mirror of
https://github.com/crewAIInc/crewAI.git
synced 2026-07-23 15:55:11 +00:00
Add Korean translations (#3307)
This commit is contained in:
124
docs/ko/observability/agentops.mdx
Normal file
124
docs/ko/observability/agentops.mdx
Normal file
@@ -0,0 +1,124 @@
|
||||
---
|
||||
title: AgentOps 통합
|
||||
description: AgentOps를 사용하여 에이전트 성능을 이해하고 로깅하기
|
||||
icon: paperclip
|
||||
---
|
||||
|
||||
# 소개
|
||||
|
||||
Observability는 대화형 AI 에이전트를 개발하고 배포하는 데 있어 핵심적인 요소입니다. 이는 개발자가 에이전트의 성능을 이해하고, 에이전트가 사용자와 어떻게 상호작용하는지, 그리고 에이전트가 외부 도구와 API를 어떻게 사용하는지를 파악할 수 있게 해줍니다.
|
||||
AgentOps는 CrewAI와 독립적인 제품으로, 에이전트를 위한 종합적인 observability 솔루션을 제공합니다.
|
||||
|
||||
## AgentOps
|
||||
|
||||
[AgentOps](https://agentops.ai/?=crew)은 에이전트에 대한 세션 리플레이, 메트릭, 모니터링을 제공합니다.
|
||||
|
||||
AgentOps는 높은 수준에서 비용, 토큰 사용량, 대기 시간, 에이전트 실패, 세션 전체 통계 등 다양한 항목을 모니터링할 수 있는 기능을 제공합니다.
|
||||
더 자세한 내용은 [AgentOps Repo](https://github.com/AgentOps-AI/agentops)를 확인하세요.
|
||||
|
||||
### 개요
|
||||
|
||||
AgentOps는 개발 및 프로덕션 환경에서 에이전트에 대한 모니터링을 제공합니다.
|
||||
에이전트 성능, 세션 리플레이, 맞춤형 리포팅을 추적할 수 있는 대시보드를 제공합니다.
|
||||
|
||||
또한, AgentOps는 Crew 에이전트 상호작용, LLM 호출, 툴 사용을 실시간으로 볼 수 있는 세션 드릴다운 기능을 제공합니다.
|
||||
이 기능은 에이전트가 사용자 및 다른 에이전트와 어떻게 상호작용하는지 디버깅하고 이해하는 데 유용합니다.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
### 특징
|
||||
|
||||
- **LLM 비용 관리 및 추적**: 기반 모델 공급자와의 지출을 추적합니다.
|
||||
- **재생 분석**: 단계별 에이전트 실행 그래프를 시청할 수 있습니다.
|
||||
- **재귀적 사고 감지**: 에이전트가 무한 루프에 빠졌는지 식별합니다.
|
||||
- **맞춤형 보고서**: 에이전트 성능에 대한 맞춤형 분석을 생성합니다.
|
||||
- **분석 대시보드**: 개발 및 운영 중인 에이전트에 대한 상위 수준 통계를 모니터링합니다.
|
||||
- **공개 모델 테스트**: 벤치마크 및 리더보드를 통해 에이전트를 테스트할 수 있습니다.
|
||||
- **맞춤형 테스트**: 도메인별 테스트로 에이전트를 실행합니다.
|
||||
- **타임 트래블 디버깅**: 체크포인트에서 세션을 재시작합니다.
|
||||
- **컴플라이언스 및 보안**: 감사 로그를 생성하고 욕설 및 PII 유출과 같은 잠재적 위협을 감지합니다.
|
||||
- **프롬프트 인젝션 감지**: 잠재적 코드 인젝션 및 시크릿 유출을 식별합니다.
|
||||
|
||||
### AgentOps 사용하기
|
||||
|
||||
<Steps>
|
||||
<Step title="API 키 생성">
|
||||
사용자 API 키를 여기서 생성하세요: [API 키 생성](https://app.agentops.ai/account)
|
||||
</Step>
|
||||
<Step title="환경 설정">
|
||||
API 키를 환경 변수에 추가하세요:
|
||||
```bash
|
||||
AGENTOPS_API_KEY=<YOUR_AGENTOPS_API_KEY>
|
||||
```
|
||||
</Step>
|
||||
<Step title="AgentOps 설치">
|
||||
다음 명령어로 AgentOps를 설치하세요:
|
||||
```bash
|
||||
pip install 'crewai[agentops]'
|
||||
```
|
||||
또는
|
||||
```bash
|
||||
pip install agentops
|
||||
```
|
||||
</Step>
|
||||
<Step title="AgentOps 초기화">
|
||||
스크립트에서 `Crew`를 사용하기 전에 다음 코드를 포함하세요:
|
||||
|
||||
```python
|
||||
import agentops
|
||||
agentops.init()
|
||||
```
|
||||
|
||||
이렇게 하면 AgentOps 세션이 시작되고 Crew 에이전트가 자동으로 추적됩니다. 더 복잡한 agentic 시스템을 구성하는 방법에 대한 자세한 정보는 [AgentOps 문서](https://docs.agentops.ai) 또는 [Discord](https://discord.gg/j4f3KbeH)를 참조하세요.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Crew + AgentOps 예시
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card
|
||||
title="Job Posting"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/job-posting"
|
||||
icon="briefcase"
|
||||
iconType="solid"
|
||||
>
|
||||
채용 공고를 생성하는 Crew agent의 예시입니다.
|
||||
</Card>
|
||||
<Card
|
||||
title="Markdown Validator"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/markdown_validator"
|
||||
icon="markdown"
|
||||
iconType="solid"
|
||||
>
|
||||
Markdown 파일을 검증하는 Crew agent의 예시입니다.
|
||||
</Card>
|
||||
<Card
|
||||
title="Instagram Post"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/instagram_post"
|
||||
icon="square-instagram"
|
||||
iconType="brands"
|
||||
>
|
||||
Instagram 게시물을 생성하는 Crew agent의 예시입니다.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### 추가 정보
|
||||
|
||||
시작하려면 [AgentOps 계정](https://agentops.ai/?=crew)을 생성하세요.
|
||||
|
||||
기능 요청이나 버그 보고가 필요하시면 [AgentOps Repo](https://github.com/AgentOps-AI/agentops)에서 AgentOps 팀에 문의해 주세요.
|
||||
|
||||
#### 추가 링크
|
||||
|
||||
<a href="https://twitter.com/agentopsai/">🐦 트위터</a>
|
||||
<span> • </span>
|
||||
<a href="https://discord.gg/JHPt4C7r">📢 디스코드</a>
|
||||
<span> • </span>
|
||||
<a href="https://app.agentops.ai/?=crew">🖇️ AgentOps 대시보드</a>
|
||||
<span> • </span>
|
||||
<a href="https://docs.agentops.ai/introduction">📙 문서화</a>
|
||||
149
docs/ko/observability/arize-phoenix.mdx
Normal file
149
docs/ko/observability/arize-phoenix.mdx
Normal file
@@ -0,0 +1,149 @@
|
||||
---
|
||||
title: Arize Phoenix
|
||||
description: OpenTelemetry 및 OpenInference가 포함된 CrewAI용 Arize Phoenix 통합
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# Arize Phoenix 통합
|
||||
|
||||
이 가이드는 [OpenInference](https://github.com/openinference/openinference) SDK를 통해 OpenTelemetry를 사용하여 **Arize Phoenix**를 **CrewAI**와 통합하는 방법을 보여줍니다. 이 가이드를 완료하면 CrewAI agent를 추적하고 agent를 쉽게 디버그할 수 있습니다.
|
||||
|
||||
> **Arize Phoenix란?** [Arize Phoenix](https://phoenix.arize.com)는 AI 애플리케이션을 위한 추적 및 평가 기능을 제공하는 LLM 가시성(observability) 플랫폼입니다.
|
||||
|
||||
[](https://www.youtube.com/watch?v=Yc5q3l6F7Ww)
|
||||
|
||||
## 시작하기
|
||||
|
||||
CrewAI를 사용하고 OpenInference를 통해 OpenTelemetry와 Arize Phoenix를 연동하는 간단한 예제를 단계별로 안내합니다.
|
||||
|
||||
이 가이드는 [Google Colab](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/crewai_tracing_tutorial.ipynb)에서도 확인하실 수 있습니다.
|
||||
|
||||
### 1단계: 의존성 설치
|
||||
|
||||
```bash
|
||||
pip install openinference-instrumentation-crewai crewai crewai-tools arize-phoenix-otel
|
||||
```
|
||||
|
||||
### 2단계: 환경 변수 설정
|
||||
|
||||
Phoenix Cloud API 키를 설정하고 OpenTelemetry를 구성하여 추적 정보를 Phoenix로 전송합니다. Phoenix Cloud는 Arize Phoenix의 호스팅 버전이지만, 이 통합을 사용하는 데 필수는 아닙니다.
|
||||
|
||||
무료 Serper API 키는 [여기](https://serper.dev/)에서 받을 수 있습니다.
|
||||
|
||||
```python
|
||||
import os
|
||||
from getpass import getpass
|
||||
|
||||
# Get your Phoenix Cloud credentials
|
||||
PHOENIX_API_KEY = getpass("🔑 Enter your Phoenix Cloud API Key: ")
|
||||
|
||||
# Get API keys for services
|
||||
OPENAI_API_KEY = getpass("🔑 Enter your OpenAI API key: ")
|
||||
SERPER_API_KEY = getpass("🔑 Enter your Serper API key: ")
|
||||
|
||||
# Set environment variables
|
||||
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
|
||||
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com" # Phoenix Cloud, change this to your own endpoint if you are using a self-hosted instance
|
||||
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
|
||||
os.environ["SERPER_API_KEY"] = SERPER_API_KEY
|
||||
```
|
||||
|
||||
### 3단계: Phoenix와 함께 OpenTelemetry 초기화하기
|
||||
|
||||
OpenInference OpenTelemetry 계측 SDK를 초기화하여 트레이스를 수집하고 Phoenix로 전송합니다.
|
||||
|
||||
```python
|
||||
from phoenix.otel import register
|
||||
|
||||
tracer_provider = register(
|
||||
project_name="crewai-tracing-demo",
|
||||
auto_instrument=True,
|
||||
)
|
||||
```
|
||||
|
||||
### 4단계: CrewAI 애플리케이션 생성하기
|
||||
|
||||
두 명의 에이전트가 협력하여 AI 발전에 관한 블로그 글을 조사하고 작성하는 CrewAI 애플리케이션을 만들어 보겠습니다.
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai_tools import SerperDevTool
|
||||
from openinference.instrumentation.crewai import CrewAIInstrumentor
|
||||
from phoenix.otel import register
|
||||
|
||||
# crew에 대한 모니터링 설정
|
||||
tracer_provider = register(
|
||||
endpoint="http://localhost:6006/v1/traces")
|
||||
CrewAIInstrumentor().instrument(skip_dep_check=True, tracer_provider=tracer_provider)
|
||||
search_tool = SerperDevTool()
|
||||
|
||||
# 역할과 목표가 설정된 에이전트 정의
|
||||
researcher = Agent(
|
||||
role="Senior Research Analyst",
|
||||
goal="AI 및 데이터 과학의 최첨단 발전 사항 발견",
|
||||
backstory="""당신은 최고 수준의 기술 싱크탱크에서 근무합니다.
|
||||
새로운 트렌드를 식별하는 데 전문성이 있습니다.
|
||||
복잡한 데이터를 분석하고 실행 가능한 인사이트로 제시하는 데 뛰어납니다.""",
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
# 원하는 모델을 지정할 수 있는 optional llm 속성을 전달할 수 있습니다.
|
||||
# llm=ChatOpenAI(model_name="gpt-3.5", temperature=0.7),
|
||||
tools=[search_tool],
|
||||
)
|
||||
writer = Agent(
|
||||
role="Tech Content Strategist",
|
||||
goal="기술 발전에 대한 매력적인 콘텐츠 작성",
|
||||
backstory="""당신은 통찰력 있고 흥미로운 기사로 유명한 콘텐츠 전략가입니다.
|
||||
복잡한 개념을 매력적인 스토리로 전환합니다.""",
|
||||
verbose=True,
|
||||
allow_delegation=True,
|
||||
)
|
||||
|
||||
# 에이전트를 위한 task 생성
|
||||
task1 = Task(
|
||||
description="""2024년 AI 분야의 최신 발전 상황에 대한 포괄적인 분석을 수행하세요.
|
||||
주요 트렌드, 획기적 기술, 산업에 미칠 잠재적 영향을 식별하세요.""",
|
||||
expected_output="주요 내용을 불릿 포인트로 정리한 전체 분석 보고서",
|
||||
agent=researcher,
|
||||
)
|
||||
|
||||
task2 = Task(
|
||||
description="""제공된 인사이트를 활용하여
|
||||
가장 중요한 AI 발전 내용을 강조하는 흥미로운 블로그 글을 작성하세요.
|
||||
글은 정보성 있고, 기술에 밝은 독자를 대상으로 하면서 읽기 쉽게 써야 합니다.
|
||||
멋지게 들리도록 쓰되, 복잡한 단어는 피하여 AI처럼 들리지 않게 하세요.""",
|
||||
expected_output="최소 4개의 단락으로 구성된 전체 블로그 글",
|
||||
agent=writer,
|
||||
)
|
||||
|
||||
# 순차 프로세스 방식으로 crew 인스턴스화
|
||||
crew = Crew(
|
||||
agents=[researcher, writer], tasks=[task1, task2], verbose=1, process=Process.sequential
|
||||
)
|
||||
|
||||
# crew에게 작업 시작 지시!
|
||||
result = crew.kickoff()
|
||||
|
||||
print("######################")
|
||||
print(result)
|
||||
```
|
||||
|
||||
### 5단계: Phoenix에서 트레이스 보기
|
||||
|
||||
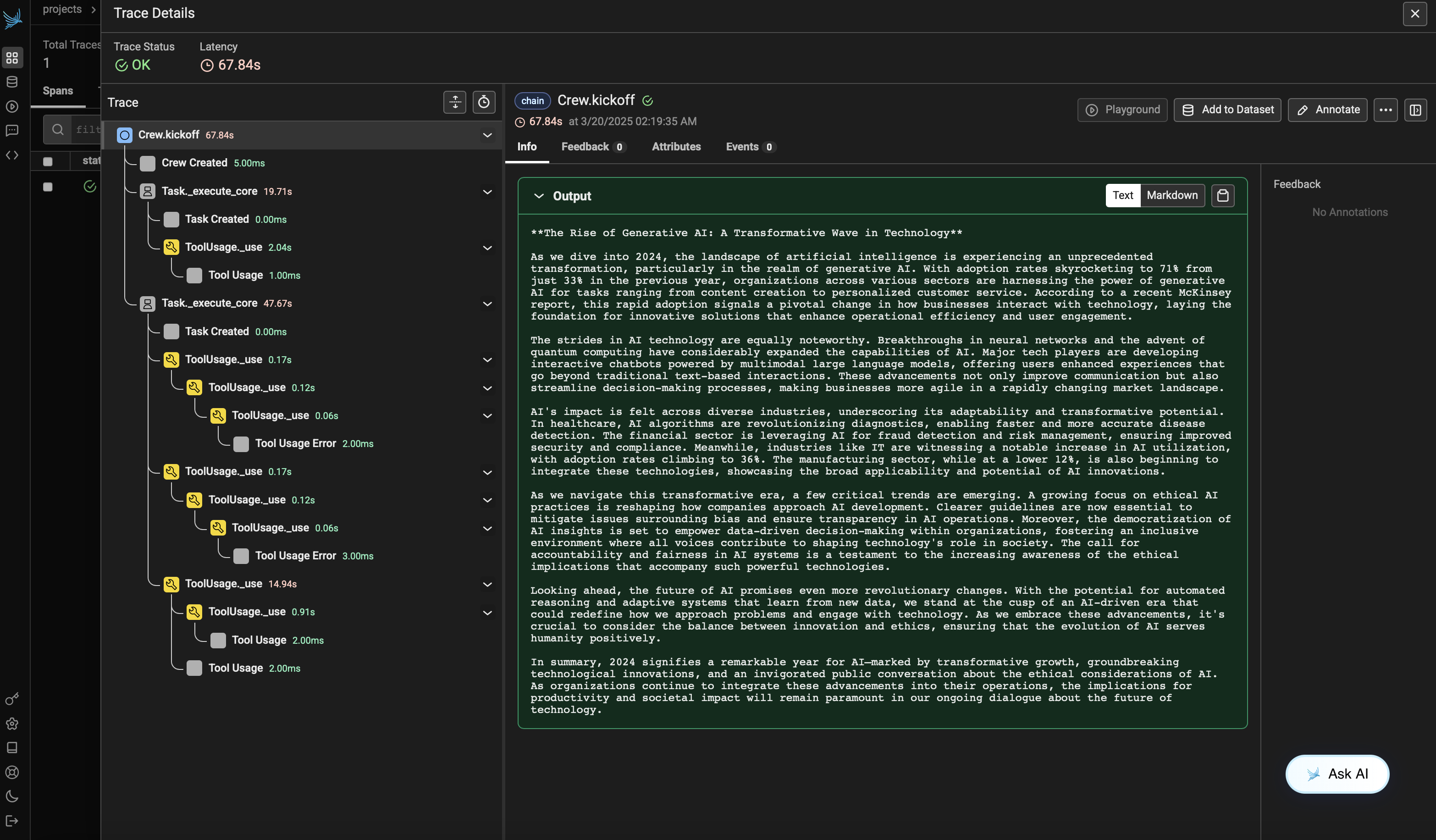
에이전트를 실행한 후, Phoenix에서 CrewAI 애플리케이션에 의해 생성된 트레이스를 볼 수 있습니다. 에이전트 상호작용과 LLM 호출의 상세한 단계가 표시되어 AI 에이전트를 디버깅하고 최적화하는 데 도움이 됩니다.
|
||||
|
||||
Phoenix Cloud 계정에 로그인한 다음 `project_name` 파라미터에서 지정한 프로젝트로 이동하세요. 모든 에이전트 상호작용, 도구 사용 및 LLM 호출이 포함된 트레이스의 타임라인 보기를 확인할 수 있습니다.
|
||||
|
||||
|
||||
|
||||
### 버전 호환성 정보
|
||||
- Python 3.8+
|
||||
- CrewAI >= 0.86.0
|
||||
- Arize Phoenix >= 7.0.1
|
||||
- OpenTelemetry SDK >= 1.31.0
|
||||
|
||||
### 참고 자료
|
||||
- [Phoenix 문서](https://docs.arize.com/phoenix/) - Phoenix 플랫폼 개요.
|
||||
- [CrewAI 문서](https://docs.crewai.com/) - CrewAI 프레임워크 개요.
|
||||
- [OpenTelemetry 문서](https://opentelemetry.io/docs/) - OpenTelemetry 가이드
|
||||
- [OpenInference GitHub](https://github.com/openinference/openinference) - OpenInference SDK 소스 코드.
|
||||
284
docs/ko/observability/langdb.mdx
Normal file
284
docs/ko/observability/langdb.mdx
Normal file
@@ -0,0 +1,284 @@
|
||||
---
|
||||
title: LangDB 통합
|
||||
description: LangDB AI Gateway로 CrewAI 워크플로우를 관리, 보안, 최적화하세요—350개 이상의 모델 액세스, 자동 라우팅, 비용 최적화, 완전한 가시성을 제공합니다.
|
||||
icon: database
|
||||
---
|
||||
|
||||
# 소개
|
||||
|
||||
[LangDB AI Gateway](https://langdb.ai)는 여러 대형 언어 모델과의 연결을 지원하는 OpenAI 호환 API를 제공하며, 350개 이상의 언어 모델에 접근할 수 있도록 해주는 관측 플랫폼입니다. 단 한 번의 `init()` 호출로 모든 에이전트 상호작용, 작업 실행 및 LLM 호출이 캡처되어, 애플리케이션을 위한 종합적인 관측성과 프로덕션 수준의 AI 인프라를 제공합니다.
|
||||
|
||||
<Frame caption="LangDB CrewAI 추적 예시">
|
||||
<img src="/images/langdb-1.png" alt="LangDB CrewAI trace example" />
|
||||
</Frame>
|
||||
|
||||
**확인:** [실시간 추적 예시 보기](https://app.langdb.ai/sharing/threads/3becbfed-a1be-ae84-ea3c-4942867a3e22)
|
||||
|
||||
## 기능
|
||||
|
||||
### AI 게이트웨이 기능
|
||||
- **350개 이상의 LLM 접근**: 단일 통합을 통해 모든 주요 언어 모델에 연결
|
||||
- **가상 모델**: 특정 매개변수와 라우팅 규칙으로 맞춤형 모델 구성 생성
|
||||
- **가상 MCP**: 에이전트 간 향상된 통신을 위해 MCP(Model Context Protocol) 시스템과의 호환성 및 통합 지원
|
||||
- **가드레일**: 에이전트 행동에 대한 안전 조치 및 컴플라이언스 제어 구현
|
||||
|
||||
### 가시성 및 추적
|
||||
- **자동 추적**: 단일 `init()` 호출로 모든 CrewAI 상호작용을 캡처
|
||||
- **엔드-투-엔드 가시성**: 에이전트 워크플로우를 시작부터 끝까지 모니터링
|
||||
- **도구 사용 추적**: 에이전트가 사용하는 도구와 그 결과를 추적
|
||||
- **모델 호출 모니터링**: LLM 상호작용에 대한 상세한 인사이트 제공
|
||||
- **성능 분석**: 지연 시간, 토큰 사용량 및 비용 모니터링
|
||||
- **디버깅 지원**: 문제 해결을 위한 단계별 실행
|
||||
- **실시간 모니터링**: 라이브 트레이스 및 메트릭 대시보드
|
||||
|
||||
## 설치 안내
|
||||
|
||||
<Steps>
|
||||
<Step title="LangDB 설치">
|
||||
CrewAI 기능 플래그와 함께 LangDB 클라이언트를 설치하세요:
|
||||
```bash
|
||||
pip install 'pylangdb[crewai]'
|
||||
```
|
||||
</Step>
|
||||
<Step title="환경 변수 설정">
|
||||
LangDB 자격 증명을 구성하세요:
|
||||
```bash
|
||||
export LANGDB_API_KEY="<your_langdb_api_key>"
|
||||
export LANGDB_PROJECT_ID="<your_langdb_project_id>"
|
||||
export LANGDB_API_BASE_URL='https://api.us-east-1.langdb.ai'
|
||||
```
|
||||
</Step>
|
||||
<Step title="추적(Tracing) 초기화">
|
||||
CrewAI 코드를 설정하기 전에 LangDB를 임포트하고 초기화하세요:
|
||||
```python
|
||||
from pylangdb.crewai import init
|
||||
# Initialize LangDB
|
||||
init()
|
||||
```
|
||||
</Step>
|
||||
<Step title="CrewAI와 LangDB 연동 설정">
|
||||
LangDB 헤더와 함께 LLM을 설정하세요:
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM
|
||||
import os
|
||||
|
||||
# Configure LLM with LangDB headers
|
||||
llm = LLM(
|
||||
model="openai/gpt-4o", # Replace with the model you want to use
|
||||
api_key=os.getenv("LANGDB_API_KEY"),
|
||||
base_url=os.getenv("LANGDB_API_BASE_URL"),
|
||||
extra_headers={"x-project-id": os.getenv("LANGDB_PROJECT_ID")}
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## 빠른 시작 예제
|
||||
|
||||
여기 LangDB와 CrewAI를 시작하는 간단한 예제가 있습니다:
|
||||
|
||||
```python
|
||||
import os
|
||||
from pylangdb.crewai import init
|
||||
from crewai import Agent, Task, Crew, LLM
|
||||
|
||||
# Initialize LangDB before any CrewAI imports
|
||||
init()
|
||||
|
||||
def create_llm(model):
|
||||
return LLM(
|
||||
model=model,
|
||||
api_key=os.environ.get("LANGDB_API_KEY"),
|
||||
base_url=os.environ.get("LANGDB_API_BASE_URL"),
|
||||
extra_headers={"x-project-id": os.environ.get("LANGDB_PROJECT_ID")}
|
||||
)
|
||||
|
||||
# Define your agent
|
||||
researcher = Agent(
|
||||
role="Research Specialist",
|
||||
goal="Research topics thoroughly",
|
||||
backstory="Expert researcher with skills in finding information",
|
||||
llm=create_llm("openai/gpt-4o"), # Replace with the model you want to use
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Create a task
|
||||
task = Task(
|
||||
description="Research the given topic and provide a comprehensive summary",
|
||||
agent=researcher,
|
||||
expected_output="Detailed research summary with key findings"
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[researcher], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
|
||||
## 완성된 예제: Research and Planning Agent
|
||||
|
||||
이 포괄적인 예제는 연구 및 기획 기능을 갖춘 multi-agent 워크플로우를 보여줍니다.
|
||||
|
||||
### 사전 준비 사항
|
||||
|
||||
```bash
|
||||
pip install crewai 'pylangdb[crewai]' crewai_tools setuptools python-dotenv
|
||||
```
|
||||
|
||||
### 환경 설정
|
||||
|
||||
```bash
|
||||
# LangDB credentials
|
||||
export LANGDB_API_KEY="<your_langdb_api_key>"
|
||||
export LANGDB_PROJECT_ID="<your_langdb_project_id>"
|
||||
export LANGDB_API_BASE_URL='https://api.us-east-1.langdb.ai'
|
||||
|
||||
# Additional API keys (optional)
|
||||
export SERPER_API_KEY="<your_serper_api_key>" # For web search capabilities
|
||||
```
|
||||
|
||||
### 전체 구현
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import os
|
||||
import sys
|
||||
from pylangdb.crewai import init
|
||||
init() # Initialize LangDB before any CrewAI imports
|
||||
from dotenv import load_dotenv
|
||||
from crewai import Agent, Task, Crew, Process, LLM
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
load_dotenv()
|
||||
|
||||
def create_llm(model):
|
||||
return LLM(
|
||||
model=model,
|
||||
api_key=os.environ.get("LANGDB_API_KEY"),
|
||||
base_url=os.environ.get("LANGDB_API_BASE_URL"),
|
||||
extra_headers={"x-project-id": os.environ.get("LANGDB_PROJECT_ID")}
|
||||
)
|
||||
|
||||
class ResearchPlanningCrew:
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
role="Research Specialist",
|
||||
goal="Research topics thoroughly and compile comprehensive information",
|
||||
backstory="Expert researcher with skills in finding and analyzing information from various sources",
|
||||
tools=[SerperDevTool()],
|
||||
llm=create_llm("openai/gpt-4o"),
|
||||
verbose=True
|
||||
)
|
||||
|
||||
def planner(self) -> Agent:
|
||||
return Agent(
|
||||
role="Strategic Planner",
|
||||
goal="Create actionable plans based on research findings",
|
||||
backstory="Strategic planner who breaks down complex challenges into executable plans",
|
||||
reasoning=True,
|
||||
max_reasoning_attempts=3,
|
||||
llm=create_llm("openai/anthropic/claude-3.7-sonnet"),
|
||||
verbose=True
|
||||
)
|
||||
|
||||
def research_task(self) -> Task:
|
||||
return Task(
|
||||
description="Research the topic thoroughly and compile comprehensive information",
|
||||
agent=self.researcher(),
|
||||
expected_output="Comprehensive research report with key findings and insights"
|
||||
)
|
||||
|
||||
def planning_task(self) -> Task:
|
||||
return Task(
|
||||
description="Create a strategic plan based on the research findings",
|
||||
agent=self.planner(),
|
||||
expected_output="Strategic execution plan with phases, goals, and actionable steps",
|
||||
context=[self.research_task()]
|
||||
)
|
||||
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[self.researcher(), self.planner()],
|
||||
tasks=[self.research_task(), self.planning_task()],
|
||||
verbose=True,
|
||||
process=Process.sequential
|
||||
)
|
||||
|
||||
def main():
|
||||
topic = sys.argv[1] if len(sys.argv) > 1 else "Artificial Intelligence in Healthcare"
|
||||
|
||||
crew_instance = ResearchPlanningCrew()
|
||||
|
||||
# Update task descriptions with the specific topic
|
||||
crew_instance.research_task().description = f"Research {topic} thoroughly and compile comprehensive information"
|
||||
crew_instance.planning_task().description = f"Create a strategic plan for {topic} based on the research findings"
|
||||
|
||||
result = crew_instance.crew().kickoff()
|
||||
print(result)
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
### 예제 실행하기
|
||||
|
||||
```bash
|
||||
python main.py "Sustainable Energy Solutions"
|
||||
```
|
||||
|
||||
## LangDB에서 트레이스 보기
|
||||
|
||||
CrewAI 애플리케이션을 실행한 후, LangDB 대시보드에서 자세한 트레이스를 확인할 수 있습니다:
|
||||
|
||||
<Frame caption="LangDB 트레이스 대시보드">
|
||||
<img src="/images/langdb-2.png" alt="LangDB 트레이스 대시보드에서 CrewAI 워크플로우 표시" />
|
||||
</Frame>
|
||||
|
||||
### 볼 수 있는 내용
|
||||
|
||||
- **에이전트 상호작용**: 에이전트 대화 및 작업 인계의 전체 흐름
|
||||
- **도구 사용**: 호출된 도구, 입력값 및 출력값
|
||||
- **모델 호출**: 프롬프트 및 응답과 함께하는 상세 LLM 상호작용
|
||||
- **성능 지표**: 지연 시간, 토큰 사용량, 비용 추적
|
||||
- **실행 타임라인**: 전체 워크플로우의 단계별 보기
|
||||
|
||||
## 문제 해결
|
||||
|
||||
### 일반적인 문제
|
||||
|
||||
- **추적이 나타나지 않음**: `init()`이 CrewAI 임포트 이전에 호출되었는지 확인하세요
|
||||
- **인증 오류**: LangDB API 키와 프로젝트 ID를 확인하세요
|
||||
|
||||
## 리소스
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="LangDB 문서" icon="book" href="https://docs.langdb.ai">
|
||||
공식 LangDB 문서 및 가이드
|
||||
</Card>
|
||||
<Card title="LangDB 가이드" icon="graduation-cap" href="https://docs.langdb.ai/guides">
|
||||
AI 에이전트 구축을 위한 단계별 튜토리얼
|
||||
</Card>
|
||||
<Card title="GitHub 예제" icon="github" href="https://github.com/langdb/langdb-samples/tree/main/examples/crewai" >
|
||||
CrewAI 통합 전체 예제
|
||||
</Card>
|
||||
<Card title="LangDB 대시보드" icon="chart-line" href="https://app.langdb.ai">
|
||||
트레이스 및 분석 액세스
|
||||
</Card>
|
||||
<Card title="모델 카탈로그" icon="list" href="https://app.langdb.ai/models">
|
||||
350개 이상의 사용 가능한 언어 모델 살펴보기
|
||||
</Card>
|
||||
<Card title="엔터프라이즈 기능" icon="building" href="https://docs.langdb.ai/enterprise">
|
||||
셀프 호스팅 옵션 및 엔터프라이즈 기능
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## 다음 단계
|
||||
|
||||
이 가이드에서는 LangDB AI Gateway를 CrewAI와 통합하는 기본 사항을 다루었습니다. AI 워크플로우를 더욱 강화하려면 다음을 탐색해보세요:
|
||||
|
||||
- **Virtual Models**: 라우팅 전략을 사용한 맞춤형 모델 구성 만들기
|
||||
- **Guardrails & Safety**: 콘텐츠 필터링 및 컴플라이언스 제어 구현
|
||||
- **Production Deployment**: 폴백, 재시도, 로드 밸런싱 구성
|
||||
|
||||
보다 고급 기능 및 사용 사례에 대해서는 [LangDB Documentation](https://docs.langdb.ai)을 방문하거나, [Model Catalog](https://app.langdb.ai/models)를 탐색하여 사용 가능한 모든 모델을 확인해 보세요.
|
||||
109
docs/ko/observability/langfuse.mdx
Normal file
109
docs/ko/observability/langfuse.mdx
Normal file
@@ -0,0 +1,109 @@
|
||||
---
|
||||
title: Langfuse 통합
|
||||
description: OpenLit을 사용하여 OpenTelemetry를 통해 CrewAI와 Langfuse를 통합하는 방법을 알아보세요
|
||||
icon: vials
|
||||
---
|
||||
|
||||
# Langfuse와 CrewAI 통합하기
|
||||
|
||||
이 노트북은 **OpenLit** SDK를 통해 OpenTelemetry를 사용하여 **Langfuse**를 **CrewAI**와 통합하는 방법을 보여줍니다. 이 노트북을 마치면 Langfuse를 사용해 CrewAI 애플리케이션을 추적하여 가시성과 디버깅을 향상시킬 수 있습니다.
|
||||
|
||||
> **Langfuse란 무엇인가요?** [Langfuse](https://langfuse.com)는 오픈 소스 LLM 엔지니어링 플랫폼입니다. 이는 LLM 애플리케이션을 위한 추적 및 모니터링 기능을 제공하며, 개발자들이 AI 시스템을 디버그, 분석 및 최적화하는 데 도움을 줍니다. Langfuse는 네이티브 통합, OpenTelemetry, API/SDK를 통해 다양한 도구 및 프레임워크와 연동됩니다.
|
||||
|
||||
[](https://langfuse.com/watch-demo)
|
||||
|
||||
## 시작하기
|
||||
|
||||
CrewAI를 사용하고 OpenLit을 통해 OpenTelemetry로 Langfuse와 통합하는 간단한 예제를 함께 살펴보겠습니다.
|
||||
|
||||
### 1단계: 의존성 설치
|
||||
|
||||
```python
|
||||
%pip install langfuse openlit crewai crewai_tools
|
||||
```
|
||||
|
||||
### 2단계: 환경 변수 설정
|
||||
|
||||
Langfuse API 키를 설정하고 OpenTelemetry 내보내기 설정을 구성하여 trace를 Langfuse로 전송합니다. Langfuse OpenTelemetry 엔드포인트 `/api/public/otel` 및 인증과 관련된 자세한 내용은 [Langfuse OpenTelemetry 문서](https://langfuse.com/docs/opentelemetry/get-started)를 참고하십시오.
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
|
||||
# 프로젝트에 대한 키를 프로젝트 설정 페이지에서 확인하세요: https://cloud.langfuse.com
|
||||
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
|
||||
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
|
||||
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 EU 지역
|
||||
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 US 지역
|
||||
|
||||
|
||||
# OpenAI 키
|
||||
os.environ["OPENAI_API_KEY"] = "sk-proj-..."
|
||||
```
|
||||
환경 변수를 설정하면 이제 Langfuse 클라이언트를 초기화할 수 있습니다. get_client()는 환경 변수에 제공된 자격 증명을 사용하여 Langfuse 클라이언트를 초기화합니다.
|
||||
|
||||
```python
|
||||
from langfuse import get_client
|
||||
|
||||
langfuse = get_client()
|
||||
|
||||
# 연결 확인
|
||||
if langfuse.auth_check():
|
||||
print("Langfuse 클라이언트가 인증되었으며 준비되었습니다!")
|
||||
else:
|
||||
print("인증에 실패했습니다. 자격 증명과 호스트를 확인하세요.")
|
||||
```
|
||||
|
||||
### 3단계: OpenLit 초기화
|
||||
|
||||
OpenLit OpenTelemetry 계측 SDK를 초기화하여 OpenTelemetry 추적을 수집하기 시작합니다.
|
||||
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
### 4단계: 간단한 CrewAI 애플리케이션 만들기
|
||||
|
||||
여러 에이전트가 협력하여 사용자의 질문에 답하는 간단한 CrewAI 애플리케이션을 만들어보겠습니다.
|
||||
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
from crewai_tools import (
|
||||
WebsiteSearchTool
|
||||
)
|
||||
|
||||
web_rag_tool = WebsiteSearchTool()
|
||||
|
||||
writer = Agent(
|
||||
role="Writer",
|
||||
goal="You make math engaging and understandable for young children through poetry",
|
||||
backstory="You're an expert in writing haikus but you know nothing of math.",
|
||||
tools=[web_rag_tool],
|
||||
)
|
||||
|
||||
task = Task(description=("What is {multiplication}?"),
|
||||
expected_output=("Compose a haiku that includes the answer."),
|
||||
agent=writer)
|
||||
|
||||
crew = Crew(
|
||||
agents=[writer],
|
||||
tasks=[task],
|
||||
share_crew=False
|
||||
)
|
||||
```
|
||||
|
||||
### 5단계: Langfuse에서 트레이스 확인하기
|
||||
|
||||
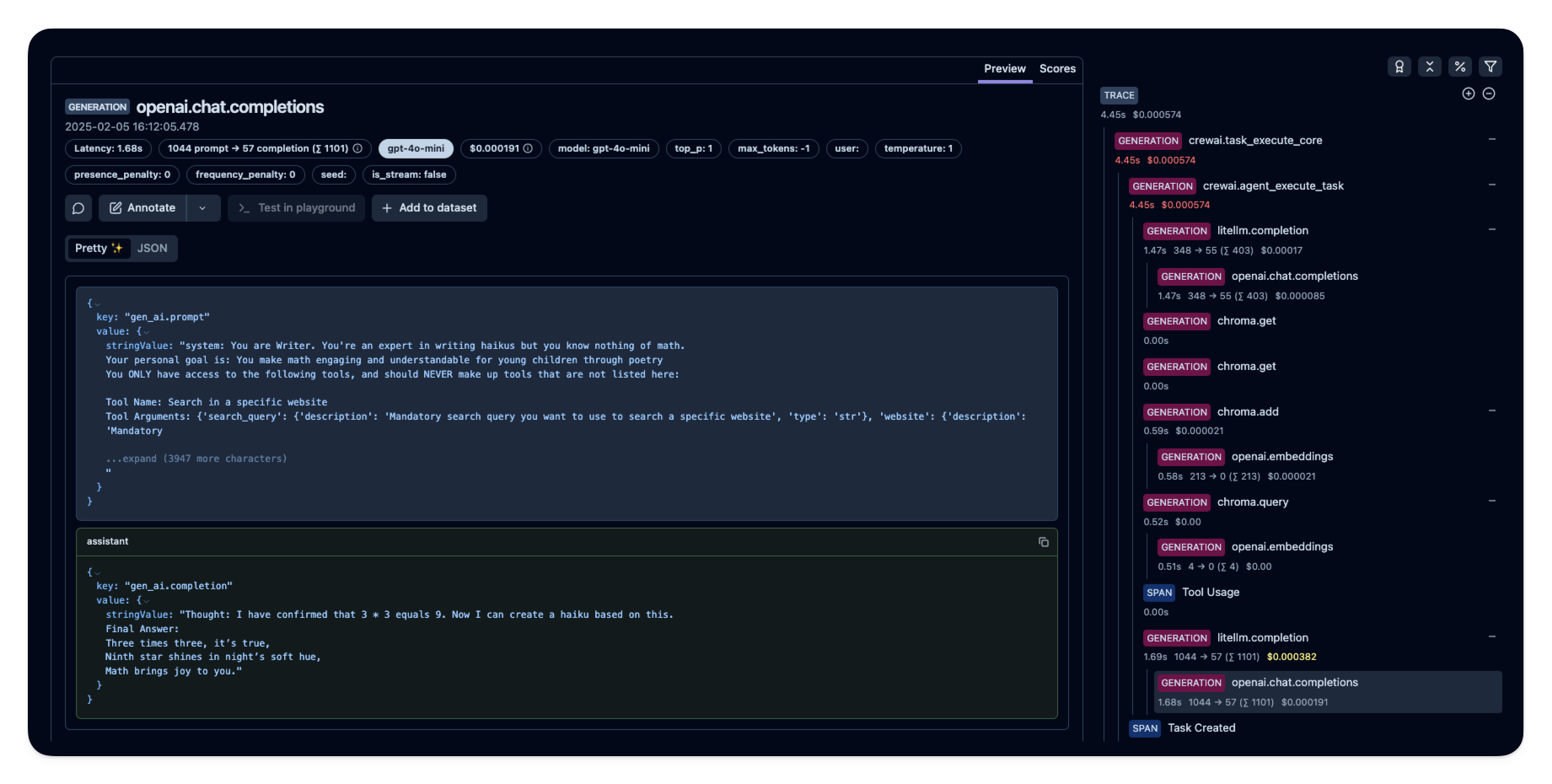
에이전트를 실행한 후 [Langfuse](https://cloud.langfuse.com)에서 CrewAI 애플리케이션에서 생성된 트레이스를 확인할 수 있습니다. 여기서 LLM 상호작용의 자세한 단계들을 볼 수 있으며, 이를 통해 AI 에이전트의 디버깅 및 최적화에 도움이 됩니다.
|
||||
|
||||
|
||||
|
||||
_[Langfuse의 공개 예시 트레이스](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/e2cf380ffc8d47d28da98f136140642b?timestamp=2025-02-05T15%3A12%3A02.717Z&observation=3b32338ee6a5d9af)_
|
||||
|
||||
## 참고 자료
|
||||
|
||||
- [Langfuse OpenTelemetry 문서](https://langfuse.com/docs/opentelemetry/get-started)
|
||||
72
docs/ko/observability/langtrace.mdx
Normal file
72
docs/ko/observability/langtrace.mdx
Normal file
@@ -0,0 +1,72 @@
|
||||
---
|
||||
title: Langtrace 연동
|
||||
description: 외부 가시성 도구인 Langtrace를 사용하여 CrewAI 에이전트의 비용, 지연 시간 및 성능을 모니터링하는 방법.
|
||||
icon: chart-line
|
||||
---
|
||||
|
||||
# Langtrace 개요
|
||||
|
||||
Langtrace는 대형 언어 모델(LLM), LLM 프레임워크, 벡터 데이터베이스에 대한 관측 가능성과 평가를 설정할 수 있도록 도와주는 오픈소스 외부 도구입니다.
|
||||
Langtrace는 CrewAI에 직접 내장되어 있지는 않지만, CrewAI와 함께 사용하여 CrewAI 에이전트의 비용, 지연 시간, 성능에 대해 깊이 있는 가시성을 확보할 수 있습니다.
|
||||
이 통합을 통해 하이퍼파라미터를 기록하고, 성능 회귀를 모니터링하며, 에이전트의 지속적인 개선을 위한 프로세스를 수립할 수 있습니다.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
## 설정 지침
|
||||
|
||||
<Steps>
|
||||
<Step title="Langtrace에 가입하기">
|
||||
[https://langtrace.ai/signup](https://langtrace.ai/signup)에서 가입하세요.
|
||||
</Step>
|
||||
<Step title="프로젝트 생성">
|
||||
프로젝트 유형을 `CrewAI`로 설정하고 API 키를 생성하세요.
|
||||
</Step>
|
||||
<Step title="CrewAI 프로젝트에 Langtrace 설치하기">
|
||||
다음 명령어를 사용하세요:
|
||||
|
||||
```bash
|
||||
pip install langtrace-python-sdk
|
||||
```
|
||||
</Step>
|
||||
<Step title="Langtrace 임포트하기">
|
||||
스크립트의 시작 부분, CrewAI를 임포트하기 전에 Langtrace를 임포트하고 초기화하세요:
|
||||
|
||||
```python
|
||||
from langtrace_python_sdk import langtrace
|
||||
langtrace.init(api_key='<LANGTRACE_API_KEY>')
|
||||
|
||||
# 이제 CrewAI 모듈을 임포트하세요
|
||||
from crewai import Agent, Task, Crew
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### 기능 및 CrewAI에의 적용
|
||||
|
||||
1. **LLM 토큰 및 비용 추적**
|
||||
|
||||
- 각 CrewAI 에이전트 상호작용에 대한 토큰 사용량과 관련 비용을 모니터링합니다.
|
||||
|
||||
2. **실행 단계에 대한 추적 그래프**
|
||||
|
||||
- CrewAI 작업의 실행 흐름을 시각화하며, 지연 시간과 로그를 포함합니다.
|
||||
- 에이전트 워크플로우의 병목 지점을 파악하는 데 유용합니다.
|
||||
|
||||
3. **수동 주석을 통한 데이터셋 큐레이션**
|
||||
|
||||
- 미래의 학습 또는 평가를 위해 CrewAI 작업 출력으로부터 데이터셋을 생성합니다.
|
||||
|
||||
4. **프롬프트 버전 관리 및 관리**
|
||||
|
||||
- CrewAI 에이전트에서 사용된 다양한 프롬프트 버전을 추적합니다.
|
||||
- A/B 테스트 및 에이전트 성능 최적화에 유용합니다.
|
||||
|
||||
5. **프롬프트 플레이그라운드 및 모델 비교**
|
||||
|
||||
- 배포 전에 CrewAI 에이전트에 사용할 다양한 프롬프트와 모델을 테스트 및 비교합니다.
|
||||
|
||||
6. **테스트 및 평가**
|
||||
|
||||
- CrewAI 에이전트 및 작업에 대한 자동화된 테스트를 설정합니다.
|
||||
226
docs/ko/observability/maxim.mdx
Normal file
226
docs/ko/observability/maxim.mdx
Normal file
@@ -0,0 +1,226 @@
|
||||
---
|
||||
title: "Maxim Integration"
|
||||
description: "에이전트 모니터링, 평가 및 가시성 시작"
|
||||
icon: "infinity"
|
||||
---
|
||||
|
||||
# Maxim 개요
|
||||
|
||||
Maxim AI는 귀하의 CrewAI 애플리케이션을 위한 포괄적인 에이전트 모니터링, 평가 및 가시성을 제공합니다. Maxim의 원라인 통합을 통해 에이전트 상호작용, 성능 지표 등을 손쉽게 추적하고 분석할 수 있습니다.
|
||||
|
||||
## 특징
|
||||
|
||||
### 프롬프트 관리
|
||||
|
||||
Maxim의 프롬프트 관리 기능을 통해 CrewAI 에이전트를 위한 프롬프트를 생성, 조직, 최적화할 수 있습니다. 지침을 하드코딩하는 대신, Maxim의 SDK를 활용하여 버전 관리가 되는 프롬프트를 동적으로 가져오고 적용하세요.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="프롬프트 플레이그라운드">
|
||||
플레이그라운드를 통해 프롬프트를 생성, 정제, 실험 및 배포할 수 있습니다. 폴더와 버전을 활용하여 프롬프트를 정리하고, 도구 및 컨텍스트를 연결하여 실제 사례로 실험해 보며, 맞춤형 로직을 기반으로 배포할 수 있습니다.
|
||||
|
||||
[**모델 구성**](https://www.getmaxim.ai/docs/introduction/quickstart/setting-up-workspace#add-model-api-keys)을 통해 여러 모델을 손쉽게 실험하고, 프롬프트 플레이그라운드 상단 드롭다운에서 원하는 모델을 선택하세요.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_playground.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="프롬프트 버전">
|
||||
팀이 AI 애플리케이션을 개발할 때, 실험의 중요한 부분은 프롬프트 구조를 반복적으로 개선하는 것입니다. 효과적으로 협업하고 변경 사항을 명확히 정리할 수 있도록 Maxim은 프롬프트 버전 관리와 버전 간 비교 실행을 지원합니다.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_versions.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="프롬프트 비교">
|
||||
AI 애플리케이션을 발전시켜 나가면서 프롬프트를 반복 개선하기 위해서는 모델, 프롬프트 구조 등 다양한 요소로 실험이 필요합니다. 버전 간 비교 및 변화에 대한 정보에 기반한 결정을 위해, 비교 플레이그라운드는 결과를 나란히 볼 수 있게 해줍니다.
|
||||
|
||||
## **프롬프트 비교를 왜 사용해야 하나요?**
|
||||
|
||||
프롬프트 비교는 여러 개의 단일 프롬프트를 하나의 뷰에서 볼 수 있도록 하여 다양한 워크플로에 streamlined 접근을 제공합니다:
|
||||
|
||||
1. **모델 비교**: 동일한 프롬프트에서 서로 다른 모델의 성능을 평가합니다.
|
||||
2. **프롬프트 최적화**: 여러 버전의 프롬프트를 비교하여 가장 효과적인 구성을 식별합니다.
|
||||
3. **교차 모델 일관성**: 동일한 프롬프트에 대해 여러 모델에서 일관된 출력을 보장합니다.
|
||||
4. **성능 벤치마킹**: 다양한 모델과 프롬프트에 대해 지연 시간, 비용, 토큰 수 등의 지표를 분석합니다.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 관찰 가능성 & 평가
|
||||
|
||||
Maxim AI는 CrewAI 에이전트에 대한 포괄적인 관찰 가능성과 평가 기능을 제공하여, 각 실행 과정에서 무슨 일이 일어나고 있는지 정확히 파악할 수 있도록 지원합니다.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Agent Tracing">
|
||||
에이전트의 전체 라이프사이클(도구 호출, 에이전트 궤적, 결정 플로우 등)을 손쉽게 추적할 수 있습니다.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_agent_tracking.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="Analytics + Evals">
|
||||
전체 트레이스 또는 개별 노드에 대해 상세 평가를 실행할 수 있으며, 다음 기능을 지원합니다:
|
||||
|
||||
- 다중 단계 상호작용 및 세분화된 트레이스 분석
|
||||
- 세션 수준 평가
|
||||
- 실제 환경 시뮬레이션 테스트
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_trace_eval.png'> </img>
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="로그 자동 평가" icon="e" href="https://www.getmaxim.ai/docs/observe/how-to/evaluate-logs/auto-evaluation">
|
||||
<p>
|
||||
필터 및 샘플링을 기준으로 UI에서 캡처된 로그를 자동으로 평가할 수 있습니다.
|
||||
</p>
|
||||
</Card>
|
||||
<Card title="로그 수동 평가" icon="hand" href="https://www.getmaxim.ai/docs/observe/how-to/evaluate-logs/human-evaluation">
|
||||
<p>
|
||||
로그의 품질을 평가하고, 사람의 평가 또는 등급을 이용해 로그를 검토할 수 있습니다.
|
||||
</p>
|
||||
</Card>
|
||||
<Card title="노드 수준 평가" icon="road" href="https://www.getmaxim.ai/docs/observe/how-to/evaluate-logs/node-level-evaluation">
|
||||
<p>
|
||||
트레이스 또는 로그의 모든 컴포넌트를 평가하여 에이전트의 행동에 대한 통찰을 얻을 수 있습니다.
|
||||
</p>
|
||||
</Card>
|
||||
</CardGroup>
|
||||
---
|
||||
</Tab>
|
||||
<Tab title="Alerting">
|
||||
**오류**, **비용, 토큰 사용량, 사용자 피드백, 지연 시간**에 임계값을 설정하고, Slack 또는 PagerDuty를 통해 실시간 알림을 받아보세요.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_alerts_1.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="Dashboards">
|
||||
시간 경과에 따른 트레이스, 사용량 측정지표, 지연 시간 및 오류율을 손쉽게 시각화할 수 있습니다.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_dashboard_1.png'> </img>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 시작하기
|
||||
|
||||
### 사전 준비 사항
|
||||
|
||||
- Python 버전 \>=3.10
|
||||
- Maxim 계정 ([여기에서 가입](https://getmaxim.ai/))
|
||||
- Maxim API 키 생성
|
||||
- CrewAI 프로젝트
|
||||
|
||||
### 설치
|
||||
|
||||
Maxim SDK를 pip을 통해 설치하세요:
|
||||
|
||||
```python
|
||||
pip install maxim-py
|
||||
```
|
||||
|
||||
또는 `requirements.txt`에 추가하세요:
|
||||
|
||||
```
|
||||
maxim-py
|
||||
```
|
||||
|
||||
### 기본 설정
|
||||
|
||||
### 1. 환경 변수 설정
|
||||
|
||||
```python
|
||||
### Environment Variables Setup
|
||||
|
||||
# Create a `.env` file in your project root:
|
||||
|
||||
# Maxim API Configuration
|
||||
MAXIM_API_KEY=your_api_key_here
|
||||
MAXIM_LOG_REPO_ID=your_repo_id_here
|
||||
```
|
||||
|
||||
### 2. 필수 패키지 임포트하기
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
from maxim import Maxim
|
||||
from maxim.logger.crewai import instrument_crewai
|
||||
```
|
||||
|
||||
### 3. API 키로 Maxim 초기화하기
|
||||
|
||||
```python {8}
|
||||
# Instrument CrewAI with just one line
|
||||
instrument_crewai(Maxim().logger())
|
||||
```
|
||||
|
||||
### 4. 일반적으로 CrewAI 애플리케이션 생성 및 실행하기
|
||||
|
||||
```python
|
||||
# Create your agent
|
||||
researcher = Agent(
|
||||
role='Senior Research Analyst',
|
||||
goal='Uncover cutting-edge developments in AI',
|
||||
backstory="You are an expert researcher at a tech think tank...",
|
||||
verbose=True,
|
||||
llm=llm
|
||||
)
|
||||
|
||||
# Define the task
|
||||
research_task = Task(
|
||||
description="Research the latest AI advancements...",
|
||||
expected_output="",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
# Configure and run the crew
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[research_task],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
try:
|
||||
result = crew.kickoff()
|
||||
finally:
|
||||
maxim.cleanup() # Ensure cleanup happens even if errors occur
|
||||
```
|
||||
|
||||
이제 끝입니다! 모든 CrewAI 에이전트 상호작용이 Maxim 대시보드에 기록되고 확인할 수 있습니다.
|
||||
|
||||
간단한 참고를 위해 이 Google Colab Notebook을 확인하세요 - [Notebook](https://colab.research.google.com/drive/1ZKIZWsmgQQ46n8TH9zLsT1negKkJA6K8?usp=sharing)
|
||||
|
||||
## 트레이스 보기
|
||||
|
||||
CrewAI 애플리케이션을 실행한 후:
|
||||
|
||||
1. [Maxim 대시보드](https://app.getmaxim.ai/login)에 로그인하세요.
|
||||
2. 리포지토리로 이동하세요.
|
||||
3. 다음을 포함한 에이전트 트레이스를 상세하게 확인할 수 있습니다:
|
||||
- 에이전트 대화 내역
|
||||
- 도구 사용 패턴
|
||||
- 성능 지표
|
||||
- 비용 분석
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/crewai_traces.gif'> </img>
|
||||
|
||||
## 문제 해결
|
||||
|
||||
### 흔한 문제
|
||||
|
||||
- **추적(trace)가 나타나지 않음**: API 키와 저장소 ID가 올바른지 확인하세요.
|
||||
- crew를 실행하기 **_전에_** 반드시 **`instrument_crewai()`를 호출**했는지 확인하세요. 이 함수가 로깅 훅(logging hook)을 올바르게 초기화합니다.
|
||||
- 내부 오류를 드러내기 위해 `instrument_crewai()` 호출 시 `debug=True`로 설정하세요:
|
||||
|
||||
```python
|
||||
instrument_crewai(logger, debug=True)
|
||||
```
|
||||
- 에이전트에서 상세 로그를 캡처하기 위해 `verbose=True`로 설정하세요:
|
||||
|
||||
```python
|
||||
agent = CrewAgent(..., verbose=True)
|
||||
```
|
||||
- `instrument_crewai()`가 에이전트를 생성하거나 실행하기 **전에** 호출되는지 다시 한 번 확인하세요. 너무 당연해 보일 수 있지만, 자주 발생하는 실수입니다.
|
||||
|
||||
## 리소스
|
||||
|
||||
<CardGroup cols="3">
|
||||
<Card title="CrewAI Docs" icon="book" href="https://docs.crewai.com/">
|
||||
공식 CrewAI 문서
|
||||
</Card>
|
||||
<Card title="Maxim Docs" icon="book" href="https://getmaxim.ai/docs">
|
||||
공식 Maxim 문서
|
||||
</Card>
|
||||
<Card title="Maxim Github" icon="github" href="https://github.com/maximhq">
|
||||
Maxim Github
|
||||
</Card>
|
||||
</CardGroup>
|
||||
205
docs/ko/observability/mlflow.mdx
Normal file
205
docs/ko/observability/mlflow.mdx
Normal file
@@ -0,0 +1,205 @@
|
||||
---
|
||||
title: MLflow 통합
|
||||
description: MLflow를 사용하여 에이전트 모니터링을 빠르게 시작하세요.
|
||||
icon: bars-staggered
|
||||
---
|
||||
|
||||
# MLflow 개요
|
||||
|
||||
[MLflow](https://mlflow.org/)는 머신러닝 실무자와 팀이 머신러닝 프로세스의 복잡성을 관리할 수 있도록 돕는 오픈소스 플랫폼입니다.
|
||||
|
||||
MLflow는 귀하의 생성형 AI 애플리케이션에서 서비스 실행에 대한 상세 정보를 캡처하여 LLM 가시성을 향상시키는 트레이싱 기능을 제공합니다.
|
||||
트레이싱은 요청의 각 중간 단계에 관련된 입력값, 출력값, 메타데이터를 기록하는 방법을 제공하여, 버그 및 예기치 않은 동작의 원인을 쉽게 찾아낼 수 있게 합니다.
|
||||
|
||||

|
||||
|
||||
### 기능
|
||||
|
||||
- **트레이싱 대시보드**: crewAI 에이전트의 활동을 입력값, 출력값, 스팬의 메타데이터와 함께 자세한 대시보드로 모니터링할 수 있습니다.
|
||||
- **자동 트레이싱**: 완전 자동화된 crewAI 통합 기능으로, `mlflow.crewai.autolog()`를 실행하여 활성화할 수 있습니다.
|
||||
- **약간의 노력만으로 수동 추적 계측**: 데코레이터, 함수 래퍼, 컨텍스트 매니저 등 MLflow의 고수준 fluent API를 통해 추적 계측을 커스터마이즈할 수 있습니다.
|
||||
- **OpenTelemetry 호환성**: MLflow Tracing은 OpenTelemetry Collector로 트레이스를 내보내는 것을 지원하며, 이를 통해 Jaeger, Zipkin, AWS X-Ray 등 다양한 백엔드로 트레이스를 내보낼 수 있습니다.
|
||||
- **에이전트 패키징 및 배포**: crewAI 에이전트를 다양한 배포 대상으로 추론 서버에 패키징 및 배포할 수 있습니다.
|
||||
- **LLM을 안전하게 호스팅**: 여러 공급자의 LLM을 MFflow 게이트웨이를 통해 하나의 통합 엔드포인트에서 호스팅할 수 있습니다.
|
||||
- **평가**: 편리한 API `mlflow.evaluate()`를 사용하여 다양한 지표로 crewAI 에이전트를 평가할 수 있습니다.
|
||||
|
||||
## 설치 안내
|
||||
|
||||
<Steps>
|
||||
<Step title="MLflow 패키지 설치">
|
||||
```shell
|
||||
# crewAI 연동은 mlflow>=2.19.0 에서 사용할 수 있습니다.
|
||||
pip install mlflow
|
||||
```
|
||||
</Step>
|
||||
<Step title="MLflow 추적 서버 시작">
|
||||
```shell
|
||||
# 이 과정은 선택 사항이지만, MLflow 추적 서버를 사용하면 더 나은 시각화와 더 많은 기능을 사용할 수 있습니다.
|
||||
mlflow server
|
||||
```
|
||||
</Step>
|
||||
<Step title="애플리케이션에서 MLflow 초기화">
|
||||
다음 두 줄을 애플리케이션 코드에 추가하세요:
|
||||
|
||||
```python
|
||||
import mlflow
|
||||
|
||||
mlflow.crewai.autolog()
|
||||
|
||||
# 선택 사항: 추적 서버를 사용하는 경우 tracking URI와 experiment 이름을 설정할 수 있습니다.
|
||||
mlflow.set_tracking_uri("http://localhost:5000")
|
||||
mlflow.set_experiment("CrewAI")
|
||||
```
|
||||
|
||||
CrewAI Agents 추적 예시 사용법:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task
|
||||
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
|
||||
from crewai_tools import SerperDevTool, WebsiteSearchTool
|
||||
|
||||
from textwrap import dedent
|
||||
|
||||
content = "Users name is John. He is 30 years old and lives in San Francisco."
|
||||
string_source = StringKnowledgeSource(
|
||||
content=content, metadata={"preference": "personal"}
|
||||
)
|
||||
|
||||
search_tool = WebsiteSearchTool()
|
||||
|
||||
|
||||
class TripAgents:
|
||||
def city_selection_agent(self):
|
||||
return Agent(
|
||||
role="City Selection Expert",
|
||||
goal="Select the best city based on weather, season, and prices",
|
||||
backstory="An expert in analyzing travel data to pick ideal destinations",
|
||||
tools=[
|
||||
search_tool,
|
||||
],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def local_expert(self):
|
||||
return Agent(
|
||||
role="Local Expert at this city",
|
||||
goal="Provide the BEST insights about the selected city",
|
||||
backstory="""A knowledgeable local guide with extensive information
|
||||
about the city, it's attractions and customs""",
|
||||
tools=[search_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
|
||||
class TripTasks:
|
||||
def identify_task(self, agent, origin, cities, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
Analyze and select the best city for the trip based
|
||||
on specific criteria such as weather patterns, seasonal
|
||||
events, and travel costs. This task involves comparing
|
||||
multiple cities, considering factors like current weather
|
||||
conditions, upcoming cultural or seasonal events, and
|
||||
overall travel expenses.
|
||||
Your final answer must be a detailed
|
||||
report on the chosen city, and everything you found out
|
||||
about it, including the actual flight costs, weather
|
||||
forecast and attractions.
|
||||
|
||||
Traveling from: {origin}
|
||||
City Options: {cities}
|
||||
Trip Date: {range}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Detailed report on the chosen city including flight costs, weather forecast, and attractions",
|
||||
)
|
||||
|
||||
def gather_task(self, agent, origin, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
As a local expert on this city you must compile an
|
||||
in-depth guide for someone traveling there and wanting
|
||||
to have THE BEST trip ever!
|
||||
Gather information about key attractions, local customs,
|
||||
special events, and daily activity recommendations.
|
||||
Find the best spots to go to, the kind of place only a
|
||||
local would know.
|
||||
This guide should provide a thorough overview of what
|
||||
the city has to offer, including hidden gems, cultural
|
||||
hotspots, must-visit landmarks, weather forecasts, and
|
||||
high level costs.
|
||||
The final answer must be a comprehensive city guide,
|
||||
rich in cultural insights and practical tips,
|
||||
tailored to enhance the travel experience.
|
||||
|
||||
Trip Date: {range}
|
||||
Traveling from: {origin}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Comprehensive city guide including hidden gems, cultural hotspots, and practical travel tips",
|
||||
)
|
||||
|
||||
|
||||
class TripCrew:
|
||||
def __init__(self, origin, cities, date_range, interests):
|
||||
self.cities = cities
|
||||
self.origin = origin
|
||||
self.interests = interests
|
||||
self.date_range = date_range
|
||||
|
||||
def run(self):
|
||||
agents = TripAgents()
|
||||
tasks = TripTasks()
|
||||
|
||||
city_selector_agent = agents.city_selection_agent()
|
||||
local_expert_agent = agents.local_expert()
|
||||
|
||||
identify_task = tasks.identify_task(
|
||||
city_selector_agent,
|
||||
self.origin,
|
||||
self.cities,
|
||||
self.interests,
|
||||
self.date_range,
|
||||
)
|
||||
gather_task = tasks.gather_task(
|
||||
local_expert_agent, self.origin, self.interests, self.date_range
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[city_selector_agent, local_expert_agent],
|
||||
tasks=[identify_task, gather_task],
|
||||
verbose=True,
|
||||
memory=True,
|
||||
knowledge={
|
||||
"sources": [string_source],
|
||||
"metadata": {"preference": "personal"},
|
||||
},
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
return result
|
||||
|
||||
|
||||
trip_crew = TripCrew("California", "Tokyo", "Dec 12 - Dec 20", "sports")
|
||||
result = trip_crew.run()
|
||||
|
||||
print(result)
|
||||
```
|
||||
더 많은 설정 및 사용 예시는 [MLflow Tracing 문서](https://mlflow.org/docs/latest/llms/tracing/index.html)를 참고하세요.
|
||||
</Step>
|
||||
<Step title="에이전트 활동 시각화">
|
||||
이제 crewAI agents의 추적 정보가 MLflow에서 캡처됩니다.
|
||||
MLflow 추적 서버에 접속하여 추적 내역을 확인하고 에이전트의 인사이트를 얻으세요.
|
||||
|
||||
브라우저에서 `127.0.0.1:5000`을 열어 MLflow 추적 서버에 접속하세요.
|
||||
<Frame caption="MLflow 추적 대시보드">
|
||||
<img src="/images/mlflow1.png" alt="MLflow tracing example with crewai" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
129
docs/ko/observability/neatlogs.mdx
Normal file
129
docs/ko/observability/neatlogs.mdx
Normal file
@@ -0,0 +1,129 @@
|
||||
---
|
||||
title: Neatlogs 통합
|
||||
description: CrewAI agent 실행을 이해하고, 디버그하며, 공유하기
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# 소개
|
||||
|
||||
Neatlogs는 **에이전트가 무엇을 했는지**, **이유는 무엇인지**, 그리고 **공유하는 방법**을 확인할 수 있도록 도와줍니다.
|
||||
|
||||
모든 단계를 캡처합니다: 생각, 도구 호출, 응답, 평가 등. 원시 로그는 없습니다. 명확하고 구조화된 추적만 제공합니다. 디버깅과 협업에 탁월합니다.
|
||||
|
||||
## 왜 Neatlogs를 사용해야 하나요?
|
||||
|
||||
CrewAI 에이전트는 여러 도구와 추론 단계를 사용합니다. 문제가 발생했을 때, 단순한 오류만으로는 충분하지 않습니다 — 맥락이 필요합니다.
|
||||
|
||||
Neatlogs를 사용하면 다음과 같은 이점이 있습니다:
|
||||
|
||||
- 전체 의사 결정 경로를 따라갈 수 있습니다
|
||||
- 단계마다 직접 피드백을 남길 수 있습니다
|
||||
- AI 어시스턴트와 함께 트레이스에 대해 채팅할 수 있습니다
|
||||
- 실행 결과를 공개적으로 공유해 피드백을 받을 수 있습니다
|
||||
- 인사이트를 업무로 전환할 수 있습니다
|
||||
|
||||
모두 한 곳에서 가능합니다.
|
||||
|
||||
트레이스를 손쉽게 관리하세요
|
||||
|
||||

|
||||

|
||||
|
||||
CrewAI 트레이스를 보기 위한 최고의 UX. 원하는 곳 어디든 댓글을 남기세요. AI를 활용해 디버깅할 수 있습니다.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
## 핵심 기능
|
||||
|
||||
- **Trace Viewer**: 사고, 도구, 결정을 순서대로 추적
|
||||
- **인라인 댓글**: 모든 trace 단계에서 팀원을 태그
|
||||
- **피드백 및 평가**: 출력물을 올바름 또는 틀림으로 표시
|
||||
- **오류 하이라이팅**: API/도구 실패 자동 감지
|
||||
- **작업 전환**: 댓글을 할당된 작업으로 변환
|
||||
- **Ask the Trace (AI)**: Neatlogs AI 봇과 trace에서 채팅
|
||||
- **공개 공유**: trace 링크를 커뮤니티에 게시
|
||||
|
||||
## CrewAI로 빠른 설정하기
|
||||
|
||||
<Steps>
|
||||
<Step title="회원가입 및 API 키 발급">
|
||||
[neatlogs.com](https://neatlogs.com/?utm_source=crewAI-docs)에 방문하여 프로젝트를 생성하고, API 키를 복사하세요.
|
||||
</Step>
|
||||
<Step title="SDK 설치">
|
||||
```bash
|
||||
pip install neatlogs
|
||||
```
|
||||
(최신 버전 0.8.0, Python 3.8+; MIT 라이선스)
|
||||
</Step>
|
||||
<Step title="Neatlogs 초기화">
|
||||
Crew 에이전트를 시작하기 전에 다음을 추가하세요:
|
||||
|
||||
```python
|
||||
import neatlogs
|
||||
neatlogs.init("YOUR_PROJECT_API_KEY")
|
||||
```
|
||||
|
||||
에이전트는 평소와 같이 실행됩니다. Neatlogs가 모든 것을 자동으로 캡처합니다.
|
||||
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## 내부 구조
|
||||
|
||||
GitHub에 따르면, Neatlogs는:
|
||||
|
||||
- 생각, 도구 호출, 응답, 오류, 그리고 토큰 통계를 캡처합니다
|
||||
- AI 기반 작업 생성과 견고한 평가 워크플로우를 지원합니다
|
||||
|
||||
이 모든 것이 단 두 줄의 코드로 가능합니다.
|
||||
|
||||
## 작동하는 모습을 살펴보기
|
||||
|
||||
### 🔍 전체 데모 (4 분)
|
||||
|
||||
<iframe
|
||||
width="100%"
|
||||
height="315"
|
||||
src="https://www.youtube.com/embed/8KDme9T2I7Q?si=b8oHteaBwFNs_Duk"
|
||||
title="YouTube video player"
|
||||
frameBorder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowFullScreen
|
||||
></iframe>
|
||||
|
||||
### ⚙️ CrewAI 통합 (30초)
|
||||
|
||||
<iframe
|
||||
className="w-full aspect-video rounded-xl"
|
||||
src="https://www.loom.com/embed/9c78b552af43452bb3e4783cb8d91230?sid=e9d7d370-a91a-49b0-809e-2f375d9e801d"
|
||||
title="Loom video player"
|
||||
frameBorder="0"
|
||||
allowFullScreen
|
||||
></iframe>
|
||||
|
||||
## 링크 & 지원
|
||||
|
||||
- 📘 [Neatlogs 문서](https://docs.neatlogs.com/)
|
||||
- 🔐 [대시보드 & API 키](https://app.neatlogs.com/)
|
||||
- 🐦 [트위터 팔로우](https://twitter.com/neatlogs)
|
||||
- 📧 문의: hello@neatlogs.com
|
||||
- 🛠 [GitHub SDK](https://github.com/NeatLogs/neatlogs)
|
||||
|
||||
## TL;DR
|
||||
|
||||
아래와 같이:
|
||||
|
||||
```bash
|
||||
pip install neatlogs
|
||||
|
||||
import neatlogs
|
||||
neatlogs.init("YOUR_API_KEY")
|
||||
|
||||
You can now capture, understand, share, and act on your CrewAI agent runs in seconds.
|
||||
No setup overhead. Full trace transparency. Full team collaboration.
|
||||
```
|
||||
|
||||
이제 몇 초 만에 CrewAI agent 실행을 캡처, 이해, 공유하고 바로 조치할 수 있습니다.
|
||||
별도의 설정이 필요하지 않습니다. 완전한 트레이스 투명성. 전체 팀 협업 지원.
|
||||
180
docs/ko/observability/openlit.mdx
Normal file
180
docs/ko/observability/openlit.mdx
Normal file
@@ -0,0 +1,180 @@
|
||||
---
|
||||
title: OpenLIT 통합
|
||||
description: OpenTelemetry와 함께 단 한 줄의 코드로 에이전트를 신속하게 모니터링을 시작하세요.
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# OpenLIT 개요
|
||||
|
||||
[OpenLIT](https://github.com/openlit/openlit?src=crewai-docs)은 오픈 소스 도구로, 단 **한** 줄의 코드만으로 AI 에이전트, LLM, VectorDB, GPU의 성능을 간편하게 모니터링할 수 있습니다.
|
||||
|
||||
OpenTelemetry-기반의 트레이싱 및 메트릭을 제공하여 비용, 지연 시간, 상호작용, 작업 시퀀스와 같은 주요 파라미터를 추적할 수 있습니다.
|
||||
이 설정을 통해 하이퍼파라미터를 추적하고 성능 문제를 모니터링하며, 시간이 지남에 따라 에이전트를 개선하고 미세 조정할 방법을 찾을 수 있습니다.
|
||||
|
||||
<Frame caption="OpenLIT 대시보드">
|
||||
<img src="/images/openlit1.png" alt="비용 및 토큰을 포함한 에이전트 사용 개요" />
|
||||
<img src="/images/openlit2.png" alt="에이전트 otel 트레이스 및 메트릭 개요" />
|
||||
<img src="/images/openlit3.png" alt="에이전트 트레이스 상세 개요" />
|
||||
</Frame>
|
||||
|
||||
### 기능
|
||||
|
||||
- **분석 대시보드**: 에이전트의 상태와 성능을 모니터링할 수 있는 대시보드를 통해 지표, 비용, 사용자 상호작용을 자세히 추적할 수 있습니다.
|
||||
- **OpenTelemetry-네이티브 가시성 SDK**: Grafana, DataDog 등 기존 가시성 도구로 추적 및 지표를 전송할 수 있는 벤더 중립적 SDK를 제공합니다.
|
||||
- **커스텀 및 파인튜닝 모델 비용 추적**: 정확한 예산 책정을 위해 커스텀 가격 파일을 사용하여 특정 모델의 비용 추정치를 맞춤화할 수 있습니다.
|
||||
- **예외 모니터링 대시보드**: 모니터링 대시보드를 통해 일반적인 예외 및 오류를 추적하여 문제를 신속하게 찾아내고 해결할 수 있습니다.
|
||||
- **컴플라이언스 및 보안**: 욕설 및 PII 유출과 같은 잠재적인 위협을 탐지합니다.
|
||||
- **프롬프트 인젝션 탐지**: 잠재적인 코드 인젝션 및 비밀 유출을 식별합니다.
|
||||
- **API 키 및 비밀 관리**: LLM API 키와 비밀을 중앙에서 안전하게 관리하여 안전하지 않은 관행을 방지합니다.
|
||||
- **프롬프트 관리**: PromptHub을 사용하여 에이전트 프롬프트를 관리 및 버전 관리하고, 모든 에이전트에서 일관되고 쉽게 접근할 수 있습니다.
|
||||
- **모델 플레이그라운드**: 배포 전에 CrewAI 에이전트에 사용할 다양한 모델을 테스트하고 비교할 수 있습니다.
|
||||
|
||||
## 설치 안내
|
||||
|
||||
<Steps>
|
||||
<Step title="OpenLIT 배포">
|
||||
<Steps>
|
||||
<Step title="OpenLIT 저장소 Git Clone">
|
||||
```shell
|
||||
git clone git@github.com:openlit/openlit.git
|
||||
```
|
||||
</Step>
|
||||
<Step title="Docker Compose 시작">
|
||||
[OpenLIT 저장소](https://github.com/openlit/openlit)의 루트 디렉토리에서 아래 명령어를 실행하세요:
|
||||
```shell
|
||||
docker compose up -d
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
</Step>
|
||||
<Step title="OpenLIT SDK 설치">
|
||||
```shell
|
||||
pip install openlit
|
||||
```
|
||||
</Step>
|
||||
<Step title="애플리케이션에서 OpenLIT 초기화">
|
||||
아래 두 줄을 애플리케이션 코드에 추가하세요:
|
||||
<Tabs>
|
||||
<Tab title="함수 인자 사용 설정">
|
||||
```python
|
||||
import openlit
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
```
|
||||
|
||||
CrewAI Agent 모니터링 예제:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
import openlit
|
||||
|
||||
openlit.init(disable_metrics=True)
|
||||
# 에이전트 정의
|
||||
researcher = Agent(
|
||||
role="Researcher",
|
||||
goal="Conduct thorough research and analysis on AI and AI agents",
|
||||
backstory="You're an expert researcher, specialized in technology, software engineering, AI, and startups. You work as a freelancer and are currently researching for a new client.",
|
||||
allow_delegation=False,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
|
||||
# 작업 정의
|
||||
task = Task(
|
||||
description="Generate a list of 5 interesting ideas for an article, then write one captivating paragraph for each idea that showcases the potential of a full article on this topic. Return the list of ideas with their paragraphs and your notes.",
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# 매니저 에이전트 정의
|
||||
manager = Agent(
|
||||
role="Project Manager",
|
||||
goal="Efficiently manage the crew and ensure high-quality task completion",
|
||||
backstory="You're an experienced project manager, skilled in overseeing complex projects and guiding teams to success. Your role is to coordinate the efforts of the crew members, ensuring that each task is completed on time and to the highest standard.",
|
||||
allow_delegation=True,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
# 커스텀 매니저로 crew 인스턴스화
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[task],
|
||||
manager_agent=manager,
|
||||
process=Process.hierarchical,
|
||||
)
|
||||
|
||||
# crew 작업 시작
|
||||
result = crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
</Tab>
|
||||
<Tab title="환경 변수 사용 설정">
|
||||
|
||||
아래 두 줄을 애플리케이션 코드에 추가하세요:
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
OTEL export endpoint를 설정하려면 다음 명령어를 실행하세요:
|
||||
```shell
|
||||
export OTEL_EXPORTER_OTLP_ENDPOINT = "http://127.0.0.1:4318"
|
||||
```
|
||||
|
||||
CrewAI Async Agent 모니터링 예제:
|
||||
|
||||
```python
|
||||
import asyncio
|
||||
from crewai import Crew, Agent, Task
|
||||
import openlit
|
||||
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
|
||||
# 코드 실행이 활성화된 에이전트 생성
|
||||
coding_agent = Agent(
|
||||
role="Python Data Analyst",
|
||||
goal="Analyze data and provide insights using Python",
|
||||
backstory="You are an experienced data analyst with strong Python skills.",
|
||||
allow_code_execution=True,
|
||||
llm="command-r"
|
||||
)
|
||||
|
||||
# 코드 실행이 필요한 작업 생성
|
||||
data_analysis_task = Task(
|
||||
description="Analyze the given dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent,
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# crew 생성 후 작업 추가
|
||||
analysis_crew = Crew(
|
||||
agents=[coding_agent],
|
||||
tasks=[data_analysis_task]
|
||||
)
|
||||
|
||||
# crew를 비동기적으로 kickoff 하는 함수
|
||||
async def async_crew_execution():
|
||||
result = await analysis_crew.kickoff_async(inputs={"ages": [25, 30, 35, 40, 45]})
|
||||
print("Crew Result:", result)
|
||||
|
||||
# 비동기 함수 실행
|
||||
asyncio.run(async_crew_execution())
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
더 고급 설정 및 사용 사례는 OpenLIT [Python SDK 저장소](https://github.com/openlit/openlit/tree/main/sdk/python)를 참고하세요.
|
||||
</Step>
|
||||
<Step title="시각화 및 분석">
|
||||
이제 에이전트 관찰 데이터가 수집되어 OpenLIT으로 전송되고 있으므로, 다음 단계는 이 데이터를 시각화하고 분석하여 에이전트의 성능, 행동 및 개선이 필요한 영역에 대한 인사이트를 얻는 것입니다.
|
||||
|
||||
브라우저에서 `127.0.0.1:3000`으로 접속하여 바로 시작할 수 있습니다. 기본 자격 증명으로 로그인 가능합니다
|
||||
- **이메일**: `user@openlit.io`
|
||||
- **비밀번호**: `openlituser`
|
||||
|
||||
<Frame caption="OpenLIT 대시보드">
|
||||
<img src="/images/openlit1.png" alt="비용 및 토큰을 포함한 에이전트 사용 개요" />
|
||||
<img src="/images/openlit2.png" alt="에이전트 otel trace 및 메트릭 개요" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
</Steps>
|
||||
130
docs/ko/observability/opik.mdx
Normal file
130
docs/ko/observability/opik.mdx
Normal file
@@ -0,0 +1,130 @@
|
||||
---
|
||||
title: Opik 통합
|
||||
description: Comet Opik을 사용하여 CrewAI 애플리케이션을 포괄적인 트레이싱, 자동 평가, 프로덕션 준비 대시보드로 디버그, 평가 및 모니터링하는 방법을 알아보세요.
|
||||
icon: meteor
|
||||
---
|
||||
|
||||
# Opik 개요
|
||||
|
||||
[Comet Opik](https://www.comet.com/docs/opik/)을(를) 사용하여, 포괄적인 트레이싱, 자동 평가, 프로덕션 준비가 된 대시보드를 통해 LLM 애플리케이션, RAG 시스템, 에이전트 워크플로우를 디버깅, 평가 및 모니터링할 수 있습니다.
|
||||
|
||||
<Frame caption="Opik 에이전트 대시보드">
|
||||
<img src="/images/opik-crewai-dashboard.png" alt="CrewAI와 함께하는 Opik 에이전트 모니터링 예시" />
|
||||
</Frame>
|
||||
|
||||
Opik은 CrewAI 애플리케이션 개발의 모든 단계에서 포괄적인 지원을 제공합니다:
|
||||
|
||||
- **로그 트레이스 및 스팬**: 개발 및 프로덕션 시스템에서 LLM 호출과 애플리케이션 로직을 자동으로 추적하여 디버깅 및 분석이 가능합니다. 프로젝트 간 응답을 수동 또는 프로그램적으로 주석 달고, 조회하고, 비교할 수 있습니다.
|
||||
- **LLM 애플리케이션 성능 평가**: 사용자 지정 테스트 세트로 평가하고, 내장된 평가 지표를 실행하거나 SDK 또는 UI에서 사용자만의 지표를 정의할 수 있습니다.
|
||||
- **CI/CD 파이프라인 내 테스트**: PyTest 기반의 Opik LLM 단위 테스트로 신뢰할 수 있는 성능 기준선을 설정하세요. 프로덕션에서 연속 모니터링을 위한 온라인 평가도 실행할 수 있습니다.
|
||||
- **프로덕션 데이터 모니터링 및 분석**: 프로덕션에서 보지 못한 데이터에 대한 모델의 성능을 이해하고, 새로운 개발 반복을 위한 데이터 세트를 생성할 수 있습니다.
|
||||
|
||||
## 설치
|
||||
|
||||
Comet은 호스팅된 Opik 플랫폼을 제공하거나, 로컬에서 플랫폼을 실행할 수도 있습니다.
|
||||
|
||||
호스팅 버전을 사용하려면 [무료 Comet 계정 만들기](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) 후 API 키를 발급받으세요.
|
||||
|
||||
Opik 플랫폼을 로컬에서 실행하려면, [설치 가이드](https://www.comet.com/docs/opik/self-host/overview/)에서 자세한 정보를 확인하세요.
|
||||
|
||||
이 가이드에서는 CrewAI의 빠른 시작 예제를 사용합니다.
|
||||
|
||||
<Steps>
|
||||
<Step title="필수 패키지 설치">
|
||||
```shell
|
||||
pip install crewai crewai-tools opik --upgrade
|
||||
```
|
||||
</Step>
|
||||
<Step title="Opik 구성">
|
||||
```python
|
||||
import opik
|
||||
opik.configure(use_local=False)
|
||||
```
|
||||
</Step>
|
||||
<Step title="환경 준비">
|
||||
먼저, LLM 제공업체의 API 키를 환경 변수로 설정합니다:
|
||||
|
||||
```python
|
||||
import os
|
||||
import getpass
|
||||
|
||||
if "OPENAI_API_KEY" not in os.environ:
|
||||
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
|
||||
```
|
||||
</Step>
|
||||
<Step title="CrewAI 사용하기">
|
||||
첫 번째 단계는 프로젝트를 만드는 것입니다. CrewAI 문서의 예제를 사용하겠습니다:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task, Process
|
||||
|
||||
|
||||
class YourCrewName:
|
||||
def agent_one(self) -> Agent:
|
||||
return Agent(
|
||||
role="Data Analyst",
|
||||
goal="Analyze data trends in the market",
|
||||
backstory="An experienced data analyst with a background in economics",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def agent_two(self) -> Agent:
|
||||
return Agent(
|
||||
role="Market Researcher",
|
||||
goal="Gather information on market dynamics",
|
||||
backstory="A diligent researcher with a keen eye for detail",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def task_one(self) -> Task:
|
||||
return Task(
|
||||
name="Collect Data Task",
|
||||
description="Collect recent market data and identify trends.",
|
||||
expected_output="A report summarizing key trends in the market.",
|
||||
agent=self.agent_one(),
|
||||
)
|
||||
|
||||
def task_two(self) -> Task:
|
||||
return Task(
|
||||
name="Market Research Task",
|
||||
description="Research factors affecting market dynamics.",
|
||||
expected_output="An analysis of factors influencing the market.",
|
||||
agent=self.agent_two(),
|
||||
)
|
||||
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[self.agent_one(), self.agent_two()],
|
||||
tasks=[self.task_one(), self.task_two()],
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
이제 Opik의 추적기를 임포트하고 crew를 실행할 수 있습니다:
|
||||
|
||||
```python
|
||||
from opik.integrations.crewai import track_crewai
|
||||
|
||||
track_crewai(project_name="crewai-integration-demo")
|
||||
|
||||
my_crew = YourCrewName().crew()
|
||||
result = my_crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
CrewAI 애플리케이션을 실행한 후에는 Opik 앱에서 다음을 확인할 수 있습니다:
|
||||
- LLM 추적, span, 메타데이터
|
||||
- 에이전트 상호작용 및 태스크 실행 흐름
|
||||
- 지연 시간, 토큰 사용량 등의 성능 지표
|
||||
- 평가 지표(내장형 또는 사용자 정의)
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## 리소스
|
||||
|
||||
- [🦉 Opik 문서](https://www.comet.com/docs/opik/)
|
||||
- [👉 Opik + CrewAI Colab](https://colab.research.google.com/github/comet-ml/opik/blob/main/apps/opik-documentation/documentation/docs/cookbook/crewai.ipynb)
|
||||
- [🐦 X](https://x.com/cometml)
|
||||
- [💬 Slack](https://slack.comet.com/)
|
||||
122
docs/ko/observability/overview.mdx
Normal file
122
docs/ko/observability/overview.mdx
Normal file
@@ -0,0 +1,122 @@
|
||||
---
|
||||
title: "개요"
|
||||
description: "포괄적인 관측 도구로 CrewAI agent를 모니터링, 평가 및 최적화하세요"
|
||||
icon: "face-smile"
|
||||
---
|
||||
|
||||
## CrewAI를 위한 관측 가능성
|
||||
|
||||
관측 가능성은 CrewAI 에이전트의 성능을 이해하고, 병목 현상을 식별하며, 프로덕션 환경에서 신뢰할 수 있는 운영을 보장하는 데 매우 중요합니다. 이 섹션에서는 에이전트 워크플로우에 대한 모니터링, 평가, 최적화 기능을 제공하는 다양한 도구와 플랫폼을 다룹니다.
|
||||
|
||||
## 관측 가능성이 중요한 이유
|
||||
|
||||
- **성능 모니터링**: 에이전트 실행 시간, 토큰 사용량, 자원 소비량 추적
|
||||
- **품질 보증**: 다양한 시나리오에서 출력 품질과 일관성 평가
|
||||
- **디버깅**: 에이전트 동작 및 태스크 실행에서의 문제 식별 및 해결
|
||||
- **비용 관리**: LLM API 사용량 및 관련 비용 모니터링
|
||||
- **지속적인 개선**: 시간 경과에 따른 에이전트 성능 최적화를 위한 인사이트 수집
|
||||
|
||||
## 사용 가능한 Observability 도구
|
||||
|
||||
### 모니터링 & 트레이싱 플랫폼
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="AgentOps" icon="paperclip" href="/ko/observability/agentops">
|
||||
에이전트 개발 및 운영을 위한 세션 리플레이, 메트릭, 모니터링 제공.
|
||||
</Card>
|
||||
|
||||
<Card title="LangDB" icon="database" href="/ko/observability/langdb">
|
||||
자동 에이전트 상호작용 캡처를 포함한 CrewAI 워크플로의 엔드-투-엔드 트레이싱.
|
||||
</Card>
|
||||
|
||||
<Card title="OpenLIT" icon="magnifying-glass-chart" href="/ko/observability/openlit">
|
||||
비용 추적 및 성능 분석 기능이 포함된 OpenTelemetry 네이티브 모니터링.
|
||||
</Card>
|
||||
|
||||
<Card title="MLflow" icon="bars-staggered" href="/ko/observability/mlflow">
|
||||
트레이싱 및 평가 기능을 갖춘 머신러닝 라이프사이클 관리.
|
||||
</Card>
|
||||
|
||||
<Card title="Langfuse" icon="link" href="/ko/observability/langfuse">
|
||||
상세한 트레이싱과 분석을 제공하는 LLM 엔지니어링 플랫폼.
|
||||
</Card>
|
||||
|
||||
<Card title="Langtrace" icon="chart-line" href="/ko/observability/langtrace">
|
||||
LLM 및 에이전트 프레임워크를 위한 오픈소스 관측성 지원.
|
||||
</Card>
|
||||
|
||||
<Card title="Arize Phoenix" icon="meteor" href="/ko/observability/arize-phoenix">
|
||||
모니터링 및 문제 해결을 위한 AI 관측성 플랫폼.
|
||||
</Card>
|
||||
|
||||
<Card title="Portkey" icon="key" href="/ko/observability/portkey">
|
||||
종합적인 모니터링 및 신뢰성 기능을 갖춘 AI 게이트웨이.
|
||||
</Card>
|
||||
|
||||
<Card title="Opik" icon="meteor" href="/ko/observability/opik">
|
||||
포괄적인 트레이싱을 통한 LLM 애플리케이션 디버깅, 평가, 모니터링.
|
||||
</Card>
|
||||
|
||||
<Card title="Weave" icon="network-wired" href="/ko/observability/weave">
|
||||
AI 애플리케이션의 추적 및 평가를 위한 Weights & Biases 플랫폼.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### 평가 및 품질 보증
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Patronus AI" icon="shield-check" href="/ko/observability/patronus-evaluation">
|
||||
LLM 출력 및 에이전트 행동에 대한 종합 평가 플랫폼입니다.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## 주요 관측성 메트릭스
|
||||
|
||||
### 성능 지표
|
||||
- **실행 시간**: 에이전트가 작업을 완료하는 데 걸리는 시간
|
||||
- **토큰 사용량**: LLM 호출 시 소비된 입력/출력 토큰
|
||||
- **API 지연 시간**: 외부 서비스의 응답 시간
|
||||
- **성공률**: 성공적으로 완료된 작업의 비율
|
||||
|
||||
### 품질 지표
|
||||
- **출력 정확성**: 에이전트 응답의 정확성
|
||||
- **일관성**: 유사한 입력에 대한 신뢰성
|
||||
- **관련성**: 출력이 기대 결과와 얼마나 잘 일치하는지
|
||||
- **안전성**: 콘텐츠 정책 및 가이드라인 준수
|
||||
|
||||
### 비용 지표
|
||||
- **API 비용**: LLM 제공자 사용에 따른 지출
|
||||
- **리소스 활용**: 컴퓨팅 및 메모리 사용량
|
||||
- **작업당 비용**: 에이전트 운영의 경제적 효율성
|
||||
- **예산 추적**: 지출 한도 대비 모니터링
|
||||
|
||||
## 시작하기
|
||||
|
||||
1. **도구 선택하기**: 필요에 맞는 Observability 플랫폼을 선택하세요
|
||||
2. **코드 계측하기**: CrewAI 애플리케이션에 모니터링을 추가하세요
|
||||
3. **대시보드 설정하기**: 주요 지표에 대한 시각화를 구성하세요
|
||||
4. **알림 정의하기**: 중요한 이벤트에 대한 알림을 생성하세요
|
||||
5. **기준선 설정하기**: 비교를 위한 초기 성능을 측정하세요
|
||||
6. **반복 및 개선**: 인사이트를 활용하여 에이전트를 최적화하세요
|
||||
|
||||
## 모범 사례
|
||||
|
||||
### 개발 단계
|
||||
- 에이전트 행동을 이해하기 위해 상세 트레이싱 사용
|
||||
- 개발 초기에 평가 지표 구현
|
||||
- 테스트 중 리소스 사용량 모니터링
|
||||
- 자동화된 품질 검사 설정
|
||||
|
||||
### 운영 단계
|
||||
- 포괄적인 모니터링 및 알림 구현
|
||||
- 시간 경과에 따른 성능 추이 추적
|
||||
- 이상 현상 및 성능 저하 모니터링
|
||||
- 비용 가시성 및 통제 유지
|
||||
|
||||
### 지속적인 개선
|
||||
- 정기적인 성과 리뷰 및 최적화
|
||||
- 다양한 에이전트 구성의 A/B 테스트
|
||||
- 품질 향상을 위한 피드백 루프
|
||||
- 교훈 문서화
|
||||
|
||||
사용 사례, 인프라, 모니터링 요구 사항에 가장 적합한 observability 도구를 선택하여 CrewAI 에이전트가 신뢰성 있고 효율적으로 작동하도록 하세요.
|
||||
205
docs/ko/observability/patronus-evaluation.mdx
Normal file
205
docs/ko/observability/patronus-evaluation.mdx
Normal file
@@ -0,0 +1,205 @@
|
||||
---
|
||||
title: Patronus AI 평가
|
||||
description: Patronus AI의 종합 평가 플랫폼을 사용하여 CrewAI 에이전트의 성능과 LLM 출력 및 에이전트 행동을 모니터링하고 평가합니다.
|
||||
icon: shield-check
|
||||
---
|
||||
|
||||
# Patronus AI 평가
|
||||
|
||||
## 개요
|
||||
|
||||
[Patronus AI](https://patronus.ai)는 CrewAI 에이전트를 위한 종합적인 평가 및 모니터링 기능을 제공하여, 모델 출력, 에이전트 동작, 전체 시스템 성능을 평가할 수 있게 해줍니다. 이 통합을 통해 품질과 신뢰성을 유지하기 위한 지속적인 평가 워크플로우를 프로덕션 환경에 구현할 수 있습니다.
|
||||
|
||||
## 주요 기능
|
||||
|
||||
- **자동 평가**: 에이전트 출력 및 행동의 실시간 평가
|
||||
- **맞춤 기준**: 사용 사례에 맞게 특정 평가 기준 정의
|
||||
- **성능 모니터링**: 에이전트 성능 지표를 시간에 따라 추적
|
||||
- **품질 보증**: 다양한 시나리오에서 일관된 출력 품질 보장
|
||||
- **안전성 및 준수**: 잠재적인 문제 및 정책 위반 모니터링
|
||||
|
||||
## 평가 도구
|
||||
|
||||
Patronus는 다양한 사용 사례를 위한 세 가지 주요 평가 도구를 제공합니다:
|
||||
|
||||
1. **PatronusEvalTool**: 에이전트가 평가 작업에 가장 적합한 평가자와 기준을 선택할 수 있도록 합니다.
|
||||
2. **PatronusPredefinedCriteriaEvalTool**: 사용자가 지정한 미리 정의된 평가자와 기준을 사용합니다.
|
||||
3. **PatronusLocalEvaluatorTool**: 사용자가 정의한 커스텀 함수 평가자를 사용합니다.
|
||||
|
||||
## 설치
|
||||
|
||||
이 도구들을 사용하려면 Patronus 패키지를 설치해야 합니다:
|
||||
|
||||
```shell
|
||||
uv add patronus
|
||||
```
|
||||
|
||||
또한 Patronus API 키를 환경 변수로 설정해야 합니다:
|
||||
|
||||
```shell
|
||||
export PATRONUS_API_KEY="your_patronus_api_key"
|
||||
```
|
||||
|
||||
## 시작 단계
|
||||
|
||||
Patronus 평가 도구를 효과적으로 사용하려면 다음 단계를 따르세요:
|
||||
|
||||
1. **Patronus 설치**: 위의 명령어를 사용하여 Patronus 패키지를 설치합니다.
|
||||
2. **API 키 설정**: Patronus API 키를 환경 변수로 설정합니다.
|
||||
3. **적합한 도구 선택**: 필요에 따라 적절한 Patronus 평가 도구를 선택합니다.
|
||||
4. **도구 구성**: 필요한 파라미터로 도구를 구성합니다.
|
||||
|
||||
## 예시
|
||||
|
||||
### PatronusEvalTool 사용하기
|
||||
|
||||
다음 예제는 에이전트가 가장 적합한 평가자와 평가 기준을 선택할 수 있도록 해주는 `PatronusEvalTool`의 사용 방법을 보여줍니다:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusEvalTool
|
||||
|
||||
# Initialize the tool
|
||||
patronus_eval_tool = PatronusEvalTool()
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code and verify that the output is code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate and evaluate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence. Select the most appropriate evaluator and criteria for evaluating your output.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### PatronusPredefinedCriteriaEvalTool 사용하기
|
||||
|
||||
다음 예제는 미리 정의된 evaluator와 criteria를 사용하는 `PatronusPredefinedCriteriaEvalTool`의 사용 방법을 보여줍니다:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
# Initialize the tool with predefined criteria
|
||||
patronus_eval_tool = PatronusPredefinedCriteriaEvalTool(
|
||||
evaluators=[{"evaluator": "judge", "criteria": "contains-code"}]
|
||||
)
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### PatronusLocalEvaluatorTool 사용하기
|
||||
|
||||
다음 예시는 커스텀 함수 평가자를 사용하는 `PatronusLocalEvaluatorTool`의 사용 방법을 보여줍니다:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusLocalEvaluatorTool
|
||||
from patronus import Client, EvaluationResult
|
||||
import random
|
||||
|
||||
# Initialize the Patronus client
|
||||
client = Client()
|
||||
|
||||
# Register a custom evaluator
|
||||
@client.register_local_evaluator("random_evaluator")
|
||||
def random_evaluator(**kwargs):
|
||||
score = random.random()
|
||||
return EvaluationResult(
|
||||
score_raw=score,
|
||||
pass_=score >= 0.5,
|
||||
explanation="example explanation",
|
||||
)
|
||||
|
||||
# Initialize the tool with the custom evaluator
|
||||
patronus_eval_tool = PatronusLocalEvaluatorTool(
|
||||
patronus_client=client,
|
||||
evaluator="random_evaluator",
|
||||
evaluated_model_gold_answer="example label",
|
||||
)
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
## 파라미터
|
||||
|
||||
### PatronusEvalTool
|
||||
|
||||
`PatronusEvalTool`은(는) 초기화 시에 어떠한 매개변수도 필요로 하지 않습니다. Patronus API에서 사용 가능한 평가자와 기준을 자동으로 가져옵니다.
|
||||
|
||||
### PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
`PatronusPredefinedCriteriaEvalTool`은(는) 초기화 시 다음과 같은 파라미터를 받습니다:
|
||||
|
||||
- **evaluators**: 필수. 사용할 evaluator와 criteria가 포함된 딕셔너리의 리스트입니다. 예시: `[{"evaluator": "judge", "criteria": "contains-code"}]`.
|
||||
|
||||
### PatronusLocalEvaluatorTool
|
||||
|
||||
`PatronusLocalEvaluatorTool`은(는) 초기화 시 다음과 같은 파라미터를 허용합니다:
|
||||
|
||||
- **patronus_client**: 필수. Patronus 클라이언트 인스턴스입니다.
|
||||
- **evaluator**: 선택 사항. 사용할 등록된 로컬 evaluator의 이름입니다. 기본값은 빈 문자열입니다.
|
||||
- **evaluated_model_gold_answer**: 선택 사항. 평가에 사용할 gold answer입니다. 기본값은 빈 문자열입니다.
|
||||
|
||||
## 사용법
|
||||
|
||||
Patronus 평가 도구를 사용할 때, 모델 입력, 출력 및 컨텍스트를 제공하면 도구가 Patronus API로부터 평가 결과를 반환합니다.
|
||||
|
||||
`PatronusEvalTool` 및 `PatronusPredefinedCriteriaEvalTool`을 호출할 때는 다음과 같은 매개변수가 필요합니다:
|
||||
|
||||
- **evaluated_model_input**: 에이전트의 작업 설명(간단한 텍스트).
|
||||
- **evaluated_model_output**: 에이전트의 작업 결과.
|
||||
- **evaluated_model_retrieved_context**: 에이전트의 컨텍스트.
|
||||
|
||||
`PatronusLocalEvaluatorTool`의 경우에도 동일한 매개변수가 필요하지만, 평가자와 정답은 초기화 시에 지정합니다.
|
||||
|
||||
## 결론
|
||||
|
||||
Patronus 평가 도구는 Patronus AI 플랫폼을 사용하여 모델 입력 및 출력을 평가하고 점수를 매길 수 있는 강력한 방법을 제공합니다. 에이전트가 자신의 출력 또는 다른 에이전트의 출력을 평가할 수 있도록 함으로써, 이러한 도구는 CrewAI 워크플로의 품질과 신뢰성을 향상시키는 데 도움을 줄 수 있습니다.
|
||||
822
docs/ko/observability/portkey.mdx
Normal file
822
docs/ko/observability/portkey.mdx
Normal file
@@ -0,0 +1,822 @@
|
||||
---
|
||||
title: Portkey 통합
|
||||
description: CrewAI에서 Portkey를 사용하는 방법
|
||||
icon: key
|
||||
---
|
||||
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-CrewAI.png" alt="Portkey CrewAI 헤더 이미지" width="70%" />
|
||||
|
||||
## 소개
|
||||
|
||||
Portkey는 CrewAI에 프로덕션 적합성을 위한 기능을 추가하여 실험적인 agent crew를 다음과 같이 견고한 시스템으로 전환합니다.
|
||||
|
||||
- **모든 agent 단계, 도구 사용, 상호작용에 대한 완전한 관찰 가능성**
|
||||
- **내장된 신뢰성**: 폴백, 재시도, 로드 밸런싱 기능 제공
|
||||
- **AI 비용 관리**를 위한 비용 추적 및 최적화
|
||||
- **단일 통합을 통한 200개 이상의 LLM 접근**
|
||||
- **agent의 행동을 안전하고 규정 준수로 유지하는 가드레일**
|
||||
- **일관된 agent 성능을 위한 버전 관리되는 prompt**
|
||||
|
||||
### 설치 및 설정
|
||||
|
||||
<Steps>
|
||||
<Step title="필요한 패키지 설치하기">
|
||||
```bash
|
||||
pip install -U crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="API 키 생성" icon="lock">
|
||||
[Portkey 대시보드](https://app.portkey.ai/)에서 예산/속도 제한을 선택적으로 설정하여 Portkey API 키를 생성하세요. 이 키에는 신뢰성, 캐싱 등 여러 가지 구성을 추가로 적용할 수 있습니다. 자세한 내용은 추후 설명합니다.
|
||||
</Step>
|
||||
|
||||
<Step title="Portkey로 CrewAI 구성하기">
|
||||
통합은 매우 간단합니다. CrewAI 설정의 LLM 구성을 다음과 같이 업데이트하기만 하면 됩니다:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Portkey 통합으로 LLM 인스턴스 생성
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy", # Virtual key를 사용하므로 이 값은 단순한 placeholder입니다.
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_LLM_VIRTUAL_KEY",
|
||||
trace_id="unique-trace-id", # 요청 추적을 위한 선택 사항
|
||||
)
|
||||
)
|
||||
|
||||
#Crew Agents에서 다음처럼 사용하세요:
|
||||
|
||||
@agent
|
||||
def lead_market_analyst(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['lead_market_analyst'],
|
||||
verbose=True,
|
||||
memory=False,
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
<Info>
|
||||
**Virtual Key란?** Portkey의 Virtual Key는 LLM 제공업체의 API 키(OpenAI, Anthropic 등)를 암호화된 금고에 안전하게 저장합니다. 이를 통해 키 교체 및 예산 관리를 더 쉽게 할 수 있습니다. [Virtual Key에 대해 자세히 알아보기](https://portkey.ai/docs/product/ai-gateway/virtual-keys).
|
||||
</Info>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## 프로덕션 기능
|
||||
|
||||
### 1. 향상된 가시성
|
||||
|
||||
Portkey는 CrewAI agent에 대한 종합적인 가시성을 제공하여 각 실행 중에 어떤 일이 일어나고 있는지 정확히 이해할 수 있게 도와줍니다.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Traces">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Product%2011.1.webp"/>
|
||||
</Frame>
|
||||
|
||||
Traces는 crew의 실행을 계층적으로 보여주며, LLM 호출, 도구 호출, 상태 전환의 순서를 확인할 수 있습니다.
|
||||
|
||||
```python
|
||||
# Portkey에서 계층적 추적을 활성화하려면 trace_id를 추가하세요
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
trace_id="unique-session-id" # 고유한 trace ID 추가
|
||||
)
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Logs">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Metadata.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey는 LLM과의 모든 상호작용을 로그로 남깁니다. 여기에는 다음이 포함됩니다:
|
||||
|
||||
- 전체 요청 및 응답 페이로드
|
||||
- 지연 시간 및 토큰 사용량 지표
|
||||
- 비용 계산
|
||||
- 도구 호출 및 함수 실행
|
||||
|
||||
모든 로그는 메타데이터, trace ID, 모델 등으로 필터링할 수 있어 특정 crew 실행을 쉽게 디버깅할 수 있습니다.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Metrics & Dashboards">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Dashboard.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey는 사용자가 다음을 할 수 있도록 지원하는 내장 대시보드를 제공합니다:
|
||||
|
||||
- 모든 crew 실행에서 비용 및 토큰 사용량 추적
|
||||
- 지연 시간, 성공률과 같은 성능 지표 분석
|
||||
- agent workflow의 병목 지점 식별
|
||||
- 서로 다른 crew 구성 및 LLM 비교
|
||||
|
||||
사용자는 모든 지표를 사용자 정의 메타데이터별로 필터링 및 세분화하여 특정 crew 유형, 사용자 그룹 또는 사용 사례를 분석할 수 있습니다.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Metadata Filtering">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png" alt="Analytics with metadata filters" />
|
||||
</Frame>
|
||||
|
||||
CrewAI LLM 구성에 사용자 정의 메타데이터를 추가하여 강력한 필터링 및 세분화를 활성화할 수 있습니다:
|
||||
|
||||
```python
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"crew_type": "research_crew",
|
||||
"environment": "production",
|
||||
"_user": "user_123", # 사용자 분석을 위한 특수 _user 필드
|
||||
"request_source": "mobile_app"
|
||||
}
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
이 메타데이터는 Portkey 대시보드에서 로그, trace, 지표를 필터링하는 데 사용될 수 있으며, 특정 crew 실행, 사용자 또는 환경을 분석할 수 있습니다.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 2. 신뢰성 - Crew를 원활하게 운영하세요
|
||||
|
||||
프로덕션에서 crew를 운영할 때, API 속도 제한, 네트워크 이슈 또는 공급자 장애와 같이 문제가 발생할 수 있습니다. Portkey의 신뢰성 기능은 문제가 발생해도 에이전트가 원활하게 동작하도록 보장합니다.
|
||||
|
||||
Portkey Config를 사용하여 CrewAI 설정에서 페일오버를 간단하게 활성화할 수 있습니다:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create LLM with fallback configuration
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
config={
|
||||
"strategy": {
|
||||
"mode": "fallback"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"provider": "openai",
|
||||
"api_key": "YOUR_OPENAI_API_KEY",
|
||||
"override_params": {"model": "gpt-4o"}
|
||||
},
|
||||
{
|
||||
"provider": "anthropic",
|
||||
"api_key": "YOUR_ANTHROPIC_API_KEY",
|
||||
"override_params": {"model": "claude-3-opus-20240229"}
|
||||
}
|
||||
]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Use this LLM configuration with your agents
|
||||
```
|
||||
|
||||
이 설정은 GPT-4o 요청이 실패할 경우 자동으로 Claude를 시도하여 crew가 계속 운영될 수 있도록 보장합니다.
|
||||
|
||||
<CardGroup cols="2">
|
||||
<Card title="자동 재시도" icon="rotate" href="https://portkey.ai/docs/ko/product/ai-gateway/automatic-retries">
|
||||
일시적인 실패를 자동으로 처리합니다. LLM 호출에 실패하면 Portkey가 지정된 횟수만큼 동일한 요청을 재시도합니다. 속도 제한이나 네트워크 장애에서 완벽하게 사용할 수 있습니다.
|
||||
</Card>
|
||||
<Card title="요청 타임아웃" icon="clock" href="https://portkey.ai/docs/ko/product/ai-gateway/request-timeouts">
|
||||
에이전트가 멈추는 것을 방지합니다. 타임아웃을 설정하여 요구되는 시간 내에 응답을 받거나(혹은 우아하게 실패할 수 있도록) 합니다.
|
||||
</Card>
|
||||
<Card title="조건부 라우팅" icon="route" href="https://portkey.ai/docs/ko/product/ai-gateway/conditional-routing">
|
||||
다양한 요청을 다양한 공급자에게 보낼 수 있습니다. 복잡한 reasoning은 GPT-4로, 창의적인 작업은 Claude로, 빠른 응답은 Gemini로 필요에 따라 라우팅하세요.
|
||||
</Card>
|
||||
<Card title="페일오버" icon="shield" href="https://portkey.ai/docs/ko/product/ai-gateway/fallbacks">
|
||||
기본 공급자가 실패해도 계속 운영됩니다. 백업 공급자로 자동으로 전환되어 가용성을 유지합니다.
|
||||
</Card>
|
||||
<Card title="로드 밸런싱" icon="scale-balanced" href="https://portkey.ai/docs/ko/product/ai-gateway/load-balancing">
|
||||
여러 API 키 또는 공급자에 요청을 분산시킵니다. 대량 crew 운영 및 속도 제한 내에서 작업할 때 유용합니다.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### 3. CrewAI에서의 프롬프트 사용
|
||||
|
||||
Portkey의 Prompt Engineering Studio는 CrewAI 에이전트에서 사용하는 프롬프트를 생성, 관리, 최적화하도록 도와줍니다. 프롬프트나 지시문을 하드코딩하는 대신 Portkey의 프롬프트 렌더링 API를 사용하여 버전 관리된 프롬프트를 동적으로 가져와 적용할 수 있습니다.
|
||||
|
||||
<Frame caption="Portkey의 프롬프트 라이브러리에서 프롬프트 관리하기">
|
||||
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Prompt Playground">
|
||||
Prompt Playground는 여러분의 AI 애플리케이션을 위해 완벽한 프롬프트를 비교, 테스트, 배포할 수 있는 공간입니다. 이곳은 다양한 모델을 실험하고, 변수들을 테스트하며, 출력값을 비교하고, 배포 전에 프롬프트 엔지니어링 전략을 다듬을 수 있는 곳입니다. 이를 통해 다음과 같은 작업이 가능합니다:
|
||||
|
||||
1. 에이전트에서 사용하기 전에 프롬프트를 반복적으로 개발
|
||||
2. 다양한 변수와 모델로 프롬프트 테스트
|
||||
3. 서로 다른 프롬프트 버전의 출력값 비교
|
||||
4. 팀원들과 프롬프트 개발 협업
|
||||
|
||||
이 시각적 환경을 통해 CrewAI 에이전트 워크플로우의 각 단계에 효과적인 프롬프트를 쉽게 작성할 수 있습니다.
|
||||
</Tab>
|
||||
|
||||
<Tab title="프롬프트 템플릿 사용하기">
|
||||
Prompt Render API를 통해 모든 파라미터가 구성된 프롬프트 템플릿을 가져올 수 있습니다:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL, Portkey
|
||||
|
||||
# Initialize Portkey admin client
|
||||
portkey_admin = Portkey(api_key="YOUR_PORTKEY_API_KEY")
|
||||
|
||||
# Retrieve prompt using the render API
|
||||
prompt_data = portkey_client.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
}
|
||||
)
|
||||
|
||||
backstory_agent_prompt=prompt_data.data.messages[0]["content"]
|
||||
|
||||
|
||||
# Set up LLM with Portkey integration
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent using the rendered prompt
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory=backstory_agent, # Use the rendered prompt
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="프롬프트 버전 관리">
|
||||
다음과 같은 작업을 수행할 수 있습니다:
|
||||
- 동일한 프롬프트의 여러 버전을 생성
|
||||
- 버전 간의 성능 비교
|
||||
- 필요시 이전 버전으로 롤백
|
||||
- 코드에서 사용할 버전을 지정:
|
||||
|
||||
```python
|
||||
# Use a specific prompt version
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID@version_number",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"agent_goal": "Discover groundbreaking insights"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="변수용 머스태시 템플릿">
|
||||
Portkey 프롬프트는 손쉬운 변수 치환을 위해 머스태시(Mustache) 스타일의 템플릿을 사용합니다:
|
||||
|
||||
```
|
||||
You are a {{agent_role}} with expertise in {{domain}}.
|
||||
|
||||
Your mission is to {{agent_goal}} by leveraging your knowledge
|
||||
and experience in the field.
|
||||
|
||||
Always maintain a {{tone}} tone and focus on providing {{focus_area}}.
|
||||
```
|
||||
|
||||
렌더링할 때는 변수를 간단하게 전달하면 됩니다:
|
||||
|
||||
```python
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"domain": "artificial intelligence",
|
||||
"agent_goal": "discover groundbreaking insights",
|
||||
"tone": "professional",
|
||||
"focus_area": "practical applications"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Card title="Prompt Engineering Studio" icon="wand-magic-sparkles" href="https://portkey.ai/docs/product/prompt-library">
|
||||
Portkey의 프롬프트 관리 기능에 대해 더 알아보기
|
||||
</Card>
|
||||
|
||||
### 4. 안전한 Crew를 위한 가드레일
|
||||
|
||||
가드레일은 CrewAI agent가 모든 상황에서 안전하게 작동하고 적절하게 응답하도록 보장합니다.
|
||||
|
||||
**가드레일을 사용하는 이유는 무엇인가요?**
|
||||
|
||||
CrewAI agent는 다양한 실패 모드를 경험할 수 있습니다:
|
||||
- 유해하거나 부적절한 콘텐츠 생성
|
||||
- PII와 같은 민감 정보 유출
|
||||
- 잘못된 정보의 환각
|
||||
- 잘못된 형식의 출력 생성
|
||||
|
||||
Portkey의 가드레일은 입력과 출력 모두에 대한 보호를 추가합니다.
|
||||
|
||||
**가드레일 구현하기**
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create LLM with guardrails
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"input_guardrails": ["guardrails-id-xxx", "guardrails-id-yyy"],
|
||||
"output_guardrails": ["guardrails-id-zzz"]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with guardrailed LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Portkey의 가드레일은 다음을 수행할 수 있습니다:
|
||||
- 입력 및 출력의 PII 감지 및 마스킹
|
||||
- 유해하거나 부적절한 콘텐츠 필터링
|
||||
- 응답 형식을 스키마에 따라 검증
|
||||
- 근거 자료와 비교하여 환각 여부 확인
|
||||
- 맞춤형 비즈니스 로직 및 규칙 적용
|
||||
|
||||
<Card title="가드레일에 대해 더 알아보기" icon="shield-check" href="https://portkey.ai/docs/product/guardrails">
|
||||
Portkey의 가드레일 기능을 탐색하여 agent의 안전성을 높여보세요
|
||||
</Card>
|
||||
|
||||
### 5. 메타데이터로 사용자 추적
|
||||
|
||||
Portkey의 메타데이터 시스템을 사용하여 CrewAI 에이전트를 통해 개별 사용자를 추적할 수 있습니다.
|
||||
|
||||
**Portkey에서의 메타데이터란?**
|
||||
|
||||
메타데이터를 사용하면 각 요청에 사용자 지정 데이터를 연결할 수 있어 필터링, 세분화, 분석이 가능합니다. 특별한 `_user` 필드는 사용자 추적을 위해 특별히 설계되었습니다.
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# 사용자 추적이 설정된 LLM 구성
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"_user": "user_123", # 사용자 분석을 위한 특별 _user 필드
|
||||
"user_tier": "premium",
|
||||
"user_company": "Acme Corp",
|
||||
"session_id": "abc-123"
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# 추적된 LLM으로 에이전트 생성
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
**사용자별로 분석 필터링**
|
||||
|
||||
메타데이터가 설정되어 있으면, 사용자별로 분석을 필터링하고 사용자 단위의 성능 지표를 분석할 수 있습니다:
|
||||
|
||||
<Frame caption="사용자별로 분석 필터링">
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png"/>
|
||||
</Frame>
|
||||
|
||||
이를 통해 다음이 가능합니다:
|
||||
- 사용자별 비용 추적 및 예산 관리
|
||||
- 개인화된 사용자 분석
|
||||
- 팀 또는 조직 단위의 지표
|
||||
- 환경별 모니터링(스테이징 vs. 프로덕션)
|
||||
|
||||
<Card title="메타데이터에 대해 더 알아보기" icon="tags" href="https://portkey.ai/docs/product/observability/metadata">
|
||||
맞춤형 메타데이터를 활용하여 분석 기능을 향상시키는 방법을 살펴보세요
|
||||
</Card>
|
||||
|
||||
### 6. 효율적인 Crews를 위한 캐싱
|
||||
|
||||
캐싱을 구현하여 CrewAI agent를 보다 효율적이고 비용 효율적으로 만드세요:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Simple Caching">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with simple caching
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "simple"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with cached LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Simple 캐싱은 입력 프롬프트에 대한 정확한 일치 항목을 수행하며, 동일한 요청을 캐시에 저장하여 중복된 모델 실행을 방지합니다.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Semantic Caching">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with semantic caching
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "semantic"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with semantically cached LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Semantic 캐싱은 입력 요청 간의 맥락적 유사성을 고려하여, 의미적으로 유사한 입력에 대한 응답을 캐시에 저장합니다.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 7. 모델 상호 운용성
|
||||
|
||||
CrewAI는 여러 LLM 제공업체를 지원하며, Portkey는 통합 인터페이스를 통해 200개 이상의 LLM에 대한 액세스를 제공함으로써 이 기능을 확장합니다. 코어 에이전트 로직을 변경하지 않고도 다양한 모델 간에 쉽게 전환할 수 있습니다:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Set up LLMs with different providers
|
||||
openai_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Choose which LLM to use for each agent based on your needs
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=openai_llm # Use anthropic_llm for Anthropic
|
||||
)
|
||||
```
|
||||
|
||||
Portkey는 다음을 포함한 제공업체의 LLM에 액세스를 제공합니다:
|
||||
|
||||
- OpenAI (GPT-4o, GPT-4 Turbo 등)
|
||||
- Anthropic (Claude 3.5 Sonnet, Claude 3 Opus 등)
|
||||
- Mistral AI (Mistral Large, Mistral Medium 등)
|
||||
- Google Vertex AI (Gemini 1.5 Pro 등)
|
||||
- Cohere (Command, Command-R 등)
|
||||
- AWS Bedrock (Claude, Titan 등)
|
||||
- 로컬/프라이빗 모델
|
||||
|
||||
<Card title="지원되는 제공업체" icon="server" href="https://portkey.ai/docs/integrations/llms">
|
||||
Portkey에서 지원하는 전체 LLM 제공업체 목록 보기
|
||||
</Card>
|
||||
|
||||
## CrewAI를 위한 엔터프라이즈 거버넌스 설정
|
||||
|
||||
**엔터프라이즈 거버넌스가 필요한 이유**
|
||||
조직 내에서 CrewAI를 사용하는 경우, 여러 거버넌스 측면을 고려해야 합니다:
|
||||
- **비용 관리**: 팀별 AI 사용 비용 통제 및 추적
|
||||
- **접근 제어**: 특정 팀이 특정 모델을 사용할 수 있도록 관리
|
||||
- **사용 분석**: 조직 전반에서 AI 사용 현황 파악
|
||||
- **보안 및 컴플라이언스**: 엔터프라이즈 수준의 보안 기준 유지
|
||||
- **신뢰성**: 모든 사용자에게 일관된 서비스 제공 보장
|
||||
|
||||
Portkey는 이러한 엔터프라이즈 요구를 해결하는 종합적인 거버넌스 계층을 추가합니다. 이제 이러한 컨트롤을 단계별로 구현해보겠습니다.
|
||||
|
||||
<Steps>
|
||||
<Step title="Virtual Key 생성">
|
||||
Virtual Key는 Portkey의 안전한 LLM 공급자 API 키 관리 방식입니다. 주요 제어 기능을 제공합니다:
|
||||
- API 사용에 대한 예산 제한
|
||||
- 속도 제한(Rate limiting) 기능
|
||||
- 안전한 API 키 저장
|
||||
|
||||
Virtual Key를 생성하려면:
|
||||
Portkey 앱에서 [Virtual Keys](https://app.portkey.ai/virtual-keys)로 이동하세요. Virtual Key ID를 저장하고 복사하세요.
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
|
||||
<Note>
|
||||
Virtual Key ID를 저장하세요. 다음 단계에서 필요합니다.
|
||||
</Note>
|
||||
</Step>
|
||||
|
||||
<Step title="기본 Config 생성">
|
||||
Portkey에서 Config는 요청 라우팅 방식을 정의하며, 고급 라우팅·폴백·재시도 등 기능을 제공합니다.
|
||||
|
||||
Config를 생성하려면:
|
||||
1. Portkey 대시보드의 [Configs](https://app.portkey.ai/configs)로 이동
|
||||
2. 아래와 같은 새 config 생성:
|
||||
```json
|
||||
{
|
||||
"virtual_key": "YOUR_VIRTUAL_KEY_FROM_STEP1",
|
||||
"override_params": {
|
||||
"model": "gpt-4o" // 선호하는 모델명
|
||||
}
|
||||
}
|
||||
```
|
||||
3. Config 이름을 저장하고 다음 단계에 사용하세요.
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Config.png" width="500"/>
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Portkey API Key 설정">
|
||||
이제 Portkey API 키를 생성하고, 2단계에서 만든 config에 연결하세요:
|
||||
|
||||
1. Portkey의 [API Keys](https://app.portkey.ai/api-keys)로 이동해 새 API 키 생성
|
||||
2. `2단계`에서 만든 config 선택
|
||||
3. API 키를 생성 및 저장
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20API%20Key.png" width="500"/>
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="CrewAI에 연결">
|
||||
Portkey API 키와 config를 설정한 후, 이를 CrewAI agent에 연결하세요:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import PORTKEY_GATEWAY_URL
|
||||
|
||||
# API 키로 LLM 구성
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="YOUR_PORTKEY_API_KEY"
|
||||
)
|
||||
|
||||
# Portkey가 적용된 LLM으로 agent 생성
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="1단계: 예산 제어 및 속도 제한 구현">
|
||||
|
||||
### 1단계: 예산 통제 및 속도 제한 구현
|
||||
|
||||
Virtual Keys를 사용하면 팀/부서 수준에서 LLM 접근을 세밀하게 제어할 수 있습니다. 이를 통해 다음과 같은 이점이 있습니다:
|
||||
- [예산 한도](https://portkey.ai/docs/product/ai-gateway/virtual-keys/budget-limits) 설정
|
||||
- 속도 제한을 통해 예기치 않은 사용량 급증 방지
|
||||
- 부서별 지출 추적
|
||||
|
||||
#### 부서별 제어 설정하기:
|
||||
1. Portkey 대시보드에서 [Virtual Keys](https://app.portkey.ai/virtual-keys)로 이동하세요.
|
||||
2. 각 부서마다 예산 한도와 속도 제한이 포함된 새로운 Virtual Key를 생성하세요.
|
||||
3. 부서별 한도를 구성하세요.
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="2단계: 모델 접근 규칙 정의">
|
||||
|
||||
### 단계 2: 모델 접근 규칙 정의
|
||||
|
||||
AI 사용이 확장됨에 따라, 각 팀이 특정 모델에 접근할 수 있도록 제어하는 것이 중요해집니다. Portkey Configs는 다음과 같은 기능을 제공하여 이러한 제어 계층을 지원합니다:
|
||||
|
||||
#### 접근 제어 기능:
|
||||
- **모델 제한**: 특정 모델에 대한 액세스 제한
|
||||
- **데이터 보호**: 민감한 데이터에 대한 가드레일 구현
|
||||
- **신뢰성 제어**: 폴백 및 재시도 로직 추가
|
||||
|
||||
#### 예시 구성:
|
||||
다음은 OpenAI, 특히 GPT-4o로 요청을 라우팅하는 기본 구성입니다:
|
||||
|
||||
```json
|
||||
{
|
||||
"strategy": {
|
||||
"mode": "single"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"virtual_key": "YOUR_OPENAI_VIRTUAL_KEY",
|
||||
"override_params": {
|
||||
"model": "gpt-4o"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Portkey 대시보드에서 [구성 페이지](https://app.portkey.ai/configs)에서 자신의 구성을 생성하세요.
|
||||
|
||||
<Note>
|
||||
구성은 언제든지 업데이트하여 실행 중인 애플리케이션에 영향을 주지 않고 제어를 조정할 수 있습니다.
|
||||
</Note>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="3단계: 액세스 제어 구현">
|
||||
### 3단계: 액세스 제어 구현
|
||||
|
||||
사용자별 API 키를 생성하면 자동으로 다음을 수행합니다:
|
||||
- 가상 키를 활용하여 사용자/팀별 사용량 추적
|
||||
- 요청 라우팅을 위한 적절한 구성 적용
|
||||
- 로그를 필터링하기 위한 관련 메타데이터 수집
|
||||
- 액세스 권한 적용
|
||||
|
||||
API 키 생성 방법:
|
||||
- [Portkey App](https://app.portkey.ai/)
|
||||
- [API Key Management API](/ko/api-reference/admin-api/control-plane/api-keys/create-api-key)
|
||||
|
||||
Python SDK를 사용한 예시:
|
||||
```python
|
||||
from portkey_ai import Portkey
|
||||
|
||||
portkey = Portkey(api_key="YOUR_ADMIN_API_KEY")
|
||||
|
||||
api_key = portkey.api_keys.create(
|
||||
name="engineering-team",
|
||||
type="organisation",
|
||||
workspace_id="YOUR_WORKSPACE_ID",
|
||||
defaults={
|
||||
"config_id": "your-config-id",
|
||||
"metadata": {
|
||||
"environment": "production",
|
||||
"department": "engineering"
|
||||
}
|
||||
},
|
||||
scopes=["logs.view", "configs.read"]
|
||||
)
|
||||
```
|
||||
|
||||
자세한 키 관리 방법은 [API 키 문서](/ko/api-reference/admin-api/control-plane/api-keys/create-api-key)를 참조하세요.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="4단계: 배포 및 모니터링">
|
||||
### 4단계: 배포 및 모니터링
|
||||
팀원들에게 API 키를 배포한 후, 엔터프라이즈 준비가 완료된 CrewAI 설정이 준비됩니다. 이제 각 팀원은 지정된 API 키로 적절한 액세스 수준 및 예산 제어와 함께 사용할 수 있습니다.
|
||||
|
||||
Portkey 대시보드에서 사용량 모니터링:
|
||||
- 부서별 비용 추적
|
||||
- 모델 사용 패턴
|
||||
- 요청량
|
||||
- 오류율
|
||||
</Accordion>
|
||||
|
||||
</AccordionGroup>
|
||||
|
||||
<Note>
|
||||
|
||||
### 엔터프라이즈 기능이 이제 사용 가능합니다
|
||||
**귀하의 CrewAI 통합에는 이제 다음과 같은 기능이 포함됩니다:**
|
||||
- 부서별 예산 관리
|
||||
- 모델 접근 거버넌스
|
||||
- 사용량 추적 및 귀속
|
||||
- 보안 가드레일
|
||||
- 신뢰성 기능
|
||||
</Note>
|
||||
|
||||
## 자주 묻는 질문
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Portkey는 CrewAI를 어떻게 향상시키나요?">
|
||||
Portkey는 종합적인 가시성(트레이스, 로그, 메트릭), 신뢰성 기능(폴백, 재시도, 캐싱) 및 통합 인터페이스를 통한 200개 이상의 LLM 접속을 통해 CrewAI에 프로덕션 환경에 적합한 기능을 추가합니다. 이를 통해 에이전트 애플리케이션을 더 쉽게 디버깅, 최적화, 확장할 수 있습니다.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Portkey를 기존 CrewAI 애플리케이션과 함께 사용할 수 있나요?">
|
||||
네! Portkey는 기존 CrewAI 애플리케이션과 매끄럽게 통합됩니다. LLM 구성 코드를 Portkey가 적용된 버전으로 업데이트하기만 하면 됩니다. 나머지 에이전트 및 crew 코드는 변경하지 않아도 됩니다.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Portkey는 모든 CrewAI 기능과 호환되나요?">
|
||||
Portkey는 에이전트, 도구, human-in-the-loop 워크플로우, 모든 태스크 프로세스 유형(순차적, 계층적 등)을 포함하여 모든 CrewAI 기능을 지원합니다. 프레임워크의 기능에 제한을 두지 않으면서 가시성과 신뢰성을 추가합니다.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Crew 내 여러 에이전트의 사용 내역을 추적할 수 있나요?">
|
||||
네, Portkey를 사용하면 crew 내 여러 에이전트에 일관된 `trace_id`를 적용하여 전체 워크플로우를 추적할 수 있습니다. 특히 여러 에이전트가 포함된 복잡한 crew에서 전체 실행 경로를 파악할 때 유용합니다.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="특정 crew 실행에 대한 로그와 트레이스를 어떻게 필터링하나요?">
|
||||
Portkey를 통해 LLM 구성에 사용자 지정 메타데이터를 추가할 수 있으며, 이를 필터링에 활용할 수 있습니다. `crew_name`, `crew_type`, `session_id`와 같은 필드를 추가해 손쉽게 특정 crew 실행을 찾아 분석할 수 있습니다.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="내 API 키를 Portkey에서 사용할 수 있나요?">
|
||||
네! Portkey는 다양한 LLM 제공업체에 대해 사용자의 API 키를 사용합니다. API 키를 가상 키로 안전하게 저장하여, 코드 변경 없이 쉽게 키를 관리하고 교체할 수 있습니다.
|
||||
</Accordion>
|
||||
|
||||
</AccordionGroup>
|
||||
|
||||
## 자료
|
||||
|
||||
<CardGroup cols="3">
|
||||
<Card title="CrewAI Docs" icon="book" href="https://docs.crewai.com/">
|
||||
<p>공식 CrewAI 문서</p>
|
||||
</Card>
|
||||
<Card title="Book a Demo" icon="calendar" href="https://calendly.com/portkey-ai">
|
||||
<p>이 통합 구현에 대한 맞춤형 안내를 받아보세요</p>
|
||||
</Card>
|
||||
</CardGroup>
|
||||
124
docs/ko/observability/weave.mdx
Normal file
124
docs/ko/observability/weave.mdx
Normal file
@@ -0,0 +1,124 @@
|
||||
---
|
||||
title: Weave 통합
|
||||
description: Weights & Biases(W&B) Weave를 사용하여 CrewAI 애플리케이션을 추적, 실험, 평가 및 개선하는 방법을 알아보세요.
|
||||
icon: radar
|
||||
---
|
||||
|
||||
# Weave 개요
|
||||
|
||||
[Weights & Biases (W&B) Weave](https://weave-docs.wandb.ai/)는 LLM 기반 애플리케이션을 추적, 실험, 평가, 배포 및 개선하기 위한 프레임워크입니다.
|
||||
|
||||

|
||||
|
||||
Weave는 CrewAI 애플리케이션 개발의 모든 단계에서 포괄적인 지원을 제공합니다:
|
||||
|
||||
- **트레이싱 및 모니터링**: LLM 호출과 애플리케이션 로직을 자동으로 추적하여 프로덕션 시스템을 디버그하고 분석
|
||||
- **체계적인 반복**: prompt, 데이터셋, 모델을 개선하고 반복
|
||||
- **평가**: 맞춤형 또는 사전 구축된 스코어러를 사용하여 agent 성능을 체계적으로 평가하고 향상
|
||||
- **가드레일**: 콘텐츠 모더레이션과 prompt 안전성을 위한 사전 및 사후 보호조치로 agent를 보호
|
||||
|
||||
Weave는 CrewAI 애플리케이션의 트레이스를 자동으로 캡처하여 agent의 성능, 상호 작용 및 실행 흐름을 모니터링하고 분석할 수 있게 해줍니다. 이를 통해 더 나은 평가 데이터셋을 구축하고 agent 워크플로우를 최적화할 수 있습니다.
|
||||
|
||||
## 설치 안내
|
||||
|
||||
<Steps>
|
||||
<Step title="필수 패키지 설치">
|
||||
```shell
|
||||
pip install crewai weave
|
||||
```
|
||||
</Step>
|
||||
<Step title="W&B 계정 설정">
|
||||
[Weights & Biases 계정](https://wandb.ai)에 가입하세요. 아직 계정이 없다면 가입이 필요합니다. 트레이스와 메트릭을 확인하려면 계정이 필요합니다.
|
||||
</Step>
|
||||
<Step title="애플리케이션에서 Weave 초기화">
|
||||
다음 코드를 애플리케이션에 추가하세요:
|
||||
|
||||
```python
|
||||
import weave
|
||||
|
||||
# 프로젝트 이름으로 Weave를 초기화
|
||||
weave.init(project_name="crewai_demo")
|
||||
```
|
||||
|
||||
초기화 후, Weave는 트레이스와 메트릭을 확인할 수 있는 URL을 제공합니다.
|
||||
</Step>
|
||||
<Step title="Crews/Flows 생성">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM, Process
|
||||
|
||||
# 결정론적 출력을 위해 temperature를 0으로 설정하여 LLM 생성
|
||||
llm = LLM(model="gpt-4o", temperature=0)
|
||||
|
||||
# 에이전트 생성
|
||||
researcher = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Find and analyze the best investment opportunities',
|
||||
backstory='Expert in financial analysis and market research',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role='Report Writer',
|
||||
goal='Write clear and concise investment reports',
|
||||
backstory='Experienced in creating detailed financial reports',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
# 작업 생성
|
||||
research_task = Task(
|
||||
description='Deep research on the {topic}',
|
||||
expected_output='Comprehensive market data including key players, market size, and growth trends.',
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description='Write a detailed report based on the research',
|
||||
expected_output='The report should be easy to read and understand. Use bullet points where applicable.',
|
||||
agent=writer
|
||||
)
|
||||
|
||||
# 크루 생성
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
)
|
||||
|
||||
# 크루 실행
|
||||
result = crew.kickoff(inputs={"topic": "AI in material science"})
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Weave에서 트레이스 보기">
|
||||
CrewAI 애플리케이션 실행 후, 초기화 시 제공된 Weave URL에 방문하여 다음 항목을 확인할 수 있습니다:
|
||||
- LLM 호출 및 그 메타데이터
|
||||
- 에이전트 상호작용 및 작업 실행 흐름
|
||||
- 대기 시간 및 토큰 사용량과 같은 성능 메트릭
|
||||
- 실행 중 발생한 오류 또는 이슈
|
||||
|
||||
<Frame caption="Weave 트레이싱 대시보드">
|
||||
<img src="/images/weave-tracing.png" alt="Weave tracing example with CrewAI" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## 특징
|
||||
|
||||
- Weave는 모든 CrewAI 작업을 자동으로 캡처합니다: agent 상호작용 및 태스크 실행; 메타데이터와 토큰 사용량을 포함한 LLM 호출; 도구 사용 및 결과.
|
||||
- 이 통합은 모든 CrewAI 실행 메서드를 지원합니다: `kickoff()`, `kickoff_for_each()`, `kickoff_async()`, 그리고 `kickoff_for_each_async()`.
|
||||
- 모든 [crewAI-tools](https://github.com/crewAIInc/crewAI-tools) 작업의 자동 추적.
|
||||
- 데코레이터 패칭(`@start`, `@listen`, `@router`, `@or_`, `@and_`)을 통한 flow 기능 지원.
|
||||
- `@weave.op()`과 함께 CrewAI `Task`에 전달된 커스텀 guardrails 추적.
|
||||
|
||||
지원되는 항목에 대한 자세한 정보는 [Weave CrewAI 문서](https://weave-docs.wandb.ai/guides/integrations/crewai/#getting-started-with-flow)를 참조하세요.
|
||||
|
||||
## 자료
|
||||
|
||||
- [📘 Weave 문서](https://weave-docs.wandb.ai)
|
||||
- [📊 예시 Weave x CrewAI 대시보드](https://wandb.ai/ayut/crewai_demo/weave/traces?cols=%7B%22wb_run_id%22%3Afalse%2C%22attributes.weave.client_version%22%3Afalse%2C%22attributes.weave.os_name%22%3Afalse%2C%22attributes.weave.os_release%22%3Afalse%2C%22attributes.weave.os_version%22%3Afalse%2C%22attributes.weave.source%22%3Afalse%2C%22attributes.weave.sys_version%22%3Afalse%7D&peekPath=%2Fayut%2Fcrewai_demo%2Fcalls%2F0195c838-38cb-71a2-8a15-651ecddf9d89)
|
||||
- [🐦 X](https://x.com/weave_wb)
|
||||
Reference in New Issue
Block a user