forecasts, and
|
||||
high level costs.
|
||||
The final answer must be a comprehensive city guide,
|
||||
rich in cultural insights and practical tips,
|
||||
tailored to enhance the travel experience.
|
||||
|
||||
Trip Date: {range}
|
||||
Traveling from: {origin}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Comprehensive city guide including hidden gems, cultural hotspots, and practical travel tips",
|
||||
)
|
||||
|
||||
|
||||
class TripCrew:
|
||||
def __init__(self, origin, cities, date_range, interests):
|
||||
self.cities = cities
|
||||
self.origin = origin
|
||||
self.interests = interests
|
||||
self.date_range = date_range
|
||||
|
||||
def run(self):
|
||||
agents = TripAgents()
|
||||
tasks = TripTasks()
|
||||
|
||||
city_selector_agent = agents.city_selection_agent()
|
||||
local_expert_agent = agents.local_expert()
|
||||
|
||||
identify_task = tasks.identify_task(
|
||||
city_selector_agent,
|
||||
self.origin,
|
||||
self.cities,
|
||||
self.interests,
|
||||
self.date_range,
|
||||
)
|
||||
gather_task = tasks.gather_task(
|
||||
local_expert_agent, self.origin, self.interests, self.date_range
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[city_selector_agent, local_expert_agent],
|
||||
tasks=[identify_task, gather_task],
|
||||
verbose=True,
|
||||
memory=True,
|
||||
knowledge={
|
||||
"sources": [string_source],
|
||||
"metadata": {"preference": "personal"},
|
||||
},
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
return result
|
||||
|
||||
|
||||
trip_crew = TripCrew("California", "Tokyo", "Dec 12 - Dec 20", "sports")
|
||||
result = trip_crew.run()
|
||||
|
||||
print(result)
|
||||
```
|
||||
Consulte a [Documentação de Tracing do MLflow](https://mlflow.org/docs/latest/llms/tracing/index.html) para mais configurações e casos de uso.
|
||||
</Step>
|
||||
<Step title="Visualize as atividades dos Agents">
|
||||
Agora os traces dos seus agentes crewAI estão sendo capturados pelo MLflow.
|
||||
Vamos acessar o servidor de tracking do MLflow para visualizar os traces e obter insights dos seus Agents.
|
||||
|
||||
Abra `127.0.0.1:5000` em seu navegador para acessar o servidor de tracking do MLflow.
|
||||
<Frame caption="Painel de Tracing do MLflow">
|
||||
<img src="/images/mlflow1.png" alt="Exemplo de tracing do MLflow com crewai" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
180
docs/pt-BR/observability/openlit.mdx
Normal file
180
docs/pt-BR/observability/openlit.mdx
Normal file
@@ -0,0 +1,180 @@
|
||||
---
|
||||
title: Integração OpenLIT
|
||||
description: Comece a monitorar seus Agentes rapidamente com apenas uma linha de código usando OpenTelemetry.
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# Visão Geral do OpenLIT
|
||||
|
||||
[OpenLIT](https://github.com/openlit/openlit?src=crewai-docs) é uma ferramenta open-source que simplifica o monitoramento de desempenho de agentes de IA, LLMs, VectorDBs e GPUs com apenas **uma** linha de código.
|
||||
|
||||
Ela oferece rastreamento e métricas nativos do OpenTelemetry para acompanhar parâmetros importantes como custo, latência, interações e sequências de tarefas.
|
||||
Essa configuração permite acompanhar hiperparâmetros e monitorar problemas de desempenho, ajudando a encontrar formas de aprimorar e refinar seus agentes com o tempo.
|
||||
|
||||
<Frame caption="Painel do OpenLIT">
|
||||
<img src="/images/openlit1.png" alt="Visão geral do uso de agentes, incluindo custo e tokens" />
|
||||
<img src="/images/openlit2.png" alt="Visão geral dos rastreamentos e métricas otel do agente" />
|
||||
<img src="/images/openlit3.png" alt="Visão detalhada dos rastreamentos do agente" />
|
||||
</Frame>
|
||||
|
||||
### Funcionalidades
|
||||
|
||||
- **Painel Analítico**: Monitore a saúde e desempenho dos seus Agentes com dashboards detalhados que acompanham métricas, custos e interações dos usuários.
|
||||
- **SDK de Observabilidade Nativo OpenTelemetry**: SDKs neutros de fornecedor para enviar rastreamentos e métricas para suas ferramentas de observabilidade existentes como Grafana, DataDog e outros.
|
||||
- **Rastreamento de Custos para Modelos Customizados e Ajustados**: Adapte estimativas de custo para modelos específicos usando arquivos de precificação customizados para orçamentos precisos.
|
||||
- **Painel de Monitoramento de Exceções**: Identifique e solucione rapidamente problemas ao rastrear exceções comuns e erros por meio de um painel de monitoramento.
|
||||
- **Conformidade e Segurança**: Detecte ameaças potenciais como profanidade e vazamento de dados sensíveis (PII).
|
||||
- **Detecção de Prompt Injection**: Identifique possíveis injeções de código e vazamentos de segredos.
|
||||
- **Gerenciamento de Chaves de API e Segredos**: Gerencie suas chaves de API e segredos do LLM de forma centralizada e segura, evitando práticas inseguras.
|
||||
- **Gerenciamento de Prompt**: Gerencie e versiona prompts de Agente usando o PromptHub para acesso consistente e fácil entre os agentes.
|
||||
- **Model Playground** Teste e compare diferentes modelos para seus agentes CrewAI antes da implantação.
|
||||
|
||||
## Instruções de Configuração
|
||||
|
||||
<Steps>
|
||||
<Step title="Implantar o OpenLIT">
|
||||
<Steps>
|
||||
<Step title="Clonar o Repositório do OpenLIT">
|
||||
```shell
|
||||
git clone git@github.com:openlit/openlit.git
|
||||
```
|
||||
</Step>
|
||||
<Step title="Iniciar o Docker Compose">
|
||||
A partir do diretório raiz do [Repositório OpenLIT](https://github.com/openlit/openlit), execute o comando abaixo:
|
||||
```shell
|
||||
docker compose up -d
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
</Step>
|
||||
<Step title="Instalar o SDK OpenLIT">
|
||||
```shell
|
||||
pip install openlit
|
||||
```
|
||||
</Step>
|
||||
<Step title="Inicializar o OpenLIT em Sua Aplicação">
|
||||
Adicione as duas linhas abaixo ao seu código de aplicação:
|
||||
<Tabs>
|
||||
<Tab title="Configuração usando argumentos de função">
|
||||
```python
|
||||
import openlit
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
```
|
||||
|
||||
Exemplo de uso para monitoramento de um Agente CrewAI:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
import openlit
|
||||
|
||||
openlit.init(disable_metrics=True)
|
||||
# Definir seus agentes
|
||||
researcher = Agent(
|
||||
role="Researcher",
|
||||
goal="Conduct thorough research and analysis on AI and AI agents",
|
||||
backstory="You're an expert researcher, specialized in technology, software engineering, AI, and startups. You work as a freelancer and are currently researching for a new client.",
|
||||
allow_delegation=False,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
|
||||
# Definir sua task
|
||||
task = Task(
|
||||
description="Generate a list of 5 interesting ideas for an article, then write one captivating paragraph for each idea that showcases the potential of a full article on this topic. Return the list of ideas with their paragraphs and your notes.",
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Definir o agente gerente
|
||||
manager = Agent(
|
||||
role="Project Manager",
|
||||
goal="Efficiently manage the crew and ensure high-quality task completion",
|
||||
backstory="You're an experienced project manager, skilled in overseeing complex projects and guiding teams to success. Your role is to coordinate the efforts of the crew members, ensuring that each task is completed on time and to the highest standard.",
|
||||
allow_delegation=True,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
# Instanciar sua crew com um manager personalizado
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[task],
|
||||
manager_agent=manager,
|
||||
process=Process.hierarchical,
|
||||
)
|
||||
|
||||
# Iniciar o trabalho da crew
|
||||
result = crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
</Tab>
|
||||
<Tab title="Configuração usando Variáveis de Ambiente">
|
||||
|
||||
Adicione as duas linhas abaixo ao seu código de aplicação:
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
Execute o seguinte comando para configurar o endpoint de exportação OTEL:
|
||||
```shell
|
||||
export OTEL_EXPORTER_OTLP_ENDPOINT = "http://127.0.0.1:4318"
|
||||
```
|
||||
|
||||
Exemplo de uso para monitoramento de um Agente CrewAI Async:
|
||||
|
||||
```python
|
||||
import asyncio
|
||||
from crewai import Crew, Agent, Task
|
||||
import openlit
|
||||
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
|
||||
# Criar um agente com execução de código habilitada
|
||||
coding_agent = Agent(
|
||||
role="Python Data Analyst",
|
||||
goal="Analyze data and provide insights using Python",
|
||||
backstory="You are an experienced data analyst with strong Python skills.",
|
||||
allow_code_execution=True,
|
||||
llm="command-r"
|
||||
)
|
||||
|
||||
# Criar uma task que exige execução de código
|
||||
data_analysis_task = Task(
|
||||
description="Analyze the given dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent,
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Criar uma crew e adicionar a task
|
||||
analysis_crew = Crew(
|
||||
agents=[coding_agent],
|
||||
tasks=[data_analysis_task]
|
||||
)
|
||||
|
||||
# Função async para iniciar a crew de forma assíncrona
|
||||
async def async_crew_execution():
|
||||
result = await analysis_crew.kickoff_async(inputs={"ages": [25, 30, 35, 40, 45]})
|
||||
print("Crew Result:", result)
|
||||
|
||||
# Executar a função async
|
||||
asyncio.run(async_crew_execution())
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
Consulte o [repositório do SDK Python do OpenLIT](https://github.com/openlit/openlit/tree/main/sdk/python) para configurações e casos de uso avançados.
|
||||
</Step>
|
||||
<Step title="Visualizar e Analisar">
|
||||
Com os dados de Observabilidade dos Agentes agora sendo coletados e enviados ao OpenLIT, o próximo passo é visualizar e analisar esses dados para obter insights sobre o desempenho, comportamento e identificar oportunidades de melhoria dos seus Agentes.
|
||||
|
||||
Basta acessar o OpenLIT em `127.0.0.1:3000` no seu navegador para começar a explorar. Você pode fazer login usando as credenciais padrão
|
||||
- **Email**: `user@openlit.io`
|
||||
- **Senha**: `openlituser`
|
||||
|
||||
<Frame caption="Painel do OpenLIT">
|
||||
<img src="/images/openlit1.png" alt="Visão geral do uso de agentes, incluindo custo e tokens" />
|
||||
<img src="/images/openlit2.png" alt="Visão geral dos rastreamentos e métricas otel do agente" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
</Steps>
|
||||
129
docs/pt-BR/observability/opik.mdx
Normal file
129
docs/pt-BR/observability/opik.mdx
Normal file
@@ -0,0 +1,129 @@
|
||||
---
|
||||
title: Integração Opik
|
||||
description: Saiba como usar o Comet Opik para depurar, avaliar e monitorar suas aplicações CrewAI com rastreamento abrangente, avaliações automatizadas e dashboards prontos para produção.
|
||||
icon: meteor
|
||||
---
|
||||
|
||||
# Visão Geral do Opik
|
||||
|
||||
Com o [Comet Opik](https://www.comet.com/docs/opik/), depure, avalie e monitore suas aplicações LLM, sistemas RAG e fluxos de trabalho agentic com rastreamento detalhado, avaliações automatizadas e dashboards prontos para produção.
|
||||
|
||||
<Frame caption="Dashboard do Agente Opik">
|
||||
<img src="/images/opik-crewai-dashboard.png" alt="Exemplo de monitoramento de agente Opik com CrewAI" />
|
||||
</Frame>
|
||||
|
||||
O Opik oferece suporte abrangente para cada etapa do desenvolvimento da sua aplicação CrewAI:
|
||||
|
||||
- **Registrar Traces e Spans**: Acompanhe automaticamente chamadas LLM e lógica da aplicação para depurar e analisar sistemas em desenvolvimento e em produção. Anote manualmente ou programaticamente, visualize e compare respostas entre projetos.
|
||||
- **Avalie a Performance da sua Aplicação LLM**: Avalie contra um conjunto de testes personalizado e execute métricas de avaliação nativas ou defina suas próprias métricas via SDK ou UI.
|
||||
- **Teste no Pipeline CI/CD**: Estabeleça bases de performance confiáveis com os testes unitários LLM do Opik, baseados em PyTest. Execute avaliações online para monitoramento contínuo em produção.
|
||||
- **Monitore & Analise Dados de Produção**: Entenda a performance dos seus modelos em dados inéditos em produção e gere conjuntos de dados para novas iterações de desenvolvimento.
|
||||
|
||||
## Configuração
|
||||
A Comet oferece uma versão hospedada da plataforma Opik, ou você pode rodar a plataforma localmente.
|
||||
|
||||
Para usar a versão hospedada, basta [criar uma conta gratuita na Comet](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) e obter sua chave de API.
|
||||
|
||||
Para rodar a plataforma Opik localmente, veja nosso [guia de instalação](https://www.comet.com/docs/opik/self-host/overview/) para mais informações.
|
||||
|
||||
Neste guia, utilizaremos o exemplo de início rápido da CrewAI.
|
||||
|
||||
<Steps>
|
||||
<Step title="Instale os pacotes necessários">
|
||||
```shell
|
||||
pip install crewai crewai-tools opik --upgrade
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure o Opik">
|
||||
```python
|
||||
import opik
|
||||
opik.configure(use_local=False)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Prepare o ambiente">
|
||||
Primeiro, configuramos nossas chaves de API do provedor LLM como variáveis de ambiente:
|
||||
|
||||
```python
|
||||
import os
|
||||
import getpass
|
||||
|
||||
if "OPENAI_API_KEY" not in os.environ:
|
||||
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
|
||||
```
|
||||
</Step>
|
||||
<Step title="Usando a CrewAI">
|
||||
O primeiro passo é criar nosso projeto. Vamos utilizar um exemplo da documentação do CrewAI:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task, Process
|
||||
|
||||
|
||||
class YourCrewName:
|
||||
def agent_one(self) -> Agent:
|
||||
return Agent(
|
||||
role="Data Analyst",
|
||||
goal="Analyze data trends in the market",
|
||||
backstory="An experienced data analyst with a background in economics",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def agent_two(self) -> Agent:
|
||||
return Agent(
|
||||
role="Market Researcher",
|
||||
goal="Gather information on market dynamics",
|
||||
backstory="A diligent researcher with a keen eye for detail",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def task_one(self) -> Task:
|
||||
return Task(
|
||||
name="Collect Data Task",
|
||||
description="Collect recent market data and identify trends.",
|
||||
expected_output="A report summarizing key trends in the market.",
|
||||
agent=self.agent_one(),
|
||||
)
|
||||
|
||||
def task_two(self) -> Task:
|
||||
return Task(
|
||||
name="Market Research Task",
|
||||
description="Research factors affecting market dynamics.",
|
||||
expected_output="An analysis of factors influencing the market.",
|
||||
agent=self.agent_two(),
|
||||
)
|
||||
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[self.agent_one(), self.agent_two()],
|
||||
tasks=[self.task_one(), self.task_two()],
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
Agora podemos importar o tracker do Opik e executar nossa crew:
|
||||
|
||||
```python
|
||||
from opik.integrations.crewai import track_crewai
|
||||
|
||||
track_crewai(project_name="crewai-integration-demo")
|
||||
|
||||
my_crew = YourCrewName().crew()
|
||||
result = my_crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
Após rodar sua aplicação CrewAI, acesse o app Opik para visualizar:
|
||||
- Traces LLM, spans e seus metadados
|
||||
- Interações dos agentes e fluxo de execução das tarefas
|
||||
- Métricas de performance, como latência e uso de tokens
|
||||
- Métricas de avaliação (nativas ou personalizadas)
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Recursos
|
||||
|
||||
- [🦉 Documentação Opik](https://www.comet.com/docs/opik/)
|
||||
- [👉 Opik + CrewAI Colab](https://colab.research.google.com/github/comet-ml/opik/blob/main/apps/opik-documentation/documentation/docs/cookbook/crewai.ipynb)
|
||||
- [🐦 X](https://x.com/cometml)
|
||||
- [💬 Slack](https://slack.comet.com/)
|
||||
118
docs/pt-BR/observability/overview.mdx
Normal file
118
docs/pt-BR/observability/overview.mdx
Normal file
@@ -0,0 +1,118 @@
|
||||
---
|
||||
title: "Visão Geral"
|
||||
description: "Monitore, avalie e otimize seus agentes CrewAI com ferramentas de observabilidade abrangentes"
|
||||
icon: "face-smile"
|
||||
---
|
||||
|
||||
## Observabilidade para CrewAI
|
||||
|
||||
A observabilidade é fundamental para entender como seus agentes CrewAI estão desempenhando, identificar gargalos e garantir uma operação confiável em ambientes de produção. Esta seção aborda diversas ferramentas e plataformas que oferecem recursos de monitoramento, avaliação e otimização dos fluxos de trabalho dos seus agentes.
|
||||
|
||||
## Por que a Observabilidade é Importante
|
||||
|
||||
- **Monitoramento de Desempenho**: Acompanhe tempos de execução dos agentes, uso de tokens e consumo de recursos
|
||||
- **Garantia de Qualidade**: Avalie a qualidade e a consistência das saídas em diferentes cenários
|
||||
- **Depuração**: Identifique e resolva problemas no comportamento dos agentes e na execução de tarefas
|
||||
- **Gestão de Custos**: Monitore o uso das APIs do LLM e os custos associados
|
||||
- **Melhoria Contínua**: Colete insights para otimizar o desempenho dos agentes ao longo do tempo
|
||||
|
||||
## Ferramentas de Observabilidade Disponíveis
|
||||
|
||||
### Plataformas de Monitoramento e Rastreamento
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="AgentOps" icon="paperclip" href="/pt-BR/observability/agentops">
|
||||
Replays de sessões, métricas e monitoramento para desenvolvimento e produção de agentes.
|
||||
</Card>
|
||||
|
||||
<Card title="OpenLIT" icon="magnifying-glass-chart" href="/pt-BR/observability/openlit">
|
||||
Monitoramento nativo OpenTelemetry com rastreamento de custos e análises de desempenho.
|
||||
</Card>
|
||||
|
||||
<Card title="MLflow" icon="bars-staggered" href="/pt-BR/observability/mlflow">
|
||||
Gerenciamento do ciclo de vida de machine learning com rastreamento e avaliação.
|
||||
</Card>
|
||||
|
||||
<Card title="Langfuse" icon="link" href="/pt-BR/observability/langfuse">
|
||||
Plataforma de engenharia de LLM com rastreamento detalhado e análises.
|
||||
</Card>
|
||||
|
||||
<Card title="Langtrace" icon="chart-line" href="/pt-BR/observability/langtrace">
|
||||
Observabilidade open-source para LLMs e frameworks de agentes.
|
||||
</Card>
|
||||
|
||||
<Card title="Arize Phoenix" icon="meteor" href="/pt-BR/observability/arize-phoenix">
|
||||
Plataforma de observabilidade de IA para monitoramento e solução de problemas.
|
||||
</Card>
|
||||
|
||||
<Card title="Portkey" icon="key" href="/pt-BR/observability/portkey">
|
||||
Gateway de IA com monitoramento abrangente e recursos de confiabilidade.
|
||||
</Card>
|
||||
|
||||
<Card title="Opik" icon="meteor" href="/pt-BR/observability/opik">
|
||||
Depure, avalie e monitore aplicações LLM com rastreamento abrangente.
|
||||
</Card>
|
||||
|
||||
<Card title="Weave" icon="network-wired" href="/pt-BR/observability/weave">
|
||||
Plataforma Weights & Biases para acompanhamento e avaliação de aplicações de IA.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### Avaliação & Garantia de Qualidade
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Patronus AI" icon="shield-check" href="/pt-BR/observability/patronus-evaluation">
|
||||
Plataforma abrangente de avaliação para saídas de LLM e comportamentos de agentes.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Principais Métricas de Observabilidade
|
||||
|
||||
### Métricas de Desempenho
|
||||
- **Tempo de Execução**: Quanto tempo os agentes levam para concluir as tarefas
|
||||
- **Uso de Tokens**: Tokens de entrada/saída consumidos pelas chamadas ao LLM
|
||||
- **Latência de API**: Tempo de resposta de serviços externos
|
||||
- **Taxa de Sucesso**: Percentual de tarefas concluídas com sucesso
|
||||
|
||||
### Métricas de Qualidade
|
||||
- **Acurácia da Saída**: Correção das respostas dos agentes
|
||||
- **Consistência**: Confiabilidade em entradas semelhantes
|
||||
- **Relevância**: Quão bem as saídas correspondem aos resultados esperados
|
||||
- **Segurança**: Conformidade com políticas de conteúdo e diretrizes
|
||||
|
||||
### Métricas de Custo
|
||||
- **Custos de API**: Gastos decorrentes do uso do provedor LLM
|
||||
- **Utilização de Recursos**: Consumo de processamento e memória
|
||||
- **Custo por Tarefa**: Eficiência econômica das operações dos agentes
|
||||
- **Acompanhamento de Orçamento**: Monitoramento em relação a limites de gastos
|
||||
|
||||
## Primeiros Passos
|
||||
|
||||
1. **Escolha suas Ferramentas**: Selecione plataformas de observabilidade que atendam às suas necessidades
|
||||
2. **Instrumente seu Código**: Adicione monitoramento às suas aplicações CrewAI
|
||||
3. **Configure Dashboards**: Prepare visualizações para as métricas principais
|
||||
4. **Defina Alertas**: Crie notificações para eventos importantes
|
||||
5. **Estabeleça Bases de Referência**: Meça o desempenho inicial para comparação futura
|
||||
6. **Itere e Melhore**: Use os insights para otimizar seus agentes
|
||||
|
||||
## Boas Práticas
|
||||
|
||||
### Fase de Desenvolvimento
|
||||
- Utilize rastreamento detalhado para entender o comportamento dos agentes
|
||||
- Implemente métricas de avaliação desde o início do desenvolvimento
|
||||
- Monitore o uso de recursos durante os testes
|
||||
- Estabeleça verificações automatizadas de qualidade
|
||||
|
||||
### Fase de Produção
|
||||
- Implemente monitoramento e alertas abrangentes
|
||||
- Acompanhe tendências de desempenho ao longo do tempo
|
||||
- Monitore anomalias e degradações
|
||||
- Mantenha visibilidade e controle dos custos
|
||||
|
||||
### Melhoria Contínua
|
||||
- Revisões regulares de desempenho e otimização
|
||||
- Testes A/B de diferentes configurações de agentes
|
||||
- Ciclos de feedback para aprimoramento da qualidade
|
||||
- Documentação de lições aprendidas
|
||||
|
||||
Escolha as ferramentas de observabilidade que melhor se encaixam no seu caso de uso, infraestrutura e requisitos de monitoramento para garantir que seus agentes CrewAI operem de forma confiável e eficiente.
|
||||
205
docs/pt-BR/observability/patronus-evaluation.mdx
Normal file
205
docs/pt-BR/observability/patronus-evaluation.mdx
Normal file
@@ -0,0 +1,205 @@
|
||||
---
|
||||
title: Avaliação Patronus AI
|
||||
description: Monitore e avalie o desempenho de agentes CrewAI utilizando a plataforma abrangente de avaliação da Patronus AI para saídas de LLM e comportamentos de agentes.
|
||||
icon: shield-check
|
||||
---
|
||||
|
||||
# Avaliação Patronus AI
|
||||
|
||||
## Visão Geral
|
||||
|
||||
[Patronus AI](https://patronus.ai) oferece capacidades abrangentes de avaliação e monitoramento para agentes CrewAI, permitindo avaliar as saídas dos modelos, comportamentos dos agentes e o desempenho geral do sistema. Essa integração possibilita implementar fluxos de avaliação contínuos que ajudam a manter a qualidade e confiabilidade em ambientes de produção.
|
||||
|
||||
## Principais Funcionalidades
|
||||
|
||||
- **Avaliação Automatizada**: Avaliação em tempo real das saídas e comportamentos dos agentes
|
||||
- **Critérios Personalizados**: Defina critérios de avaliação específicos para seus casos de uso
|
||||
- **Monitoramento de Desempenho**: Acompanhe métricas de desempenho dos agentes ao longo do tempo
|
||||
- **Garantia de Qualidade**: Assegure consistência na qualidade das saídas em diferentes cenários
|
||||
- **Segurança & Conformidade**: Monitore possíveis problemas e violações de políticas
|
||||
|
||||
## Ferramentas de Avaliação
|
||||
|
||||
A Patronus disponibiliza três principais ferramentas de avaliação para diferentes casos de uso:
|
||||
|
||||
1. **PatronusEvalTool**: Permite que os agentes selecionem o avaliador e os critérios mais apropriados para a tarefa de avaliação.
|
||||
2. **PatronusPredefinedCriteriaEvalTool**: Utiliza avaliador e critérios predefinidos, especificados pelo usuário.
|
||||
3. **PatronusLocalEvaluatorTool**: Utiliza avaliadores customizados definidos pelo usuário.
|
||||
|
||||
## Instalação
|
||||
|
||||
Para utilizar essas ferramentas, é necessário instalar o pacote Patronus:
|
||||
|
||||
```shell
|
||||
uv add patronus
|
||||
```
|
||||
|
||||
Você também precisará configurar sua chave de API da Patronus como uma variável de ambiente:
|
||||
|
||||
```shell
|
||||
export PATRONUS_API_KEY="your_patronus_api_key"
|
||||
```
|
||||
|
||||
## Passos para Começar
|
||||
|
||||
Para utilizar as ferramentas de avaliação da Patronus de forma eficaz, siga estes passos:
|
||||
|
||||
1. **Instale o Patronus**: Instale o pacote Patronus usando o comando acima.
|
||||
2. **Configure a Chave de API**: Defina sua chave de API da Patronus como uma variável de ambiente.
|
||||
3. **Escolha a Ferramenta Certa**: Selecione a ferramenta de avaliação Patronus mais adequada às suas necessidades.
|
||||
4. **Configure a Ferramenta**: Configure a ferramenta com os parâmetros necessários.
|
||||
|
||||
## Exemplos
|
||||
|
||||
### Utilizando PatronusEvalTool
|
||||
|
||||
O exemplo a seguir demonstra como usar o `PatronusEvalTool`, que permite aos agentes selecionar o avaliador e critérios mais apropriados:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusEvalTool
|
||||
|
||||
# Initialize the tool
|
||||
patronus_eval_tool = PatronusEvalTool()
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code and verify that the output is code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate and evaluate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence. Select the most appropriate evaluator and criteria for evaluating your output.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Utilizando PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
O exemplo a seguir demonstra como usar o `PatronusPredefinedCriteriaEvalTool`, que utiliza avaliador e critérios predefinidos:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
# Initialize the tool with predefined criteria
|
||||
patronus_eval_tool = PatronusPredefinedCriteriaEvalTool(
|
||||
evaluators=[{"evaluator": "judge", "criteria": "contains-code"}]
|
||||
)
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Utilizando PatronusLocalEvaluatorTool
|
||||
|
||||
O exemplo a seguir demonstra como usar o `PatronusLocalEvaluatorTool`, que utiliza avaliadores customizados via função:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusLocalEvaluatorTool
|
||||
from patronus import Client, EvaluationResult
|
||||
import random
|
||||
|
||||
# Initialize the Patronus client
|
||||
client = Client()
|
||||
|
||||
# Register a custom evaluator
|
||||
@client.register_local_evaluator("random_evaluator")
|
||||
def random_evaluator(**kwargs):
|
||||
score = random.random()
|
||||
return EvaluationResult(
|
||||
score_raw=score,
|
||||
pass_=score >= 0.5,
|
||||
explanation="example explanation",
|
||||
)
|
||||
|
||||
# Initialize the tool with the custom evaluator
|
||||
patronus_eval_tool = PatronusLocalEvaluatorTool(
|
||||
patronus_client=client,
|
||||
evaluator="random_evaluator",
|
||||
evaluated_model_gold_answer="example label",
|
||||
)
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
## Parâmetros
|
||||
|
||||
### PatronusEvalTool
|
||||
|
||||
O `PatronusEvalTool` não exige parâmetros durante a inicialização. Ele busca automaticamente os avaliadores e critérios disponíveis a partir da API da Patronus.
|
||||
|
||||
### PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
O `PatronusPredefinedCriteriaEvalTool` aceita os seguintes parâmetros durante a inicialização:
|
||||
|
||||
- **evaluators**: Obrigatório. Uma lista de dicionários contendo o avaliador e os critérios a serem utilizados. Por exemplo: `[{"evaluator": "judge", "criteria": "contains-code"}]`.
|
||||
|
||||
### PatronusLocalEvaluatorTool
|
||||
|
||||
O `PatronusLocalEvaluatorTool` aceita os seguintes parâmetros durante a inicialização:
|
||||
|
||||
- **patronus_client**: Obrigatório. Instância do cliente Patronus.
|
||||
- **evaluator**: Opcional. O nome do avaliador local registrado a ser utilizado. Default é uma string vazia.
|
||||
- **evaluated_model_gold_answer**: Opcional. A resposta padrão (“gold answer”) para uso na avaliação. O padrão é uma string vazia.
|
||||
|
||||
## Uso
|
||||
|
||||
Ao utilizar as ferramentas de avaliação Patronus, você fornece a entrada do modelo, a saída e o contexto, e a ferramenta retorna os resultados da avaliação a partir da API da Patronus.
|
||||
|
||||
Para o `PatronusEvalTool` e o `PatronusPredefinedCriteriaEvalTool`, os seguintes parâmetros são obrigatórios ao chamar a ferramenta:
|
||||
|
||||
- **evaluated_model_input**: A descrição da tarefa do agente, em texto simples.
|
||||
- **evaluated_model_output**: A saída da tarefa pelo agente.
|
||||
- **evaluated_model_retrieved_context**: O contexto do agente.
|
||||
|
||||
Para o `PatronusLocalEvaluatorTool`, os mesmos parâmetros são necessários, mas o avaliador e a resposta padrão são especificados durante a inicialização.
|
||||
|
||||
## Conclusão
|
||||
|
||||
As ferramentas de avaliação da Patronus fornecem uma forma poderosa de avaliar e pontuar entradas e saídas de modelos utilizando a plataforma Patronus AI. Ao possibilitar que agentes avaliem suas próprias saídas ou as de outros agentes, essas ferramentas ajudam a aprimorar a qualidade e confiabilidade dos fluxos de trabalho do CrewAI.
|
||||
824
docs/pt-BR/observability/portkey.mdx
Normal file
824
docs/pt-BR/observability/portkey.mdx
Normal file
@@ -0,0 +1,824 @@
|
||||
---
|
||||
title: Integração com Portkey
|
||||
description: Como usar Portkey com CrewAI
|
||||
icon: key
|
||||
---
|
||||
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-CrewAI.png" alt="Portkey CrewAI Header Image" width="70%" />
|
||||
|
||||
|
||||
|
||||
## Introdução
|
||||
|
||||
Portkey aprimora o CrewAI com recursos prontos para produção, transformando seus crews de agentes experimentais em sistemas robustos ao fornecer:
|
||||
|
||||
- **Observabilidade completa** de cada etapa do agente, uso de ferramentas e interações
|
||||
- **Confiabilidade incorporada** com fallbacks, tentativas automáticas e balanceamento de carga
|
||||
- **Rastreamento e otimização de custos** para gerenciar seus gastos com IA
|
||||
- **Acesso a mais de 200 LLMs** por meio de uma única integração
|
||||
- **Guardrails** para manter o comportamento dos agentes seguro e em conformidade
|
||||
- **Prompts versionados** para desempenho consistente dos agentes
|
||||
|
||||
|
||||
### Instalação & Configuração
|
||||
|
||||
<Steps>
|
||||
<Step title="Instale os pacotes necessários">
|
||||
```bash
|
||||
pip install -U crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="Gere a Chave de API" icon="lock">
|
||||
Crie uma chave de API Portkey com limites de orçamento/taxa opcionais no [painel da Portkey](https://app.portkey.ai/). Você também pode adicionar configurações para confiabilidade, cache e outros recursos a essa chave. Mais sobre isso em breve.
|
||||
</Step>
|
||||
|
||||
<Step title="Configure o CrewAI com Portkey">
|
||||
A integração é simples – basta atualizar a configuração do LLM no seu setup do CrewAI:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Crie uma instância do LLM com integração Portkey
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy", # Estamos usando uma chave virtual, então isso é apenas um placeholder
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_LLM_VIRTUAL_KEY",
|
||||
trace_id="unique-trace-id", # Opcional, para rastreamento da requisição
|
||||
)
|
||||
)
|
||||
|
||||
#Use-os nos seus Crew Agents assim:
|
||||
|
||||
@agent
|
||||
def lead_market_analyst(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['lead_market_analyst'],
|
||||
verbose=True,
|
||||
memory=False,
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
<Info>
|
||||
**O que são Virtual Keys?** Virtual keys no Portkey armazenam com segurança suas chaves de API dos provedores LLM (OpenAI, Anthropic, etc.) em um cofre criptografado. Elas facilitam a rotação de chaves e o gerenciamento de orçamento. [Saiba mais sobre virtual keys aqui](https://portkey.ai/docs/product/ai-gateway/virtual-keys).
|
||||
</Info>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Recursos para Produção
|
||||
|
||||
### 1. Observabilidade Avançada
|
||||
|
||||
Portkey oferece observabilidade abrangente para seus agentes CrewAI, ajudando você a entender exatamente o que está acontecendo durante cada execução.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Traces">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Product%2011.1.webp"/>
|
||||
</Frame>
|
||||
|
||||
Os traces fornecem uma visão hierárquica da execução do seu crew, mostrando a sequência de chamadas LLM, ativações de ferramentas e transições de estado.
|
||||
|
||||
```python
|
||||
# Adicione trace_id para habilitar o tracing hierárquico no Portkey
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
trace_id="unique-session-id" # Adicione um trace ID único
|
||||
)
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Logs">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Metadata.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey registra cada interação com LLMs, incluindo:
|
||||
|
||||
- Payloads completos das requisições e respostas
|
||||
- Métricas de latência e uso de tokens
|
||||
- Cálculos de custo
|
||||
- Chamadas de ferramentas e execuções de funções
|
||||
|
||||
Todos os logs podem ser filtrados por metadados, trace IDs, modelos e mais, tornando mais fácil depurar execuções específicas do crew.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Métricas & Dashboards">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Dashboard.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey oferece dashboards integrados que ajudam você a:
|
||||
|
||||
- Rastrear custos e uso de tokens em todas as execuções do crew
|
||||
- Analisar métricas de desempenho, como latência e taxas de sucesso
|
||||
- Identificar gargalos nos fluxos de trabalho dos agentes
|
||||
- Comparar diferentes configurações de crew e LLMs
|
||||
|
||||
Você pode filtrar e segmentar todas as métricas por metadados personalizados para analisar tipos de crew, grupos de usuários ou casos de uso específicos.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Filtragem por Metadados">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png" alt="Analytics with metadata filters" />
|
||||
</Frame>
|
||||
|
||||
Adicione metadados personalizados à configuração LLM do seu CrewAI para permitir filtragem e segmentação poderosas:
|
||||
|
||||
```python
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"crew_type": "research_crew",
|
||||
"environment": "production",
|
||||
"_user": "user_123", # Campo especial _user para analytics de usuários
|
||||
"request_source": "mobile_app"
|
||||
}
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
Esses metadados podem ser usados para filtrar logs, traces e métricas no painel do Portkey, permitindo analisar execuções específicas do crew, usuários ou ambientes.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 2. Confiabilidade - Mantenha Seus Crews Funcionando Sem Interrupções
|
||||
|
||||
Ao executar crews em produção, problemas podem ocorrer – limites de taxa da API, problemas de rede ou indisponibilidade do provedor. Os recursos de confiabilidade do Portkey garantem que seus agentes continuem funcionando mesmo quando problemas surgem.
|
||||
|
||||
É simples habilitar fallback na sua configuração CrewAI usando um Config do Portkey:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Crie LLM com configuração de fallback
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
config={
|
||||
"strategy": {
|
||||
"mode": "fallback"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"provider": "openai",
|
||||
"api_key": "YOUR_OPENAI_API_KEY",
|
||||
"override_params": {"model": "gpt-4o"}
|
||||
},
|
||||
{
|
||||
"provider": "anthropic",
|
||||
"api_key": "YOUR_ANTHROPIC_API_KEY",
|
||||
"override_params": {"model": "claude-3-opus-20240229"}
|
||||
}
|
||||
]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Use essa configuração LLM com seus agentes
|
||||
```
|
||||
|
||||
Essa configuração automaticamente tentará o Claude caso a requisição para o GPT-4o falhe, garantindo que seu crew continue funcionando.
|
||||
|
||||
<CardGroup cols="2">
|
||||
<Card title="Tentativas Automáticas" icon="rotate" href="https://portkey.ai/docs/product/ai-gateway/automatic-retries">
|
||||
Lida automaticamente com falhas temporárias. Se uma chamada LLM falhar, o Portkey fará novas tentativas o número especificado de vezes – perfeito para limites de taxa ou instabilidades de rede.
|
||||
</Card>
|
||||
<Card title="Timeouts de Requisição" icon="clock" href="https://portkey.ai/docs/product/ai-gateway/request-timeouts">
|
||||
Evite que seus agentes fiquem travados. Defina timeouts para garantir respostas (ou falhas controladas) dentro do tempo necessário.
|
||||
</Card>
|
||||
<Card title="Roteamento Condicional" icon="route" href="https://portkey.ai/docs/product/ai-gateway/conditional-routing">
|
||||
Envie diferentes solicitações para diferentes provedores. Direcione raciocínios complexos para o GPT-4, tarefas criativas para Claude e respostas rápidas para Gemini conforme sua necessidade.
|
||||
</Card>
|
||||
<Card title="Fallbacks" icon="shield" href="https://portkey.ai/docs/product/ai-gateway/fallbacks">
|
||||
Mantenha-se em funcionamento mesmo se seu provedor principal falhar. Troque automaticamente para provedores de backup para manter a disponibilidade.
|
||||
</Card>
|
||||
<Card title="Balanceamento de Carga" icon="scale-balanced" href="https://portkey.ai/docs/product/ai-gateway/load-balancing">
|
||||
Distribua solicitações entre várias chaves de API ou provedores. Ótimo para operações de crew em grande escala e para permanecer dentro dos limites de taxa.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### 3. Prompting no CrewAI
|
||||
|
||||
O Prompt Engineering Studio do Portkey ajuda você a criar, gerenciar e otimizar os prompts usados em seus agentes CrewAI. Em vez de codificar prompts ou instruções manualmente, use a API de renderização de prompts do Portkey para buscar e aplicar dinâmicamente seus prompts versionados.
|
||||
|
||||
<Frame caption="Gerencie prompts na Prompt Library do Portkey">
|
||||
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Prompt Playground">
|
||||
Prompt Playground é um local para comparar, testar e implantar prompts perfeitos para sua aplicação de IA. É onde você experimenta com diferentes modelos, testa variáveis, compara saídas e refina sua estratégia de engenharia de prompts antes de implantar em produção. Ele permite:
|
||||
|
||||
1. Desenvolver prompts de forma iterativa antes de usá-los em seus agentes
|
||||
2. Testar prompts com diferentes variáveis e modelos
|
||||
3. Comparar saídas entre diferentes versões de prompts
|
||||
4. Colaborar com membros da equipe no desenvolvimento de prompts
|
||||
|
||||
Esse ambiente visual facilita a criação de prompts eficazes para cada etapa do fluxo de trabalho dos seus agentes CrewAI.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Usando Templates de Prompt">
|
||||
A API Prompt Render recupera seus templates de prompt com todos os parâmetros configurados:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL, Portkey
|
||||
|
||||
# Inicialize o cliente admin do Portkey
|
||||
portkey_admin = Portkey(api_key="YOUR_PORTKEY_API_KEY")
|
||||
|
||||
# Recupere o prompt usando a render API
|
||||
prompt_data = portkey_client.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
}
|
||||
)
|
||||
|
||||
backstory_agent_prompt=prompt_data.data.messages[0]["content"]
|
||||
|
||||
|
||||
# Configure o LLM com integração Portkey
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Crie o agente utilizando o prompt renderizado
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory=backstory_agent, # Use o prompt renderizado
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Versionamento de Prompts">
|
||||
Você pode:
|
||||
- Criar múltiplas versões do mesmo prompt
|
||||
- Comparar o desempenho entre versões
|
||||
- Voltar a versões anteriores se necessário
|
||||
- Especificar qual versão usar em seu código:
|
||||
|
||||
```python
|
||||
# Use uma versão específica do prompt
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID@version_number",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"agent_goal": "Discover groundbreaking insights"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Mustache Templating para variáveis">
|
||||
Os prompts do Portkey usam modelos estilo Mustache para fácil substituição de variáveis:
|
||||
|
||||
```
|
||||
You are a {{agent_role}} with expertise in {{domain}}.
|
||||
|
||||
Your mission is to {{agent_goal}} by leveraging your knowledge
|
||||
and experience in the field.
|
||||
|
||||
Always maintain a {{tone}} tone and focus on providing {{focus_area}}.
|
||||
```
|
||||
|
||||
Ao renderizar, basta passar as variáveis:
|
||||
|
||||
```python
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"domain": "artificial intelligence",
|
||||
"agent_goal": "discover groundbreaking insights",
|
||||
"tone": "professional",
|
||||
"focus_area": "practical applications"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Card title="Prompt Engineering Studio" icon="wand-magic-sparkles" href="https://portkey.ai/docs/product/prompt-library">
|
||||
Saiba mais sobre os recursos de gerenciamento de prompts do Portkey
|
||||
</Card>
|
||||
|
||||
### 4. Guardrails para Crews Seguros
|
||||
|
||||
Guardrails garantem que seus agentes CrewAI operem com segurança e respondam adequadamente em todas as situações.
|
||||
|
||||
**Por que usar Guardrails?**
|
||||
|
||||
Os agentes CrewAI podem apresentar falhas de diversos tipos:
|
||||
- Gerar conteúdo nocivo ou inapropriado
|
||||
- Vazamento de informações sensíveis como PII
|
||||
- Alucinar informações incorretas
|
||||
- Gerar saídas em formatos incorretos
|
||||
|
||||
Os guardrails do Portkey fornecem proteções tanto para entradas quanto para saídas.
|
||||
|
||||
**Implementando Guardrails**
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Crie LLM com guardrails
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"input_guardrails": ["guardrails-id-xxx", "guardrails-id-yyy"],
|
||||
"output_guardrails": ["guardrails-id-zzz"]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Crie agente com LLM guardrailed
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Os guardrails do Portkey podem:
|
||||
- Detectar e redigir PII tanto em entradas quanto em saídas
|
||||
- Filtrar conteúdo prejudicial ou inapropriado
|
||||
- Validar formatos de resposta contra schemas
|
||||
- Verificar alucinações comparando com ground truth
|
||||
- Aplicar lógica e regras de negócio personalizadas
|
||||
|
||||
<Card title="Saiba Mais Sobre Guardrails" icon="shield-check" href="https://portkey.ai/docs/product/guardrails">
|
||||
Explore os recursos de guardrails do Portkey para aumentar a segurança dos agentes
|
||||
</Card>
|
||||
|
||||
### 5. Rastreamento de Usuário com Metadados
|
||||
|
||||
Rastreie usuários individuais através dos seus agentes CrewAI utilizando o sistema de metadados do Portkey.
|
||||
|
||||
**O que é Metadata no Portkey?**
|
||||
|
||||
Metadados permitem associar dados personalizados a cada requisição, possibilitando filtragem, segmentação e analytics. O campo especial `_user` é projetado especificamente para rastreamento de usuário.
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure o LLM com rastreamento de usuário
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"_user": "user_123", # Campo especial _user para analytics de usuários
|
||||
"user_tier": "premium",
|
||||
"user_company": "Acme Corp",
|
||||
"session_id": "abc-123"
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Crie agente com LLM rastreado
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
**Filtre Analytics por Usuário**
|
||||
|
||||
Com os metadados configurados, você pode filtrar analytics por usuário e analisar métricas de desempenho individualmente:
|
||||
|
||||
<Frame caption="Filtre analytics por usuário">
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png"/>
|
||||
</Frame>
|
||||
|
||||
Isso permite:
|
||||
- Rastreamento de custos e orçamento por usuário
|
||||
- Analytics personalizados por usuário
|
||||
- Métricas por equipe ou organização
|
||||
- Monitoramento específico por ambiente (homologação x produção)
|
||||
|
||||
<Card title="Saiba Mais Sobre Metadata" icon="tags" href="https://portkey.ai/docs/product/observability/metadata">
|
||||
Veja como usar metadados personalizados para aprimorar seus analytics
|
||||
</Card>
|
||||
|
||||
### 6. Cache para Crews Eficientes
|
||||
|
||||
Implemente caching para tornar seus agentes CrewAI mais eficientes e econômicos:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Caching Simples">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure o LLM com caching simples
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "simple"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Crie agente com LLM cacheado
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
O caching simples realiza correspondências exatas de prompts de entrada, cacheando requisições idênticas para evitar execuções redundantes do modelo.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Cache Semântico">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure o LLM com cache semântico
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "semantic"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Crie agente com LLM com cache semântico
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
O cache semântico considera a similaridade contextual entre solicitações de entrada, armazenando respostas para entradas semanticamente similares.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 7. Interoperabilidade de Modelos
|
||||
|
||||
O CrewAI oferece suporte a múltiplos provedores de LLM, e o Portkey amplia essa capacidade fornecendo acesso a mais de 200 LLMs por meio de uma interface unificada. Você pode facilmente alternar entre diferentes modelos sem alterar a lógica central do seu agente:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLMs com diferentes provedores
|
||||
openai_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Escolha qual LLM usar para cada agente conforme necessário
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=openai_llm # Use anthropic_llm para Anthropic
|
||||
)
|
||||
```
|
||||
|
||||
Portkey oferece acesso a LLMs de provedores como:
|
||||
|
||||
- OpenAI (GPT-4o, GPT-4 Turbo, etc.)
|
||||
- Anthropic (Claude 3.5 Sonnet, Claude 3 Opus, etc.)
|
||||
- Mistral AI (Mistral Large, Mistral Medium, etc.)
|
||||
- Google Vertex AI (Gemini 1.5 Pro, etc.)
|
||||
- Cohere (Command, Command-R, etc.)
|
||||
- AWS Bedrock (Claude, Titan, etc.)
|
||||
- Modelos locais/privados
|
||||
|
||||
<Card title="Provedores Suportados" icon="server" href="https://portkey.ai/docs/integrations/llms">
|
||||
Veja a lista completa de provedores LLM suportados pelo Portkey
|
||||
</Card>
|
||||
|
||||
## Configure Governança Corporativa para o CrewAI
|
||||
|
||||
**Por que Governança Corporativa?**
|
||||
Se você utiliza CrewAI dentro de sua organização, é importante considerar diversos aspectos de governança:
|
||||
- **Gestão de Custos**: Controlar e rastrear os gastos com IA entre equipes
|
||||
- **Controle de Acesso**: Gerenciar quais equipes podem usar modelos específicos
|
||||
- **Analytics de Uso**: Compreender como a IA está sendo utilizada na organização
|
||||
- **Segurança & Compliance**: Manutenção de padrões corporativos de segurança
|
||||
- **Confiabilidade**: Garantir serviço consistente para todos os usuários
|
||||
|
||||
O Portkey adiciona uma camada abrangente de governança para atender a essas necessidades corporativas. Vamos implementar esses controles passo a passo.
|
||||
|
||||
<Steps>
|
||||
<Step title="Crie uma Virtual Key">
|
||||
Virtual Keys são a maneira segura do Portkey para gerenciar as chaves de API dos provedores de LLM. Elas fornecem controles essenciais como:
|
||||
- Limites de orçamento para uso da API
|
||||
- Capacidade de rate limiting
|
||||
- Armazenamento seguro das chaves de API
|
||||
|
||||
Para criar uma virtual key:
|
||||
Vá até [Virtual Keys](https://app.portkey.ai/virtual-keys) no app Portkey. Salve e copie o ID da virtual key
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
|
||||
<Note>
|
||||
Salve o ID da sua virtual key – você precisará dele no próximo passo.
|
||||
</Note>
|
||||
</Step>
|
||||
|
||||
<Step title="Crie um Config Padrão">
|
||||
Os Configs no Portkey definem como suas requisições são roteadas, com recursos como roteamento avançado, fallbacks e tentativas automáticas.
|
||||
|
||||
Para criar seu config:
|
||||
1. Vá até [Configs](https://app.portkey.ai/configs) no painel Portkey
|
||||
2. Crie um novo config com:
|
||||
```json
|
||||
{
|
||||
"virtual_key": "YOUR_VIRTUAL_KEY_FROM_STEP1",
|
||||
"override_params": {
|
||||
"model": "gpt-4o" // Nome do seu modelo preferido
|
||||
}
|
||||
}
|
||||
```
|
||||
3. Salve e anote o nome do Config para o próximo passo
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Config.png" width="500"/>
|
||||
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Configure a Chave de API Portkey">
|
||||
Agora crie uma chave de API Portkey e anexe a config criada no Passo 2:
|
||||
|
||||
1. Vá até [API Keys](https://app.portkey.ai/api-keys) na Portkey e crie uma nova chave de API
|
||||
2. Selecione sua config do `Passo 2`
|
||||
3. Gere e salve sua chave de API
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20API%20Key.png" width="500"/>
|
||||
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Conecte ao CrewAI">
|
||||
Após configurar sua chave de API Portkey com a config anexada, conecte-a aos seus agentes CrewAI:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure o LLM com sua chave de API
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="YOUR_PORTKEY_API_KEY"
|
||||
)
|
||||
|
||||
# Crie agente com LLM habilitado para Portkey
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Etapa 1: Implementar Controles de Orçamento & Rate Limits">
|
||||
### Etapa 1: Implementar Controles de Orçamento & Rate Limits
|
||||
|
||||
Virtual Keys permitem controle granular sobre o acesso ao LLM por equipe/departamento. Isso ajuda você a:
|
||||
- Definir [limites de orçamento](https://portkey.ai/docs/product/ai-gateway/virtual-keys/budget-limits)
|
||||
- Prevenir picos inesperados de uso através de Rate limits
|
||||
- Rastrear gastos por departamento
|
||||
|
||||
#### Configurando controles específicos de departamento:
|
||||
1. Vá até [Virtual Keys](https://app.portkey.ai/virtual-keys) no painel Portkey
|
||||
2. Crie uma nova Virtual Key para cada departamento com limites de orçamento e rate limits
|
||||
3. Configure limites específicos por departamento
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Etapa 2: Definir Regras de Acesso a Modelos">
|
||||
### Etapa 2: Definir Regras de Acesso a Modelos
|
||||
|
||||
À medida que o uso de IA cresce, controlar quais equipes têm acesso a quais modelos se torna fundamental. Os Configs do Portkey fornecem essa camada de controle com recursos como:
|
||||
|
||||
#### Recursos de Controle de Acesso:
|
||||
- **Restrições de Modelo**: Limite o acesso a modelos específicos
|
||||
- **Proteção de Dados**: Implemente guardrails para dados sensíveis
|
||||
- **Controles de Confiabilidade**: Adicione fallbacks e tentativas automáticas
|
||||
|
||||
#### Exemplo de Configuração:
|
||||
Aqui está um exemplo básico para rotear requisições ao OpenAI, usando especificamente o GPT-4o:
|
||||
|
||||
```json
|
||||
{
|
||||
"strategy": {
|
||||
"mode": "single"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"virtual_key": "YOUR_OPENAI_VIRTUAL_KEY",
|
||||
"override_params": {
|
||||
"model": "gpt-4o"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Crie seu config na [página de Configs](https://app.portkey.ai/configs) no painel do Portkey.
|
||||
|
||||
<Note>
|
||||
Os configs podem ser atualizados a qualquer momento para ajustar controles sem afetar aplicações em execução.
|
||||
</Note>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Etapa 3: Implementar Controles de Acesso">
|
||||
### Etapa 3: Implementar Controles de Acesso
|
||||
|
||||
Crie chaves de API específicas por usuário que automaticamente:
|
||||
- Rastreiam uso por usuário/equipe com o auxílio das virtual keys
|
||||
- Aplicam configs adequadas para rotear requisições
|
||||
- Coletam metadados relevantes para filtragem de logs
|
||||
- Impõem permissões de acesso
|
||||
|
||||
Crie chaves de API através de:
|
||||
- [Portkey App](https://app.portkey.ai/)
|
||||
- [API Key Management API](/pt-BR/api-reference/admin-api/control-plane/api-keys/create-api-key)
|
||||
|
||||
Exemplo usando Python SDK:
|
||||
```python
|
||||
from portkey_ai import Portkey
|
||||
|
||||
portkey = Portkey(api_key="YOUR_ADMIN_API_KEY")
|
||||
|
||||
api_key = portkey.api_keys.create(
|
||||
name="engineering-team",
|
||||
type="organisation",
|
||||
workspace_id="YOUR_WORKSPACE_ID",
|
||||
defaults={
|
||||
"config_id": "your-config-id",
|
||||
"metadata": {
|
||||
"environment": "production",
|
||||
"department": "engineering"
|
||||
}
|
||||
},
|
||||
scopes=["logs.view", "configs.read"]
|
||||
)
|
||||
```
|
||||
|
||||
Para instruções detalhadas de gerenciamento de chaves, veja nossa [documentação de API Keys](/pt-BR/api-reference/admin-api/control-plane/api-keys/create-api-key).
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Etapa 4: Implante & Monitore">
|
||||
### Etapa 4: Implante & Monitore
|
||||
Após distribuir as chaves de API para os membros da equipe, seu setup corporativo CrewAI está pronto. Cada membro pode agora usar suas chaves designadas com os níveis de acesso e controles de orçamento apropriados.
|
||||
|
||||
Monitore o uso no painel Portkey:
|
||||
- Rastreamento de custos por departamento
|
||||
- Padrões de uso de modelos
|
||||
- Volume de requisições
|
||||
- Taxa de erros
|
||||
</Accordion>
|
||||
|
||||
</AccordionGroup>
|
||||
|
||||
<Note>
|
||||
### Recursos Corporativos Agora Disponíveis
|
||||
**Sua integração CrewAI agora conta com:**
|
||||
- Controles de orçamento departamental
|
||||
- Governança de acesso a modelos
|
||||
- Rastreamento de uso & atribuição
|
||||
- Guardrails de segurança
|
||||
- Recursos de confiabilidade
|
||||
</Note>
|
||||
|
||||
## Perguntas Frequentes
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Como o Portkey aprimora o CrewAI?">
|
||||
Portkey adiciona prontidão para produção ao CrewAI através de observabilidade abrangente (traces, logs, métricas), recursos de confiabilidade (fallbacks, tentativas automáticas, cache) e acesso a mais de 200 LLMs por meio de uma interface unificada. Isso facilita depurar, otimizar e escalar suas aplicações de agentes.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Posso usar Portkey com aplicações CrewAI existentes?">
|
||||
Sim! Portkey integra-se perfeitamente a aplicações CrewAI existentes. Basta atualizar o código de configuração do LLM com a versão habilitada do Portkey. O restante do seu código de agente e crew permanece inalterado.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Portkey funciona com todos os recursos do CrewAI?">
|
||||
Portkey suporta todos os recursos do CrewAI, incluindo agentes, ferramentas, workflows human-in-the-loop e todos os tipos de processo de tarefas (sequencial, hierárquico, etc.). Ele adiciona observabilidade e confiabilidade sem limitar nenhuma funcionalidade do framework.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Posso rastrear o uso em múltiplos agentes de um crew?">
|
||||
Sim, o Portkey permite que você use um `trace_id` consistente em múltiplos agentes de um crew para rastrear todo o fluxo de trabalho. Isso é especialmente útil para crews complexos onde você deseja entender o caminho completo de execução entre os agentes.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Como filtro logs e traces para execuções específicas de crew?">
|
||||
O Portkey permite adicionar metadados personalizados à configuração do seu LLM, que podem ser usados para filtragem. Adicione campos como `crew_name`, `crew_type`, ou `session_id` para encontrar e analisar facilmente execuções específicas do crew.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Posso usar minhas próprias chaves de API com o Portkey?">
|
||||
Sim! O Portkey utiliza suas próprias chaves de API dos provedores LLM. Elas são armazenadas com segurança como virtual keys, permitindo que você gerencie e gire as chaves facilmente sem alterar seu código.
|
||||
</Accordion>
|
||||
|
||||
</AccordionGroup>
|
||||
|
||||
## Recursos
|
||||
|
||||
<CardGroup cols="3">
|
||||
<Card title="CrewAI Docs" icon="book" href="https://docs.crewai.com/">
|
||||
<p>Documentação oficial do CrewAI</p>
|
||||
</Card>
|
||||
<Card title="Agende uma Demonstração" icon="calendar" href="https://calendly.com/portkey-ai">
|
||||
<p>Receba orientação personalizada sobre como implementar essa integração</p>
|
||||
</Card>
|
||||
</CardGroup>
|
||||
124
docs/pt-BR/observability/weave.mdx
Normal file
124
docs/pt-BR/observability/weave.mdx
Normal file
@@ -0,0 +1,124 @@
|
||||
---
|
||||
title: Integração com Weave
|
||||
description: Saiba como usar o Weights & Biases (W&B) Weave para rastrear, experimentar, avaliar e melhorar suas aplicações CrewAI.
|
||||
icon: radar
|
||||
---
|
||||
|
||||
# Visão Geral do Weave
|
||||
|
||||
[Weights & Biases (W&B) Weave](https://weave-docs.wandb.ai/) é um framework para rastreamento, experimentação, avaliação, implementação e aprimoramento de aplicações baseadas em LLM.
|
||||
|
||||

|
||||
|
||||
O Weave oferece suporte completo para todas as etapas do desenvolvimento da sua aplicação CrewAI:
|
||||
|
||||
- **Rastreamento e Monitoramento**: Acompanhe automaticamente chamadas LLM e a lógica da aplicação para depuração e análise de sistemas em produção
|
||||
- **Iteração Sistemática**: Aperfeiçoe e itere em prompts, conjuntos de dados e modelos
|
||||
- **Avaliação**: Utilize avaliadores personalizados ou pré-construídos para avaliar e aprimorar sistematicamente o desempenho dos agentes
|
||||
- **Guardrails**: Proteja seus agentes com salvaguardas pré e pós-execução para moderação de conteúdo e segurança de prompts
|
||||
|
||||
O Weave captura automaticamente rastreamentos (traces) de suas aplicações CrewAI, permitindo monitorar e analisar o desempenho, as interações e o fluxo de execução dos seus agentes. Isso te ajuda a construir melhores conjuntos de dados para avaliação e a otimizar os fluxos de trabalho dos agentes.
|
||||
|
||||
## Instruções de Configuração
|
||||
|
||||
<Steps>
|
||||
<Step title="Instale os pacotes necessários">
|
||||
```shell
|
||||
pip install crewai weave
|
||||
```
|
||||
</Step>
|
||||
<Step title="Crie uma conta no W&B">
|
||||
Cadastre-se em uma [conta Weights & Biases](https://wandb.ai) caso ainda não tenha uma. Você precisará dela para visualizar rastreamentos e métricas.
|
||||
</Step>
|
||||
<Step title="Inicialize o Weave na sua aplicação">
|
||||
Adicione o seguinte código à sua aplicação:
|
||||
|
||||
```python
|
||||
import weave
|
||||
|
||||
# Inicialize o Weave com o nome do seu projeto
|
||||
weave.init(project_name="crewai_demo")
|
||||
```
|
||||
|
||||
Após a inicialização, o Weave fornecerá uma URL onde você poderá visualizar seus rastreamentos e métricas.
|
||||
</Step>
|
||||
<Step title="Crie seus Crews/Flows">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM, Process
|
||||
|
||||
# Crie um LLM com temperatura 0 para garantir saídas determinísticas
|
||||
llm = LLM(model="gpt-4o", temperature=0)
|
||||
|
||||
# Crie os agentes
|
||||
researcher = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Find and analyze the best investment opportunities',
|
||||
backstory='Expert in financial analysis and market research',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role='Report Writer',
|
||||
goal='Write clear and concise investment reports',
|
||||
backstory='Experienced in creating detailed financial reports',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
# Crie as tarefas
|
||||
research_task = Task(
|
||||
description='Deep research on the {topic}',
|
||||
expected_output='Comprehensive market data including key players, market size, and growth trends.',
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description='Write a detailed report based on the research',
|
||||
expected_output='The report should be easy to read and understand. Use bullet points where applicable.',
|
||||
agent=writer
|
||||
)
|
||||
|
||||
# Crie o crew
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
)
|
||||
|
||||
# Execute o crew
|
||||
result = crew.kickoff(inputs={"topic": "AI in material science"})
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Visualize rastreamentos no Weave">
|
||||
Após executar sua aplicação CrewAI, acesse a URL do Weave fornecida durante a inicialização para visualizar:
|
||||
- Chamadas LLM e seus metadados
|
||||
- Interações dos agentes e fluxo de execução das tarefas
|
||||
- Métricas de desempenho como latência e uso de tokens
|
||||
- Quaisquer erros ou problemas ocorridos durante a execução
|
||||
|
||||
<Frame caption="Painel de Rastreamento do Weave">
|
||||
<img src="/images/weave-tracing.png" alt="Exemplo de rastreamento do Weave com CrewAI" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Funcionalidades
|
||||
|
||||
- O Weave captura automaticamente todas as operações do CrewAI: interações dos agentes e execuções das tarefas; chamadas LLM com metadados e uso de tokens; uso de ferramentas e resultados.
|
||||
- A integração suporta todos os métodos de execução do CrewAI: `kickoff()`, `kickoff_for_each()`, `kickoff_async()` e `kickoff_for_each_async()`.
|
||||
- Rastreamento automático de todas as [crewAI-tools](https://github.com/crewAIInc/crewAI-tools).
|
||||
- Suporte ao recurso flow com patching por decorador (`@start`, `@listen`, `@router`, `@or_`, `@and_`).
|
||||
- Rastreie guardrails personalizados passados para o `Task` do CrewAI com `@weave.op()`.
|
||||
|
||||
Para informações detalhadas sobre o que é suportado, acesse a [documentação do Weave CrewAI](https://weave-docs.wandb.ai/guides/integrations/crewai/#getting-started-with-flow).
|
||||
|
||||
## Recursos
|
||||
|
||||
- [📘 Documentação do Weave](https://weave-docs.wandb.ai)
|
||||
- [📊 Exemplo de dashboard Weave x CrewAI](https://wandb.ai/ayut/crewai_demo/weave/traces?cols=%7B%22wb_run_id%22%3Afalse%2C%22attributes.weave.client_version%22%3Afalse%2C%22attributes.weave.os_name%22%3Afalse%2C%22attributes.weave.os_release%22%3Afalse%2C%22attributes.weave.os_version%22%3Afalse%2C%22attributes.weave.source%22%3Afalse%2C%22attributes.weave.sys_version%22%3Afalse%7D&peekPath=%2Fayut%2Fcrewai_demo%2Fcalls%2F0195c838-38cb-71a2-8a15-651ecddf9d89)
|
||||
- [🐦 X](https://x.com/weave_wb)
|
||||
Reference in New Issue
Block a user