mirror of
https://github.com/crewAIInc/crewAI.git
synced 2026-07-26 01:05:10 +00:00
docs: Add transparency features for prompts and memory systems (#2902)
* docs: Fix major memory system documentation issues - Remove misleading deprecation warnings, fix confusing comments, clearly separate three memory approaches, provide accurate examples that match implementation * fix: Correct broken image paths in README - Update crewai_logo.png and asset.png paths to point to docs/images/ directory instead of docs/ directly * docs: Add system prompt transparency and customization guide - Add 'Understanding Default System Instructions' section to address black-box concerns - Document what CrewAI automatically injects into prompts - Provide code examples to inspect complete system prompts - Show 3 methods to override default instructions - Include observability integration examples with Langfuse - Add best practices for production prompt management * docs: Fix implementation accuracy issues in memory documentation - Fix Ollama embedding URL parameter and remove unsupported Cohere input_type parameter * docs: Reference observability docs instead of showing specific tool examples * docs: Reorganize knowledge documentation for better developer experience - Move quickstart examples right after overview for immediate hands-on experience - Create logical learning progression: basics → configuration → advanced → troubleshooting - Add comprehensive agent vs crew knowledge guide with working examples - Consolidate debugging and troubleshooting in dedicated section - Organize best practices by topic in accordion format - Improve content flow from simple concepts to advanced features - Ensure all examples are grounded in actual codebase implementation * docs: enhance custom LLM documentation with comprehensive examples and accurate imports * docs: reorganize observability tools into dedicated section with comprehensive overview and improved navigation * docs: rename how-to section to learn and add comprehensive overview page * docs: finalize documentation reorganization and update navigation labels * docs: enhance README with comprehensive badges, navigation links, and getting started video
This commit is contained in:
126
docs/observability/agentops.mdx
Normal file
126
docs/observability/agentops.mdx
Normal file
@@ -0,0 +1,126 @@
|
||||
---
|
||||
title: AgentOps Integration
|
||||
description: Understanding and logging your agent performance with AgentOps.
|
||||
icon: paperclip
|
||||
---
|
||||
|
||||
# Introduction
|
||||
|
||||
Observability is a key aspect of developing and deploying conversational AI agents. It allows developers to understand how their agents are performing,
|
||||
how their agents are interacting with users, and how their agents use external tools and APIs.
|
||||
AgentOps is a product independent of CrewAI that provides a comprehensive observability solution for agents.
|
||||
|
||||
## AgentOps
|
||||
|
||||
[AgentOps](https://agentops.ai/?=crew) provides session replays, metrics, and monitoring for agents.
|
||||
|
||||
At a high level, AgentOps gives you the ability to monitor cost, token usage, latency, agent failures, session-wide statistics, and more.
|
||||
For more info, check out the [AgentOps Repo](https://github.com/AgentOps-AI/agentops).
|
||||
|
||||
### Overview
|
||||
|
||||
AgentOps provides monitoring for agents in development and production.
|
||||
It provides a dashboard for tracking agent performance, session replays, and custom reporting.
|
||||
|
||||
Additionally, AgentOps provides session drilldowns for viewing Crew agent interactions, LLM calls, and tool usage in real-time.
|
||||
This feature is useful for debugging and understanding how agents interact with users as well as other agents.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
### Features
|
||||
|
||||
- **LLM Cost Management and Tracking**: Track spend with foundation model providers.
|
||||
- **Replay Analytics**: Watch step-by-step agent execution graphs.
|
||||
- **Recursive Thought Detection**: Identify when agents fall into infinite loops.
|
||||
- **Custom Reporting**: Create custom analytics on agent performance.
|
||||
- **Analytics Dashboard**: Monitor high-level statistics about agents in development and production.
|
||||
- **Public Model Testing**: Test your agents against benchmarks and leaderboards.
|
||||
- **Custom Tests**: Run your agents against domain-specific tests.
|
||||
- **Time Travel Debugging**: Restart your sessions from checkpoints.
|
||||
- **Compliance and Security**: Create audit logs and detect potential threats such as profanity and PII leaks.
|
||||
- **Prompt Injection Detection**: Identify potential code injection and secret leaks.
|
||||
|
||||
### Using AgentOps
|
||||
|
||||
<Steps>
|
||||
<Step title="Create an API Key">
|
||||
Create a user API key here: [Create API Key](https://app.agentops.ai/account)
|
||||
</Step>
|
||||
<Step title="Configure Your Environment">
|
||||
Add your API key to your environment variables:
|
||||
```bash
|
||||
AGENTOPS_API_KEY=<YOUR_AGENTOPS_API_KEY>
|
||||
```
|
||||
</Step>
|
||||
<Step title="Install AgentOps">
|
||||
Install AgentOps with:
|
||||
```bash
|
||||
pip install 'crewai[agentops]'
|
||||
```
|
||||
or
|
||||
```bash
|
||||
pip install agentops
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize AgentOps">
|
||||
Before using `Crew` in your script, include these lines:
|
||||
|
||||
```python
|
||||
import agentops
|
||||
agentops.init()
|
||||
```
|
||||
|
||||
This will initiate an AgentOps session as well as automatically track Crew agents. For further info on how to outfit more complex agentic systems,
|
||||
check out the [AgentOps documentation](https://docs.agentops.ai) or join the [Discord](https://discord.gg/j4f3KbeH).
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Crew + AgentOps Examples
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card
|
||||
title="Job Posting"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/job-posting"
|
||||
icon="briefcase"
|
||||
iconType="solid"
|
||||
>
|
||||
Example of a Crew agent that generates job posts.
|
||||
</Card>
|
||||
<Card
|
||||
title="Markdown Validator"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/markdown_validator"
|
||||
icon="markdown"
|
||||
iconType="solid"
|
||||
>
|
||||
Example of a Crew agent that validates Markdown files.
|
||||
</Card>
|
||||
<Card
|
||||
title="Instagram Post"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/instagram_post"
|
||||
icon="square-instagram"
|
||||
iconType="brands"
|
||||
>
|
||||
Example of a Crew agent that generates Instagram posts.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### Further Information
|
||||
|
||||
To get started, create an [AgentOps account](https://agentops.ai/?=crew).
|
||||
|
||||
For feature requests or bug reports, please reach out to the AgentOps team on the [AgentOps Repo](https://github.com/AgentOps-AI/agentops).
|
||||
|
||||
#### Extra links
|
||||
|
||||
<a href="https://twitter.com/agentopsai/">🐦 Twitter</a>
|
||||
<span> • </span>
|
||||
<a href="https://discord.gg/JHPt4C7r">📢 Discord</a>
|
||||
<span> • </span>
|
||||
<a href="https://app.agentops.ai/?=crew">🖇️ AgentOps Dashboard</a>
|
||||
<span> • </span>
|
||||
<a href="https://docs.agentops.ai/introduction">📙 Documentation</a>
|
||||
151
docs/observability/arize-phoenix.mdx
Normal file
151
docs/observability/arize-phoenix.mdx
Normal file
@@ -0,0 +1,151 @@
|
||||
---
|
||||
title: Arize Phoenix
|
||||
description: Arize Phoenix integration for CrewAI with OpenTelemetry and OpenInference
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# Arize Phoenix Integration
|
||||
|
||||
This guide demonstrates how to integrate **Arize Phoenix** with **CrewAI** using OpenTelemetry via the [OpenInference](https://github.com/openinference/openinference) SDK. By the end of this guide, you will be able to trace your CrewAI agents and easily debug your agents.
|
||||
|
||||
> **What is Arize Phoenix?** [Arize Phoenix](https://phoenix.arize.com) is an LLM observability platform that provides tracing and evaluation for AI applications.
|
||||
|
||||
[](https://www.youtube.com/watch?v=Yc5q3l6F7Ww)
|
||||
|
||||
## Get Started
|
||||
|
||||
We'll walk through a simple example of using CrewAI and integrating it with Arize Phoenix via OpenTelemetry using OpenInference.
|
||||
|
||||
You can also access this guide on [Google Colab](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/crewai_tracing_tutorial.ipynb).
|
||||
|
||||
### Step 1: Install Dependencies
|
||||
|
||||
```bash
|
||||
pip install openinference-instrumentation-crewai crewai crewai-tools arize-phoenix-otel
|
||||
```
|
||||
|
||||
### Step 2: Set Up Environment Variables
|
||||
|
||||
Setup Phoenix Cloud API keys and configure OpenTelemetry to send traces to Phoenix. Phoenix Cloud is a hosted version of Arize Phoenix, but it is not required to use this integration.
|
||||
|
||||
You can get your free Serper API key [here](https://serper.dev/).
|
||||
|
||||
```python
|
||||
import os
|
||||
from getpass import getpass
|
||||
|
||||
# Get your Phoenix Cloud credentials
|
||||
PHOENIX_API_KEY = getpass("🔑 Enter your Phoenix Cloud API Key: ")
|
||||
|
||||
# Get API keys for services
|
||||
OPENAI_API_KEY = getpass("🔑 Enter your OpenAI API key: ")
|
||||
SERPER_API_KEY = getpass("🔑 Enter your Serper API key: ")
|
||||
|
||||
# Set environment variables
|
||||
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
|
||||
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com" # Phoenix Cloud, change this to your own endpoint if you are using a self-hosted instance
|
||||
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
|
||||
os.environ["SERPER_API_KEY"] = SERPER_API_KEY
|
||||
```
|
||||
|
||||
### Step 3: Initialize OpenTelemetry with Phoenix
|
||||
|
||||
Initialize the OpenInference OpenTelemetry instrumentation SDK to start capturing traces and send them to Phoenix.
|
||||
|
||||
```python
|
||||
from phoenix.otel import register
|
||||
|
||||
tracer_provider = register(
|
||||
project_name="crewai-tracing-demo",
|
||||
auto_instrument=True,
|
||||
)
|
||||
```
|
||||
|
||||
### Step 4: Create a CrewAI Application
|
||||
|
||||
We'll create a CrewAI application where two agents collaborate to research and write a blog post about AI advancements.
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai_tools import SerperDevTool
|
||||
from openinference.instrumentation.crewai import CrewAIInstrumentor
|
||||
from phoenix.otel import register
|
||||
|
||||
# setup monitoring for your crew
|
||||
tracer_provider = register(
|
||||
endpoint="http://localhost:6006/v1/traces")
|
||||
CrewAIInstrumentor().instrument(skip_dep_check=True, tracer_provider=tracer_provider)
|
||||
search_tool = SerperDevTool()
|
||||
|
||||
# Define your agents with roles and goals
|
||||
researcher = Agent(
|
||||
role="Senior Research Analyst",
|
||||
goal="Uncover cutting-edge developments in AI and data science",
|
||||
backstory="""You work at a leading tech think tank.
|
||||
Your expertise lies in identifying emerging trends.
|
||||
You have a knack for dissecting complex data and presenting actionable insights.""",
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
# You can pass an optional llm attribute specifying what model you wanna use.
|
||||
# llm=ChatOpenAI(model_name="gpt-3.5", temperature=0.7),
|
||||
tools=[search_tool],
|
||||
)
|
||||
writer = Agent(
|
||||
role="Tech Content Strategist",
|
||||
goal="Craft compelling content on tech advancements",
|
||||
backstory="""You are a renowned Content Strategist, known for your insightful and engaging articles.
|
||||
You transform complex concepts into compelling narratives.""",
|
||||
verbose=True,
|
||||
allow_delegation=True,
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description="""Conduct a comprehensive analysis of the latest advancements in AI in 2024.
|
||||
Identify key trends, breakthrough technologies, and potential industry impacts.""",
|
||||
expected_output="Full analysis report in bullet points",
|
||||
agent=researcher,
|
||||
)
|
||||
|
||||
task2 = Task(
|
||||
description="""Using the insights provided, develop an engaging blog
|
||||
post that highlights the most significant AI advancements.
|
||||
Your post should be informative yet accessible, catering to a tech-savvy audience.
|
||||
Make it sound cool, avoid complex words so it doesn't sound like AI.""",
|
||||
expected_output="Full blog post of at least 4 paragraphs",
|
||||
agent=writer,
|
||||
)
|
||||
|
||||
# Instantiate your crew with a sequential process
|
||||
crew = Crew(
|
||||
agents=[researcher, writer], tasks=[task1, task2], verbose=1, process=Process.sequential
|
||||
)
|
||||
|
||||
# Get your crew to work!
|
||||
result = crew.kickoff()
|
||||
|
||||
print("######################")
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Step 5: View Traces in Phoenix
|
||||
|
||||
After running the agent, you can view the traces generated by your CrewAI application in Phoenix. You should see detailed steps of the agent interactions and LLM calls, which can help you debug and optimize your AI agents.
|
||||
|
||||
Log into your Phoenix Cloud account and navigate to the project you specified in the `project_name` parameter. You'll see a timeline view of your trace with all the agent interactions, tool usages, and LLM calls.
|
||||
|
||||
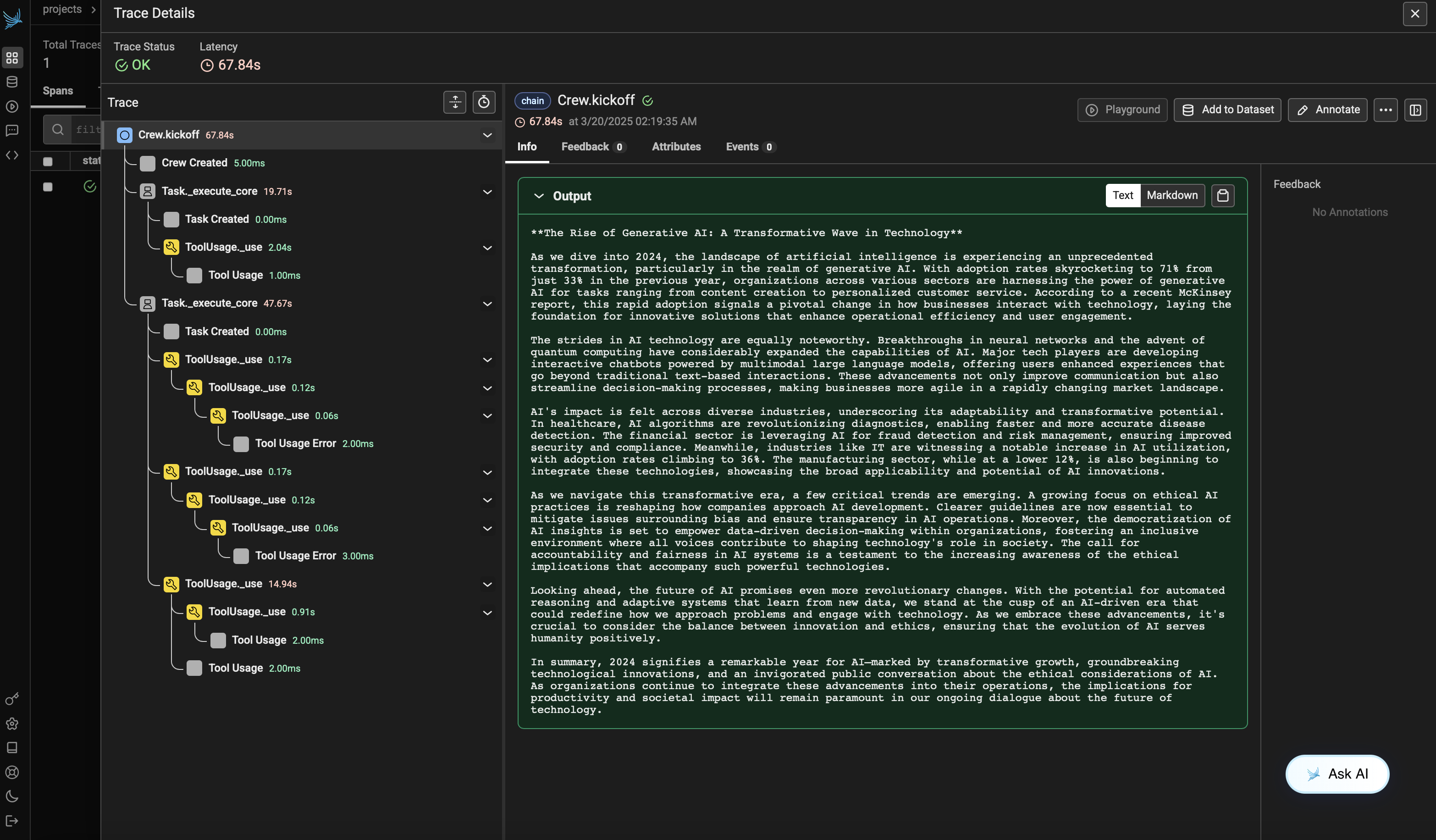
|
||||
|
||||
|
||||
### Version Compatibility Information
|
||||
- Python 3.8+
|
||||
- CrewAI >= 0.86.0
|
||||
- Arize Phoenix >= 7.0.1
|
||||
- OpenTelemetry SDK >= 1.31.0
|
||||
|
||||
|
||||
### References
|
||||
- [Phoenix Documentation](https://docs.arize.com/phoenix/) - Overview of the Phoenix platform.
|
||||
- [CrewAI Documentation](https://docs.crewai.com/) - Overview of the CrewAI framework.
|
||||
- [OpenTelemetry Docs](https://opentelemetry.io/docs/) - OpenTelemetry guide
|
||||
- [OpenInference GitHub](https://github.com/openinference/openinference) - Source code for OpenInference SDK.
|
||||
100
docs/observability/langfuse.mdx
Normal file
100
docs/observability/langfuse.mdx
Normal file
@@ -0,0 +1,100 @@
|
||||
---
|
||||
title: Langfuse Integration
|
||||
description: Learn how to integrate Langfuse with CrewAI via OpenTelemetry using OpenLit
|
||||
icon: vials
|
||||
---
|
||||
|
||||
# Integrate Langfuse with CrewAI
|
||||
|
||||
This notebook demonstrates how to integrate **Langfuse** with **CrewAI** using OpenTelemetry via the **OpenLit** SDK. By the end of this notebook, you will be able to trace your CrewAI applications with Langfuse for improved observability and debugging.
|
||||
|
||||
> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source LLM engineering platform. It provides tracing and monitoring capabilities for LLM applications, helping developers debug, analyze, and optimize their AI systems. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and APIs/SDKs.
|
||||
|
||||
[](https://langfuse.com/watch-demo)
|
||||
|
||||
## Get Started
|
||||
|
||||
We'll walk through a simple example of using CrewAI and integrating it with Langfuse via OpenTelemetry using OpenLit.
|
||||
|
||||
### Step 1: Install Dependencies
|
||||
|
||||
|
||||
```python
|
||||
%pip install langfuse openlit crewai crewai_tools
|
||||
```
|
||||
|
||||
### Step 2: Set Up Environment Variables
|
||||
|
||||
Set your Langfuse API keys and configure OpenTelemetry export settings to send traces to Langfuse. Please refer to the [Langfuse OpenTelemetry Docs](https://langfuse.com/docs/opentelemetry/get-started) for more information on the Langfuse OpenTelemetry endpoint `/api/public/otel` and authentication.
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
import base64
|
||||
|
||||
LANGFUSE_PUBLIC_KEY="pk-lf-..."
|
||||
LANGFUSE_SECRET_KEY="sk-lf-..."
|
||||
LANGFUSE_AUTH=base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
|
||||
|
||||
os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel" # EU data region
|
||||
# os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://us.cloud.langfuse.com/api/public/otel" # US data region
|
||||
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
|
||||
|
||||
# your openai key
|
||||
os.environ["OPENAI_API_KEY"] = "sk-..."
|
||||
```
|
||||
|
||||
### Step 3: Initialize OpenLit
|
||||
|
||||
Initialize the OpenLit OpenTelemetry instrumentation SDK to start capturing OpenTelemetry traces.
|
||||
|
||||
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
### Step 4: Create a Simple CrewAI Application
|
||||
|
||||
We'll create a simple CrewAI application where multiple agents collaborate to answer a user's question.
|
||||
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
from crewai_tools import (
|
||||
WebsiteSearchTool
|
||||
)
|
||||
|
||||
web_rag_tool = WebsiteSearchTool()
|
||||
|
||||
writer = Agent(
|
||||
role="Writer",
|
||||
goal="You make math engaging and understandable for young children through poetry",
|
||||
backstory="You're an expert in writing haikus but you know nothing of math.",
|
||||
tools=[web_rag_tool],
|
||||
)
|
||||
|
||||
task = Task(description=("What is {multiplication}?"),
|
||||
expected_output=("Compose a haiku that includes the answer."),
|
||||
agent=writer)
|
||||
|
||||
crew = Crew(
|
||||
agents=[writer],
|
||||
tasks=[task],
|
||||
share_crew=False
|
||||
)
|
||||
```
|
||||
|
||||
### Step 5: See Traces in Langfuse
|
||||
|
||||
After running the agent, you can view the traces generated by your CrewAI application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.
|
||||
|
||||
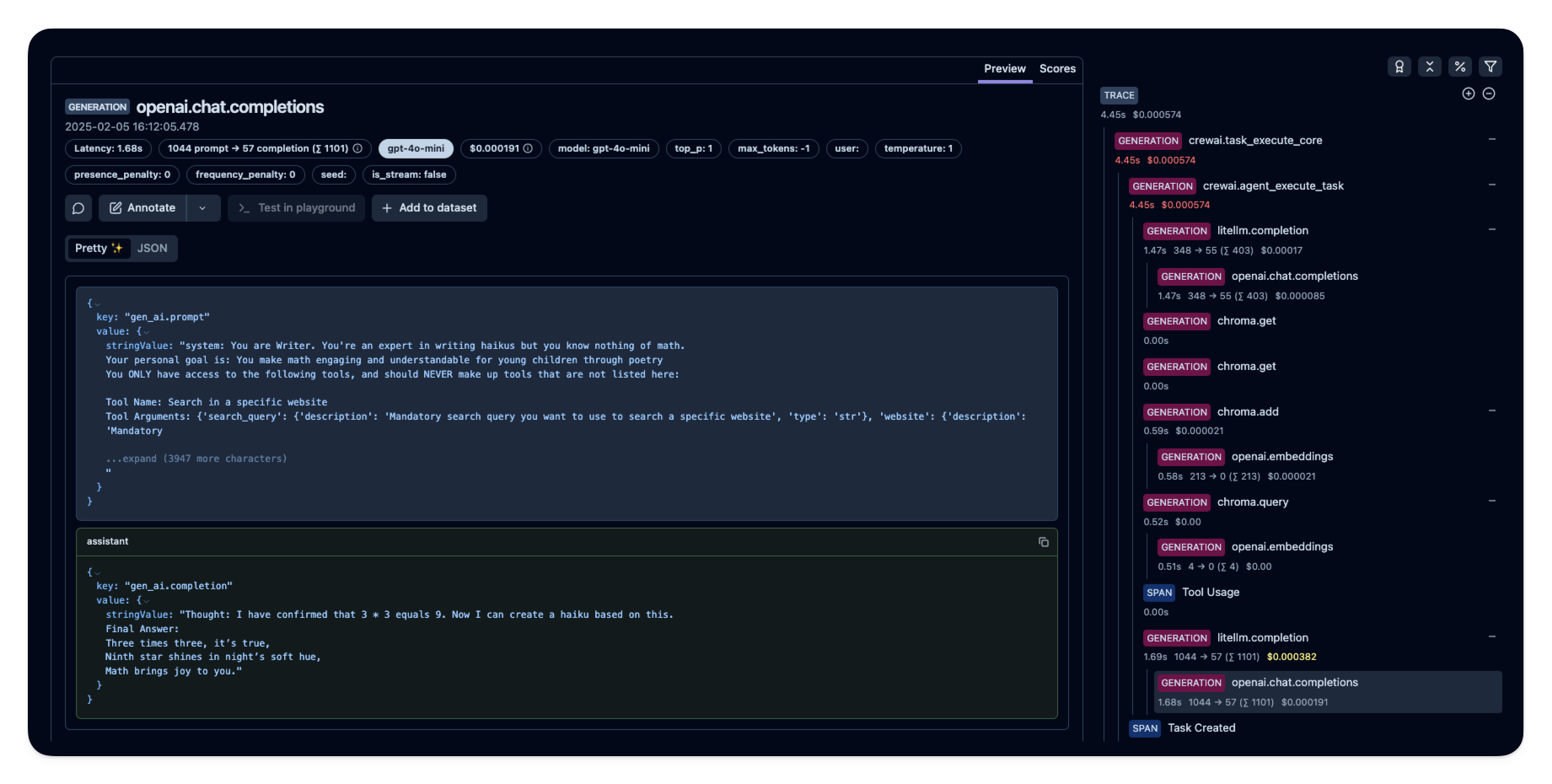
|
||||
|
||||
_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/e2cf380ffc8d47d28da98f136140642b?timestamp=2025-02-05T15%3A12%3A02.717Z&observation=3b32338ee6a5d9af)_
|
||||
|
||||
## References
|
||||
|
||||
- [Langfuse OpenTelemetry Docs](https://langfuse.com/docs/opentelemetry/get-started)
|
||||
72
docs/observability/langtrace.mdx
Normal file
72
docs/observability/langtrace.mdx
Normal file
@@ -0,0 +1,72 @@
|
||||
---
|
||||
title: Langtrace Integration
|
||||
description: How to monitor cost, latency, and performance of CrewAI Agents using Langtrace, an external observability tool.
|
||||
icon: chart-line
|
||||
---
|
||||
|
||||
# Langtrace Overview
|
||||
|
||||
Langtrace is an open-source, external tool that helps you set up observability and evaluations for Large Language Models (LLMs), LLM frameworks, and Vector Databases.
|
||||
While not built directly into CrewAI, Langtrace can be used alongside CrewAI to gain deep visibility into the cost, latency, and performance of your CrewAI Agents.
|
||||
This integration allows you to log hyperparameters, monitor performance regressions, and establish a process for continuous improvement of your Agents.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Sign up for Langtrace">
|
||||
Sign up by visiting [https://langtrace.ai/signup](https://langtrace.ai/signup).
|
||||
</Step>
|
||||
<Step title="Create a project">
|
||||
Set the project type to `CrewAI` and generate an API key.
|
||||
</Step>
|
||||
<Step title="Install Langtrace in your CrewAI project">
|
||||
Use the following command:
|
||||
|
||||
```bash
|
||||
pip install langtrace-python-sdk
|
||||
```
|
||||
</Step>
|
||||
<Step title="Import Langtrace">
|
||||
Import and initialize Langtrace at the beginning of your script, before any CrewAI imports:
|
||||
|
||||
```python
|
||||
from langtrace_python_sdk import langtrace
|
||||
langtrace.init(api_key='<LANGTRACE_API_KEY>')
|
||||
|
||||
# Now import CrewAI modules
|
||||
from crewai import Agent, Task, Crew
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Features and Their Application to CrewAI
|
||||
|
||||
1. **LLM Token and Cost Tracking**
|
||||
|
||||
- Monitor the token usage and associated costs for each CrewAI agent interaction.
|
||||
|
||||
2. **Trace Graph for Execution Steps**
|
||||
|
||||
- Visualize the execution flow of your CrewAI tasks, including latency and logs.
|
||||
- Useful for identifying bottlenecks in your agent workflows.
|
||||
|
||||
3. **Dataset Curation with Manual Annotation**
|
||||
|
||||
- Create datasets from your CrewAI task outputs for future training or evaluation.
|
||||
|
||||
4. **Prompt Versioning and Management**
|
||||
|
||||
- Keep track of different versions of prompts used in your CrewAI agents.
|
||||
- Useful for A/B testing and optimizing agent performance.
|
||||
|
||||
5. **Prompt Playground with Model Comparisons**
|
||||
|
||||
- Test and compare different prompts and models for your CrewAI agents before deployment.
|
||||
|
||||
6. **Testing and Evaluations**
|
||||
|
||||
- Set up automated tests for your CrewAI agents and tasks.
|
||||
206
docs/observability/mlflow.mdx
Normal file
206
docs/observability/mlflow.mdx
Normal file
@@ -0,0 +1,206 @@
|
||||
---
|
||||
title: MLflow Integration
|
||||
description: Quickly start monitoring your Agents with MLflow.
|
||||
icon: bars-staggered
|
||||
---
|
||||
|
||||
# MLflow Overview
|
||||
|
||||
[MLflow](https://mlflow.org/) is an open-source platform to assist machine learning practitioners and teams in handling the complexities of the machine learning process.
|
||||
|
||||
It provides a tracing feature that enhances LLM observability in your Generative AI applications by capturing detailed information about the execution of your application’s services.
|
||||
Tracing provides a way to record the inputs, outputs, and metadata associated with each intermediate step of a request, enabling you to easily pinpoint the source of bugs and unexpected behaviors.
|
||||
|
||||

|
||||
|
||||
### Features
|
||||
|
||||
- **Tracing Dashboard**: Monitor activities of your crewAI agents with detailed dashboards that include inputs, outputs and metadata of spans.
|
||||
- **Automated Tracing**: A fully automated integration with crewAI, which can be enabled by running `mlflow.crewai.autolog()`.
|
||||
- **Manual Trace Instrumentation with minor efforts**: Customize trace instrumentation through MLflow's high-level fluent APIs such as decorators, function wrappers and context managers.
|
||||
- **OpenTelemetry Compatibility**: MLflow Tracing supports exporting traces to an OpenTelemetry Collector, which can then be used to export traces to various backends such as Jaeger, Zipkin, and AWS X-Ray.
|
||||
- **Package and Deploy Agents**: Package and deploy your crewAI agents to an inference server with a variety of deployment targets.
|
||||
- **Securely Host LLMs**: Host multiple LLM from various providers in one unified endpoint through MFflow gateway.
|
||||
- **Evaluation**: Evaluate your crewAI agents with a wide range of metrics using a convenient API `mlflow.evaluate()`.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Install MLflow package">
|
||||
```shell
|
||||
# The crewAI integration is available in mlflow>=2.19.0
|
||||
pip install mlflow
|
||||
```
|
||||
</Step>
|
||||
<Step title="Start MFflow tracking server">
|
||||
```shell
|
||||
# This process is optional, but it is recommended to use MLflow tracking server for better visualization and broader features.
|
||||
mlflow server
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize MLflow in Your Application">
|
||||
Add the following two lines to your application code:
|
||||
|
||||
```python
|
||||
import mlflow
|
||||
|
||||
mlflow.crewai.autolog()
|
||||
|
||||
# Optional: Set a tracking URI and an experiment name if you have a tracking server
|
||||
mlflow.set_tracking_uri("http://localhost:5000")
|
||||
mlflow.set_experiment("CrewAI")
|
||||
```
|
||||
|
||||
Example Usage for tracing CrewAI Agents:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task
|
||||
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
|
||||
from crewai_tools import SerperDevTool, WebsiteSearchTool
|
||||
|
||||
from textwrap import dedent
|
||||
|
||||
content = "Users name is John. He is 30 years old and lives in San Francisco."
|
||||
string_source = StringKnowledgeSource(
|
||||
content=content, metadata={"preference": "personal"}
|
||||
)
|
||||
|
||||
search_tool = WebsiteSearchTool()
|
||||
|
||||
|
||||
class TripAgents:
|
||||
def city_selection_agent(self):
|
||||
return Agent(
|
||||
role="City Selection Expert",
|
||||
goal="Select the best city based on weather, season, and prices",
|
||||
backstory="An expert in analyzing travel data to pick ideal destinations",
|
||||
tools=[
|
||||
search_tool,
|
||||
],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def local_expert(self):
|
||||
return Agent(
|
||||
role="Local Expert at this city",
|
||||
goal="Provide the BEST insights about the selected city",
|
||||
backstory="""A knowledgeable local guide with extensive information
|
||||
about the city, it's attractions and customs""",
|
||||
tools=[search_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
|
||||
class TripTasks:
|
||||
def identify_task(self, agent, origin, cities, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
Analyze and select the best city for the trip based
|
||||
on specific criteria such as weather patterns, seasonal
|
||||
events, and travel costs. This task involves comparing
|
||||
multiple cities, considering factors like current weather
|
||||
conditions, upcoming cultural or seasonal events, and
|
||||
overall travel expenses.
|
||||
Your final answer must be a detailed
|
||||
report on the chosen city, and everything you found out
|
||||
about it, including the actual flight costs, weather
|
||||
forecast and attractions.
|
||||
|
||||
Traveling from: {origin}
|
||||
City Options: {cities}
|
||||
Trip Date: {range}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Detailed report on the chosen city including flight costs, weather forecast, and attractions",
|
||||
)
|
||||
|
||||
def gather_task(self, agent, origin, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
As a local expert on this city you must compile an
|
||||
in-depth guide for someone traveling there and wanting
|
||||
to have THE BEST trip ever!
|
||||
Gather information about key attractions, local customs,
|
||||
special events, and daily activity recommendations.
|
||||
Find the best spots to go to, the kind of place only a
|
||||
local would know.
|
||||
This guide should provide a thorough overview of what
|
||||
the city has to offer, including hidden gems, cultural
|
||||
hotspots, must-visit landmarks, weather forecasts, and
|
||||
high level costs.
|
||||
The final answer must be a comprehensive city guide,
|
||||
rich in cultural insights and practical tips,
|
||||
tailored to enhance the travel experience.
|
||||
|
||||
Trip Date: {range}
|
||||
Traveling from: {origin}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Comprehensive city guide including hidden gems, cultural hotspots, and practical travel tips",
|
||||
)
|
||||
|
||||
|
||||
class TripCrew:
|
||||
def __init__(self, origin, cities, date_range, interests):
|
||||
self.cities = cities
|
||||
self.origin = origin
|
||||
self.interests = interests
|
||||
self.date_range = date_range
|
||||
|
||||
def run(self):
|
||||
agents = TripAgents()
|
||||
tasks = TripTasks()
|
||||
|
||||
city_selector_agent = agents.city_selection_agent()
|
||||
local_expert_agent = agents.local_expert()
|
||||
|
||||
identify_task = tasks.identify_task(
|
||||
city_selector_agent,
|
||||
self.origin,
|
||||
self.cities,
|
||||
self.interests,
|
||||
self.date_range,
|
||||
)
|
||||
gather_task = tasks.gather_task(
|
||||
local_expert_agent, self.origin, self.interests, self.date_range
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[city_selector_agent, local_expert_agent],
|
||||
tasks=[identify_task, gather_task],
|
||||
verbose=True,
|
||||
memory=True,
|
||||
knowledge={
|
||||
"sources": [string_source],
|
||||
"metadata": {"preference": "personal"},
|
||||
},
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
return result
|
||||
|
||||
|
||||
trip_crew = TripCrew("California", "Tokyo", "Dec 12 - Dec 20", "sports")
|
||||
result = trip_crew.run()
|
||||
|
||||
print(result)
|
||||
```
|
||||
Refer to [MLflow Tracing Documentation](https://mlflow.org/docs/latest/llms/tracing/index.html) for more configurations and use cases.
|
||||
</Step>
|
||||
<Step title="Visualize Activities of Agents">
|
||||
Now traces for your crewAI agents are captured by MLflow.
|
||||
Let's visit MLflow tracking server to view the traces and get insights into your Agents.
|
||||
|
||||
Open `127.0.0.1:5000` on your browser to visit MLflow tracking server.
|
||||
<Frame caption="MLflow Tracing Dashboard">
|
||||
<img src="/images/mlflow1.png" alt="MLflow tracing example with crewai" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
181
docs/observability/openlit.mdx
Normal file
181
docs/observability/openlit.mdx
Normal file
@@ -0,0 +1,181 @@
|
||||
---
|
||||
title: OpenLIT Integration
|
||||
description: Quickly start monitoring your Agents in just a single line of code with OpenTelemetry.
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# OpenLIT Overview
|
||||
|
||||
[OpenLIT](https://github.com/openlit/openlit?src=crewai-docs) is an open-source tool that makes it simple to monitor the performance of AI agents, LLMs, VectorDBs, and GPUs with just **one** line of code.
|
||||
|
||||
It provides OpenTelemetry-native tracing and metrics to track important parameters like cost, latency, interactions and task sequences.
|
||||
This setup enables you to track hyperparameters and monitor for performance issues, helping you find ways to enhance and fine-tune your agents over time.
|
||||
|
||||
<Frame caption="OpenLIT Dashboard">
|
||||
<img src="/images/openlit1.png" alt="Overview Agent usage including cost and tokens" />
|
||||
<img src="/images/openlit2.png" alt="Overview of agent otel traces and metrics" />
|
||||
<img src="/images/openlit3.png" alt="Overview of agent traces in details" />
|
||||
</Frame>
|
||||
|
||||
### Features
|
||||
|
||||
- **Analytics Dashboard**: Monitor your Agents health and performance with detailed dashboards that track metrics, costs, and user interactions.
|
||||
- **OpenTelemetry-native Observability SDK**: Vendor-neutral SDKs to send traces and metrics to your existing observability tools like Grafana, DataDog and more.
|
||||
- **Cost Tracking for Custom and Fine-Tuned Models**: Tailor cost estimations for specific models using custom pricing files for precise budgeting.
|
||||
- **Exceptions Monitoring Dashboard**: Quickly spot and resolve issues by tracking common exceptions and errors with a monitoring dashboard.
|
||||
- **Compliance and Security**: Detect potential threats such as profanity and PII leaks.
|
||||
- **Prompt Injection Detection**: Identify potential code injection and secret leaks.
|
||||
- **API Keys and Secrets Management**: Securely handle your LLM API keys and secrets centrally, avoiding insecure practices.
|
||||
- **Prompt Management**: Manage and version Agent prompts using PromptHub for consistent and easy access across Agents.
|
||||
- **Model Playground** Test and compare different models for your CrewAI agents before deployment.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Deploy OpenLIT">
|
||||
<Steps>
|
||||
<Step title="Git Clone OpenLIT Repository">
|
||||
```shell
|
||||
git clone git@github.com:openlit/openlit.git
|
||||
```
|
||||
</Step>
|
||||
<Step title="Start Docker Compose">
|
||||
From the root directory of the [OpenLIT Repo](https://github.com/openlit/openlit), Run the below command:
|
||||
```shell
|
||||
docker compose up -d
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
</Step>
|
||||
<Step title="Install OpenLIT SDK">
|
||||
```shell
|
||||
pip install openlit
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize OpenLIT in Your Application">
|
||||
Add the following two lines to your application code:
|
||||
<Tabs>
|
||||
<Tab title="Setup using function arguments">
|
||||
```python
|
||||
import openlit
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
```
|
||||
|
||||
Example Usage for monitoring a CrewAI Agent:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
import openlit
|
||||
|
||||
openlit.init(disable_metrics=True)
|
||||
# Define your agents
|
||||
researcher = Agent(
|
||||
role="Researcher",
|
||||
goal="Conduct thorough research and analysis on AI and AI agents",
|
||||
backstory="You're an expert researcher, specialized in technology, software engineering, AI, and startups. You work as a freelancer and are currently researching for a new client.",
|
||||
allow_delegation=False,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
|
||||
# Define your task
|
||||
task = Task(
|
||||
description="Generate a list of 5 interesting ideas for an article, then write one captivating paragraph for each idea that showcases the potential of a full article on this topic. Return the list of ideas with their paragraphs and your notes.",
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Define the manager agent
|
||||
manager = Agent(
|
||||
role="Project Manager",
|
||||
goal="Efficiently manage the crew and ensure high-quality task completion",
|
||||
backstory="You're an experienced project manager, skilled in overseeing complex projects and guiding teams to success. Your role is to coordinate the efforts of the crew members, ensuring that each task is completed on time and to the highest standard.",
|
||||
allow_delegation=True,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
# Instantiate your crew with a custom manager
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[task],
|
||||
manager_agent=manager,
|
||||
process=Process.hierarchical,
|
||||
)
|
||||
|
||||
# Start the crew's work
|
||||
result = crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
</Tab>
|
||||
<Tab title="Setup using Environment Variables">
|
||||
|
||||
Add the following two lines to your application code:
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
Run the following command to configure the OTEL export endpoint:
|
||||
```shell
|
||||
export OTEL_EXPORTER_OTLP_ENDPOINT = "http://127.0.0.1:4318"
|
||||
```
|
||||
|
||||
Example Usage for monitoring a CrewAI Async Agent:
|
||||
|
||||
```python
|
||||
import asyncio
|
||||
from crewai import Crew, Agent, Task
|
||||
import openlit
|
||||
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
|
||||
# Create an agent with code execution enabled
|
||||
coding_agent = Agent(
|
||||
role="Python Data Analyst",
|
||||
goal="Analyze data and provide insights using Python",
|
||||
backstory="You are an experienced data analyst with strong Python skills.",
|
||||
allow_code_execution=True,
|
||||
llm="command-r"
|
||||
)
|
||||
|
||||
# Create a task that requires code execution
|
||||
data_analysis_task = Task(
|
||||
description="Analyze the given dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent,
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Create a crew and add the task
|
||||
analysis_crew = Crew(
|
||||
agents=[coding_agent],
|
||||
tasks=[data_analysis_task]
|
||||
)
|
||||
|
||||
# Async function to kickoff the crew asynchronously
|
||||
async def async_crew_execution():
|
||||
result = await analysis_crew.kickoff_async(inputs={"ages": [25, 30, 35, 40, 45]})
|
||||
print("Crew Result:", result)
|
||||
|
||||
# Run the async function
|
||||
asyncio.run(async_crew_execution())
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
Refer to OpenLIT [Python SDK repository](https://github.com/openlit/openlit/tree/main/sdk/python) for more advanced configurations and use cases.
|
||||
</Step>
|
||||
<Step title="Visualize and Analyze">
|
||||
With the Agent Observability data now being collected and sent to OpenLIT, the next step is to visualize and analyze this data to get insights into your Agent's performance, behavior, and identify areas of improvement.
|
||||
|
||||
Just head over to OpenLIT at `127.0.0.1:3000` on your browser to start exploring. You can login using the default credentials
|
||||
- **Email**: `user@openlit.io`
|
||||
- **Password**: `openlituser`
|
||||
|
||||
<Frame caption="OpenLIT Dashboard">
|
||||
<img src="/images/openlit1.png" alt="Overview Agent usage including cost and tokens" />
|
||||
<img src="/images/openlit2.png" alt="Overview of agent otel traces and metrics" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
129
docs/observability/opik.mdx
Normal file
129
docs/observability/opik.mdx
Normal file
@@ -0,0 +1,129 @@
|
||||
---
|
||||
title: Opik Integration
|
||||
description: Learn how to use Comet Opik to debug, evaluate, and monitor your CrewAI applications with comprehensive tracing, automated evaluations, and production-ready dashboards.
|
||||
icon: meteor
|
||||
---
|
||||
|
||||
# Opik Overview
|
||||
|
||||
With [Comet Opik](https://www.comet.com/docs/opik/), debug, evaluate, and monitor your LLM applications, RAG systems, and agentic workflows with comprehensive tracing, automated evaluations, and production-ready dashboards.
|
||||
|
||||
<Frame caption="Opik Agent Dashboard">
|
||||
<img src="/images/opik-crewai-dashboard.png" alt="Opik agent monitoring example with CrewAI" />
|
||||
</Frame>
|
||||
|
||||
Opik provides comprehensive support for every stage of your CrewAI application development:
|
||||
|
||||
- **Log Traces and Spans**: Automatically track LLM calls and application logic to debug and analyze development and production systems. Manually or programmatically annotate, view, and compare responses across projects.
|
||||
- **Evaluate Your LLM Application's Performance**: Evaluate against a custom test set and run built-in evaluation metrics or define your own metrics in the SDK or UI.
|
||||
- **Test Within Your CI/CD Pipeline**: Establish reliable performance baselines with Opik's LLM unit tests, built on PyTest. Run online evaluations for continuous monitoring in production.
|
||||
- **Monitor & Analyze Production Data**: Understand your models' performance on unseen data in production and generate datasets for new dev iterations.
|
||||
|
||||
## Setup
|
||||
Comet provides a hosted version of the Opik platform, or you can run the platform locally.
|
||||
|
||||
To use the hosted version, simply [create a free Comet account](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) and grab you API Key.
|
||||
|
||||
To run the Opik platform locally, see our [installation guide](https://www.comet.com/docs/opik/self-host/overview/) for more information.
|
||||
|
||||
For this guide we will use CrewAI’s quickstart example.
|
||||
|
||||
<Steps>
|
||||
<Step title="Install required packages">
|
||||
```shell
|
||||
pip install crewai crewai-tools opik --upgrade
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure Opik">
|
||||
```python
|
||||
import opik
|
||||
opik.configure(use_local=False)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Prepare environment">
|
||||
First, we set up our API keys for our LLM-provider as environment variables:
|
||||
|
||||
```python
|
||||
import os
|
||||
import getpass
|
||||
|
||||
if "OPENAI_API_KEY" not in os.environ:
|
||||
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
|
||||
```
|
||||
</Step>
|
||||
<Step title="Using CrewAI">
|
||||
The first step is to create our project. We will use an example from CrewAI’s documentation:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task, Process
|
||||
|
||||
|
||||
class YourCrewName:
|
||||
def agent_one(self) -> Agent:
|
||||
return Agent(
|
||||
role="Data Analyst",
|
||||
goal="Analyze data trends in the market",
|
||||
backstory="An experienced data analyst with a background in economics",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def agent_two(self) -> Agent:
|
||||
return Agent(
|
||||
role="Market Researcher",
|
||||
goal="Gather information on market dynamics",
|
||||
backstory="A diligent researcher with a keen eye for detail",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def task_one(self) -> Task:
|
||||
return Task(
|
||||
name="Collect Data Task",
|
||||
description="Collect recent market data and identify trends.",
|
||||
expected_output="A report summarizing key trends in the market.",
|
||||
agent=self.agent_one(),
|
||||
)
|
||||
|
||||
def task_two(self) -> Task:
|
||||
return Task(
|
||||
name="Market Research Task",
|
||||
description="Research factors affecting market dynamics.",
|
||||
expected_output="An analysis of factors influencing the market.",
|
||||
agent=self.agent_two(),
|
||||
)
|
||||
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[self.agent_one(), self.agent_two()],
|
||||
tasks=[self.task_one(), self.task_two()],
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
Now we can import Opik’s tracker and run our crew:
|
||||
|
||||
```python
|
||||
from opik.integrations.crewai import track_crewai
|
||||
|
||||
track_crewai(project_name="crewai-integration-demo")
|
||||
|
||||
my_crew = YourCrewName().crew()
|
||||
result = my_crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
After running your CrewAI application, visit the Opik app to view:
|
||||
- LLM traces, spans, and their metadata
|
||||
- Agent interactions and task execution flow
|
||||
- Performance metrics like latency and token usage
|
||||
- Evaluation metrics (built-in or custom)
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Resources
|
||||
|
||||
- [🦉 Opik Documentation](https://www.comet.com/docs/opik/)
|
||||
- [👉 Opik + CrewAI Colab](https://colab.research.google.com/github/comet-ml/opik/blob/main/apps/opik-documentation/documentation/docs/cookbook/crewai.ipynb)
|
||||
- [🐦 X](https://x.com/cometml)
|
||||
- [💬 Slack](https://slack.comet.com/)
|
||||
118
docs/observability/overview.mdx
Normal file
118
docs/observability/overview.mdx
Normal file
@@ -0,0 +1,118 @@
|
||||
---
|
||||
title: "Overview"
|
||||
description: "Monitor, evaluate, and optimize your CrewAI agents with comprehensive observability tools"
|
||||
icon: "face-smile"
|
||||
---
|
||||
|
||||
## Observability for CrewAI
|
||||
|
||||
Observability is crucial for understanding how your CrewAI agents perform, identifying bottlenecks, and ensuring reliable operation in production environments. This section covers various tools and platforms that provide monitoring, evaluation, and optimization capabilities for your agent workflows.
|
||||
|
||||
## Why Observability Matters
|
||||
|
||||
- **Performance Monitoring**: Track agent execution times, token usage, and resource consumption
|
||||
- **Quality Assurance**: Evaluate output quality and consistency across different scenarios
|
||||
- **Debugging**: Identify and resolve issues in agent behavior and task execution
|
||||
- **Cost Management**: Monitor LLM API usage and associated costs
|
||||
- **Continuous Improvement**: Gather insights to optimize agent performance over time
|
||||
|
||||
## Available Observability Tools
|
||||
|
||||
### Monitoring & Tracing Platforms
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="AgentOps" icon="paperclip" href="/observability/agentops">
|
||||
Session replays, metrics, and monitoring for agent development and production.
|
||||
</Card>
|
||||
|
||||
<Card title="OpenLIT" icon="magnifying-glass-chart" href="/observability/openlit">
|
||||
OpenTelemetry-native monitoring with cost tracking and performance analytics.
|
||||
</Card>
|
||||
|
||||
<Card title="MLflow" icon="bars-staggered" href="/observability/mlflow">
|
||||
Machine learning lifecycle management with tracing and evaluation capabilities.
|
||||
</Card>
|
||||
|
||||
<Card title="Langfuse" icon="link" href="/observability/langfuse">
|
||||
LLM engineering platform with detailed tracing and analytics.
|
||||
</Card>
|
||||
|
||||
<Card title="Langtrace" icon="chart-line" href="/observability/langtrace">
|
||||
Open-source observability for LLMs and agent frameworks.
|
||||
</Card>
|
||||
|
||||
<Card title="Arize Phoenix" icon="meteor" href="/observability/arize-phoenix">
|
||||
AI observability platform for monitoring and troubleshooting.
|
||||
</Card>
|
||||
|
||||
<Card title="Portkey" icon="key" href="/observability/portkey">
|
||||
AI gateway with comprehensive monitoring and reliability features.
|
||||
</Card>
|
||||
|
||||
<Card title="Opik" icon="meteor" href="/observability/opik">
|
||||
Debug, evaluate, and monitor LLM applications with comprehensive tracing.
|
||||
</Card>
|
||||
|
||||
<Card title="Weave" icon="network-wired" href="/observability/weave">
|
||||
Weights & Biases platform for tracking and evaluating AI applications.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### Evaluation & Quality Assurance
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="Patronus AI" icon="shield-check" href="/observability/patronus-evaluation">
|
||||
Comprehensive evaluation platform for LLM outputs and agent behaviors.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Key Observability Metrics
|
||||
|
||||
### Performance Metrics
|
||||
- **Execution Time**: How long agents take to complete tasks
|
||||
- **Token Usage**: Input/output tokens consumed by LLM calls
|
||||
- **API Latency**: Response times from external services
|
||||
- **Success Rate**: Percentage of successfully completed tasks
|
||||
|
||||
### Quality Metrics
|
||||
- **Output Accuracy**: Correctness of agent responses
|
||||
- **Consistency**: Reliability across similar inputs
|
||||
- **Relevance**: How well outputs match expected results
|
||||
- **Safety**: Compliance with content policies and guidelines
|
||||
|
||||
### Cost Metrics
|
||||
- **API Costs**: Expenses from LLM provider usage
|
||||
- **Resource Utilization**: Compute and memory consumption
|
||||
- **Cost per Task**: Economic efficiency of agent operations
|
||||
- **Budget Tracking**: Monitoring against spending limits
|
||||
|
||||
## Getting Started
|
||||
|
||||
1. **Choose Your Tools**: Select observability platforms that match your needs
|
||||
2. **Instrument Your Code**: Add monitoring to your CrewAI applications
|
||||
3. **Set Up Dashboards**: Configure visualizations for key metrics
|
||||
4. **Define Alerts**: Create notifications for important events
|
||||
5. **Establish Baselines**: Measure initial performance for comparison
|
||||
6. **Iterate and Improve**: Use insights to optimize your agents
|
||||
|
||||
## Best Practices
|
||||
|
||||
### Development Phase
|
||||
- Use detailed tracing to understand agent behavior
|
||||
- Implement evaluation metrics early in development
|
||||
- Monitor resource usage during testing
|
||||
- Set up automated quality checks
|
||||
|
||||
### Production Phase
|
||||
- Implement comprehensive monitoring and alerting
|
||||
- Track performance trends over time
|
||||
- Monitor for anomalies and degradation
|
||||
- Maintain cost visibility and control
|
||||
|
||||
### Continuous Improvement
|
||||
- Regular performance reviews and optimization
|
||||
- A/B testing of different agent configurations
|
||||
- Feedback loops for quality improvement
|
||||
- Documentation of lessons learned
|
||||
|
||||
Choose the observability tools that best fit your use case, infrastructure, and monitoring requirements to ensure your CrewAI agents perform reliably and efficiently.
|
||||
205
docs/observability/patronus-evaluation.mdx
Normal file
205
docs/observability/patronus-evaluation.mdx
Normal file
@@ -0,0 +1,205 @@
|
||||
---
|
||||
title: Patronus AI Evaluation
|
||||
description: Monitor and evaluate CrewAI agent performance using Patronus AI's comprehensive evaluation platform for LLM outputs and agent behaviors.
|
||||
icon: shield-check
|
||||
---
|
||||
|
||||
# Patronus AI Evaluation
|
||||
|
||||
## Overview
|
||||
|
||||
[Patronus AI](https://patronus.ai) provides comprehensive evaluation and monitoring capabilities for CrewAI agents, enabling you to assess model outputs, agent behaviors, and overall system performance. This integration allows you to implement continuous evaluation workflows that help maintain quality and reliability in production environments.
|
||||
|
||||
## Key Features
|
||||
|
||||
- **Automated Evaluation**: Real-time assessment of agent outputs and behaviors
|
||||
- **Custom Criteria**: Define specific evaluation criteria tailored to your use cases
|
||||
- **Performance Monitoring**: Track agent performance metrics over time
|
||||
- **Quality Assurance**: Ensure consistent output quality across different scenarios
|
||||
- **Safety & Compliance**: Monitor for potential issues and policy violations
|
||||
|
||||
## Evaluation Tools
|
||||
|
||||
Patronus provides three main evaluation tools for different use cases:
|
||||
|
||||
1. **PatronusEvalTool**: Allows agents to select the most appropriate evaluator and criteria for the evaluation task.
|
||||
2. **PatronusPredefinedCriteriaEvalTool**: Uses predefined evaluator and criteria specified by the user.
|
||||
3. **PatronusLocalEvaluatorTool**: Uses custom function evaluators defined by the user.
|
||||
|
||||
## Installation
|
||||
|
||||
To use these tools, you need to install the Patronus package:
|
||||
|
||||
```shell
|
||||
uv add patronus
|
||||
```
|
||||
|
||||
You'll also need to set up your Patronus API key as an environment variable:
|
||||
|
||||
```shell
|
||||
export PATRONUS_API_KEY="your_patronus_api_key"
|
||||
```
|
||||
|
||||
## Steps to Get Started
|
||||
|
||||
To effectively use the Patronus evaluation tools, follow these steps:
|
||||
|
||||
1. **Install Patronus**: Install the Patronus package using the command above.
|
||||
2. **Set Up API Key**: Set your Patronus API key as an environment variable.
|
||||
3. **Choose the Right Tool**: Select the appropriate Patronus evaluation tool based on your needs.
|
||||
4. **Configure the Tool**: Configure the tool with the necessary parameters.
|
||||
|
||||
## Examples
|
||||
|
||||
### Using PatronusEvalTool
|
||||
|
||||
The following example demonstrates how to use the `PatronusEvalTool`, which allows agents to select the most appropriate evaluator and criteria:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusEvalTool
|
||||
|
||||
# Initialize the tool
|
||||
patronus_eval_tool = PatronusEvalTool()
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code and verify that the output is code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate and evaluate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence. Select the most appropriate evaluator and criteria for evaluating your output.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Using PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
The following example demonstrates how to use the `PatronusPredefinedCriteriaEvalTool`, which uses predefined evaluator and criteria:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
# Initialize the tool with predefined criteria
|
||||
patronus_eval_tool = PatronusPredefinedCriteriaEvalTool(
|
||||
evaluators=[{"evaluator": "judge", "criteria": "contains-code"}]
|
||||
)
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Using PatronusLocalEvaluatorTool
|
||||
|
||||
The following example demonstrates how to use the `PatronusLocalEvaluatorTool`, which uses custom function evaluators:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import PatronusLocalEvaluatorTool
|
||||
from patronus import Client, EvaluationResult
|
||||
import random
|
||||
|
||||
# Initialize the Patronus client
|
||||
client = Client()
|
||||
|
||||
# Register a custom evaluator
|
||||
@client.register_local_evaluator("random_evaluator")
|
||||
def random_evaluator(**kwargs):
|
||||
score = random.random()
|
||||
return EvaluationResult(
|
||||
score_raw=score,
|
||||
pass_=score >= 0.5,
|
||||
explanation="example explanation",
|
||||
)
|
||||
|
||||
# Initialize the tool with the custom evaluator
|
||||
patronus_eval_tool = PatronusLocalEvaluatorTool(
|
||||
patronus_client=client,
|
||||
evaluator="random_evaluator",
|
||||
evaluated_model_gold_answer="example label",
|
||||
)
|
||||
|
||||
# Define an agent that uses the tool
|
||||
coding_agent = Agent(
|
||||
role="Coding Agent",
|
||||
goal="Generate high quality code",
|
||||
backstory="An experienced coder who can generate high quality python code.",
|
||||
tools=[patronus_eval_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# Example task to generate code
|
||||
generate_code_task = Task(
|
||||
description="Create a simple program to generate the first N numbers in the Fibonacci sequence.",
|
||||
expected_output="Program that generates the first N numbers in the Fibonacci sequence.",
|
||||
agent=coding_agent,
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(agents=[coding_agent], tasks=[generate_code_task])
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
## Parameters
|
||||
|
||||
### PatronusEvalTool
|
||||
|
||||
The `PatronusEvalTool` does not require any parameters during initialization. It automatically fetches available evaluators and criteria from the Patronus API.
|
||||
|
||||
### PatronusPredefinedCriteriaEvalTool
|
||||
|
||||
The `PatronusPredefinedCriteriaEvalTool` accepts the following parameters during initialization:
|
||||
|
||||
- **evaluators**: Required. A list of dictionaries containing the evaluator and criteria to use. For example: `[{"evaluator": "judge", "criteria": "contains-code"}]`.
|
||||
|
||||
### PatronusLocalEvaluatorTool
|
||||
|
||||
The `PatronusLocalEvaluatorTool` accepts the following parameters during initialization:
|
||||
|
||||
- **patronus_client**: Required. The Patronus client instance.
|
||||
- **evaluator**: Optional. The name of the registered local evaluator to use. Default is an empty string.
|
||||
- **evaluated_model_gold_answer**: Optional. The gold answer to use for evaluation. Default is an empty string.
|
||||
|
||||
## Usage
|
||||
|
||||
When using the Patronus evaluation tools, you provide the model input, output, and context, and the tool returns the evaluation results from the Patronus API.
|
||||
|
||||
For the `PatronusEvalTool` and `PatronusPredefinedCriteriaEvalTool`, the following parameters are required when calling the tool:
|
||||
|
||||
- **evaluated_model_input**: The agent's task description in simple text.
|
||||
- **evaluated_model_output**: The agent's output of the task.
|
||||
- **evaluated_model_retrieved_context**: The agent's context.
|
||||
|
||||
For the `PatronusLocalEvaluatorTool`, the same parameters are required, but the evaluator and gold answer are specified during initialization.
|
||||
|
||||
## Conclusion
|
||||
|
||||
The Patronus evaluation tools provide a powerful way to evaluate and score model inputs and outputs using the Patronus AI platform. By enabling agents to evaluate their own outputs or the outputs of other agents, these tools can help improve the quality and reliability of CrewAI workflows.
|
||||
202
docs/observability/portkey.mdx
Normal file
202
docs/observability/portkey.mdx
Normal file
@@ -0,0 +1,202 @@
|
||||
---
|
||||
title: Portkey Integration
|
||||
description: How to use Portkey with CrewAI
|
||||
icon: key
|
||||
---
|
||||
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-CrewAI.png" alt="Portkey CrewAI Header Image" width="70%" />
|
||||
|
||||
|
||||
[Portkey](https://portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) is a 2-line upgrade to make your CrewAI agents reliable, cost-efficient, and fast.
|
||||
|
||||
Portkey adds 4 core production capabilities to any CrewAI agent:
|
||||
1. Routing to **200+ LLMs**
|
||||
2. Making each LLM call more robust
|
||||
3. Full-stack tracing & cost, performance analytics
|
||||
4. Real-time guardrails to enforce behavior
|
||||
|
||||
## Getting Started
|
||||
|
||||
<Steps>
|
||||
<Step title="Install CrewAI and Portkey">
|
||||
```bash
|
||||
pip install -qU crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure the LLM Client">
|
||||
To build CrewAI Agents with Portkey, you'll need two keys:
|
||||
- **Portkey API Key**: Sign up on the [Portkey app](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) and copy your API key
|
||||
- **Virtual Key**: Virtual Keys securely manage your LLM API keys in one place. Store your LLM provider API keys securely in Portkey's vault
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy", # We are using Virtual key
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_VIRTUAL_KEY", # Enter your Virtual key from Portkey
|
||||
)
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Create and Run Your First Agent">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
# Define your agents with roles and goals
|
||||
coder = Agent(
|
||||
role='Software developer',
|
||||
goal='Write clear, concise code on demand',
|
||||
backstory='An expert coder with a keen eye for software trends.',
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description="Define the HTML for making a simple website with heading- Hello World! Portkey is working!",
|
||||
expected_output="A clear and concise HTML code",
|
||||
agent=coder
|
||||
)
|
||||
|
||||
# Instantiate your crew
|
||||
crew = Crew(
|
||||
agents=[coder],
|
||||
tasks=[task1],
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Key Features
|
||||
|
||||
| Feature | Description |
|
||||
|:--------|:------------|
|
||||
| 🌐 Multi-LLM Support | Access OpenAI, Anthropic, Gemini, Azure, and 250+ providers through a unified interface |
|
||||
| 🛡️ Production Reliability | Implement retries, timeouts, load balancing, and fallbacks |
|
||||
| 📊 Advanced Observability | Track 40+ metrics including costs, tokens, latency, and custom metadata |
|
||||
| 🔍 Comprehensive Logging | Debug with detailed execution traces and function call logs |
|
||||
| 🚧 Security Controls | Set budget limits and implement role-based access control |
|
||||
| 🔄 Performance Analytics | Capture and analyze feedback for continuous improvement |
|
||||
| 💾 Intelligent Caching | Reduce costs and latency with semantic or simple caching |
|
||||
|
||||
|
||||
## Production Features with Portkey Configs
|
||||
|
||||
All features mentioned below are through Portkey's Config system. Portkey's Config system allows you to define routing strategies using simple JSON objects in your LLM API calls. You can create and manage Configs directly in your code or through the Portkey Dashboard. Each Config has a unique ID for easy reference.
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/Portkey-AI/docs-core/refs/heads/main/images/libraries/libraries-3.avif"/>
|
||||
</Frame>
|
||||
|
||||
|
||||
### 1. Use 250+ LLMs
|
||||
Access various LLMs like Anthropic, Gemini, Mistral, Azure OpenAI, and more with minimal code changes. Switch between providers or use them together seamlessly. [Learn more about Universal API](https://portkey.ai/docs/product/ai-gateway/universal-api)
|
||||
|
||||
|
||||
Easily switch between different LLM providers:
|
||||
|
||||
```python
|
||||
# Anthropic Configuration
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY", #You don't need provider when using Virtual keys
|
||||
trace_id="anthropic_agent"
|
||||
)
|
||||
)
|
||||
|
||||
# Azure OpenAI Configuration
|
||||
azure_llm = LLM(
|
||||
model="gpt-4",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_AZURE_VIRTUAL_KEY", #You don't need provider when using Virtual keys
|
||||
trace_id="azure_agent"
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
### 2. Caching
|
||||
Improve response times and reduce costs with two powerful caching modes:
|
||||
- **Simple Cache**: Perfect for exact matches
|
||||
- **Semantic Cache**: Matches responses for requests that are semantically similar
|
||||
[Learn more about Caching](https://portkey.ai/docs/product/ai-gateway/cache-simple-and-semantic)
|
||||
|
||||
```py
|
||||
config = {
|
||||
"cache": {
|
||||
"mode": "semantic", # or "simple" for exact matching
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 3. Production Reliability
|
||||
Portkey provides comprehensive reliability features:
|
||||
- **Automatic Retries**: Handle temporary failures gracefully
|
||||
- **Request Timeouts**: Prevent hanging operations
|
||||
- **Conditional Routing**: Route requests based on specific conditions
|
||||
- **Fallbacks**: Set up automatic provider failovers
|
||||
- **Load Balancing**: Distribute requests efficiently
|
||||
|
||||
[Learn more about Reliability Features](https://portkey.ai/docs/product/ai-gateway/)
|
||||
|
||||
|
||||
|
||||
### 4. Metrics
|
||||
|
||||
Agent runs are complex. Portkey automatically logs **40+ comprehensive metrics** for your AI agents, including cost, tokens used, latency, etc. Whether you need a broad overview or granular insights into your agent runs, Portkey's customizable filters provide the metrics you need.
|
||||
|
||||
|
||||
- Cost per agent interaction
|
||||
- Response times and latency
|
||||
- Token usage and efficiency
|
||||
- Success/failure rates
|
||||
- Cache hit rates
|
||||
|
||||
<img src="https://github.com/siddharthsambharia-portkey/Portkey-Product-Images/blob/main/Portkey-Dashboard.png?raw=true" width="70%" alt="Portkey Dashboard" />
|
||||
|
||||
### 5. Detailed Logging
|
||||
Logs are essential for understanding agent behavior, diagnosing issues, and improving performance. They provide a detailed record of agent activities and tool use, which is crucial for debugging and optimizing processes.
|
||||
|
||||
|
||||
Access a dedicated section to view records of agent executions, including parameters, outcomes, function calls, and errors. Filter logs based on multiple parameters such as trace ID, model, tokens used, and metadata.
|
||||
|
||||
<details>
|
||||
<summary><b>Traces</b></summary>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-Traces.png" alt="Portkey Traces" width="70%" />
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary><b>Logs</b></summary>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-Logs.png" alt="Portkey Logs" width="70%" />
|
||||
</details>
|
||||
|
||||
### 6. Enterprise Security Features
|
||||
- Set budget limit and rate limts per Virtual Key (disposable API keys)
|
||||
- Implement role-based access control
|
||||
- Track system changes with audit logs
|
||||
- Configure data retention policies
|
||||
|
||||
|
||||
|
||||
For detailed information on creating and managing Configs, visit the [Portkey documentation](https://docs.portkey.ai/product/ai-gateway/configs).
|
||||
|
||||
## Resources
|
||||
|
||||
- [📘 Portkey Documentation](https://docs.portkey.ai)
|
||||
- [📊 Portkey Dashboard](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai)
|
||||
- [🐦 Twitter](https://twitter.com/portkeyai)
|
||||
- [💬 Discord Community](https://discord.gg/DD7vgKK299)
|
||||
124
docs/observability/weave.mdx
Normal file
124
docs/observability/weave.mdx
Normal file
@@ -0,0 +1,124 @@
|
||||
---
|
||||
title: Weave Integration
|
||||
description: Learn how to use Weights & Biases (W&B) Weave to track, experiment with, evaluate, and improve your CrewAI applications.
|
||||
icon: radar
|
||||
---
|
||||
|
||||
# Weave Overview
|
||||
|
||||
[Weights & Biases (W&B) Weave](https://weave-docs.wandb.ai/) is a framework for tracking, experimenting with, evaluating, deploying, and improving LLM-based applications.
|
||||
|
||||

|
||||
|
||||
Weave provides comprehensive support for every stage of your CrewAI application development:
|
||||
|
||||
- **Tracing & Monitoring**: Automatically track LLM calls and application logic to debug and analyze production systems
|
||||
- **Systematic Iteration**: Refine and iterate on prompts, datasets, and models
|
||||
- **Evaluation**: Use custom or pre-built scorers to systematically assess and enhance agent performance
|
||||
- **Guardrails**: Protect your agents with pre- and post-safeguards for content moderation and prompt safety
|
||||
|
||||
Weave automatically captures traces for your CrewAI applications, enabling you to monitor and analyze your agents' performance, interactions, and execution flow. This helps you build better evaluation datasets and optimize your agent workflows.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Install required packages">
|
||||
```shell
|
||||
pip install crewai weave
|
||||
```
|
||||
</Step>
|
||||
<Step title="Set up W&B Account">
|
||||
Sign up for a [Weights & Biases account](https://wandb.ai) if you haven't already. You'll need this to view your traces and metrics.
|
||||
</Step>
|
||||
<Step title="Initialize Weave in Your Application">
|
||||
Add the following code to your application:
|
||||
|
||||
```python
|
||||
import weave
|
||||
|
||||
# Initialize Weave with your project name
|
||||
weave.init(project_name="crewai_demo")
|
||||
```
|
||||
|
||||
After initialization, Weave will provide a URL where you can view your traces and metrics.
|
||||
</Step>
|
||||
<Step title="Create your Crews/Flows">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM, Process
|
||||
|
||||
# Create an LLM with a temperature of 0 to ensure deterministic outputs
|
||||
llm = LLM(model="gpt-4o", temperature=0)
|
||||
|
||||
# Create agents
|
||||
researcher = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Find and analyze the best investment opportunities',
|
||||
backstory='Expert in financial analysis and market research',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role='Report Writer',
|
||||
goal='Write clear and concise investment reports',
|
||||
backstory='Experienced in creating detailed financial reports',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
# Create tasks
|
||||
research_task = Task(
|
||||
description='Deep research on the {topic}',
|
||||
expected_output='Comprehensive market data including key players, market size, and growth trends.',
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description='Write a detailed report based on the research',
|
||||
expected_output='The report should be easy to read and understand. Use bullet points where applicable.',
|
||||
agent=writer
|
||||
)
|
||||
|
||||
# Create a crew
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
result = crew.kickoff(inputs={"topic": "AI in material science"})
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
<Step title="View Traces in Weave">
|
||||
After running your CrewAI application, visit the Weave URL provided during initialization to view:
|
||||
- LLM calls and their metadata
|
||||
- Agent interactions and task execution flow
|
||||
- Performance metrics like latency and token usage
|
||||
- Any errors or issues that occurred during execution
|
||||
|
||||
<Frame caption="Weave Tracing Dashboard">
|
||||
<img src="/images/weave-tracing.png" alt="Weave tracing example with CrewAI" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Features
|
||||
|
||||
- Weave automatically captures all CrewAI operations: agent interactions and task executions; LLM calls with metadata and token usage; tool usage and results.
|
||||
- The integration supports all CrewAI execution methods: `kickoff()`, `kickoff_for_each()`, `kickoff_async()`, and `kickoff_for_each_async()`.
|
||||
- Automatic tracing of all [crewAI-tools](https://github.com/crewAIInc/crewAI-tools).
|
||||
- Flow feature support with decorator patching (`@start`, `@listen`, `@router`, `@or_`, `@and_`).
|
||||
- Track custom guardrails passed to CrewAI `Task` with `@weave.op()`.
|
||||
|
||||
For detailed information on what's supported, visit the [Weave CrewAI documentation](https://weave-docs.wandb.ai/guides/integrations/crewai/#getting-started-with-flow).
|
||||
|
||||
## Resources
|
||||
|
||||
- [📘 Weave Documentation](https://weave-docs.wandb.ai)
|
||||
- [📊 Example Weave x CrewAI dashboard](https://wandb.ai/ayut/crewai_demo/weave/traces?cols=%7B%22wb_run_id%22%3Afalse%2C%22attributes.weave.client_version%22%3Afalse%2C%22attributes.weave.os_name%22%3Afalse%2C%22attributes.weave.os_release%22%3Afalse%2C%22attributes.weave.os_version%22%3Afalse%2C%22attributes.weave.source%22%3Afalse%2C%22attributes.weave.sys_version%22%3Afalse%7D&peekPath=%2Fayut%2Fcrewai_demo%2Fcalls%2F0195c838-38cb-71a2-8a15-651ecddf9d89)
|
||||
- [🐦 X](https://x.com/weave_wb)
|
||||
Reference in New Issue
Block a user