mirror of
https://github.com/crewAIInc/crewAI.git
synced 2026-01-25 16:18:13 +00:00
docs: Add transparency features for prompts and memory systems (#2902)
* docs: Fix major memory system documentation issues - Remove misleading deprecation warnings, fix confusing comments, clearly separate three memory approaches, provide accurate examples that match implementation * fix: Correct broken image paths in README - Update crewai_logo.png and asset.png paths to point to docs/images/ directory instead of docs/ directly * docs: Add system prompt transparency and customization guide - Add 'Understanding Default System Instructions' section to address black-box concerns - Document what CrewAI automatically injects into prompts - Provide code examples to inspect complete system prompts - Show 3 methods to override default instructions - Include observability integration examples with Langfuse - Add best practices for production prompt management * docs: Fix implementation accuracy issues in memory documentation - Fix Ollama embedding URL parameter and remove unsupported Cohere input_type parameter * docs: Reference observability docs instead of showing specific tool examples * docs: Reorganize knowledge documentation for better developer experience - Move quickstart examples right after overview for immediate hands-on experience - Create logical learning progression: basics → configuration → advanced → troubleshooting - Add comprehensive agent vs crew knowledge guide with working examples - Consolidate debugging and troubleshooting in dedicated section - Organize best practices by topic in accordion format - Improve content flow from simple concepts to advanced features - Ensure all examples are grounded in actual codebase implementation * docs: enhance custom LLM documentation with comprehensive examples and accurate imports * docs: reorganize observability tools into dedicated section with comprehensive overview and improved navigation * docs: rename how-to section to learn and add comprehensive overview page * docs: finalize documentation reorganization and update navigation labels * docs: enhance README with comprehensive badges, navigation links, and getting started video
This commit is contained in:
@@ -1,126 +0,0 @@
|
||||
---
|
||||
title: AgentOps Integration
|
||||
description: Understanding and logging your agent performance with AgentOps.
|
||||
icon: paperclip
|
||||
---
|
||||
|
||||
# Introduction
|
||||
|
||||
Observability is a key aspect of developing and deploying conversational AI agents. It allows developers to understand how their agents are performing,
|
||||
how their agents are interacting with users, and how their agents use external tools and APIs.
|
||||
AgentOps is a product independent of CrewAI that provides a comprehensive observability solution for agents.
|
||||
|
||||
## AgentOps
|
||||
|
||||
[AgentOps](https://agentops.ai/?=crew) provides session replays, metrics, and monitoring for agents.
|
||||
|
||||
At a high level, AgentOps gives you the ability to monitor cost, token usage, latency, agent failures, session-wide statistics, and more.
|
||||
For more info, check out the [AgentOps Repo](https://github.com/AgentOps-AI/agentops).
|
||||
|
||||
### Overview
|
||||
|
||||
AgentOps provides monitoring for agents in development and production.
|
||||
It provides a dashboard for tracking agent performance, session replays, and custom reporting.
|
||||
|
||||
Additionally, AgentOps provides session drilldowns for viewing Crew agent interactions, LLM calls, and tool usage in real-time.
|
||||
This feature is useful for debugging and understanding how agents interact with users as well as other agents.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
### Features
|
||||
|
||||
- **LLM Cost Management and Tracking**: Track spend with foundation model providers.
|
||||
- **Replay Analytics**: Watch step-by-step agent execution graphs.
|
||||
- **Recursive Thought Detection**: Identify when agents fall into infinite loops.
|
||||
- **Custom Reporting**: Create custom analytics on agent performance.
|
||||
- **Analytics Dashboard**: Monitor high-level statistics about agents in development and production.
|
||||
- **Public Model Testing**: Test your agents against benchmarks and leaderboards.
|
||||
- **Custom Tests**: Run your agents against domain-specific tests.
|
||||
- **Time Travel Debugging**: Restart your sessions from checkpoints.
|
||||
- **Compliance and Security**: Create audit logs and detect potential threats such as profanity and PII leaks.
|
||||
- **Prompt Injection Detection**: Identify potential code injection and secret leaks.
|
||||
|
||||
### Using AgentOps
|
||||
|
||||
<Steps>
|
||||
<Step title="Create an API Key">
|
||||
Create a user API key here: [Create API Key](https://app.agentops.ai/account)
|
||||
</Step>
|
||||
<Step title="Configure Your Environment">
|
||||
Add your API key to your environment variables:
|
||||
```bash
|
||||
AGENTOPS_API_KEY=<YOUR_AGENTOPS_API_KEY>
|
||||
```
|
||||
</Step>
|
||||
<Step title="Install AgentOps">
|
||||
Install AgentOps with:
|
||||
```bash
|
||||
pip install 'crewai[agentops]'
|
||||
```
|
||||
or
|
||||
```bash
|
||||
pip install agentops
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize AgentOps">
|
||||
Before using `Crew` in your script, include these lines:
|
||||
|
||||
```python
|
||||
import agentops
|
||||
agentops.init()
|
||||
```
|
||||
|
||||
This will initiate an AgentOps session as well as automatically track Crew agents. For further info on how to outfit more complex agentic systems,
|
||||
check out the [AgentOps documentation](https://docs.agentops.ai) or join the [Discord](https://discord.gg/j4f3KbeH).
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Crew + AgentOps Examples
|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card
|
||||
title="Job Posting"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/job-posting"
|
||||
icon="briefcase"
|
||||
iconType="solid"
|
||||
>
|
||||
Example of a Crew agent that generates job posts.
|
||||
</Card>
|
||||
<Card
|
||||
title="Markdown Validator"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/markdown_validator"
|
||||
icon="markdown"
|
||||
iconType="solid"
|
||||
>
|
||||
Example of a Crew agent that validates Markdown files.
|
||||
</Card>
|
||||
<Card
|
||||
title="Instagram Post"
|
||||
color="#F3A78B"
|
||||
href="https://github.com/joaomdmoura/crewAI-examples/tree/main/instagram_post"
|
||||
icon="square-instagram"
|
||||
iconType="brands"
|
||||
>
|
||||
Example of a Crew agent that generates Instagram posts.
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
### Further Information
|
||||
|
||||
To get started, create an [AgentOps account](https://agentops.ai/?=crew).
|
||||
|
||||
For feature requests or bug reports, please reach out to the AgentOps team on the [AgentOps Repo](https://github.com/AgentOps-AI/agentops).
|
||||
|
||||
#### Extra links
|
||||
|
||||
<a href="https://twitter.com/agentopsai/">🐦 Twitter</a>
|
||||
<span> • </span>
|
||||
<a href="https://discord.gg/JHPt4C7r">📢 Discord</a>
|
||||
<span> • </span>
|
||||
<a href="https://app.agentops.ai/?=crew">🖇️ AgentOps Dashboard</a>
|
||||
<span> • </span>
|
||||
<a href="https://docs.agentops.ai/introduction">📙 Documentation</a>
|
||||
@@ -1,151 +0,0 @@
|
||||
---
|
||||
title: Arize Phoenix
|
||||
description: Arize Phoenix integration for CrewAI with OpenTelemetry and OpenInference
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# Arize Phoenix Integration
|
||||
|
||||
This guide demonstrates how to integrate **Arize Phoenix** with **CrewAI** using OpenTelemetry via the [OpenInference](https://github.com/openinference/openinference) SDK. By the end of this guide, you will be able to trace your CrewAI agents and easily debug your agents.
|
||||
|
||||
> **What is Arize Phoenix?** [Arize Phoenix](https://phoenix.arize.com) is an LLM observability platform that provides tracing and evaluation for AI applications.
|
||||
|
||||
[](https://www.youtube.com/watch?v=Yc5q3l6F7Ww)
|
||||
|
||||
## Get Started
|
||||
|
||||
We'll walk through a simple example of using CrewAI and integrating it with Arize Phoenix via OpenTelemetry using OpenInference.
|
||||
|
||||
You can also access this guide on [Google Colab](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/crewai_tracing_tutorial.ipynb).
|
||||
|
||||
### Step 1: Install Dependencies
|
||||
|
||||
```bash
|
||||
pip install openinference-instrumentation-crewai crewai crewai-tools arize-phoenix-otel
|
||||
```
|
||||
|
||||
### Step 2: Set Up Environment Variables
|
||||
|
||||
Setup Phoenix Cloud API keys and configure OpenTelemetry to send traces to Phoenix. Phoenix Cloud is a hosted version of Arize Phoenix, but it is not required to use this integration.
|
||||
|
||||
You can get your free Serper API key [here](https://serper.dev/).
|
||||
|
||||
```python
|
||||
import os
|
||||
from getpass import getpass
|
||||
|
||||
# Get your Phoenix Cloud credentials
|
||||
PHOENIX_API_KEY = getpass("🔑 Enter your Phoenix Cloud API Key: ")
|
||||
|
||||
# Get API keys for services
|
||||
OPENAI_API_KEY = getpass("🔑 Enter your OpenAI API key: ")
|
||||
SERPER_API_KEY = getpass("🔑 Enter your Serper API key: ")
|
||||
|
||||
# Set environment variables
|
||||
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
|
||||
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com" # Phoenix Cloud, change this to your own endpoint if you are using a self-hosted instance
|
||||
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
|
||||
os.environ["SERPER_API_KEY"] = SERPER_API_KEY
|
||||
```
|
||||
|
||||
### Step 3: Initialize OpenTelemetry with Phoenix
|
||||
|
||||
Initialize the OpenInference OpenTelemetry instrumentation SDK to start capturing traces and send them to Phoenix.
|
||||
|
||||
```python
|
||||
from phoenix.otel import register
|
||||
|
||||
tracer_provider = register(
|
||||
project_name="crewai-tracing-demo",
|
||||
auto_instrument=True,
|
||||
)
|
||||
```
|
||||
|
||||
### Step 4: Create a CrewAI Application
|
||||
|
||||
We'll create a CrewAI application where two agents collaborate to research and write a blog post about AI advancements.
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Process, Task
|
||||
from crewai_tools import SerperDevTool
|
||||
from openinference.instrumentation.crewai import CrewAIInstrumentor
|
||||
from phoenix.otel import register
|
||||
|
||||
# setup monitoring for your crew
|
||||
tracer_provider = register(
|
||||
endpoint="http://localhost:6006/v1/traces")
|
||||
CrewAIInstrumentor().instrument(skip_dep_check=True, tracer_provider=tracer_provider)
|
||||
search_tool = SerperDevTool()
|
||||
|
||||
# Define your agents with roles and goals
|
||||
researcher = Agent(
|
||||
role="Senior Research Analyst",
|
||||
goal="Uncover cutting-edge developments in AI and data science",
|
||||
backstory="""You work at a leading tech think tank.
|
||||
Your expertise lies in identifying emerging trends.
|
||||
You have a knack for dissecting complex data and presenting actionable insights.""",
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
# You can pass an optional llm attribute specifying what model you wanna use.
|
||||
# llm=ChatOpenAI(model_name="gpt-3.5", temperature=0.7),
|
||||
tools=[search_tool],
|
||||
)
|
||||
writer = Agent(
|
||||
role="Tech Content Strategist",
|
||||
goal="Craft compelling content on tech advancements",
|
||||
backstory="""You are a renowned Content Strategist, known for your insightful and engaging articles.
|
||||
You transform complex concepts into compelling narratives.""",
|
||||
verbose=True,
|
||||
allow_delegation=True,
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description="""Conduct a comprehensive analysis of the latest advancements in AI in 2024.
|
||||
Identify key trends, breakthrough technologies, and potential industry impacts.""",
|
||||
expected_output="Full analysis report in bullet points",
|
||||
agent=researcher,
|
||||
)
|
||||
|
||||
task2 = Task(
|
||||
description="""Using the insights provided, develop an engaging blog
|
||||
post that highlights the most significant AI advancements.
|
||||
Your post should be informative yet accessible, catering to a tech-savvy audience.
|
||||
Make it sound cool, avoid complex words so it doesn't sound like AI.""",
|
||||
expected_output="Full blog post of at least 4 paragraphs",
|
||||
agent=writer,
|
||||
)
|
||||
|
||||
# Instantiate your crew with a sequential process
|
||||
crew = Crew(
|
||||
agents=[researcher, writer], tasks=[task1, task2], verbose=1, process=Process.sequential
|
||||
)
|
||||
|
||||
# Get your crew to work!
|
||||
result = crew.kickoff()
|
||||
|
||||
print("######################")
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Step 5: View Traces in Phoenix
|
||||
|
||||
After running the agent, you can view the traces generated by your CrewAI application in Phoenix. You should see detailed steps of the agent interactions and LLM calls, which can help you debug and optimize your AI agents.
|
||||
|
||||
Log into your Phoenix Cloud account and navigate to the project you specified in the `project_name` parameter. You'll see a timeline view of your trace with all the agent interactions, tool usages, and LLM calls.
|
||||
|
||||
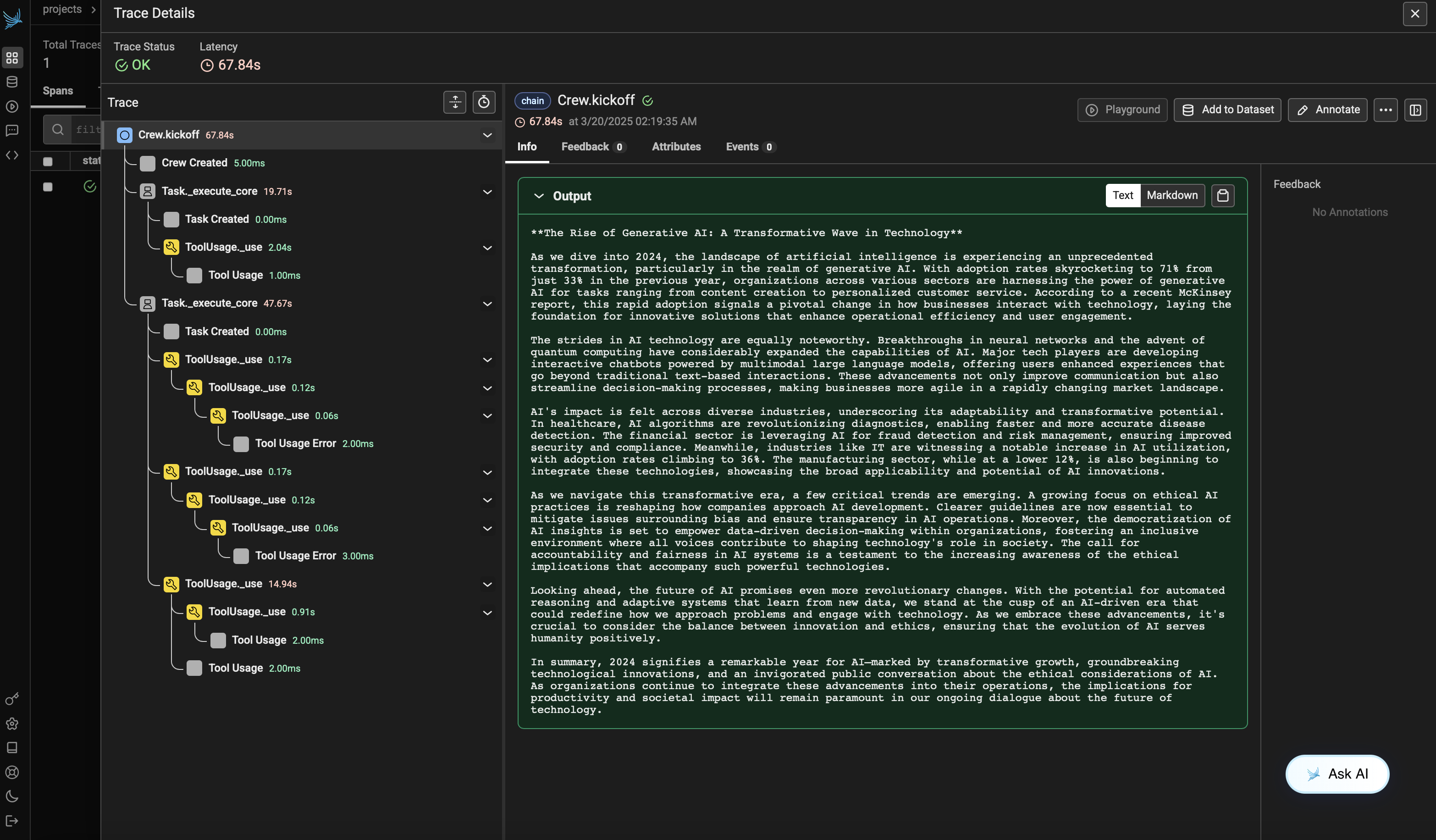
|
||||
|
||||
|
||||
### Version Compatibility Information
|
||||
- Python 3.8+
|
||||
- CrewAI >= 0.86.0
|
||||
- Arize Phoenix >= 7.0.1
|
||||
- OpenTelemetry SDK >= 1.31.0
|
||||
|
||||
|
||||
### References
|
||||
- [Phoenix Documentation](https://docs.arize.com/phoenix/) - Overview of the Phoenix platform.
|
||||
- [CrewAI Documentation](https://docs.crewai.com/) - Overview of the CrewAI framework.
|
||||
- [OpenTelemetry Docs](https://opentelemetry.io/docs/) - OpenTelemetry guide
|
||||
- [OpenInference GitHub](https://github.com/openinference/openinference) - Source code for OpenInference SDK.
|
||||
@@ -1,61 +0,0 @@
|
||||
---
|
||||
title: Before and After Kickoff Hooks
|
||||
description: Learn how to use before and after kickoff hooks in CrewAI
|
||||
---
|
||||
|
||||
CrewAI provides hooks that allow you to execute code before and after a crew's kickoff. These hooks are useful for preprocessing inputs or post-processing results.
|
||||
|
||||
## Before Kickoff Hook
|
||||
|
||||
The before kickoff hook is executed before the crew starts its tasks. It receives the input dictionary and can modify it before passing it to the crew. You can use this hook to set up your environment, load necessary data, or preprocess your inputs. This is useful in scenarios where the input data might need enrichment or validation before being processed by the crew.
|
||||
|
||||
Here's an example of defining a before kickoff function in your `crew.py`:
|
||||
|
||||
```python
|
||||
from crewai import CrewBase
|
||||
from crewai.project import before_kickoff
|
||||
|
||||
@CrewBase
|
||||
class MyCrew:
|
||||
@before_kickoff
|
||||
def prepare_data(self, inputs):
|
||||
# Preprocess or modify inputs
|
||||
inputs['processed'] = True
|
||||
return inputs
|
||||
|
||||
#...
|
||||
```
|
||||
|
||||
In this example, the prepare_data function modifies the inputs by adding a new key-value pair indicating that the inputs have been processed.
|
||||
|
||||
## After Kickoff Hook
|
||||
|
||||
The after kickoff hook is executed after the crew has completed its tasks. It receives the result object, which contains the outputs of the crew's execution. This hook is ideal for post-processing results, such as logging, data transformation, or further analysis.
|
||||
|
||||
Here's how you can define an after kickoff function in your `crew.py`:
|
||||
|
||||
```python
|
||||
from crewai import CrewBase
|
||||
from crewai.project import after_kickoff
|
||||
|
||||
@CrewBase
|
||||
class MyCrew:
|
||||
@after_kickoff
|
||||
def log_results(self, result):
|
||||
# Log or modify the results
|
||||
print("Crew execution completed with result:", result)
|
||||
return result
|
||||
|
||||
# ...
|
||||
```
|
||||
|
||||
|
||||
In the `log_results` function, the results of the crew execution are simply printed out. You can extend this to perform more complex operations such as sending notifications or integrating with other services.
|
||||
|
||||
## Utilizing Both Hooks
|
||||
|
||||
Both hooks can be used together to provide a comprehensive setup and teardown process for your crew's execution. They are particularly useful in maintaining clean code architecture by separating concerns and enhancing the modularity of your CrewAI implementations.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Before and after kickoff hooks in CrewAI offer powerful ways to interact with the lifecycle of a crew's execution. By understanding and utilizing these hooks, you can greatly enhance the robustness and flexibility of your AI agents.
|
||||
@@ -1,443 +0,0 @@
|
||||
---
|
||||
title: Bring your own agent
|
||||
description: Learn how to bring your own agents that work within a Crew.
|
||||
icon: robots
|
||||
---
|
||||
|
||||
Interoperability is a core concept in CrewAI. This guide will show you how to bring your own agents that work within a Crew.
|
||||
|
||||
|
||||
## Adapter Guide for Bringing your own agents (Langgraph Agents, OpenAI Agents, etc...)
|
||||
We require 3 adapters to turn any agent from different frameworks to work within crew.
|
||||
|
||||
1. BaseAgentAdapter
|
||||
2. BaseToolAdapter
|
||||
3. BaseConverter
|
||||
|
||||
|
||||
## BaseAgentAdapter
|
||||
This abstract class defines the common interface and functionality that all
|
||||
agent adapters must implement. It extends BaseAgent to maintain compatibility
|
||||
with the CrewAI framework while adding adapter-specific requirements.
|
||||
|
||||
Required Methods:
|
||||
|
||||
1. `def configure_tools`
|
||||
2. `def configure_structured_output`
|
||||
|
||||
## Creating your own Adapter
|
||||
To integrate an agent from a different framework (e.g., LangGraph, Autogen, OpenAI Assistants) into CrewAI, you need to create a custom adapter by inheriting from `BaseAgentAdapter`. This adapter acts as a compatibility layer, translating between the CrewAI interfaces and the specific requirements of your external agent.
|
||||
|
||||
Here's how you implement your custom adapter:
|
||||
|
||||
1. **Inherit from `BaseAgentAdapter`**:
|
||||
```python
|
||||
from crewai.agents.agent_adapters.base_agent_adapter import BaseAgentAdapter
|
||||
from crewai.tools import BaseTool
|
||||
from typing import List, Optional, Any, Dict
|
||||
|
||||
class MyCustomAgentAdapter(BaseAgentAdapter):
|
||||
# ... implementation details ...
|
||||
```
|
||||
|
||||
2. **Implement `__init__`**:
|
||||
The constructor should call the parent class constructor `super().__init__(**kwargs)` and perform any initialization specific to your external agent. You can use the optional `agent_config` dictionary passed during CrewAI's `Agent` initialization to configure your adapter and the underlying agent.
|
||||
|
||||
```python
|
||||
def __init__(self, agent_config: Optional[Dict[str, Any]] = None, **kwargs: Any):
|
||||
super().__init__(agent_config=agent_config, **kwargs)
|
||||
# Initialize your external agent here, possibly using agent_config
|
||||
# Example: self.external_agent = initialize_my_agent(agent_config)
|
||||
print(f"Initializing MyCustomAgentAdapter with config: {agent_config}")
|
||||
```
|
||||
|
||||
3. **Implement `configure_tools`**:
|
||||
This abstract method is crucial. It receives a list of CrewAI `BaseTool` instances. Your implementation must convert or adapt these tools into the format expected by your external agent framework. This might involve wrapping them, extracting specific attributes, or registering them with the external agent instance.
|
||||
|
||||
```python
|
||||
def configure_tools(self, tools: Optional[List[BaseTool]] = None) -> None:
|
||||
if tools:
|
||||
adapted_tools = []
|
||||
for tool in tools:
|
||||
# Adapt CrewAI BaseTool to the format your agent expects
|
||||
# Example: adapted_tool = adapt_to_my_framework(tool)
|
||||
# adapted_tools.append(adapted_tool)
|
||||
pass # Replace with your actual adaptation logic
|
||||
|
||||
# Configure the external agent with the adapted tools
|
||||
# Example: self.external_agent.set_tools(adapted_tools)
|
||||
print(f"Configuring tools for MyCustomAgentAdapter: {adapted_tools}") # Placeholder
|
||||
else:
|
||||
# Handle the case where no tools are provided
|
||||
# Example: self.external_agent.set_tools([])
|
||||
print("No tools provided for MyCustomAgentAdapter.")
|
||||
```
|
||||
|
||||
4. **Implement `configure_structured_output`**:
|
||||
This method is called when the CrewAI `Agent` is configured with structured output requirements (e.g., `output_json` or `output_pydantic`). Your adapter needs to ensure the external agent is set up to comply with these requirements. This might involve setting specific parameters on the external agent or ensuring its underlying model supports the requested format. If the external agent doesn't support structured output in a way compatible with CrewAI's expectations, you might need to handle the conversion or raise an appropriate error.
|
||||
|
||||
```python
|
||||
def configure_structured_output(self, structured_output: Any) -> None:
|
||||
# Configure your external agent to produce output in the specified format
|
||||
# Example: self.external_agent.set_output_format(structured_output)
|
||||
self.adapted_structured_output = True # Signal that structured output is handled
|
||||
print(f"Configuring structured output for MyCustomAgentAdapter: {structured_output}")
|
||||
```
|
||||
|
||||
By implementing these methods, your `MyCustomAgentAdapter` will allow your custom agent implementation to function correctly within a CrewAI crew, interacting with tasks and tools seamlessly. Remember to replace the example comments and print statements with your actual adaptation logic specific to the external agent framework you are integrating.
|
||||
|
||||
## BaseToolAdapter implementation
|
||||
The `BaseToolAdapter` class is responsible for converting CrewAI's native `BaseTool` objects into a format that your specific external agent framework can understand and utilize. Different agent frameworks (like LangGraph, OpenAI Assistants, etc.) have their own unique ways of defining and handling tools, and the `BaseToolAdapter` acts as the translator.
|
||||
|
||||
Here's how you implement your custom tool adapter:
|
||||
|
||||
1. **Inherit from `BaseToolAdapter`**:
|
||||
```python
|
||||
from crewai.agents.agent_adapters.base_tool_adapter import BaseToolAdapter
|
||||
from crewai.tools import BaseTool
|
||||
from typing import List, Any
|
||||
|
||||
class MyCustomToolAdapter(BaseToolAdapter):
|
||||
# ... implementation details ...
|
||||
```
|
||||
|
||||
2. **Implement `configure_tools`**:
|
||||
This is the core abstract method you must implement. It receives a list of CrewAI `BaseTool` instances provided to the agent. Your task is to iterate through this list, adapt each `BaseTool` into the format expected by your external framework, and store the converted tools in the `self.converted_tools` list (which is initialized in the base class constructor).
|
||||
|
||||
```python
|
||||
def configure_tools(self, tools: List[BaseTool]) -> None:
|
||||
"""Configure and convert CrewAI tools for the specific implementation."""
|
||||
self.converted_tools = [] # Reset in case it's called multiple times
|
||||
for tool in tools:
|
||||
# Sanitize the tool name if required by the target framework
|
||||
sanitized_name = self.sanitize_tool_name(tool.name)
|
||||
|
||||
# --- Your Conversion Logic Goes Here ---
|
||||
# Example: Convert BaseTool to a dictionary format for LangGraph
|
||||
# converted_tool = {
|
||||
# "name": sanitized_name,
|
||||
# "description": tool.description,
|
||||
# "parameters": tool.args_schema.schema() if tool.args_schema else {},
|
||||
# # Add any other framework-specific fields
|
||||
# }
|
||||
|
||||
# Example: Convert BaseTool to an OpenAI function definition
|
||||
# converted_tool = {
|
||||
# "type": "function",
|
||||
# "function": {
|
||||
# "name": sanitized_name,
|
||||
# "description": tool.description,
|
||||
# "parameters": tool.args_schema.schema() if tool.args_schema else {"type": "object", "properties": {}},
|
||||
# }
|
||||
# }
|
||||
|
||||
# --- Replace above examples with your actual adaptation ---
|
||||
converted_tool = self.adapt_tool_to_my_framework(tool, sanitized_name) # Placeholder
|
||||
|
||||
self.converted_tools.append(converted_tool)
|
||||
print(f"Adapted tool '{tool.name}' to '{sanitized_name}' for MyCustomToolAdapter") # Placeholder
|
||||
|
||||
print(f"MyCustomToolAdapter finished configuring tools: {len(self.converted_tools)} adapted.") # Placeholder
|
||||
|
||||
# --- Helper method for adaptation (Example) ---
|
||||
def adapt_tool_to_my_framework(self, tool: BaseTool, sanitized_name: str) -> Any:
|
||||
# Replace this with the actual logic to convert a CrewAI BaseTool
|
||||
# to the format needed by your specific external agent framework.
|
||||
# This will vary greatly depending on the target framework.
|
||||
adapted_representation = {
|
||||
"framework_specific_name": sanitized_name,
|
||||
"framework_specific_description": tool.description,
|
||||
"inputs": tool.args_schema.schema() if tool.args_schema else None,
|
||||
"implementation_reference": tool.run # Or however the framework needs to call it
|
||||
}
|
||||
# Also ensure the tool works both sync and async
|
||||
async def async_tool_wrapper(*args, **kwargs):
|
||||
output = tool.run(*args, **kwargs)
|
||||
if inspect.isawaitable(output):
|
||||
return await output
|
||||
else:
|
||||
return output
|
||||
|
||||
adapted_tool = MyFrameworkTool(
|
||||
name=sanitized_name,
|
||||
description=tool.description,
|
||||
inputs=tool.args_schema.schema() if tool.args_schema else None,
|
||||
implementation_reference=async_tool_wrapper
|
||||
)
|
||||
|
||||
return adapted_representation
|
||||
|
||||
```
|
||||
|
||||
3. **Using the Adapter**:
|
||||
Typically, you would instantiate your `MyCustomToolAdapter` within your `MyCustomAgentAdapter`'s `configure_tools` method and use it to process the tools before configuring your external agent.
|
||||
|
||||
```python
|
||||
# Inside MyCustomAgentAdapter.configure_tools
|
||||
def configure_tools(self, tools: Optional[List[BaseTool]] = None) -> None:
|
||||
if tools:
|
||||
tool_adapter = MyCustomToolAdapter() # Instantiate your tool adapter
|
||||
tool_adapter.configure_tools(tools) # Convert the tools
|
||||
adapted_tools = tool_adapter.tools() # Get the converted tools
|
||||
|
||||
# Now configure your external agent with the adapted_tools
|
||||
# Example: self.external_agent.set_tools(adapted_tools)
|
||||
print(f"Configuring external agent with adapted tools: {adapted_tools}") # Placeholder
|
||||
else:
|
||||
# Handle no tools case
|
||||
print("No tools provided for MyCustomAgentAdapter.")
|
||||
```
|
||||
|
||||
By creating a `BaseToolAdapter`, you decouple the tool conversion logic from the agent adaptation, making the integration cleaner and more modular. Remember to replace the placeholder examples with the actual conversion logic required by your specific external agent framework.
|
||||
|
||||
## BaseConverter
|
||||
The `BaseConverterAdapter` plays a crucial role when a CrewAI `Task` requires an agent to return its final output in a specific structured format, such as JSON or a Pydantic model. It bridges the gap between CrewAI's structured output requirements and the capabilities of your external agent.
|
||||
|
||||
Its primary responsibilities are:
|
||||
1. **Configuring the Agent for Structured Output:** Based on the `Task`'s requirements (`output_json` or `output_pydantic`), it instructs the associated `BaseAgentAdapter` (and indirectly, the external agent) on what format is expected.
|
||||
2. **Enhancing the System Prompt:** It modifies the agent's system prompt to include clear instructions on *how* to generate the output in the required structure.
|
||||
3. **Post-processing the Result:** It takes the raw output from the agent and attempts to parse, validate, and format it according to the required structure, ultimately returning a string representation (e.g., a JSON string).
|
||||
|
||||
Here's how you implement your custom converter adapter:
|
||||
|
||||
1. **Inherit from `BaseConverterAdapter`**:
|
||||
```python
|
||||
from crewai.agents.agent_adapters.base_converter_adapter import BaseConverterAdapter
|
||||
# Assuming you have your MyCustomAgentAdapter defined
|
||||
# from .my_custom_agent_adapter import MyCustomAgentAdapter
|
||||
from crewai.task import Task
|
||||
from typing import Any
|
||||
|
||||
class MyCustomConverterAdapter(BaseConverterAdapter):
|
||||
# Store the expected output type (e.g., 'json', 'pydantic', 'text')
|
||||
_output_type: str = 'text'
|
||||
_output_schema: Any = None # Store JSON schema or Pydantic model
|
||||
|
||||
# ... implementation details ...
|
||||
```
|
||||
|
||||
2. **Implement `__init__`**:
|
||||
The constructor must accept the corresponding `agent_adapter` instance it will work with.
|
||||
|
||||
```python
|
||||
def __init__(self, agent_adapter: Any): # Use your specific AgentAdapter type hint
|
||||
self.agent_adapter = agent_adapter
|
||||
print(f"Initializing MyCustomConverterAdapter for agent adapter: {type(agent_adapter).__name__}")
|
||||
```
|
||||
|
||||
3. **Implement `configure_structured_output`**:
|
||||
This method receives the CrewAI `Task` object. You need to check the task's `output_json` and `output_pydantic` attributes to determine the required output structure. Store this information (e.g., in `_output_type` and `_output_schema`) and potentially call configuration methods on your `self.agent_adapter` if the external agent needs specific setup for structured output (which might have been partially handled in the agent adapter's `configure_structured_output` already).
|
||||
|
||||
```python
|
||||
def configure_structured_output(self, task: Task) -> None:
|
||||
"""Configure the expected structured output based on the task."""
|
||||
if task.output_pydantic:
|
||||
self._output_type = 'pydantic'
|
||||
self._output_schema = task.output_pydantic
|
||||
print(f"Converter: Configured for Pydantic output: {self._output_schema.__name__}")
|
||||
elif task.output_json:
|
||||
self._output_type = 'json'
|
||||
self._output_schema = task.output_json
|
||||
print(f"Converter: Configured for JSON output with schema: {self._output_schema}")
|
||||
else:
|
||||
self._output_type = 'text'
|
||||
self._output_schema = None
|
||||
print("Converter: Configured for standard text output.")
|
||||
|
||||
# Optionally, inform the agent adapter if needed
|
||||
# self.agent_adapter.set_output_mode(self._output_type, self._output_schema)
|
||||
```
|
||||
|
||||
4. **Implement `enhance_system_prompt`**:
|
||||
This method takes the agent's base system prompt string and should append instructions tailored to the currently configured `_output_type` and `_output_schema`. The goal is to guide the LLM powering the agent to produce output in the correct format.
|
||||
|
||||
```python
|
||||
def enhance_system_prompt(self, base_prompt: str) -> str:
|
||||
"""Enhance the system prompt with structured output instructions."""
|
||||
if self._output_type == 'text':
|
||||
return base_prompt # No enhancement needed for plain text
|
||||
|
||||
instructions = "\n\nYour final answer MUST be formatted as "
|
||||
if self._output_type == 'json':
|
||||
schema_str = json.dumps(self._output_schema, indent=2)
|
||||
instructions += f"a JSON object conforming to the following schema:\n```json\n{schema_str}\n```"
|
||||
elif self._output_type == 'pydantic':
|
||||
schema_str = json.dumps(self._output_schema.model_json_schema(), indent=2)
|
||||
instructions += f"a JSON object conforming to the Pydantic model '{self._output_schema.__name__}' with the following schema:\n```json\n{schema_str}\n```"
|
||||
|
||||
instructions += "\nEnsure your entire response is ONLY the valid JSON object, without any introductory text, explanations, or concluding remarks."
|
||||
|
||||
print(f"Converter: Enhancing prompt for {self._output_type} output.")
|
||||
return base_prompt + instructions
|
||||
```
|
||||
*Note: The exact prompt engineering might need tuning based on the agent/LLM being used.*
|
||||
|
||||
5. **Implement `post_process_result`**:
|
||||
This method receives the raw string output from the agent. If structured output was requested (`json` or `pydantic`), you should attempt to parse the string into the expected format. Handle potential parsing errors (e.g., log them, attempt simple fixes, or raise an exception). Crucially, the method must **always return a string**, even if the intermediate format was a dictionary or Pydantic object (e.g., by serializing it back to a JSON string).
|
||||
|
||||
```python
|
||||
import json
|
||||
from pydantic import ValidationError
|
||||
|
||||
def post_process_result(self, result: str) -> str:
|
||||
"""Post-process the agent's result to ensure it matches the expected format."""
|
||||
print(f"Converter: Post-processing result for {self._output_type} output.")
|
||||
if self._output_type == 'json':
|
||||
try:
|
||||
# Attempt to parse and re-serialize to ensure validity and consistent format
|
||||
parsed_json = json.loads(result)
|
||||
# Optional: Validate against self._output_schema if it's a JSON schema dictionary
|
||||
# from jsonschema import validate
|
||||
# validate(instance=parsed_json, schema=self._output_schema)
|
||||
return json.dumps(parsed_json)
|
||||
except json.JSONDecodeError as e:
|
||||
print(f"Error: Failed to parse JSON output: {e}\nRaw output:\n{result}")
|
||||
# Handle error: return raw, raise exception, or try to fix
|
||||
return result # Example: return raw output on failure
|
||||
# except Exception as e: # Catch validation errors if using jsonschema
|
||||
# print(f"Error: JSON output failed schema validation: {e}\nRaw output:\n{result}")
|
||||
# return result
|
||||
elif self._output_type == 'pydantic':
|
||||
try:
|
||||
# Attempt to parse into the Pydantic model
|
||||
model_instance = self._output_schema.model_validate_json(result)
|
||||
# Return the model serialized back to JSON
|
||||
return model_instance.model_dump_json()
|
||||
except ValidationError as e:
|
||||
print(f"Error: Failed to validate Pydantic output: {e}\nRaw output:\n{result}")
|
||||
# Handle error
|
||||
return result # Example: return raw output on failure
|
||||
except json.JSONDecodeError as e:
|
||||
print(f"Error: Failed to parse JSON for Pydantic model: {e}\nRaw output:\n{result}")
|
||||
return result
|
||||
else: # 'text'
|
||||
return result # No processing needed for plain text
|
||||
```
|
||||
|
||||
By implementing these methods, your `MyCustomConverterAdapter` ensures that structured output requests from CrewAI tasks are correctly handled by your integrated external agent, improving the reliability and usability of your custom agent within the CrewAI framework.
|
||||
|
||||
## Out of the Box Adapters
|
||||
|
||||
We provide out of the box adapters for the following frameworks:
|
||||
1. LangGraph
|
||||
2. OpenAI Agents
|
||||
|
||||
## Kicking off a crew with adapted agents:
|
||||
|
||||
```python
|
||||
import json
|
||||
import os
|
||||
from typing import List
|
||||
|
||||
from crewai_tools import SerperDevTool
|
||||
from src.crewai import Agent, Crew, Task
|
||||
from langchain_openai import ChatOpenAI
|
||||
from pydantic import BaseModel
|
||||
|
||||
from crewai.agents.agent_adapters.langgraph.langgraph_adapter import (
|
||||
LangGraphAgentAdapter,
|
||||
)
|
||||
from crewai.agents.agent_adapters.openai_agents.openai_adapter import OpenAIAgentAdapter
|
||||
|
||||
# CrewAI Agent
|
||||
code_helper_agent = Agent(
|
||||
role="Code Helper",
|
||||
goal="Help users solve coding problems effectively and provide clear explanations.",
|
||||
backstory="You are an experienced programmer with deep knowledge across multiple programming languages and frameworks. You specialize in solving complex coding challenges and explaining solutions clearly.",
|
||||
allow_delegation=False,
|
||||
verbose=True,
|
||||
)
|
||||
# OpenAI Agent Adapter
|
||||
link_finder_agent = OpenAIAgentAdapter(
|
||||
role="Link Finder",
|
||||
goal="Find the most relevant and high-quality resources for coding tasks.",
|
||||
backstory="You are a research specialist with a talent for finding the most helpful resources. You're skilled at using search tools to discover documentation, tutorials, and examples that directly address the user's coding needs.",
|
||||
tools=[SerperDevTool()],
|
||||
allow_delegation=False,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
# LangGraph Agent Adapter
|
||||
reporter_agent = LangGraphAgentAdapter(
|
||||
role="Reporter",
|
||||
goal="Report the results of the tasks.",
|
||||
backstory="You are a reporter who reports the results of the other tasks",
|
||||
llm=ChatOpenAI(model="gpt-4o"),
|
||||
allow_delegation=True,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
|
||||
class Code(BaseModel):
|
||||
code: str
|
||||
|
||||
|
||||
task = Task(
|
||||
description="Give an answer to the coding question: {task}",
|
||||
expected_output="A thorough answer to the coding question: {task}",
|
||||
agent=code_helper_agent,
|
||||
output_json=Code,
|
||||
)
|
||||
task2 = Task(
|
||||
description="Find links to resources that can help with coding tasks. Use the serper tool to find resources that can help.",
|
||||
expected_output="A list of links to resources that can help with coding tasks",
|
||||
agent=link_finder_agent,
|
||||
)
|
||||
|
||||
|
||||
class Report(BaseModel):
|
||||
code: str
|
||||
links: List[str]
|
||||
|
||||
|
||||
task3 = Task(
|
||||
description="Report the results of the tasks.",
|
||||
expected_output="A report of the results of the tasks. this is the code produced and then the links to the resources that can help with the coding task.",
|
||||
agent=reporter_agent,
|
||||
output_json=Report,
|
||||
)
|
||||
# Use in CrewAI
|
||||
crew = Crew(
|
||||
agents=[code_helper_agent, link_finder_agent, reporter_agent],
|
||||
tasks=[task, task2, task3],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
result = crew.kickoff(
|
||||
inputs={"task": "How do you implement an abstract class in python?"}
|
||||
)
|
||||
|
||||
# Print raw result first
|
||||
print("Raw result:", result)
|
||||
|
||||
# Handle result based on its type
|
||||
if hasattr(result, "json_dict") and result.json_dict:
|
||||
json_result = result.json_dict
|
||||
print("\nStructured JSON result:")
|
||||
print(f"{json.dumps(json_result, indent=2)}")
|
||||
|
||||
# Access fields safely
|
||||
if isinstance(json_result, dict):
|
||||
if "code" in json_result:
|
||||
print("\nCode:")
|
||||
print(
|
||||
json_result["code"][:200] + "..."
|
||||
if len(json_result["code"]) > 200
|
||||
else json_result["code"]
|
||||
)
|
||||
|
||||
if "links" in json_result:
|
||||
print("\nLinks:")
|
||||
for link in json_result["links"][:5]: # Print first 5 links
|
||||
print(f"- {link}")
|
||||
if len(json_result["links"]) > 5:
|
||||
print(f"...and {len(json_result['links']) - 5} more links")
|
||||
elif hasattr(result, "pydantic") and result.pydantic:
|
||||
print("\nPydantic model result:")
|
||||
print(result.pydantic.model_dump_json(indent=2))
|
||||
else:
|
||||
# Fallback to raw output
|
||||
print("\nNo structured result available, using raw output:")
|
||||
print(result.raw[:500] + "..." if len(result.raw) > 500 else result.raw)
|
||||
|
||||
```
|
||||
@@ -1,95 +0,0 @@
|
||||
---
|
||||
title: Coding Agents
|
||||
description: Learn how to enable your CrewAI Agents to write and execute code, and explore advanced features for enhanced functionality.
|
||||
icon: rectangle-code
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
CrewAI Agents now have the powerful ability to write and execute code, significantly enhancing their problem-solving capabilities. This feature is particularly useful for tasks that require computational or programmatic solutions.
|
||||
|
||||
## Enabling Code Execution
|
||||
|
||||
To enable code execution for an agent, set the `allow_code_execution` parameter to `True` when creating the agent.
|
||||
|
||||
Here's an example:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent
|
||||
|
||||
coding_agent = Agent(
|
||||
role="Senior Python Developer",
|
||||
goal="Craft well-designed and thought-out code",
|
||||
backstory="You are a senior Python developer with extensive experience in software architecture and best practices.",
|
||||
allow_code_execution=True
|
||||
)
|
||||
```
|
||||
|
||||
<Note>
|
||||
Note that `allow_code_execution` parameter defaults to `False`.
|
||||
</Note>
|
||||
|
||||
## Important Considerations
|
||||
|
||||
1. **Model Selection**: It is strongly recommended to use more capable models like Claude 3.5 Sonnet and GPT-4 when enabling code execution.
|
||||
These models have a better understanding of programming concepts and are more likely to generate correct and efficient code.
|
||||
|
||||
2. **Error Handling**: The code execution feature includes error handling. If executed code raises an exception, the agent will receive the error message and can attempt to correct the code or
|
||||
provide alternative solutions. The `max_retry_limit` parameter, which defaults to 2, controls the maximum number of retries for a task.
|
||||
|
||||
3. **Dependencies**: To use the code execution feature, you need to install the `crewai_tools` package. If not installed, the agent will log an info message:
|
||||
"Coding tools not available. Install crewai_tools."
|
||||
|
||||
## Code Execution Process
|
||||
|
||||
When an agent with code execution enabled encounters a task requiring programming:
|
||||
|
||||
<Steps>
|
||||
<Step title="Task Analysis">
|
||||
The agent analyzes the task and determines that code execution is necessary.
|
||||
</Step>
|
||||
<Step title="Code Formulation">
|
||||
It formulates the Python code needed to solve the problem.
|
||||
</Step>
|
||||
<Step title="Code Execution">
|
||||
The code is sent to the internal code execution tool (`CodeInterpreterTool`).
|
||||
</Step>
|
||||
<Step title="Result Interpretation">
|
||||
The agent interprets the result and incorporates it into its response or uses it for further problem-solving.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Example Usage
|
||||
|
||||
Here's a detailed example of creating an agent with code execution capabilities and using it in a task:
|
||||
|
||||
```python Code
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
# Create an agent with code execution enabled
|
||||
coding_agent = Agent(
|
||||
role="Python Data Analyst",
|
||||
goal="Analyze data and provide insights using Python",
|
||||
backstory="You are an experienced data analyst with strong Python skills.",
|
||||
allow_code_execution=True
|
||||
)
|
||||
|
||||
# Create a task that requires code execution
|
||||
data_analysis_task = Task(
|
||||
description="Analyze the given dataset and calculate the average age of participants.",
|
||||
agent=coding_agent
|
||||
)
|
||||
|
||||
# Create a crew and add the task
|
||||
analysis_crew = Crew(
|
||||
agents=[coding_agent],
|
||||
tasks=[data_analysis_task]
|
||||
)
|
||||
|
||||
# Execute the crew
|
||||
result = analysis_crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
|
||||
In this example, the `coding_agent` can write and execute Python code to perform data analysis tasks.
|
||||
@@ -1,89 +0,0 @@
|
||||
---
|
||||
title: Conditional Tasks
|
||||
description: Learn how to use conditional tasks in a crewAI kickoff
|
||||
icon: diagram-subtask
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
Conditional Tasks in crewAI allow for dynamic workflow adaptation based on the outcomes of previous tasks.
|
||||
This powerful feature enables crews to make decisions and execute tasks selectively, enhancing the flexibility and efficiency of your AI-driven processes.
|
||||
|
||||
## Example Usage
|
||||
|
||||
```python Code
|
||||
from typing import List
|
||||
from pydantic import BaseModel
|
||||
from crewai import Agent, Crew
|
||||
from crewai.tasks.conditional_task import ConditionalTask
|
||||
from crewai.tasks.task_output import TaskOutput
|
||||
from crewai.task import Task
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
# Define a condition function for the conditional task
|
||||
# If false, the task will be skipped, if true, then execute the task.
|
||||
def is_data_missing(output: TaskOutput) -> bool:
|
||||
return len(output.pydantic.events) < 10 # this will skip this task
|
||||
|
||||
# Define the agents
|
||||
data_fetcher_agent = Agent(
|
||||
role="Data Fetcher",
|
||||
goal="Fetch data online using Serper tool",
|
||||
backstory="Backstory 1",
|
||||
verbose=True,
|
||||
tools=[SerperDevTool()]
|
||||
)
|
||||
|
||||
data_processor_agent = Agent(
|
||||
role="Data Processor",
|
||||
goal="Process fetched data",
|
||||
backstory="Backstory 2",
|
||||
verbose=True
|
||||
)
|
||||
|
||||
summary_generator_agent = Agent(
|
||||
role="Summary Generator",
|
||||
goal="Generate summary from fetched data",
|
||||
backstory="Backstory 3",
|
||||
verbose=True
|
||||
)
|
||||
|
||||
class EventOutput(BaseModel):
|
||||
events: List[str]
|
||||
|
||||
task1 = Task(
|
||||
description="Fetch data about events in San Francisco using Serper tool",
|
||||
expected_output="List of 10 things to do in SF this week",
|
||||
agent=data_fetcher_agent,
|
||||
output_pydantic=EventOutput,
|
||||
)
|
||||
|
||||
conditional_task = ConditionalTask(
|
||||
description="""
|
||||
Check if data is missing. If we have less than 10 events,
|
||||
fetch more events using Serper tool so that
|
||||
we have a total of 10 events in SF this week..
|
||||
""",
|
||||
expected_output="List of 10 Things to do in SF this week",
|
||||
condition=is_data_missing,
|
||||
agent=data_processor_agent,
|
||||
)
|
||||
|
||||
task3 = Task(
|
||||
description="Generate summary of events in San Francisco from fetched data",
|
||||
expected_output="A complete report on the customer and their customers and competitors, including their demographics, preferences, market positioning and audience engagement.",
|
||||
agent=summary_generator_agent,
|
||||
)
|
||||
|
||||
# Create a crew with the tasks
|
||||
crew = Crew(
|
||||
agents=[data_fetcher_agent, data_processor_agent, summary_generator_agent],
|
||||
tasks=[task1, conditional_task, task3],
|
||||
verbose=True,
|
||||
planning=True
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
result = crew.kickoff()
|
||||
print("results", result)
|
||||
```
|
||||
@@ -1,69 +0,0 @@
|
||||
---
|
||||
title: Create Custom Tools
|
||||
description: Comprehensive guide on crafting, using, and managing custom tools within the CrewAI framework, including new functionalities and error handling.
|
||||
icon: hammer
|
||||
---
|
||||
|
||||
## Creating and Utilizing Tools in CrewAI
|
||||
|
||||
This guide provides detailed instructions on creating custom tools for the CrewAI framework and how to efficiently manage and utilize these tools,
|
||||
incorporating the latest functionalities such as tool delegation, error handling, and dynamic tool calling. It also highlights the importance of collaboration tools,
|
||||
enabling agents to perform a wide range of actions.
|
||||
|
||||
### Subclassing `BaseTool`
|
||||
|
||||
To create a personalized tool, inherit from `BaseTool` and define the necessary attributes, including the `args_schema` for input validation, and the `_run` method.
|
||||
|
||||
```python Code
|
||||
from typing import Type
|
||||
from crewai.tools import BaseTool
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
class MyToolInput(BaseModel):
|
||||
"""Input schema for MyCustomTool."""
|
||||
argument: str = Field(..., description="Description of the argument.")
|
||||
|
||||
class MyCustomTool(BaseTool):
|
||||
name: str = "Name of my tool"
|
||||
description: str = "What this tool does. It's vital for effective utilization."
|
||||
args_schema: Type[BaseModel] = MyToolInput
|
||||
|
||||
def _run(self, argument: str) -> str:
|
||||
# Your tool's logic here
|
||||
return "Tool's result"
|
||||
```
|
||||
|
||||
### Using the `tool` Decorator
|
||||
|
||||
Alternatively, you can use the tool decorator `@tool`. This approach allows you to define the tool's attributes and functionality directly within a function,
|
||||
offering a concise and efficient way to create specialized tools tailored to your needs.
|
||||
|
||||
```python Code
|
||||
from crewai.tools import tool
|
||||
|
||||
@tool("Tool Name")
|
||||
def my_simple_tool(question: str) -> str:
|
||||
"""Tool description for clarity."""
|
||||
# Tool logic here
|
||||
return "Tool output"
|
||||
```
|
||||
|
||||
### Defining a Cache Function for the Tool
|
||||
|
||||
To optimize tool performance with caching, define custom caching strategies using the `cache_function` attribute.
|
||||
|
||||
```python Code
|
||||
@tool("Tool with Caching")
|
||||
def cached_tool(argument: str) -> str:
|
||||
"""Tool functionality description."""
|
||||
return "Cacheable result"
|
||||
|
||||
def my_cache_strategy(arguments: dict, result: str) -> bool:
|
||||
# Define custom caching logic
|
||||
return True if some_condition else False
|
||||
|
||||
cached_tool.cache_function = my_cache_strategy
|
||||
```
|
||||
|
||||
By adhering to these guidelines and incorporating new functionalities and collaboration tools into your tool creation and management processes,
|
||||
you can leverage the full capabilities of the CrewAI framework, enhancing both the development experience and the efficiency of your AI agents.
|
||||
@@ -1,646 +0,0 @@
|
||||
---
|
||||
title: Custom LLM Implementation
|
||||
description: Learn how to create custom LLM implementations in CrewAI.
|
||||
icon: code
|
||||
---
|
||||
|
||||
## Custom LLM Implementations
|
||||
|
||||
CrewAI now supports custom LLM implementations through the `BaseLLM` abstract base class. This allows you to create your own LLM implementations that don't rely on litellm's authentication mechanism.
|
||||
|
||||
To create a custom LLM implementation, you need to:
|
||||
|
||||
1. Inherit from the `BaseLLM` abstract base class
|
||||
2. Implement the required methods:
|
||||
- `call()`: The main method to call the LLM with messages
|
||||
- `supports_function_calling()`: Whether the LLM supports function calling
|
||||
- `supports_stop_words()`: Whether the LLM supports stop words
|
||||
- `get_context_window_size()`: The context window size of the LLM
|
||||
|
||||
## Example: Basic Custom LLM
|
||||
|
||||
```python
|
||||
from crewai import BaseLLM
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
class CustomLLM(BaseLLM):
|
||||
def __init__(self, api_key: str, endpoint: str):
|
||||
super().__init__() # Initialize the base class to set default attributes
|
||||
if not api_key or not isinstance(api_key, str):
|
||||
raise ValueError("Invalid API key: must be a non-empty string")
|
||||
if not endpoint or not isinstance(endpoint, str):
|
||||
raise ValueError("Invalid endpoint URL: must be a non-empty string")
|
||||
self.api_key = api_key
|
||||
self.endpoint = endpoint
|
||||
self.stop = [] # You can customize stop words if needed
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
"""Call the LLM with the given messages.
|
||||
|
||||
Args:
|
||||
messages: Input messages for the LLM.
|
||||
tools: Optional list of tool schemas for function calling.
|
||||
callbacks: Optional list of callback functions.
|
||||
available_functions: Optional dict mapping function names to callables.
|
||||
|
||||
Returns:
|
||||
Either a text response from the LLM or the result of a tool function call.
|
||||
|
||||
Raises:
|
||||
TimeoutError: If the LLM request times out.
|
||||
RuntimeError: If the LLM request fails for other reasons.
|
||||
ValueError: If the response format is invalid.
|
||||
"""
|
||||
# Implement your own logic to call the LLM
|
||||
# For example, using requests:
|
||||
import requests
|
||||
|
||||
try:
|
||||
headers = {
|
||||
"Authorization": f"Bearer {self.api_key}",
|
||||
"Content-Type": "application/json"
|
||||
}
|
||||
|
||||
# Convert string message to proper format if needed
|
||||
if isinstance(messages, str):
|
||||
messages = [{"role": "user", "content": messages}]
|
||||
|
||||
data = {
|
||||
"messages": messages,
|
||||
"tools": tools
|
||||
}
|
||||
|
||||
response = requests.post(
|
||||
self.endpoint,
|
||||
headers=headers,
|
||||
json=data,
|
||||
timeout=30 # Set a reasonable timeout
|
||||
)
|
||||
response.raise_for_status() # Raise an exception for HTTP errors
|
||||
return response.json()["choices"][0]["message"]["content"]
|
||||
except requests.Timeout:
|
||||
raise TimeoutError("LLM request timed out")
|
||||
except requests.RequestException as e:
|
||||
raise RuntimeError(f"LLM request failed: {str(e)}")
|
||||
except (KeyError, IndexError, ValueError) as e:
|
||||
raise ValueError(f"Invalid response format: {str(e)}")
|
||||
|
||||
def supports_function_calling(self) -> bool:
|
||||
"""Check if the LLM supports function calling.
|
||||
|
||||
Returns:
|
||||
True if the LLM supports function calling, False otherwise.
|
||||
"""
|
||||
# Return True if your LLM supports function calling
|
||||
return True
|
||||
|
||||
def supports_stop_words(self) -> bool:
|
||||
"""Check if the LLM supports stop words.
|
||||
|
||||
Returns:
|
||||
True if the LLM supports stop words, False otherwise.
|
||||
"""
|
||||
# Return True if your LLM supports stop words
|
||||
return True
|
||||
|
||||
def get_context_window_size(self) -> int:
|
||||
"""Get the context window size of the LLM.
|
||||
|
||||
Returns:
|
||||
The context window size as an integer.
|
||||
"""
|
||||
# Return the context window size of your LLM
|
||||
return 8192
|
||||
```
|
||||
|
||||
## Error Handling Best Practices
|
||||
|
||||
When implementing custom LLMs, it's important to handle errors properly to ensure robustness and reliability. Here are some best practices:
|
||||
|
||||
### 1. Implement Try-Except Blocks for API Calls
|
||||
|
||||
Always wrap API calls in try-except blocks to handle different types of errors:
|
||||
|
||||
```python
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
try:
|
||||
# API call implementation
|
||||
response = requests.post(
|
||||
self.endpoint,
|
||||
headers=self.headers,
|
||||
json=self.prepare_payload(messages),
|
||||
timeout=30 # Set a reasonable timeout
|
||||
)
|
||||
response.raise_for_status() # Raise an exception for HTTP errors
|
||||
return response.json()["choices"][0]["message"]["content"]
|
||||
except requests.Timeout:
|
||||
raise TimeoutError("LLM request timed out")
|
||||
except requests.RequestException as e:
|
||||
raise RuntimeError(f"LLM request failed: {str(e)}")
|
||||
except (KeyError, IndexError, ValueError) as e:
|
||||
raise ValueError(f"Invalid response format: {str(e)}")
|
||||
```
|
||||
|
||||
### 2. Implement Retry Logic for Transient Failures
|
||||
|
||||
For transient failures like network issues or rate limiting, implement retry logic with exponential backoff:
|
||||
|
||||
```python
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
import time
|
||||
|
||||
max_retries = 3
|
||||
retry_delay = 1 # seconds
|
||||
|
||||
for attempt in range(max_retries):
|
||||
try:
|
||||
response = requests.post(
|
||||
self.endpoint,
|
||||
headers=self.headers,
|
||||
json=self.prepare_payload(messages),
|
||||
timeout=30
|
||||
)
|
||||
response.raise_for_status()
|
||||
return response.json()["choices"][0]["message"]["content"]
|
||||
except (requests.Timeout, requests.ConnectionError) as e:
|
||||
if attempt < max_retries - 1:
|
||||
time.sleep(retry_delay * (2 ** attempt)) # Exponential backoff
|
||||
continue
|
||||
raise TimeoutError(f"LLM request failed after {max_retries} attempts: {str(e)}")
|
||||
except requests.RequestException as e:
|
||||
raise RuntimeError(f"LLM request failed: {str(e)}")
|
||||
```
|
||||
|
||||
### 3. Validate Input Parameters
|
||||
|
||||
Always validate input parameters to prevent runtime errors:
|
||||
|
||||
```python
|
||||
def __init__(self, api_key: str, endpoint: str):
|
||||
super().__init__()
|
||||
if not api_key or not isinstance(api_key, str):
|
||||
raise ValueError("Invalid API key: must be a non-empty string")
|
||||
if not endpoint or not isinstance(endpoint, str):
|
||||
raise ValueError("Invalid endpoint URL: must be a non-empty string")
|
||||
self.api_key = api_key
|
||||
self.endpoint = endpoint
|
||||
```
|
||||
|
||||
### 4. Handle Authentication Errors Gracefully
|
||||
|
||||
Provide clear error messages for authentication failures:
|
||||
|
||||
```python
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
try:
|
||||
response = requests.post(self.endpoint, headers=self.headers, json=data)
|
||||
if response.status_code == 401:
|
||||
raise ValueError("Authentication failed: Invalid API key or token")
|
||||
elif response.status_code == 403:
|
||||
raise ValueError("Authorization failed: Insufficient permissions")
|
||||
response.raise_for_status()
|
||||
# Process response
|
||||
except Exception as e:
|
||||
# Handle error
|
||||
raise
|
||||
```
|
||||
|
||||
## Example: JWT-based Authentication
|
||||
|
||||
For services that use JWT-based authentication instead of API keys, you can implement a custom LLM like this:
|
||||
|
||||
```python
|
||||
from crewai import BaseLLM, Agent, Task
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
class JWTAuthLLM(BaseLLM):
|
||||
def __init__(self, jwt_token: str, endpoint: str):
|
||||
super().__init__() # Initialize the base class to set default attributes
|
||||
if not jwt_token or not isinstance(jwt_token, str):
|
||||
raise ValueError("Invalid JWT token: must be a non-empty string")
|
||||
if not endpoint or not isinstance(endpoint, str):
|
||||
raise ValueError("Invalid endpoint URL: must be a non-empty string")
|
||||
self.jwt_token = jwt_token
|
||||
self.endpoint = endpoint
|
||||
self.stop = [] # You can customize stop words if needed
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
"""Call the LLM with JWT authentication.
|
||||
|
||||
Args:
|
||||
messages: Input messages for the LLM.
|
||||
tools: Optional list of tool schemas for function calling.
|
||||
callbacks: Optional list of callback functions.
|
||||
available_functions: Optional dict mapping function names to callables.
|
||||
|
||||
Returns:
|
||||
Either a text response from the LLM or the result of a tool function call.
|
||||
|
||||
Raises:
|
||||
TimeoutError: If the LLM request times out.
|
||||
RuntimeError: If the LLM request fails for other reasons.
|
||||
ValueError: If the response format is invalid.
|
||||
"""
|
||||
# Implement your own logic to call the LLM with JWT authentication
|
||||
import requests
|
||||
|
||||
try:
|
||||
headers = {
|
||||
"Authorization": f"Bearer {self.jwt_token}",
|
||||
"Content-Type": "application/json"
|
||||
}
|
||||
|
||||
# Convert string message to proper format if needed
|
||||
if isinstance(messages, str):
|
||||
messages = [{"role": "user", "content": messages}]
|
||||
|
||||
data = {
|
||||
"messages": messages,
|
||||
"tools": tools
|
||||
}
|
||||
|
||||
response = requests.post(
|
||||
self.endpoint,
|
||||
headers=headers,
|
||||
json=data,
|
||||
timeout=30 # Set a reasonable timeout
|
||||
)
|
||||
|
||||
if response.status_code == 401:
|
||||
raise ValueError("Authentication failed: Invalid JWT token")
|
||||
elif response.status_code == 403:
|
||||
raise ValueError("Authorization failed: Insufficient permissions")
|
||||
|
||||
response.raise_for_status() # Raise an exception for HTTP errors
|
||||
return response.json()["choices"][0]["message"]["content"]
|
||||
except requests.Timeout:
|
||||
raise TimeoutError("LLM request timed out")
|
||||
except requests.RequestException as e:
|
||||
raise RuntimeError(f"LLM request failed: {str(e)}")
|
||||
except (KeyError, IndexError, ValueError) as e:
|
||||
raise ValueError(f"Invalid response format: {str(e)}")
|
||||
|
||||
def supports_function_calling(self) -> bool:
|
||||
"""Check if the LLM supports function calling.
|
||||
|
||||
Returns:
|
||||
True if the LLM supports function calling, False otherwise.
|
||||
"""
|
||||
return True
|
||||
|
||||
def supports_stop_words(self) -> bool:
|
||||
"""Check if the LLM supports stop words.
|
||||
|
||||
Returns:
|
||||
True if the LLM supports stop words, False otherwise.
|
||||
"""
|
||||
return True
|
||||
|
||||
def get_context_window_size(self) -> int:
|
||||
"""Get the context window size of the LLM.
|
||||
|
||||
Returns:
|
||||
The context window size as an integer.
|
||||
"""
|
||||
return 8192
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
Here are some common issues you might encounter when implementing custom LLMs and how to resolve them:
|
||||
|
||||
### 1. Authentication Failures
|
||||
|
||||
**Symptoms**: 401 Unauthorized or 403 Forbidden errors
|
||||
|
||||
**Solutions**:
|
||||
- Verify that your API key or JWT token is valid and not expired
|
||||
- Check that you're using the correct authentication header format
|
||||
- Ensure that your token has the necessary permissions
|
||||
|
||||
### 2. Timeout Issues
|
||||
|
||||
**Symptoms**: Requests taking too long or timing out
|
||||
|
||||
**Solutions**:
|
||||
- Implement timeout handling as shown in the examples
|
||||
- Use retry logic with exponential backoff
|
||||
- Consider using a more reliable network connection
|
||||
|
||||
### 3. Response Parsing Errors
|
||||
|
||||
**Symptoms**: KeyError, IndexError, or ValueError when processing responses
|
||||
|
||||
**Solutions**:
|
||||
- Validate the response format before accessing nested fields
|
||||
- Implement proper error handling for malformed responses
|
||||
- Check the API documentation for the expected response format
|
||||
|
||||
### 4. Rate Limiting
|
||||
|
||||
**Symptoms**: 429 Too Many Requests errors
|
||||
|
||||
**Solutions**:
|
||||
- Implement rate limiting in your custom LLM
|
||||
- Add exponential backoff for retries
|
||||
- Consider using a token bucket algorithm for more precise rate control
|
||||
|
||||
## Advanced Features
|
||||
|
||||
### Logging
|
||||
|
||||
Adding logging to your custom LLM can help with debugging and monitoring:
|
||||
|
||||
```python
|
||||
import logging
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
class LoggingLLM(BaseLLM):
|
||||
def __init__(self, api_key: str, endpoint: str):
|
||||
super().__init__()
|
||||
self.api_key = api_key
|
||||
self.endpoint = endpoint
|
||||
self.logger = logging.getLogger("crewai.llm.custom")
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
self.logger.info(f"Calling LLM with {len(messages) if isinstance(messages, list) else 1} messages")
|
||||
try:
|
||||
# API call implementation
|
||||
response = self._make_api_call(messages, tools)
|
||||
self.logger.debug(f"LLM response received: {response[:100]}...")
|
||||
return response
|
||||
except Exception as e:
|
||||
self.logger.error(f"LLM call failed: {str(e)}")
|
||||
raise
|
||||
```
|
||||
|
||||
### Rate Limiting
|
||||
|
||||
Implementing rate limiting can help avoid overwhelming the LLM API:
|
||||
|
||||
```python
|
||||
import time
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
class RateLimitedLLM(BaseLLM):
|
||||
def __init__(
|
||||
self,
|
||||
api_key: str,
|
||||
endpoint: str,
|
||||
requests_per_minute: int = 60
|
||||
):
|
||||
super().__init__()
|
||||
self.api_key = api_key
|
||||
self.endpoint = endpoint
|
||||
self.requests_per_minute = requests_per_minute
|
||||
self.request_times: List[float] = []
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
self._enforce_rate_limit()
|
||||
# Record this request time
|
||||
self.request_times.append(time.time())
|
||||
# Make the actual API call
|
||||
return self._make_api_call(messages, tools)
|
||||
|
||||
def _enforce_rate_limit(self) -> None:
|
||||
"""Enforce the rate limit by waiting if necessary."""
|
||||
now = time.time()
|
||||
# Remove request times older than 1 minute
|
||||
self.request_times = [t for t in self.request_times if now - t < 60]
|
||||
|
||||
if len(self.request_times) >= self.requests_per_minute:
|
||||
# Calculate how long to wait
|
||||
oldest_request = min(self.request_times)
|
||||
wait_time = 60 - (now - oldest_request)
|
||||
if wait_time > 0:
|
||||
time.sleep(wait_time)
|
||||
```
|
||||
|
||||
### Metrics Collection
|
||||
|
||||
Collecting metrics can help you monitor your LLM usage:
|
||||
|
||||
```python
|
||||
import time
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
class MetricsCollectingLLM(BaseLLM):
|
||||
def __init__(self, api_key: str, endpoint: str):
|
||||
super().__init__()
|
||||
self.api_key = api_key
|
||||
self.endpoint = endpoint
|
||||
self.metrics: Dict[str, Any] = {
|
||||
"total_calls": 0,
|
||||
"total_tokens": 0,
|
||||
"errors": 0,
|
||||
"latency": []
|
||||
}
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
start_time = time.time()
|
||||
self.metrics["total_calls"] += 1
|
||||
|
||||
try:
|
||||
response = self._make_api_call(messages, tools)
|
||||
# Estimate tokens (simplified)
|
||||
if isinstance(messages, str):
|
||||
token_estimate = len(messages) // 4
|
||||
else:
|
||||
token_estimate = sum(len(m.get("content", "")) // 4 for m in messages)
|
||||
self.metrics["total_tokens"] += token_estimate
|
||||
return response
|
||||
except Exception as e:
|
||||
self.metrics["errors"] += 1
|
||||
raise
|
||||
finally:
|
||||
latency = time.time() - start_time
|
||||
self.metrics["latency"].append(latency)
|
||||
|
||||
def get_metrics(self) -> Dict[str, Any]:
|
||||
"""Return the collected metrics."""
|
||||
avg_latency = sum(self.metrics["latency"]) / len(self.metrics["latency"]) if self.metrics["latency"] else 0
|
||||
return {
|
||||
**self.metrics,
|
||||
"avg_latency": avg_latency
|
||||
}
|
||||
```
|
||||
|
||||
## Advanced Usage: Function Calling
|
||||
|
||||
If your LLM supports function calling, you can implement the function calling logic in your custom LLM:
|
||||
|
||||
```python
|
||||
import json
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
def call(
|
||||
self,
|
||||
messages: Union[str, List[Dict[str, str]]],
|
||||
tools: Optional[List[dict]] = None,
|
||||
callbacks: Optional[List[Any]] = None,
|
||||
available_functions: Optional[Dict[str, Any]] = None,
|
||||
) -> Union[str, Any]:
|
||||
import requests
|
||||
|
||||
try:
|
||||
headers = {
|
||||
"Authorization": f"Bearer {self.jwt_token}",
|
||||
"Content-Type": "application/json"
|
||||
}
|
||||
|
||||
# Convert string message to proper format if needed
|
||||
if isinstance(messages, str):
|
||||
messages = [{"role": "user", "content": messages}]
|
||||
|
||||
data = {
|
||||
"messages": messages,
|
||||
"tools": tools
|
||||
}
|
||||
|
||||
response = requests.post(
|
||||
self.endpoint,
|
||||
headers=headers,
|
||||
json=data,
|
||||
timeout=30
|
||||
)
|
||||
response.raise_for_status()
|
||||
response_data = response.json()
|
||||
|
||||
# Check if the LLM wants to call a function
|
||||
if response_data["choices"][0]["message"].get("tool_calls"):
|
||||
tool_calls = response_data["choices"][0]["message"]["tool_calls"]
|
||||
|
||||
# Process each tool call
|
||||
for tool_call in tool_calls:
|
||||
function_name = tool_call["function"]["name"]
|
||||
function_args = json.loads(tool_call["function"]["arguments"])
|
||||
|
||||
if available_functions and function_name in available_functions:
|
||||
function_to_call = available_functions[function_name]
|
||||
function_response = function_to_call(**function_args)
|
||||
|
||||
# Add the function response to the messages
|
||||
messages.append({
|
||||
"role": "tool",
|
||||
"tool_call_id": tool_call["id"],
|
||||
"name": function_name,
|
||||
"content": str(function_response)
|
||||
})
|
||||
|
||||
# Call the LLM again with the updated messages
|
||||
return self.call(messages, tools, callbacks, available_functions)
|
||||
|
||||
# Return the text response if no function call
|
||||
return response_data["choices"][0]["message"]["content"]
|
||||
except requests.Timeout:
|
||||
raise TimeoutError("LLM request timed out")
|
||||
except requests.RequestException as e:
|
||||
raise RuntimeError(f"LLM request failed: {str(e)}")
|
||||
except (KeyError, IndexError, ValueError) as e:
|
||||
raise ValueError(f"Invalid response format: {str(e)}")
|
||||
```
|
||||
|
||||
## Using Your Custom LLM with CrewAI
|
||||
|
||||
Once you've implemented your custom LLM, you can use it with CrewAI agents and crews:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
from typing import Dict, Any
|
||||
|
||||
# Create your custom LLM instance
|
||||
jwt_llm = JWTAuthLLM(
|
||||
jwt_token="your.jwt.token",
|
||||
endpoint="https://your-llm-endpoint.com/v1/chat/completions"
|
||||
)
|
||||
|
||||
# Use it with an agent
|
||||
agent = Agent(
|
||||
role="Research Assistant",
|
||||
goal="Find information on a topic",
|
||||
backstory="You are a research assistant tasked with finding information.",
|
||||
llm=jwt_llm,
|
||||
)
|
||||
|
||||
# Create a task for the agent
|
||||
task = Task(
|
||||
description="Research the benefits of exercise",
|
||||
agent=agent,
|
||||
expected_output="A summary of the benefits of exercise",
|
||||
)
|
||||
|
||||
# Execute the task
|
||||
result = agent.execute_task(task)
|
||||
print(result)
|
||||
|
||||
# Or use it with a crew
|
||||
crew = Crew(
|
||||
agents=[agent],
|
||||
tasks=[task],
|
||||
manager_llm=jwt_llm, # Use your custom LLM for the manager
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
|
||||
## Implementing Your Own Authentication Mechanism
|
||||
|
||||
The `BaseLLM` class allows you to implement any authentication mechanism you need, not just JWT or API keys. You can use:
|
||||
|
||||
- OAuth tokens
|
||||
- Client certificates
|
||||
- Custom headers
|
||||
- Session-based authentication
|
||||
- Any other authentication method required by your LLM provider
|
||||
|
||||
Simply implement the appropriate authentication logic in your custom LLM class.
|
||||
@@ -1,90 +0,0 @@
|
||||
---
|
||||
title: Custom Manager Agent
|
||||
description: Learn how to set a custom agent as the manager in CrewAI, providing more control over task management and coordination.
|
||||
icon: user-shield
|
||||
---
|
||||
|
||||
# Setting a Specific Agent as Manager in CrewAI
|
||||
|
||||
CrewAI allows users to set a specific agent as the manager of the crew, providing more control over the management and coordination of tasks.
|
||||
This feature enables the customization of the managerial role to better fit your project's requirements.
|
||||
|
||||
## Using the `manager_agent` Attribute
|
||||
|
||||
### Custom Manager Agent
|
||||
|
||||
The `manager_agent` attribute allows you to define a custom agent to manage the crew. This agent will oversee the entire process, ensuring that tasks are completed efficiently and to the highest standard.
|
||||
|
||||
### Example
|
||||
|
||||
```python Code
|
||||
import os
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
|
||||
# Define your agents
|
||||
researcher = Agent(
|
||||
role="Researcher",
|
||||
goal="Conduct thorough research and analysis on AI and AI agents",
|
||||
backstory="You're an expert researcher, specialized in technology, software engineering, AI, and startups. You work as a freelancer and are currently researching for a new client.",
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role="Senior Writer",
|
||||
goal="Create compelling content about AI and AI agents",
|
||||
backstory="You're a senior writer, specialized in technology, software engineering, AI, and startups. You work as a freelancer and are currently writing content for a new client.",
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
# Define your task
|
||||
task = Task(
|
||||
description="Generate a list of 5 interesting ideas for an article, then write one captivating paragraph for each idea that showcases the potential of a full article on this topic. Return the list of ideas with their paragraphs and your notes.",
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Define the manager agent
|
||||
manager = Agent(
|
||||
role="Project Manager",
|
||||
goal="Efficiently manage the crew and ensure high-quality task completion",
|
||||
backstory="You're an experienced project manager, skilled in overseeing complex projects and guiding teams to success. Your role is to coordinate the efforts of the crew members, ensuring that each task is completed on time and to the highest standard.",
|
||||
allow_delegation=True,
|
||||
)
|
||||
|
||||
# Instantiate your crew with a custom manager
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[task],
|
||||
manager_agent=manager,
|
||||
process=Process.hierarchical,
|
||||
)
|
||||
|
||||
# Start the crew's work
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
## Benefits of a Custom Manager Agent
|
||||
|
||||
- **Enhanced Control**: Tailor the management approach to fit the specific needs of your project.
|
||||
- **Improved Coordination**: Ensure efficient task coordination and management by an experienced agent.
|
||||
- **Customizable Management**: Define managerial roles and responsibilities that align with your project's goals.
|
||||
|
||||
## Setting a Manager LLM
|
||||
|
||||
If you're using the hierarchical process and don't want to set a custom manager agent, you can specify the language model for the manager:
|
||||
|
||||
```python Code
|
||||
from crewai import LLM
|
||||
|
||||
manager_llm = LLM(model="gpt-4o")
|
||||
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[task],
|
||||
process=Process.hierarchical,
|
||||
manager_llm=manager_llm
|
||||
)
|
||||
```
|
||||
|
||||
<Note>
|
||||
Either `manager_agent` or `manager_llm` must be set when using the hierarchical process.
|
||||
</Note>
|
||||
@@ -1,111 +0,0 @@
|
||||
---
|
||||
title: Customize Agents
|
||||
description: A comprehensive guide to tailoring agents for specific roles, tasks, and advanced customizations within the CrewAI framework.
|
||||
icon: user-pen
|
||||
---
|
||||
|
||||
## Customizable Attributes
|
||||
|
||||
Crafting an efficient CrewAI team hinges on the ability to dynamically tailor your AI agents to meet the unique requirements of any project. This section covers the foundational attributes you can customize.
|
||||
|
||||
### Key Attributes for Customization
|
||||
|
||||
| Attribute | Description |
|
||||
|:-----------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **Role** | Specifies the agent's job within the crew, such as 'Analyst' or 'Customer Service Rep'. |
|
||||
| **Goal** | Defines the agent’s objectives, aligned with its role and the crew’s overarching mission. |
|
||||
| **Backstory** | Provides depth to the agent's persona, enhancing motivations and engagements within the crew. |
|
||||
| **Tools** *(Optional)* | Represents the capabilities or methods the agent uses for tasks, from simple functions to complex integrations. |
|
||||
| **Cache** *(Optional)* | Determines if the agent should use a cache for tool usage. |
|
||||
| **Max RPM** | Sets the maximum requests per minute (`max_rpm`). Can be set to `None` for unlimited requests to external services. |
|
||||
| **Verbose** *(Optional)* | Enables detailed logging for debugging and optimization, providing insights into execution processes. |
|
||||
| **Allow Delegation** *(Optional)* | Controls task delegation to other agents, default is `False`. |
|
||||
| **Max Iter** *(Optional)* | Limits the maximum number of iterations (`max_iter`) for a task to prevent infinite loops, with a default of 25. |
|
||||
| **Max Execution Time** *(Optional)* | Sets the maximum time allowed for an agent to complete a task. |
|
||||
| **System Template** *(Optional)* | Defines the system format for the agent. |
|
||||
| **Prompt Template** *(Optional)* | Defines the prompt format for the agent. |
|
||||
| **Response Template** *(Optional)* | Defines the response format for the agent. |
|
||||
| **Use System Prompt** *(Optional)* | Controls whether the agent will use a system prompt during task execution. |
|
||||
| **Respect Context Window** | Enables a sliding context window by default, maintaining context size. |
|
||||
| **Max Retry Limit** | Sets the maximum number of retries (`max_retry_limit`) for an agent in case of errors. |
|
||||
|
||||
## Advanced Customization Options
|
||||
|
||||
Beyond the basic attributes, CrewAI allows for deeper customization to enhance an agent's behavior and capabilities significantly.
|
||||
|
||||
### Language Model Customization
|
||||
|
||||
Agents can be customized with specific language models (`llm`) and function-calling language models (`function_calling_llm`), offering advanced control over their processing and decision-making abilities.
|
||||
It's important to note that setting the `function_calling_llm` allows for overriding the default crew function-calling language model, providing a greater degree of customization.
|
||||
|
||||
## Performance and Debugging Settings
|
||||
|
||||
Adjusting an agent's performance and monitoring its operations are crucial for efficient task execution.
|
||||
|
||||
### Verbose Mode and RPM Limit
|
||||
|
||||
- **Verbose Mode**: Enables detailed logging of an agent's actions, useful for debugging and optimization. Specifically, it provides insights into agent execution processes, aiding in the optimization of performance.
|
||||
- **RPM Limit**: Sets the maximum number of requests per minute (`max_rpm`). This attribute is optional and can be set to `None` for no limit, allowing for unlimited queries to external services if needed.
|
||||
|
||||
### Maximum Iterations for Task Execution
|
||||
|
||||
The `max_iter` attribute allows users to define the maximum number of iterations an agent can perform for a single task, preventing infinite loops or excessively long executions.
|
||||
The default value is set to 25, providing a balance between thoroughness and efficiency. Once the agent approaches this number, it will try its best to give a good answer.
|
||||
|
||||
## Customizing Agents and Tools
|
||||
|
||||
Agents are customized by defining their attributes and tools during initialization. Tools are critical for an agent's functionality, enabling them to perform specialized tasks.
|
||||
The `tools` attribute should be an array of tools the agent can utilize, and it's initialized as an empty list by default. Tools can be added or modified post-agent initialization to adapt to new requirements.
|
||||
|
||||
```shell
|
||||
pip install 'crewai[tools]'
|
||||
```
|
||||
|
||||
### Example: Assigning Tools to an Agent
|
||||
|
||||
```python Code
|
||||
import os
|
||||
from crewai import Agent
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
# Set API keys for tool initialization
|
||||
os.environ["OPENAI_API_KEY"] = "Your Key"
|
||||
os.environ["SERPER_API_KEY"] = "Your Key"
|
||||
|
||||
# Initialize a search tool
|
||||
search_tool = SerperDevTool()
|
||||
|
||||
# Initialize the agent with advanced options
|
||||
agent = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Provide up-to-date market analysis',
|
||||
backstory='An expert analyst with a keen eye for market trends.',
|
||||
tools=[search_tool],
|
||||
memory=True, # Enable memory
|
||||
verbose=True,
|
||||
max_rpm=None, # No limit on requests per minute
|
||||
max_iter=25, # Default value for maximum iterations
|
||||
)
|
||||
```
|
||||
|
||||
## Delegation and Autonomy
|
||||
|
||||
Controlling an agent's ability to delegate tasks or ask questions is vital for tailoring its autonomy and collaborative dynamics within the CrewAI framework. By default,
|
||||
the `allow_delegation` attribute is now set to `False`, disabling agents to seek assistance or delegate tasks as needed. This default behavior can be changed to promote collaborative problem-solving and
|
||||
efficiency within the CrewAI ecosystem. If needed, delegation can be enabled to suit specific operational requirements.
|
||||
|
||||
### Example: Disabling Delegation for an Agent
|
||||
|
||||
```python Code
|
||||
agent = Agent(
|
||||
role='Content Writer',
|
||||
goal='Write engaging content on market trends',
|
||||
backstory='A seasoned writer with expertise in market analysis.',
|
||||
allow_delegation=True # Enabling delegation
|
||||
)
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
|
||||
Customizing agents in CrewAI by setting their roles, goals, backstories, and tools, alongside advanced options like language model customization, memory, performance settings, and delegation preferences,
|
||||
equips a nuanced and capable AI team ready for complex challenges.
|
||||
@@ -1,73 +0,0 @@
|
||||
---
|
||||
title: "Image Generation with DALL-E"
|
||||
description: "Learn how to use DALL-E for AI-powered image generation in your CrewAI projects"
|
||||
icon: "image"
|
||||
---
|
||||
|
||||
CrewAI supports integration with OpenAI's DALL-E, allowing your AI agents to generate images as part of their tasks. This guide will walk you through how to set up and use the DALL-E tool in your CrewAI projects.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- crewAI installed (latest version)
|
||||
- OpenAI API key with access to DALL-E
|
||||
|
||||
## Setting Up the DALL-E Tool
|
||||
|
||||
<Steps>
|
||||
<Step title="Import the DALL-E tool">
|
||||
```python
|
||||
from crewai_tools import DallETool
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="Add the DALL-E tool to your agent configuration">
|
||||
```python
|
||||
@agent
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['researcher'],
|
||||
tools=[SerperDevTool(), DallETool()], # Add DallETool to the list of tools
|
||||
allow_delegation=False,
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Using the DALL-E Tool
|
||||
|
||||
Once you've added the DALL-E tool to your agent, it can generate images based on text prompts. The tool will return a URL to the generated image, which can be used in the agent's output or passed to other agents for further processing.
|
||||
|
||||
### Example Agent Configuration
|
||||
|
||||
```yaml
|
||||
role: >
|
||||
LinkedIn Profile Senior Data Researcher
|
||||
goal: >
|
||||
Uncover detailed LinkedIn profiles based on provided name {name} and domain {domain}
|
||||
Generate a Dall-e image based on domain {domain}
|
||||
backstory: >
|
||||
You're a seasoned researcher with a knack for uncovering the most relevant LinkedIn profiles.
|
||||
Known for your ability to navigate LinkedIn efficiently, you excel at gathering and presenting
|
||||
professional information clearly and concisely.
|
||||
```
|
||||
|
||||
### Expected Output
|
||||
|
||||
The agent with the DALL-E tool will be able to generate the image and provide a URL in its response. You can then download the image.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/enterprise/dall-e-image.png" alt="DALL-E Image" />
|
||||
</Frame>
|
||||
|
||||
## Best Practices
|
||||
|
||||
1. **Be specific in your image generation prompts** to get the best results.
|
||||
2. **Consider generation time** - Image generation can take some time, so factor this into your task planning.
|
||||
3. **Follow usage policies** - Always comply with OpenAI's usage policies when generating images.
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
1. **Check API access** - Ensure your OpenAI API key has access to DALL-E.
|
||||
2. **Version compatibility** - Check that you're using the latest version of crewAI and crewai-tools.
|
||||
3. **Tool configuration** - Verify that the DALL-E tool is correctly added to the agent's tool list.
|
||||
@@ -1,50 +0,0 @@
|
||||
---
|
||||
title: Force Tool Output as Result
|
||||
description: Learn how to force tool output as the result in an Agent's task in CrewAI.
|
||||
icon: wrench-simple
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
In CrewAI, you can force the output of a tool as the result of an agent's task.
|
||||
This feature is useful when you want to ensure that the tool output is captured and returned as the task result, avoiding any agent modification during the task execution.
|
||||
|
||||
## Forcing Tool Output as Result
|
||||
|
||||
To force the tool output as the result of an agent's task, you need to set the `result_as_answer` parameter to `True` when adding a tool to the agent.
|
||||
This parameter ensures that the tool output is captured and returned as the task result, without any modifications by the agent.
|
||||
|
||||
Here's an example of how to force the tool output as the result of an agent's task:
|
||||
|
||||
```python Code
|
||||
from crewai.agent import Agent
|
||||
from my_tool import MyCustomTool
|
||||
|
||||
# Create a coding agent with the custom tool
|
||||
coding_agent = Agent(
|
||||
role="Data Scientist",
|
||||
goal="Produce amazing reports on AI",
|
||||
backstory="You work with data and AI",
|
||||
tools=[MyCustomTool(result_as_answer=True)],
|
||||
)
|
||||
|
||||
# Assuming the tool's execution and result population occurs within the system
|
||||
task_result = coding_agent.execute_task(task)
|
||||
```
|
||||
|
||||
## Workflow in Action
|
||||
|
||||
<Steps>
|
||||
<Step title="Task Execution">
|
||||
The agent executes the task using the tool provided.
|
||||
</Step>
|
||||
<Step title="Tool Output">
|
||||
The tool generates the output, which is captured as the task result.
|
||||
</Step>
|
||||
<Step title="Agent Interaction">
|
||||
The agent may reflect and take learnings from the tool but the output is not modified.
|
||||
</Step>
|
||||
<Step title="Result Return">
|
||||
The tool output is returned as the task result without any modifications.
|
||||
</Step>
|
||||
</Steps>
|
||||
@@ -1,112 +0,0 @@
|
||||
---
|
||||
title: Hierarchical Process
|
||||
description: A comprehensive guide to understanding and applying the hierarchical process within your CrewAI projects, updated to reflect the latest coding practices and functionalities.
|
||||
icon: sitemap
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
The hierarchical process in CrewAI introduces a structured approach to task management, simulating traditional organizational hierarchies for efficient task delegation and execution.
|
||||
This systematic workflow enhances project outcomes by ensuring tasks are handled with optimal efficiency and accuracy.
|
||||
|
||||
<Tip>
|
||||
The hierarchical process is designed to leverage advanced models like GPT-4, optimizing token usage while handling complex tasks with greater efficiency.
|
||||
</Tip>
|
||||
|
||||
## Hierarchical Process Overview
|
||||
|
||||
By default, tasks in CrewAI are managed through a sequential process. However, adopting a hierarchical approach allows for a clear hierarchy in task management,
|
||||
where a 'manager' agent coordinates the workflow, delegates tasks, and validates outcomes for streamlined and effective execution. This manager agent can now be either
|
||||
automatically created by CrewAI or explicitly set by the user.
|
||||
|
||||
### Key Features
|
||||
|
||||
- **Task Delegation**: A manager agent allocates tasks among crew members based on their roles and capabilities.
|
||||
- **Result Validation**: The manager evaluates outcomes to ensure they meet the required standards.
|
||||
- **Efficient Workflow**: Emulates corporate structures, providing an organized approach to task management.
|
||||
- **System Prompt Handling**: Optionally specify whether the system should use predefined prompts.
|
||||
- **Stop Words Control**: Optionally specify whether stop words should be used, supporting various models including the o1 models.
|
||||
- **Context Window Respect**: Prioritize important context by enabling respect of the context window, which is now the default behavior.
|
||||
- **Delegation Control**: Delegation is now disabled by default to give users explicit control.
|
||||
- **Max Requests Per Minute**: Configurable option to set the maximum number of requests per minute.
|
||||
- **Max Iterations**: Limit the maximum number of iterations for obtaining a final answer.
|
||||
|
||||
|
||||
## Implementing the Hierarchical Process
|
||||
|
||||
To utilize the hierarchical process, it's essential to explicitly set the process attribute to `Process.hierarchical`, as the default behavior is `Process.sequential`.
|
||||
Define a crew with a designated manager and establish a clear chain of command.
|
||||
|
||||
<Tip>
|
||||
Assign tools at the agent level to facilitate task delegation and execution by the designated agents under the manager's guidance.
|
||||
Tools can also be specified at the task level for precise control over tool availability during task execution.
|
||||
</Tip>
|
||||
|
||||
<Tip>
|
||||
Configuring the `manager_llm` parameter is crucial for the hierarchical process.
|
||||
The system requires a manager LLM to be set up for proper function, ensuring tailored decision-making.
|
||||
</Tip>
|
||||
|
||||
```python Code
|
||||
from crewai import Crew, Process, Agent
|
||||
|
||||
# Agents are defined with attributes for backstory, cache, and verbose mode
|
||||
researcher = Agent(
|
||||
role='Researcher',
|
||||
goal='Conduct in-depth analysis',
|
||||
backstory='Experienced data analyst with a knack for uncovering hidden trends.',
|
||||
)
|
||||
writer = Agent(
|
||||
role='Writer',
|
||||
goal='Create engaging content',
|
||||
backstory='Creative writer passionate about storytelling in technical domains.',
|
||||
)
|
||||
|
||||
# Establishing the crew with a hierarchical process and additional configurations
|
||||
project_crew = Crew(
|
||||
tasks=[...], # Tasks to be delegated and executed under the manager's supervision
|
||||
agents=[researcher, writer],
|
||||
manager_llm="gpt-4o", # Specify which LLM the manager should use
|
||||
process=Process.hierarchical,
|
||||
planning=True,
|
||||
)
|
||||
```
|
||||
|
||||
### Using a Custom Manager Agent
|
||||
|
||||
Alternatively, you can create a custom manager agent with specific attributes tailored to your project's management needs. This gives you more control over the manager's behavior and capabilities.
|
||||
|
||||
```python
|
||||
# Define a custom manager agent
|
||||
manager = Agent(
|
||||
role="Project Manager",
|
||||
goal="Efficiently manage the crew and ensure high-quality task completion",
|
||||
backstory="You're an experienced project manager, skilled in overseeing complex projects and guiding teams to success.",
|
||||
allow_delegation=True,
|
||||
)
|
||||
|
||||
# Use the custom manager in your crew
|
||||
project_crew = Crew(
|
||||
tasks=[...],
|
||||
agents=[researcher, writer],
|
||||
manager_agent=manager, # Use your custom manager agent
|
||||
process=Process.hierarchical,
|
||||
planning=True,
|
||||
)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
For more details on creating and customizing a manager agent, check out the [Custom Manager Agent documentation](https://docs.crewai.com/how-to/custom-manager-agent#custom-manager-agent).
|
||||
</Tip>
|
||||
|
||||
|
||||
### Workflow in Action
|
||||
|
||||
1. **Task Assignment**: The manager assigns tasks strategically, considering each agent's capabilities and available tools.
|
||||
2. **Execution and Review**: Agents complete their tasks with the option for asynchronous execution and callback functions for streamlined workflows.
|
||||
3. **Sequential Task Progression**: Despite being a hierarchical process, tasks follow a logical order for smooth progression, facilitated by the manager's oversight.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Adopting the hierarchical process in CrewAI, with the correct configurations and understanding of the system's capabilities, facilitates an organized and efficient approach to project management.
|
||||
Utilize the advanced features and customizations to tailor the workflow to your specific needs, ensuring optimal task execution and project success.
|
||||
@@ -1,78 +0,0 @@
|
||||
---
|
||||
title: "Human-in-the-Loop (HITL) Workflows"
|
||||
description: "Learn how to implement Human-in-the-Loop workflows in CrewAI for enhanced decision-making"
|
||||
icon: "user-check"
|
||||
---
|
||||
|
||||
Human-in-the-Loop (HITL) is a powerful approach that combines artificial intelligence with human expertise to enhance decision-making and improve task outcomes. This guide shows you how to implement HITL within CrewAI.
|
||||
|
||||
## Setting Up HITL Workflows
|
||||
|
||||
<Steps>
|
||||
<Step title="Configure Your Task">
|
||||
Set up your task with human input enabled:
|
||||
<Frame>
|
||||
<img src="/images/enterprise/crew-human-input.png" alt="Crew Human Input" />
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Provide Webhook URL">
|
||||
When kicking off your crew, include a webhook URL for human input:
|
||||
<Frame>
|
||||
<img src="/images/enterprise/crew-webhook-url.png" alt="Crew Webhook URL" />
|
||||
</Frame>
|
||||
</Step>
|
||||
|
||||
<Step title="Receive Webhook Notification">
|
||||
Once the crew completes the task requiring human input, you'll receive a webhook notification containing:
|
||||
- Execution ID
|
||||
- Task ID
|
||||
- Task output
|
||||
</Step>
|
||||
|
||||
<Step title="Review Task Output">
|
||||
The system will pause in the `Pending Human Input` state. Review the task output carefully.
|
||||
</Step>
|
||||
|
||||
<Step title="Submit Human Feedback">
|
||||
Call the resume endpoint of your crew with the following information:
|
||||
<Frame>
|
||||
<img src="/images/enterprise/crew-resume-endpoint.png" alt="Crew Resume Endpoint" />
|
||||
</Frame>
|
||||
<Warning>
|
||||
**Feedback Impact on Task Execution**:
|
||||
It's crucial to exercise care when providing feedback, as the entire feedback content will be incorporated as additional context for further task executions.
|
||||
</Warning>
|
||||
This means:
|
||||
- All information in your feedback becomes part of the task's context.
|
||||
- Irrelevant details may negatively influence it.
|
||||
- Concise, relevant feedback helps maintain task focus and efficiency.
|
||||
- Always review your feedback carefully before submission to ensure it contains only pertinent information that will positively guide the task's execution.
|
||||
</Step>
|
||||
<Step title="Handle Negative Feedback">
|
||||
If you provide negative feedback:
|
||||
- The crew will retry the task with added context from your feedback.
|
||||
- You'll receive another webhook notification for further review.
|
||||
- Repeat steps 4-6 until satisfied.
|
||||
</Step>
|
||||
|
||||
<Step title="Execution Continuation">
|
||||
When you submit positive feedback, the execution will proceed to the next steps.
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Best Practices
|
||||
|
||||
- **Be Specific**: Provide clear, actionable feedback that directly addresses the task at hand
|
||||
- **Stay Relevant**: Only include information that will help improve the task execution
|
||||
- **Be Timely**: Respond to HITL prompts promptly to avoid workflow delays
|
||||
- **Review Carefully**: Double-check your feedback before submitting to ensure accuracy
|
||||
|
||||
## Common Use Cases
|
||||
|
||||
HITL workflows are particularly valuable for:
|
||||
- Quality assurance and validation
|
||||
- Complex decision-making scenarios
|
||||
- Sensitive or high-stakes operations
|
||||
- Creative tasks requiring human judgment
|
||||
- Compliance and regulatory reviews
|
||||
@@ -1,98 +0,0 @@
|
||||
---
|
||||
title: Human Input on Execution
|
||||
description: Integrating CrewAI with human input during execution in complex decision-making processes and leveraging the full capabilities of the agent's attributes and tools.
|
||||
icon: user-check
|
||||
---
|
||||
|
||||
## Human input in agent execution
|
||||
|
||||
Human input is critical in several agent execution scenarios, allowing agents to request additional information or clarification when necessary.
|
||||
This feature is especially useful in complex decision-making processes or when agents require more details to complete a task effectively.
|
||||
|
||||
## Using human input with CrewAI
|
||||
|
||||
To integrate human input into agent execution, set the `human_input` flag in the task definition. When enabled, the agent prompts the user for input before delivering its final answer.
|
||||
This input can provide extra context, clarify ambiguities, or validate the agent's output.
|
||||
|
||||
### Example:
|
||||
|
||||
```shell
|
||||
pip install crewai
|
||||
```
|
||||
|
||||
```python Code
|
||||
import os
|
||||
from crewai import Agent, Task, Crew
|
||||
from crewai_tools import SerperDevTool
|
||||
|
||||
os.environ["SERPER_API_KEY"] = "Your Key" # serper.dev API key
|
||||
os.environ["OPENAI_API_KEY"] = "Your Key"
|
||||
|
||||
# Loading Tools
|
||||
search_tool = SerperDevTool()
|
||||
|
||||
# Define your agents with roles, goals, tools, and additional attributes
|
||||
researcher = Agent(
|
||||
role='Senior Research Analyst',
|
||||
goal='Uncover cutting-edge developments in AI and data science',
|
||||
backstory=(
|
||||
"You are a Senior Research Analyst at a leading tech think tank. "
|
||||
"Your expertise lies in identifying emerging trends and technologies in AI and data science. "
|
||||
"You have a knack for dissecting complex data and presenting actionable insights."
|
||||
),
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
tools=[search_tool]
|
||||
)
|
||||
writer = Agent(
|
||||
role='Tech Content Strategist',
|
||||
goal='Craft compelling content on tech advancements',
|
||||
backstory=(
|
||||
"You are a renowned Tech Content Strategist, known for your insightful and engaging articles on technology and innovation. "
|
||||
"With a deep understanding of the tech industry, you transform complex concepts into compelling narratives."
|
||||
),
|
||||
verbose=True,
|
||||
allow_delegation=True,
|
||||
tools=[search_tool],
|
||||
cache=False, # Disable cache for this agent
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description=(
|
||||
"Conduct a comprehensive analysis of the latest advancements in AI in 2025. "
|
||||
"Identify key trends, breakthrough technologies, and potential industry impacts. "
|
||||
"Compile your findings in a detailed report. "
|
||||
"Make sure to check with a human if the draft is good before finalizing your answer."
|
||||
),
|
||||
expected_output='A comprehensive full report on the latest AI advancements in 2025, leave nothing out',
|
||||
agent=researcher,
|
||||
human_input=True
|
||||
)
|
||||
|
||||
task2 = Task(
|
||||
description=(
|
||||
"Using the insights from the researcher\'s report, develop an engaging blog post that highlights the most significant AI advancements. "
|
||||
"Your post should be informative yet accessible, catering to a tech-savvy audience. "
|
||||
"Aim for a narrative that captures the essence of these breakthroughs and their implications for the future."
|
||||
),
|
||||
expected_output='A compelling 3 paragraphs blog post formatted as markdown about the latest AI advancements in 2025',
|
||||
agent=writer,
|
||||
human_input=True
|
||||
)
|
||||
|
||||
# Instantiate your crew with a sequential process
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[task1, task2],
|
||||
verbose=True,
|
||||
memory=True,
|
||||
planning=True # Enable planning feature for the crew
|
||||
)
|
||||
|
||||
# Get your crew to work!
|
||||
result = crew.kickoff()
|
||||
|
||||
print("######################")
|
||||
print(result)
|
||||
```
|
||||
@@ -1,122 +0,0 @@
|
||||
---
|
||||
title: Kickoff Crew Asynchronously
|
||||
description: Kickoff a Crew Asynchronously
|
||||
icon: rocket-launch
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
CrewAI provides the ability to kickoff a crew asynchronously, allowing you to start the crew execution in a non-blocking manner.
|
||||
This feature is particularly useful when you want to run multiple crews concurrently or when you need to perform other tasks while the crew is executing.
|
||||
|
||||
## Asynchronous Crew Execution
|
||||
|
||||
To kickoff a crew asynchronously, use the `kickoff_async()` method. This method initiates the crew execution in a separate thread, allowing the main thread to continue executing other tasks.
|
||||
|
||||
### Method Signature
|
||||
|
||||
```python Code
|
||||
def kickoff_async(self, inputs: dict) -> CrewOutput:
|
||||
```
|
||||
|
||||
### Parameters
|
||||
|
||||
- `inputs` (dict): A dictionary containing the input data required for the tasks.
|
||||
|
||||
### Returns
|
||||
|
||||
- `CrewOutput`: An object representing the result of the crew execution.
|
||||
|
||||
## Potential Use Cases
|
||||
|
||||
- **Parallel Content Generation**: Kickoff multiple independent crews asynchronously, each responsible for generating content on different topics. For example, one crew might research and draft an article on AI trends, while another crew generates social media posts about a new product launch. Each crew operates independently, allowing content production to scale efficiently.
|
||||
|
||||
- **Concurrent Market Research Tasks**: Launch multiple crews asynchronously to conduct market research in parallel. One crew might analyze industry trends, while another examines competitor strategies, and yet another evaluates consumer sentiment. Each crew independently completes its task, enabling faster and more comprehensive insights.
|
||||
|
||||
- **Independent Travel Planning Modules**: Execute separate crews to independently plan different aspects of a trip. One crew might handle flight options, another handles accommodation, and a third plans activities. Each crew works asynchronously, allowing various components of the trip to be planned simultaneously and independently for faster results.
|
||||
|
||||
## Example: Single Asynchronous Crew Execution
|
||||
|
||||
Here's an example of how to kickoff a crew asynchronously using asyncio and awaiting the result:
|
||||
|
||||
```python Code
|
||||
import asyncio
|
||||
from crewai import Crew, Agent, Task
|
||||
|
||||
# Create an agent with code execution enabled
|
||||
coding_agent = Agent(
|
||||
role="Python Data Analyst",
|
||||
goal="Analyze data and provide insights using Python",
|
||||
backstory="You are an experienced data analyst with strong Python skills.",
|
||||
allow_code_execution=True
|
||||
)
|
||||
|
||||
# Create a task that requires code execution
|
||||
data_analysis_task = Task(
|
||||
description="Analyze the given dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent,
|
||||
expected_output="The average age of the participants."
|
||||
)
|
||||
|
||||
# Create a crew and add the task
|
||||
analysis_crew = Crew(
|
||||
agents=[coding_agent],
|
||||
tasks=[data_analysis_task]
|
||||
)
|
||||
|
||||
# Async function to kickoff the crew asynchronously
|
||||
async def async_crew_execution():
|
||||
result = await analysis_crew.kickoff_async(inputs={"ages": [25, 30, 35, 40, 45]})
|
||||
print("Crew Result:", result)
|
||||
|
||||
# Run the async function
|
||||
asyncio.run(async_crew_execution())
|
||||
```
|
||||
|
||||
## Example: Multiple Asynchronous Crew Executions
|
||||
|
||||
In this example, we'll show how to kickoff multiple crews asynchronously and wait for all of them to complete using `asyncio.gather()`:
|
||||
|
||||
```python Code
|
||||
import asyncio
|
||||
from crewai import Crew, Agent, Task
|
||||
|
||||
# Create an agent with code execution enabled
|
||||
coding_agent = Agent(
|
||||
role="Python Data Analyst",
|
||||
goal="Analyze data and provide insights using Python",
|
||||
backstory="You are an experienced data analyst with strong Python skills.",
|
||||
allow_code_execution=True
|
||||
)
|
||||
|
||||
# Create tasks that require code execution
|
||||
task_1 = Task(
|
||||
description="Analyze the first dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent,
|
||||
expected_output="The average age of the participants."
|
||||
)
|
||||
|
||||
task_2 = Task(
|
||||
description="Analyze the second dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent,
|
||||
expected_output="The average age of the participants."
|
||||
)
|
||||
|
||||
# Create two crews and add tasks
|
||||
crew_1 = Crew(agents=[coding_agent], tasks=[task_1])
|
||||
crew_2 = Crew(agents=[coding_agent], tasks=[task_2])
|
||||
|
||||
# Async function to kickoff multiple crews asynchronously and wait for all to finish
|
||||
async def async_multiple_crews():
|
||||
result_1 = crew_1.kickoff_async(inputs={"ages": [25, 30, 35, 40, 45]})
|
||||
result_2 = crew_2.kickoff_async(inputs={"ages": [20, 22, 24, 28, 30]})
|
||||
|
||||
# Wait for both crews to finish
|
||||
results = await asyncio.gather(result_1, result_2)
|
||||
|
||||
for i, result in enumerate(results, 1):
|
||||
print(f"Crew {i} Result:", result)
|
||||
|
||||
# Run the async function
|
||||
asyncio.run(async_multiple_crews())
|
||||
```
|
||||
@@ -1,53 +0,0 @@
|
||||
---
|
||||
title: Kickoff Crew for Each
|
||||
description: Kickoff Crew for Each Item in a List
|
||||
icon: at
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
CrewAI provides the ability to kickoff a crew for each item in a list, allowing you to execute the crew for each item in the list.
|
||||
This feature is particularly useful when you need to perform the same set of tasks for multiple items.
|
||||
|
||||
## Kicking Off a Crew for Each Item
|
||||
|
||||
To kickoff a crew for each item in a list, use the `kickoff_for_each()` method.
|
||||
This method executes the crew for each item in the list, allowing you to process multiple items efficiently.
|
||||
|
||||
Here's an example of how to kickoff a crew for each item in a list:
|
||||
|
||||
```python Code
|
||||
from crewai import Crew, Agent, Task
|
||||
|
||||
# Create an agent with code execution enabled
|
||||
coding_agent = Agent(
|
||||
role="Python Data Analyst",
|
||||
goal="Analyze data and provide insights using Python",
|
||||
backstory="You are an experienced data analyst with strong Python skills.",
|
||||
allow_code_execution=True
|
||||
)
|
||||
|
||||
# Create a task that requires code execution
|
||||
data_analysis_task = Task(
|
||||
description="Analyze the given dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent,
|
||||
expected_output="The average age calculated from the dataset"
|
||||
)
|
||||
|
||||
# Create a crew and add the task
|
||||
analysis_crew = Crew(
|
||||
agents=[coding_agent],
|
||||
tasks=[data_analysis_task],
|
||||
verbose=True,
|
||||
memory=False
|
||||
)
|
||||
|
||||
datasets = [
|
||||
{ "ages": [25, 30, 35, 40, 45] },
|
||||
{ "ages": [20, 25, 30, 35, 40] },
|
||||
{ "ages": [30, 35, 40, 45, 50] }
|
||||
]
|
||||
|
||||
# Execute the crew
|
||||
result = analysis_crew.kickoff_for_each(inputs=datasets)
|
||||
```
|
||||
@@ -1,100 +0,0 @@
|
||||
---
|
||||
title: Langfuse Integration
|
||||
description: Learn how to integrate Langfuse with CrewAI via OpenTelemetry using OpenLit
|
||||
icon: vials
|
||||
---
|
||||
|
||||
# Integrate Langfuse with CrewAI
|
||||
|
||||
This notebook demonstrates how to integrate **Langfuse** with **CrewAI** using OpenTelemetry via the **OpenLit** SDK. By the end of this notebook, you will be able to trace your CrewAI applications with Langfuse for improved observability and debugging.
|
||||
|
||||
> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source LLM engineering platform. It provides tracing and monitoring capabilities for LLM applications, helping developers debug, analyze, and optimize their AI systems. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and APIs/SDKs.
|
||||
|
||||
[](https://langfuse.com/watch-demo)
|
||||
|
||||
## Get Started
|
||||
|
||||
We'll walk through a simple example of using CrewAI and integrating it with Langfuse via OpenTelemetry using OpenLit.
|
||||
|
||||
### Step 1: Install Dependencies
|
||||
|
||||
|
||||
```python
|
||||
%pip install langfuse openlit crewai crewai_tools
|
||||
```
|
||||
|
||||
### Step 2: Set Up Environment Variables
|
||||
|
||||
Set your Langfuse API keys and configure OpenTelemetry export settings to send traces to Langfuse. Please refer to the [Langfuse OpenTelemetry Docs](https://langfuse.com/docs/opentelemetry/get-started) for more information on the Langfuse OpenTelemetry endpoint `/api/public/otel` and authentication.
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
import base64
|
||||
|
||||
LANGFUSE_PUBLIC_KEY="pk-lf-..."
|
||||
LANGFUSE_SECRET_KEY="sk-lf-..."
|
||||
LANGFUSE_AUTH=base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
|
||||
|
||||
os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel" # EU data region
|
||||
# os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://us.cloud.langfuse.com/api/public/otel" # US data region
|
||||
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
|
||||
|
||||
# your openai key
|
||||
os.environ["OPENAI_API_KEY"] = "sk-..."
|
||||
```
|
||||
|
||||
### Step 3: Initialize OpenLit
|
||||
|
||||
Initialize the OpenLit OpenTelemetry instrumentation SDK to start capturing OpenTelemetry traces.
|
||||
|
||||
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
### Step 4: Create a Simple CrewAI Application
|
||||
|
||||
We'll create a simple CrewAI application where multiple agents collaborate to answer a user's question.
|
||||
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
from crewai_tools import (
|
||||
WebsiteSearchTool
|
||||
)
|
||||
|
||||
web_rag_tool = WebsiteSearchTool()
|
||||
|
||||
writer = Agent(
|
||||
role="Writer",
|
||||
goal="You make math engaging and understandable for young children through poetry",
|
||||
backstory="You're an expert in writing haikus but you know nothing of math.",
|
||||
tools=[web_rag_tool],
|
||||
)
|
||||
|
||||
task = Task(description=("What is {multiplication}?"),
|
||||
expected_output=("Compose a haiku that includes the answer."),
|
||||
agent=writer)
|
||||
|
||||
crew = Crew(
|
||||
agents=[writer],
|
||||
tasks=[task],
|
||||
share_crew=False
|
||||
)
|
||||
```
|
||||
|
||||
### Step 5: See Traces in Langfuse
|
||||
|
||||
After running the agent, you can view the traces generated by your CrewAI application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.
|
||||
|
||||
|
||||
|
||||
_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/e2cf380ffc8d47d28da98f136140642b?timestamp=2025-02-05T15%3A12%3A02.717Z&observation=3b32338ee6a5d9af)_
|
||||
|
||||
## References
|
||||
|
||||
- [Langfuse OpenTelemetry Docs](https://langfuse.com/docs/opentelemetry/get-started)
|
||||
@@ -1,72 +0,0 @@
|
||||
---
|
||||
title: Langtrace Integration
|
||||
description: How to monitor cost, latency, and performance of CrewAI Agents using Langtrace, an external observability tool.
|
||||
icon: chart-line
|
||||
---
|
||||
|
||||
# Langtrace Overview
|
||||
|
||||
Langtrace is an open-source, external tool that helps you set up observability and evaluations for Large Language Models (LLMs), LLM frameworks, and Vector Databases.
|
||||
While not built directly into CrewAI, Langtrace can be used alongside CrewAI to gain deep visibility into the cost, latency, and performance of your CrewAI Agents.
|
||||
This integration allows you to log hyperparameters, monitor performance regressions, and establish a process for continuous improvement of your Agents.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Sign up for Langtrace">
|
||||
Sign up by visiting [https://langtrace.ai/signup](https://langtrace.ai/signup).
|
||||
</Step>
|
||||
<Step title="Create a project">
|
||||
Set the project type to `CrewAI` and generate an API key.
|
||||
</Step>
|
||||
<Step title="Install Langtrace in your CrewAI project">
|
||||
Use the following command:
|
||||
|
||||
```bash
|
||||
pip install langtrace-python-sdk
|
||||
```
|
||||
</Step>
|
||||
<Step title="Import Langtrace">
|
||||
Import and initialize Langtrace at the beginning of your script, before any CrewAI imports:
|
||||
|
||||
```python
|
||||
from langtrace_python_sdk import langtrace
|
||||
langtrace.init(api_key='<LANGTRACE_API_KEY>')
|
||||
|
||||
# Now import CrewAI modules
|
||||
from crewai import Agent, Task, Crew
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### Features and Their Application to CrewAI
|
||||
|
||||
1. **LLM Token and Cost Tracking**
|
||||
|
||||
- Monitor the token usage and associated costs for each CrewAI agent interaction.
|
||||
|
||||
2. **Trace Graph for Execution Steps**
|
||||
|
||||
- Visualize the execution flow of your CrewAI tasks, including latency and logs.
|
||||
- Useful for identifying bottlenecks in your agent workflows.
|
||||
|
||||
3. **Dataset Curation with Manual Annotation**
|
||||
|
||||
- Create datasets from your CrewAI task outputs for future training or evaluation.
|
||||
|
||||
4. **Prompt Versioning and Management**
|
||||
|
||||
- Keep track of different versions of prompts used in your CrewAI agents.
|
||||
- Useful for A/B testing and optimizing agent performance.
|
||||
|
||||
5. **Prompt Playground with Model Comparisons**
|
||||
|
||||
- Test and compare different prompts and models for your CrewAI agents before deployment.
|
||||
|
||||
6. **Testing and Evaluations**
|
||||
|
||||
- Set up automated tests for your CrewAI agents and tasks.
|
||||
@@ -1,185 +0,0 @@
|
||||
---
|
||||
title: Connect to any LLM
|
||||
description: Comprehensive guide on integrating CrewAI with various Large Language Models (LLMs) using LiteLLM, including supported providers and configuration options.
|
||||
icon: brain-circuit
|
||||
---
|
||||
|
||||
## Connect CrewAI to LLMs
|
||||
|
||||
CrewAI uses LiteLLM to connect to a wide variety of Language Models (LLMs). This integration provides extensive versatility, allowing you to use models from numerous providers with a simple, unified interface.
|
||||
|
||||
<Note>
|
||||
By default, CrewAI uses the `gpt-4o-mini` model. This is determined by the `OPENAI_MODEL_NAME` environment variable, which defaults to "gpt-4o-mini" if not set.
|
||||
You can easily configure your agents to use a different model or provider as described in this guide.
|
||||
</Note>
|
||||
|
||||
## Supported Providers
|
||||
|
||||
LiteLLM supports a wide range of providers, including but not limited to:
|
||||
|
||||
- OpenAI
|
||||
- Anthropic
|
||||
- Google (Vertex AI, Gemini)
|
||||
- Azure OpenAI
|
||||
- AWS (Bedrock, SageMaker)
|
||||
- Cohere
|
||||
- VoyageAI
|
||||
- Hugging Face
|
||||
- Ollama
|
||||
- Mistral AI
|
||||
- Replicate
|
||||
- Together AI
|
||||
- AI21
|
||||
- Cloudflare Workers AI
|
||||
- DeepInfra
|
||||
- Groq
|
||||
- SambaNova
|
||||
- [NVIDIA NIMs](https://docs.api.nvidia.com/nim/reference/models-1)
|
||||
- And many more!
|
||||
|
||||
For a complete and up-to-date list of supported providers, please refer to the [LiteLLM Providers documentation](https://docs.litellm.ai/docs/providers).
|
||||
|
||||
## Changing the LLM
|
||||
|
||||
To use a different LLM with your CrewAI agents, you have several options:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Using a String Identifier">
|
||||
Pass the model name as a string when initializing the agent:
|
||||
<CodeGroup>
|
||||
```python Code
|
||||
from crewai import Agent
|
||||
|
||||
# Using OpenAI's GPT-4
|
||||
openai_agent = Agent(
|
||||
role='OpenAI Expert',
|
||||
goal='Provide insights using GPT-4',
|
||||
backstory="An AI assistant powered by OpenAI's latest model.",
|
||||
llm='gpt-4'
|
||||
)
|
||||
|
||||
# Using Anthropic's Claude
|
||||
claude_agent = Agent(
|
||||
role='Anthropic Expert',
|
||||
goal='Analyze data using Claude',
|
||||
backstory="An AI assistant leveraging Anthropic's language model.",
|
||||
llm='claude-2'
|
||||
)
|
||||
```
|
||||
</CodeGroup>
|
||||
</Tab>
|
||||
<Tab title="Using the LLM Class">
|
||||
For more detailed configuration, use the LLM class:
|
||||
<CodeGroup>
|
||||
```python Code
|
||||
from crewai import Agent, LLM
|
||||
|
||||
llm = LLM(
|
||||
model="gpt-4",
|
||||
temperature=0.7,
|
||||
base_url="https://api.openai.com/v1",
|
||||
api_key="your-api-key-here"
|
||||
)
|
||||
|
||||
agent = Agent(
|
||||
role='Customized LLM Expert',
|
||||
goal='Provide tailored responses',
|
||||
backstory="An AI assistant with custom LLM settings.",
|
||||
llm=llm
|
||||
)
|
||||
```
|
||||
</CodeGroup>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Configuration Options
|
||||
|
||||
When configuring an LLM for your agent, you have access to a wide range of parameters:
|
||||
|
||||
| Parameter | Type | Description |
|
||||
|:----------|:-----:|:-------------|
|
||||
| **model** | `str` | The name of the model to use (e.g., "gpt-4", "claude-2") |
|
||||
| **temperature** | `float` | Controls randomness in output (0.0 to 1.0) |
|
||||
| **max_tokens** | `int` | Maximum number of tokens to generate |
|
||||
| **top_p** | `float` | Controls diversity of output (0.0 to 1.0) |
|
||||
| **frequency_penalty** | `float` | Penalizes new tokens based on their frequency in the text so far |
|
||||
| **presence_penalty** | `float` | Penalizes new tokens based on their presence in the text so far |
|
||||
| **stop** | `str`, `List[str]` | Sequence(s) to stop generation |
|
||||
| **base_url** | `str` | The base URL for the API endpoint |
|
||||
| **api_key** | `str` | Your API key for authentication |
|
||||
|
||||
For a complete list of parameters and their descriptions, refer to the LLM class documentation.
|
||||
|
||||
## Connecting to OpenAI-Compatible LLMs
|
||||
|
||||
You can connect to OpenAI-compatible LLMs using either environment variables or by setting specific attributes on the LLM class:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Using Environment Variables">
|
||||
<CodeGroup>
|
||||
```python Code
|
||||
import os
|
||||
|
||||
os.environ["OPENAI_API_KEY"] = "your-api-key"
|
||||
os.environ["OPENAI_API_BASE"] = "https://api.your-provider.com/v1"
|
||||
os.environ["OPENAI_MODEL_NAME"] = "your-model-name"
|
||||
```
|
||||
</CodeGroup>
|
||||
</Tab>
|
||||
<Tab title="Using LLM Class Attributes">
|
||||
<CodeGroup>
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="custom-model-name",
|
||||
api_key="your-api-key",
|
||||
base_url="https://api.your-provider.com/v1"
|
||||
)
|
||||
agent = Agent(llm=llm, ...)
|
||||
```
|
||||
</CodeGroup>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Using Local Models with Ollama
|
||||
|
||||
For local models like those provided by Ollama:
|
||||
|
||||
<Steps>
|
||||
<Step title="Download and install Ollama">
|
||||
[Click here to download and install Ollama](https://ollama.com/download)
|
||||
</Step>
|
||||
<Step title="Pull the desired model">
|
||||
For example, run `ollama pull llama3.2` to download the model.
|
||||
</Step>
|
||||
<Step title="Configure your agent">
|
||||
<CodeGroup>
|
||||
```python Code
|
||||
agent = Agent(
|
||||
role='Local AI Expert',
|
||||
goal='Process information using a local model',
|
||||
backstory="An AI assistant running on local hardware.",
|
||||
llm=LLM(model="ollama/llama3.2", base_url="http://localhost:11434")
|
||||
)
|
||||
```
|
||||
</CodeGroup>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Changing the Base API URL
|
||||
|
||||
You can change the base API URL for any LLM provider by setting the `base_url` parameter:
|
||||
|
||||
```python Code
|
||||
llm = LLM(
|
||||
model="custom-model-name",
|
||||
base_url="https://api.your-provider.com/v1",
|
||||
api_key="your-api-key"
|
||||
)
|
||||
agent = Agent(llm=llm, ...)
|
||||
```
|
||||
|
||||
This is particularly useful when working with OpenAI-compatible APIs or when you need to specify a different endpoint for your chosen provider.
|
||||
|
||||
## Conclusion
|
||||
|
||||
By leveraging LiteLLM, CrewAI offers seamless integration with a vast array of LLMs. This flexibility allows you to choose the most suitable model for your specific needs, whether you prioritize performance, cost-efficiency, or local deployment. Remember to consult the [LiteLLM documentation](https://docs.litellm.ai/docs/) for the most up-to-date information on supported models and configuration options.
|
||||
@@ -1,206 +0,0 @@
|
||||
---
|
||||
title: MLflow Integration
|
||||
description: Quickly start monitoring your Agents with MLflow.
|
||||
icon: bars-staggered
|
||||
---
|
||||
|
||||
# MLflow Overview
|
||||
|
||||
[MLflow](https://mlflow.org/) is an open-source platform to assist machine learning practitioners and teams in handling the complexities of the machine learning process.
|
||||
|
||||
It provides a tracing feature that enhances LLM observability in your Generative AI applications by capturing detailed information about the execution of your application’s services.
|
||||
Tracing provides a way to record the inputs, outputs, and metadata associated with each intermediate step of a request, enabling you to easily pinpoint the source of bugs and unexpected behaviors.
|
||||
|
||||

|
||||
|
||||
### Features
|
||||
|
||||
- **Tracing Dashboard**: Monitor activities of your crewAI agents with detailed dashboards that include inputs, outputs and metadata of spans.
|
||||
- **Automated Tracing**: A fully automated integration with crewAI, which can be enabled by running `mlflow.crewai.autolog()`.
|
||||
- **Manual Trace Instrumentation with minor efforts**: Customize trace instrumentation through MLflow's high-level fluent APIs such as decorators, function wrappers and context managers.
|
||||
- **OpenTelemetry Compatibility**: MLflow Tracing supports exporting traces to an OpenTelemetry Collector, which can then be used to export traces to various backends such as Jaeger, Zipkin, and AWS X-Ray.
|
||||
- **Package and Deploy Agents**: Package and deploy your crewAI agents to an inference server with a variety of deployment targets.
|
||||
- **Securely Host LLMs**: Host multiple LLM from various providers in one unified endpoint through MFflow gateway.
|
||||
- **Evaluation**: Evaluate your crewAI agents with a wide range of metrics using a convenient API `mlflow.evaluate()`.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Install MLflow package">
|
||||
```shell
|
||||
# The crewAI integration is available in mlflow>=2.19.0
|
||||
pip install mlflow
|
||||
```
|
||||
</Step>
|
||||
<Step title="Start MFflow tracking server">
|
||||
```shell
|
||||
# This process is optional, but it is recommended to use MLflow tracking server for better visualization and broader features.
|
||||
mlflow server
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize MLflow in Your Application">
|
||||
Add the following two lines to your application code:
|
||||
|
||||
```python
|
||||
import mlflow
|
||||
|
||||
mlflow.crewai.autolog()
|
||||
|
||||
# Optional: Set a tracking URI and an experiment name if you have a tracking server
|
||||
mlflow.set_tracking_uri("http://localhost:5000")
|
||||
mlflow.set_experiment("CrewAI")
|
||||
```
|
||||
|
||||
Example Usage for tracing CrewAI Agents:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task
|
||||
from crewai.knowledge.source.string_knowledge_source import StringKnowledgeSource
|
||||
from crewai_tools import SerperDevTool, WebsiteSearchTool
|
||||
|
||||
from textwrap import dedent
|
||||
|
||||
content = "Users name is John. He is 30 years old and lives in San Francisco."
|
||||
string_source = StringKnowledgeSource(
|
||||
content=content, metadata={"preference": "personal"}
|
||||
)
|
||||
|
||||
search_tool = WebsiteSearchTool()
|
||||
|
||||
|
||||
class TripAgents:
|
||||
def city_selection_agent(self):
|
||||
return Agent(
|
||||
role="City Selection Expert",
|
||||
goal="Select the best city based on weather, season, and prices",
|
||||
backstory="An expert in analyzing travel data to pick ideal destinations",
|
||||
tools=[
|
||||
search_tool,
|
||||
],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def local_expert(self):
|
||||
return Agent(
|
||||
role="Local Expert at this city",
|
||||
goal="Provide the BEST insights about the selected city",
|
||||
backstory="""A knowledgeable local guide with extensive information
|
||||
about the city, it's attractions and customs""",
|
||||
tools=[search_tool],
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
|
||||
class TripTasks:
|
||||
def identify_task(self, agent, origin, cities, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
Analyze and select the best city for the trip based
|
||||
on specific criteria such as weather patterns, seasonal
|
||||
events, and travel costs. This task involves comparing
|
||||
multiple cities, considering factors like current weather
|
||||
conditions, upcoming cultural or seasonal events, and
|
||||
overall travel expenses.
|
||||
Your final answer must be a detailed
|
||||
report on the chosen city, and everything you found out
|
||||
about it, including the actual flight costs, weather
|
||||
forecast and attractions.
|
||||
|
||||
Traveling from: {origin}
|
||||
City Options: {cities}
|
||||
Trip Date: {range}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Detailed report on the chosen city including flight costs, weather forecast, and attractions",
|
||||
)
|
||||
|
||||
def gather_task(self, agent, origin, interests, range):
|
||||
return Task(
|
||||
description=dedent(
|
||||
f"""
|
||||
As a local expert on this city you must compile an
|
||||
in-depth guide for someone traveling there and wanting
|
||||
to have THE BEST trip ever!
|
||||
Gather information about key attractions, local customs,
|
||||
special events, and daily activity recommendations.
|
||||
Find the best spots to go to, the kind of place only a
|
||||
local would know.
|
||||
This guide should provide a thorough overview of what
|
||||
the city has to offer, including hidden gems, cultural
|
||||
hotspots, must-visit landmarks, weather forecasts, and
|
||||
high level costs.
|
||||
The final answer must be a comprehensive city guide,
|
||||
rich in cultural insights and practical tips,
|
||||
tailored to enhance the travel experience.
|
||||
|
||||
Trip Date: {range}
|
||||
Traveling from: {origin}
|
||||
Traveler Interests: {interests}
|
||||
"""
|
||||
),
|
||||
agent=agent,
|
||||
expected_output="Comprehensive city guide including hidden gems, cultural hotspots, and practical travel tips",
|
||||
)
|
||||
|
||||
|
||||
class TripCrew:
|
||||
def __init__(self, origin, cities, date_range, interests):
|
||||
self.cities = cities
|
||||
self.origin = origin
|
||||
self.interests = interests
|
||||
self.date_range = date_range
|
||||
|
||||
def run(self):
|
||||
agents = TripAgents()
|
||||
tasks = TripTasks()
|
||||
|
||||
city_selector_agent = agents.city_selection_agent()
|
||||
local_expert_agent = agents.local_expert()
|
||||
|
||||
identify_task = tasks.identify_task(
|
||||
city_selector_agent,
|
||||
self.origin,
|
||||
self.cities,
|
||||
self.interests,
|
||||
self.date_range,
|
||||
)
|
||||
gather_task = tasks.gather_task(
|
||||
local_expert_agent, self.origin, self.interests, self.date_range
|
||||
)
|
||||
|
||||
crew = Crew(
|
||||
agents=[city_selector_agent, local_expert_agent],
|
||||
tasks=[identify_task, gather_task],
|
||||
verbose=True,
|
||||
memory=True,
|
||||
knowledge={
|
||||
"sources": [string_source],
|
||||
"metadata": {"preference": "personal"},
|
||||
},
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
return result
|
||||
|
||||
|
||||
trip_crew = TripCrew("California", "Tokyo", "Dec 12 - Dec 20", "sports")
|
||||
result = trip_crew.run()
|
||||
|
||||
print(result)
|
||||
```
|
||||
Refer to [MLflow Tracing Documentation](https://mlflow.org/docs/latest/llms/tracing/index.html) for more configurations and use cases.
|
||||
</Step>
|
||||
<Step title="Visualize Activities of Agents">
|
||||
Now traces for your crewAI agents are captured by MLflow.
|
||||
Let's visit MLflow tracking server to view the traces and get insights into your Agents.
|
||||
|
||||
Open `127.0.0.1:5000` on your browser to visit MLflow tracking server.
|
||||
<Frame caption="MLflow Tracing Dashboard">
|
||||
<img src="/images/mlflow1.png" alt="MLflow tracing example with crewai" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
@@ -1,140 +0,0 @@
|
||||
---
|
||||
title: Using Multimodal Agents
|
||||
description: Learn how to enable and use multimodal capabilities in your agents for processing images and other non-text content within the CrewAI framework.
|
||||
icon: video
|
||||
---
|
||||
|
||||
## Using Multimodal Agents
|
||||
|
||||
CrewAI supports multimodal agents that can process both text and non-text content like images. This guide will show you how to enable and use multimodal capabilities in your agents.
|
||||
|
||||
### Enabling Multimodal Capabilities
|
||||
|
||||
To create a multimodal agent, simply set the `multimodal` parameter to `True` when initializing your agent:
|
||||
|
||||
```python
|
||||
from crewai import Agent
|
||||
|
||||
agent = Agent(
|
||||
role="Image Analyst",
|
||||
goal="Analyze and extract insights from images",
|
||||
backstory="An expert in visual content interpretation with years of experience in image analysis",
|
||||
multimodal=True # This enables multimodal capabilities
|
||||
)
|
||||
```
|
||||
|
||||
When you set `multimodal=True`, the agent is automatically configured with the necessary tools for handling non-text content, including the `AddImageTool`.
|
||||
|
||||
### Working with Images
|
||||
|
||||
The multimodal agent comes pre-configured with the `AddImageTool`, which allows it to process images. You don't need to manually add this tool - it's automatically included when you enable multimodal capabilities.
|
||||
|
||||
Here's a complete example showing how to use a multimodal agent to analyze an image:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
# Create a multimodal agent
|
||||
image_analyst = Agent(
|
||||
role="Product Analyst",
|
||||
goal="Analyze product images and provide detailed descriptions",
|
||||
backstory="Expert in visual product analysis with deep knowledge of design and features",
|
||||
multimodal=True
|
||||
)
|
||||
|
||||
# Create a task for image analysis
|
||||
task = Task(
|
||||
description="Analyze the product image at https://example.com/product.jpg and provide a detailed description",
|
||||
expected_output="A detailed description of the product image",
|
||||
agent=image_analyst
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(
|
||||
agents=[image_analyst],
|
||||
tasks=[task]
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Advanced Usage with Context
|
||||
|
||||
You can provide additional context or specific questions about the image when creating tasks for multimodal agents. The task description can include specific aspects you want the agent to focus on:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
# Create a multimodal agent for detailed analysis
|
||||
expert_analyst = Agent(
|
||||
role="Visual Quality Inspector",
|
||||
goal="Perform detailed quality analysis of product images",
|
||||
backstory="Senior quality control expert with expertise in visual inspection",
|
||||
multimodal=True # AddImageTool is automatically included
|
||||
)
|
||||
|
||||
# Create a task with specific analysis requirements
|
||||
inspection_task = Task(
|
||||
description="""
|
||||
Analyze the product image at https://example.com/product.jpg with focus on:
|
||||
1. Quality of materials
|
||||
2. Manufacturing defects
|
||||
3. Compliance with standards
|
||||
Provide a detailed report highlighting any issues found.
|
||||
""",
|
||||
expected_output="A detailed report highlighting any issues found",
|
||||
agent=expert_analyst
|
||||
)
|
||||
|
||||
# Create and run the crew
|
||||
crew = Crew(
|
||||
agents=[expert_analyst],
|
||||
tasks=[inspection_task]
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
```
|
||||
|
||||
### Tool Details
|
||||
|
||||
When working with multimodal agents, the `AddImageTool` is automatically configured with the following schema:
|
||||
|
||||
```python
|
||||
class AddImageToolSchema:
|
||||
image_url: str # Required: The URL or path of the image to process
|
||||
action: Optional[str] = None # Optional: Additional context or specific questions about the image
|
||||
```
|
||||
|
||||
The multimodal agent will automatically handle the image processing through its built-in tools, allowing it to:
|
||||
- Access images via URLs or local file paths
|
||||
- Process image content with optional context or specific questions
|
||||
- Provide analysis and insights based on the visual information and task requirements
|
||||
|
||||
### Best Practices
|
||||
|
||||
When working with multimodal agents, keep these best practices in mind:
|
||||
|
||||
1. **Image Access**
|
||||
- Ensure your images are accessible via URLs that the agent can reach
|
||||
- For local images, consider hosting them temporarily or using absolute file paths
|
||||
- Verify that image URLs are valid and accessible before running tasks
|
||||
|
||||
2. **Task Description**
|
||||
- Be specific about what aspects of the image you want the agent to analyze
|
||||
- Include clear questions or requirements in the task description
|
||||
- Consider using the optional `action` parameter for focused analysis
|
||||
|
||||
3. **Resource Management**
|
||||
- Image processing may require more computational resources than text-only tasks
|
||||
- Some language models may require base64 encoding for image data
|
||||
- Consider batch processing for multiple images to optimize performance
|
||||
|
||||
4. **Environment Setup**
|
||||
- Verify that your environment has the necessary dependencies for image processing
|
||||
- Ensure your language model supports multimodal capabilities
|
||||
- Test with small images first to validate your setup
|
||||
|
||||
5. **Error Handling**
|
||||
- Implement proper error handling for image loading failures
|
||||
- Have fallback strategies for when image processing fails
|
||||
- Monitor and log image processing operations for debugging
|
||||
@@ -1,181 +0,0 @@
|
||||
---
|
||||
title: OpenLIT Integration
|
||||
description: Quickly start monitoring your Agents in just a single line of code with OpenTelemetry.
|
||||
icon: magnifying-glass-chart
|
||||
---
|
||||
|
||||
# OpenLIT Overview
|
||||
|
||||
[OpenLIT](https://github.com/openlit/openlit?src=crewai-docs) is an open-source tool that makes it simple to monitor the performance of AI agents, LLMs, VectorDBs, and GPUs with just **one** line of code.
|
||||
|
||||
It provides OpenTelemetry-native tracing and metrics to track important parameters like cost, latency, interactions and task sequences.
|
||||
This setup enables you to track hyperparameters and monitor for performance issues, helping you find ways to enhance and fine-tune your agents over time.
|
||||
|
||||
<Frame caption="OpenLIT Dashboard">
|
||||
<img src="/images/openlit1.png" alt="Overview Agent usage including cost and tokens" />
|
||||
<img src="/images/openlit2.png" alt="Overview of agent otel traces and metrics" />
|
||||
<img src="/images/openlit3.png" alt="Overview of agent traces in details" />
|
||||
</Frame>
|
||||
|
||||
### Features
|
||||
|
||||
- **Analytics Dashboard**: Monitor your Agents health and performance with detailed dashboards that track metrics, costs, and user interactions.
|
||||
- **OpenTelemetry-native Observability SDK**: Vendor-neutral SDKs to send traces and metrics to your existing observability tools like Grafana, DataDog and more.
|
||||
- **Cost Tracking for Custom and Fine-Tuned Models**: Tailor cost estimations for specific models using custom pricing files for precise budgeting.
|
||||
- **Exceptions Monitoring Dashboard**: Quickly spot and resolve issues by tracking common exceptions and errors with a monitoring dashboard.
|
||||
- **Compliance and Security**: Detect potential threats such as profanity and PII leaks.
|
||||
- **Prompt Injection Detection**: Identify potential code injection and secret leaks.
|
||||
- **API Keys and Secrets Management**: Securely handle your LLM API keys and secrets centrally, avoiding insecure practices.
|
||||
- **Prompt Management**: Manage and version Agent prompts using PromptHub for consistent and easy access across Agents.
|
||||
- **Model Playground** Test and compare different models for your CrewAI agents before deployment.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Deploy OpenLIT">
|
||||
<Steps>
|
||||
<Step title="Git Clone OpenLIT Repository">
|
||||
```shell
|
||||
git clone git@github.com:openlit/openlit.git
|
||||
```
|
||||
</Step>
|
||||
<Step title="Start Docker Compose">
|
||||
From the root directory of the [OpenLIT Repo](https://github.com/openlit/openlit), Run the below command:
|
||||
```shell
|
||||
docker compose up -d
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
</Step>
|
||||
<Step title="Install OpenLIT SDK">
|
||||
```shell
|
||||
pip install openlit
|
||||
```
|
||||
</Step>
|
||||
<Step title="Initialize OpenLIT in Your Application">
|
||||
Add the following two lines to your application code:
|
||||
<Tabs>
|
||||
<Tab title="Setup using function arguments">
|
||||
```python
|
||||
import openlit
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
```
|
||||
|
||||
Example Usage for monitoring a CrewAI Agent:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, Process
|
||||
import openlit
|
||||
|
||||
openlit.init(disable_metrics=True)
|
||||
# Define your agents
|
||||
researcher = Agent(
|
||||
role="Researcher",
|
||||
goal="Conduct thorough research and analysis on AI and AI agents",
|
||||
backstory="You're an expert researcher, specialized in technology, software engineering, AI, and startups. You work as a freelancer and are currently researching for a new client.",
|
||||
allow_delegation=False,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
|
||||
# Define your task
|
||||
task = Task(
|
||||
description="Generate a list of 5 interesting ideas for an article, then write one captivating paragraph for each idea that showcases the potential of a full article on this topic. Return the list of ideas with their paragraphs and your notes.",
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Define the manager agent
|
||||
manager = Agent(
|
||||
role="Project Manager",
|
||||
goal="Efficiently manage the crew and ensure high-quality task completion",
|
||||
backstory="You're an experienced project manager, skilled in overseeing complex projects and guiding teams to success. Your role is to coordinate the efforts of the crew members, ensuring that each task is completed on time and to the highest standard.",
|
||||
allow_delegation=True,
|
||||
llm='command-r'
|
||||
)
|
||||
|
||||
# Instantiate your crew with a custom manager
|
||||
crew = Crew(
|
||||
agents=[researcher],
|
||||
tasks=[task],
|
||||
manager_agent=manager,
|
||||
process=Process.hierarchical,
|
||||
)
|
||||
|
||||
# Start the crew's work
|
||||
result = crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
</Tab>
|
||||
<Tab title="Setup using Environment Variables">
|
||||
|
||||
Add the following two lines to your application code:
|
||||
```python
|
||||
import openlit
|
||||
|
||||
openlit.init()
|
||||
```
|
||||
|
||||
Run the following command to configure the OTEL export endpoint:
|
||||
```shell
|
||||
export OTEL_EXPORTER_OTLP_ENDPOINT = "http://127.0.0.1:4318"
|
||||
```
|
||||
|
||||
Example Usage for monitoring a CrewAI Async Agent:
|
||||
|
||||
```python
|
||||
import asyncio
|
||||
from crewai import Crew, Agent, Task
|
||||
import openlit
|
||||
|
||||
openlit.init(otlp_endpoint="http://127.0.0.1:4318")
|
||||
|
||||
# Create an agent with code execution enabled
|
||||
coding_agent = Agent(
|
||||
role="Python Data Analyst",
|
||||
goal="Analyze data and provide insights using Python",
|
||||
backstory="You are an experienced data analyst with strong Python skills.",
|
||||
allow_code_execution=True,
|
||||
llm="command-r"
|
||||
)
|
||||
|
||||
# Create a task that requires code execution
|
||||
data_analysis_task = Task(
|
||||
description="Analyze the given dataset and calculate the average age of participants. Ages: {ages}",
|
||||
agent=coding_agent,
|
||||
expected_output="5 bullet points, each with a paragraph and accompanying notes.",
|
||||
)
|
||||
|
||||
# Create a crew and add the task
|
||||
analysis_crew = Crew(
|
||||
agents=[coding_agent],
|
||||
tasks=[data_analysis_task]
|
||||
)
|
||||
|
||||
# Async function to kickoff the crew asynchronously
|
||||
async def async_crew_execution():
|
||||
result = await analysis_crew.kickoff_async(inputs={"ages": [25, 30, 35, 40, 45]})
|
||||
print("Crew Result:", result)
|
||||
|
||||
# Run the async function
|
||||
asyncio.run(async_crew_execution())
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
Refer to OpenLIT [Python SDK repository](https://github.com/openlit/openlit/tree/main/sdk/python) for more advanced configurations and use cases.
|
||||
</Step>
|
||||
<Step title="Visualize and Analyze">
|
||||
With the Agent Observability data now being collected and sent to OpenLIT, the next step is to visualize and analyze this data to get insights into your Agent's performance, behavior, and identify areas of improvement.
|
||||
|
||||
Just head over to OpenLIT at `127.0.0.1:3000` on your browser to start exploring. You can login using the default credentials
|
||||
- **Email**: `user@openlit.io`
|
||||
- **Password**: `openlituser`
|
||||
|
||||
<Frame caption="OpenLIT Dashboard">
|
||||
<img src="/images/openlit1.png" alt="Overview Agent usage including cost and tokens" />
|
||||
<img src="/images/openlit2.png" alt="Overview of agent otel traces and metrics" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
@@ -1,129 +0,0 @@
|
||||
---
|
||||
title: Opik Integration
|
||||
description: Learn how to use Comet Opik to debug, evaluate, and monitor your CrewAI applications with comprehensive tracing, automated evaluations, and production-ready dashboards.
|
||||
icon: meteor
|
||||
---
|
||||
|
||||
# Opik Overview
|
||||
|
||||
With [Comet Opik](https://www.comet.com/docs/opik/), debug, evaluate, and monitor your LLM applications, RAG systems, and agentic workflows with comprehensive tracing, automated evaluations, and production-ready dashboards.
|
||||
|
||||
<Frame caption="Opik Agent Dashboard">
|
||||
<img src="/images/opik-crewai-dashboard.png" alt="Opik agent monitoring example with CrewAI" />
|
||||
</Frame>
|
||||
|
||||
Opik provides comprehensive support for every stage of your CrewAI application development:
|
||||
|
||||
- **Log Traces and Spans**: Automatically track LLM calls and application logic to debug and analyze development and production systems. Manually or programmatically annotate, view, and compare responses across projects.
|
||||
- **Evaluate Your LLM Application's Performance**: Evaluate against a custom test set and run built-in evaluation metrics or define your own metrics in the SDK or UI.
|
||||
- **Test Within Your CI/CD Pipeline**: Establish reliable performance baselines with Opik's LLM unit tests, built on PyTest. Run online evaluations for continuous monitoring in production.
|
||||
- **Monitor & Analyze Production Data**: Understand your models' performance on unseen data in production and generate datasets for new dev iterations.
|
||||
|
||||
## Setup
|
||||
Comet provides a hosted version of the Opik platform, or you can run the platform locally.
|
||||
|
||||
To use the hosted version, simply [create a free Comet account](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) and grab you API Key.
|
||||
|
||||
To run the Opik platform locally, see our [installation guide](https://www.comet.com/docs/opik/self-host/overview/) for more information.
|
||||
|
||||
For this guide we will use CrewAI’s quickstart example.
|
||||
|
||||
<Steps>
|
||||
<Step title="Install required packages">
|
||||
```shell
|
||||
pip install crewai crewai-tools opik --upgrade
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure Opik">
|
||||
```python
|
||||
import opik
|
||||
opik.configure(use_local=False)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Prepare environment">
|
||||
First, we set up our API keys for our LLM-provider as environment variables:
|
||||
|
||||
```python
|
||||
import os
|
||||
import getpass
|
||||
|
||||
if "OPENAI_API_KEY" not in os.environ:
|
||||
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
|
||||
```
|
||||
</Step>
|
||||
<Step title="Using CrewAI">
|
||||
The first step is to create our project. We will use an example from CrewAI’s documentation:
|
||||
|
||||
```python
|
||||
from crewai import Agent, Crew, Task, Process
|
||||
|
||||
|
||||
class YourCrewName:
|
||||
def agent_one(self) -> Agent:
|
||||
return Agent(
|
||||
role="Data Analyst",
|
||||
goal="Analyze data trends in the market",
|
||||
backstory="An experienced data analyst with a background in economics",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def agent_two(self) -> Agent:
|
||||
return Agent(
|
||||
role="Market Researcher",
|
||||
goal="Gather information on market dynamics",
|
||||
backstory="A diligent researcher with a keen eye for detail",
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
def task_one(self) -> Task:
|
||||
return Task(
|
||||
name="Collect Data Task",
|
||||
description="Collect recent market data and identify trends.",
|
||||
expected_output="A report summarizing key trends in the market.",
|
||||
agent=self.agent_one(),
|
||||
)
|
||||
|
||||
def task_two(self) -> Task:
|
||||
return Task(
|
||||
name="Market Research Task",
|
||||
description="Research factors affecting market dynamics.",
|
||||
expected_output="An analysis of factors influencing the market.",
|
||||
agent=self.agent_two(),
|
||||
)
|
||||
|
||||
def crew(self) -> Crew:
|
||||
return Crew(
|
||||
agents=[self.agent_one(), self.agent_two()],
|
||||
tasks=[self.task_one(), self.task_two()],
|
||||
process=Process.sequential,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
Now we can import Opik’s tracker and run our crew:
|
||||
|
||||
```python
|
||||
from opik.integrations.crewai import track_crewai
|
||||
|
||||
track_crewai(project_name="crewai-integration-demo")
|
||||
|
||||
my_crew = YourCrewName().crew()
|
||||
result = my_crew.kickoff()
|
||||
|
||||
print(result)
|
||||
```
|
||||
After running your CrewAI application, visit the Opik app to view:
|
||||
- LLM traces, spans, and their metadata
|
||||
- Agent interactions and task execution flow
|
||||
- Performance metrics like latency and token usage
|
||||
- Evaluation metrics (built-in or custom)
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Resources
|
||||
|
||||
- [🦉 Opik Documentation](https://www.comet.com/docs/opik/)
|
||||
- [👉 Opik + CrewAI Colab](https://colab.research.google.com/github/comet-ml/opik/blob/main/apps/opik-documentation/documentation/docs/cookbook/crewai.ipynb)
|
||||
- [🐦 X](https://x.com/cometml)
|
||||
- [💬 Slack](https://slack.comet.com/)
|
||||
@@ -1,202 +0,0 @@
|
||||
---
|
||||
title: Portkey Integration
|
||||
description: How to use Portkey with CrewAI
|
||||
icon: key
|
||||
---
|
||||
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-CrewAI.png" alt="Portkey CrewAI Header Image" width="70%" />
|
||||
|
||||
|
||||
[Portkey](https://portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) is a 2-line upgrade to make your CrewAI agents reliable, cost-efficient, and fast.
|
||||
|
||||
Portkey adds 4 core production capabilities to any CrewAI agent:
|
||||
1. Routing to **200+ LLMs**
|
||||
2. Making each LLM call more robust
|
||||
3. Full-stack tracing & cost, performance analytics
|
||||
4. Real-time guardrails to enforce behavior
|
||||
|
||||
## Getting Started
|
||||
|
||||
<Steps>
|
||||
<Step title="Install CrewAI and Portkey">
|
||||
```bash
|
||||
pip install -qU crewai portkey-ai
|
||||
```
|
||||
</Step>
|
||||
<Step title="Configure the LLM Client">
|
||||
To build CrewAI Agents with Portkey, you'll need two keys:
|
||||
- **Portkey API Key**: Sign up on the [Portkey app](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai) and copy your API key
|
||||
- **Virtual Key**: Virtual Keys securely manage your LLM API keys in one place. Store your LLM provider API keys securely in Portkey's vault
|
||||
|
||||
```python
|
||||
from crewai import LLM
|
||||
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
|
||||
|
||||
gpt_llm = LLM(
|
||||
model="gpt-4",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy", # We are using Virtual key
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_VIRTUAL_KEY", # Enter your Virtual key from Portkey
|
||||
)
|
||||
)
|
||||
```
|
||||
</Step>
|
||||
<Step title="Create and Run Your First Agent">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew
|
||||
|
||||
# Define your agents with roles and goals
|
||||
coder = Agent(
|
||||
role='Software developer',
|
||||
goal='Write clear, concise code on demand',
|
||||
backstory='An expert coder with a keen eye for software trends.',
|
||||
llm=gpt_llm
|
||||
)
|
||||
|
||||
# Create tasks for your agents
|
||||
task1 = Task(
|
||||
description="Define the HTML for making a simple website with heading- Hello World! Portkey is working!",
|
||||
expected_output="A clear and concise HTML code",
|
||||
agent=coder
|
||||
)
|
||||
|
||||
# Instantiate your crew
|
||||
crew = Crew(
|
||||
agents=[coder],
|
||||
tasks=[task1],
|
||||
)
|
||||
|
||||
result = crew.kickoff()
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Key Features
|
||||
|
||||
| Feature | Description |
|
||||
|:--------|:------------|
|
||||
| 🌐 Multi-LLM Support | Access OpenAI, Anthropic, Gemini, Azure, and 250+ providers through a unified interface |
|
||||
| 🛡️ Production Reliability | Implement retries, timeouts, load balancing, and fallbacks |
|
||||
| 📊 Advanced Observability | Track 40+ metrics including costs, tokens, latency, and custom metadata |
|
||||
| 🔍 Comprehensive Logging | Debug with detailed execution traces and function call logs |
|
||||
| 🚧 Security Controls | Set budget limits and implement role-based access control |
|
||||
| 🔄 Performance Analytics | Capture and analyze feedback for continuous improvement |
|
||||
| 💾 Intelligent Caching | Reduce costs and latency with semantic or simple caching |
|
||||
|
||||
|
||||
## Production Features with Portkey Configs
|
||||
|
||||
All features mentioned below are through Portkey's Config system. Portkey's Config system allows you to define routing strategies using simple JSON objects in your LLM API calls. You can create and manage Configs directly in your code or through the Portkey Dashboard. Each Config has a unique ID for easy reference.
|
||||
|
||||
<Frame>
|
||||
<img src="https://raw.githubusercontent.com/Portkey-AI/docs-core/refs/heads/main/images/libraries/libraries-3.avif"/>
|
||||
</Frame>
|
||||
|
||||
|
||||
### 1. Use 250+ LLMs
|
||||
Access various LLMs like Anthropic, Gemini, Mistral, Azure OpenAI, and more with minimal code changes. Switch between providers or use them together seamlessly. [Learn more about Universal API](https://portkey.ai/docs/product/ai-gateway/universal-api)
|
||||
|
||||
|
||||
Easily switch between different LLM providers:
|
||||
|
||||
```python
|
||||
# Anthropic Configuration
|
||||
anthropic_llm = LLM(
|
||||
model="claude-3-5-sonnet-latest",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_ANTHROPIC_VIRTUAL_KEY", #You don't need provider when using Virtual keys
|
||||
trace_id="anthropic_agent"
|
||||
)
|
||||
)
|
||||
|
||||
# Azure OpenAI Configuration
|
||||
azure_llm = LLM(
|
||||
model="gpt-4",
|
||||
base_url=PORTKEY_GATEWAY_URL,
|
||||
api_key="dummy",
|
||||
extra_headers=createHeaders(
|
||||
api_key="YOUR_PORTKEY_API_KEY",
|
||||
virtual_key="YOUR_AZURE_VIRTUAL_KEY", #You don't need provider when using Virtual keys
|
||||
trace_id="azure_agent"
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
### 2. Caching
|
||||
Improve response times and reduce costs with two powerful caching modes:
|
||||
- **Simple Cache**: Perfect for exact matches
|
||||
- **Semantic Cache**: Matches responses for requests that are semantically similar
|
||||
[Learn more about Caching](https://portkey.ai/docs/product/ai-gateway/cache-simple-and-semantic)
|
||||
|
||||
```py
|
||||
config = {
|
||||
"cache": {
|
||||
"mode": "semantic", # or "simple" for exact matching
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 3. Production Reliability
|
||||
Portkey provides comprehensive reliability features:
|
||||
- **Automatic Retries**: Handle temporary failures gracefully
|
||||
- **Request Timeouts**: Prevent hanging operations
|
||||
- **Conditional Routing**: Route requests based on specific conditions
|
||||
- **Fallbacks**: Set up automatic provider failovers
|
||||
- **Load Balancing**: Distribute requests efficiently
|
||||
|
||||
[Learn more about Reliability Features](https://portkey.ai/docs/product/ai-gateway/)
|
||||
|
||||
|
||||
|
||||
### 4. Metrics
|
||||
|
||||
Agent runs are complex. Portkey automatically logs **40+ comprehensive metrics** for your AI agents, including cost, tokens used, latency, etc. Whether you need a broad overview or granular insights into your agent runs, Portkey's customizable filters provide the metrics you need.
|
||||
|
||||
|
||||
- Cost per agent interaction
|
||||
- Response times and latency
|
||||
- Token usage and efficiency
|
||||
- Success/failure rates
|
||||
- Cache hit rates
|
||||
|
||||
<img src="https://github.com/siddharthsambharia-portkey/Portkey-Product-Images/blob/main/Portkey-Dashboard.png?raw=true" width="70%" alt="Portkey Dashboard" />
|
||||
|
||||
### 5. Detailed Logging
|
||||
Logs are essential for understanding agent behavior, diagnosing issues, and improving performance. They provide a detailed record of agent activities and tool use, which is crucial for debugging and optimizing processes.
|
||||
|
||||
|
||||
Access a dedicated section to view records of agent executions, including parameters, outcomes, function calls, and errors. Filter logs based on multiple parameters such as trace ID, model, tokens used, and metadata.
|
||||
|
||||
<details>
|
||||
<summary><b>Traces</b></summary>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-Traces.png" alt="Portkey Traces" width="70%" />
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary><b>Logs</b></summary>
|
||||
<img src="https://raw.githubusercontent.com/siddharthsambharia-portkey/Portkey-Product-Images/main/Portkey-Logs.png" alt="Portkey Logs" width="70%" />
|
||||
</details>
|
||||
|
||||
### 6. Enterprise Security Features
|
||||
- Set budget limit and rate limts per Virtual Key (disposable API keys)
|
||||
- Implement role-based access control
|
||||
- Track system changes with audit logs
|
||||
- Configure data retention policies
|
||||
|
||||
|
||||
|
||||
For detailed information on creating and managing Configs, visit the [Portkey documentation](https://docs.portkey.ai/product/ai-gateway/configs).
|
||||
|
||||
## Resources
|
||||
|
||||
- [📘 Portkey Documentation](https://docs.portkey.ai)
|
||||
- [📊 Portkey Dashboard](https://app.portkey.ai/?utm_source=crewai&utm_medium=crewai&utm_campaign=crewai)
|
||||
- [🐦 Twitter](https://twitter.com/portkeyai)
|
||||
- [💬 Discord Community](https://discord.gg/DD7vgKK299)
|
||||
@@ -1,78 +0,0 @@
|
||||
---
|
||||
title: Replay Tasks from Latest Crew Kickoff
|
||||
description: Replay tasks from the latest crew.kickoff(...)
|
||||
icon: arrow-right
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
CrewAI provides the ability to replay from a task specified from the latest crew kickoff. This feature is particularly useful when you've finished a kickoff and may want to retry certain tasks or don't need to refetch data over and your agents already have the context saved from the kickoff execution so you just need to replay the tasks you want to.
|
||||
|
||||
<Note>
|
||||
You must run `crew.kickoff()` before you can replay a task.
|
||||
Currently, only the latest kickoff is supported, so if you use `kickoff_for_each`, it will only allow you to replay from the most recent crew run.
|
||||
</Note>
|
||||
|
||||
Here's an example of how to replay from a task:
|
||||
|
||||
### Replaying from Specific Task Using the CLI
|
||||
|
||||
To use the replay feature, follow these steps:
|
||||
|
||||
<Steps>
|
||||
<Step title="Open your terminal or command prompt."></Step>
|
||||
<Step title="Navigate to the directory where your CrewAI project is located."></Step>
|
||||
<Step title="Run the following commands:">
|
||||
To view the latest kickoff task_ids use:
|
||||
|
||||
```shell
|
||||
crewai log-tasks-outputs
|
||||
```
|
||||
|
||||
Once you have your `task_id` to replay, use:
|
||||
|
||||
```shell
|
||||
crewai replay -t <task_id>
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<Note>
|
||||
Ensure `crewai` is installed and configured correctly in your development environment.
|
||||
</Note>
|
||||
|
||||
### Replaying from a Task Programmatically
|
||||
|
||||
To replay from a task programmatically, use the following steps:
|
||||
|
||||
<Steps>
|
||||
<Step title="Specify the `task_id` and input parameters for the replay process.">
|
||||
Specify the `task_id` and input parameters for the replay process.
|
||||
</Step>
|
||||
<Step title="Execute the replay command within a try-except block to handle potential errors.">
|
||||
Execute the replay command within a try-except block to handle potential errors.
|
||||
<CodeGroup>
|
||||
```python Code
|
||||
def replay():
|
||||
"""
|
||||
Replay the crew execution from a specific task.
|
||||
"""
|
||||
task_id = '<task_id>'
|
||||
inputs = {"topic": "CrewAI Training"} # This is optional; you can pass in the inputs you want to replay; otherwise, it uses the previous kickoff's inputs.
|
||||
try:
|
||||
YourCrewName_Crew().crew().replay(task_id=task_id, inputs=inputs)
|
||||
|
||||
except subprocess.CalledProcessError as e:
|
||||
raise Exception(f"An error occurred while replaying the crew: {e}")
|
||||
|
||||
except Exception as e:
|
||||
raise Exception(f"An unexpected error occurred: {e}")
|
||||
```
|
||||
</CodeGroup>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Conclusion
|
||||
|
||||
With the above enhancements and detailed functionality, replaying specific tasks in CrewAI has been made more efficient and robust.
|
||||
Ensure you follow the commands and steps precisely to make the most of these features.
|
||||
@@ -1,127 +0,0 @@
|
||||
---
|
||||
title: Sequential Processes
|
||||
description: A comprehensive guide to utilizing the sequential processes for task execution in CrewAI projects.
|
||||
icon: forward
|
||||
---
|
||||
|
||||
## Introduction
|
||||
|
||||
CrewAI offers a flexible framework for executing tasks in a structured manner, supporting both sequential and hierarchical processes.
|
||||
This guide outlines how to effectively implement these processes to ensure efficient task execution and project completion.
|
||||
|
||||
## Sequential Process Overview
|
||||
|
||||
The sequential process ensures tasks are executed one after the other, following a linear progression.
|
||||
This approach is ideal for projects requiring tasks to be completed in a specific order.
|
||||
|
||||
### Key Features
|
||||
|
||||
- **Linear Task Flow**: Ensures orderly progression by handling tasks in a predetermined sequence.
|
||||
- **Simplicity**: Best suited for projects with clear, step-by-step tasks.
|
||||
- **Easy Monitoring**: Facilitates easy tracking of task completion and project progress.
|
||||
|
||||
## Implementing the Sequential Process
|
||||
|
||||
To use the sequential process, assemble your crew and define tasks in the order they need to be executed.
|
||||
|
||||
```python Code
|
||||
from crewai import Crew, Process, Agent, Task, TaskOutput, CrewOutput
|
||||
|
||||
# Define your agents
|
||||
researcher = Agent(
|
||||
role='Researcher',
|
||||
goal='Conduct foundational research',
|
||||
backstory='An experienced researcher with a passion for uncovering insights'
|
||||
)
|
||||
analyst = Agent(
|
||||
role='Data Analyst',
|
||||
goal='Analyze research findings',
|
||||
backstory='A meticulous analyst with a knack for uncovering patterns'
|
||||
)
|
||||
writer = Agent(
|
||||
role='Writer',
|
||||
goal='Draft the final report',
|
||||
backstory='A skilled writer with a talent for crafting compelling narratives'
|
||||
)
|
||||
|
||||
# Define your tasks
|
||||
research_task = Task(
|
||||
description='Gather relevant data...',
|
||||
agent=researcher,
|
||||
expected_output='Raw Data'
|
||||
)
|
||||
analysis_task = Task(
|
||||
description='Analyze the data...',
|
||||
agent=analyst,
|
||||
expected_output='Data Insights'
|
||||
)
|
||||
writing_task = Task(
|
||||
description='Compose the report...',
|
||||
agent=writer,
|
||||
expected_output='Final Report'
|
||||
)
|
||||
|
||||
# Form the crew with a sequential process
|
||||
report_crew = Crew(
|
||||
agents=[researcher, analyst, writer],
|
||||
tasks=[research_task, analysis_task, writing_task],
|
||||
process=Process.sequential
|
||||
)
|
||||
|
||||
# Execute the crew
|
||||
result = report_crew.kickoff()
|
||||
|
||||
# Accessing the type-safe output
|
||||
task_output: TaskOutput = result.tasks[0].output
|
||||
crew_output: CrewOutput = result.output
|
||||
```
|
||||
|
||||
### Note:
|
||||
|
||||
Each task in a sequential process **must** have an agent assigned. Ensure that every `Task` includes an `agent` parameter.
|
||||
|
||||
### Workflow in Action
|
||||
|
||||
1. **Initial Task**: In a sequential process, the first agent completes their task and signals completion.
|
||||
2. **Subsequent Tasks**: Agents pick up their tasks based on the process type, with outcomes of preceding tasks or directives guiding their execution.
|
||||
3. **Completion**: The process concludes once the final task is executed, leading to project completion.
|
||||
|
||||
## Advanced Features
|
||||
|
||||
### Task Delegation
|
||||
|
||||
In sequential processes, if an agent has `allow_delegation` set to `True`, they can delegate tasks to other agents in the crew.
|
||||
This feature is automatically set up when there are multiple agents in the crew.
|
||||
|
||||
### Asynchronous Execution
|
||||
|
||||
Tasks can be executed asynchronously, allowing for parallel processing when appropriate.
|
||||
To create an asynchronous task, set `async_execution=True` when defining the task.
|
||||
|
||||
### Memory and Caching
|
||||
|
||||
CrewAI supports both memory and caching features:
|
||||
|
||||
- **Memory**: Enable by setting `memory=True` when creating the Crew. This allows agents to retain information across tasks.
|
||||
- **Caching**: By default, caching is enabled. Set `cache=False` to disable it.
|
||||
|
||||
### Callbacks
|
||||
|
||||
You can set callbacks at both the task and step level:
|
||||
|
||||
- `task_callback`: Executed after each task completion.
|
||||
- `step_callback`: Executed after each step in an agent's execution.
|
||||
|
||||
### Usage Metrics
|
||||
|
||||
CrewAI tracks token usage across all tasks and agents. You can access these metrics after execution.
|
||||
|
||||
## Best Practices for Sequential Processes
|
||||
|
||||
1. **Order Matters**: Arrange tasks in a logical sequence where each task builds upon the previous one.
|
||||
2. **Clear Task Descriptions**: Provide detailed descriptions for each task to guide the agents effectively.
|
||||
3. **Appropriate Agent Selection**: Match agents' skills and roles to the requirements of each task.
|
||||
4. **Use Context**: Leverage the context from previous tasks to inform subsequent ones.
|
||||
|
||||
This updated documentation ensures that details accurately reflect the latest changes in the codebase and clearly describes how to leverage new features and configurations.
|
||||
The content is kept simple and direct to ensure easy understanding.
|
||||
@@ -1,141 +0,0 @@
|
||||
---
|
||||
title: "Using Annotations in crew.py"
|
||||
description: "Learn how to use annotations to properly structure agents, tasks, and components in CrewAI"
|
||||
icon: "at"
|
||||
---
|
||||
|
||||
This guide explains how to use annotations to properly reference **agents**, **tasks**, and other components in the `crew.py` file.
|
||||
|
||||
## Introduction
|
||||
|
||||
Annotations in the CrewAI framework are used to decorate classes and methods, providing metadata and functionality to various components of your crew. These annotations help in organizing and structuring your code, making it more readable and maintainable.
|
||||
|
||||
## Available Annotations
|
||||
|
||||
The CrewAI framework provides the following annotations:
|
||||
|
||||
- `@CrewBase`: Used to decorate the main crew class.
|
||||
- `@agent`: Decorates methods that define and return Agent objects.
|
||||
- `@task`: Decorates methods that define and return Task objects.
|
||||
- `@crew`: Decorates the method that creates and returns the Crew object.
|
||||
- `@llm`: Decorates methods that initialize and return Language Model objects.
|
||||
- `@tool`: Decorates methods that initialize and return Tool objects.
|
||||
- `@callback`: Used for defining callback methods.
|
||||
- `@output_json`: Used for methods that output JSON data.
|
||||
- `@output_pydantic`: Used for methods that output Pydantic models.
|
||||
- `@cache_handler`: Used for defining cache handling methods.
|
||||
|
||||
## Usage Examples
|
||||
|
||||
Let's go through examples of how to use these annotations:
|
||||
|
||||
### 1. Crew Base Class
|
||||
|
||||
```python
|
||||
@CrewBase
|
||||
class LinkedinProfileCrew():
|
||||
"""LinkedinProfile crew"""
|
||||
agents_config = 'config/agents.yaml'
|
||||
tasks_config = 'config/tasks.yaml'
|
||||
```
|
||||
|
||||
The `@CrewBase` annotation is used to decorate the main crew class. This class typically contains configurations and methods for creating agents, tasks, and the crew itself.
|
||||
|
||||
### 2. Tool Definition
|
||||
|
||||
```python
|
||||
@tool
|
||||
def myLinkedInProfileTool(self):
|
||||
return LinkedInProfileTool()
|
||||
```
|
||||
|
||||
The `@tool` annotation is used to decorate methods that return tool objects. These tools can be used by agents to perform specific tasks.
|
||||
|
||||
### 3. LLM Definition
|
||||
|
||||
```python
|
||||
@llm
|
||||
def groq_llm(self):
|
||||
api_key = os.getenv('api_key')
|
||||
return ChatGroq(api_key=api_key, temperature=0, model_name="mixtral-8x7b-32768")
|
||||
```
|
||||
|
||||
The `@llm` annotation is used to decorate methods that initialize and return Language Model objects. These LLMs are used by agents for natural language processing tasks.
|
||||
|
||||
### 4. Agent Definition
|
||||
|
||||
```python
|
||||
@agent
|
||||
def researcher(self) -> Agent:
|
||||
return Agent(
|
||||
config=self.agents_config['researcher']
|
||||
)
|
||||
```
|
||||
|
||||
The `@agent` annotation is used to decorate methods that define and return Agent objects.
|
||||
|
||||
### 5. Task Definition
|
||||
|
||||
```python
|
||||
@task
|
||||
def research_task(self) -> Task:
|
||||
return Task(
|
||||
config=self.tasks_config['research_linkedin_task'],
|
||||
agent=self.researcher()
|
||||
)
|
||||
```
|
||||
|
||||
The `@task` annotation is used to decorate methods that define and return Task objects. These methods specify the task configuration and the agent responsible for the task.
|
||||
|
||||
### 6. Crew Creation
|
||||
|
||||
```python
|
||||
@crew
|
||||
def crew(self) -> Crew:
|
||||
"""Creates the LinkedinProfile crew"""
|
||||
return Crew(
|
||||
agents=self.agents,
|
||||
tasks=self.tasks,
|
||||
process=Process.sequential,
|
||||
verbose=True
|
||||
)
|
||||
```
|
||||
|
||||
The `@crew` annotation is used to decorate the method that creates and returns the `Crew` object. This method assembles all the components (agents and tasks) into a functional crew.
|
||||
|
||||
## YAML Configuration
|
||||
|
||||
The agent configurations are typically stored in a YAML file. Here's an example of how the `agents.yaml` file might look for the researcher agent:
|
||||
|
||||
```yaml
|
||||
researcher:
|
||||
role: >
|
||||
LinkedIn Profile Senior Data Researcher
|
||||
goal: >
|
||||
Uncover detailed LinkedIn profiles based on provided name {name} and domain {domain}
|
||||
Generate a Dall-E image based on domain {domain}
|
||||
backstory: >
|
||||
You're a seasoned researcher with a knack for uncovering the most relevant LinkedIn profiles.
|
||||
Known for your ability to navigate LinkedIn efficiently, you excel at gathering and presenting
|
||||
professional information clearly and concisely.
|
||||
allow_delegation: False
|
||||
verbose: True
|
||||
llm: groq_llm
|
||||
tools:
|
||||
- myLinkedInProfileTool
|
||||
- mySerperDevTool
|
||||
- myDallETool
|
||||
```
|
||||
|
||||
This YAML configuration corresponds to the researcher agent defined in the `LinkedinProfileCrew` class. The configuration specifies the agent's role, goal, backstory, and other properties such as the LLM and tools it uses.
|
||||
|
||||
Note how the `llm` and `tools` in the YAML file correspond to the methods decorated with `@llm` and `@tool` in the Python class.
|
||||
|
||||
## Best Practices
|
||||
|
||||
- **Consistent Naming**: Use clear and consistent naming conventions for your methods. For example, agent methods could be named after their roles (e.g., researcher, reporting_analyst).
|
||||
- **Environment Variables**: Use environment variables for sensitive information like API keys.
|
||||
- **Flexibility**: Design your crew to be flexible by allowing easy addition or removal of agents and tasks.
|
||||
- **YAML-Code Correspondence**: Ensure that the names and structures in your YAML files correspond correctly to the decorated methods in your Python code.
|
||||
|
||||
By following these guidelines and properly using annotations, you can create well-structured and maintainable crews using the CrewAI framework.
|
||||
@@ -1,124 +0,0 @@
|
||||
---
|
||||
title: Weave Integration
|
||||
description: Learn how to use Weights & Biases (W&B) Weave to track, experiment with, evaluate, and improve your CrewAI applications.
|
||||
icon: radar
|
||||
---
|
||||
|
||||
# Weave Overview
|
||||
|
||||
[Weights & Biases (W&B) Weave](https://weave-docs.wandb.ai/) is a framework for tracking, experimenting with, evaluating, deploying, and improving LLM-based applications.
|
||||
|
||||

|
||||
|
||||
Weave provides comprehensive support for every stage of your CrewAI application development:
|
||||
|
||||
- **Tracing & Monitoring**: Automatically track LLM calls and application logic to debug and analyze production systems
|
||||
- **Systematic Iteration**: Refine and iterate on prompts, datasets, and models
|
||||
- **Evaluation**: Use custom or pre-built scorers to systematically assess and enhance agent performance
|
||||
- **Guardrails**: Protect your agents with pre- and post-safeguards for content moderation and prompt safety
|
||||
|
||||
Weave automatically captures traces for your CrewAI applications, enabling you to monitor and analyze your agents' performance, interactions, and execution flow. This helps you build better evaluation datasets and optimize your agent workflows.
|
||||
|
||||
## Setup Instructions
|
||||
|
||||
<Steps>
|
||||
<Step title="Install required packages">
|
||||
```shell
|
||||
pip install crewai weave
|
||||
```
|
||||
</Step>
|
||||
<Step title="Set up W&B Account">
|
||||
Sign up for a [Weights & Biases account](https://wandb.ai) if you haven't already. You'll need this to view your traces and metrics.
|
||||
</Step>
|
||||
<Step title="Initialize Weave in Your Application">
|
||||
Add the following code to your application:
|
||||
|
||||
```python
|
||||
import weave
|
||||
|
||||
# Initialize Weave with your project name
|
||||
weave.init(project_name="crewai_demo")
|
||||
```
|
||||
|
||||
After initialization, Weave will provide a URL where you can view your traces and metrics.
|
||||
</Step>
|
||||
<Step title="Create your Crews/Flows">
|
||||
```python
|
||||
from crewai import Agent, Task, Crew, LLM, Process
|
||||
|
||||
# Create an LLM with a temperature of 0 to ensure deterministic outputs
|
||||
llm = LLM(model="gpt-4o", temperature=0)
|
||||
|
||||
# Create agents
|
||||
researcher = Agent(
|
||||
role='Research Analyst',
|
||||
goal='Find and analyze the best investment opportunities',
|
||||
backstory='Expert in financial analysis and market research',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
writer = Agent(
|
||||
role='Report Writer',
|
||||
goal='Write clear and concise investment reports',
|
||||
backstory='Experienced in creating detailed financial reports',
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
allow_delegation=False,
|
||||
)
|
||||
|
||||
# Create tasks
|
||||
research_task = Task(
|
||||
description='Deep research on the {topic}',
|
||||
expected_output='Comprehensive market data including key players, market size, and growth trends.',
|
||||
agent=researcher
|
||||
)
|
||||
|
||||
writing_task = Task(
|
||||
description='Write a detailed report based on the research',
|
||||
expected_output='The report should be easy to read and understand. Use bullet points where applicable.',
|
||||
agent=writer
|
||||
)
|
||||
|
||||
# Create a crew
|
||||
crew = Crew(
|
||||
agents=[researcher, writer],
|
||||
tasks=[research_task, writing_task],
|
||||
verbose=True,
|
||||
process=Process.sequential,
|
||||
)
|
||||
|
||||
# Run the crew
|
||||
result = crew.kickoff(inputs={"topic": "AI in material science"})
|
||||
print(result)
|
||||
```
|
||||
</Step>
|
||||
<Step title="View Traces in Weave">
|
||||
After running your CrewAI application, visit the Weave URL provided during initialization to view:
|
||||
- LLM calls and their metadata
|
||||
- Agent interactions and task execution flow
|
||||
- Performance metrics like latency and token usage
|
||||
- Any errors or issues that occurred during execution
|
||||
|
||||
<Frame caption="Weave Tracing Dashboard">
|
||||
<img src="/images/weave-tracing.png" alt="Weave tracing example with CrewAI" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Features
|
||||
|
||||
- Weave automatically captures all CrewAI operations: agent interactions and task executions; LLM calls with metadata and token usage; tool usage and results.
|
||||
- The integration supports all CrewAI execution methods: `kickoff()`, `kickoff_for_each()`, `kickoff_async()`, and `kickoff_for_each_async()`.
|
||||
- Automatic tracing of all [crewAI-tools](https://github.com/crewAIInc/crewAI-tools).
|
||||
- Flow feature support with decorator patching (`@start`, `@listen`, `@router`, `@or_`, `@and_`).
|
||||
- Track custom guardrails passed to CrewAI `Task` with `@weave.op()`.
|
||||
|
||||
For detailed information on what's supported, visit the [Weave CrewAI documentation](https://weave-docs.wandb.ai/guides/integrations/crewai/#getting-started-with-flow).
|
||||
|
||||
## Resources
|
||||
|
||||
- [📘 Weave Documentation](https://weave-docs.wandb.ai)
|
||||
- [📊 Example Weave x CrewAI dashboard](https://wandb.ai/ayut/crewai_demo/weave/traces?cols=%7B%22wb_run_id%22%3Afalse%2C%22attributes.weave.client_version%22%3Afalse%2C%22attributes.weave.os_name%22%3Afalse%2C%22attributes.weave.os_release%22%3Afalse%2C%22attributes.weave.os_version%22%3Afalse%2C%22attributes.weave.source%22%3Afalse%2C%22attributes.weave.sys_version%22%3Afalse%7D&peekPath=%2Fayut%2Fcrewai_demo%2Fcalls%2F0195c838-38cb-71a2-8a15-651ecddf9d89)
|
||||
- [🐦 X](https://x.com/weave_wb)
|
||||
Reference in New Issue
Block a user