 +
+  This matrix helps visualize how different approaches align with varying requirements for complexity and precision. Let's explore what each quadrant means and how it guides your architectural choices.
@@ -497,7 +497,7 @@ You now have a framework for evaluating CrewAI use cases and choosing the right
## Next Steps
-- Learn more about [crafting effective agents](/guides/agents/crafting-effective-agents)
-- Explore [building your first crew](/guides/crews/first-crew)
-- Dive into [mastering flow state management](/guides/flows/mastering-flow-state)
-- Check out the [core concepts](/concepts/agents) for deeper understanding
\ No newline at end of file
+- Learn more about [crafting effective agents](/en/guides/agents/crafting-effective-agents)
+- Explore [building your first crew](/en/guides/crews/first-crew)
+- Dive into [mastering flow state management](/en/guides/flows/mastering-flow-state)
+- Check out the [core concepts](/en/concepts/agents) for deeper understanding
diff --git a/docs/guides/crews/first-crew.mdx b/docs/en/guides/crews/first-crew.mdx
similarity index 96%
rename from docs/guides/crews/first-crew.mdx
rename to docs/en/guides/crews/first-crew.mdx
index 6cd35aebf..95c2bbf66 100644
--- a/docs/guides/crews/first-crew.mdx
+++ b/docs/en/guides/crews/first-crew.mdx
@@ -32,9 +32,9 @@ Let's get started building your first crew!
Before starting, make sure you have:
-1. Installed CrewAI following the [installation guide](/installation)
+1. Installed CrewAI following the [installation guide](/en/installation)
2. Set up your LLM API key in your environment, following the [LLM setup
- guide](/concepts/llms#setting-up-your-llm)
+ guide](/en/concepts/llms#setting-up-your-llm)
3. Basic understanding of Python
## Step 1: Create a New CrewAI Project
@@ -54,7 +54,7 @@ This will generate a project with the basic structure needed for your crew. The
- A main script to run the crew
-
This matrix helps visualize how different approaches align with varying requirements for complexity and precision. Let's explore what each quadrant means and how it guides your architectural choices.
@@ -497,7 +497,7 @@ You now have a framework for evaluating CrewAI use cases and choosing the right
## Next Steps
-- Learn more about [crafting effective agents](/guides/agents/crafting-effective-agents)
-- Explore [building your first crew](/guides/crews/first-crew)
-- Dive into [mastering flow state management](/guides/flows/mastering-flow-state)
-- Check out the [core concepts](/concepts/agents) for deeper understanding
\ No newline at end of file
+- Learn more about [crafting effective agents](/en/guides/agents/crafting-effective-agents)
+- Explore [building your first crew](/en/guides/crews/first-crew)
+- Dive into [mastering flow state management](/en/guides/flows/mastering-flow-state)
+- Check out the [core concepts](/en/concepts/agents) for deeper understanding
diff --git a/docs/guides/crews/first-crew.mdx b/docs/en/guides/crews/first-crew.mdx
similarity index 96%
rename from docs/guides/crews/first-crew.mdx
rename to docs/en/guides/crews/first-crew.mdx
index 6cd35aebf..95c2bbf66 100644
--- a/docs/guides/crews/first-crew.mdx
+++ b/docs/en/guides/crews/first-crew.mdx
@@ -32,9 +32,9 @@ Let's get started building your first crew!
Before starting, make sure you have:
-1. Installed CrewAI following the [installation guide](/installation)
+1. Installed CrewAI following the [installation guide](/en/installation)
2. Set up your LLM API key in your environment, following the [LLM setup
- guide](/concepts/llms#setting-up-your-llm)
+ guide](/en/concepts/llms#setting-up-your-llm)
3. Basic understanding of Python
## Step 1: Create a New CrewAI Project
@@ -54,7 +54,7 @@ This will generate a project with the basic structure needed for your crew. The
- A main script to run the crew
-  +
+  @@ -287,7 +287,7 @@ SERPER_API_KEY=your_serper_api_key
# Add your provider's API key here too.
```
-See the [LLM Setup guide](/concepts/llms#setting-up-your-llm) for details on configuring your provider of choice. You can get a Serper API key from [Serper.dev](https://serper.dev/).
+See the [LLM Setup guide](/en/concepts/llms#setting-up-your-llm) for details on configuring your provider of choice. You can get a Serper API key from [Serper.dev](https://serper.dev/).
## Step 8: Install Dependencies
@@ -388,7 +388,7 @@ Now that you've built your first crew, you can:
2. Try more complex task structures and workflows
3. Implement custom tools to give your agents new capabilities
4. Apply your crew to different topics or problem domains
-5. Explore [CrewAI Flows](/guides/flows/first-flow) for more advanced workflows with procedural programming
+5. Explore [CrewAI Flows](/en/guides/flows/first-flow) for more advanced workflows with procedural programming
@@ -287,7 +287,7 @@ SERPER_API_KEY=your_serper_api_key
# Add your provider's API key here too.
```
-See the [LLM Setup guide](/concepts/llms#setting-up-your-llm) for details on configuring your provider of choice. You can get a Serper API key from [Serper.dev](https://serper.dev/).
+See the [LLM Setup guide](/en/concepts/llms#setting-up-your-llm) for details on configuring your provider of choice. You can get a Serper API key from [Serper.dev](https://serper.dev/).
## Step 8: Install Dependencies
@@ -388,7 +388,7 @@ Now that you've built your first crew, you can:
2. Try more complex task structures and workflows
3. Implement custom tools to give your agents new capabilities
4. Apply your crew to different topics or problem domains
-5. Explore [CrewAI Flows](/guides/flows/first-flow) for more advanced workflows with procedural programming
+5. Explore [CrewAI Flows](/en/guides/flows/first-flow) for more advanced workflows with procedural programming
 +
+  ## Step 2: Understanding the Project Structure
@@ -443,7 +443,7 @@ This is the power of flows - combining different types of processing (user inter
## Step 6: Set Up Your Environment Variables
Create a `.env` file in your project root with your API keys. See the [LLM setup
-guide](/concepts/llms#setting-up-your-llm) for details on configuring a provider.
+guide](/en/concepts/llms#setting-up-your-llm) for details on configuring a provider.
```sh .env
OPENAI_API_KEY=your_openai_api_key
diff --git a/docs/guides/flows/mastering-flow-state.mdx b/docs/en/guides/flows/mastering-flow-state.mdx
similarity index 99%
rename from docs/guides/flows/mastering-flow-state.mdx
rename to docs/en/guides/flows/mastering-flow-state.mdx
index ad61a05fe..4d1fac515 100644
--- a/docs/guides/flows/mastering-flow-state.mdx
+++ b/docs/en/guides/flows/mastering-flow-state.mdx
@@ -767,5 +767,5 @@ You've now mastered the concepts and practices of state management in CrewAI Flo
- Experiment with both structured and unstructured state in your flows
- Try implementing state persistence for long-running workflows
-- Explore [building your first crew](/guides/crews/first-crew) to see how crews and flows can work together
-- Check out the [Flow reference documentation](/concepts/flows) for more advanced features
\ No newline at end of file
+- Explore [building your first crew](/en/guides/crews/first-crew) to see how crews and flows can work together
+- Check out the [Flow reference documentation](/en/concepts/flows) for more advanced features
diff --git a/docs/installation.mdx b/docs/en/installation.mdx
similarity index 99%
rename from docs/installation.mdx
rename to docs/en/installation.mdx
index fedc374f0..3a2b342cc 100644
--- a/docs/installation.mdx
+++ b/docs/en/installation.mdx
@@ -186,7 +186,7 @@ For teams and organizations, CrewAI offers enterprise deployment options that el
## Step 2: Understanding the Project Structure
@@ -443,7 +443,7 @@ This is the power of flows - combining different types of processing (user inter
## Step 6: Set Up Your Environment Variables
Create a `.env` file in your project root with your API keys. See the [LLM setup
-guide](/concepts/llms#setting-up-your-llm) for details on configuring a provider.
+guide](/en/concepts/llms#setting-up-your-llm) for details on configuring a provider.
```sh .env
OPENAI_API_KEY=your_openai_api_key
diff --git a/docs/guides/flows/mastering-flow-state.mdx b/docs/en/guides/flows/mastering-flow-state.mdx
similarity index 99%
rename from docs/guides/flows/mastering-flow-state.mdx
rename to docs/en/guides/flows/mastering-flow-state.mdx
index ad61a05fe..4d1fac515 100644
--- a/docs/guides/flows/mastering-flow-state.mdx
+++ b/docs/en/guides/flows/mastering-flow-state.mdx
@@ -767,5 +767,5 @@ You've now mastered the concepts and practices of state management in CrewAI Flo
- Experiment with both structured and unstructured state in your flows
- Try implementing state persistence for long-running workflows
-- Explore [building your first crew](/guides/crews/first-crew) to see how crews and flows can work together
-- Check out the [Flow reference documentation](/concepts/flows) for more advanced features
\ No newline at end of file
+- Explore [building your first crew](/en/guides/crews/first-crew) to see how crews and flows can work together
+- Check out the [Flow reference documentation](/en/concepts/flows) for more advanced features
diff --git a/docs/installation.mdx b/docs/en/installation.mdx
similarity index 99%
rename from docs/installation.mdx
rename to docs/en/installation.mdx
index fedc374f0..3a2b342cc 100644
--- a/docs/installation.mdx
+++ b/docs/en/installation.mdx
@@ -186,7 +186,7 @@ For teams and organizations, CrewAI offers enterprise deployment options that el
 +
| Component | Description | Key Features |
@@ -64,7 +64,7 @@ With over 100,000 developers certified through our community courses, CrewAI is
+
| Component | Description | Key Features |
@@ -64,7 +64,7 @@ With over 100,000 developers certified through our community courses, CrewAI is
 +
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+  +
+
+
+  +
+ - Configure quaisquer ações adicionais necessárias
+ - Revise as etapas do seu workflow para garantir que tudo está configurado corretamente
+ - Ative o workflow
+
+
+
+ - Configure quaisquer ações adicionais necessárias
+ - Revise as etapas do seu workflow para garantir que tudo está configurado corretamente
+ - Ative o workflow
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+
+
+  +
+
+## Próximos Passos
+
+- Personalize o estilo do componente para combinar com o design da sua aplicação
+- Adicione props adicionais para configuração
+- Integre com o gerenciamento de estado da sua aplicação
+- Adicione tratamento de erros e estados de carregamento
\ No newline at end of file
diff --git a/docs/pt-BR/enterprise/guides/salesforce-trigger.mdx b/docs/pt-BR/enterprise/guides/salesforce-trigger.mdx
new file mode 100644
index 000000000..9b44f624a
--- /dev/null
+++ b/docs/pt-BR/enterprise/guides/salesforce-trigger.mdx
@@ -0,0 +1,44 @@
+---
+title: "Trigger Salesforce"
+description: "Dispare equipes CrewAI a partir de fluxos de trabalho do Salesforce para automação de CRM"
+icon: "salesforce"
+---
+
+A CrewAI Enterprise pode ser acionada a partir do Salesforce para automatizar fluxos de trabalho de gestão de relacionamento com o cliente e aprimorar suas operações de vendas.
+
+## Visão Geral
+
+O Salesforce é uma das principais plataformas de gestão de relacionamento com o cliente (CRM), que ajuda empresas a otimizar operações de vendas, atendimento e marketing. Ao configurar triggers da CrewAI a partir do Salesforce, você pode:
+
+- Automatizar a classificação e qualificação de leads
+- Gerar materiais de vendas personalizados
+- Aprimorar o atendimento ao cliente com respostas baseadas em IA
+- Otimizar análise e relatórios de dados
+
+## Demonstração
+
+
+
+
+
+## Primeiros Passos
+
+Para configurar triggers no Salesforce:
+
+1. **Contato com o Suporte**: Entre em contato com o suporte da CrewAI Enterprise para obter assistência na configuração dos triggers no Salesforce
+2. **Revisar Requisitos**: Certifique-se de possuir as permissões necessárias no Salesforce e acesso à API
+3. **Configurar Conexão**: Trabalhe com a equipe de suporte para estabelecer a conexão entre a CrewAI e sua instância do Salesforce
+4. **Testar Triggers**: Verifique se os triggers funcionam corretamente para os seus casos de uso específicos
+
+## Casos de Uso
+
+Cenários comuns de uso de triggers Salesforce + CrewAI incluem:
+
+- **Processamento de Leads**: Analisar e classificar leads recebidos automaticamente
+- **Geração de Propostas**: Criar propostas personalizadas com base nos dados das oportunidades
+- **Insights de Clientes**: Gerar relatórios de análise a partir do histórico de interações com clientes
+- **Automação de Follow-up**: Criar mensagens de follow-up e recomendações personalizadas
+
+## Próximos Passos
+
+Para instruções detalhadas de configuração e opções avançadas, entre em contato com o suporte da CrewAI Enterprise, que pode fornecer orientações personalizadas para o seu ambiente Salesforce e necessidades de negócio.
\ No newline at end of file
diff --git a/docs/pt-BR/enterprise/guides/slack-trigger.mdx b/docs/pt-BR/enterprise/guides/slack-trigger.mdx
new file mode 100644
index 000000000..fc916888c
--- /dev/null
+++ b/docs/pt-BR/enterprise/guides/slack-trigger.mdx
@@ -0,0 +1,61 @@
+---
+title: "Slack Trigger"
+description: "Acione crews do CrewAI diretamente do Slack usando comandos de barra"
+icon: "slack"
+---
+
+Este guia explica como iniciar um crew diretamente do Slack usando triggers do CrewAI.
+
+## Pré-requisitos
+
+- Trigger do CrewAI para Slack instalado e conectado ao seu workspace do Slack
+- Pelo menos um crew configurado no CrewAI
+
+## Etapas de Configuração
+
+
+
+
+## Próximos Passos
+
+- Personalize o estilo do componente para combinar com o design da sua aplicação
+- Adicione props adicionais para configuração
+- Integre com o gerenciamento de estado da sua aplicação
+- Adicione tratamento de erros e estados de carregamento
\ No newline at end of file
diff --git a/docs/pt-BR/enterprise/guides/salesforce-trigger.mdx b/docs/pt-BR/enterprise/guides/salesforce-trigger.mdx
new file mode 100644
index 000000000..9b44f624a
--- /dev/null
+++ b/docs/pt-BR/enterprise/guides/salesforce-trigger.mdx
@@ -0,0 +1,44 @@
+---
+title: "Trigger Salesforce"
+description: "Dispare equipes CrewAI a partir de fluxos de trabalho do Salesforce para automação de CRM"
+icon: "salesforce"
+---
+
+A CrewAI Enterprise pode ser acionada a partir do Salesforce para automatizar fluxos de trabalho de gestão de relacionamento com o cliente e aprimorar suas operações de vendas.
+
+## Visão Geral
+
+O Salesforce é uma das principais plataformas de gestão de relacionamento com o cliente (CRM), que ajuda empresas a otimizar operações de vendas, atendimento e marketing. Ao configurar triggers da CrewAI a partir do Salesforce, você pode:
+
+- Automatizar a classificação e qualificação de leads
+- Gerar materiais de vendas personalizados
+- Aprimorar o atendimento ao cliente com respostas baseadas em IA
+- Otimizar análise e relatórios de dados
+
+## Demonstração
+
+
+
+
+
+## Primeiros Passos
+
+Para configurar triggers no Salesforce:
+
+1. **Contato com o Suporte**: Entre em contato com o suporte da CrewAI Enterprise para obter assistência na configuração dos triggers no Salesforce
+2. **Revisar Requisitos**: Certifique-se de possuir as permissões necessárias no Salesforce e acesso à API
+3. **Configurar Conexão**: Trabalhe com a equipe de suporte para estabelecer a conexão entre a CrewAI e sua instância do Salesforce
+4. **Testar Triggers**: Verifique se os triggers funcionam corretamente para os seus casos de uso específicos
+
+## Casos de Uso
+
+Cenários comuns de uso de triggers Salesforce + CrewAI incluem:
+
+- **Processamento de Leads**: Analisar e classificar leads recebidos automaticamente
+- **Geração de Propostas**: Criar propostas personalizadas com base nos dados das oportunidades
+- **Insights de Clientes**: Gerar relatórios de análise a partir do histórico de interações com clientes
+- **Automação de Follow-up**: Criar mensagens de follow-up e recomendações personalizadas
+
+## Próximos Passos
+
+Para instruções detalhadas de configuração e opções avançadas, entre em contato com o suporte da CrewAI Enterprise, que pode fornecer orientações personalizadas para o seu ambiente Salesforce e necessidades de negócio.
\ No newline at end of file
diff --git a/docs/pt-BR/enterprise/guides/slack-trigger.mdx b/docs/pt-BR/enterprise/guides/slack-trigger.mdx
new file mode 100644
index 000000000..fc916888c
--- /dev/null
+++ b/docs/pt-BR/enterprise/guides/slack-trigger.mdx
@@ -0,0 +1,61 @@
+---
+title: "Slack Trigger"
+description: "Acione crews do CrewAI diretamente do Slack usando comandos de barra"
+icon: "slack"
+---
+
+Este guia explica como iniciar um crew diretamente do Slack usando triggers do CrewAI.
+
+## Pré-requisitos
+
+- Trigger do CrewAI para Slack instalado e conectado ao seu workspace do Slack
+- Pelo menos um crew configurado no CrewAI
+
+## Etapas de Configuração
+
+ +
+
+ Verifique se o Slack está listado e conectado.
+
+
+
+ Verifique se o Slack está listado e conectado.
+  +
+ - Pressione Enter ou selecione a opção "**Kickoff crew**". Uma caixa de diálogo intitulada "**Kickoff an AI Crew**" aparecerá.
+
+
+ - Pressione Enter ou selecione a opção "**Kickoff crew**". Uma caixa de diálogo intitulada "**Kickoff an AI Crew**" aparecerá.
+  +
+ - Se o seu crew exigir algum input, clique no botão "**Add Inputs**" para fornecê-los.
+
+
+ - Se o seu crew exigir algum input, clique no botão "**Add Inputs**" para fornecê-los.
+  +
+ - O crew começará a ser executado e você verá os resultados no canal do Slack.
+
+
+
+ - O crew começará a ser executado e você verá os resultados no canal do Slack.
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+ - Clique no botão `Add Role` para adicionar uma nova função.
+ - Insira os detalhes e as permissões da função e clique no botão `Create Role` para criar a função.
+
+
+
+ - Clique no botão `Add Role` para adicionar uma nova função.
+ - Insira os detalhes e as permissões da função e clique no botão `Create Role` para criar a função.
+
+  +
+
+
+  +
+ - Após o membro aceitar o convite, você poderá adicionar uma função a ele.
+ - Volte para a aba `Roles`
+ - Vá até o membro ao qual deseja adicionar uma função e, na coluna `Role`, clique no menu suspenso
+ - Selecione a função que deseja atribuir ao membro
+ - Clique no botão `Update` para salvar a função
+
+
+
+ - Após o membro aceitar o convite, você poderá adicionar uma função a ele.
+ - Volte para a aba `Roles`
+ - Vá até o membro ao qual deseja adicionar uma função e, na coluna `Role`, clique no menu suspenso
+ - Selecione a função que deseja atribuir ao membro
+ - Clique no botão `Update` para salvar a função
+
+  +
+
+
+  +
+
+
+  +
+
+ 3. Adicione uma etapa de ação HTTP
+ - Configure a ação como `Send HTTP request`
+ - Use o método `POST`
+ - Defina a URL para o endpoint de kickoff do CrewAI Enterprise
+ - Adicione os headers necessários (ex.: `Bearer Token`)
+
+
+
+
+ 3. Adicione uma etapa de ação HTTP
+ - Configure a ação como `Send HTTP request`
+ - Use o método `POST`
+ - Defina a URL para o endpoint de kickoff do CrewAI Enterprise
+ - Adicione os headers necessários (ex.: `Bearer Token`)
+
+  +
+
+ - No corpo, inclua o conteúdo JSON conforme configurado na etapa 2
+
+
+
+
+ - No corpo, inclua o conteúdo JSON conforme configurado na etapa 2
+
+  +
+
+ - O crew será iniciado no horário pré-definido.
+
+
+
+ - O crew será iniciado no horário pré-definido.
+  +
+
+ 2. Adicione uma etapa de webhook como gatilho:
+ - Selecione `Catch Webhook` como tipo de gatilho
+ - Isso irá gerar uma URL única que receberá requisições HTTP e disparará seu flow
+
+
+
+
+ 2. Adicione uma etapa de webhook como gatilho:
+ - Selecione `Catch Webhook` como tipo de gatilho
+ - Isso irá gerar uma URL única que receberá requisições HTTP e disparará seu flow
+
+  +
+
+ - Configure o e-mail para usar o corpo de texto do webhook do crew
+
+
+
+
+ - Configure o e-mail para usar o corpo de texto do webhook do crew
+
+  +
+
+
+  +
+
+
+  +
+ - Selecione `New Pushed Message` como o Evento de Trigger.
+ - Conecte sua conta Slack, caso ainda não tenha feito isso.
+
+
+ - Selecione `New Pushed Message` como o Evento de Trigger.
+ - Conecte sua conta Slack, caso ainda não tenha feito isso.
+  +
+
+
+  +
+ - Configure as entradas para o Crew usando os dados da mensagem do Slack.
+
+
+ - Configure as entradas para o Crew usando os dados da mensagem do Slack.
+  +
+
+
+
+
+  +
+
+
+  +
+
+
+  +
+
+ - Selecione o botão de três pontos e então escolha Push to Zapier
+
+
+
+
+
+ - Selecione o botão de três pontos e então escolha Push to Zapier
+
+
+  +
+
+
+  +
+
+
+  +
+
+CrewAI Enterprise expande o poder do framework open-source com funcionalidades projetadas para implantações em produção, colaboração e escalabilidade. Implemente seus crews em uma infraestrutura gerenciada e monitore sua execução em tempo real.
+
+## Principais Funcionalidades
+
+
+
+
+CrewAI Enterprise expande o poder do framework open-source com funcionalidades projetadas para implantações em produção, colaboração e escalabilidade. Implemente seus crews em uma infraestrutura gerenciada e monitore sua execução em tempo real.
+
+## Principais Funcionalidades
+
+ +
+
+## Boas Práticas
+
+1. **Seja específico nos prompts de geração de imagem** para obter melhores resultados.
+2. **Considere o tempo de geração** - A geração de imagens pode levar algum tempo, então inclua isso no seu planejamento de tarefas.
+3. **Siga as políticas de uso** - Sempre cumpra as políticas de uso da OpenAI ao gerar imagens.
+
+## Solução de Problemas
+
+1. **Verifique o acesso à API** - Certifique-se de que sua chave de API OpenAI possui acesso ao DALL-E.
+2. **Compatibilidade de versões** - Verifique se você está utilizando a versão mais recente do crewAI e crewai-tools.
+3. **Configuração da ferramenta** - Confirme que a ferramenta DALL-E foi corretamente adicionada à lista de ferramentas do agente.
\ No newline at end of file
diff --git a/docs/pt-BR/learn/force-tool-output-as-result.mdx b/docs/pt-BR/learn/force-tool-output-as-result.mdx
new file mode 100644
index 000000000..56d236381
--- /dev/null
+++ b/docs/pt-BR/learn/force-tool-output-as-result.mdx
@@ -0,0 +1,50 @@
+---
+title: Forçar a Saída da Ferramenta como Resultado
+description: Aprenda como forçar a saída de uma ferramenta como resultado em uma tarefa de Agent no CrewAI.
+icon: wrench-simple
+---
+
+## Introdução
+
+No CrewAI, você pode forçar a saída de uma ferramenta como o resultado de uma tarefa de um agent.
+Esse recurso é útil quando você deseja garantir que a saída da ferramenta seja capturada e retornada como resultado da tarefa, evitando quaisquer modificações pelo agent durante a execução da tarefa.
+
+## Forçando a Saída da Ferramenta como Resultado
+
+Para forçar a saída da ferramenta como resultado da tarefa de um agent, você precisa definir o parâmetro `result_as_answer` como `True` ao adicionar uma ferramenta ao agent.
+Esse parâmetro garante que a saída da ferramenta seja capturada e retornada como resultado da tarefa, sem qualquer modificação pelo agent.
+
+Veja um exemplo de como forçar a saída da ferramenta como resultado da tarefa de um agent:
+
+```python Code
+from crewai.agent import Agent
+from my_tool import MyCustomTool
+
+# Create a coding agent with the custom tool
+coding_agent = Agent(
+ role="Data Scientist",
+ goal="Produce amazing reports on AI",
+ backstory="You work with data and AI",
+ tools=[MyCustomTool(result_as_answer=True)],
+ )
+
+# Assuming the tool's execution and result population occurs within the system
+task_result = coding_agent.execute_task(task)
+```
+
+## Fluxo de Trabalho em Ação
+
+
+
+
+## Boas Práticas
+
+1. **Seja específico nos prompts de geração de imagem** para obter melhores resultados.
+2. **Considere o tempo de geração** - A geração de imagens pode levar algum tempo, então inclua isso no seu planejamento de tarefas.
+3. **Siga as políticas de uso** - Sempre cumpra as políticas de uso da OpenAI ao gerar imagens.
+
+## Solução de Problemas
+
+1. **Verifique o acesso à API** - Certifique-se de que sua chave de API OpenAI possui acesso ao DALL-E.
+2. **Compatibilidade de versões** - Verifique se você está utilizando a versão mais recente do crewAI e crewai-tools.
+3. **Configuração da ferramenta** - Confirme que a ferramenta DALL-E foi corretamente adicionada à lista de ferramentas do agente.
\ No newline at end of file
diff --git a/docs/pt-BR/learn/force-tool-output-as-result.mdx b/docs/pt-BR/learn/force-tool-output-as-result.mdx
new file mode 100644
index 000000000..56d236381
--- /dev/null
+++ b/docs/pt-BR/learn/force-tool-output-as-result.mdx
@@ -0,0 +1,50 @@
+---
+title: Forçar a Saída da Ferramenta como Resultado
+description: Aprenda como forçar a saída de uma ferramenta como resultado em uma tarefa de Agent no CrewAI.
+icon: wrench-simple
+---
+
+## Introdução
+
+No CrewAI, você pode forçar a saída de uma ferramenta como o resultado de uma tarefa de um agent.
+Esse recurso é útil quando você deseja garantir que a saída da ferramenta seja capturada e retornada como resultado da tarefa, evitando quaisquer modificações pelo agent durante a execução da tarefa.
+
+## Forçando a Saída da Ferramenta como Resultado
+
+Para forçar a saída da ferramenta como resultado da tarefa de um agent, você precisa definir o parâmetro `result_as_answer` como `True` ao adicionar uma ferramenta ao agent.
+Esse parâmetro garante que a saída da ferramenta seja capturada e retornada como resultado da tarefa, sem qualquer modificação pelo agent.
+
+Veja um exemplo de como forçar a saída da ferramenta como resultado da tarefa de um agent:
+
+```python Code
+from crewai.agent import Agent
+from my_tool import MyCustomTool
+
+# Create a coding agent with the custom tool
+coding_agent = Agent(
+ role="Data Scientist",
+ goal="Produce amazing reports on AI",
+ backstory="You work with data and AI",
+ tools=[MyCustomTool(result_as_answer=True)],
+ )
+
+# Assuming the tool's execution and result population occurs within the system
+task_result = coding_agent.execute_task(task)
+```
+
+## Fluxo de Trabalho em Ação
+
+ +
+
+
+  +
+  +
+  +
+
+### Funcionalidades
+
+- **Painel Analítico**: Monitore a saúde e desempenho dos seus Agentes com dashboards detalhados que acompanham métricas, custos e interações dos usuários.
+- **SDK de Observabilidade Nativo OpenTelemetry**: SDKs neutros de fornecedor para enviar rastreamentos e métricas para suas ferramentas de observabilidade existentes como Grafana, DataDog e outros.
+- **Rastreamento de Custos para Modelos Customizados e Ajustados**: Adapte estimativas de custo para modelos específicos usando arquivos de precificação customizados para orçamentos precisos.
+- **Painel de Monitoramento de Exceções**: Identifique e solucione rapidamente problemas ao rastrear exceções comuns e erros por meio de um painel de monitoramento.
+- **Conformidade e Segurança**: Detecte ameaças potenciais como profanidade e vazamento de dados sensíveis (PII).
+- **Detecção de Prompt Injection**: Identifique possíveis injeções de código e vazamentos de segredos.
+- **Gerenciamento de Chaves de API e Segredos**: Gerencie suas chaves de API e segredos do LLM de forma centralizada e segura, evitando práticas inseguras.
+- **Gerenciamento de Prompt**: Gerencie e versiona prompts de Agente usando o PromptHub para acesso consistente e fácil entre os agentes.
+- **Model Playground** Teste e compare diferentes modelos para seus agentes CrewAI antes da implantação.
+
+## Instruções de Configuração
+
+
+
+
+### Funcionalidades
+
+- **Painel Analítico**: Monitore a saúde e desempenho dos seus Agentes com dashboards detalhados que acompanham métricas, custos e interações dos usuários.
+- **SDK de Observabilidade Nativo OpenTelemetry**: SDKs neutros de fornecedor para enviar rastreamentos e métricas para suas ferramentas de observabilidade existentes como Grafana, DataDog e outros.
+- **Rastreamento de Custos para Modelos Customizados e Ajustados**: Adapte estimativas de custo para modelos específicos usando arquivos de precificação customizados para orçamentos precisos.
+- **Painel de Monitoramento de Exceções**: Identifique e solucione rapidamente problemas ao rastrear exceções comuns e erros por meio de um painel de monitoramento.
+- **Conformidade e Segurança**: Detecte ameaças potenciais como profanidade e vazamento de dados sensíveis (PII).
+- **Detecção de Prompt Injection**: Identifique possíveis injeções de código e vazamentos de segredos.
+- **Gerenciamento de Chaves de API e Segredos**: Gerencie suas chaves de API e segredos do LLM de forma centralizada e segura, evitando práticas inseguras.
+- **Gerenciamento de Prompt**: Gerencie e versiona prompts de Agente usando o PromptHub para acesso consistente e fácil entre os agentes.
+- **Model Playground** Teste e compare diferentes modelos para seus agentes CrewAI antes da implantação.
+
+## Instruções de Configuração
+
+ +
+
+O Opik oferece suporte abrangente para cada etapa do desenvolvimento da sua aplicação CrewAI:
+
+- **Registrar Traces e Spans**: Acompanhe automaticamente chamadas LLM e lógica da aplicação para depurar e analisar sistemas em desenvolvimento e em produção. Anote manualmente ou programaticamente, visualize e compare respostas entre projetos.
+- **Avalie a Performance da sua Aplicação LLM**: Avalie contra um conjunto de testes personalizado e execute métricas de avaliação nativas ou defina suas próprias métricas via SDK ou UI.
+- **Teste no Pipeline CI/CD**: Estabeleça bases de performance confiáveis com os testes unitários LLM do Opik, baseados em PyTest. Execute avaliações online para monitoramento contínuo em produção.
+- **Monitore & Analise Dados de Produção**: Entenda a performance dos seus modelos em dados inéditos em produção e gere conjuntos de dados para novas iterações de desenvolvimento.
+
+## Configuração
+A Comet oferece uma versão hospedada da plataforma Opik, ou você pode rodar a plataforma localmente.
+
+Para usar a versão hospedada, basta [criar uma conta gratuita na Comet](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) e obter sua chave de API.
+
+Para rodar a plataforma Opik localmente, veja nosso [guia de instalação](https://www.comet.com/docs/opik/self-host/overview/) para mais informações.
+
+Neste guia, utilizaremos o exemplo de início rápido da CrewAI.
+
+
+
+
+O Opik oferece suporte abrangente para cada etapa do desenvolvimento da sua aplicação CrewAI:
+
+- **Registrar Traces e Spans**: Acompanhe automaticamente chamadas LLM e lógica da aplicação para depurar e analisar sistemas em desenvolvimento e em produção. Anote manualmente ou programaticamente, visualize e compare respostas entre projetos.
+- **Avalie a Performance da sua Aplicação LLM**: Avalie contra um conjunto de testes personalizado e execute métricas de avaliação nativas ou defina suas próprias métricas via SDK ou UI.
+- **Teste no Pipeline CI/CD**: Estabeleça bases de performance confiáveis com os testes unitários LLM do Opik, baseados em PyTest. Execute avaliações online para monitoramento contínuo em produção.
+- **Monitore & Analise Dados de Produção**: Entenda a performance dos seus modelos em dados inéditos em produção e gere conjuntos de dados para novas iterações de desenvolvimento.
+
+## Configuração
+A Comet oferece uma versão hospedada da plataforma Opik, ou você pode rodar a plataforma localmente.
+
+Para usar a versão hospedada, basta [criar uma conta gratuita na Comet](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) e obter sua chave de API.
+
+Para rodar a plataforma Opik localmente, veja nosso [guia de instalação](https://www.comet.com/docs/opik/self-host/overview/) para mais informações.
+
+Neste guia, utilizaremos o exemplo de início rápido da CrewAI.
+
+ +
+
+
+## Introdução
+
+Portkey aprimora o CrewAI com recursos prontos para produção, transformando seus crews de agentes experimentais em sistemas robustos ao fornecer:
+
+- **Observabilidade completa** de cada etapa do agente, uso de ferramentas e interações
+- **Confiabilidade incorporada** com fallbacks, tentativas automáticas e balanceamento de carga
+- **Rastreamento e otimização de custos** para gerenciar seus gastos com IA
+- **Acesso a mais de 200 LLMs** por meio de uma única integração
+- **Guardrails** para manter o comportamento dos agentes seguro e em conformidade
+- **Prompts versionados** para desempenho consistente dos agentes
+
+
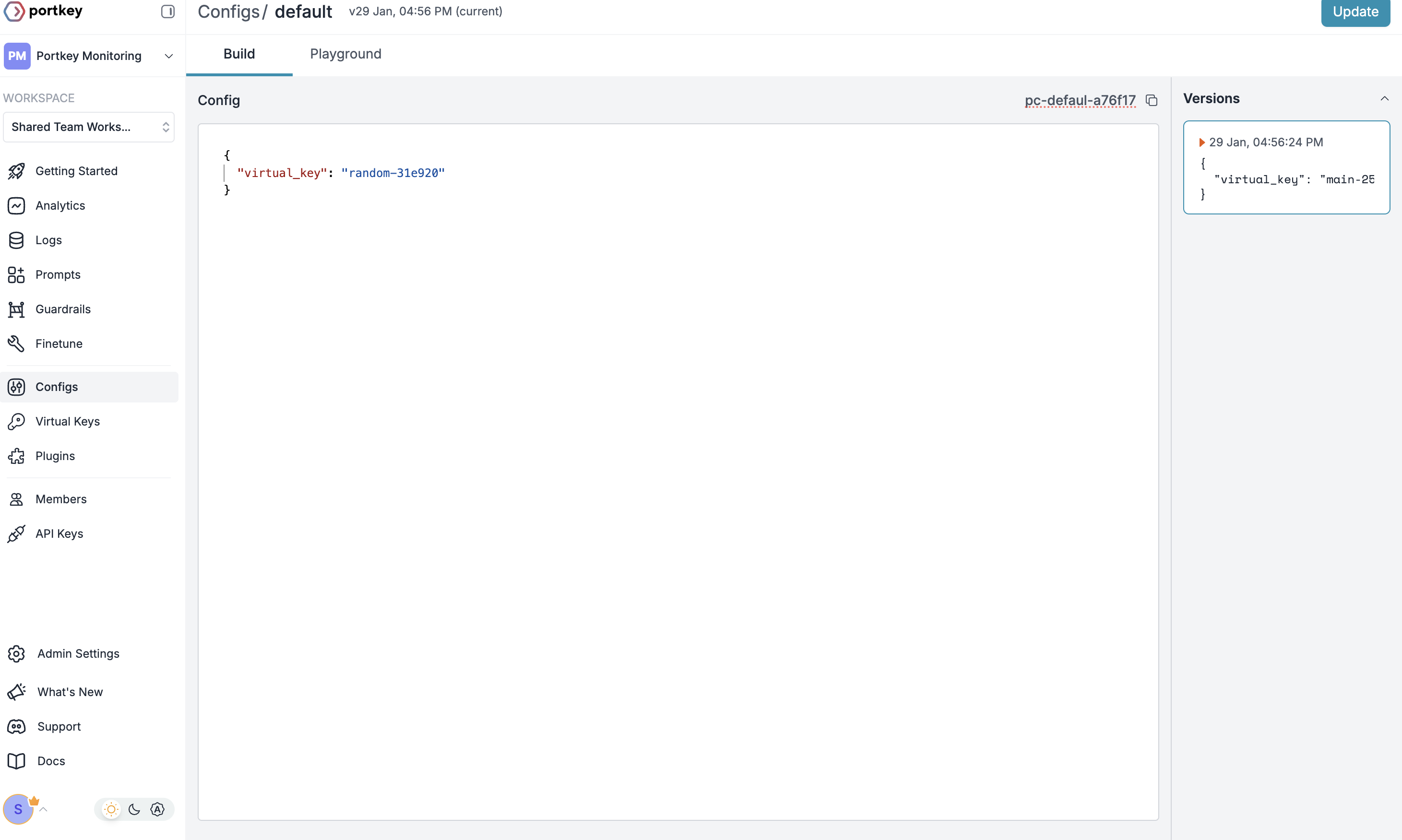
+### Instalação & Configuração
+
+
+
+
+
+## Introdução
+
+Portkey aprimora o CrewAI com recursos prontos para produção, transformando seus crews de agentes experimentais em sistemas robustos ao fornecer:
+
+- **Observabilidade completa** de cada etapa do agente, uso de ferramentas e interações
+- **Confiabilidade incorporada** com fallbacks, tentativas automáticas e balanceamento de carga
+- **Rastreamento e otimização de custos** para gerenciar seus gastos com IA
+- **Acesso a mais de 200 LLMs** por meio de uma única integração
+- **Guardrails** para manter o comportamento dos agentes seguro e em conformidade
+- **Prompts versionados** para desempenho consistente dos agentes
+
+
+### Instalação & Configuração
+
+ +
+
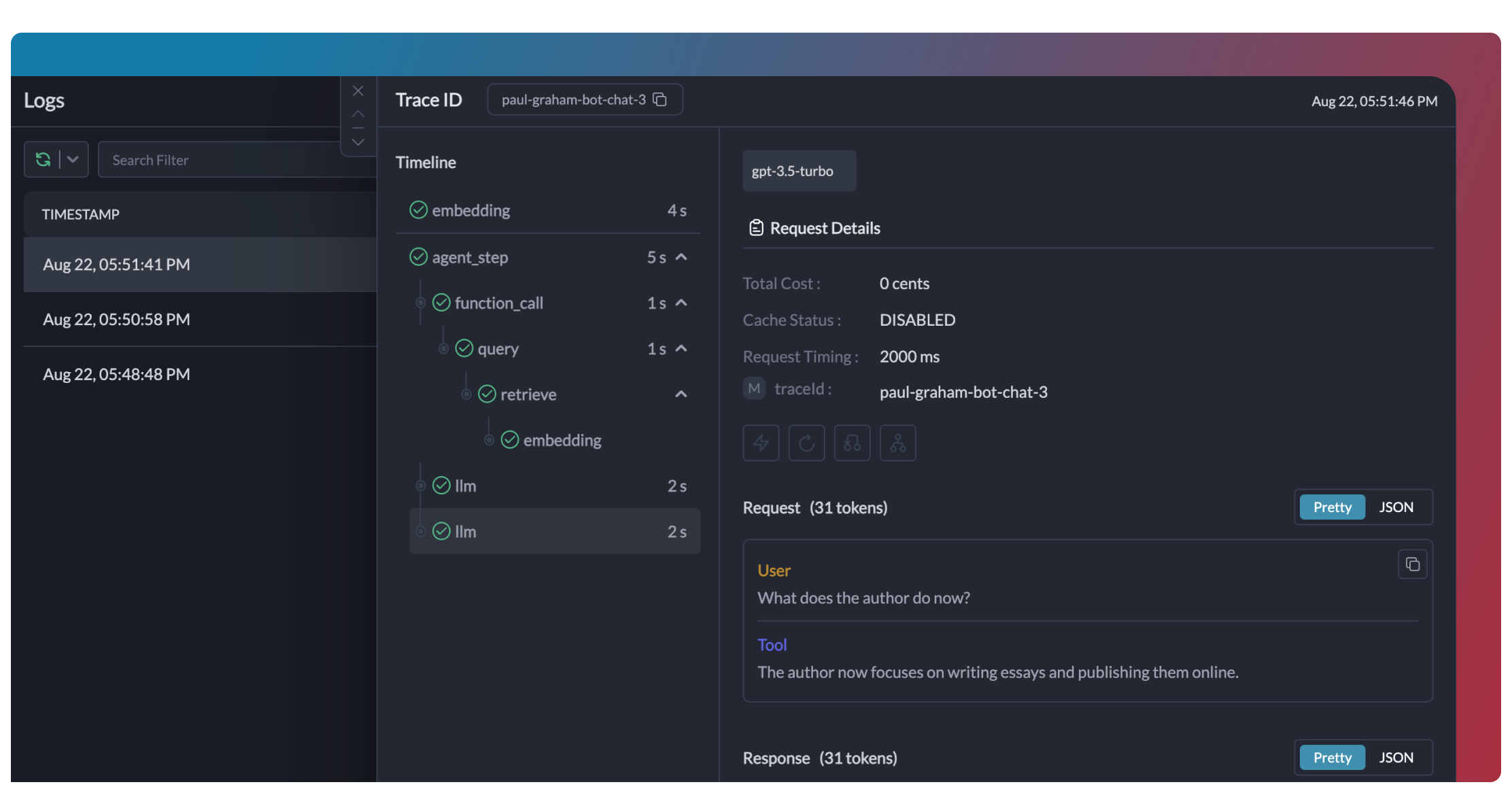
+Os traces fornecem uma visão hierárquica da execução do seu crew, mostrando a sequência de chamadas LLM, ativações de ferramentas e transições de estado.
+
+```python
+# Adicione trace_id para habilitar o tracing hierárquico no Portkey
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ trace_id="unique-session-id" # Adicione um trace ID único
+ )
+)
+```
+
+
+
+Os traces fornecem uma visão hierárquica da execução do seu crew, mostrando a sequência de chamadas LLM, ativações de ferramentas e transições de estado.
+
+```python
+# Adicione trace_id para habilitar o tracing hierárquico no Portkey
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ trace_id="unique-session-id" # Adicione um trace ID único
+ )
+)
+```
+  +
+
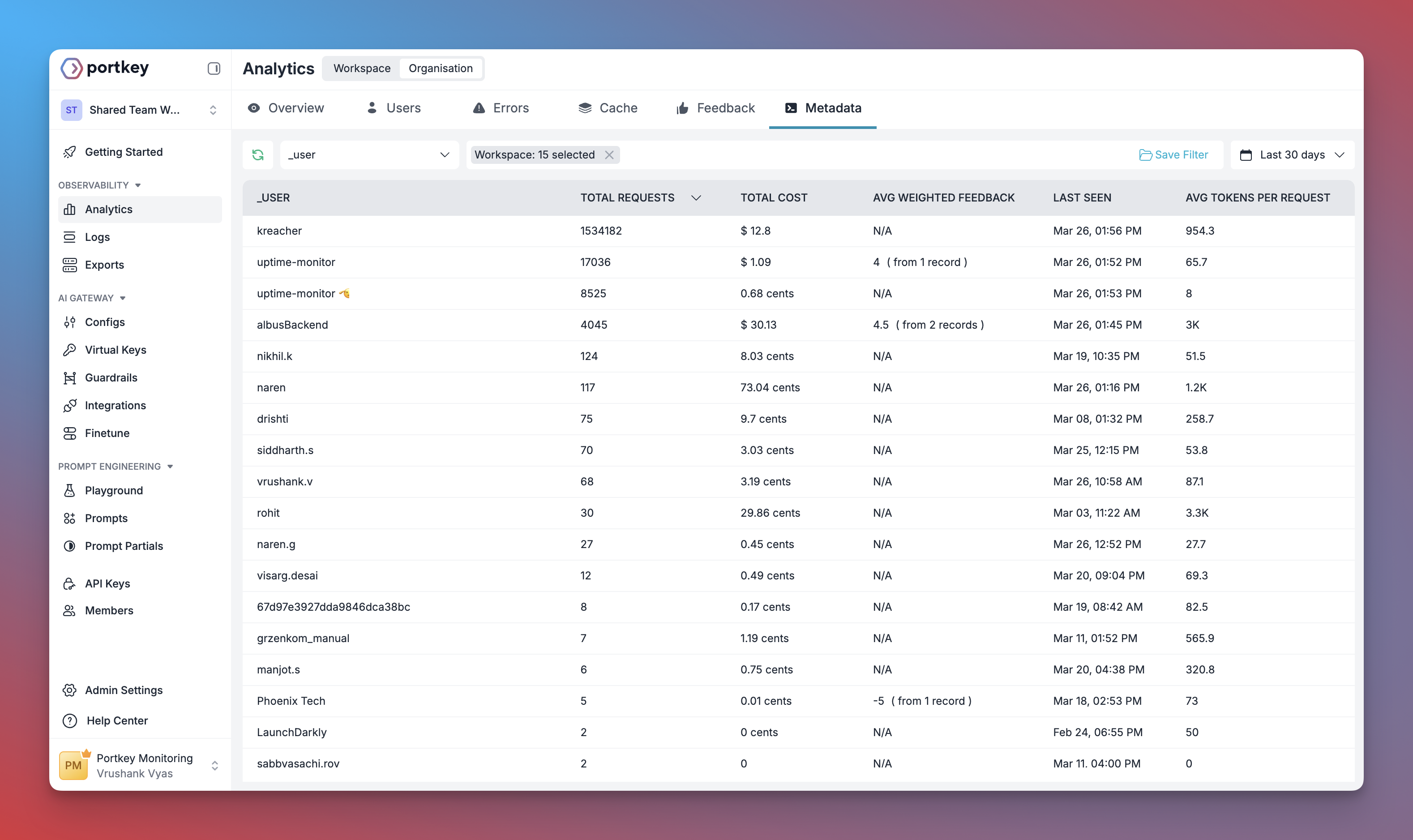
+Portkey registra cada interação com LLMs, incluindo:
+
+- Payloads completos das requisições e respostas
+- Métricas de latência e uso de tokens
+- Cálculos de custo
+- Chamadas de ferramentas e execuções de funções
+
+Todos os logs podem ser filtrados por metadados, trace IDs, modelos e mais, tornando mais fácil depurar execuções específicas do crew.
+
+
+
+Portkey registra cada interação com LLMs, incluindo:
+
+- Payloads completos das requisições e respostas
+- Métricas de latência e uso de tokens
+- Cálculos de custo
+- Chamadas de ferramentas e execuções de funções
+
+Todos os logs podem ser filtrados por metadados, trace IDs, modelos e mais, tornando mais fácil depurar execuções específicas do crew.
+  +
+
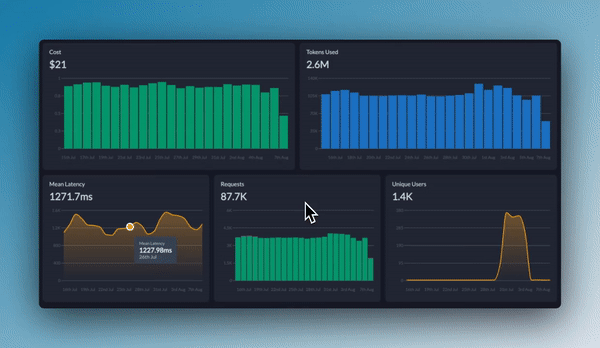
+Portkey oferece dashboards integrados que ajudam você a:
+
+- Rastrear custos e uso de tokens em todas as execuções do crew
+- Analisar métricas de desempenho, como latência e taxas de sucesso
+- Identificar gargalos nos fluxos de trabalho dos agentes
+- Comparar diferentes configurações de crew e LLMs
+
+Você pode filtrar e segmentar todas as métricas por metadados personalizados para analisar tipos de crew, grupos de usuários ou casos de uso específicos.
+
+
+
+Portkey oferece dashboards integrados que ajudam você a:
+
+- Rastrear custos e uso de tokens em todas as execuções do crew
+- Analisar métricas de desempenho, como latência e taxas de sucesso
+- Identificar gargalos nos fluxos de trabalho dos agentes
+- Comparar diferentes configurações de crew e LLMs
+
+Você pode filtrar e segmentar todas as métricas por metadados personalizados para analisar tipos de crew, grupos de usuários ou casos de uso específicos.
+  +
+
+Adicione metadados personalizados à configuração LLM do seu CrewAI para permitir filtragem e segmentação poderosas:
+
+```python
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ metadata={
+ "crew_type": "research_crew",
+ "environment": "production",
+ "_user": "user_123", # Campo especial _user para analytics de usuários
+ "request_source": "mobile_app"
+ }
+ )
+)
+```
+
+Esses metadados podem ser usados para filtrar logs, traces e métricas no painel do Portkey, permitindo analisar execuções específicas do crew, usuários ou ambientes.
+
+
+
+Adicione metadados personalizados à configuração LLM do seu CrewAI para permitir filtragem e segmentação poderosas:
+
+```python
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ metadata={
+ "crew_type": "research_crew",
+ "environment": "production",
+ "_user": "user_123", # Campo especial _user para analytics de usuários
+ "request_source": "mobile_app"
+ }
+ )
+)
+```
+
+Esses metadados podem ser usados para filtrar logs, traces e métricas no painel do Portkey, permitindo analisar execuções específicas do crew, usuários ou ambientes.
+  +
+
+
+
+
+ +
+
+
+
+
+ +
+
+
+
+
+ +
+
+
+