 +
+  +
+
+
+
+
+  +
+
+
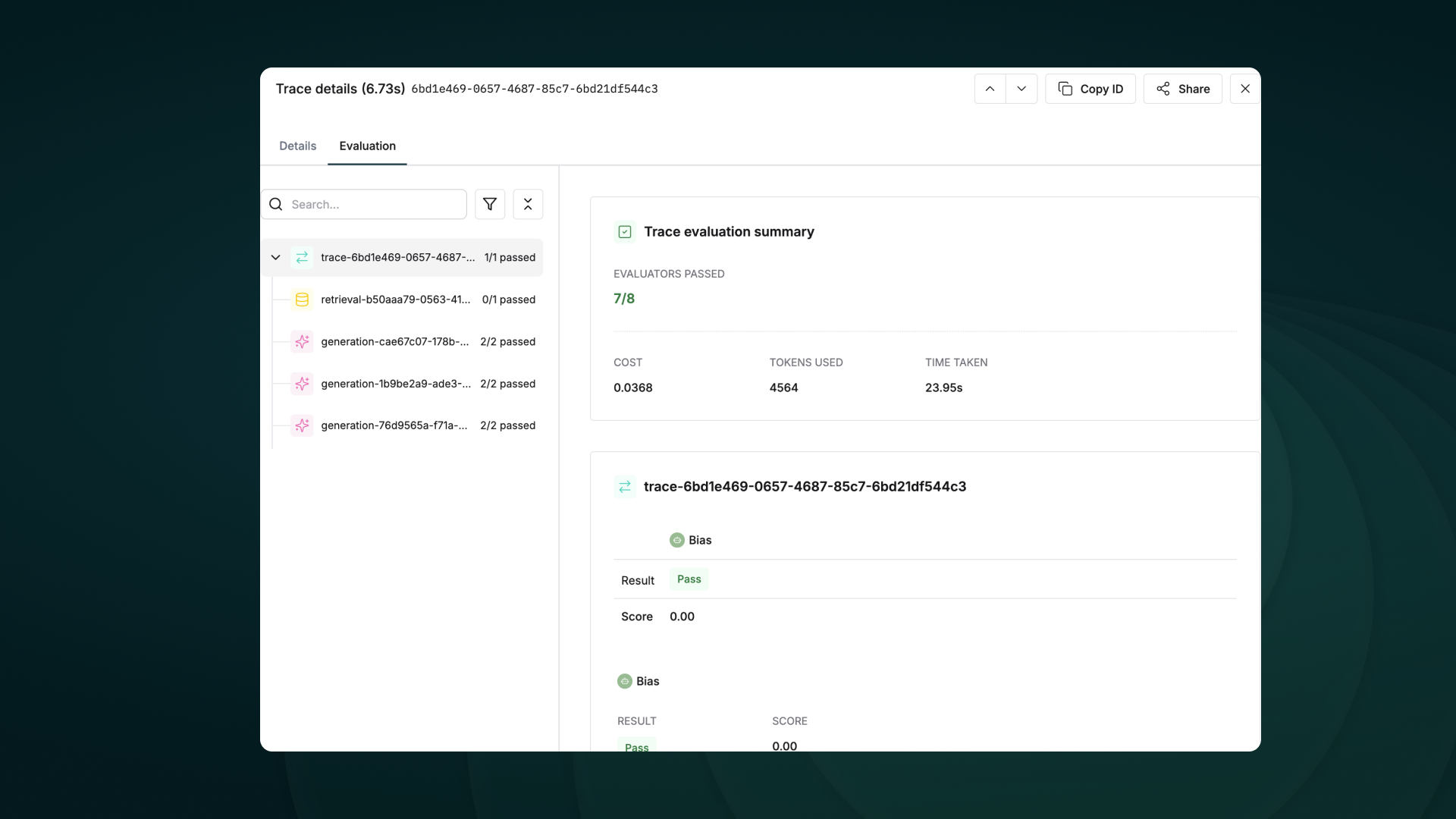
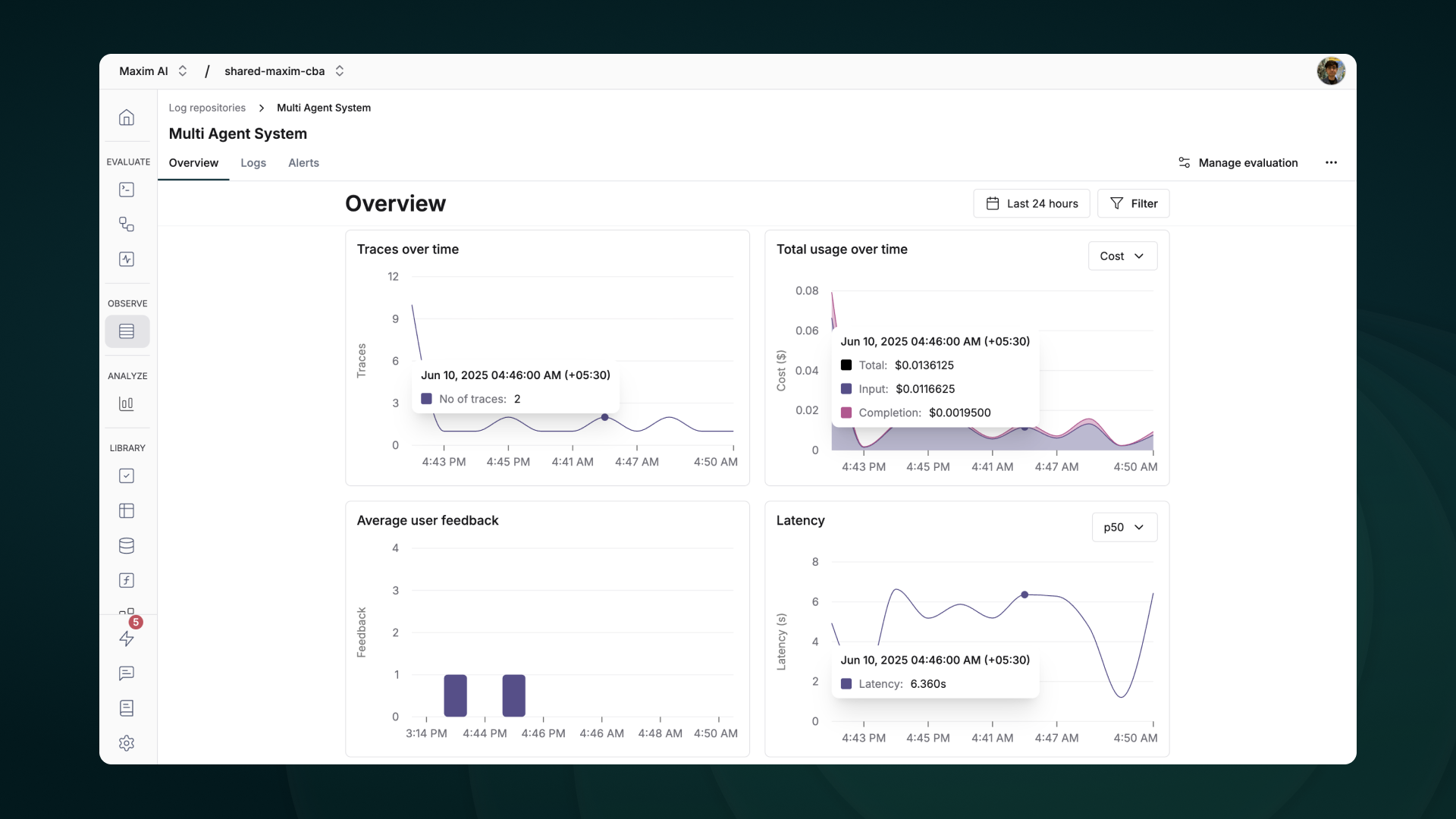
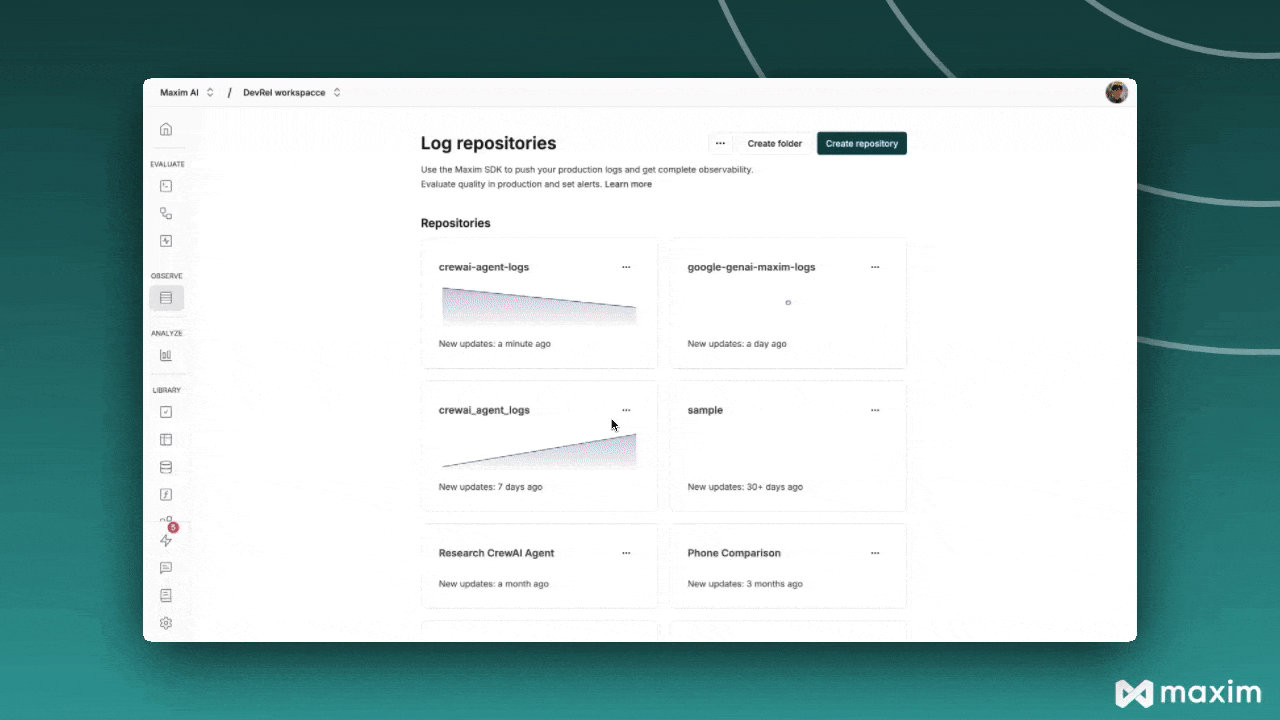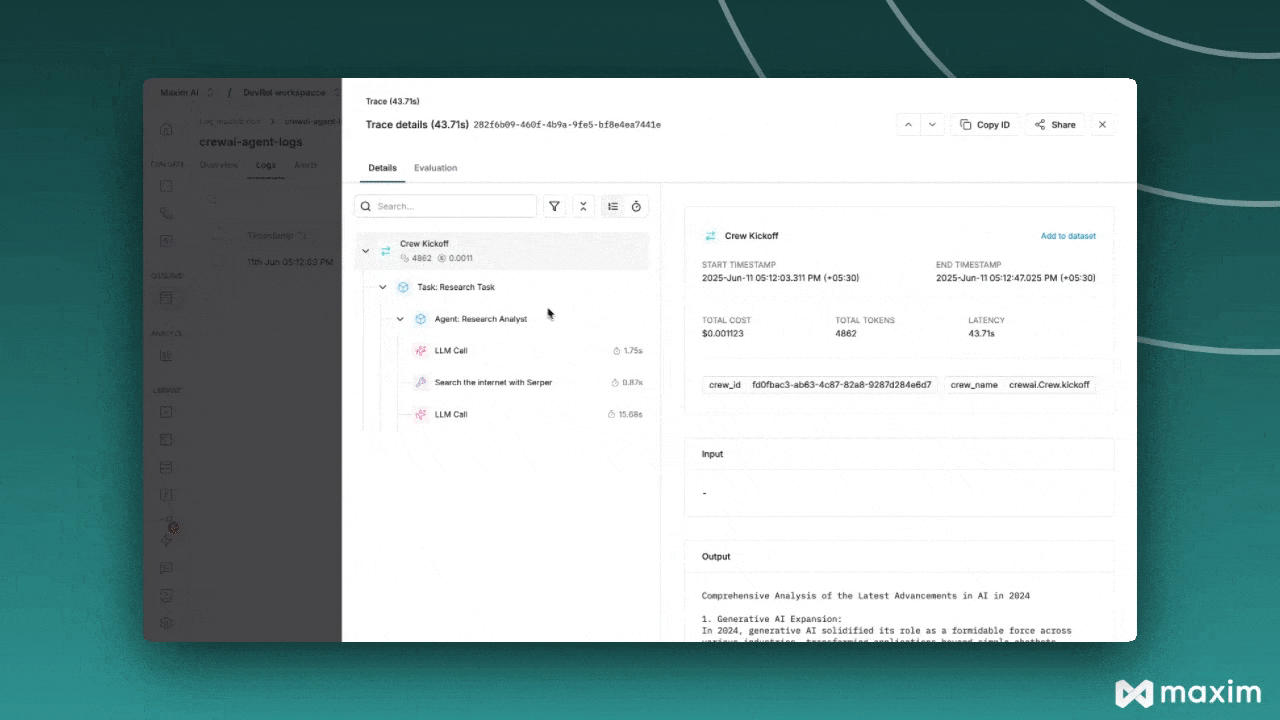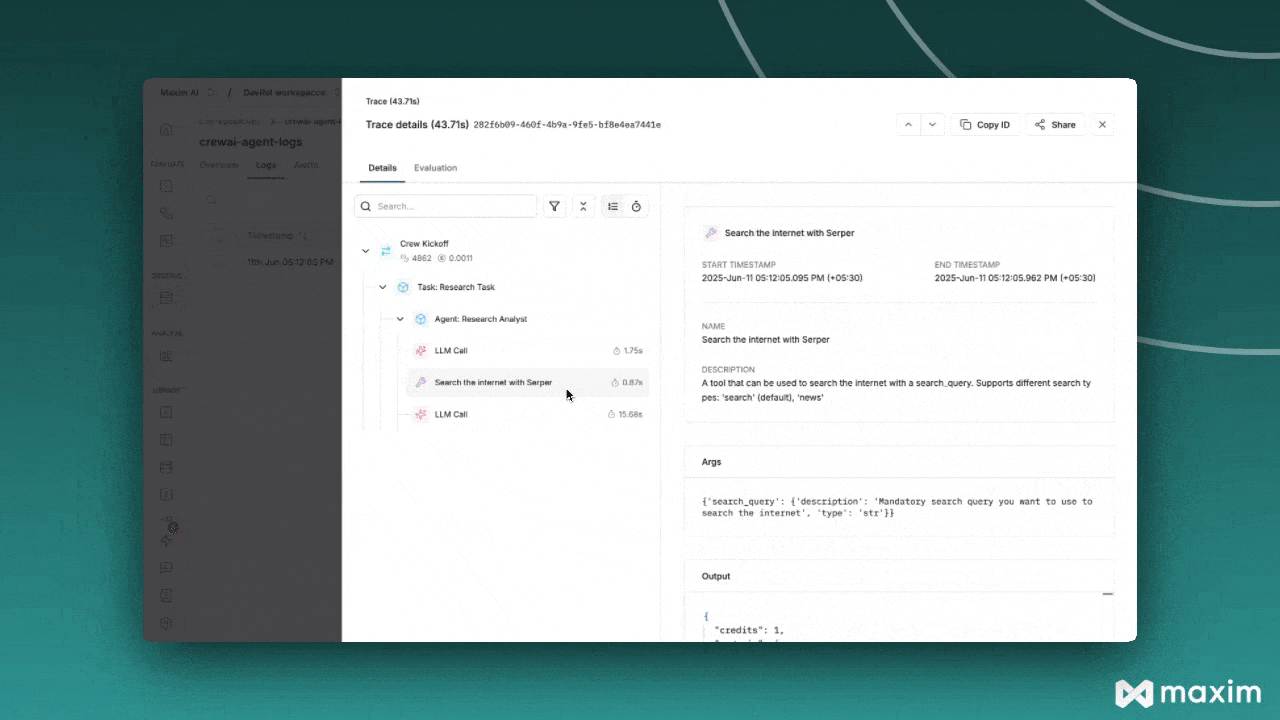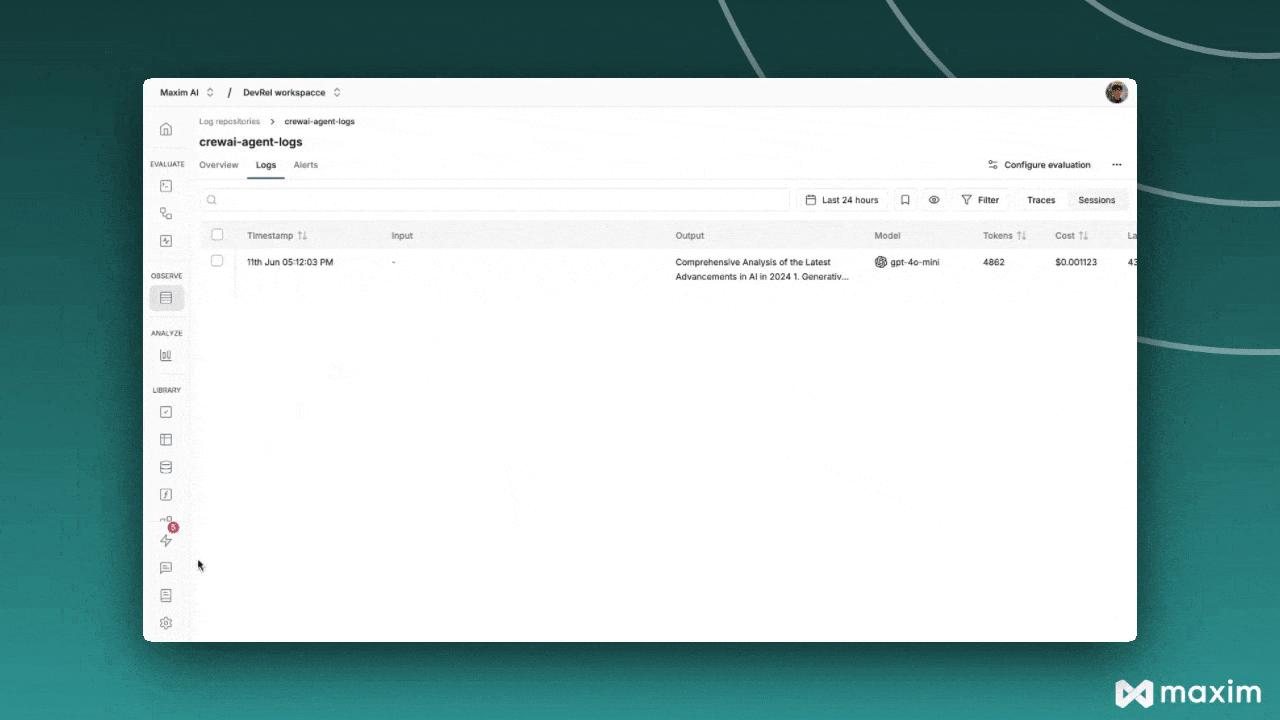
+ + Evaluate captured logs automatically from the UI based on filters and sampling + +
++ Use human evaluation or rating to assess the quality of your logs and evaluate them. + +
++ Evaluate any component of your trace or log to gain insights into your agent’s behavior. + +
+ +
+  +
+  ## Troubleshooting
### Common Issues
-- **No traces appearing**: Ensure your API key and repository ID are correc
-- Ensure you've **called `instrument_crewai()`** ***before*** running your crew. This initializes logging hooks correctly.
+- **No traces appearing**: Ensure your API key and repository ID are correct
+- Ensure you've **`called instrument_crewai()`** **_before_** running your crew. This initializes logging hooks correctly.
- Set `debug=True` in your `instrument_crewai()` call to surface any internal errors:
-
- ```python
- instrument_crewai(logger, debug=True)
- ```
-
+
+ ```python
+ instrument_crewai(logger, debug=True)
+ ```
- Configure your agents with `verbose=True` to capture detailed logs:
-
- ```python
-
- agent = CrewAgent(..., verbose=True)
- ```
-
+
+ ```python
+ agent = CrewAgent(..., verbose=True)
+ ```
- Double-check that `instrument_crewai()` is called **before** creating or executing agents. This might be obvious, but it's a common oversight.
-### Support
+## Resources
-If you encounter any issues:
-
-- Check the [Maxim Documentation](https://getmaxim.ai/docs)
-- Maxim Github [Link](https://github.com/maximhq)
+
## Troubleshooting
### Common Issues
-- **No traces appearing**: Ensure your API key and repository ID are correc
-- Ensure you've **called `instrument_crewai()`** ***before*** running your crew. This initializes logging hooks correctly.
+- **No traces appearing**: Ensure your API key and repository ID are correct
+- Ensure you've **`called instrument_crewai()`** **_before_** running your crew. This initializes logging hooks correctly.
- Set `debug=True` in your `instrument_crewai()` call to surface any internal errors:
-
- ```python
- instrument_crewai(logger, debug=True)
- ```
-
+
+ ```python
+ instrument_crewai(logger, debug=True)
+ ```
- Configure your agents with `verbose=True` to capture detailed logs:
-
- ```python
-
- agent = CrewAgent(..., verbose=True)
- ```
-
+
+ ```python
+ agent = CrewAgent(..., verbose=True)
+ ```
- Double-check that `instrument_crewai()` is called **before** creating or executing agents. This might be obvious, but it's a common oversight.
-### Support
+## Resources
-If you encounter any issues:
-
-- Check the [Maxim Documentation](https://getmaxim.ai/docs)
-- Maxim Github [Link](https://github.com/maximhq)
+