mirror of
https://github.com/crewAIInc/crewAI.git
synced 2026-07-04 22:49:23 +00:00
feat: adopt directory-based docs versioning with Edge channel
Switch docs.crewai.com from navigation-only versioning (every version selector entry rendered the same docs/<lang>/* source files) to Mintlify's directory-based versioning so each version selector entry renders its own snapshot. Add an "Edge" channel under docs/edge/<lang>/* that always reflects main HEAD for unreleased work, eliminating pre-release leakage onto frozen release labels. External links to canonical /<lang>/* URLs are preserved via wildcard redirects that always land on the current default version. Layout: - docs/edge/<lang>/* rolling source (you edit here) - docs/edge/enterprise-api.*.yaml - docs/v<X.Y.Z>/<lang>/* frozen, immutable snapshots - docs/v<X.Y.Z>/enterprise-api.*.yaml - docs/images/ shared, append-only - docs/docs.json nav + redirects URLs follow the Mintlify-idiomatic shape: /edge/<lang>/<page> for Edge, /v<X.Y.Z>/<lang>/<page> for every frozen snapshot. The wildcard redirects /<lang>/:slug* -> /<default>/<lang>/:slug* keep stale links working, and every freeze rewrites them (plus all per-section/per-page redirects) so destinations always resolve to the current default without depending on a second redirect hop. Release flow integration (devtools release): - New module crewai_devtools.docs_versioning.freeze() materialises docs/v<X.Y.Z>/ from docs/edge/, rewrites openapi: refs inside the snapshot, inserts the version into every language block in docs.json, and refreshes all redirect destinations. - _update_docs_and_create_pr() in cli.py now calls that freeze during Phase 2 of devtools release. Edge changelogs are updated first (so the snapshot freeze picks them up), then the snapshot is staged alongside docs.json, branched as docs/freeze-v<X.Y.Z>, and the PR is titled [docs-freeze] docs: snapshot and changelog for v<X.Y.Z> — the title prefix the new CI guard reads. - The PR still gates tag, GitHub release, PyPI publish, and the enterprise release as before; no new PRs are added. - Pre-releases (1.X.YaN, 1.X.YbN, ...) skip the snapshot — they ride Edge — and the docs PR title omits the [docs-freeze] prefix. - docs_check (AI-generated docs scaffolding) writes to docs/edge/<lang>/* so newly-generated unreleased docs land in Edge and never accidentally touch a frozen snapshot. Migration scripts (one-shot): - scripts/docs/freeze_historical_versions.py reconstructs all 16 historical snapshots (v1.10.0 .. v1.14.7) from git tags via git archive | tar, rewriting openapi: MDX refs so each snapshot reads its own enterprise-api YAML rather than the live one. - scripts/docs/prefix_version_paths.py one-shot-migrates docs.json: rewrites every page path in 16 versioned blocks to point under docs/v<X.Y.Z>/, inserts a new Edge entry per language, tags v1.14.7 as Latest (default), prunes pages whose target file doesn't exist in the snapshot (e.g. docs/ar/ didn't exist before v1.12.0), and writes the wildcard + per-section redirects. - scripts/docs/freeze_current_edge.py is now a thin CLI wrapper around docs_versioning.freeze for manual one-off freezes (e.g. retroactively snapshotting a forgotten release). CI guards (.github/workflows/docs-snapshots.yml): - Frozen snapshots under docs/v[0-9]*/ are immutable; only PRs whose title contains [docs-freeze] (i.e. release-cut PRs generated by devtools release or the manual wrapper) may modify them. - Images under docs/images/ are append-only since snapshots share a single image directory. Deleting or renaming an image breaks every historical snapshot that still references it. Restored docs/images/crewai-otel-export.png from PR #3673; it was deleted in PR #4908 but v1.10.0 / v1.10.1 snapshots still reference it. Restoring instead of editing the snapshots preserves historical rendering fidelity and validates the new append-only rule retroactively. Tests: - lib/devtools/tests/test_docs_versioning.py covers the freeze: file copy, openapi rewrite, version insertion, default demotion, redirect upserts, per-section redirect rewriting, idempotency, and invalid inputs. Verified locally with mintlify broken-links: 0 broken links across the full site (Edge + 16 frozen versions, 4 locales). AGENTS.md (repo root) is the contributor guide for the new model; RELEASING.md is the release-cut runbook; README's Contribution section links to both. Co-authored-by: Cursor <cursoragent@cursor.com>
This commit is contained in:
152
docs/edge/en/observability/arize-phoenix.mdx
Normal file
152
docs/edge/en/observability/arize-phoenix.mdx
Normal file
@@ -0,0 +1,152 @@
|
||||
---
|
||||
title: Arize Phoenix
|
||||
description: Arize Phoenix integration for CrewAI with OpenTelemetry and OpenInference
|
||||
icon: magnifying-glass-chart
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Arize Phoenix Integration
|
||||
|
||||
This guide demonstrates how to integrate **Arize Phoenix** with **CrewAI** using OpenTelemetry via the [OpenInference](https://github.com/openinference/openinference) SDK. By the end of this guide, you will be able to trace your CrewAI agents and easily debug your agents.
|
||||
|
||||
> **What is Arize Phoenix?** [Arize Phoenix](https://phoenix.arize.com) is an LLM observability platform that provides tracing and evaluation for AI applications.
|
||||
|
||||
[](https://www.youtube.com/watch?v=Yc5q3l6F7Ww)
|
||||
|
||||
## Get Started
|
||||
|
||||
We'll walk through a simple example of using CrewAI and integrating it with Arize Phoenix via OpenTelemetry using OpenInference.
|
||||
|
||||
You can also access this guide on [Google Colab](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/crewai_tracing_tutorial.ipynb).
|
||||
|
||||
### Step 1: Install Dependencies
|
||||
|
||||
```bash
|
||||
pip install openinference-instrumentation-crewai crewai crewai-tools arize-phoenix-otel
|
||||
```
|
||||
|
||||
### Step 2: Set Up Environment Variables
|
||||
|
||||
Setup Phoenix Cloud API keys and configure OpenTelemetry to send traces to Phoenix. Phoenix Cloud is a hosted version of Arize Phoenix, but it is not required to use this integration.
|
||||
|
||||
You can get your free Serper API key [here](https://serper.dev/).
|
||||
|
||||
```python
|
||||
import os
|
||||
from getpass import getpass
|
||||
|
||||
# Get your Phoenix Cloud credentials
|
||||
PHOENIX_API_KEY = getpass("🔑 Enter your Phoenix Cloud API Key: ")
|
||||
|
||||
# Get API keys for services
|
||||
OPENAI_API_KEY = getpass("🔑 Enter your OpenAI API key: ")
|
||||
SERPER_API_KEY = getpass("🔑 Enter your Serper API key: ")
|
||||
|
||||
# Set environment variables
|
||||
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
|
||||
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com" # Phoenix Cloud, change this to your own endpoint if you are using a self-hosted instance
|
||||
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
|
||||
os.environ["SERPER_API_KEY"] = SERPER_API_KEY
|
||||
```
|
||||
|
||||
### Step 3: Initialize OpenTelemetry with Phoenix
|
||||
|
||||
Initialize the OpenInference OpenTelemetry instrumentation SDK to start capturing traces and send them to Phoenix.
|
||||
|
||||
```python
|
||||
from phoenix.otel import register
|
||||
|
||||
tracer_provider = register(
|
||||
project_name="crewai-tracing-demo",
|
||||
auto_instrument=True,
|
||||
)
|
||||
```
|
||||
|
||||
### Step 4: Create a CrewAI Application
|
||||
|
||||
We'll create a CrewAI application where two agents collaborate to research and write a blog post about AI advancements.
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai_tools import SerperDevTool
|
||||
from openinference.instrumentation.crewai import CrewAIInstrumentor
|
||||
from phoenix.otel import register
|
||||
|
||||
# setup monitoring for your crew
|
||||
tracer_provider = register(
|
||||
endpoint="http://localhost:6006/v1/traces")
|
||||
CrewAIInstrumentor().instrument(skip_dep_check=True, tracer_provider=tracer_provider)
|
||||
search_tool = SerperDevTool()
|
||||
|
||||
# Define your agents with roles and goals
|
||||
researcher = Agent(
|
||||
role="Senior Research Analyst",
|
||||
goal="Uncover cutting-edge developments in AI and data science",
|
||||
backstory="""You work at a leading tech think tank.
|
||||
Your expertise lies in identifying emerging trends.
|
||||
You have a knack for dissecting complex data and presenting actionable insights.""",
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
# You can pass an optional llm attribute specifying what model you wanna use.
|
||||
# llm=ChatOpenAI(model_name="gpt-3.5", temperature=0.7),
|
||||
tools=[search_tool],
|
||||
)
|
||||
writer = Agent(
|
||||
role="Tech Content Strategist",
|
||||
goal="Craft compelling content on tech advancements",
|
||||
backstory="""You are a renowned Content Strategist, known for your insightful and engaging articles.
|
||||
You transform complex concepts into compelling narratives.""",
|
||||
verbose=True,
|
||||
allow_delegation=True,
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description="""Conduct a comprehensive analysis of the latest advancements in AI in 2024.
|
||||
Identify key trends, breakthrough technologies, and potential industry impacts.""",
|
||||
expected_output="Full analysis report in bullet points",
|
||||
agent=researcher,
|
||||
)
|
||||
|
||||
task2 = Task(
|
||||
description="""Using the insights provided, develop an engaging blog
|
||||
post that highlights the most significant AI advancements.
|
||||
Your post should be informative yet accessible, catering to a tech-savvy audience.
|
||||
Make it sound cool, avoid complex words so it doesn't sound like AI.""",
|
||||
expected_output="Full blog post of at least 4 paragraphs",
|
||||
agent=writer,
|
||||
)
|
||||
|
||||
# Instantiate your crew with a sequential process
|
||||
crew = Crew(
|
||||
agents=[researcher, writer], tasks=[task1, task2], verbose=1, process=Process.sequential
|
||||
)
|
||||
|
||||
# Get your crew to work!
|
||||
result = crew.kickoff()
|
||||
|
||||
print("######################")
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Step 5: View Traces in Phoenix
|
||||
|
||||
After running the agent, you can view the traces generated by your CrewAI application in Phoenix. You should see detailed steps of the agent interactions and LLM calls, which can help you debug and optimize your AI agents.
|
||||
|
||||
Log into your Phoenix Cloud account and navigate to the project you specified in the `project_name` parameter. You'll see a timeline view of your trace with all the agent interactions, tool usages, and LLM calls.
|
||||
|
||||
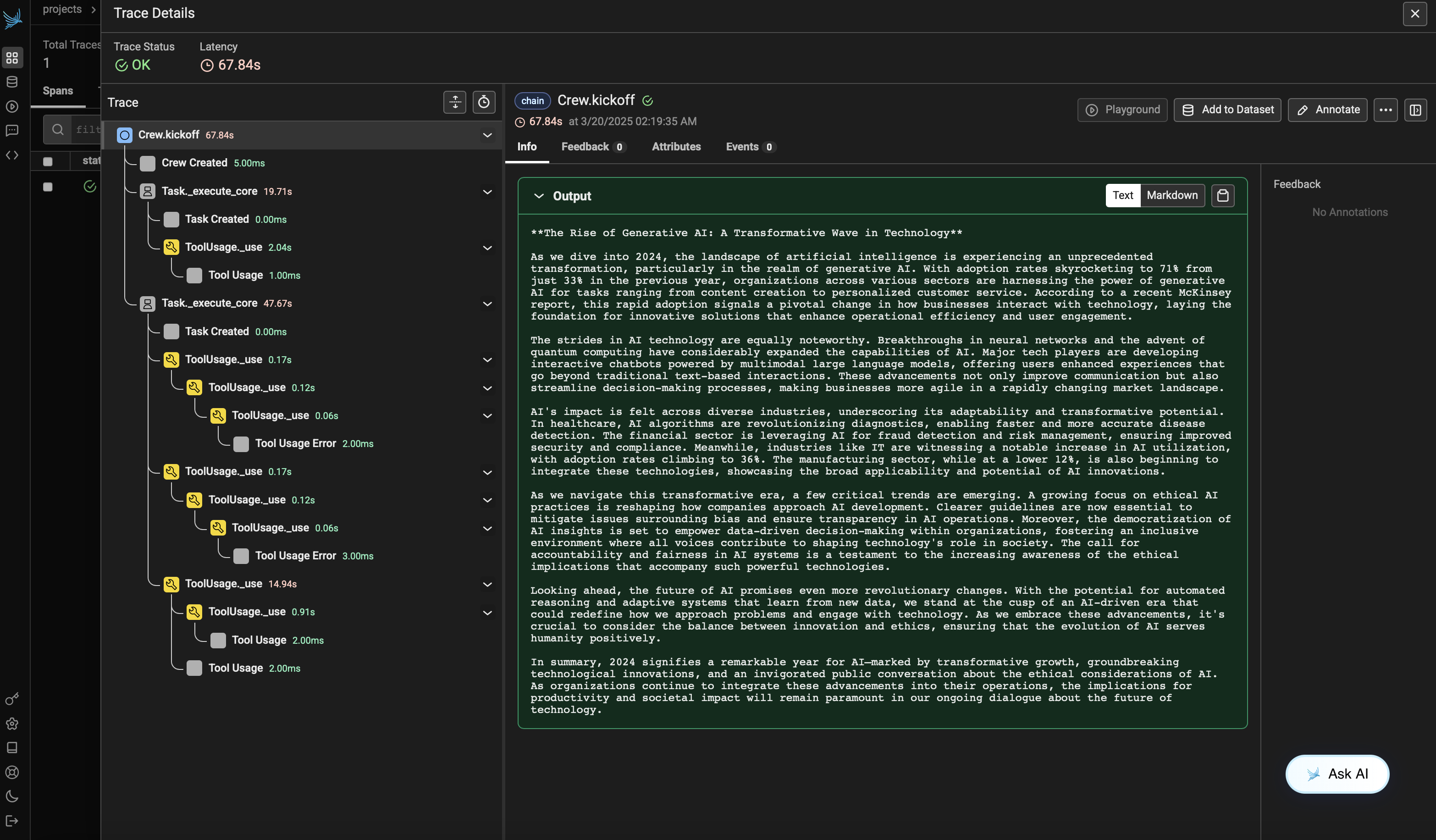
|
||||
|
||||
|
||||
### Version Compatibility Information
|
||||
- Python 3.8+
|
||||
- CrewAI >= 0.86.0
|
||||
- Arize Phoenix >= 7.0.1
|
||||
- OpenTelemetry SDK >= 1.31.0
|
||||
|
||||
|
||||
### References
|
||||
- [Phoenix Documentation](https://docs.arize.com/phoenix/) - Overview of the Phoenix platform.
|
||||
- [CrewAI Documentation](https://docs.crewai.com/) - Overview of the CrewAI framework.
|
||||
- [OpenTelemetry Docs](https://opentelemetry.io/docs/) - OpenTelemetry guide
|
||||
- [OpenInference GitHub](https://github.com/openinference/openinference) - Source code for OpenInference SDK.
|
||||
237
docs/edge/en/observability/braintrust.mdx
Normal file
237
docs/edge/en/observability/braintrust.mdx
Normal file
@@ -0,0 +1,237 @@
|
||||
---
|
||||
title: Braintrust
|
||||
description: Braintrust integration for CrewAI with OpenTelemetry tracing and evaluation
|
||||
icon: magnifying-glass-chart
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Braintrust Integration
|
||||
|
||||
This guide demonstrates how to integrate **Braintrust** with **CrewAI** using OpenTelemetry for comprehensive tracing and evaluation. By the end of this guide, you will be able to trace your CrewAI agents, monitor their performance, and evaluate their outputs using Braintrust's powerful observability platform.
|
||||
|
||||
> **What is Braintrust?** [Braintrust](https://www.braintrust.dev) is an AI evaluation and observability platform that provides comprehensive tracing, evaluation, and monitoring for AI applications with built-in experiment tracking and performance analytics.
|
||||
|
||||
## Get Started
|
||||
|
||||
We'll walk through a simple example of using CrewAI and integrating it with Braintrust via OpenTelemetry for comprehensive observability and evaluation.
|
||||
|
||||
### Step 1: Install Dependencies
|
||||
|
||||
```bash
|
||||
uv add braintrust[otel] crewai crewai-tools opentelemetry-instrumentation-openai opentelemetry-instrumentation-crewai python-dotenv
|
||||
```
|
||||
|
||||
### Step 2: Set Up Environment Variables
|
||||
|
||||
Setup Braintrust API keys and configure OpenTelemetry to send traces to Braintrust. You'll need a Braintrust API key and your OpenAI API key.
|
||||
|
||||
```python
|
||||
import os
|
||||
from getpass import getpass
|
||||
|
||||
# Get your Braintrust credentials
|
||||
BRAINTRUST_API_KEY = getpass("🔑 Enter your Braintrust API Key: ")
|
||||
|
||||
# Get API keys for services
|
||||
OPENAI_API_KEY = getpass("🔑 Enter your OpenAI API key: ")
|
||||
|
||||
# Set environment variables
|
||||
os.environ["BRAINTRUST_API_KEY"] = BRAINTRUST_API_KEY
|
||||
os.environ["BRAINTRUST_PARENT"] = "project_name:crewai-demo"
|
||||
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
|
||||
```
|
||||
|
||||
### Step 3: Initialize OpenTelemetry with Braintrust
|
||||
|
||||
Initialize the Braintrust OpenTelemetry instrumentation to start capturing traces and send them to Braintrust.
|
||||
|
||||
```python
|
||||
import os
|
||||
from typing import Any, Dict
|
||||
|
||||
from braintrust.otel import BraintrustSpanProcessor
|
||||
from crewai import Agent, Crew, Task
|
||||
from crewai.llm import LLM
|
||||
from opentelemetry import trace
|
||||
from opentelemetry.instrumentation.crewai import CrewAIInstrumentor
|
||||
from opentelemetry.instrumentation.openai import OpenAIInstrumentor
|
||||
from opentelemetry.sdk.trace import TracerProvider
|
||||
|
||||
def setup_tracing() -> None:
|
||||
"""Setup OpenTelemetry tracing with Braintrust."""
|
||||
current_provider = trace.get_tracer_provider()
|
||||
if isinstance(current_provider, TracerProvider):
|
||||
provider = current_provider
|
||||
else:
|
||||
provider = TracerProvider()
|
||||
trace.set_tracer_provider(provider)
|
||||
|
||||
provider.add_span_processor(BraintrustSpanProcessor())
|
||||
CrewAIInstrumentor().instrument(tracer_provider=provider)
|
||||
OpenAIInstrumentor().instrument(tracer_provider=provider)
|
||||
|
||||
|
||||
setup_tracing()
|
||||
```
|
||||
|
||||
### Step 4: Create a CrewAI Application
|
||||
|
||||
We'll create a CrewAI application where two agents collaborate to research and write a blog post about AI advancements, with comprehensive tracing enabled.
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
def create_crew() -> Crew:
|
||||
"""Create a crew with multiple agents for comprehensive tracing."""
|
||||
llm = LLM(model="gpt-4o-mini")
|
||||
search_tool = SerperDevTool()
|
||||
|
||||
# Define agents with specific roles
|
||||
researcher = Agent(
|
||||
role="Senior Research Analyst",
|
||||
goal="Uncover cutting-edge developments in AI and data science",
|
||||
backstory="""You work at a leading tech think tank.
|
||||
Your expertise lies in identifying emerging trends.
|
||||
You have a knack for dissecting complex data and presenting actionable insights.""",
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
llm=llm,
|
||||
tools=[search_tool],
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role="Tech Content Strategist",
|
||||
goal="Craft compelling content on tech advancements",
|
||||
backstory="""You are a renowned Content Strategist, known for your insightful and engaging articles.
|
||||
You transform complex concepts into compelling narratives.""",
|
||||
verbose=True,
|
||||
allow_delegation=True,
|
||||
llm=llm,
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
research_task = Task(
|
||||
description="""Conduct a comprehensive analysis of the latest advancements in {topic}.
|
||||
Identify key trends, breakthrough technologies, and potential industry impacts.""",
|
||||
expected_output="Full analysis report in bullet points",
|
||||
agent=researcher,
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description="""Using the insights provided, develop an engaging blog
|
||||
post that highlights the most significant {topic} advancements.
|
||||
Your post should be informative yet accessible, catering to a tech-savvy audience.
|
||||
Make it sound cool, avoid complex words so it doesn't sound like AI.""",
|
||||
expected_output="Full blog post of at least 4 paragraphs",
|
||||
agent=writer,
|
||||
context=[research_task],
|
||||
)
|
||||
|
||||
# Instantiate your crew with a sequential process
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
verbose=True,
|
||||
process=Process.sequential
|
||||
)
|
||||
|
||||
return crew
|
||||
|
||||
def run_crew():
|
||||
"""Run the crew and return results."""
|
||||
crew = create_crew()
|
||||
result = crew.kickoff(inputs={"topic": "AI developments"})
|
||||
return result
|
||||
|
||||
# Run your crew
|
||||
if __name__ == "__main__":
|
||||
# Instrumentation is already initialized above in this module
|
||||
result = run_crew()
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Step 5: View Traces in Braintrust
|
||||
|
||||
After running your crew, you can view comprehensive traces in Braintrust through different perspectives:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Trace">
|
||||
<Frame>
|
||||
<img src="/images/braintrust-trace-view.png" alt="Braintrust Trace View"/>
|
||||
</Frame>
|
||||
</Tab>
|
||||
|
||||
<Tab title="Timeline">
|
||||
<Frame>
|
||||
<img src="/images/braintrust-timeline-view.png" alt="Braintrust Timeline View"/>
|
||||
</Frame>
|
||||
</Tab>
|
||||
|
||||
<Tab title="Thread">
|
||||
<Frame>
|
||||
<img src="/images/braintrust-thread-view.png" alt="Braintrust Thread View"/>
|
||||
</Frame>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### Step 6: Evaluate via SDK (Experiments)
|
||||
|
||||
You can also run evaluations using Braintrust's Eval SDK. This is useful for comparing versions or scoring outputs offline. Below is a Python example using the `Eval` class with the crew we created above:
|
||||
|
||||
```python
|
||||
# eval_crew.py
|
||||
from braintrust import Eval
|
||||
from autoevals import Levenshtein
|
||||
|
||||
def evaluate_crew_task(input_data):
|
||||
"""Task function that wraps our crew for evaluation."""
|
||||
crew = create_crew()
|
||||
result = crew.kickoff(inputs={"topic": input_data["topic"]})
|
||||
return str(result)
|
||||
|
||||
Eval(
|
||||
"AI Research Crew", # Project name
|
||||
{
|
||||
"data": lambda: [
|
||||
{"topic": "artificial intelligence trends 2024"},
|
||||
{"topic": "machine learning breakthroughs"},
|
||||
{"topic": "AI ethics and governance"},
|
||||
],
|
||||
"task": evaluate_crew_task,
|
||||
"scores": [Levenshtein],
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
Setup your API key and run:
|
||||
|
||||
```bash
|
||||
export BRAINTRUST_API_KEY="YOUR_API_KEY"
|
||||
braintrust eval eval_crew.py
|
||||
```
|
||||
|
||||
See the [Braintrust Eval SDK guide](https://www.braintrust.dev/docs/start/eval-sdk) for more details.
|
||||
|
||||
### Key Features of Braintrust Integration
|
||||
|
||||
- **Comprehensive Tracing**: Track all agent interactions, tool usage, and LLM calls
|
||||
- **Performance Monitoring**: Monitor execution times, token usage, and success rates
|
||||
- **Experiment Tracking**: Compare different crew configurations and models
|
||||
- **Automated Evaluation**: Set up custom evaluation metrics for crew outputs
|
||||
- **Error Tracking**: Monitor and debug failures across your crew executions
|
||||
- **Cost Analysis**: Track token usage and associated costs
|
||||
|
||||
### Version Compatibility Information
|
||||
- Python 3.8+
|
||||
- CrewAI >= 0.86.0
|
||||
- Braintrust >= 0.1.0
|
||||
- OpenTelemetry SDK >= 1.31.0
|
||||
|
||||
### References
|
||||
- [Braintrust Documentation](https://www.braintrust.dev/docs) - Overview of the Braintrust platform
|
||||
- [Braintrust CrewAI Integration](https://www.braintrust.dev/docs/integrations/crew-ai) - Official CrewAI integration guide
|
||||
- [Braintrust Eval SDK](https://www.braintrust.dev/docs/start/eval-sdk) - Run experiments via the SDK
|
||||
- [CrewAI Documentation](https://docs.crewai.com/) - Overview of the CrewAI framework
|
||||
- [OpenTelemetry Docs](https://opentelemetry.io/docs/) - OpenTelemetry guide
|
||||
- [Braintrust GitHub](https://github.com/braintrustdata/braintrust) - Source code for Braintrust SDK
|
||||
109
docs/edge/en/observability/datadog.mdx
Normal file
109
docs/edge/en/observability/datadog.mdx
Normal file
@@ -0,0 +1,109 @@
|
||||
---
|
||||
title: Datadog Integration
|
||||
description: Learn how to integrate Datadog with CrewAI to submit LLM Observability traces to Datadog.
|
||||
icon: dog
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Integrate Datadog with CrewAI
|
||||
|
||||
This guide will demonstrate how to integrate **[Datadog LLM Observability](https://docs.datadoghq.com/llm_observability/)** with **CrewAI** using [Datadog auto-instrumentation](https://docs.datadoghq.com/llm_observability/instrumentation/auto_instrumentation?tab=python). By the end of this guide, you will be able to submit LLM Observability traces to Datadog and view your CrewAI agent runs in Datadog LLM Observability's [Agentic Execution View](https://docs.datadoghq.com/llm_observability/monitoring/agent_monitoring).
|
||||
|
||||
## What is Datadog LLM Observability?
|
||||
|
||||
[Datadog LLM Observability](https://www.datadoghq.com/product/llm-observability/) helps AI engineers, data scientists, and application developers quickly develop, evaluate, and monitor LLM applications. Confidently improve output quality, performance, costs, and overall risk with structured experiments, end-to-end tracing across AI agents, and evaluations.
|
||||
|
||||
## Getting Started
|
||||
|
||||
### Install Dependencies
|
||||
|
||||
```shell
|
||||
pip install ddtrace crewai crewai-tools
|
||||
```
|
||||
|
||||
### Set Environment Variables
|
||||
|
||||
If you do not have a Datadog API key, you can [create an account](https://www.datadoghq.com/) and [get your API key](https://docs.datadoghq.com/account_management/api-app-keys/#api-keys).
|
||||
|
||||
You will also need to specify an ML Application name in the following environment variables. An ML Application is a grouping of LLM Observability traces associated with a specific LLM-based application. See [ML Application Naming Guidelines](https://docs.datadoghq.com/llm_observability/instrumentation/sdk?tab=python#application-naming-guidelines) for more information on limitations with ML Application names.
|
||||
|
||||
```shell
|
||||
export DD_API_KEY=<YOUR_DD_API_KEY>
|
||||
export DD_SITE=<YOUR_DD_SITE>
|
||||
export DD_LLMOBS_ENABLED=true
|
||||
export DD_LLMOBS_ML_APP=<YOUR_ML_APP_NAME>
|
||||
export DD_LLMOBS_AGENTLESS_ENABLED=true
|
||||
export DD_APM_TRACING_ENABLED=false
|
||||
```
|
||||
|
||||
Additionally, configure any LLM provider API keys
|
||||
|
||||
```shell
|
||||
export OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>
|
||||
export ANTHROPIC_API_KEY=<YOUR_ANTHROPIC_API_KEY>
|
||||
export GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>
|
||||
...
|
||||
```
|
||||
|
||||
### Create a CrewAI Agent Application
|
||||
|
||||
```python
|
||||
# crewai_agent.py
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
from crewai_tools import (
|
||||
WebsiteSearchTool
|
||||
)
|
||||
|
||||
web_rag_tool = WebsiteSearchTool()
|
||||
|
||||
writer = Agent(
|
||||
role="Writer",
|
||||
goal="You make math engaging and understandable for young children through poetry",
|
||||
backstory="You're an expert in writing haikus but you know nothing of math.",
|
||||
tools=[web_rag_tool],
|
||||
)
|
||||
|
||||
task = Task(
|
||||
description=("What is {multiplication}?"),
|
||||
expected_output=("Compose a haiku that includes the answer."),
|
||||
agent=writer
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[writer],
|
||||
tasks=[task],
|
||||
share_crew=False
|
||||
)
|
||||
|
||||
output = crew.kickoff(dict(multiplication="2 * 2"))
|
||||
```
|
||||
|
||||
### Run the Application with Datadog Auto-Instrumentation
|
||||
|
||||
With the [environment variables](#set-environment-variables) set, you can now run the application with Datadog auto-instrumentation.
|
||||
|
||||
```shell
|
||||
ddtrace-run python crewai_agent.py
|
||||
```
|
||||
|
||||
### View the Traces in Datadog
|
||||
|
||||
After running the application, you can view the traces in [Datadog LLM Observability's Traces View](https://app.datadoghq.com/llm/traces), selecting the ML Application name you chose from the top-left dropdown.
|
||||
|
||||
Clicking on a trace will show you the details of the trace, including total tokens used, number of LLM calls, models used, and estimated cost. Clicking into a specific span will narrow down these details, and show related input, output, and metadata.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/datadog-llm-observability-1.png" alt="Datadog LLM Observability Trace View" />
|
||||
</Frame>
|
||||
|
||||
Additionally, you can view the execution graph view of the trace, which shows the control and data flow of the trace, which will scale with larger agents to show handoffs and relationships between LLM calls, tool calls, and agent interactions.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/datadog-llm-observability-2.png" alt="Datadog LLM Observability Agent Execution Flow View" />
|
||||
</Frame>
|
||||
|
||||
## References
|
||||
|
||||
- [Datadog LLM Observability](https://www.datadoghq.com/product/llm-observability/)
|
||||
- [Datadog LLM Observability CrewAI Auto-Instrumentation](https://docs.datadoghq.com/llm_observability/instrumentation/auto_instrumentation?tab=python#crew-ai)
|
||||
115
docs/edge/en/observability/galileo.mdx
Normal file
115
docs/edge/en/observability/galileo.mdx
Normal file
@@ -0,0 +1,115 @@
|
||||
---
|
||||
title: Galileo
|
||||
description: Galileo integration for CrewAI tracing and evaluation
|
||||
icon: telescope
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
This guide demonstrates how to integrate **Galileo** with **CrewAI**
|
||||
for comprehensive tracing and Evaluation Engineering.
|
||||
By the end of this guide, you will be able to trace your CrewAI agents,
|
||||
monitor their performance, and evaluate their behaviour with
|
||||
Galileo's powerful observability platform.
|
||||
|
||||
> **What is Galileo?** [Galileo](https://galileo.ai) is AI evaluation and observability
|
||||
platform that delivers end-to-end tracing, evaluation,
|
||||
and monitoring for AI applications. It enables teams to capture ground truth,
|
||||
create robust guardrails, and run systematic experiments with
|
||||
built-in experiment tracking and performance analytics—ensuring reliability,
|
||||
transparency, and continuous improvement across the AI lifecycle.
|
||||
|
||||
## Getting started
|
||||
|
||||
This tutorial follows the [CrewAI quickstart](/en/quickstart) and shows how to add
|
||||
Galileo's [CrewAIEventListener](https://v2docs.galileo.ai/sdk-api/python/reference/handlers/crewai/handler),
|
||||
an event handler.
|
||||
For more information, see Galileo’s
|
||||
[Add Galileo to a CrewAI Application](https://v2docs.galileo.ai/how-to-guides/third-party-integrations/add-galileo-to-crewai/add-galileo-to-crewai)
|
||||
how-to guide.
|
||||
|
||||
> **Note** This tutorial assumes you have completed the [CrewAI quickstart](/en/quickstart).
|
||||
If you want a completed comprehensive example, see the Galileo
|
||||
[CrewAI sdk-example repo](https://github.com/rungalileo/sdk-examples/tree/main/python/agent/crew-ai).
|
||||
|
||||
### Step 1: Install dependencies
|
||||
|
||||
Install the required dependencies for your app.
|
||||
Create a virtual environment using your preferred method,
|
||||
then install dependencies inside that environment using your
|
||||
preferred tool:
|
||||
|
||||
```bash
|
||||
uv add galileo
|
||||
```
|
||||
|
||||
### Step 2: Add to the .env file from the [CrewAI quickstart](/en/quickstart)
|
||||
|
||||
```bash
|
||||
# Your Galileo API key
|
||||
GALILEO_API_KEY="your-galileo-api-key"
|
||||
|
||||
# Your Galileo project name
|
||||
GALILEO_PROJECT="your-galileo-project-name"
|
||||
|
||||
# The name of the Log stream you want to use for logging
|
||||
GALILEO_LOG_STREAM="your-galileo-log-stream "
|
||||
```
|
||||
|
||||
### Step 3: Add the Galileo event listener
|
||||
|
||||
To enable logging with Galileo, you need to create an instance of the `CrewAIEventListener`.
|
||||
Import the Galileo CrewAI handler package by
|
||||
adding the following code at the top of your main.py file:
|
||||
|
||||
```python
|
||||
from galileo.handlers.crewai.handler import CrewAIEventListener
|
||||
```
|
||||
|
||||
At the start of your run function, create the event listener:
|
||||
|
||||
```python
|
||||
def run():
|
||||
# Create the event listener
|
||||
CrewAIEventListener()
|
||||
# The rest of your existing code goes here
|
||||
```
|
||||
|
||||
When you create the listener instance, it is automatically
|
||||
registered with CrewAI.
|
||||
|
||||
### Step 4: Run your crew
|
||||
|
||||
Run your crew with the CrewAI CLI:
|
||||
|
||||
```bash
|
||||
crewai run
|
||||
```
|
||||
|
||||
### Step 5: View the traces in Galileo
|
||||
|
||||
Once your crew has finished, the traces will be flushed and appear in Galileo.
|
||||
|
||||

|
||||
|
||||
## Understanding the Galileo Integration
|
||||
|
||||
Galileo integrates with CrewAI by registering an event listener
|
||||
that captures Crew execution events (e.g., agent actions, tool calls, model responses)
|
||||
and forwards them to Galileo for observability and evaluation.
|
||||
|
||||
### Understanding the event listener
|
||||
|
||||
Creating a `CrewAIEventListener()` instance is all that’s
|
||||
required to enable Galileo for a CrewAI run. When instantiated, the listener:
|
||||
|
||||
- Automatically registers itself with CrewAI
|
||||
- Reads Galileo configuration from environment variables
|
||||
- Logs all run data to the Galileo project and log stream specified by
|
||||
`GALILEO_PROJECT` and `GALILEO_LOG_STREAM`
|
||||
|
||||
No additional configuration or code changes are required.
|
||||
All data from this run is logged to the Galileo project and
|
||||
log stream specified by your environment configuration
|
||||
(for example, GALILEO_PROJECT and GALILEO_LOG_STREAM).
|
||||
287
docs/edge/en/observability/langdb.mdx
Normal file
287
docs/edge/en/observability/langdb.mdx
Normal file
@@ -0,0 +1,287 @@
|
||||
---
|
||||
title: LangDB Integration
|
||||
description: Govern, secure, and optimize your CrewAI workflows with LangDB AI Gateway—access 350+ models, automatic routing, cost optimization, and full observability.
|
||||
icon: database
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Introduction
|
||||
|
||||
[LangDB AI Gateway](https://langdb.ai) provides OpenAI-compatible APIs to connect with multiple Large Language Models and serves as an observability platform that makes it effortless to trace CrewAI workflows end-to-end while providing access to 350+ language models. With a single `init()` call, all agent interactions, task executions, and LLM calls are captured, providing comprehensive observability and production-ready AI infrastructure for your applications.
|
||||
|
||||
<Frame caption="LangDB CrewAI Trace Example">
|
||||
<img src="/images/langdb-1.png" alt="LangDB CrewAI trace example" />
|
||||
</Frame>
|
||||
|
||||
**Checkout:** [View the live trace example](https://app.langdb.ai/sharing/threads/3becbfed-a1be-ae84-ea3c-4942867a3e22)
|
||||
|
||||
## Features
|
||||
|
||||
### AI Gateway Capabilities
|
||||
- **Access to 350+ LLMs**: Connect to all major language models through a single integration
|
||||
- **Virtual Models**: Create custom model configurations with specific parameters and routing rules
|
||||
- **Virtual MCP**: Enable compatibility and integration with MCP (Model Context Protocol) systems for enhanced agent communication
|
||||
- **Guardrails**: Implement safety measures and compliance controls for agent behavior
|
||||
|
||||
### Observability & Tracing
|
||||
- **Automatic Tracing**: Single `init()` call captures all CrewAI interactions
|
||||
- **End-to-End Visibility**: Monitor agent workflows from start to finish
|
||||
- **Tool Usage Tracking**: Track which tools agents use and their outcomes
|
||||
- **Model Call Monitoring**: Detailed insights into LLM interactions
|
||||
- **Performance Analytics**: Monitor latency, token usage, and costs
|
||||
- **Debugging Support**: Step-through execution for troubleshooting
|
||||
- **Real-time Monitoring**: Live traces and metrics dashboard
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Install LangDB">
|
||||
Install the LangDB client with CrewAI feature flag:
|
||||
```bash
|
||||
pip install 'pylangdb[crewai]'
|
||||
```
|
||||
</Step>
|
||||
<Step title="Set Environment Variables">
|
||||
Configure your LangDB credentials:
|
||||
```bash
|
||||
export LANGDB_API_KEY="<your_langdb_api_key>"
|
||||
export LANGDB_PROJECT_ID="<your_langdb_project_id>"
|
||||
export LANGDB_API_BASE_URL='https://api.us-east-1.langdb.ai'
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize Tracing">
|
||||
Import and initialize LangDB before configuring your CrewAI code:
|
||||
```python
|
||||
from pylangdb.crewai import init
|
||||
# Initialize LangDB
|
||||
init()
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure CrewAI with LangDB">
|
||||
Set up your LLM with LangDB headers:
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM
|
||||
import os
|
||||
|
||||
# Configure LLM with LangDB headers
|
||||
llm = LLM(
|
||||
model="openai/gpt-4o", # Replace with the model you want to use
|
||||
api_key=os.getenv("LANGDB_API_KEY"),
|
||||
base_url=os.getenv("LANGDB_API_BASE_URL"),
|
||||
extra_headers={"x-project-id": os.getenv("LANGDB_PROJECT_ID")}
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Quick Start Example
|
||||
|
||||
Here's a simple example to get you started with LangDB and CrewAI:
|
||||
|
||||
```python
|
||||
import os
|
||||
from pylangdb.crewai import init
|
||||
from crewai import Agent, Task, Crew, LLM
|
||||
|
||||
# Initialize LangDB before any CrewAI imports
|
||||
init()
|
||||
|
||||
def create_llm(model):
|
||||
return LLM(
|
||||
model=model,
|
||||
api_key=os.environ.get("LANGDB_API_KEY"),
|
||||
base_url=os.environ.get("LANGDB_API_BASE_URL"),
|
||||
extra_headers={"x-project-id": os.environ.get("LANGDB_PROJECT_ID")}
|
||||
)
|
||||
|
||||
# Define your agent
|
||||
researcher = Agent(
|
||||
role="Research Specialist",
|
||||
goal="Research topics thoroughly",
|
||||
backstory="Expert researcher with skills in finding information",
|
||||
llm=create_llm("openai/gpt-4o"), # Replace with the model you want to use
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Create a task
|
||||
task = Task(
|
||||
description="Research the given topic and provide a comprehensive summary",
|
||||
agent=researcher,
|
||||
expected_output="Detailed research summary with key findings"
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[researcher], tasks=[task])
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
|
||||
## Complete Example: Research and Planning Agent
|
||||
|
||||
This comprehensive example demonstrates a multi-agent workflow with research and planning capabilities.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
```bash
|
||||
pip install crewai 'pylangdb[crewai]' crewai_tools setuptools python-dotenv
|
||||
```
|
||||
|
||||
### Environment Setup
|
||||
|
||||
```bash
|
||||
# LangDB credentials
|
||||
export LANGDB_API_KEY="<your_langdb_api_key>"
|
||||
export LANGDB_PROJECT_ID="<your_langdb_project_id>"
|
||||
export LANGDB_API_BASE_URL='https://api.us-east-1.langdb.ai'
|
||||
|
||||
# Additional API keys (optional)
|
||||
export SERPER_API_KEY="<your_serper_api_key>" # For web search capabilities
|
||||
```
|
||||
|
||||
### Complete Implementation
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import os
|
||||
import sys
|
||||
from pylangdb.crewai import init
|
||||
init() # Initialize LangDB before any CrewAI imports
|
||||
from dotenv import load_dotenv
|
||||
from crewai import Agent, Task, Crew, Process, LLM
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
load_dotenv()
|
||||
|
||||
def create_llm(model):
|
||||
return LLM(
|
||||
model=model,
|
||||
api_key=os.environ.get("LANGDB_API_KEY"),
|
||||
base_url=os.environ.get("LANGDB_API_BASE_URL"),
|
||||
extra_headers={"x-project-id": os.environ.get("LANGDB_PROJECT_ID")}
|
||||
)
|
||||
|
||||
class ResearchPlanningCrew:
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
role="Research Specialist",
|
||||
goal="Research topics thoroughly and compile comprehensive information",
|
||||
backstory="Expert researcher with skills in finding and analyzing information from various sources",
|
||||
tools=[SerperDevTool()],
|
||||
llm=create_llm("openai/gpt-4o"),
|
||||
verbose=True
|
||||
)
|
||||
|
||||
def planner(self) -> Agent:
|
||||
return Agent(
|
||||
role="Strategic Planner",
|
||||
goal="Create actionable plans based on research findings",
|
||||
backstory="Strategic planner who breaks down complex challenges into executable plans",
|
||||
reasoning=True,
|
||||
max_reasoning_attempts=3,
|
||||
llm=create_llm("openai/anthropic/claude-3.7-sonnet"),
|
||||
verbose=True
|
||||
)
|
||||
|
||||
def research_task(self) -> Task:
|
||||
return Task(
|
||||
description="Research the topic thoroughly and compile comprehensive information",
|
||||
agent=self.researcher(),
|
||||
expected_output="Comprehensive research report with key findings and insights"
|
||||
)
|
||||
|
||||
def planning_task(self) -> Task:
|
||||
return Task(
|
||||
description="Create a strategic plan based on the research findings",
|
||||
agent=self.planner(),
|
||||
expected_output="Strategic execution plan with phases, goals, and actionable steps",
|
||||
context=[self.research_task()]
|
||||
)
|
||||
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[self.researcher(), self.planner()],
|
||||
tasks=[self.research_task(), self.planning_task()],
|
||||
verbose=True,
|
||||
process=Process.sequential
|
||||
)
|
||||
|
||||
def main():
|
||||
topic = sys.argv[1] if len(sys.argv) > 1 else "Artificial Intelligence in Healthcare"
|
||||
|
||||
crew_instance = ResearchPlanningCrew()
|
||||
|
||||
# Update task descriptions with the specific topic
|
||||
crew_instance.research_task().description = f"Research {topic} thoroughly and compile comprehensive information"
|
||||
crew_instance.planning_task().description = f"Create a strategic plan for {topic} based on the research findings"
|
||||
|
||||
result = crew_instance.crew().kickoff()
|
||||
print(result)
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
### Running the Example
|
||||
|
||||
```bash
|
||||
python main.py "Sustainable Energy Solutions"
|
||||
```
|
||||
|
||||
## Viewing Traces in LangDB
|
||||
|
||||
After running your CrewAI application, you can view detailed traces in the LangDB dashboard:
|
||||
|
||||
<Frame caption="LangDB Trace Dashboard">
|
||||
<img src="/images/langdb-2.png" alt="LangDB trace dashboard showing CrewAI workflow" />
|
||||
</Frame>
|
||||
|
||||
### What You'll See
|
||||
|
||||
- **Agent Interactions**: Complete flow of agent conversations and task handoffs
|
||||
- **Tool Usage**: Which tools were called, their inputs, and outputs
|
||||
- **Model Calls**: Detailed LLM interactions with prompts image.pngand responses
|
||||
- **Performance Metrics**: Latency, token usage, and cost tracking
|
||||
- **Execution Timeline**: Step-by-step view of the entire workflow
|
||||
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
- **No traces appearing**: Ensure `init()` is called before any CrewAI imports
|
||||
- **Authentication errors**: Verify your LangDB API key and project ID
|
||||
|
||||
|
||||
## Resources
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="LangDB Documentation" icon="book" href="https://docs.langdb.ai">
|
||||
Official LangDB documentation and guides
|
||||
</Card>
|
||||
<Card title="LangDB Guides" icon="graduation-cap" href="https://docs.langdb.ai/guides">
|
||||
Step-by-step tutorials for building AI agents
|
||||
</Card>
|
||||
<Card title="GitHub Examples" icon="github" href="https://github.com/langdb/langdb-samples/tree/main/examples/crewai" >
|
||||
Complete CrewAI integration examples
|
||||
</Card>
|
||||
<Card title="LangDB Dashboard" icon="chart-line" href="https://app.langdb.ai">
|
||||
Access your traces and analytics
|
||||
</Card>
|
||||
<Card title="Model Catalog" icon="list" href="https://app.langdb.ai/models">
|
||||
Browse 350+ available language models
|
||||
</Card>
|
||||
<Card title="Enterprise Features" icon="building" href="https://docs.langdb.ai/enterprise">
|
||||
Self-hosted options and enterprise capabilities
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Next Steps
|
||||
|
||||
This guide covered the basics of integrating LangDB AI Gateway with CrewAI. To further enhance your AI workflows, explore:
|
||||
|
||||
- **Virtual Models**: Create custom model configurations with routing strategies
|
||||
- **Guardrails & Safety**: Implement content filtering and compliance controls
|
||||
- **Production Deployment**: Configure fallbacks, retries, and load balancing
|
||||
|
||||
For more advanced features and use cases, visit the [LangDB Documentation](https://docs.langdb.ai) or explore the [Model Catalog](https://app.langdb.ai/models) to discover all available models.
|
||||
112
docs/edge/en/observability/langfuse.mdx
Normal file
112
docs/edge/en/observability/langfuse.mdx
Normal file
@@ -0,0 +1,112 @@
|
||||
---
|
||||
title: Langfuse Integration
|
||||
description: Learn how to integrate Langfuse with CrewAI via OpenTelemetry using OpenLit
|
||||
icon: vials
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Integrate Langfuse with CrewAI
|
||||
|
||||
This notebook demonstrates how to integrate **Langfuse** with **CrewAI** using OpenTelemetry via the **OpenLit** SDK. By the end of this notebook, you will be able to trace your CrewAI applications with Langfuse for improved observability and debugging.
|
||||
|
||||
> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source LLM engineering platform. It provides tracing and monitoring capabilities for LLM applications, helping developers debug, analyze, and optimize their AI systems. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and APIs/SDKs.
|
||||
|
||||
[](https://langfuse.com/watch-demo)
|
||||
|
||||
## Get Started
|
||||
|
||||
We'll walk through a simple example of using CrewAI and integrating it with Langfuse via OpenTelemetry using OpenLit.
|
||||
|
||||
### Step 1: Install Dependencies
|
||||
|
||||
|
||||
```python
|
||||
%pip install langfuse openlit crewai crewai_tools
|
||||
```
|
||||
|
||||
### Step 2: Set Up Environment Variables
|
||||
|
||||
Set your Langfuse API keys and configure OpenTelemetry export settings to send traces to Langfuse. Please refer to the [Langfuse OpenTelemetry Docs](https://langfuse.com/docs/opentelemetry/get-started) for more information on the Langfuse OpenTelemetry endpoint `/api/public/otel` and authentication.
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
|
||||
# Get keys for your project from the project settings page: https://cloud.langfuse.com
|
||||
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
|
||||
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
|
||||
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 EU region
|
||||
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 US region
|
||||
|
||||
|
||||
# Your OpenAI key
|
||||
os.environ["OPENAI_API_KEY"] = "sk-proj-..."
|
||||
```
|
||||
With the environment variables set, we can now initialize the Langfuse client. get_client() initializes the Langfuse client using the credentials provided in the environment variables.
|
||||
|
||||
```python
|
||||
from langfuse import get_client
|
||||
|
||||
langfuse = get_client()
|
||||
|
||||
# Verify connection
|
||||
if langfuse.auth_check():
|
||||
print("Langfuse client is authenticated and ready!")
|
||||
else:
|
||||
print("Authentication failed. Please check your credentials and host.")
|
||||
```
|
||||
|
||||
### Step 3: Initialize OpenLit
|
||||
|
||||
Initialize the OpenLit OpenTelemetry instrumentation SDK to start capturing OpenTelemetry traces.
|
||||
|
||||
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
### Step 4: Create a Simple CrewAI Application
|
||||
|
||||
We'll create a simple CrewAI application where multiple agents collaborate to answer a user's question.
|
||||
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
from crewai_tools import (
|
||||
WebsiteSearchTool
|
||||
)
|
||||
|
||||
web_rag_tool = WebsiteSearchTool()
|
||||
|
||||
writer = Agent(
|
||||
role="Writer",
|
||||
goal="You make math engaging and understandable for young children through poetry",
|
||||
backstory="You're an expert in writing haikus but you know nothing of math.",
|
||||
tools=[web_rag_tool],
|
||||
)
|
||||
|
||||
task = Task(description=("What is {multiplication}?"),
|
||||
expected_output=("Compose a haiku that includes the answer."),
|
||||
agent=writer)
|
||||
|
||||
crew = Crew(
|
||||
agents=[writer],
|
||||
tasks=[task],
|
||||
share_crew=False
|
||||
)
|
||||
```
|
||||
|
||||
### Step 5: See Traces in Langfuse
|
||||
|
||||
After running the agent, you can view the traces generated by your CrewAI application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.
|
||||
|
||||
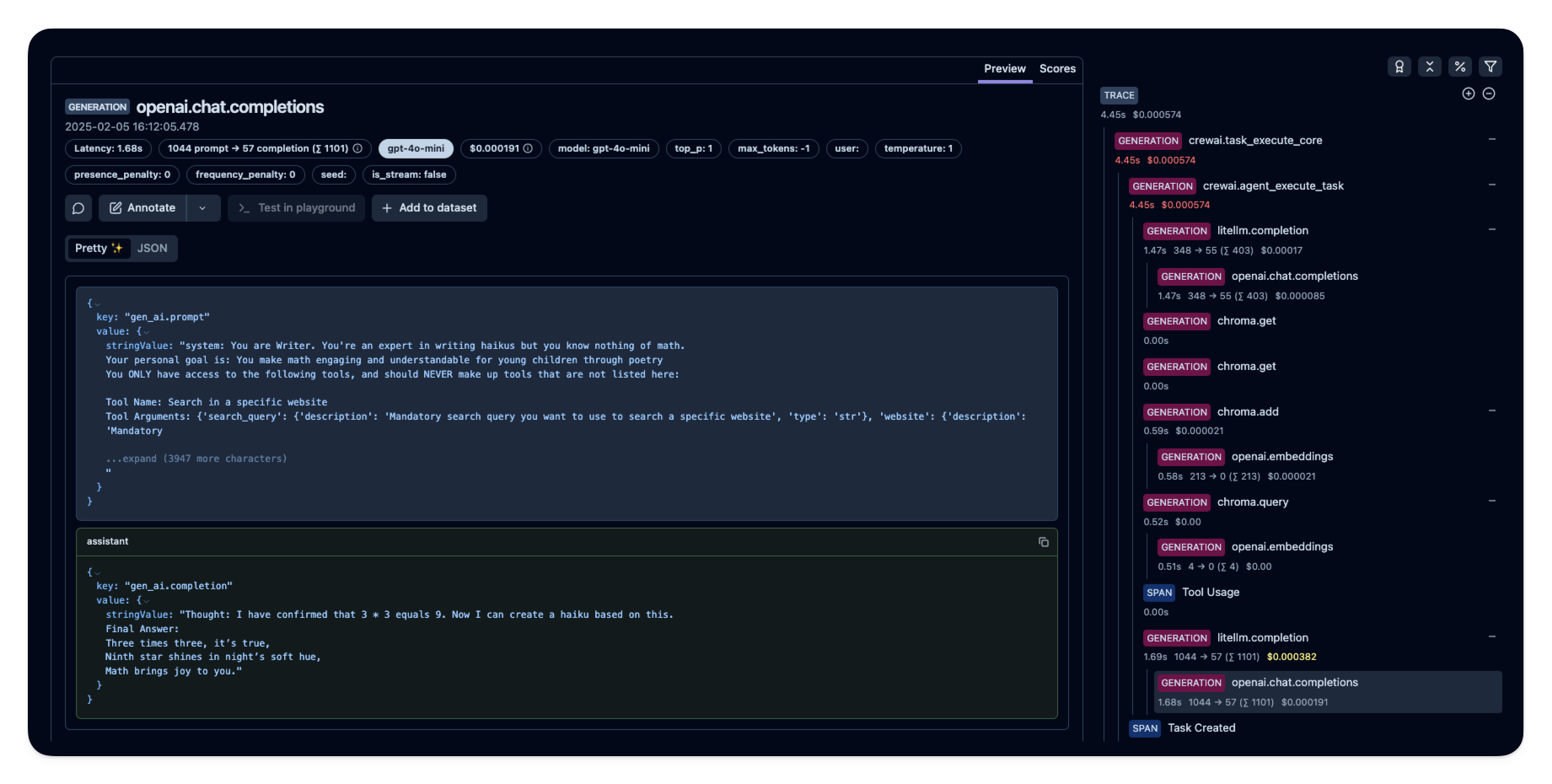
|
||||
|
||||
_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/e2cf380ffc8d47d28da98f136140642b?timestamp=2025-02-05T15%3A12%3A02.717Z&observation=3b32338ee6a5d9af)_
|
||||
|
||||
## References
|
||||
|
||||
- [Langfuse OpenTelemetry Docs](https://langfuse.com/docs/opentelemetry/get-started)
|
||||
73
docs/edge/en/observability/langtrace.mdx
Normal file
73
docs/edge/en/observability/langtrace.mdx
Normal file
@@ -0,0 +1,73 @@
|
||||
---
|
||||
title: Langtrace Integration
|
||||
description: How to monitor cost, latency, and performance of CrewAI Agents using Langtrace, an external observability tool.
|
||||
icon: chart-line
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Langtrace Overview
|
||||
|
||||
Langtrace is an open-source, external tool that helps you set up observability and evaluations for Large Language Models (LLMs), LLM frameworks, and Vector Databases.
|
||||
While not built directly into CrewAI, Langtrace can be used alongside CrewAI to gain deep visibility into the cost, latency, and performance of your CrewAI Agents.
|
||||
This integration allows you to log hyperparameters, monitor performance regressions, and establish a process for continuous improvement of your Agents.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Sign up for Langtrace">
|
||||
Sign up by visiting [https://langtrace.ai/signup](https://langtrace.ai/signup).
|
||||
</Step>
|
||||
<Step title="Create a project">
|
||||
Set the project type to `CrewAI` and generate an API key.
|
||||
</Step>
|
||||
<Step title="Install Langtrace in your CrewAI project">
|
||||
Use the following command:
|
||||
|
||||
```bash
|
||||
pip install langtrace-python-sdk
|
||||
```
|
||||
</Step>
|
||||
<Step title="Import Langtrace">
|
||||
Import and initialize Langtrace at the beginning of your script, before any CrewAI imports:
|
||||
|
||||
```python
|
||||
from langtrace_python_sdk import langtrace
|
||||
langtrace.init(api_key='<LANGTRACE_API_KEY>')
|
||||
|
||||
# Now import CrewAI modules
|
||||
from crewai import Agent, Task, Crew
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Features and Their Application to CrewAI
|
||||
|
||||
1. **LLM Token and Cost Tracking**
|
||||
|
||||
- Monitor the token usage and associated costs for each CrewAI agent interaction.
|
||||
|
||||
2. **Trace Graph for Execution Steps**
|
||||
|
||||
- Visualize the execution flow of your CrewAI tasks, including latency and logs.
|
||||
- Useful for identifying bottlenecks in your agent workflows.
|
||||
|
||||
3. **Dataset Curation with Manual Annotation**
|
||||
|
||||
- Create datasets from your CrewAI task outputs for future training or evaluation.
|
||||
|
||||
4. **Prompt Versioning and Management**
|
||||
|
||||
- Keep track of different versions of prompts used in your CrewAI agents.
|
||||
- Useful for A/B testing and optimizing agent performance.
|
||||
|
||||
5. **Prompt Playground with Model Comparisons**
|
||||
|
||||
- Test and compare different prompts and models for your CrewAI agents before deployment.
|
||||
|
||||
6. **Testing and Evaluations**
|
||||
|
||||
- Set up automated tests for your CrewAI agents and tasks.
|
||||
232
docs/edge/en/observability/maxim.mdx
Normal file
232
docs/edge/en/observability/maxim.mdx
Normal file
@@ -0,0 +1,232 @@
|
||||
---
|
||||
title: "Maxim Integration"
|
||||
description: "Start Agent monitoring, evaluation, and observability"
|
||||
icon: "infinity"
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Maxim Overview
|
||||
|
||||
Maxim AI provides comprehensive agent monitoring, evaluation, and observability for your CrewAI applications. With Maxim's one-line integration, you can easily trace and analyse agent interactions, performance metrics, and more.
|
||||
|
||||
## Features
|
||||
|
||||
### Prompt Management
|
||||
|
||||
Maxim's Prompt Management capabilities enable you to create, organize, and optimize prompts for your CrewAI agents. Rather than hardcoding instructions, leverage Maxim’s SDK to dynamically retrieve and apply version-controlled prompts.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Prompt Playground">
|
||||
Create, refine, experiment and deploy your prompts via the playground. Organize of your prompts using folders and versions, experimenting with the real world cases by linking tools and context, and deploying based on custom logic.
|
||||
|
||||
Easily experiment across models by [**configuring models**](https://www.getmaxim.ai/docs/introduction/quickstart/setting-up-workspace#add-model-api-keys) and selecting the relevant model from the dropdown at the top of the prompt playground.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_playground.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="Prompt Versions">
|
||||
As teams build their AI applications, a big part of experimentation is iterating on the prompt structure. In order to collaborate effectively and organize your changes clearly, Maxim allows prompt versioning and comparison runs across versions.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_versions.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="Prompt Comparisons">
|
||||
Iterating on Prompts as you evolve your AI application would need experiments across models, prompt structures, etc. In order to compare versions and make informed decisions about changes, the comparison playground allows a side by side view of results.
|
||||
|
||||
## **Why use Prompt comparison?**
|
||||
|
||||
Prompt comparison combines multiple single Prompts into one view, enabling a streamlined approach for various workflows:
|
||||
|
||||
1. **Model comparison**: Evaluate the performance of different models on the same Prompt.
|
||||
2. **Prompt optimization**: Compare different versions of a Prompt to identify the most effective formulation.
|
||||
3. **Cross-Model consistency**: Ensure consistent outputs across various models for the same Prompt.
|
||||
4. **Performance benchmarking**: Analyze metrics like latency, cost, and token count across different models and Prompts.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### Observability & Evals
|
||||
|
||||
Maxim AI provides comprehensive observability & evaluation for your CrewAI agents, helping you understand exactly what's happening during each execution.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Agent Tracing">
|
||||
Track your agent’s complete lifecycle, including tool calls, agent trajectories, and decision flows effortlessly.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_agent_tracking.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="Analytics + Evals">
|
||||
Run detailed evaluations on full traces or individual nodes with support for:
|
||||
|
||||
- Multi-step interactions and granular trace analysis
|
||||
- Session Level Evaluations
|
||||
- Simulations for real-world testing
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_trace_eval.png'> </img>
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="Auto Evals on Logs" icon="e" href="https://www.getmaxim.ai/docs/observe/how-to/evaluate-logs/auto-evaluation">
|
||||
<p>
|
||||
Evaluate captured logs automatically from the UI based on filters and sampling
|
||||
|
||||
</p>
|
||||
</Card>
|
||||
<Card title="Human Evals on Logs" icon="hand" href="https://www.getmaxim.ai/docs/observe/how-to/evaluate-logs/human-evaluation">
|
||||
<p>
|
||||
Use human evaluation or rating to assess the quality of your logs and evaluate them.
|
||||
|
||||
</p>
|
||||
</Card>
|
||||
<Card title="Node Level Evals" icon="road" href="https://www.getmaxim.ai/docs/observe/how-to/evaluate-logs/node-level-evaluation">
|
||||
<p>
|
||||
Evaluate any component of your trace or log to gain insights into your agent’s behavior.
|
||||
|
||||
</p>
|
||||
</Card>
|
||||
</CardGroup>
|
||||
---
|
||||
</Tab>
|
||||
<Tab title="Alerting">
|
||||
Set thresholds on **error**, **cost, token usage, user feedback, latency** and get real-time alerts via Slack or PagerDuty.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_alerts_1.png'> </img>
|
||||
</Tab>
|
||||
<Tab title="Dashboards">
|
||||
Visualize Traces over time, usage metrics, latency & error rates with ease.
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/maxim_dashboard_1.png'> </img>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Getting Started
|
||||
|
||||
### Prerequisites
|
||||
|
||||
|
||||
- Python version \>=3.10
|
||||
- A Maxim account ([sign up here](https://getmaxim.ai/))
|
||||
- Generate Maxim API Key
|
||||
- A CrewAI project
|
||||
|
||||
### Installation
|
||||
|
||||
Install the Maxim SDK via pip:
|
||||
|
||||
```python
|
||||
pip install maxim-py
|
||||
```
|
||||
|
||||
Or add it to your `requirements.txt`:
|
||||
|
||||
```
|
||||
maxim-py
|
||||
```
|
||||
### Basic Setup
|
||||
|
||||
### 1. Set up environment variables
|
||||
|
||||
```python
|
||||
### Environment Variables Setup
|
||||
|
||||
# Create a `.env` file in your project root:
|
||||
|
||||
# Maxim API Configuration
|
||||
MAXIM_API_KEY=your_api_key_here
|
||||
MAXIM_LOG_REPO_ID=your_repo_id_here
|
||||
```
|
||||
|
||||
### 2. Import the required packages
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
from maxim import Maxim
|
||||
from maxim.logger.crewai import instrument_crewai
|
||||
```
|
||||
|
||||
### 3. Initialise Maxim with your API key
|
||||
|
||||
|
||||
```python {8}
|
||||
# Instrument CrewAI with just one line
|
||||
instrument_crewai(Maxim().logger())
|
||||
```
|
||||
|
||||
### 4. Create and run your CrewAI application as usual
|
||||
|
||||
```python
|
||||
# Create your agent
|
||||
researcher = Agent(
|
||||
role='Senior Research Analyst',
|
||||
goal='Uncover cutting-edge developments in AI',
|
||||
backstory="You are an expert researcher at a tech think tank...",
|
||||
verbose=True,
|
||||
llm=llm
|
||||
)
|
||||
|
||||
# Define the task
|
||||
research_task = Task(
|
||||
description="Research the latest AI advancements...",
|
||||
expected_output="",
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
# Configure and run the crew
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[research_task],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
try:
|
||||
result = crew.kickoff()
|
||||
finally:
|
||||
maxim.cleanup() # Ensure cleanup happens even if errors occur
|
||||
```
|
||||
|
||||
|
||||
That's it\! All your CrewAI agent interactions will now be logged and available in your Maxim dashboard.
|
||||
|
||||
Check this Google Colab Notebook for a quick reference - [Notebook](https://colab.research.google.com/drive/1ZKIZWsmgQQ46n8TH9zLsT1negKkJA6K8?usp=sharing)
|
||||
|
||||
## Viewing Your Traces
|
||||
|
||||
After running your CrewAI application:
|
||||
|
||||
1. Log in to your [Maxim Dashboard](https://app.getmaxim.ai/login)
|
||||
2. Navigate to your repository
|
||||
3. View detailed agent traces, including:
|
||||
- Agent conversations
|
||||
- Tool usage patterns
|
||||
- Performance metrics
|
||||
- Cost analytics
|
||||
|
||||
<img src='https://raw.githubusercontent.com/akmadan/crewAI/docs_maxim_observability/docs/images/crewai_traces.gif'> </img>
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
- **No traces appearing**: Ensure your API key and repository ID are correct
|
||||
- Ensure you've **`called instrument_crewai()`** **_before_** running your crew. This initializes logging hooks correctly.
|
||||
- Set `debug=True` in your `instrument_crewai()` call to surface any internal errors:
|
||||
|
||||
```python
|
||||
instrument_crewai(logger, debug=True)
|
||||
```
|
||||
- Configure your agents with `verbose=True` to capture detailed logs:
|
||||
|
||||
```python
|
||||
agent = CrewAgent(..., verbose=True)
|
||||
```
|
||||
- Double-check that `instrument_crewai()` is called **before** creating or executing agents. This might be obvious, but it's a common oversight.
|
||||
|
||||
## Resources
|
||||
|
||||
<CardGroup cols="3">
|
||||
<Card title="CrewAI Docs" icon="book" href="https://docs.crewai.com/">
|
||||
Official CrewAI documentation
|
||||
</Card>
|
||||
<Card title="Maxim Docs" icon="book" href="https://getmaxim.ai/docs">
|
||||
Official Maxim documentation
|
||||
</Card>
|
||||
<Card title="Maxim Github" icon="github" href="https://github.com/maximhq">
|
||||
Maxim Github
|
||||
</Card>
|
||||
</CardGroup>
|
||||
207
docs/edge/en/observability/mlflow.mdx
Normal file
207
docs/edge/en/observability/mlflow.mdx
Normal file
@@ -0,0 +1,207 @@
|
||||
---
|
||||
title: MLflow Integration
|
||||
description: Quickly start monitoring your Agents with MLflow.
|
||||
icon: bars-staggered
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# MLflow Overview
|
||||
|
||||
[MLflow](https://mlflow.org/) is an open-source platform to assist machine learning practitioners and teams in handling the complexities of the machine learning process.
|
||||
|
||||
It provides a tracing feature that enhances LLM observability in your Generative AI applications by capturing detailed information about the execution of your application’s services.
|
||||
Tracing provides a way to record the inputs, outputs, and metadata associated with each intermediate step of a request, enabling you to easily pinpoint the source of bugs and unexpected behaviors.
|
||||
|
||||

|
||||
|
||||
### Features
|
||||
|
||||
- **Tracing Dashboard**: Monitor activities of your crewAI agents with detailed dashboards that include inputs, outputs and metadata of spans.
|
||||
- **Automated Tracing**: A fully automated integration with crewAI, which can be enabled by running `mlflow.crewai.autolog()`.
|
||||
- **Manual Trace Instrumentation with minor efforts**: Customize trace instrumentation through MLflow's high-level fluent APIs such as decorators, function wrappers and context managers.
|
||||
- **OpenTelemetry Compatibility**: MLflow Tracing supports exporting traces to an OpenTelemetry Collector, which can then be used to export traces to various backends such as Jaeger, Zipkin, and AWS X-Ray.
|
||||
- **Package and Deploy Agents**: Package and deploy your crewAI agents to an inference server with a variety of deployment targets.
|
||||
- **Securely Host LLMs**: Host multiple LLM from various providers in one unified endpoint through MFflow gateway.
|
||||
- **Evaluation**: Evaluate your crewAI agents with a wide range of metrics using a convenient API `mlflow.evaluate()`.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Install MLflow package">
|
||||
```shell
|
||||
# The crewAI integration is available in mlflow>=2.19.0
|
||||
pip install mlflow
|
||||
```
|
||||
</Step>
|
||||
<Step title="Start MFflow tracking server">
|
||||
```shell
|
||||
# This process is optional, but it is recommended to use MLflow tracking server for better visualization and broader features.
|
||||
mlflow server
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize MLflow in Your Application">
|
||||
Add the following two lines to your application code:
|
||||
|
||||
```python
|
||||
import mlflow
|
||||
|
||||
mlflow.crewai.autolog()
|
||||
|
||||
# Optional: Set a tracking URI and an experiment name if you have a tracking server
|
||||
mlflow.set_tracking_uri("http://localhost:5000")
|
||||
mlflow.set_experiment("CrewAI")
|
||||
```
|
||||
|
||||
Example Usage for tracing CrewAI Agents:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task
|
||||
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
|
||||
from crewai_tools import SerperDevTool, WebsiteSearchTool
|
||||
|
||||
from textwrap import dedent
|
||||
|
||||
content = "Users name is John. He is 30 years old and lives in San Francisco."
|
||||
string_source = StringKnowledgeSource(
|
||||
content=content, metadata={"preference": "personal"}
|
||||
)
|
||||
|
||||
search_tool = WebsiteSearchTool()
|
||||
|
||||
|
||||
class TripAgents:
|
||||
def city_selection_agent(self):
|
||||
return Agent(
|
||||
role="City Selection Expert",
|
||||
goal="Select the best city based on weather, season, and prices",
|
||||
backstory="An expert in analyzing travel data to pick ideal destinations",
|
||||
tools=[
|
||||
search_tool,
|
||||
],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def local_expert(self):
|
||||
return Agent(
|
||||
role="Local Expert at this city",
|
||||
goal="Provide the BEST insights about the selected city",
|
||||
backstory="""A knowledgeable local guide with extensive information
|
||||
about the city, it's attractions and customs""",
|
||||
tools=[search_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
|
||||
class TripTasks:
|
||||
def identify_task(self, agent, origin, cities, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
Analyze and select the best city for the trip based
|
||||
on specific criteria such as weather patterns, seasonal
|
||||
events, and travel costs. This task involves comparing
|
||||
multiple cities, considering factors like current weather
|
||||
conditions, upcoming cultural or seasonal events, and
|
||||
overall travel expenses.
|
||||
Your final answer must be a detailed
|
||||
report on the chosen city, and everything you found out
|
||||
about it, including the actual flight costs, weather
|
||||
forecast and attractions.
|
||||
|
||||
Traveling from: {origin}
|
||||
City Options: {cities}
|
||||
Trip Date: {range}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Detailed report on the chosen city including flight costs, weather forecast, and attractions",
|
||||
)
|
||||
|
||||
def gather_task(self, agent, origin, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
As a local expert on this city you must compile an
|
||||
in-depth guide for someone traveling there and wanting
|
||||
to have THE BEST trip ever!
|
||||
Gather information about key attractions, local customs,
|
||||
special events, and daily activity recommendations.
|
||||
Find the best spots to go to, the kind of place only a
|
||||
local would know.
|
||||
This guide should provide a thorough overview of what
|
||||
the city has to offer, including hidden gems, cultural
|
||||
hotspots, must-visit landmarks, weather forecasts, and
|
||||
high level costs.
|
||||
The final answer must be a comprehensive city guide,
|
||||
rich in cultural insights and practical tips,
|
||||
tailored to enhance the travel experience.
|
||||
|
||||
Trip Date: {range}
|
||||
Traveling from: {origin}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Comprehensive city guide including hidden gems, cultural hotspots, and practical travel tips",
|
||||
)
|
||||
|
||||
|
||||
class TripCrew:
|
||||
def __init__(self, origin, cities, date_range, interests):
|
||||
self.cities = cities
|
||||
self.origin = origin
|
||||
self.interests = interests
|
||||
self.date_range = date_range
|
||||
|
||||
def run(self):
|
||||
agents = TripAgents()
|
||||
tasks = TripTasks()
|
||||
|
||||
city_selector_agent = agents.city_selection_agent()
|
||||
local_expert_agent = agents.local_expert()
|
||||
|
||||
identify_task = tasks.identify_task(
|
||||
city_selector_agent,
|
||||
self.origin,
|
||||
self.cities,
|
||||
self.interests,
|
||||
self.date_range,
|
||||
)
|
||||
gather_task = tasks.gather_task(
|
||||
local_expert_agent, self.origin, self.interests, self.date_range
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[city_selector_agent, local_expert_agent],
|
||||
tasks=[identify_task, gather_task],
|
||||
verbose=True,
|
||||
memory=True,
|
||||
knowledge={
|
||||
"sources": [string_source],
|
||||
"metadata": {"preference": "personal"},
|
||||
},
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
return result
|
||||
|
||||
|
||||
trip_crew = TripCrew("California", "Tokyo", "Dec 12 - Dec 20", "sports")
|
||||
result = trip_crew.run()
|
||||
|
||||
print(result)
|
||||
```
|
||||
Refer to [MLflow Tracing Documentation](https://mlflow.org/docs/latest/llms/tracing/index.html) for more configurations and use cases.
|
||||
</Step>
|
||||
<Step title="Visualize Activities of Agents">
|
||||
Now traces for your crewAI agents are captured by MLflow.
|
||||
Let's visit MLflow tracking server to view the traces and get insights into your Agents.
|
||||
|
||||
Open `127.0.0.1:5000` on your browser to visit MLflow tracking server.
|
||||
<Frame caption="MLflow Tracing Dashboard">
|
||||
<img src="/images/mlflow1.png" alt="MLflow tracing example with crewai" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
134
docs/edge/en/observability/neatlogs.mdx
Normal file
134
docs/edge/en/observability/neatlogs.mdx
Normal file
@@ -0,0 +1,134 @@
|
||||
---
|
||||
title: Neatlogs Integration
|
||||
description: Understand, debug, and share your CrewAI agent runs
|
||||
icon: magnifying-glass-chart
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Introduction
|
||||
|
||||
Neatlogs helps you **see what your agent did**, **why**, and **share it**.
|
||||
|
||||
It captures every step: thoughts, tool calls, responses, evaluations. No raw logs. Just clear, structured traces. Great for debugging and collaboration.
|
||||
|
||||
## Why use Neatlogs?
|
||||
|
||||
CrewAI agents use multiple tools and reasoning steps. When something goes wrong, you need context — not just errors.
|
||||
|
||||
Neatlogs lets you:
|
||||
|
||||
- Follow the full decision path
|
||||
- Add feedback directly on steps
|
||||
- Chat with the trace using AI assistant
|
||||
- Share runs publicly for feedback
|
||||
- Turn insights into tasks
|
||||
|
||||
All in one place.
|
||||
|
||||
Manage your traces effortlessly
|
||||
|
||||

|
||||

|
||||
|
||||
The best UX to view a CrewAI trace. Post comments anywhere you want. Use AI to debug.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
## Core Features
|
||||
|
||||
- **Trace Viewer**: Track thoughts, tools, and decisions in sequence
|
||||
- **Inline Comments**: Tag teammates on any trace step
|
||||
- **Feedback & Evaluation**: Mark outputs as correct or incorrect
|
||||
- **Error Highlighting**: Automatic flagging of API/tool failures
|
||||
- **Task Conversion**: Convert comments into assigned tasks
|
||||
- **Ask the Trace (AI)**: Chat with your trace using Neatlogs AI bot
|
||||
- **Public Sharing**: Publish trace links to your community
|
||||
|
||||
## Quick Setup with CrewAI
|
||||
|
||||
<Steps>
|
||||
<Step title="Sign Up & Get API Key">
|
||||
Visit [neatlogs.com](https://neatlogs.com/?utm_source=crewAI-docs), create a project, copy the API key.
|
||||
</Step>
|
||||
<Step title="Install SDK">
|
||||
```bash
|
||||
pip install neatlogs
|
||||
```
|
||||
(Latest version 0.8.0, Python 3.8+; MIT license)
|
||||
</Step>
|
||||
<Step title="Initialize Neatlogs">
|
||||
Before starting Crew agents, add:
|
||||
|
||||
```python
|
||||
import neatlogs
|
||||
neatlogs.init("YOUR_PROJECT_API_KEY")
|
||||
```
|
||||
|
||||
Agents run as usual. Neatlogs captures everything automatically.
|
||||
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
|
||||
|
||||
## Under the Hood
|
||||
|
||||
According to GitHub, Neatlogs:
|
||||
|
||||
- Captures thoughts, tool calls, responses, errors, and token stats
|
||||
- Supports AI-powered task generation and robust evaluation workflows
|
||||
|
||||
All with just two lines of code.
|
||||
|
||||
|
||||
|
||||
## Watch It Work
|
||||
|
||||
### 🔍 Full Demo (4 min)
|
||||
|
||||
<iframe
|
||||
className="w-full aspect-video rounded-xl"
|
||||
src="https://www.youtube.com/embed/8KDme9T2I7Q?si=b8oHteaBwFNs_Duk"
|
||||
title="NeatLogs overview"
|
||||
frameBorder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowFullScreen
|
||||
></iframe>
|
||||
|
||||
### ⚙️ CrewAI Integration (30 s)
|
||||
|
||||
<iframe
|
||||
className="w-full aspect-video rounded-xl"
|
||||
src="https://www.loom.com/embed/9c78b552af43452bb3e4783cb8d91230?sid=e9d7d370-a91a-49b0-809e-2f375d9e801d"
|
||||
title="Loom video player"
|
||||
frameBorder="0"
|
||||
allowFullScreen
|
||||
></iframe>
|
||||
|
||||
|
||||
|
||||
## Links & Support
|
||||
|
||||
- 📘 [Neatlogs Docs](https://docs.neatlogs.com/)
|
||||
- 🔐 [Dashboard & API Key](https://app.neatlogs.com/)
|
||||
- 🐦 [Follow on Twitter](https://twitter.com/neatlogs)
|
||||
- 📧 Contact: hello@neatlogs.com
|
||||
- 🛠 [GitHub SDK](https://github.com/NeatLogs/neatlogs)
|
||||
|
||||
|
||||
|
||||
## TL;DR
|
||||
|
||||
With just:
|
||||
|
||||
```bash
|
||||
pip install neatlogs
|
||||
|
||||
import neatlogs
|
||||
neatlogs.init("YOUR_API_KEY")
|
||||
|
||||
You can now capture, understand, share, and act on your CrewAI agent runs in seconds.
|
||||
No setup overhead. Full trace transparency. Full team collaboration.
|
||||
```
|
||||
182
docs/edge/en/observability/openlit.mdx
Normal file
182
docs/edge/en/observability/openlit.mdx
Normal file
@@ -0,0 +1,182 @@
|
||||
---
|
||||
title: OpenLIT Integration
|
||||
description: Quickly start monitoring your Agents in just a single line of code with OpenTelemetry.
|
||||
icon: magnifying-glass-chart
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# OpenLIT Overview
|
||||
|
||||
[OpenLIT](https://github.com/openlit/openlit?src=crewai-docs) is an open-source tool that makes it simple to monitor the performance of AI agents, LLMs, VectorDBs, and GPUs with just **one** line of code.
|
||||
|
||||
It provides OpenTelemetry-native tracing and metrics to track important parameters like cost, latency, interactions and task sequences.
|
||||
This setup enables you to track hyperparameters and monitor for performance issues, helping you find ways to enhance and fine-tune your agents over time.
|
||||
|
||||
<Frame caption="OpenLIT Dashboard">
|
||||
<img src="/images/openlit1.png" alt="Overview Agent usage including cost and tokens" />
|
||||
<img src="/images/openlit2.png" alt="Overview of agent otel traces and metrics" />
|
||||
<img src="/images/openlit3.png" alt="Overview of agent traces in details" />
|
||||
</Frame>
|
||||
|
||||
### Features
|
||||
|
||||
- **Analytics Dashboard**: Monitor your Agents health and performance with detailed dashboards that track metrics, costs, and user interactions.
|
||||
- **OpenTelemetry-native Observability SDK**: Vendor-neutral SDKs to send traces and metrics to your existing observability tools like Grafana, DataDog and more.
|
||||
- **Cost Tracking for Custom and Fine-Tuned Models**: Tailor cost estimations for specific models using custom pricing files for precise budgeting.
|
||||
- **Exceptions Monitoring Dashboard**: Quickly spot and resolve issues by tracking common exceptions and errors with a monitoring dashboard.
|
||||
- **Compliance and Security**: Detect potential threats such as profanity and PII leaks.
|
||||
- **Prompt Injection Detection**: Identify potential code injection and secret leaks.
|
||||
- **API Keys and Secrets Management**: Securely handle your LLM API keys and secrets centrally, avoiding insecure practices.
|
||||
- **Prompt Management**: Manage and version Agent prompts using PromptHub for consistent and easy access across Agents.
|
||||
- **Model Playground** Test and compare different models for your CrewAI agents before deployment.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Deploy OpenLIT">
|
||||
<Steps>
|
||||
<Step title="Git Clone OpenLIT Repository">
|
||||
```shell
|
||||
git clone git@github.com:openlit/openlit.git
|
||||
```
|
||||
</Step>
|
||||
<Step title="Start Docker Compose">
|
||||
From the root directory of the [OpenLIT Repo](https://github.com/openlit/openlit), Run the below command:
|
||||
```shell
|
||||
docker compose up -d
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
</Step>
|
||||
<Step title="Install OpenLIT SDK">
|
||||
```shell
|
||||
pip install openlit
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize OpenLIT in Your Application">
|
||||
Add the following two lines to your application code:
|
||||
<Tabs>
|
||||
<Tab title="Setup using function arguments">
|
||||
```python
|
||||
import openlit
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
```
|
||||
|
||||
Example Usage for monitoring a CrewAI Agent:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
import openlit
|
||||
|
||||
openlit.init(disable_metrics=True)
|
||||
# Define your agents
|
||||
researcher = Agent(
|
||||
role="Researcher",
|
||||
goal="Conduct thorough research and analysis on AI and AI agents",
|
||||
backstory="You're an expert researcher, specialized in technology, software engineering, AI, and startups. You work as a freelancer and are currently researching for a new client.",
|
||||
allow_delegation=False,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
|
||||
# Define your task
|
||||
task = Task(
|
||||
description="Generate a list of 5 interesting ideas for an article, then write one captivating paragraph for each idea that showcases the potential of a full article on this topic. Return the list of ideas with their paragraphs and your notes.",
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Define the manager agent
|
||||
manager = Agent(
|
||||
role="Project Manager",
|
||||
goal="Efficiently manage the crew and ensure high-quality task completion",
|
||||
backstory="You're an experienced project manager, skilled in overseeing complex projects and guiding teams to success. Your role is to coordinate the efforts of the crew members, ensuring that each task is completed on time and to the highest standard.",
|
||||
allow_delegation=True,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
# Instantiate your crew with a custom manager
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[task],
|
||||
manager_agent=manager,
|
||||
process=Process.hierarchical,
|
||||
)
|
||||
|
||||
# Start the crew's work
|
||||
result = crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
</Tab>
|
||||
<Tab title="Setup using Environment Variables">
|
||||
|
||||
Add the following two lines to your application code:
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
Run the following command to configure the OTEL export endpoint:
|
||||
```shell
|
||||
export OTEL_EXPORTER_OTLP_ENDPOINT = "http://127.0.0.1:4318"
|
||||
```
|
||||
|
||||
Example Usage for monitoring a CrewAI Async Agent:
|
||||
|
||||
```python
|
||||
import asyncio
|
||||
from crewai import Crew, Agent, Task
|
||||
import openlit
|
||||
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
|
||||
# Create an agent with code execution enabled
|
||||
coding_agent = Agent(
|
||||
role="Python Data Analyst",
|
||||
goal="Analyze data and provide insights using Python",
|
||||
backstory="You are an experienced data analyst with strong Python skills.",
|
||||
allow_code_execution=True,
|
||||
llm="command-r"
|
||||
)
|
||||
|
||||
# Create a task that requires code execution
|
||||
data_analysis_task = Task(
|
||||
description="Analyze the given dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent,
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Create a crew and add the task
|
||||
analysis_crew = Crew(
|
||||
agents=[coding_agent],
|
||||
tasks=[data_analysis_task]
|
||||
)
|
||||
|
||||
# Async function to kickoff the crew asynchronously
|
||||
async def async_crew_execution():
|
||||
result = await analysis_crew.kickoff_async(inputs={"ages": [25, 30, 35, 40, 45]})
|
||||
print("Crew Result:", result)
|
||||
|
||||
# Run the async function
|
||||
asyncio.run(async_crew_execution())
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
Refer to OpenLIT [Python SDK repository](https://github.com/openlit/openlit/tree/main/sdk/python) for more advanced configurations and use cases.
|
||||
</Step>
|
||||
<Step title="Visualize and Analyze">
|
||||
With the Agent Observability data now being collected and sent to OpenLIT, the next step is to visualize and analyze this data to get insights into your Agent's performance, behavior, and identify areas of improvement.
|
||||
|
||||
Just head over to OpenLIT at `127.0.0.1:3000` on your browser to start exploring. You can login using the default credentials
|
||||
- **Email**: `user@openlit.io`
|
||||
- **Password**: `openlituser`
|
||||
|
||||
<Frame caption="OpenLIT Dashboard">
|
||||
<img src="/images/openlit1.png" alt="Overview Agent usage including cost and tokens" />
|
||||
<img src="/images/openlit2.png" alt="Overview of agent otel traces and metrics" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
130
docs/edge/en/observability/opik.mdx
Normal file
130
docs/edge/en/observability/opik.mdx
Normal file
@@ -0,0 +1,130 @@
|
||||
---
|
||||
title: Opik Integration
|
||||
description: Learn how to use Comet Opik to debug, evaluate, and monitor your CrewAI applications with comprehensive tracing, automated evaluations, and production-ready dashboards.
|
||||
icon: meteor
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Opik Overview
|
||||
|
||||
With [Comet Opik](https://www.comet.com/docs/opik/), debug, evaluate, and monitor your LLM applications, RAG systems, and agentic workflows with comprehensive tracing, automated evaluations, and production-ready dashboards.
|
||||
|
||||
<Frame caption="Opik Agent Dashboard">
|
||||
<img src="/images/opik-crewai-dashboard.png" alt="Opik agent monitoring example with CrewAI" />
|
||||
</Frame>
|
||||
|
||||
Opik provides comprehensive support for every stage of your CrewAI application development:
|
||||
|
||||
- **Log Traces and Spans**: Automatically track LLM calls and application logic to debug and analyze development and production systems. Manually or programmatically annotate, view, and compare responses across projects.
|
||||
- **Evaluate Your LLM Application's Performance**: Evaluate against a custom test set and run built-in evaluation metrics or define your own metrics in the SDK or UI.
|
||||
- **Test Within Your CI/CD Pipeline**: Establish reliable performance baselines with Opik's LLM unit tests, built on PyTest. Run online evaluations for continuous monitoring in production.
|
||||
- **Monitor & Analyze Production Data**: Understand your models' performance on unseen data in production and generate datasets for new dev iterations.
|
||||
|
||||
## Setup
|
||||
Comet provides a hosted version of the Opik platform, or you can run the platform locally.
|
||||
|
||||
To use the hosted version, simply [create a free Comet account](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) and grab you API Key.
|
||||
|
||||
To run the Opik platform locally, see our [installation guide](https://www.comet.com/docs/opik/self-host/overview/) for more information.
|
||||
|
||||
For this guide we will use CrewAI’s quickstart example.
|
||||
|
||||
<Steps>
|
||||
<Step title="Install required packages">
|
||||
```shell
|
||||
pip install crewai crewai-tools opik --upgrade
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure Opik">
|
||||
```python
|
||||
import opik
|
||||
opik.configure(use_local=False)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Prepare environment">
|
||||
First, we set up our API keys for our LLM-provider as environment variables:
|
||||
|
||||
```python
|
||||
import os
|
||||
import getpass
|
||||
|
||||
if "OPENAI_API_KEY" not in os.environ:
|
||||
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
|
||||
```
|
||||
</Step>
|
||||
<Step title="Using CrewAI">
|
||||
The first step is to create our project. We will use an example from CrewAI’s documentation:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task, Process
|
||||
|
||||
|
||||
class YourCrewName:
|
||||
def agent_one(self) -> Agent:
|
||||
return Agent(
|
||||
role="Data Analyst",
|
||||
goal="Analyze data trends in the market",
|
||||
backstory="An experienced data analyst with a background in economics",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def agent_two(self) -> Agent:
|
||||
return Agent(
|
||||
role="Market Researcher",
|
||||
goal="Gather information on market dynamics",
|
||||
backstory="A diligent researcher with a keen eye for detail",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def task_one(self) -> Task:
|
||||
return Task(
|
||||
name="Collect Data Task",
|
||||
description="Collect recent market data and identify trends.",
|
||||
expected_output="A report summarizing key trends in the market.",
|
||||
agent=self.agent_one(),
|
||||
)
|
||||
|
||||
def task_two(self) -> Task:
|
||||
return Task(
|
||||
name="Market Research Task",
|
||||
description="Research factors affecting market dynamics.",
|
||||
expected_output="An analysis of factors influencing the market.",
|
||||
agent=self.agent_two(),
|
||||
)
|
||||
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[self.agent_one(), self.agent_two()],
|
||||
tasks=[self.task_one(), self.task_two()],
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
Now we can import Opik’s tracker and run our crew:
|
||||
|
||||
```python
|
||||
from opik.integrations.crewai import track_crewai
|
||||
|
||||
track_crewai(project_name="crewai-integration-demo")
|
||||
|
||||
my_crew = YourCrewName().crew()
|
||||
result = my_crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
After running your CrewAI application, visit the Opik app to view:
|
||||
- LLM traces, spans, and their metadata
|
||||
- Agent interactions and task execution flow
|
||||
- Performance metrics like latency and token usage
|
||||
- Evaluation metrics (built-in or custom)
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Resources
|
||||
|
||||
- [🦉 Opik Documentation](https://www.comet.com/docs/opik/)
|
||||
- [👉 Opik + CrewAI Colab](https://colab.research.google.com/github/comet-ml/opik/blob/main/apps/opik-documentation/documentation/docs/cookbook/crewai.ipynb)
|
||||
- [🐦 X](https://x.com/cometml)
|
||||
- [💬 Slack](https://slack.comet.com/)
|
||||
120
docs/edge/en/observability/overview.mdx
Normal file
120
docs/edge/en/observability/overview.mdx
Normal file
@@ -0,0 +1,120 @@
|
||||
---
|
||||
title: "Overview"
|
||||
description: "Monitor, evaluate, and optimize your CrewAI agents with comprehensive observability tools"
|
||||
icon: "face-smile"
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
## Observability for CrewAI
|
||||
|
||||
Observability is crucial for understanding how your CrewAI agents perform, identifying bottlenecks, and ensuring reliable operation in production environments. This section covers various tools and platforms that provide monitoring, evaluation, and optimization capabilities for your agent workflows.
|
||||
|
||||
## Why Observability Matters
|
||||
|
||||
- **Performance Monitoring**: Track agent execution times, token usage, and resource consumption
|
||||
- **Quality Assurance**: Evaluate output quality and consistency across different scenarios
|
||||
- **Debugging**: Identify and resolve issues in agent behavior and task execution
|
||||
- **Cost Management**: Monitor LLM API usage and associated costs
|
||||
- **Continuous Improvement**: Gather insights to optimize agent performance over time
|
||||
|
||||
## Available Observability Tools
|
||||
|
||||
### Monitoring & Tracing Platforms
|
||||
|
||||
<CardGroup cols={2}>
|
||||
|
||||
<Card title="LangDB" icon="database" href="/en/observability/langdb">
|
||||
End-to-end tracing for CrewAI workflows with automatic agent interaction capture.
|
||||
</Card>
|
||||
|
||||
<Card title="OpenLIT" icon="magnifying-glass-chart" href="/en/observability/openlit">
|
||||
OpenTelemetry-native monitoring with cost tracking and performance analytics.
|
||||
</Card>
|
||||
|
||||
<Card title="MLflow" icon="bars-staggered" href="/en/observability/mlflow">
|
||||
Machine learning lifecycle management with tracing and evaluation capabilities.
|
||||
</Card>
|
||||
|
||||
<Card title="Langfuse" icon="link" href="/en/observability/langfuse">
|
||||
LLM engineering platform with detailed tracing and analytics.
|
||||
</Card>
|
||||
|
||||
<Card title="Langtrace" icon="chart-line" href="/en/observability/langtrace">
|
||||
Open-source observability for LLMs and agent frameworks.
|
||||
</Card>
|
||||
|
||||
<Card title="Arize Phoenix" icon="meteor" href="/en/observability/arize-phoenix">
|
||||
AI observability platform for monitoring and troubleshooting.
|
||||
</Card>
|
||||
|
||||
<Card title="Portkey" icon="key" href="/en/observability/portkey">
|
||||
AI gateway with comprehensive monitoring and reliability features.
|
||||
</Card>
|
||||
|
||||
<Card title="Opik" icon="meteor" href="/en/observability/opik">
|
||||
Debug, evaluate, and monitor LLM applications with comprehensive tracing.
|
||||
</Card>
|
||||
|
||||
<Card title="Weave" icon="network-wired" href="/en/observability/weave">
|
||||
Weights & Biases platform for tracking and evaluating AI applications.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### Evaluation & Quality Assurance
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Patronus AI" icon="shield-check" href="/en/observability/patronus-evaluation">
|
||||
Comprehensive evaluation platform for LLM outputs and agent behaviors.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Key Observability Metrics
|
||||
|
||||
### Performance Metrics
|
||||
- **Execution Time**: How long agents take to complete tasks
|
||||
- **Token Usage**: Input/output tokens consumed by LLM calls
|
||||
- **API Latency**: Response times from external services
|
||||
- **Success Rate**: Percentage of successfully completed tasks
|
||||
|
||||
### Quality Metrics
|
||||
- **Output Accuracy**: Correctness of agent responses
|
||||
- **Consistency**: Reliability across similar inputs
|
||||
- **Relevance**: How well outputs match expected results
|
||||
- **Safety**: Compliance with content policies and guidelines
|
||||
|
||||
### Cost Metrics
|
||||
- **API Costs**: Expenses from LLM provider usage
|
||||
- **Resource Utilization**: Compute and memory consumption
|
||||
- **Cost per Task**: Economic efficiency of agent operations
|
||||
- **Budget Tracking**: Monitoring against spending limits
|
||||
|
||||
## Getting Started
|
||||
|
||||
1. **Choose Your Tools**: Select observability platforms that match your needs
|
||||
2. **Instrument Your Code**: Add monitoring to your CrewAI applications
|
||||
3. **Set Up Dashboards**: Configure visualizations for key metrics
|
||||
4. **Define Alerts**: Create notifications for important events
|
||||
5. **Establish Baselines**: Measure initial performance for comparison
|
||||
6. **Iterate and Improve**: Use insights to optimize your agents
|
||||
|
||||
## Best Practices
|
||||
|
||||
### Development Phase
|
||||
- Use detailed tracing to understand agent behavior
|
||||
- Implement evaluation metrics early in development
|
||||
- Monitor resource usage during testing
|
||||
- Set up automated quality checks
|
||||
|
||||
### Production Phase
|
||||
- Implement comprehensive monitoring and alerting
|
||||
- Track performance trends over time
|
||||
- Monitor for anomalies and degradation
|
||||
- Maintain cost visibility and control
|
||||
|
||||
### Continuous Improvement
|
||||
- Regular performance reviews and optimization
|
||||
- A/B testing of different agent configurations
|
||||
- Feedback loops for quality improvement
|
||||
- Documentation of lessons learned
|
||||
|
||||
Choose the observability tools that best fit your use case, infrastructure, and monitoring requirements to ensure your CrewAI agents perform reliably and efficiently.
|
||||
206
docs/edge/en/observability/patronus-evaluation.mdx
Normal file
206
docs/edge/en/observability/patronus-evaluation.mdx
Normal file
@@ -0,0 +1,206 @@
|
||||
---
|
||||
title: Patronus AI Evaluation
|
||||
description: Monitor and evaluate CrewAI agent performance using Patronus AI's comprehensive evaluation platform for LLM outputs and agent behaviors.
|
||||
icon: shield-check
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Patronus AI Evaluation
|
||||
|
||||
## Overview
|
||||
|
||||
[Patronus AI](https://patronus.ai) provides comprehensive evaluation and monitoring capabilities for CrewAI agents, enabling you to assess model outputs, agent behaviors, and overall system performance. This integration allows you to implement continuous evaluation workflows that help maintain quality and reliability in production environments.
|
||||
|
||||
## Key Features
|
||||
|
||||
- **Automated Evaluation**: Real-time assessment of agent outputs and behaviors
|
||||
- **Custom Criteria**: Define specific evaluation criteria tailored to your use cases
|
||||
- **Performance Monitoring**: Track agent performance metrics over time
|
||||
- **Quality Assurance**: Ensure consistent output quality across different scenarios
|
||||
- **Safety & Compliance**: Monitor for potential issues and policy violations
|
||||
|
||||
## Evaluation Tools
|
||||
|
||||
Patronus provides three main evaluation tools for different use cases:
|
||||
|
||||
1. **PatronusEvalTool**: Allows agents to select the most appropriate evaluator and criteria for the evaluation task.
|
||||
2. **PatronusPredefinedCriteriaEvalTool**: Uses predefined evaluator and criteria specified by the user.
|
||||
3. **PatronusLocalEvaluatorTool**: Uses custom function evaluators defined by the user.
|
||||
|
||||
## Installation
|
||||
|
||||
To use these tools, you need to install the Patronus package:
|
||||
|
||||
```shell
|
||||
uv add patronus
|
||||
```
|
||||
|
||||
You'll also need to set up your Patronus API key as an environment variable:
|
||||
|
||||
```shell
|
||||
export PATRONUS_API_KEY="your_patronus_api_key"
|
||||
```
|
||||
|
||||
## Steps to Get Started
|
||||
|
||||
To effectively use the Patronus evaluation tools, follow these steps:
|
||||
|
||||
1. **Install Patronus**: Install the Patronus package using the command above.
|
||||
2. **Set Up API Key**: Set your Patronus API key as an environment variable.
|
||||
3. **Choose the Right Tool**: Select the appropriate Patronus evaluation tool based on your needs.
|
||||
4. **Configure the Tool**: Configure the tool with the necessary parameters.
|
||||
|
||||
## Examples
|
||||
|
||||
### Using PatronusEvalTool
|
||||
|
||||
The following example demonstrates how to use the `PatronusEvalTool`, which allows agents to select the most appropriate evaluator and criteria:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusEvalTool
|
||||
|
||||
# Initialize the tool
|
||||
patronus_eval_tool = PatronusEvalTool()
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code and verify that the output is code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate and evaluate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence. Select the most appropriate evaluator and criteria for evaluating your output.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Using PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
The following example demonstrates how to use the `PatronusPredefinedCriteriaEvalTool`, which uses predefined evaluator and criteria:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
# Initialize the tool with predefined criteria
|
||||
patronus_eval_tool = PatronusPredefinedCriteriaEvalTool(
|
||||
evaluators=[{"evaluator": "judge", "criteria": "contains-code"}]
|
||||
)
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Using PatronusLocalEvaluatorTool
|
||||
|
||||
The following example demonstrates how to use the `PatronusLocalEvaluatorTool`, which uses custom function evaluators:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusLocalEvaluatorTool
|
||||
from patronus import Client, EvaluationResult
|
||||
import random
|
||||
|
||||
# Initialize the Patronus client
|
||||
client = Client()
|
||||
|
||||
# Register a custom evaluator
|
||||
@client.register_local_evaluator("random_evaluator")
|
||||
def random_evaluator(**kwargs):
|
||||
score = random.random()
|
||||
return EvaluationResult(
|
||||
score_raw=score,
|
||||
pass_=score >= 0.5,
|
||||
explanation="example explanation",
|
||||
)
|
||||
|
||||
# Initialize the tool with the custom evaluator
|
||||
patronus_eval_tool = PatronusLocalEvaluatorTool(
|
||||
patronus_client=client,
|
||||
evaluator="random_evaluator",
|
||||
evaluated_model_gold_answer="example label",
|
||||
)
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
## Parameters
|
||||
|
||||
### PatronusEvalTool
|
||||
|
||||
The `PatronusEvalTool` does not require any parameters during initialization. It automatically fetches available evaluators and criteria from the Patronus API.
|
||||
|
||||
### PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
The `PatronusPredefinedCriteriaEvalTool` accepts the following parameters during initialization:
|
||||
|
||||
- **evaluators**: Required. A list of dictionaries containing the evaluator and criteria to use. For example: `[{"evaluator": "judge", "criteria": "contains-code"}]`.
|
||||
|
||||
### PatronusLocalEvaluatorTool
|
||||
|
||||
The `PatronusLocalEvaluatorTool` accepts the following parameters during initialization:
|
||||
|
||||
- **patronus_client**: Required. The Patronus client instance.
|
||||
- **evaluator**: Optional. The name of the registered local evaluator to use. Default is an empty string.
|
||||
- **evaluated_model_gold_answer**: Optional. The gold answer to use for evaluation. Default is an empty string.
|
||||
|
||||
## Usage
|
||||
|
||||
When using the Patronus evaluation tools, you provide the model input, output, and context, and the tool returns the evaluation results from the Patronus API.
|
||||
|
||||
For the `PatronusEvalTool` and `PatronusPredefinedCriteriaEvalTool`, the following parameters are required when calling the tool:
|
||||
|
||||
- **evaluated_model_input**: The agent's task description in simple text.
|
||||
- **evaluated_model_output**: The agent's output of the task.
|
||||
- **evaluated_model_retrieved_context**: The agent's context.
|
||||
|
||||
For the `PatronusLocalEvaluatorTool`, the same parameters are required, but the evaluator and gold answer are specified during initialization.
|
||||
|
||||
## Conclusion
|
||||
|
||||
The Patronus evaluation tools provide a powerful way to evaluate and score model inputs and outputs using the Patronus AI platform. By enabling agents to evaluate their own outputs or the outputs of other agents, these tools can help improve the quality and reliability of CrewAI workflows.
|
||||
823
docs/edge/en/observability/portkey.mdx
Normal file
823
docs/edge/en/observability/portkey.mdx
Normal file
@@ -0,0 +1,823 @@
|
||||
---
|
||||
title: Portkey Integration
|
||||
description: How to use Portkey with CrewAI
|
||||
icon: key
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-CrewAI.png" alt="Portkey CrewAI Header Image" width="70%" />
|
||||
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
Portkey enhances CrewAI with production-readiness features, turning your experimental agent crews into robust systems by providing:
|
||||
|
||||
- **Complete observability** of every agent step, tool use, and interaction
|
||||
- **Built-in reliability** with fallbacks, retries, and load balancing
|
||||
- **Cost tracking and optimization** to manage your AI spend
|
||||
- **Access to 200+ LLMs** through a single integration
|
||||
- **Guardrails** to keep agent behavior safe and compliant
|
||||
- **Version-controlled prompts** for consistent agent performance
|
||||
|
||||
|
||||
### Installation & Setup
|
||||
|
||||
<Steps>
|
||||
<Step title="Install the required packages">
|
||||
```bash
|
||||
pip install -U crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="Generate API Key" icon="lock">
|
||||
Create a Portkey API key with optional budget/rate limits from the [Portkey dashboard](https://app.portkey.ai/). You can also attach configurations for reliability, caching, and more to this key. More on this later.
|
||||
</Step>
|
||||
|
||||
<Step title="Configure CrewAI with Portkey">
|
||||
The integration is simple - you just need to update the LLM configuration in your CrewAI setup:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create an LLM instance with Portkey integration
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy", # We are using a Virtual key, so this is a placeholder
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_LLM_VIRTUAL_KEY",
|
||||
trace_id="unique-trace-id", # Optional, for request tracing
|
||||
)
|
||||
)
|
||||
|
||||
#Use them in your Crew Agents like this:
|
||||
|
||||
@agent
|
||||
def lead_market_analyst(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['lead_market_analyst'],
|
||||
verbose=True,
|
||||
memory=False,
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
<Info>
|
||||
**What are Virtual Keys?** Virtual keys in Portkey securely store your LLM provider API keys (OpenAI, Anthropic, etc.) in an encrypted vault. They allow for easier key rotation and budget management. [Learn more about virtual keys here](https://portkey.ai/docs/product/ai-gateway/virtual-keys).
|
||||
</Info>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Production Features
|
||||
|
||||
### 1. Enhanced Observability
|
||||
|
||||
Portkey provides comprehensive observability for your CrewAI agents, helping you understand exactly what's happening during each execution.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Traces">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Product%2011.1.webp"/>
|
||||
</Frame>
|
||||
|
||||
Traces provide a hierarchical view of your crew's execution, showing the sequence of LLM calls, tool invocations, and state transitions.
|
||||
|
||||
```python
|
||||
# Add trace_id to enable hierarchical tracing in Portkey
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
trace_id="unique-session-id" # Add unique trace ID
|
||||
)
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Logs">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Metadata.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey logs every interaction with LLMs, including:
|
||||
|
||||
- Complete request and response payloads
|
||||
- Latency and token usage metrics
|
||||
- Cost calculations
|
||||
- Tool calls and function executions
|
||||
|
||||
All logs can be filtered by metadata, trace IDs, models, and more, making it easy to debug specific crew runs.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Metrics & Dashboards">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Dashboard.png"/>
|
||||
</Frame>
|
||||
|
||||
Portkey provides built-in dashboards that help you:
|
||||
|
||||
- Track cost and token usage across all crew runs
|
||||
- Analyze performance metrics like latency and success rates
|
||||
- Identify bottlenecks in your agent workflows
|
||||
- Compare different crew configurations and LLMs
|
||||
|
||||
You can filter and segment all metrics by custom metadata to analyze specific crew types, user groups, or use cases.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Metadata Filtering">
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png" alt="Analytics with metadata filters" />
|
||||
</Frame>
|
||||
|
||||
Add custom metadata to your CrewAI LLM configuration to enable powerful filtering and segmentation:
|
||||
|
||||
```python
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"crew_type": "research_crew",
|
||||
"environment": "production",
|
||||
"_user": "user_123", # Special _user field for user analytics
|
||||
"request_source": "mobile_app"
|
||||
}
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
This metadata can be used to filter logs, traces, and metrics on the Portkey dashboard, allowing you to analyze specific crew runs, users, or environments.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 2. Reliability - Keep Your Crews Running Smoothly
|
||||
|
||||
When running crews in production, things can go wrong - API rate limits, network issues, or provider outages. Portkey's reliability features ensure your agents keep running smoothly even when problems occur.
|
||||
|
||||
It's simple to enable fallback in your CrewAI setup by using a Portkey Config:
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create LLM with fallback configuration
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
config={
|
||||
"strategy": {
|
||||
"mode": "fallback"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"provider": "openai",
|
||||
"api_key": "YOUR_OPENAI_API_KEY",
|
||||
"override_params": {"model": "gpt-4o"}
|
||||
},
|
||||
{
|
||||
"provider": "anthropic",
|
||||
"api_key": "YOUR_ANTHROPIC_API_KEY",
|
||||
"override_params": {"model": "claude-3-opus-20240229"}
|
||||
}
|
||||
]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Use this LLM configuration with your agents
|
||||
```
|
||||
|
||||
This configuration will automatically try Claude if the GPT-4o request fails, ensuring your crew can continue operating.
|
||||
|
||||
<CardGroup cols="2">
|
||||
<Card title="Automatic Retries" icon="rotate" href="https://portkey.ai/docs/product/ai-gateway/automatic-retries">
|
||||
Handles temporary failures automatically. If an LLM call fails, Portkey will retry the same request for the specified number of times - perfect for rate limits or network blips.
|
||||
</Card>
|
||||
<Card title="Request Timeouts" icon="clock" href="https://portkey.ai/docs/product/ai-gateway/request-timeouts">
|
||||
Prevent your agents from hanging. Set timeouts to ensure you get responses (or can fail gracefully) within your required timeframes.
|
||||
</Card>
|
||||
<Card title="Conditional Routing" icon="route" href="https://portkey.ai/docs/product/ai-gateway/conditional-routing">
|
||||
Send different requests to different providers. Route complex reasoning to GPT-4, creative tasks to Claude, and quick responses to Gemini based on your needs.
|
||||
</Card>
|
||||
<Card title="Fallbacks" icon="shield" href="https://portkey.ai/docs/product/ai-gateway/fallbacks">
|
||||
Keep running even if your primary provider fails. Automatically switch to backup providers to maintain availability.
|
||||
</Card>
|
||||
<Card title="Load Balancing" icon="scale-balanced" href="https://portkey.ai/docs/product/ai-gateway/load-balancing">
|
||||
Spread requests across multiple API keys or providers. Great for high-volume crew operations and staying within rate limits.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### 3. Prompting in CrewAI
|
||||
|
||||
Portkey's Prompt Engineering Studio helps you create, manage, and optimize the prompts used in your CrewAI agents. Instead of hardcoding prompts or instructions, use Portkey's prompt rendering API to dynamically fetch and apply your versioned prompts.
|
||||
|
||||
<Frame caption="Manage prompts in Portkey's Prompt Library">
|
||||
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Prompt Playground">
|
||||
Prompt Playground is a place to compare, test and deploy perfect prompts for your AI application. It's where you experiment with different models, test variables, compare outputs, and refine your prompt engineering strategy before deploying to production. It allows you to:
|
||||
|
||||
1. Iteratively develop prompts before using them in your agents
|
||||
2. Test prompts with different variables and models
|
||||
3. Compare outputs between different prompt versions
|
||||
4. Collaborate with team members on prompt development
|
||||
|
||||
This visual environment makes it easier to craft effective prompts for each step in your CrewAI agents' workflow.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Using Prompt Templates">
|
||||
The Prompt Render API retrieves your prompt templates with all parameters configured:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL, Portkey
|
||||
|
||||
# Initialize Portkey admin client
|
||||
portkey_admin = Portkey(api_key="YOUR_PORTKEY_API_KEY")
|
||||
|
||||
# Retrieve prompt using the render API
|
||||
prompt_data = portkey_client.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
}
|
||||
)
|
||||
|
||||
backstory_agent_prompt=prompt_data.data.messages[0]["content"]
|
||||
|
||||
|
||||
# Set up LLM with Portkey integration
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent using the rendered prompt
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory=backstory_agent, # Use the rendered prompt
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Prompt Versioning">
|
||||
You can:
|
||||
- Create multiple versions of the same prompt
|
||||
- Compare performance between versions
|
||||
- Roll back to previous versions if needed
|
||||
- Specify which version to use in your code:
|
||||
|
||||
```python
|
||||
# Use a specific prompt version
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID@version_number",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"agent_goal": "Discover groundbreaking insights"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="Mustache Templating for variables">
|
||||
Portkey prompts use Mustache-style templating for easy variable substitution:
|
||||
|
||||
```
|
||||
You are a {{agent_role}} with expertise in {{domain}}.
|
||||
|
||||
Your mission is to {{agent_goal}} by leveraging your knowledge
|
||||
and experience in the field.
|
||||
|
||||
Always maintain a {{tone}} tone and focus on providing {{focus_area}}.
|
||||
```
|
||||
|
||||
When rendering, simply pass the variables:
|
||||
|
||||
```python
|
||||
prompt_data = portkey_admin.prompts.render(
|
||||
prompt_id="YOUR_PROMPT_ID",
|
||||
variables={
|
||||
"agent_role": "Senior Research Scientist",
|
||||
"domain": "artificial intelligence",
|
||||
"agent_goal": "discover groundbreaking insights",
|
||||
"tone": "professional",
|
||||
"focus_area": "practical applications"
|
||||
}
|
||||
)
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Card title="Prompt Engineering Studio" icon="wand-magic-sparkles" href="https://portkey.ai/docs/product/prompt-library">
|
||||
Learn more about Portkey's prompt management features
|
||||
</Card>
|
||||
|
||||
### 4. Guardrails for Safe Crews
|
||||
|
||||
Guardrails ensure your CrewAI agents operate safely and respond appropriately in all situations.
|
||||
|
||||
**Why Use Guardrails?**
|
||||
|
||||
CrewAI agents can experience various failure modes:
|
||||
- Generating harmful or inappropriate content
|
||||
- Leaking sensitive information like PII
|
||||
- Hallucinating incorrect information
|
||||
- Generating outputs in incorrect formats
|
||||
|
||||
Portkey's guardrails add protections for both inputs and outputs.
|
||||
|
||||
**Implementing Guardrails**
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Create LLM with guardrails
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"input_guardrails": ["guardrails-id-xxx", "guardrails-id-yyy"],
|
||||
"output_guardrails": ["guardrails-id-zzz"]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with guardrailed LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Portkey's guardrails can:
|
||||
- Detect and redact PII in both inputs and outputs
|
||||
- Filter harmful or inappropriate content
|
||||
- Validate response formats against schemas
|
||||
- Check for hallucinations against ground truth
|
||||
- Apply custom business logic and rules
|
||||
|
||||
<Card title="Learn More About Guardrails" icon="shield-check" href="https://portkey.ai/docs/product/guardrails">
|
||||
Explore Portkey's guardrail features to enhance agent safety
|
||||
</Card>
|
||||
|
||||
### 5. User Tracking with Metadata
|
||||
|
||||
Track individual users through your CrewAI agents using Portkey's metadata system.
|
||||
|
||||
**What is Metadata in Portkey?**
|
||||
|
||||
Metadata allows you to associate custom data with each request, enabling filtering, segmentation, and analytics. The special `_user` field is specifically designed for user tracking.
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with user tracking
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
metadata={
|
||||
"_user": "user_123", # Special _user field for user analytics
|
||||
"user_tier": "premium",
|
||||
"user_company": "Acme Corp",
|
||||
"session_id": "abc-123"
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with tracked LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
**Filter Analytics by User**
|
||||
|
||||
With metadata in place, you can filter analytics by user and analyze performance metrics on a per-user basis:
|
||||
|
||||
<Frame caption="Filter analytics by user">
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Metadata%20Filters%20from%20CrewAI.png"/>
|
||||
</Frame>
|
||||
|
||||
This enables:
|
||||
- Per-user cost tracking and budgeting
|
||||
- Personalized user analytics
|
||||
- Team or organization-level metrics
|
||||
- Environment-specific monitoring (staging vs. production)
|
||||
|
||||
<Card title="Learn More About Metadata" icon="tags" href="https://portkey.ai/docs/product/observability/metadata">
|
||||
Explore how to use custom metadata to enhance your analytics
|
||||
</Card>
|
||||
|
||||
### 6. Caching for Efficient Crews
|
||||
|
||||
Implement caching to make your CrewAI agents more efficient and cost-effective:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Simple Caching">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with simple caching
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "simple"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with cached LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Simple caching performs exact matches on input prompts, caching identical requests to avoid redundant model executions.
|
||||
</Tab>
|
||||
|
||||
<Tab title="Semantic Caching">
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with semantic caching
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
|
||||
config={
|
||||
"cache": {
|
||||
"mode": "semantic"
|
||||
}
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Create agent with semantically cached LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
|
||||
Semantic caching considers the contextual similarity between input requests, caching responses for semantically similar inputs.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 7. Model Interoperability
|
||||
|
||||
CrewAI supports multiple LLM providers, and Portkey extends this capability by providing access to over 200 LLMs through a unified interface. You can easily switch between different models without changing your core agent logic:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
# Set up LLMs with different providers
|
||||
openai_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_OPENAI_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
max_tokens=1000,
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY"
|
||||
)
|
||||
)
|
||||
|
||||
# Choose which LLM to use for each agent based on your needs
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=openai_llm # Use anthropic_llm for Anthropic
|
||||
)
|
||||
```
|
||||
|
||||
Portkey provides access to LLMs from providers including:
|
||||
|
||||
- OpenAI (GPT-4o, GPT-4 Turbo, etc.)
|
||||
- Anthropic (Claude 3.5 Sonnet, Claude 3 Opus, etc.)
|
||||
- Mistral AI (Mistral Large, Mistral Medium, etc.)
|
||||
- Google Vertex AI (Gemini 1.5 Pro, etc.)
|
||||
- Cohere (Command, Command-R, etc.)
|
||||
- AWS Bedrock (Claude, Titan, etc.)
|
||||
- Local/Private Models
|
||||
|
||||
<Card title="Supported Providers" icon="server" href="https://portkey.ai/docs/integrations/llms">
|
||||
See the full list of LLM providers supported by Portkey
|
||||
</Card>
|
||||
|
||||
## Set Up Enterprise Governance for CrewAI
|
||||
|
||||
**Why Enterprise Governance?**
|
||||
If you are using CrewAI inside your organization, you need to consider several governance aspects:
|
||||
- **Cost Management**: Controlling and tracking AI spending across teams
|
||||
- **Access Control**: Managing which teams can use specific models
|
||||
- **Usage Analytics**: Understanding how AI is being used across the organization
|
||||
- **Security & Compliance**: Maintaining enterprise security standards
|
||||
- **Reliability**: Ensuring consistent service across all users
|
||||
|
||||
Portkey adds a comprehensive governance layer to address these enterprise needs. Let's implement these controls step by step.
|
||||
|
||||
<Steps>
|
||||
<Step title="Create Virtual Key">
|
||||
Virtual Keys are Portkey's secure way to manage your LLM provider API keys. They provide essential controls like:
|
||||
- Budget limits for API usage
|
||||
- Rate limiting capabilities
|
||||
- Secure API key storage
|
||||
|
||||
To create a virtual key:
|
||||
Go to [Virtual Keys](https://app.portkey.ai/virtual-keys) in the Portkey App. Save and copy the virtual key ID
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
|
||||
<Note>
|
||||
Save your virtual key ID - you'll need it for the next step.
|
||||
</Note>
|
||||
</Step>
|
||||
|
||||
<Step title="Create Default Config">
|
||||
Configs in Portkey define how your requests are routed, with features like advanced routing, fallbacks, and retries.
|
||||
|
||||
To create your config:
|
||||
1. Go to [Configs](https://app.portkey.ai/configs) in Portkey dashboard
|
||||
2. Create new config with:
|
||||
```json
|
||||
{
|
||||
"virtual_key": "YOUR_VIRTUAL_KEY_FROM_STEP1",
|
||||
"override_params": {
|
||||
"model": "gpt-4o" // Your preferred model name
|
||||
}
|
||||
}
|
||||
```
|
||||
3. Save and note the Config name for the next step
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20Portkey%20Docs%20Config.png" width="500"/>
|
||||
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Configure Portkey API Key">
|
||||
Now create a Portkey API key and attach the config you created in Step 2:
|
||||
|
||||
1. Go to [API Keys](https://app.portkey.ai/api-keys) in Portkey and Create new API key
|
||||
2. Select your config from `Step 2`
|
||||
3. Generate and save your API key
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/CrewAI%20API%20Key.png" width="500"/>
|
||||
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Connect to CrewAI">
|
||||
After setting up your Portkey API key with the attached config, connect it to your CrewAI agents:
|
||||
|
||||
```python
|
||||
from crewai import Agent, LLM
|
||||
from portkey_ai import PORTKEY_GATEWAY_URL
|
||||
|
||||
# Configure LLM with your API key
|
||||
portkey_llm = LLM(
|
||||
model="gpt-4o",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="YOUR_PORTKEY_API_KEY"
|
||||
)
|
||||
|
||||
# Create agent with Portkey-enabled LLM
|
||||
researcher = Agent(
|
||||
role="Senior Research Scientist",
|
||||
goal="Discover groundbreaking insights about the assigned topic",
|
||||
backstory="You are an expert researcher with deep domain knowledge.",
|
||||
verbose=True,
|
||||
llm=portkey_llm
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Step 1: Implement Budget Controls & Rate Limits">
|
||||
### Step 1: Implement Budget Controls & Rate Limits
|
||||
|
||||
Virtual Keys enable granular control over LLM access at the team/department level. This helps you:
|
||||
- Set up [budget limits](https://portkey.ai/docs/product/ai-gateway/virtual-keys/budget-limits)
|
||||
- Prevent unexpected usage spikes using Rate limits
|
||||
- Track departmental spending
|
||||
|
||||
#### Setting Up Department-Specific Controls:
|
||||
1. Navigate to [Virtual Keys](https://app.portkey.ai/virtual-keys) in Portkey dashboard
|
||||
2. Create new Virtual Key for each department with budget limits and rate limits
|
||||
3. Configure department-specific limits
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/refs/heads/main/Virtual%20Key%20from%20Portkey%20Docs.png" width="500"/>
|
||||
</Frame>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Step 2: Define Model Access Rules">
|
||||
### Step 2: Define Model Access Rules
|
||||
|
||||
As your AI usage scales, controlling which teams can access specific models becomes crucial. Portkey Configs provide this control layer with features like:
|
||||
|
||||
#### Access Control Features:
|
||||
- **Model Restrictions**: Limit access to specific models
|
||||
- **Data Protection**: Implement guardrails for sensitive data
|
||||
- **Reliability Controls**: Add fallbacks and retry logic
|
||||
|
||||
#### Example Configuration:
|
||||
Here's a basic configuration to route requests to OpenAI, specifically using GPT-4o:
|
||||
|
||||
```json
|
||||
{
|
||||
"strategy": {
|
||||
"mode": "single"
|
||||
},
|
||||
"targets": [
|
||||
{
|
||||
"virtual_key": "YOUR_OPENAI_VIRTUAL_KEY",
|
||||
"override_params": {
|
||||
"model": "gpt-4o"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Create your config on the [Configs page](https://app.portkey.ai/configs) in your Portkey dashboard.
|
||||
|
||||
<Note>
|
||||
Configs can be updated anytime to adjust controls without affecting running applications.
|
||||
</Note>
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Step 3: Implement Access Controls">
|
||||
### Step 3: Implement Access Controls
|
||||
|
||||
Create User-specific API keys that automatically:
|
||||
- Track usage per user/team with the help of virtual keys
|
||||
- Apply appropriate configs to route requests
|
||||
- Collect relevant metadata to filter logs
|
||||
- Enforce access permissions
|
||||
|
||||
Create API keys through the [Portkey App](https://app.portkey.ai/)
|
||||
|
||||
Example using Python SDK:
|
||||
```python
|
||||
from portkey_ai import Portkey
|
||||
|
||||
portkey = Portkey(api_key="YOUR_ADMIN_API_KEY")
|
||||
|
||||
api_key = portkey.api_keys.create(
|
||||
name="engineering-team",
|
||||
type="organisation",
|
||||
workspace_id="YOUR_WORKSPACE_ID",
|
||||
defaults={
|
||||
"config_id": "your-config-id",
|
||||
"metadata": {
|
||||
"environment": "production",
|
||||
"department": "engineering"
|
||||
}
|
||||
},
|
||||
scopes=["logs.view", "configs.read"]
|
||||
)
|
||||
```
|
||||
|
||||
For detailed key management instructions, see the [Portkey documentation](https://portkey.ai/docs).
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Step 4: Deploy & Monitor">
|
||||
### Step 4: Deploy & Monitor
|
||||
After distributing API keys to your team members, your enterprise-ready CrewAI setup is ready to go. Each team member can now use their designated API keys with appropriate access levels and budget controls.
|
||||
|
||||
Monitor usage in Portkey dashboard:
|
||||
- Cost tracking by department
|
||||
- Model usage patterns
|
||||
- Request volumes
|
||||
- Error rates
|
||||
</Accordion>
|
||||
|
||||
</AccordionGroup>
|
||||
|
||||
<Note>
|
||||
### Enterprise Features Now Available
|
||||
**Your CrewAI integration now has:**
|
||||
- Departmental budget controls
|
||||
- Model access governance
|
||||
- Usage tracking & attribution
|
||||
- Security guardrails
|
||||
- Reliability features
|
||||
</Note>
|
||||
|
||||
## Frequently Asked Questions
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="How does Portkey enhance CrewAI?">
|
||||
Portkey adds production-readiness to CrewAI through comprehensive observability (traces, logs, metrics), reliability features (fallbacks, retries, caching), and access to 200+ LLMs through a unified interface. This makes it easier to debug, optimize, and scale your agent applications.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Can I use Portkey with existing CrewAI applications?">
|
||||
Yes! Portkey integrates seamlessly with existing CrewAI applications. You just need to update your LLM configuration code with the Portkey-enabled version. The rest of your agent and crew code remains unchanged.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Does Portkey work with all CrewAI features?">
|
||||
Portkey supports all CrewAI features, including agents, tools, human-in-the-loop workflows, and all task process types (sequential, hierarchical, etc.). It adds observability and reliability without limiting any of the framework's functionality.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Can I track usage across multiple agents in a crew?">
|
||||
Yes, Portkey allows you to use a consistent `trace_id` across multiple agents in a crew to track the entire workflow. This is especially useful for complex crews where you want to understand the full execution path across multiple agents.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="How do I filter logs and traces for specific crew runs?">
|
||||
Portkey allows you to add custom metadata to your LLM configuration, which you can then use for filtering. Add fields like `crew_name`, `crew_type`, or `session_id` to easily find and analyze specific crew executions.
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Can I use my own API keys with Portkey?">
|
||||
Yes! Portkey uses your own API keys for the various LLM providers. It securely stores them as virtual keys, allowing you to easily manage and rotate keys without changing your code.
|
||||
</Accordion>
|
||||
|
||||
</AccordionGroup>
|
||||
|
||||
## Resources
|
||||
|
||||
<CardGroup cols="3">
|
||||
<Card title="CrewAI Docs" icon="book" href="https://docs.crewai.com/">
|
||||
<p>Official CrewAI documentation</p>
|
||||
</Card>
|
||||
<Card title="Book a Demo" icon="calendar" href="https://calendly.com/portkey-ai">
|
||||
<p>Get personalized guidance on implementing this integration</p>
|
||||
</Card>
|
||||
</CardGroup>
|
||||
214
docs/edge/en/observability/tracing.mdx
Normal file
214
docs/edge/en/observability/tracing.mdx
Normal file
@@ -0,0 +1,214 @@
|
||||
---
|
||||
title: CrewAI Tracing
|
||||
description: Built-in tracing for CrewAI Crews and Flows with the CrewAI AMP platform
|
||||
icon: magnifying-glass-chart
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# CrewAI Built-in Tracing
|
||||
|
||||
CrewAI provides built-in tracing capabilities that allow you to monitor and debug your Crews and Flows in real-time. This guide demonstrates how to enable tracing for both **Crews** and **Flows** using CrewAI's integrated observability platform.
|
||||
|
||||
> **What is CrewAI Tracing?** CrewAI's built-in tracing provides comprehensive observability for your AI agents, including agent decisions, task execution timelines, tool usage, and LLM calls - all accessible through the [CrewAI AMP platform](https://app.crewai.com).
|
||||
|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before you can use CrewAI tracing, you need:
|
||||
|
||||
1. **CrewAI AMP Account**: Sign up for a free account at [app.crewai.com](https://app.crewai.com)
|
||||
2. **CLI Authentication**: Use the CrewAI CLI to authenticate your local environment
|
||||
|
||||
```bash
|
||||
crewai login
|
||||
```
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
### Step 1: Create Your CrewAI AMP Account
|
||||
|
||||
Visit [app.crewai.com](https://app.crewai.com) and create your free account. This will give you access to the CrewAI AMP platform where you can view traces, metrics, and manage your crews.
|
||||
|
||||
### Step 2: Install CrewAI CLI and Authenticate
|
||||
|
||||
If you haven't already, install CrewAI with the CLI tools:
|
||||
|
||||
```bash
|
||||
uv add 'crewai[tools]'
|
||||
```
|
||||
|
||||
Then authenticate your CLI with your CrewAI AMP account:
|
||||
|
||||
```bash
|
||||
crewai login
|
||||
```
|
||||
|
||||
This command will:
|
||||
|
||||
1. Open your browser to the authentication page
|
||||
2. Prompt you to enter a device code
|
||||
3. Authenticate your local environment with your CrewAI AMP account
|
||||
4. Enable tracing capabilities for your local development
|
||||
|
||||
### Step 3: Enable Tracing in Your Crew
|
||||
|
||||
You can enable tracing for your Crew by setting the `tracing` parameter to `True`:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
# Define your agents
|
||||
researcher = Agent(
|
||||
role="Senior Research Analyst",
|
||||
goal="Uncover cutting-edge developments in AI and data science",
|
||||
backstory="""You work at a leading tech think tank.
|
||||
Your expertise lies in identifying emerging trends.
|
||||
You have a knack for dissecting complex data and presenting actionable insights.""",
|
||||
verbose=True,
|
||||
tools=[SerperDevTool()],
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role="Tech Content Strategist",
|
||||
goal="Craft compelling content on tech advancements",
|
||||
backstory="""You are a renowned Content Strategist, known for your insightful and engaging articles.
|
||||
You transform complex concepts into compelling narratives.""",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
research_task = Task(
|
||||
description="""Conduct a comprehensive analysis of the latest advancements in AI in 2024.
|
||||
Identify key trends, breakthrough technologies, and potential industry impacts.""",
|
||||
expected_output="Full analysis report in bullet points",
|
||||
agent=researcher,
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description="""Using the insights provided, develop an engaging blog
|
||||
post that highlights the most significant AI advancements.
|
||||
Your post should be informative yet accessible, catering to a tech-savvy audience.""",
|
||||
expected_output="Full blog post of at least 4 paragraphs",
|
||||
agent=writer,
|
||||
)
|
||||
|
||||
# Enable tracing in your crew
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
process=Process.sequential,
|
||||
tracing=True, # Enable built-in tracing
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Execute your crew
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Step 4: Enable Tracing in Your Flow
|
||||
|
||||
Similarly, you can enable tracing for CrewAI Flows:
|
||||
|
||||
```python
|
||||
from crewai.flow.flow import Flow, listen, start
|
||||
from pydantic import BaseModel
|
||||
|
||||
class ExampleState(BaseModel):
|
||||
counter: int = 0
|
||||
message: str = ""
|
||||
|
||||
class ExampleFlow(Flow[ExampleState]):
|
||||
def __init__(self):
|
||||
super().__init__(tracing=True) # Enable tracing for the flow
|
||||
|
||||
@start()
|
||||
def first_method(self):
|
||||
print("Starting the flow")
|
||||
self.state.counter = 1
|
||||
self.state.message = "Flow started"
|
||||
return "continue"
|
||||
|
||||
@listen("continue")
|
||||
def second_method(self):
|
||||
print("Continuing the flow")
|
||||
self.state.counter += 1
|
||||
self.state.message = "Flow continued"
|
||||
return "finish"
|
||||
|
||||
@listen("finish")
|
||||
def final_method(self):
|
||||
print("Finishing the flow")
|
||||
self.state.counter += 1
|
||||
self.state.message = "Flow completed"
|
||||
|
||||
# Create and run the flow with tracing enabled
|
||||
flow = ExampleFlow(tracing=True)
|
||||
result = flow.kickoff()
|
||||
```
|
||||
|
||||
### Step 5: View Traces in the CrewAI AMP Dashboard
|
||||
|
||||
After running the crew or flow, you can view the traces generated by your CrewAI application in the CrewAI AMP dashboard. You should see detailed steps of the agent interactions, tool usages, and LLM calls.
|
||||
Just click on the link below to view the traces or head over to the traces tab in the dashboard [here](https://app.crewai.com/crewai_plus/trace_batches)
|
||||

|
||||
|
||||
### Alternative: Environment Variable Configuration
|
||||
|
||||
You can also enable tracing globally by setting an environment variable:
|
||||
|
||||
```bash
|
||||
export CREWAI_TRACING_ENABLED=true
|
||||
```
|
||||
|
||||
Or add it to your `.env` file:
|
||||
|
||||
```env
|
||||
CREWAI_TRACING_ENABLED=true
|
||||
```
|
||||
|
||||
When this environment variable is set, all Crews and Flows will automatically have tracing enabled, even without explicitly setting `tracing=True`.
|
||||
|
||||
## Viewing Your Traces
|
||||
|
||||
### Access the CrewAI AMP Dashboard
|
||||
|
||||
1. Visit [app.crewai.com](https://app.crewai.com) and log in to your account
|
||||
2. Navigate to your project dashboard
|
||||
3. Click on the **Traces** tab to view execution details
|
||||
|
||||
### What You'll See in Traces
|
||||
|
||||
CrewAI tracing provides comprehensive visibility into:
|
||||
|
||||
- **Agent Decisions**: See how agents reason through tasks and make decisions
|
||||
- **Task Execution Timeline**: Visual representation of task sequences and dependencies
|
||||
- **Tool Usage**: Monitor which tools are called and their results
|
||||
- **LLM Calls**: Track all language model interactions, including prompts and responses
|
||||
- **Performance Metrics**: Execution times, token usage, and costs
|
||||
- **Error Tracking**: Detailed error information and stack traces
|
||||
|
||||
### Trace Features
|
||||
|
||||
- **Execution Timeline**: Click through different stages of execution
|
||||
- **Detailed Logs**: Access comprehensive logs for debugging
|
||||
- **Performance Analytics**: Analyze execution patterns and optimize performance
|
||||
- **Export Capabilities**: Download traces for further analysis
|
||||
|
||||
### Authentication Issues
|
||||
|
||||
If you encounter authentication problems:
|
||||
|
||||
1. Ensure you're logged in: `crewai login`
|
||||
2. Check your internet connection
|
||||
3. Verify your account at [app.crewai.com](https://app.crewai.com)
|
||||
|
||||
### Traces Not Appearing
|
||||
|
||||
If traces aren't showing up in the dashboard:
|
||||
|
||||
1. Confirm `tracing=True` is set in your Crew/Flow
|
||||
2. Check that `CREWAI_TRACING_ENABLED=true` if using environment variables
|
||||
3. Ensure you're authenticated with `crewai login`
|
||||
4. Verify your crew/flow is actually executing
|
||||
147
docs/edge/en/observability/truefoundry.mdx
Normal file
147
docs/edge/en/observability/truefoundry.mdx
Normal file
@@ -0,0 +1,147 @@
|
||||
---
|
||||
title: TrueFoundry Integration
|
||||
icon: chart-line
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
TrueFoundry provides an enterprise-ready [AI Gateway](https://www.truefoundry.com/ai-gateway) which can integrate with agentic frameworks like CrewAI and provides governance and observability for your AI Applications. TrueFoundry AI Gateway serves as a unified interface for LLM access, providing:
|
||||
|
||||
- **Unified API Access**: Connect to 250+ LLMs (OpenAI, Claude, Gemini, Groq, Mistral) through one API
|
||||
- **Low Latency**: Sub-3ms internal latency with intelligent routing and load balancing
|
||||
- **Enterprise Security**: SOC 2, HIPAA, GDPR compliance with RBAC and audit logging
|
||||
- **Quota and cost management**: Token-based quotas, rate limiting, and comprehensive usage tracking
|
||||
- **Observability**: Full request/response logging, metrics, and traces with customizable retention
|
||||
|
||||
## How TrueFoundry Integrates with CrewAI
|
||||
|
||||
|
||||
### Installation & Setup
|
||||
|
||||
<Steps>
|
||||
<Step title="Install CrewAI">
|
||||
```bash
|
||||
pip install crewai
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="Get TrueFoundry Access Token">
|
||||
1. Sign up for a [TrueFoundry account](https://www.truefoundry.com/register)
|
||||
2. Follow the steps here in [Quick start](https://docs.truefoundry.com/gateway/quick-start)
|
||||
</Step>
|
||||
|
||||
<Step title="Configure CrewAI with TrueFoundry">
|
||||

|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
|
||||
# Create an LLM instance with TrueFoundry AI Gateway
|
||||
truefoundry_llm = LLM(
|
||||
model="openai-main/gpt-4o", # Similarly, you can call any model from any provider
|
||||
base_url="your_truefoundry_gateway_base_url",
|
||||
api_key="your_truefoundry_api_key"
|
||||
)
|
||||
|
||||
# Use in your CrewAI agents
|
||||
from crewai import Agent
|
||||
|
||||
@agent
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['researcher'],
|
||||
llm=truefoundry_llm,
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Complete CrewAI Example
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM
|
||||
|
||||
# Configure LLM with TrueFoundry
|
||||
llm = LLM(
|
||||
model="openai-main/gpt-4o",
|
||||
base_url="your_truefoundry_gateway_base_url",
|
||||
api_key="your_truefoundry_api_key"
|
||||
)
|
||||
|
||||
# Create agents
|
||||
researcher = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Conduct detailed market research',
|
||||
backstory='Expert market analyst with attention to detail',
|
||||
llm=llm,
|
||||
verbose=True
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role='Content Writer',
|
||||
goal='Create comprehensive reports',
|
||||
backstory='Experienced technical writer',
|
||||
llm=llm,
|
||||
verbose=True
|
||||
)
|
||||
|
||||
# Create tasks
|
||||
research_task = Task(
|
||||
description='Research AI market trends for 2024',
|
||||
agent=researcher,
|
||||
expected_output='Comprehensive research summary'
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description='Create a market research report',
|
||||
agent=writer,
|
||||
expected_output='Well-structured report with insights',
|
||||
context=[research_task]
|
||||
)
|
||||
|
||||
# Create and execute crew
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
verbose=True
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Observability and Governance
|
||||
|
||||
Monitor your CrewAI agents through TrueFoundry's metrics tab:
|
||||

|
||||
|
||||
With Truefoundry's AI gateway, you can monitor and analyze:
|
||||
|
||||
- **Performance Metrics**: Track key latency metrics like Request Latency, Time to First Token (TTFS), and Inter-Token Latency (ITL) with P99, P90, and P50 percentiles
|
||||
- **Cost and Token Usage**: Gain visibility into your application's costs with detailed breakdowns of input/output tokens and the associated expenses for each model
|
||||
- **Usage Patterns**: Understand how your application is being used with detailed analytics on user activity, model distribution, and team-based usage
|
||||
- **Rate limit and Load balancing**: You can set up rate limiting, load balancing and fallback for your models
|
||||
|
||||
## Tracing
|
||||
|
||||
For a more detailed understanding on tracing, please see [getting-started-tracing](https://docs.truefoundry.com/docs/tracing/tracing-getting-started).For tracing, you can add the Traceloop SDK:
|
||||
For tracing, you can add the Traceloop SDK:
|
||||
|
||||
```bash
|
||||
pip install traceloop-sdk
|
||||
```
|
||||
|
||||
```python
|
||||
from traceloop.sdk import Traceloop
|
||||
|
||||
# Initialize enhanced tracing
|
||||
Traceloop.init(
|
||||
api_endpoint="https://your-truefoundry-endpoint/api/tracing",
|
||||
headers={
|
||||
"Authorization": f"Bearer {your_truefoundry_pat_token}",
|
||||
"TFY-Tracing-Project": "your_project_name",
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
This provides additional trace correlation across your entire CrewAI workflow.
|
||||

|
||||
125
docs/edge/en/observability/weave.mdx
Normal file
125
docs/edge/en/observability/weave.mdx
Normal file
@@ -0,0 +1,125 @@
|
||||
---
|
||||
title: Weave Integration
|
||||
description: Learn how to use Weights & Biases (W&B) Weave to track, experiment with, evaluate, and improve your CrewAI applications.
|
||||
icon: radar
|
||||
mode: "wide"
|
||||
---
|
||||
|
||||
# Weave Overview
|
||||
|
||||
[Weights & Biases (W&B) Weave](https://weave-docs.wandb.ai/) is a framework for tracking, experimenting with, evaluating, deploying, and improving LLM-based applications.
|
||||
|
||||

|
||||
|
||||
Weave provides comprehensive support for every stage of your CrewAI application development:
|
||||
|
||||
- **Tracing & Monitoring**: Automatically track LLM calls and application logic to debug and analyze production systems
|
||||
- **Systematic Iteration**: Refine and iterate on prompts, datasets, and models
|
||||
- **Evaluation**: Use custom or pre-built scorers to systematically assess and enhance agent performance
|
||||
- **Guardrails**: Protect your agents with pre- and post-safeguards for content moderation and prompt safety
|
||||
|
||||
Weave automatically captures traces for your CrewAI applications, enabling you to monitor and analyze your agents' performance, interactions, and execution flow. This helps you build better evaluation datasets and optimize your agent workflows.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Install required packages">
|
||||
```shell
|
||||
pip install crewai weave
|
||||
```
|
||||
</Step>
|
||||
<Step title="Set up W&B Account">
|
||||
Sign up for a [Weights & Biases account](https://wandb.ai) if you haven't already. You'll need this to view your traces and metrics.
|
||||
</Step>
|
||||
<Step title="Initialize Weave in Your Application">
|
||||
Add the following code to your application:
|
||||
|
||||
```python
|
||||
import weave
|
||||
|
||||
# Initialize Weave with your project name
|
||||
weave.init(project_name="crewai_demo")
|
||||
```
|
||||
|
||||
After initialization, Weave will provide a URL where you can view your traces and metrics.
|
||||
</Step>
|
||||
<Step title="Create your Crews/Flows">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM, Process
|
||||
|
||||
# Create an LLM with a temperature of 0 to ensure deterministic outputs
|
||||
llm = LLM(model="gpt-4o", temperature=0)
|
||||
|
||||
# Create agents
|
||||
researcher = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Find and analyze the best investment opportunities',
|
||||
backstory='Expert in financial analysis and market research',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role='Report Writer',
|
||||
goal='Write clear and concise investment reports',
|
||||
backstory='Experienced in creating detailed financial reports',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
# Create tasks
|
||||
research_task = Task(
|
||||
description='Deep research on the {topic}',
|
||||
expected_output='Comprehensive market data including key players, market size, and growth trends.',
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description='Write a detailed report based on the research',
|
||||
expected_output='The report should be easy to read and understand. Use bullet points where applicable.',
|
||||
agent=writer
|
||||
)
|
||||
|
||||
# Create a crew
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
result = crew.kickoff(inputs={"topic": "AI in material science"})
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
<Step title="View Traces in Weave">
|
||||
After running your CrewAI application, visit the Weave URL provided during initialization to view:
|
||||
- LLM calls and their metadata
|
||||
- Agent interactions and task execution flow
|
||||
- Performance metrics like latency and token usage
|
||||
- Any errors or issues that occurred during execution
|
||||
|
||||
<Frame caption="Weave Tracing Dashboard">
|
||||
<img src="/images/weave-tracing.png" alt="Weave tracing example with CrewAI" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Features
|
||||
|
||||
- Weave automatically captures all CrewAI operations: agent interactions and task executions; LLM calls with metadata and token usage; tool usage and results.
|
||||
- The integration supports all CrewAI execution methods: `kickoff()`, `kickoff_for_each()`, `kickoff_async()`, and `kickoff_for_each_async()`.
|
||||
- Automatic tracing of all [crewAI-tools](https://github.com/crewAIInc/crewAI-tools).
|
||||
- Flow feature support with decorator patching (`@start`, `@listen`, `@router`, `@or_`, `@and_`).
|
||||
- Track custom guardrails passed to CrewAI `Task` with `@weave.op()`.
|
||||
|
||||
For detailed information on what's supported, visit the [Weave CrewAI documentation](https://weave-docs.wandb.ai/guides/integrations/crewai/#getting-started-with-flow).
|
||||
|
||||
## Resources
|
||||
|
||||
- [📘 Weave Documentation](https://weave-docs.wandb.ai)
|
||||
- [📊 Example Weave x CrewAI dashboard](https://wandb.ai/ayut/crewai_demo/weave/traces?cols=%7B%22wb_run_id%22%3Afalse%2C%22attributes.weave.client_version%22%3Afalse%2C%22attributes.weave.os_name%22%3Afalse%2C%22attributes.weave.os_release%22%3Afalse%2C%22attributes.weave.os_version%22%3Afalse%2C%22attributes.weave.source%22%3Afalse%2C%22attributes.weave.sys_version%22%3Afalse%7D&peekPath=%2Fayut%2Fcrewai_demo%2Fcalls%2F0195c838-38cb-71a2-8a15-651ecddf9d89)
|
||||
- [🐦 X](https://x.com/weave_wb)
|
||||
Reference in New Issue
Block a user