stop 파라미터를 보낼 필요가 없다면 LLM 호출에서 제외할 수 있습니다:
+
+ ```python
+ from crewai import LLM
+ import os
+
+ os.environ["OPENAI_API_KEY"] = " +
+
+
+  +
+
+
+  +
+ - 필요에 따라 추가 작업을 구성합니다.
+ - 모든 워크플로우 단계를 검토하여 올바르게 설정되었는지 확인합니다.
+ - 워크플로우를 활성화합니다.
+
+
+
+ - 필요에 따라 추가 작업을 구성합니다.
+ - 모든 워크플로우 단계를 검토하여 올바르게 설정되었는지 확인합니다.
+ - 워크플로우를 활성화합니다.
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+
+
+ );
+ }
+
+ export default App;
+ ```
+ - `YOUR_API_BASE_URL` 및 `YOUR_BEARER_TOKEN` 부분을 실제 API 값으로 바꿔주세요.
+  +
+
+
+
+
+  +
+
+## 다음 단계
+
+- 구성 요소 스타일을 애플리케이션 디자인에 맞게 맞춤화하세요
+- 추가 구성을 위한 props를 추가하세요
+- 애플리케이션의 상태 관리와 통합하세요
+- 오류 처리 및 로딩 상태를 추가하세요
\ No newline at end of file
diff --git a/docs/ko/enterprise/guides/salesforce-trigger.mdx b/docs/ko/enterprise/guides/salesforce-trigger.mdx
new file mode 100644
index 000000000..b95e3a217
--- /dev/null
+++ b/docs/ko/enterprise/guides/salesforce-trigger.mdx
@@ -0,0 +1,44 @@
+---
+title: "Salesforce 트리거"
+description: "Salesforce 워크플로우에서 CrewAI crew를 트리거하여 CRM 자동화"
+icon: "salesforce"
+---
+
+CrewAI Enterprise는 Salesforce에서 트리거되어 고객 관계 관리 워크플로우를 자동화하고 영업 운영을 강화할 수 있습니다.
+
+## 개요
+
+Salesforce는 기업이 영업, 서비스, 마케팅 운영을 효율화할 수 있도록 돕는 선도적인 고객 관계 관리(CRM) 플랫폼입니다. Salesforce에서 CrewAI 트리거를 설정하면 다음과 같은 작업을 수행할 수 있습니다:
+
+- 리드 점수 산정 및 자격 심사 자동화
+- 개인화된 영업 자료 생성
+- AI 기반 응답으로 고객 서비스 강화
+- 데이터 분석 및 보고 간소화
+
+## 데모
+
+
+
+
+
+## 시작하기
+
+Salesforce 트리거를 설정하려면:
+
+1. **지원팀 문의**: Salesforce 트리거 설정을 위해 CrewAI Enterprise 지원팀에 연락하세요.
+2. **요구 사항 검토**: 필요한 Salesforce 권한과 API 액세스 권한이 있는지 확인하세요.
+3. **연결 구성**: 지원팀과 협력하여 CrewAI와 귀하의 Salesforce 인스턴스 간의 연결을 설정하세요.
+4. **트리거 테스트**: 트리거가 귀하의 특정 사용 사례에 맞게 올바르게 작동하는지 확인하세요.
+
+## 사용 사례
+
+일반적인 Salesforce + CrewAI 트리거 시나리오는 다음과 같습니다:
+
+- **Lead 처리**: 들어오는 리드를 자동으로 분석하고 점수화
+- **제안서 생성**: 기회 데이터를 기반으로 맞춤형 제안서 생성
+- **고객 인사이트**: 고객 상호작용 이력에서 분석 보고서 생성
+- **후속 조치 자동화**: 개인화된 후속 메시지 및 추천 생성
+
+## 다음 단계
+
+자세한 설정 지침 및 고급 구성 옵션에 대해서는 CrewAI Enterprise 지원팀에 문의해 주시기 바랍니다. 지원팀은 귀하의 특정 Salesforce 환경과 비즈니스 요구에 맞는 맞춤형 안내를 제공해 드릴 수 있습니다.
\ No newline at end of file
diff --git a/docs/ko/enterprise/guides/slack-trigger.mdx b/docs/ko/enterprise/guides/slack-trigger.mdx
new file mode 100644
index 000000000..565b0a212
--- /dev/null
+++ b/docs/ko/enterprise/guides/slack-trigger.mdx
@@ -0,0 +1,61 @@
+---
+title: "Slack 트리거"
+description: "슬래시 명령어를 사용해 Slack에서 CrewAI crew를 직접 트리거합니다"
+icon: "slack"
+---
+
+이 가이드는 CrewAI 트리거를 사용하여 Slack에서 직접 crew를 시작하는 방법을 설명합니다.
+
+## 사전 요구 사항
+
+- CrewAI Slack 트리거가 설치되어 있고 Slack 워크스페이스에 연결되어 있음
+- CrewAI에서 하나 이상의 crew가 구성되어 있음
+
+## 설정 단계
+
+
+
+
+## 다음 단계
+
+- 구성 요소 스타일을 애플리케이션 디자인에 맞게 맞춤화하세요
+- 추가 구성을 위한 props를 추가하세요
+- 애플리케이션의 상태 관리와 통합하세요
+- 오류 처리 및 로딩 상태를 추가하세요
\ No newline at end of file
diff --git a/docs/ko/enterprise/guides/salesforce-trigger.mdx b/docs/ko/enterprise/guides/salesforce-trigger.mdx
new file mode 100644
index 000000000..b95e3a217
--- /dev/null
+++ b/docs/ko/enterprise/guides/salesforce-trigger.mdx
@@ -0,0 +1,44 @@
+---
+title: "Salesforce 트리거"
+description: "Salesforce 워크플로우에서 CrewAI crew를 트리거하여 CRM 자동화"
+icon: "salesforce"
+---
+
+CrewAI Enterprise는 Salesforce에서 트리거되어 고객 관계 관리 워크플로우를 자동화하고 영업 운영을 강화할 수 있습니다.
+
+## 개요
+
+Salesforce는 기업이 영업, 서비스, 마케팅 운영을 효율화할 수 있도록 돕는 선도적인 고객 관계 관리(CRM) 플랫폼입니다. Salesforce에서 CrewAI 트리거를 설정하면 다음과 같은 작업을 수행할 수 있습니다:
+
+- 리드 점수 산정 및 자격 심사 자동화
+- 개인화된 영업 자료 생성
+- AI 기반 응답으로 고객 서비스 강화
+- 데이터 분석 및 보고 간소화
+
+## 데모
+
+
+
+
+
+## 시작하기
+
+Salesforce 트리거를 설정하려면:
+
+1. **지원팀 문의**: Salesforce 트리거 설정을 위해 CrewAI Enterprise 지원팀에 연락하세요.
+2. **요구 사항 검토**: 필요한 Salesforce 권한과 API 액세스 권한이 있는지 확인하세요.
+3. **연결 구성**: 지원팀과 협력하여 CrewAI와 귀하의 Salesforce 인스턴스 간의 연결을 설정하세요.
+4. **트리거 테스트**: 트리거가 귀하의 특정 사용 사례에 맞게 올바르게 작동하는지 확인하세요.
+
+## 사용 사례
+
+일반적인 Salesforce + CrewAI 트리거 시나리오는 다음과 같습니다:
+
+- **Lead 처리**: 들어오는 리드를 자동으로 분석하고 점수화
+- **제안서 생성**: 기회 데이터를 기반으로 맞춤형 제안서 생성
+- **고객 인사이트**: 고객 상호작용 이력에서 분석 보고서 생성
+- **후속 조치 자동화**: 개인화된 후속 메시지 및 추천 생성
+
+## 다음 단계
+
+자세한 설정 지침 및 고급 구성 옵션에 대해서는 CrewAI Enterprise 지원팀에 문의해 주시기 바랍니다. 지원팀은 귀하의 특정 Salesforce 환경과 비즈니스 요구에 맞는 맞춤형 안내를 제공해 드릴 수 있습니다.
\ No newline at end of file
diff --git a/docs/ko/enterprise/guides/slack-trigger.mdx b/docs/ko/enterprise/guides/slack-trigger.mdx
new file mode 100644
index 000000000..565b0a212
--- /dev/null
+++ b/docs/ko/enterprise/guides/slack-trigger.mdx
@@ -0,0 +1,61 @@
+---
+title: "Slack 트리거"
+description: "슬래시 명령어를 사용해 Slack에서 CrewAI crew를 직접 트리거합니다"
+icon: "slack"
+---
+
+이 가이드는 CrewAI 트리거를 사용하여 Slack에서 직접 crew를 시작하는 방법을 설명합니다.
+
+## 사전 요구 사항
+
+- CrewAI Slack 트리거가 설치되어 있고 Slack 워크스페이스에 연결되어 있음
+- CrewAI에서 하나 이상의 crew가 구성되어 있음
+
+## 설정 단계
+
+ +
+
+ Slack이 나열되어 있고 연결되어 있는지 확인합니다.
+
+
+
+ Slack이 나열되어 있고 연결되어 있는지 확인합니다.
+  +
+ - Enter를 누르거나 "**Kickoff crew**" 옵션을 선택합니다. "**Kickoff an AI Crew**"라는 제목의 대화상자가 나타납니다.
+
+
+ - Enter를 누르거나 "**Kickoff crew**" 옵션을 선택합니다. "**Kickoff an AI Crew**"라는 제목의 대화상자가 나타납니다.
+  +
+ - crew에 입력값이 필요한 경우 "**Add Inputs**" 버튼을 클릭하여 입력값을 제공합니다.
+
+
+ - crew에 입력값이 필요한 경우 "**Add Inputs**" 버튼을 클릭하여 입력값을 제공합니다.
+  +
+ - crew가 실행을 시작하면 Slack 채널에서 결과를 확인할 수 있습니다.
+
+
+
+ - crew가 실행을 시작하면 Slack 채널에서 결과를 확인할 수 있습니다.
+
+  +
+
+
+  +
+
+
+  +
+
+
+
+
+
+
+  +
+ - 새로운 역할을 추가하려면 `Add Role` 버튼을 클릭하세요.
+ - 역할의 세부 정보와 권한을 입력한 후 `Create Role` 버튼을 클릭하여 역할을 생성하세요.
+
+
+
+ - 새로운 역할을 추가하려면 `Add Role` 버튼을 클릭하세요.
+ - 역할의 세부 정보와 권한을 입력한 후 `Create Role` 버튼을 클릭하여 역할을 생성하세요.
+
+  +
+
+
+  +
+ - 멤버가 초대를 수락하면 역할을 추가할 수 있습니다.
+ - 다시 `Roles` 탭으로 이동하세요
+ - 역할을 추가할 멤버로 이동한 후 `Role` 열에서 드롭다운을 클릭하세요
+ - 멤버에게 추가할 역할을 선택하세요
+ - `Update` 버튼을 클릭하여 역할을 저장하세요
+
+
+
+ - 멤버가 초대를 수락하면 역할을 추가할 수 있습니다.
+ - 다시 `Roles` 탭으로 이동하세요
+ - 역할을 추가할 멤버로 이동한 후 `Role` 열에서 드롭다운을 클릭하세요
+ - 멤버에게 추가할 역할을 선택하세요
+ - `Update` 버튼을 클릭하여 역할을 저장하세요
+
+  +
+
+
+  +
+
+
+  +
+
+ 3. HTTP 액션 단계를 추가하세요.
+ - 액션을 `Send HTTP request`로 설정하세요.
+ - 메소드는 `POST`로 사용하세요.
+ - URL은 CrewAI Enterprise kickoff 엔드포인트로 설정하세요.
+ - 필요한 헤더 추가 (예: `Bearer Token`)
+
+
+
+
+ 3. HTTP 액션 단계를 추가하세요.
+ - 액션을 `Send HTTP request`로 설정하세요.
+ - 메소드는 `POST`로 사용하세요.
+ - URL은 CrewAI Enterprise kickoff 엔드포인트로 설정하세요.
+ - 필요한 헤더 추가 (예: `Bearer Token`)
+
+  +
+
+ - Body에는 2단계에서 구성한 JSON content를 포함하세요.
+
+
+
+
+ - Body에는 2단계에서 구성한 JSON content를 포함하세요.
+
+  +
+
+ - crew가 미리 정의된 시간에 kickoff됩니다.
+
+
+
+ - crew가 미리 정의된 시간에 kickoff됩니다.
+  +
+
+ 2. 트리거로 webhook 단계를 추가하세요:
+ - 트리거 유형으로 `Catch Webhook`을 선택하세요.
+ - 이 작업을 통해 HTTP 요청을 수신하고 flow를 트리거하는 고유 URL이 생성됩니다.
+
+
+
+
+ 2. 트리거로 webhook 단계를 추가하세요:
+ - 트리거 유형으로 `Catch Webhook`을 선택하세요.
+ - 이 작업을 통해 HTTP 요청을 수신하고 flow를 트리거하는 고유 URL이 생성됩니다.
+
+  +
+
+ - 이메일이 crew webhook 본문 텍스트를 사용하도록 구성하세요.
+
+
+
+
+ - 이메일이 crew webhook 본문 텍스트를 사용하도록 구성하세요.
+
+  +
+
+
+  +
+
+
+  +
+ - 트리거 이벤트로 `New Pushed Message`를 선택합니다.
+ - 아직 Slack 계정을 연결하지 않았다면 연결하세요.
+
+
+ - 트리거 이벤트로 `New Pushed Message`를 선택합니다.
+ - 아직 Slack 계정을 연결하지 않았다면 연결하세요.
+  +
+
+
+  +
+ - Slack 메시지의 데이터를 사용하여 Crew의 입력값을 구성하세요.
+
+
+ - Slack 메시지의 데이터를 사용하여 Crew의 입력값을 구성하세요.
+  +
+
+
+
+
+  +
+
+
+  +
+
+
+  +
+
+ - 3점 버튼을 선택한 후 'Push to Zapier'를 선택하세요.
+
+
+
+
+
+ - 3점 버튼을 선택한 후 'Push to Zapier'를 선택하세요.
+
+
+  +
+
+
+  +
+
+
+  +
+
+CrewAI Enterprise는 오픈 소스 프레임워크의 강력함에 프로덕션 배포, 협업, 확장성을 위한 기능을 더했습니다. crew를 관리형 인프라에 배포하고, 실행을 실시간으로 모니터링하세요.
+
+## 주요 기능
+
+
+
+
+CrewAI Enterprise는 오픈 소스 프레임워크의 강력함에 프로덕션 배포, 협업, 확장성을 위한 기능을 더했습니다. crew를 관리형 인프라에 배포하고, 실행을 실시간으로 모니터링하세요.
+
+## 주요 기능
+
+ +
+
+이 매트릭스를 통해 다양한 방식이 복잡성과 정밀성에 대한 요구 사항과 어떻게 일치하는지 시각적으로 확인할 수 있습니다. 각 사분면이 의미하는 바와 그것이 아키텍처 선택에 어떻게 도움이 되는지 함께 살펴보겠습니다.
+
+## 복잡성-정밀도 행렬 설명
+
+### 복잡성이란 무엇인가?
+
+CrewAI 애플리케이션의 맥락에서 **복잡성**은 다음을 의미합니다:
+
+- 요구되는 뚜렷한 단계 또는 작업 수
+- 수행해야 할 작업의 다양성
+- 서로 다른 구성 요소 간의 상호 의존성
+- 조건부 로직과 분기의 필요성
+- 전체 워크플로우의 정교함
+
+### 정밀성이란 무엇인가?
+
+**정밀성**은 이 맥락에서 다음을 의미합니다:
+
+- 최종 결과물에 요구되는 정확성
+- 구조화되고 예측 가능한 결과의 필요성
+- 재현성의 중요성
+- 각 단계에 대한 통제 수준
+- 출력의 변동 허용치
+
+### 네 가지 사분면
+
+#### 1. 낮은 복잡도, 낮은 정밀도
+
+**특징:**
+- 단순하고 직관적인 작업
+- 출력 결과의 일부 변형 허용
+- 제한된 단계 수
+- 창의적이거나 탐색적인 응용
+
+**권장 접근법:** 최소한의 에이전트를 가진 Simple Crews
+
+**예시 사용 사례:**
+- 기본 콘텐츠 생성
+- 아이디어 브레인스토밍
+- 간단한 요약 작업
+- 창의적 글쓰기 보조
+
+#### 2. 낮은 복잡성, 높은 정밀도
+
+**특징:**
+- 정확하고 구조화된 결과물이 요구되는 단순한 워크플로우
+- 재현 가능한 결과가 필요한 경우
+- 단계는 제한적이지만, 높은 정확도가 요구됨
+- 주로 데이터 처리 또는 변환이 포함됨
+
+**권장 방식:** 직접적인 LLM 호출이나 구조화된 출력이 있는 간단한 Crew 사용
+
+**예시 활용 사례:**
+- 데이터 추출 및 변환
+- 양식 작성 및 검증
+- 구조화된 콘텐츠 생성(JSON, XML)
+- 단순 분류 작업
+
+#### 3. 높은 복잡성, 낮은 정밀도
+
+**특징:**
+- 여러 단계로 이루어진 다단계 프로세스
+- 창의적이거나 탐색적인 출력물
+- 구성 요소 간의 복잡한 상호작용
+- 최종 결과의 변동성 허용
+
+**권장 접근 방식:** 여러 전문화된 agent가 포함된 Complex Crew
+
+**예시 사용 사례:**
+- 연구 및 분석
+- 콘텐츠 생성 파이프라인
+- 탐색적 데이터 분석
+- 창의적 문제 해결
+
+#### 4. 높은 복잡성, 높은 정밀도
+
+**특징:**
+- 구조화된 산출물이 요구되는 복잡한 워크플로
+- 엄격한 정확성 요구사항을 가진 여러 상호 의존적인 단계
+- 정교한 처리와 정밀한 결과 모두 필요
+- 종종 임무에 중요한 애플리케이션
+
+**권장 접근 방식:** 검증 단계를 포함한 여러 Crew를 오케스트레이션하는 Flows
+
+**예시 사용 사례:**
+- 엔터프라이즈 의사결정 지원 시스템
+- 복잡한 데이터 처리 파이프라인
+- 다단계 문서 처리
+- 규제 산업 애플리케이션
+
+## 크루와 플로우 중에서 선택하기
+
+### Crews를 선택해야 할 때
+
+Crews는 다음과 같은 경우에 이상적입니다:
+
+1. **협업 지능이 필요할 때** - 서로 다른 전문성을 가진 여러 agent들이 함께 작업해야 할 때
+2. **문제가 창발적 사고를 요구할 때** - 다양한 관점과 접근 방식에서의 해결책이 이득이 될 때
+3. **작업이 주로 창의적이거나 분석적일 때** - 작업이 리서치, 콘텐츠 제작, 분석을 포함할 때
+4. **엄격한 구조보다는 적응력을 중시할 때** - agent의 자율성이 workflow에 도움이 될 때
+5. **출력 형식이 다소 유연할 수 있을 때** - 출력 구조에 약간의 변동이 허용될 때
+
+```python
+# Example: Research Crew for market analysis
+from crewai import Agent, Crew, Process, Task
+
+# Create specialized agents
+researcher = Agent(
+ role="Market Research Specialist",
+ goal="Find comprehensive market data on emerging technologies",
+ backstory="You are an expert at discovering market trends and gathering data."
+)
+
+analyst = Agent(
+ role="Market Analyst",
+ goal="Analyze market data and identify key opportunities",
+ backstory="You excel at interpreting market data and spotting valuable insights."
+)
+
+# Define their tasks
+research_task = Task(
+ description="Research the current market landscape for AI-powered healthcare solutions",
+ expected_output="Comprehensive market data including key players, market size, and growth trends",
+ agent=researcher
+)
+
+analysis_task = Task(
+ description="Analyze the market data and identify the top 3 investment opportunities",
+ expected_output="Analysis report with 3 recommended investment opportunities and rationale",
+ agent=analyst,
+ context=[research_task]
+)
+
+# Create the crew
+market_analysis_crew = Crew(
+ agents=[researcher, analyst],
+ tasks=[research_task, analysis_task],
+ process=Process.sequential,
+ verbose=True
+)
+
+# Run the crew
+result = market_analysis_crew.kickoff()
+```
+
+### 플로우를 선택해야 할 때
+
+플로우는 다음과 같은 경우에 이상적입니다:
+
+1. **실행에 대한 정밀한 제어가 필요할 때** - 워크플로우에 정확한 순서 지정과 상태 관리가 필요한 경우
+2. **애플리케이션에 복잡한 상태 요구사항이 있을 때** - 여러 단계에 걸쳐 상태를 유지하고 변환해야 하는 경우
+3. **구조화되고 예측 가능한 출력이 필요할 때** - 애플리케이션에서 일관되고 포맷된 결과가 필요한 경우
+4. **워크플로우에 조건부 로직이 포함될 때** - 중간 결과에 따라 다른 경로를 선택해야 하는 경우
+5. **AI와 절차적 코드를 결합해야 할 때** - 솔루션에 AI 기능과 전통적인 프로그래밍이 모두 필요한 경우
+
+```python
+# Example: Customer Support Flow with structured processing
+from crewai.flow.flow import Flow, listen, router, start
+from pydantic import BaseModel
+from typing import List, Dict
+
+# Define structured state
+class SupportTicketState(BaseModel):
+ ticket_id: str = ""
+ customer_name: str = ""
+ issue_description: str = ""
+ category: str = ""
+ priority: str = "medium"
+ resolution: str = ""
+ satisfaction_score: int = 0
+
+class CustomerSupportFlow(Flow[SupportTicketState]):
+ @start()
+ def receive_ticket(self):
+ # In a real app, this might come from an API
+ self.state.ticket_id = "TKT-12345"
+ self.state.customer_name = "Alex Johnson"
+ self.state.issue_description = "Unable to access premium features after payment"
+ return "Ticket received"
+
+ @listen(receive_ticket)
+ def categorize_ticket(self, _):
+ # Use a direct LLM call for categorization
+ from crewai import LLM
+ llm = LLM(model="openai/gpt-4o-mini")
+
+ prompt = f"""
+ Categorize the following customer support issue into one of these categories:
+ - Billing
+ - Account Access
+ - Technical Issue
+ - Feature Request
+ - Other
+
+ Issue: {self.state.issue_description}
+
+ Return only the category name.
+ """
+
+ self.state.category = llm.call(prompt).strip()
+ return self.state.category
+
+ @router(categorize_ticket)
+ def route_by_category(self, category):
+ # Route to different handlers based on category
+ return category.lower().replace(" ", "_")
+
+ @listen("billing")
+ def handle_billing_issue(self):
+ # Handle billing-specific logic
+ self.state.priority = "high"
+ # More billing-specific processing...
+ return "Billing issue handled"
+
+ @listen("account_access")
+ def handle_access_issue(self):
+ # Handle access-specific logic
+ self.state.priority = "high"
+ # More access-specific processing...
+ return "Access issue handled"
+
+ # Additional category handlers...
+
+ @listen("billing", "account_access", "technical_issue", "feature_request", "other")
+ def resolve_ticket(self, resolution_info):
+ # Final resolution step
+ self.state.resolution = f"Issue resolved: {resolution_info}"
+ return self.state.resolution
+
+# Run the flow
+support_flow = CustomerSupportFlow()
+result = support_flow.kickoff()
+```
+
+### 크루와 플로우를 결합해야 할 때
+
+가장 정교한 애플리케이션은 종종 크루와 플로우를 결합할 때 이점을 얻습니다:
+
+1. **복잡한 다단계 프로세스** - 플로우를 사용해 전체 프로세스를 오케스트레이션하고, 크루를 통해 복잡한 하위 작업을 처리합니다.
+2. **창의성과 구조가 모두 필요한 애플리케이션** - 창의적인 작업에는 크루를 사용하고, 구조적인 처리는 플로우로 처리합니다.
+3. **엔터프라이즈급 AI 애플리케이션** - 플로우로 상태 및 프로세스 흐름을 관리하면서, 크루를 활용해 특화된 작업을 수행합니다.
+
+```python
+# Example: Content Production Pipeline combining Crews and Flows
+from crewai.flow.flow import Flow, listen, start
+from crewai import Agent, Crew, Process, Task
+from pydantic import BaseModel
+from typing import List, Dict
+
+class ContentState(BaseModel):
+ topic: str = ""
+ target_audience: str = ""
+ content_type: str = ""
+ outline: Dict = {}
+ draft_content: str = ""
+ final_content: str = ""
+ seo_score: int = 0
+
+class ContentProductionFlow(Flow[ContentState]):
+ @start()
+ def initialize_project(self):
+ # Set initial parameters
+ self.state.topic = "Sustainable Investing"
+ self.state.target_audience = "Millennial Investors"
+ self.state.content_type = "Blog Post"
+ return "Project initialized"
+
+ @listen(initialize_project)
+ def create_outline(self, _):
+ # Use a research crew to create an outline
+ researcher = Agent(
+ role="Content Researcher",
+ goal=f"Research {self.state.topic} for {self.state.target_audience}",
+ backstory="You are an expert researcher with deep knowledge of content creation."
+ )
+
+ outliner = Agent(
+ role="Content Strategist",
+ goal=f"Create an engaging outline for a {self.state.content_type}",
+ backstory="You excel at structuring content for maximum engagement."
+ )
+
+ research_task = Task(
+ description=f"Research {self.state.topic} focusing on what would interest {self.state.target_audience}",
+ expected_output="Comprehensive research notes with key points and statistics",
+ agent=researcher
+ )
+
+ outline_task = Task(
+ description=f"Create an outline for a {self.state.content_type} about {self.state.topic}",
+ expected_output="Detailed content outline with sections and key points",
+ agent=outliner,
+ context=[research_task]
+ )
+
+ outline_crew = Crew(
+ agents=[researcher, outliner],
+ tasks=[research_task, outline_task],
+ process=Process.sequential,
+ verbose=True
+ )
+
+ # Run the crew and store the result
+ result = outline_crew.kickoff()
+
+ # Parse the outline (in a real app, you might use a more robust parsing approach)
+ import json
+ try:
+ self.state.outline = json.loads(result.raw)
+ except:
+ # Fallback if not valid JSON
+ self.state.outline = {"sections": result.raw}
+
+ return "Outline created"
+
+ @listen(create_outline)
+ def write_content(self, _):
+ # Use a writing crew to create the content
+ writer = Agent(
+ role="Content Writer",
+ goal=f"Write engaging content for {self.state.target_audience}",
+ backstory="You are a skilled writer who creates compelling content."
+ )
+
+ editor = Agent(
+ role="Content Editor",
+ goal="Ensure content is polished, accurate, and engaging",
+ backstory="You have a keen eye for detail and a talent for improving content."
+ )
+
+ writing_task = Task(
+ description=f"Write a {self.state.content_type} about {self.state.topic} following this outline: {self.state.outline}",
+ expected_output="Complete draft content in markdown format",
+ agent=writer
+ )
+
+ editing_task = Task(
+ description="Edit and improve the draft content for clarity, engagement, and accuracy",
+ expected_output="Polished final content in markdown format",
+ agent=editor,
+ context=[writing_task]
+ )
+
+ writing_crew = Crew(
+ agents=[writer, editor],
+ tasks=[writing_task, editing_task],
+ process=Process.sequential,
+ verbose=True
+ )
+
+ # Run the crew and store the result
+ result = writing_crew.kickoff()
+ self.state.final_content = result.raw
+
+ return "Content created"
+
+ @listen(write_content)
+ def optimize_for_seo(self, _):
+ # Use a direct LLM call for SEO optimization
+ from crewai import LLM
+ llm = LLM(model="openai/gpt-4o-mini")
+
+ prompt = f"""
+ Analyze this content for SEO effectiveness for the keyword "{self.state.topic}".
+ Rate it on a scale of 1-100 and provide 3 specific recommendations for improvement.
+
+ Content: {self.state.final_content[:1000]}... (truncated for brevity)
+
+ Format your response as JSON with the following structure:
+ {{
+ "score": 85,
+ "recommendations": [
+ "Recommendation 1",
+ "Recommendation 2",
+ "Recommendation 3"
+ ]
+ }}
+ """
+
+ seo_analysis = llm.call(prompt)
+
+ # Parse the SEO analysis
+ import json
+ try:
+ analysis = json.loads(seo_analysis)
+ self.state.seo_score = analysis.get("score", 0)
+ return analysis
+ except:
+ self.state.seo_score = 50
+ return {"score": 50, "recommendations": ["Unable to parse SEO analysis"]}
+
+# Run the flow
+content_flow = ContentProductionFlow()
+result = content_flow.kickoff()
+```
+
+## 실용적인 평가 프레임워크
+
+특정 사용 사례에 맞는 올바른 접근 방식을 결정하려면 다음 단계별 평가 프레임워크를 따르세요:
+
+### 1단계: 복잡성 평가
+
+아래와 같은 기준으로 애플리케이션의 복잡성을 1~10점 척도로 평가하세요:
+
+1. **단계 수**: 얼마나 많은 개별 작업이 필요한가요?
+ - 1-3단계: 낮은 복잡성 (1-3)
+ - 4-7단계: 중간 복잡성 (4-7)
+ - 8단계 이상: 높은 복잡성 (8-10)
+
+2. **상호 의존성**: 서로 다른 부분 간의 연결성은 어느 정도인가요?
+ - 의존성이 거의 없음: 낮은 복잡성 (1-3)
+ - 다소 의존성 있음: 중간 복잡성 (4-7)
+ - 복잡한 다중 의존성: 높은 복잡성 (8-10)
+
+3. **조건부 논리**: 얼마나 많은 분기 및 의사결정이 필요한가요?
+ - 선형 프로세스: 낮은 복잡성 (1-3)
+ - 분기가 일부 있음: 중간 복잡성 (4-7)
+ - 복잡한 결정 트리: 높은 복잡성 (8-10)
+
+4. **도메인 지식**: 요구되는 지식의 전문성은 어느 정도인가요?
+ - 일반적인 지식: 낮은 복잡성 (1-3)
+ - 일부 전문 지식 필요: 중간 복잡성 (4-7)
+ - 여러 도메인에 대한 깊은 전문성 필요: 높은 복잡성 (8-10)
+
+평균 점수를 계산하여 전체 복잡성을 결정하세요.
+
+### 2단계: 정밀도 요구사항 평가
+
+정밀도 요구사항을 1-10점 척도로 평가하세요. 다음을 고려합니다:
+
+1. **출력 구조**: 출력이 얼마나 구조화되어야 합니까?
+ - 자유형 텍스트: 낮은 정밀도 (1-3)
+ - 반구조화: 중간 정밀도 (4-7)
+ - 엄격한 포맷(JSON, XML): 높은 정밀도 (8-10)
+
+2. **정확성 필요성**: 사실적 정확성이 얼마나 중요합니까?
+ - 창의적 콘텐츠: 낮은 정밀도 (1-3)
+ - 정보성 콘텐츠: 중간 정밀도 (4-7)
+ - 중요한 정보: 높은 정밀도 (8-10)
+
+3. **재현성**: 실행마다 결과가 얼마나 일관되어야 합니까?
+ - 변동 허용: 낮은 정밀도 (1-3)
+ - 어느 정도 일관성 필요: 중간 정밀도 (4-7)
+ - 정확한 재현성 필요: 높은 정밀도 (8-10)
+
+4. **오류 허용도**: 오류의 영향은 어느 정도입니까?
+ - 영향 적음: 낮은 정밀도 (1-3)
+ - 영향 보통: 중간 정밀도 (4-7)
+ - 영향 큼: 높은 정밀도 (8-10)
+
+평균 점수를 계산하여 전체 정밀도 요구사항을 결정하세요.
+
+### 3단계: 매트릭스에 매핑하기
+
+복잡도와 정밀도 점수를 매트릭스에 표시하세요:
+
+- **낮은 복잡도(1-4), 낮은 정밀도(1-4)**: Simple Crews
+- **낮은 복잡도(1-4), 높은 정밀도(5-10)**: 직접적인 LLM 호출이 있는 Flows
+- **높은 복잡도(5-10), 낮은 정밀도(1-4)**: Complex Crews
+- **높은 복잡도(5-10), 높은 정밀도(5-10)**: Crews를 오케스트레이션하는 Flows
+
+### 4단계: 추가 요소 고려
+
+복잡성과 정밀성 외에도 다음을 고려하세요:
+
+1. **개발 시간**: crew는 프로토타입을 더 빠르게 만들 수 있습니다
+2. **유지보수 필요**: flow는 장기적인 유지보수에 더 적합합니다
+3. **팀 전문성**: 팀이 다양한 접근법에 얼마나 익숙한지 고려하세요
+4. **확장성 요구 사항**: flow는 일반적으로 복잡한 애플리케이션에 더 잘 확장됩니다
+5. **통합 필요**: 솔루션이 기존 시스템과 어떻게 통합될지 고려하세요
+
+## 결론
+
+Crews와 Flows 중에서 선택하거나 결합하는 것은 CrewAI 애플리케이션의 효과성, 유지 관리성, 확장성에 영향을 미치는 중요한 아키텍처적 결정입니다. 복잡성과 정밀성이라는 차원에서 사용 사례를 평가함으로써, 귀하의 특정 요구 사항에 부합하는 정보에 기반한 결정을 내릴 수 있습니다.
+
+가장 좋은 접근방식은 애플리케이션이 성숙해지면서 종종 진화한다는 점을 기억하세요. 귀하의 요구를 충족하는 가장 간단한 해결책으로 시작하고, 경험이 쌓이고 요구 사항이 명확해지면 아키텍처를 개선할 준비를 하세요.
+
+
+
+
+이 매트릭스를 통해 다양한 방식이 복잡성과 정밀성에 대한 요구 사항과 어떻게 일치하는지 시각적으로 확인할 수 있습니다. 각 사분면이 의미하는 바와 그것이 아키텍처 선택에 어떻게 도움이 되는지 함께 살펴보겠습니다.
+
+## 복잡성-정밀도 행렬 설명
+
+### 복잡성이란 무엇인가?
+
+CrewAI 애플리케이션의 맥락에서 **복잡성**은 다음을 의미합니다:
+
+- 요구되는 뚜렷한 단계 또는 작업 수
+- 수행해야 할 작업의 다양성
+- 서로 다른 구성 요소 간의 상호 의존성
+- 조건부 로직과 분기의 필요성
+- 전체 워크플로우의 정교함
+
+### 정밀성이란 무엇인가?
+
+**정밀성**은 이 맥락에서 다음을 의미합니다:
+
+- 최종 결과물에 요구되는 정확성
+- 구조화되고 예측 가능한 결과의 필요성
+- 재현성의 중요성
+- 각 단계에 대한 통제 수준
+- 출력의 변동 허용치
+
+### 네 가지 사분면
+
+#### 1. 낮은 복잡도, 낮은 정밀도
+
+**특징:**
+- 단순하고 직관적인 작업
+- 출력 결과의 일부 변형 허용
+- 제한된 단계 수
+- 창의적이거나 탐색적인 응용
+
+**권장 접근법:** 최소한의 에이전트를 가진 Simple Crews
+
+**예시 사용 사례:**
+- 기본 콘텐츠 생성
+- 아이디어 브레인스토밍
+- 간단한 요약 작업
+- 창의적 글쓰기 보조
+
+#### 2. 낮은 복잡성, 높은 정밀도
+
+**특징:**
+- 정확하고 구조화된 결과물이 요구되는 단순한 워크플로우
+- 재현 가능한 결과가 필요한 경우
+- 단계는 제한적이지만, 높은 정확도가 요구됨
+- 주로 데이터 처리 또는 변환이 포함됨
+
+**권장 방식:** 직접적인 LLM 호출이나 구조화된 출력이 있는 간단한 Crew 사용
+
+**예시 활용 사례:**
+- 데이터 추출 및 변환
+- 양식 작성 및 검증
+- 구조화된 콘텐츠 생성(JSON, XML)
+- 단순 분류 작업
+
+#### 3. 높은 복잡성, 낮은 정밀도
+
+**특징:**
+- 여러 단계로 이루어진 다단계 프로세스
+- 창의적이거나 탐색적인 출력물
+- 구성 요소 간의 복잡한 상호작용
+- 최종 결과의 변동성 허용
+
+**권장 접근 방식:** 여러 전문화된 agent가 포함된 Complex Crew
+
+**예시 사용 사례:**
+- 연구 및 분석
+- 콘텐츠 생성 파이프라인
+- 탐색적 데이터 분석
+- 창의적 문제 해결
+
+#### 4. 높은 복잡성, 높은 정밀도
+
+**특징:**
+- 구조화된 산출물이 요구되는 복잡한 워크플로
+- 엄격한 정확성 요구사항을 가진 여러 상호 의존적인 단계
+- 정교한 처리와 정밀한 결과 모두 필요
+- 종종 임무에 중요한 애플리케이션
+
+**권장 접근 방식:** 검증 단계를 포함한 여러 Crew를 오케스트레이션하는 Flows
+
+**예시 사용 사례:**
+- 엔터프라이즈 의사결정 지원 시스템
+- 복잡한 데이터 처리 파이프라인
+- 다단계 문서 처리
+- 규제 산업 애플리케이션
+
+## 크루와 플로우 중에서 선택하기
+
+### Crews를 선택해야 할 때
+
+Crews는 다음과 같은 경우에 이상적입니다:
+
+1. **협업 지능이 필요할 때** - 서로 다른 전문성을 가진 여러 agent들이 함께 작업해야 할 때
+2. **문제가 창발적 사고를 요구할 때** - 다양한 관점과 접근 방식에서의 해결책이 이득이 될 때
+3. **작업이 주로 창의적이거나 분석적일 때** - 작업이 리서치, 콘텐츠 제작, 분석을 포함할 때
+4. **엄격한 구조보다는 적응력을 중시할 때** - agent의 자율성이 workflow에 도움이 될 때
+5. **출력 형식이 다소 유연할 수 있을 때** - 출력 구조에 약간의 변동이 허용될 때
+
+```python
+# Example: Research Crew for market analysis
+from crewai import Agent, Crew, Process, Task
+
+# Create specialized agents
+researcher = Agent(
+ role="Market Research Specialist",
+ goal="Find comprehensive market data on emerging technologies",
+ backstory="You are an expert at discovering market trends and gathering data."
+)
+
+analyst = Agent(
+ role="Market Analyst",
+ goal="Analyze market data and identify key opportunities",
+ backstory="You excel at interpreting market data and spotting valuable insights."
+)
+
+# Define their tasks
+research_task = Task(
+ description="Research the current market landscape for AI-powered healthcare solutions",
+ expected_output="Comprehensive market data including key players, market size, and growth trends",
+ agent=researcher
+)
+
+analysis_task = Task(
+ description="Analyze the market data and identify the top 3 investment opportunities",
+ expected_output="Analysis report with 3 recommended investment opportunities and rationale",
+ agent=analyst,
+ context=[research_task]
+)
+
+# Create the crew
+market_analysis_crew = Crew(
+ agents=[researcher, analyst],
+ tasks=[research_task, analysis_task],
+ process=Process.sequential,
+ verbose=True
+)
+
+# Run the crew
+result = market_analysis_crew.kickoff()
+```
+
+### 플로우를 선택해야 할 때
+
+플로우는 다음과 같은 경우에 이상적입니다:
+
+1. **실행에 대한 정밀한 제어가 필요할 때** - 워크플로우에 정확한 순서 지정과 상태 관리가 필요한 경우
+2. **애플리케이션에 복잡한 상태 요구사항이 있을 때** - 여러 단계에 걸쳐 상태를 유지하고 변환해야 하는 경우
+3. **구조화되고 예측 가능한 출력이 필요할 때** - 애플리케이션에서 일관되고 포맷된 결과가 필요한 경우
+4. **워크플로우에 조건부 로직이 포함될 때** - 중간 결과에 따라 다른 경로를 선택해야 하는 경우
+5. **AI와 절차적 코드를 결합해야 할 때** - 솔루션에 AI 기능과 전통적인 프로그래밍이 모두 필요한 경우
+
+```python
+# Example: Customer Support Flow with structured processing
+from crewai.flow.flow import Flow, listen, router, start
+from pydantic import BaseModel
+from typing import List, Dict
+
+# Define structured state
+class SupportTicketState(BaseModel):
+ ticket_id: str = ""
+ customer_name: str = ""
+ issue_description: str = ""
+ category: str = ""
+ priority: str = "medium"
+ resolution: str = ""
+ satisfaction_score: int = 0
+
+class CustomerSupportFlow(Flow[SupportTicketState]):
+ @start()
+ def receive_ticket(self):
+ # In a real app, this might come from an API
+ self.state.ticket_id = "TKT-12345"
+ self.state.customer_name = "Alex Johnson"
+ self.state.issue_description = "Unable to access premium features after payment"
+ return "Ticket received"
+
+ @listen(receive_ticket)
+ def categorize_ticket(self, _):
+ # Use a direct LLM call for categorization
+ from crewai import LLM
+ llm = LLM(model="openai/gpt-4o-mini")
+
+ prompt = f"""
+ Categorize the following customer support issue into one of these categories:
+ - Billing
+ - Account Access
+ - Technical Issue
+ - Feature Request
+ - Other
+
+ Issue: {self.state.issue_description}
+
+ Return only the category name.
+ """
+
+ self.state.category = llm.call(prompt).strip()
+ return self.state.category
+
+ @router(categorize_ticket)
+ def route_by_category(self, category):
+ # Route to different handlers based on category
+ return category.lower().replace(" ", "_")
+
+ @listen("billing")
+ def handle_billing_issue(self):
+ # Handle billing-specific logic
+ self.state.priority = "high"
+ # More billing-specific processing...
+ return "Billing issue handled"
+
+ @listen("account_access")
+ def handle_access_issue(self):
+ # Handle access-specific logic
+ self.state.priority = "high"
+ # More access-specific processing...
+ return "Access issue handled"
+
+ # Additional category handlers...
+
+ @listen("billing", "account_access", "technical_issue", "feature_request", "other")
+ def resolve_ticket(self, resolution_info):
+ # Final resolution step
+ self.state.resolution = f"Issue resolved: {resolution_info}"
+ return self.state.resolution
+
+# Run the flow
+support_flow = CustomerSupportFlow()
+result = support_flow.kickoff()
+```
+
+### 크루와 플로우를 결합해야 할 때
+
+가장 정교한 애플리케이션은 종종 크루와 플로우를 결합할 때 이점을 얻습니다:
+
+1. **복잡한 다단계 프로세스** - 플로우를 사용해 전체 프로세스를 오케스트레이션하고, 크루를 통해 복잡한 하위 작업을 처리합니다.
+2. **창의성과 구조가 모두 필요한 애플리케이션** - 창의적인 작업에는 크루를 사용하고, 구조적인 처리는 플로우로 처리합니다.
+3. **엔터프라이즈급 AI 애플리케이션** - 플로우로 상태 및 프로세스 흐름을 관리하면서, 크루를 활용해 특화된 작업을 수행합니다.
+
+```python
+# Example: Content Production Pipeline combining Crews and Flows
+from crewai.flow.flow import Flow, listen, start
+from crewai import Agent, Crew, Process, Task
+from pydantic import BaseModel
+from typing import List, Dict
+
+class ContentState(BaseModel):
+ topic: str = ""
+ target_audience: str = ""
+ content_type: str = ""
+ outline: Dict = {}
+ draft_content: str = ""
+ final_content: str = ""
+ seo_score: int = 0
+
+class ContentProductionFlow(Flow[ContentState]):
+ @start()
+ def initialize_project(self):
+ # Set initial parameters
+ self.state.topic = "Sustainable Investing"
+ self.state.target_audience = "Millennial Investors"
+ self.state.content_type = "Blog Post"
+ return "Project initialized"
+
+ @listen(initialize_project)
+ def create_outline(self, _):
+ # Use a research crew to create an outline
+ researcher = Agent(
+ role="Content Researcher",
+ goal=f"Research {self.state.topic} for {self.state.target_audience}",
+ backstory="You are an expert researcher with deep knowledge of content creation."
+ )
+
+ outliner = Agent(
+ role="Content Strategist",
+ goal=f"Create an engaging outline for a {self.state.content_type}",
+ backstory="You excel at structuring content for maximum engagement."
+ )
+
+ research_task = Task(
+ description=f"Research {self.state.topic} focusing on what would interest {self.state.target_audience}",
+ expected_output="Comprehensive research notes with key points and statistics",
+ agent=researcher
+ )
+
+ outline_task = Task(
+ description=f"Create an outline for a {self.state.content_type} about {self.state.topic}",
+ expected_output="Detailed content outline with sections and key points",
+ agent=outliner,
+ context=[research_task]
+ )
+
+ outline_crew = Crew(
+ agents=[researcher, outliner],
+ tasks=[research_task, outline_task],
+ process=Process.sequential,
+ verbose=True
+ )
+
+ # Run the crew and store the result
+ result = outline_crew.kickoff()
+
+ # Parse the outline (in a real app, you might use a more robust parsing approach)
+ import json
+ try:
+ self.state.outline = json.loads(result.raw)
+ except:
+ # Fallback if not valid JSON
+ self.state.outline = {"sections": result.raw}
+
+ return "Outline created"
+
+ @listen(create_outline)
+ def write_content(self, _):
+ # Use a writing crew to create the content
+ writer = Agent(
+ role="Content Writer",
+ goal=f"Write engaging content for {self.state.target_audience}",
+ backstory="You are a skilled writer who creates compelling content."
+ )
+
+ editor = Agent(
+ role="Content Editor",
+ goal="Ensure content is polished, accurate, and engaging",
+ backstory="You have a keen eye for detail and a talent for improving content."
+ )
+
+ writing_task = Task(
+ description=f"Write a {self.state.content_type} about {self.state.topic} following this outline: {self.state.outline}",
+ expected_output="Complete draft content in markdown format",
+ agent=writer
+ )
+
+ editing_task = Task(
+ description="Edit and improve the draft content for clarity, engagement, and accuracy",
+ expected_output="Polished final content in markdown format",
+ agent=editor,
+ context=[writing_task]
+ )
+
+ writing_crew = Crew(
+ agents=[writer, editor],
+ tasks=[writing_task, editing_task],
+ process=Process.sequential,
+ verbose=True
+ )
+
+ # Run the crew and store the result
+ result = writing_crew.kickoff()
+ self.state.final_content = result.raw
+
+ return "Content created"
+
+ @listen(write_content)
+ def optimize_for_seo(self, _):
+ # Use a direct LLM call for SEO optimization
+ from crewai import LLM
+ llm = LLM(model="openai/gpt-4o-mini")
+
+ prompt = f"""
+ Analyze this content for SEO effectiveness for the keyword "{self.state.topic}".
+ Rate it on a scale of 1-100 and provide 3 specific recommendations for improvement.
+
+ Content: {self.state.final_content[:1000]}... (truncated for brevity)
+
+ Format your response as JSON with the following structure:
+ {{
+ "score": 85,
+ "recommendations": [
+ "Recommendation 1",
+ "Recommendation 2",
+ "Recommendation 3"
+ ]
+ }}
+ """
+
+ seo_analysis = llm.call(prompt)
+
+ # Parse the SEO analysis
+ import json
+ try:
+ analysis = json.loads(seo_analysis)
+ self.state.seo_score = analysis.get("score", 0)
+ return analysis
+ except:
+ self.state.seo_score = 50
+ return {"score": 50, "recommendations": ["Unable to parse SEO analysis"]}
+
+# Run the flow
+content_flow = ContentProductionFlow()
+result = content_flow.kickoff()
+```
+
+## 실용적인 평가 프레임워크
+
+특정 사용 사례에 맞는 올바른 접근 방식을 결정하려면 다음 단계별 평가 프레임워크를 따르세요:
+
+### 1단계: 복잡성 평가
+
+아래와 같은 기준으로 애플리케이션의 복잡성을 1~10점 척도로 평가하세요:
+
+1. **단계 수**: 얼마나 많은 개별 작업이 필요한가요?
+ - 1-3단계: 낮은 복잡성 (1-3)
+ - 4-7단계: 중간 복잡성 (4-7)
+ - 8단계 이상: 높은 복잡성 (8-10)
+
+2. **상호 의존성**: 서로 다른 부분 간의 연결성은 어느 정도인가요?
+ - 의존성이 거의 없음: 낮은 복잡성 (1-3)
+ - 다소 의존성 있음: 중간 복잡성 (4-7)
+ - 복잡한 다중 의존성: 높은 복잡성 (8-10)
+
+3. **조건부 논리**: 얼마나 많은 분기 및 의사결정이 필요한가요?
+ - 선형 프로세스: 낮은 복잡성 (1-3)
+ - 분기가 일부 있음: 중간 복잡성 (4-7)
+ - 복잡한 결정 트리: 높은 복잡성 (8-10)
+
+4. **도메인 지식**: 요구되는 지식의 전문성은 어느 정도인가요?
+ - 일반적인 지식: 낮은 복잡성 (1-3)
+ - 일부 전문 지식 필요: 중간 복잡성 (4-7)
+ - 여러 도메인에 대한 깊은 전문성 필요: 높은 복잡성 (8-10)
+
+평균 점수를 계산하여 전체 복잡성을 결정하세요.
+
+### 2단계: 정밀도 요구사항 평가
+
+정밀도 요구사항을 1-10점 척도로 평가하세요. 다음을 고려합니다:
+
+1. **출력 구조**: 출력이 얼마나 구조화되어야 합니까?
+ - 자유형 텍스트: 낮은 정밀도 (1-3)
+ - 반구조화: 중간 정밀도 (4-7)
+ - 엄격한 포맷(JSON, XML): 높은 정밀도 (8-10)
+
+2. **정확성 필요성**: 사실적 정확성이 얼마나 중요합니까?
+ - 창의적 콘텐츠: 낮은 정밀도 (1-3)
+ - 정보성 콘텐츠: 중간 정밀도 (4-7)
+ - 중요한 정보: 높은 정밀도 (8-10)
+
+3. **재현성**: 실행마다 결과가 얼마나 일관되어야 합니까?
+ - 변동 허용: 낮은 정밀도 (1-3)
+ - 어느 정도 일관성 필요: 중간 정밀도 (4-7)
+ - 정확한 재현성 필요: 높은 정밀도 (8-10)
+
+4. **오류 허용도**: 오류의 영향은 어느 정도입니까?
+ - 영향 적음: 낮은 정밀도 (1-3)
+ - 영향 보통: 중간 정밀도 (4-7)
+ - 영향 큼: 높은 정밀도 (8-10)
+
+평균 점수를 계산하여 전체 정밀도 요구사항을 결정하세요.
+
+### 3단계: 매트릭스에 매핑하기
+
+복잡도와 정밀도 점수를 매트릭스에 표시하세요:
+
+- **낮은 복잡도(1-4), 낮은 정밀도(1-4)**: Simple Crews
+- **낮은 복잡도(1-4), 높은 정밀도(5-10)**: 직접적인 LLM 호출이 있는 Flows
+- **높은 복잡도(5-10), 낮은 정밀도(1-4)**: Complex Crews
+- **높은 복잡도(5-10), 높은 정밀도(5-10)**: Crews를 오케스트레이션하는 Flows
+
+### 4단계: 추가 요소 고려
+
+복잡성과 정밀성 외에도 다음을 고려하세요:
+
+1. **개발 시간**: crew는 프로토타입을 더 빠르게 만들 수 있습니다
+2. **유지보수 필요**: flow는 장기적인 유지보수에 더 적합합니다
+3. **팀 전문성**: 팀이 다양한 접근법에 얼마나 익숙한지 고려하세요
+4. **확장성 요구 사항**: flow는 일반적으로 복잡한 애플리케이션에 더 잘 확장됩니다
+5. **통합 필요**: 솔루션이 기존 시스템과 어떻게 통합될지 고려하세요
+
+## 결론
+
+Crews와 Flows 중에서 선택하거나 결합하는 것은 CrewAI 애플리케이션의 효과성, 유지 관리성, 확장성에 영향을 미치는 중요한 아키텍처적 결정입니다. 복잡성과 정밀성이라는 차원에서 사용 사례를 평가함으로써, 귀하의 특정 요구 사항에 부합하는 정보에 기반한 결정을 내릴 수 있습니다.
+
+가장 좋은 접근방식은 애플리케이션이 성숙해지면서 종종 진화한다는 점을 기억하세요. 귀하의 요구를 충족하는 가장 간단한 해결책으로 시작하고, 경험이 쌓이고 요구 사항이 명확해지면 아키텍처를 개선할 준비를 하세요.
+
+ +
+
+## 2단계: 프로젝트 구조 살펴보기
+
+CLI가 생성한 프로젝트 구조를 이해하는 시간을 가져봅시다. CrewAI는 Python 프로젝트의 모범 사례를 따르므로, crew가 더 복잡해질수록 코드를 쉽게 유지 관리하고 확장할 수 있습니다.
+
+```
+research_crew/
+├── .gitignore
+├── pyproject.toml
+├── README.md
+├── .env
+└── src/
+ └── research_crew/
+ ├── __init__.py
+ ├── main.py
+ ├── crew.py
+ ├── tools/
+ │ ├── custom_tool.py
+ │ └── __init__.py
+ └── config/
+ ├── agents.yaml
+ └── tasks.yaml
+```
+
+이 구조는 Python 프로젝트의 모범 사례를 따르며, 코드를 체계적으로 구성할 수 있도록 해줍니다. 설정 파일(YAML)과 구현 코드(Python)의 분리로 인해, 기본 코드를 변경하지 않고도 crew의 동작을 쉽게 수정할 수 있습니다.
+
+## 3단계: 에이전트 구성하기
+
+이제 재미있는 단계가 시작됩니다 - 여러분의 AI 에이전트를 정의하는 것입니다! CrewAI에서 에이전트는 특정 역할, 목표 및 배경을 가진 전문화된 엔터티로, 이들이 어떻게 행동할지를 결정합니다. 각각 고유한 성격과 목적을 지닌 연극의 등장인물로 생각하면 됩니다.
+
+우리의 리서치 crew를 위해 두 명의 에이전트를 만들겠습니다:
+1. 정보를 찾아 정리하는 데 뛰어난 **리서처**
+2. 연구 결과를 해석하고 통찰력 있는 보고서를 작성할 수 있는 **애널리스트**
+
+이러한 전문화된 에이전트를 정의하기 위해 `agents.yaml` 파일을 수정해봅시다. `llm` 항목은 사용 중인 제공업체에 맞게 설정하세요.
+
+```yaml
+# src/research_crew/config/agents.yaml
+researcher:
+ role: >
+ Senior Research Specialist for {topic}
+ goal: >
+ Find comprehensive and accurate information about {topic}
+ with a focus on recent developments and key insights
+ backstory: >
+ You are an experienced research specialist with a talent for
+ finding relevant information from various sources. You excel at
+ organizing information in a clear and structured manner, making
+ complex topics accessible to others.
+ llm: provider/model-id # e.g. openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
+
+analyst:
+ role: >
+ Data Analyst and Report Writer for {topic}
+ goal: >
+ Analyze research findings and create a comprehensive, well-structured
+ report that presents insights in a clear and engaging way
+ backstory: >
+ You are a skilled analyst with a background in data interpretation
+ and technical writing. You have a talent for identifying patterns
+ and extracting meaningful insights from research data, then
+ communicating those insights effectively through well-crafted reports.
+ llm: provider/model-id # e.g. openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
+```
+
+각 에이전트가 고유한 역할, 목표, 그리고 배경을 가지고 있다는 점에 주목하세요. 이 요소들은 단순한 설명 그 이상으로, 실제로 에이전트가 자신의 과업을 어떻게 접근하는지에 적극적으로 영향을 미칩니다. 이러한 부분을 신중하게 설계함으로써 서로 보완하는 전문적인 역량과 관점을 가진 에이전트를 만들 수 있습니다.
+
+## 4단계: 작업 정의하기
+
+이제 agent들을 정의했으니, 이들에게 수행할 구체적인 작업을 지정해야 합니다. CrewAI의 작업(task)은 agent가 수행할 구체적인 업무를 나타내며, 자세한 지침과 예상 결과물이 포함됩니다.
+
+연구 crew를 위해 두 가지 주요 작업을 정의하겠습니다:
+1. 포괄적인 정보 수집을 위한 **연구 작업**
+2. 인사이트 있는 보고서 생성을 위한 **분석 작업**
+
+`tasks.yaml` 파일을 다음과 같이 수정해 보겠습니다:
+
+```yaml
+# src/research_crew/config/tasks.yaml
+research_task:
+ description: >
+ {topic}에 대해 철저한 연구를 수행하세요. 다음에 중점을 두세요:
+ 1. 주요 개념 및 정의
+ 2. 역사적 발전과 최근 동향
+ 3. 주요 과제와 기회
+ 4. 주목할 만한 적용 사례 또는 케이스 스터디
+ 5. 향후 전망과 잠재적 발전
+
+ 반드시 명확한 섹션으로 구성된 구조화된 형식으로 결과를 정리하세요.
+ expected_output: >
+ {topic}의 모든 요구 사항을 다루는, 잘 구성된 섹션이 포함된 포괄적인 연구 문서.
+ 필요에 따라 구체적인 사실, 수치, 예시를 포함하세요.
+ agent: researcher
+
+analysis_task:
+ description: >
+ 연구 결과를 분석하고 {topic}에 대한 포괄적인 보고서를 작성하세요.
+ 보고서에는 다음 내용이 포함되어야 합니다:
+ 1. 간결한 요약(executive summary)으로 시작
+ 2. 연구의 모든 주요 정보 포함
+ 3. 동향과 패턴에 대한 통찰력 있는 분석 제공
+ 4. 추천사항 또는 미래 고려 사항 제시
+ 5. 명확한 제목과 함께 전문적이고 읽기 쉬운 형식으로 작성
+
+ expected_output: >
+ 연구 결과와 추가 분석, 인사이트를 포함한 {topic}에 대한 정제되고 전문적인 보고서.
+ 보고서는 간결한 요약, 본문, 결론 등으로 잘 구조화되어 있어야 합니다.
+ agent: analyst
+ context:
+ - research_task
+ output_file: output/report.md
+```
+
+분석 작업 내의 `context` 필드에 주목하세요. 이 강력한 기능을 통해 analyst가 연구 작업의 결과물을 참조할 수 있습니다. 이를 통해 정보가 human team에서처럼 agent 간에 자연스럽게 흐르는 워크플로우가 만들어집니다.
+
+## 5단계: 크루 구성 설정하기
+
+이제 크루를 구성하여 모든 것을 하나로 모을 시간입니다. 크루는 에이전트들이 함께 작업을 완료하는 방식을 조율하는 컨테이너 역할을 합니다.
+
+`crew.py` 파일을 다음과 같이 수정해보겠습니다:
+
+```python
+# src/research_crew/crew.py
+from crewai import Agent, Crew, Process, Task
+from crewai.project import CrewBase, agent, crew, task
+from crewai_tools import SerperDevTool
+from crewai.agents.agent_builder.base_agent import BaseAgent
+from typing import List
+
+@CrewBase
+class ResearchCrew():
+ """Research crew for comprehensive topic analysis and reporting"""
+
+ agents: List[BaseAgent]
+ tasks: List[Task]
+
+ @agent
+ def researcher(self) -> Agent:
+ return Agent(
+ config=self.agents_config['researcher'], # type: ignore[index]
+ verbose=True,
+ tools=[SerperDevTool()]
+ )
+
+ @agent
+ def analyst(self) -> Agent:
+ return Agent(
+ config=self.agents_config['analyst'], # type: ignore[index]
+ verbose=True
+ )
+
+ @task
+ def research_task(self) -> Task:
+ return Task(
+ config=self.tasks_config['research_task'] # type: ignore[index]
+ )
+
+ @task
+ def analysis_task(self) -> Task:
+ return Task(
+ config=self.tasks_config['analysis_task'], # type: ignore[index]
+ output_file='output/report.md'
+ )
+
+ @crew
+ def crew(self) -> Crew:
+ """Creates the research crew"""
+ return Crew(
+ agents=self.agents,
+ tasks=self.tasks,
+ process=Process.sequential,
+ verbose=True,
+ )
+```
+
+이 코드에서는 다음을 수행합니다:
+1. researcher 에이전트를 생성하고, SerperDevTool을 장착하여 웹 검색 기능을 추가합니다.
+2. analyst 에이전트를 생성합니다.
+3. research와 analysis 작업(task)을 설정합니다.
+4. 크루가 작업을 순차적으로 수행하도록 설정합니다(analyst가 researcher가 끝날 때까지 대기).
+
+여기서 마법이 일어납니다. 몇 줄의 코드만으로도, 특화된 에이전트들이 조율된 프로세스 내에서 협업하는 협동 AI 시스템을 정의할 수 있습니다.
+
+## 6단계: 메인 스크립트 설정
+
+이제 우리 crew를 실행할 메인 스크립트를 설정해 보겠습니다. 이곳에서 crew가 리서치할 구체적인 주제를 지정합니다.
+
+```python
+#!/usr/bin/env python
+# src/research_crew/main.py
+import os
+from research_crew.crew import ResearchCrew
+
+# Create output directory if it doesn't exist
+os.makedirs('output', exist_ok=True)
+
+def run():
+ """
+ Run the research crew.
+ """
+ inputs = {
+ 'topic': 'Artificial Intelligence in Healthcare'
+ }
+
+ # Create and run the crew
+ result = ResearchCrew().crew().kickoff(inputs=inputs)
+
+ # Print the result
+ print("\n\n=== FINAL REPORT ===\n\n")
+ print(result.raw)
+
+ print("\n\nReport has been saved to output/report.md")
+
+if __name__ == "__main__":
+ run()
+```
+
+이 스크립트는 환경을 준비하고, 리서치 주제를 지정하며, crew의 작업을 시작합니다. CrewAI의 강력함은 이 코드가 얼마나 간단한지에서 드러납니다. 여러 AI 에이전트를 관리하는 모든 복잡함이 프레임워크에 의해 처리됩니다.
+
+## 7단계: 환경 변수 설정하기
+
+프로젝트 루트에 `.env` 파일을 생성하고 API 키를 입력하세요:
+
+```sh
+SERPER_API_KEY=your_serper_api_key
+# Add your provider's API key here too.
+```
+
+선택한 provider를 구성하는 방법에 대한 자세한 내용은 [LLM 설정 가이드](/ko/concepts/llms#setting-up-your-llm)를 참고하세요. Serper API 키는 [Serper.dev](https://serper.dev/)에서 받을 수 있습니다.
+
+## 8단계: 필수 종속성 설치
+
+CrewAI CLI를 사용하여 필요한 종속성을 설치하세요:
+
+```bash
+crewai install
+```
+
+이 명령어는 다음을 수행합니다:
+1. 프로젝트 구성에서 종속성을 읽어옵니다
+2. 필요하다면 가상 환경을 생성합니다
+3. 모든 필수 패키지를 설치합니다
+
+## 9단계: Crew 실행하기
+
+이제 흥미로운 순간입니다 - crew를 실행하여 AI 협업이 어떻게 이루어지는지 직접 확인해보세요!
+
+```bash
+crewai run
+```
+
+이 명령어를 실행하면 crew가 즉시 작동하는 모습을 볼 수 있습니다. researcher는 지정된 주제에 대한 정보를 수집하고, analyst가 그 연구를 바탕으로 종합 보고서를 작성합니다. 에이전트들의 사고 과정, 행동, 결과물이 실시간으로 표시되며 서로 협력하여 작업을 완수하는 모습을 확인할 수 있습니다.
+
+## 10단계: 결과물 검토
+
+crew가 작업을 완료하면, 최종 보고서는 `output/report.md` 파일에서 확인할 수 있습니다. 보고서에는 다음과 같은 내용이 포함됩니다:
+
+1. 요약 보고서
+2. 주제에 대한 상세 정보
+3. 분석 및 인사이트
+4. 권장사항 또는 향후 고려사항
+
+지금까지 달성한 것을 잠시 돌아보세요. 여러분은 여러 AI 에이전트가 협업하여 각자의 전문적인 기술을 발휘함으로써, 단일 에이전트가 혼자서 이루어낼 수 있는 것보다 더 뛰어난 결과를 만들어내는 시스템을 구축한 것입니다.
+
+## 기타 CLI 명령어 탐색
+
+CrewAI는 crew 작업을 위한 몇 가지 유용한 CLI 명령어를 추가로 제공합니다:
+
+```bash
+# 모든 사용 가능한 명령어 보기
+crewai --help
+
+# crew 실행
+crewai run
+
+# crew 테스트
+crewai test
+
+# crew 메모리 초기화
+crewai reset-memories
+
+# 특정 task에서 재실행
+crewai replay -t
+
+
+## 2단계: 프로젝트 구조 살펴보기
+
+CLI가 생성한 프로젝트 구조를 이해하는 시간을 가져봅시다. CrewAI는 Python 프로젝트의 모범 사례를 따르므로, crew가 더 복잡해질수록 코드를 쉽게 유지 관리하고 확장할 수 있습니다.
+
+```
+research_crew/
+├── .gitignore
+├── pyproject.toml
+├── README.md
+├── .env
+└── src/
+ └── research_crew/
+ ├── __init__.py
+ ├── main.py
+ ├── crew.py
+ ├── tools/
+ │ ├── custom_tool.py
+ │ └── __init__.py
+ └── config/
+ ├── agents.yaml
+ └── tasks.yaml
+```
+
+이 구조는 Python 프로젝트의 모범 사례를 따르며, 코드를 체계적으로 구성할 수 있도록 해줍니다. 설정 파일(YAML)과 구현 코드(Python)의 분리로 인해, 기본 코드를 변경하지 않고도 crew의 동작을 쉽게 수정할 수 있습니다.
+
+## 3단계: 에이전트 구성하기
+
+이제 재미있는 단계가 시작됩니다 - 여러분의 AI 에이전트를 정의하는 것입니다! CrewAI에서 에이전트는 특정 역할, 목표 및 배경을 가진 전문화된 엔터티로, 이들이 어떻게 행동할지를 결정합니다. 각각 고유한 성격과 목적을 지닌 연극의 등장인물로 생각하면 됩니다.
+
+우리의 리서치 crew를 위해 두 명의 에이전트를 만들겠습니다:
+1. 정보를 찾아 정리하는 데 뛰어난 **리서처**
+2. 연구 결과를 해석하고 통찰력 있는 보고서를 작성할 수 있는 **애널리스트**
+
+이러한 전문화된 에이전트를 정의하기 위해 `agents.yaml` 파일을 수정해봅시다. `llm` 항목은 사용 중인 제공업체에 맞게 설정하세요.
+
+```yaml
+# src/research_crew/config/agents.yaml
+researcher:
+ role: >
+ Senior Research Specialist for {topic}
+ goal: >
+ Find comprehensive and accurate information about {topic}
+ with a focus on recent developments and key insights
+ backstory: >
+ You are an experienced research specialist with a talent for
+ finding relevant information from various sources. You excel at
+ organizing information in a clear and structured manner, making
+ complex topics accessible to others.
+ llm: provider/model-id # e.g. openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
+
+analyst:
+ role: >
+ Data Analyst and Report Writer for {topic}
+ goal: >
+ Analyze research findings and create a comprehensive, well-structured
+ report that presents insights in a clear and engaging way
+ backstory: >
+ You are a skilled analyst with a background in data interpretation
+ and technical writing. You have a talent for identifying patterns
+ and extracting meaningful insights from research data, then
+ communicating those insights effectively through well-crafted reports.
+ llm: provider/model-id # e.g. openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
+```
+
+각 에이전트가 고유한 역할, 목표, 그리고 배경을 가지고 있다는 점에 주목하세요. 이 요소들은 단순한 설명 그 이상으로, 실제로 에이전트가 자신의 과업을 어떻게 접근하는지에 적극적으로 영향을 미칩니다. 이러한 부분을 신중하게 설계함으로써 서로 보완하는 전문적인 역량과 관점을 가진 에이전트를 만들 수 있습니다.
+
+## 4단계: 작업 정의하기
+
+이제 agent들을 정의했으니, 이들에게 수행할 구체적인 작업을 지정해야 합니다. CrewAI의 작업(task)은 agent가 수행할 구체적인 업무를 나타내며, 자세한 지침과 예상 결과물이 포함됩니다.
+
+연구 crew를 위해 두 가지 주요 작업을 정의하겠습니다:
+1. 포괄적인 정보 수집을 위한 **연구 작업**
+2. 인사이트 있는 보고서 생성을 위한 **분석 작업**
+
+`tasks.yaml` 파일을 다음과 같이 수정해 보겠습니다:
+
+```yaml
+# src/research_crew/config/tasks.yaml
+research_task:
+ description: >
+ {topic}에 대해 철저한 연구를 수행하세요. 다음에 중점을 두세요:
+ 1. 주요 개념 및 정의
+ 2. 역사적 발전과 최근 동향
+ 3. 주요 과제와 기회
+ 4. 주목할 만한 적용 사례 또는 케이스 스터디
+ 5. 향후 전망과 잠재적 발전
+
+ 반드시 명확한 섹션으로 구성된 구조화된 형식으로 결과를 정리하세요.
+ expected_output: >
+ {topic}의 모든 요구 사항을 다루는, 잘 구성된 섹션이 포함된 포괄적인 연구 문서.
+ 필요에 따라 구체적인 사실, 수치, 예시를 포함하세요.
+ agent: researcher
+
+analysis_task:
+ description: >
+ 연구 결과를 분석하고 {topic}에 대한 포괄적인 보고서를 작성하세요.
+ 보고서에는 다음 내용이 포함되어야 합니다:
+ 1. 간결한 요약(executive summary)으로 시작
+ 2. 연구의 모든 주요 정보 포함
+ 3. 동향과 패턴에 대한 통찰력 있는 분석 제공
+ 4. 추천사항 또는 미래 고려 사항 제시
+ 5. 명확한 제목과 함께 전문적이고 읽기 쉬운 형식으로 작성
+
+ expected_output: >
+ 연구 결과와 추가 분석, 인사이트를 포함한 {topic}에 대한 정제되고 전문적인 보고서.
+ 보고서는 간결한 요약, 본문, 결론 등으로 잘 구조화되어 있어야 합니다.
+ agent: analyst
+ context:
+ - research_task
+ output_file: output/report.md
+```
+
+분석 작업 내의 `context` 필드에 주목하세요. 이 강력한 기능을 통해 analyst가 연구 작업의 결과물을 참조할 수 있습니다. 이를 통해 정보가 human team에서처럼 agent 간에 자연스럽게 흐르는 워크플로우가 만들어집니다.
+
+## 5단계: 크루 구성 설정하기
+
+이제 크루를 구성하여 모든 것을 하나로 모을 시간입니다. 크루는 에이전트들이 함께 작업을 완료하는 방식을 조율하는 컨테이너 역할을 합니다.
+
+`crew.py` 파일을 다음과 같이 수정해보겠습니다:
+
+```python
+# src/research_crew/crew.py
+from crewai import Agent, Crew, Process, Task
+from crewai.project import CrewBase, agent, crew, task
+from crewai_tools import SerperDevTool
+from crewai.agents.agent_builder.base_agent import BaseAgent
+from typing import List
+
+@CrewBase
+class ResearchCrew():
+ """Research crew for comprehensive topic analysis and reporting"""
+
+ agents: List[BaseAgent]
+ tasks: List[Task]
+
+ @agent
+ def researcher(self) -> Agent:
+ return Agent(
+ config=self.agents_config['researcher'], # type: ignore[index]
+ verbose=True,
+ tools=[SerperDevTool()]
+ )
+
+ @agent
+ def analyst(self) -> Agent:
+ return Agent(
+ config=self.agents_config['analyst'], # type: ignore[index]
+ verbose=True
+ )
+
+ @task
+ def research_task(self) -> Task:
+ return Task(
+ config=self.tasks_config['research_task'] # type: ignore[index]
+ )
+
+ @task
+ def analysis_task(self) -> Task:
+ return Task(
+ config=self.tasks_config['analysis_task'], # type: ignore[index]
+ output_file='output/report.md'
+ )
+
+ @crew
+ def crew(self) -> Crew:
+ """Creates the research crew"""
+ return Crew(
+ agents=self.agents,
+ tasks=self.tasks,
+ process=Process.sequential,
+ verbose=True,
+ )
+```
+
+이 코드에서는 다음을 수행합니다:
+1. researcher 에이전트를 생성하고, SerperDevTool을 장착하여 웹 검색 기능을 추가합니다.
+2. analyst 에이전트를 생성합니다.
+3. research와 analysis 작업(task)을 설정합니다.
+4. 크루가 작업을 순차적으로 수행하도록 설정합니다(analyst가 researcher가 끝날 때까지 대기).
+
+여기서 마법이 일어납니다. 몇 줄의 코드만으로도, 특화된 에이전트들이 조율된 프로세스 내에서 협업하는 협동 AI 시스템을 정의할 수 있습니다.
+
+## 6단계: 메인 스크립트 설정
+
+이제 우리 crew를 실행할 메인 스크립트를 설정해 보겠습니다. 이곳에서 crew가 리서치할 구체적인 주제를 지정합니다.
+
+```python
+#!/usr/bin/env python
+# src/research_crew/main.py
+import os
+from research_crew.crew import ResearchCrew
+
+# Create output directory if it doesn't exist
+os.makedirs('output', exist_ok=True)
+
+def run():
+ """
+ Run the research crew.
+ """
+ inputs = {
+ 'topic': 'Artificial Intelligence in Healthcare'
+ }
+
+ # Create and run the crew
+ result = ResearchCrew().crew().kickoff(inputs=inputs)
+
+ # Print the result
+ print("\n\n=== FINAL REPORT ===\n\n")
+ print(result.raw)
+
+ print("\n\nReport has been saved to output/report.md")
+
+if __name__ == "__main__":
+ run()
+```
+
+이 스크립트는 환경을 준비하고, 리서치 주제를 지정하며, crew의 작업을 시작합니다. CrewAI의 강력함은 이 코드가 얼마나 간단한지에서 드러납니다. 여러 AI 에이전트를 관리하는 모든 복잡함이 프레임워크에 의해 처리됩니다.
+
+## 7단계: 환경 변수 설정하기
+
+프로젝트 루트에 `.env` 파일을 생성하고 API 키를 입력하세요:
+
+```sh
+SERPER_API_KEY=your_serper_api_key
+# Add your provider's API key here too.
+```
+
+선택한 provider를 구성하는 방법에 대한 자세한 내용은 [LLM 설정 가이드](/ko/concepts/llms#setting-up-your-llm)를 참고하세요. Serper API 키는 [Serper.dev](https://serper.dev/)에서 받을 수 있습니다.
+
+## 8단계: 필수 종속성 설치
+
+CrewAI CLI를 사용하여 필요한 종속성을 설치하세요:
+
+```bash
+crewai install
+```
+
+이 명령어는 다음을 수행합니다:
+1. 프로젝트 구성에서 종속성을 읽어옵니다
+2. 필요하다면 가상 환경을 생성합니다
+3. 모든 필수 패키지를 설치합니다
+
+## 9단계: Crew 실행하기
+
+이제 흥미로운 순간입니다 - crew를 실행하여 AI 협업이 어떻게 이루어지는지 직접 확인해보세요!
+
+```bash
+crewai run
+```
+
+이 명령어를 실행하면 crew가 즉시 작동하는 모습을 볼 수 있습니다. researcher는 지정된 주제에 대한 정보를 수집하고, analyst가 그 연구를 바탕으로 종합 보고서를 작성합니다. 에이전트들의 사고 과정, 행동, 결과물이 실시간으로 표시되며 서로 협력하여 작업을 완수하는 모습을 확인할 수 있습니다.
+
+## 10단계: 결과물 검토
+
+crew가 작업을 완료하면, 최종 보고서는 `output/report.md` 파일에서 확인할 수 있습니다. 보고서에는 다음과 같은 내용이 포함됩니다:
+
+1. 요약 보고서
+2. 주제에 대한 상세 정보
+3. 분석 및 인사이트
+4. 권장사항 또는 향후 고려사항
+
+지금까지 달성한 것을 잠시 돌아보세요. 여러분은 여러 AI 에이전트가 협업하여 각자의 전문적인 기술을 발휘함으로써, 단일 에이전트가 혼자서 이루어낼 수 있는 것보다 더 뛰어난 결과를 만들어내는 시스템을 구축한 것입니다.
+
+## 기타 CLI 명령어 탐색
+
+CrewAI는 crew 작업을 위한 몇 가지 유용한 CLI 명령어를 추가로 제공합니다:
+
+```bash
+# 모든 사용 가능한 명령어 보기
+crewai --help
+
+# crew 실행
+crewai run
+
+# crew 테스트
+crewai test
+
+# crew 메모리 초기화
+crewai reset-memories
+
+# 특정 task에서 재실행
+crewai replay -t  +
+
+## 2단계: 프로젝트 구조 이해하기
+
+생성된 프로젝트는 다음과 같은 구조를 가지고 있습니다. 잠시 시간을 내어 이 구조에 익숙해지세요. 구조를 이해하면 앞으로 더 복잡한 flow를 만드는 데 도움이 됩니다.
+
+```
+guide_creator_flow/
+├── .gitignore
+├── pyproject.toml
+├── README.md
+├── .env
+├── main.py
+├── crews/
+│ └── poem_crew/
+│ ├── config/
+│ │ ├── agents.yaml
+│ │ └── tasks.yaml
+│ └── poem_crew.py
+└── tools/
+ └── custom_tool.py
+```
+
+이 구조는 flow의 다양한 구성 요소를 명확하게 분리해줍니다:
+- `main.py` 파일의 main flow 로직
+- `crews` 디렉터리의 특화된 crew들
+- `tools` 디렉터리의 custom tool들
+
+이제 이 구조를 수정하여 guide creator flow를 만들 것입니다. 이 flow는 포괄적인 학습 가이드 생성을 조직하는 역할을 합니다.
+
+## 3단계: Content Writer Crew 추가
+
+우리 flow에는 콘텐츠 생성 프로세스를 처리할 전문화된 crew가 필요합니다. CrewAI CLI를 사용하여 content writer crew를 추가해봅시다:
+
+```bash
+crewai flow add-crew content-crew
+```
+
+이 명령어는 자동으로 crew에 필요한 디렉터리와 템플릿 파일을 생성합니다. content writer crew는 가이드의 각 섹션을 작성하고 검토하는 역할을 담당하며, 메인 애플리케이션에 의해 조율되는 전체 flow 내에서 작업하게 됩니다.
+
+## 4단계: 콘텐츠 작가 Crew 구성
+
+이제 콘텐츠 작가 crew를 위해 생성된 파일을 수정해보겠습니다. 우리는 가이드의 고품질 콘텐츠를 만들기 위해 협업하는 두 명의 전문 에이전트 - 작가와 리뷰어 - 를 설정할 것입니다.
+
+1. 먼저, 에이전트 구성 파일을 업데이트하여 콘텐츠 제작 팀을 정의합니다:
+
+ `llm`을 사용 중인 공급자로 설정해야 함을 기억하세요.
+
+```yaml
+# src/guide_creator_flow/crews/content_crew/config/agents.yaml
+content_writer:
+ role: >
+ 교육 콘텐츠 작가
+ goal: >
+ 할당된 주제를 철저히 설명하고 독자에게 소중한 통찰력을 제공하는 흥미롭고 유익한 콘텐츠를 제작합니다
+ backstory: >
+ 당신은 명확하고 흥미로운 콘텐츠를 만드는 데 능숙한 교육 전문 작가입니다. 복잡한 개념도 쉽게 설명하며,
+ 정보를 독자가 이해하기 쉽게 조직할 수 있습니다.
+ llm: provider/model-id # 예: openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
+
+content_reviewer:
+ role: >
+ 교육 콘텐츠 검토자 및 에디터
+ goal: >
+ 콘텐츠가 정확하고, 포괄적이며, 잘 구조화되어 있고, 이전에 작성된 섹션과의 일관성을 유지하도록 합니다
+ backstory: >
+ 당신은 수년간 교육 콘텐츠를 검토해 온 꼼꼼한 에디터입니다. 세부 사항, 명확성, 일관성에 뛰어나며,
+ 원 저자의 목소리를 유지하면서도 콘텐츠의 품질을 향상시키는 데 능숙합니다.
+ llm: provider/model-id # 예: openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
+```
+
+이 에이전트 정의는 AI 에이전트가 콘텐츠 제작을 접근하는 전문화된 역할과 관점을 구성합니다. 각 에이전트가 뚜렷한 목적과 전문성을 지니고 있음을 확인하세요.
+
+2. 다음으로, 작업 구성 파일을 업데이트하여 구체적인 작성 및 검토 작업을 정의합니다:
+
+```yaml
+# src/guide_creator_flow/crews/content_crew/config/tasks.yaml
+write_section_task:
+ description: >
+ 주제에 대한 포괄적인 섹션을 작성하세요: "{section_title}"
+
+ 섹션 설명: {section_description}
+ 대상 독자: {audience_level} 수준 학습자
+
+ 작성 시 아래 사항을 반드시 지켜주세요:
+ 1. 섹션 주제에 대한 간략한 소개로 시작
+ 2. 모든 주요 개념을 예시와 함께 명확하게 설명
+ 3. 적절하다면 실용적인 활용 사례나 연습문제 포함
+ 4. 주요 포인트 요약으로 마무리
+ 5. 대략 500-800단어 분량
+
+ 콘텐츠는 적절한 제목, 목록, 강조를 포함해 Markdown 형식으로 작성하세요.
+
+ 이전에 작성된 섹션:
+ {previous_sections}
+
+ 반드시 콘텐츠가 이전에 쓴 섹션과 일관성을 유지하고 앞에서 설명된 개념을 바탕으로 작성되도록 하세요.
+ expected_output: >
+ 주제를 철저히 설명하고 대상 독자에게 적합한, 구조가 잘 잡힌 Markdown 형식의 포괄적 섹션
+ agent: content_writer
+
+review_section_task:
+ description: >
+ 아래 "{section_title}" 섹션의 내용을 검토하고 개선하세요:
+
+ {draft_content}
+
+ 대상 독자: {audience_level} 수준 학습자
+
+ 이전에 작성된 섹션:
+ {previous_sections}
+
+ 검토 시 아래 사항을 반드시 지켜주세요:
+ 1. 문법/철자 오류 수정
+ 2. 명확성 및 가독성 향상
+ 3. 내용이 포괄적이고 정확한지 확인
+ 4. 이전에 쓴 섹션과 일관성 유지
+ 5. 구조와 흐름 강화
+ 6. 누락된 핵심 정보 추가
+
+ 개선된 버전의 섹션을 Markdown 형식으로 제공하세요.
+ expected_output: >
+ 원래의 구조를 유지하면서도 명확성, 정확성, 일관성을 향상시킨 세련된 개선본
+ agent: content_reviewer
+ context:
+ - write_section_task
+```
+
+이 작업 정의는 에이전트에게 세부적인 지침을 제공하여 우리의 품질 기준에 부합하는 콘텐츠를 생산하게 합니다. review 작업의 `context` 파라미터를 통해 리뷰어가 작가의 결과물에 접근할 수 있는 워크플로우가 생성됨에 주의하세요.
+
+3. 이제 crew 구현 파일을 업데이트하여 에이전트와 작업이 어떻게 연동되는지 정의합니다:
+
+```python
+# src/guide_creator_flow/crews/content_crew/content_crew.py
+from crewai import Agent, Crew, Process, Task
+from crewai.project import CrewBase, agent, crew, task
+from crewai.agents.agent_builder.base_agent import BaseAgent
+from typing import List
+
+@CrewBase
+class ContentCrew():
+ """Content writing crew"""
+
+ agents: List[BaseAgent]
+ tasks: List[Task]
+
+ @agent
+ def content_writer(self) -> Agent:
+ return Agent(
+ config=self.agents_config['content_writer'], # type: ignore[index]
+ verbose=True
+ )
+
+ @agent
+ def content_reviewer(self) -> Agent:
+ return Agent(
+ config=self.agents_config['content_reviewer'], # type: ignore[index]
+ verbose=True
+ )
+
+ @task
+ def write_section_task(self) -> Task:
+ return Task(
+ config=self.tasks_config['write_section_task'] # type: ignore[index]
+ )
+
+ @task
+ def review_section_task(self) -> Task:
+ return Task(
+ config=self.tasks_config['review_section_task'], # type: ignore[index]
+ context=[self.write_section_task()]
+ )
+
+ @crew
+ def crew(self) -> Crew:
+ """Creates the content writing crew"""
+ return Crew(
+ agents=self.agents,
+ tasks=self.tasks,
+ process=Process.sequential,
+ verbose=True,
+ )
+```
+
+이 crew 정의는 에이전트와 작업 간의 관계를 설정하여, 콘텐츠 작가가 초안을 작성하고 리뷰어가 이를 개선하는 순차적 과정을 만듭니다. 이 crew는 독립적으로도 작동할 수 있지만, 우리의 플로우에서 더 큰 시스템의 일부로 오케스트레이션될 예정입니다.
+
+## 5단계: 플로우(Flow) 생성
+
+이제 가장 흥미로운 부분입니다 - 전체 가이드 생성 과정을 오케스트레이션할 플로우를 만드는 단계입니다. 이곳에서 우리는 일반 Python 코드, 직접적인 LLM 호출, 그리고 우리의 컨텐츠 제작 crew를 결합하여 일관된 시스템으로 만듭니다.
+
+우리의 플로우는 다음과 같은 일을 수행합니다:
+1. 주제와 대상 독자 수준에 대한 사용자 입력을 받습니다.
+2. 구조화된 가이드 개요를 만들기 위해 직접 LLM 호출을 합니다.
+3. 컨텐츠 writer crew를 사용하여 각 섹션을 순차적으로 처리합니다.
+4. 모든 내용을 결합하여 최종 종합 문서를 완성합니다.
+
+`main.py` 파일에 우리의 플로우를 생성해봅시다:
+
+```python
+#!/usr/bin/env python
+import json
+import os
+from typing import List, Dict
+from pydantic import BaseModel, Field
+from crewai import LLM
+from crewai.flow.flow import Flow, listen, start
+from guide_creator_flow.crews.content_crew.content_crew import ContentCrew
+
+# Define our models for structured data
+class Section(BaseModel):
+ title: str = Field(description="Title of the section")
+ description: str = Field(description="Brief description of what the section should cover")
+
+class GuideOutline(BaseModel):
+ title: str = Field(description="Title of the guide")
+ introduction: str = Field(description="Introduction to the topic")
+ target_audience: str = Field(description="Description of the target audience")
+ sections: List[Section] = Field(description="List of sections in the guide")
+ conclusion: str = Field(description="Conclusion or summary of the guide")
+
+# Define our flow state
+class GuideCreatorState(BaseModel):
+ topic: str = ""
+ audience_level: str = ""
+ guide_outline: GuideOutline = None
+ sections_content: Dict[str, str] = {}
+
+class GuideCreatorFlow(Flow[GuideCreatorState]):
+ """Flow for creating a comprehensive guide on any topic"""
+
+ @start()
+ def get_user_input(self):
+ """Get input from the user about the guide topic and audience"""
+ print("\n=== Create Your Comprehensive Guide ===\n")
+
+ # Get user input
+ self.state.topic = input("What topic would you like to create a guide for? ")
+
+ # Get audience level with validation
+ while True:
+ audience = input("Who is your target audience? (beginner/intermediate/advanced) ").lower()
+ if audience in ["beginner", "intermediate", "advanced"]:
+ self.state.audience_level = audience
+ break
+ print("Please enter 'beginner', 'intermediate', or 'advanced'")
+
+ print(f"\nCreating a guide on {self.state.topic} for {self.state.audience_level} audience...\n")
+ return self.state
+
+ @listen(get_user_input)
+ def create_guide_outline(self, state):
+ """Create a structured outline for the guide using a direct LLM call"""
+ print("Creating guide outline...")
+
+ # Initialize the LLM
+ llm = LLM(model="openai/gpt-4o-mini", response_format=GuideOutline)
+
+ # Create the messages for the outline
+ messages = [
+ {"role": "system", "content": "You are a helpful assistant designed to output JSON."},
+ {"role": "user", "content": f"""
+ Create a detailed outline for a comprehensive guide on "{state.topic}" for {state.audience_level} level learners.
+
+ The outline should include:
+ 1. A compelling title for the guide
+ 2. An introduction to the topic
+ 3. 4-6 main sections that cover the most important aspects of the topic
+ 4. A conclusion or summary
+
+ For each section, provide a clear title and a brief description of what it should cover.
+ """}
+ ]
+
+ # Make the LLM call with JSON response format
+ response = llm.call(messages=messages)
+
+ # Parse the JSON response
+ outline_dict = json.loads(response)
+ self.state.guide_outline = GuideOutline(**outline_dict)
+
+ # Ensure output directory exists before saving
+ os.makedirs("output", exist_ok=True)
+
+ # Save the outline to a file
+ with open("output/guide_outline.json", "w") as f:
+ json.dump(outline_dict, f, indent=2)
+
+ print(f"Guide outline created with {len(self.state.guide_outline.sections)} sections")
+ return self.state.guide_outline
+
+ @listen(create_guide_outline)
+ def write_and_compile_guide(self, outline):
+ """Write all sections and compile the guide"""
+ print("Writing guide sections and compiling...")
+ completed_sections = []
+
+ # Process sections one by one to maintain context flow
+ for section in outline.sections:
+ print(f"Processing section: {section.title}")
+
+ # Build context from previous sections
+ previous_sections_text = ""
+ if completed_sections:
+ previous_sections_text = "# Previously Written Sections\n\n"
+ for title in completed_sections:
+ previous_sections_text += f"## {title}\n\n"
+ previous_sections_text += self.state.sections_content.get(title, "") + "\n\n"
+ else:
+ previous_sections_text = "No previous sections written yet."
+
+ # Run the content crew for this section
+ result = ContentCrew().crew().kickoff(inputs={
+ "section_title": section.title,
+ "section_description": section.description,
+ "audience_level": self.state.audience_level,
+ "previous_sections": previous_sections_text,
+ "draft_content": ""
+ })
+
+ # Store the content
+ self.state.sections_content[section.title] = result.raw
+ completed_sections.append(section.title)
+ print(f"Section completed: {section.title}")
+
+ # Compile the final guide
+ guide_content = f"# {outline.title}\n\n"
+ guide_content += f"## Introduction\n\n{outline.introduction}\n\n"
+
+ # Add each section in order
+ for section in outline.sections:
+ section_content = self.state.sections_content.get(section.title, "")
+ guide_content += f"\n\n{section_content}\n\n"
+
+ # Add conclusion
+ guide_content += f"## Conclusion\n\n{outline.conclusion}\n\n"
+
+ # Save the guide
+ with open("output/complete_guide.md", "w") as f:
+ f.write(guide_content)
+
+ print("\nComplete guide compiled and saved to output/complete_guide.md")
+ return "Guide creation completed successfully"
+
+def kickoff():
+ """Run the guide creator flow"""
+ GuideCreatorFlow().kickoff()
+ print("\n=== Flow Complete ===")
+ print("Your comprehensive guide is ready in the output directory.")
+ print("Open output/complete_guide.md to view it.")
+
+def plot():
+ """Generate a visualization of the flow"""
+ flow = GuideCreatorFlow()
+ flow.plot("guide_creator_flow")
+ print("Flow visualization saved to guide_creator_flow.html")
+
+if __name__ == "__main__":
+ kickoff()
+```
+
+이 플로우에서 일어나는 과정을 분석해봅시다:
+
+1. 구조화된 데이터에 대한 Pydantic 모델을 정의하여 타입 안전성과 명확한 데이터 표현을 보장합니다.
+2. 플로우 단계별로 데이터를 유지하기 위한 state 클래스를 생성합니다.
+3. 세 가지 주요 플로우 단계를 구현합니다:
+ - `@start()` 데코레이터로 사용자 입력을 받습니다.
+ - 직접 LLM 호출로 가이드 개요를 생성합니다.
+ - content crew로 각 섹션을 처리합니다.
+4. `@listen()` 데코레이터를 활용해 단계 간 이벤트 기반 관계를 설정합니다.
+
+이것이 바로 flows의 힘입니다 - 다양한 처리 유형(사용자 상호작용, 직접적인 LLM 호출, crew 기반 작업)을 하나의 일관된 이벤트 기반 시스템으로 결합할 수 있습니다.
+
+## 6단계: 환경 변수 설정하기
+
+프로젝트 루트에 `.env` 파일을 생성하고 API 키를 입력하세요. 공급자 구성에 대한 자세한 내용은 [LLM 설정 가이드](/ko/concepts/llms#setting-up-your-llm)를 참고하세요.
+
+```sh .env
+OPENAI_API_KEY=your_openai_api_key
+# or
+GEMINI_API_KEY=your_gemini_api_key
+# or
+ANTHROPIC_API_KEY=your_anthropic_api_key
+```
+
+## 7단계: 의존성 설치
+
+필수 의존성을 설치합니다:
+
+```bash
+crewai install
+```
+
+## 8단계: Flow 실행하기
+
+이제 여러분의 flow가 실제로 작동하는 모습을 볼 차례입니다! CrewAI CLI를 사용하여 flow를 실행하세요:
+
+```bash
+crewai flow kickoff
+```
+
+이 명령어를 실행하면 flow가 다음과 같이 작동하는 것을 확인할 수 있습니다:
+1. 주제와 대상 수준을 입력하라는 메시지가 표시됩니다.
+2. 가이드의 체계적인 개요를 생성합니다.
+3. 각 섹션을 처리할 때 content writer와 reviewer가 협업합니다.
+4. 마지막으로 모든 내용을 종합하여 완성도 높은 가이드를 만듭니다.
+
+이는 여러 구성요소(인공지능 및 비인공지능 모두)가 포함된 복잡한 프로세스를 flows가 어떻게 조정할 수 있는지 보여줍니다.
+
+## 9단계: Flow 시각화하기
+
+flow의 강력한 기능 중 하나는 구조를 시각화할 수 있다는 점입니다.
+
+```bash
+crewai flow plot
+```
+
+이 명령은 flow의 구조를 보여주는 HTML 파일을 생성하며, 각 단계 간의 관계와 그 사이에 흐르는 데이터를 확인할 수 있습니다. 이러한 시각화는 복잡한 flow를 이해하고 디버깅하는 데 매우 유용합니다.
+
+## 10단계: 출력물 검토하기
+
+flow가 완료되면 `output` 디렉토리에서 두 개의 파일을 찾을 수 있습니다:
+
+1. `guide_outline.json`: 가이드의 구조화된 개요가 포함되어 있습니다
+2. `complete_guide.md`: 모든 섹션이 포함된 종합적인 가이드입니다
+
+이 파일들을 잠시 검토하고 여러분이 구축한 시스템을 되돌아보세요. 이 시스템은 사용자 입력, 직접적인 AI 상호작용, 협업 에이전트 작업을 결합하여 복잡하고 고품질의 결과물을 만들어냅니다.
+
+## 가능한 것의 예술: 첫 번째 Flow 그 이상
+
+이 가이드에서 배운 내용은 훨씬 더 정교한 AI 시스템을 만드는 데 기반이 됩니다. 다음은 이 기본 flow를 확장할 수 있는 몇 가지 방법입니다:
+
+### 사용자 상호작용 향상
+
+더욱 인터랙티브한 플로우를 만들 수 있습니다:
+- 입력 및 출력을 위한 웹 인터페이스
+- 실시간 진행 상황 업데이트
+- 인터랙티브한 피드백 및 개선 루프
+- 다단계 사용자 상호작용
+
+### 추가 처리 단계 추가하기
+
+다음과 같은 추가 단계로 flow를 확장할 수 있습니다:
+- 개요 작성 전 사전 리서치
+- 일러스트를 위한 이미지 생성
+- 기술 가이드용 코드 스니펫 생성
+- 최종 품질 보증 및 사실 확인
+
+### 더 복잡한 Flows 생성하기
+
+더 정교한 flow 패턴을 구현할 수 있습니다:
+- 사용자 선호도나 콘텐츠 유형에 따른 조건 분기
+- 독립적인 섹션의 병렬 처리
+- 피드백과 함께하는 반복적 개선 루프
+- 외부 API 및 서비스와의 통합
+
+### 다양한 도메인에 적용하기
+
+동일한 패턴을 사용하여 다음과 같은 flow를 만들 수 있습니다:
+- **대화형 스토리텔링**: 사용자 입력을 바탕으로 개인화된 이야기를 생성
+- **비즈니스 인텔리전스**: 데이터를 처리하고, 인사이트를 도출하며, 리포트를 생성
+- **제품 개발**: 아이디어 구상, 디자인, 기획을 지원
+- **교육 시스템**: 개인화된 학습 경험을 제공
+
+## 주요 특징 시연
+
+이 guide creator flow에서는 CrewAI의 여러 강력한 기능을 시연합니다:
+
+1. **사용자 상호작용**: flow는 사용자로부터 직접 입력을 수집합니다
+2. **직접적인 LLM 호출**: 효율적이고 단일 목적의 AI 상호작용을 위해 LLM 클래스를 사용합니다
+3. **Pydantic을 통한 구조화된 데이터**: 타입 안정성을 보장하기 위해 Pydantic 모델을 사용합니다
+4. **컨텍스트를 활용한 순차 처리**: 섹션을 순서대로 작성하면서 이전 섹션을 컨텍스트로 제공합니다
+5. **멀티 에이전트 crew**: 콘텐츠 생성을 위해 특화된 에이전트(writer 및 reviewer)를 활용합니다
+6. **상태 관리**: 프로세스의 다양한 단계에 걸쳐 상태를 유지합니다
+7. **이벤트 기반 아키텍처**: 이벤트에 응답하기 위해 `@listen` 데코레이터를 사용합니다
+
+## 플로우 구조 이해하기
+
+플로우의 주요 구성 요소를 분해하여 자신만의 플로우를 만드는 방법을 이해할 수 있도록 도와드리겠습니다:
+
+### 1. 직접 LLM 호출
+
+Flow를 사용하면 간단하고 구조화된 응답이 필요할 때 언어 모델에 직접 호출할 수 있습니다:
+
+```python
+llm = LLM(
+ model="model-id-here", # gpt-4o, gemini-2.0-flash, anthropic/claude...
+ response_format=GuideOutline
+)
+response = llm.call(messages=messages)
+```
+
+특정하고 구조화된 출력이 필요할 때 crew를 사용하는 것보다 더 효율적입니다.
+
+### 2. 이벤트 기반 아키텍처
+
+Flows는 데코레이터를 사용하여 컴포넌트 간의 관계를 설정합니다:
+
+```python
+@start()
+def get_user_input(self):
+ # First step in the flow
+ # ...
+
+@listen(get_user_input)
+def create_guide_outline(self, state):
+ # This runs when get_user_input completes
+ # ...
+```
+
+이렇게 하면 애플리케이션에 명확하고 선언적인 구조가 만들어집니다.
+
+### 3. 상태 관리
+
+flow는 단계 간 상태를 유지하여 데이터를 쉽게 공유할 수 있습니다:
+
+```python
+class GuideCreatorState(BaseModel):
+ topic: str = ""
+ audience_level: str = ""
+ guide_outline: GuideOutline = None
+ sections_content: Dict[str, str] = {}
+```
+
+이 방식은 flow 전반에 걸쳐 데이터를 추적하고 변환하는 타입 안전(type-safe)한 방법을 제공합니다.
+
+### 4. Crew 통합
+
+Flow는 복잡한 협업 작업을 위해 crew와 원활하게 통합될 수 있습니다:
+
+```python
+result = ContentCrew().crew().kickoff(inputs={
+ "section_title": section.title,
+ # ...
+})
+```
+
+이를 통해 애플리케이션의 각 부분에 적합한 도구를 사용할 수 있습니다. 단순한 작업에는 직접적인 LLM 호출을, 복잡한 협업에는 crew를 사용할 수 있습니다.
+
+## 다음 단계
+
+이제 첫 번째 flow를 구축했으니 다음을 시도해 볼 수 있습니다:
+
+1. 더 복잡한 flow 구조와 패턴을 실험해 보세요.
+2. `@router()`를 사용하여 flow에서 조건부 분기를 만들어 보세요.
+3. 더 복잡한 병렬 실행을 위해 `and_` 및 `or_` 함수를 탐색해 보세요.
+4. flow를 외부 API, 데이터베이스 또는 사용자 인터페이스에 연결해 보세요.
+5. 여러 전문화된 crew를 하나의 flow에서 결합해 보세요.
+
+
+
+
+| 구성 요소 | 설명 | 주요 특징 |
+|:--------------|:---------------------:|:----------|
+| **크루** | 최상위 조직 | • AI 에이전트 팀 관리
+
+
+## 2단계: 프로젝트 구조 이해하기
+
+생성된 프로젝트는 다음과 같은 구조를 가지고 있습니다. 잠시 시간을 내어 이 구조에 익숙해지세요. 구조를 이해하면 앞으로 더 복잡한 flow를 만드는 데 도움이 됩니다.
+
+```
+guide_creator_flow/
+├── .gitignore
+├── pyproject.toml
+├── README.md
+├── .env
+├── main.py
+├── crews/
+│ └── poem_crew/
+│ ├── config/
+│ │ ├── agents.yaml
+│ │ └── tasks.yaml
+│ └── poem_crew.py
+└── tools/
+ └── custom_tool.py
+```
+
+이 구조는 flow의 다양한 구성 요소를 명확하게 분리해줍니다:
+- `main.py` 파일의 main flow 로직
+- `crews` 디렉터리의 특화된 crew들
+- `tools` 디렉터리의 custom tool들
+
+이제 이 구조를 수정하여 guide creator flow를 만들 것입니다. 이 flow는 포괄적인 학습 가이드 생성을 조직하는 역할을 합니다.
+
+## 3단계: Content Writer Crew 추가
+
+우리 flow에는 콘텐츠 생성 프로세스를 처리할 전문화된 crew가 필요합니다. CrewAI CLI를 사용하여 content writer crew를 추가해봅시다:
+
+```bash
+crewai flow add-crew content-crew
+```
+
+이 명령어는 자동으로 crew에 필요한 디렉터리와 템플릿 파일을 생성합니다. content writer crew는 가이드의 각 섹션을 작성하고 검토하는 역할을 담당하며, 메인 애플리케이션에 의해 조율되는 전체 flow 내에서 작업하게 됩니다.
+
+## 4단계: 콘텐츠 작가 Crew 구성
+
+이제 콘텐츠 작가 crew를 위해 생성된 파일을 수정해보겠습니다. 우리는 가이드의 고품질 콘텐츠를 만들기 위해 협업하는 두 명의 전문 에이전트 - 작가와 리뷰어 - 를 설정할 것입니다.
+
+1. 먼저, 에이전트 구성 파일을 업데이트하여 콘텐츠 제작 팀을 정의합니다:
+
+ `llm`을 사용 중인 공급자로 설정해야 함을 기억하세요.
+
+```yaml
+# src/guide_creator_flow/crews/content_crew/config/agents.yaml
+content_writer:
+ role: >
+ 교육 콘텐츠 작가
+ goal: >
+ 할당된 주제를 철저히 설명하고 독자에게 소중한 통찰력을 제공하는 흥미롭고 유익한 콘텐츠를 제작합니다
+ backstory: >
+ 당신은 명확하고 흥미로운 콘텐츠를 만드는 데 능숙한 교육 전문 작가입니다. 복잡한 개념도 쉽게 설명하며,
+ 정보를 독자가 이해하기 쉽게 조직할 수 있습니다.
+ llm: provider/model-id # 예: openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
+
+content_reviewer:
+ role: >
+ 교육 콘텐츠 검토자 및 에디터
+ goal: >
+ 콘텐츠가 정확하고, 포괄적이며, 잘 구조화되어 있고, 이전에 작성된 섹션과의 일관성을 유지하도록 합니다
+ backstory: >
+ 당신은 수년간 교육 콘텐츠를 검토해 온 꼼꼼한 에디터입니다. 세부 사항, 명확성, 일관성에 뛰어나며,
+ 원 저자의 목소리를 유지하면서도 콘텐츠의 품질을 향상시키는 데 능숙합니다.
+ llm: provider/model-id # 예: openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude...
+```
+
+이 에이전트 정의는 AI 에이전트가 콘텐츠 제작을 접근하는 전문화된 역할과 관점을 구성합니다. 각 에이전트가 뚜렷한 목적과 전문성을 지니고 있음을 확인하세요.
+
+2. 다음으로, 작업 구성 파일을 업데이트하여 구체적인 작성 및 검토 작업을 정의합니다:
+
+```yaml
+# src/guide_creator_flow/crews/content_crew/config/tasks.yaml
+write_section_task:
+ description: >
+ 주제에 대한 포괄적인 섹션을 작성하세요: "{section_title}"
+
+ 섹션 설명: {section_description}
+ 대상 독자: {audience_level} 수준 학습자
+
+ 작성 시 아래 사항을 반드시 지켜주세요:
+ 1. 섹션 주제에 대한 간략한 소개로 시작
+ 2. 모든 주요 개념을 예시와 함께 명확하게 설명
+ 3. 적절하다면 실용적인 활용 사례나 연습문제 포함
+ 4. 주요 포인트 요약으로 마무리
+ 5. 대략 500-800단어 분량
+
+ 콘텐츠는 적절한 제목, 목록, 강조를 포함해 Markdown 형식으로 작성하세요.
+
+ 이전에 작성된 섹션:
+ {previous_sections}
+
+ 반드시 콘텐츠가 이전에 쓴 섹션과 일관성을 유지하고 앞에서 설명된 개념을 바탕으로 작성되도록 하세요.
+ expected_output: >
+ 주제를 철저히 설명하고 대상 독자에게 적합한, 구조가 잘 잡힌 Markdown 형식의 포괄적 섹션
+ agent: content_writer
+
+review_section_task:
+ description: >
+ 아래 "{section_title}" 섹션의 내용을 검토하고 개선하세요:
+
+ {draft_content}
+
+ 대상 독자: {audience_level} 수준 학습자
+
+ 이전에 작성된 섹션:
+ {previous_sections}
+
+ 검토 시 아래 사항을 반드시 지켜주세요:
+ 1. 문법/철자 오류 수정
+ 2. 명확성 및 가독성 향상
+ 3. 내용이 포괄적이고 정확한지 확인
+ 4. 이전에 쓴 섹션과 일관성 유지
+ 5. 구조와 흐름 강화
+ 6. 누락된 핵심 정보 추가
+
+ 개선된 버전의 섹션을 Markdown 형식으로 제공하세요.
+ expected_output: >
+ 원래의 구조를 유지하면서도 명확성, 정확성, 일관성을 향상시킨 세련된 개선본
+ agent: content_reviewer
+ context:
+ - write_section_task
+```
+
+이 작업 정의는 에이전트에게 세부적인 지침을 제공하여 우리의 품질 기준에 부합하는 콘텐츠를 생산하게 합니다. review 작업의 `context` 파라미터를 통해 리뷰어가 작가의 결과물에 접근할 수 있는 워크플로우가 생성됨에 주의하세요.
+
+3. 이제 crew 구현 파일을 업데이트하여 에이전트와 작업이 어떻게 연동되는지 정의합니다:
+
+```python
+# src/guide_creator_flow/crews/content_crew/content_crew.py
+from crewai import Agent, Crew, Process, Task
+from crewai.project import CrewBase, agent, crew, task
+from crewai.agents.agent_builder.base_agent import BaseAgent
+from typing import List
+
+@CrewBase
+class ContentCrew():
+ """Content writing crew"""
+
+ agents: List[BaseAgent]
+ tasks: List[Task]
+
+ @agent
+ def content_writer(self) -> Agent:
+ return Agent(
+ config=self.agents_config['content_writer'], # type: ignore[index]
+ verbose=True
+ )
+
+ @agent
+ def content_reviewer(self) -> Agent:
+ return Agent(
+ config=self.agents_config['content_reviewer'], # type: ignore[index]
+ verbose=True
+ )
+
+ @task
+ def write_section_task(self) -> Task:
+ return Task(
+ config=self.tasks_config['write_section_task'] # type: ignore[index]
+ )
+
+ @task
+ def review_section_task(self) -> Task:
+ return Task(
+ config=self.tasks_config['review_section_task'], # type: ignore[index]
+ context=[self.write_section_task()]
+ )
+
+ @crew
+ def crew(self) -> Crew:
+ """Creates the content writing crew"""
+ return Crew(
+ agents=self.agents,
+ tasks=self.tasks,
+ process=Process.sequential,
+ verbose=True,
+ )
+```
+
+이 crew 정의는 에이전트와 작업 간의 관계를 설정하여, 콘텐츠 작가가 초안을 작성하고 리뷰어가 이를 개선하는 순차적 과정을 만듭니다. 이 crew는 독립적으로도 작동할 수 있지만, 우리의 플로우에서 더 큰 시스템의 일부로 오케스트레이션될 예정입니다.
+
+## 5단계: 플로우(Flow) 생성
+
+이제 가장 흥미로운 부분입니다 - 전체 가이드 생성 과정을 오케스트레이션할 플로우를 만드는 단계입니다. 이곳에서 우리는 일반 Python 코드, 직접적인 LLM 호출, 그리고 우리의 컨텐츠 제작 crew를 결합하여 일관된 시스템으로 만듭니다.
+
+우리의 플로우는 다음과 같은 일을 수행합니다:
+1. 주제와 대상 독자 수준에 대한 사용자 입력을 받습니다.
+2. 구조화된 가이드 개요를 만들기 위해 직접 LLM 호출을 합니다.
+3. 컨텐츠 writer crew를 사용하여 각 섹션을 순차적으로 처리합니다.
+4. 모든 내용을 결합하여 최종 종합 문서를 완성합니다.
+
+`main.py` 파일에 우리의 플로우를 생성해봅시다:
+
+```python
+#!/usr/bin/env python
+import json
+import os
+from typing import List, Dict
+from pydantic import BaseModel, Field
+from crewai import LLM
+from crewai.flow.flow import Flow, listen, start
+from guide_creator_flow.crews.content_crew.content_crew import ContentCrew
+
+# Define our models for structured data
+class Section(BaseModel):
+ title: str = Field(description="Title of the section")
+ description: str = Field(description="Brief description of what the section should cover")
+
+class GuideOutline(BaseModel):
+ title: str = Field(description="Title of the guide")
+ introduction: str = Field(description="Introduction to the topic")
+ target_audience: str = Field(description="Description of the target audience")
+ sections: List[Section] = Field(description="List of sections in the guide")
+ conclusion: str = Field(description="Conclusion or summary of the guide")
+
+# Define our flow state
+class GuideCreatorState(BaseModel):
+ topic: str = ""
+ audience_level: str = ""
+ guide_outline: GuideOutline = None
+ sections_content: Dict[str, str] = {}
+
+class GuideCreatorFlow(Flow[GuideCreatorState]):
+ """Flow for creating a comprehensive guide on any topic"""
+
+ @start()
+ def get_user_input(self):
+ """Get input from the user about the guide topic and audience"""
+ print("\n=== Create Your Comprehensive Guide ===\n")
+
+ # Get user input
+ self.state.topic = input("What topic would you like to create a guide for? ")
+
+ # Get audience level with validation
+ while True:
+ audience = input("Who is your target audience? (beginner/intermediate/advanced) ").lower()
+ if audience in ["beginner", "intermediate", "advanced"]:
+ self.state.audience_level = audience
+ break
+ print("Please enter 'beginner', 'intermediate', or 'advanced'")
+
+ print(f"\nCreating a guide on {self.state.topic} for {self.state.audience_level} audience...\n")
+ return self.state
+
+ @listen(get_user_input)
+ def create_guide_outline(self, state):
+ """Create a structured outline for the guide using a direct LLM call"""
+ print("Creating guide outline...")
+
+ # Initialize the LLM
+ llm = LLM(model="openai/gpt-4o-mini", response_format=GuideOutline)
+
+ # Create the messages for the outline
+ messages = [
+ {"role": "system", "content": "You are a helpful assistant designed to output JSON."},
+ {"role": "user", "content": f"""
+ Create a detailed outline for a comprehensive guide on "{state.topic}" for {state.audience_level} level learners.
+
+ The outline should include:
+ 1. A compelling title for the guide
+ 2. An introduction to the topic
+ 3. 4-6 main sections that cover the most important aspects of the topic
+ 4. A conclusion or summary
+
+ For each section, provide a clear title and a brief description of what it should cover.
+ """}
+ ]
+
+ # Make the LLM call with JSON response format
+ response = llm.call(messages=messages)
+
+ # Parse the JSON response
+ outline_dict = json.loads(response)
+ self.state.guide_outline = GuideOutline(**outline_dict)
+
+ # Ensure output directory exists before saving
+ os.makedirs("output", exist_ok=True)
+
+ # Save the outline to a file
+ with open("output/guide_outline.json", "w") as f:
+ json.dump(outline_dict, f, indent=2)
+
+ print(f"Guide outline created with {len(self.state.guide_outline.sections)} sections")
+ return self.state.guide_outline
+
+ @listen(create_guide_outline)
+ def write_and_compile_guide(self, outline):
+ """Write all sections and compile the guide"""
+ print("Writing guide sections and compiling...")
+ completed_sections = []
+
+ # Process sections one by one to maintain context flow
+ for section in outline.sections:
+ print(f"Processing section: {section.title}")
+
+ # Build context from previous sections
+ previous_sections_text = ""
+ if completed_sections:
+ previous_sections_text = "# Previously Written Sections\n\n"
+ for title in completed_sections:
+ previous_sections_text += f"## {title}\n\n"
+ previous_sections_text += self.state.sections_content.get(title, "") + "\n\n"
+ else:
+ previous_sections_text = "No previous sections written yet."
+
+ # Run the content crew for this section
+ result = ContentCrew().crew().kickoff(inputs={
+ "section_title": section.title,
+ "section_description": section.description,
+ "audience_level": self.state.audience_level,
+ "previous_sections": previous_sections_text,
+ "draft_content": ""
+ })
+
+ # Store the content
+ self.state.sections_content[section.title] = result.raw
+ completed_sections.append(section.title)
+ print(f"Section completed: {section.title}")
+
+ # Compile the final guide
+ guide_content = f"# {outline.title}\n\n"
+ guide_content += f"## Introduction\n\n{outline.introduction}\n\n"
+
+ # Add each section in order
+ for section in outline.sections:
+ section_content = self.state.sections_content.get(section.title, "")
+ guide_content += f"\n\n{section_content}\n\n"
+
+ # Add conclusion
+ guide_content += f"## Conclusion\n\n{outline.conclusion}\n\n"
+
+ # Save the guide
+ with open("output/complete_guide.md", "w") as f:
+ f.write(guide_content)
+
+ print("\nComplete guide compiled and saved to output/complete_guide.md")
+ return "Guide creation completed successfully"
+
+def kickoff():
+ """Run the guide creator flow"""
+ GuideCreatorFlow().kickoff()
+ print("\n=== Flow Complete ===")
+ print("Your comprehensive guide is ready in the output directory.")
+ print("Open output/complete_guide.md to view it.")
+
+def plot():
+ """Generate a visualization of the flow"""
+ flow = GuideCreatorFlow()
+ flow.plot("guide_creator_flow")
+ print("Flow visualization saved to guide_creator_flow.html")
+
+if __name__ == "__main__":
+ kickoff()
+```
+
+이 플로우에서 일어나는 과정을 분석해봅시다:
+
+1. 구조화된 데이터에 대한 Pydantic 모델을 정의하여 타입 안전성과 명확한 데이터 표현을 보장합니다.
+2. 플로우 단계별로 데이터를 유지하기 위한 state 클래스를 생성합니다.
+3. 세 가지 주요 플로우 단계를 구현합니다:
+ - `@start()` 데코레이터로 사용자 입력을 받습니다.
+ - 직접 LLM 호출로 가이드 개요를 생성합니다.
+ - content crew로 각 섹션을 처리합니다.
+4. `@listen()` 데코레이터를 활용해 단계 간 이벤트 기반 관계를 설정합니다.
+
+이것이 바로 flows의 힘입니다 - 다양한 처리 유형(사용자 상호작용, 직접적인 LLM 호출, crew 기반 작업)을 하나의 일관된 이벤트 기반 시스템으로 결합할 수 있습니다.
+
+## 6단계: 환경 변수 설정하기
+
+프로젝트 루트에 `.env` 파일을 생성하고 API 키를 입력하세요. 공급자 구성에 대한 자세한 내용은 [LLM 설정 가이드](/ko/concepts/llms#setting-up-your-llm)를 참고하세요.
+
+```sh .env
+OPENAI_API_KEY=your_openai_api_key
+# or
+GEMINI_API_KEY=your_gemini_api_key
+# or
+ANTHROPIC_API_KEY=your_anthropic_api_key
+```
+
+## 7단계: 의존성 설치
+
+필수 의존성을 설치합니다:
+
+```bash
+crewai install
+```
+
+## 8단계: Flow 실행하기
+
+이제 여러분의 flow가 실제로 작동하는 모습을 볼 차례입니다! CrewAI CLI를 사용하여 flow를 실행하세요:
+
+```bash
+crewai flow kickoff
+```
+
+이 명령어를 실행하면 flow가 다음과 같이 작동하는 것을 확인할 수 있습니다:
+1. 주제와 대상 수준을 입력하라는 메시지가 표시됩니다.
+2. 가이드의 체계적인 개요를 생성합니다.
+3. 각 섹션을 처리할 때 content writer와 reviewer가 협업합니다.
+4. 마지막으로 모든 내용을 종합하여 완성도 높은 가이드를 만듭니다.
+
+이는 여러 구성요소(인공지능 및 비인공지능 모두)가 포함된 복잡한 프로세스를 flows가 어떻게 조정할 수 있는지 보여줍니다.
+
+## 9단계: Flow 시각화하기
+
+flow의 강력한 기능 중 하나는 구조를 시각화할 수 있다는 점입니다.
+
+```bash
+crewai flow plot
+```
+
+이 명령은 flow의 구조를 보여주는 HTML 파일을 생성하며, 각 단계 간의 관계와 그 사이에 흐르는 데이터를 확인할 수 있습니다. 이러한 시각화는 복잡한 flow를 이해하고 디버깅하는 데 매우 유용합니다.
+
+## 10단계: 출력물 검토하기
+
+flow가 완료되면 `output` 디렉토리에서 두 개의 파일을 찾을 수 있습니다:
+
+1. `guide_outline.json`: 가이드의 구조화된 개요가 포함되어 있습니다
+2. `complete_guide.md`: 모든 섹션이 포함된 종합적인 가이드입니다
+
+이 파일들을 잠시 검토하고 여러분이 구축한 시스템을 되돌아보세요. 이 시스템은 사용자 입력, 직접적인 AI 상호작용, 협업 에이전트 작업을 결합하여 복잡하고 고품질의 결과물을 만들어냅니다.
+
+## 가능한 것의 예술: 첫 번째 Flow 그 이상
+
+이 가이드에서 배운 내용은 훨씬 더 정교한 AI 시스템을 만드는 데 기반이 됩니다. 다음은 이 기본 flow를 확장할 수 있는 몇 가지 방법입니다:
+
+### 사용자 상호작용 향상
+
+더욱 인터랙티브한 플로우를 만들 수 있습니다:
+- 입력 및 출력을 위한 웹 인터페이스
+- 실시간 진행 상황 업데이트
+- 인터랙티브한 피드백 및 개선 루프
+- 다단계 사용자 상호작용
+
+### 추가 처리 단계 추가하기
+
+다음과 같은 추가 단계로 flow를 확장할 수 있습니다:
+- 개요 작성 전 사전 리서치
+- 일러스트를 위한 이미지 생성
+- 기술 가이드용 코드 스니펫 생성
+- 최종 품질 보증 및 사실 확인
+
+### 더 복잡한 Flows 생성하기
+
+더 정교한 flow 패턴을 구현할 수 있습니다:
+- 사용자 선호도나 콘텐츠 유형에 따른 조건 분기
+- 독립적인 섹션의 병렬 처리
+- 피드백과 함께하는 반복적 개선 루프
+- 외부 API 및 서비스와의 통합
+
+### 다양한 도메인에 적용하기
+
+동일한 패턴을 사용하여 다음과 같은 flow를 만들 수 있습니다:
+- **대화형 스토리텔링**: 사용자 입력을 바탕으로 개인화된 이야기를 생성
+- **비즈니스 인텔리전스**: 데이터를 처리하고, 인사이트를 도출하며, 리포트를 생성
+- **제품 개발**: 아이디어 구상, 디자인, 기획을 지원
+- **교육 시스템**: 개인화된 학습 경험을 제공
+
+## 주요 특징 시연
+
+이 guide creator flow에서는 CrewAI의 여러 강력한 기능을 시연합니다:
+
+1. **사용자 상호작용**: flow는 사용자로부터 직접 입력을 수집합니다
+2. **직접적인 LLM 호출**: 효율적이고 단일 목적의 AI 상호작용을 위해 LLM 클래스를 사용합니다
+3. **Pydantic을 통한 구조화된 데이터**: 타입 안정성을 보장하기 위해 Pydantic 모델을 사용합니다
+4. **컨텍스트를 활용한 순차 처리**: 섹션을 순서대로 작성하면서 이전 섹션을 컨텍스트로 제공합니다
+5. **멀티 에이전트 crew**: 콘텐츠 생성을 위해 특화된 에이전트(writer 및 reviewer)를 활용합니다
+6. **상태 관리**: 프로세스의 다양한 단계에 걸쳐 상태를 유지합니다
+7. **이벤트 기반 아키텍처**: 이벤트에 응답하기 위해 `@listen` 데코레이터를 사용합니다
+
+## 플로우 구조 이해하기
+
+플로우의 주요 구성 요소를 분해하여 자신만의 플로우를 만드는 방법을 이해할 수 있도록 도와드리겠습니다:
+
+### 1. 직접 LLM 호출
+
+Flow를 사용하면 간단하고 구조화된 응답이 필요할 때 언어 모델에 직접 호출할 수 있습니다:
+
+```python
+llm = LLM(
+ model="model-id-here", # gpt-4o, gemini-2.0-flash, anthropic/claude...
+ response_format=GuideOutline
+)
+response = llm.call(messages=messages)
+```
+
+특정하고 구조화된 출력이 필요할 때 crew를 사용하는 것보다 더 효율적입니다.
+
+### 2. 이벤트 기반 아키텍처
+
+Flows는 데코레이터를 사용하여 컴포넌트 간의 관계를 설정합니다:
+
+```python
+@start()
+def get_user_input(self):
+ # First step in the flow
+ # ...
+
+@listen(get_user_input)
+def create_guide_outline(self, state):
+ # This runs when get_user_input completes
+ # ...
+```
+
+이렇게 하면 애플리케이션에 명확하고 선언적인 구조가 만들어집니다.
+
+### 3. 상태 관리
+
+flow는 단계 간 상태를 유지하여 데이터를 쉽게 공유할 수 있습니다:
+
+```python
+class GuideCreatorState(BaseModel):
+ topic: str = ""
+ audience_level: str = ""
+ guide_outline: GuideOutline = None
+ sections_content: Dict[str, str] = {}
+```
+
+이 방식은 flow 전반에 걸쳐 데이터를 추적하고 변환하는 타입 안전(type-safe)한 방법을 제공합니다.
+
+### 4. Crew 통합
+
+Flow는 복잡한 협업 작업을 위해 crew와 원활하게 통합될 수 있습니다:
+
+```python
+result = ContentCrew().crew().kickoff(inputs={
+ "section_title": section.title,
+ # ...
+})
+```
+
+이를 통해 애플리케이션의 각 부분에 적합한 도구를 사용할 수 있습니다. 단순한 작업에는 직접적인 LLM 호출을, 복잡한 협업에는 crew를 사용할 수 있습니다.
+
+## 다음 단계
+
+이제 첫 번째 flow를 구축했으니 다음을 시도해 볼 수 있습니다:
+
+1. 더 복잡한 flow 구조와 패턴을 실험해 보세요.
+2. `@router()`를 사용하여 flow에서 조건부 분기를 만들어 보세요.
+3. 더 복잡한 병렬 실행을 위해 `and_` 및 `or_` 함수를 탐색해 보세요.
+4. flow를 외부 API, 데이터베이스 또는 사용자 인터페이스에 연결해 보세요.
+5. 여러 전문화된 crew를 하나의 flow에서 결합해 보세요.
+
+
+
+
+| 구성 요소 | 설명 | 주요 특징 |
+|:--------------|:---------------------:|:----------|
+| **크루** | 최상위 조직 | • AI 에이전트 팀 관리• 워크플로우 감독
• 협업 보장
• 결과 전달 | +| **AI 에이전트** | 전문 팀원 | • 특정 역할 보유(연구원, 작가 등)
• 지정된 도구 사용
• 작업 위임 가능
• 자율적 의사결정 가능 | +| **프로세스** | 워크플로우 관리 시스템 | • 협업 패턴 정의
• 작업 할당 제어
• 상호작용 관리
• 효율적 실행 보장 | +| **작업** | 개별 할당 | • 명확한 목표 보유
• 특정 도구 사용
• 더 큰 프로세스에 기여
• 실행 가능한 결과 도출 | + +### 어떻게 모두 함께 작동하는가 + +1. **Crew**가 전체 운영을 조직합니다 +2. **AI Agents**가 자신들의 전문 작업을 수행합니다 +3. **Process**가 원활한 협업을 보장합니다 +4. **Tasks**가 완료되어 목표를 달성합니다 + +## 주요 기능 + +
+
+
+| 구성 요소 | 설명 | 주요 기능 |
+|:----------|:-----------:|:------------|
+| **Flow** | 구조화된 워크플로우 오케스트레이션 | • 실행 경로 관리• 상태 전환 처리
• 작업 순서 제어
• 신뢰성 있는 실행 보장 | +| **Events** | 워크플로우 액션 트리거 | • 특정 프로세스 시작
• 동적 응답 가능
• 조건부 분기 지원
• 실시간 적응 허용 | +| **States** | 워크플로우 실행 컨텍스트 | • 실행 데이터 유지
• 데이터 영속성 지원
• 재개 가능성 보장
• 실행 무결성 확보 | +| **Crew Support** | 워크플로우 자동화 강화 | • 필요할 때 agency 삽입
• 구조화된 워크플로우 보완
• 자동화와 인텔리전스의 균형
• 적응적 의사결정 지원 | + +### 주요 기능 + +
 +
+
+## 모범 사례
+
+1. **이미지 생성 프롬프트를 구체적으로 작성하세요**. 그래야 최상의 결과를 얻을 수 있습니다.
+2. **생성 시간을 고려하세요** - 이미지 생성에는 시간이 걸릴 수 있으므로 작업 계획에 이를 반영하세요.
+3. **사용 정책을 준수하세요** - 이미지를 생성할 때 항상 OpenAI의 사용 정책을 준수해야 합니다.
+
+## 문제 해결
+
+1. **API 접근 확인** - OpenAI API 키가 DALL-E에 접근 권한이 있는지 확인하세요.
+2. **버전 호환성** - 최신 버전의 crewAI와 crewai-tools를 사용하고 있는지 확인하세요.
+3. **도구 구성** - DALL-E 도구가 agent의 도구 목록에 올바르게 추가되어 있는지 확인하세요.
\ No newline at end of file
diff --git a/docs/ko/learn/force-tool-output-as-result.mdx b/docs/ko/learn/force-tool-output-as-result.mdx
new file mode 100644
index 000000000..4d53860fd
--- /dev/null
+++ b/docs/ko/learn/force-tool-output-as-result.mdx
@@ -0,0 +1,50 @@
+---
+title: 도구 출력 결과로 강제 지정하기
+description: CrewAI에서 에이전트의 작업에서 도구 출력을 결과로 강제 지정하는 방법을 알아봅니다.
+icon: wrench-simple
+---
+
+## 소개
+
+CrewAI에서는 도구의 출력을 에이전트 작업의 결과로 강제로 사용할 수 있습니다.
+이 기능은 작업 실행 중에 에이전트가 출력을 수정하지 못하도록 하고, 도구의 출력이 반드시 캡처되어 작업 결과로 반환되도록 보장하고 싶을 때 유용합니다.
+
+## 도구 출력을 결과로 강제 지정하기
+
+도구의 출력을 에이전트 작업의 결과로 강제 지정하려면, 에이전트에 도구를 추가할 때 `result_as_answer` 매개변수를 `True`로 설정해야 합니다.
+이 매개변수는 도구의 출력이 에이전트에 의해 수정되지 않고 작업 결과로 캡처되어 반환되도록 보장합니다.
+
+다음은 에이전트 작업의 결과로 도구 출력을 강제 지정하는 방법의 예시입니다:
+
+```python Code
+from crewai.agent import Agent
+from my_tool import MyCustomTool
+
+# Create a coding agent with the custom tool
+coding_agent = Agent(
+ role="Data Scientist",
+ goal="Produce amazing reports on AI",
+ backstory="You work with data and AI",
+ tools=[MyCustomTool(result_as_answer=True)],
+ )
+
+# Assuming the tool's execution and result population occurs within the system
+task_result = coding_agent.execute_task(task)
+```
+
+## 워크플로우 실행
+
+
+
+
+
+
+
+
+
+
+## 모범 사례
+
+1. **이미지 생성 프롬프트를 구체적으로 작성하세요**. 그래야 최상의 결과를 얻을 수 있습니다.
+2. **생성 시간을 고려하세요** - 이미지 생성에는 시간이 걸릴 수 있으므로 작업 계획에 이를 반영하세요.
+3. **사용 정책을 준수하세요** - 이미지를 생성할 때 항상 OpenAI의 사용 정책을 준수해야 합니다.
+
+## 문제 해결
+
+1. **API 접근 확인** - OpenAI API 키가 DALL-E에 접근 권한이 있는지 확인하세요.
+2. **버전 호환성** - 최신 버전의 crewAI와 crewai-tools를 사용하고 있는지 확인하세요.
+3. **도구 구성** - DALL-E 도구가 agent의 도구 목록에 올바르게 추가되어 있는지 확인하세요.
\ No newline at end of file
diff --git a/docs/ko/learn/force-tool-output-as-result.mdx b/docs/ko/learn/force-tool-output-as-result.mdx
new file mode 100644
index 000000000..4d53860fd
--- /dev/null
+++ b/docs/ko/learn/force-tool-output-as-result.mdx
@@ -0,0 +1,50 @@
+---
+title: 도구 출력 결과로 강제 지정하기
+description: CrewAI에서 에이전트의 작업에서 도구 출력을 결과로 강제 지정하는 방법을 알아봅니다.
+icon: wrench-simple
+---
+
+## 소개
+
+CrewAI에서는 도구의 출력을 에이전트 작업의 결과로 강제로 사용할 수 있습니다.
+이 기능은 작업 실행 중에 에이전트가 출력을 수정하지 못하도록 하고, 도구의 출력이 반드시 캡처되어 작업 결과로 반환되도록 보장하고 싶을 때 유용합니다.
+
+## 도구 출력을 결과로 강제 지정하기
+
+도구의 출력을 에이전트 작업의 결과로 강제 지정하려면, 에이전트에 도구를 추가할 때 `result_as_answer` 매개변수를 `True`로 설정해야 합니다.
+이 매개변수는 도구의 출력이 에이전트에 의해 수정되지 않고 작업 결과로 캡처되어 반환되도록 보장합니다.
+
+다음은 에이전트 작업의 결과로 도구 출력을 강제 지정하는 방법의 예시입니다:
+
+```python Code
+from crewai.agent import Agent
+from my_tool import MyCustomTool
+
+# Create a coding agent with the custom tool
+coding_agent = Agent(
+ role="Data Scientist",
+ goal="Produce amazing reports on AI",
+ backstory="You work with data and AI",
+ tools=[MyCustomTool(result_as_answer=True)],
+ )
+
+# Assuming the tool's execution and result population occurs within the system
+task_result = coding_agent.execute_task(task)
+```
+
+## 워크플로우 실행
+
+
+
+
+
+
+
+  +
+
+**확인:** [실시간 추적 예시 보기](https://app.langdb.ai/sharing/threads/3becbfed-a1be-ae84-ea3c-4942867a3e22)
+
+## 기능
+
+### AI 게이트웨이 기능
+- **350개 이상의 LLM 접근**: 단일 통합을 통해 모든 주요 언어 모델에 연결
+- **가상 모델**: 특정 매개변수와 라우팅 규칙으로 맞춤형 모델 구성 생성
+- **가상 MCP**: 에이전트 간 향상된 통신을 위해 MCP(Model Context Protocol) 시스템과의 호환성 및 통합 지원
+- **가드레일**: 에이전트 행동에 대한 안전 조치 및 컴플라이언스 제어 구현
+
+### 가시성 및 추적
+- **자동 추적**: 단일 `init()` 호출로 모든 CrewAI 상호작용을 캡처
+- **엔드-투-엔드 가시성**: 에이전트 워크플로우를 시작부터 끝까지 모니터링
+- **도구 사용 추적**: 에이전트가 사용하는 도구와 그 결과를 추적
+- **모델 호출 모니터링**: LLM 상호작용에 대한 상세한 인사이트 제공
+- **성능 분석**: 지연 시간, 토큰 사용량 및 비용 모니터링
+- **디버깅 지원**: 문제 해결을 위한 단계별 실행
+- **실시간 모니터링**: 라이브 트레이스 및 메트릭 대시보드
+
+## 설치 안내
+
+
+
+
+**확인:** [실시간 추적 예시 보기](https://app.langdb.ai/sharing/threads/3becbfed-a1be-ae84-ea3c-4942867a3e22)
+
+## 기능
+
+### AI 게이트웨이 기능
+- **350개 이상의 LLM 접근**: 단일 통합을 통해 모든 주요 언어 모델에 연결
+- **가상 모델**: 특정 매개변수와 라우팅 규칙으로 맞춤형 모델 구성 생성
+- **가상 MCP**: 에이전트 간 향상된 통신을 위해 MCP(Model Context Protocol) 시스템과의 호환성 및 통합 지원
+- **가드레일**: 에이전트 행동에 대한 안전 조치 및 컴플라이언스 제어 구현
+
+### 가시성 및 추적
+- **자동 추적**: 단일 `init()` 호출로 모든 CrewAI 상호작용을 캡처
+- **엔드-투-엔드 가시성**: 에이전트 워크플로우를 시작부터 끝까지 모니터링
+- **도구 사용 추적**: 에이전트가 사용하는 도구와 그 결과를 추적
+- **모델 호출 모니터링**: LLM 상호작용에 대한 상세한 인사이트 제공
+- **성능 분석**: 지연 시간, 토큰 사용량 및 비용 모니터링
+- **디버깅 지원**: 문제 해결을 위한 단계별 실행
+- **실시간 모니터링**: 라이브 트레이스 및 메트릭 대시보드
+
+## 설치 안내
+
+ +
+
+### 볼 수 있는 내용
+
+- **에이전트 상호작용**: 에이전트 대화 및 작업 인계의 전체 흐름
+- **도구 사용**: 호출된 도구, 입력값 및 출력값
+- **모델 호출**: 프롬프트 및 응답과 함께하는 상세 LLM 상호작용
+- **성능 지표**: 지연 시간, 토큰 사용량, 비용 추적
+- **실행 타임라인**: 전체 워크플로우의 단계별 보기
+
+## 문제 해결
+
+### 일반적인 문제
+
+- **추적이 나타나지 않음**: `init()`이 CrewAI 임포트 이전에 호출되었는지 확인하세요
+- **인증 오류**: LangDB API 키와 프로젝트 ID를 확인하세요
+
+## 리소스
+
+
+
+
+### 볼 수 있는 내용
+
+- **에이전트 상호작용**: 에이전트 대화 및 작업 인계의 전체 흐름
+- **도구 사용**: 호출된 도구, 입력값 및 출력값
+- **모델 호출**: 프롬프트 및 응답과 함께하는 상세 LLM 상호작용
+- **성능 지표**: 지연 시간, 토큰 사용량, 비용 추적
+- **실행 타임라인**: 전체 워크플로우의 단계별 보기
+
+## 문제 해결
+
+### 일반적인 문제
+
+- **추적이 나타나지 않음**: `init()`이 CrewAI 임포트 이전에 호출되었는지 확인하세요
+- **인증 오류**: LangDB API 키와 프로젝트 ID를 확인하세요
+
+## 리소스
+
+ +
+  +
+  +
+
+
+ + 필터 및 샘플링을 기준으로 UI에서 캡처된 로그를 자동으로 평가할 수 있습니다. +
++ 로그의 품질을 평가하고, 사람의 평가 또는 등급을 이용해 로그를 검토할 수 있습니다. +
++ 트레이스 또는 로그의 모든 컴포넌트를 평가하여 에이전트의 행동에 대한 통찰을 얻을 수 있습니다. +
+ +
+ 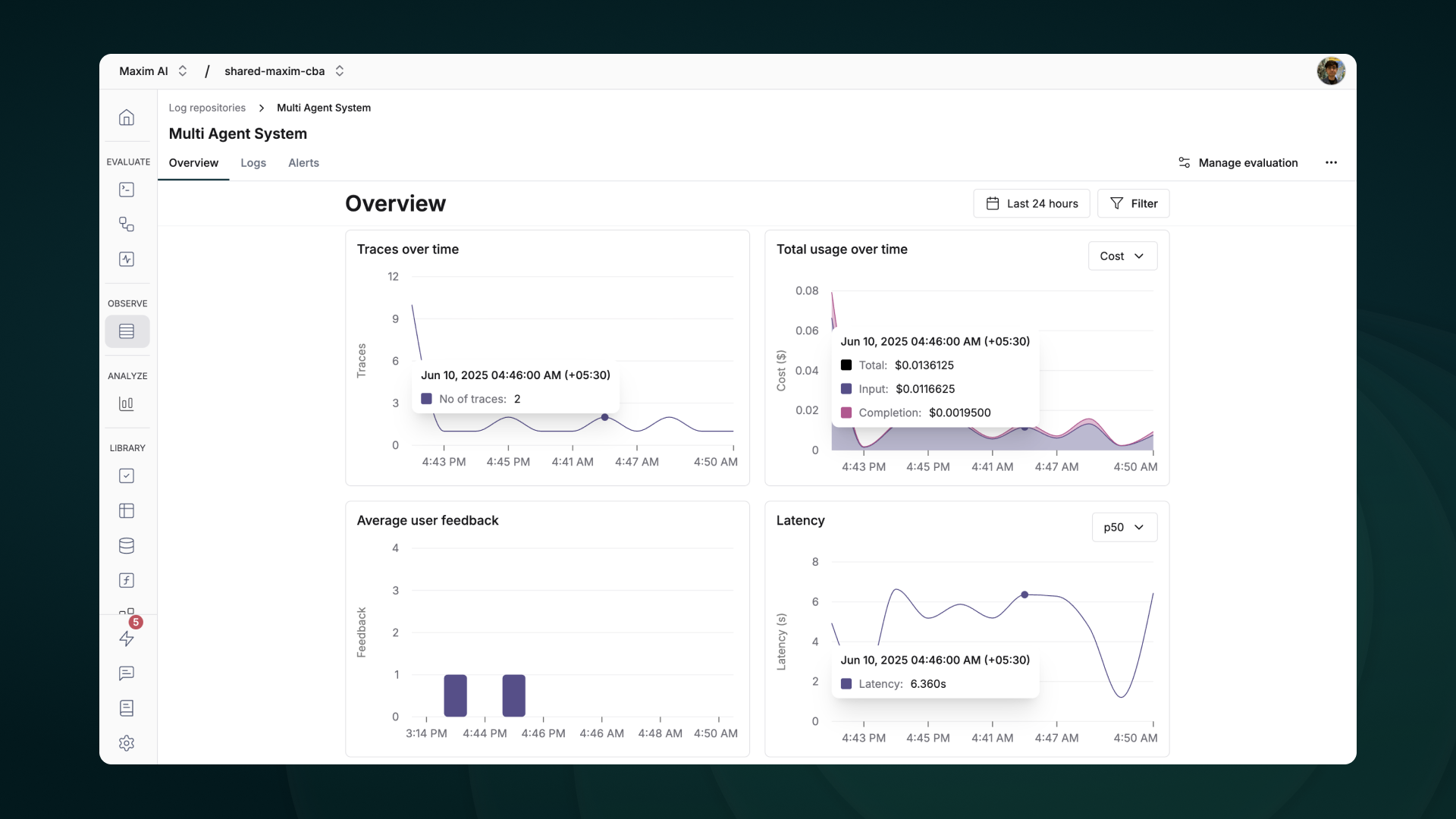 +
+ 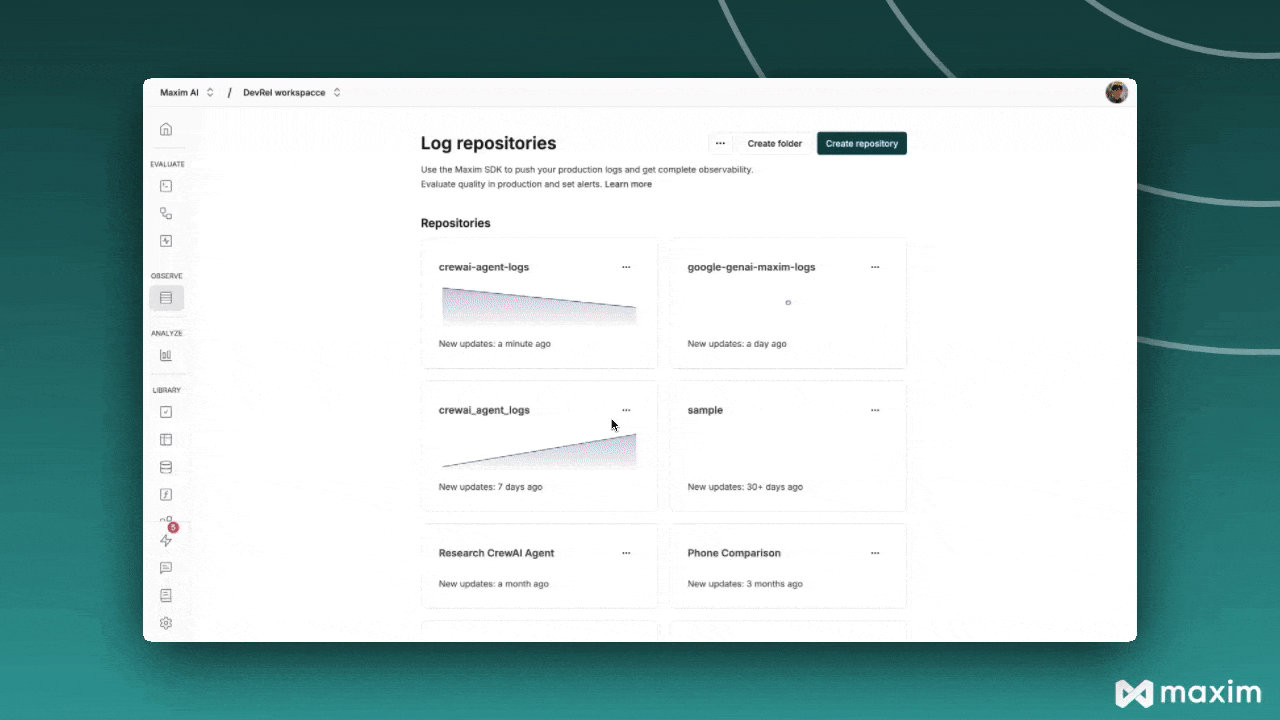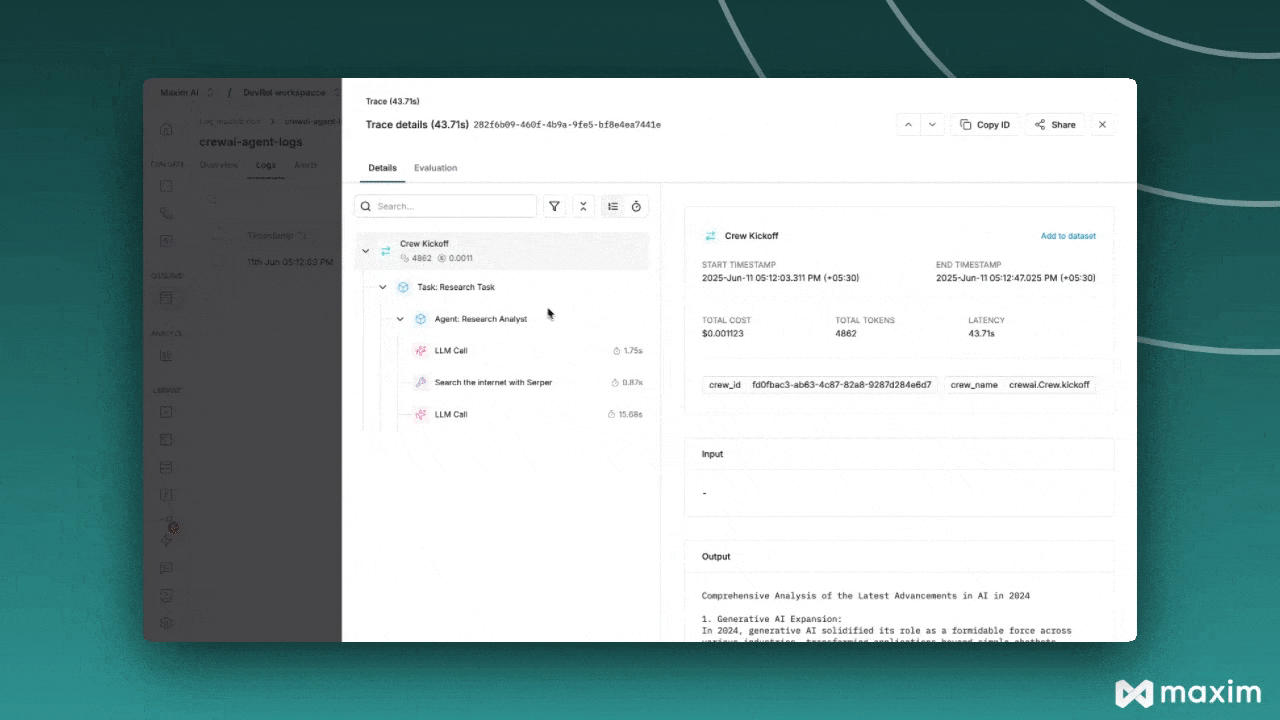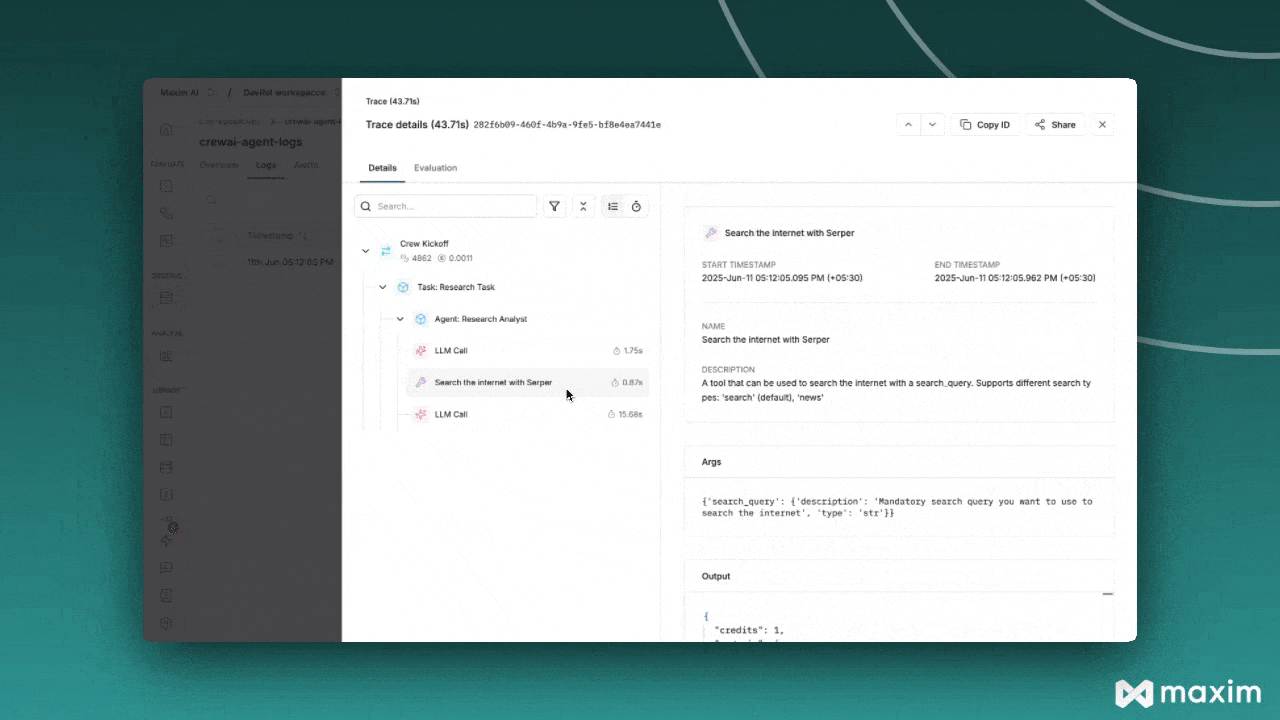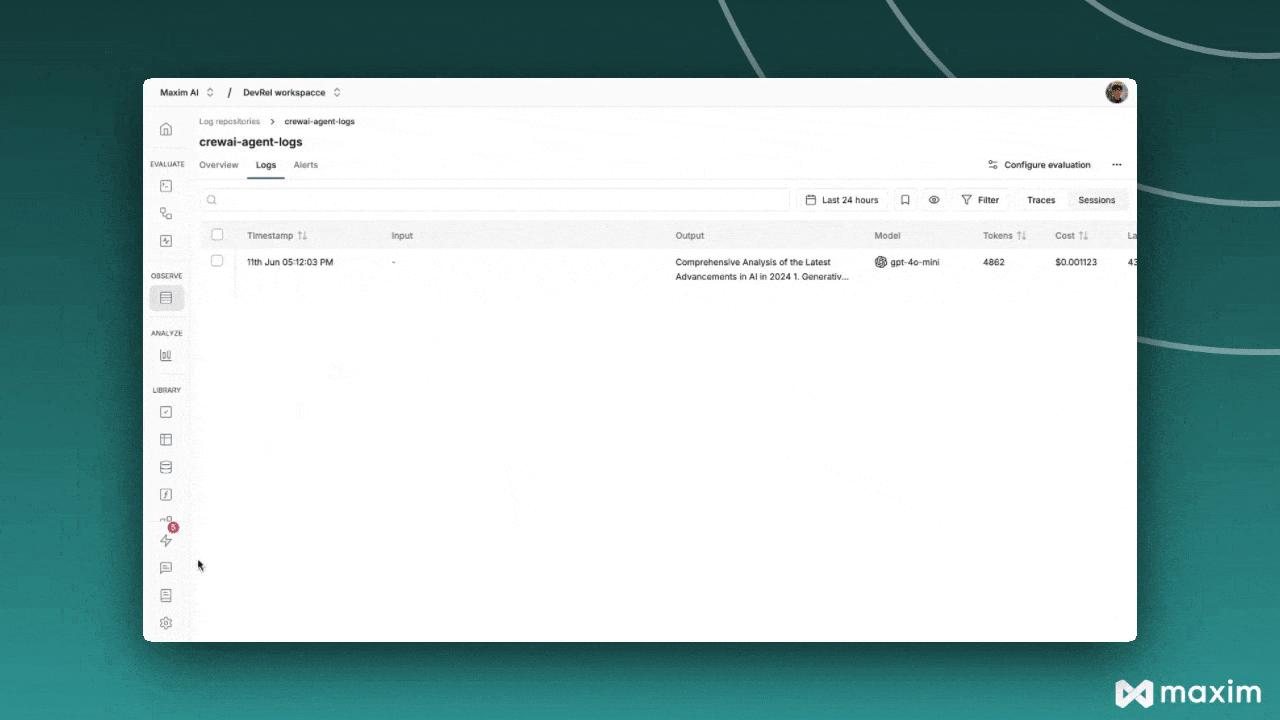 +
+## 문제 해결
+
+### 흔한 문제
+
+- **추적(trace)가 나타나지 않음**: API 키와 저장소 ID가 올바른지 확인하세요.
+- crew를 실행하기 **_전에_** 반드시 **`instrument_crewai()`를 호출**했는지 확인하세요. 이 함수가 로깅 훅(logging hook)을 올바르게 초기화합니다.
+- 내부 오류를 드러내기 위해 `instrument_crewai()` 호출 시 `debug=True`로 설정하세요:
+
+ ```python
+ instrument_crewai(logger, debug=True)
+ ```
+- 에이전트에서 상세 로그를 캡처하기 위해 `verbose=True`로 설정하세요:
+
+ ```python
+ agent = CrewAgent(..., verbose=True)
+ ```
+- `instrument_crewai()`가 에이전트를 생성하거나 실행하기 **전에** 호출되는지 다시 한 번 확인하세요. 너무 당연해 보일 수 있지만, 자주 발생하는 실수입니다.
+
+## 리소스
+
+
+
+## 문제 해결
+
+### 흔한 문제
+
+- **추적(trace)가 나타나지 않음**: API 키와 저장소 ID가 올바른지 확인하세요.
+- crew를 실행하기 **_전에_** 반드시 **`instrument_crewai()`를 호출**했는지 확인하세요. 이 함수가 로깅 훅(logging hook)을 올바르게 초기화합니다.
+- 내부 오류를 드러내기 위해 `instrument_crewai()` 호출 시 `debug=True`로 설정하세요:
+
+ ```python
+ instrument_crewai(logger, debug=True)
+ ```
+- 에이전트에서 상세 로그를 캡처하기 위해 `verbose=True`로 설정하세요:
+
+ ```python
+ agent = CrewAgent(..., verbose=True)
+ ```
+- `instrument_crewai()`가 에이전트를 생성하거나 실행하기 **전에** 호출되는지 다시 한 번 확인하세요. 너무 당연해 보일 수 있지만, 자주 발생하는 실수입니다.
+
+## 리소스
+
+ +
+
+
+  +
+  +
+  +
+
+### 기능
+
+- **분석 대시보드**: 에이전트의 상태와 성능을 모니터링할 수 있는 대시보드를 통해 지표, 비용, 사용자 상호작용을 자세히 추적할 수 있습니다.
+- **OpenTelemetry-네이티브 가시성 SDK**: Grafana, DataDog 등 기존 가시성 도구로 추적 및 지표를 전송할 수 있는 벤더 중립적 SDK를 제공합니다.
+- **커스텀 및 파인튜닝 모델 비용 추적**: 정확한 예산 책정을 위해 커스텀 가격 파일을 사용하여 특정 모델의 비용 추정치를 맞춤화할 수 있습니다.
+- **예외 모니터링 대시보드**: 모니터링 대시보드를 통해 일반적인 예외 및 오류를 추적하여 문제를 신속하게 찾아내고 해결할 수 있습니다.
+- **컴플라이언스 및 보안**: 욕설 및 PII 유출과 같은 잠재적인 위협을 탐지합니다.
+- **프롬프트 인젝션 탐지**: 잠재적인 코드 인젝션 및 비밀 유출을 식별합니다.
+- **API 키 및 비밀 관리**: LLM API 키와 비밀을 중앙에서 안전하게 관리하여 안전하지 않은 관행을 방지합니다.
+- **프롬프트 관리**: PromptHub을 사용하여 에이전트 프롬프트를 관리 및 버전 관리하고, 모든 에이전트에서 일관되고 쉽게 접근할 수 있습니다.
+- **모델 플레이그라운드**: 배포 전에 CrewAI 에이전트에 사용할 다양한 모델을 테스트하고 비교할 수 있습니다.
+
+## 설치 안내
+
+
+
+
+
+
+
+
+### 기능
+
+- **분석 대시보드**: 에이전트의 상태와 성능을 모니터링할 수 있는 대시보드를 통해 지표, 비용, 사용자 상호작용을 자세히 추적할 수 있습니다.
+- **OpenTelemetry-네이티브 가시성 SDK**: Grafana, DataDog 등 기존 가시성 도구로 추적 및 지표를 전송할 수 있는 벤더 중립적 SDK를 제공합니다.
+- **커스텀 및 파인튜닝 모델 비용 추적**: 정확한 예산 책정을 위해 커스텀 가격 파일을 사용하여 특정 모델의 비용 추정치를 맞춤화할 수 있습니다.
+- **예외 모니터링 대시보드**: 모니터링 대시보드를 통해 일반적인 예외 및 오류를 추적하여 문제를 신속하게 찾아내고 해결할 수 있습니다.
+- **컴플라이언스 및 보안**: 욕설 및 PII 유출과 같은 잠재적인 위협을 탐지합니다.
+- **프롬프트 인젝션 탐지**: 잠재적인 코드 인젝션 및 비밀 유출을 식별합니다.
+- **API 키 및 비밀 관리**: LLM API 키와 비밀을 중앙에서 안전하게 관리하여 안전하지 않은 관행을 방지합니다.
+- **프롬프트 관리**: PromptHub을 사용하여 에이전트 프롬프트를 관리 및 버전 관리하고, 모든 에이전트에서 일관되고 쉽게 접근할 수 있습니다.
+- **모델 플레이그라운드**: 배포 전에 CrewAI 에이전트에 사용할 다양한 모델을 테스트하고 비교할 수 있습니다.
+
+## 설치 안내
+
+
+
+
+
+  +
+
+Opik은 CrewAI 애플리케이션 개발의 모든 단계에서 포괄적인 지원을 제공합니다:
+
+- **로그 트레이스 및 스팬**: 개발 및 프로덕션 시스템에서 LLM 호출과 애플리케이션 로직을 자동으로 추적하여 디버깅 및 분석이 가능합니다. 프로젝트 간 응답을 수동 또는 프로그램적으로 주석 달고, 조회하고, 비교할 수 있습니다.
+- **LLM 애플리케이션 성능 평가**: 사용자 지정 테스트 세트로 평가하고, 내장된 평가 지표를 실행하거나 SDK 또는 UI에서 사용자만의 지표를 정의할 수 있습니다.
+- **CI/CD 파이프라인 내 테스트**: PyTest 기반의 Opik LLM 단위 테스트로 신뢰할 수 있는 성능 기준선을 설정하세요. 프로덕션에서 연속 모니터링을 위한 온라인 평가도 실행할 수 있습니다.
+- **프로덕션 데이터 모니터링 및 분석**: 프로덕션에서 보지 못한 데이터에 대한 모델의 성능을 이해하고, 새로운 개발 반복을 위한 데이터 세트를 생성할 수 있습니다.
+
+## 설치
+
+Comet은 호스팅된 Opik 플랫폼을 제공하거나, 로컬에서 플랫폼을 실행할 수도 있습니다.
+
+호스팅 버전을 사용하려면 [무료 Comet 계정 만들기](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) 후 API 키를 발급받으세요.
+
+Opik 플랫폼을 로컬에서 실행하려면, [설치 가이드](https://www.comet.com/docs/opik/self-host/overview/)에서 자세한 정보를 확인하세요.
+
+이 가이드에서는 CrewAI의 빠른 시작 예제를 사용합니다.
+
+
+
+
+Opik은 CrewAI 애플리케이션 개발의 모든 단계에서 포괄적인 지원을 제공합니다:
+
+- **로그 트레이스 및 스팬**: 개발 및 프로덕션 시스템에서 LLM 호출과 애플리케이션 로직을 자동으로 추적하여 디버깅 및 분석이 가능합니다. 프로젝트 간 응답을 수동 또는 프로그램적으로 주석 달고, 조회하고, 비교할 수 있습니다.
+- **LLM 애플리케이션 성능 평가**: 사용자 지정 테스트 세트로 평가하고, 내장된 평가 지표를 실행하거나 SDK 또는 UI에서 사용자만의 지표를 정의할 수 있습니다.
+- **CI/CD 파이프라인 내 테스트**: PyTest 기반의 Opik LLM 단위 테스트로 신뢰할 수 있는 성능 기준선을 설정하세요. 프로덕션에서 연속 모니터링을 위한 온라인 평가도 실행할 수 있습니다.
+- **프로덕션 데이터 모니터링 및 분석**: 프로덕션에서 보지 못한 데이터에 대한 모델의 성능을 이해하고, 새로운 개발 반복을 위한 데이터 세트를 생성할 수 있습니다.
+
+## 설치
+
+Comet은 호스팅된 Opik 플랫폼을 제공하거나, 로컬에서 플랫폼을 실행할 수도 있습니다.
+
+호스팅 버전을 사용하려면 [무료 Comet 계정 만들기](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) 후 API 키를 발급받으세요.
+
+Opik 플랫폼을 로컬에서 실행하려면, [설치 가이드](https://www.comet.com/docs/opik/self-host/overview/)에서 자세한 정보를 확인하세요.
+
+이 가이드에서는 CrewAI의 빠른 시작 예제를 사용합니다.
+
+ +
+## 소개
+
+Portkey는 CrewAI에 프로덕션 적합성을 위한 기능을 추가하여 실험적인 agent crew를 다음과 같이 견고한 시스템으로 전환합니다.
+
+- **모든 agent 단계, 도구 사용, 상호작용에 대한 완전한 관찰 가능성**
+- **내장된 신뢰성**: 폴백, 재시도, 로드 밸런싱 기능 제공
+- **AI 비용 관리**를 위한 비용 추적 및 최적화
+- **단일 통합을 통한 200개 이상의 LLM 접근**
+- **agent의 행동을 안전하고 규정 준수로 유지하는 가드레일**
+- **일관된 agent 성능을 위한 버전 관리되는 prompt**
+
+### 설치 및 설정
+
+
+
+## 소개
+
+Portkey는 CrewAI에 프로덕션 적합성을 위한 기능을 추가하여 실험적인 agent crew를 다음과 같이 견고한 시스템으로 전환합니다.
+
+- **모든 agent 단계, 도구 사용, 상호작용에 대한 완전한 관찰 가능성**
+- **내장된 신뢰성**: 폴백, 재시도, 로드 밸런싱 기능 제공
+- **AI 비용 관리**를 위한 비용 추적 및 최적화
+- **단일 통합을 통한 200개 이상의 LLM 접근**
+- **agent의 행동을 안전하고 규정 준수로 유지하는 가드레일**
+- **일관된 agent 성능을 위한 버전 관리되는 prompt**
+
+### 설치 및 설정
+
+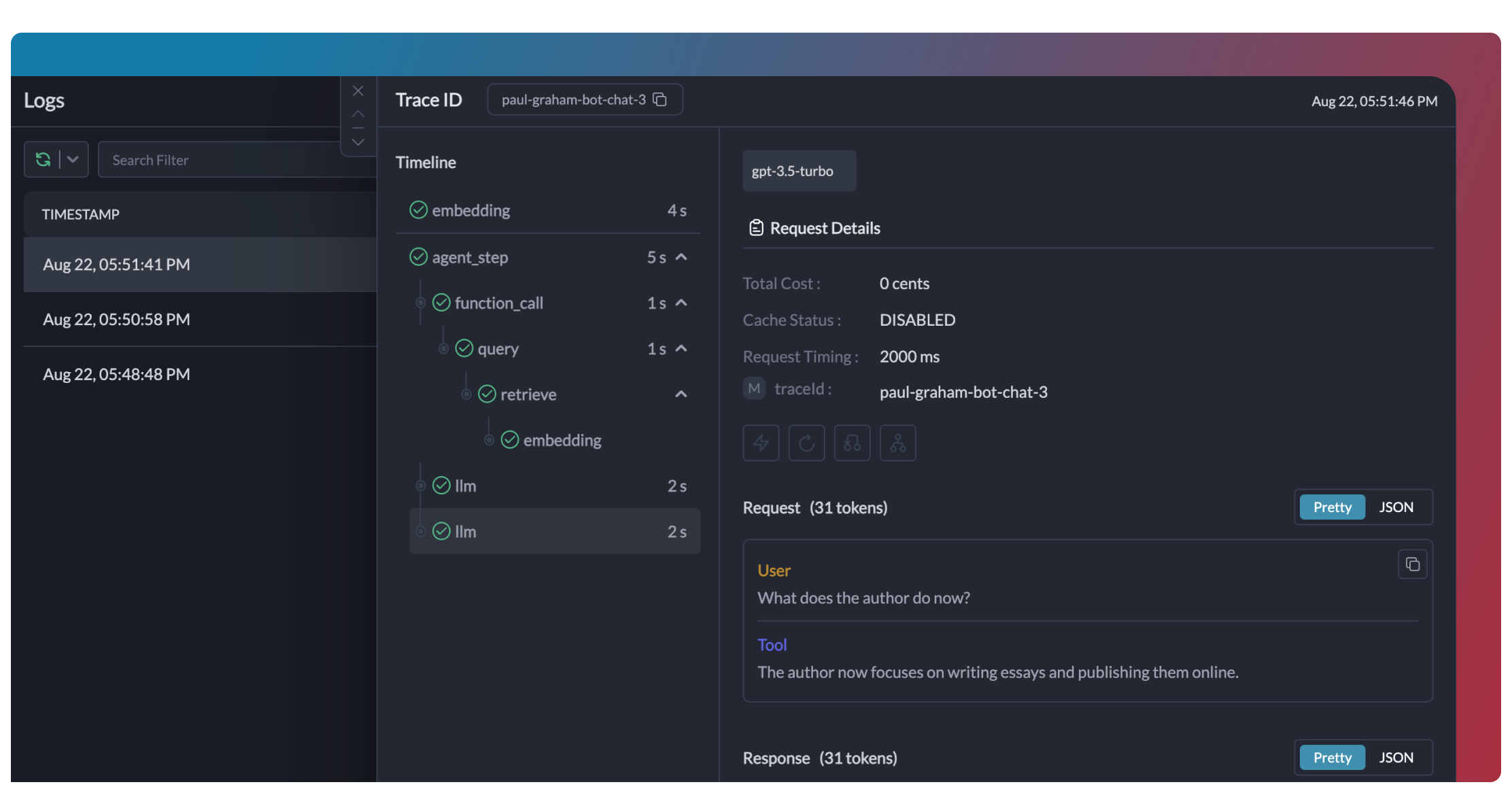 +
+
+Traces는 crew의 실행을 계층적으로 보여주며, LLM 호출, 도구 호출, 상태 전환의 순서를 확인할 수 있습니다.
+
+```python
+# Portkey에서 계층적 추적을 활성화하려면 trace_id를 추가하세요
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ trace_id="unique-session-id" # 고유한 trace ID 추가
+ )
+)
+```
+
+
+
+Traces는 crew의 실행을 계층적으로 보여주며, LLM 호출, 도구 호출, 상태 전환의 순서를 확인할 수 있습니다.
+
+```python
+# Portkey에서 계층적 추적을 활성화하려면 trace_id를 추가하세요
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ trace_id="unique-session-id" # 고유한 trace ID 추가
+ )
+)
+```
+ 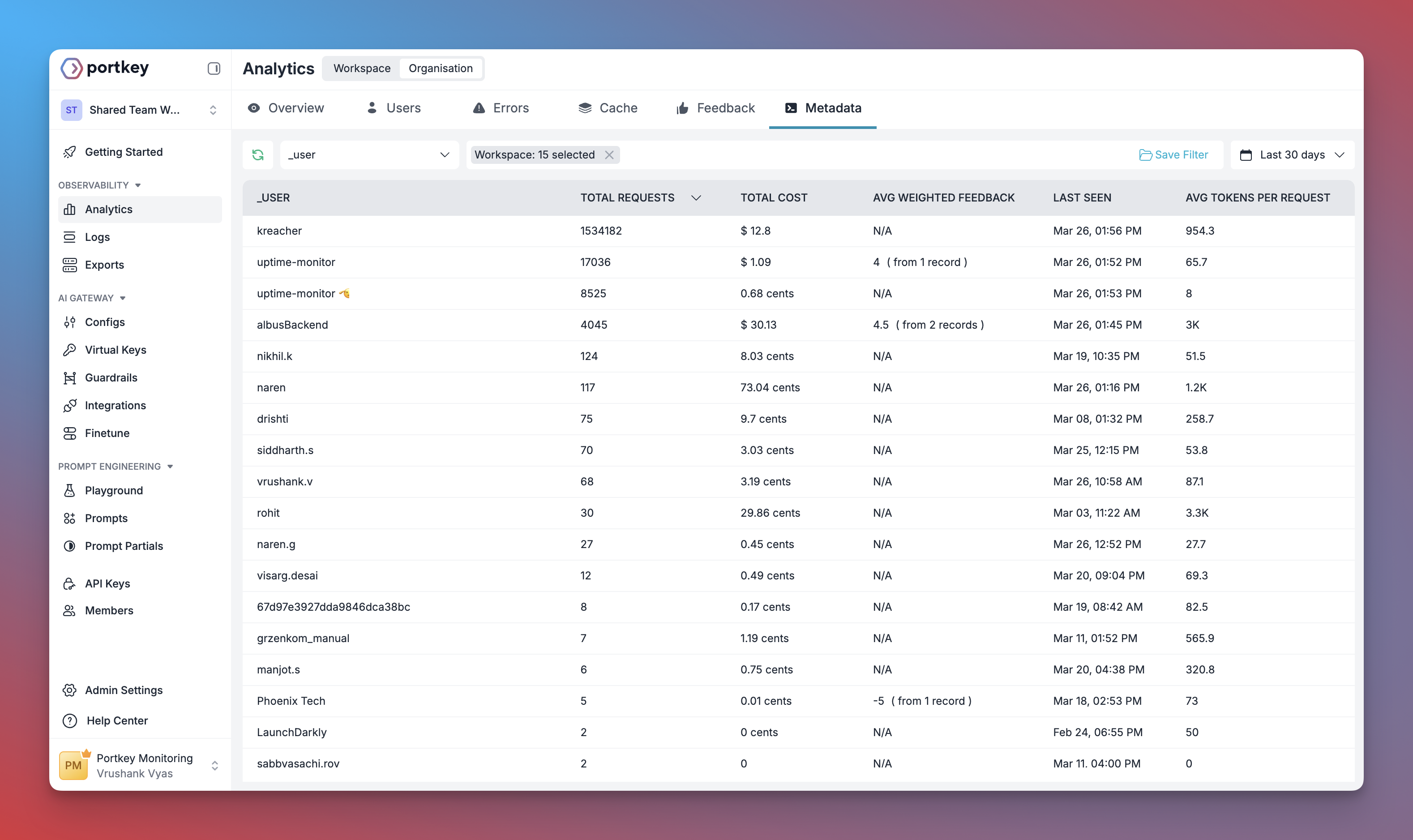 +
+
+Portkey는 LLM과의 모든 상호작용을 로그로 남깁니다. 여기에는 다음이 포함됩니다:
+
+- 전체 요청 및 응답 페이로드
+- 지연 시간 및 토큰 사용량 지표
+- 비용 계산
+- 도구 호출 및 함수 실행
+
+모든 로그는 메타데이터, trace ID, 모델 등으로 필터링할 수 있어 특정 crew 실행을 쉽게 디버깅할 수 있습니다.
+
+
+
+Portkey는 LLM과의 모든 상호작용을 로그로 남깁니다. 여기에는 다음이 포함됩니다:
+
+- 전체 요청 및 응답 페이로드
+- 지연 시간 및 토큰 사용량 지표
+- 비용 계산
+- 도구 호출 및 함수 실행
+
+모든 로그는 메타데이터, trace ID, 모델 등으로 필터링할 수 있어 특정 crew 실행을 쉽게 디버깅할 수 있습니다.
+ 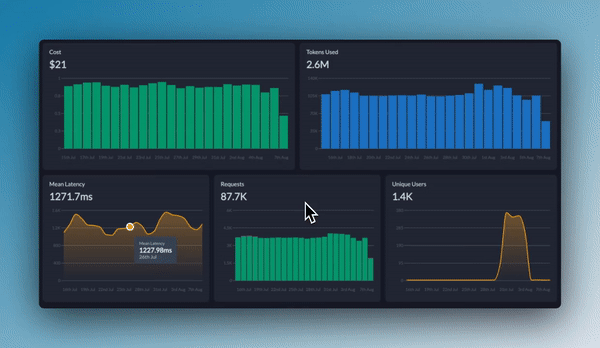 +
+
+Portkey는 사용자가 다음을 할 수 있도록 지원하는 내장 대시보드를 제공합니다:
+
+- 모든 crew 실행에서 비용 및 토큰 사용량 추적
+- 지연 시간, 성공률과 같은 성능 지표 분석
+- agent workflow의 병목 지점 식별
+- 서로 다른 crew 구성 및 LLM 비교
+
+사용자는 모든 지표를 사용자 정의 메타데이터별로 필터링 및 세분화하여 특정 crew 유형, 사용자 그룹 또는 사용 사례를 분석할 수 있습니다.
+
+
+
+Portkey는 사용자가 다음을 할 수 있도록 지원하는 내장 대시보드를 제공합니다:
+
+- 모든 crew 실행에서 비용 및 토큰 사용량 추적
+- 지연 시간, 성공률과 같은 성능 지표 분석
+- agent workflow의 병목 지점 식별
+- 서로 다른 crew 구성 및 LLM 비교
+
+사용자는 모든 지표를 사용자 정의 메타데이터별로 필터링 및 세분화하여 특정 crew 유형, 사용자 그룹 또는 사용 사례를 분석할 수 있습니다.
+  +
+
+CrewAI LLM 구성에 사용자 정의 메타데이터를 추가하여 강력한 필터링 및 세분화를 활성화할 수 있습니다:
+
+```python
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ metadata={
+ "crew_type": "research_crew",
+ "environment": "production",
+ "_user": "user_123", # 사용자 분석을 위한 특수 _user 필드
+ "request_source": "mobile_app"
+ }
+ )
+)
+```
+
+이 메타데이터는 Portkey 대시보드에서 로그, trace, 지표를 필터링하는 데 사용될 수 있으며, 특정 crew 실행, 사용자 또는 환경을 분석할 수 있습니다.
+
+
+
+이를 통해 다음이 가능합니다:
+- 사용자별 비용 추적 및 예산 관리
+- 개인화된 사용자 분석
+- 팀 또는 조직 단위의 지표
+- 환경별 모니터링(스테이징 vs. 프로덕션)
+
+
+
+
+CrewAI LLM 구성에 사용자 정의 메타데이터를 추가하여 강력한 필터링 및 세분화를 활성화할 수 있습니다:
+
+```python
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ metadata={
+ "crew_type": "research_crew",
+ "environment": "production",
+ "_user": "user_123", # 사용자 분석을 위한 특수 _user 필드
+ "request_source": "mobile_app"
+ }
+ )
+)
+```
+
+이 메타데이터는 Portkey 대시보드에서 로그, trace, 지표를 필터링하는 데 사용될 수 있으며, 특정 crew 실행, 사용자 또는 환경을 분석할 수 있습니다.
+
+
+
+이를 통해 다음이 가능합니다:
+- 사용자별 비용 추적 및 예산 관리
+- 개인화된 사용자 분석
+- 팀 또는 조직 단위의 지표
+- 환경별 모니터링(스테이징 vs. 프로덕션)
+
+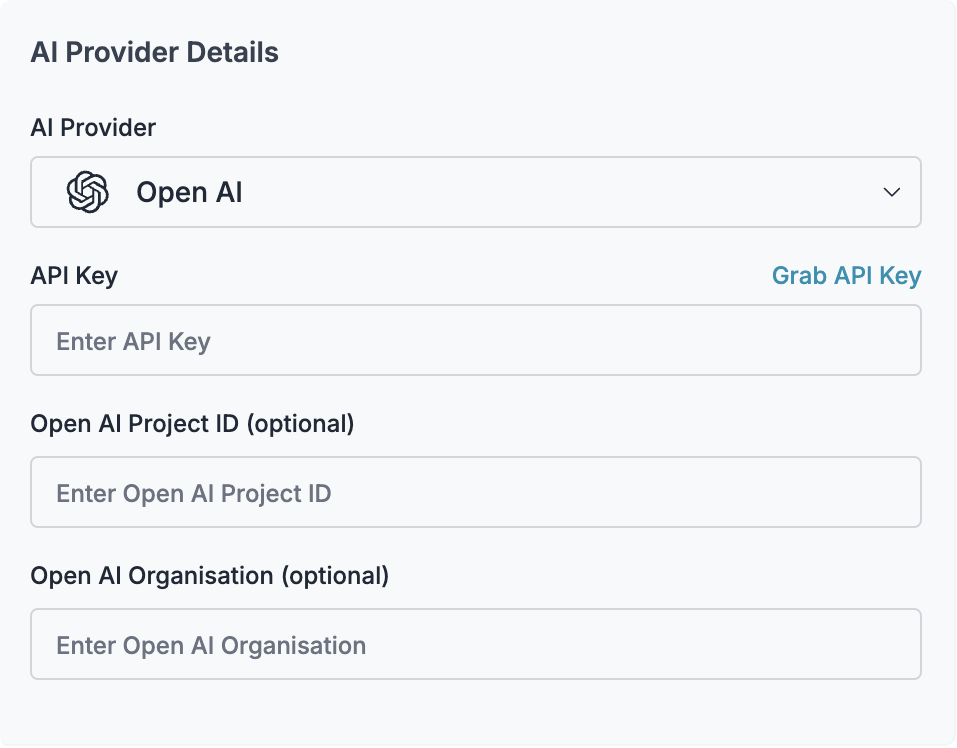 +
+
+
+
+
+ +
+
+
+ +
+
+
+
+
+
+
+공식 CrewAI 문서
+이 통합 구현에 대한 맞춤형 안내를 받아보세요
+ +
+
+
+