---
title: Portkey Integration
description: How to use Portkey with CrewAI
icon: key
---
 [Portkey](https://portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) is a comprehensive AI gateway that enhances CrewAI agents with production-ready capabilities for reliability, cost-efficiency, and performance optimization.
Portkey adds 4 core production capabilities to any CrewAI agent:
1. Routing to **250+ LLMs** with unified API
2. Enhanced reliability with retries, fallbacks, and load balancing
3. Comprehensive observability with 40+ metrics and detailed tracing
4. Advanced security controls and real-time guardrails
## Getting Started
```bash
pip install -qU crewai portkey-ai
```
To build CrewAI Agents with Portkey, you'll need two keys:
- **Portkey API Key**: Sign up on the [Portkey app](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) and copy your API key
- **Virtual Key**: Virtual Keys securely manage your LLM API keys in one place. Store your LLM provider API keys securely in Portkey's vault
### Modern Integration (Recommended)
The latest Portkey SDK (v1.13.0+) is built directly on top of the OpenAI SDK, providing seamless compatibility:
```python
from crewai import LLM
import os
# Set environment variables
os.environ["PORTKEY_API_KEY"] = "YOUR_PORTKEY_API_KEY"
os.environ["PORTKEY_VIRTUAL_KEY"] = "YOUR_VIRTUAL_KEY"
# Modern Portkey integration with CrewAI
gpt_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"]
}
)
```
### Legacy Integration (Deprecated)
For backward compatibility, the older pattern is still supported but not recommended:
```python
from crewai import LLM
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
gpt_llm = LLM(
model="gpt-4",
base_url=PORTKEY_GATEWAY_URL,
api_key="dummy",
extra_headers=createHeaders(
api_key="YOUR_PORTKEY_API_KEY",
virtual_key="YOUR_VIRTUAL_KEY"
)
)
```
```python
from crewai import Agent, Task, Crew
# Define your agents with roles and goals
coder = Agent(
role='Software developer',
goal='Write clear, concise code on demand',
backstory='An expert coder with a keen eye for software trends.',
llm=gpt_llm
)
# Create tasks for your agents
task1 = Task(
description="Define the HTML for making a simple website with heading- Hello World! Portkey is working!",
expected_output="A clear and concise HTML code",
agent=coder
)
# Instantiate your crew with Portkey observability
crew = Crew(
agents=[coder],
tasks=[task1],
)
result = crew.kickoff()
print(result)
```
## Async Support
Portkey fully supports async operations with CrewAI for high-performance applications:
```python
import asyncio
from crewai import Agent, Task, Crew, LLM
import os
# Configure async LLM with Portkey
async_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"]
}
)
async def run_async_crew():
agent = Agent(
role='Data Analyst',
goal='Analyze data efficiently',
backstory='Expert in data analysis and insights.',
llm=async_llm
)
task = Task(
description="Analyze the latest market trends",
expected_output="Comprehensive market analysis report",
agent=agent
)
crew = Crew(agents=[agent], tasks=[task])
result = await crew.kickoff_async()
return result
# Run async crew
result = asyncio.run(run_async_crew())
```
## Key Features
| Feature | Description |
|:--------|:------------|
| 🌐 Multi-LLM Support | Access OpenAI, Anthropic, Gemini, Azure, and 250+ providers through a unified interface |
| 🛡️ Production Reliability | Implement retries, timeouts, load balancing, and fallbacks |
| 📊 Advanced Observability | Track 40+ metrics including costs, tokens, latency, and custom metadata |
| 🔍 Comprehensive Logging | Debug with detailed execution traces and function call logs |
| 🚧 Security Controls | Set budget limits and implement role-based access control |
| 🔄 Performance Analytics | Capture and analyze feedback for continuous improvement |
| 💾 Intelligent Caching | Reduce costs and latency with semantic or simple caching |
## Production Features with Portkey Configs
All features mentioned below are through Portkey's Config system. Portkey's Config system allows you to define routing strategies using simple JSON objects in your LLM API calls. You can create and manage Configs directly in your code or through the Portkey Dashboard. Each Config has a unique ID for easy reference.
[Portkey](https://portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) is a comprehensive AI gateway that enhances CrewAI agents with production-ready capabilities for reliability, cost-efficiency, and performance optimization.
Portkey adds 4 core production capabilities to any CrewAI agent:
1. Routing to **250+ LLMs** with unified API
2. Enhanced reliability with retries, fallbacks, and load balancing
3. Comprehensive observability with 40+ metrics and detailed tracing
4. Advanced security controls and real-time guardrails
## Getting Started
```bash
pip install -qU crewai portkey-ai
```
To build CrewAI Agents with Portkey, you'll need two keys:
- **Portkey API Key**: Sign up on the [Portkey app](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) and copy your API key
- **Virtual Key**: Virtual Keys securely manage your LLM API keys in one place. Store your LLM provider API keys securely in Portkey's vault
### Modern Integration (Recommended)
The latest Portkey SDK (v1.13.0+) is built directly on top of the OpenAI SDK, providing seamless compatibility:
```python
from crewai import LLM
import os
# Set environment variables
os.environ["PORTKEY_API_KEY"] = "YOUR_PORTKEY_API_KEY"
os.environ["PORTKEY_VIRTUAL_KEY"] = "YOUR_VIRTUAL_KEY"
# Modern Portkey integration with CrewAI
gpt_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"]
}
)
```
### Legacy Integration (Deprecated)
For backward compatibility, the older pattern is still supported but not recommended:
```python
from crewai import LLM
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
gpt_llm = LLM(
model="gpt-4",
base_url=PORTKEY_GATEWAY_URL,
api_key="dummy",
extra_headers=createHeaders(
api_key="YOUR_PORTKEY_API_KEY",
virtual_key="YOUR_VIRTUAL_KEY"
)
)
```
```python
from crewai import Agent, Task, Crew
# Define your agents with roles and goals
coder = Agent(
role='Software developer',
goal='Write clear, concise code on demand',
backstory='An expert coder with a keen eye for software trends.',
llm=gpt_llm
)
# Create tasks for your agents
task1 = Task(
description="Define the HTML for making a simple website with heading- Hello World! Portkey is working!",
expected_output="A clear and concise HTML code",
agent=coder
)
# Instantiate your crew with Portkey observability
crew = Crew(
agents=[coder],
tasks=[task1],
)
result = crew.kickoff()
print(result)
```
## Async Support
Portkey fully supports async operations with CrewAI for high-performance applications:
```python
import asyncio
from crewai import Agent, Task, Crew, LLM
import os
# Configure async LLM with Portkey
async_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"]
}
)
async def run_async_crew():
agent = Agent(
role='Data Analyst',
goal='Analyze data efficiently',
backstory='Expert in data analysis and insights.',
llm=async_llm
)
task = Task(
description="Analyze the latest market trends",
expected_output="Comprehensive market analysis report",
agent=agent
)
crew = Crew(agents=[agent], tasks=[task])
result = await crew.kickoff_async()
return result
# Run async crew
result = asyncio.run(run_async_crew())
```
## Key Features
| Feature | Description |
|:--------|:------------|
| 🌐 Multi-LLM Support | Access OpenAI, Anthropic, Gemini, Azure, and 250+ providers through a unified interface |
| 🛡️ Production Reliability | Implement retries, timeouts, load balancing, and fallbacks |
| 📊 Advanced Observability | Track 40+ metrics including costs, tokens, latency, and custom metadata |
| 🔍 Comprehensive Logging | Debug with detailed execution traces and function call logs |
| 🚧 Security Controls | Set budget limits and implement role-based access control |
| 🔄 Performance Analytics | Capture and analyze feedback for continuous improvement |
| 💾 Intelligent Caching | Reduce costs and latency with semantic or simple caching |
## Production Features with Portkey Configs
All features mentioned below are through Portkey's Config system. Portkey's Config system allows you to define routing strategies using simple JSON objects in your LLM API calls. You can create and manage Configs directly in your code or through the Portkey Dashboard. Each Config has a unique ID for easy reference.
 ### 1. Use 250+ LLMs
Access various LLMs like Anthropic, Gemini, Mistral, Azure OpenAI, and more with minimal code changes. Switch between providers or use them together seamlessly. [Learn more about Universal API](https://portkey.ai/docs/product/ai-gateway/universal-api)
Easily switch between different LLM providers using the modern integration pattern:
```python
import os
# Anthropic Configuration
anthropic_llm = LLM(
model="claude-3-5-sonnet-latest",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["ANTHROPIC_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["ANTHROPIC_VIRTUAL_KEY"],
"x-portkey-trace-id": "anthropic_agent"
}
)
# Azure OpenAI Configuration
azure_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["AZURE_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["AZURE_VIRTUAL_KEY"],
"x-portkey-trace-id": "azure_agent"
}
)
# Google Gemini Configuration
gemini_llm = LLM(
model="gemini-2.0-flash-exp",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["GEMINI_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["GEMINI_VIRTUAL_KEY"],
"x-portkey-trace-id": "gemini_agent"
}
)
# Mistral Configuration
mistral_llm = LLM(
model="mistral-large-latest",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["MISTRAL_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["MISTRAL_VIRTUAL_KEY"],
"x-portkey-trace-id": "mistral_agent"
}
)
```
### 2. Caching
Improve response times and reduce costs with two powerful caching modes:
- **Simple Cache**: Perfect for exact matches
- **Semantic Cache**: Matches responses for requests that are semantically similar
[Learn more about Caching](https://portkey.ai/docs/product/ai-gateway/cache-simple-and-semantic)
```python
import json
# Enable caching for CrewAI agents
cached_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"],
"x-portkey-config": json.dumps({
"cache": {
"mode": "semantic", # or "simple" for exact matching
"max_age": 3600 # Cache for 1 hour
}
})
}
)
# Use with CrewAI agents for improved performance
research_agent = Agent(
role='Research Analyst',
goal='Conduct thorough research with cached responses',
backstory='Expert researcher who values efficiency.',
llm=cached_llm
)
```
### 3. Production Reliability
Portkey provides comprehensive reliability features essential for production CrewAI deployments:
#### Automatic Retries and Fallbacks
```python
import json
# Configure LLM with automatic retries and fallbacks
reliable_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-config": json.dumps({
"retry": {
"attempts": 3,
"on_status_codes": [429, 500, 502, 503, 504]
},
"fallbacks": [
{"virtual_key": os.environ["OPENAI_VIRTUAL_KEY"]},
{"virtual_key": os.environ["ANTHROPIC_VIRTUAL_KEY"]}
]
})
}
)
```
#### Load Balancing
```python
# Distribute requests across multiple models for optimal performance
load_balanced_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-config": json.dumps({
"strategy": {
"mode": "loadbalance",
"targets": [
{"virtual_key": os.environ["OPENAI_VIRTUAL_KEY"], "weight": 70},
{"virtual_key": os.environ["ANTHROPIC_VIRTUAL_KEY"], "weight": 30}
]
}
})
}
)
```
#### Request Timeouts and Conditional Routing
```python
# Configure timeouts and conditional routing for CrewAI workflows
production_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-config": json.dumps({
"request_timeout": 30000, # 30 seconds
"conditional_routing": {
"rules": [
{
"condition": "request.model == 'gpt-4'",
"target": {"virtual_key": os.environ["OPENAI_VIRTUAL_KEY"]}
}
]
}
})
}
)
```
[Learn more about Reliability Features](https://portkey.ai/docs/product/ai-gateway/)
### 4. Comprehensive Observability
CrewAI workflows involve complex multi-agent interactions. Portkey automatically logs **40+ comprehensive metrics** for your AI agents, providing deep insights into agent behavior, performance, and costs.
#### Key Metrics for CrewAI Workflows
- **Agent Performance**: Individual agent response times and success rates
- **Task Execution**: Time spent on each task and completion rates
- **Cost Analysis**: Token usage and costs per agent, task, and crew
- **Multi-Agent Coordination**: Communication patterns between agents
- **Tool Usage**: Frequency and success rates of tool calls
- **Memory Operations**: Knowledge retrieval and storage metrics
- **Cache Efficiency**: Hit rates and performance improvements
#### Custom Metadata for CrewAI
```python
import json
# Add custom metadata to track CrewAI-specific metrics
crew_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"],
"x-portkey-metadata": json.dumps({
"crew_id": "marketing_crew_v1",
"agent_role": "content_writer",
"task_type": "blog_generation",
"environment": "production"
})
}
)
```
### 1. Use 250+ LLMs
Access various LLMs like Anthropic, Gemini, Mistral, Azure OpenAI, and more with minimal code changes. Switch between providers or use them together seamlessly. [Learn more about Universal API](https://portkey.ai/docs/product/ai-gateway/universal-api)
Easily switch between different LLM providers using the modern integration pattern:
```python
import os
# Anthropic Configuration
anthropic_llm = LLM(
model="claude-3-5-sonnet-latest",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["ANTHROPIC_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["ANTHROPIC_VIRTUAL_KEY"],
"x-portkey-trace-id": "anthropic_agent"
}
)
# Azure OpenAI Configuration
azure_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["AZURE_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["AZURE_VIRTUAL_KEY"],
"x-portkey-trace-id": "azure_agent"
}
)
# Google Gemini Configuration
gemini_llm = LLM(
model="gemini-2.0-flash-exp",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["GEMINI_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["GEMINI_VIRTUAL_KEY"],
"x-portkey-trace-id": "gemini_agent"
}
)
# Mistral Configuration
mistral_llm = LLM(
model="mistral-large-latest",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["MISTRAL_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["MISTRAL_VIRTUAL_KEY"],
"x-portkey-trace-id": "mistral_agent"
}
)
```
### 2. Caching
Improve response times and reduce costs with two powerful caching modes:
- **Simple Cache**: Perfect for exact matches
- **Semantic Cache**: Matches responses for requests that are semantically similar
[Learn more about Caching](https://portkey.ai/docs/product/ai-gateway/cache-simple-and-semantic)
```python
import json
# Enable caching for CrewAI agents
cached_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"],
"x-portkey-config": json.dumps({
"cache": {
"mode": "semantic", # or "simple" for exact matching
"max_age": 3600 # Cache for 1 hour
}
})
}
)
# Use with CrewAI agents for improved performance
research_agent = Agent(
role='Research Analyst',
goal='Conduct thorough research with cached responses',
backstory='Expert researcher who values efficiency.',
llm=cached_llm
)
```
### 3. Production Reliability
Portkey provides comprehensive reliability features essential for production CrewAI deployments:
#### Automatic Retries and Fallbacks
```python
import json
# Configure LLM with automatic retries and fallbacks
reliable_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-config": json.dumps({
"retry": {
"attempts": 3,
"on_status_codes": [429, 500, 502, 503, 504]
},
"fallbacks": [
{"virtual_key": os.environ["OPENAI_VIRTUAL_KEY"]},
{"virtual_key": os.environ["ANTHROPIC_VIRTUAL_KEY"]}
]
})
}
)
```
#### Load Balancing
```python
# Distribute requests across multiple models for optimal performance
load_balanced_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-config": json.dumps({
"strategy": {
"mode": "loadbalance",
"targets": [
{"virtual_key": os.environ["OPENAI_VIRTUAL_KEY"], "weight": 70},
{"virtual_key": os.environ["ANTHROPIC_VIRTUAL_KEY"], "weight": 30}
]
}
})
}
)
```
#### Request Timeouts and Conditional Routing
```python
# Configure timeouts and conditional routing for CrewAI workflows
production_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-config": json.dumps({
"request_timeout": 30000, # 30 seconds
"conditional_routing": {
"rules": [
{
"condition": "request.model == 'gpt-4'",
"target": {"virtual_key": os.environ["OPENAI_VIRTUAL_KEY"]}
}
]
}
})
}
)
```
[Learn more about Reliability Features](https://portkey.ai/docs/product/ai-gateway/)
### 4. Comprehensive Observability
CrewAI workflows involve complex multi-agent interactions. Portkey automatically logs **40+ comprehensive metrics** for your AI agents, providing deep insights into agent behavior, performance, and costs.
#### Key Metrics for CrewAI Workflows
- **Agent Performance**: Individual agent response times and success rates
- **Task Execution**: Time spent on each task and completion rates
- **Cost Analysis**: Token usage and costs per agent, task, and crew
- **Multi-Agent Coordination**: Communication patterns between agents
- **Tool Usage**: Frequency and success rates of tool calls
- **Memory Operations**: Knowledge retrieval and storage metrics
- **Cache Efficiency**: Hit rates and performance improvements
#### Custom Metadata for CrewAI
```python
import json
# Add custom metadata to track CrewAI-specific metrics
crew_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"],
"x-portkey-metadata": json.dumps({
"crew_id": "marketing_crew_v1",
"agent_role": "content_writer",
"task_type": "blog_generation",
"environment": "production"
})
}
)
```
 ### 5. Advanced Logging and Tracing
Portkey provides comprehensive logging capabilities specifically designed for complex multi-agent systems like CrewAI. Track every interaction, decision, and outcome across your entire crew workflow.
#### CrewAI-Specific Logging Features
- **Agent Conversation Flows**: Complete conversation history between agents
- **Task Execution Traces**: Step-by-step task completion with timing
- **Tool Call Monitoring**: Detailed logs of all tool invocations and results
- **Memory Access Patterns**: Track knowledge retrieval and storage operations
- **Error Propagation**: Trace how errors flow through multi-agent workflows
#### Implementing Structured Logging
```python
import json
import os
from datetime import datetime
# Configure detailed logging for CrewAI workflows
logged_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"],
"x-portkey-trace-id": f"crew_execution_{datetime.now().isoformat()}",
"x-portkey-metadata": json.dumps({
"workflow_type": "multi_agent_research",
"crew_size": 3,
"expected_duration": "5_minutes"
})
}
)
# Use with CrewAI for comprehensive observability
research_crew = Crew(
agents=[researcher, writer, reviewer],
tasks=[research_task, writing_task, review_task],
verbose=True # Enable CrewAI's built-in logging
)
```
### 5. Advanced Logging and Tracing
Portkey provides comprehensive logging capabilities specifically designed for complex multi-agent systems like CrewAI. Track every interaction, decision, and outcome across your entire crew workflow.
#### CrewAI-Specific Logging Features
- **Agent Conversation Flows**: Complete conversation history between agents
- **Task Execution Traces**: Step-by-step task completion with timing
- **Tool Call Monitoring**: Detailed logs of all tool invocations and results
- **Memory Access Patterns**: Track knowledge retrieval and storage operations
- **Error Propagation**: Trace how errors flow through multi-agent workflows
#### Implementing Structured Logging
```python
import json
import os
from datetime import datetime
# Configure detailed logging for CrewAI workflows
logged_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"],
"x-portkey-trace-id": f"crew_execution_{datetime.now().isoformat()}",
"x-portkey-metadata": json.dumps({
"workflow_type": "multi_agent_research",
"crew_size": 3,
"expected_duration": "5_minutes"
})
}
)
# Use with CrewAI for comprehensive observability
research_crew = Crew(
agents=[researcher, writer, reviewer],
tasks=[research_task, writing_task, review_task],
verbose=True # Enable CrewAI's built-in logging
)
```
Traces
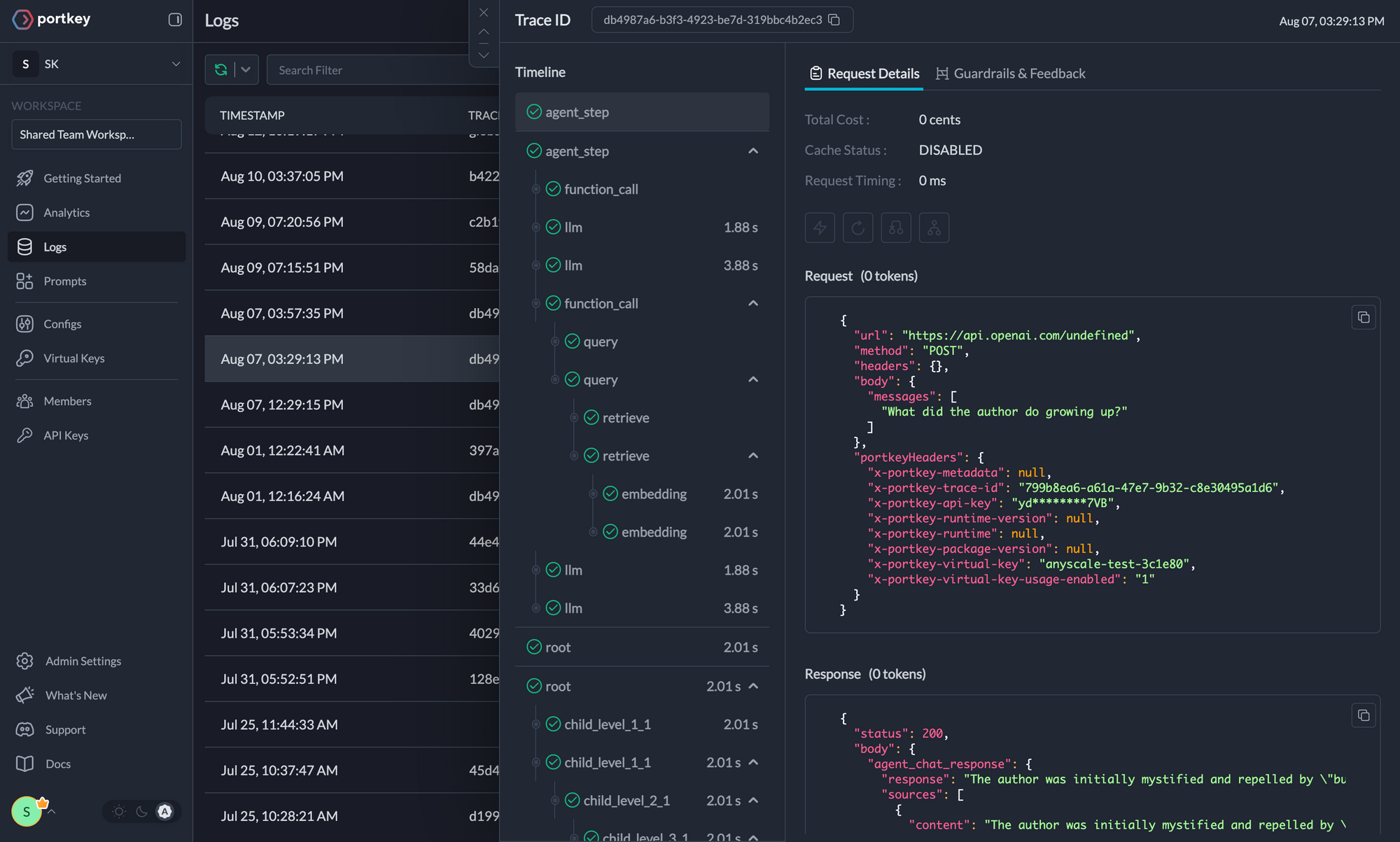
Logs
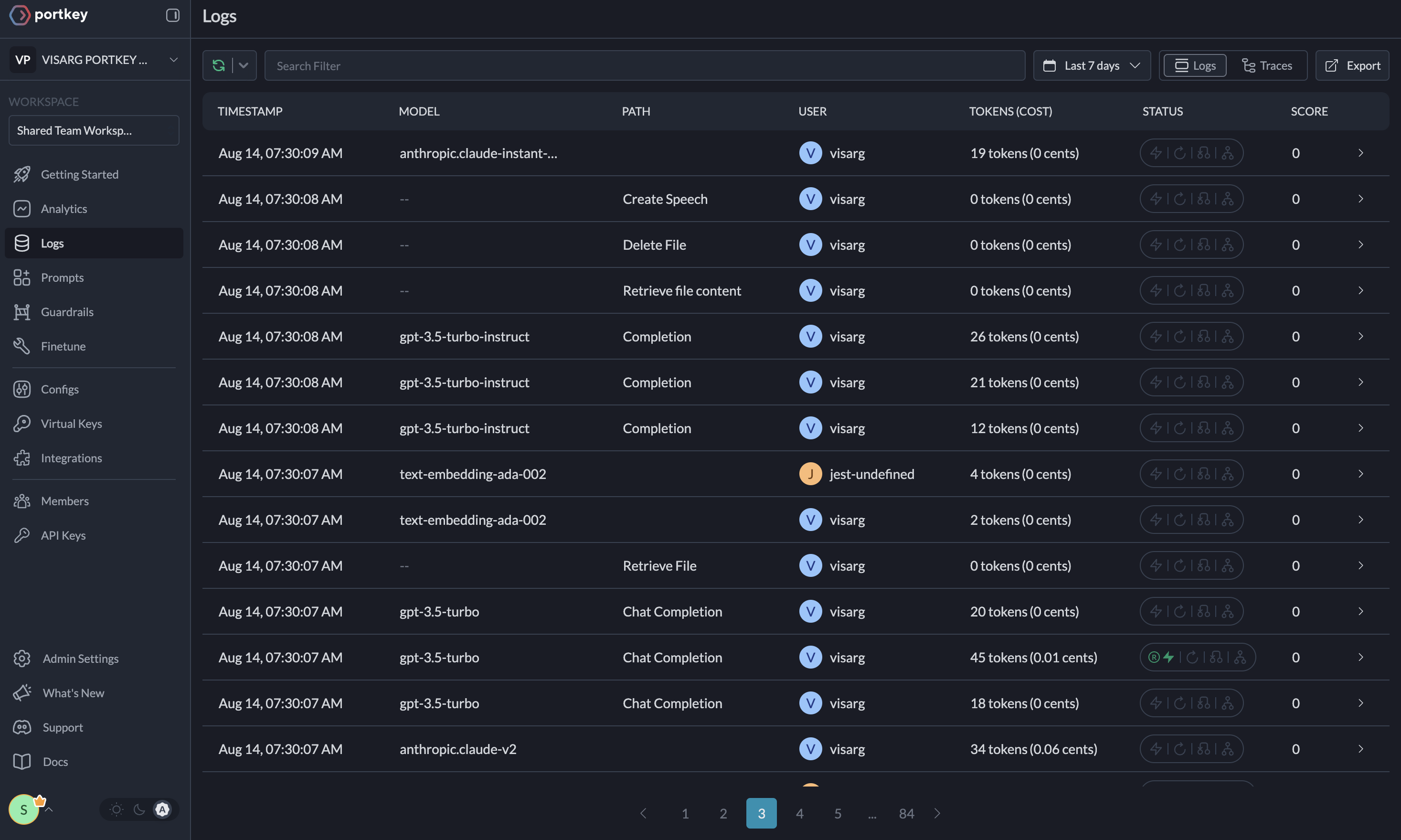
### 6. Enterprise Security Features
- **Budget Controls**: Set spending limits per Virtual Key to prevent cost overruns
- **Rate Limiting**: Control request frequency to prevent abuse
- **Role-Based Access**: Implement fine-grained permissions for team members
- **Audit Logging**: Track all system changes and access patterns
- **Data Retention**: Configure policies for log and metric retention
- **API Key Rotation**: Automated rotation of Virtual Keys for enhanced security
```python
import json
import os
# Example of budget-controlled LLM for production CrewAI deployments
budget_controlled_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"],
"x-portkey-config": json.dumps({
"budget": {
"limit": 100.0, # $100 monthly limit
"period": "monthly"
},
"rate_limit": {
"requests_per_minute": 60
}
})
}
)
```
## CrewAI-Specific Integration Patterns
### Integration with CrewAI Flows
Portkey seamlessly integrates with CrewAI's Flow system for event-driven workflows:
```python
import json
import os
from crewai.flow.flow import Flow, listen, start
from crewai import Agent, Task
class ResearchFlow(Flow):
@start()
def initiate_research(self):
researcher = Agent(
role='Senior Researcher',
goal='Conduct comprehensive research',
backstory='Expert researcher with access to multiple data sources.',
llm=reliable_llm # Using Portkey-configured LLM
)
research_task = Task(
description="Research the latest trends in {topic}",
expected_output="Comprehensive research report",
agent=researcher
)
return research_task.execute()
@listen(initiate_research)
def analyze_findings(self, research_result):
analyst = Agent(
role='Data Analyst',
goal='Analyze research findings',
backstory='Expert in data analysis and pattern recognition.',
llm=cached_llm # Using cached LLM for efficiency
)
analysis_task = Task(
description="Analyze the research findings: {research_result}",
expected_output="Detailed analysis with insights",
agent=analyst
)
return analysis_task.execute()
# Run the flow with Portkey observability
flow = ResearchFlow()
result = flow.kickoff(inputs={"topic": "AI in healthcare"})
```
### Integration with CrewAI Memory Systems
Enhance CrewAI's memory capabilities with Portkey's observability:
```python
import json
import os
from crewai.memory import LongTermMemory, ShortTermMemory
# Configure memory-aware agents with Portkey tracking
memory_llm = LLM(
model="gpt-4",
base_url="https://api.portkey.ai/v1",
api_key=os.environ["PORTKEY_VIRTUAL_KEY"],
extra_headers={
"x-portkey-api-key": os.environ["PORTKEY_API_KEY"],
"x-portkey-virtual-key": os.environ["PORTKEY_VIRTUAL_KEY"],
"x-portkey-metadata": json.dumps({
"memory_enabled": True,
"memory_type": "long_term"
})
}
)
# Create crew with memory and Portkey observability
memory_crew = Crew(
agents=[knowledge_agent],
tasks=[learning_task],
memory=True, # Enable CrewAI memory
verbose=True
)
```
### Tool Integration Monitoring
Track tool usage across your CrewAI workflows:
```python
import os
from crewai_tools import SerperDevTool, FileReadTool
# Configure tools with Portkey tracking
search_tool = SerperDevTool()
file_tool = FileReadTool()
tool_aware_agent = Agent(
role='Research Assistant',
goal='Use tools effectively for research',
backstory='Expert in using various research tools.',
llm=logged_llm, # Portkey will track all tool calls
tools=[search_tool, file_tool]
)
```
## Troubleshooting and Best Practices
### Common Integration Issues
#### API Key Configuration
```python
# Ensure proper environment variable setup
import os
required_vars = [
"PORTKEY_API_KEY",
"PORTKEY_VIRTUAL_KEY"
]
for var in required_vars:
if not os.getenv(var):
raise ValueError(f"Missing required environment variable: {var}")
```
#### Error Handling
```python
# Implement robust error handling for production deployments
try:
result = crew.kickoff()
except Exception as e:
# Portkey will automatically log the error with full context
print(f"Crew execution failed: {e}")
# Implement fallback logic here
```
### Performance Optimization Tips
1. **Use Caching**: Enable semantic caching for repetitive tasks
2. **Load Balancing**: Distribute requests across multiple providers
3. **Batch Operations**: Group similar requests when possible
4. **Monitor Metrics**: Regularly review performance dashboards
5. **Optimize Prompts**: Use Portkey's prompt analytics to improve efficiency
### Security Best Practices
1. **Environment Variables**: Never hardcode API keys in source code
2. **Virtual Keys**: Use Virtual Keys instead of direct provider keys
3. **Budget Limits**: Set appropriate spending limits for production
4. **Access Control**: Implement role-based access for team members
5. **Regular Rotation**: Rotate API keys periodically
For detailed information on creating and managing Configs, visit the [Portkey documentation](https://portkey.ai/docs/product/ai-gateway/configs).
## Resources
- [📘 Portkey Documentation](https://portkey.ai/docs)
- [📊 Portkey Dashboard](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai)
- [🔧 Portkey Python SDK](https://github.com/Portkey-AI/portkey-python-sdk)
- [📦 PyPI Package](https://pypi.org/project/portkey-ai/)
- [🐦 Twitter](https://twitter.com/portkeyai)
- [💬 Discord Community](https://discord.gg/DD7vgKK299)
- [📚 CrewAI Examples with Portkey](https://github.com/crewAIInc/crewAI-examples)